西瓜书读书笔记整理(五)—— 第四章 决策树
第四章 决策树
- 4.1 基本流程
- 4.1.1 什么是决策树算法
- 4.1.2 决策树学习的目的
- 4.1.3 决策树学习基本过程
- 4.1.4 决策树学习基本算法
- 4.1.5 递归结束的三种情况
- 4.2 划分选择
- 4.2.1 信息增益(information gain)—— ID3 决策树学习算法属性划分准则
- 4.2.2 信息增益率(information gain rate)—— C4.5 决策树学习算法属性划分准则
- 4.2.3 基尼指数(Gini index)—— CART 决策树学习算法属性划分准则
- 4.3 剪枝算法
- 4.3.1 剪枝的目的
- 4.3.2 预剪枝(prepuning)
- 4.3.3 后剪枝(postpruning)
- 4.4 连续与缺失值
- 4.4.1 连续值处理
- 4.4.2 缺失值处理
- 4.5 多变量决策树
- 4.6 总结
4.1 基本流程
4.1.1 什么是决策树算法
决策树算法 是一种通过构建 树形结构 进行分类和回归的机器学习算法。
4.1.2 决策树学习的目的
决策树学习的目的是为了产生一棵泛化能力强,即处理未见示例能力强的决策树,其基本流程遵循简单且直观的 “分而治之”(divide-and-conquer)策略。
4.1.3 决策树学习基本过程
决策树学习的基本过程如下:
-
数据准备:首先,收集和准备用于训练的数据集,包含输入特征和对应的标签(类别或数值)。
-
特征选择:根据特征的不同属性(离散或连续),选择合适的特征选择方法来找到对分类或回归预测有最大信息增益、基尼系数或均方误差等的特征。这一步骤是决策树学习中最重要的一步。
-
数据划分:将数据集按照选定的特征划分为更小的子集。每个子集中的数据都具有相同的特征值,或者至少有类似的特征属性。
-
递归构建树:从根节点开始,对每个子集递归地进行特征选择和数据划分,直到满足某个终止条件。终止条件可以是:节点中的数据属于同一类别,节点中的数据样本数量小于某个阈值,或者达到了预先设定的树深度。
-
叶节点标记:在构建树的过程中,每个叶节点都对应着一个类别标签或回归数值,这些标签或数值由训练数据决定。
-
剪枝(可选):为了避免过拟合,可以对构建完成的决策树进行剪枝,即去掉一些分支,使得树的结构更简单,同时也可以提高泛化能力。
-
预测:使用构建好的决策树对新的输入数据进行预测。从根节点开始,根据输入数据的特征值逐步遍历决策树的分支,直到到达叶节点,然后输出叶节点的类别标签或回归数值作为预测结果。
-
模型评估:使用测试数据集来评估决策树的性能,通常使用准确率、召回率、F1 分数等指标来评估分类问题的性能,均方误差等指标来评估回归问题的性能。
4.1.4 决策树学习基本算法
原书第 74 页图 4.2

定义一个函数 TreeGenerate(D,A) 并且这是一个递归算法,因此算法伪代码最后将会重新调用本方法,直到所有的特种特征用尽为止。
面试常常问的可能是其中某一个环节、或者是大体概述整个过程。
4.1.5 递归结束的三种情况
- 当前结点包含的样本全属于同一类别,无需划分;
- 当前属性集为空,或是所有样本在所有属性上取值相同,无法划分;
- 当前结点包含的样本集合为空,无法划分。
4.2 划分选择
即 如何选择最优划分属性 (选择属性问题)
4.2.1 信息增益(information gain)—— ID3 决策树学习算法属性划分准则
“信息熵” (information entropy)是度量样本集合纯度最常用的一种指标。
假定当前样本集合 D D D 中第 k k k 类样本所占的比例为 p k ( k = 1 , 2 , . . . , ∣ Y ∣ ) p_k(k=1,2,...,|\mathcal{Y}|) pk(k=1,2,...,∣Y∣),则 D D D 的信息熵定义为
Ent ( D ) = − ∑ k = 1 ∣ Y ∣ p k log 2 p k . (4.1) \operatorname{Ent}(D)=-\sum_{k=1}^{|\mathcal{Y}|} p_k \log _2 p_k. \tag{4.1} Ent(D)=−k=1∑∣Y∣pklog2pk.(4.1)
Ent ( D ) \operatorname{Ent}(D) Ent(D) 的值越小,则 D D D 的纯度越高。
假设离散属性 a a a 有 V V V 个可能的取值 { a 1 , a 2 , . . . , a V } \{a^1, a^2, ...,a^V\} {a1,a2,...,aV},若使用 a a a 对样本集 D D D 进行划分,则会产生 V V V 个分支结点,其中第 v v v 个分支结点包含了 D D D 中所有在属性 a a a 上取值为 a v a^v av 的样本,记作 D v D^v Dv。我们可根据式 ( 4.1 ) (4.1) (4.1) 计算出 D v D^v Dv 的信息熵,再考虑到不同的分支结点所包含的样本数不同,给分支结点赋予权重 ∣ D v ∣ / ∣ D ∣ |D^v|/|D| ∣Dv∣/∣D∣,即样本数越多的分支结点的影响越大,于是可计算出用属性 a a a 对样本集 D D D 进行划分所获得的 “信息增益” (information gain)
Gain ( D , a ) = Ent ( D ) − ∑ v = 1 V ∣ D v ∣ ∣ D ∣ Ent ( D v ) (4.2) \operatorname{Gain}(D, a)=\operatorname{Ent}(D)-\sum_{v=1}^V \frac{\left|D^v\right|}{|D|} \operatorname{Ent}\left(D^v\right) \tag{4.2} Gain(D,a)=Ent(D)−v=1∑V∣D∣∣Dv∣Ent(Dv)(4.2)
一般而言,信息增益越大,则意味着使用属性 a a a 进行划分所获得的 “纯度提升” 越大。因此,我们用信息增益来进行决策树的划分属性选择。著名的 ID3 决策树学习算法就是以信息增益为准则来选择划分属性。
4.2.2 信息增益率(information gain rate)—— C4.5 决策树学习算法属性划分准则
实际上,信息增益准则对可取值数目较多的属性有所偏好 ,为了减少这种偏好可能带来的不利影响,著名的 C4.5 决策树算法不直接使用信息增益,而使用 “增益率(gain rate)” 来选择最优划分属性。
Gain_ratio ( D , a ) = Gain ( D , a ) IV ( a ) (4.3) \operatorname{Gain\_ ratio}(D, a)=\frac{\operatorname{Gain}(D, a)}{\operatorname{IV}(a)} \tag{4.3} Gain_ratio(D,a)=IV(a)Gain(D,a)(4.3)
其中,
IV ( a ) = − ∑ v = 1 V ∣ D v ∣ ∣ D ∣ log 2 ∣ D v ∣ ∣ D ∣ (4.4) \operatorname{IV}(a)=-\sum_{v=1}^V \frac{\left|D^v\right|}{|D|} \log _2 \frac{\left|D^v\right|}{|D|} \tag{4.4} IV(a)=−v=1∑V∣D∣∣Dv∣log2∣D∣∣Dv∣(4.4)
称为属性 a a a 的 “固有值” (intrinsic value)。属性 a a a 的可能性取值数目越多(即 V V V 越大),则 I V ( a ) IV(a) IV(a) 的值通常会越大。
需注意的是,增益率准则对可取值数目较少的属性有所偏好,因此,C4.5 算法并不是直接选择增益率最大的候选划分属性,而是使用了一个启发式:先从候选划分属性中找出信息增益高于平均水平的属性,再从中选择增益率最高的。
4.2.3 基尼指数(Gini index)—— CART 决策树学习算法属性划分准则
CART 决策树使用 “基尼系数” 来选择划分属性。
Gini ( D ) = ∑ k = 1 ∣ Y ∣ ∑ k ′ ≠ k p k p k ′ = 1 − ∑ k = 1 ∣ Y ∣ p k 2 . (4.5) \begin{aligned} \operatorname{Gini}(D) & =\sum_{k=1}^{|\mathcal{Y}|} \sum_{k^{\prime} \neq k} p_k p_{k^{\prime}} \\ & =1-\sum_{k=1}^{|\mathcal{Y}|} p_k^2 . \end{aligned} \tag{4.5} Gini(D)=k=1∑∣Y∣k′=k∑pkpk′=1−k=1∑∣Y∣pk2.(4.5)
直观来说, G i n i ( D ) Gini(D) Gini(D) 反映了从数据集 D D D 中随机选取两个样本,其类别标记不一致的概率。因此, G i n i ( D ) Gini(D) Gini(D) 越小,则数据集 D D D 的纯度越高。
属性 a a a 的基尼指数定义为:
Gini_index ( D , a ) = ∑ v = 1 V ∣ D v ∣ ∣ D ∣ Gini ( D v ) (4.6) \operatorname{Gini\_ index}(D, a)=\sum_{v=1}^V \frac{\left|D^v\right|}{|D|} \operatorname{Gini}\left(D^v\right) \tag{4.6} Gini_index(D,a)=v=1∑V∣D∣∣Dv∣Gini(Dv)(4.6)
于是,我们在候选属性集 A A A 中,选择那个使得划分后基尼指数最小的属性作为最优划分属性,即 a ∗ = arg min a ∈ A Gini_index ( D , a ) a_*=\underset{a \in A}\argmin \operatorname{Gini\_index}(D, a) a∗=a∈AargminGini_index(D,a)。
4.3 剪枝算法
人类的局限性导致人类在解决一个问题的同时,往往会制造新的问题。
4.3.1 剪枝的目的
剪枝(pruning)是决策树学习算法对付 “过拟合” 的主要手段。
4.3.2 预剪枝(prepuning)
预剪枝是指在决策树生成过程中,对每个结点在划分前先进行估计,若当前结点的划分不能带来决策树泛化性能提升,则停止划分并将当前结点标记为叶结点。
4.3.3 后剪枝(postpruning)
后剪枝则是先从训练集生成一棵完整的决策树,然后自底向上对非叶子结点进行考察,若将该结点对应的子树替换为叶结点能带来决策树泛化性能提升,则将该子树替换为叶结点。
4.4 连续与缺失值
4.4.1 连续值处理
决策树通常通过二分法来处理连续值特征。在构建决策树的过程中,对于连续值特征,需要选择一个阈值来将其划分为两个子集。以下是处理连续值特征的一般步骤:
-
特征选择:从所有特征中选择一个连续值特征作为当前节点的划分依据。通常,使用特征选择方法(例如信息增益、信息增益比、基尼系数等)来选择最优的特征。
-
阈值选择:对于选定的连续值特征,选择一个合适的阈值来将其划分为两个子集。通常的做法是遍历所有可能的阈值,并选择使得划分后的子集使得目标函数最优的阈值。
-
样本划分:使用选择的阈值,将训练数据中的连续值特征划分为两个子集,一个子集包含小于等于阈值的样本,另一个子集包含大于阈值的样本。
-
递归构建:对于每个子集,递归地重复步骤1至步骤3,直到满足停止条件(例如达到预定深度、样本数量少于阈值等)。
-
叶节点标签确定:对于每个划分后的子集,决定叶节点的标签。在分类问题中,通常选择子集中最频繁出现的类别作为叶节点的标签。在回归问题中,可以选择子集中样本标签的平均值作为叶节点标签。
需要注意的是,决策树的构建过程中,连续值特征的选择和阈值的确定是至关重要的,直接影响到决策树的性能和泛化能力。因此,对于连续值特征,特征选择和阈值的选择是决策树算法中的重要环节。在实际应用中,可以使用不同的特征选择方法和阈值搜索策略,或者采用其他预处理技术(如离散化)来更好地处理连续值特征。
4.4.2 缺失值处理
决策树在处理缺失值时有几种常见的策略:
-
缺失值剔除:最简单的方法是直接删除带有缺失值的样本。这样做可以简化问题,但可能会导致数据的信息损失,特别是当缺失值的数量较大时。
-
缺失值填充:另一种常见的方法是填充缺失值,使得样本在该特征上具有有效的值。填充方法可以采用均值、中位数、众数等简单的统计量,或者使用其他预测模型来估计缺失值。
-
缺失值作为单独类别:对于分类问题,可以将缺失值视为一个单独的类别,让决策树根据数据的其他特征来判断样本是否属于缺失值类别。
-
缺失值分支:在决策树的构建过程中,如果遇到某个样本在某个特征上缺失值,可以考虑将其划分到不同的分支中。这样,在测试时,如果样本的该特征缺失,就可以根据不同分支的情况来进行预测。
-
缺失值处理算法:一些特定的决策树算法或扩展版本(如XGBoost)具有内置的缺失值处理能力,可以自动处理缺失值并在构建树时考虑缺失值的影响。
需要根据具体情况选择合适的缺失值处理方法。对于某些数据集,直接删除缺失值可能是合理的选择,而在其他情况下,填充缺失值或将其视为独立类别可能更为适用。重要的是在处理缺失值时要注意不引入额外的偏见或错误,并考虑缺失值对模型性能的影响。
4.5 多变量决策树
多变量决策树(Multivariate Decision Trees)是对传统决策树算法的一种扩展,旨在处理多个特征之间的相互作用和关联。传统的决策树算法(如ID3、C4.5、CART)每次只考虑一个特征来进行划分,因此可能无法充分捕捉多个特征之间的复杂关系。
多变量决策树通过同时考虑多个特征来进行划分,以更好地建模多个特征之间的交互作用。在构建每个节点的决策条件时,它会考虑多个特征的联合情况,而不仅仅是单个特征的划分。这样可以更好地处理特征之间的相关性和非线性关系,提高模型的表现和泛化能力。
多变量决策树的构建过程相对复杂,需要考虑更多的特征组合和划分方式。通常,多变量决策树的构建过程可以通过以下几种方法来实现:
-
多变量划分准则:传统决策树使用单变量划分准则(如信息增益、基尼系数)来选择最优划分特征。而多变量决策树可以使用多变量划分准则来选择多个特征的组合作为划分依据。
-
贪心算法:多变量决策树的构建可以采用贪心算法,每次选择能够最大程度提升整体模型性能的多变量划分。
-
剪枝策略:在多变量决策树的构建过程中,为了防止过拟合,可以采用剪枝策略来简化模型。
-
集成学习:多变量决策树也可以与集成学习方法(如随机森林、梯度提升树)相结合,进一步提高模型的性能。
需要注意的是,多变量决策树的构建和优化相对复杂,可能需要更多的计算资源和时间。在实际应用中,根据数据集的大小和复杂性,需要权衡不同决策树算法的优势和劣势,选择合适的方法来构建和训练多变量决策树模型。
4.6 总结
决策树算法是一种非常经典、可解释性强的算法,值得好好学习,并把这个作为其他更加复杂、更加高效的算法的学习基础。
Smileyan
2023.08.06 21:54
相关文章:
西瓜书读书笔记整理(五)—— 第四章 决策树
第四章 决策树 4.1 基本流程4.1.1 什么是决策树算法4.1.2 决策树学习的目的4.1.3 决策树学习基本过程4.1.4 决策树学习基本算法4.1.5 递归结束的三种情况 4.2 划分选择4.2.1 信息增益(information gain)—— ID3 决策树学习算法属性划分准则4.2.2 信息增…...
STM32 4G学习
硬件连接 ATK-IDM750C模块可直接与正点原子 MiniSTM32F103开发板板载的ATK模块接口(ATK-MODULE)进行连接。 功能说明 ATK-IDM750C是正点原子(ALIENTEK)团队开发的一款高性能4G Cat1 DTU产品,支持移动4G、联通4G和…...

Golang 中实现实时聊天通讯
客户端代码 package mainimport ("fmt""log""net/url""os""os/signal""time""github.com/gorilla/websocket" )func main() {interrupt : make(chan os.Signal, 1)signal.Notify(interrupt, os.Interr…...
每天10个小知识点)
前端面试的性能优化部分(5)每天10个小知识点
目录 系列文章目录前端面试的性能优化部分(1)每天10个小知识点前端面试的性能优化部分(2)每天10个小知识点前端面试的性能优化部分(3)每天10个小知识点前端面试的性能优化部分(4)每天…...

【链表OJ 1】移除链表元素val
大家好,欢迎来到我的博客,此题是关于链表oj的第一题,此后还会陆续更新博客,如有错误,欢迎大家指正。 来源:https://leetcode.cn/problems/remove-linked-list-elements/description/ 题目: 方法一:定义prev和cur指针…...

复原 IP 地址——力扣93
文章目录 题目描述回溯题目描述 回溯 class Solution{public:static constexpr int seg_count=4<...
OSPF综合实验
实验题目如下: 实验拓扑如下: 实验要求如下: 【1】R4为ISP,其上只能配置IP地址: R4与其他所有直连设备间使用公有 【2】R3---R5/6/7为MGRE环境,R3为中心站点 【3】整个OSPF环境IP地址为172.16.0.0/16 【4】所有设备…...

安卓4G核心板开发板_MTK6785/MT6785(Helio G95)安卓手机主板方案
联发科MTK6785(Helio G95)安卓核心板采用八核 CPU 具有两个强大的 Arm Cortex-A76 处理器内核,主频高达 2.05GHz,外加六个 Cortex-A55 高效处理器。其强大的图形性能由 Arm Mali-G76 MC4 提供,速度可提升至 900MHz 。 …...
Linux 匿名页的生命周期
目录 匿名页的生成 匿名页生成时的状态 do_anonymous_page缺页中断源码 从匿名页加入Inactive lru引出 一个非常重要内核patch 匿名页何时回收 本文以Linux5.9源码讲述 匿名页的生成 用户空间malloc/mmap(非映射文件时)来分配内存,在内核空间发生…...
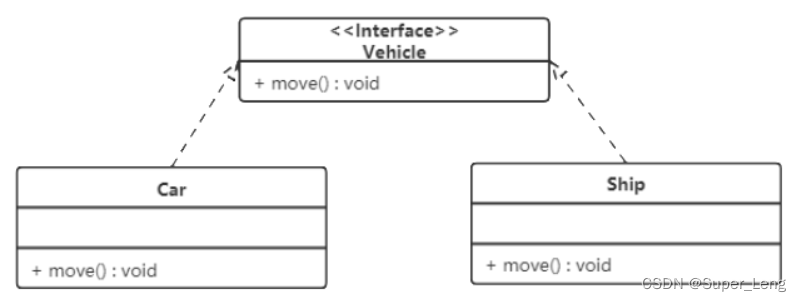
设计模式概述与UML图
文章目录 一、设计模式概述1. 软件设计模式的产生背景2. 软件设计模式的概念3. 学习设计模式的必要性4. 设计模式分类(1)创建型模式(2)结构型模式(3)行为型模式 二、UML图1. 类图概述2. 类图作用3. 类图表示…...
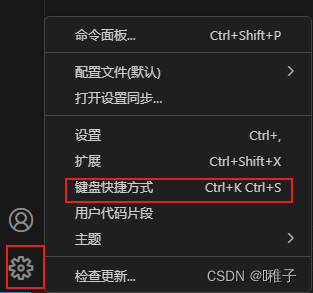
使用Vscode编辑keil工程
一、需要安装的插件 1. Keil Assistant 2. C/C 3. 中文配置: 二、插件配置 1. Keil Assistant 添加Keil的安装路径 接下来就可以使用vscode编辑Keil的工程了,调试编译和下载程序需要返回到Keil中进行操作。 三、Vscode常用快捷键 可以自定义进行配置…...

编译工具:CMake(一) | 简介与安装
编译工具:CMake(一) | 简介与安装 1. CMake简介1.1CMake的特点 2. CMake 安装 这个是CMake的图标 1. CMake简介 cmake 是 kitware 公司以及一些开源开发者在开发几个工具套件(VTK)的过程中衍生品,最终形成体系,成为一…...
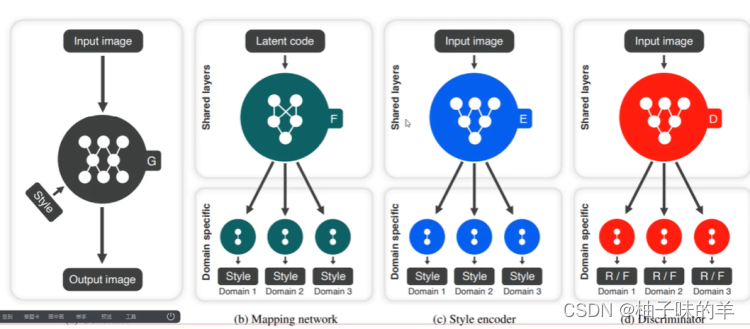
深度学习(34)—— StarGAN(1)
深度学习(34)—— StarGAN(1) 文章目录 深度学习(34)—— StarGAN(1)1. 背景2. 基本思路3. 整体流程4. StarGAN v2(1) 网络结构(2) mapping network(3) style encoder(4)Loss 和之前…...
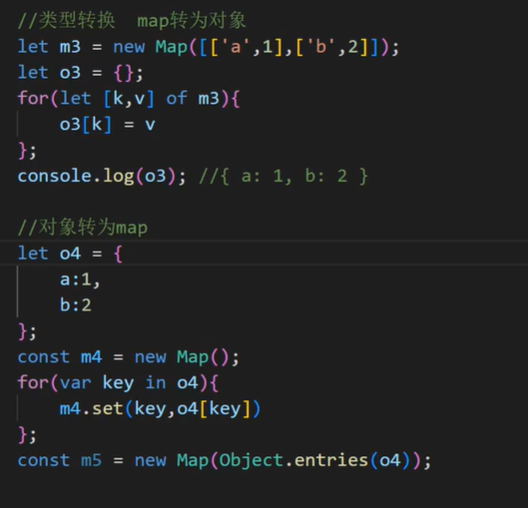
ES6系列之let、const、箭头函数使用的坑
变量提升块级作用域的重要性箭头函数this的指向rest参数和arguments 1.ECMAScript与Js的关系 2.Babel转码器 Babel是一个广泛使用的ES6转码器,可以将ES6代码转为ES5代码,从而在老版本的浏览器执行。这意味着,你可以用ES6的方式编写程序&…...
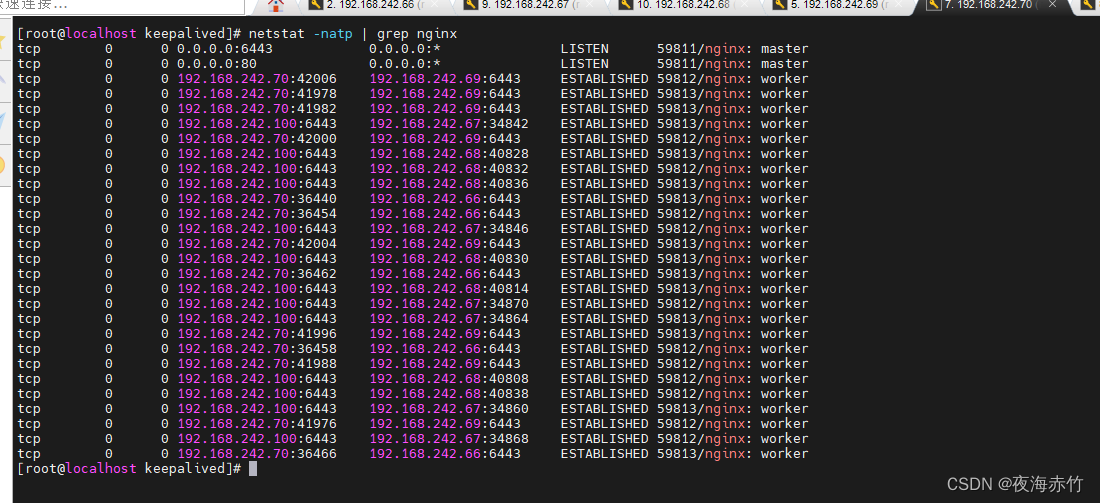
4.DNS和负载均衡
文章目录 coreDNS概念部署croeDNS测试 kubernetes多master集群结构master节点部署 负载均衡配置部署nginx做四层反向代理安装高可用 keepalivednginx监控脚本修改k8s中组件的配置文件 coreDNS 概念 coreDNS是kubernetes的默认DNS实现。可以为集群中的service资源创建一个资源名…...

【JavaEE进阶】Spring核心与设计思想
文章目录 一. Spring框架概述1. 什么是Spring框架2. 为什么要学习框架?3. Spring框架学习的难点 二. Spring 核心与设计思想1. 什么是容器?2. 什么是IoC?3. Spring是IoC容器4. DI(依赖注入)5. DL(依赖查找) 一. Spring框架概述…...

实习周记第三周
第二周总结 第二周主要是做了一些PC端细节内容。大的地方改的不多,但是小的细节蛮多。 值得一提的是,第二周做的微信小程序,改了很多逻辑。改逻辑需要与后端进行联调,收获很大,思路也愈发清楚。 记录做了什么是好习…...
11. 使用tomcat中碰到的一些问题
文章目录 问题一:Tomcat的startup.bat启动后出现乱码问题二:一闪而退之端口占用问题三:非端口问题的一闪而退问题四:服务器的乱码和跨域问题问题五: 在tomcat\webapps\下创建文件夹为什么tomcat重启就会丢失问题六:Tom…...

C++解决TCP粘包
目录 TCP粘包问题TCP客户端TCP服务端源码测试 TCP粘包问题 TCP是面向连接的,面向流的可靠性传输。TCP会将多个间隔较小且数据量小的数据,合并成一个大的数据块,然后进行封包发送,这样一个数据包里就可能含有多个消息的数据&#…...

最长快乐前缀——力扣1392
文章目录 题目描述KMP题目描述 KMP class Solution {public:string longestPrefix(string s) {int n = s...

抖音图片怎么去水印?2026年在线去水印工具+方法盘点,总有一款适合你
开篇:为什么要去水印? 保存抖音图片时,总会遇到水印的困扰。这些水印包含抖音logo、发布者名称,有时还会有账号信息。对于自媒体创作者、内容整理者或普通用户来说,去除水印往往是必需的。本文将介绍当下最实用的抖音图…...

3DS游戏格式转换实战指南:5步完成CCI到CIA的高效转换
3DS游戏格式转换实战指南:5步完成CCI到CIA的高效转换 【免费下载链接】3dsconv Python script to convert Nintendo 3DS CCI (".cci", ".3ds") files to the CIA format 项目地址: https://gitcode.com/gh_mirrors/3d/3dsconv 作为一名3…...

多智能体的协作成本:沟通开销、上下文膨胀与优化手段
多智能体的协作成本:沟通开销、上下文膨胀与优化手段 1. 标题 (Title) 多智能体系统的协作困境:解析沟通开销与上下文膨胀 从理论到实践:优化多智能体协作成本的完整指南 协作的代价:多智能体系统中的沟通、上下文与优化策略 打破协作壁垒:如何有效降低多智能体系统的运行…...

AI Agent架构深度解析:从核心原理到工程实践
1. 项目概述:一次关于AI Agent的深度技术探险最近在GitHub上看到一个名为“tvytlx/ai-agent-deep-dive”的项目,光看标题就让人眼前一亮。这显然不是一个简单的“Hello World”式教程,而是一次对AI Agent(智能体)技术的…...

AI量化交易实战:从机器学习模型到加密货币对冲基金系统构建
1. 项目概述:一个面向加密货币的AI对冲基金框架最近几年,AI在量化交易领域的应用已经从实验室走向了实战,尤其是在波动性极高的加密货币市场。如果你对量化交易和机器学习感兴趣,并且想找一个能直接上手、结构清晰的实战项目来学习…...

Excalidraw草图AI技能:从图形解析到自动化代码生成实战
1. 项目概述:一个能“读懂”你草图的AI技能如果你经常用Excalidraw画流程图、架构图或者UI草图,那你一定遇到过这样的场景:画完一张图,想把它整理成文档,或者想基于这张图生成一些代码,又或者想让它自己动起…...

Linux磁盘挂载与开机自启配置
Linux磁盘挂载与开机自启配置磁盘挂载是 Linux 存储管理中的基础操作。很多线上问题都与挂载配置有关,例如重启后数据盘没挂上、路径指向错误分区、应用因挂载点缺失而启动失败。中级阶段不仅要会临时挂载,更要理解永久挂载的配置方式和风险控制。一、先…...

G-Helper终极指南:3分钟让你的华硕笔记本性能翻倍!
G-Helper终极指南:3分钟让你的华硕笔记本性能翻倍! 【免费下载链接】g-helper Lightweight Armoury Crate alternative for Asus laptops with nearly the same functionality. Works with ROG Zephyrus, Flow, TUF, Strix, Scar, ProArt, Vivobook, Zen…...

企业信息采集神器:10分钟掌握天眼查企查查双平台爬虫
企业信息采集神器:10分钟掌握天眼查&企查查双平台爬虫 【免费下载链接】company-crawler 天眼查爬虫&企查查爬虫,指定关键字爬取公司信息 项目地址: https://gitcode.com/gh_mirrors/co/company-crawler 还在为获取企业信息而烦恼吗&…...

NRF52832串口DFU保姆级教程:不用nRFgo Studio,手把手教你用nrfutil命令行搞定固件合并与升级
NRF52832串口DFU全流程实战:从密钥管理到自动化升级脚本 在嵌入式开发中,固件升级能力已成为现代IoT设备的核心需求。NRF52832作为Nordic Semiconductor的明星BLE SoC,其串口DFU功能为设备维护提供了可靠的有线升级方案。与依赖nRFgo Studio等…...