VGGNet剪枝实战:使用VGGNet训练、稀疏训练、剪枝、微调等,剪枝出只有3M的模型
摘要
本文讲解如何实现VGGNet的剪枝操作。剪枝的原理:在BN层网络中加入稀疏因子,训练使得BN层稀疏化,对稀疏训练的后的模型中所有BN层权重进行统计排序,获取指定保留BN层数量即取得排序后权重阈值thres。遍历模型中的BN层权重,制作各层mask(权重>thres值为1,权重<thres值为0)。剪枝操作,根据各层的mask构建新模型结构(各层保留的通道数),获取BN层权重mask非零值的索引,非零索引对应的原始conv层、BN层、linear层各通道的权重、偏置等值赋值给新模型各层。加载剪枝后模型,进行fine-tune。
通过本文你可以学到:
1、如何使用VGGNet训练模型。
2、如何使用VGGNet稀疏训练模型。
3、如何实现剪枝,已及保存剪枝模型和使用剪枝模型预测等操作。
4、如何微调剪枝模型。
剪枝流程分为:
第一步、使用VGGNet训练模型。保存训练结果,方便将来的比对!
第二步、在BN层网络中加入稀疏因子,训练模型。
第三步、剪枝操作。
第四步、fine-tune模型,提高模型的ACC。
接下来,我们一起实现对VGGNet的剪枝。
项目结构
Slimming_Demo├─checkpoints│ ├─vgg│ ├─vgg_pruned│ └─vgg_sp├─data│ ├─train│ │ ├─Black-grass│ │ ├─Charlock│ │ ├─Cleavers│ │ ├─Common Chickweed│ │ ├─Common wheat│ │ ├─Fat Hen│ │ ├─Loose Silky-bent│ │ ├─Maize│ │ ├─Scentless Mayweed│ │ ├─Shepherds Purse│ │ ├─Small-flowered Cranesbill│ │ └─Sugar beet│ └─val│ ├─Black-grass│ ├─Charlock│ ├─Cleavers│ ├─Common Chickweed│ ├─Common wheat│ ├─Fat Hen│ ├─Loose Silky-bent│ ├─Maize│ ├─Scentless Mayweed│ └─Shepherds Purse├─vgg.py├─train.py├─train_sp.py├─prune.py└─train_prune.py
train.py:训练脚本,训练VGGNet原始模型
vgg.py:模型脚本
train_sp.py:稀疏训练脚本。
prune.py:模型剪枝脚本。
train_prune.py:微调模型脚本。
测试结果
| 模型 | 大小 | ACC |
|---|---|---|
| VGG模型 | 67.4M | 95.6% |
| VGG裁剪模型 | 3.58M | 95% |
VGGNet模型
VGGNet在原有的基础做了修改,增加了模型的cfg,定义了每层卷积的channel,“M”代表池化。
import torch
import torch.nn as nn
from torch.autograd import Variable
import math # initclass VGG(nn.Module):def __init__(self, num_classes, init_weights=True, cfg=None):super(VGG, self).__init__()if cfg is None:cfg = [64, 64, 'M', 128, 128, 'M', 256, 256, 256, 256, 'M', 512, 512, 512, 512, 'M', 512, 512, 512, 'M']self.feature = self.make_layers(cfg, True)print(self.feature)self.classifier = nn.Linear(cfg[-2], num_classes)if init_weights:self._initialize_weights()def make_layers(self, cfg, batch_norm=False):layers = []in_channels = 3for v in cfg:if v == 'M':layers += [nn.MaxPool2d(kernel_size=2, stride=2)]else:conv2d = nn.Conv2d(in_channels, v, kernel_size=3, padding=1, bias=False)if batch_norm:layers += [conv2d, nn.BatchNorm2d(v), nn.LeakyReLU(inplace=True)]else:layers += [conv2d, nn.LeakyReLU(inplace=True)]in_channels = vreturn nn.Sequential(*layers)def forward(self, x):x = self.feature(x)x = nn.AdaptiveAvgPool2d(1)(x)x = x.view(x.size(0), -1)y = self.classifier(x)return ydef _initialize_weights(self):for m in self.modules():if isinstance(m, nn.Conv2d):n = m.kernel_size[0] * m.kernel_size[1] * m.out_channelsm.weight.data.normal_(0, math.sqrt(2. / n))if m.bias is not None:m.bias.data.zero_()elif isinstance(m, nn.BatchNorm2d):m.weight.data.fill_(0.5)m.bias.data.zero_()elif isinstance(m, nn.Linear):m.weight.data.normal_(0, 0.01)m.bias.data.zero_()if __name__ == '__main__':net = VGG(12)print(net)x = Variable(torch.FloatTensor(1, 3, 224, 224))y = net(x)print(y.data.shape)
需要安装的库
1、tim库
pip install timm2、sklearn
pip install -U scikit-learn
3、tensorboard
pip install tensorboard
训练VGGNet
新建train.py脚本。接下来,详解train.py脚本中的代码。
导入项目所需要的库
import torch.optim as optim
import torch
import torch.nn as nn
import torch.nn.parallel
import torch.optim
import torch.utils.data
import torch.utils.data.distributed
import torchvision.transforms as transforms
from sklearn.metrics import classification_report
from vgg import VGG
import os
from torchvision import datasets
import json
import matplotlib.pyplot as plt
from timm.data.mixup import Mixup
from timm.loss import SoftTargetCrossEntropy
import warnings
from torch.utils.tensorboard import SummaryWriter
warnings.filterwarnings("ignore")
设置随机因子
设置随机因子后,再次训练时,图像的加载顺序不会改变,能够更好的复现训练结果。代码如下:
def seed_everything(seed=42):os.environ['PYHTONHASHSEED'] = str(seed)torch.manual_seed(seed)torch.cuda.manual_seed(seed)torch.backends.cudnn.deterministic = True
BN层可视化
使用tensorboard 可视化BN的状态,方便对比!
writer = SummaryWriter(comment='vgg')def showBN(model):# =============== show bn weights ===================== #module_list = []module_bias_list = []for i, layer in model.named_modules():if isinstance(layer, nn.BatchNorm2d) :bnw = layer.state_dict()['weight']bnb = layer.state_dict()['bias']module_list.append(bnw)module_bias_list.append(bnb)size_list = [idx.data.shape[0] for idx in module_list]bn_weights = torch.zeros(sum(size_list))bnb_weights = torch.zeros(sum(size_list))index = 0for idx, size in enumerate(size_list):bn_weights[index:(index + size)] = module_list[idx].data.abs().clone()bnb_weights[index:(index + size)] = module_bias_list[idx].data.abs().clone()index += sizeprint("bn_weights:", torch.sort(bn_weights))print("bn_bias:", torch.sort(bnb_weights))writer.add_histogram('bn_weights/hist', bn_weights.numpy(), epoch, bins='doane')writer.add_histogram('bn_bias/hist', bnb_weights.numpy(), epoch, bins='doane')
定义全局参数
全局参数包括学习率、批大小、轮数、类别数量等一些模型用到的超参数。
if __name__ == '__main__':# 创建保存模型的文件夹file_dir = 'checkpoints/vgg'if os.path.exists(file_dir):print('true')os.makedirs(file_dir, exist_ok=True)else:os.makedirs(file_dir)# 设置全局参数model_lr = 1e-4BATCH_SIZE = 16EPOCHS = 300DEVICE = torch.device('cuda:0' if torch.cuda.is_available() else 'cpu')classes = 12resume = NoneBest_ACC = 0 # 记录最高得分SEED = 42seed_everything(42)start_epoch = 1
数据增强
t = [transforms.CenterCrop((224, 224)), transforms.GaussianBlur(kernel_size=(5, 5), sigma=(0.1, 3.0)),transforms.ColorJitter(brightness=0.5, contrast=0.5, saturation=0.5)]# 数据预处理7transform = transforms.Compose([transforms.AutoAugment(),transforms.Resize((224, 224)),transforms.ToTensor(),transforms.Normalize(mean=[0.48214436, 0.42969334, 0.33318862], std=[0.2642221, 0.23746745, 0.21696019])])transform_test = transforms.Compose([transforms.Resize((224, 224)),transforms.ToTensor(),transforms.Normalize(mean=[0.48214436, 0.42969334, 0.33318862], std=[0.2642221, 0.23746745, 0.21696019])])mixup_fn = Mixup(mixup_alpha=0.8, cutmix_alpha=1.0, cutmix_minmax=None,prob=0.1, switch_prob=0.5, mode='batch',label_smoothing=0.1, num_classes=classes)增强选用了AutoAugment,自动增强,默认是ImageNet的增强。在实际的项目中,需要选用适合的方式来增强图像数据。过多增强或带来负面的影响。
声明MIxUp函数,Mix是一种非常有效的增强方法。加入之后不仅可以提高ACC,对泛化性也有很大的提高。
这里注意下Resize的大小,由于选用的ResNet模型输入是224×224的大小,所以要Resize为224×224。
加载数据
# 读取数据dataset_train = datasets.ImageFolder('data/train', transform=transform)dataset_test = datasets.ImageFolder("data/val", transform=transform_test)with open('class.txt', 'w',encoding='utf-8') as file:file.write(str(dataset_train.class_to_idx))with open('class.json', 'w', encoding='utf-8') as file:file.write(json.dumps(dataset_train.class_to_idx))# 导入数据train_loader = torch.utils.data.DataLoader(dataset_train, batch_size=BATCH_SIZE, pin_memory=True, shuffle=True,drop_last=True)test_loader = torch.utils.data.DataLoader(dataset_test, batch_size=BATCH_SIZE, pin_memory=True, shuffle=False)加载训练集和验证集的数据,并将class_to_idx保存。然后分别声明训练和验证的DataLoader。
定义Loss
多类别分类的loss一般使用交叉熵。代码如下:
# 实例化模型并且移动到GPUcriterion_train = SoftTargetCrossEntropy().cuda()criterion_val = torch.nn.CrossEntropyLoss().cuda()
SoftTargetCrossEntropy,成为软交叉熵,当Label做了平滑之后,使用SoftTargetCrossEntropy。
定义模型、优化器以及学习率调整策略
# 设置模型model_ft = VGG(classes,True)if resume:model = torch.load(resume)model_ft.load_state_dict(model['state_dict'])Best_ACC = model['Best_ACC']start_epoch = model['epoch'] + 1model_ft.to(DEVICE)print(model_ft)# 选择简单暴力的Adam优化器,学习率调低optimizer = optim.AdamW(model_ft.parameters(), lr=model_lr)cosine_schedule = optim.lr_scheduler.CosineAnnealingLR(optimizer=optimizer, T_max=20, eta_min=1e-6)
模型就选用前面定义的VGG模型。
优化器选用AdamW。
学习率调整策略选用CosineAnnealingLR。
训练函数
# 定义训练过程
def train(model, device, train_loader, optimizer, epoch, criterion,epochs):model.train()sum_loss = 0correct = 0total_num = len(train_loader.dataset)print(total_num, len(train_loader))for batch_idx, (data, target) in enumerate(train_loader):data, target = data.to(device, non_blocking=True), target.to(device, non_blocking=True)samples, targets = mixup_fn(data, target)output = model(samples)loss = criterion(output, targets)optimizer.zero_grad()loss.backward()optimizer.step()print_loss = loss.data.item()_, pred = torch.max(output.data, 1)correct += torch.sum(pred == target)sum_loss += print_lossif (batch_idx + 1) % 10 == 0:print('Train Epoch: {} [{}/{} ({:.0f}%)]\tLoss: {:.6f}'.format(epoch, (batch_idx + 1) * len(data), len(train_loader.dataset),100. * (batch_idx + 1) / len(train_loader), loss.item()))ave_loss = sum_loss / len(train_loader)correct = correct.data.item()acc = correct / total_numprint('epoch:{},loss:{}'.format(epoch, ave_loss))return ave_loss, acc
训练的主要步骤:
1、 model.train()切换成训练模型。启用 BatchNormalization 和 Dropout。初始化sum_loss 为0,计算训练集图片的数量赋给total_num。correct设置为0
2、进入循环,将data和target放入device上,non_blocking设置为True。如果pin_memory=True的话,将数据放入GPU的时候,也应该把non_blocking打开,这样就只把数据放入GPU而不取出,访问时间会大大减少。
如果pin_memory=False时,则将non_blocking设置为False。
3、samples, targets = mixup_fn(data, target),使用mixup_fn方式,计算Mixup后的图像数据和标签数据。然后,将Mixup后的图像数据samples输入model,输出预测结果,然后再计算loss。
4、 optimizer.zero_grad() 梯度清零,把loss关于weight的导数变成0。
5、反向传播求梯度。
6、获取loss,并赋值给print_loss 。
7、torch.sum(pred == target)计算当前Batch内,预测正确的数量,然后累加到correct 。
8、sum_loss 累加print_loss ,求得总的loss。所以,单个epoch的loss就是总的sum_loss 除以train_loader的长度。
等待一个epoch训练完成后,计算平均loss。然后将其打印出来。并返回loss和acc。
验证函数
验证过程增加了对预测数据和Label数据的保存,所以,需要定义两个list保存,然后将其返回!
# 验证过程
def val(model, device, test_loader,criterion):model.eval()test_loss = 0correct = 0total_num = len(test_loader.dataset)print(total_num, len(test_loader))val_list = []pred_list = []with torch.no_grad():for data, target in test_loader:data, target = data.to(device, non_blocking=True), target.to(device, non_blocking=True)for t in target:val_list.append(t.data.item())output = model(data)loss = criterion(output, target)_, pred = torch.max(output.data, 1)for p in pred:pred_list.append(p.data.item())correct += torch.sum(pred == target)print_loss = loss.data.item()test_loss += print_losscorrect = correct.data.item()acc = correct / total_numavgloss = test_loss / len(test_loader)print('\nVal set: Average loss: {:.4f}, Accuracy: {}/{} ({:.0f}%)\n'.format(avgloss, correct, len(test_loader.dataset), 100 * acc))return val_list, pred_list, avgloss, acc验证的过程和训练的过程大致相似,主要步骤:
1、model.eval(),切换验证模型,不启用 BatchNormalization 和 Dropout。
2、定义参数:
test_loss : 测试的loss
correct :统计正确类别的数量。
total_num:验证集图片的总数。
val_list :保存验证集的Label数据。
pred_list :保存预测的Label数据。
3、torch.no_grad():反向传播时就不会自动求导了。
4、进入循环,迭代test_loader:
5、acc = correct / total_num,计算出acc。 avgloss = test_loss / len(test_loader)计算loss。 最后返回val_list, pred_list,loss,acc将label保存到val_list。
将data和target放入device上,non_blocking设置为True。
遍历target,将Label保存到val_list 。
将data输入到model中,求出预测值,然后输入到loss函数中,求出loss。在验证集中,不用求辅助分类器的loss。
调用torch.max函数,将预测值转为对应的label。
遍历pred,将预测的Label保存到pred_list。
correct += torch.sum(pred == target),计算出识别对的数量,并累加到correct 变量上。
训练、验证、保存模型
# 训练log_dir = {}train_loss_list, val_loss_list, train_acc_list, val_acc_list, epoch_list = [], [], [], [], []if resume and os.path.isfile("result.json"):with open('result.json', 'r', encoding='utf-8') as file:logs = json.load(file)train_acc_list = logs['train_acc']train_loss_list = logs['train_loss']val_acc_list = logs['val_acc']val_loss_list = logs['val_loss']epoch_list = logs['epoch_list']for epoch in range(start_epoch, EPOCHS + 1):epoch_list.append(epoch)log_dir['epoch_list'] = epoch_listtrain_loss, train_acc = train(model_ft, DEVICE, train_loader, optimizer, epoch, criterion_train,epochs=EPOCHS)showBN(model_ft)train_loss_list.append(train_loss)train_acc_list.append(train_acc)log_dir['train_acc'] = train_acc_listlog_dir['train_loss'] = train_loss_listval_list, pred_list, val_loss, val_acc = val(model_ft, DEVICE, test_loader, criterion_val)print(classification_report(val_list, pred_list, target_names=dataset_train.class_to_idx))val_loss_list.append(val_loss)val_acc_list.append(val_acc)log_dir['val_acc'] = val_acc_listlog_dir['val_loss'] = val_loss_listlog_dir['best_acc'] = Best_ACCwith open('result.json', 'w', encoding='utf-8') as file:file.write(json.dumps(log_dir))if val_acc >= Best_ACC:Best_ACC = val_acctorch.save(model_ft, file_dir + "/" + 'best.pth')state = {'epoch': epoch,'state_dict': model_ft.state_dict(),'Best_ACC': Best_ACC}torch.save(state, file_dir + "/" + 'model_' + str(epoch) + '_' + str(round(val_acc, 3)) + '.pth')cosine_schedule.step()fig = plt.figure(1)plt.plot(epoch_list, train_loss_list, 'r-', label=u'Train Loss')# 显示图例plt.plot(epoch_list, val_loss_list, 'b-', label=u'Val Loss')plt.legend(["Train Loss", "Val Loss"], loc="upper right")plt.xlabel(u'epoch')plt.ylabel(u'loss')plt.title('Model Loss ')plt.savefig(file_dir + "/loss.png")plt.close(1)fig2 = plt.figure(2)plt.plot(epoch_list, train_acc_list, 'r-', label=u'Train Acc')plt.plot(epoch_list, val_acc_list, 'b-', label=u'Val Acc')plt.legend(["Train Acc", "Val Acc"], loc="lower right")plt.title("Model Acc")plt.ylabel("acc")plt.xlabel("epoch")plt.savefig(file_dir + "/acc.png")plt.close(2)
思路:
定义记录log的字典,声明loss和acc的list。如果是接着上次的断点继续训练则读取log文件,然后把log取出来,赋值到对应的list上。
循环调用train函数和val函数,train函数返回train_loss, train_acc,val函数返回val_list, pred_list, val_loss, val_acc。loss和acc用于绘制曲线。
记录BN的权重状态。
将log字典保存到json文件中。
将val_list, pred_list和dataset_train.class_to_idx传入模型,计算模型指标。
判断acc是否大于Best_ACC,如果大于则保存模型,这里保存的是整个模型。
接下来是保存每个epoch的模型,新建state ,字典的参数:- epoch:当前的epoch。- state_dict:权重参数。 model_ft.state_dict(),只保存模型的权重参数。- Best_ACC:Best_ACC的数值。然后,调用 torch.save保存模型。cosine_schedule.step(),执行学习率调整算法。最后使用plt.plot绘制loss和acc曲线图
然后,点击train.py运行脚本。
测试结果
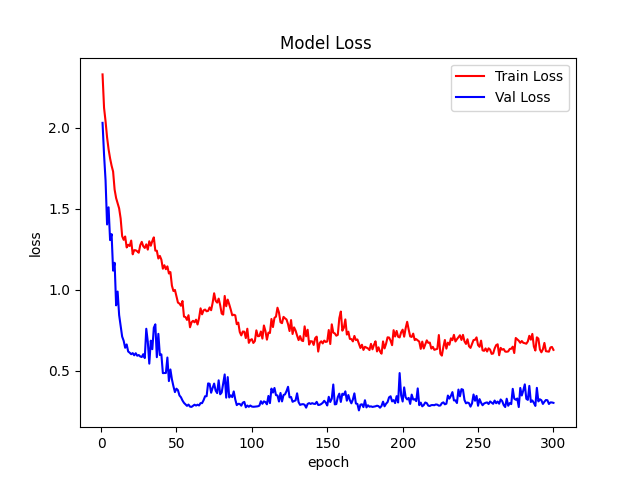
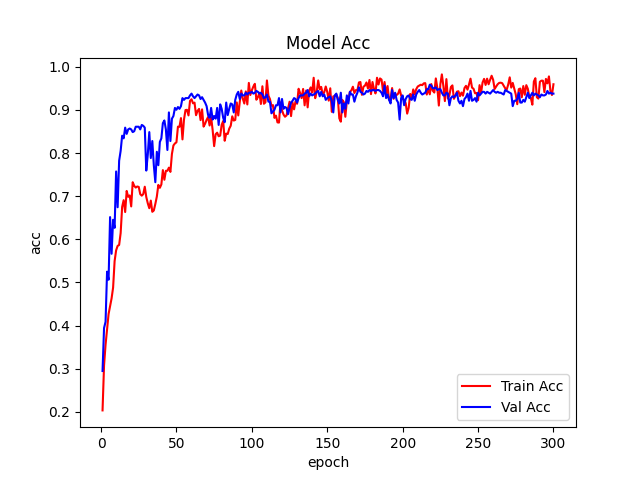
最好的模型ACC是95.6%。
稀疏训练VGGNet
微调结果
Val set: Average loss: 0.2845, Accuracy: 457/482 (95%)precision recall f1-score supportBlack-grass 0.79 0.86 0.83 36Charlock 1.00 1.00 1.00 42Cleavers 1.00 0.96 0.98 50Common Chickweed 0.94 0.91 0.93 34Common wheat 0.93 1.00 0.97 42Fat Hen 0.97 0.97 0.97 34Loose Silky-bent 0.88 0.78 0.83 46Maize 0.96 1.00 0.98 45Scentless Mayweed 0.93 0.96 0.95 45Shepherds Purse 0.97 0.97 0.97 35
Small-flowered Cranesbill 1.00 0.97 0.99 36Sugar beet 1.00 1.00 1.00 37accuracy 0.95 482macro avg 0.95 0.95 0.95 482weighted avg 0.95 0.95 0.95 482
相关文章:
VGGNet剪枝实战:使用VGGNet训练、稀疏训练、剪枝、微调等,剪枝出只有3M的模型
摘要 本文讲解如何实现VGGNet的剪枝操作。剪枝的原理:在BN层网络中加入稀疏因子,训练使得BN层稀疏化,对稀疏训练的后的模型中所有BN层权重进行统计排序,获取指定保留BN层数量即取得排序后权重阈值thres。遍历模型中的BN层权重&am…...

【iOS】GCD深入学习
关于GCD和队列的简单介绍请看:【iOS】GCD学习 本篇主要介绍GCD中的方法。 栅栏方法:dispatch_barrier_async 我们有时候需要异步执行两组操作,而且第一组操作执行完之后,才能开始执行第二组操作,当然操作组里也可以包含一个或者…...

Webpack开启本地服务器;HMR热模块替换;devServer配置;开发与生成环境的区分与配置
目录 1_开启本地服务器1.1_开启本地服务器原因1.2_webpack-dev-server 2_HMR热模块替换2.1_认识2.2_开启HMR2.3_框架的HMR 3_devServer配置3.1_host配置3.2_port、open、compress 4_开发与生成环境4.1_如何区分开发环境4.2_入口文件解析4.3_区分开发和生成环境配置 1_开启本地服…...

opencv 31-图像平滑处理-方框滤波cv2.boxFilter()
方框滤波(Box Filtering)是一种简单的图像平滑处理方法,它主要用于去除图像中的噪声和减少细节,同时保持图像的整体亮度分布。 方框滤波的原理很简单:对于图像中的每个像素,将其周围的一个固定大小的邻域内…...
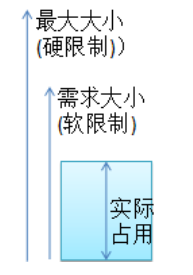
Kubernetes关于cpu资源分配的设计
kubernetes资源 在K8s中定义Pod中运行容器有两个维度的限制: 资源需求(Requests):即运行Pod的节点必须满足运行Pod的最基本需求才能运行Pod。如 Pod运行至少需要2G内存,1核CPU。(软限制)资源限额(Limits):即运行Pod期间,可能内存使用量会增加,那最多能使用多少内存,这…...

Flink读取mysql数据库(java)
代码如下: package com.weilanaoli.ruge.vlink.flink;import com.ververica.cdc.connectors.mysql.source.MySqlSource; import com.ververica.cdc.connectors.mysql.table.StartupOptions; import com.ververica.cdc.debezium.JsonDebeziumDeserializationSchema; import org…...
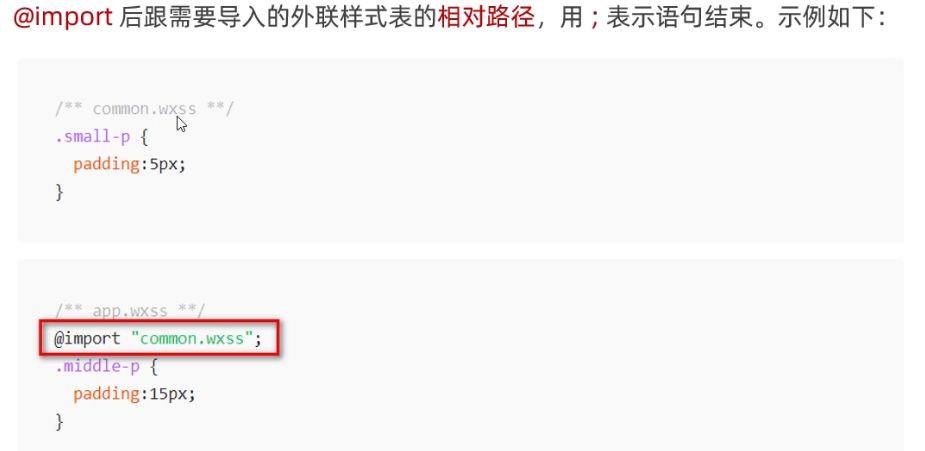
小程序学习(五):WXSS模板语法
1.什么是WXSS WXSS是一套样式语言,用于美化WXML的组件样式,类似于网页开发中的CSS 2.WXSS和CSS的关系 WXSS模板样式-rpx 3.什么是rpx尺寸单位 4.rpx的实现原理 5.rpx与px之间的单位换算* WXSS模板样式-样式导入 6.什么是样式导入 使用WXSS提供的import语法,可以导入外联的样式…...

注解 @JsonFormat 与 @DateTimeFormat 的使用
文章目录 JsonFormat (双端互传)DateTimeFormat (前端传后端日期格式转化)情况一 前端是时间组件 <el-date-picker 或其他情况二 前端未设置组件 JsonFormat (双端互传) com.fasterxml.jackson.annotation.JsonFormat; 将字符串的时间转换成Date类型…...
Python实现决策树算法:完整源码逐行解析
决策树是一种常用的机器学习算法,它可以用来解决分类和回归问题。决策树的优点是易于理解和解释,可以处理数值和类别数据,可以处理缺失值和异常值,可以进行特征选择和剪枝等操作。决策树的缺点是容易过拟合,对噪声和不…...

Linux文本三剑客---grep、sed、awk
目录标题 1、grep1.1 命令格式1.2命令功能1.3命令参数1.4grep实战演练 2、sed2.1 认识sed2.2命令格式2.3常用选项options2.4地址定界2.5 编辑命令command2.6用法演示2.6.1常用选项options演示2.6.2地址界定演示2.6.3编辑命令command演示 3、awk3.1认识awk3.2常用命令选项3.3awk…...
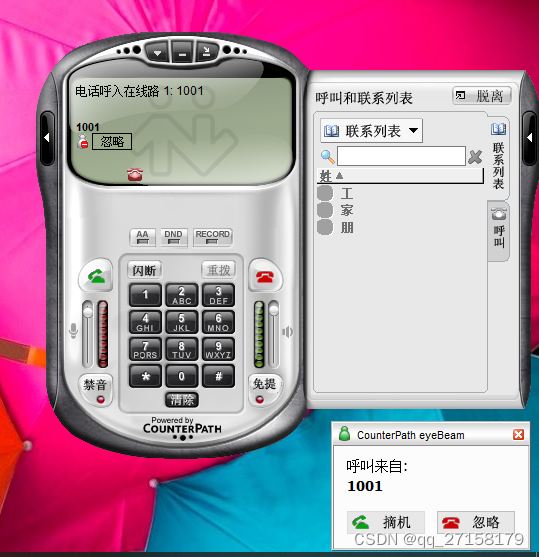
局域网VoIP网络电话测试
0. 环境 ubuntu18或者ubuntu22 - SIP服务器 win10 - SIP客户端1 ubuntu18 - SIP客户端2 1. SIP服务器搭建asterisk 1.0 环境 虚拟机ubuntu18 或者ubuntu22 1.1 直接安装 sudo apt-get install asterisk 1.2 配置用户信息 分为两个部分,第一部分是修改genera…...
el-table 去掉边框(修改颜色)
原始: 去掉表格的border属性,每一行下面还会有一条线,并且不能再拖拽表头 为了满足在隐藏表格边框的情况下还能拖动表头,修改相关css即可,如下代码 <style lang"less"> .table {//避免单元格之间出现白…...

redis与MongoDB的区别
1.Redis与MongoDB的概念 1.1 MongoDB MongoDB 是由C语言编写的,是一个基于分布式文件存储的开源数据库系统。 在高负载的情况下,添加更多的节点,可以保证服务器性能。 MongoDB 旨在为WEB应用提供可扩展的高性能数据存储解决方案。 MongoDB …...

CSS设置高度
要设置 article.content 的恰当高度,您可以使用 CSS 来控制元素的外观。有几种方法可以设置元素的高度,具体取决于你的需求和布局。 以下是几种常见的方法: 1. 固定高度:你可以直接为 article.content 设置一个固定的高度值&…...

开源免费用|Apache Doris 2.0 推出跨集群数据复制功能
随着企业业务的发展,系统架构趋于复杂、数据规模不断增大,数据分布存储在不同的地域、数据中心或云平台上的现象越发普遍,如何保证数据的可靠性和在线服务的连续性成为人们关注的重点。在此基础上,跨集群复制(Cross-Cl…...

【docker】docker-compose服务编排
目录 一、服务编排概念二、docker compose2.1 定义2.2 使用步骤2.3 docker-compose安装2.4 docker-compose卸载 三、编排示例 一、服务编排概念 1.微服务架构的应用系统中一般包含若干个微服务,每个微服务一般都会部署多个实例,如果每个微服务都要手动启…...
EdgeBox_tx1_A200 PyTorch v1.9.0 环境部署
大家好,我是虎哥,今天远程帮助几个小伙伴在A200 控制器上安装PyTorch v1.9.0 torchvision v0.10.0,中间也是经历了很多波折,当然,大部分是网络问题和版本适配问题,所以完事后,将自己完整可用的过…...

【雕爷学编程】MicroPython动手做(33)——物联网之天气预报
天气(自然现象) 是指某一个地区距离地表较近的大气层在短时间内的具体状态。而天气现象则是指发生在大气中的各种自然现象,即某瞬时内大气中各种气象要素(如气温、气压、湿度、风、云、雾、雨、闪、雪、霜、雷、雹、霾等ÿ…...
分库分表之基于Shardingjdbc+docker+mysql主从架构实现读写分离 (三)
本篇主要说明: 1. 因为这个mysql版本是8.0,所以当其中一台mysql节点挂掉之后,主从同步,甚至双向数据同步都失效了,所以本篇主要记录下当其中的节点挂掉之后如何再次生效。另外推荐大家使用mysql5.7的版本,这…...
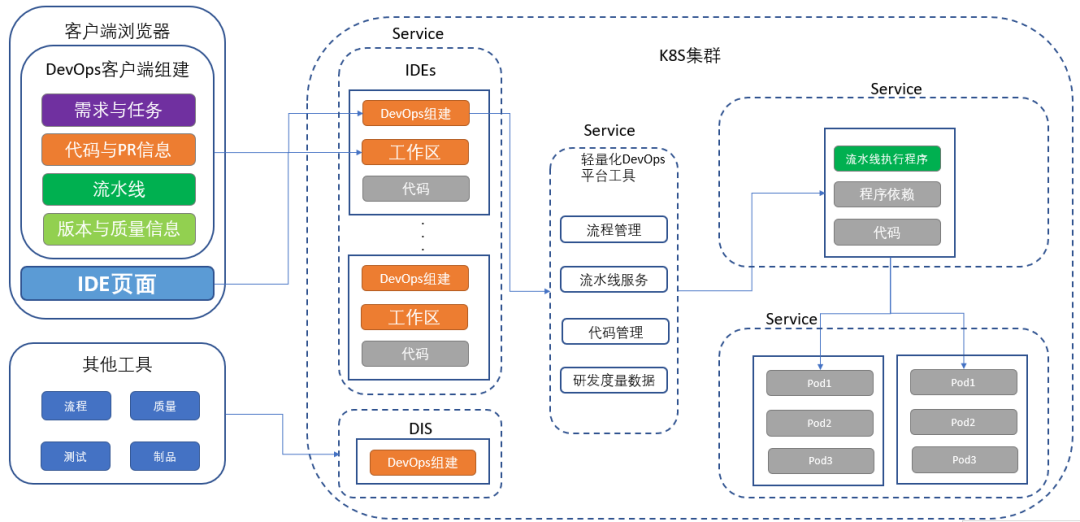
探秘企业DevOps一体化平台建设终极形态丨IDCF
笔者从事为企业提供研发效能改进解决方案相关工作十几年,为国内上百家企业提供过DevOps咨询及解决方案落地解决方案,涉及行业包括:金融、通信、制造、互联网、快销等多种行业。 DevOps的核心是研发效能改进,效能的提升离不开强大…...

【硬件实战】从栅极驱动芯片到H桥:MOS管驱动电路设计精要
1. 栅极驱动芯片选型与核心参数解析 第一次用IR2104做H桥驱动时,我犯了个低级错误——没仔细看芯片的驱动能力参数,结果MOS管开关速度慢得像老牛拉车,电机发热严重。这个教训让我明白,选对栅极驱动芯片是H桥设计的首要任务。 目前…...

基于NirDiamant/agents-towards-production项目的LangSmith可观测性实践指南
基于NirDiamant/agents-towards-production项目的LangSmith可观测性实践指南 【免费下载链接】agents-towards-production End-to-end, code-first tutorials for building production-grade GenAI agents. From prototype to enterprise deployment. 项目地址: https://gitc…...

OpenUPM安全最佳实践:保护你的Unity包注册表完全指南 [特殊字符]
OpenUPM安全最佳实践:保护你的Unity包注册表完全指南 🔒 【免费下载链接】openupm OpenUPM - Open Source Unity Package Registry (UPM) 项目地址: https://gitcode.com/gh_mirrors/op/openupm OpenUPM作为开源Unity包管理器(UPM&…...

低查重AI教材生成利器,AI写教材工具让你1周完成40万字书稿!
在撰写教材的过程中,总是难以避免“慢节奏”的所有坑。当框架和资料都已准备妥当时,却常常因为撰写内容而停滞不前——一句话反复斟酌半小时,仍觉得不够准确;章节间的衔接更是让人绞尽脑汁,找不到合适的表达方式&#…...

Linux内核驱动开发:从传统proc接口到现代seq_file与proc_ops的迁移指南
1. 项目概述:为什么我们需要关注/proc的新接口?如果你在Linux内核驱动开发领域摸爬滚打过几年,一定对/proc文件系统这个“老伙计”又爱又恨。爱它,是因为在调试和状态监控时,它提供了一个极其简单、直观的窗口…...

WeChatExporter:将你的数字记忆转化为永恒的数字档案
WeChatExporter:将你的数字记忆转化为永恒的数字档案 【免费下载链接】WeChatExporter 一个可以快速导出、查看你的微信聊天记录的工具 项目地址: https://gitcode.com/gh_mirrors/wec/WeChatExporter 你是否曾有过这样的经历?深夜翻看旧手机&…...

5分钟快速上手Figma中文界面:设计师必备的终极汉化插件指南
5分钟快速上手Figma中文界面:设计师必备的终极汉化插件指南 【免费下载链接】figmaCN 中文 Figma 插件,设计师人工翻译校验 项目地址: https://gitcode.com/gh_mirrors/fi/figmaCN 还在为Figma全英文界面而苦恼吗?FigmaCN中文插件是你…...

Kubernetes原生部署Jenkins:全栈方案与生产级实践指南
1. 项目概述:一个为Kubernetes而生的Jenkins全栈部署方案在容器化和云原生技术席卷全球的今天,Jenkins作为持续集成与持续交付领域的常青树,其部署形态也正经历着深刻的变革。直接将Jenkins部署在物理机或虚拟机上,虽然简单直接&a…...

Arm DynamIQ™ DSU架构解析与多核设计优化
1. Arm DynamIQ™ Shared Unit架构深度解析 在当代SoC设计中,多核处理器架构面临的核心挑战是如何在提升计算密度的同时,维持高效的数据一致性与灵活的功耗管理。Arm DynamIQ™ Shared Unit(DSU)作为解决这一问题的创新设计&#…...

独立开发者应对Claude Code封号风险的备用方案与接入实践
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 独立开发者应对Claude Code封号风险的备用方案与接入实践 对于依赖Claude Code进行日常开发的独立开发者或小型团队而言࿰…...