计算机毕设 深度学习疫情社交安全距离检测算法 - python opencv cnn
文章目录
- 0 前言
- 1 课题背景
- 2 实现效果
- 3 相关技术
- 3.1 YOLOV4
- 3.2 基于 DeepSort 算法的行人跟踪
- 4 最后
0 前言
🔥 这两年开始毕业设计和毕业答辩的要求和难度不断提升,传统的毕设题目缺少创新和亮点,往往达不到毕业答辩的要求,这两年不断有学弟学妹告诉学长自己做的项目系统达不到老师的要求。
为了大家能够顺利以及最少的精力通过毕设,学长分享优质毕业设计项目,今天要分享的是
🚩 **基于深度学习疫情社交安全距离检测算法 **
🥇学长这里给一个题目综合评分(每项满分5分)
- 难度系数:3分
- 工作量:3分
- 创新点:5分
1 课题背景
安全的社交距离是公共预防传染病毒的途径之一。所以,在人群密集的区域进行社交距离的安全评估是十分重要的。社交距离的测量旨在保持个体之间的物理距离和减少相互接触的人群来减缓或阻止病毒传播,在抗击病毒和预防大流感中发挥重要作用。但时刻保持安全距离具有一定的难度,特别是在校园,工厂等场所,在这种情况下,开发智能摄像头等技术尤为关键。将人工智能,深度学习集成至安全摄像头对行人进行社交距离评估。现阶段针对疫情防范的要求,主要采用人工干预和计算机处理技术。人工干预存在人力资源要求高,风险大,时间成本高等等缺点。计算机处理等人工智能技术的发展,对社交安全距离的安全评估具有良好的效果。
2 实现效果
通过距离分类人群的高危险和低危险距离。
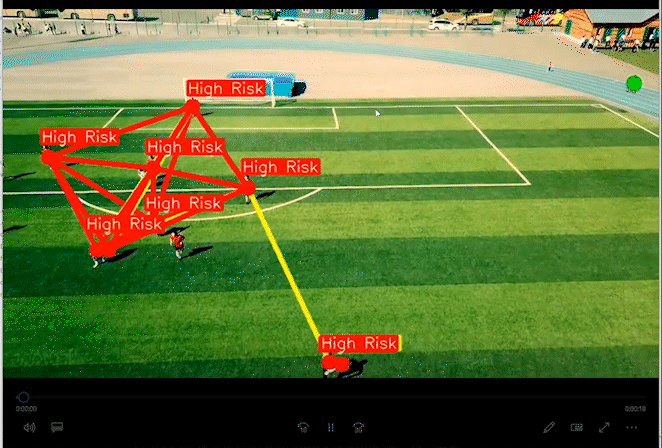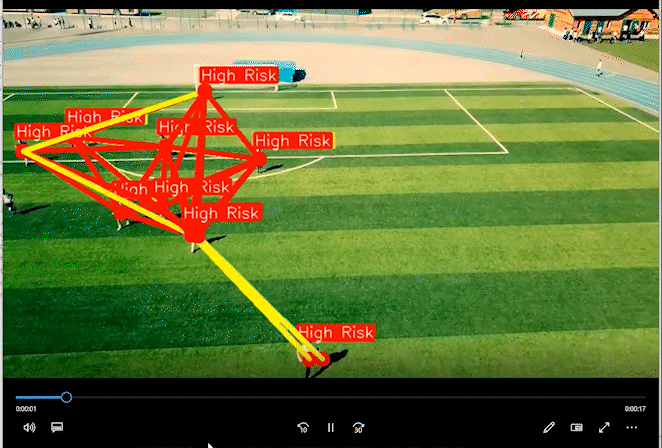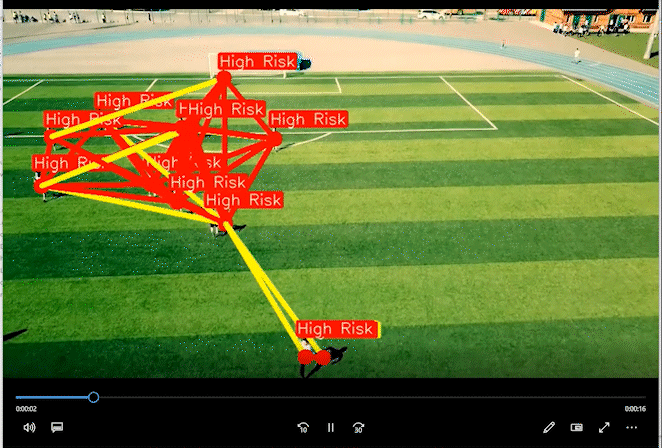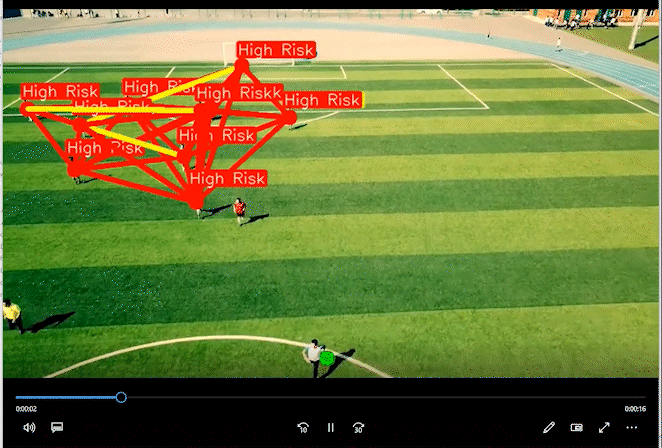
相关代码
import argparse
from utils.datasets import *
from utils.utils import *def detect(save_img=False):out, source, weights, view_img, save_txt, imgsz = \opt.output, opt.source, opt.weights, opt.view_img, opt.save_txt, opt.img_sizewebcam = source == '0' or source.startswith('rtsp') or source.startswith('http') or source.endswith('.txt')# Initializedevice = torch_utils.select_device(opt.device)if os.path.exists(out):shutil.rmtree(out) # delete output folderos.makedirs(out) # make new output folderhalf = device.type != 'cpu' # half precision only supported on CUDA# Load modelgoogle_utils.attempt_download(weights)model = torch.load(weights, map_location=device)['model'].float() # load to FP32# torch.save(torch.load(weights, map_location=device), weights) # update model if SourceChangeWarning# model.fuse()model.to(device).eval()if half:model.half() # to FP16# Second-stage classifierclassify = Falseif classify:modelc = torch_utils.load_classifier(name='resnet101', n=2) # initializemodelc.load_state_dict(torch.load('weights/resnet101.pt', map_location=device)['model']) # load weightsmodelc.to(device).eval()# Set Dataloadervid_path, vid_writer = None, Noneif webcam:view_img = Truetorch.backends.cudnn.benchmark = True # set True to speed up constant image size inferencedataset = LoadStreams(source, img_size=imgsz)else:save_img = Truedataset = LoadImages(source, img_size=imgsz)# Get names and colorsnames = model.names if hasattr(model, 'names') else model.modules.namescolors = [[random.randint(0, 255) for _ in range(3)] for _ in range(len(names))]# Run inferencet0 = time.time()img = torch.zeros((1, 3, imgsz, imgsz), device=device) # init img_ = model(img.half() if half else img) if device.type != 'cpu' else None # run oncefor path, img, im0s, vid_cap in dataset:img = torch.from_numpy(img).to(device)img = img.half() if half else img.float() # uint8 to fp16/32img /= 255.0 # 0 - 255 to 0.0 - 1.0if img.ndimension() == 3:img = img.unsqueeze(0)# Inferencet1 = torch_utils.time_synchronized()pred = model(img, augment=opt.augment)[0]# Apply NMSpred = non_max_suppression(pred, opt.conf_thres, opt.iou_thres,fast=True, classes=opt.classes, agnostic=opt.agnostic_nms)t2 = torch_utils.time_synchronized()# Apply Classifierif classify:pred = apply_classifier(pred, modelc, img, im0s)# List to store bounding coordinates of peoplepeople_coords = []# Process detectionsfor i, det in enumerate(pred): # detections per imageif webcam: # batch_size >= 1p, s, im0 = path[i], '%g: ' % i, im0s[i].copy()else:p, s, im0 = path, '', im0ssave_path = str(Path(out) / Path(p).name)s += '%gx%g ' % img.shape[2:] # print stringgn = torch.tensor(im0.shape)[[1, 0, 1, 0]] # normalization gain whwhif det is not None and len(det):# Rescale boxes from img_size to im0 sizedet[:, :4] = scale_coords(img.shape[2:], det[:, :4], im0.shape).round()# Print resultsfor c in det[:, -1].unique():n = (det[:, -1] == c).sum() # detections per classs += '%g %ss, ' % (n, names[int(c)]) # add to string# Write resultsfor *xyxy, conf, cls in det:if save_txt: # Write to filexywh = (xyxy2xywh(torch.tensor(xyxy).view(1, 4)) / gn).view(-1).tolist() # normalized xywhwith open(save_path[:save_path.rfind('.')] + '.txt', 'a') as file:file.write(('%g ' * 5 + '\n') % (cls, *xywh)) # label formatif save_img or view_img: # Add bbox to imagelabel = '%s %.2f' % (names[int(cls)], conf)if label is not None:if (label.split())[0] == 'person':people_coords.append(xyxy)# plot_one_box(xyxy, im0, line_thickness=3)plot_dots_on_people(xyxy, im0)# Plot lines connecting peopledistancing(people_coords, im0, dist_thres_lim=(200,250))# Print time (inference + NMS)print('%sDone. (%.3fs)' % (s, t2 - t1))# Stream resultsif view_img:cv2.imshow(p, im0)if cv2.waitKey(1) == ord('q'): # q to quitraise StopIteration# Save results (image with detections)if save_img:if dataset.mode == 'images':cv2.imwrite(save_path, im0)else:if vid_path != save_path: # new videovid_path = save_pathif isinstance(vid_writer, cv2.VideoWriter):vid_writer.release() # release previous video writerfps = vid_cap.get(cv2.CAP_PROP_FPS)w = int(vid_cap.get(cv2.CAP_PROP_FRAME_WIDTH))h = int(vid_cap.get(cv2.CAP_PROP_FRAME_HEIGHT))vid_writer = cv2.VideoWriter(save_path, cv2.VideoWriter_fourcc(*opt.fourcc), fps, (w, h))vid_writer.write(im0)if save_txt or save_img:print('Results saved to %s' % os.getcwd() + os.sep + out)if platform == 'darwin': # MacOSos.system('open ' + save_path)print('Done. (%.3fs)' % (time.time() - t0))3 相关技术
3.1 YOLOV4
YOLOv4使用卷积网络 CSPDarknet-53 特征提取,网络结构模型如图 2 所示。在每个 Darknet-53的残块行加上 CSP(Cross Stage Partial)结构13,将基础层划分为两部分,再通过跨层次结构的特征融合进行合并。并采用 FPN( feature pyramid networks)结构加强特征金字塔,最后用不同层的特征的高分辨率来提取不同尺度特征图进行对象检测。最终网络输出 3 个不同尺度的特征图,在三个不同尺度特征图上分别使用 3 个不同的先验框(anchors)进行预测识别,使得远近大小目标均能得到较好的检测。
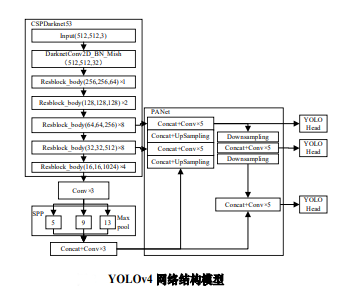
YOLOv4 的先验框尺寸是经PASCALL_VOC,COCO 数据集包含的种类复杂而生成的,并不一定完全适合行人。本研究旨在研究行人之间的社交距离,针对行人目标检测,利用聚类算法对 YOLOv4 的先验框微调,首先将行人数据集F依据相似性分为i个对象,即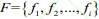 ,其中每个对象都具有 m 个维度的属性。聚类算法的目的是 i 个对象依据相似性聚集到指定的 j 个类簇,每个对象属于且仅属于一个其到类簇中心距离最小的类簇中心。初始化 j 个 聚 类 中 心
,其中每个对象都具有 m 个维度的属性。聚类算法的目的是 i 个对象依据相似性聚集到指定的 j 个类簇,每个对象属于且仅属于一个其到类簇中心距离最小的类簇中心。初始化 j 个 聚 类 中 心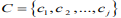 ,计算每一个对象到每一个聚类中心的欧式距离,见公式
,计算每一个对象到每一个聚类中心的欧式距离,见公式
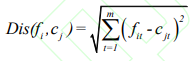
之后,依次比较每个对象到每个聚类中心的距离,将对象分配至距离最近的簇类中心的类簇中,
得到 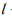 个类簇
个类簇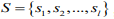 ,聚类算法中定义了类簇的原型,类簇中心就是类簇内所有对象在各个维度的均值,其公式见
,聚类算法中定义了类簇的原型,类簇中心就是类簇内所有对象在各个维度的均值,其公式见
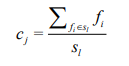
相关代码
def check_anchors(dataset, model, thr=4.0, imgsz=640):# Check anchor fit to data, recompute if necessaryprint('\nAnalyzing anchors... ', end='')m = model.module.model[-1] if hasattr(model, 'module') else model.model[-1] # Detect()shapes = imgsz * dataset.shapes / dataset.shapes.max(1, keepdims=True)wh = torch.tensor(np.concatenate([l[:, 3:5] * s for s, l in zip(shapes, dataset.labels)])).float() # whdef metric(k): # compute metricr = wh[:, None] / k[None]x = torch.min(r, 1. / r).min(2)[0] # ratio metricbest = x.max(1)[0] # best_xreturn (best > 1. / thr).float().mean() # best possible recallbpr = metric(m.anchor_grid.clone().cpu().view(-1, 2))print('Best Possible Recall (BPR) = %.4f' % bpr, end='')if bpr < 0.99: # threshold to recomputeprint('. Attempting to generate improved anchors, please wait...' % bpr)na = m.anchor_grid.numel() // 2 # number of anchorsnew_anchors = kmean_anchors(dataset, n=na, img_size=imgsz, thr=thr, gen=1000, verbose=False)new_bpr = metric(new_anchors.reshape(-1, 2))if new_bpr > bpr: # replace anchorsnew_anchors = torch.tensor(new_anchors, device=m.anchors.device).type_as(m.anchors)m.anchor_grid[:] = new_anchors.clone().view_as(m.anchor_grid) # for inferencem.anchors[:] = new_anchors.clone().view_as(m.anchors) / m.stride.to(m.anchors.device).view(-1, 1, 1) # lossprint('New anchors saved to model. Update model *.yaml to use these anchors in the future.')else:print('Original anchors better than new anchors. Proceeding with original anchors.')print('') # newline
3.2 基于 DeepSort 算法的行人跟踪
YOLOv4中完成行人目标检测后生成边界框(Bounding box,Bbox),Bbox 含有包含最小化行人边框矩形的坐标信息,本研究引入 DeepSort 算法[18]完成对行人的质点进行跟踪,目的是为了在运动矢量分析时算行人安全社交距离中。首先,对行人进行质点化计算。其质点计算公式如
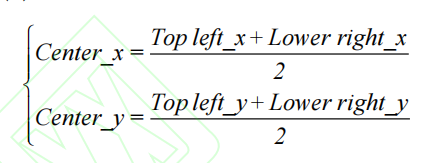
确定行人质点后,利用 DeepSort 算法实现对多个目标的精确定位与跟踪,其核心算法流程如图所示:
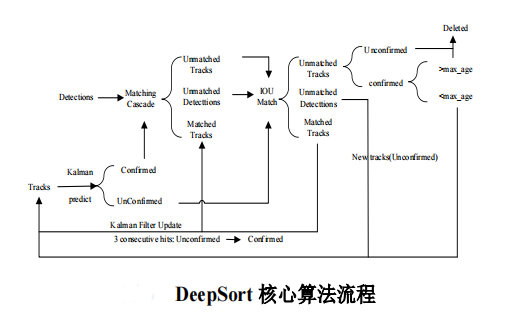
相关代码
class TrackState:'''单个轨迹的三种状态'''Tentative = 1 #不确定态Confirmed = 2 #确定态Deleted = 3 #删除态class Track:def __init__(self, mean, covariance, track_id, class_id, conf, n_init, max_age,feature=None):'''mean:位置、速度状态分布均值向量,维度(8×1)convariance:位置、速度状态分布方差矩阵,维度(8×8)track_id:轨迹IDclass_id:轨迹所属类别hits:轨迹更新次数(初始化为1),即轨迹与目标连续匹配成功次数age:轨迹连续存在的帧数(初始化为1),即轨迹出现到被删除的连续总帧数time_since_update:轨迹距离上次更新后的连续帧数(初始化为0),即轨迹与目标连续匹配失败次数state:轨迹状态features:轨迹所属目标的外观语义特征,轨迹匹配成功时添加当前帧的新外观语义特征conf:轨迹所属目标的置信度得分_n_init:轨迹状态由不确定态到确定态所需连续匹配成功的次数_max_age:轨迹状态由不确定态到删除态所需连续匹配失败的次数''' self.mean = meanself.covariance = covarianceself.track_id = track_idself.class_id = int(class_id)self.hits = 1self.age = 1self.time_since_update = 0self.state = TrackState.Tentativeself.features = []if feature is not None:self.features.append(feature) #若不为None,初始化外观语义特征self.conf = confself._n_init = n_initself._max_age = max_agedef increment_age(self):'''预测下一帧轨迹时调用'''self.age += 1 #轨迹连续存在帧数+1self.time_since_update += 1 #轨迹连续匹配失败次数+1def predict(self, kf):'''预测下一帧轨迹信息'''self.mean, self.covariance = kf.predict(self.mean, self.covariance) #卡尔曼滤波预测下一帧轨迹的状态均值和方差self.increment_age() #调用函数,age+1,time_since_update+1def update(self, kf, detection, class_id, conf):'''更新匹配成功的轨迹信息'''self.conf = conf #更新置信度得分self.mean, self.covariance = kf.update(self.mean, self.covariance, detection.to_xyah()) #卡尔曼滤波更新轨迹的状态均值和方差self.features.append(detection.feature) #添加轨迹对应目标框的外观语义特征self.class_id = class_id.int() #更新轨迹所属类别self.hits += 1 #轨迹匹配成功次数+1self.time_since_update = 0 #匹配成功时,轨迹连续匹配失败次数归0if self.state == TrackState.Tentative and self.hits >= self._n_init:self.state = TrackState.Confirmed #当连续匹配成功次数达标时轨迹由不确定态转为确定态def mark_missed(self):'''将轨迹状态转为删除态'''if self.state == TrackState.Tentative:self.state = TrackState.Deleted #当级联匹配和IOU匹配后仍为不确定态elif self.time_since_update > self._max_age:self.state = TrackState.Deleted #当连续匹配失败次数超标'''该部分还存在一些轨迹坐标转化及状态判定函数,具体可参考代码来源'''4 最后
相关文章:
计算机毕设 深度学习疫情社交安全距离检测算法 - python opencv cnn
文章目录 0 前言1 课题背景2 实现效果3 相关技术3.1 YOLOV43.2 基于 DeepSort 算法的行人跟踪 4 最后 0 前言 🔥 这两年开始毕业设计和毕业答辩的要求和难度不断提升,传统的毕设题目缺少创新和亮点,往往达不到毕业答辩的要求,这两…...

四数之和——力扣18
文章目录 题目描述双指针法题目描述 双指针法 class Solution {public:vector<vector<int>>...

Serializable 和 Externalizable区别?
Serializable接口 java.io.Serializable 接口没有方法或字段,仅用于标识可序列化的语义。 public interface Serializable { }可序列化类的所有子类型本身都是可序列化的。在进行序列化操作时,会判断要被序列化的类是否是Enum、Array和 Serializable类…...
2023 电赛 E 题 K210 方案--K210实现矩形识别
相关库介绍 sensor(摄像头) sensor.reset() sensor.set_pixformat(sensor.RGB565) sensor.set_framesize(sensor.QVGA) sensor.skip_frames(10) reset():重置并初始化单目摄像头 set_pixformat():设置摄像头输出格式,…...

【雕爷学编程】MicroPython动手做(29)——物联网之SIoT 2
知识点:什么是掌控板? 掌控板是一块普及STEAM创客教育、人工智能教育、机器人编程教育的开源智能硬件。它集成ESP-32高性能双核芯片,支持WiFi和蓝牙双模通信,可作为物联网节点,实现物联网应用。同时掌控板上集成了OLED…...

chapter13:springboot与任务
Spring Boot与任务视频 1. 异步任务 使用注解 Async 开启一个异步线程任务, 需要在主启动类上添加注解EnableAsync开启异步配置; Service public class AsyncService {Asyncpublic void hello() {try {Thread.sleep(3000);} catch (InterruptedExcept…...
(十一)大数据实战——hadoop高可用之HDFS手动模式高可用
前言 本节内容我们介绍一下hadoop在手动模式下如何实现HDFS的高可用,HDFS的高可用功能是通过配置多个 NameNodes(Active/Standby)实现在集群中对 NameNode 的热备来解决上述问题。如果出现故障,如机器崩溃或机器需要升级维护,这时可通过此种…...
problem(3):python IDE和python解释器
为什么写这篇文章呢?遇到了下面的问题,相同的解释器,如果运行angr库的代码,会出现 这样的情况,但是用spyder IDE 会显示正常,很奇怪 应该就是IDE的原因 IDE的循环导入问题 检查IDE配置: 如果可…...

【C语言进阶篇】模拟实现通讯录 (内附源码)
🎬 鸽芷咕:个人主页 🔥 个人专栏:《C语言初阶篇》 《C语言进阶篇》 ⛺️生活的理想,就是为了理想的生活! 文章目录 📋 前言一 、 通讯录的简介1.1 联系人的类型定义1.2 通讯录的定义1.3 通讯录要实现的功能 二 、 如何…...

Python web实战之 Django 的模板语言详解
关键词: Python、web开发、Django、模板语言 概要 作为 Python Web 开发的框架之一,Django 提供了一套完整的 MVC 模式,其中的模板语言为开发者提供了强大的渲染和控制前端的能力。本文介绍 Django 的模板语言。 1. Django 模板语言入门 Dj…...

使用ChatGPT编写技术文档
技术文档对于任何项目都是至关重要的,因为它确保所有利益相关者都在同一层面上,并允许有效的沟通和协作。创建详细而准确的技术文档可能既耗时又具有挑战性,特别是对于那些不熟悉主题或缺乏强大写作技巧的人来说。ChatGPT 是一个强大的人工智…...

Java超级玛丽小游戏制作过程讲解 第四天 创建并完成常量类03
今天继续来完成常量类。 package com.sxt;import javax.imageio.ImageIO; import java.awt.image.BufferedImage; import java.io.File; import java.io.IOException; import java.util.ArrayList; import java.util.List;public class StaticValue {//背景public static Buff…...
webpack基础知识八:说说如何借助webpack来优化前端性能?
一、背景 随着前端的项目逐渐扩大,必然会带来的一个问题就是性能 尤其在大型复杂的项目中,前端业务可能因为一个小小的数据依赖,导致整个页面卡顿甚至奔溃 一般项目在完成后,会通过webpack进行打包,利用webpack对前…...
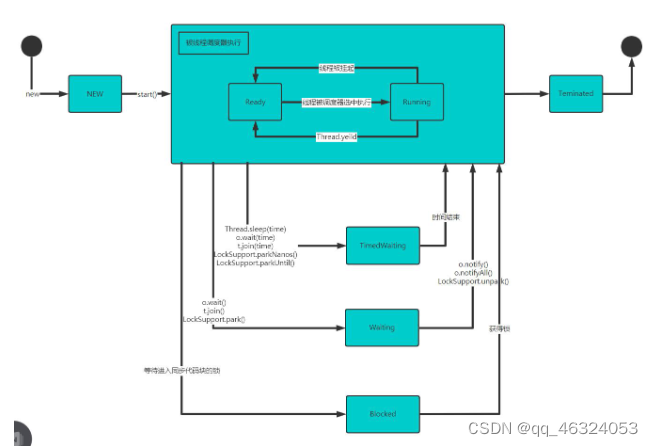
JAVA SE -- 第十五天
(全部来自“韩顺平教育”) 多线程 一、线程相关概念 1、程序:是为完成特定任务、用某种语言编写的一组指令的集合。 2、进程:是指运行中的程序,如QQ,就启动了一个进程,操作系统就会为该进程…...

macOS 环境变量加载探究
使用 macOS 安装环境,见到过很数种环境变量配置方法,每次也都是按照别人的代码,人家配置在哪 我就配置在哪,其实不太清楚有什么区别,决定记录下。 本机 macOS 13.3,从 macOS Catalina(10.15) 开始…...
)的返回值是一个无效值)
在程序中如何判断该线程的线程id(get_id())的返回值是一个无效值
std::thread::id() 是std::thread::id的默认构造函数,它会创建一个空的std::thread::id对象。一个空的std::thread::id对象代表一个无效的线程标识符。 可以通过 std::thread::id 的成员函数 std::thread::id::operator() 来判断一个 std::thread::id 是否是一个空值…...

ffmpeg-ffplay代码架构简述
全局变量 /* Minimum SDL audio buffer size, in samples. */ // 最小音频缓冲 #define SDL_AUDIO_MIN_BUFFER_SIZE 512 /* Calculate actual buffer size keeping in mind not cause too frequent audio callbacks */ // 计算实际音频缓冲大小,并不需要太频繁…...

⛳ 多线程面试-什么是多线程上下文切换?
目录 ⛳ 多线程面试-什么是多线程上下文切换?🎁 Java中用到的线程调度算法是什么?🎨 什么是线程饥饿 ?你对线程优先级的理解是什么? ⛳ 多线程面试-什么是多线程上下文切换ÿ…...

vb+SQL车辆管理系统设计与实现
摘 要 随着信息时代的到来,信息高速公路的兴起,全球信息化进入了一个新的发展时期。人们越来越认识到计算机强大的信息模块处理功能,使之成为信息产业的基础和支柱。 我国经济的快速发展,汽车已经成为人们不可缺少的交通工具。对于拥有大量车辆的机关企事业来说,车辆的…...

java的枚举类
枚举类的概念和使用 1.枚举类的理解:类的对象只有有限个,确定的。我们称此为枚举类。 2.当需要定义一组常量时,强烈建议使用枚举类。对象便是所指的常量。 3.如果枚举类中只有一个对象,则可以作为单例模式的实现方式。 定义枚举类…...

独立开发者如何利用 Taotoken 模型广场低成本试错选型
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 独立开发者如何利用 Taotoken 模型广场低成本试错选型 对于资源有限的独立开发者或小型团队而言,在产品开发初期选择合…...

Obsidian Quiz Generator:用AI与间隔重复打造动态知识库
1. 项目概述:当笔记遇上主动回忆如果你和我一样,是 Obsidian 的用户,并且对知识管理、学习效率有追求,那么你一定遇到过这个困境:笔记越记越多,知识库越来越庞大,但真正能“记住”并“调用”的知…...

为什么你的Linux桌面还缺少一个触手可及的OCR助手?
为什么你的Linux桌面还缺少一个触手可及的OCR助手? 【免费下载链接】Umi-OCR OCR software, free and offline. 开源、免费的离线OCR软件。支持截屏/批量导入图片,PDF文档识别,排除水印/页眉页脚,扫描/生成二维码。内置多国语言库…...

从电机控制到服务器电源:详解功率MOSFET栅极外加电容CGS与CGD的选型计算与布局要点
功率MOSFET栅极电容设计实战:从电机驱动到服务器电源的差异化策略 在电力电子系统的核心地带,功率MOSFET如同精密交响乐团的指挥,其开关性能直接决定整个系统的效率与可靠性。当我们面对电机驱动系统要求快速切换以降低损耗,或是服…...

如何用D2DX游戏优化工具突破《暗黑破坏神2》25fps限制:宽屏适配与性能提升的终极解决方案
如何用D2DX游戏优化工具突破《暗黑破坏神2》25fps限制:宽屏适配与性能提升的终极解决方案 【免费下载链接】d2dx D2DX is a complete solution to make Diablo II run well on modern PCs, with high fps and better resolutions. 项目地址: https://gitcode.com/…...
)
零基础转行网安:3个月学习路线+就业方向(2026最新)
零基础转行网安:3 个月学习路线 就业方向(2026 最新) 最近刷到很多小白在问: “2026 年零基础还能转行网安吗?”“没有学历、没有基础、不会代码,多久能找到工作?”“网上教程杂乱,…...

iOS设备激活锁绕过全指南:AppleRa1n离线解锁解决方案
iOS设备激活锁绕过全指南:AppleRa1n离线解锁解决方案 【免费下载链接】applera1n icloud bypass for ios 15-16 项目地址: https://gitcode.com/gh_mirrors/ap/applera1n 你是否曾遇到过这样的情况:购买了一台二手iPhone,却发现设备被…...

音频智能切片工具:快速解放双手的终极音频分割解决方案
音频智能切片工具:快速解放双手的终极音频分割解决方案 【免费下载链接】audio-slicer A simple GUI application that slices audio with silence detection 项目地址: https://gitcode.com/gh_mirrors/aud/audio-slicer 还在为处理冗长的音频文件而烦恼吗&…...

RAG实战指南:让大模型学会检索外部知识
RAG:给 LLM 装上知识库——从原理到完整可运行系统LLM 的知识截止在训练日期。RAG 让 AI 能「查资料」回答——这是 Agent 有「长期记忆」的基础。一、为什么需要 RAG 用户:HarmonyOS NEXT 的 Observed 装饰器怎么用?没有 RAG 的 LLM…...

Arm DynamIQ DSU L3缓存电源管理技术解析
1. Arm DynamIQ DSU L3缓存电源管理技术全景解析在现代处理器架构设计中,缓存子系统往往占据芯片总功耗的30%-40%,其中L3共享末级缓存因其大容量特性成为功耗优化的重点对象。Arm DynamIQ™架构创新的DSU(DynamIQ Shared Unit)通过…...