java操作PDF:转换、合成、切分
将PDF每一页切割成图片
PDFUtils.cutPNG("D:/tmp/1.pdf","D:/tmp/输出图片路径/");将PDF转换成一张长图片
PDFUtils.transition_ONE_PNG("D:/tmp/1.pdf");将多张图片合并成一个PDF文件
PDFUtils.merge_PNG("D:/tmp/测试图片/");将多个PDF合并成一个PDF文件
PDFUtils.merge_PDF("D:/tmp/测试图片/");取出指定PDF的起始和结束页码作为新的pdf
PDFUtils.getPartPDF("D:/tmp/1.pdf",3,5);
引入依赖
<!-- apache PDF转图片--><dependency><groupId>org.apache.pdfbox</groupId><artifactId>pdfbox</artifactId><version>2.0.24</version></dependency>
<!-- itext 图片合成PDF--><dependency><groupId>com.itextpdf</groupId><artifactId>itextpdf</artifactId><version>5.5.13.2</version></dependency>代码(如下4个java类放在一起直接使用即可)
PDFUtils.java
import com.itextpdf.text.Document;
import com.itextpdf.text.DocumentException;
import com.itextpdf.text.Image;
import com.itextpdf.text.pdf.*;
import org.apache.pdfbox.io.MemoryUsageSetting;
import org.apache.pdfbox.multipdf.PDFMergerUtility;
import org.apache.pdfbox.multipdf.Splitter;
import org.apache.pdfbox.pdmodel.PDDocument;
import org.apache.pdfbox.pdmodel.PDPage;
import org.apache.pdfbox.pdmodel.PDResources;
import org.apache.pdfbox.pdmodel.common.PDRectangle;
import org.apache.pdfbox.rendering.ImageType;
import org.apache.pdfbox.rendering.PDFRenderer;import javax.imageio.ImageIO;
import java.awt.image.BufferedImage;
import java.io.File;
import java.io.FileOutputStream;
import java.io.FilenameFilter;
import java.io.IOException;
import java.util.ArrayList;
import java.util.List;/*** pdf工具类*/
public class PDFUtils {/*** PDF分解图片文件** @param pdfPath pdf文件路径*/public static void cutPNG(String pdfPath) throws IOException {File pdf = new File(pdfPath);cutPNG(pdfPath, pdf.getParent() + File.separator + pdf.getName() + "_pngs");}/*** PDF分解图片文件** @param pdfPath pdf文件路径* @param outPath 输出文件夹路径*/public static void cutPNG(String pdfPath, String outPath) throws IOException {File outDir = new File(outPath);if (!outDir.exists()) outDir.mkdirs();cutPNG(new File(pdfPath), outDir);}/*** PDF分解图片文件** @param pdf pdf文件* @param outDir 输出文件夹*/public static void cutPNG(File pdf, File outDir) throws IOException {LogUtils.info("PDF分解图片工作开始");List<BufferedImage> list = getImgList(pdf);LogUtils.info(pdf.getName() + " 一共发现了 " + list.size() + " 页");FileUtils.cleanDir(outDir);for (int i = 0; i < list.size(); i++) {IMGUtils.saveImageToFile(list.get(i), outDir.getAbsolutePath() + File.separator + (i + 1) + ".png");LogUtils.info("已保存图片:" + (i + 1) + ".png");}LogUtils.info("PDF分解图片工作结束,一共分解出" + list.size() + "个图片文件,保存至:" + outDir.getAbsolutePath());}/*** 将pdf文件转换成一张图片** @param pdfPath pdf文件路径*/public static void transition_ONE_PNG(String pdfPath) throws IOException {transition_ONE_PNG(new File(pdfPath));}/*** 将pdf文件转换成一张图片** @param pdf pdf文件*/public static void transition_ONE_PNG(File pdf) throws IOException {LogUtils.info("PDF转换长图工作开始");List<BufferedImage> list = getImgList(pdf);LogUtils.info(pdf.getName() + " 一共发现了 " + list.size() + " 页");BufferedImage image = list.get(0);for (int i = 1; i < list.size(); i++) {image = IMGUtils.verticalJoinTwoImage(image, list.get(i));}byte[] data = IMGUtils.getBytes(image);String imgPath = pdf.getParent() + File.separator + pdf.getName().replaceAll("\\.", "_") + ".png";FileUtils.saveDataToFile(imgPath, data);LogUtils.info("PDF转换长图工作结束,合成尺寸:" + image.getWidth() + "x" + image.getHeight() + ",合成文件大小:" + data.length / 1024 + "KB,保存至:" + imgPath);}/*** 将PDF文档拆分成图像列表** @param pdf PDF文件*/private static List<BufferedImage> getImgList(File pdf) throws IOException {PDDocument pdfDoc = PDDocument.load(pdf);List<BufferedImage> imgList = new ArrayList<>();PDFRenderer pdfRenderer = new PDFRenderer(pdfDoc);int numPages = pdfDoc.getNumberOfPages();for (int i = 0; i < numPages; i++) {BufferedImage image = pdfRenderer.renderImageWithDPI(i, 300, ImageType.RGB);imgList.add(image);}pdfDoc.close();return imgList;}/*** 图片合成PDF** @param pngsDirPath 图片文件夹路径*/public static void merge_PNG(String pngsDirPath) throws Exception {File pngsDir = new File(pngsDirPath);merge_PNG(pngsDir, pngsDir.getName() + ".pdf");}/*** 图片合成pdf** @param pngsDir 图片文件夹* @param pdfName 合成pdf名称*/private static void merge_PNG(File pngsDir, String pdfName) throws Exception {File pdf = new File(pngsDir.getParent() + File.separator + pdfName);if (!pdf.exists()) pdf.createNewFile();File[] pngList = pngsDir.listFiles((dir, name) -> name.toLowerCase().endsWith(".png"));LogUtils.info("在" + pngsDir.getAbsolutePath() + ",一共发现" + pngList.length + "个PNG文件");Document document = new Document();FileOutputStream fo = new FileOutputStream(pdf);PdfWriter writer = PdfWriter.getInstance(document, fo);document.open();for (File f : pngList) {document.newPage();byte[] bytes = FileUtils.getFileBytes(f);Image image = Image.getInstance(bytes);float heigth = image.getHeight();float width = image.getWidth();int percent = getPercent2(heigth, width);image.setAlignment(Image.MIDDLE);image.scalePercent(percent + 3);// 表示是原来图像的比例;document.add(image);System.out.println("正在合成" + f.getName());}document.close();writer.close();System.out.println("PDF文件生成地址:" + pdf.getAbsolutePath());}private static int getPercent2(float h, float w) {int p = 0;float p2 = 0.0f;p2 = 530 / w * 100;p = Math.round(p2);return p;}/*** 多PDF合成** @param pngsDirPath pdf所在文件夹路径*/public static void merge_PDF(String pngsDirPath) throws IOException {File pngsDir = new File(pngsDirPath);merge_PDF(pngsDir, pngsDir.getName() + "_合并.pdf");}/*** 多PDF合成** @param pngsDir pdf所在文件夹* @param pdfName 合成pdf文件名*/private static void merge_PDF(File pngsDir, String pdfName) throws IOException {File[] pdfList = pngsDir.listFiles((dir, name) -> name.toLowerCase().endsWith(".pdf"));LogUtils.info("在" + pngsDir.getAbsolutePath() + ",一共发现" + pdfList.length + "个PDF文件");PDFMergerUtility pdfMergerUtility = new PDFMergerUtility();pdfMergerUtility.setDestinationFileName(pngsDir.getParent() + File.separator + pdfName);for (File f : pdfList) {pdfMergerUtility.addSource(f);}pdfMergerUtility.mergeDocuments(MemoryUsageSetting.setupMainMemoryOnly());}public static void getPartPDF(String pdfPath, int from, int end) throws Exception {pdfPath = pdfPath.trim();Document document = null;PdfCopy copy = null;PdfReader reader = new PdfReader(pdfPath);int n = reader.getNumberOfPages();if (end == 0) {end = n;}document = new Document(reader.getPageSize(1));copy = new PdfCopy(document, new FileOutputStream(pdfPath.substring(0, pdfPath.length() - 4) + "_" + from + "_" + end + ".pdf"));document.open();for (int j = from; j <= end; j++) {document.newPage();PdfImportedPage page = copy.getImportedPage(reader, j);copy.addPage(page);}document.close();}}
IMGUtils.java
import javax.imageio.ImageIO;
import java.awt.*;
import java.awt.image.BufferedImage;
import java.io.ByteArrayInputStream;
import java.io.ByteArrayOutputStream;
import java.io.FileInputStream;
import java.io.IOException;public class IMGUtils {/*** 将图像转为png文件的字节数据* @param image 目标图像* @return 返回数据*/public static byte[] getBytes(BufferedImage image){return getBytes(image,"png");}/*** 将图像转换为指定媒体文件类型的字节数据* @param image 目标图像* @param fileType 文件类型(后缀名)* @return 返回数据*/public static byte[] getBytes(BufferedImage image,String fileType){ByteArrayOutputStream outStream = new ByteArrayOutputStream();try {ImageIO.write(image,fileType,outStream);} catch (IOException e) {e.printStackTrace();}return outStream.toByteArray();}/*** 读取图像,通过文件* @param filePath 文件路径* @return BufferedImage*/public static BufferedImage getImage(String filePath){try {return ImageIO.read(new FileInputStream(filePath));} catch (IOException e) {e.printStackTrace();}return null;}/*** 读取图像,通过字节数据* @param data 字节数据* @return BufferedImage*/public static BufferedImage getImage(byte[] data){try {return ImageIO.read(new ByteArrayInputStream(data));} catch (IOException e) {e.printStackTrace();}return null;}/*** 保存图像到指定文件* @param image 图像* @param filePath 文件路径*/public static void saveImageToFile(BufferedImage image,String filePath) throws IOException {FileUtils.saveDataToFile(filePath,getBytes(image));}/*** 纵向拼接图片*/public static BufferedImage verticalJoinTwoImage(BufferedImage image1, BufferedImage image2){if(image1==null)return image2;if(image2==null)return image1;BufferedImage image=new BufferedImage(image1.getWidth(),image1.getHeight()+image2.getHeight(),image1.getType());Graphics2D g2d = image.createGraphics();g2d.setRenderingHint(RenderingHints.KEY_INTERPOLATION, RenderingHints.VALUE_INTERPOLATION_BILINEAR);g2d.drawImage(image1, 0, 0, image1.getWidth(), image1.getHeight(), null);g2d.drawImage(image2, 0, image1.getHeight(), image2.getWidth(), image2.getHeight(), null);g2d.dispose();// 释放图形上下文使用的系统资源return image;}/*** 剪裁图片* @param image 对象* @param x 顶点x* @param y 顶点y* @param width 宽度* @param height 高度* @return 剪裁后的对象*/public static BufferedImage cutImage(BufferedImage image,int x,int y,int width,int height){if(image==null)return null;return image.getSubimage(x,y,width,height);}}
FileUtils.java
import java.io.*;public class FileUtils {/*** 将数据保存到指定文件路径*/public static void saveDataToFile(String filePath,byte[] data) throws IOException {File file = new File(filePath);if(!file.exists())file.createNewFile() ;FileOutputStream outStream = new FileOutputStream(file);outStream.write(data);outStream.flush();outStream.close();}/*** 读取文件数据*/public static byte[] getFileBytes(File file) throws IOException {if(!file.exists()||(file.exists()&&!file.isFile()))return null;InputStream inStream=new FileInputStream(file);ByteArrayOutputStream outStream = new ByteArrayOutputStream();byte[] buffer = new byte[1024];int len;while ((len = inStream.read(buffer)) != -1) {outStream.write(buffer, 0, len);}inStream.close();return outStream.toByteArray();}/*** 读取文本文件字*/public static String getFileText(String path){try {byte[] data= getFileBytes(new File(path));return new String(data);} catch (Exception e) {return "";}}/*** 清空文件夹下所有文件*/public static void cleanDir(File dir){if(dir!=null&&dir.isDirectory()){for(File file:dir.listFiles()){if(file.isFile())file.delete();if(file.isDirectory())cleanDir(file);}}}}
LogUtils.java
public class LogUtils {public static void info(String context){System.out.println(context);}public static void warn(String context){System.out.println(context);}public static void error(String context){System.out.println(context);}}
相关文章:

java操作PDF:转换、合成、切分
将PDF每一页切割成图片 PDFUtils.cutPNG("D:/tmp/1.pdf","D:/tmp/输出图片路径/"); 将PDF转换成一张长图片 PDFUtils.transition_ONE_PNG("D:/tmp/1.pdf"); 将多张图片合并成一个PDF文件 PDFUtils.merge_PNG("D:/tmp/测试图片/"); 将多…...
递增子序列——力扣491
文章目录 题目描述递归枚举 + 减枝题目描述 递归枚举 + 减枝 递归枚举子序列的通用模板 vector<vector<int>> ans; vector<int> temp; void dfs(int cur...

解密!品牌独立站为何能成为外国消费者的心头爱?
中国人做事强调要知其然、知其所以然、知其所以必然。这一理念非常符合新时代中国跨境出海品牌独立站的发展思路。在做好品牌独立站之前,我们也必须知其然(什么是独立站?),知其所以然(为什么要建独立站&…...
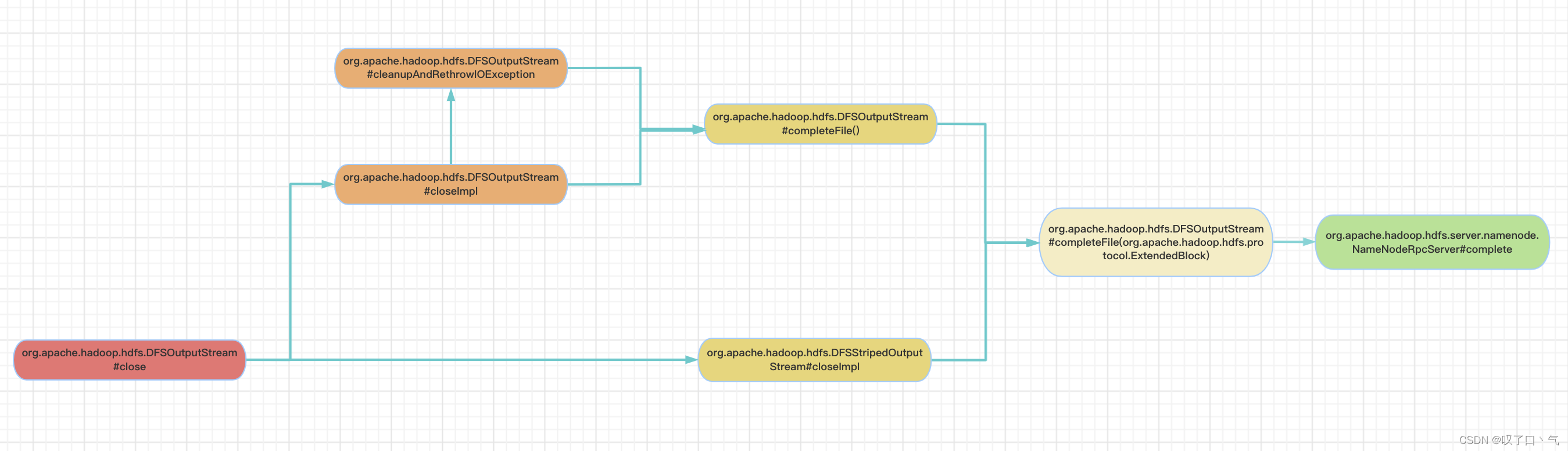
【HDFS】每天一个RPC系列----complete(二):客户端侧
上图给出了最终会调用到complete RPC的客户端侧方法链路(除去Router那条线了)。 org.apache.hadoop.hdfs.DFSOutputStream#completeFile(org.apache.hadoop.hdfs.protocol.ExtendedBlock): 下面这个方法在complete rpc返回true之前,会进行重试,直到超过最大重试次数抛异…...
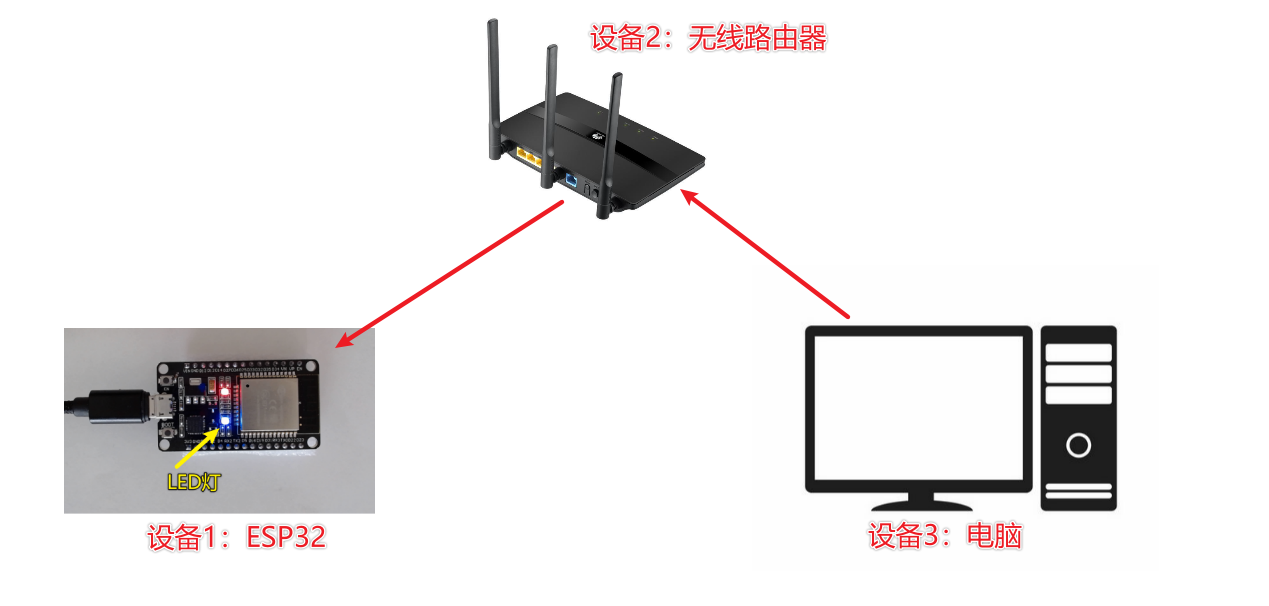
五、PC远程控制ESP32 LED灯
1. 整体思路 2. 代码 # 整体流程 # 1. 链接wifi # 2. 启动网络功能(UDP) # 3. 接收网络数据 # 4. 处理接收的数据import socket import time import network import machinedef do_connect():wlan = network.WLAN(network.STA_IF)wlan.active(True)if not wlan.isconnected(…...

详解PHP反射API
PHP中的反射API就像Java中的java.lang.reflect包一样。它由一系列可以分析属性、方法和类的内置类组成。它在某些方面和对象函数相似,比如get_class_vars(),但是更加灵活,而且可以提供更多信息。反射API也可与PHP最新的面向对象特性一起工作&…...

打开虚拟机进行ip addr无网络连接
打开虚拟机进行ip addr无网络连接 参考地址:https://www.cnblogs.com/Courage129/p/16796390.html 打开虚拟机进行ip addr无网络连接。 输入下面的命令, sudo dhclient ens33 会重新分配一个新的ip地址,但是此时的ip地址已经不是我原先在虚…...
Spring Boot如何整合mybatisplus
文章目录 1. 相关配置和代码2. 整合原理2.1 spring boot自动配置2.2 MybatisPlusAutoConfiguration2.3 debug流程2.3.1 MapperScannerRegistrar2.3.2MapperScannerConfigurer2.3.3 创建MybatisPlusAutoConfiguration2.3.4 创建sqlSessionFactory2.3.5 创建SqlSessionTemplate2.…...
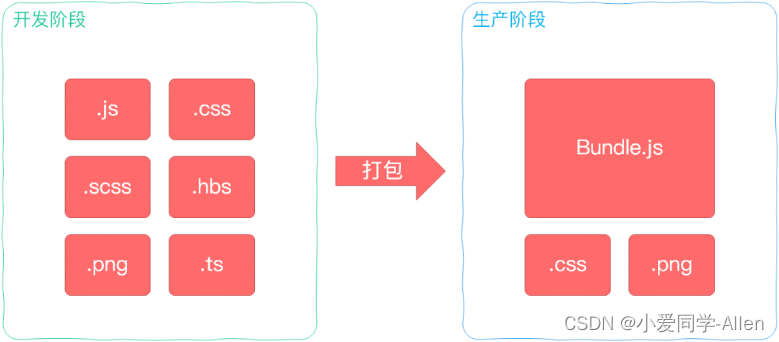
webpack基础知识一:说说你对webpack的理解?解决了什么问题?
一、背景 Webpack 最初的目标是实现前端项目的模块化,旨在更高效地管理和维护项目中的每一个资源 模块化 最早的时候,我们会通过文件划分的形式实现模块化,也就是将每个功能及其相关状态数据各自单独放到不同的JS 文件中 约定每个文件是一…...
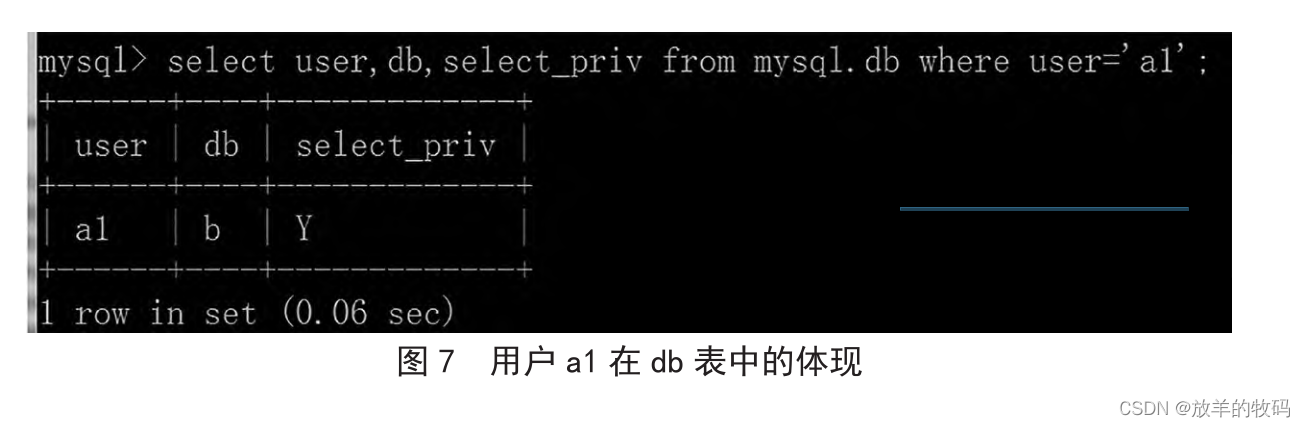
小研究 - 基于 MySQL 数据库的数据安全应用设计(二)
信息系统工程领域对数据安全的要求比较高,MySQL 数据库管理系统普遍应用于各种信息系统应用软件的开发之中,而角色与权限设计不仅关乎数据库中数据保密性的性能高低,也关系到用户使用数据库的最低要求。在对数据库的安全性进行设计时…...

大数据-数据内容分类
大数据-数据内容分类 结构化数据 可以使用关系型数据库表示和存储,可以用二维表来逻辑表达实现的数据 结构化数据:二维表(关系型) 结构化数据:先有结构、再有数据 数据以行为单位,一行数据表示一个实体…...

Babel编译与Webpack
目录 Babel初识BabelBabel 使用方式使用 Babel 前的准备工作 WebpackWebpack介绍Webpack初体验Webpack核心概念入口(entry)出口(output)加载 (loader)插件(plugins) Babel Babel官网: https://babeljs.io/…...

0805hw
1. #include <myhead.h> void Bub_sort(int *arr,int n)//冒泡排序 {for(int i1;i<n;i){int count0;for(int j0;j<n-i;j){if(arr[j]>arr[j1]){int temparr[j];arr[j]arr[j1];arr[j1]temp;count;}}if(count0){break;}}printf("冒泡排序后输出结果:\n"…...

ROS实现机器人移动
开源项目 使用是github上六合机器人工坊的项目。 https://github.com/6-robot/wpr_simulation.git 机器人运动模型 运动模型如下所示:👇 机器人运动的消息包: 实现思路:👇 为什么要使用/cmd_vel话题。因为这…...
Dockerfile构建LNMP镜像
建立工作目录 [rootlocalhost ~]# mkdir lnmp [rootlocalhost ~]# cd lnmp/ 编写Dockerfile文件 [rootlocalhost lnmp]# vim Dockerfile [rootlocalhost lnmp]# ll 总用量 4 -rw-r--r--. 1 root root 774 8月 3 14:54 Dockerfile [rootlocalhost lnmp]# vim Dockerfile #基础…...

总结七大排序!
排序总览 外部排序:依赖硬盘(外部存储器)进行的排序。对于数据集合的要求特别高,只能在特定场合下使用(比如一个省的高考成绩排序)。包括桶排序,基数排序,计数排序,都是o…...

没有fastjson,rust怎么方便的解析提取复杂json呢?
在 Rust 中解析和提取复杂的 JSON 结构,你可以使用 serde_json 库来处理。 serde_json 提供了一组功能强大的方法来解析和操作 JSON 数据。 下面是一个示例,展示了如何解析和提取复杂的 JSON 结构: use serde_json::{Value, Result}; fn mai…...
Docker制作SpringBoot镜像
Dcokerfile目录 编写Dockerfile FROM openjdk:8 #发布到网上时只会把jar包和Dockerfile发布上去RUN mkdir -p /opt/javaCOPY app.jar /opt/java/app.jar #地址映射 #CMD ["--server.port8080"] #对外暴露端口(可以任意修改) EXPOSE 15009 #执行命令 #ENTRYPOINT [&q…...
)
力扣:53. 最大子数组和(Python3)
题目: 给你一个整数数组 nums ,请你找出一个具有最大和的连续子数组(子数组最少包含一个元素),返回其最大和。 子数组 是数组中的一个连续部分。 来源:力扣(LeetCode) 链接ÿ…...

利用appium抓取app中的信息
一、appium简介 二、appium环境安装 三、联调测试环境 四、利用appium自动控制移动设备并提取数据...

精通yum/dnf:从依赖地狱到高效Linux软件包管理
1. 从“依赖地狱”到“一键管理”:为什么你需要精通yum/dnf在Linux世界里,尤其是Red Hat系(RHEL、CentOS、Fedora、Rocky Linux、AlmaLinux)的用户,软件包管理是绕不开的日常。如果你还在用rpm -ivh一个接一个地手动安…...
——run with profiler查看我们所运行程序的描述、计算指标、内存、峰值内存和数量)
Google Earth Engine(GEE)——run with profiler查看我们所运行程序的描述、计算指标、内存、峰值内存和数量
分析器显示有关特定算法和计算的其他部分消耗的资源(CPU 时间、内存)的信息。这有助于诊断脚本运行缓慢或由于内存限制而失败的原因。要使用探查器,请单击“运行”按钮下拉菜单中的“使用探查器运行”选项。作为快捷方式,按住 Alt(或 Mac 上的 Option)并单击运行,或按 C…...

5分钟快速上手Figma中文界面:设计师必备的终极汉化插件指南
5分钟快速上手Figma中文界面:设计师必备的终极汉化插件指南 【免费下载链接】figmaCN 中文 Figma 插件,设计师人工翻译校验 项目地址: https://gitcode.com/gh_mirrors/fi/figmaCN 还在为Figma全英文界面而苦恼吗?FigmaCN中文插件是你…...
错误的区别)
别只会关规则!深入理解TypeScript项目里ESLint的no-unused-vars警告与ts(6133)错误的区别
深度解析TypeScript项目中ESLint与TypeScript的未使用变量检测机制 在TypeScript与React结合的项目中,开发者常常会遇到一个看似相同却本质不同的警告:变量声明后未被使用。VSCode可能会同时显示两种提示——来自TypeScript编译器的ts(6133)错误和来自ES…...

STM32F103C8T6连接移远EC200N-CN 4G模块:从硬件接线到TCP透传的保姆级避坑指南
STM32F103C8T6与移远EC200N-CN 4G模块深度开发实战 在物联网终端设备开发中,稳定可靠的网络连接是实现远程数据交互的核心基础。本文将详细介绍如何基于STM32F103C8T6微控制器与移远EC200N-CN 4G Cat.1模块构建完整的联网解决方案,涵盖硬件设计、AT指令交…...

PrismLauncher-Cracked:当网络离线时,你还能畅玩Minecraft吗?
PrismLauncher-Cracked:当网络离线时,你还能畅玩Minecraft吗? 【免费下载链接】PrismLauncher-Cracked This project is a Fork of Prism Launcher, which aims to unblock the use of Offline Accounts, disabling the restriction of havin…...

为什么92%的团队在2026年前仓促重构AI栈?——主流框架弃用预警、许可证变更清单与平滑迁移路线图
更多请点击: https://intelliparadigm.com 第一章:2026年AI工具栈搭建完整指南 构建面向生产环境的AI工具栈,需兼顾前沿性、稳定性与可扩展性。2026年主流实践已从单点模型调用转向模块化、可观测、可编排的智能工作流基础设施。以下为推荐技…...

【困难】不用任何比较判断找出两个数中较大的数-Java:解法一
分享一个大牛的人工智能教程。零基础!通俗易懂!风趣幽默!希望你也加入到人工智能的队伍中来!请轻击人工智能教程大家好!欢迎来到我的网站! 人工智能被认为是一种拯救世界、终结世界的技术。毋庸置疑&#x…...

信步NSE SVX-C2304嵌入式主板拆解:Elkhart Lake平台在工业边缘计算的应用
1. 项目概述:一块嵌入式主板的深度拆解最近在整理一个工业边缘计算项目的硬件选型方案,手头拿到了一块信步科技(Seavo)的NSE SVX-C2304嵌入式主板。这名字听起来可能有点“板正”,不像消费级产品那样花哨,但…...

HS2-HF_Patch:3步完成Honey Select 2汉化去码与插件整合
HS2-HF_Patch:3步完成Honey Select 2汉化去码与插件整合 【免费下载链接】HS2-HF_Patch Automatically translate, uncensor and update HoneySelect2! 项目地址: https://gitcode.com/gh_mirrors/hs/HS2-HF_Patch 还在为《Honey Select 2》的游戏体验而烦恼…...