Docker下快速搭建RabbitMQ单例及集群
单机 docker(要想快 先看问题 避免踩坑)
rabbitmq-plugins enable rabbitmq_managementrabbitmqctl add_user admin StrongPassword
rabbitmqctl set_user_tags admin administrator
rabbitmqctl set_permissions -p / admin “.*” “.*” “.*”
遇到的问题
docker pull rabbitmqdocker pull rabbitmq:managementdocker run -di --name=rbtmq-mst -p 5671:5671 -p 5672:5672 -p 4369:4369 -p 15671:15671 -p 15672:15672 -p 25672:25672 rabbitmq:management
docker ps
docker exec -it 镜像ID /bin/bash
rabbitmq-plugins enable rabbitmq_managementdocker exec -it {rabbitmq容器名称或者id} /bin/bash
#进入容器后,cd到以下路径
cd /etc/rabbitmq/conf.d/
#修改 management_agent.disable_metrics_collector = false
echo management_agent.disable_metrics_collector = false > management_agent.disable_metrics_collector.conf
#退出容器
exit
#重启rabbitmq容器
docker restart {rabbitmq容器id或容器名称}关于cluster集群
docker run -di --hostname rbtmq_mst --name rbtmq_mst -p 5671:5671 -p 5672:5672 -p 4369:4369 -p 15671:15671 -p 15672:15672 -p 25672:25672 -e RABBITMQ_ERLANG_COOKIE='rabbitcookie' rabbitmq:management
docker run -di --hostname rbtmq_slv1 --name rbtmq_slv1 -p 5871:5671 -p 5872:5672 -p 4569:4369 -p 17671:15671 -p 17672:15672 -p 27672:25672 --link rbtmq_mst:rbtmq_mst -e RABBITMQ_ERLANG_COOKIE='rabbitcookie' rabbitmq:management
docker run -di --hostname rbtmq_slv2 --name rbtmq_slv2 -p 5971:5671 -p 5972:5672 -p 4769:4369 -p 19671:15671 -p 19672:15672 -p 29672:25672 --link rbtmq_mst:rbtmq_mst --link rbtmq_slv1:rbtmq_slv1 -e RABBITMQ_ERLANG_COOKIE='rabbitcookie' rabbitmq:managementroot@rbtmq_slv1:/# rabbitmqctl stop_app
root@rbtmq_slv1:/# rabbitmqctl reset
root@rbtmq_slv1:/# rabbitmqctl join_cluster --ram rabbit@rbtmq_mst
Clustering node rabbit@rbtmq_slv1 with rabbit@rbtmq_mst
root@rbtmq_slv1:/# rabbitmqctl start_app
Starting node rabbit@rbtmq_slv1 ...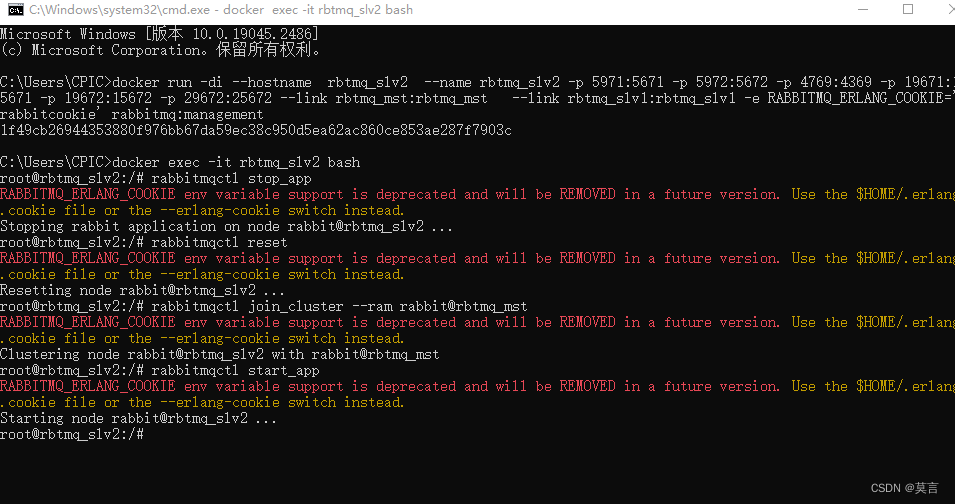
--ram 和--disc区别RabbitMQ对于queue中的message的保存方式有两种方式:disc和ram。如果采用disc,则需要对exchange/queue/delivery mode都要设置成durable模式。Disc方式的好处是当RabbitMQ失效了,message仍然可以在重启之后恢复。使用ram方式,RabbitMQ处理message的效率要高很多,ram和disc两种方式的效率比大概是3:1。所以如果在有其它HA手段保障的情况下,选用ram方式是可以提高消息队列的工作效率的。如果使用ram方式,RabbitMQ能够承载的访问量则取决于可用的内存数了。RabbitMQ使用两个参数来限制使用系统的内存,避免系统被自己独占。作者:Bogon链接:https://www.jianshu.com/p/6df48edda72e来源:简书著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
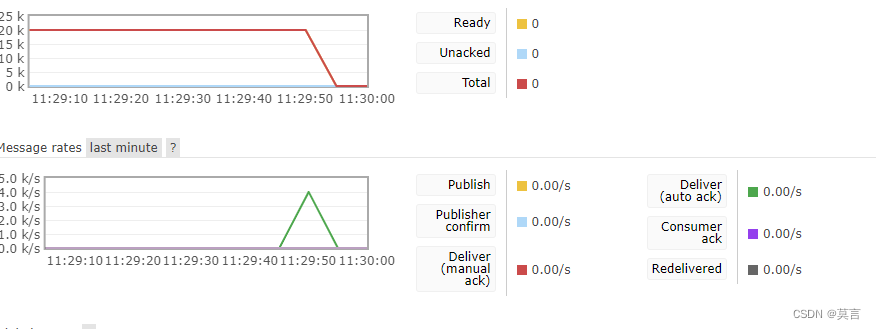
测试用例[用PY唯快,无他尔]
发消息
# This is a sample Python script.
import pika
# Press Shift+F10 to execute it or replace it with your code.
# Press Double Shift to search everywhere for classes, files, tool windows, actions, and settings.
def print_hi(name):# Use a breakpoint in the code line below to debug your script.print(f'Hi, {name}') # Press Ctrl+F8 to toggle the breakpoint.
# Press the green button in the gutter to run the script.
if __name__ == '__main__':print_hi('PyCharm')connection = pika.BlockingConnection(pika.ConnectionParameters('localhost'))
channel = connection.channel()
channel.queue_declare(queue='hello')
for i in range (9999999,0,-1):channel.basic_publish(exchange='',routing_key='hello',body='helllllllo '+str(i))print("[x] send message")
# See PyCharm help at https://www.jetbrains.com/help/pycharm/消费消息
import pikaconnection = pika.BlockingConnection(pika.ConnectionParameters('localhost'))
channel = connection.channel()
channel.queue_declare(queue='hello')
def callback(ch,method,properties,body):print("[x] Rev %r" % body)channel.basic_consume(queue='hello',auto_ack=True,on_message_callback=callback)print('[*] Waiting for MSG. Exit by Ctrl+C')channel.start_consuming()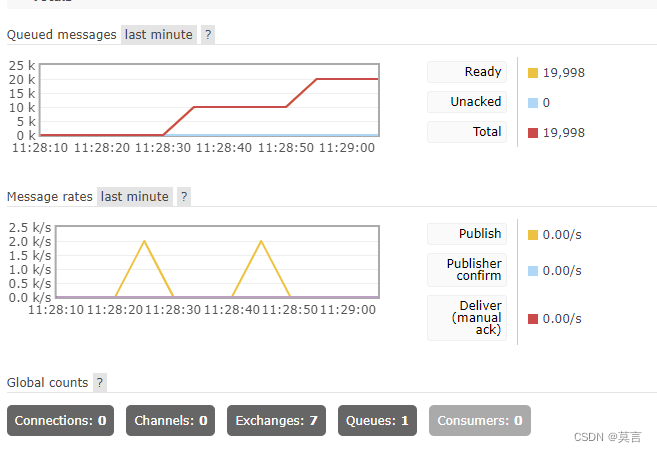
相关文章:
Docker下快速搭建RabbitMQ单例及集群
引子生命在于折腾,为上数据实时化用到了消息传送的内容,当时也和总公司人员商量选型,kafka不能区分分公司就暂定用了RbtMQ刚好个人也在研究容器及分布式部署相关内容就在docker上实践单机 docker(要想快 先看问题 避免踩坑&#x…...

python代码写开心消消乐
♥️作者:小刘在C站 ♥️个人主页:小刘主页 ♥️每天分享云计算网络运维课堂笔记,努力不一定有收获,但一定会有收获加油!一起努力,共赴美好人生! ♥️夕阳下,是最美的绽放,树高千尺,落叶归根人生不易,人间真情 目录 一.python是什么 二.游戏代码效果呈现 三.主代...
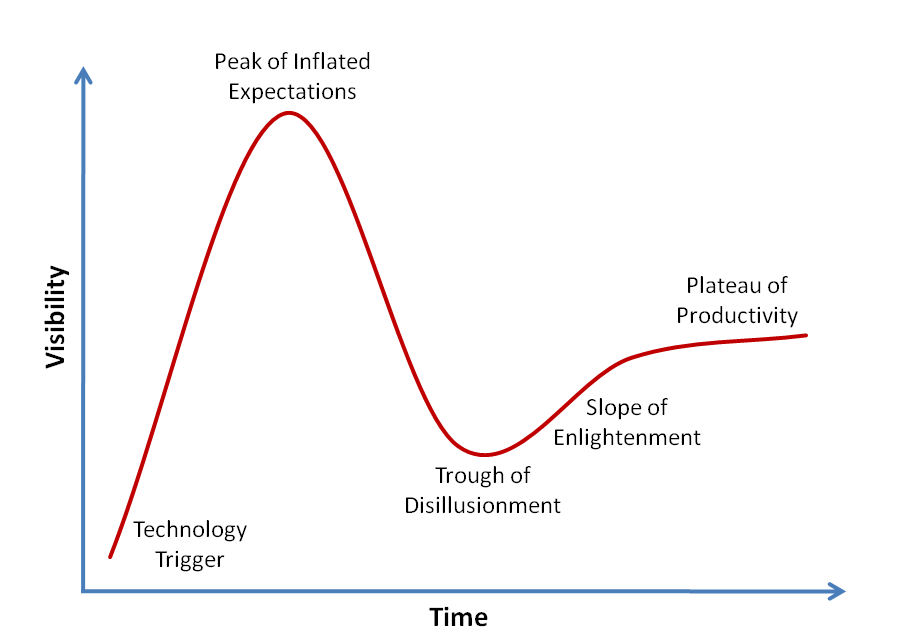
【郭东白架构课 模块一:生存法则】09|法则四:为什么要顺应技术的生命周期?
你好,我是郭东白。今天我们来讲架构师的第四条生存法则,那就是尊重技术的生命周期。 人类的各种活动都要遵循事物的客观生命周期。不论是农业社会种田打渔,还是资本社会投资创业,行动太早或太晚,都会颗粒无收。技术也…...
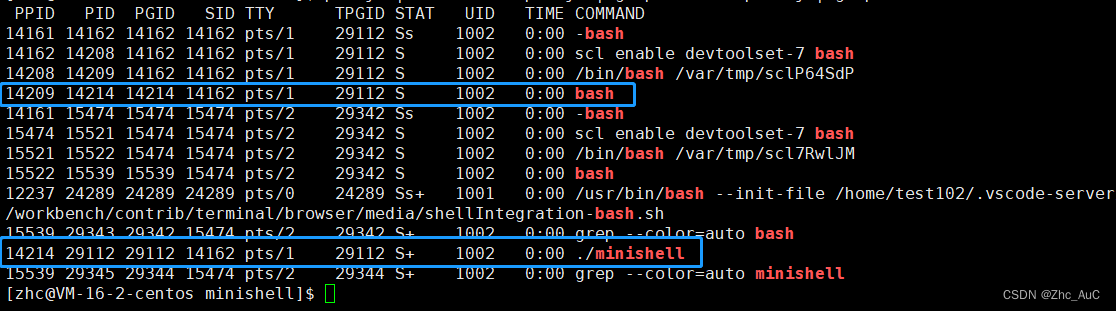
Linux之进程控制
一.进程创建 1.1 fork函数 我们创建进程的方式有./xxx和fork()两种 在linux中fork函数时非常重要的函数,它从已存在进程中创建一个新进程。新进程为子进程,而原进程为父进程。 #include <unistd.h> pid_t fork(void); 返回值:自进程…...

SpringBoot社区版专业版带你配置热部署
💟💟前言 友友们大家好,我是你们的小王同学😗😗 今天给大家打来的是 SpringBoot社区版专业版带你配置热部署 希望能给大家带来有用的知识 觉得小王写的不错的话麻烦动动小手 点赞👍 收藏⭐ 评论…...

影响AFE采样精度的因素有哪些?
**AFE(Analog Front End)**是模拟前端电路的缩写,它是模拟信号传感器和数字信号处理器之间的连接点。AFE采样精度是指模拟信号被数字化后的准确度,对于很多电子设备来说,这是一个至关重要的性能指标。本文将介绍影响AF…...

mysqlbackup备份报error:redo log was overwritten
问题原因 备份时redo log被覆盖 解决方案 方法1:增加innodb_log_file_size、innodb_log_files_in_group大小,需要重启数据库 vi my.cnf innodb_log_file_size 2G innodb_log_files_in_group 4 方法2: 动态配置redo log archive,不需要重启…...

Android支持库
# 支持库 注意:Android 9.0(API 级别 28)发布后,新版支持库 AndroidX 也随之诞生,它属于 Jetpack。除了现有的支持库,AndroidX 库还包含最新的 Jetpack 组件。 您可以继续使用此支持库以往的工件(这里指的是版本 27 及更早版本,且已打包为 android.support.*)在 Googl…...
Vue:filters过滤器
日期、时间格式化是Vue前端项目中较为常遇到的一个需求点,此处,围绕Vue的过滤器来介绍如何更为优雅的解决此类需求。 过滤器filters使用注意点 Vue允许开发者自定义过滤器,可以实现一些常见的文本格式化等需求。 使用时要注意的点在于&#…...
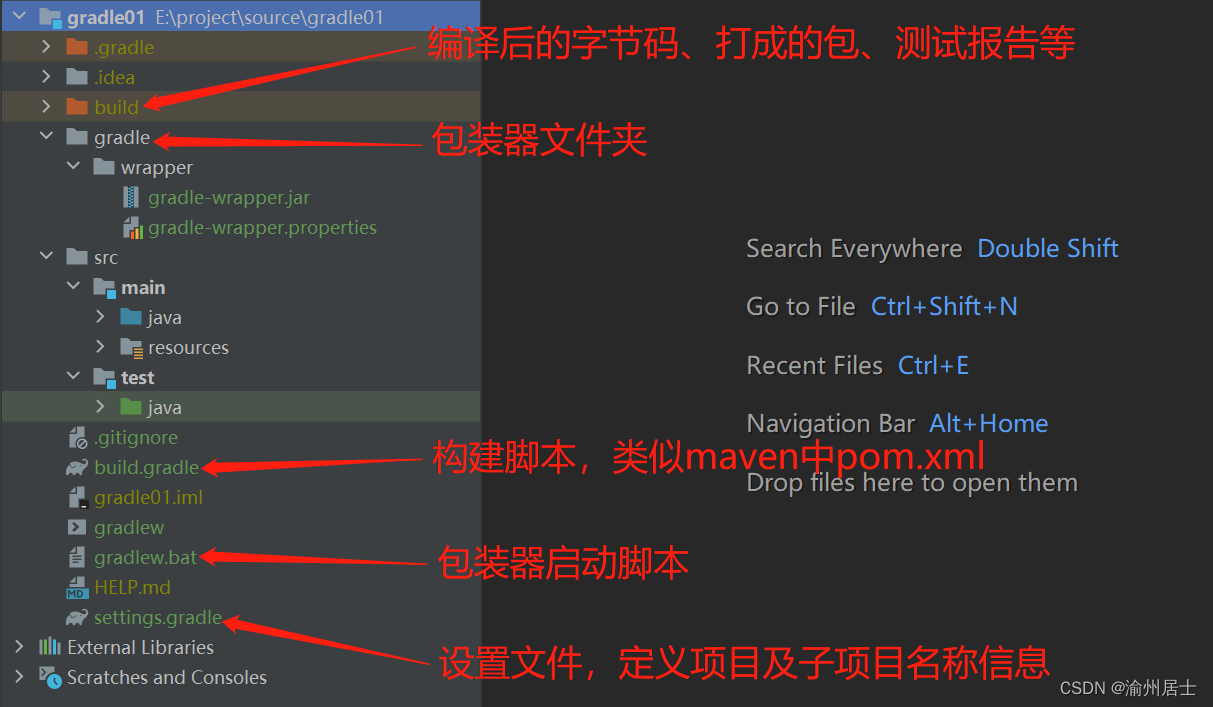
Windows环境下安装和配置Gradle
1. 概述 Gradle是Google公司基于JVM开发的一款项目构建工具,支持Maven,JCenter多种第三方仓库,支持传递性依赖管理,使用更加简洁和支持多种语言的build脚步文件,更多详情可以参阅Gradle官网 2. 下载 由于Gradle与S…...

数据结构时间空间复杂度笔记
🕺作者: 迷茫的启明星 本篇内容:数据结构时间空间复杂度笔记 😘欢迎关注:👍点赞🙌收藏✍️留言 🏇家人们,码字不易,你的👍点赞🙌收藏❤…...
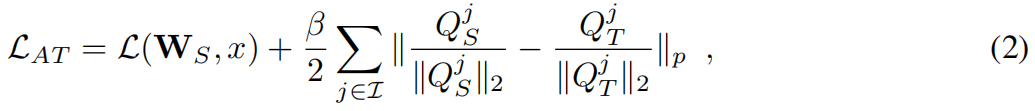
基于注意力的知识蒸馏Attention Transfer原理与代码解析
paper:Paying More Attention to Attention: Improving the Performance of Convolutional Neural Networks via Attention Transfercode:https://github.com/megvii-research/mdistiller/blob/master/mdistiller/distillers/AT.py背景一个流行的假设是存…...

利尔达在北交所上市:总市值突破29亿元,叶文光为董事长
2月17日,利尔达科技集团股份有限公司(下称“利尔达”,BJ:832149)在北京证券交易所上市。本次上市,利尔达的发行价格为5.00元/股,发行数量为1980万股,发行市盈率为12.29倍,募资总额为…...
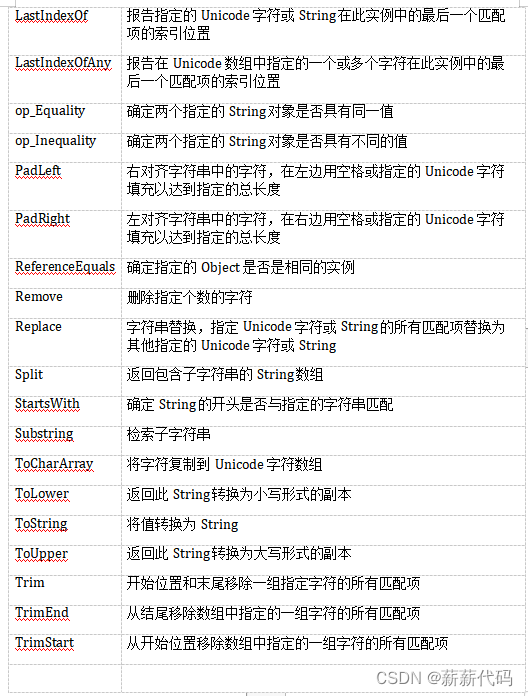
C#操作字符串方法 [万余字总结 · 详细]
C#操作字符串方法总结C#常用字符串函数大全C#常用字符串操作方法C#操作字符串方法总结C#常用字符串函数大全 Compare 比较字符串的内容,考虑文化背景(场所),确定某些字符是否相等 CompareOrdinal 与Compare一样,但不考虑文化背景 Format 格…...

极兔一面:10亿级ES海量搜索狂飙10倍,该怎么办?
背景说明: ES高性能全文索引,如果不会用,或者没有用过,在面试中,会非常吃亏。 所以ES的实操和底层原理,大家要好好准备。 另外,ES调优是一个非常、非常核心的面试知识点,大家要非…...
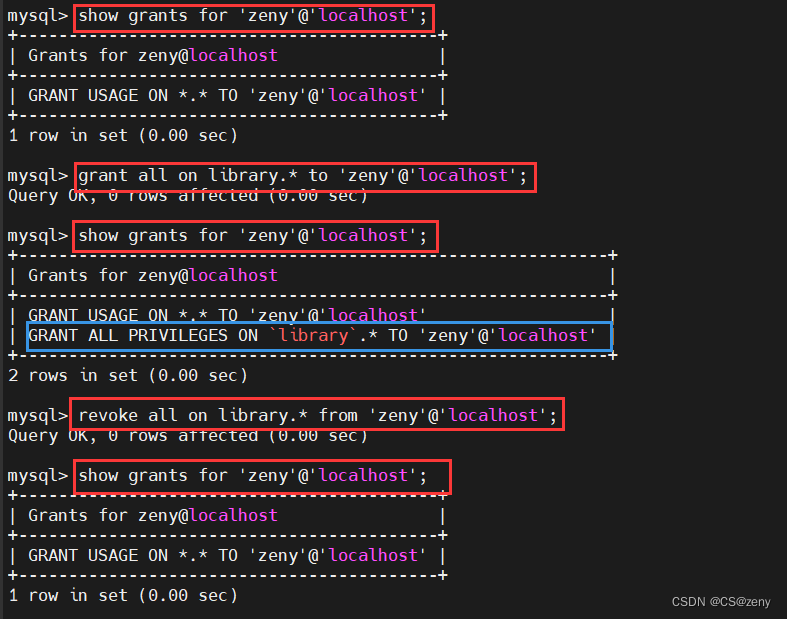
【Mysql基础 —— SQL语句(一)】
文章目录概述使用启动/停止mysql服务连接mysql客户端数据模型SQLSQL语句分类DDL数据库操作表操作查询创建数据类型修改删除DML添加数据修改数据删除数据DQL基础查询条件查询聚合函数分组查询排序查询分页查询执行顺序DCL管理用户权限控制概述 数据库(Database&#…...
 | 机试题算法思路)
华为OD机试 - 新员工座位安排系统(Python) | 机试题算法思路
最近更新的博客 华为OD机试 - 招聘(Python) | 备考思路,刷题要点,答疑 【新解法】华为OD机试 - 五键键盘 | 备考思路,刷题要点,答疑 【新解法】华为OD机试 - 热点网络统计 | 备考思路,刷题要点,答疑 【新解法】华为OD机试 - 路灯照明 | 备考思路,刷题要点,答疑 【新解…...

MySQL - 介绍
前言 本篇介绍认识MySQL,重装mysql操作 如有错误,请在评论区指正,让我们一起交流,共同进步! 本文开始 1.什么是数据库? 数据库: 一种通过SQL语言操作管理数据的软件; 重装数据库的卸载数据库步骤 : ① 停止MySQL服…...

ChatGPT国内镜像站初体验:聊天、Python代码生成等
ChatGPT国内镜像站初体验,聊天、Python代码生成。 (本文获得CSDN质量评分【92】)【学习的细节是欢悦的历程】Python 官网:https://www.python.org/ Free:大咖免费“圣经”教程《 python 完全自学教程》,不仅仅是基础那么简单………...
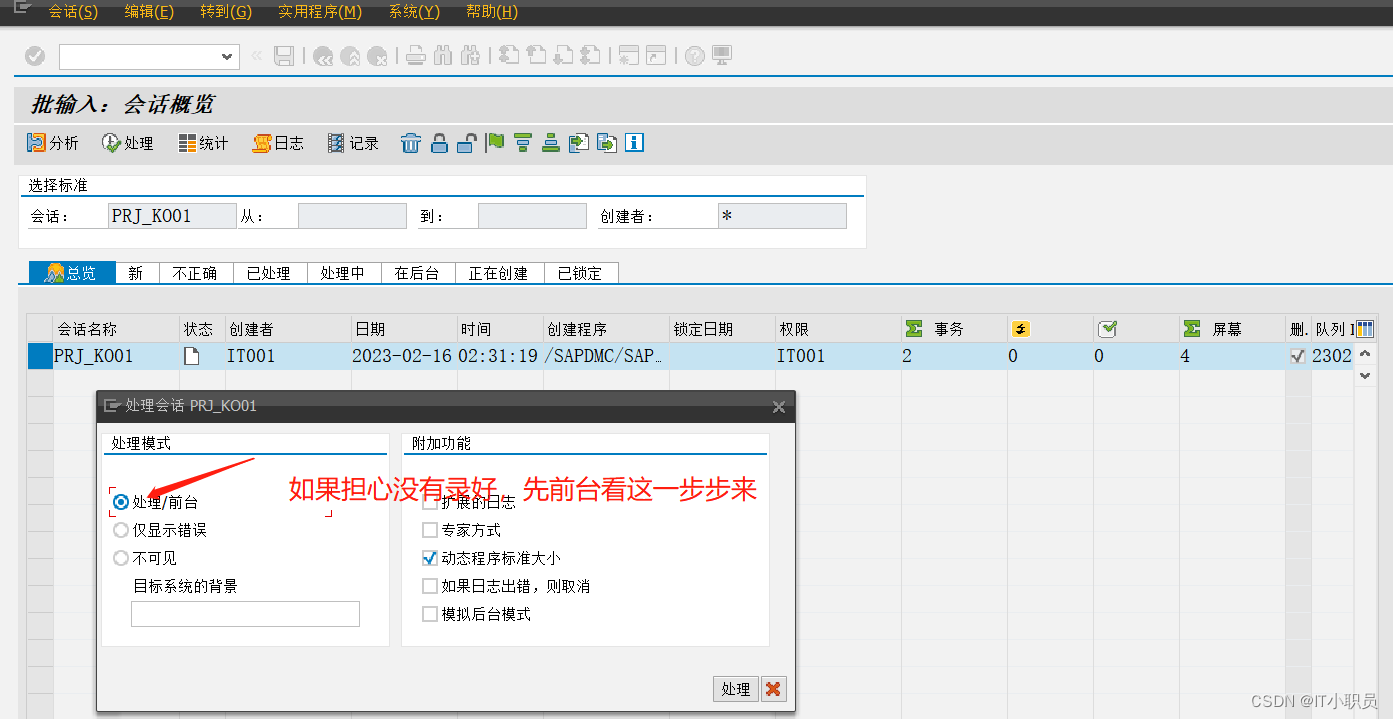
SAP数据导入工具(LSMW) 超级详细教程(批量导入内部订单)
目录 第一步:记录批导步骤编辑数据源对应字段 第二步:维护数据源 第三步:维护数据源对应字段(重要) 第四步:维护数据源关系。 第五步:维护数据源与导入字段的对应关系。 第六步࿰…...

reverse-shell工作原理深度解析:智能检测与多语言payload实现
reverse-shell工作原理深度解析:智能检测与多语言payload实现 【免费下载链接】reverse-shell Reverse Shell as a Service 项目地址: https://gitcode.com/gh_mirrors/re/reverse-shell reverse-shell作为一种强大的网络安全工具,其核心功能是让…...

AI编程工具实战指南:从Claude Code到Cursor的深度技巧与工作流设计
1. 项目概述:一份写给实干派开发者的AI编程工具实战手册 如果你和我一样,是个在一线写代码写了十来年的老程序员,那你肯定已经感受到了,这两年AI编程工具的出现,彻底改变了我们写代码的方式。从最开始GitHub Copilot那…...

如何快速上手Python财经数据分析:AKShare完整新手指南
如何快速上手Python财经数据分析:AKShare完整新手指南 【免费下载链接】akshare AKShare is an elegant and simple financial data interface library for Python, built for human beings! 开源财经数据接口库 项目地址: https://gitcode.com/gh_mirrors/aks/ak…...

C语言程序设计核心详解 函数和预编译命令
1.函数的定义和使用1.1 函数定义C语言程序的框架有两种:一个main()单框架一个main()多个子函数注:一个源程序文件可由一个或多个函数组成一个C语言程序可以由一个或多个源程序文件组成C程序执行总是从main()开始,结束于main()结束;…...

终极SOCD清理工具:Hitboxer让你的游戏操作精准如职业选手
终极SOCD清理工具:Hitboxer让你的游戏操作精准如职业选手 【免费下载链接】socd Key remapper for epic gamers 项目地址: https://gitcode.com/gh_mirrors/so/socd 你是否曾在激烈的游戏对战中,明明同时按下了左右方向键,角色却做出奇…...
)
Vue项目里用Video.js播m3u8直播流,我踩过的那些坑(videojs-contrib-hls版)
Vue项目中Video.js集成m3u8直播流的深度排坑指南 1. 引言:当流媒体遇上Vue生态 在Vue项目中实现m3u8直播流播放,看似只是简单的播放器集成,实则暗藏玄机。作为经历过多个企业级视频平台开发的老手,我必须坦言:官方文档…...

Torch-Pruning:基于DepGraph的PyTorch结构化模型剪枝实战指南
1. 项目概述与核心价值 如果你正在为部署一个庞大的深度学习模型而发愁,看着动辄几十上百亿的参数和令人咋舌的算力需求感到束手无策,那么“模型剪枝”这项技术很可能就是你一直在寻找的解决方案。简单来说,模型剪枝就像给一棵枝繁叶茂的大树…...

3步构建永久小说资产库:番茄小说下载器技术深度解析
3步构建永久小说资产库:番茄小说下载器技术深度解析 【免费下载链接】fanqienovel-downloader 下载番茄小说 项目地址: https://gitcode.com/gh_mirrors/fa/fanqienovel-downloader 在数字内容快速迭代的时代,网络文学如同流动的沙丘,…...

从接入到观测 Taotoken 为开发者提供的全链路体验
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 从接入到观测 Taotoken 为开发者提供的全链路体验 对于开发者而言,将大模型能力集成到自己的应用或项目中,…...

如何为你的Nextjs应用快速添加Taotoken大模型对话功能
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 如何为你的Nextjs应用快速添加Taotoken大模型对话功能 1. 项目准备与环境变量配置 在开始集成之前,你需要一个可运行的…...