【黑马头条之kafka及异步通知文章上下架】
本笔记内容为黑马头条项目的kafka及异步通知文章上下架部分
目录
一、kafka概述
二、kafka安装配置
三、kafka入门
四、kafka高可用设计
1、集群
2、备份机制(Replication)
五、kafka生产者详解
1、发送类型
2、参数详解
六、kafka消费者详解
1、消费者组
2、消息有序性
3、提交和偏移量
七、springboot集成kafka
1、入门
2、传递消息为对象
八、自媒体文章上下架功能完成
1、需求分析
2、流程说明
3、接口定义
4、自媒体文章上下架-功能实现
5、消息通知article端文章上下架
一、kafka概述
消息中间件对比
| 特性 | ActiveMQ | RabbitMQ | RocketMQ | Kafka |
|---|---|---|---|---|
| 开发语言 | java | erlang | java | scala |
| 单机吞吐量 | 万级 | 万级 | 10万级 | 100万级 |
| 时效性 | ms | us | ms | ms级以内 |
| 可用性 | 高(主从) | 高(主从) | 非常高(分布式) | 非常高(分布式) |
| 功能特性 | 成熟的产品、较全的文档、各种协议支持好 | 并发能力强、性能好、延迟低 | MQ功能比较完善,扩展性佳 | 只支持主要的MQ功能,主要应用于大数据领域 |
消息中间件对比-选择建议
| 消息中间件 | 建议 |
|---|---|
| Kafka | 追求高吞吐量,适合产生大量数据的互联网服务的数据收集业务 |
| RocketMQ | 可靠性要求很高的金融互联网领域,稳定性高,经历了多次阿里双11考验 |
| RabbitMQ | 性能较好,社区活跃度高,数据量没有那么大,优先选择功能比较完备的RabbitMQ |
kafka介绍
Kafka 是一个分布式流媒体平台,类似于消息队列或企业消息传递系统。kafka官网:Apache Kafka 
kafka介绍-名词解释
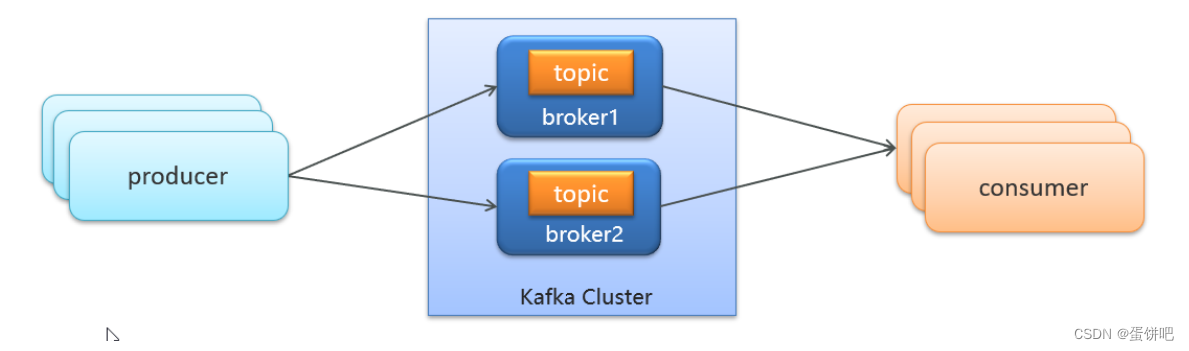
-
producer:发布消息的对象称之为主题生产者(Kafka topic producer)
-
topic:Kafka将消息分门别类,每一类的消息称之为一个主题(Topic)
-
consumer:订阅消息并处理发布的消息的对象称之为主题消费者(consumers)
-
broker:已发布的消息保存在一组服务器中,称之为Kafka集群。集群中的每一个服务器都是一个代理(Broker)。 消费者可以订阅一个或多个主题(topic),并从Broker拉数据,从而消费这些已发布的消息。
二、kafka安装配置
Kafka对于zookeeper是强依赖,保存kafka相关的节点数据,所以安装Kafka之前必须先安装zookeeper
Docker安装zookeeper
下载镜像:
docker pull zookeeper:3.4.14创建容器
docker run -d --name zookeeper -p 2181:2181 zookeeper:3.4.14Docker安装kafka
下载镜像:
docker pull wurstmeister/kafka:2.12-2.3.1创建容器
docker run -d --name kafka \
--env KAFKA_ADVERTISED_HOST_NAME=192.168.200.130 \
--env KAFKA_ZOOKEEPER_CONNECT=192.168.200.130:2181 \
--env KAFKA_ADVERTISED_LISTENERS=PLAINTEXT://192.168.200.130:9092 \
--env KAFKA_LISTENERS=PLAINTEXT://0.0.0.0:9092 \
--env KAFKA_HEAP_OPTS="-Xmx256M -Xms256M" \
--net=host wurstmeister/kafka:2.12-2.3.1三、kafka入门
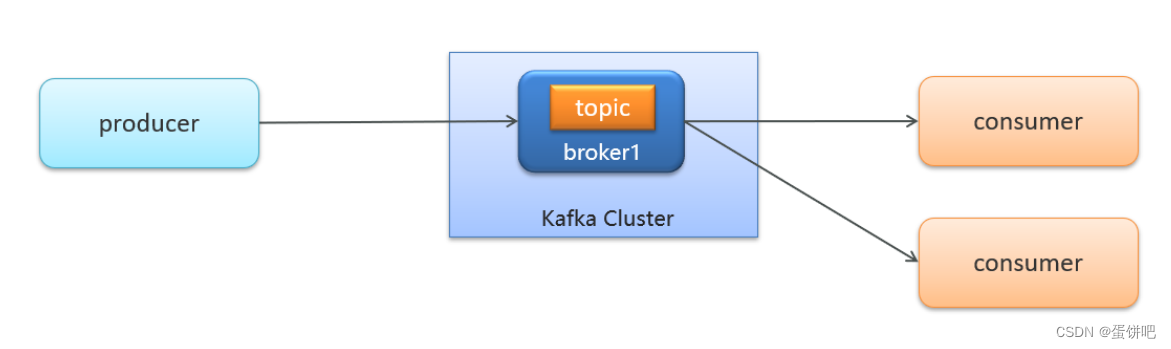
-
生产者发送消息,多个消费者只能有一个消费者接收到消息
-
生产者发送消息,多个消费者都可以接收到消息
(1)创建kafka-demo项目,导入依赖
<dependency><groupId>org.apache.kafka</groupId><artifactId>kafka-clients</artifactId>
</dependency>(2)生产者发送消息
package com.heima.kafka.sample;import org.apache.kafka.clients.producer.KafkaProducer;
import org.apache.kafka.clients.producer.ProducerConfig;
import org.apache.kafka.clients.producer.ProducerRecord;import java.util.Properties;/*** 生产者*/
public class ProducerQuickStart {public static void main(String[] args) {//1.kafka的配置信息Properties properties = new Properties();//kafka的连接地址properties.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG,"192.168.200.130:9092");//发送失败,失败的重试次数properties.put(ProducerConfig.RETRIES_CONFIG,5);//消息key的序列化器properties.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG,"org.apache.kafka.common.serialization.StringSerializer");//消息value的序列化器properties.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG,"org.apache.kafka.common.serialization.StringSerializer");//2.生产者对象KafkaProducer<String,String> producer = new KafkaProducer<String, String>(properties);//封装发送的消息ProducerRecord<String,String> record = new ProducerRecord<String, String>("itheima-topic","100001","hello kafka");//3.发送消息producer.send(record);//4.关闭消息通道,必须关闭,否则消息发送不成功producer.close();}}(3)消费者接收消息
package com.heima.kafka.sample;import org.apache.kafka.clients.consumer.ConsumerConfig;
import org.apache.kafka.clients.consumer.ConsumerRecord;
import org.apache.kafka.clients.consumer.ConsumerRecords;
import org.apache.kafka.clients.consumer.KafkaConsumer;import java.time.Duration;
import java.util.Collections;
import java.util.Properties;/*** 消费者*/
public class ConsumerQuickStart {public static void main(String[] args) {//1.添加kafka的配置信息Properties properties = new Properties();//kafka的连接地址properties.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, "192.168.200.130:9092");//消费者组properties.put(ConsumerConfig.GROUP_ID_CONFIG, "group2");//消息的反序列化器properties.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, "org.apache.kafka.common.serialization.StringDeserializer");properties.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, "org.apache.kafka.common.serialization.StringDeserializer");//2.消费者对象KafkaConsumer<String, String> consumer = new KafkaConsumer<String, String>(properties);//3.订阅主题consumer.subscribe(Collections.singletonList("itheima-topic"));//当前线程一直处于监听状态while (true) {//4.获取消息ConsumerRecords<String, String> consumerRecords = consumer.poll(Duration.ofMillis(1000));for (ConsumerRecord<String, String> consumerRecord : consumerRecords) {System.out.println(consumerRecord.key());System.out.println(consumerRecord.value());}}}}总结
-
生产者发送消息,多个消费者订阅同一个主题,只能有一个消费者收到消息(一对一)
-
生产者发送消息,多个消费者订阅同一个主题,所有消费者都能收到消息(一对多)
四、kafka高可用设计
1、集群

-
Kafka 的服务器端由被称为 Broker 的服务进程构成,即一个 Kafka 集群由多个 Broker 组成
-
这样如果集群中某一台机器宕机,其他机器上的 Broker 也依然能够对外提供服务。这其实就是 Kafka 提供高可用的手段之一
2、备份机制(Replication)

Kafka 中消息的备份又叫做 副本(Replica)
Kafka 定义了两类副本:
-
领导者副本(Leader Replica)
-
追随者副本(Follower Replica)
同步方式
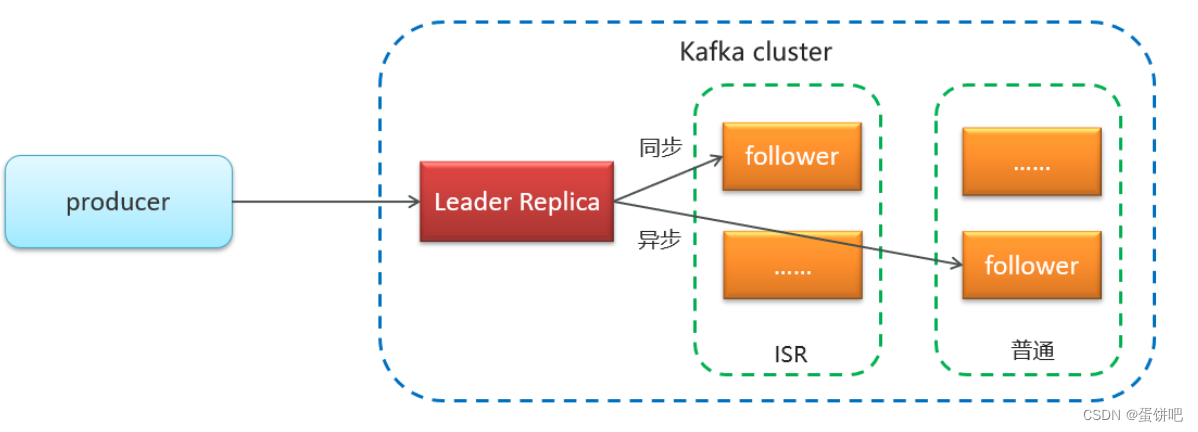
ISR(in-sync replica)需要同步复制保存的follower
如果leader失效后,需要选出新的leader,选举的原则如下:
第一:选举时优先从ISR中选定,因为这个列表中follower的数据是与leader同步的
第二:如果ISR列表中的follower都不行了,就只能从其他follower中选取
极端情况,就是所有副本都失效了,这时有两种方案
第一:等待ISR中的一个活过来,选为Leader,数据可靠,但活过来的时间不确定
第二:选择第一个活过来的Replication,不一定是ISR中的,选为leader,以最快速度恢复可用性,但数据不一定完整
五、kafka生产者详解
1、发送类型
同步发送
使用send()方法发送,它会返回一个Future对象,调用get()方法进行等待,就可以知道消息是否发送成功
RecordMetadata recordMetadata = producer.send(kvProducerRecord).get();
System.out.println(recordMetadata.offset());异步发送
调用send()方法,并指定一个回调函数,服务器在返回响应时调用函数
//异步消息发送
producer.send(kvProducerRecord, new Callback() {@Overridepublic void onCompletion(RecordMetadata recordMetadata, Exception e) {if(e != null){System.out.println("记录异常信息到日志表中");}System.out.println(recordMetadata.offset());}
});2、参数详解
ack
代码的配置方式:
//ack配置 消息确认机制
prop.put(ProducerConfig.ACKS_CONFIG,"all");参数的选择说明
| 确认机制 | 说明 |
|---|---|
| acks=0 | 生产者在成功写入消息之前不会等待任何来自服务器的响应,消息有丢失的风险,但是速度最快 |
| acks=1(默认值) | 只要集群首领节点收到消息,生产者就会收到一个来自服务器的成功响应 |
| acks=all | 只有当所有参与赋值的节点全部收到消息时,生产者才会收到一个来自服务器的成功响应 |
retries
生产者从服务器收到的错误有可能是临时性错误,在这种情况下,retries参数的值决定了生产者可以重发消息的次数,如果达到这个次数,生产者会放弃重试返回错误,默认情况下,生产者会在每次重试之间等待100ms
代码中配置方式:
//重试次数
prop.put(ProducerConfig.RETRIES_CONFIG,10);消息压缩
默认情况下, 消息发送时不会被压缩。
代码中配置方式:
//数据压缩
prop.put(ProducerConfig.COMPRESSION_TYPE_CONFIG,"lz4");| 压缩算法 | 说明 |
|---|---|
| snappy | 占用较少的 CPU, 却能提供较好的性能和相当可观的压缩比, 如果看重性能和网络带宽,建议采用 |
| lz4 | 占用较少的 CPU, 压缩和解压缩速度较快,压缩比也很客观 |
| gzip | 占用较多的 CPU,但会提供更高的压缩比,网络带宽有限,可以使用这种算法 |
使用压缩可以降低网络传输开销和存储开销,而这往往是向 Kafka 发送消息的瓶颈所在。
六、kafka消费者详解
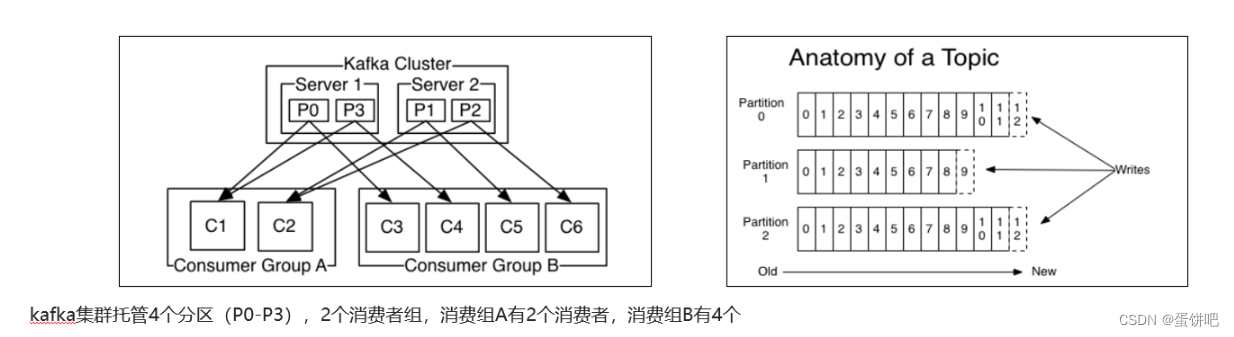
1、消费者组

-
消费者组(Consumer Group) :指的就是由一个或多个消费者组成的群体
-
一个发布在Topic上消息被分发给此消费者组中的一个消费者
-
所有的消费者都在一个组中,那么这就变成了queue模型
-
所有的消费者都在不同的组中,那么就完全变成了发布-订阅模型
-
2、消息有序性
应用场景:
-
即时消息中的单对单聊天和群聊,保证发送方消息发送顺序与接收方的顺序一致
-
充值转账两个渠道在同一个时间进行余额变更,短信通知必须要有顺序
 topic分区中消息只能由消费者组中的唯一一个消费者处理,所以消息肯定是按照先后顺序进行处理的。但是它也仅仅是保证Topic的一个分区顺序处理,不能保证跨分区的消息先后处理顺序。 所以,如果你想要顺序的处理Topic的所有消息,那就只提供一个分区。
topic分区中消息只能由消费者组中的唯一一个消费者处理,所以消息肯定是按照先后顺序进行处理的。但是它也仅仅是保证Topic的一个分区顺序处理,不能保证跨分区的消息先后处理顺序。 所以,如果你想要顺序的处理Topic的所有消息,那就只提供一个分区。
3、提交和偏移量
kafka不会像其他JMS队列那样需要得到消费者的确认,消费者可以使用kafka来追踪消息在分区的位置(偏移量)
消费者会往一个叫做_consumer_offset的特殊主题发送消息,消息里包含了每个分区的偏移量。如果消费者发生崩溃或有新的消费者加入群组,就会触发再均衡

正常的情况

如果消费者2挂掉以后,会发生再均衡,消费者2负责的分区会被其他消费者进行消费
再均衡后不可避免会出现一些问题
问题一:
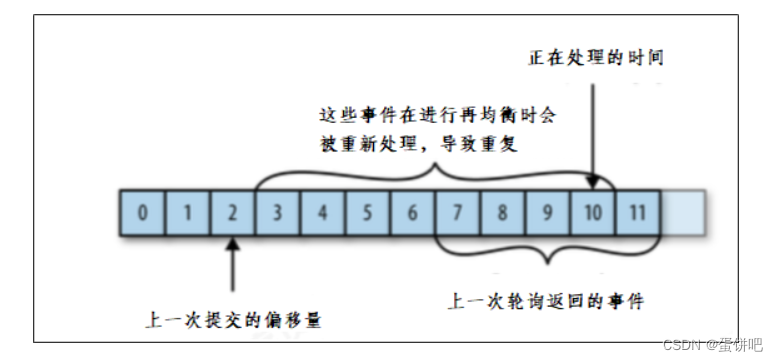
如果提交偏移量小于客户端处理的最后一个消息的偏移量,那么处于两个偏移量之间的消息就会被重复处理。
问题二:
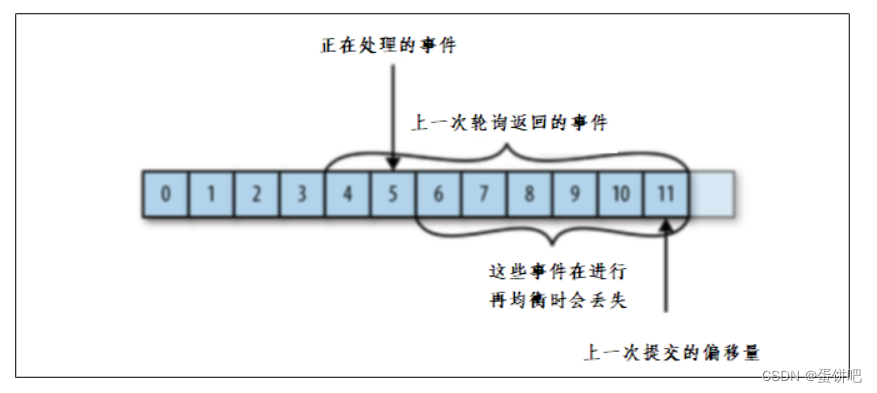
如果提交的偏移量大于客户端的最后一个消息的偏移量,那么处于两个偏移量之间的消息将会丢失。
如果想要解决这些问题,还要知道目前kafka提交偏移量的方式:
提交偏移量的方式有两种,分别是自动提交偏移量和手动提交
- 自动提交偏移量
当enable.auto.commit被设置为true,提交方式就是让消费者自动提交偏移量,每隔5秒消费者会自动把从poll()方法接收的最大偏移量提交上去
- 手动提交 ,当enable.auto.commit被设置为false可以有以下三种提交方式
-
提交当前偏移量(同步提交)
-
异步提交
-
同步和异步组合提交
-
1.提交当前偏移量(同步提交)
把enable.auto.commit设置为false,让应用程序决定何时提交偏移量。使用commitSync()提交偏移量,commitSync()将会提交poll返回的最新的偏移量,所以在处理完所有记录后要确保调用了commitSync()方法。否则还是会有消息丢失的风险。
只要没有发生不可恢复的错误,commitSync()方法会一直尝试直至提交成功,如果提交失败也可以记录到错误日志里。
while (true){ConsumerRecords<String, String> records = consumer.poll(Duration.ofMillis(1000));for (ConsumerRecord<String, String> record : records) {System.out.println(record.value());System.out.println(record.key());try {consumer.commitSync();//同步提交当前最新的偏移量}catch (CommitFailedException e){System.out.println("记录提交失败的异常:"+e);}}
}2.异步提交
手动提交有一个缺点,那就是当发起提交调用时应用会阻塞。当然我们可以减少手动提交的频率,但这个会增加消息重复的概率(和自动提交一样)。另外一个解决办法是,使用异步提交的API。
while (true){ConsumerRecords<String, String> records = consumer.poll(Duration.ofMillis(1000));for (ConsumerRecord<String, String> record : records) {System.out.println(record.value());System.out.println(record.key());}consumer.commitAsync(new OffsetCommitCallback() {@Overridepublic void onComplete(Map<TopicPartition, OffsetAndMetadata> map, Exception e) {if(e!=null){System.out.println("记录错误的提交偏移量:"+ map+",异常信息"+e);}}});
}3.同步和异步组合提交
异步提交也有个缺点,那就是如果服务器返回提交失败,异步提交不会进行重试。相比较起来,同步提交会进行重试直到成功或者最后抛出异常给应用。异步提交没有实现重试是因为,如果同时存在多个异步提交,进行重试可能会导致位移覆盖。
举个例子,假如我们发起了一个异步提交commitA,此时的提交位移为2000,随后又发起了一个异步提交commitB且位移为3000;commitA提交失败但commitB提交成功,此时commitA进行重试并成功的话,会将实际上将已经提交的位移从3000回滚到2000,导致消息重复消费。
try {while (true){ConsumerRecords<String, String> records = consumer.poll(Duration.ofMillis(1000));for (ConsumerRecord<String, String> record : records) {System.out.println(record.value());System.out.println(record.key());}consumer.commitAsync();}
}catch (Exception e){+e.printStackTrace();System.out.println("记录错误信息:"+e);
}finally {try {consumer.commitSync();}finally {consumer.close();}
}七、springboot集成kafka
1、入门
1.导入spring-kafka依赖信息
<dependencies><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-web</artifactId></dependency><!-- kafkfa --><dependency><groupId>org.springframework.kafka</groupId><artifactId>spring-kafka</artifactId><exclusions><exclusion><groupId>org.apache.kafka</groupId><artifactId>kafka-clients</artifactId></exclusion></exclusions></dependency><dependency><groupId>org.apache.kafka</groupId><artifactId>kafka-clients</artifactId></dependency><dependency><groupId>com.alibaba</groupId><artifactId>fastjson</artifactId></dependency>
</dependencies>2.在resources下创建文件application.yml
server:port: 9991
spring:application:name: kafka-demokafka:bootstrap-servers: 192.168.200.130:9092producer:retries: 10key-serializer: org.apache.kafka.common.serialization.StringSerializervalue-serializer: org.apache.kafka.common.serialization.StringSerializerconsumer:group-id: ${spring.application.name}-testkey-deserializer: org.apache.kafka.common.serialization.StringDeserializervalue-deserializer: org.apache.kafka.common.serialization.StringDeserializer3.消息生产者
package com.heima.kafka.controller;import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.kafka.core.KafkaTemplate;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.RestController;@RestController
public class HelloController {@Autowiredprivate KafkaTemplate<String,String> kafkaTemplate;@GetMapping("/hello")public String hello(){kafkaTemplate.send("itcast-topic","黑马程序员");return "ok";}
}4.消息消费者
package com.heima.kafka.listener;import org.springframework.kafka.annotation.KafkaListener;
import org.springframework.stereotype.Component;
import org.springframework.util.StringUtils;@Component
public class HelloListener {@KafkaListener(topics = "itcast-topic")public void onMessage(String message){if(!StringUtils.isEmpty(message)){System.out.println(message);}}
}2、传递消息为对象
目前springboot整合后的kafka,因为序列化器是StringSerializer,这个时候如果需要传递对象可以有两种方式
方式一:可以自定义序列化器,对象类型众多,这种方式通用性不强,本章节不介绍
方式二:可以把要传递的对象进行转json字符串,接收消息后再转为对象即可,本项目采用这种方式
发送消息
@GetMapping("/hello")
public String hello(){User user = new User();user.setUsername("xiaowang");user.setAge(18);kafkaTemplate.send("user-topic", JSON.toJSONString(user));return "ok";
}接收消息
package com.heima.kafka.listener;import com.alibaba.fastjson.JSON;
import com.heima.kafka.pojo.User;
import org.springframework.kafka.annotation.KafkaListener;
import org.springframework.stereotype.Component;
import org.springframework.util.StringUtils;@Component
public class HelloListener {@KafkaListener(topics = "user-topic")public void onMessage(String message){if(!StringUtils.isEmpty(message)){User user = JSON.parseObject(message, User.class);System.out.println(user);}}
}八、自媒体文章上下架功能完成
1、需求分析

-
已发表且已上架的文章可以下架
-
已发表且已下架的文章可以上架
2、流程说明

3、接口定义
| 说明 | |
|---|---|
| 接口路径 | /api/v1/news/down_or_up |
| 请求方式 | POST |
| 参数 | DTO |
| 响应结果 | ResponseResult |
DTO
@Data
public class WmNewsDto {private Integer id;/*** 是否上架 0 下架 1 上架*/private Short enable;}ResponseResult
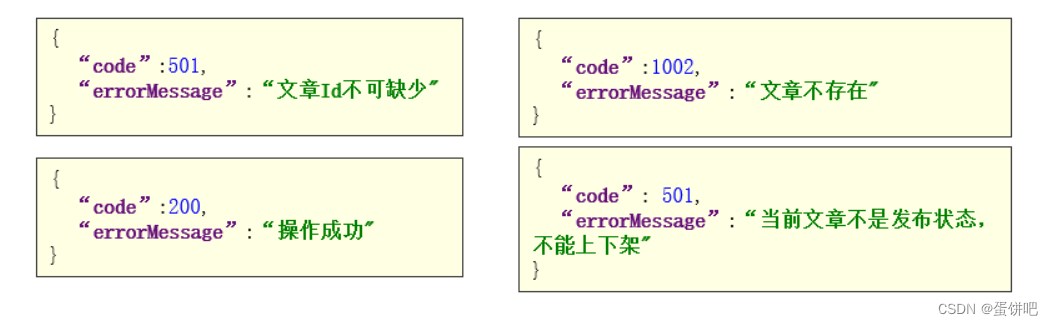
4、自媒体文章上下架-功能实现
1.接口定义
在heima-leadnews-wemedia工程下的WmNewsController新增方法
@PostMapping("/down_or_up")
public ResponseResult downOrUp(@RequestBody WmNewsDto dto){return null;
}在WmNewsDto中新增enable属性 ,完整的代码如下:
package com.heima.model.wemedia.dtos;import lombok.Data;import java.util.Date;
import java.util.List;@Data
public class WmNewsDto {private Integer id;/*** 标题*/private String title;/*** 频道id*/private Integer channelId;/*** 标签*/private String labels;/*** 发布时间*/private Date publishTime;/*** 文章内容*/private String content;/*** 文章封面类型 0 无图 1 单图 3 多图 -1 自动*/private Short type;/*** 提交时间*/private Date submitedTime; /*** 状态 提交为1 草稿为0*/private Short status;/*** 封面图片列表 多张图以逗号隔开*/private List<String> images;/*** 上下架 0 下架 1 上架*/private Short enable;
}2.业务层编写
在WmNewsService新增方法
/*** 文章的上下架* @param dto* @return*/
public ResponseResult downOrUp(WmNewsDto dto);实现方法
/*** 文章的上下架* @param dto* @return*/
@Override
public ResponseResult downOrUp(WmNewsDto dto) {//1.检查参数if(dto.getId() == null){return ResponseResult.errorResult(AppHttpCodeEnum.PARAM_INVALID);}//2.查询文章WmNews wmNews = getById(dto.getId());if(wmNews == null){return ResponseResult.errorResult(AppHttpCodeEnum.DATA_NOT_EXIST,"文章不存在");}//3.判断文章是否已发布if(!wmNews.getStatus().equals(WmNews.Status.PUBLISHED.getCode())){return ResponseResult.errorResult(AppHttpCodeEnum.PARAM_INVALID,"当前文章不是发布状态,不能上下架");}//4.修改文章enableif(dto.getEnable() != null && dto.getEnable() > -1 && dto.getEnable() < 2){update(Wrappers.<WmNews>lambdaUpdate().set(WmNews::getEnable,dto.getEnable()).eq(WmNews::getId,wmNews.getId()));}return ResponseResult.okResult(AppHttpCodeEnum.SUCCESS);
}3.控制器
@PostMapping("/down_or_up")
public ResponseResult downOrUp(@RequestBody WmNewsDto dto){return wmNewsService.downOrUp(dto);
}测试
5、消息通知article端文章上下架
1.在heima-leadnews-common模块下导入kafka依赖
<!-- kafkfa -->
<dependency><groupId>org.springframework.kafka</groupId><artifactId>spring-kafka</artifactId>
</dependency>
<dependency><groupId>org.apache.kafka</groupId><artifactId>kafka-clients</artifactId>
</dependency>2.在自媒体端的nacos配置中心配置kafka的生产者
spring:kafka:bootstrap-servers: 192.168.200.130:9092producer:retries: 10key-serializer: org.apache.kafka.common.serialization.StringSerializervalue-serializer: org.apache.kafka.common.serialization.StringSerializer3.在自媒体端文章上下架后发送消息
//发送消息,通知article端修改文章配置
if(wmNews.getArticleId() != null){Map<String,Object> map = new HashMap<>();map.put("articleId",wmNews.getArticleId());map.put("enable",dto.getEnable());kafkaTemplate.send(WmNewsMessageConstants.WM_NEWS_UP_OR_DOWN_TOPIC,JSON.toJSONString(map));
}常量类:
public class WmNewsMessageConstants {public static final String WM_NEWS_UP_OR_DOWN_TOPIC="wm.news.up.or.down.topic";
}4.在article端的nacos配置中心配置kafka的消费者
spring:kafka:bootstrap-servers: 192.168.200.130:9092consumer:group-id: ${spring.application.name}key-deserializer: org.apache.kafka.common.serialization.StringDeserializervalue-deserializer: org.apache.kafka.common.serialization.StringDeserializer5.在article端编写监听,接收数据
package com.heima.article.listener;import com.alibaba.fastjson.JSON;
import com.heima.article.service.ApArticleConfigService;
import lombok.extern.slf4j.Slf4j;
import org.apache.commons.lang3.StringUtils;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.kafka.annotation.KafkaListener;
import org.springframework.stereotype.Component;import java.util.Map;@Component
@Slf4j
public class ArtilceIsDownListener {@Autowiredprivate ApArticleConfigService apArticleConfigService;@KafkaListener(topics = WmNewsMessageConstants.WM_NEWS_UP_OR_DOWN_TOPIC)public void onMessage(String message){if(StringUtils.isNotBlank(message)){Map map = JSON.parseObject(message, Map.class);apArticleConfigService.updateByMap(map);log.info("article端文章配置修改,articleId={}",map.get("articleId"));}}
}6.修改ap_article_config表的数据
新建ApArticleConfigService
package com.heima.article.service;import com.baomidou.mybatisplus.extension.service.IService;
import com.heima.model.article.pojos.ApArticleConfig;import java.util.Map;public interface ApArticleConfigService extends IService<ApArticleConfig> {/*** 修改文章配置* @param map*/public void updateByMap(Map map);
}实现类:
package com.heima.article.service.impl;import com.baomidou.mybatisplus.core.toolkit.Wrappers;
import com.baomidou.mybatisplus.extension.service.impl.ServiceImpl;
import com.heima.article.mapper.ApArticleConfigMapper;
import com.heima.article.service.ApArticleConfigService;
import com.heima.model.article.pojos.ApArticleConfig;
import lombok.extern.slf4j.Slf4j;
import org.springframework.stereotype.Service;
import org.springframework.transaction.annotation.Transactional;import java.util.Map;@Service
@Slf4j
@Transactional
public class ApArticleConfigServiceImpl extends ServiceImpl<ApArticleConfigMapper, ApArticleConfig> implements ApArticleConfigService {/*** 修改文章配置* @param map*/@Overridepublic void updateByMap(Map map) {//0 下架 1 上架Object enable = map.get("enable");boolean isDown = true;if(enable.equals(1)){isDown = false;}//修改文章配置update(Wrappers.<ApArticleConfig>lambdaUpdate().eq(ApArticleConfig::getArticleId,map.get("articleId")).set(ApArticleConfig::getIsDown,isDown));}
}结束!
相关文章:
【黑马头条之kafka及异步通知文章上下架】
本笔记内容为黑马头条项目的kafka及异步通知文章上下架部分 目录 一、kafka概述 二、kafka安装配置 三、kafka入门 四、kafka高可用设计 1、集群 2、备份机制(Replication) 五、kafka生产者详解 1、发送类型 2、参数详解 六、kafka消费者详解 1、消费者…...
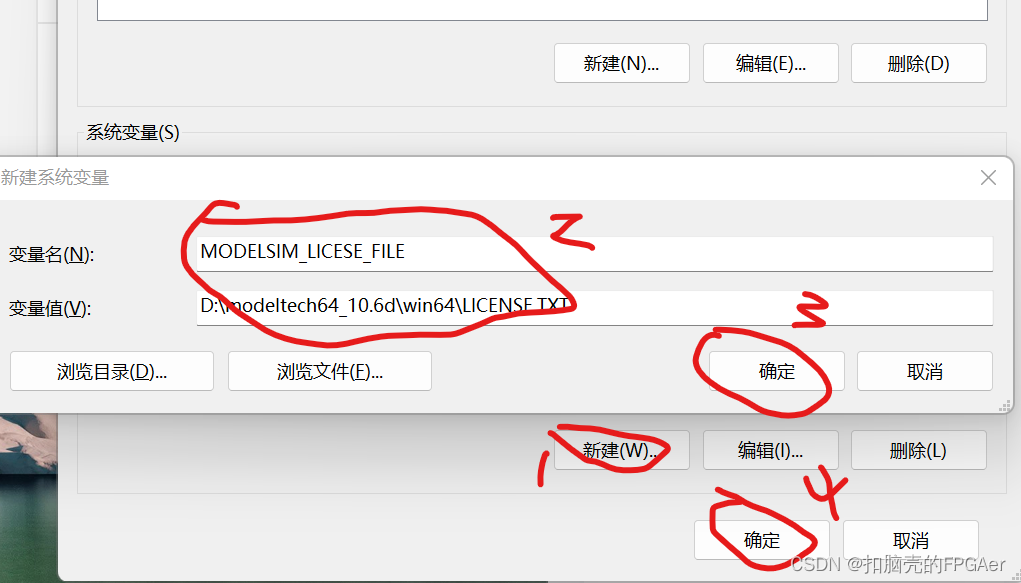
Modelsim打开后报unable to checkout a viewer license
找到Modelsim安装包中的MentorKG.exe文件和patch64_dll.bat文件,将这两个文件拷贝到Modelsim安装目录中的win64文件夹: 在win64文件夹中找到mgls64.dll,将它拷贝粘贴一份后修改名字为mgls.dll: 双击win64文件夹中的patch64_dll.ba…...
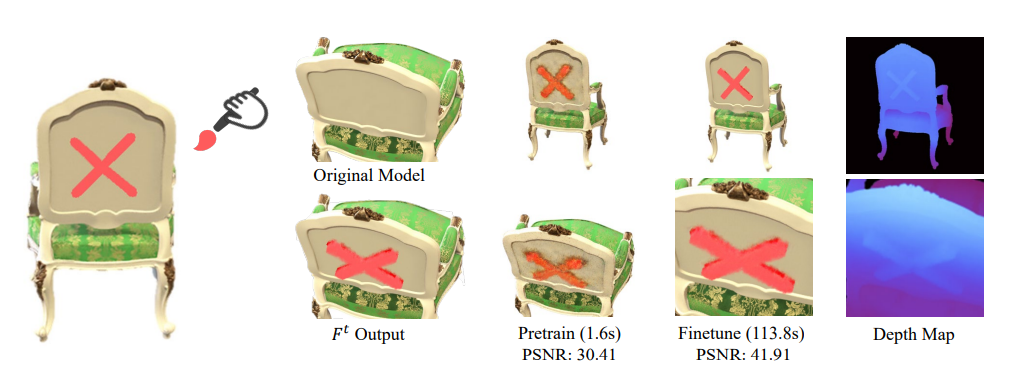
计算机视觉与图形学-神经渲染专题-Seal-3D(基于NeRF的像素级交互式编辑)
摘要 随着隐式神经表示或神经辐射场 (NeRF) 的流行,迫切需要与隐式 3D 模型交互的编辑方法,以完成后处理重建场景和 3D 内容创建等任务。虽然之前的作品从不同角度探索了 NeRF 编辑,但它们在编辑灵活性、质量和速度方面受到限制,无…...

synchronized的底层实现原理
技术主题 synchronized 是 Java 中用于实现线程同步的关键字。它的底层原理涉及到对象头、Monitor(监视器)和内存屏障等概念。 技术原理 技术一:对象头 对象头:每个 Java 对象在内存中都有一个对象头,用于存储对象的元数据信息,比如对象的哈希码、GC 信息以及锁状态等…...
屏幕取色器Mac版_苹果屏幕取色工具_屏幕取色器工具
Sip for Mac 是Mac系统平台上的一款老牌的颜色拾取工具,是设计师和前端开发工作者必不可少的屏幕取色软件,你只需要用鼠标点一下即可轻松地对屏幕上的任何颜色进行采样和编码,并将颜色数据自动存到剪切板,方便随时粘贴出来。 Sip…...

HDFS中的Federation联邦机制
HDFS中的Federation联邦机制 当前HDFS体系架构--简介局限性 联邦Federation架构简介好处配置示例 当前HDFS体系架构–简介 当前的HDFS结构有两个主要的层: 命名空间(namespace) 由文件,块和目录组成的统一抽象的目录树结构。由n…...

Spring Boot 单元测试
目录 1.什么是单元测试? 2.单元测试的优点 3.Spring Boot 单元测试使用 3.1 生成单元测试的类 3.2 添加 Spring Boot 框架测试注解:SpringBootTest 3.3 添加单元测试业务逻辑 3.4 注解 Transactional 4. 断言 1.什么是单元测试? 单元…...

k8s部署nginx访问Tomcat
1.nginx打包镜像 #1、编写DockerFilemkdir /opt/my_nginx_dockerfilecd /opt/my_nginx_dockerfile cat >default.conf<<EOF server {listen 80;listen [::]:80;server_name localhost;#access_log /var/log/nginx/host.access.log main;location / {root …...
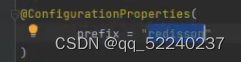
springboot配置文件的使用
目录 1.application.properties是springboot默认的配置文件,但是比较繁琐,一般用.yml文件 2. 配置文件的作用 3.配置文件的使用 1.application.properties是springboot默认的配置文件,但是比较繁琐,一般用.yml文件 ①、properti…...

blender 毛发粒子
新建平面,点击右侧粒子系统,选择毛发,调整毛发长度,数量(Number),调整数量是为了避免电脑卡顿; 上面设置的每一根柱子都可以变成一个物体,点击渲染,渲染为选择…...

. 在css中的应用
正好看到一个用 &. 的css语句,感觉不太明白就去查了一下,感觉C站上缺少相关内容,所以这里就来补上一篇 &. 实际上是一种sass语法,在 Sass 中 & 表示父选择器的引用,可以用于创建更具体的选择器࿰…...
黑马程序员SpringMVC练手项目
目录 1、需求 2、项目准备 pom.xml SQL jdbc.properties log4j.properties applicationContext.xml spring-mvc.xml web.xml 3、工作流程 4、难点 项目已经上传到gitee:https://gitee.com/xzl-it/my-projects 1、需求 SpringMVC项目练习:数…...
)
SQL注入 ❤ ~~~ 网络空间安全及计算机领域常见英语单词及短语——网络安全(二)
SQL注入 ❤ 学网安英语 大白话讲SQL注入SQL注入原理1. 用恶意拼接查询进行SQL注入攻击2. 利用注释执行非法命令进行SQL注入攻击3. 利用传入非法参数进行SQL注入攻击4. 添加额外条件进行SQL注入攻击 时间和布尔盲注时间盲注(Time-Based Blind SQL Injection…...
【外卖系统】新增菜品
需求分析 在后台中,通过新增功能来添加一个新的菜品,在添加菜品时需要选择当前菜品所属的菜品分类,并且需要上传的菜品图片。 代码开发 需要添加的类和基本接口:实体类DishFlavor、Mapper接口DishFlavorMapper、业务层接口Dish…...
使用docker搭建GPT服务
不用ChatGPT账号,不用API,直接免费使用上官方原版的GPT4.0! 这个操作主要使用的是GitHub上的一个开源项目freegpt。 通过docker把这个项目打包到本地电脑上,直接就能使用上原版GPT4.0。 第一步:下载Docker 下载网址:docker.com 根据自己的电脑系统下载对应的版本即可 下…...
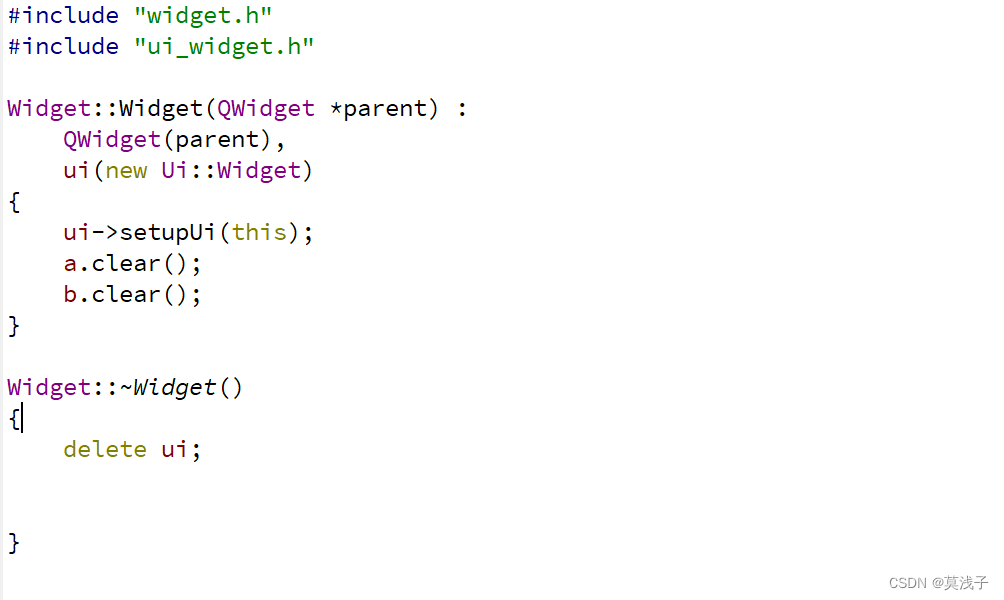
Qt项目---简单的计算器
在这篇技术博客中,我们将介绍如何使用Qt框架实现一个简单的计算器应用。我们将使用C编程语言和Qt的图形用户界面库来开发这个应用,并展示如何实现基本的算术操作。 项目设置 首先,我们需要在Qt Creator中创建一个新的Qt Widgets应用程序项目…...
Flutter游戏引擎Flame系列笔记 - 1.Flame引擎概述
Flutter游戏引擎Flame系列笔记 1.Flame引擎概述 - 文章信息 - Author: 李俊才(jcLee95) Visit me at: https://jclee95.blog.csdn.netEmail: 291148484163.com. Shenzhen ChinaAddress of this article:https://blog.csdn.net/qq_28550263/article/details/132119035 【介绍】…...

基于SpringBoot+Vue的地方美食分享网站设计与实现(源码+LW+部署文档等)
博主介绍: 大家好,我是一名在Java圈混迹十余年的程序员,精通Java编程语言,同时也熟练掌握微信小程序、Python和Android等技术,能够为大家提供全方位的技术支持和交流。 我擅长在JavaWeb、SSH、SSM、SpringBoot等框架…...

在java中操作redis_Data
1.引入依赖 <dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-data-redis</artifactId></dependency> 2.配置Redis数据源 redis:host: ${sky.redis.host}port: ${sky.redis.port}password: ${sk…...

嵌入式开发学习(STC51-14-时钟)
内容 在数码管上显示时间,时分秒,格式为“XX-XX-XX”; DS1302时钟芯片介绍 简介 DS1302是DALLAS公司推出的涓流充电时钟芯片,内含有一个实时时钟/日历和31字节静态RAM,通过简单的串行接口与单片机进行通信…...
的第一个步骤是**识别问题域中的对象和类**(也称为“识别对象与类”或“确定问题域中的概念类”))
面向对象分析(OOA)的第一个步骤是**识别问题域中的对象和类**(也称为“识别对象与类”或“确定问题域中的概念类”)
面向对象分析(OOA)的第一个步骤是识别问题域中的对象和类(也称为“识别对象与类”或“确定问题域中的概念类”)。 这一步要求分析师深入理解用户需求和现实世界的问题背景,通过用例分析、领域建模、名词提取等方法&…...

BFloat16指令集与矩阵乘法优化技术详解
1. BFloat16指令集概述BFloat16(Brain Floating Point 16)是Google Brain团队提出的一种16位浮点格式,专为深度学习应用优化。这种格式保留了与IEEE 754单精度浮点数(FP32)相同的8位指数位,但将尾数位从23位…...

MAA明日方舟自动化工具终极指南:如何一键解放双手轻松长草
MAA明日方舟自动化工具终极指南:如何一键解放双手轻松长草 【免费下载链接】MaaAssistantArknights 《明日方舟》小助手,全日常一键长草!| A one-click tool for the daily tasks of Arknights, supporting all clients. 项目地址: https:/…...

Windows Cleaner终极指南:3分钟解决C盘爆满,让电脑重获新生![特殊字符]
Windows Cleaner终极指南:3分钟解决C盘爆满,让电脑重获新生!🚀 【免费下载链接】WindowsCleaner Windows Cleaner——专治C盘爆红及各种不服! 项目地址: https://gitcode.com/gh_mirrors/wi/WindowsCleaner 你是…...

GPU缓存架构优化与AI加速器内存技术解析
1. GPU缓存架构与AI加速器的内存挑战在AI计算领域,内存子系统已成为制约性能提升的关键瓶颈。传统GPU采用的多级缓存架构(L1/L2/L3)虽然能有效缓解"内存墙"问题,但随着Transformer等大模型参数量呈指数级增长࿰…...

长期使用Taotoken聚合服务对开发效率的实际提升感受
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 长期使用Taotoken聚合服务对开发效率的实际提升感受 作为一名在多个项目中集成大模型能力的开发者,我过去需要为不同的…...
)
别只盯着SysTick_Config:用CubeMX配置STM32的SysTick中断并驱动OLED(附代码)
从CubeMX到OLED:SysTick中断在HAL库中的实战应用 引言 在嵌入式开发领域,精确的时间控制往往是项目成功的关键。对于STM32开发者而言,SysTick定时器作为Cortex-M内核的标准配置,提供了简单可靠的时间基准解决方案。不同于传统寄存…...
)
ESP32项目编译后,如何看懂Output里的内存占用(DRAM/IRAM/Flash详解)
ESP32项目编译后内存占用分析:从DRAM到Flash的深度解读 当你在VSCode中按下编译按钮,看到终端输出那一连串内存占用数据时,是否曾感到困惑?这些数字背后隐藏着ESP32内存架构的秘密,也直接关系到你的项目性能和稳定性。…...

NotebookLM播客工作流优化实战:3个被92%用户忽略的关键提示词配置,提升生成质量400%
更多请点击: https://kaifayun.com 第一章:NotebookLM播客生成的核心原理与局限性 NotebookLM 是 Google 推出的基于用户自有文档进行 AI 助理交互的实验性工具,其播客生成功能并非独立模块,而是依托于底层的“多文档理解 指令驱…...

全网最全短临降水预报方向科研辅导
...