SpringBoot整合Sfl4j+logback的实践
一、概述
对于一个web项目来说,日志框架是必不可少的,日志的记录可以帮助我们在开发以及维护过程中快速的定位错误。slf4j,log4j,logback,JDK Logging等这些日志框架都是我们常见的日志框架,本文主要介绍这些常见的日志框架关系和SpringBoot整合Sfl4j+logback的实践。
二、日志系统介绍
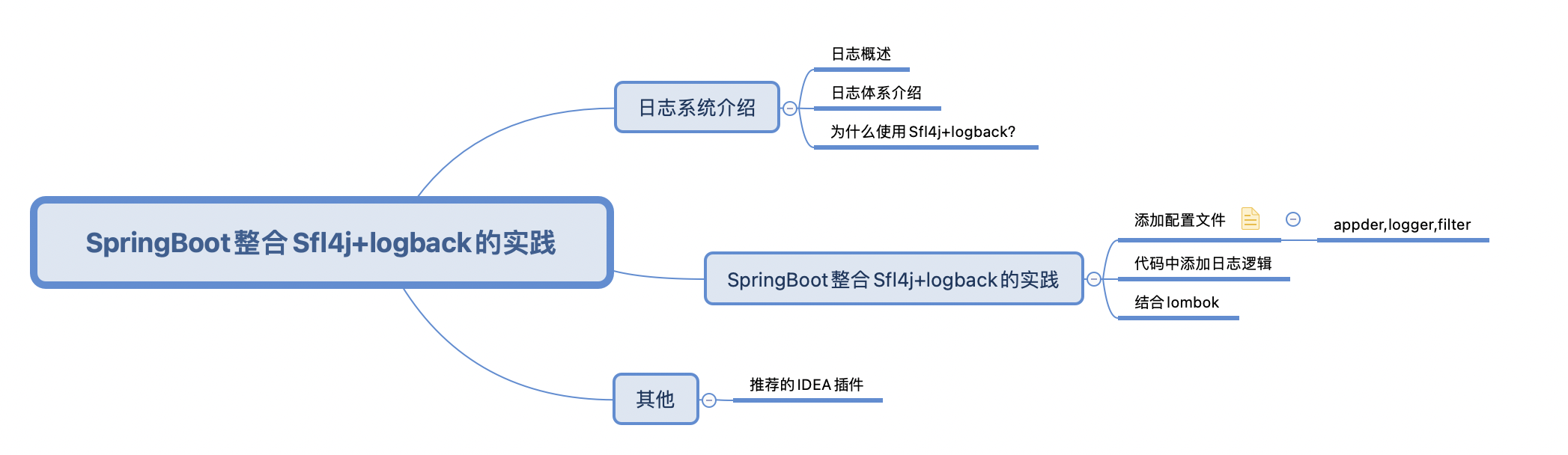
1.日志系统介绍
首先slf4j可以理解为规则的制定者,是一个抽象层,定义了日志相关的接口。log4j,logback,JDK Logging都是slf4j的实现层,只是出处不同,当然使用起来也就各有千秋。
2.为什么使用Sfl4j+logback?
slf4j+logback是这些组合中最常见的日志搭配。总结起来起核心的优势有:(1)使用slf4j+logback的性能更高;(2)slf4j和logback框架的作者是同一个,所以兼容性更好。
三、SpringBoot整合Sfl4j+logback的实践
网上很多教程说明配置Sfl4j+logback时,都会要求引入logback-classic等依赖,这在使用Spring框架的时候确实是必须的,但在使用Springboot框架是没必须的,因为在spring-boot-starter中已经整合了Sfl4j+logback日志系统。
<dependency> <groupId>ch.qos.logback</groupId><artifactId>logback-classic</artifactId><version>1.2.3</version>
</dependency>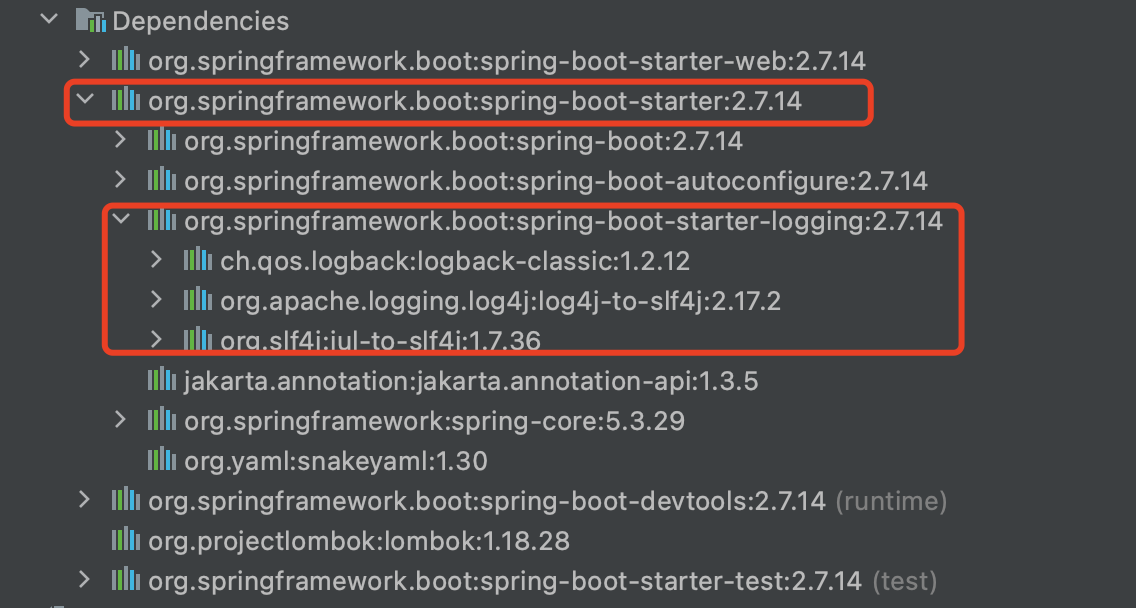
1.添加logback-spring.xml配置文件
以下是一个logback-spring.xm的常见配置,我们以以下这个模板来说明其中配置项的含义。
<?xml version="1.0" encoding="UTF-8"?>
<!-- 一般根节点不需要写属性了,使用默认的就好 -->
<configuration><contextName>demo</contextName><!-- 该变量代表日志文件存放的目录名 --><property name="log.dir" value="logs"/><!-- 该变量代表日志文件名 --><property name="log.appname" value="eran"/><!--定义一个将日志输出到控制台的appender,名称为STDOUT --><appender name="STDOUT" class="ch.qos.logback.core.ConsoleAppender"><!-- 内容待定 --></appender><!--定义一个将日志输出到文件的appender,名称为FILE_LOG --><appender name="FILE_LOG" class="ch.qos.logback.core.FileAppender"><!-- 内容待定 --></appender><!-- 指定com.demo包下的日志打印级别为INFO,但是由于没有引用appender,所以该logger不会打印日志信息,日志信息向上传递 --><logger name="com.demo" level="INFO"/><!-- 指定最基础的日志输出级别为DEBUG,并且绑定了名为STDOUT的appender,表示将日志信息输出到控制台 --><root level="debug"><appender-ref ref="STDOUT" /></root>
</configuration>1. 标签
定义日志策略的节点,一个日志策略对应一个<appender>,一个配置文件中可以有零个或者多该节点,但一个配置文件如果没有定义至少一个<appender>,虽然程序不会报错,但就不会有任何的日志信息输出,也失去了意义。该节点有两个必要的属性:
- name:指定该节点的名称,方便之后的引用。
- class:指定该节点的全限定名,所谓的全限定名就是定义该节点为哪种类型的日志策略,比如我们需要将日志输出到控制台,就需要指定class的值为ch.qos.logback.core.ConsoleAppender;需要将日志输出到文件,则class的值为ch.qos.logback.core.FileAppender等。
2. 标签
用来设置某个包或者类的日志打印级别,并且可以引用 绑定日志策略,在该节点内可以添加子节点 <appender-ref>,该节点有一个必填的属性 ref,值为我们定义的 <appender>节点的 name属性的值。该节点有三个属性:
- name:用来指定受此 约束的包或者类。
- level:可选属性,用来指定日志的输出级别,如果不设置,那么当前 会继承上级的级别。
- additivity:是否向上级传递输出信息,两个可选值true or false,默认为true。
3. 标签
- 根
<logger>一个特殊的<logger>,即默认name属性为root的<logger>,因为是根<logger>,所以不存在向上传递一说,故没有additivity属性,所以该节点只有一个level属性。
常见的
<pattern>[Eran]%date [%thread %line] %level >> %msg >> %logger{10}%n</pattern>异步写入日志AsyncAppender。AsyncAppender并不处理日志,只是将日志缓冲到一个BlockingQueue里面去,并在内部创建一个工作线程从队列头部获取日志,之后将获取的日志循环记录到附加的其他appender上去,从而达到不阻塞主线程的效果。因此AsynAppender仅仅充当事件转发器,必须引用另一个appender来写日志。常见的配置如下:
<appender name ="ASYNC" class= "ch.qos.logback.classic.AsyncAppender"> <!-- 不丢失日志.默认的,如果队列的80%已满,则会丢弃TRACT、DEBUG、INFO级别的日志 --> <discardingThreshold >0</discardingThreshold> <!-- 更改默认的队列的深度,该值会影响性能.默认值为256 --> <queueSize>512</queueSize> <!-- 添加附加的appender,最多只能添加一个 --> <appender-ref ref ="FILE_LOG"/>
</appender>2.代码中添加日志逻辑
添加好logback-spring.xml配置文件后,就可以在代码中添加日志逻辑,添加也很简单,只需要通过log.info()这样的方式来实现。
import lombok.extern.slf4j.Slf4j;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RestController;@RestController
@Slf4j
public class TestController01 {@RequestMapping("/hello")public String index() {log.debug("hello world0.");log.info("hello world.");log.warn("hello world1.");log.error("hello world2.");return "Hello World.";}}Slf4j有四个级别的log level可供选择,级别从上到下由低到高,优先级高的将被打印出来。
- debug:简单来说,对程序调试有利的信息都可以debug输出
- info:对用户有用的信息
- warn:可能会导致错误的信息
- error:顾名思义,发生错误的地方
为了简化创建logger对象的逻辑,可以直接使用lombok的@Slf4j的注解,只需要在pom文件中引入以下依赖:
<dependency><groupId>org.projectlombok</groupId><artifactId>lombok</artifactId><version>1.18.10</version><scope>provided</scope>
</dependency>具体代码实现和配置文件:https://github.com/yangnk/SpringBoot_Learning/tree/master/SpringbootLogDemo
四、其他
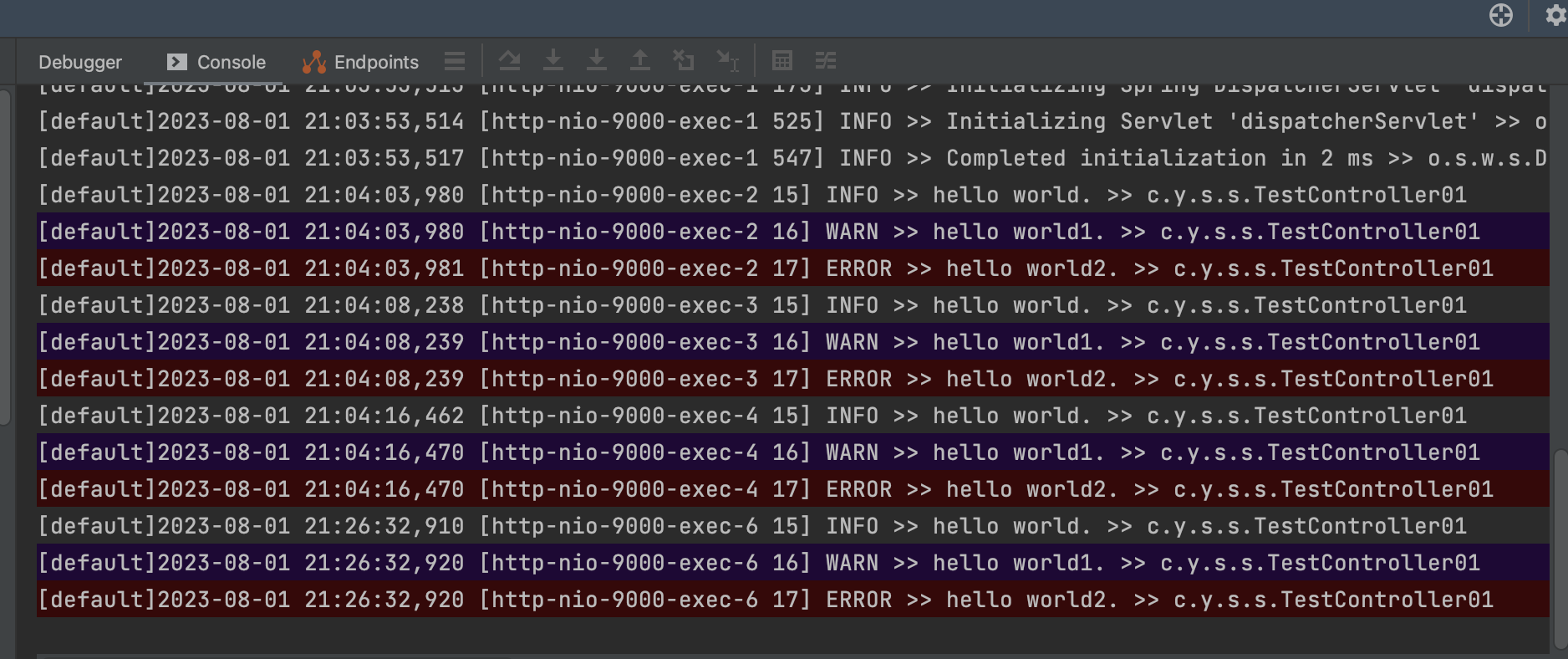
推荐一个IDEA中日志查看插件:Grep Console。这是一个帮你分析控制台日志的插件,可以对不同级别的日志进行不同颜色的高亮显示,具体效果如下:
参考资料
- slf4j官网:https://www.slf4j.org/manual.html
- 一步一步带你熟悉SpringBoot 配置slf4j+logback:https://blog.csdn.net/weixin_49307478/article/details/126836019
- SpringBoot整合logback,slf4j:https://blog.csdn.net/weixin_42259925/article/details/103954982
本文由博客一文多发平台 OpenWrite 发布!
相关文章:
SpringBoot整合Sfl4j+logback的实践
一、概述 对于一个web项目来说,日志框架是必不可少的,日志的记录可以帮助我们在开发以及维护过程中快速的定位错误。slf4j,log4j,logback,JDK Logging等这些日志框架都是我们常见的日志框架,本文主要介绍这些常见的日志框架关系和SpringBoot…...

IT 基础架构自动化
什么是 IT 基础架构自动化 IT 基础架构自动化是通过使用技术来控制和管理构成 IT 基础架构的软件、硬件、存储和其他网络组件来减少人为干预的过程,目标是构建高效、可靠的 IT 环境。 为什么要自动化 IT 基础架构 为客户和员工提供无缝的数字体验已成为企业的当务…...
Docker入门——保姆级
Docker概述 —— Notes from WAX through KuangShen 准确来说,这是一篇学习笔记!!! Docker为什么出现 一款产品:开发—上线 两套环境!应用环境如何铜鼓? 开发 – 运维。避免“在我的电脑…...

MONGODB ---- Austindatabases 历年文章合集
开头还是介绍一下群,如果感兴趣polardb ,mongodb ,mysql ,postgresql ,redis 等有问题,有需求都可以加群群内有各大数据库行业大咖,CTO,可以解决你的问题。加群请联系 liuaustin3 ,在新加的朋友会分到2群(共…...
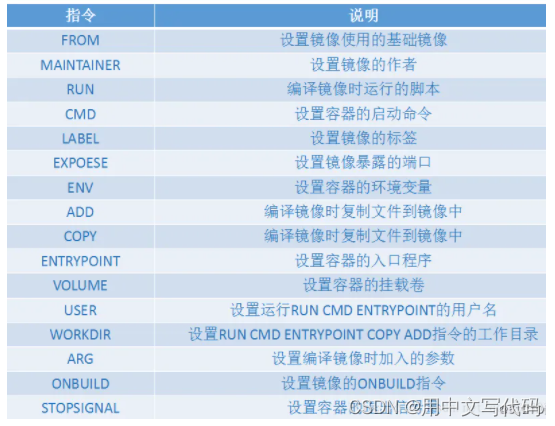
菠萝头 pinia和vuex对比 pinia比vuex更香 Pinia数据持久化及数据加密
前言 毕竟尤大佬都推荐使用pinia,支持vue2和vue3! 如果熟悉vuex,花个把小时把pinia看一下,就不想用vuex了 支持选项式api和组合式api写法pinia没有mutations,只有:state、getters、actionspinia分模块不…...

机器学习笔记 - 关于GPT-4的一些问题清单
一、简述 据报道,GPT-4 的系统由八个模型组成,每个模型都有 2200 亿个参数。GPT-4 的参数总数估计约为 1.76 万亿个。 近年来,得益于 GPT-4 等高级语言模型的发展,自然语言处理(NLP) 取得了长足的进步。凭借其前所未有的规模和能力,GPT-4为语言 AI设立了新标准,并为机…...

sql 参数自动替换
需求:看日志时,有的sql 非常的长,参数比较多,无法直接在sql 客户端工具执行,如果一个一个的把问号占位符替换为参数太麻烦,因此写个html 小工具,批量替换: 代码: <!…...
Linux——设备树
目录 一、Linux 设备树的由来 二、Linux设备树的目的 1.平台识别 2.实时配置 3.设备植入 三、Linux 设备树的使用 1.基本数据格式 2.设备树实例解析 四、使用设备树的LED 驱动 五、习题 一、Linux 设备树的由来 在 Linux 内核源码的ARM 体系结构引入设备树之前&#x…...
网络:从socket编程的角度说明UDP和TCP的关系,http和tcp的区别
尝试从编程的角度解释各种网络协议。 UDP和TCP的关系 从Python的socket编程角度出发,UDP(User Datagram Protocol)和TCP(Transmission Control Protocol)是两种不同的传输协议。 TCP是一种面向连接的协议,…...
大数据技术之Hadoop:HDFS集群安装篇(三)
目录 分布式文件系统HDFS安装篇 一、为什么海量数据需要分布式存储 二、 分布式的基础架构分析 三、 HDFS的基础架构 四 HDFS集群环境部署 4.1 下载安装包 4.2 集群规划 4.3 上传解压 4.4 配置HDFS集群 4.5 准备数据目录 4.6 分发hadoop到其他服务器 4.7 配置环境变…...

移动开发最佳实践:为 Android 和 iOS 构建成功应用的策略
您可以将本文作为指南,确保您的应用程序符合可行的最重要标准。请注意,这份清单远非详尽无遗;您可以加以利用,并添加一些自己的见解。 了解您的目标受众 要制作一个成功的应用程序,你需要了解你是为谁制作的。从创建…...
)
2023年第二届网络安全国际会议(CSW 2023)
会议简介 Brief Introduction 2023年第二届网络安全国际会议(CSW 2023) 会议时间:2023年10月13日-15日 召开地点:中国杭州 大会官网:www.cybersecurityworkshop.org 2023年第二届网络安全国际会议(CSW 2023)由杭州电子科技大学,国…...
【100天精通python】Day23:正则表达式,基本语法与re模块详解示例
目录 专栏导读 1 正则表达式概述 2 正则表达式语法 2.1 正则表达式语法元素 2.2 正则表达式的分组操作 3 re 模块详解与示例 4 正则表达式修饰符 专栏导读 专栏订阅地址:https://blog.csdn.net/qq_35831906/category_12375510.html 1 正则表达式概述 python 的…...
C++ 派生类成员的标识与访问——作用域分辨符
在派生类中,成员可以按访问属性分为以下四种: (1)不可访问成员。这是从基类私有成员继承下来的,派生类或是建立派生类对象的模块都无法访问到它们,如果从派生类继续派生新类,也是无法访问的。 &…...

SQL注入实操三(SQLilabs Less41-65)
文章目录 一、sqli-labs靶场1.轮子模式总结2.Less-41 stacked Query Intiger type blinda.注入点判断b.轮子测试c.获取数据库名称d.堆叠注入e.堆叠注入外带注入获取表名f.堆叠注入外带注入获取列名g.堆叠注入外带注入获取表内数据 3.Less-42 Stacked Query error baseda.注入点…...
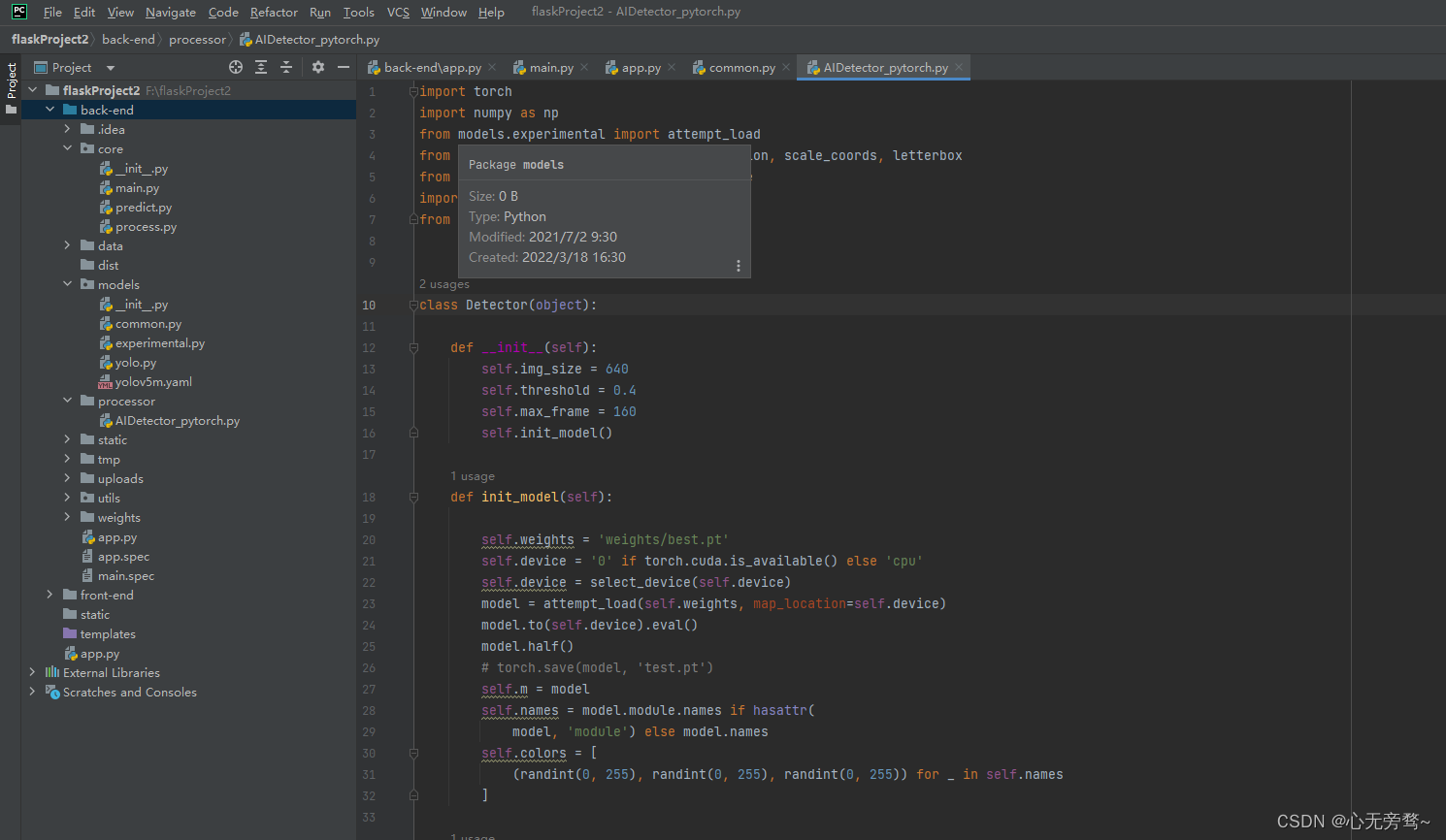
(亲测解决)PyCharm 从目录下导包提示 unresolved reference(完整图解)
最近在进行一个Flask项目的过程中遇到了unresolved reference 包名的问题,在网上找了好久解决方案,并没有一个能让我一步到位解决问题的。 后来,我对该问题和网上的解决方案进行了分析,发现网上大多数都是针对项目同一目录下的py…...
【AI量化模型】跑通baseline
跑通baseline 任务学习内容特征工程模型训练与验证 bug未纠错的结果 任务 教程部署在百度 AI Studio,可以一键fork运行代码,选择*v100 32g1*的配置,baseline运行大约20分钟,再加上进阶部分大约40分钟 学习内容 特征工程 构建基…...
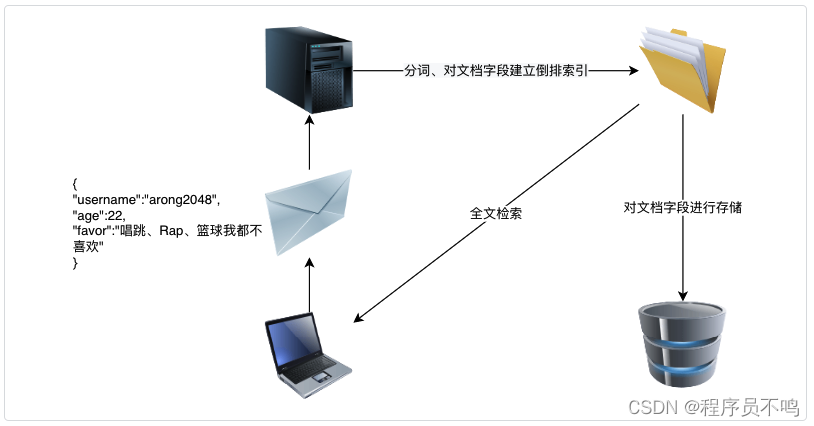
ElasticSearch:全文检索及倒排索引原理
1.从全文检索说起 首先介绍一下结构化与非结构化数据: 结构化数据将数据具有的特征事先以结构化的形式定义好,数据有固定的格式或有限的长度。典型的结构化数据就是传统关系型数据库的表结构,数据特征直接体现在表结构的字段上,…...

blk_mq_alloc_tag_set函数struct blk_mq_tag_set结构体学习
struct blk_mq_tag_set结构体 include/linux/blk-mq.h struct blk_mq_tag_set {unsigned int *mq_map;const struct blk_mq_ops *ops;unsigned int nr_hw_queues;unsigned int queue_depth; /* max hw supported */unsigned int reserved_tags;unsigned int cmd_size; /…...
Windows搭建Snort环境及使用方式
目录 0x01 前置环境0x02修改配置文件0x03 自测0x04 使用0x05 感言 0x01 前置环境 环境描述windows10snort2.9.2https://www.snort.org/downloads 先把上面环境下载好! 需要注意的是安装npcap这个软件 0x02修改配置文件 软件安装目录:C:/Snort/ 配置文…...

淘宝淘金币自动化脚本:3步解放你的双手,每天多赚30分钟自由时间
淘宝淘金币自动化脚本:3步解放你的双手,每天多赚30分钟自由时间 【免费下载链接】taojinbi 淘宝淘金币自动执行脚本,包含蚂蚁森林收取能量,芭芭农场全任务,解放你的双手 项目地址: https://gitcode.com/gh_mirrors/t…...

HarmonyOS ,你所不知道的事件发布/订阅的通信机制-EventEmitter
在鸿蒙(HarmonyOS)开发中,EventEmitter 是一种用于事件发布/订阅的通信机制,常用于组件、Ability、线程或模块之间的解耦通信。它允许一个对象(发布者)发出事件,而其他对象(订阅者&a…...

PostHog完整指南:5分钟搭建开源产品分析平台,免费监控用户行为
PostHog完整指南:5分钟搭建开源产品分析平台,免费监控用户行为 【免费下载链接】posthog.com Official docs, website, and handbook for PostHog. 项目地址: https://gitcode.com/GitHub_Trending/po/posthog.com PostHog是一款功能强大的开源产…...

ChatGPT-web-midjourney-proxy 项目常见问题解决方案
ChatGPT-web-midjourney-proxy 项目常见问题解决方案 1. 项目基础介绍和主要编程语言 ChatGPT-web-midjourney-proxy 是一个开源项目,它基于 ChatGPT 和 Midjourney-proxy 技术构建,提供了丰富的文生图、图生文、文生视频等功能。该项目支持自定义 API k…...

GLSL优化器核心优化技术详解:函数内联、死代码消除与常量传播
GLSL优化器核心优化技术详解:函数内联、死代码消除与常量传播 【免费下载链接】glsl-optimizer GLSL optimizer based on Mesas GLSL compiler. Used to be used in Unity for mobile shader optimization. 项目地址: https://gitcode.com/gh_mirrors/gl/glsl-opt…...

中兴B863AV3.2-M刷机避坑指南:S905L3A芯片识别、固件选择与Amlogic USB Burning Tool 2.2.0配置详解
中兴B863AV3.2-M刷机全流程精解:从芯片识别到固件烧录的进阶实践 在智能电视盒的玩家圈子里,中兴B863AV3.2-M因其出色的硬件配置和可玩性备受关注。这款搭载Amlogic S905L3A芯片的设备,通过刷机可以解锁更多功能,但过程中暗藏的&q…...

抖音批量下载终极指南:如何用开源工具高效采集视频素材
抖音批量下载终极指南:如何用开源工具高效采集视频素材 【免费下载链接】douyin-downloader A practical Douyin downloader for both single-item and profile batch downloads, with progress display, retries, SQLite deduplication, and browser fallback supp…...

IC617保姆级教程:用ADEXL和Calculator两步搞定CMOS晶体管的gmid设计曲线
IC617高效设计指南:ADEXL与Calculator协同生成CMOS晶体管gmid曲线的实战解析 在模拟集成电路设计中,gmid曲线作为评估晶体管工作状态的核心工具,直接影响着放大器的增益、噪声和功耗等关键指标。传统方法往往需要反复切换多个工具界面&#x…...

微信单向好友检测:3分钟找出谁悄悄删了你
微信单向好友检测:3分钟找出谁悄悄删了你 【免费下载链接】WechatRealFriends 微信好友关系一键检测,基于微信ipad协议,看看有没有朋友偷偷删掉或者拉黑你 项目地址: https://gitcode.com/gh_mirrors/we/WechatRealFriends 你是否曾经…...

别再死记硬背了!用Wireshark抓包带你搞懂PPPoE的Discovery、Session、Terminate三阶段
用Wireshark透视PPPoE全流程:从Discovery到Session的实战诊断手册 当你面对一台华为路由器,PPPoE拨号配置看似完美却频繁出现认证超时,或是NAT转换后外网访问时断时续,传统的命令行检查往往只能告诉你"哪里出错"&#x…...