大数据开发面试必问:Hive调优技巧系列二
接上次分享的Hive调优技巧系列一: 数据倾斜、HiveJob优化
第1章 数据倾斜(重点)
绝大部分任务都很快完成,只有一个或者少数几个任务执行的很慢甚至最终执行失败,这样的现象为数据倾斜现象。
一定要和数据过量导致的现象区分开,数据过量的表现为所有任务都执行的很慢,这个时候只有提高执行资源才可以优化HQL的执行效率。
综合来看,导致数据倾斜的原因在于按照Key分组以后,少量的任务负责绝大部分数据的计算,也就是说产生数据倾斜的HQL中一定存在分组操作,那么从HQL的角度,我们可以将数据倾斜分为单表携带了GroupBy字段的查询和两表(或者多表)Join的查询。
1.1 Map倾斜
Map 端是 MR 任务的起始阶段, Map 端的主要功能是从磁盘中将数据读人内存,Map 端读数据时,由于读人数据的文件大小分布不均匀,因此会导致有些 Map Instance 读取并且处理的数据特别 多,而有些 MapInstance 处理的数据特别少,造成 Map 端长尾。以下两种情况可能会导Map 端长尾:
1.上游表文件的大小特别不均匀,并且小文件特别多,导致当前表Map 端读取的数据分布不均匀,引起长尾。
2.Map 端做聚合时,由于某些 Map Instance 读取文件的某个值特别多而引起长尾,主要是指 Count Distinct 操作。
第一种情况导致的 Map 端长尾,可通过对上游合并小文件,同时调节本节点的小文件的参数来进行优化,即通过设置“ set odps.sql. mapper.merge.limit.size 64 ”和“ set odps .s ql.mapper.s plit.size=256个参数来调节,其中第一个参数用于调节 Map 任务的 Map Instance个数:第二个参数用于调节单个 Map Instance 读取的小文件个数,防止由于小文件过多导致 Map Instance 读取的数据量很不均匀;两个参数配合调整
第二种情况的处理方式通过“distribute by rand ()”会将 Map 端分发后的数据重新按照随机值再进行一次分发。原先不加随机分发函数时, Map 阶段需要与使用MapJoin 的小表进行笛卡儿积操作, Map 端完成了大小表的分发和笛卡儿积操作。使用随机分布函数后, Map 端只负责数据的分发,不再有复杂的聚合或者笛卡儿积操作,因此不会导致 Map 端长尾。

1.2 Join倾斜
Join 操作需要参与 Map Reduce 的整个阶段。SQL Join 执行阶会将 Join Key 相同的数据分发到同一个执行 Instance 上处理 。如果某个Key 上的数据量比较大,则会导致该 Instance 执行时间较长。其表现为:在执行日志中该 Join Task 的大部分 Instance 都已执行完成,但少数几Instance 一直处于执行中(这种现象称之为长尾)。
1.Join 的某路输入比较小,可以采用 MapJoin ,避免分发引起长尾;
2.Join 的每路输入都较大,且长尾是空值导致的,可以将空值处理成随机值,避免聚集;
3.Join 的每路输入都较大,且长尾是热点值导致的,可以对热点值和非热点值分别进行处理,再合并数据。
1.3 Reduce倾斜
Reduce 端负责的是对 Map 端梳理后的有 key-value 键值对进行聚合,即进行 Count Sum Avg 等聚合操作,得到最终聚合的结果。Reduce 端产生长尾的主要原因就是 key 的数据分布不均匀。比如有些 Reduce 任务 Instance 处理的数据记录多,有些处理的数据记录少,造成 Reduce 端长尾 。如下几种情况会造成 Reduce 端长尾:
1.对同个表按照维度对不同的列进行 Count Distinct 操作,造成Map 端数据膨胀,从而使得下游的 Join Reduce 出现链路上的长尾;
2.Map 端直接做聚合时出现 key 值分布不均匀,造成 Reduce 端长尾;
3.动态分区数过多时可能造成小文件过多,从而引起 Reduce 端长尾;
4.多个 Distinct 同时出现在 SQL 代码中时,数据会被分发多次,不仅会造成数据膨胀 n倍,还会把长尾现象放大n倍。
对于上面提到的第2种情况,可以对热点 key 进行单独处理,然后通过“ union All ”合并。这种解决方案已经在“Join 倾斜”一节中介绍过。对于上面提到的第3种情况,可以把符合不同条件的数据放到不同的分区,避免通过多次“Insert Overwrite ,,写人表中,特别是分区数比较多时,能够很好地简化代码。对于第4种情况,我们可以先多粒度聚合,然后在子查询外进行口径粒度聚合。
第2章 Hive Job优化
2.1 Hive Map优化
2.1.1 复杂文件增加Map数
当input的文件都很大,任务逻辑复杂,map执行非常慢的时候,可以考虑增加Map数,来使得每个map处理的数据量减少,从而提高任务的执行效率。增加map的方法为:根据computeSliteSize(Math.max(minSize,Math.min(maxSize,blocksize)))=blocksize=128M公式,调整maxSize最大值。让maxSize最大值低于blocksize就可以增加map的个数。
2.1.2 小文件进行合并
1)在map执行前合并小文件,减少map数:CombineHiveInputFormat具有对小文件进行合并的功能(系统默认的格式)。HiveInputFormat没有对小文件合并功能。
set hive.input.format= org.apache.hadoop.hive.ql.io.CombineHiveInputFormat;2)在Map-Reduce的任务结束时合并小文件的设置:
#在map-only任务结束时合并小文件,默认trueset hive.merge.mapfiles = true;#在map-reduce任务结束时合并小文件,默认falseset hive.merge.mapredfiles = true;#合并文件的大小,默认256Mset hive.merge.size.per.task = 268435456;#当输出文件的平均大小小于该值时,启动一个独立的map-reduce任务进行文件mergeset hive.merge.smallfiles.avgsize = 16777216;

2.1.3 Map端聚合
set hive.map.aggr=true;#相当于map端执行combiner
2.1.4 推测执行
set mapred.map.tasks.speculative.execution = true#默认是true
2.2 Hive Reduce优化
2.2.1 合理设置Reduce数
1)调整reduce个数方法一:
(1)每个Reduce处理的数据量默认是256MB。
set hive.exec.reducers.bytes.per.reducer = 256000000(2)每个任务最大的reduce数,默认为1009
set hive.exec.reducers.max = 1009(3)计算reducer数的公式
N=min(参数2,总输入数据量/参数1)(参数2 指的是上面的1009,参数1值得是256M)2)调整reduce个数方法二:
在hadoop的mapred-default.xml文件中修改,设置每个job的Reduce个数;
set mapreduce.job.reduces = 15;3)reduce个数并不是越多越好
(1)过多的启动和初始化reduce也会消耗时间和资源;
(2)另外,有多少个reduce,就会有多少个输出文件,如果生成了很多个小文件,那么如果这些小文件作为下一个任务的输入,则也会出现小文件过多的问题;
Tips---在设置reduce个数的时候也需要考虑这两个原则:处理大数据量利用合适的reduce数;使单个reduce任务处理数据量大小要合适;
2.3 Hive 任务整体优化
2.3.1 Fetch抓取
Fetch抓取是指,Hive中对某些情况的查询可以不必使用MapReduce计算。例如:SELECT * FROM emp;在这种情况下,Hive可以简单地读取emp对应的存储目录下的文件,然后输出查询结果到控制台。
在hive-default.xml.template文件中hive.fetch.task.conversion默认是more,老版本hive默认是minimal,该属性修改为more以后,在全局查找、字段查找、limit查找等都不走mapreduce。
<property><name>hive.fetch.task.conversion</name><value>more</value><description>Expects one of [none, minimal, more].Some select queries can be converted to single FETCH task minimizing latency.Currently the query should be single sourced not having any subquery and should not have any aggregations or distincts (which incurs RS), lateral views and joins.0. none : disable hive.fetch.task.conversion1. minimal : SELECT STAR, FILTER on partition columns, LIMIT only2. more : SELECT, FILTER, LIMIT only (support TABLESAMPLE and virtual columns)</description>
</property>1)案例实操:
(1)把hive.fetch.task.conversion设置成none,然后执行查询语句,都会执行mapreduce程序;
hive (default)> set hive.fetch.task.conversion=none;
hive (default)> select * from emp;
hive (default)> select ename from emp;
hive (default)> select ename from emp limit 3;(2)把hive.fetch.task.conversion设置成more,然后执行查询语句,如下查询方式都不会执行mapreduce程序;
hive (default)> set hive.fetch.task.conversion=more;
hive (default)> select * from emp;
hive (default)> select ename from emp;
hive (default)> select ename from emp limit 3;2.3.2 本地模式
大多数的Hadoop Job是需要Hadoop提供的完整的可扩展性来处理大数据集的。不过,有时Hive的输入数据量是非常小的。在这种情况下,为查询触发执行任务消耗的时间可能会比实际job的执行时间要多的多。对于大多数这种情况,Hive可以通过本地模式在单台机器上处理所有的任务。对于小数据集,执行时间可以明显被缩短。
用户可以通过设置hive.exec.mode.local.auto的值为true,来让Hive在适当的时候自动启动这个优化。
set hive.exec.mode.local.auto=true; //开启本地mr
//设置local mr的最大输入数据量,当输入数据量小于这个值时采用local mr的方式,默认为134217728,即128M
set hive.exec.mode.local.auto.inputbytes.max=50000000;
//设置local mr的最大输入文件个数,当输入文件个数小于这个值时采用local mr的方式,默认为4
set hive.exec.mode.local.auto.input.files.max=10;案例实操:
1)开启本地模式,并执行查询语句;
hive (default)> set hive.exec.mode.local.auto=true;
hive (default)> select * from emp cluster by deptno;
Time taken: 1.328 seconds, Fetched: 14 row(s)(2)关闭本地模式,并执行查询语句(注意执行时间);
hive (default)> set hive.exec.mode.local.auto=false;
hive (default)> select * from emp cluster by deptno;
Time taken: 20.09 seconds, Fetched: 14 row(s)2.3.3 并行执行
Hive会将一个查询转化成一个或者多个阶段。这样的阶段可以是MapReduce阶段、抽样阶段、合并阶段、limit阶段。或者Hive执行过程中可能需要的其他阶段。默认情况下,Hive一次只会执行一个阶段。不过,某个特定的job可能包含众多的阶段,而这些阶段可能并非完全互相依赖的,也就是说有些阶段是可以并行执行的,这样可能使得整个job的执行时间缩短。不过,如果有更多的阶段可以并行执行,那么job可能就越快完成。
通过设置参数hive.exec.parallel值为true,就可以开启并发执行。不过,在共享集群中,需要注意下,如果job中并行阶段增多,那么集群利用率就会增加。
set hive.exec.parallel=true; //打开任务并行执行,默认为false
set hive.exec.parallel.thread.number=16; //同一个sql允许最大并行度,默认为8(建议在数据量大,sql很长的时候使用,数据量小,sql比较的小开启有可能还不如之前快)。
2.3.4 严格模式
Hive可以通过设置防止一些危险操作:、
1)分区表不使用分区过滤
将hive.strict.checks.no.partition.filter设置为true时,对于分区表,除非where语句中含有分区字段过滤条件来限制范围,否则不允许执行。换句话说,就是用户不允许扫描所有分区。进行这个限制的原因是,通常分区表都拥有非常大的数据集,而且数据增加迅速。没有进行分区限制的查询可能会消耗令人不可接受的巨大资源来处理这个表。
2)使用order by没有limit过滤
将hive.strict.checks.orderby.no.limit设置为true时,对于使用了order by语句的查询,要求必须使用limit语句。因为order by为了执行排序过程会将所有的结果数据分发到同一个Reducer中进行处理,强制要求用户增加这个LIMIT语句可以防止Reducer额外执行很长一段时间(开启了limit可以在数据进入到reduce之前就减少一部分数据)。
3)笛卡尔积
将hive.strict.checks.cartesian.product设置为true时,会限制笛卡尔积的查询。对关系型数据库非常了解的用户可能期望在 执行JOIN查询的时候不使用ON语句而是使用where语句,这样关系数据库的执行优化器就可以高效地将WHERE语句转化成那个ON语句。不幸的是,Hive并不会执行这种优化,因此,如果表足够大,那么这个查询就会出现不可控的情况。
2.3.5 JVM重用
小文件过多的时候使用。

相关文章:
大数据开发面试必问:Hive调优技巧系列二
接上次分享的Hive调优技巧系列一: 数据倾斜、HiveJob优化 第1章 数据倾斜(重点) 绝大部分任务都很快完成,只有一个或者少数几个任务执行的很慢甚至最终执行失败,这样的现象为数据倾斜现象。 一定要和数据过量导致的…...

【C++】STL——list的模拟实现、构造函数、迭代器类的实现、运算符重载、增删查改
文章目录 1.模拟实现list1.1构造函数1.2迭代器类的实现1.3运算符重载1.4增删查改 1.模拟实现list list使用文章 1.1构造函数 析构函数 在定义了一个类模板list时。我们让该类模板包含了一个内部结构体_list_node,用于表示链表的节点。该结构体包含了指向前一个节点…...

vscode 插件::EIDE
最新最全 VSCODE 插件推荐(2023版)_vscode_白墨石-华为云开发者联盟 (csdn.net) 超好用的开发工具-VScode插件EIDE_vscode eide_桃成蹊2.0的博客-CSDN博客 Setup | Embedded IDE For VSCode (em-ide.com)...

Python 网络编程
Python 网络编程 Python 提供了两个级别访问的网络服务: 低级别的网络服务支持基本的 Socket,它提供了标准的 BSD Sockets API,可以访问底层操作系统 Socket 接口的全部方法。高级别的网络服务模块 SocketServer, 它提供了服务器…...
SQL 数据科学:了解和利用联接
推荐:使用 NSDT场景编辑器助你快速搭建可编辑的3D应用场景 什么是 SQL 中的连接? SQL 联接允许您基于公共列合并来自多个数据库表的数据。这样,您就可以将信息合并在一起,并在相关数据集之间创建有意义的连接。 SQL 中的连接类型…...
第五章决策树——四五节:决策树的剪枝,CART算法)
(统计学习方法|李航)第五章决策树——四五节:决策树的剪枝,CART算法
目录 一,决策数的剪枝 二,CART算法 1.CART生成 (1)回归树的生成 (2)分类树的生成 2.CART剪枝 (1)剪枝,形成一个子树序列 (2)在剪枝得到的子…...

C语言--结构体定义
整型数,浮点数,字符串是分散的数据表示,有时候我们需要很多类型表示一个整体,比如学生信息。 数组是元素类型一样的数据集合,如果是元素类型不同的数据集合,就要用到结构体 结构体一般是个模板,…...

解决Element Plus中Select在El Dialog里层级过低的问题(修改select选项框样式)
Element Plus是Vue.js的一套基于Element UI的组件库,提供了丰富的组件用于构建现代化的Web应用程序。其中,<el-select>是一个常用的下拉选择器组件,但在某些情况下,当<el-select>组件嵌套在<el-dialog>…...
【数据结构】二叉树 链式结构的相关问题
本篇文章来详细介绍一下二叉树链式结构经常使用的相关函数,以及相关的的OJ题。 目录 1.前置说明 2.二叉树的遍历 2.1 前序、中序以及后序遍历 2.2 层次遍历 3.节点个数相关函数实现 3.1 二叉树节点个数 3.2 二叉树叶子节点个数 3.3 二叉树第k层节点个数 3…...
【无标题】云原生在工业互联网的落地及好处!
什么是工业互联网? 工业互联网(Industrial Internet)是新一代信息通信技术与工业经济深度融合的新型基础设施、应用模式和工业生态,通过对人、机、物、系统等的全面连接,构建起覆盖全产业链、全价值链的全新制造和服务…...

人工智能在心电信号分类中的应用
目录 1 引言 2 传统机器学习中的特征提取与选择 3 深度学习中的特征提取与选择...
【Linux 网络】网络层协议之IP协议
IP协议 IP协议所处的位置网络层要解决的问题IP协议格式分片与组装网段划分特殊的IP地址IP地址的数量限制私网IP地址和公网IP地址路由 IP协议所处的位置 IP指网际互连协议,Internet Protocol的缩写,是TCP/IP体系中的网络层协议。 网络层要解决的问题 网络…...

.meta 文件
.meta 文件的作用简单来说是建立 Unity 与资源之间的“桥梁”。 在游戏中引用一个游戏资源,Unity 并不是直接按照文件的路径或者名称,而是使用一个独一无二的 GUID 来指向工程里该资源文件。 这个 GUID 就是存储在 Unity 工程为每一个资源和文件…...
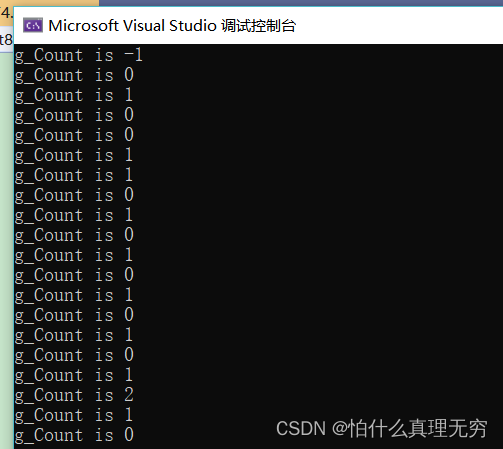
CRITICAL_SECTION 用法
#include <stdio.h> #include <windows.h> typedef RTL_CRITICAL_SECTION CRITICAL_SECTION; CRITICAL_SECTION g_cs; //声明关键段 // 共享资源 char g_cArray[10]; unsigned int g_Count 0; DWORD WINAPI ThreadProc10(LPVOID pParam) { // 进入临界区 …...
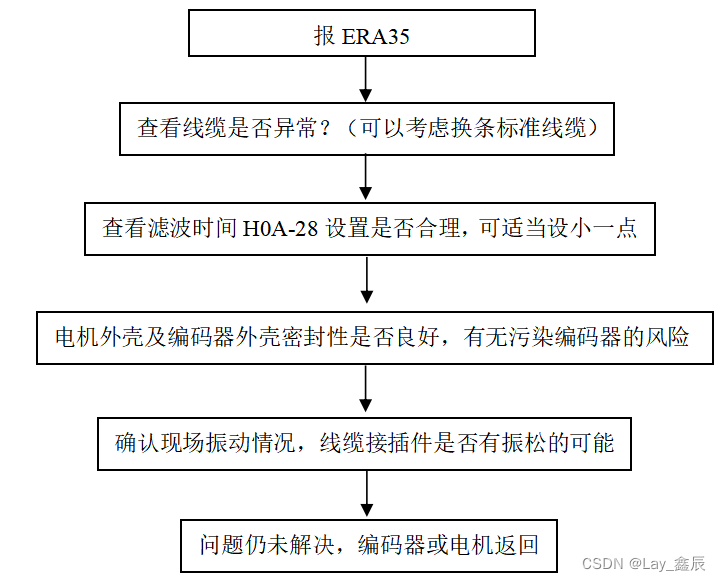
汇川运动控制产品故障排查
针对汇川伺服产品(IS600/IS620)的基本检测和一些出现频率较高的故障进行检测判断方法,适用于服务人员在现场排查/判断机器故障时,准确定位问题。 一、简单故障排查 注1:接线错误:1、UVW相序是否正确&#…...
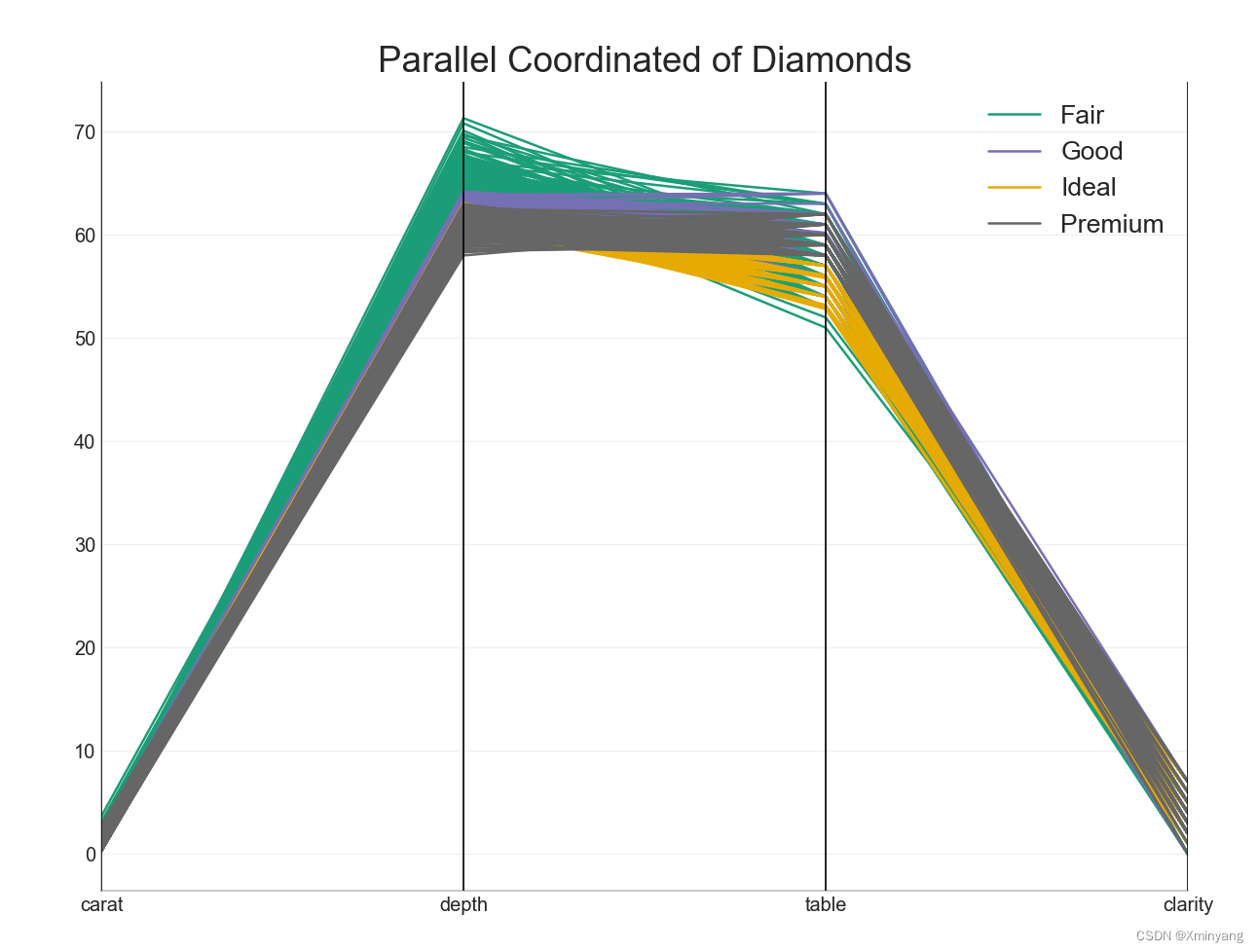
【Groups】50 Matplotlib Visualizations, Python实现,源码可复现
详情请参考博客: Top 50 matplotlib Visualizations 因编译更新问题,本文将稍作更改,以便能够顺利运行。 1 Dendrogram 树状图根据给定的距离度量将相似的点组合在一起,并根据点的相似性将它们组织成树状的链接。 新建文件Dendrogram.py: …...
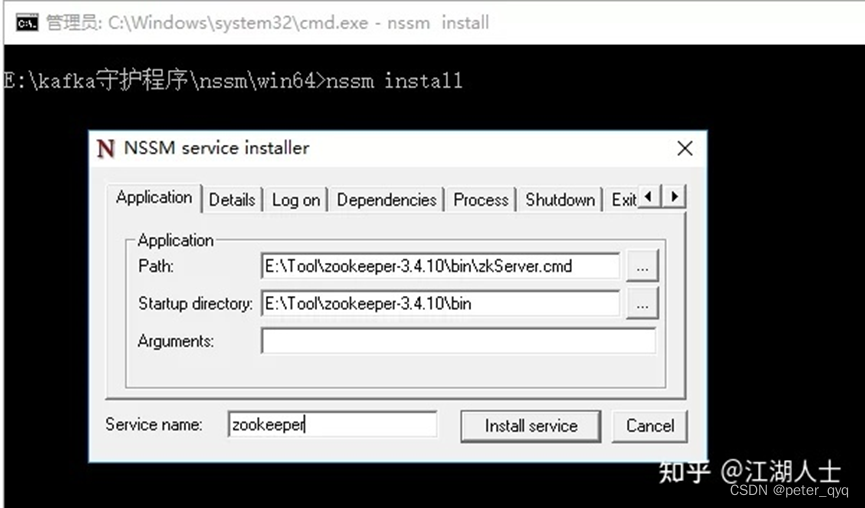
windows安装kafka配置SASL-PLAIN安全认证
目录 1.Windows安装zookeeper: 1.1下载zookeeper 1.2 解压之后如图二 1.3创建日志文件 1.4复制 “zoo_sample.cfg” 文件 1.5更改 “zoo.cfg” 配置 1.6新建zk_server_jaas.conf 1.7修改zkEnv.cmd 1.8导入相关jar 1.9以上配置就配好啦,接下来启…...
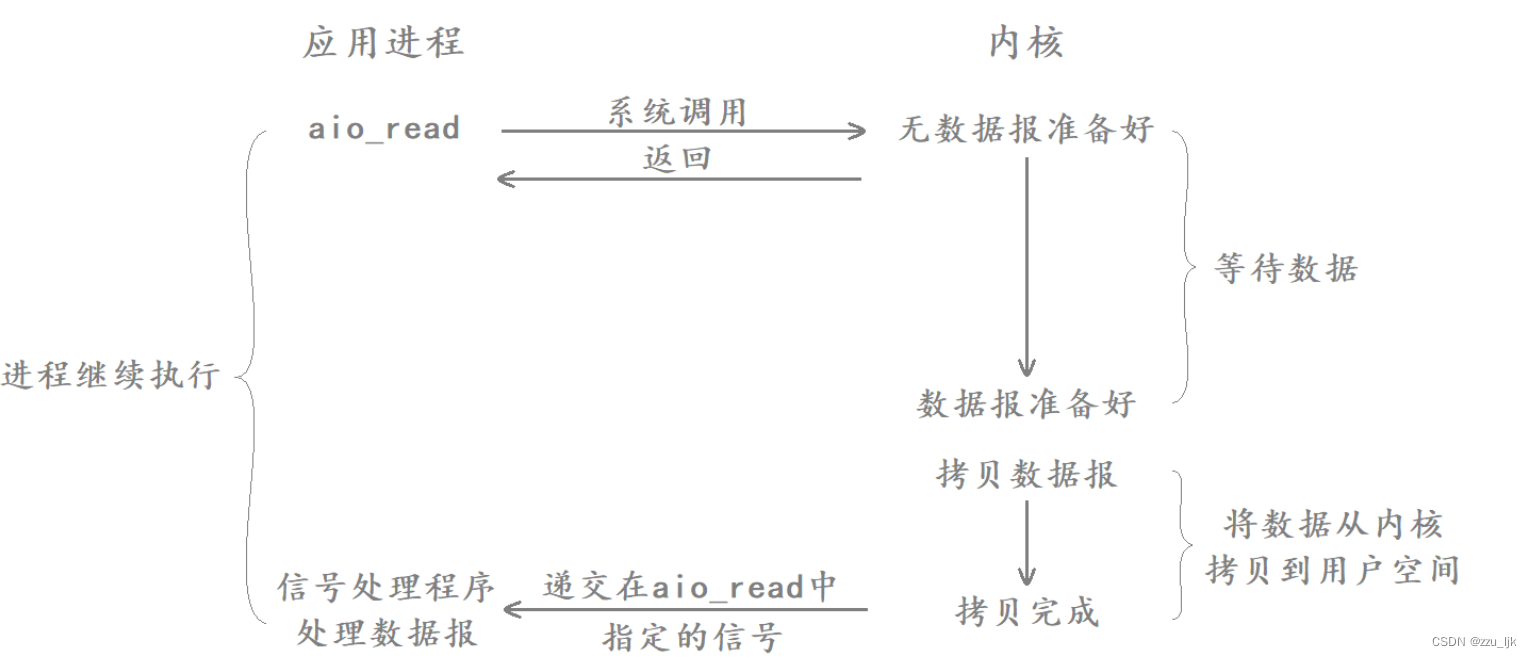
【Linux】五种IO模型
文章目录 1. IO基本概念2. 五种IO模型2.1 五个钓鱼的例子2.2 五种IO模型2.2.1 阻塞IO2.2.2 非阻塞IO2.2.3 信号驱动IO2.2.4 IO多路转接2.2.5 异步IO 1. IO基本概念 认识IO IO就是输入和输出,在冯诺依曼体系结构中,将数据从输入设备拷贝到内存就叫输入&am…...

SCT82A30DHKR_5.5V-100V Vin同步降压控制器
SCT82A30是一款100V电压模式控制同步降压控制器,具有线路前馈。40ns受控高压侧MOSFET的最小导通时间支持高转换比,实现从48V输入到低压轨的直接降压转换,降低了系统复杂性和解决方案成本。如果需要,在低至6V的输入电压下降期间&am…...

备忘录模式(C++)
定义 在不破坏封装性的前提下,捕获一-个对象的内部状态,并在该对象之外保存这个状态。这样以后就可以将该对象恢复到原先保存的状态。 应用场景 ➢在软件构建过程中,某些对象的状态在转换过程中,可能由于某种需要,要…...
)
保姆级教程:在ROS2 Humble/Foxy的Gazebo中配置RGB-D相机(附解决点云颜色/坐标问题)
ROS2 Humble/Foxy中Gazebo深度相机仿真全攻略:从配置到点云问题解决在机器人仿真开发中,深度相机(RGB-D)是不可或缺的传感器之一。它能够同时提供彩色图像和深度信息,为SLAM、物体识别、避障等任务提供关键数据支持。本…...

Vulnhub-DC-1
1.信息收集 使用工具nmap扫描主机端口 这是Drupal是使用PHP语言编写的开源内容管理框架(CMF),它由内容管理系统(CMS)和PHP开发框架(Framework)共同构成 Web指纹扫描 发现是:drupal…...

照着用就行:2026 最新降AIGC软件测评与推荐
2026年真正好用的AI论文降重与改写工具,核心看降重效果、去AI味、格式保留、学术适配四大指标。综合实测,千笔AI、ThouPen、豆包、DeepSeek、Grammarly 是当前最值得推荐的梯队,覆盖从免费到付费、从中文到英文、从文科到理工的全场景需求。 …...

FeHelper前端助手:30+开发工具集,让你的浏览器变身效率神器
FeHelper前端助手:30开发工具集,让你的浏览器变身效率神器 【免费下载链接】FeHelper 😍FeHelper--Web前端助手(Awesome!Chrome & Firefox & MS-Edge Extension, All in one Toolbox!) 项目地址:…...

【DeepSeek架构评审功能深度解密】:20年架构师亲授3大避坑指南与5步落地 checklist
更多请点击: https://kaifayun.com 第一章:DeepSeek架构评审功能全景概览 DeepSeek架构评审功能是一套面向大模型系统设计与工程落地的自动化分析框架,聚焦于模型结构合理性、计算图优化潜力、内存访问模式、算子兼容性及部署约束等多维度评…...

告别CAJ格式困扰:3分钟学会用开源工具将知网文献转为PDF
告别CAJ格式困扰:3分钟学会用开源工具将知网文献转为PDF 【免费下载链接】caj2pdf Convert CAJ (China Academic Journals) files to PDF. 转换中国知网 CAJ 格式文献为 PDF。佛系转换,成功与否,皆是玄学。 项目地址: https://gitcode.com/…...

3个步骤彻底解决WSA安装失败问题:从错误代码到完美运行
3个步骤彻底解决WSA安装失败问题:从错误代码到完美运行 【免费下载链接】WSABuilds Run Windows Subsystem For Android on your Windows 10 and Windows 11 PC using prebuilt binaries with Google Play Store (MindTheGapps) and/or Magisk or KernelSU (root so…...

观察不同模型在统一 API 下的响应速度与输出风格差异
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 观察不同模型在统一 API 下的响应速度与输出风格差异 在为大语言模型应用选择模型时,开发者通常会关注两个核心维度&am…...

基于CNN的食双星光变曲线自动化参数初估模型EBOP MAVEN
1. 项目概述与核心价值在恒星天体物理领域,食双星系统一直扮演着“宇宙实验室”的关键角色。通过分析两颗恒星相互绕转时周期性相互遮挡产生的光变曲线,我们可以像解谜一样,精确反演出恒星的质量、半径、轨道倾角等基本物理参数。这些参数是构…...

解决claude code频繁封号与token不足的taotoken接入方案
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 解决Claude Code频繁封号与Token不足的Taotoken接入方案 1. 问题背景:Claude Code用户面临的挑战 对于依赖Claude Cod…...