基于ChatYuan-large-v2 语言模型 Fine-tuning 微调训练 广告生成 任务
一、ChatYuan-large-v2
ChatYuan-large-v2是一个开源的支持中英双语的功能型对话语言大模型,与其他 LLM 不同的是模型十分轻量化,并且在轻量化的同时效果相对还不错,仅仅通过0.7B参数量就可以实现10B模型的基础效果,正是其如此的轻量级,使其可以在普通显卡、 CPU、甚至手机上进行推理,而且 INT4 量化后的最低只需 400M 。
v2 版本相对于以前的 v1 版本,是使用了相同的技术方案,但在指令微调、人类反馈强化学习、思维链等方面进行了优化。
在本专栏前面文章介绍了 ChatYuan-large-v2 和 langchain 相结合的使用,地址如下:
LangChain 本地化方案 - 使用 ChatYuan-large-v2 作为 LLM 大语言模型
本篇文章以 ChatYuan-large-v2 模型为基础 Fine-tuning 广告生成 任务。
二、数据集处理
数据集这里使用 ChatGLM 官方在 Fine-tuning 中使用到的 广告生成 数据集。
下载地址如下:
https://drive.google.com/file/d/13_vf0xRTQsyneRKdD1bZIr93vBGOczrk/view
数据已 JSON 的形式存放,分为了 train 和 dev 两种类型:

数据格式如下所示:
{"content":"类型#裤*版型#宽松*风格#性感*图案#线条*裤型#阔腿裤","summary":"宽松的阔腿裤这两年真的吸粉不少,明星时尚达人的心头爱。毕竟好穿时尚,谁都能穿出腿长2米的效果宽松的裤腿,当然是遮肉小能手啊。上身随性自然不拘束,面料亲肤舒适贴身体验感棒棒哒。系带部分增加设计看点,还让单品的设计感更强。腿部线条若隐若现的,性感撩人。颜色敲温柔的,与裤子本身所呈现的风格有点反差萌。"
}
{"content":"类型#裤*版型#宽松*风格#性感*图案#线条*裤型#阔腿裤","summary":"宽松的阔腿裤这两年真的吸粉不少,明星时尚达人的心头爱。毕竟好穿时尚,谁都能穿出腿长2米的效果宽松的裤腿,当然是遮肉小能手啊。上身随性自然不拘束,面料亲肤舒适贴身体验感棒棒哒。系带部分增加设计看点,还让单品的设计感更强。腿部线条若隐若现的,性感撩人。颜色敲温柔的,与裤子本身所呈现的风格有点反差萌。"
}
{"content":"类型#裙*风格#简约*图案#条纹*图案#线条*图案#撞色*裙型#鱼尾裙*裙袖长#无袖","summary":"圆形领口修饰脖颈线条,适合各种脸型,耐看有气质。无袖设计,尤显清凉,简约横条纹装饰,使得整身人鱼造型更为生动立体。加之撞色的鱼尾下摆,深邃富有诗意。收腰包臀,修饰女性身体曲线,结合别出心裁的鱼尾裙摆设计,勾勒出自然流畅的身体轮廓,展现了婀娜多姿的迷人姿态。"
}
{"content":"类型#上衣*版型#宽松*颜色#粉红色*图案#字母*图案#文字*图案#线条*衣样式#卫衣*衣款式#不规则","summary":"宽松的卫衣版型包裹着整个身材,宽大的衣身与身材形成鲜明的对比描绘出纤瘦的身形。下摆与袖口的不规则剪裁设计,彰显出时尚前卫的形态。被剪裁过的样式呈现出布条状自然地垂坠下来,别具有一番设计感。线条分明的字母样式有着花式的外观,棱角分明加上具有少女元气的枣红色十分有年轻活力感。粉红色的衣身把肌肤衬托得很白嫩又健康。"
}
{"content":"类型#裙*版型#宽松*材质#雪纺*风格#清新*裙型#a字*裙长#连衣裙","summary":"踩着轻盈的步伐享受在午后的和煦风中,让放松与惬意感为你免去一身的压力与束缚,仿佛要将灵魂也寄托在随风摇曳的雪纺连衣裙上,吐露出<UNK>微妙而又浪漫的清新之意。宽松的a字版型除了能够带来足够的空间,也能以上窄下宽的方式强化立体层次,携带出自然优雅的曼妙体验。"
}
{"content":"类型#上衣*材质#棉*颜色#蓝色*风格#潮*衣样式#polo*衣领型#polo领*衣袖长#短袖*衣款式#拼接","summary":"想要在人群中脱颖而出吗?那么最适合您的莫过于这款polo衫短袖,采用了经典的polo领口和柔软纯棉面料,让您紧跟时尚潮流。再配合上潮流的蓝色拼接设计,使您的风格更加出众。就算单从选料上来说,这款polo衫的颜色沉稳经典,是这个季度十分受大众喜爱的风格了,而且兼具舒适感和时尚感。"
}
其中任务的方式为根据输入(content)生成一段广告词(summary)。
train.json 共有 114599 条记录,这里为了演示效果取前 50000 条数据进行训练、5000 条数据进行验证:
import os# 将训练集进行提取
def doHandle(json_path, train_size, val_size, out_json_path):train_count = 0val_count = 0train_f = open(os.path.join(out_json_path, "train.json"), "a", encoding='utf-8')val_f = open(os.path.join(out_json_path, "val.json"), "a", encoding='utf-8')with open(json_path, "r", encoding='utf-8') as f:for line in f:if train_count < train_size:train_f.writelines(line)train_count = train_count + 1elif val_count < val_size:val_f.writelines(line)val_count = val_count + 1else:breakprint("数据处理完毕!")train_f.close()val_f.close()if __name__ == '__main__':json_path = "./data/AdvertiseGen/train.json"out_json_path = "./data/"train_size = 50000val_size = 5000doHandle(json_path, train_size, val_size, out_json_path)处理之后可以看到两个生成的文件:

下面基于上面的数据格式构建 Dataset :
from torch.utils.data import Dataset, DataLoader, RandomSampler, SequentialSampler
import torch
import jsonclass SummaryDataSet(Dataset):def __init__(self, json_path: str, tokenizer, max_length=300):self.tokenizer = tokenizerself.max_length = max_lengthself.content_data = []self.summary_data = []with open(json_path, "r", encoding='utf-8') as f:for line in f:if not line or line == "":continuejson_line = json.loads(line)content = json_line["content"]summary = json_line["summary"]self.content_data.append(content)self.summary_data.append(summary)print("data load , size:", len(self.content_data))def __len__(self):return len(self.content_data)def __getitem__(self, index):source_text = str(self.content_data[index])target_text = str(self.summary_data[index])source = self.tokenizer.batch_encode_plus([source_text],max_length=self.max_length,pad_to_max_length=True,truncation=True,padding="max_length",return_tensors="pt",)target = self.tokenizer.batch_encode_plus([target_text],max_length=self.max_length,pad_to_max_length=True,truncation=True,padding="max_length",return_tensors="pt",)source_ids = source["input_ids"].squeeze()source_mask = source["attention_mask"].squeeze()target_ids = target["input_ids"].squeeze()target_mask = target["attention_mask"].squeeze()return {"source_ids": source_ids.to(dtype=torch.long),"source_mask": source_mask.to(dtype=torch.long),"target_ids": target_ids.to(dtype=torch.long),"target_ids_y": target_ids.to(dtype=torch.long),}三、模型训练
下载 ChatYuan-large-v2 模型:
https://huggingface.co/ClueAI/ChatYuan-large-v2/tree/main
下面基于 ChatYuan-large-v2 进行训练:
import pandas as pd
import torch
from torch.utils.data import DataLoader
import os, time
from transformers import T5Tokenizer, T5ForConditionalGeneration
from gen_dataset import SummaryDataSetdef train(epoch, tokenizer, model, device, loader, optimizer):model.train()time1 = time.time()for _, data in enumerate(loader, 0):y = data["target_ids"].to(device, dtype=torch.long)y_ids = y[:, :-1].contiguous()lm_labels = y[:, 1:].clone().detach()lm_labels[y[:, 1:] == tokenizer.pad_token_id] = -100ids = data["source_ids"].to(device, dtype=torch.long)mask = data["source_mask"].to(device, dtype=torch.long)outputs = model(input_ids=ids,attention_mask=mask,decoder_input_ids=y_ids,labels=lm_labels,)loss = outputs[0]# 每100步打印日志if _ % 100 == 0 and _ != 0:time2 = time.time()print(_, "epoch:" + str(epoch) + "-loss:" + str(loss) + ";each step's time spent:" + str(float(time2 - time1) / float(_ + 0.0001)))optimizer.zero_grad()loss.backward()optimizer.step()def validate(epoch, tokenizer, model, device, loader, max_length):model.eval()predictions = []actuals = []with torch.no_grad():for _, data in enumerate(loader, 0):y = data['target_ids'].to(device, dtype=torch.long)ids = data['source_ids'].to(device, dtype=torch.long)mask = data['source_mask'].to(device, dtype=torch.long)generated_ids = model.generate(input_ids=ids,attention_mask=mask,max_length=max_length,num_beams=2,repetition_penalty=2.5,length_penalty=1.0,early_stopping=True)preds = [tokenizer.decode(g, skip_special_tokens=True, clean_up_tokenization_spaces=True) for g ingenerated_ids]target = [tokenizer.decode(t, skip_special_tokens=True, clean_up_tokenization_spaces=True) for t in y]if _ % 1000 == 0:print(f'Completed {_}')predictions.extend(preds)actuals.extend(target)return predictions, actualsdef T5Trainer(train_json_path, val_json_path, model_dir, batch_size, epochs, output_dir, max_length=300):tokenizer = T5Tokenizer.from_pretrained(model_dir)model = T5ForConditionalGeneration.from_pretrained(model_dir)device = torch.device("cuda" if torch.cuda.is_available() else "cpu")model = model.to(device)train_params = {"batch_size": batch_size,"shuffle": True,"num_workers": 0,}training_set = SummaryDataSet(train_json_path, tokenizer, max_length=max_length)training_loader = DataLoader(training_set, **train_params)val_params = {"batch_size": batch_size,"shuffle": False,"num_workers": 0,}val_set = SummaryDataSet(val_json_path, tokenizer, max_length=max_length)val_loader = DataLoader(val_set, **val_params)optimizer = torch.optim.Adam(params=model.parameters(), lr=1e-4)for epoch in range(epochs):train(epoch, tokenizer, model, device, training_loader, optimizer)print("保存模型")model.save_pretrained(output_dir)tokenizer.save_pretrained(output_dir)# 验证with torch.no_grad():predictions, actuals = validate(epoch, tokenizer, model, device, val_loader, max_length)# 验证结果存储final_df = pd.DataFrame({"Generated Text": predictions, "Actual Text": actuals})final_df.to_csv(os.path.join(output_dir, "predictions.csv"))if __name__ == '__main__':train_json_path = "./data/train.json"val_json_path = "./data/val.json"# 下载模型目录位置model_dir = "chatyuan_large_v2"batch_size = 5epochs = 1max_length = 300output_dir = "./model"# 开始训练T5Trainer(train_json_path,val_json_path,model_dir,batch_size,epochs,output_dir,max_length)运行后可以看到如下日志打印,训练大概占用 33G 的显存,如果显存不够可以调低些 batch_size 的大小:

等待训练结束后:
可以在 model 下看到保存的模型:
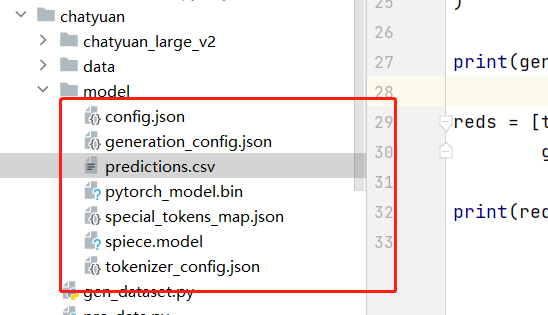
这里可以先看下 predictions.csv 验证集的效果:

可以看到模型生成的结果有点不太好,这里仅对前 50000 条进行了训练,并且就训练了一个 epoch ,后面可以增加数据集大小和增加 epoch 应该能达到更好的效果,下面通过调用模型测试一下生成的文本效果。
四、模型测试
# -*- coding: utf-8 -*-
from transformers import T5Tokenizer, T5ForConditionalGeneration
import torch# 这里是模型下载的位置
model_dir = './model'tokenizer = T5Tokenizer.from_pretrained(model_dir)
model = T5ForConditionalGeneration.from_pretrained(model_dir)while True:text = input("请输入内容: \n ")if not text or text == "":continueif text == "q":breakencoded_input = tokenizer(text, padding="max_length", truncation=True, max_length=300)input_ids = torch.tensor([encoded_input['input_ids']])attention_mask = torch.tensor([encoded_input['attention_mask']])generated_ids = model.generate(input_ids=input_ids,attention_mask=attention_mask,max_length=300,num_beams=2,repetition_penalty=2.5,length_penalty=1.0,early_stopping=True)reds = [tokenizer.decode(g, skip_special_tokens=True, clean_up_tokenization_spaces=True) for g ingenerated_ids]print(reds)效果测试:

相关文章:
基于ChatYuan-large-v2 语言模型 Fine-tuning 微调训练 广告生成 任务
一、ChatYuan-large-v2 ChatYuan-large-v2是一个开源的支持中英双语的功能型对话语言大模型,与其他 LLM 不同的是模型十分轻量化,并且在轻量化的同时效果相对还不错,仅仅通过0.7B参数量就可以实现10B模型的基础效果,正是其如此的…...
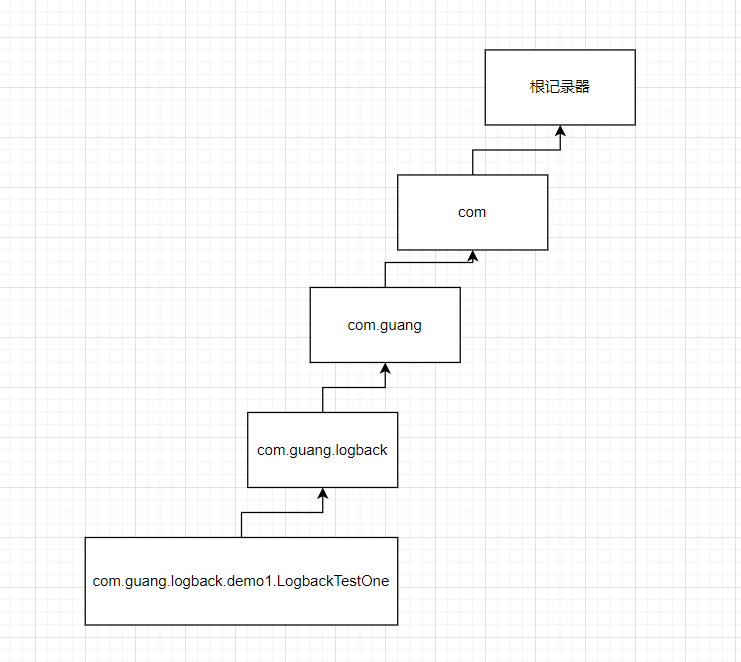
SpringBoot集成Logback日志
SpringBoot集成Logback日志 文章目录 SpringBoot集成Logback日志一、什么是日志二、Logback简单介绍三、SpringBoot项目中使用Logback四、概念介绍一、日志记录器Logger1.1、日志记录器对象生成1.2、记录器的层级结构1.3、过滤器1.4、logger设置日志级别1.5、java代码演示1.6、…...
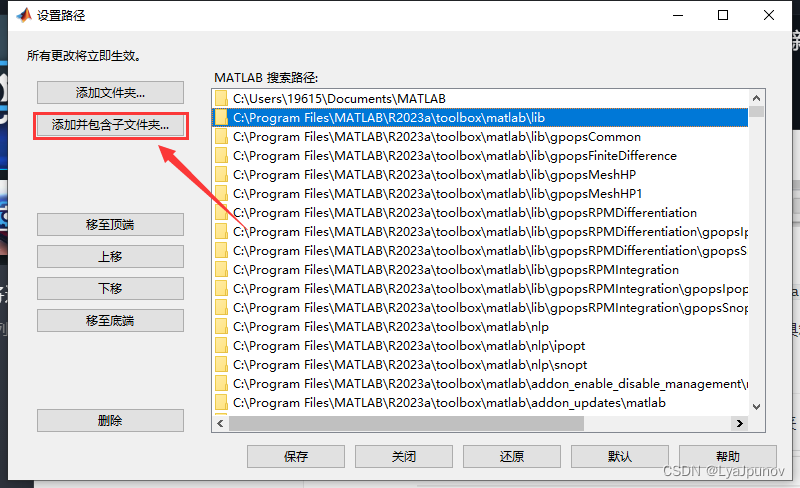
MATLAB(R2023a)添加工具箱TooLbox的方法-以GPOPS为例
一、找到工具箱存放位置 首先我们需要找到工具箱的存放位置,点击这个设置路径可以看到 我们的matlab工具箱的存放位置 C:\Program Files\MATLAB\R2023a\toolbox\matlab 从资源管理器中打开这个位置,可以看到里面各种工具箱 二、放入工具箱 解压我们…...
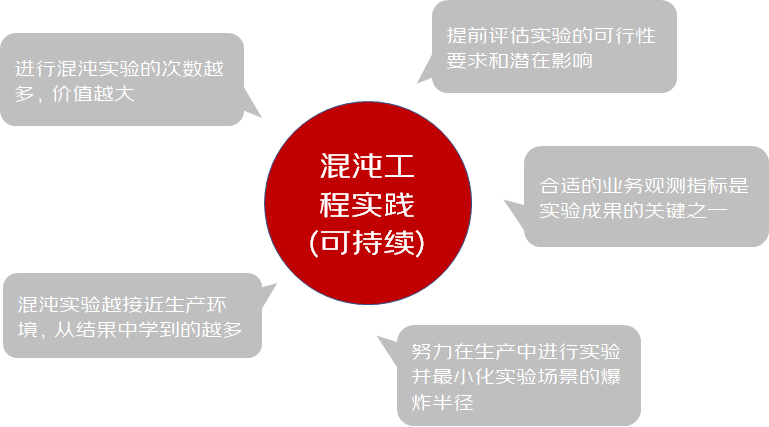
助力618-Y的混沌实践之路 | 京东云技术团队
一、写在前面 1、混沌是什么? 混沌工程(Chaos Engineering)的概念由 Netflix 在 2010 年提出,通过主动向系统中引入异常状态,并根据系统在各种压力下的行为表现确定优化策略,是保障系统稳定性的新型手段。…...

Python系统学习1-4-物理行、逻辑行、选择语句
一、行 (1) 物理行:程序员编写代码的行。 (2) 逻辑行:python解释器需要执行的指令。 (3) 建议: 一个逻辑行在一个物理行上。 如果一个物理行中使用多个逻辑行,需要使用分号;隔开。 (4) 换行: 如果…...
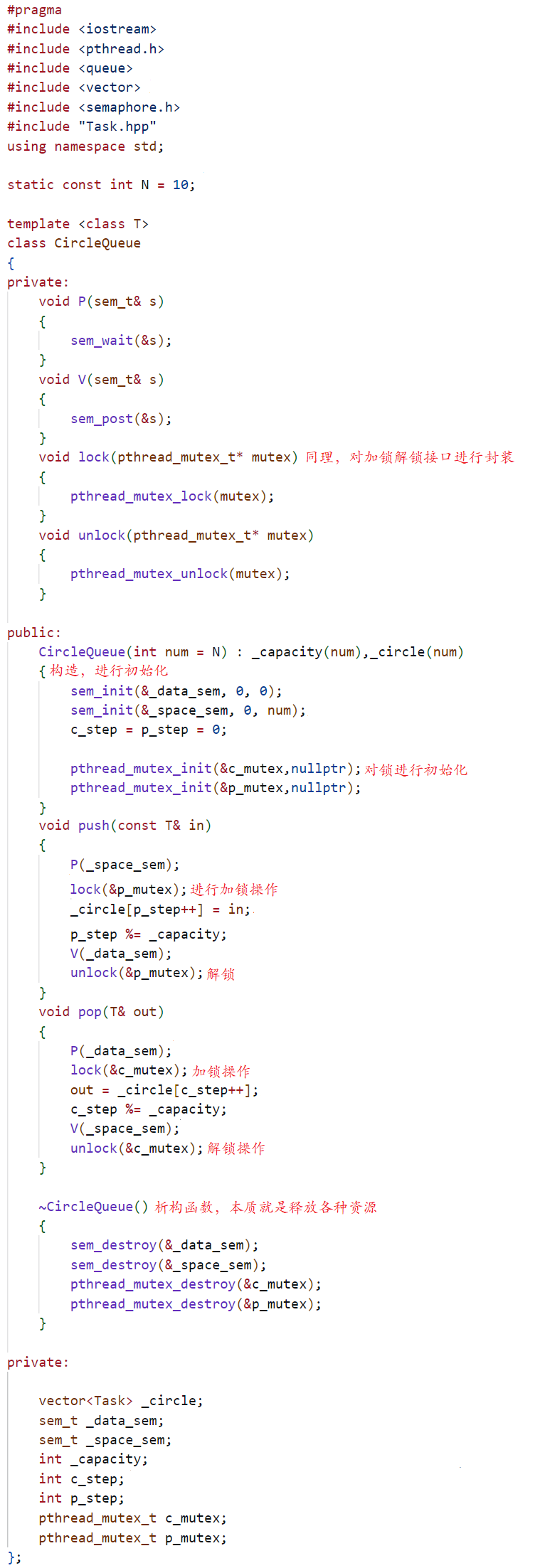
学习系统编程No.35【基于信号量的CP问题】
引言: 北京时间:2023/8/2/12:52,时间飞逝,恍惚间已经来到了八月,给我的第一感觉就是快开学了,别的感觉其实没有,哈哈!看着身边的好友网络相关知识都要全部学完了,就好像…...
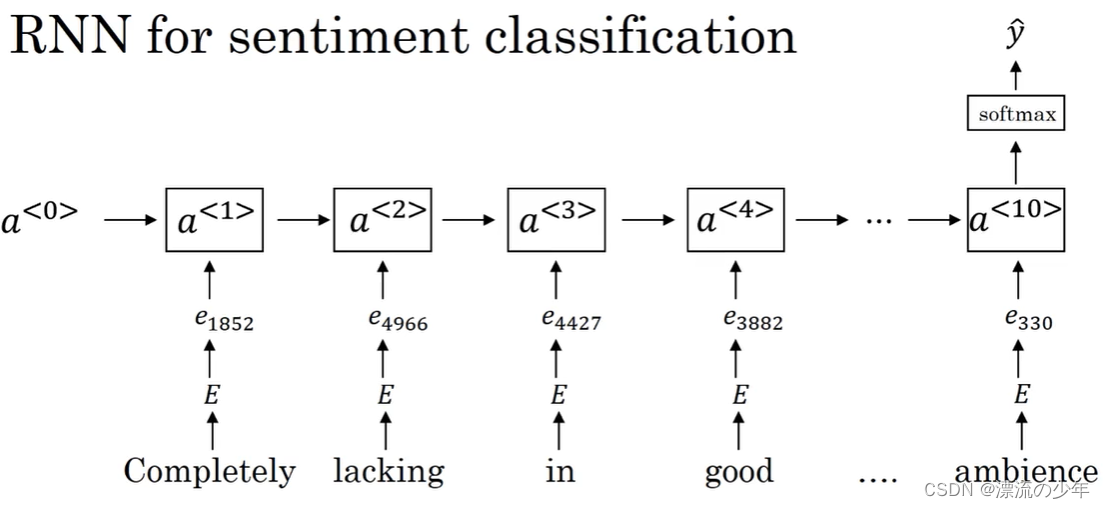
词嵌入、情感分类任务
目录 1.词嵌入(word embedding) 对单词使用one-hot编码的缺点是难以看出词与词之间的关系。 所以需要使用更加特征化的表示(featurized representation),如下图所示,我们可以得到每个词的向量表达。 假设…...

TypeScript使用技巧
文章目录 使用技巧TypeScript内置的工具类型keyofextends 限定泛型interface 与 type 区别 TypeScript作为JavaScript的超集,通过提供静态类型系统和对ES6新特性的支持,使JavaScript开发变得更加高效和可维护。掌握TypeScript的使用技巧,可以帮助我们更好地开发和组织JavaScrip…...
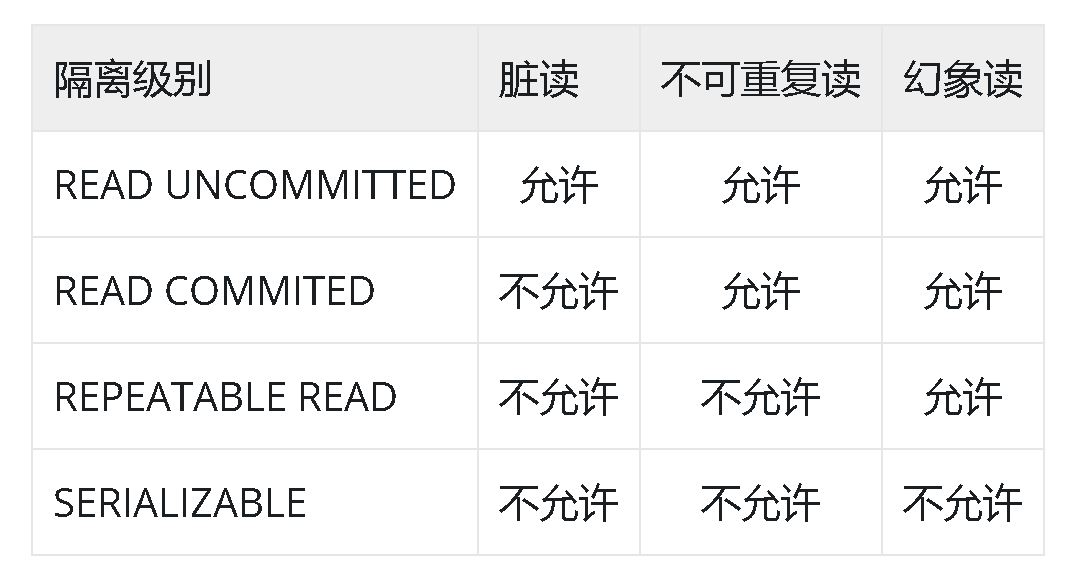
MySQL — InnoDB事务
文章目录 事务定义事务特性事务隔离级别READ UNCOMMITTEDREPEATABLE READREAD COMMITTEDSERIALIZABLE 事务存在的问题脏读(Dirty Read)不可重复读(Non-repeatable Read)幻读(Phantom Read) 事务定义 数据库…...
LeetCode 42. 接雨水(动态规划 / 单调栈)
题目: 链接:LeetCode 42. 接雨水 难度:困难 给定 n 个非负整数表示每个宽度为 1 的柱子的高度图,计算按此排列的柱子,下雨之后能接多少雨水。 示例 1: 输入:height [0,1,0,2,1,0,1,3,2,1,2…...

顺序表、链表刷题指南(力扣OJ)
目录 前言 题目一:删除有序数组中的重复项 思路: 题解: 题目二:合并两个有序数组 思路: 分析: 题解: 题目三:反转链表 思路: 分析: 题解: 题目四&…...

Lambda表达式总结
Lambda作为Java8的新特性,本篇文章主要想总结一下常用的一下用法和api 1.接口内默认方法实现 public interface Formula {double calculate(int a);// 默认方法default double sqrt(int a) {return Math.sqrt(a);} }public static void main(String[] args) {Form…...

岛屿的最大面积
给你一个大小为 m x n 的二进制矩阵 grid 。 岛屿 是由一些相邻的 1 (代表土地) 构成的组合,这里的「相邻」要求两个 1 必须在 水平或者竖直的四个方向上 相邻。你可以假设 grid 的四个边缘都被 0(代表水)包围着。 岛屿的面积是岛上值为 1 …...
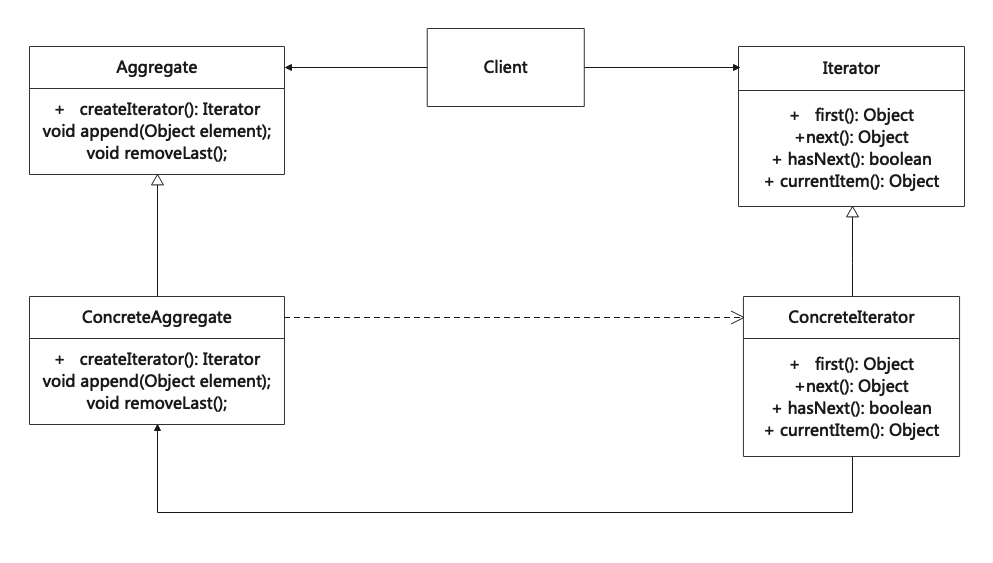
迭代器模式(Iterator)
迭代器模式是一种行为设计模式,可以在不暴露底层实现(列表、栈或树等)的情况下,遍历一个聚合对象中所有的元素。 Iterator is a behavior design pattern that can traverse all elements of an aggregate object without exposing the internal imple…...
Goland搭建远程Linux开发
Windows和Linux都需要先构建好go环境,启用ssh服务。 打开Windows上的Goland,建立项目。 点击添加配置,选择go构建 点击运行于,选择ssh 填上Linux机器的IP地址和用户名 输入密码 没有问题 为了不让每次运行程序和调试程序都生…...

react中PureComponent的理解与使用
一、作用 它是一个纯组件,会做一个数据的浅比较,当props和state没改变的时候,不会render重新渲染, 改变后才会render重新渲染,提高性能。 二、使用 三、注意 它不能和shouldComponentUpdate生命周期同时使用。因为它…...

洛谷——P5714 【深基3.例7】肥胖问题
文章目录 题目题目描述输入格式输出格式样例 #1样例输入 #1样例输出 #1 样例 #2样例输入 #2样例输出 #2 提示 AC代码 题目 题目描述 BMI 指数是国际上常用的衡量人体胖瘦程度的一个标准,其算法是 m h 2 \dfrac{m}{h^2} h2m,其中 m m m 是指体重&am…...

Mac隐藏和显示文件
由于之前没有使用过Mac本,所以很多地方都不太清楚,在下载git项目的时候,发现没有.git文件, 一开始还以为下载错了,但是git命令是可以看到远端分支以及当前分支的,之后在一次解压文件的时候发现,…...

软件工程中应用的几种图辨析
【软件工程】软件工程中应用的几种图辨析:系统流程图、数据流图、数据字典、实体联系图、状态转换图、层次方框图、Warnier图、IPO图、层次图、HIPO图、结构图、程序流程图、盒图、PAD图、判定表_眩晕李的博客-CSDN博客 软件工程——实体关系图 状态转换图 数据流…...
下载离线版的VS Visual Studio 并下载指定的版本
一、先下载引导程序 下载地址VS VisualStudio官网 在这个页面翻到最下面 在这里下载需要的版本 下载引导程序 二、下载离线安装包 写一个批处理文件(vs.bat) 命令格式如下 <vs引导程序exe> --layout <离线安装包下载的路径> --add <功能…...
)
告别龟速采样!用DDIM加速你的扩散模型推理(附PyTorch代码)
加速扩散模型推理:DDIM核心原理与实战优化指南 在图像生成领域,扩散模型以其卓越的质量表现迅速成为研究热点,但传统DDPM(Denoising Diffusion Probabilistic Models)的致命缺陷在于其缓慢的采样速度——生成一张图片往…...

终极指南:10分钟掌握SPT-AKI存档编辑器完整使用教程
终极指南:10分钟掌握SPT-AKI存档编辑器完整使用教程 【免费下载链接】SPT-AKI-Profile-Editor Программа для редактирования профиля игрока на сервере SPT-AKI 项目地址: https://gitcode.com/gh_mirrors/sp/…...
)
保姆级教程:在CentOS 7/8服务器上部署DrissionPage爬虫(含Chrome无头模式配置)
CentOS服务器上DrissionPage爬虫的工业级部署指南 1. 环境准备与Chrome浏览器安装 在CentOS服务器上部署基于DrissionPage的爬虫系统,首要任务是构建稳定可靠的浏览器运行环境。与个人开发环境不同,生产服务器通常需要面对无图形界面、资源受限等特殊场景…...

告别Python依赖!手把手教你用C++复现Librosa的Mel频谱和MFCC特征提取
高性能C音频特征提取实战:从Librosa原理到嵌入式部署优化 在语音识别和音频分析领域,Mel频谱和MFCC特征提取是基础但关键的技术环节。许多开发者习惯使用Python的Librosa库快速实现原型,但当需要部署到生产环境时,Python的解释器性…...

OpenSpire:开源贡献者协作平台的设计理念与实战指南
1. 项目概述:一个面向开源贡献者的协作平台最近在和一些刚接触开源的朋友交流时,发现一个挺普遍的现象:很多人对参与开源项目充满热情,但第一步“如何找到合适的项目并上手”就卡住了。GitHub上项目浩如烟海,一个新手面…...

Python数据聚合抓取工具:从配置化引擎到实战避坑指南
1. 项目概述:一个多功能的“聚合爪”工具最近在GitHub上闲逛,发现了一个名字挺有意思的项目:al1enjesus/polyclawster。这个名字拆开看,“poly”代表多,“clawster”听起来像是“claw”(爪子)和…...

Godot引擎实验项目解析:从角色控制到着色器优化的实战指南
1. 项目概述与核心价值如果你是一名游戏开发者,尤其是对独立游戏开发充满热情,那么“Godot”这个名字对你来说一定不陌生。它是一个功能强大、开源免费的游戏引擎,以其轻量、高效和友好的编辑器而闻名。然而,引擎本身只是一个工具…...

RFM69无线通信进阶:从基础收发到可靠数据传输系统构建
1. 项目概述:从点对点收发迈向可靠通信在物联网和嵌入式开发领域,无线通信模块是连接物理世界与数字世界的桥梁。RFM69系列模块,特别是工作在433MHz或915MHz等Sub-GHz频段的RFM69HCW,因其出色的抗干扰能力、较远的传输距离以及相对…...

AI智能体分类学:从原理到实践,构建高效Agent系统的设计指南
1. 项目概述与核心价值最近在折腾AI智能体(Agent)相关的项目,发现一个挺有意思的现象:大家聊起Agent,要么是“它能帮我写代码”,要么是“它能自动处理客服”,但很少有人能系统地说清楚ÿ…...

RTX 5090功耗传闻解析:600W显卡对PC生态的挑战与应对
1. 项目概述:从一则功耗新闻到显卡生态的深度思考最近,英伟达下一代旗舰显卡RTX 5090的功耗传闻在硬件圈里炸开了锅。消息称其TGP(总图形功耗)可能高达600W,相比RTX 4090的450W,直接激增了150W。这不仅仅是…...