【100天精通python】Day23:正则表达式,基本语法与re模块详解示例
目录
专栏导读
1 正则表达式概述
2 正则表达式语法
2.1 正则表达式语法元素
2.2 正则表达式的分组操作
3 re 模块详解与示例
4 正则表达式修饰符
专栏导读

专栏订阅地址:https://blog.csdn.net/qq_35831906/category_12375510.html

1 正则表达式概述
python 的正则表达式是什么,有哪些内容,有什么功能,怎么用?
Python的正则表达式是一种用于处理字符串的强大工具,由re模块提供支持。正则表达式允许你根据特定模式来匹配、搜索、替换和提取文本数据。
正则表达式的基本组成包括:
- 字面字符:普通的字符,例如'a'、'b'等,它们直接匹配相应的字符。
- 元字符:具有特殊含义的字符,例如'.'匹配任意字符、'\d'匹配数字等。
- 限定符:用于指定模式的匹配次数,例如'*'匹配0次或多次、'+'匹配1次或多次等。
- 字符类:用于匹配一组字符中的任意一个字符,例如'[abc]'匹配'a'、'b'或'c'。
- 排除字符:在字符类中使用'^'来排除指定的字符。
- 转义字符:用于匹配特殊字符本身,例如使用'.'匹配实际的点号。
正则表达式在文本处理中有很多功能:
- 模式匹配:查找字符串中是否包含特定的模式。
- 文本搜索:在字符串中搜索匹配模式的第一个出现。
- 查找所有:查找字符串中所有匹配模式的出现,并返回所有匹配结果的列表。
- 分割:根据模式将字符串分割成多个部分。
- 替换:将匹配模式的部分替换为指定的字符串。
以下是一个简单的使用正则表达式的示例:
import repattern = r'\d+' # 匹配一个或多个数字
text = "There are 123 apples and 456 oranges."# 搜索
search_result = re.search(pattern, text)
if search_result:print("Found:", search_result.group())# 查找所有
findall_result = re.findall(pattern, text)
print(findall_result) # Output: ['123', '456']
上述代码中,
re.search()函数搜索第一个匹配的数字,而re.findall()函数查找字符串中所有匹配的数字。使用正则表达式时,应当确保模式能够正确匹配目标文本,同时注意处理可能出现的异常情况。熟练掌握正则表达式,可以在文本处理中实现高效和灵活的匹配、搜索和替换操作
2 正则表达式语法
2.1 正则表达式语法元素
行定位符、元字符、限定符、字符类、排除字符、选择字符和转义字符是正则表达式的基本组成部分,它们用于描述和匹配字符串的模式。
行定位符:
"^":匹配字符串的开头。"$":匹配字符串的结尾。元字符:
".":匹配任意字符(除了换行符)。"\d":匹配任意数字字符,等同于[0-9]。"\D":匹配任意非数字字符,等同于[^0-9]。"\w":匹配任意字母、数字或下划线字符,等同于[a-zA-Z0-9_]。"\W":匹配任意非字母、数字或下划线字符,等同于[^a-zA-Z0-9_]。"\s":匹配任意空白字符,包括空格、制表符、换行符等。"\S":匹配任意非空白字符。限定符:
"*":匹配前一个字符零次或多次。"+":匹配前一个字符一次或多次。"?":匹配前一个字符零次或一次。"{n}":匹配前一个字符恰好n次。"{n,}":匹配前一个字符至少n次。"{n, m}":匹配前一个字符至少n次,但不超过m次。字符类:
"[...]":匹配方括号内的任意一个字符。"[^...]":匹配除方括号内的字符之外的任意一个字符。排除字符:
"^":在字符类内使用,表示排除指定字符。选择字符:
"|":逻辑或,匹配两个模式之一。转义字符:
"\":用于转义特殊字符,使其失去特殊含义,例如\.匹配实际的点号这些元字符和特殊符号组合形成了正则表达式的模式,使得正则表达式可以描述非常复杂的字符串匹配规则。要使用正则表达式,你可以使用Python的
re模块提供的函数进行匹配、搜索、替换等操作。熟悉这些基本元素有助于编写更加强大和灵活的正则表达式。
示例:
import re# 行定位符
pattern1 = r'^Hello' # 匹配以"Hello"开头的字符串
print(re.match(pattern1, "Hello, World!")) # Output: <re.Match object; span=(0, 5), match='Hello'>pattern2 = r'World$' # 匹配以"World"结尾的字符串
print(re.search(pattern2, "Hello, World!")) # Output: <re.Match object; span=(7, 12), match='World'># 元字符
pattern3 = r'a.c' # 匹配"a"、任意字符、"c"
print(re.search(pattern3, "abc")) # Output: <re.Match object; span=(0, 3), match='abc'>
print(re.search(pattern3, "adc")) # Output: <re.Match object; span=(0, 3), match='adc'>
print(re.search(pattern3, "a,c")) # Output: <re.Match object; span=(0, 3), match='a,c'>pattern4 = r'ab*' # 匹配"a"、"b"出现0次或多次
print(re.search(pattern4, "abbb")) # Output: <re.Match object; span=(0, 1), match='a'>
print(re.search(pattern4, "ac")) # Output: <re.Match object; span=(0, 0), match=''>pattern5 = r'ab+' # 匹配"a"、"b"出现1次或多次
print(re.search(pattern5, "abbb")) # Output: <re.Match object; span=(0, 4), match='abbb'>
print(re.search(pattern5, "ac")) # Output: Nonepattern6 = r'ab?' # 匹配"a"、"b"出现0次或1次
print(re.search(pattern6, "abbb")) # Output: <re.Match object; span=(0, 1), match='a'>
print(re.search(pattern6, "ac")) # Output: <re.Match object; span=(0, 0), match=''># 限定符
pattern7 = r'a{3}' # 匹配"a"出现3次
print(re.search(pattern7, "aaa")) # Output: <re.Match object; span=(0, 3), match='aaa'>
print(re.search(pattern7, "aaaa")) # Output: <re.Match object; span=(0, 3), match='aaa'>
print(re.search(pattern7, "aa")) # Output: Nonepattern8 = r'a{3,5}' # 匹配"a"出现3次到5次
print(re.search(pattern8, "aaa")) # Output: <re.Match object; span=(0, 3), match='aaa'>
print(re.search(pattern8, "aaaaa")) # Output: <re.Match object; span=(0, 5), match='aaaaa'>
print(re.search(pattern8, "aaaaaa")) # Output: <re.Match object; span=(0, 5), match='aaaaa'># 字符类和排除字符
pattern9 = r'[aeiou]' # 匹配任意一个小写元音字母
print(re.search(pattern9, "apple")) # Output: <re.Match object; span=(0, 1), match='a'>
print(re.search(pattern9, "banana")) # Output: <re.Match object; span=(1, 2), match='a'>
print(re.search(pattern9, "xyz")) # Output: Nonepattern10 = r'[^0-9]' # 匹配任意一个非数字字符
print(re.search(pattern10, "hello")) # Output: <re.Match object; span=(0, 1), match='h'>
print(re.search(pattern10, "123")) # Output: None# 转义字符
pattern11 = r'\.' # 匹配句号
print(re.search(pattern11, "www.example.com")) # Output: <re.Match object; span=(3, 4), match='.'># 分组
pattern12 = r'(ab)+' # 匹配"ab"出现1次或多次作为一个整体
print(re.search(pattern12, "ababab")) # Output: <re.Match object; span=(0, 6), match='ababab'>
输出结果显示了匹配的子字符串的起始位置和结束位置,以及匹配的实际字符串内容。
常用元字符
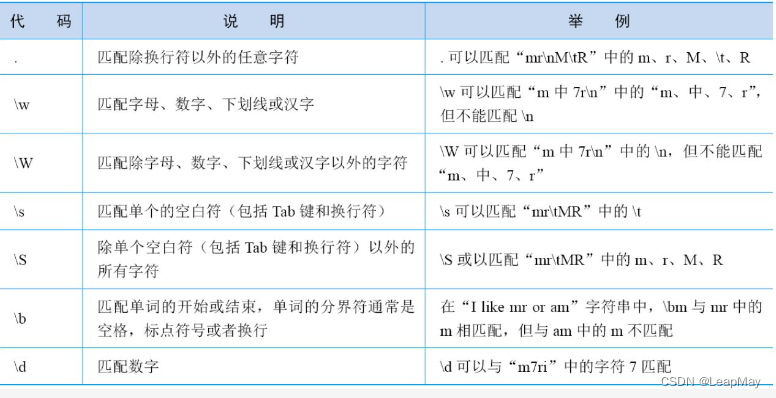
常用限定符
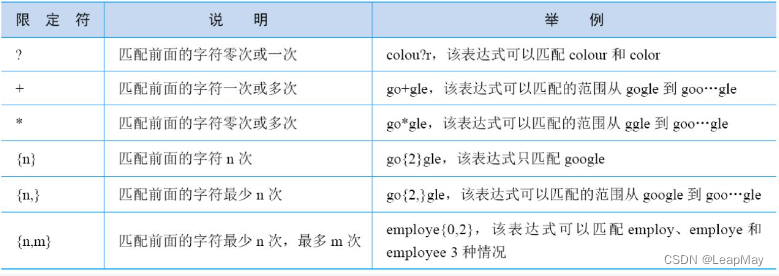
2.2 正则表达式的分组操作
在正则表达式中,分组是一种将多个子模式组合在一起并对其进行单独处理的机制。通过使用括号()来创建分组,可以实现更复杂的匹配和提取操作。
分组的作用包括:
-
优先级控制:可以使用分组来改变子模式的优先级,确保正确的匹配顺序。
-
子模式重用:可以对某个子模式进行命名,并在后续的正则表达式中引用这个名称,实现对同一模式的重用。
-
子模式提取:可以通过分组来提取匹配的子串,方便对其中的内容进行进一步处理。
示例:
import retext = "John has 3 cats and Mary has 2 dogs."# 使用分组提取匹配的数字和动物名称
pattern = r'(\d+)\s+(\w+)' # 使用括号创建两个分组:一个用于匹配数字,另一个用于匹配动物名称
matches = re.findall(pattern, text) # 查找所有匹配的结果并返回一个列表for match in matches:count, animal = match # 将匹配结果拆分为两个部分:数字和动物名称print(f"{count} {animal}")# 使用命名分组
pattern_with_name = r'(?P<Count>\d+)\s+(?P<Animal>\w+)' # 使用命名分组,给子模式指定名称Count和Animal
matches_with_name = re.findall(pattern_with_name, text) # 查找所有匹配的结果并返回一个列表for match in matches_with_name:count = match['Count'] # 通过名称获取匹配结果中的数字部分animal = match['Animal'] # 通过名称获取匹配结果中的动物名称部分print(f"{count} {animal}")
以上代码演示了如何使用分组提取正则表达式中匹配的子串。第一个正则表达式使用了普通分组,通过括号将数字和动物名称分别提取出来。第二个正则表达式使用了命名分组,通过
(?P<Name>...)的语法形式给子模式指定了名称,从而在匹配结果中可以通过名称获取对应的子串。这样可以使代码更具可读性,方便后续对匹配结果的处理和使用。
上述代码报错如下
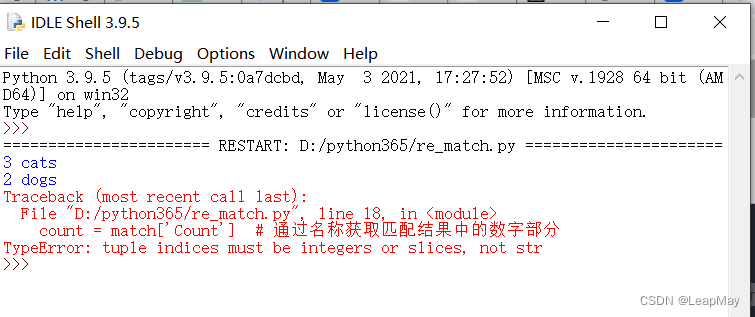
"TypeError: tuple indices must be integers or slices, not str" 这个错误意味着在代码中尝试使用字符串作为元组的索引,但元组的索引只能是整数或切片。
当使用元组的时候,需要用整数或切片来获取元组中的元素,如:
my_tuple[0]或my_tuple[1:3],这些是合法的索引方式。但如果你尝试使用字符串来索引元组中的元素,比如:my_tuple['key'],这就是不合法的,因为元组并没有与字符串索引相关联的键值对。
更正:用 re.finditer()替代第二个 re.findall(),用match.group()获取匹配结果中的内容。
更正后代码:
import retext = "John has 3 cats and Mary has 2 dogs."# 使用分组提取匹配的数字和动物名称
pattern = r'(\d+)\s+(\w+)' # 使用括号创建两个分组:一个用于匹配数字,另一个用于匹配动物名称
matches = re.findall(pattern, text) # 查找所有匹配的结果并返回一个列表for match in matches:count, animal = match # 将匹配结果拆分为两个部分:数字和动物名称print(f"{count} {animal}")# 使用命名分组
pattern_with_name = r'(?P<Count>\d+)\s+(?P<Animal>\w+)' # 使用命名分组,给子模式指定名称Count和Animal
matches_with_name = re.finditer(pattern_with_name, text) # 使用re.finditer()查找所有匹配的结果for match in matches_with_name:count = match.group('Count') # 通过名称获取匹配结果中的数字部分animal = match.group('Animal') # 通过名称获取匹配结果中的动物名称部分print(f"{count} {animal}")注:
re.findall()和re.finditer()都是Python中用于正则表达式匹配的函数,它们的区别在于返回的结果类型不同。
re.findall(pattern, string):findall函数会返回所有与正则表达式pattern匹配的结果,并将它们以列表的形式返回。每个匹配结果将作为一个字符串元素存储在列表中。如果正则表达式中有分组,findall只会返回分组中的内容而不返回完整的匹配结果。
re.finditer(pattern, string):finditer函数也会返回所有与正则表达式pattern匹配的结果,但不同于findall,finditer返回的是一个迭代器。每个迭代器对象代表一个匹配结果,可以通过迭代器的group()方法来获取匹配结果中的内容。如果正则表达式中有分组,可以使用group()方法来访问各个分组的内容。总结起来,
re.findall()返回一个列表,而re.finditer()返回一个迭代器。如果需要处理多个匹配结果,使用finditer更加灵活和高效,因为它不会一次性返回所有匹配结果,而是在需要时按需提供。
3 re 模块详解与示例
re模块是Python中用于处理正则表达式的内置模块,提供了一系列函数来进行字符串匹配、搜索、替换和分割等操作。以下是re模块的主要函数:
re.compile(pattern, flags=0): 编译正则表达式模式,返回一个正则表达式对象。如果要多次使用相同的正则表达式,可以使用这个函数预编译,提高性能。
re.match(pattern, string, flags=0): 尝试从字符串的开头开始匹配模式,如果匹配成功,则返回匹配对象;否则返回None。
re.search(pattern, string, flags=0): 在整个字符串中搜索匹配模式的第一个出现,如果匹配成功,则返回匹配对象;否则返回None。
re.findall(pattern, string, flags=0): 查找字符串中所有匹配模式的出现,返回所有匹配结果的列表。
re.finditer(pattern, string, flags=0): 查找字符串中所有匹配模式的出现,返回一个迭代器,可以通过迭代器获取匹配对象。
re.split(pattern, string, maxsplit=0, flags=0): 根据模式将字符串分割成多个部分,并返回一个列表。
re.sub(pattern, replacement, string, count=0, flags=0): 将匹配模式的部分替换为指定的字符串,并返回替换后的字符串。
在上述函数中,pattern是正则表达式的模式,string是要进行匹配或处理的字符串,flags是可选参数,用于指定正则表达式的修饰符。其中,flags参数可以使用多个修饰符进行组合,例如使用re.IGNORECASE | re.MULTILINE来指定忽略大小写和多行匹配。
以下示例展示了re模块中各种函数的使用,并涵盖了匹配、搜索、替换、分割、命名分组等功能:
import retext = "John has 3 cats, Mary has 2 dogs."# 使用re.search()搜索匹配模式的第一个出现
pattern_search = r'\d+\s+\w+'
search_result = re.search(pattern_search, text)
if search_result:print("Search result:", search_result.group()) # Output: "3 cats"# 使用re.findall()查找所有匹配模式的出现,并返回一个列表
pattern_findall = r'\d+'
findall_result = re.findall(pattern_findall, text)
print("Find all result:", findall_result) # Output: ['3', '2']# 使用re.sub()将匹配模式的部分替换为指定的字符串
pattern_sub = r'\d+'
replacement = "X"
sub_result = re.sub(pattern_sub, replacement, text)
print("Sub result:", sub_result) # Output: "John has X cats, Mary has X dogs."# 使用re.split()根据模式将字符串分割成多个部分
pattern_split = r'\s*,\s*' # 匹配逗号并去除前后空格
split_result = re.split(pattern_split, text)
print("Split result:", split_result) # Output: ['John has 3 cats', 'Mary has 2 dogs.']# 使用命名分组
pattern_named_group = r'(?P<Name>\w+)\s+has\s+(?P<Count>\d+)\s+(?P<Animal>\w+)'
matches_with_name = re.finditer(pattern_named_group, text)
for match in matches_with_name:name = match.group('Name')count = match.group('Count')animal = match.group('Animal')print(f"{name} has {count} {animal}")# 使用re.compile()预编译正则表达式
pattern_compile = re.compile(r'\d+')
matches_compiled = pattern_compile.findall(text)
print("Compiled findall result:", matches_compiled) # Output: ['3', '2']
上述示例展示了使用
re模块进行正则表达式的匹配、搜索、替换、分割和命名分组的功能。注释说明了每个步骤的作用和预期输出,通过合理使用正则表达式,可以快速实现对字符串的复杂处理需求。
4 正则表达式修饰符
在Python的正则表达式中,修饰符(也称为标志或模式标志)是一些可选参数,它们可以在编译正则表达式时传递给re.compile()函数或直接在正则表达式字符串中使用,用于改变匹配的行为。
以下是常用的正则表达式修饰符:
re.IGNORECASE或re.I: 忽略大小写匹配。使用该修饰符后,可以在匹配时忽略大小写的差异。
re.MULTILINE或re.M: 多行匹配。使用该修饰符后,^和$分别匹配字符串的开头和结尾,还可以匹配字符串中每一行的开头和结尾(每行以换行符分隔)。
re.DOTALL或re.S: 单行匹配。使用该修饰符后,.将匹配包括换行符在内的任意字符。
re.ASCII或re.A: 使非ASCII字符只匹配其对应的ASCII字符。例如,\w将只匹配ASCII字母、数字和下划线,而不匹配非ASCII字符。
re.UNICODE或re.U: 使用Unicode匹配。在Python 3中,默认情况下正则表达式使用Unicode匹配。
re.VERBOSE或re.X: 使用“可读性更好”的正则表达式。可以在表达式中添加注释和空格,这样可以使正则表达式更易读。
在Python中,正则表达式修饰符(也称为标志)是可选的参数,用于调整正则表达式的匹配行为。修饰符可以在正则表达式模式的末尾添加,以影响模式的匹配方式。以下是常用的正则表达式修饰符:
下面通过示例来演示这些修饰符的用法:
import re# 不区分大小写匹配
pattern1 = r'apple'
text1 = "Apple is a fruit."
match1 = re.search(pattern1, text1, re.I)
print(match1.group()) # Output: "Apple"# 多行匹配
pattern2 = r'^fruit'
text2 = "Fruit is sweet.\nFruit is healthy."
match2 = re.search(pattern2, text2, re.M)
print(match2.group()) # Output: "Fruit"# 点号匹配所有字符
pattern3 = r'apple.*orange'
text3 = "apple is a fruit.\noranges are fruits."
match3 = re.search(pattern3, text3, re.S)
print(match3.group()) # Output: "apple is a fruit.\noranges"# 忽略空白和注释
pattern4 = r'''apple # This is a fruit\s+ # Match one or more whitespace charactersis # followed by "is"\s+ # Match one or more whitespace charactersa # followed by "a"\s+ # Match one or more whitespace charactersfruit # followed by "fruit"'''
text4 = "Apple is a fruit."
match4 = re.search(pattern4, text4, re.X)
print(match4.group()) # Output: "apple is a fruit"
相关文章:
【100天精通python】Day23:正则表达式,基本语法与re模块详解示例
目录 专栏导读 1 正则表达式概述 2 正则表达式语法 2.1 正则表达式语法元素 2.2 正则表达式的分组操作 3 re 模块详解与示例 4 正则表达式修饰符 专栏导读 专栏订阅地址:https://blog.csdn.net/qq_35831906/category_12375510.html 1 正则表达式概述 python 的…...
C++ 派生类成员的标识与访问——作用域分辨符
在派生类中,成员可以按访问属性分为以下四种: (1)不可访问成员。这是从基类私有成员继承下来的,派生类或是建立派生类对象的模块都无法访问到它们,如果从派生类继续派生新类,也是无法访问的。 &…...

SQL注入实操三(SQLilabs Less41-65)
文章目录 一、sqli-labs靶场1.轮子模式总结2.Less-41 stacked Query Intiger type blinda.注入点判断b.轮子测试c.获取数据库名称d.堆叠注入e.堆叠注入外带注入获取表名f.堆叠注入外带注入获取列名g.堆叠注入外带注入获取表内数据 3.Less-42 Stacked Query error baseda.注入点…...
(亲测解决)PyCharm 从目录下导包提示 unresolved reference(完整图解)
最近在进行一个Flask项目的过程中遇到了unresolved reference 包名的问题,在网上找了好久解决方案,并没有一个能让我一步到位解决问题的。 后来,我对该问题和网上的解决方案进行了分析,发现网上大多数都是针对项目同一目录下的py…...
【AI量化模型】跑通baseline
跑通baseline 任务学习内容特征工程模型训练与验证 bug未纠错的结果 任务 教程部署在百度 AI Studio,可以一键fork运行代码,选择*v100 32g1*的配置,baseline运行大约20分钟,再加上进阶部分大约40分钟 学习内容 特征工程 构建基…...
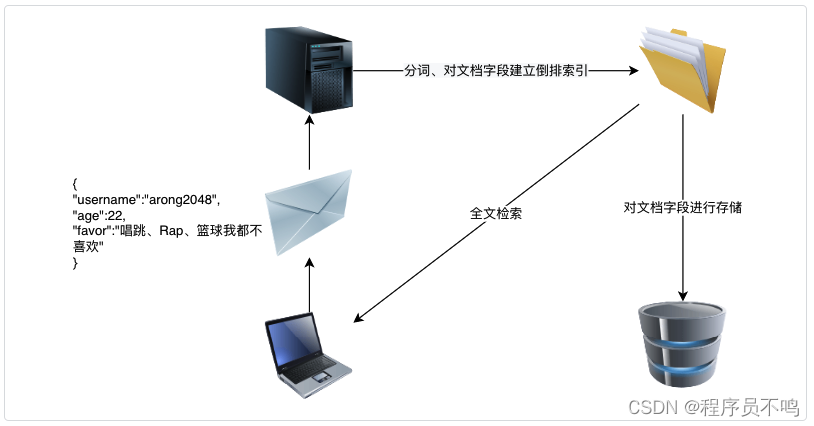
ElasticSearch:全文检索及倒排索引原理
1.从全文检索说起 首先介绍一下结构化与非结构化数据: 结构化数据将数据具有的特征事先以结构化的形式定义好,数据有固定的格式或有限的长度。典型的结构化数据就是传统关系型数据库的表结构,数据特征直接体现在表结构的字段上,…...

blk_mq_alloc_tag_set函数struct blk_mq_tag_set结构体学习
struct blk_mq_tag_set结构体 include/linux/blk-mq.h struct blk_mq_tag_set {unsigned int *mq_map;const struct blk_mq_ops *ops;unsigned int nr_hw_queues;unsigned int queue_depth; /* max hw supported */unsigned int reserved_tags;unsigned int cmd_size; /…...
Windows搭建Snort环境及使用方式
目录 0x01 前置环境0x02修改配置文件0x03 自测0x04 使用0x05 感言 0x01 前置环境 环境描述windows10snort2.9.2https://www.snort.org/downloads 先把上面环境下载好! 需要注意的是安装npcap这个软件 0x02修改配置文件 软件安装目录:C:/Snort/ 配置文…...
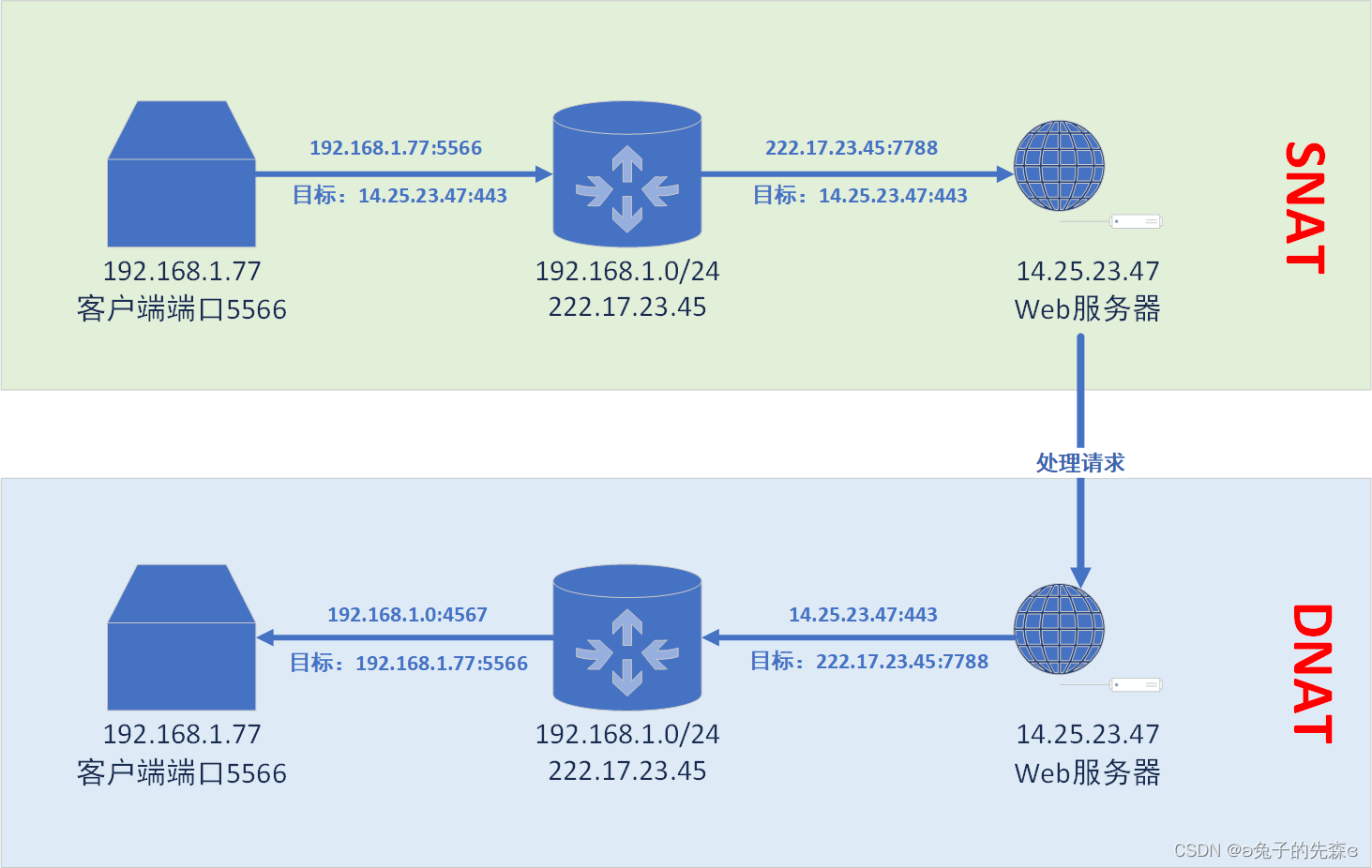
Android network — iptables四表五链
Android network — iptables四表五链 1. iptables简介2. iptables的四表五链2.1 iptables流程图2.2 四表2.3 五链2.4 iptables的常见情况 3. NAT工作原理3.1 BNAT3.2 NAPT 4. iptables配置 本文主要介绍了iptables的基本工作原理和四表五链等基本概念以及NAT的工作原理。 1. i…...
【C++从0到王者】第十六站:stack和queue的使用
文章目录 一、stack的使用1.stack的介绍2.stack的使用 二、queue的使用1.queue的护额晒2.queue的使用 三、stack和queue相关算法题1.最小栈2.栈的压入、弹出序列3.逆波兰表达式4.两个栈实现一个队列5.用两个队列实现栈6.二叉树的层序遍历1.双队列2.用一个变量levelSize去控制 7…...

centos7 部署Tomcat和jpress应用
目录 一、静态、动态、伪静态 二、Web 1.0 和 Web 2.0 三、centos7 部署Tomcat 3.1 安装、配置jdk 3.2 安装 Tomcat 3.3 配置服务启动脚本 3.3.1 创建用户和组 3.3.2 创建tomcat.conf文件 3.3.3 创建服务脚本(tomcat.service) 3.3.4 重新加载守护进程并且测试 四、部…...

Unity Shader:常用的C#与shader交互的方法
俗话说久病成医,虽然不是专业技术美术,但代码写久了自然会积累一些常用的shader交互方法。零零散散的,总结如下: 1,改变UGUI的材质球属性 有时候我们需要改变ui的一些属性,从而实现想要的效果。通常UGUI上…...

luajit 使用 clang编译的坑
为了尝试将LuaJIT接入虚幻Lua插件之中,需要预编译LuaJIT链接库,在桌面平台问题不大, 主要是移动平台,涉及跨平台编译,因为对跨平台编译具体细节没有系统研究,这里先记录一下跨平台编译LuaJIT的主要过程 由于官方提供的…...

[SWPUCTF 2021 新生赛]Do_you_know_http
打开环境,根据题目提示,应该是考察http相关的东西 打开环境提示说请使用wLLm浏览器访问 那我们更改浏览器信息,在burp重发器中发包后发现是302重定向,但是提示说success成功,说明 我们修改是成功的,既然是…...

web前端之CSS
文章目录 一、CSS简介1.1 CSS语法规则 二、CSS的引用方法2.1 定义行内样式表2.2定义内部样式表2.3链入外部样式表2.4导入外部样式表 三、CSS选择符3.1 基本选择符3.1.1 标签选择符3.1.2 class类选择符3.1.3 id选择符 3.2 复合选择符3.2.1 交集选择符(合并选择器&…...

HarmonyOS元服务开发实践:桌面卡片字典
一、项目说明 1.DEMO创意为卡片字典。 2.不同卡片显示不同内容:微卡、小卡、中卡、大卡,根据不同卡片特征显示同一个字的不同内容,基于用户习惯可选择喜欢的卡片。 3.万能卡片刷新:用户点击卡片刷新按钮查看新内容,同时…...
xLua学习
xLua教程:https://github.com/Tencent/xLua/blob/master/Assets/XLua/Doc/XLua%E6%95%99%E7%A8%8B.md xLua配置:https://github.com/Tencent/xLua/blob/master/Assets/XLua/Doc/configure.md FAQ:https://github.com/Tencent/xLua/blob/maste…...

Web3到底是个啥?
Web3到底是个啥? Web3是近两年来科技领域最火热的概念之一,但是目前对于Web3的定义却仍然没有形成标准答案,相当多对于Web3的理解,都是建立在虚拟货币行业(即俗称的“币圈”)的逻辑基础之上的。 区块链服务…...
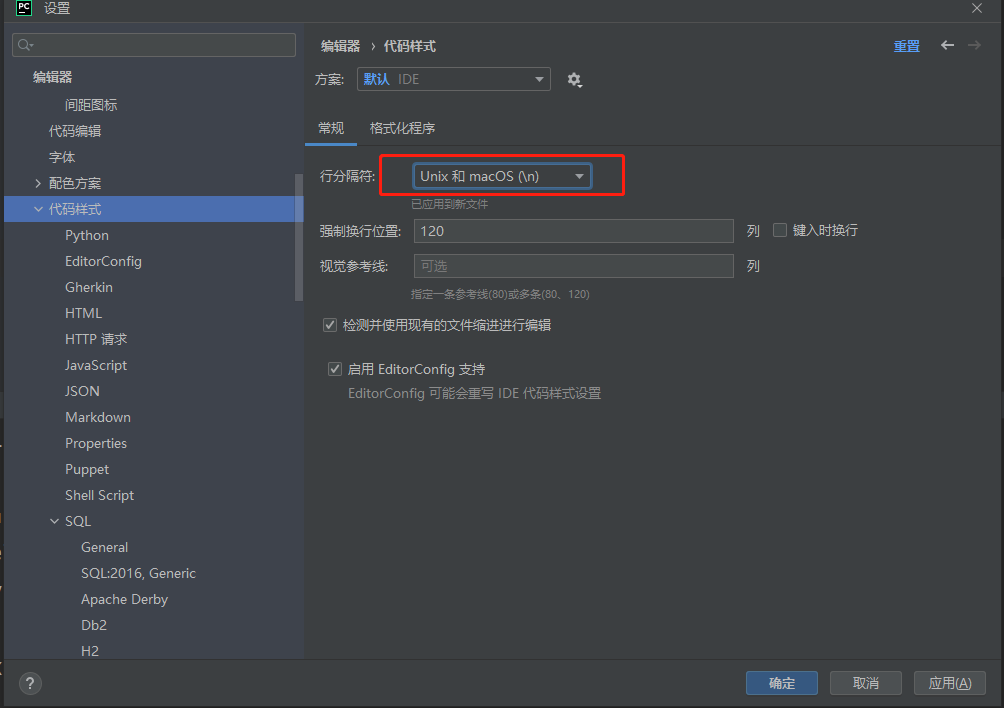
pycharm、idea、golang等JetBrains其他IDE修改行分隔符(换行符)
文章目录 pycharm、idea、golang系列修改行分隔符我应该选择什么换行符JetBrains IDE,默认行分隔符 是跟随系统修改JetBrains IDE,默认行分隔符 pycharm、idea、golang系列修改行分隔符 一般来说,不同的开发环境和项目对换行格式的使用偏好不同: Windo…...

ThinkPHP函数深度解析
ThinkPHP是一个具有丰富功能和强大灵活性的PHP开发框架。在这篇文章中,我们将详细介绍ThinkPHP的一些关键函数,以帮助开发人员更好地理解和使用这个框架。 1. 入门:ThinkPHP的核心函数 1.1 C()函数 C()函数用于读取和设置配置参数。它是Thin…...

如何将普通桌面实时转换为3D立体视频?nunif iw3-desktop完全指南
如何将普通桌面实时转换为3D立体视频?nunif iw3-desktop完全指南 【免费下载链接】nunif Misc; latest version of waifu2x; 2D video to stereo 3D video conversion 项目地址: https://gitcode.com/gh_mirrors/nu/nunif 你是否曾想过在VR头显中观看你的电脑…...

Word文档保护技巧:防止内容被轻易复制
Word文档如何防止复制呢?其实,Word根本没有真正意义上的禁止复制,因为用户按一下手机截图,或者拍张照片,内容照样能拿走。但是,我们可以提高复制门槛,也就是让其他用户通过“CtrlC”无法直接复制…...

美国签证预约机器人:3分钟掌握24小时智能抢号终极方案
美国签证预约机器人:3分钟掌握24小时智能抢号终极方案 【免费下载链接】us-visa-bot US Visa Bot 项目地址: https://gitcode.com/gh_mirrors/us/us-visa-bot 还在为美国签证面试预约的漫长等待而烦恼吗?面对有限的面试名额和激烈的竞争环境&…...

LeetCode 15:三数之和 | 双指针法详解与进阶应用
LeetCode 15:三数之和 | 双指针法详解与进阶应用 引言 三数之和(3Sum)是 LeetCode 中一道经典的高频面试题,编号为 15,属于 Medium 难度范畴。这道题的核心要求是在一个整数数组中找出所有不重复的三元组,使…...

2026网盘横评:国民级云盘领衔,这几款备选也值得一看
前言作为长期接触AI资源、代码项目、大文件存储的从业者,日常高频使用各类网盘。很多朋友都会纠结主流网盘该如何选择,不同产品的存储能力、传输表现、功能适配差距明显。本文摒弃夸张测评,以客观分享的视角,从传输、存储、功能、…...

如何10倍提升英语学习效率:词达人自动化助手终极教程
如何10倍提升英语学习效率:词达人自动化助手终极教程 【免费下载链接】cdr 微信词达人,高正确率,高效简洁。支持班级任务及自选任务 项目地址: https://gitcode.com/gh_mirrors/cd/cdr 核心关键词:词达人自动化助手、Pytho…...

LLM 认知框架:揭秘时间序列与空间结构,洞悉 AI 未来!
一、简明摘要 本文是一篇概念说明与方法论文章,核心问题是:LLM 到底是什么,它与 AI、AGI、Agent、Skill 有什么关系。全文先区分 AI、AGI、LLM 三个层级,再说明 LLM 的现实形态已经从“文本生成模型”扩展为“模型、上下文、外部知…...

8.C# —— 随机数、DateTime时间、字符串
一、C# 随机数(伪随机 安全随机)1. 核心概念计算机中没有真正的随机数,生成的都是伪随机数(通过算法 种子计算得出)。种子相同 → 生成的随机数序列完全相同不指定种子 → 默认使用系统当前时间作为种子,…...

日薪2700的护网HW面试,以及HW全面熟悉必看流程
前言 参与hvv的事情还是要想办法规避掉很多坑的。网络安全这个行业现阶段还是主要政策驱动,后面应该是客户意识,现在用户教育成本明显比以前低太多。 1.关于HVV的一个简单流程 首先我带大家从甲方和厂商的角度来分解一下整个护网流程的核心逻辑 第一阶段…...

Sequin实战教程:构建企业级变更数据捕获管道
Sequin实战教程:构建企业级变更数据捕获管道 【免费下载链接】sequin Postgres change data capture to streams, queues, and search indexes like Kafka, SQS, Elasticsearch, HTTP endpoints, and more 项目地址: https://gitcode.com/gh_mirrors/se/sequin …...