使用一个python脚本抓取大量网站【1/3】
一、说明
二、可以抓取的数据类型
大多数抓取机器人都是为了抓取表格数据或列表而创建的。在标记方面,表和列表本质上是相同的。在容器中,它们保存带有填充值的单元格的行。因此,脚本的算法:
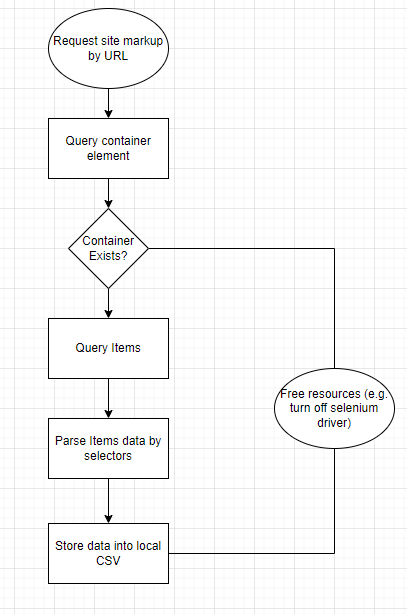
Flowchart of application
三、抓取网站的过程
为了扩展潜在的抓取目标列表,我决定使用python和Selenium的老式组合。虽然我确实喜欢使用 Scrapy 并且在创建自己的解析脚本时受到其可配置设计的高度影响,但它在解析具有分页的站点方面有一定的限制,所以我不得不选择已经提到的解决方案。
为了稳定起见,我还决定使用 dockerized 版本的 chromedriver。在本地Chrome更新期间,它为我节省了一些痛苦,并且始终在那里,为我准备好了,与您在操作系统上安装的版本不同,该版本可能会因系统更新或安装新软件而混乱。
假设您的机器上已经运行了 docker 服务,使用 chromedriver 启动一个新容器就像运行两个命令一样简单:
docker pull selenium/standalone-chrome$ docker run -d -p 4444:4444 -p 7900:7900 — shm-size=”2g” selenium/standalone-chrome
My python script for scraping websites 这篇文章的核心——代码共享段落。首先,我将向您介绍帮助程序方法:
from selenium import webdriver
from selenium.webdriver import Chrome, ChromeOptions
from selenium.webdriver.common.desired_capabilities import DesiredCapabilitiesdef get_local_safe_setup():options = ChromeOptions() options.add_argument("--disable-blink-features")options.add_argument("--disable-blink-features=AutomationControlled")options.add_argument("--disable-infobars")options.add_argument("--disable-popup-blocking")options.add_argument("--disable-notifications")driver = Chrome(desired_capabilities = options.to_capabilities())return driverdef get_safe_setup():options = ChromeOptions() options.add_argument("--disable-dev-shm-usage") options.add_argument("--disable-blink-features")options.add_argument("--disable-blink-features=AutomationControlled")options.add_argument("--disable-infobars")options.add_argument("--disable-popup-blocking")options.add_argument("--disable-notifications")driver = webdriver.Remote("http://127.0.0.1:4444/wd/hub", desired_capabilities = options.to_capabilities())return driver当我需要在开发过程中调试某些内容时,这两个允许我在 Selenium 的 dockerized 版本和本地版本之间切换。
def get_text_by_selector(container, selector):elem = container.find_elements_by_class_name(selector)if len(elem) > 0:return next(iter(elem)).text.replace('\n',' ').strip()else: print(f'Missing value for selector {selector}')return ''还有一种简单的方法可以从我正在使用的HTML元素中提取文本。在不久的将来,我计划添加助手以自动提取链接和图像。如果对这个主题感兴趣,我可以分享脚本的更新版本。
这种硒基蜘蛛的本质在下面的要点中。请通读评论,如果对它的工作原理有任何疑问 - 请在评论中告诉我。
import os
import timefrom tqdm import tqdmimport pandas as pd
import argparsefrom selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as ECfrom tools.helpers import get_text_by_selector
from tools.setups import get_safe_setup
from tools.loaders import load_configclass Spider:def __init__(self, driver, config):self.__driver = driverself.__config = configdef parse(self, url: str) -> pd.DataFrame:"""Scrapes a website from url using predefined config, returns DataFrameparameters:url: stringreturns:pandas Dataframe"""self.__driver.get(url)container_element = WebDriverWait(self.__driver, 5).until(EC.presence_of_element_located((By.CLASS_NAME, self.__config['container_class'])))items = self.__driver.find_elements_by_class_name(self.__config['items_class'])items_content = [[get_text_by_selector(div, selector) for selector in self.__config['data_selectors']]for div in items]return pd.DataFrame(items_content, columns = self.__config['data_column_titles']) def parse_pages(self, url: str):"""Scrapes a website with pagination from url using predefined config, yields list of pandas DataFramesparameters:url: string"""pagination_config = self.__config['pagination'] for i in tqdm(range(1, pagination_config['crawl_pages'] + 1)):yield self.parse(url.replace("$p$", str(i)))time.sleep(int(pagination_config['delay']/1000)) def scrape(args): config = load_config(args.config)pagination_config = config['pagination']url = config['url']driver = get_safe_setup()spider = Spider(driver, config)os.makedirs(os.path.dirname(args.output), exist_ok = True)try:if pagination_config['crawl_pages'] > 0:data = spider.parse_pages(url)df = pd.concat(list(data), axis = 0)else:df = spider.parse(url)df.to_csv(args.output, index = False)except Exception as e:print(f'Parsing failed due to {str(e)}')finally:driver.quit()if __name__ == "__main__":parser = argparse.ArgumentParser()parser.add_argument('-c', '--config', help='Configuration of spider learning')parser.add_argument('-o', '--output', help='Output file path')args = parser.parse_args()scrape(args)四、如何使用脚本抓取网站
在这一部分中,我将演示如何使用此脚本。首先,您需要创建一个 YAML 配置文件,然后运行爬虫。例如,让我们刮擦旧的 quotes.toscrape.com。它的配置示例如下所示:
url: https://quotes.toscrape.com/page/$p$/
container_class: col-md-8
items_class: quote
data_selectors:- text- author- keywords
data_column_titles:- Text- Author- Keywords
pagination:crawl_pages: 5delay: 5000首先,请注意 $p$ 是未来页码的占位符。这是因为大多数网站提供的页面内容在 URL 中发生了明显变化。你的任务是确定它是如何从一个页面到另一个页面的变化,并用这个面具为你的蜘蛛配置它。
请注意,在data_selectors和data_column_titles中,顺序很重要。例如,引号的文本将从选择器“.text”(duh)解析。
准备好配置后,您可以使用以下命令执行它:
python -m spider -c “./configs/quotes.yaml” -o “./outputs/quotes/$(date +%Y-%m-%d).csv” 上面的 Bash 行从“./configs/quotes.yaml”文件中获取配置,并将 CSV 文件中的结果存储到 “./outputs/quotes/current_date.csv”
五、关于如何改进刮削过程的提示
- 使用代理
Selenium 允许您传递代理 IP 地址,就像向其构造函数添加参数一样简单。 在StackOverflow有一个完美的答案,所以我不会尝试发明轮子。
- 对要解析的网站保持温和
检查机器人.txt并遵守。使用特定超时运行请求以平滑负载。使用计划在晚上或您认为站点的传入流量较低时运行脚本。
六、结果
敏捷抓取机器人最好的事情之一是,您不必为要解析的每个站点编写新的机器人。您只需要一个可以针对每个站点或域进行调整的好脚本。回想一下你今年到目前为止的所有抓取项目——你想让我在我的脚本中添加什么?
相关文章:
使用一个python脚本抓取大量网站【1/3】
一、说明 您是否曾经想过抓取网站,但又不想为像Octoparse这样的抓取工具付费?或者,也许您只需要从网站上抓取几页,并且不想经历设置抓取脚本的麻烦。在这篇博文中,我将向您展示我如何创建一个工具,该工具能…...
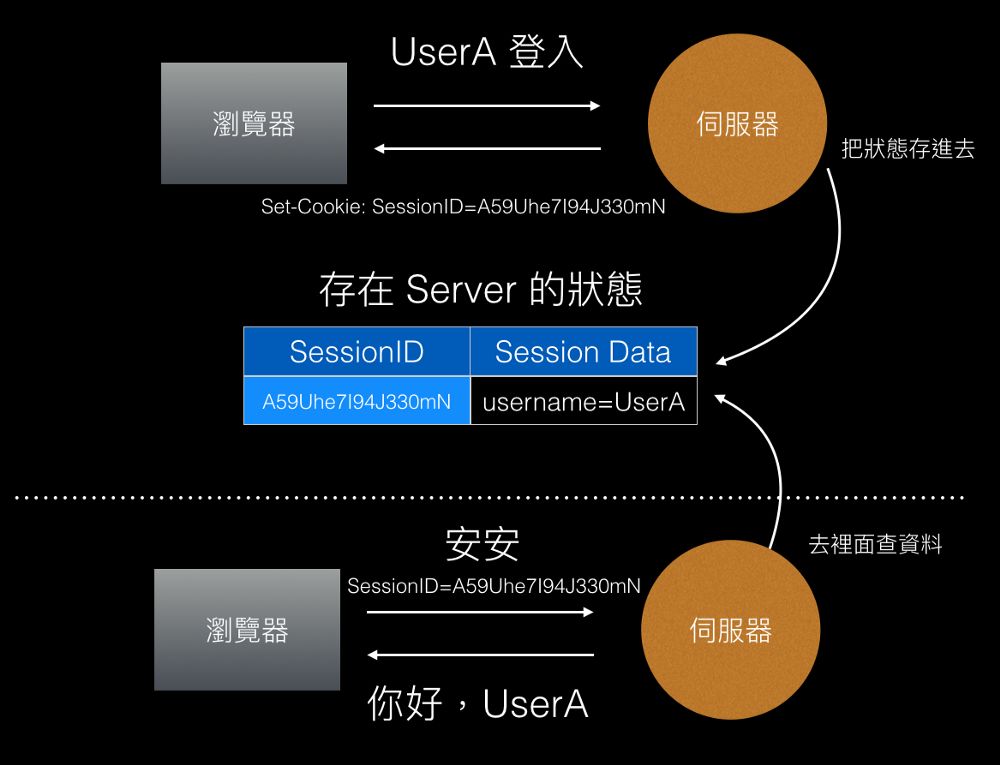
Session与Cookie的区别(五)
储存状态的方式 小明的故事说完了,该来把上面这一段变成网络的实际案例了。其实在网络世界中问题也是一样的。 前面已经提到过我们会把状态存在 Cookie 里面,让 Request 之间能够变得有关联。 假设我们今天要来做一个会员系统,那我要怎么知道…...

【Linux】网络编程套接字
目录 1 预备知识 1.1 IP地址 1.2 端口号 1.3 TCP协议和UDP协议 1.4 网络字节序 2 socket 编程接口 2.0 socket 常见 API 2.1 socket 系统调用 2.2 bind 系统调用 2.3 recvfrom 系统调用 2.4 sendto 系统调用 2.5 listen 系统调用 2.6 accept 系统调用 2.7 con…...

【C++】语法小课堂 --- auto关键字 typeid查看实际类型 范围for循环 空指针nullptr
文章目录 🍟一、auto关键字(C11)🍩1、auto的简介🍩2、auto的使用细则🚩auto与指针和引用结合起来使用🚩 在同一行定义多个变量 🍩3、auto不能推导的场景1️⃣auto不能作为函数的参数…...
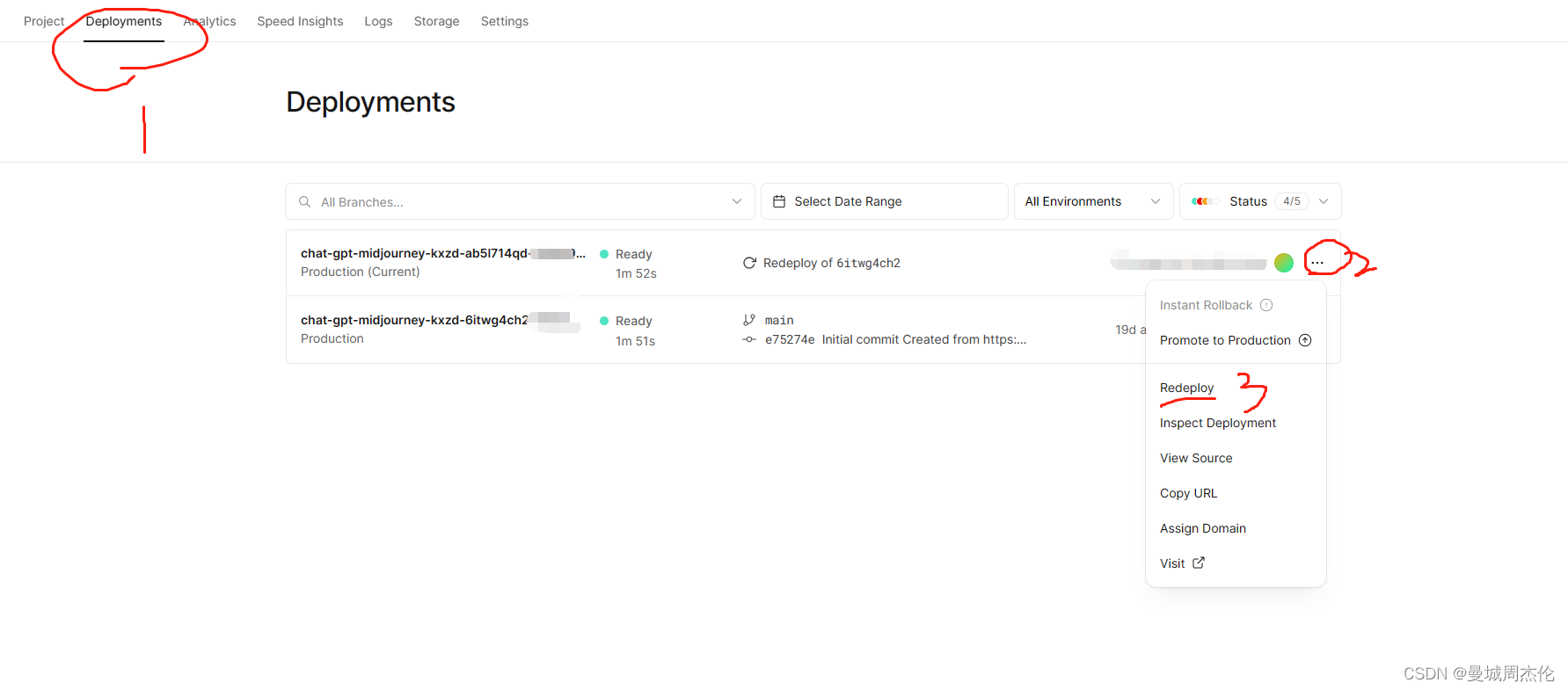
Vercel 部署的项目发现APIkeys过期了怎么办
好不容易部署的Vercel,发现APIkeys过期了显示,查了查资料发现只要更新下新的apikeys,然后再重新部署下就好了。 重新设置APIkeys 1.1. 进去 Vercel 项目内部控制台,点击顶部的 Settings 按钮; 1.2 点击环境变量Enviorn…...
【HMS Core】推送报错907135701、分析数据查看
【关键字】 HMS、推送服务、分析服务 【问题描述1】 集成推送服务,获取Token时报错 907135701: scope list empty 【解决方案】 907135701OpenGW没有配置Scope 1、您可以检查下网络是否有问题,手机是否可以正常连接互联网 2、查看推送服务开关是否正…...

Air32 | 合宙Air001单片机内部FLASH读写示例
Air32 | 合宙Air001单片机内部FLASH读写示例 代码已经通过测试,开发环境KEIL-MDK 5.36。 测试代码 void FLASH_RdWrTest(void) {uint32_t Address;uint32_t PageReadBuffer[FLASH_PAGE_SIZE >> 2];uint32_t PageWriteBuffer[FLASH_PAGE_SIZE >> 2];mem…...

C语言基本语法-第一章
C 语言基本语法 语句 C 语言的代码由一行行语句(statement)组成。语句就是程序执行的一个操作命令。C 语言规定,语句必须使用分号结尾,除非有明确规定可以不写分号。 int x 1;上面就是一个变量声明语句,声明整数变…...

八、Spring 整合 MyBatis
文章目录 一、Spring 整合 MyBatis 的关键点二、Spring 整合 MyBatis 的步骤2.1 创建 Maven 项目,并导入相关依赖2.2 配置 Mybatis 部分2.3 配置 Spring 部分2.3 配置测试类 一、Spring 整合 MyBatis 的关键点 1、 将 Mybatis 的 DataSource (数据来源)的创建和管理…...

Flutter Flar动画实战
在Flare动面出现之前,Flare动画大体可以分为使用AnimationController控制的基础动画以及使用Hero的转场动画,如果遇到一些复杂的场景,使用这些动画方案实现起来还是有难度的。不过,随着Flutter开始支持Flare矢量动面,Flutter的动画开发也变得越来越简单。事实上,Flare动画…...

A stop job is running for xxxxxx
有时候服务器关机时,会有个进程卡在那里,使系统无法关闭 提示: A stop job is running for xxxxxx方法: 设置一个启动/停止的默认超时时间即可 vim /etc/systemd/system.conf DefaultTimeoutStartSec300s DefaultTimeoutStopSe…...

C++入门之stl六大组件--List源码深度剖析及模拟实现
文章目录 前言 一、List源码阅读 二、List常用接口模拟实现 1.定义一个list节点 2.实现一个迭代器 2.2const迭代器 3.定义一个链表,以及实现链表的常用接口 三、List和Vector 总结 前言 本文中出现的模拟实现经过本地vs测试无误,文件已上传gite…...
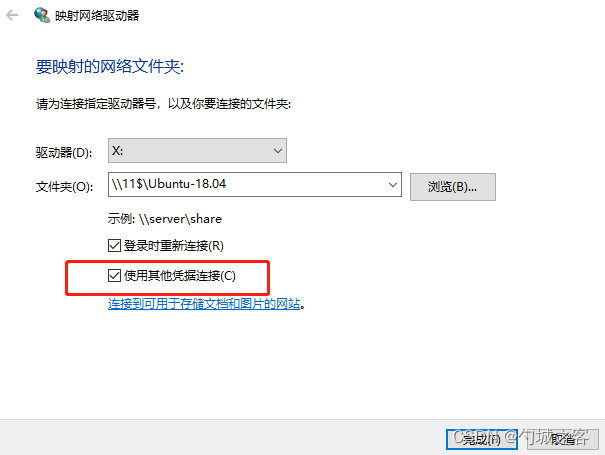
windows下以指定用户访问SMB服务器进行读写
一 概述 最近遇到一个问题,linux 的 smb服务器开启匿名访问,windows访问linux文件夹不需要用户名密码就可以进去使用,但是存在一个问题,ssh连接到linux 后修改的文件,在windows已smb方式下打开某个文件修改 是没有权限…...
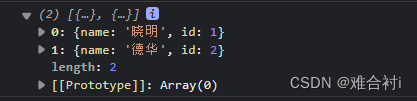
数组根据属性去重
利用reduce函数处理,直接上代码! let data [{name:晓明,id:1},{name:德华,id:2},{name:德华,id:2},{name:晓明,id:1},] var obj {}; let arr data.reduce(function (item, next) {obj[next.id] ? : obj[next.id] true && item.push(next)…...

无损音乐从哪找?五个网站+免费下载,你确定不来看看?
hi,大家好我是技术苟,每天晚上22点准时上线为你带来实用黑科技!由于公众号改版,现在的公众号消息已经不再按照时间顺序排送了。因此小伙伴们就很容易错过精彩内容。喜欢黑科技的小伙伴,可以将黑科技百科公众号设为标星…...

2023华数杯数学建模B题思路模型论文分析
目录 一.2023华数杯数学建模最新思路:比赛开始后第一时间更新 更新查看文末名片 二.华数杯简介 三.往年华数杯赛题简介分析: 一.2023华数杯数学建模最新思路:比赛开始后第一时间更新 更新查看文末名片 二.华数杯简介 华数杯简介 国赛前…...
K8S系列文章之 使用Kind部署K8S 并发布服务
简单介绍 kind 即 Kubernetes In Docker,顾名思义,就是将 k8s 所需要的所有组件,全部部署在一个docker容器中,是一套开箱即用的 k8s 环境搭建方案。使用 kind 搭建的集群无法在生产中使用,但是如果你只是想在本地简单…...
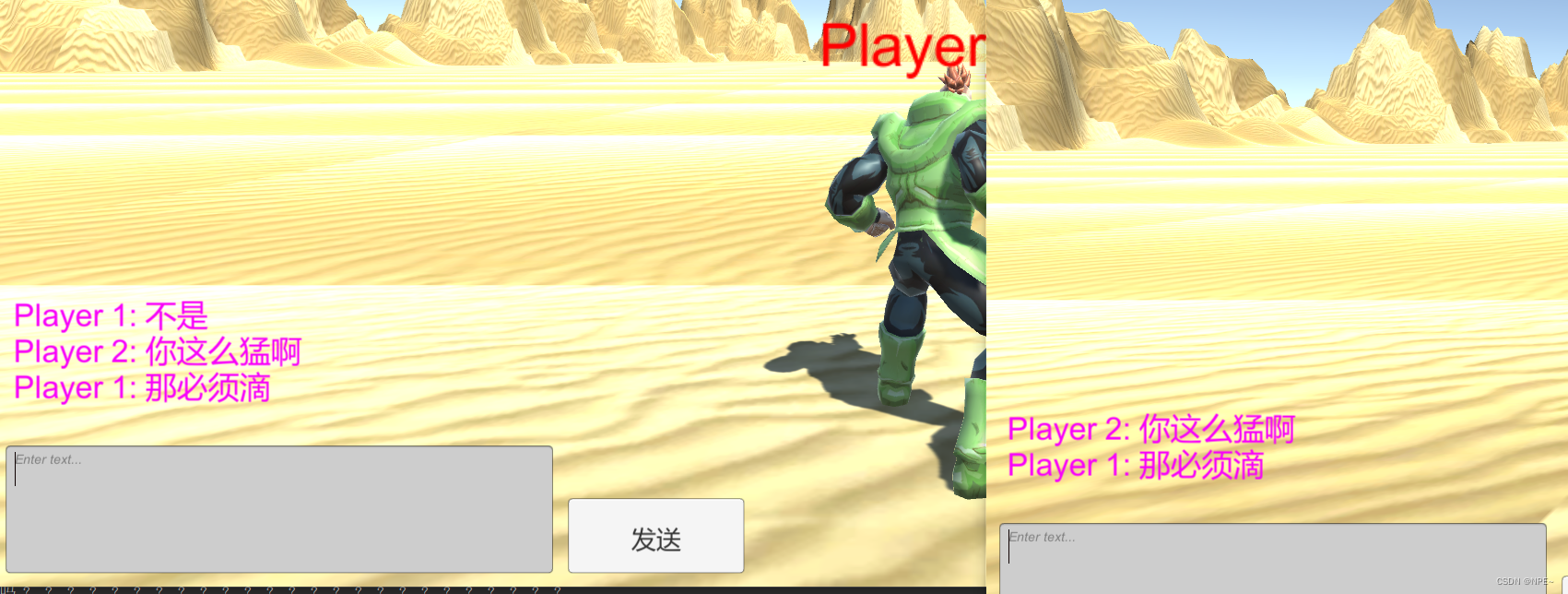
从0到1开发go-tcp框架【4实战片— — 开发MMO之玩家聊天篇】
从0到1开发go-tcp框架【实战片— — 开发MMO】 MMO(MassiveMultiplayerOnlineGame):大型多人在线游戏(多人在线网游) 1 AOI兴趣点的算法 游戏中的坐标模型: 场景相关数值计算 ● 场景大小: 250…...

无重复字符的最长子串 LeetCode热题100
题目 给定一个字符串 s ,请你找出其中不含有重复字符的 最长连续子字符串 的长度。 思路 使用滑动窗口,记录窗口区间的长度大小,取最大值。用map存储滑动窗口内所有字符,字符作为key,每个字符的数量作为value。遍历…...

Docker搭建zookeeper
问题背景 前言 本文参考自:docker-compose快速搭建Zookeeper集群还有一种更加详细更加全面的部署方式:Docker之docker-compose一键部署Zookeeper集群,但笔者还未验证,先记录下来 搭建 安装docker-ce 此处不赘述 安装docker-co…...

ComfyUI-Manager终极指南:3个核心功能彻底解决AI工作流管理难题
ComfyUI-Manager终极指南:3个核心功能彻底解决AI工作流管理难题 【免费下载链接】ComfyUI-Manager ComfyUI-Manager is an extension designed to enhance the usability of ComfyUI. It offers management functions to install, remove, disable, and enable vari…...

Python基础语法:访问器@property和修改器@xxx.setter
一、简介 访问器和修改器也是装饰器的一种。 property: 访问器,getter xxx.setter: 修改器,setter 访问器和修改器的根本目的是想将属性私有化,提供getter&setter去访问。 访问器和修改器能够做到访问属性其实在调用getter方法࿰…...
)
保姆级教程:在CentOS 7上用达梦8搭建DCA练习环境(附ulimit、VNC、ODBC全配置)
达梦8 DCA认证实战:CentOS 7环境搭建与调优全指南 在国产数据库技术快速发展的今天,达梦数据库作为核心产品之一,其DCA认证已成为众多从业者提升竞争力的重要选择。与理论为主的认证不同,DCA更注重实际操作能力,而一个…...

用C语言解决‘换硬币’问题?我来教你如何调试和验证你的循环逻辑
用C语言解决‘换硬币’问题?我来教你如何调试和验证你的循环逻辑 当你第一次面对"换硬币"这类组合问题时,那种既兴奋又困惑的感觉我至今记忆犹新。作为C语言初学者,理解多重循环的运作机制就像在迷宫中寻找出口——每次你以为找到了…...

为什么视频代剪辑会影响你的内容传播效果
为什么你精心拍的视频,发出去却没人看? 你有没有过这样的经历:花了一整天拍Vlog,素材画质高清、内容真实,可一剪出来就显得平淡无奇,点赞寥寥?或者婚礼当天感动全场,回看成片却像流水…...

基于声卡与电流互感器的安全交流功率测量系统设计与实践
1. 项目概述:用声卡安全测量交流功率我一直对各种测量技术抱有浓厚的兴趣,毕竟“测量即认知”这句老话在今天依然适用。对于电力消耗和产出,没有什么比直接测量更能说明问题了。交流功率的测量,核心在于同时获取电压和电流的瞬时值…...

机器学习与SHAP在教育公平研究中的应用:精准定位学业困境根源
1. 项目概述:当机器学习遇见教育公平,我们如何精准定位学业困境的根源?在拉丁美洲的教育研究领域,一个长期困扰政策制定者和研究者的核心问题是:究竟是什么因素,在复杂的社会经济背景下,系统性地…...

从CTF题看RSA安全:为什么你的密钥不能‘共享素数’?
从CTF实战看RSA密钥安全:那些年我们踩过的坑 在网络安全竞赛和实际渗透测试中,RSA算法的错误实现方式往往成为突破的关键点。本文将通过典型CTF赛题案例,揭示五种常见RSA实现漏洞背后的数学原理和安全启示,帮助开发者在实际项目中…...

AI算力要上天?别笑,太空数据中心真能干翻地球电费!
前言你有没有算过,训练一个大模型,相当于烧掉多少吨煤?如今AI狂飙突进,算力需求指数级增长,可地球上的电——不够用了!更别说建个数据中心还得跟地方政府“斗智斗勇”,抢地皮、配储能、扛审批&a…...

INT8量化下TVA注意力对齐精度保障方案
重磅预告:本专栏将独家连载系列丛书《智能体视觉技术与应用》部分精华内容,该书是世界首套系统阐述“因式智能体”视觉理论与实践的专著,特邀美国 TypeOne 公司首席科学家、斯坦福大学博士 Bohan 担任技术顾问。Bohan先生师从美国三院院士、“…...