DALLE2论文解读及实现(一)
DALLE2: Hierarchical Text-Conditional Image Generation with CLIP Latents
paper: https://cdn.openai.com/papers/dall-e-2.pdf
github: https://github.com/lucidrains/DALLE2-pytorch
DALLE2概览:
- CLIP模型:
用于生成text embedding zt 和image embedding zi
- prior模型:
1) 模型输入:为 the encoded text,the CLIP text embedding,time_embed,image_embed,learned_queries,(文本整体embedding,文本序列embedding,时间步embedding,当前t步对应的图片embedding,用于输出transformer 结果手动构造用于学习的embedding )
2) 模型: diffusion model使用transformer(不是unet)直接预测x0,然后通过diffusion递推公式生成前一步图片embedding.
3)最终输出:为 image Embedding (不同于上面CLIP生成的image embedding )
- decoder 模型
1)模型输入:为 prior 输出的image Embedding
2)模型:diffusion model使用unet网络,预测噪声z (不同于prior模型直接预测x0)
3)模型输出:经过T步去噪后,最后一步x0即为模型输出
0 Abstract
基于对比学习思想,我们提出了两阶段模型,
①一个先验模型prior:
- 在给定文本条件下生成CLIP的 image embedding
② 一个decoder模型:
- 在给定imge embedding 条件下,生成图片
We use diffusion models for the decoder and experiment with both autoregressive and diffusion models for the prior, finding that the latter are computationally more efficient and produce higher quality samples.
我们使用diffusion 模型作为decoder 模型,实验了自回归autoregressive 和diffusion模型作为prior模型,发现diffusion 模型作为先验模型效过更好
1 Introduction
- 虚线上面的是CLIP模型,通过CLIP模型可以学习到text 和image的embedding,
- 虚线以下是文本到图片的生成过程,
① CLIP的 text embedding 喂给autoregressive或者diffusion模型( prior模型),生成image embedding
② 然后根据上面的image embedding喂给decoder 模型,生成最终的图片image


2 Method
- Our training dataset consists of pairs (x, y) of images x and their corresponding captions y. Given an image x,let zi and zt be its CLIP image and text embeddings, respectively. We design our generative stack to produce images from captions using two components:
- 我们训练数据集由成对的(x,y)组成,x是图片,y是文本,给定x和y,通过CLIP模型,可以分别生成image 和text embedding,zi和 zt。
- A prior P(zi|y) that produces CLIP image embeddings zi conditioned on captions y.
一个prior 模型用在给定文本时,生成image embedding zi. - A decoder P(x|zi, y) that produces images x conditioned on CLIP image embeddings zi (and optionally text captions y).
decoder 模型用于在给定条件zi时,生成最终图片 x。
整个过程如下所示

2.1 Decoder
-
We use diffusion models to produce images conditioned on CLIP image embeddings (and optionally text captions).
-
在prior模型生成的image embedding的基础上, 我们使用 diffusion models生成image。
-
将image embedding作为条件直接加上timestep embedding(也可以选择添加加text embedding,实验发现用处不大),然后通过下面的diffusion 去噪公式 ,选择unet网络预测噪声,生成最终的图片x
μ ˉ t = 1 α t ( x t − 1 − α t 1 − α ˉ t z t ) \bar \mu_t=\frac{1 } {\sqrt \alpha_{t}} (x_t -\frac{1-\alpha_t } {\sqrt{1- \bar \alpha_{t}}} z_t) μˉt=αt1(xt−1−αˉt1−αtzt)
2.2 Prior
• While a decoder can invert CLIP image embeddings zi to produce images x, we need a prior model that produces zi from captions y to enable image generations from text captions.
decoder 模型输入 image embedding zi 生成image x,需要prior模型生成的zi.
• Diffusion prior: The continuous vector zi is directly modelled using a Gaussian diffusion model conditioned on the caption y.
Diffusion prior : 给定文本y(clip 模型生成的文本向量)时,通过Gaussian diffusion model 直接生成 zi。为了改善样本质量,训练时我们随机mask掉10%的文本数据。

- 对于 diffusion prior,我们训练一个 decoder-only的Transformer模型,对输入序列使用causal attention mask。用于预测x0 (重点:不是噪声zt)
- Transformer模型的输入: the encoded text,the CLIP text embedding,time_embed,image_embed,learned_queries,(文本整体embedding,文本序列embedding,时间步embedding,当前t步对应的图片embedding,用于输出transformer 结果手动构造用于学习的embedding )
- diffusion 过程: 随机初始化xt,dffusion通过下面公式反向传播公式生成x(t-1)数据(transformer 模型直接生成x0),直到最后一步x0
μ ˉ t ( x t , x 0 ) = α t ( 1 − α ˉ t − 1 ) 1 − α ˉ t x t + α ˉ t − 1 ( 1 − α t ) 1 − α ˉ t x 0 \bar \mu_t(x_t,x_0)=\frac{\sqrt{\alpha_{t}}(1-\bar \alpha_{t-1} ) } {1- \bar \alpha_{t}} x_t +\frac{\sqrt{\bar \alpha_{t-1}}(1-\alpha_t) } {1- \bar \alpha_{t}} x_0 μˉt(xt,x0)=1−αˉtαt(1−αˉt−1)xt+1−αˉtαˉt−1(1−αt)x0
相关文章:
DALLE2论文解读及实现(一)
DALLE2: Hierarchical Text-Conditional Image Generation with CLIP Latents paper: https://cdn.openai.com/papers/dall-e-2.pdf github: https://github.com/lucidrains/DALLE2-pytorch DALLE2概览: - CLIP模型: 用于生成text embedding zt 和image …...
RabbitMQ-API
这里写目录标题 Hello word 模式添加依赖生产者消费者获取信道工具类 Work Queues模式消费者代码 C1开启多线程运行启动 消费者代码 C2生产者代码 消息应答自动应答消息应答的方法Multiple 的解释消息自动重新入队消息手动应答代码消费者API 队列持久化消息持久化不公平分发消息…...
外边距实现居中的写法
1、代码实例 2、默认是贴到左侧对齐的,但我们想要把他贴到中间对齐 3、居中的写法 4、这样就可以保证盒子居中了 5、以上写法仅适于行内元素和行内块元素的写法,有没有什么方法适用于行内块元素:可以添加text-align:center进行添加࿰…...
)
剑指 Offer 20. 表示数值的字符串 (正则 逐步分解)
文章目录 题目描述题目分析法一:完整代码: 法二:完整代码: 题目描述 请实现一个函数用来判断字符串是否表示数值(包括整数和小数)。 数值(按顺序)可以分成以下几个部分: 若干空格 一个 小数 或者…...

【深度学习】Transformer,Self-Attention,Multi-Head Attention
必读文章: https://blog.csdn.net/qq_37541097/article/details/117691873 论文名:Attention Is All You Need 文章目录 1、Self-Attention 自注意力机制2、Multi-Head Attention 1、Self-Attention 自注意力机制 Query(Q)表示当…...
CADintosh X for mac CAD绘图软件2D CAD 程序 兼容 M1
CADintosh X for Mac是一个功能强大的2D CAD绘图程序,专为Mac用户设计。它由Lemke Software开发,提供了一套丰富的工具和功能,使用户能够轻松创建高质量的技术图纸,平面图和设计。 CADintosh X for Mac具有直观的用户界面&#x…...

【读书笔记】《厌女》- [日]上野千鹤子 - 2010年出版
不停的阅读,然后形成自己的知识体系。 2023.08. 读 《厌女》- [日]上野千鹤子 - 2010年出版 - 豆瓣读书 文章目录 2023年中文版作者序2015年中文版作者序第一章 喜欢女人的男人的厌女症 2023年中文版作者序 ‘厌女症’的现象本来如‘房间里的大象’,因为…...

Android 从其他xml文件中获取View组件数据
问题 Android Studio 我想在 trace.java 从setting.java绑定的页面activity_setting.xml中 的editview中获取数据 解决方案 仅适用于 在同一应用的不同组件之间共享数据 在 SettingActivity.java 中,当用户准备离开当前活动时,可以将 EditText 中的数…...
java 数组的使用
数组 基本介绍 数组可以存放多个同一类型的数据,数组也是一种数据类型,是引用类型。 即:数组就是一组数据。 数组的使用 1、数组的定义 方法一 -> 单独声明 数据类型[] 数组名 new 数据类型[大小] 说明:int[] a new int…...

Jmeter(一) - 从入门到精通 - 环境搭建(详解教程)
1.JMeter 介绍 Apache JMeter是100%纯JAVA桌面应用程序,被设计为用于测试客户端/服务端结构的软件(例如web应用程序)。它可以用来测试静态和动态资源的性能,例如:静态文件,Java Servlet,CGI Scripts,Java Object,数据库和FTP服务器…...
外贸企业选择CRM的三大特点
外贸营销管理CRM云平台可以帮助外贸企业实现更高质量的营销管理和客户管理。无论是销售、市场营销或客户服务团队的成员,CRM都可以帮助企业更好地理解客户需求,并提供更好的服务。 1.便捷轻量级 云平台的一大优势是用户可以随时随地访问数据࿰…...

软件测试与游戏测试的区别
软件测试和游戏测试是两种不同领域的测试活动,它们之间存在一些区别,包括以下几个方面: 1. 测试目标 软件测试主要是验证和确认软件功能是否符合预期,通常关注软件的正确性、稳定性和兼容性等方面;而游戏测试则更关注游…...

Programming Abstractions in C阅读笔记:p72-p75
《Programming Abstractions In C》阅读P72-p75,每次阅读其实都有很多内容需要总结,这里摘抄其中一部分。 一、技术总结 1.字符串数组 学习《Programming Abstractions in C》第75页的时候,遇到一段代码: static string bigCitie…...

bash测试test详解
bash测试test详解 概述 任何相对完整的计算机语言都能够测试某个条件,然后根据测试的结果采取不同的动作。对于测试条件, Bash使用test命令、各种方括号和圆括号、if/then结构等来测试条件。 7.1. Test Constructs 一个if/then语句结构测试一个或多个命…...

你来问我来答,ChatGPT对话软件测试!主题互动
你来问我来答,ChatGPT对话软件测试! 大家好,我是聪明而有趣的ChatGPT。作为IT专家,我将竭尽全力为你解答技术问题,并提供适合各个级别人群理解的解决方案。无论你是初学者还是专业人士,我都会用智能、简单…...

无人机巢的作用及应用领域解析
无人机巢作为无人机领域的创新设备,不仅可以实现无人机的自主充电和电池交换,还为无人机提供安全便捷的存放空间。为了帮助大家更好地了解无人机巢,本文将着重解析无人机巢的作用和应用领域。 一、无人机巢的作用 无人机巢作为无人机技术的重…...
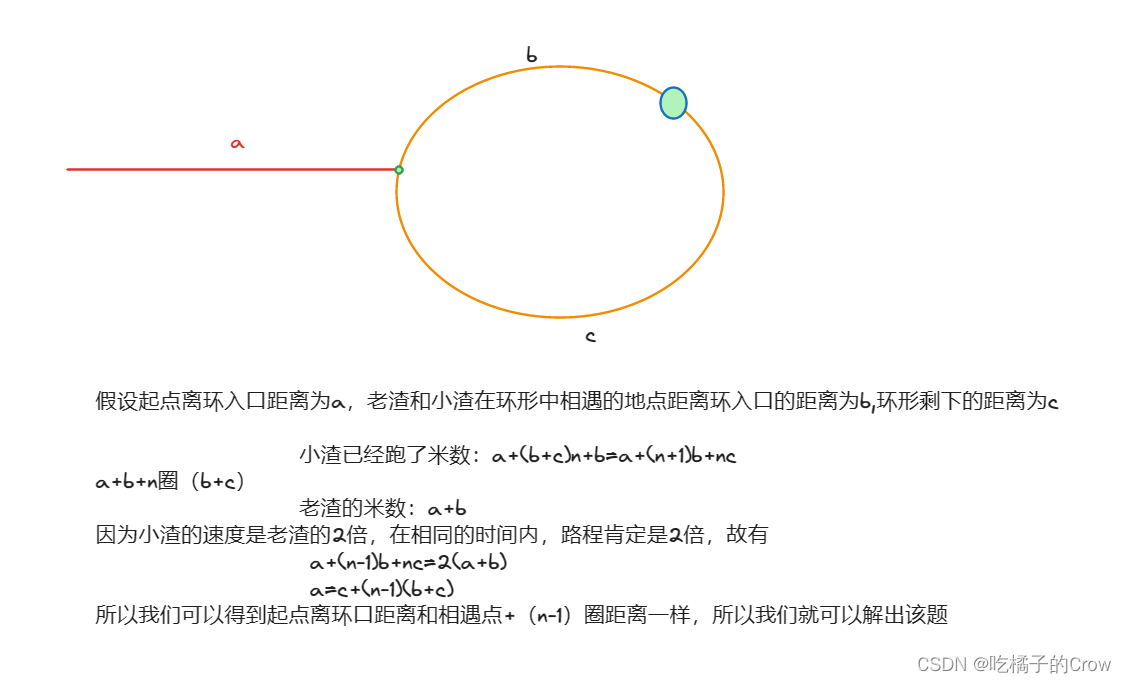
面试热题(环形链表II)
给定一个链表,返回链表开始入环的第一个节点。 从链表的头节点开始沿着 next 指针进入环的第一个节点为环的入口节点。如果链表无环,则返回 null。 为了表示给定链表中的环,我们使用整数 pos 来表示链表尾连接到链表中的位置(索引…...

策略模式:优雅地实现可扩展的设计
策略模式:优雅地实现可扩展的设计 摘要: 策略模式是一种常用的设计模式,它可以帮助我们实现可扩展的、灵活的代码结构。本文将通过一个计算器案例来介绍策略模式的概念、使用场景以及如何在实际项目中应用策略模式来提高代码的可维护性和可扩…...
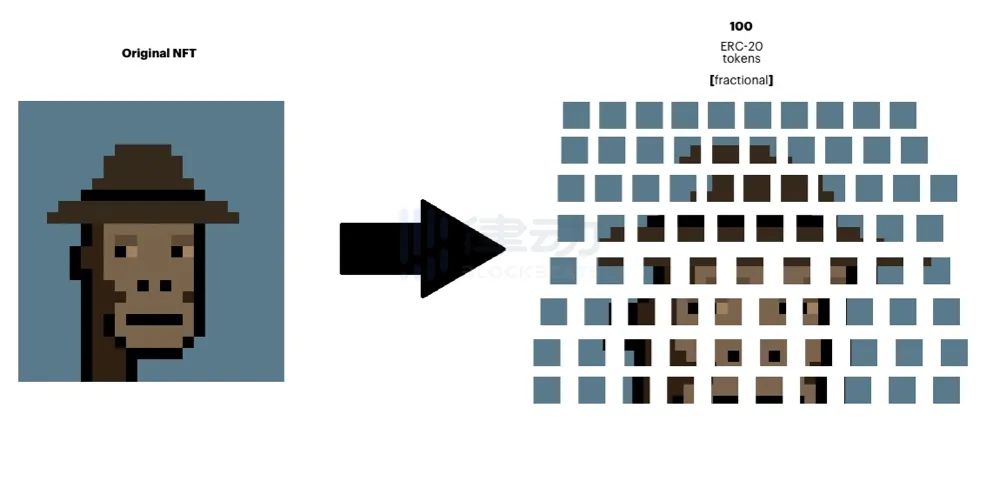
从8个新 NFT AMM,聊聊能如何为 NFT 提供流动性
DeFi 的出现,开启了数字金融民主化的革命。其中,通过 AMM 自由创建流动性池极大地增加了 ERC-20 Token 的流动性,并为一些长尾 Token 解锁了价值的发现,因而今天在链上可以看到各种丰富的交易、借贷和杠杆等活动。 而另一方面&am…...
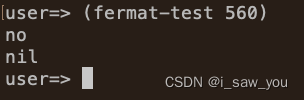
习题1.27
先写代码 (defn square [x] (* x x)) (defn expmod[base exp m](cond ( exp 0) 1(even? exp) (mod (square (expmod base (/ exp 2) m)) m):else (mod (* base (expmod base (- exp 1) m)) m)))(defn fermat-test[n](defn try-it [a](cond ( a n) (println "test end&qu…...

如何快速获取网易云和QQ音乐的精准LRC歌词?这款免费工具帮你一键搞定!
如何快速获取网易云和QQ音乐的精准LRC歌词?这款免费工具帮你一键搞定! 【免费下载链接】163MusicLyrics 云音乐歌词获取处理工具【网易云、QQ音乐】 项目地址: https://gitcode.com/GitHub_Trending/16/163MusicLyrics 还在为音乐播放器缺少歌词而…...

MLT框架的“Producer”到底有多智能?深入loader.dict与avformat揭秘媒体文件自动解析
MLT框架的“Producer”智能解析机制:从loader.dict到avformat的深度探索 当你在MLT框架中写下Producer(profile, nullptr, "video.mp4")这样一行看似简单的代码时,背后其实隐藏着一套精妙的媒体文件自动解析系统。这个系统能够根据文件扩展名、…...

创业团队如何借助Taotoken的多模型与透明计费快速验证AI产品原型
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 创业团队如何借助Taotoken的多模型与透明计费快速验证AI产品原型 对于资源有限的创业团队而言,在产品开发初期快速验证…...
资源下载推荐)
【免费下载】 探索8051开发新境界:IAR for 8051(8.10版本)资源下载推荐
探索8051开发新境界:IAR for 8051(8.10版本)资源下载推荐 【下载地址】IARfor80518.10版本资源下载 IAR for 8051(8.10版本)资源下载 项目地址: https://gitcode.com/open-source-toolkit/1b6d8 项目介绍 在嵌…...

全面掌握AMD Ryzen硬件调试:SMUDebugTool完整使用指南
全面掌握AMD Ryzen硬件调试:SMUDebugTool完整使用指南 【免费下载链接】SMUDebugTool A dedicated tool to help write/read various parameters of Ryzen-based systems, such as manual overclock, SMU, PCI, CPUID, MSR and Power Table. 项目地址: https://gi…...

重新定义开源协作:GitHub中文界面如何突破语言认知边界
重新定义开源协作:GitHub中文界面如何突破语言认知边界 【免费下载链接】github-chinese GitHub 汉化插件,GitHub 中文化界面。 (GitHub Translation To Chinese) 项目地址: https://gitcode.com/gh_mirrors/gi/github-chinese GitHub中文汉化插件…...

CA-IS3741:四通道高速数字隔离芯片的选型、实测与光耦替代实战
1. 为什么需要高速数字隔离芯片? 在工业自动化、医疗设备、新能源等领域的电子系统中,不同模块之间经常需要进行电气隔离。传统的光耦器件(如PC817、TLP521等)虽然成本低廉,但在高速信号传输场景下暴露出明显短板。我曾…...

电容触摸传感与微控制器互动:打造万圣节智能蝙蝠装饰
1. 项目概述:当电容触摸遇上万圣节蝙蝠又到了一年一度可以名正言顺“吓唬人”的季节。每年万圣节,除了南瓜灯和糖果,我总想搞点不一样的、能和人互动的装饰。市面上的那些一动就吱呀乱叫的塑料道具,总觉得少了点灵魂和“技术含量”…...

SmartDock:让Android设备拥有桌面级生产力的智能启动器
SmartDock:让Android设备拥有桌面级生产力的智能启动器 【免费下载链接】smartdock A user-friendly desktop mode launcher that offers a modern and customizable user interface 项目地址: https://gitcode.com/gh_mirrors/smar/smartdock 你是否曾经想过…...

离子阱量子计算机与SIMD编译优化技术解析
1. 离子阱量子计算机与SIMD的奇妙结合在量子计算领域,离子阱系统因其独特的物理特性而备受关注。与传统超导量子比特不同,离子阱量子计算机通过电磁场将带电原子(通常是镱或钙离子)悬浮在真空中,利用激光操控这些离子的…...