SpringCloud系列(十三)[分布式搜索引擎篇] - ElasticSearch 的概念及 Centos 7 下详细安装步骤
打开淘宝, 搜索 狂飙 会出现各种价格有关狂飙的书籍, 当然也有高启强同款的孙子兵法!!! 如下图所示:
那么面对海量的数据, 如何快速且准确的找到我们想要的内容呢? 淘宝界面已经可以按照综合排序 / 销量 / 信用 / 价格等进行筛选, 是如何做到的呢?

ElasticSearch 1
- 1 ElasticSearch 的概念
- 1.1 基本概念
- 1.2 ELK 技术栈
- 1.3 ElasticSearch 与 Lucene
- 1.4 ElasticSearch 与 MySQL
- 2 正向索引及倒排索引
- 2.1 正向索引
- 2.2 倒排索引
- 2.3 总结
- 3 部署 ElasticSearch
- 4 部署 Kibana
- 5 安装 IK 分词器
1 ElasticSearch 的概念
1.1 基本概念
ElasticSearch 是一款非常强大的开源搜索引擎, 那么其功能也就是帮助我们在海量的数据中找到想要的数据内容, 如上面我们在淘宝界面搜索狂飙展现出的内容, 如我们敲代码遇到 BUG 复制到百度看到的内容.
ElasticSearch 是面向文档 (Document) 存储的, 可以是数据库中的一条商品数据或者是一个订单信息, 文档数据会被序列化为 json 格式后存储在 ElasticSearch 中;

1.2 ELK 技术栈
在学习分布式搜索引擎之前, 先来了解一下 ELK 技术栈的概念, Elasticsearch / Logstash( / Beats) 和 Kibana 这三个技术就是常说的 ELK 技术栈, 这三个技术的结合是大数据领域中一个很巧妙的设计, 当然这也是一种经典的 MVC 模型思想.
- Logstash 担任控制层的角色, 负责数据的搜集及过滤;
- Elasticsearch 担任数据持久层的角色, 负责数据的存储;
- Kibana 则是一个开源的分析与可视化平台, 设计的初衷也是用来搭配 ElasticSearch 的使用, 可以用 Kibana 搜索和查看存放在 ElasticSearch 中的数据, Kibana 与 Elasticsearch 的交互方式是各种不同的图表 / 表格 / 地图等,直观的展示数据,从而达到高级的数据分析与可视化的目的。

通过上面的概念可知 ElasticSearch 是 ELK 技术栈的核心, 毕竟其主要工作便是 存储 / 搜索 / 分析数据.
1.3 ElasticSearch 与 Lucene
Lucene 是 Java 语言的搜索引擎类库, 为 Apache 公司的项目, 而 ElasticSearch 的底层就是基于 Lucene 来实现的, 两者的优缺点如下: Lucene: * 易扩展 / 高性能; * 只限于 Java 语言开发 / 不支持水平扩展;
ElasticSearch:
- 支持分布式, 可水平扩展;
- 提供了 Restful 接口, 可被任何语言调用.
1.4 ElasticSearch 与 MySQL
MySQL 更擅长事务类型的操作, 可以确保数据的安全性和一致性;
ElasticSearch 更擅长海量数据的搜索 / 分析 / 计算.
因此, 在企业中往往两种结合在一起使用, 场景如下:
- 对查询性能要求较高的搜索需求使用 ElasticSearch 实现;
- 对安全性要求较高的写操作往往使用 MySQL 实现.

2 正向索引及倒排索引
关于索引和映射之间的区别:
- 索引就是相同类型的文档的集合, 如所有商品的文档可以放在一块进行组织, 成为商品的索引; 如所有的用户都放在一起进行组织就称之为用户的索引;
- 因为数据库中各个表中的数据基本都是相同类型, 因此数据库中的表可以称之为是索引;
- 因为数据库中的表会有约束信息, 用来定义表的结构 / 字段的名称或者类型等信息, 因此索引库中就有映射 (mapping), 关于映射的概念可以理解为索引中文档的字段约束信息, 类似于表结构的约束.
2.1 正向索引
在学习倒排索引之前, 先了解正向索引的概念, 如下图 MySQL 表;

如果是根据 id 进行查询可以直接 select * from gen_table where table_id=93, 但是如果在此表中进行模糊搜索 “信息” 这两个字眼, 只能逐行进行搜索, select * from gen_table where table_comment like '%信息%', 步骤如下:
1 用户根据 table_comment 这个条件进行搜索数据;
2 逐行获取数据, 从 id 为 93 这一行开始;
3 判断数据中的 table_comment 是否符合用户的搜索条件;
4 如果符合, 则放入结果集, 否则就丢弃, 回到步骤 1 进行重复.
如果表中的数据比较少, 还可以这样进行查询, 但是如果数据量巨大, 全表搜索查询效率将会非常低, 你能忍受搜索数据等待个小时为单位的时间么?
2.2 倒排索引
倒排索引的两个比较重要的概念:
- 文档(Document): 用来搜索的数据, 其中的每一条数据就是一个文档, 如一个网页或者是一件商品信息;
- 词条(Term): 对文档数据或用户搜索数据, 利用某种算法分词, 得到的具备含义的词语就是词条, 如 “狂飙这部剧真好看” 就可以分为: "狂, 狂飙, 这, 部, 剧, 真, 好看"这样的词条.
主要流程:
创建倒排索引是对正向索引的一种特殊处理, 如下:
- 将每一个文档的数据利用算法进行分词, 得到多个词条;
- 创建表, 每行数据包含词条 / 词条所在文档的 id 及位置等信息;
- 因为词条的唯一性, 因此可以给词条创建索引, 如 hash 表结构索引.

例如: 使用倒排索引搜索 “阿迪篮球鞋” 流程如下:
- 我们输入 “阿迪篮球鞋” 进行搜索;
- 对输入的内容进行分词, 得到两个词条: 阿迪, 篮球鞋;
- 根据这两个词条在倒排索引中进行查找, 可以得到包含词条的文档 id 为: 1, 2;
- 拿着文档 id 在正向索引中查找到具体的文档.

2.3 总结
- 正向索引
-
- 优点:
-
-
- 可以为多个字段创建索引;
-
-
-
- 根据索引字段进行搜索, 速度比较快;
-
-
- 缺点:
-
-
- 根据非索引字段或者索引字段中的部分词条查找时, 只能全表扫描;
-
- 倒排索引
-
- 优点:
-
-
- 根据词条搜索或者模糊搜索时, 速度非常快;
-
-
- 缺点:
-
-
- 只能给词条创建索引, 而不是字段;
-
-
-
- 无法根据字段进行排序.
-
3 部署 ElasticSearch
在安装 ElasticSearch 时遇到了很多 “坑”, 如果有在安装的过程中报错, 请点击此链接来查看解决办法: 【Debug】Centos 7 下部署 ElasticSearch 及 Kibana 时踩过的坑;
声明此安装是在 Centos 7 环境下的安装.
步骤一: 创建网络;
因为我们需要部署 Kibana 容器, 因此需要让 ElasticSearch 和 Kibana 容器进行关联, 因此需要创建一个网络: docker network create es-net;
步骤二: 加载镜像;
这里需要注意 ElasticSearch 的版本和 Kibana 的版本一致, 主要方式有两种, 如下:
- 自己在官网下载包, 官网下载点击此处, 然后上传到虚拟机中, 运行
docker load -i elasticsearch.tar执行加载即可; 大部分的电脑这种操作还是没问题的, 但是我的电脑这种方式不妥, 其实最保险的方式还是下面这种方式; - 在 docker 镜像仓库查找指令, 网站为: Docker 镜像仓库, 这里我选的是 7.17.7 版本,
docker pull elasticsearch:7.17.7, 如下图所示:


步骤三: 运行并部署 ElasticSearch, 指令如下:
docker run -d \--name es \-e "ES_JAVA_OPTS=-Xms512m -Xmx512m" \-e "discovery.type=single-node" \-v es-data:/usr/share/elasticsearch/data \-v es-plugins:/usr/share/elasticsearch/plugins \--privileged \--network es-net \-p 9200:9200 \-p 9300:9300 \
elasticsearch:7.17.7
指令解析:

4 部署 Kibana
步骤一: 建议直接拉去, 指令: docker pull kibana:7.17.7;

步骤二: 运行并部署;
docker run -d \
--name kibana \
-e ELASTICSEARCH_HOSTS=http://es:9200 \
--network=es-net \
-p 5601:5601 \
kibana:7.17.7
指令解析:

步骤三: 浏览器输入 http://172.16.00.99:5601 (去看自己虚拟机的 ip) 查看是否出现界面;

5 安装 IK 分词器
步骤一: 进入容器内部, 执行指令: docker exec -it es /bin/bash, es 为我的容器名称, 这里写自己命名的 ElasticSearch 容器的名称;

将指令 ./bin/elasticsearch-plugin install https://github.com/medcl/elasticsearch-analysis-ik/releases/download/v7.17.7/elasticsearch-analysis-ik-7.17.7.zip 复制进去回车;因为我的电脑已经安装过, 所以报错已存在;

步骤二: 执行 exit 指令并重启 ElasticSearch 容器: docker restart es;
步骤三: 测试;

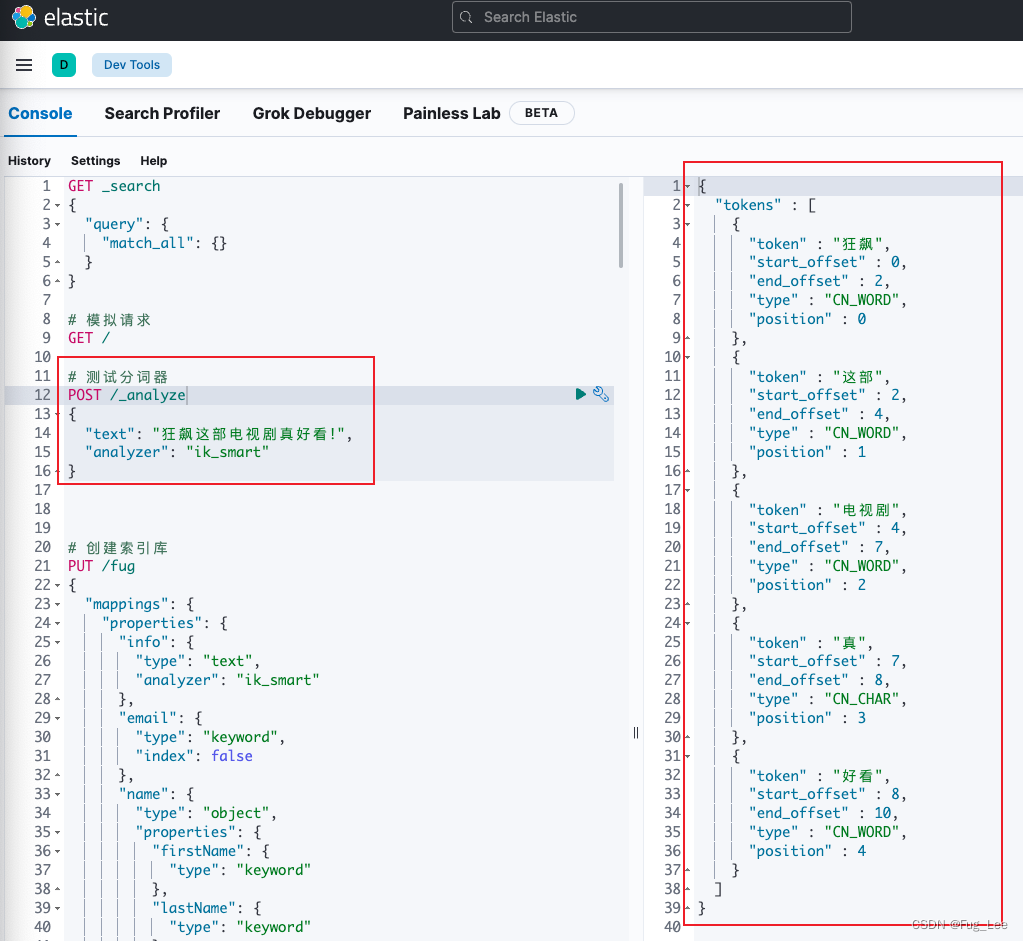
总结:
1 分词器的作用:
- 创建倒排索引时对文档分词;
- 用户搜索时对输入的内容进行分词.
2 IK 分词器的两种模式:
- ik_smart: 智能切分, 粗粒度;
- ik_max_word: 最细切分, 细粒度.
相关文章:
SpringCloud系列(十三)[分布式搜索引擎篇] - ElasticSearch 的概念及 Centos 7 下详细安装步骤
打开淘宝, 搜索 狂飙 会出现各种价格有关狂飙的书籍, 当然也有高启强同款的孙子兵法!!! 如下图所示: 那么面对海量的数据, 如何快速且准确的找到我们想要的内容呢? 淘宝界面已经可以按照综合排序 / 销量 / 信用 / 价格等进行筛选, 是如何做到的呢? ElasticSearch 11 Elastic…...

04_Docker 镜像和仓库
04_Docker 镜像和仓库 文章目录04_Docker 镜像和仓库4.1 什么是 Docker 镜像4.2 列出 Docker 镜像4.3 拉取镜像4.4 查找镜像4.5 构建镜像4.5.1 创建 Docker Hub 账号4.5.2 用 Docker 的 commit 命令创建镜像4.5.3 用 Dockerfile 构建镜像4.5.5 基于 Dockerfile 构建新镜像4.5.5…...
postman-enterprise-API
Postman 是一个用于构建和使用 API 的 API 平台。Postman 简化了 API 生命周期的每个步骤并简化了协作,因此您可以更快地创建更好的 API。 API存储库 在一个中央平台上围绕您的所有 API 工件轻松存储、编目和协作。Postman 可以存储和管理 API 规范、文档、工作流配…...

【ESP 保姆级教程】玩转emqx MQTT篇② ——保留消息和遗嘱消息
忘记过去,超越自己 ❤️ 博客主页 单片机菜鸟哥,一个野生非专业硬件IOT爱好者 ❤️❤️ 本篇创建记录 2023-02-18 ❤️❤️ 本篇更新记录 2023-02-18 ❤️🎉 欢迎关注 🔎点赞 👍收藏 ⭐️留言📝🙏 此博客均由博主单独编写,不存在任何商业团队运营,如发现错误,请…...

开启慢查询日志方法
步骤 开启慢查询日志 SET GLOBAL slow_query_log on;SHOW VARIABLES like slow_query_log;设置时间限制 SET GLOBAL long_query_time 1; -- 单位sSHOW VARIABLES LIKE %long_query_time%;因为long_query_time参数只对新的数据库连接生效,所以还需要重启msql客户端…...
宝塔搭建实战人才求职管理系统admin前端vue源码(二)
大家好啊,我是测评君,欢迎来到web测评。 上一期给大家分享骑士cms后台端在宝塔的搭建部署方式,这套系统是前后端分离的架构,前端是用vue2开发的,还需要在本地打包手动发布上宝塔,所以本期给大家分享&#x…...
SpringMVC——基础知识
基本概念 SpringMVC是基于servlet api构造的原始web框架,全称是Spring Web MVC 而MVC的全称是Model View Controller,翻译成中文分别是“模型”,“视图”,“控制器”,这是一种软件的架构模式 Model:用来…...

论文浅尝 | SpCQL: 一个自然语言转换Cypher的语义解析数据集
笔记整理:郭爱博,国防科技大学博士论文发表会议:The 31th ACM International Conference on Information and Knowledge Management,CIKM 2022动机随着社交、电子商务、金融等行业的快速发展,现实世界编织出一张庞大而…...

MongoDB 使用规范与限制及最佳实践
MongoDB 灵活文档的优势 灵活库/集合命名及字段增减同一字段可存储不同类型数据Json 文档可多层次嵌套文档对于开发而言最自然的表达 MongoDB 灵活文档的烦恼 数据库集合字段名千奇百怪同一字段数据类型各不一样业务异常可能写入“脏”数据 1.1 库命名规范 不能为空字符串 &…...
第五十六章 树状数组(一)
第五十六章 树状数组一、前缀和的缺陷二、树状数组1、作用2、算法分析3、算法实现(1)lowbits()(2)插入(3)查询三、例题1、问题题目描述输入格式输出格式样例 #1样例输入 #1样例输出 #1提示2、代码一、前缀和…...
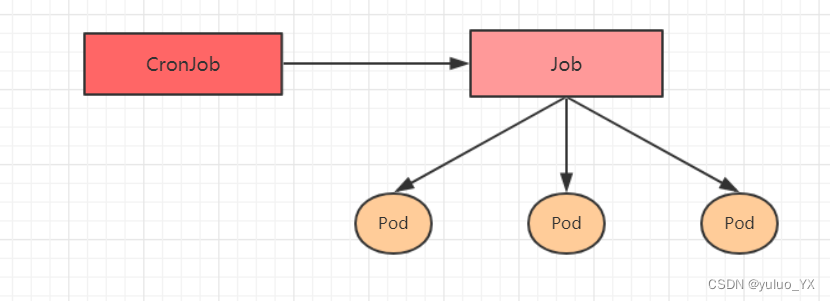
kubernetes教程 --Pod控制器详解
Pod控制器详解 介绍 Pod是kubernetes的最小管理单元,在kubernetes中,按照pod的创建方式可以将其分为两类: 自主式pod:kubernetes直接创建出来的Pod,这种pod删除后就没有了,也不会重建控制器创建的pod&am…...

N2750A Agilent Keysight HP 差分探头1.5GHz
N2750A Agilent Keysight HP 差分探头13554860890 N2750A 是 Agilent Keysight HP 的 1.5 GHz 差分探头。 特征: N2750A:1.5 GHz 衰减比:2:1 或 10:1(可切换) 动态范围: 5 V 或 10 Vpp(10:1 时…...

一文搞懂Linux内核进程CPU调度基本原理
为什么需要调度 进程调度的概念比较简单,我们假设在一个单核处理器的系统中,同一时刻只有一个进程可以拥有处理器资源,那么其他的进程只能在就绪队列中等待,等到处理器空闲之后才有计划获得处理器资源来运行。在这种场景下&#…...
java ssm爱宠宠物医院挂号预约系统管理系统设计与实现
本课题所实现的宠物医院网站是基于网页,它可以实现网上预约挂号,评价等基本功能。用户只要手边有一部手机或者一台电脑,可以上网浏览网页,便可以使用本系统,没有时间和地点的限制,使得就医预约,…...
自动化测试工具_Jmeter
【课程简介】 接口测试是测试系统组件间接口的一种测试,接口测试天生为高复杂性的平台带来高效的缺陷监测和质量监督能力,平台越复杂,系统越庞大,接口测试的效果越明显。在接口测试大行其道的今天,测试工具也愈发重要,Jmeter作为一款纯 Java 开发的测试…...

不是所有人都适合职场
一个读者的提问: 洋哥,我目前工作五年在一家大厂,属于那种什么事情上手都很快的人,并且搞定新问题能产生沉浸般的快感。我的本职是程序员,但运营思路产品方法也都会一些,甚至有时候提出的方案效果比产品&a…...
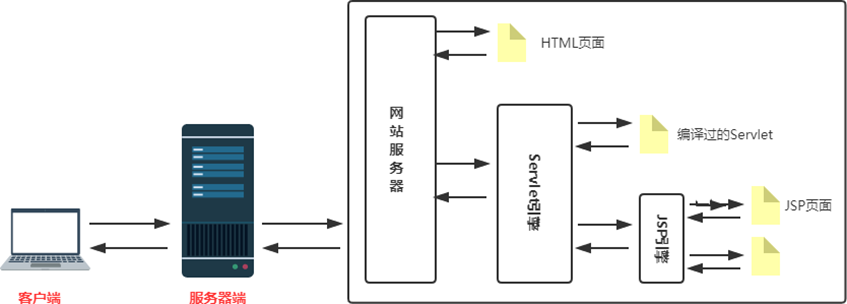
JSP 和 JSTL
文章目录🍓摘要🍓一、JSP🍉1.1 JSP的基础语法🍫1.1.1 简介🍫1.1.2 依赖🍫1.1.3 注释🍫1.1.4 Scriptlet 脚本🍉1.2 JSP的指令标签🍫1.2.1 include 静态包含🍫1…...

数据分析| Pandas200道练习题,使用Pandas连接MySQL数据库
文章目录使用Pandas连接数据库编码环境依赖包read_sql_query()的使用read_sql_table()的使用read_sql() 函数的使用to_sql()写入数据库的操作删除操作更新操作总结:使用Pandas连接数据库 通过pandas实现数据库的读,写操作时,首先需要进行数据…...

【Node.js】全局可用变量、函数和对象
文章目录前言_dirname和_filename变量全局函数setTimeout(cb,ms)clearTimeout(t)setInterval(cb,ms)clearInterval(t)setImmediate(cb)clearImmediate()console对象console.info([data][,...])console.error([data][,...])console.warn([data][,...])console.dir(obj[,options]…...

package.json 开发依赖与运行时依赖
文章目录前言一、生产环境与开发环境二、dependencies二、devDependencies总结前言 我已经使用npm接近两年了, 但对于package.json内的dependencies 和devDependencies也只是知道什么依赖该放什么部分, 至于为什么放到这个部分, 我不是很了解… 呃, 还是去了解一下. 一、生产环…...

轻量神经网络在量子比特实时控制中的嵌入式部署实践
1. 项目概述:当机器学习遇见量子控制在量子计算这个前沿领域,我们每天都在与微观世界的“幽灵”打交道。一个量子比特的状态,就像地球仪上的一个点,可以用布洛赫球面上的经度和纬度来描述。要让这个点精确地旋转到我们指定的位置&…...

【避坑指南】Midscene.js 常见报错解析:Timeout、模型幻觉与跨域问题的终极解法
开篇:当AI自动化“翻车”时,你在想什么? 凌晨两点,你的CI/CD流水线又红了。点开日志一看——TimeoutError: AI model request timed out。改了timeout参数重新跑,这次倒是没超时,但AI模型信誓旦旦地点了一个根本不存在的按钮。第三次,脚本直接抛出403,提示跨域被拦截。…...

3分钟为Blender相机添加真实抖动:Camera Shakify新手完全指南
3分钟为Blender相机添加真实抖动:Camera Shakify新手完全指南 【免费下载链接】camera_shakify 项目地址: https://gitcode.com/gh_mirrors/ca/camera_shakify 想让你的Blender动画瞬间拥有电影级的真实感吗?Camera Shakify这款神奇的插件就是你…...

2000-2025年地市级数字技术创新水平
数字技术创新水平是衡量地级及以上城市在政府工作报告中系统提及数字技术相关词汇密度的综合指标,用以反映该地区数字技术创新活动的活跃程度与发展态势。本数据集基于全国地级及以上城市的政府工作报告文本构建,覆盖各年度、各城市的官方政策表述。核心…...

N_m3u8DL-RE深度解析:现代流媒体下载引擎的架构设计与实战应用
N_m3u8DL-RE深度解析:现代流媒体下载引擎的架构设计与实战应用 【免费下载链接】N_m3u8DL-RE Cross-Platform, modern and powerful stream downloader for MPD/M3U8/ISM. English/简体中文/繁體中文. 项目地址: https://gitcode.com/GitHub_Trending/nm3/N_m3u8…...

3分钟快速上手:Unlock Music音乐解锁工具终极指南
3分钟快速上手:Unlock Music音乐解锁工具终极指南 【免费下载链接】unlock-music 在浏览器中解锁加密的音乐文件。原仓库: 1. https://github.com/unlock-music/unlock-music ;2. https://git.unlock-music.dev/um/web 项目地址: https://g…...

NsEmuTools:终极NS模拟器自动化管理解决方案
NsEmuTools:终极NS模拟器自动化管理解决方案 【免费下载链接】ns-emu-tools 一个用于安装/更新 NS 模拟器的工具 项目地址: https://gitcode.com/gh_mirrors/ns/ns-emu-tools 想要在电脑上畅玩任天堂Switch游戏,却被复杂的模拟器安装、配置和更新…...

3步解锁:开源工具Applera1n完全指南——iOS 15-16激活锁绕过方案
3步解锁:开源工具Applera1n完全指南——iOS 15-16激活锁绕过方案 【免费下载链接】applera1n icloud bypass for ios 15-16 项目地址: https://gitcode.com/gh_mirrors/ap/applera1n Applera1n是一款专为iOS 15-16系统设计的免费开源激活锁绕过工具ÿ…...

如何用WeChatMsg永久保存微信聊天记录:3步轻松备份完整指南
如何用WeChatMsg永久保存微信聊天记录:3步轻松备份完整指南 【免费下载链接】WeChatMsg 提取微信聊天记录,将其导出成HTML、Word、CSV文档永久保存,对聊天记录进行分析生成年度聊天报告 项目地址: https://gitcode.com/GitHub_Trending/we/…...

如何在Windows电脑上安装安卓应用:APK安装器终极指南
如何在Windows电脑上安装安卓应用:APK安装器终极指南 【免费下载链接】APK-Installer An Android Application Installer for Windows 项目地址: https://gitcode.com/GitHub_Trending/ap/APK-Installer 想在Windows电脑上畅玩手机游戏、使用安卓专属应用吗&…...