SpringBoot集成Logback日志
SpringBoot集成Logback日志
文章目录
- SpringBoot集成Logback日志
- 一、什么是日志
- 二、Logback简单介绍
- 三、SpringBoot项目中使用Logback
- 四、概念介绍
- 一、日志记录器Logger
- 1.1、日志记录器对象生成
- 1.2、记录器的层级结构
- 1.3、过滤器
- 1.4、logger设置日志级别
- 1.5、java代码演示
- 1.6、使用配置文件演示
- 二、附加器
- 2.1、什么是附加器?
- 2.2、附加器使用方式
- 2.3、输出格式
- 2.4、记录器的可加性
- 问题产生
- 解决方法
- 五、SpringBoot中使用Logback日志
- 5.1、日志文件命名和位置
- 5.2、logback.xml中使用环境变量信息
- 六、日志记录中的一些坑
- 6.1、情景一
- 6.2、情景二
- 6.3、情景三
- 6.4、情景四
- 6.5、情景五:日志无法删除情况
- 七、SpringBoot中切换日志
- 八、阿里巴巴日志规约
一、什么是日志
日志的作用是用来追踪和记录我们的程序运行中的信息,我们可以利用日志很快定位问题,追踪分析。
如果没有日志,程序一旦出现问题,很难一下子就能定位问题。尤其是访问第三方接口、随机或偶尔出现的问题、很难再现的问题。
之前听说过一句话:“只有在程序出问题以后才会知道打一个好的日志有多么重要。”
二、Logback简单介绍
目前比较常用的Java日志框架: Logback、log4j、log4j2、JUL等等。
Logback是在log4j 的基础上重新开发的一套日志框架,是完全实现SLF4J接口API(也叫日志门面)。
Logback 的架构非常通用,可以应用于不同的环境。目前logback分为三个模块,logback-core、logback-classic和logback-access。logback-core 模块为其他两个模块奠定了基础。logback-classic模块原生实现了SLF4J API,因此您可以轻松地在 logback 和其他日志记录框架(例如 log4j 1.x 或 java.util.logging (JUL))之间来回切换。
logback-access 模块与 Tomcat 和 Jetty 等 Servlet 容器集成,以提供 HTTP 访问日志功能。请注意,您可以轻松地在 logback-core 之上构建自己的模块。
三、SpringBoot项目中使用Logback
logback是springboot-web自带的,无需引入外部依赖即可使用。可以来看下对应的依赖:
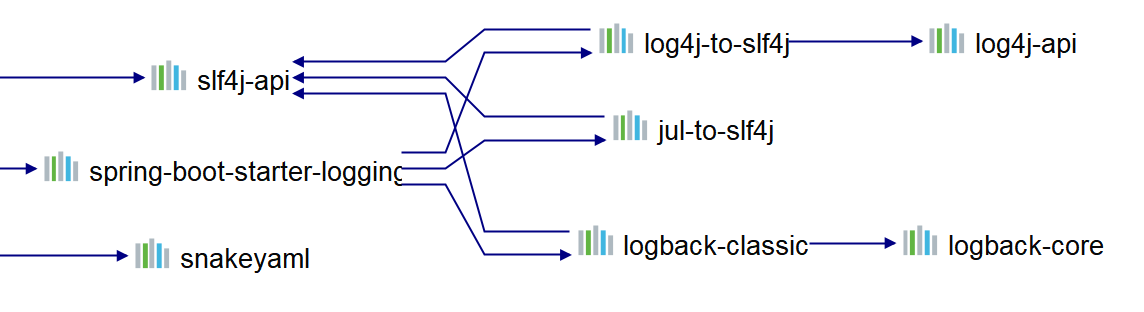
四、概念介绍
一、日志记录器Logger
日志记录器(Logger):控制要输出哪些日志记录语句,对日志信息进行级别限制。
1.1、日志记录器对象生成
如何生成记录器:
final static Logger logger = LoggerFactory.getLogger(“名称”);
这里有两个点需要说明的是:
1、日志记录器是单例的。也就是说第一次发现是没有的,那么创建;第二次直接拿到日志记录器进行使用即可;
2、括号中的无论是字符串还是对应的class类型,最终都会打印成当前的类的全限定类名(正常逻辑)
如下所示:
private static Logger logger = LoggerFactory.getLogger(UserController.class);private static Logger logger = LoggerFactory.getLogger("com.guang.springbootlogback.user.controller.UserController");
上面二者相同,如果传递的是Class,那么最终也会调用getName来获取得到最终的值。
1.2、记录器的层级结构
类似于java中的体系结构,记录器也是有对应的层级结构的:
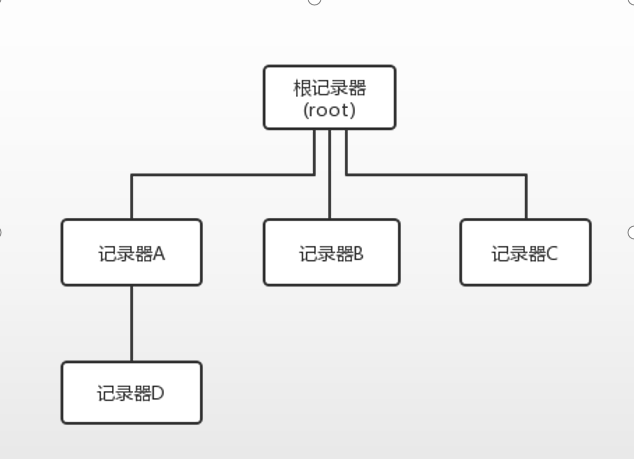
根记录器是logback自带的,本身就已经存在。而对于记录器A、B、C来说,根记录器是其父类,对于记录器D来说,是其祖先记录器。
如果对于记录器ABCD都没有设置自身的日志级别的话,那么默认都是继承了根记录器的日志级别。
如果任意一个子记录器设置了自己的日志级别,那么子记录器就可以使用使用对应级别的打印输出内容了。
比如记录器A,继承了根记录器,默认是DEBUG,如果记录器A设置了日志级别为INFO,如果记录器D没有设置的话,将会来继承记录器A的日志级别。
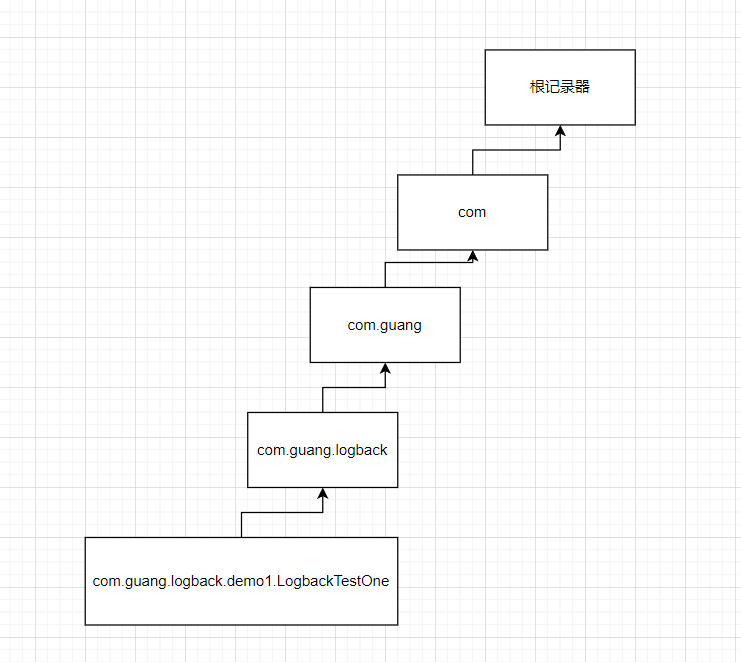
那么分别来创建几个记录器:
private static final Logger logger = LoggerFactory.getLogger("com.guang.logback.demo1.LogbackTestOne");private static final Logger logger1 = LoggerFactory.getLogger("com.guang.logback");private static final Logger logger2 = LoggerFactory.getLogger("com.guang");private static final Logger logger3 = LoggerFactory.getLogger("com");
说明:
1、上面创建了四个记录器,对于logger、logger1、logger2来说,都是继承于logger3的,因为记录器的层级关系是通过包名来进行设置的。
2、对于记录器logger来说,它会创建出来一个具备这层级关系的记录器;
3、对于记录器logger3来说,是继承于根记录器的;
对应图如下所示:
1.3、过滤器
filter中最重要的两个过滤器为:LevelFilter、ThresholdFilter。
LevelFilter根据精确的级别匹配过滤事件。如果事件的级别等于配置的级别,则筛选器接受或拒绝该事件,具体取决于onMatch和onMismatch属性的配置。
例如下面配置将只打印INFO级别的日志,其余的全部禁止打印输出:
<configuration><appender name="CONSOLE" class="ch.qos.logback.core.ConsoleAppender"><filter class="ch.qos.logback.classic.filter.LevelFilter"><level>INFO</level><onMatch>ACCEPT</onMatch><onMismatch>DENY</onMismatch></filter><encoder><pattern>%-4relative [%thread] %-5level %logger{30} - %msg%n</pattern></encoder></appender><root level="DEBUG"><appender-ref ref="CONSOLE" /></root>
</configuration>
ThresholdFilter过滤低于指定阈值的事件。 对于等于或高于阈值的事件,ThresholdFilter将在调用其decision()方法时响应NEUTRAL。
但是,将拒绝级别低于阈值的事件,例如下面的配置将拒绝所有低于INFO级别的日志,只输出INFO以及以上级别的日志:
<configuration><appender name="CONSOLE"class="ch.qos.logback.core.ConsoleAppender"><!-- deny all events with a level below INFO, that is TRACE and DEBUG --><filter class="ch.qos.logback.classic.filter.ThresholdFilter"><level>INFO</level></filter><encoder><pattern>%-4relative [%thread] %-5level %logger{30} - %msg%n</pattern></encoder></appender><root level="DEBUG"><appender-ref ref="CONSOLE" /></root>
</configuration>
1.4、logger设置日志级别
在logback中有五大日志级别,按照从小到大的顺序进行排列:TRACE < DEBUG < INFO < WARN < ERROR
如果设置的级别是DEBUG,那么在程序打印出来的级别只能够大于等于DEBUG的,而不会打印TRACE。
那么logback中默认日志级别是DEBUG
首先需要明确的是对于每个记录器来说,都有日志记录器的名称、级别和获取得到日志级别的方法。
1、name:记录器的名称2、level:日志记录器的级别,也是日志的级别。五个日志级别:TRACE < DEBUG < INFO < WARN < ERROR设置的时候可以通过配置文件,也可以通过代码来进行设置。如果没有设置级别,那么将会从父记录器或者是祖先记录器中来进行继承日志级别3、获取得到级别的方法:logger.setLevel():设置的级别,只会对这个级别及其之上的起作用logger.getLevel():获取得到设置的级别logger.getEffectiveLevel():和getLevel相同additivity:是否允许叠加打印日志,true或者是false。也就是子记录器和父记录器进行叠加打印,可以理解成是重复打印问题。后续会来解决这个问题
1.5、java代码演示
来利用java代码来设置日志级别,做一个案例演示:
public static void main(String[] args) {// 不能够使用接口,因为接口中没有这个方法,需要找到具体的实现类ch.qos.logback.classic.Logger logger = (ch.qos.logback.classic.Logger) LoggerFactory.getLogger(LogbackTestThree.class);// 在设置之前看下本身的日志级别 为什么?因为直接继承了父记录器都没有设置,那么最终都将会继承根记录器,因为根记录器设置 // 的日志级别是DEBUG,所以默认级别是DEBUGSystem.out.println("默认的记录器级别:"+logger.getEffectiveLevel());// 可以修改父记录器的级别,然后让子记录器来进行继承,子记录器打印的是父记录器的级别logger.setLevel(Level.INFO);// 当前级别logger.info("hello,world");// 输出更高级别logger.error("hello,world");// 输出比当前级别低的 不会来打印logger.debug("hello,logback---debug");
}
1.6、使用配置文件演示
使用java代码来设置日志级别是不方便的,所以最方便的使用方式是使用配置文件来进行输出
这里需要使用到附加器的内容,所以看完附加器再来看这个:
<?xml version="1.0" encoding="UTF-8"?>
<!-- 日志级别从低到高分为TRACE < DEBUG < INFO < WARN < ERROR < FATAL,如果设置为WARN,则低于WARN的信息都不会输出 -->
<!-- scan:当此属性设置为true时,配置文件如果发生改变,将会被重新加载,默认值为true -->
<!-- scanPeriod:设置监测配置文件是否有修改的时间间隔,如果没有给出时间单位,默认单位是毫秒。当scan为true时,此属性生效。默认的时间间隔为1分钟。 -->
<!-- debug:当此属性设置为true时,将打印出logback内部日志信息,实时查看logback运行状态。默认值为false。 -->
<!--<configuration scan="true" scanPeriod="10 seconds">-->
<configuration><!--滚动文件附加器--><appender name="File" class="ch.qos.logback.core.rolling.RollingFileAppender"><!--日志名,指定最新的文件名,其他文件名使用FileNamePattern --><!--也就是说当out.log文件超过了rollingPolicy中的配置信息,那么将会命名成FileNamePattern中的格式--><File>C:\\Users\\lig\\Desktop\\log\\out.log</File><append>true</append><!--文件生成策略:生成文件的文件名称以及什么时候生成文件--><!--滚动文件:可以按照天、月、日来进行生成,也可以按照大小来生成对应的文件--><rollingPolicy class="ch.qos.logback.core.rolling.SizeAndTimeBasedRollingPolicy"><!--日志文件输出的文件名,可设置文件类型为gz,开启文件压缩--><!-- 按天生成--><FileNamePattern>log_/date-%d{yyyy-MM-dd HH-mm-ss}-%i.log</FileNamePattern><!--只保证最近的30个文件--><MaxHistory>30</MaxHistory><!--所有的log文件不能够超过3MB,如果超过了将会来进行删除--><totalSizeCap>3MB</totalSizeCap><!--所有文件的总大小如果超过500MB也会来进行删除--><!--文件超过500MB会将其归档成为一个上面设置格式的一个文件--><maxFileSize>500MB</maxFileSize></rollingPolicy><!--编码器 输出格式--><encoder class="ch.qos.logback.classic.encoder.PatternLayoutEncoder"><!--格式化输出:%d表示日期,%thread表示线程名,%-5level:级别从左显示5个字符宽度%msg:日志消息,%n是换行符--><pattern>%d{yyyy-MM-dd HH:mm:ss.SSS} [%thread] %-5level %logger{60} - %msg%n</pattern><!--设置编码--><charset>UTF-8</charset></encoder></appender><!--这里就相当于是利用java代码来创建一个记录器--><logger name="com.guang.logback.demo2"><appender-ref ref="File"/></logger><!--根记录器中引入附加器,将附加器中的信息输出到日志中来--><root level="info"/></configuration>
二、附加器
2.1、什么是附加器?
记录器会将输出日志的任务交给附加器完成,不同的附加器会将日志记录器中记录的信息输出到不同的地方。比如控制台附加器、文件附加器、网络附加器等等。
不同的附加器会将logger.info(“xxx”)中的输出信息输出到不同的地方中去
常用的附加器控制台附加器:
| 附加器实现类 | 说明 | 作用 |
|---|---|---|
| ch.qos.logback.core.ConsoleAppender | 控制台附加器 | 将输出信息输出到控制台 |
| ch.qos.logback.core.FileAppender | 文件附加器 | 将输出信息输出到文件中去,文件只有一个 |
| ch.qos.logback.core.rolling.RollingFileAppender | 滚动文件附加器,是文件附加器的子类 | 将输出信息输出到文件中去,可以输出到不同文件中去 |
也就是说将日志输出在哪里?是由附加器来进行完成的
2.2、附加器使用方式
附加器就是将信息输出到哪里,但是需要得到日志记录器的支持。所以二者要联合来进行使用。
<?xml version="1.0" encoding="UTF-8"?>
<configuration debug="true"><!-- appender是configuration的子节点,是负责写日志的组件。 --><!-- ConsoleAppender:把日志输出到控制台 --><appender name="STDOUT" class="ch.qos.logback.core.ConsoleAppender"><!-- 默认情况下,每个日志事件都会立即刷新到基础输出流。 这种默认方法更安全,因为如果应用程序在没有正确关闭appender的情况下退出,则日志事件不会丢失。但是,为了显着增加日志记录吞吐量,您可能希望将immediateFlush属性设置为false--><!--<immediateFlush>true</immediateFlush>--><encoder><!-- %37():如果字符没有37个字符长度,则左侧用空格补齐 --><!-- %-37():如果字符没有37个字符长度,则右侧用空格补齐 --><!-- %15.15():如果记录的线程字符长度小于15(第一个)则用空格在左侧补齐,如果字符长度大于15(第二个),则从开头开始截断多余的字符 --><!-- %-40.40():如果记录的logger字符长度小于40(第一个)则用空格在右侧补齐,如果字符长度大于40(第二个),则从开头开始截断多余的字符 --><!-- %msg:日志打印详情 --><!-- %n:换行符 --><!-- %highlight():转换说明符以粗体红色显示其级别为ERROR的事件,红色为WARN,BLUE为INFO,以及其他级别的默认颜色。 --><pattern>%d{yyyy-MM-dd HH:mm:ss.SSS} %highlight(%-5level) --- [%15.15(%thread)] %cyan(%-40.40(%logger{40})) : %msg%n</pattern><!-- 控制台也要使用UTF-8,不要使用GBK,否则会中文乱码 --><charset>UTF-8</charset></encoder></appender><!-- info 日志--><!-- RollingFileAppender:滚动记录文件,先将日志记录到指定文件,当符合某个条件时,将日志记录到其他文件 --><!-- 以下的大概意思是:1.先按日期存日志,日期变了,将前一天的日志文件名重命名为XXX%日期%索引,新的日志仍然是project_info.log --><!-- 2.如果日期没有发生变化,但是当前日志的文件大小超过10MB时,对当前日志进行分割 重命名--><appender name="info_log" class="ch.qos.logback.core.rolling.RollingFileAppender"><!--日志文件路径和名称--><File>logs/project_info.log</File><!--是否追加到文件末尾,默认为true--><append>true</append><filter class="ch.qos.logback.classic.filter.LevelFilter"><level>ERROR</level><!-- 如果命中ERROR就禁止这条日志 --><onMatch>DENY</onMatch><!-- 如果没有命中就使用这条规则 --><onMismatch>ACCEPT</onMismatch></filter><!--有两个与RollingFileAppender交互的重要子组件。 第一个RollingFileAppender子组件,即RollingPolicy:负责执行翻转所需的操作。RollingFileAppender的第二个子组件,即TriggeringPolicy:将确定是否以及何时发生翻转。 因此,RollingPolicy负责什么和TriggeringPolicy负责什么时候.作为任何用途,RollingFileAppender必须同时设置RollingPolicy和TriggeringPolicy.但是,如果其RollingPolicy也实现了TriggeringPolicy接口,则只需要显式指定前者。--><rollingPolicy class="ch.qos.logback.core.rolling.SizeAndTimeBasedRollingPolicy"><!-- 日志文件的名字会根据fileNamePattern的值,每隔一段时间改变一次 --><!-- 文件名:logs/project_info.2017-12-05.0.log --><!-- 注意:SizeAndTimeBasedRollingPolicy中 %i和%d令牌都是强制性的,必须存在,要不会报错 --><fileNamePattern>logs/project_info.%d.%i.log</fileNamePattern><!-- 每产生一个日志文件,该日志文件的保存期限为30天, ps:maxHistory的单位是根据fileNamePattern中的翻转策略自动推算出来的。例如上面选用了yyyy-MM-dd,则单位为天;如果上面选用了yyyy-MM,则单位为月,另外上面的单位默认为yyyy-MM-dd--><maxHistory>30</maxHistory><!-- 每个日志文件到10mb的时候开始切分,最多保留30天,但最大到20GB,哪怕没到30天也要删除多余的日志 --><totalSizeCap>20GB</totalSizeCap><!-- maxFileSize:这是活动文件的大小,默认值是10MB,测试时可改成5KB看效果 --><maxFileSize>10MB</maxFileSize></rollingPolicy><!--编码器--><encoder><!-- pattern节点,用来设置日志的输入格式 ps:日志文件中没有设置颜色,否则颜色部分会有ESC[0:39em等乱码--><pattern>%d{yyyy-MM-dd HH:mm:ss.SSS} %-5level --- [%15.15(%thread)] %-40.40(%logger{40}) : %msg%n</pattern><!-- 记录日志的编码:此处设置字符集 - --><charset>UTF-8</charset></encoder></appender><!-- error 日志--><!-- RollingFileAppender:滚动记录文件,先将日志记录到指定文件,当符合某个条件时,将日志记录到其他文件 --><!-- 以下的大概意思是:1.先按日期存日志,日期变了,将前一天的日志文件名重命名为XXX%日期%索引,新的日志仍然是project_error.log --><!-- 2.如果日期没有发生变化,但是当前日志的文件大小超过10MB时,对当前日志进行分割 重命名--><appender name="error_log" class="ch.qos.logback.core.rolling.RollingFileAppender"><!--日志文件路径和名称--><File>logs/project_error.log</File><!--是否追加到文件末尾,默认为true--><append>true</append><!-- ThresholdFilter过滤低于指定阈值的事件。 对于等于或高于阈值的事件,ThresholdFilter将在调用其decision()方法时响应NEUTRAL。 但是,将拒绝级别低于阈值的事件 --><filter class="ch.qos.logback.classic.filter.ThresholdFilter"><level>ERROR</level><!-- 低于ERROR级别的日志(debug,info)将被拒绝,等于或者高于ERROR的级别将相应NEUTRAL --></filter><!--有两个与RollingFileAppender交互的重要子组件。 第一个RollingFileAppender子组件,即RollingPolicy:负责执行翻转所需的操作。RollingFileAppender的第二个子组件,即TriggeringPolicy:将确定是否以及何时发生翻转。 因此,RollingPolicy负责什么和TriggeringPolicy负责什么时候.作为任何用途,RollingFileAppender必须同时设置RollingPolicy和TriggeringPolicy,但是,如果其RollingPolicy也实现了TriggeringPolicy接口,则只需要显式指定前者。--><rollingPolicy class="ch.qos.logback.core.rolling.SizeAndTimeBasedRollingPolicy"><!-- 活动文件的名字会根据fileNamePattern的值,每隔一段时间改变一次 --><!-- 文件名:logs/project_error.2017-12-05.0.log --><!-- 注意:SizeAndTimeBasedRollingPolicy中 %i和%d令牌都是强制性的,必须存在,要不会报错 --><fileNamePattern>logs/project_error.%d.%i.log</fileNamePattern><!-- 每产生一个日志文件,该日志文件的保存期限为30天, ps:maxHistory的单位是根据fileNamePattern中的翻转策略自动推算出来的,例如上面选用了yyyy-MM-dd,则单位为天如果上面选用了yyyy-MM,则单位为月,另外上面的单位默认为yyyy-MM-dd--><maxHistory>30</maxHistory><!-- 每个日志文件到10mb的时候开始切分,最多保留30天,但最大到20GB,哪怕没到30天也要删除多余的日志 --><totalSizeCap>20GB</totalSizeCap><!-- maxFileSize:这是活动文件的大小,默认值是10MB,测试时可改成5KB看效果 --><maxFileSize>10MB</maxFileSize></rollingPolicy><!--编码器--><encoder><!-- pattern节点,用来设置日志的输入格式 ps:日志文件中没有设置颜色,否则颜色部分会有ESC[0:39em等乱码--><pattern>%d{yyyy-MM-dd HH:mm:ss.SSS} %-5level --- [%15.15(%thread)] %-40.40(%logger{40}) : %msg%n</pattern><!-- 记录日志的编码:此处设置字符集 - --><charset>UTF-8</charset></encoder></appender><!--给定记录器的每个启用的日志记录请求都将转发到该记录器中的所有appender以及层次结构中较高的appender(不用在意level值)。换句话说,appender是从记录器层次结构中附加地继承的。例如,如果将控制台appender添加到根记录器,则所有启用的日志记录请求将至少在控制台上打印。如果另外将文件追加器添加到记录器(例如L),则对L和L'子项启用的记录请求将打印在文件和控制台上。通过将记录器的additivity标志设置为false,可以覆盖此默认行为,以便不再添加appender累积--><!-- configuration中最多允许一个root,别的logger如果没有设置级别则从父级别root继承 --><root level="INFO"><appender-ref ref="STDOUT" /></root><!-- 指定项目中某个包,当有日志操作行为时的日志记录级别 --><!-- 级别依次为【从高到低】:FATAL > ERROR > WARN > INFO > DEBUG > TRACE --><logger name="com.sailing.springbootmybatis" level="INFO"><appender-ref ref="info_log" /><appender-ref ref="error_log" /></logger><!-- 利用logback输入mybatis的sql日志,注意:如果不加 additivity="false" 则此logger会将输出转发到自身以及祖先的logger中,就会出现日志文件中sql重复打印--><logger name="com.sailing.springbootmybatis.mapper" level="DEBUG" additivity="false"><appender-ref ref="info_log" /><appender-ref ref="error_log" /></logger><!-- additivity=false代表禁止默认累计的行为,即com.atomikos中的日志只会记录到日志文件中,不会输出层次级别更高的任何appender--><logger name="com.atomikos" level="INFO" additivity="false"><appender-ref ref="info_log" /><appender-ref ref="error_log" /></logger></configuration>
2.3、输出格式
如果将输出设置的单调,那么将无法来进行定位问题,所以需要对日志产生的时间、位置、进程名称、日志级别等等信息进行打印,方便我们来定位问题。我们可以指定输出信息的模板,将输出信息进行模板格式化,而Pattern标签就是用来做这个事情的
Pattern由文字文本和转换说明符的格式控制表达式组成 。您可以在其中自由插入任何文字文本。每个转换说明符都以百分号 ‘%’ ,后跟可选的 格式修饰符、转换字和大括号之间的可选参数。转换字控制要转换的数据字段,例如记录器名称、级别、日期或线程名称。格式修饰符控制字段宽度、填充以及左对齐或右对齐。
常见的有如下所示:


2.4、记录器的可加性
之前还有一个属性没有来得及进行介绍,这里也来介绍下,记录器的可加性指的就是日志的重复输出问题。
问题产生
分别看下对应的问题和解决方式:
<?xml version="1.0" encoding="UTF-8"?>
<configuration scan="true" scanPeriod="10 seconds"><!--输出到控制台--><appender name="STOUT" class="ch.qos.logback.core.ConsoleAppender"><!--输出格式--><encoder><pattern>%10date %level [%thread] %logger{60} %line %msg %n</pattern></encoder></appender><!--可加性 不设置默认为true--><logger name="com.guang.springbootlogback.controller" level="debug"><appender-ref ref="STOUT"/></logger><root level="info"><appender-ref ref="STOUT"/></root>
</configuration>
对应的案例:
@RequestMapping("deleteUser")public String deleteUser(){logger.info("hello,world");return "hello,logback";}
访问的时候会打印两次,根记录器和父记录器分别户打印一次:
2022-04-20 11:54:59,543 INFO [http-nio-8080-exec-1] com.guang.springbootlogback.user.controller.UserController 32 hello,world
2022-04-20 11:54:59,543 INFO [http-nio-8080-exec-1] com.guang.springbootlogback.user.controller.UserController 32 hello,world
查看一下对应的记录器树层次结构:
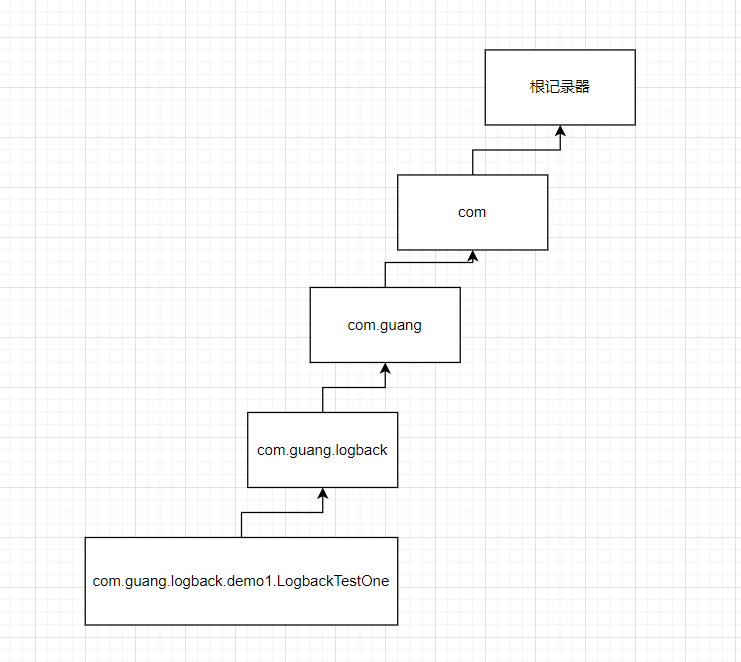
产生原因解释:如果子记录器中的附加器来进行打印的时候,父类记录器中的附加器也会打印日志,直到根记录器中的附加器也会来打印;
解决方法
那么为了防止这种重复打印的情况,直接建议使用下面这种方式:
来自阿里巴巴规范中
【强制】避免重复打印日志,浪费磁盘空间,务必在 log4j.xml 中设置 additivity=false。
正例:<logger name="com.taobao.dubbo.config" additivity="false">
直接设置只有当前记录器可输出
<?xml version="1.0" encoding="UTF-8"?>
<configuration scan="true" scanPeriod="10 seconds"><!--输出到控制台--><appender name="STOUT" class="ch.qos.logback.core.ConsoleAppender"><!--输出格式--><encoder><pattern>%10date %level [%thread] %logger{60} %line %msg %n</pattern></encoder></appender><!--可加性 不设置默认为true。设置为false之后,表示的是只有当前的记录器才会来打印,其他的记录器不会打印 --><logger name="com.guang.springbootlogback" level="debug" additivity="false"><appender-ref ref="STOUT"/></logger><root level="info"><appender-ref ref="STOUT"/></root>
</configuration>
五、SpringBoot中使用Logback日志
直接参考官方文档:https://docs.spring.io/spring-boot/docs/2.5.14/reference/html/features.html#features.logging
5.1、日志文件命名和位置
Spring Boot官方推荐优先使用带有-spring的文件名作为你的日志配置(如使用logback-spring.xml,而不是logback.xml),命名为logback-spring.xml的日志配置文件,将xml放至 src/main/resource下面。
也可以使用自定义的名称,比如logback-config.xml,只需要在application.properties文件中使用logging.config=classpath:logback-config.xml指定即可。
5.2、logback.xml中使用环境变量信息
<springProfile name="staging"><!-- configuration to be enabled when the "staging" profile is active -->
</springProfile><springProfile name="dev | staging"><!-- configuration to be enabled when the "dev" or "staging" profiles are active -->
</springProfile><springProfile name="!production"><!-- configuration to be enabled when the "production" profile is not active -->
</springProfile><springProperty scope="context" name="fluentHost" source="myapp.fluentd.host"defaultValue="localhost"/>
<appender name="FLUENT" class="ch.qos.logback.more.appenders.DataFluentAppender"><remoteHost>${fluentHost}</remoteHost>...
</appender>六、日志记录中的一些坑
6.1、情景一
这里再说下log日志输出代码,一般有人可能在代码中使用如下方式输出:
Object entry = new SomeObject();
logger.debug("The entry is " + entry);
上面看起来没什么问题,但是会存在两个问题:
1、构造消息参数的成本,即将entry转换成字符串相加;
2、无论是否记录消息,都是如此,即:那怕日志级别为INFO,也会执行括号里面的操作,但是日志不会输出,下面是优化后的写法:
if(logger.isDebugEnabled()) { Object entry = new SomeObject(); logger.debug("The entry is " + entry);
}
6.2、情景二
针对上面的写法,首先对设置的日志级别进行了判断,如果为debug模式,才进行参数的构造,对第一种写法进行了改善。
不过还有最好的写法,使用占位符:
Object entry = new SomeObject();
logger.debug("The entry is {}.", entry);
只有在评估是否记录之后,并且只有在决策是肯定的情况下,记录器实现才会格式化消息并将“{}”对替换为条目的字符串值。 换句话说,当禁用日志语句时,此表单不会产生参数构造的成本。
logback作者进行测试得出:第一种和第三种写法将产生完全相同的输出。 但是,在禁用日志记录语句的情况下,第三个变体将比第一个变体优于至少30倍。
6.3、情景三
如果有多个参数,写法如下:
logger.debug("The new entry is {}. It replaces {}.", entry, oldEntry);
如果需要传递三个或更多参数,则还可以使用Object []变体:
Object[] paramArray = {newVal, below, above};
logger.debug("Value {} was inserted between {} and {}.", paramArray);
6.4、情景四
记录日志的时候我们可能需要在文件中记录下异常的堆栈信息,经过测试,logger.error(e) 不会打印出堆栈信息,正确的写法是:
logger.error("程序异常, 详细信息:{}", e.getLocalizedMessage() , e);
6.5、情景五:日志无法删除情况
看下下面的情况:
<!--基于时间和空间的滚动日志,单个文件最大10MB,保留天数最大30天,所以日志保留最大空间是20GB -->
<rollingPolicy class="ch.qos.logback.core.rolling.SizeAndTimeBasedRollingPolicy"><fileNamePattern>/root/demo/logs/hornet_%d{yyyyMMdd}.%i.log</fileNamePattern><maxFileSize>10mb</maxFileSize><maxHistory>30</maxHistory><totalSizeCap>20GB</totalSizeCap>
</rollingPolicy>
从配置可以看出,可以从 SizeAndTimeBasedRollingPolicy.class 着手
public class SizeAndTimeBasedRollingPolicy<E> extends TimeBasedRollingPolicy<E> {FileSize maxFileSize;@Overridepublic void start() {SizeAndTimeBasedFNATP<E> sizeAndTimeBasedFNATP = new SizeAndTimeBasedFNATP<E>(Usage.EMBEDDED); if(maxFileSize == null) {addError("maxFileSize property is mandatory.");return;} else {// 每个文件大小限制在maxFileSize大小addInfo("Archive files will be limited to ["+maxFileSize+"] each.");}sizeAndTimeBasedFNATP.setMaxFileSize(maxFileSize);timeBasedFileNamingAndTriggeringPolicy = sizeAndTimeBasedFNATP;// 1、totalSizeCap不能为0// 2、如果总大小小于其中一个文件大小,抛出异常if(!isUnboundedTotalSizeCap() && totalSizeCap.getSize() < maxFileSize.getSize()) {addError("totalSizeCap of ["+totalSizeCap+"] is smaller than maxFileSize ["+maxFileSize+"] which is non-sensical");return;}// most work is done by the parent// 执行父类中的方法super.start();}// ....
}
然后执行父类中的方法:ch.qos.logback.core.rolling.TimeBasedRollingPolicy#start
public void start() {// set the LR for our utility objectrenameUtil.setContext(this.context);// find out period from the filename patternif (fileNamePatternStr != null) {fileNamePattern = new FileNamePattern(fileNamePatternStr, this.context);determineCompressionMode();} else {addWarn(FNP_NOT_SET);addWarn(CoreConstants.SEE_FNP_NOT_SET);throw new IllegalStateException(FNP_NOT_SET + CoreConstants.SEE_FNP_NOT_SET);}compressor = new Compressor(compressionMode);compressor.setContext(context);// wcs : without compression suffixfileNamePatternWithoutCompSuffix = new FileNamePattern(Compressor.computeFileNameStrWithoutCompSuffix(fileNamePatternStr, compressionMode), this.context);addInfo("Will use the pattern " + fileNamePatternWithoutCompSuffix + " for the active file");if (compressionMode == CompressionMode.ZIP) {String zipEntryFileNamePatternStr = transformFileNamePattern2ZipEntry(fileNamePatternStr);zipEntryFileNamePattern = new FileNamePattern(zipEntryFileNamePatternStr, context);}if (timeBasedFileNamingAndTriggeringPolicy == null) {timeBasedFileNamingAndTriggeringPolicy = new DefaultTimeBasedFileNamingAndTriggeringPolicy<E>();}timeBasedFileNamingAndTriggeringPolicy.setContext(context);timeBasedFileNamingAndTriggeringPolicy.setTimeBasedRollingPolicy(this);timeBasedFileNamingAndTriggeringPolicy.start();if (!timeBasedFileNamingAndTriggeringPolicy.isStarted()) {addWarn("Subcomponent did not start. TimeBasedRollingPolicy will not start.");return;}//*********** 可以看到这里有 maxHistory,也就是最大保留天数//*********** 可以看到这里有 maxHistory,也就是最大保留天数//*********** 可以看到这里有 maxHistory,也就是最大保留天数//*********** 大概意思就是判断是否初始化,然后把参数设置到archiveRemover中,//*********** 后面调用archiveRemover.cleanAsynchronously方法进行清理!!! // the maxHistory property is given to TimeBasedRollingPolicy instead of to// the TimeBasedFileNamingAndTriggeringPolicy. This makes it more convenient// for the user at the cost of inconsistency here.if (maxHistory != UNBOUND_HISTORY) {archiveRemover = timeBasedFileNamingAndTriggeringPolicy.getArchiveRemover();archiveRemover.setMaxHistory(maxHistory);archiveRemover.setTotalSizeCap(totalSizeCap.getSize());if (cleanHistoryOnStart) {addInfo("Cleaning on start up");Date now = new Date(timeBasedFileNamingAndTriggeringPolicy.getCurrentTime());cleanUpFuture = archiveRemover.cleanAsynchronously(now);}} else if (!isUnboundedTotalSizeCap()) {addWarn("'maxHistory' is not set, ignoring 'totalSizeCap' option with value ["+totalSizeCap+"]");}super.start();
}进入 TimeBasedArchiveRemover.class,可以看到这是一个异步任务,重点在 clean()
public Future<?> cleanAsynchronously(Date now) {ArhiveRemoverRunnable runnable = new ArhiveRemoverRunnable(now);ExecutorService executorService = context.getScheduledExecutorService();Future<?> future = executorService.submit(runnable);return future;
}public class ArhiveRemoverRunnable implements Runnable {Date now;ArhiveRemoverRunnable(Date now) {this.now = now;}@Overridepublic void run() {clean(now);if (totalSizeCap != UNBOUNDED_TOTAL_SIZE_CAP && totalSizeCap > 0) {capTotalSize(now);}}
}
重点在 clean() ,清理,得到 periodsElapsed 天数,然后遍历清理 (-maxHistory+1)+i 天
public void clean(Date now) {// 获取得到现在的时间long nowInMillis = now.getTime();// for a live appender periodsElapsed is expected to be 1// 如何进行计算的?int periodsElapsed = computeElapsedPeriodsSinceLastClean(nowInMillis);lastHeartBeat = nowInMillis;if (periodsElapsed > 1) {addInfo("Multiple periods, i.e. " + periodsElapsed + " periods, seem to have elapsed. This is expected at application start.");}for (int i = 0; i < periodsElapsed; i++) {int offset = getPeriodOffsetForDeletionTarget() - i;// 获取需要删除的日志日期 如今天是2022-09-15 maxHistory为30 // 则dateOfPeriodToClean是从2022-08-15到2022-07-15 过早的日志则需要手动删除Date dateOfPeriodToClean = rc.getEndOfNextNthPeriod(now, offset);cleanPeriod(dateOfPeriodToClean);}
}
重要 computeElapsedPeriodsSinceLastClean() 计算 periodsElapsed 天数
int computeElapsedPeriodsSinceLastClean(long nowInMillis) {long periodsElapsed = 0;// UNINITIALIZED判断是否没有进行初始化if (lastHeartBeat == UNINITIALIZED) {addInfo("first clean up after appender initialization");// periodBarriersCrossed 计算过期出天数// 默认32天?periodsElapsed = rc.periodBarriersCrossed(nowInMillis, nowInMillis + INACTIVITY_TOLERANCE_IN_MILLIS);periodsElapsed = Math.min(periodsElapsed, MAX_VALUE_FOR_INACTIVITY_PERIODS);} else {periodsElapsed = rc.periodBarriersCrossed(lastHeartBeat, nowInMillis);// periodsElapsed of zero is possible for size and time based policies}return (int) periodsElapsed;
}
结论:
如果要在项目启动时就删除历史日志文件,需要在logback-spring.xml中添加true。
另外,过于古老的日志是无法自动清除的。logback只能删除最近maxHistory天到maxHistory-32天的日志文件。
如今天是2022-09-15 maxHistory为30 则日志删除的范围是从 2022-07-15 到 2022-08-15 ,过早的日志则需要手动删除
七、SpringBoot中切换日志
因为SpringBoot默认的Logback,在springboot中默认在spring-boot-starter-web中自动引入了spring-boot-starter-logging
如果想要切换到log4j2,那么只需要在spring-boot-starter-web排除掉spring-boot-starter-logging,然后引入新的日志框架对应的坐标。
<dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-web</artifactId><exclusions><exclusion><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-logging</artifactId></exclusion></exclusions>
</dependency>
<dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-log4j2</artifactId>
</dependency>
这里涉及到的步骤有如下所示:
1、在依赖中先从spring-boot-starter-web中点进去,找到spring-boot-starter;
2、再从spring-boot-starter中点进去,找到spring-boot-starter-logging;
3、然后在spring-boot-starter-web下写下排除的坐标;直接从第二步中拷贝下来;
八、阿里巴巴日志规约
1、【强制】应用中不可直接使用日志系统(Log4j、Logback)中的 API,而应依赖使用日志框架
(SLF4J、JCL–Jakarta Commons Logging)中的 API,使用门面模式的日志框架,有利于维护和各个类的日志处理方式统一。
说明:日志框架(SLF4J、JCL–Jakarta Commons Logging)的使用方式(推荐使用 SLF4J)
使用 SLF4J:
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
private static final Logger logger = LoggerFactory.getLogger(Test.class);
使用 JCL:
import org.apache.commons.logging.Log;
import org.apache.commons.logging.LogFactory;
private static final Log log = LogFactory.getLog(Test.class);
2、【强制】所有日志文件至少保存 15 天,因为有些异常具备以“周”为频次发生的特点。对于当天日志,以“应用名.log”来保存,保存在/home/admin/应用名/logs/目录下,过往日志格式为: {logname}.log.{保存日期},日期格式:yyyy-MM-dd
说明:以 mppserver 应用为例,日志保存在/home/admin/mppserver/logs/mppserver.log,历史日志名称为 mppserver.log.2016-08-01
3、【强制】在日志输出时,字符串变量之间的拼接使用占位符的方式。
说明:因为 String 字符串的拼接会使用 StringBuilder 的 append()方式,有一定的性能损耗。使用占位符仅是替换动作,可以有效提升性能。
正例:logger.debug(“Processing trade with id: {} and symbol: {}”, id, symbol);
4、【强制】对于 trace/debug/info 级别的日志输出,必须进行日志级别的开关判断。
说明:虽然在 debug(参数)的方法体内第一行代码 isDisabled(Level.DEBUG_INT)为真时(Slf4j 的常见实现Log4j 和 Logback),就直接 return,但是参数可能会进行字符串拼接运算。此外,如果 debug(getName()),这种参数内有 getName()方法调用,无谓浪费方法调用的开销。
正例:
// 如果判断为真,那么可以输出 trace 和 debug 级别的日志
if (logger.isDebugEnabled()) {
logger.debug(“Current ID is: {} and name is: {}”, id, getName());
}
5、【强制】避免重复打印日志,浪费磁盘空间,务必在 log4j.xml 中设置 additivity=false。
正例:
6、【强制】生产环境禁止直接使用 System.out 或 System.err 输出日志或使用e.printStackTrace()打印异常堆栈。
说明:标准日志输出与标准错误输出文件每次 Jboss 重启时才滚动,如果大量输出送往这两个文件,容易造成文件大小超过操作系统大小限制。
7、【强制】异常信息应该包括两类信息:案发现场信息和异常堆栈信息。如果不处理,那么通过关键字 throws 往上抛出。
正例:logger.error(各类参数或者对象 toString() + “_” + e.getMessage(), e);
8、【强制】日志打印时禁止直接用 JSON 工具将对象转换成 String。
说明:如果对象里某些 get 方法被重写,存在抛出异常的情况,则可能会因为打印日志而影响正常业务流程的执行。
正例:打印日志时仅打印出业务相关属性值或者调用其对象的 toString()方法。
9、【推荐】谨慎地记录日志。生产环境禁止输出 debug 日志;有选择地输出 info 日志;如果使用
warn 来记录刚上线时的业务行为信息,一定要注意日志输出量的问题,避免把服务器磁盘撑爆,并记得及时删除这些观察日志。
说明:大量地输出无效日志,不利于系统性能提升,也不利于快速定位错误点。
记录日志时请思考:这些日志真的有人看吗?看到这条日志你能做什么?能不能给问题排查带来好处?
10、【推荐】可以使用 warn 日志级别来记录用户输入参数错误的情况,避免用户投诉时,无所适从。如非必要,请不要在此场景打出 error 级别,避免频繁报警。
说明:注意日志输出的级别,error 级别只记录系统逻辑出错、异常或者重要的错误信息。
相关文章:
SpringBoot集成Logback日志
SpringBoot集成Logback日志 文章目录 SpringBoot集成Logback日志一、什么是日志二、Logback简单介绍三、SpringBoot项目中使用Logback四、概念介绍一、日志记录器Logger1.1、日志记录器对象生成1.2、记录器的层级结构1.3、过滤器1.4、logger设置日志级别1.5、java代码演示1.6、…...
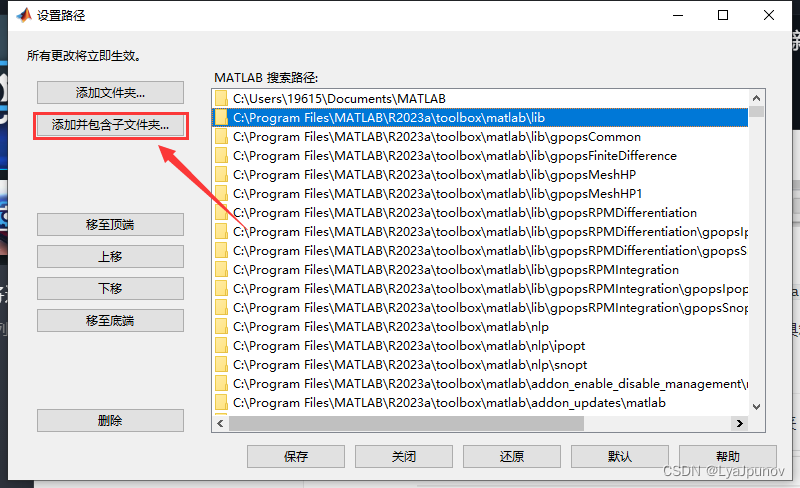
MATLAB(R2023a)添加工具箱TooLbox的方法-以GPOPS为例
一、找到工具箱存放位置 首先我们需要找到工具箱的存放位置,点击这个设置路径可以看到 我们的matlab工具箱的存放位置 C:\Program Files\MATLAB\R2023a\toolbox\matlab 从资源管理器中打开这个位置,可以看到里面各种工具箱 二、放入工具箱 解压我们…...
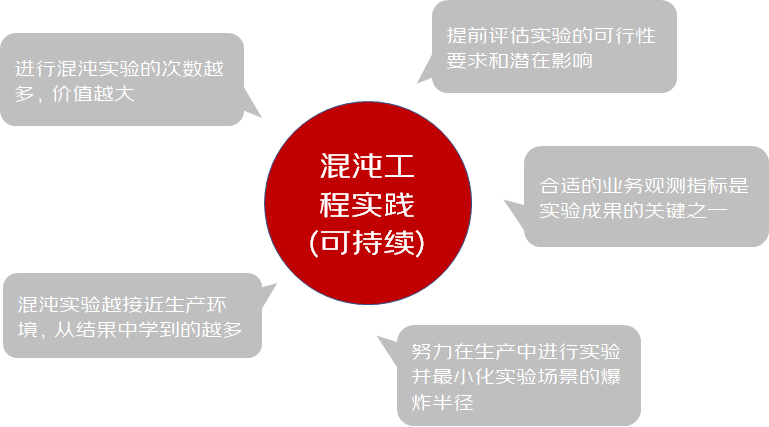
助力618-Y的混沌实践之路 | 京东云技术团队
一、写在前面 1、混沌是什么? 混沌工程(Chaos Engineering)的概念由 Netflix 在 2010 年提出,通过主动向系统中引入异常状态,并根据系统在各种压力下的行为表现确定优化策略,是保障系统稳定性的新型手段。…...

Python系统学习1-4-物理行、逻辑行、选择语句
一、行 (1) 物理行:程序员编写代码的行。 (2) 逻辑行:python解释器需要执行的指令。 (3) 建议: 一个逻辑行在一个物理行上。 如果一个物理行中使用多个逻辑行,需要使用分号;隔开。 (4) 换行: 如果…...
学习系统编程No.35【基于信号量的CP问题】
引言: 北京时间:2023/8/2/12:52,时间飞逝,恍惚间已经来到了八月,给我的第一感觉就是快开学了,别的感觉其实没有,哈哈!看着身边的好友网络相关知识都要全部学完了,就好像…...
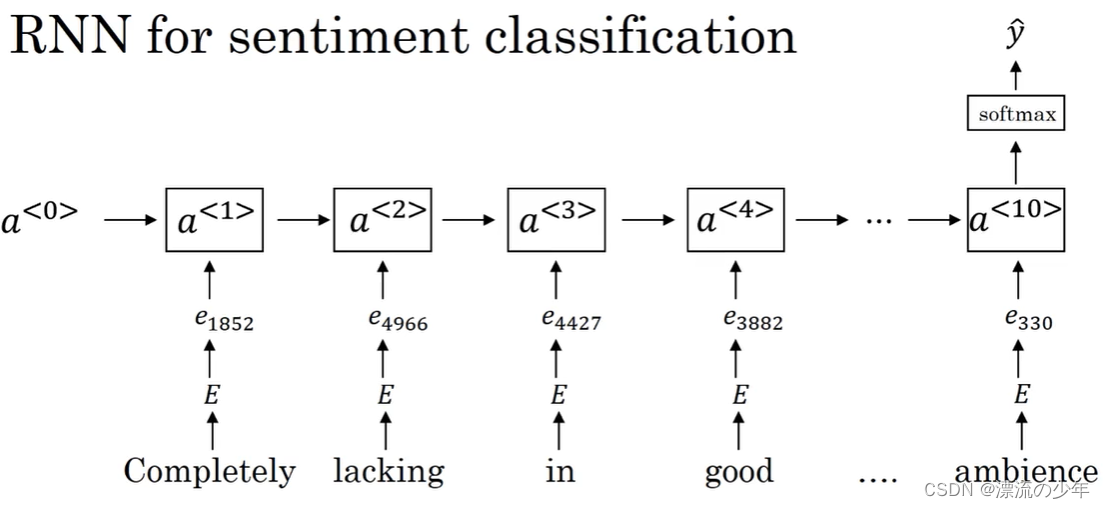
词嵌入、情感分类任务
目录 1.词嵌入(word embedding) 对单词使用one-hot编码的缺点是难以看出词与词之间的关系。 所以需要使用更加特征化的表示(featurized representation),如下图所示,我们可以得到每个词的向量表达。 假设…...

TypeScript使用技巧
文章目录 使用技巧TypeScript内置的工具类型keyofextends 限定泛型interface 与 type 区别 TypeScript作为JavaScript的超集,通过提供静态类型系统和对ES6新特性的支持,使JavaScript开发变得更加高效和可维护。掌握TypeScript的使用技巧,可以帮助我们更好地开发和组织JavaScrip…...
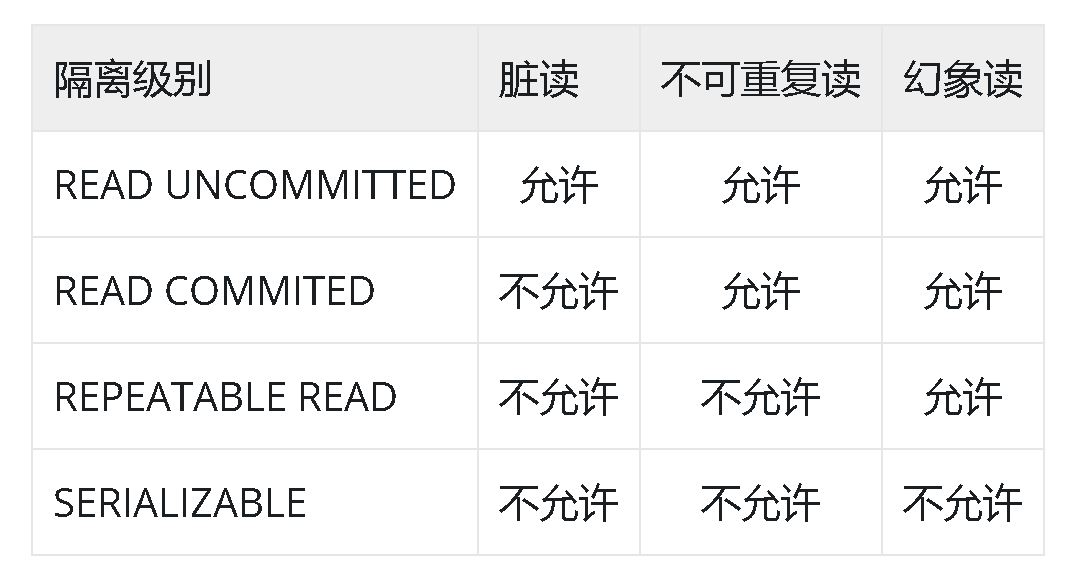
MySQL — InnoDB事务
文章目录 事务定义事务特性事务隔离级别READ UNCOMMITTEDREPEATABLE READREAD COMMITTEDSERIALIZABLE 事务存在的问题脏读(Dirty Read)不可重复读(Non-repeatable Read)幻读(Phantom Read) 事务定义 数据库…...
LeetCode 42. 接雨水(动态规划 / 单调栈)
题目: 链接:LeetCode 42. 接雨水 难度:困难 给定 n 个非负整数表示每个宽度为 1 的柱子的高度图,计算按此排列的柱子,下雨之后能接多少雨水。 示例 1: 输入:height [0,1,0,2,1,0,1,3,2,1,2…...

顺序表、链表刷题指南(力扣OJ)
目录 前言 题目一:删除有序数组中的重复项 思路: 题解: 题目二:合并两个有序数组 思路: 分析: 题解: 题目三:反转链表 思路: 分析: 题解: 题目四&…...

Lambda表达式总结
Lambda作为Java8的新特性,本篇文章主要想总结一下常用的一下用法和api 1.接口内默认方法实现 public interface Formula {double calculate(int a);// 默认方法default double sqrt(int a) {return Math.sqrt(a);} }public static void main(String[] args) {Form…...

岛屿的最大面积
给你一个大小为 m x n 的二进制矩阵 grid 。 岛屿 是由一些相邻的 1 (代表土地) 构成的组合,这里的「相邻」要求两个 1 必须在 水平或者竖直的四个方向上 相邻。你可以假设 grid 的四个边缘都被 0(代表水)包围着。 岛屿的面积是岛上值为 1 …...
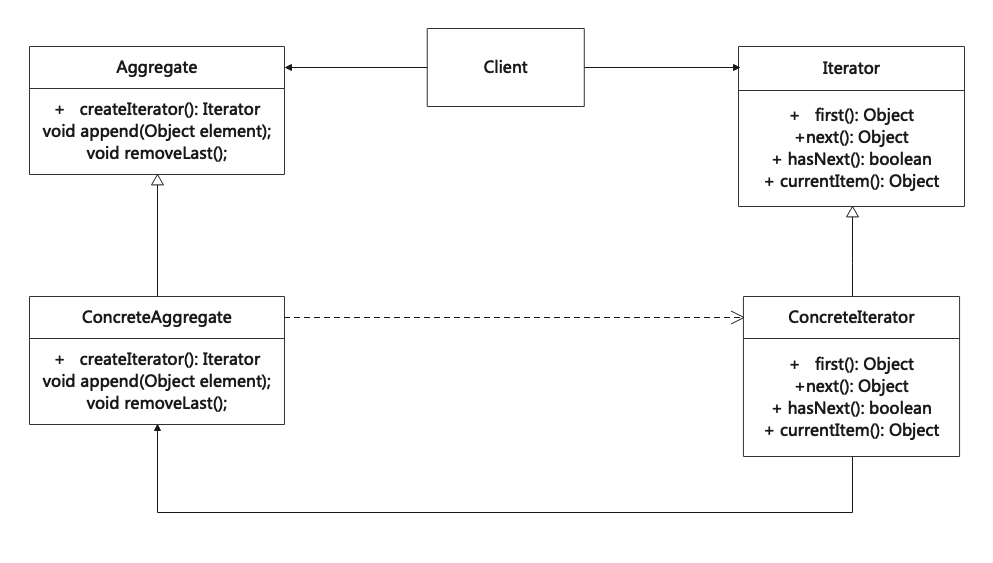
迭代器模式(Iterator)
迭代器模式是一种行为设计模式,可以在不暴露底层实现(列表、栈或树等)的情况下,遍历一个聚合对象中所有的元素。 Iterator is a behavior design pattern that can traverse all elements of an aggregate object without exposing the internal imple…...
Goland搭建远程Linux开发
Windows和Linux都需要先构建好go环境,启用ssh服务。 打开Windows上的Goland,建立项目。 点击添加配置,选择go构建 点击运行于,选择ssh 填上Linux机器的IP地址和用户名 输入密码 没有问题 为了不让每次运行程序和调试程序都生…...

react中PureComponent的理解与使用
一、作用 它是一个纯组件,会做一个数据的浅比较,当props和state没改变的时候,不会render重新渲染, 改变后才会render重新渲染,提高性能。 二、使用 三、注意 它不能和shouldComponentUpdate生命周期同时使用。因为它…...

洛谷——P5714 【深基3.例7】肥胖问题
文章目录 题目题目描述输入格式输出格式样例 #1样例输入 #1样例输出 #1 样例 #2样例输入 #2样例输出 #2 提示 AC代码 题目 题目描述 BMI 指数是国际上常用的衡量人体胖瘦程度的一个标准,其算法是 m h 2 \dfrac{m}{h^2} h2m,其中 m m m 是指体重&am…...

Mac隐藏和显示文件
由于之前没有使用过Mac本,所以很多地方都不太清楚,在下载git项目的时候,发现没有.git文件, 一开始还以为下载错了,但是git命令是可以看到远端分支以及当前分支的,之后在一次解压文件的时候发现,…...

软件工程中应用的几种图辨析
【软件工程】软件工程中应用的几种图辨析:系统流程图、数据流图、数据字典、实体联系图、状态转换图、层次方框图、Warnier图、IPO图、层次图、HIPO图、结构图、程序流程图、盒图、PAD图、判定表_眩晕李的博客-CSDN博客 软件工程——实体关系图 状态转换图 数据流…...
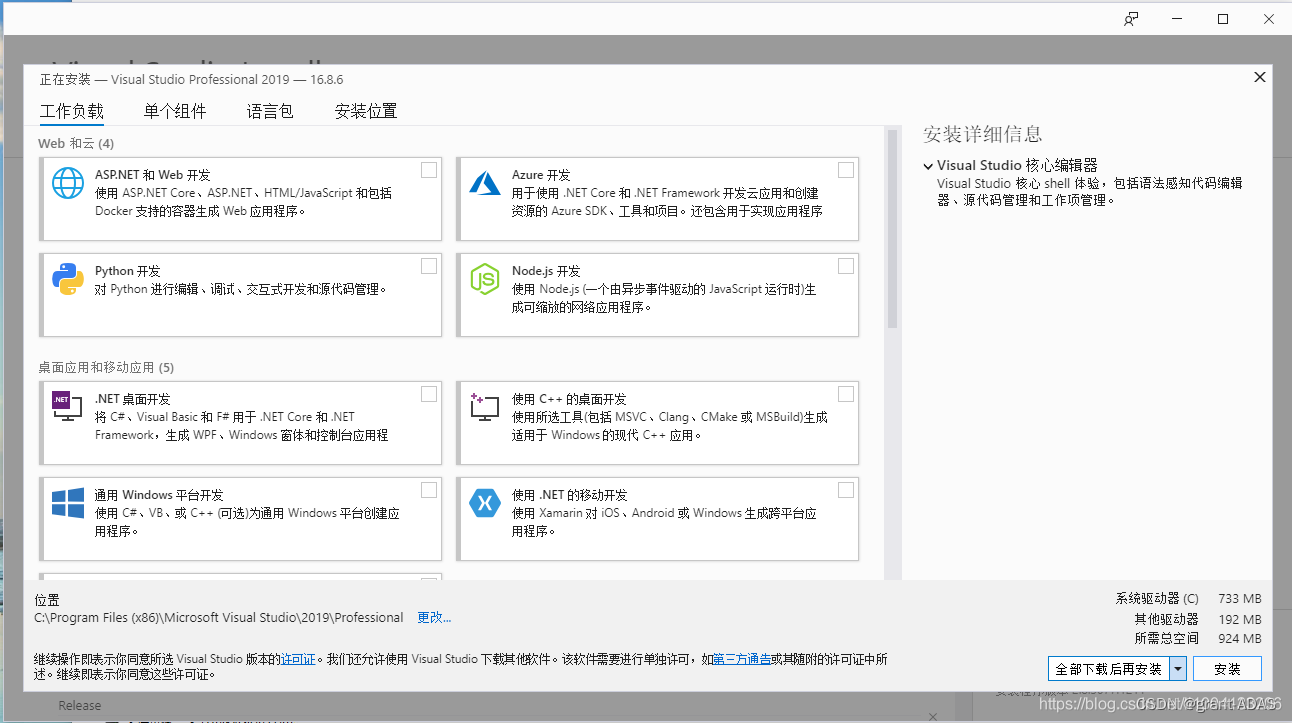
下载离线版的VS Visual Studio 并下载指定的版本
一、先下载引导程序 下载地址VS VisualStudio官网 在这个页面翻到最下面 在这里下载需要的版本 下载引导程序 二、下载离线安装包 写一个批处理文件(vs.bat) 命令格式如下 <vs引导程序exe> --layout <离线安装包下载的路径> --add <功能…...
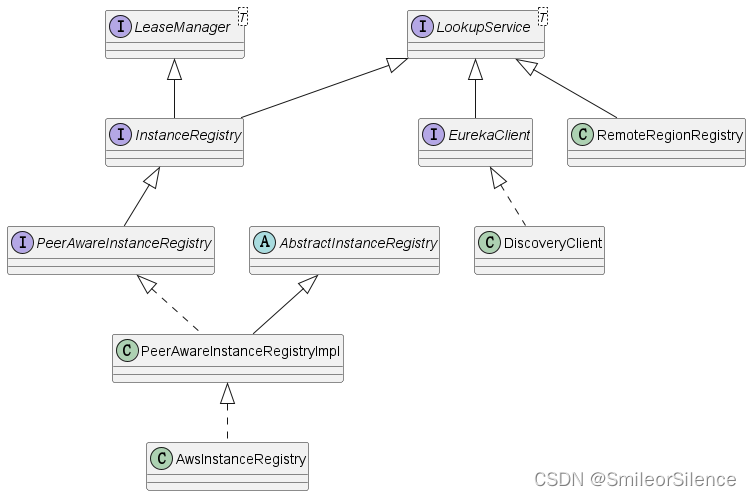
Eureka 学习笔记5:InstanceRegistry
版本 awsVersion ‘1.11.277’ LeaseManager 接口管理实例的租约信息,提供以下功能: 注册实例取消注册实例实例续约剔除过期实例 public interface LeaseManager<T> {/** 注册实例并续约*/void register(T r, int leaseDuration, boolean isRep…...

从Scratch图形化到Python代码:用树莓派给LeArm机械臂做二次开发实战
从Scratch图形化到Python代码:用树莓派给LeArm机械臂做二次开发实战 当Scratch积木块拼接的机械臂动作开始显得单调时,便是时候揭开底层控制的神秘面纱了。本文将带您跨越图形化编程的舒适区,用树莓派的Python环境重新定义LeArm机械臂的智能—…...

无线渗透测试框架Airecon:自动化工具链整合与实战应用
1. 项目概述与核心价值最近在整理自己的渗透测试工具箱时,又翻出了pikpikcu/airecon这个老伙计。说实话,在无线安全评估这个细分领域里,它可能不是名气最响的那个,但绝对是我个人在内部网络渗透和红队演练中最顺手、最高效的“组合…...

别再只盯着wx.login了!SpringBoot后端实战:用getPhoneNumber接口搞定小程序用户手机号绑定
微信小程序用户手机号绑定:SpringBoot后端深度实践指南 在当今移动互联网生态中,微信小程序已成为连接用户与服务的重要桥梁。对于需要强实名认证或直接触达用户的业务场景(如电商交易、金融服务、政务办理等),仅依赖w…...

从零构建个人知识库:Go+React全栈项目RocketNotes实战解析
1. 项目概述:从零到一构建个人知识管理工具最近在整理个人笔记和代码片段时,发现了一个挺有意思的开源项目fynnfluegge/rocketnotes。乍一看这个名字,可能会联想到火箭(Rocket)和笔记(Notes)的结…...
)
用Keras和MNIST数据集,5分钟搞定一个图像去噪的CNN自编码器(附完整代码)
5分钟实战:用Keras构建图像去噪自编码器的极简指南 当一张布满噪点的老照片在AI处理后重现清晰画面时,这种"数字魔法"背后往往是自编码器在发挥作用。作为深度学习领域的瑞士军刀,自编码器不仅能用于图像去噪,还在数据压…...

如何在10分钟内搭建个人游戏流媒体服务器:Sunshine跨平台游戏串流完全指南
如何在10分钟内搭建个人游戏流媒体服务器:Sunshine跨平台游戏串流完全指南 【免费下载链接】Sunshine Self-hosted game stream host for Moonlight. 项目地址: https://gitcode.com/GitHub_Trending/su/Sunshine 您是否梦想过在任何设备上畅玩PC游戏&#x…...

利用OCI免费套餐构建高可用Kubernetes集群实战指南
1. 项目概述:在免费云上构建企业级K8s集群最近在技术社区里,一个名为“nce/oci-free-cloud-k8s”的项目引起了我的注意。这个标题乍一看有点“黑话”的味道,但拆解开来,它指向了一个非常具体且极具吸引力的场景:利用Or…...
搞定Linux视频编解码缓冲区)
别再为嵌入式设备大内存发愁了!手把手教你用CMA(连续内存分配器)搞定Linux视频编解码缓冲区
嵌入式多媒体开发中的连续内存优化实战:CMA技术深度解析 在嵌入式多媒体开发领域,视频编解码、图像处理等任务对内存管理提出了严苛要求。当你在树莓派上部署视频监控系统,或在工业摄像头中实现实时H.264编码时,是否经常遇到这样的…...

怎么找到一个行业的源头工厂、绕开中间商?一套五步识别流程
你下了单,货到了,质量也还行。但心里一直有个疙瘩:这家供应商到底是自己在生产,还是从别处转手赚了你一道差价? 这个问题对采购方和跨境卖家不是洁癖,是真金白银。同一款产品,源头工厂和中间商的…...

从零打造会“看”的电子眼:Teensy与OLED的嵌入式图形与传感器实践
1. 项目概述:打造一个会“看”的电子生命体几年前,我第一次在创客社区看到“Uncanny Eyes”项目时就被深深吸引了。一个微小的OLED屏幕,在代码驱动下,竟然能呈现出如此逼真、灵动的眼球运动,那种介于生命与机械之间的诡…...