【动态网页抓取】 :用Python抓取所有内容的指南
一、说明
加入我们的分步教程,了解有关使用 Python 进行动态网页抓取的所有信息——该做什么和不该做什么、挑战和解决方案,以及介于两者之间的一切。

二、什么是动态网站?
动态网站是指没有直接在其静态HTML中包含所有内容的网站。它使用服务器端或客户端来显示数据,有时基于用户的操作(例如,单击、滚动等)。
简而言之,这些网站在每个服务器请求中显示不同的内容或布局。这有助于缩短加载时间,因为用户每次想要查看“新”内容时都无需重新加载相同的信息。
如何识别它们?一种方法是在浏览器的命令面板中禁用 JavaScript。如果网站是动态的,内容将消失。
让我们以 Saleor React Storefront 为例。这是它的首页的样子:
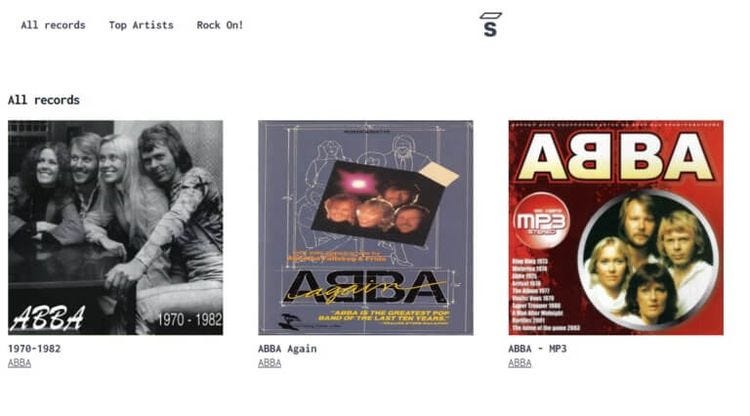
注意标题、图像和艺术家姓名。
现在,让我们使用以下步骤禁用 JavaScript:
- 检查页面:右键单击并选择“检查”以打开“DevTools 窗口”。
- 导航到命令面板:CTRL/CMD + SHIFT + P。
- 搜索“JavaScript”。
- 单击禁用 JavaScript。
- 点击刷新。
结果如何?见下文:

你自己看!禁用 JavaScript 会删除所有动态 Web 内容。
三、使用 Python 进行动态网页抓取的替代方案
所以,你想用Python抓取动态网站......
由于 Beautiful Soup 或 Requests 等库不会自动获取动态内容,因此您有两个选项来完成任务:
- 将内容馈送到标准库。
- 在抓取时执行页面的内部 JavaScript。
但是,并非所有动态页面都相同。有些通过 JS API 呈现内容,可以通过检查“网络”选项卡来访问这些内容。其他人将JS渲染的内容作为JSON存储在DOM(文档对象模型)中的某个位置。
好消息是,我们可以解析 JSON 字符串以在这两种情况下提取必要的数据。
请记住,在某些情况下,这些解决方案不适用。对于此类网站,您可以使用无头浏览器来呈现页面并提取所需的数据。
使用 Python 抓取动态网页的替代方法是:
- 手动查找数据并解析 JSON 字符串。
- 使用无头浏览器执行页面的内部JavaScript(例如,Selenium或Pyppeteer,Puppeteer的非官方Python端口)。
四、在 Python 中抓取动态网站的最简单方法是什么?
的确,无头浏览器可能很慢且性能密集。但是,他们取消了对网络抓取的所有限制。也就是说,如果您不计算反机器人检测。而且您不应该这样做,因为我们已经告诉您如何绕过此类保护。
手动查找数据并解析 JSON 字符串假定可以访问动态数据的 JSON 版本。不幸的是,情况并非总是如此,尤其是在涉及高级单页应用程序 (SPA) 时。
更不用说模仿 API 请求是不可扩展的。他们通常需要 cookie 和身份验证以及其他可以轻松阻止您的限制。
在 Python 中抓取动态网页的最佳方法取决于您的目标和资源。如果您可以访问网站的 JSON 并希望提取单个页面的数据,则可能不需要无头浏览器。
然而,除了这一小部分情况,大多数时候使用美丽的汤和硒是你最好和最简单的选择。
是时候弄脏我们的手了!准备好编写一些代码,并准确地了解如何在 Python 中抓取动态网站!
五、先决条件
若要遵循本教程,需要满足一些要求。我们将使用以下工具:
- Python 3:最新版本的 Python 将运行得最好。在撰写本文时,这是 3.11.2。
- 硒
- Web驱动程序管理器:这将确保浏览器和驱动程序的版本匹配。您不必为此目的手动下载 Web 驱动程序。
pip install selenium webdriver-manager 您现在拥有所需的一切。我们走吧!
六、方法#1:使用Beautiful Soup使用Python进行动态网页抓取
Beautiful Soup可以说是用于抓取HTML数据的最流行的Python库。
要使用它提取信息,我们需要目标页面的 HTML 字符串。但是,动态内容并不直接存在于网站的静态 HTML 中。这意味着 Beautiful Soup 无法访问 JavaScript 生成的数据。
这是一个解决方案:如果网站使用 AJAX 请求加载内容,则可以从 XHR 请求中提取数据。
七、方法#2:使用Selenium在Python中抓取动态网页
要了解Selenium如何帮助您抓取动态网站,首先,我们需要检查常规库(例如)如何与它们交互。Requests
我们将使用 Angular 作为我们的目标网站:

让我们尝试刮擦它,看看结果。在此之前,我们必须安装可以使用该命令执行的库。RequestsRequestspip
pip install requests 我们的代码如下所示:
import requests
url = 'https://angular.io/'
response = requests.get(url)
html = response.text
print(html)如您所见,仅提取了以下 HTML:
<noscript> <div class="background-sky hero"></div> <section id="intro" style="text-shadow: 1px 1px #1976d2;"> <div class="hero-logo"></div> <div class="homepage-container"> <div class="hero-headline">The modern web<br>developer's platform</div> </div> </section> <h2 style="color: red; margin-top: 40px; position: relative; text-align: center; text-shadow: 1px 1px #fafafa; border-top: none;"> <b><i>This website requires JavaScript.</i></b> </h2>
</noscript>
但是,检查网站显示的内容比检索的内容多。
当我们在页面上禁用JavaScript时,就会发生这种情况:

这正是能够返回的原因。该库在解析来自网站静态 HTML 的数据时不会察觉到任何错误,这正是它创建时要做的事情。Requests
在这种情况下,不可能获得与网站上显示的结果相同的结果。你能猜出为什么吗?没错,这是因为这是一个动态网页。
要访问整个内容并提取我们的目标数据,我们必须渲染 JavaScript。
是时候用硒动态网页抓取来纠正它了。
我们将使用以下脚本快速抓取目标网站:
from selenium import webdriver
from selenium.webdriver.chrome.service import Service as ChromeService
from webdriver_manager.chrome import ChromeDriverManager url = 'https://angular.io/' driver = webdriver.Chrome(service=ChromeService( ChromeDriverManager().install())) driver.get(url) print(driver.page_source)
你有它!页面的完整 HTML,包括动态 Web 内容。
祝贺!您刚刚抓取了您的第一个动态网站。
八、选择硒(Selenium)中的元素
有不同的方法可以访问硒中的元素。我们在 Python 中的硒网络抓取指南中深入讨论了这个问题。
不过,我们将通过一个例子来解释这一点。让我们只选择目标网站上的 H2:

在开始之前,我们需要检查网站并确定要提取的元素的位置。
我们可以看到,这些头条新闻很常见。我们复制它并映射 H2s 以使用 Chrome 驱动程序获取元素。class="text-container"

粘贴此代码:
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.chrome.service import Service as ChromeService
from webdriver_manager.chrome import ChromeDriverManager # instantiate options
options = webdriver.ChromeOptions() # run browser in headless mode
options.headless = True # instantiate driver
driver = webdriver.Chrome(service=ChromeService( ChromeDriverManager().install()), options=options) # load website
url = 'https://angular.io/' # get the entire website content
driver.get(url) # select elements by class name
elements = driver.find_elements(By.CLASS_NAME, 'text-container')
for title in elements: # select H2s, within element, by tag name heading = title.find_element(By.TAG_NAME, 'h2').text # print H2s print(heading)
您将获得以下内容:
"DEVELOP ACROSS ALL PLATFORMS"
"SPEED & PERFORMANCE"
"INCREDIBLE TOOLING"
"LOVED BY MILLIONS"
很好,很容易!您现在可以毫不费力地用硒抓取动态网站。
九、如何用硒抓取无限滚动网页
当用户向下滚动到页面底部时,某些动态页面会加载更多内容。这些被称为“精细滚动网站”。爬行它们更具挑战性。为此,我们需要指示我们的蜘蛛滚动到底部,等待所有新内容加载,然后才开始抓取。
通过一个例子来理解这一点。让我们使用刮擦俱乐部的示例页面。
此脚本将滚动浏览前 20 个结果并提取其标题:
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.chrome.service import Service as ChromeService
from webdriver_manager.chrome import ChromeDriverManager
import time options = webdriver.ChromeOptions()
options.headless = True
driver = webdriver.Chrome(service=ChromeService( ChromeDriverManager().install()), options=options) # load target website
url = 'https://scrapingclub.com/exercise/list_infinite_scroll/' # get website content
driver.get(url) # instantiate items
items = [] # instantiate height of webpage
last_height = driver.execute_script('return document.body.scrollHeight') # set target count
itemTargetCount = 20 # scroll to bottom of webpage
while itemTargetCount > len(items): driver.execute_script('window.scrollTo(0, document.body.scrollHeight);') # wait for content to load time.sleep(1) new_height = driver.execute_script('return document.body.scrollHeight') if new_height == last_height: break last_height == new_height # select elements by XPath elements = driver.find_elements(By.XPATH, "//div[@class='card-body']/h4/a") h4_texts = [element.text for element in elements] items.extend(h4_texts) # print title print(h4_texts)
备注:为无限滚动页面设置目标计数非常重要,这样您就可以在某个时候结束脚本。
在前面的示例中,我们使用了另一个选择器:。它将基于 XPath 而不是类和 ID 来定位元素,如前所述。检查页面,右键单击包含要抓取的元素的 ,然后选择复制路径。By.XPath<div>
您的结果应如下所示:
['Short Dress', 'Patterned Slacks', 'Short Chiffon Dress', 'Off-the-shoulder Dress', ...]
你有它,前 4 种产品的 H20!
备注:使用硒进行动态网页抓取可能会因硒的持续更新而变得棘手。最好通过最新的变化。
十、结论
动态网页无处不在。因此,您在数据提取工作中遇到它们的可能性足够高。请记住,熟悉其结构将帮助您确定检索目标信息的最佳方法。
我们在本文中探讨的所有方法都有其自身的缺点和缺点。所以,看看ZenRows必须提供什么。该解决方案允许您使用简单的 API 调用抓取动态网站。立即免费试用,节省自己的时间和资源。
你觉得内容有帮助吗?传播这个词并在Twitter,LinkedIn或Facebook上分享。
本文最初发表于 ZenRows: Dynamic Web Pages Scraping with Python: Guide to Scrape All Content
相关文章:
【动态网页抓取】 :用Python抓取所有内容的指南
一、说明 您在抓取动态网页内容时是否得到了糟糕的结果?不仅仅是你。对于标准抓取工具来说,爬网动态数据是一项具有挑战性的任务(至少可以说)。这是因为当发出HTTP请求时,响应程序的某些部分JavaScript在后台运行&…...

Spring Boot数据访问基础知识与JDBC简单实现
目录 Spring Boot数据访问基础知识 Spring Data ORM JDBC JPA JDBC简单实现 步骤1:新建Maven项目,添加依赖 步骤2:配置数据源—让程序可以访问到 步骤3:配置数据源—让IDEA可以访问到 步骤4:添加数据库和表 …...

ubuntu添加万能头文件
ubuntu的C头文件目录为/usr/include 在/usr/include下新建文件夹 bits sudo mkdir bits进入bits,新建stdc.h,并修改权限为744/777 cd bits;sudo touch stdc.h;sudo chmod 777 stdc.h将以下内容粘贴到stdc.h,保存退出 // C includes used …...

聊一聊关于前端语法 ?? 的那些事
当我们在编写前端代码时,语法是非常重要的。正确的语法可以确保我们的代码能够正常运行,并且易于维护和理解。在本文中,我们将探讨一些前端语法的问题,例如空值合并运算符(??)。 空值合并运算符是ES2020…...
宝塔Linux面板升级“获取更新包失败”怎么解决?
宝塔Linux面板执行升级命令后失败,提示“获取更新包失败,请稍后更新或联系宝塔运维”如何解决?新手站长分享宝塔面板升级失败的解决方法: 宝塔面板升级失败解决方法 1、使用root账户登录到你的云服务器上,宝塔Linux面…...

训练强化学习的经验回放策略:experience replay
经验回放:Experience Replay(训练DQN的一种策略) 优点:可以重复利用离线经验数据;连续的经验具有相关性,经验回放可以在离线经验BUFFER随机抽样,减少相关性; 超参数:Rep…...

uniapp学习
1 简单的表单校验 <!--uniapp:参考模板和字段生成页面 字段stuNumber 输入框 学号stuName 输入框 学生姓名teacher 输入框 辅导员submitDate 日期选择 填报日期morningTemperature 输入框(数字校验一位小数) 早上体温noonTemperature 输入框&…...
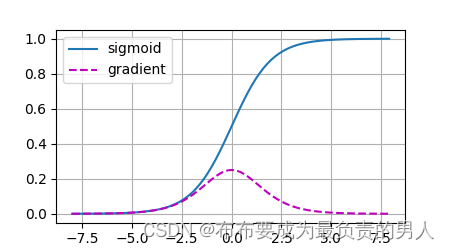
机器学习深度学习——数值稳定性和模型化参数(详细数学推导)
👨🎓作者简介:一位即将上大四,正专攻机器学习的保研er 🌌上期文章:机器学习&&深度学习——Dropout 📚订阅专栏:机器学习&&深度学习 希望文章对你们有所帮助 这一部…...

layui 整合UEditor 百度编辑器
layui 整合UEditor 百度编辑器 第一步:下载百度编辑器并配置好路径 百度编辑器下载地址:http://fex.baidu.com/ueditor/ 第二步:引入百度编辑器 代码如下: <div class"layui-form-item layui-form-text"><…...
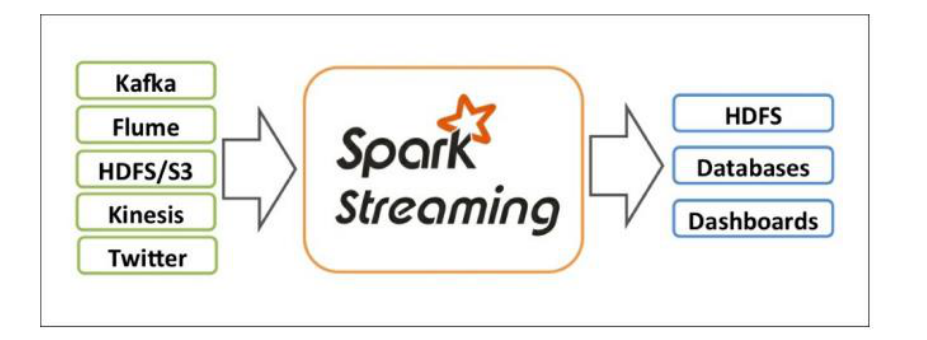
1、sparkStreaming概述
1、sparkStreaming概述 1.1 SparkStreaming是什么 它是一个可扩展,高吞吐具有容错性的流式计算框架 吞吐量:单位时间内成功传输数据的数量 之前我们接触的spark-core和spark-sql都是处理属于离线批处理任务,数据一般都是在固定位置上&…...
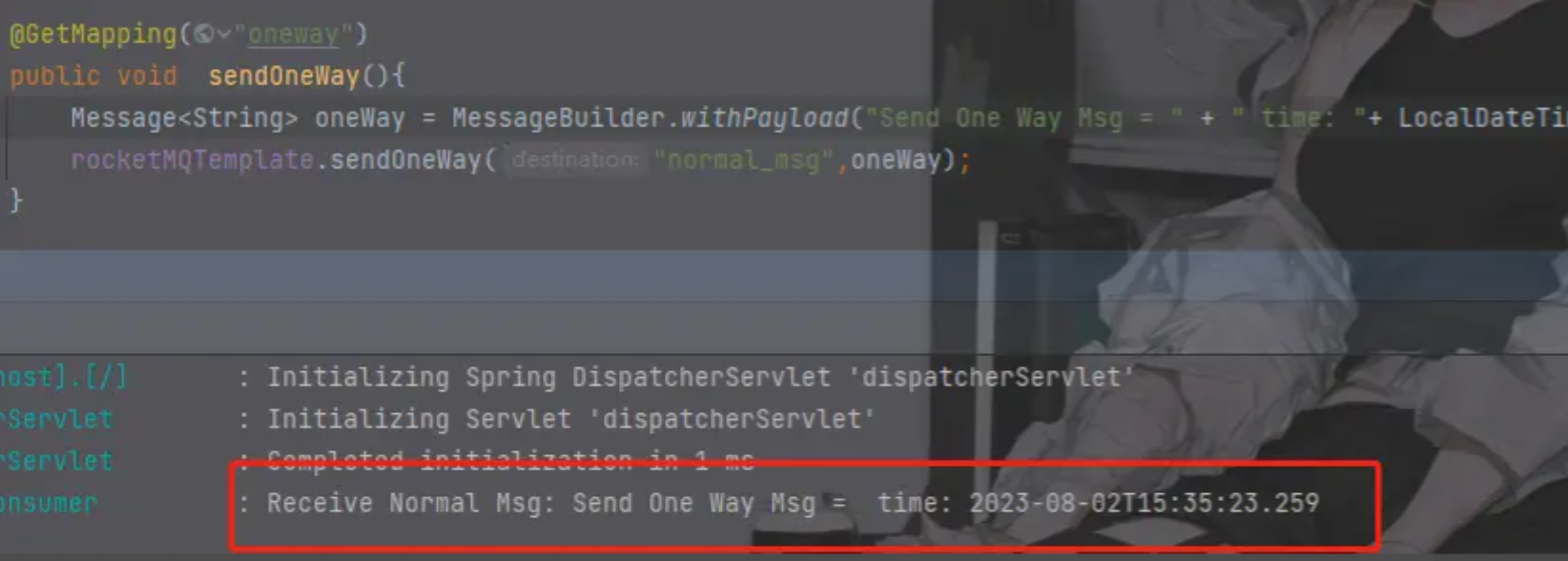
【Spring Boot】Spring Boot 集成 RocketMQ 实现简单的消息发送和消费
文章目录 前言基本概念消息和主题相关发送普通消息 发送顺序消息RocketMQTemplate的API介绍参考资料: 前言 本文主要有以下内容: 简单消息的发送顺序消息的发送RocketMQTemplate的API介绍 环境搭建: RocketMQ的安装教程:在官网…...

uniapp:图片验证码检验问题处理
图形验证码功能实现 uniapp:解决图形验证码问题及利用arraybuffer二进制转base64格式图片(后端传的图片数据形式:x00\x10JFIF\x00\x01\x02\x00…)_❆VE❆的博客-CSDN博客 UI稿: 需求:向后端请求验证码图片&…...
将Visio和Excel导出成没有白边的PDF文件
1、VISIO如何无白边导出pdf格式 在使用Latex时,要导入矢量图eps格式。但是VISIO无法输出eps格式,这就需要将其导出为pdf。但是导出pdf时,往往会有大量的白边。VISIO无白边导出pdf格式的方法如下: 1.文件——开发工具——显示sha…...
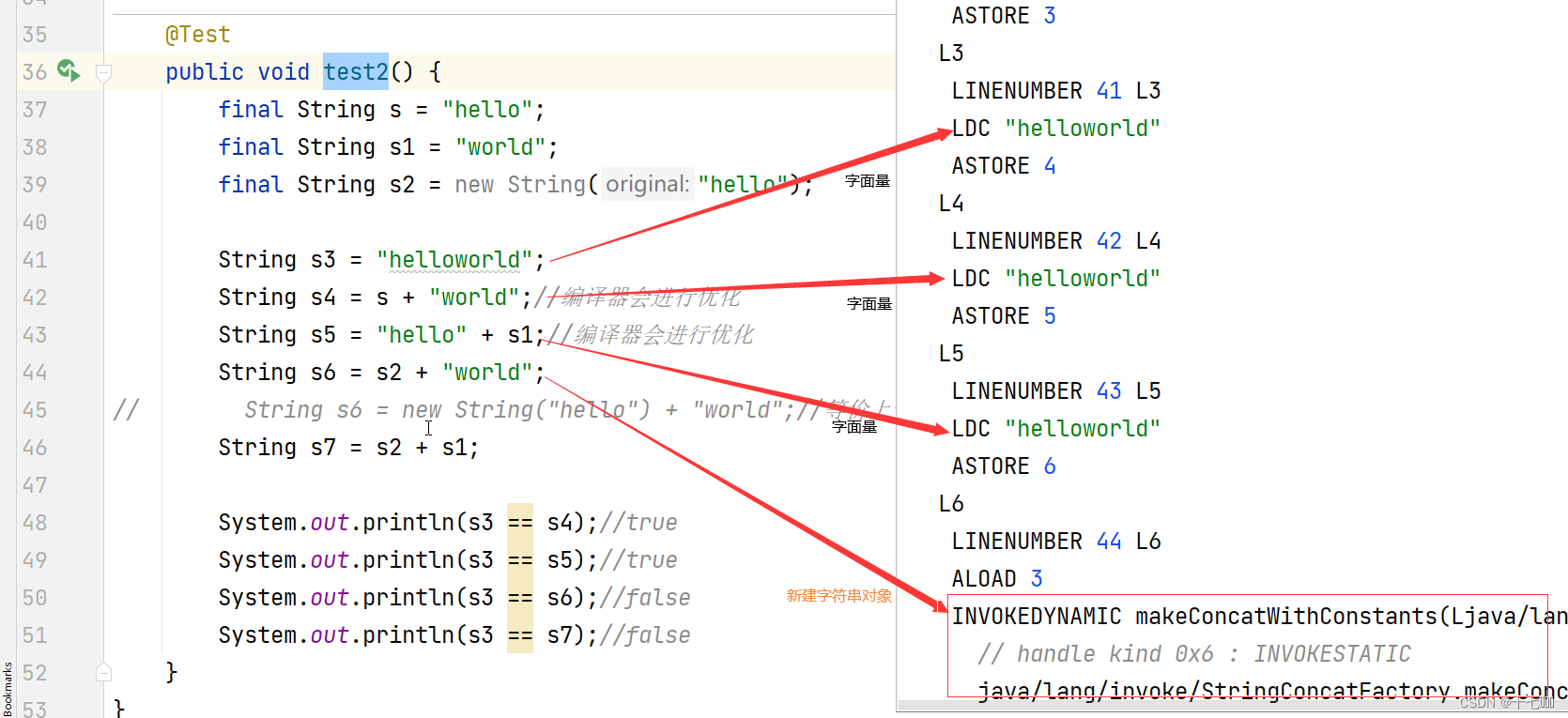
String类及其工具类
一、String类 1.字符串对象 String str new String("hello");String对象是final修饰的,不可修改的,修改后的字符串对象是另外一个对象,只是修改了引用地址。每次创建都会创建一个新的对象。 2. 字面量 String s "hello&…...
踩坑(5)整合kafka 报错 java.net.UnknownHostException: 不知道这样的主机
java.net.UnknownHostException: 不知道这样的主机。 (5c0c3c629db9)at java.base/java.net.Inet6AddressImpl.lookupAllHostAddr(Native Method) ~[na:na]at java.base/java.net.InetAddress$PlatformNameService.lookupAllHostAddr(InetAddress.java:933) ~[na:na]at java.ba…...

rust持续学习 get_or_insert_with
通常使用一个值 if(xnull)xsome_valid_value 忽然今天看见一段代码 pub fn get_id() -> u64 { let mut res struct.data.borrow_mut(); *res.get_or_insert_with(||{let mut xx ...... some logiclet id xx.id; id}); }感觉这个名字蛮奇怪的 insert 然后翻了一下代码&a…...
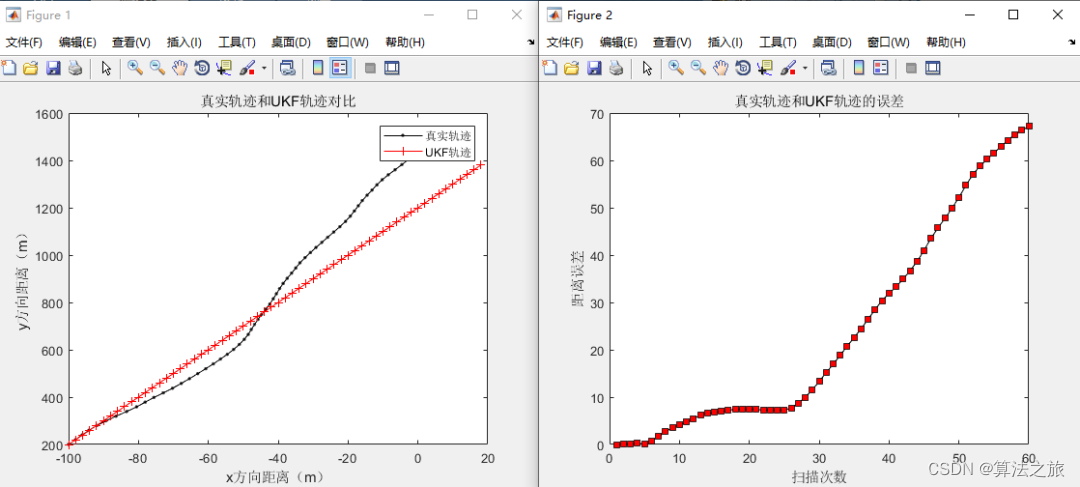
卡尔曼滤波 | Matlab实现无迹kalman滤波仿真
文章目录 效果一览文章概述研究内容程序设计参考资料效果一览 文章概述 卡尔曼滤波 | Matlab实现无迹kalman滤波仿真 研究内容 无迹kalman滤波(UKF)不是采用的将非线性函数线性化的做法。无迹kalman仍然采用的是线性kalman滤波的架构,对于一步预测方程,使用无迹变换(UT)来…...
C++---list常用接口和模拟实现
list---模拟实现 list的简介list函数的使用构造函数迭代器的使用list的capacitylist element accesslist modifiers list的模拟实现构造函数,拷贝构造函数和迭代器begin和endinsert和eraseclear和析构函数 源码 list的简介 list是用双向带头联表实现的一个容器&…...

[openCV]基于赛道追踪的智能车巡线方案V1
import cv2 as cv import os import numpy as npimport time# 遍历文件夹函数 def getFileList(dir, Filelist, extNone):"""获取文件夹及其子文件夹中文件列表输入 dir:文件夹根目录输入 ext: 扩展名返回: 文件路径列表""&quo…...
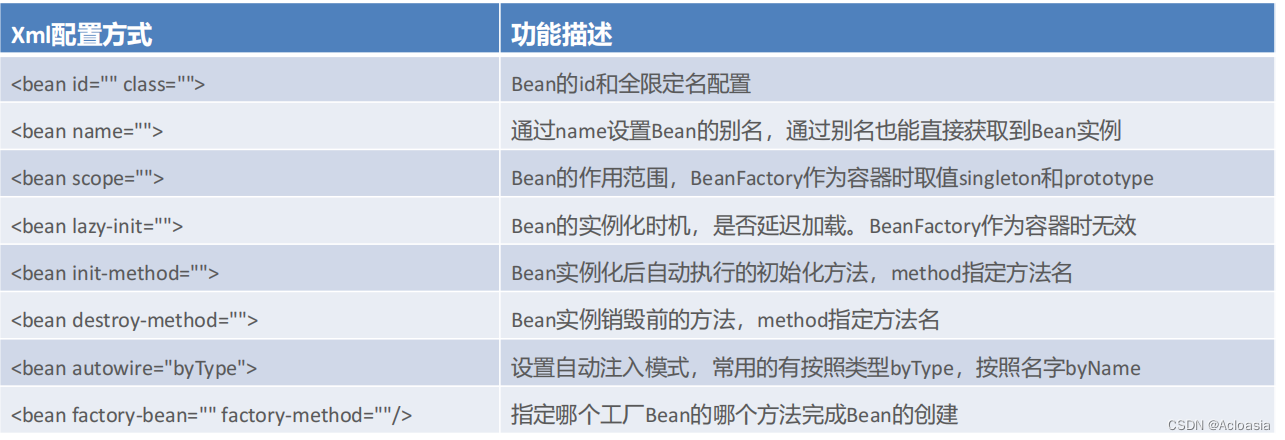
SpringIoc-个人学习笔记
Spring的Ioc、DI、AOP思想 Ioc Ioc思想:Inversion of Control,控制反转,在创建Bean的权利反转给第三方 DI DI思想:Dependency Injection,依赖注入,强调Bean之间的关系,这种关系由第三方负责去设…...

第二章 小程序目录结构与核心文件详解
第二章 小程序目录结构与核心文件详解 📚 系列教程:微信小程序投票系统完整开发 🔗 上一章:第一章 - 微信小程序概述与开发准备 🔗 下一章:第三章 - WXML 所有表单组件与使用 2.1 完整目录结构 wx/page/ …...

RISC-V RT-Thread Smart用户态应用编译与QEMU运行实战指南
1. 项目概述:从内核到应用的完整RISC-V生态体验最近在折腾RT-Thread Smart(简称RTT-Smart)这个微内核实时操作系统,目标平台是qemu模拟的64位RISC-V虚拟机(qemu-virt64-riscv)。整个过程的核心,…...

3个核心优势:重新定义Windows平台Fastboot工具的工作流
3个核心优势:重新定义Windows平台Fastboot工具的工作流 【免费下载链接】FastbootEnhance A user-friendly Fastboot ToolBox & Payload Dumper for Windows 项目地址: https://gitcode.com/gh_mirrors/fa/FastbootEnhance FastbootEnhance是一款专为Win…...

别再替换同义词!2026实测论文降AIGC工具:一次降至10%以下的排版保护指南
自从央视公开探讨初稿写作的AI味儿现象:据相关数据显示,近六成师生习惯使用生成式辅助,其中近三成学生将其用于核心初稿的撰写,各高校针对AIGC的审查便日益严格。 正是因为这种大背景,四月一到,定稿通知刚…...

Python 簡單的 股市資料 API 呼叫範例
前言 假如我們想從某個外部服務取得股市資料,藉由Python API 呼叫,可以讓我們從雅虎財經的API下載市場數據。以下簡單得介紹一個API , yfinance 一個 Python 開源函式庫,使用者可以輕鬆地取得股票、指數、貨幣、ETF、基金以及期貨…...

2026 及下一阶段 工业 AI 与企业级 Agent 布局
JBoltAI 作为面向企业 Java 技术团队的 AI 应用开发框架,围绕 工业 AI 与企业级 Agent 领域的向量空间应用,明确了 2026 年及下一阶段的核心布局方向,聚焦产业实际需求推进技术落地。工业场景的 AI 落地,核心难点并非技术本身&…...

机械爪开发速查手册:从通信协议到PID控制的嵌入式实战指南
1. 项目概述:一份为开发者量身定制的“机械爪”速查手册最近在整理一个涉及硬件控制与嵌入式开发的项目时,我发现自己总是在几个关键的控制算法和通信协议上反复查阅资料,效率很低。后来在GitHub上偶然发现了kyrie-louy/openclaw-cheatsheet这…...

zen-rails-security-checklist测试策略:安全测试用例与自动化扫描
zen-rails-security-checklist测试策略:安全测试用例与自动化扫描 【免费下载链接】zen-rails-security-checklist Checklist of security precautions for Ruby on Rails applications. 项目地址: https://gitcode.com/gh_mirrors/ze/zen-rails-security-checkli…...

深度学习在甲状腺细胞病理诊断中的创新应用
1. 深度学习在甲状腺细胞病理学中的应用背景甲状腺癌是全球范围内最常见的内分泌系统恶性肿瘤之一,其发病率在过去几十年中持续上升。细针穿刺活检(FNAB)作为甲状腺结节诊断的金标准,其准确率直接影响后续治疗方案的选择。然而&am…...

PaddleOCR-VL 1.5 + ROCm:让开发者从文档解析 Demo 走向高性能生产部署
很多文档解析 Demo 看起来都很惊艳:上传一张图片,模型识别出文字、表格、公式,甚至还能输出 Markdown。但真正进入生产环境后,问题很快就会暴露出来。企业里的文档不是干净样例,而是 PDF、扫描件、合同、票据、财报、检…...