Redis 总结【6.0版本的】
还差什么?【按照这个为基础,对照他的Redis路线图,冲冲冲】
Redis的常见操作和命令:Redis基本操作命令(图文详解)_redis 命令_进击小高的博客-CSDN博客
Redis的持久化,一致性:AOF,快照,事务如何保证、双写一致性
个人总结全技术栈思维导图(持续更新) | feiye's blog
Redis的多线程这个:啥时候多线程不理解
看完小林的面经后去问问
Redis 是 C语言写的
如果源码不编译,是无法实现自动跳转的,
Redis在win上编译有点麻烦,我是使用的CentOS环境,Clion编译
编译完就可以直接通过shell连接Redis server了
server.c 中放的是就是主类 :6000多行左右是入口main()函数位置
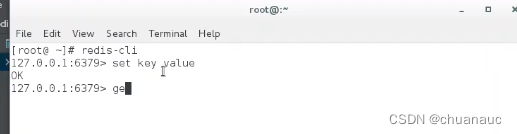
Redis的使用:
通过redis.conf 文件的如下位置 配置 Redis有多少个数据库:

select 0 select 1对应就是数据库的序号,16个数据库对应0-15下标
使用 `help @list`去查看所有的List操作
解释一下数据类型:例如我们使用的命令是"ZADD"那么,Redis就知道我们操作的数据类型一定是Zset数据类型,因此,一定会在代码中检查 ZADD 后面的 操作对象是不是 zset数据类型
。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。
下图就是数据库的结构:
其中最重要的一项就是存放该数据库key-value对的:715行 dict 类型的 *dict指针
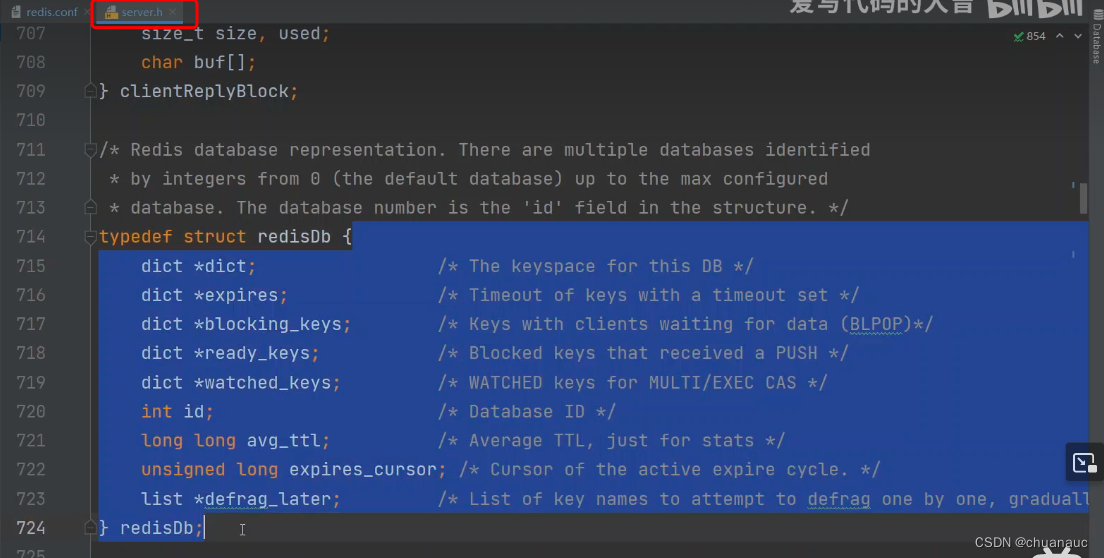
。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。
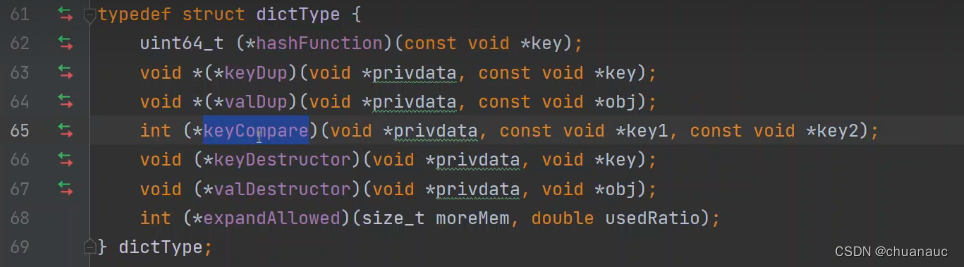
dict 数据类型如下定义:
83行有两个dictht 类型的数组:就是对应存放 老HashTable 和 新扩容的HashTable

。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。
62:hashFunction() 给出 key 求对应的哈希值
65:keyCompare() 比较两个Key是否一致,是否出现冲突,一致的话执行后续逻辑操作
。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。
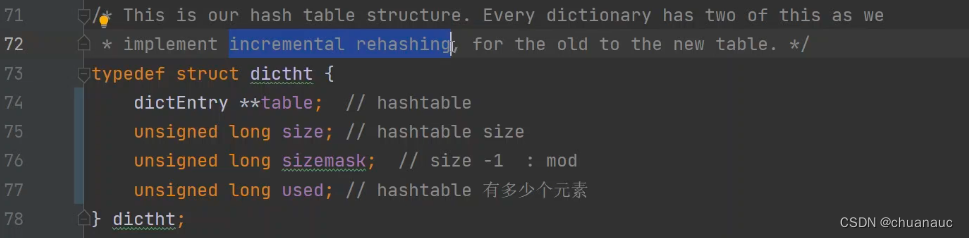
HashTable的数据结构:
74 指向一个哈希表 -->dictEntry就是哈希表中真正存放的entry的数据结构
。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。
哈希表中的每一个entry其数据结构:
53行就是 val 指针 ,指向封装的RedisObject 各数据类型的对象
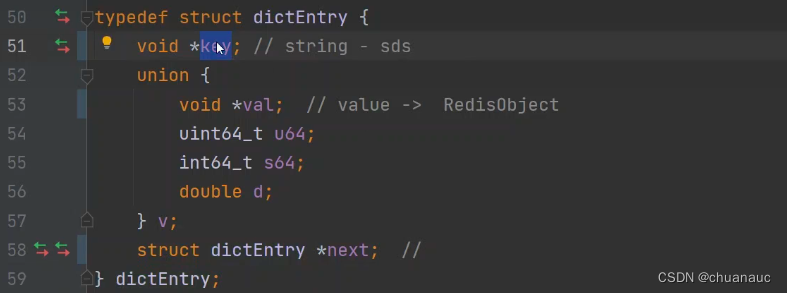
。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。
下图就是 RedisObject这个数据类型:
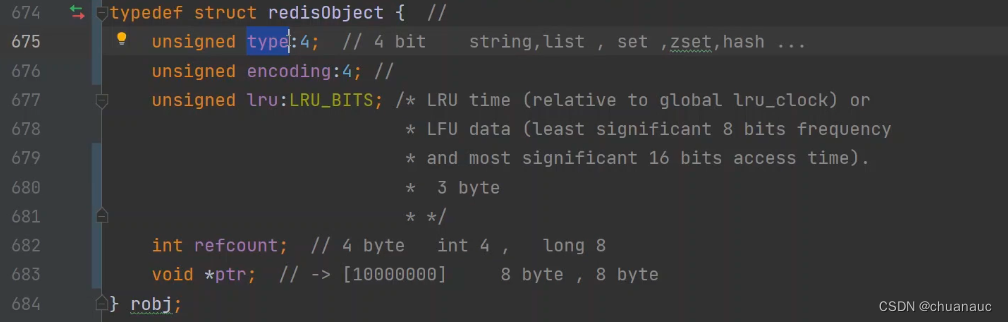
// 解释下675、676 这些行的 ":4" 是啥意思:含义是强制要求这个变量只使用4bit
(1 byte =8 byte),算下来,RedisObject占 16 byte
(1)type表征了这个RedisObject里面盛放的数据类型是什么,是string list zset 还是啥别的
(2) encoding 表征了数值在内存中的编码方式:RedisObject的对象类型取决于是用什么API:
如下图使用API “set” 来创建对象,那么,无论对象赋值是什么,都会被封装成string类型
而使用API “LPUSH” 则会被封装成list 类型

同时,即使是相同的数据类型,根据数据的不同值,在内存里面用不同的方式去存储,导致type相同,但底层的编码都是不一样的
且,数据值发生变化的时候,Redis底层会帮我们把数据的encoding方式改变,做一些优化
(3)refcount 表征 这个 RedisObject 被引用了多少次,引用计数法的简单实现罢了,作用也是:垃圾回收
(4)ptr 是一个真正纸箱内存区域的一个指针,代表我们将RedisObject存放到了哪里 ==》根据ptr就能知道数据到底真正存放在内存的哪里
(4.1)同时,Redis也对 ptr做了优化:
由于指针是8个byte,而对于数值类型一般最长也就8byte:
由于我们的value是SDS类型,判断下SDS这个buf是不是小于20位(因为有符号long 类型就20位),若小于,那么,有希望将该value转化为long 类型保存
由于指针字节和数值字节长度一致,因此,Redis在能将SDS的内容转换为数值类型是就会执行转换,让ptr存放数值,而非指向SDS的地址指针
把已经存放数值的value变量强转为(void*)类型再赋值给ptr ,如下图所示,就可以减少内存使用,减少一次IO
![]()
(4.2)Redis存放字符串的时候,他的底层编码方式:
若字符串SDS的buf[]内容 <= 44字节:encoding 方式是 embstr
> 44字节:encoding 方式是 raw
为啥是44呢?
【回答】:CPU 通过地址总线 从内存中拿数据:并不是想拿多少拿多少
而是每次CPU至少要拿64byte(这个大小就是 缓存行大小 cache line -- 这是为了缓存一致性原理的优化体现),即,即使CPU需要的数据很少,几个byte而已,但是一次CPU与内存的交互 也会顺带把那些不需要的数据也拿上,凑够64byte
我们观察 RedisObject 这个结构体,它的大小是16byte,CPU取指定的 RedisObject的某个结构体,除了需要的16byte,还得去会不相干的48byte,于是Redis的优化是 想把 RedisObject的ptr指向的数据内容放到这48byte上,这样,就可以不用先将RedisObject对象放到L1 cache,在找到ptr,把ptr指向的地址中对应的数据内容加载到L1 cache了
而对于存放数据,48字节的字符串应该对应的是 sdshdr8能表示的数据范围里,而sdshdr8结构体中,表征信息的len、alloc变量等需要4字节,那么还剩下44字节,因此,只要SDS的中的buf[]大小少于44字节,就可以将该字符串内容和RedisObject实例存放在一起,占满64Byte的空间,一次被CPU读到L1cache中
这种数据和RedisObject一起在分配空间上分配到一起的存放方式 就是 embstr (embedding string 嵌入式字符串)
Redis数据库的各个数据类型总览:
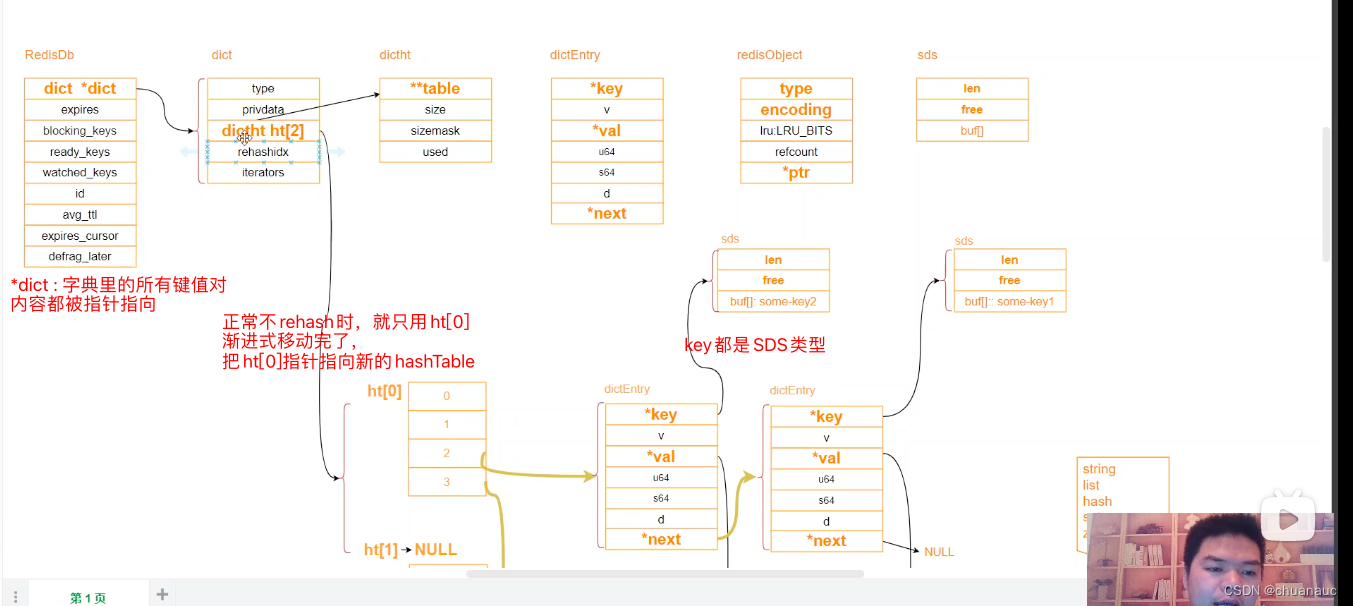
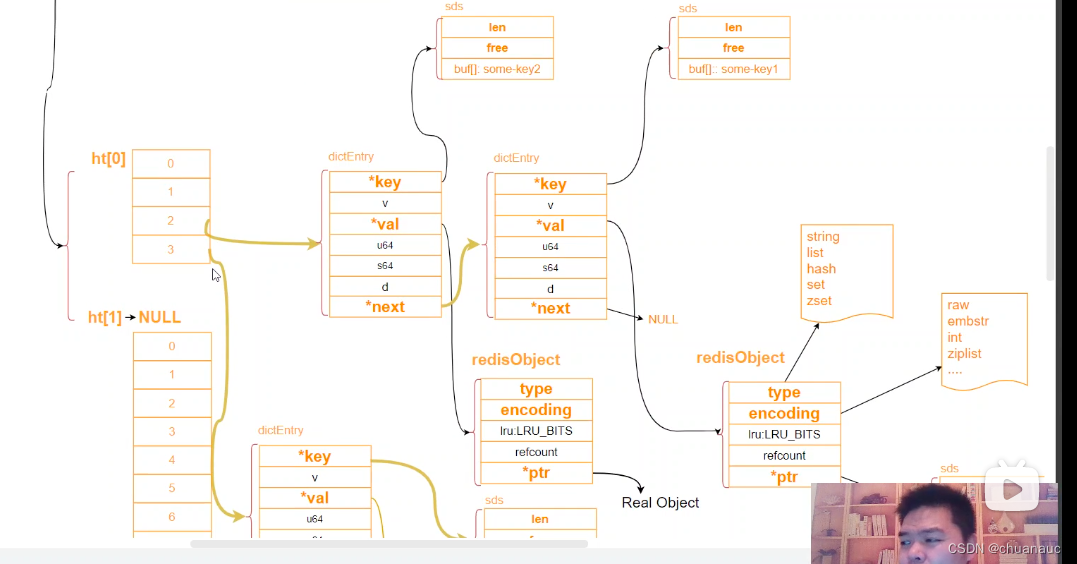
哪怕是同一种RedisObject 的 type结构,底层数据类型实现也有很多不同:如 int 、raw 、embstr 、quicklist 等等
而value最后都会放到 RedisObject里面进行封装:
。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。
。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。
Redis的所有命令都会被封装到RedisCommand这个类里面:
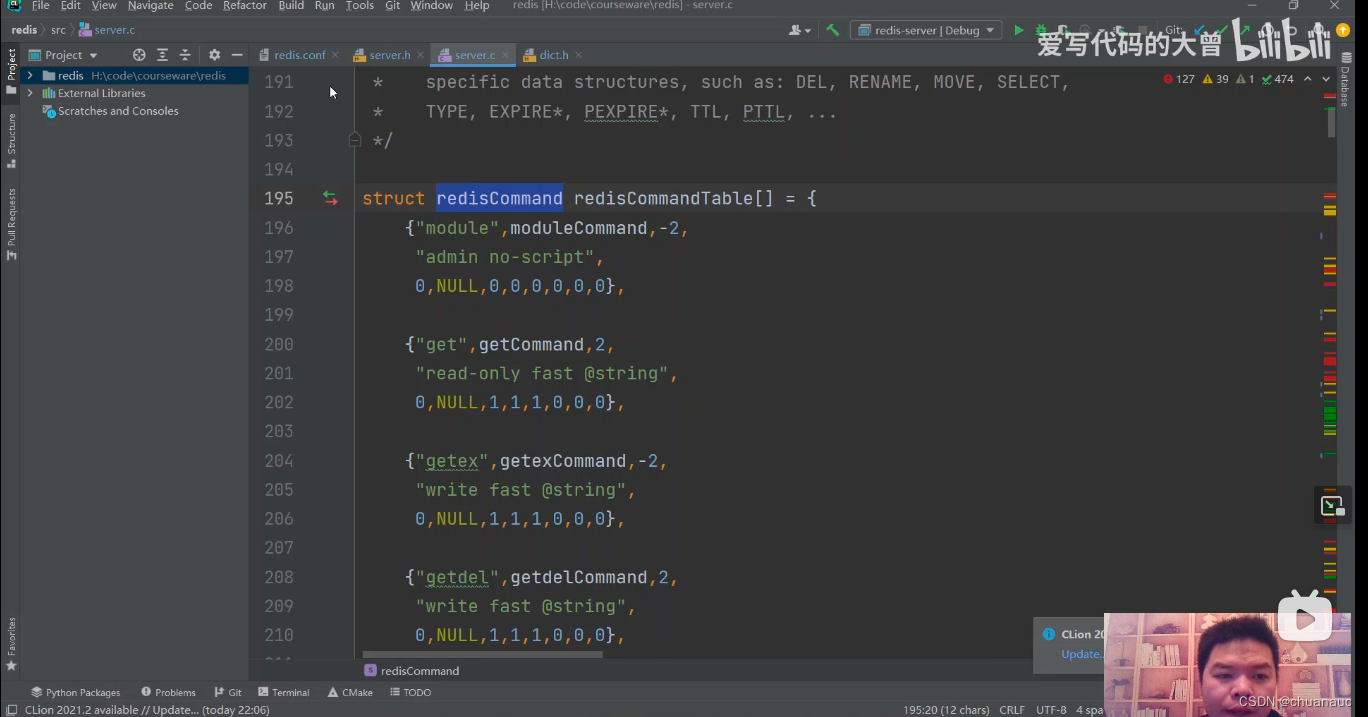
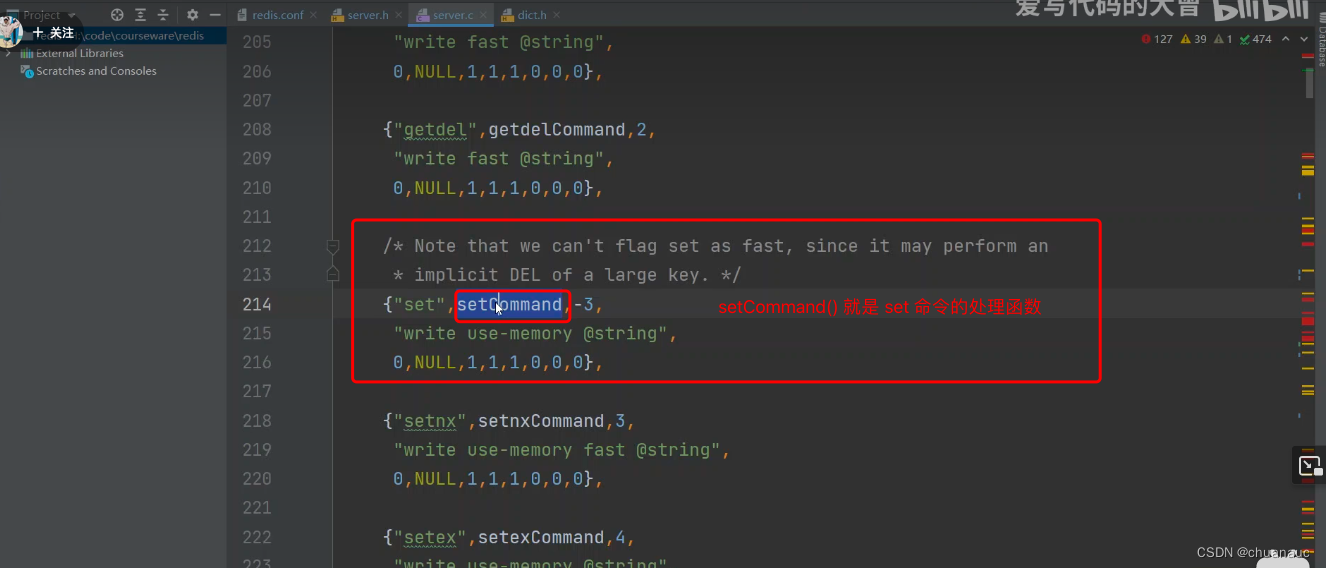
Redis 底层设计方式,Redis底层 如何 管理数据:
Redis通过 HashTable 来 存放数据:
我们知道 Redis 维护的是一个个 key-value 的项entry,而组织存放这些entry的数据结构是 HashTable,HashTable是一个数组:
通过对 entry 中 key 的 hash() 处理,并且按照HashTable大小取模,这样,把key对应到为一个int 值。该 int 值作为下标,HashTable[i] 中就存放 该entry 的 value 内容的地址,即,存放的是指向value值存放空间的指针(注意,HashTable中存的是地址,不是把entry直接存进去了)
由于hash函数会导致哈希冲突,即,不同的key可能会哈希到同一个值:Redis 通过拉链法,即,在HashTable的值指向一个个 结构体:结构体内容包括:key值,value的地址,和 next指针(用于指向下一个哈希到相同位置的entry条目),同时每次出现哈希冲突,新的entry对应的结构体以头插法的方式插入到链表头部,新头插的entry可能会在最近被访问的概率大
而哈希冲突越来越频繁的时候,拉链越来越长,找到一个对应的entry时间也越来越长,此时,HashTable就会考虑扩容:HashTable扩容的条件是:若出现一条拉链链表的长度>HashTable的长度,那么,HashTable扩容。
HashTable扩容的方式:成倍扩容:原来HashTable长度是 8 ,扩容后会开辟一个新的大小为8*2=16的空间,放置扩容的HashTable。
而后将旧的HashTable中的拉链上的各个entry结构体重新执行哈希函数,插入到扩容后的HashTable中。这个操作就被称为 rehash
主动渐进式将entry移动到新的HashTable中,操作是:不管get set 等任何访问HashTable的操作,只要访问了HashTable,就按顺序移动一个hash槽(一个哈希槽对应所有被哈希函数处理后对应到该位置的entry)内的所有内容。这么做是由于,我们使用Redis就是为了加速,而大批量新旧HashTable的数据转移会影响Redis正常功能,因此要渐进式移动数据。
在渐进式移动HashTable时,调用get()要求获得某个数据的value:执行顺序 :先去旧HashTable寻找,找不到再去新的HashTable寻找
调用set()时,直接向新的HashTable中插入(这就是为啥访问get时,会出现key找不到,是因为get的value是新set的数据,已经被插入到新的HashTable中了)
Redis对于dict(就是Redis中的数据库)rehash操作时,若如208行所示:若访问已经发现n*10个哈希槽中都没有数据(有一个字段empty_visit记录发现了多少个空哈希槽),此次访问就不rehash了,下次再有操作再说。【这说明只有部分哈希槽冲突严重,其他哈希槽都还好】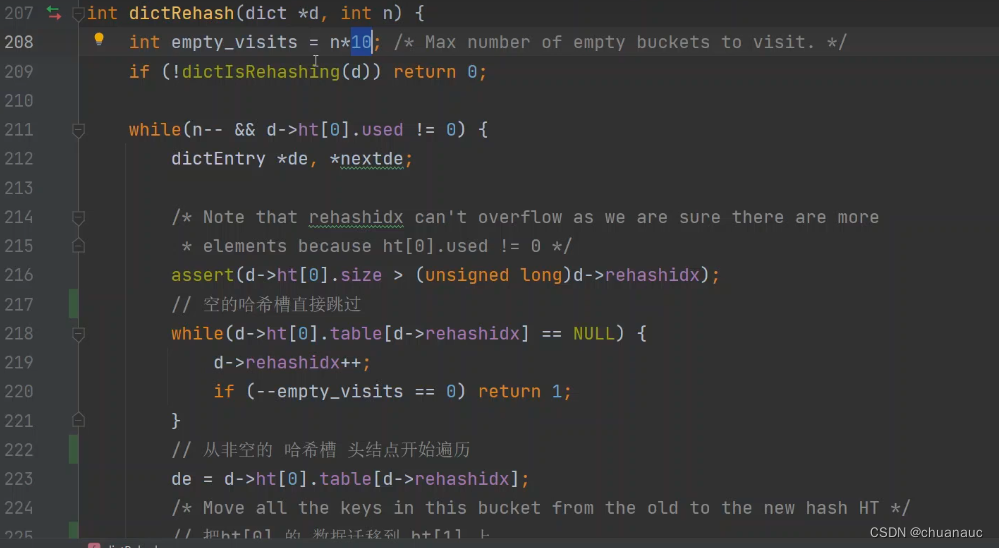
注意:HashTable大小一般是2^X大小,因为, 如下图所示, 当HashTable大小为2^X时,取模就可以使用位运算加速

Redis 的 key 数据类型:
Redis 在使用时,key可以是 整形、浮点、字符串 、音频视频等,但实际上,Redis服务器端会将无论是什么数据类型的key都转换成 String对象
SDS数据类型:
【SDS相较于char[] 做了哪些优化】
(一)减少len这个属性占的空间:
3.2和3.2版本之前SDS 数据结构用 int 来描述SDS的buf[]长度:
int占4个字节,但是buf[]长度可能只有10个,造成SDS实例空间浪费
结局方案是:Redis6版本提出了SDS 新的数据类型实现:sdshdr5
结构中包括:char类型的 flag,和 存放内容的buf[]
char占8字节,前3位用于表明这是个SDS的数据类型,后5位用来指示buf[]的长度
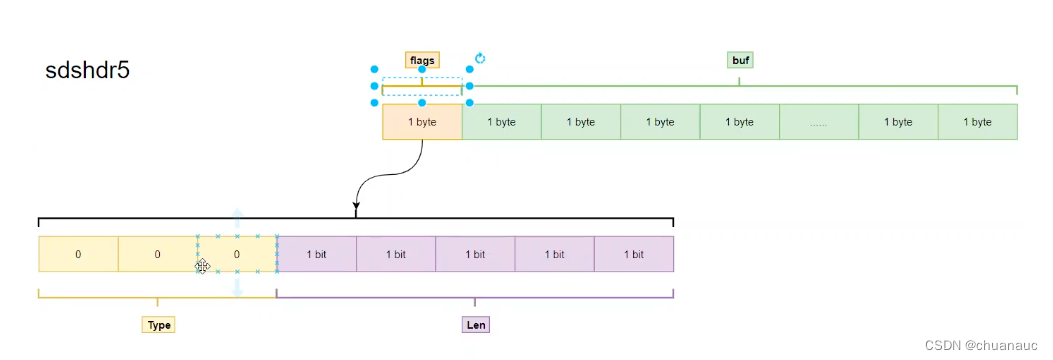
啥叫SDS数据类型:因为SDS为了不同长度的buf定义了多种不同的 sdshdrX 数据类型,有sdshdr5 , sdshdr8 等等:
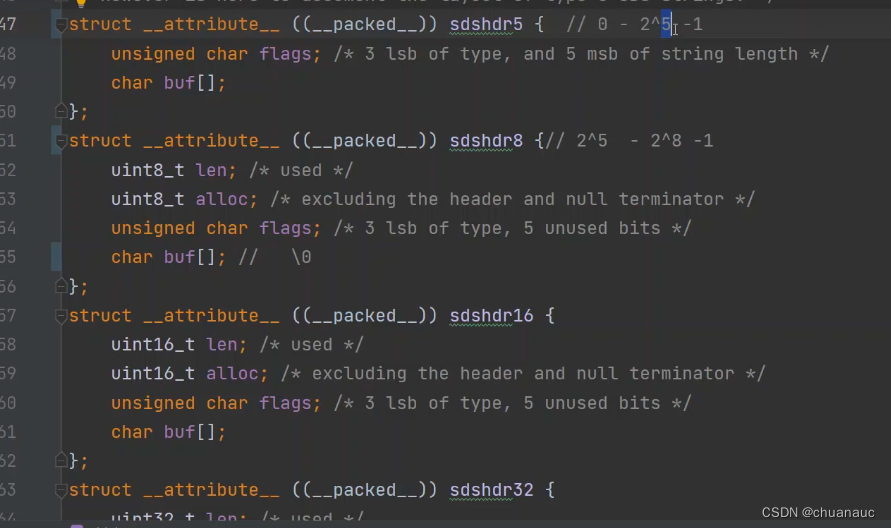
(二)预分配、懒回收:
定义字符串 ss = "lalala"时,系统会自动 malloc出6个char大小存放
此时我们想在后面加一个字符,就得重新malloc(),malloc()函数调用要很长的时间,因此,每次出现扩容需求的时候,若扩容内容<1M : 倍增原来的buf数组长度,若>1M,则满足新的buf数组的长度后在追加1M的大小
SDS的free变量(在6版本的Redis中改了个名字 叫 alloc,还是一个意思一个用法)就是记录这个每次与分配后,还剩余的空间(free也因为buf的长度不同 优化为了 uint8_t 或者 uint16_t)
(三)Redis 赋值buf[]时,也会 以 `\0`结尾,为了兼容C语言,其实就是为了少写点函数,用用C语言的函数
所以,就比如上图的sdshdr8这个结构:就是8bit的len,8bit的alloc,8bit的char,同时,由于buf[]为了和C语言字符串统一,也是以'\0'结尾,因此,要保存8bit的char,总结下来就是4个字节
(四)二进制安全,即使buf[]中出现 `\0`也没关系,不会被处理为内容结束
List数据类型:
List的常见用法API:
1. 向list中追加元素:
`LPUSH alist a b c` ==》向名为alist的列表中从左侧加入了3个元素
因此 alist的内存摆放是:c,b,a
2. 从list中取出元素:
`LPOP alist` ==》从名为alist的列表中从左侧取出元素,并从列表中删除该元素
//由于我们刚存放的方式是 c,b,a 因此,第一次LPOP取出的是 'c'
当列表alist中的元素全被取出,Redis会把 alist 这个key也释放掉
[可以感受到,list 是个双端队列]:同一边放,同一边取,list就是个栈;
一边放,另一边取,list就是个队列
而`BLPOP key timeout` 这种语句,可以设置阻塞和超时,若list中没有元素,就等着阻塞,阻塞超过设置的超时时间,就不等待了
这种阻塞API读取都有,参数类似:`BLPOP` `BRPOP`
3. `BRPOPPUSH source distination timeout` :
目的是构建类似消息队列的数据结构,当一个消息被pop出去,在处理过程中宕机或错误处理,那么,这则消息就相当于丢失了,BRPOPPUSH则选择对于list中的每个元素,pop之前加入到source队列中,这样就算处理失败,该元素也不会消失,依旧存在
list的底层设计:
1. list中存放的元素 长度不定,同时操作从list两边去读写 ==》因此会想到使用双端链表
但是,双端链表需要2个指针,一个指针8字节,因此,哪怕list存储的元素所占内存很少,list也至少需要16字节来存放指针等基本信息。
这样的内存开销Redis不能接受,因此,Redis选择ziplist 作为底层数据结构,存放list的各个元素
2. ziplist 底层编码:【ziplist是紧凑的二进制数据编码类型,每次数据发生变动都需要:新建存储空间,数据移动复制,指向新的空间三个步骤】
由于向ziplist中追加数据时,由于 ziplist存放数据内容的空间是一段连续的空间,因此,每次追加都需要新开辟足够的空间、将就空间的数据赋值移动,再吧新加入的数据append到新空间,这个操作在ziplist存放的数据量打的时候很费时间(因为又要开辟空间,又要O(n)复制),因此,采用双层结构,quicklist组织quickNode,quickNode节点中的数据部分就是ziplist数据类型的。(ziplist这种二进制编码方式也注定他只能每次修改数据都要 重新开辟一次空间),因此,现在多了quickNode,并有专门的属性控制:若quickNode节点中的ziplist长度过长,在修改时就会影响效率,那么就把一个QuickNode中的ziplist内容拆分成两个QuickNode中的ziplist 内容
如下图所示:头结点尾结点的quicklist的quicknode节点不压缩这个优化的原因是:因为经常使用的就是头尾节点,因此,不压缩就是好的

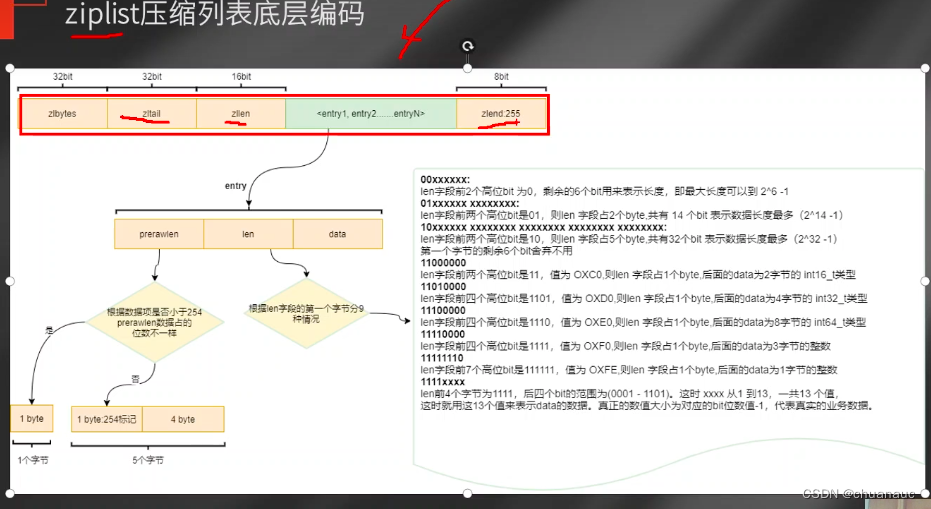

一次新开辟一个比较连续的内存空间存放ziplist:黄色部分是ziplist的描述信息:
第一块32bits:描述 绿色部分的数据部分占多少个字节
第二块32bits:最后的一个元素在绿色数据部分的位置(记录偏移量) -- 因为不一定全都把数据部分用满
第三块16bits:在绿色数据部分存放了多少个元素
最后一块8bits :用于表明是ziplist的结尾
数据元素 放在绿色部分:每个元素是一个entry类型:
【压缩存放太复杂了别看了】-- 就是 数据存储不是字符,而是二进制方式存储
而list的底层实现:是用双端链表整合多个ziplist,组成最终的list:
quicklist 包含 以quicklsNode为元素的双端队列,quicklsNode 中的数据部分就是 ziplist
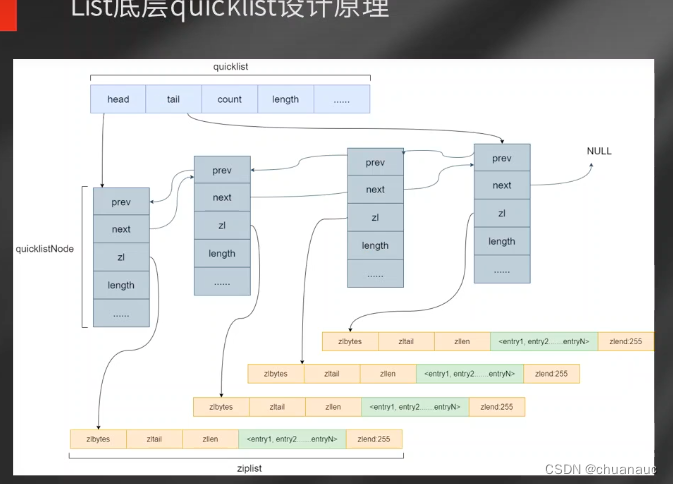
==》list 的type 是list ,编码类型(通过encoding Object aalist)获得,是quicklist
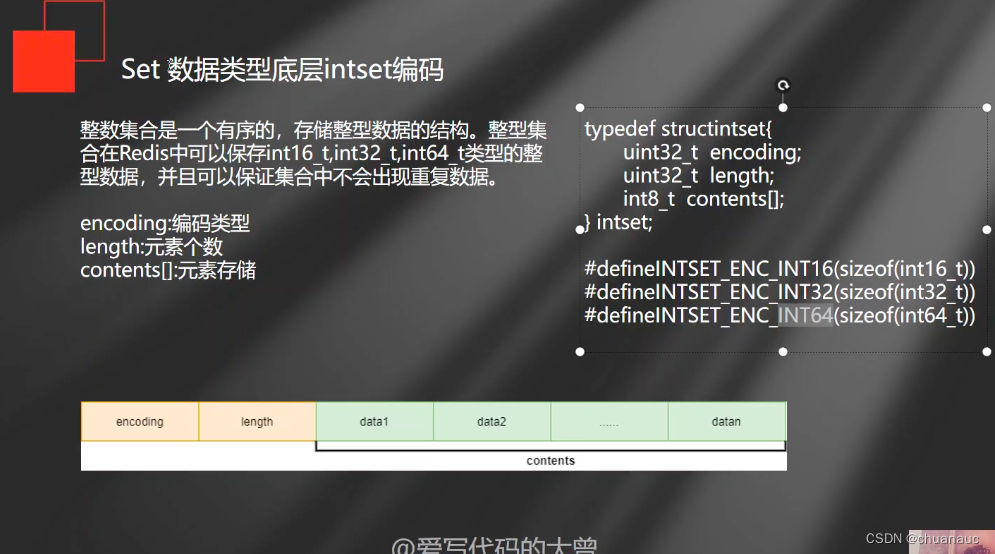
Set数据类型:
Set的API:
1. 向aset 中添加内容 :`SADD aset 1 2 3 4 3 100 77 66 `
2. 获得set中的元素:`SMEMBERS aset`
==>此时展示的aset中的数据内容是否有序和不重复其实因为 把数据中的内容 编码为intset,因此库有序但无重复
当向 aset中添加其他数据类型(如string后),Redis的底层编码就会变为HashTable,而此时再次调用 `SMEMBERS aset` 就会发现 元素 无序且不重复(因为HashTable是无序的)
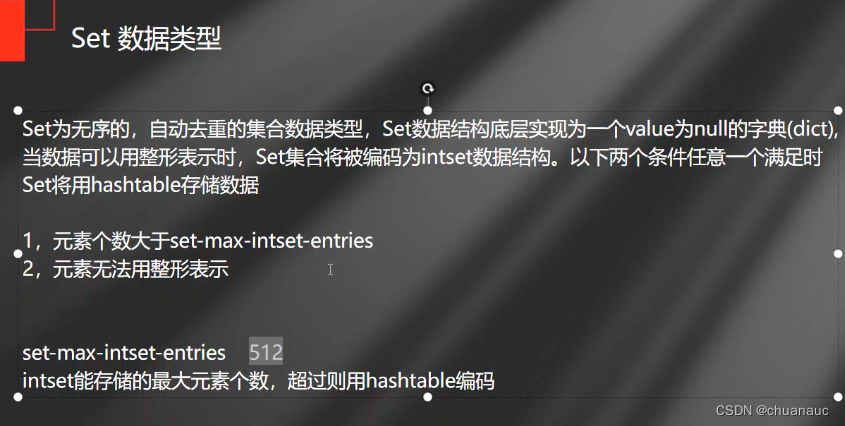
intset数据类型就是一个数组:如果往 intset中添加新元素,如果存值的数组空间不够,就得扩容;空间够的话,就把intset的部分数据往后移,流出空间放新的插入数据i
不过intset由于都是数值,因此,可以很方便 二分查找定位元素
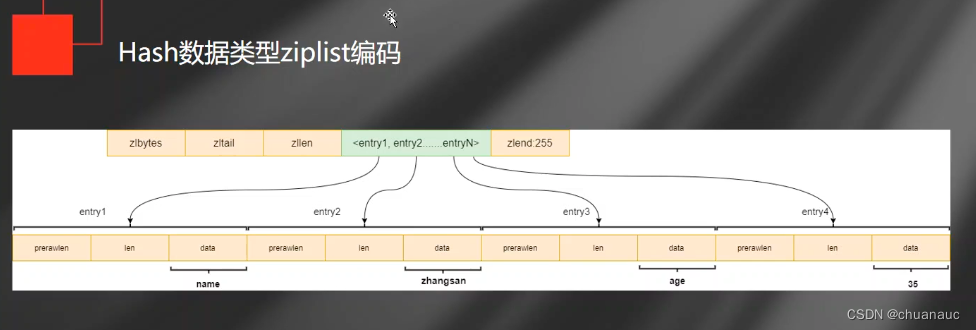
Hash 数据类型:
常见hash的API:
1. 定义一个hash对象ahash ,加入键值对 <k1,v1> <k2,v2> hset ahash k1 v1 k2 v2
hash编码方式:

当Hash数据类型时 ziplist编码时,就会按顺序存放
当内容过大时,就会采用hashtable存放key和value的内容,此时就不再有序了
zset数据类型:有序的无重复列表
zset常见API:
1. 向 zset中添加元素 :`ZADD azset 100 a 200 b 50 c` ==》向azset中添加元素和他们的分值,让zset根据分值排序
2. 由于zset中元素有序,获取zset中 某个区间的元素集 : `ZRANGE azset 0 3 withscores` ==> 获取从第0名到第3名的全部元素和他们的分值
zset 默认升序排列,也可以通过 `ZrevRANGE azset 0 3 withscores` 获得降序排列
zset编码方式:
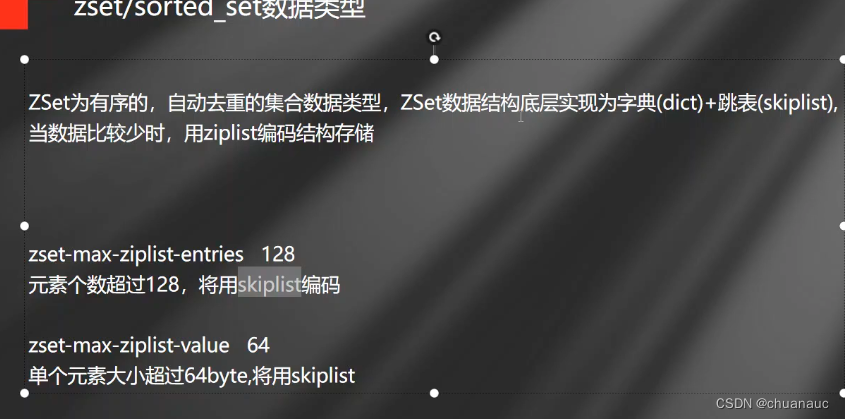
当数据量小的时候使用ziplist
当数据量大的时候使用skiplist
跳表:
由于链表要求有序,但只有序是的链表也只能O(n)复杂度,因此,提一层索引层,可以加速查找,先确定范围之后下沉一层,去查找,,,如下图所示:

真正实现会有很多层索引,比较索引 -- 下沉查找 -- 比较索引 -- 下沉查找,直到确定范围
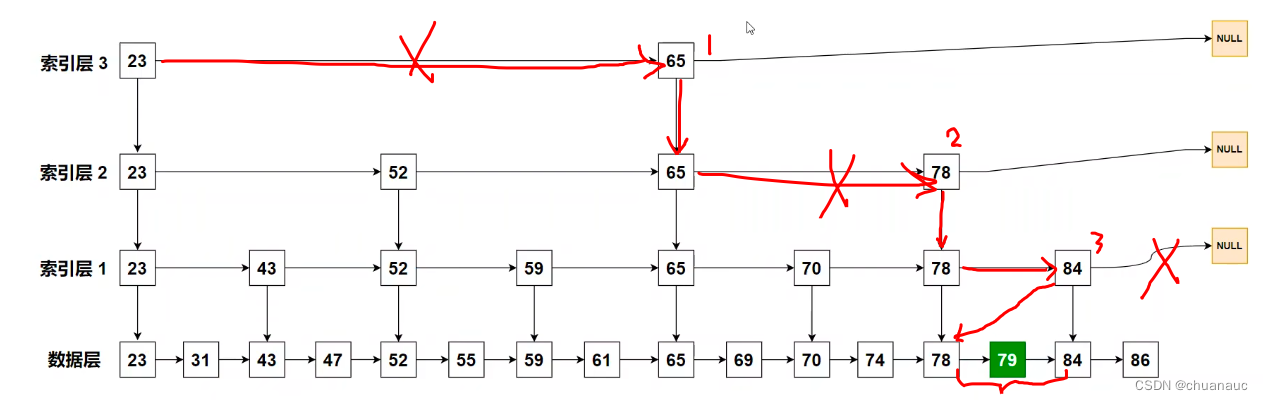
下沉一层去查找,每次可以减少一半的查找范围,故,跳表时间复杂度logN,N就是几层的索引
跳表的数据结构:
zset的跳表数据编码的方式如下:
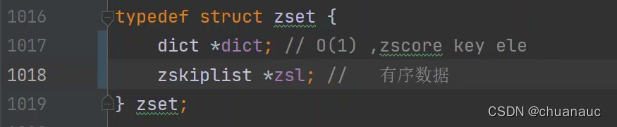
dict字典类型 将分值 和 key进行存储
如1018所示,(当key或value值过大)zset中的编码实现就是 跳表zskiplist
。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。
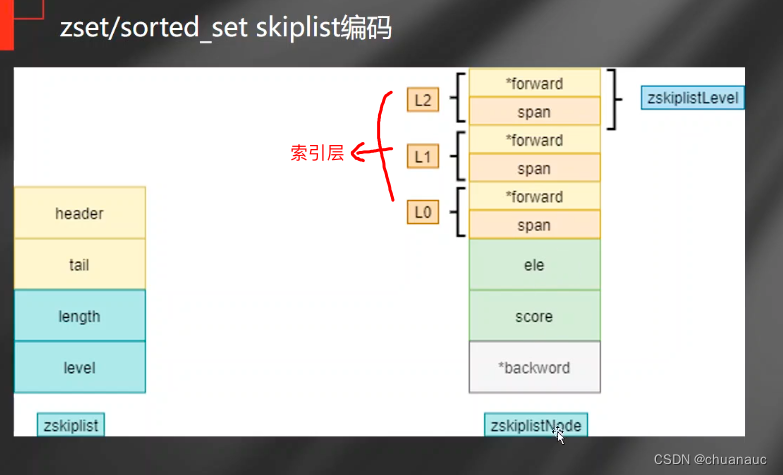
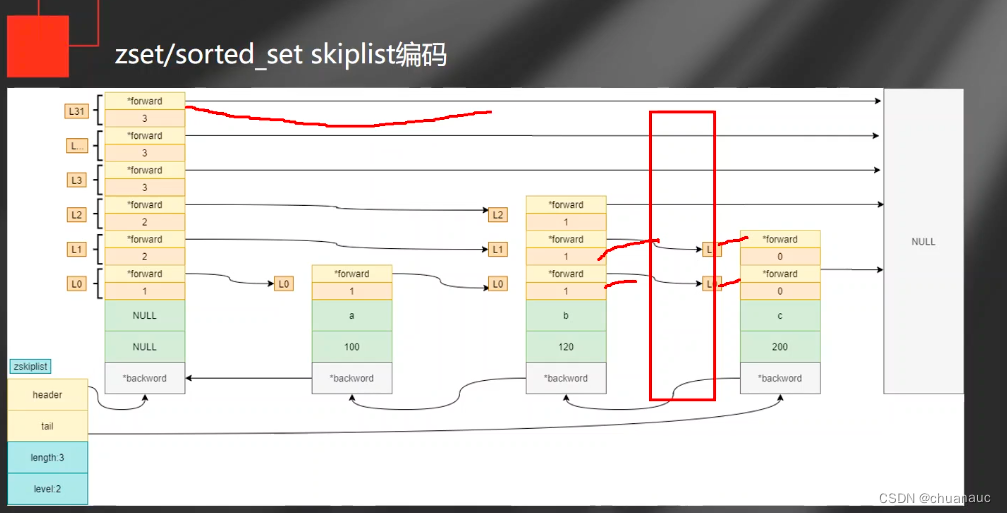
下图是zskiplist的数据结构:
level记录索引的层次个数
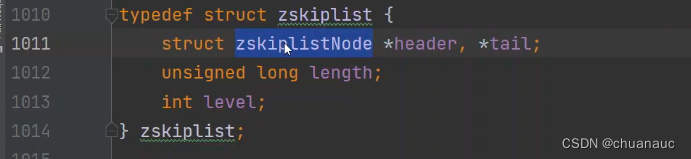
zskiplistLevel就是 索引层 ,其中的span数据表明该层次的索引中,两个索引间隔多少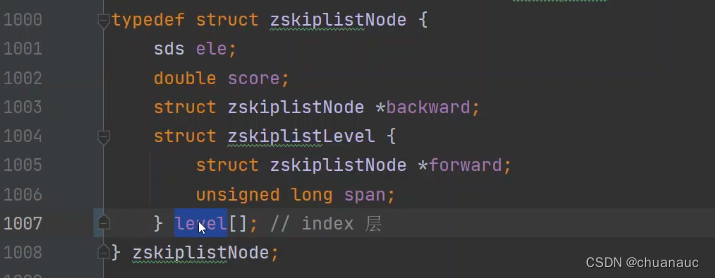
跳表中的元素存在,但分数发生改变:若新的分时还能使得该元素在原来的位置,直接重置值即可;若位置改变,先把原来的元素删去,在把新的元素-分数插入进zset
相关文章:
Redis 总结【6.0版本的】
还差什么?【按照这个为基础,对照他的Redis路线图,冲冲冲】 Redis的常见操作和命令:Redis基本操作命令(图文详解)_redis 命令_进击小高的博客-CSDN博客 Redis的持久化,一致性:AOF&…...

状态模式(C++)
定义 允许一个对象在其内部状态改变时改变它的行为。从而使对象看起来似乎修改了其行为。 应用场景 在软件构建过程中,某些对象的状态如果改变,其行为也会随之,而发生变化,比如文档处于只读状态,其支持的行为和读写…...

承泰科技Q3再获30多个智驾项目,新增订单0.86亿!累计近11亿!
中国毫米波雷达市场正处于高速发展期,以承泰科技为代表的本土供应商在前装量产赛道上展示出加速度。 高工智能汽车研究院预测,随着L2及L2持续处于市场增长的高速期,对应毫米波雷达上车量将在2023年实现30-50%的同比增速。 根据高工智能汽车…...

以太网Ethernet通信协议
一、以太网简介 计算机网络可分为局域网(LAN)、 城域网(MAN)、广域网(WAN)、互联网(Initernet)。局域网按传输介质所使用的访问控制方法可分为:以太网(Ethernet)、光纤分布式数据接口(FDDI)、异步传输模式(ATM)、令牌环网(Token Ring)、交换网(Switching) 等&#x…...

内网横向移动—资源约束委派
内网横向移动—资源约束委派 1. 资源约束委派1.1. 基于资源的约束委派的优势1.2. 约束性委派和基于资源的约束性委派配置的差别1.3. 利用条件1.3.1. 什么用户能够修改msDS-AllowedToActOnBehalfOfOtherIdentity属性1.3.2. 将机器加入域的域用户 2. 案例操作2.1. 获取目标信息2.…...

Spring Boot Logback日志格式改为JSON
在阿里云、或者日志分析时使用JSON格式输出日志更加方便。 依赖 增加Logbak JSON解析依赖。 另外需要注意的是JSON格式输出依赖Jackson,根据工程情况按需添加Jackson依赖。 <!--日志--><dependency><groupId>ch.qos.logback.contrib</grou…...

Linux 块设备操作函数
和字符设备的fil_operations一样,块设备也有操作集,为结构体block_device_operations,此结构体定义在include/linux/blkdev.h中,结构体内容如下: struct block_device_operations {int (*open) (struct block_device …...

linux c++网络编程基础:服务端与客户端的实现
在Linux环境下,我们可以使用socket编程来实现网络通信。下面是一个简单的C++版本的客户端和服务端的示例代码。 服务端代码: #include <sys/socket.h> #include <netinet/in.h> #include <unistd.h> #include <string.h> #...

坐标转换-使用geotools读取和转换地理空间表的坐标系(sqlserver、postgresql)
前言: 业务上通过GIS软件将空间数据导入到数据库时,因为不同的数据来源和软件设置,可能导入到数据库的空间表坐标系是各种各样的。 如果要把数据库空间表发布到geoserver并且统一坐标系,只是在geoserver单纯的设置坐标系只是改了…...

JavaScript的主要应用场景有哪些?请描述一下JavaScript的基本数据类型和引用数据类型分别是哪些?
1、JavaScript的主要应用场景有哪些? JavaScript是一种广泛使用的编程语言,它主要用于Web开发、移动应用开发、游戏开发、物联网设备开发等场景。以下是JavaScript的主要应用场景: Web开发:JavaScript是Web开发中最常用的编程语…...
webpack性能优化
文章目录 1. 性能优化-分包2. 动态导入3. 自定义分包4. Prefetch和Preload5. CDN加载配置6. CSS的提取7. terser压缩7.1 Terser在webpack中配置7.2 css压缩 8. Tree Shaking 消除未使用的代码8.1 usedExports 配置8.2 sideEffects配置8.3 CSS实现Tree Shaking 9. Scope Hoistin…...

保存和读取带有透明通道的视频
保存带有透明通道的视频: import osimport imageio from rembg import remove as removBg,new_session from PIL import Image import numpy as np import cv2 from tqdm import tqdmclass cls_rembg():def __init__(self,model_pth):self.session new_session(mo…...
bilibili的评论ip属地显示未知
现象 出于某些原因,我们在日常使用中的大部分平台都开启了IP地址显示,一般会显示当事人所在的地址,这其中就有一些奇怪的地址,(在此不谈魔法)就比如我最近在刷B站的时候,就在评论区发现了一些显…...
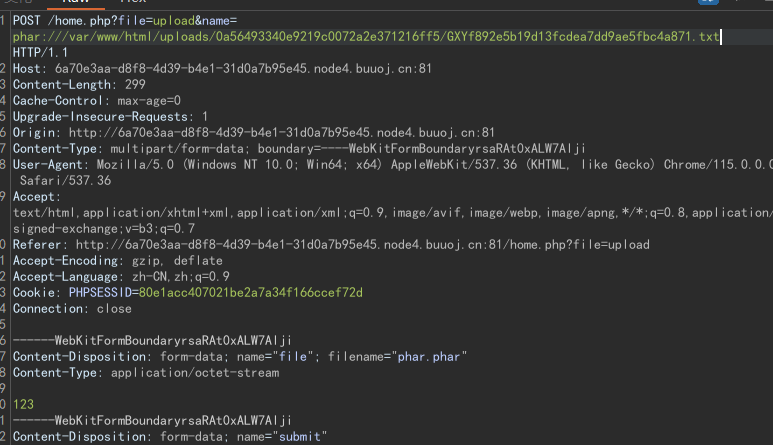
[BabysqliV3.0]phar反序列化
文章目录 [BabysqliV3.0]phar反序列化 [BabysqliV3.0]phar反序列化 开始以为是sql注入 [外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-ST1jvadM-1691302941344)(https://raw.githubusercontent.com/leekosss/photoBed/master/202308032140269.png)…...

数据库架构演变过程
🚀 ShardingSphere 🚀 🌲 算法刷题专栏 | 面试必备算法 | 面试高频算法 🍀 🌲 越难的东西,越要努力坚持,因为它具有很高的价值,算法就是这样✨ 🌲 作者简介:硕风和炜&…...

webpack 静态模块打包工具
webpack 为什么? 把静态模块内容,压缩,整合,转译等(前端工程化) 把less/sass转成css代码把ES6 降级成ES5支持多种模块文件类型,多种模块标准语法 vite 为什么不直接学习vite 而学习webpack 因为很多项目还是基于webpack来进…...

万界星空科技/免费开源MES系统/免费仓库管理
仓库管理(仓储管理),指对仓库及仓库内部的物资进行收发、结存等有效控制和管理,确保仓储货物的完好无损,保证生产经营活动的正常进行,在此基础上对货物进行分类记录,通过报表分析展示仓库状态、…...

【暑期每日一练】 Epilogue
目录 选择题(1)解析: (2)解析: (3)解析: (4)解析: (5)解析: 编程题题一描述输入描述:输…...

Go微服务实践 - Rpc核心概念理解
概述 从0研究一下Golang已经Golang的微服务生态体系,Golang的微服务首先要从Rpc开始,在升级到Grpc,详细介绍这些技术点都在解决什么技术问题。 Rpc Rpc (Remote Procedure Call) 远程过程调用,简单的理解是一个节点请求另一个节…...

Effective Java笔记(27)消除非受检的警告
用泛型编程时会遇到讲多编译器警告 : 非受检转换警告( unchecked cast warning )、非受检方法调用警告、非受检参数化可变参数类型警告( unchecked parameterized vararg type warning),以及非受检转换警告…...

Unity-MCP协议:可嵌入、可协商的AI上下文通信标准
1. 这不是又一个“AI插件”,而是Unity开发工作流的底层重定义你有没有过这样的时刻:在Unity里反复调整Animator Controller的过渡条件,只为让角色转身动画不穿模;写完一段NavMesh寻路逻辑,却要花两小时调试Agent卡在斜…...

如何进行TVA仿真引擎的“光照地狱”训练?
重磅预告:本专栏将独家连载系列丛书《智能体视觉技术与应用》部分精华内容,该书是世界首套系统阐述“因式智能体”视觉理论与实践的专著,特邀美国 TypeOne 公司首席科学家、斯坦福大学博士 Bohan 担任技术顾问。Bohan先生师从美国三院院士、“…...
)
毕业设计 yolov11骨折检测医疗辅助系统(源码+论文)
文章目录 0 前言1 项目运行效果2 课题背景2.1 研究背景2.2 国内外研究现状2.3 研究意义 3 设计框架(骨折检测系统设计框架说明)3.1. 系统架构图3.2. 技术选型3.2.1 核心组件3.2.2 辅助工具 3.3. 核心模块设计3.3.1 YOLO模型训练模块训练流程图关键伪代码…...

AI学习 - 大模型基础入门
AI学习 - 大模型基础入门 从零开始:Ollama 安装 → 本地模型运行 → Python 代码接入 → 理解核心概念 摘要 本文记录了在 Windows 上使用 Ollama 部署本地大模型、并通过 Python 代码接入调用的完整过程。内容涵盖:Ollama 安装与模型拉取、大模型基础概…...

XML 服务器
XML 服务器 引言 XML(可扩展标记语言)服务器在现代互联网技术中扮演着至关重要的角色。它为数据的传输和处理提供了灵活且高效的方式。本文将深入探讨XML服务器的概念、工作原理、应用场景及其在软件开发中的重要性。 什么是XML服务器? XML服务器是一种用于存储、处理和…...

【紧急预警】Lindy衰减临界点已提前至第8.3个月!2024最新《营销自动化寿命健康度白皮书》限时开放前500份
更多请点击: https://kaifayun.com 第一章:Lindy衰减临界点的理论重构与实证突破 Lindy效应传统上描述“越老越长寿”的非线性生存规律,但其在现代软件系统、开源生态与协议层技术栈中的适用边界正遭遇结构性挑战。本文首次将Lindy模型从静…...
)
Postgresql基础实践教程(八)
⭐️⭐️⭐️⭐️⭐️ 完整数据详见 练习数据免费 ⭐️⭐️⭐️⭐️⭐️ 六十九、查找会员ID 27的向上推荐链 问题 查找会员ID 27的向上推荐链:即推荐该会员的人,以及推荐那个人的人,依此类推。返回会员ID、名字和姓氏。按会员ID降序排列。…...
与 NOT EXISTS 优化)
PostgreSQL Join 执行策略(Nested Loop、Hash Join、Merge Join)与 NOT EXISTS 优化
以集成数据压缩 SQL 优化为例,用大白话讲清楚 Nested Loop、Hash Join、Merge Join 三种执行策略。一、背景:一条慢 SQL 引发的思考 在对上游下发数据做压缩时,有这样一条 UPDATE SQL: -- ❌ 原始写法 UPDATE magellan_nk_order_i…...

公共卫生机器学习项目中的算法公平性实践:ACAR框架详解
1. 项目概述:当机器学习遇见公共卫生,公平性为何成为“必答题”?在公共卫生领域,机器学习(ML)正以前所未有的速度渗透到疾病监测、风险分层和资源分配等核心环节。想象一下,一个模型被用来预测某…...

ncmdumpGUI终极指南:3分钟搞定网易云音乐NCM文件转换
ncmdumpGUI终极指南:3分钟搞定网易云音乐NCM文件转换 【免费下载链接】ncmdumpGUI C#版本网易云音乐ncm文件格式转换,Windows图形界面版本 项目地址: https://gitcode.com/gh_mirrors/nc/ncmdumpGUI 还在为网易云音乐的NCM加密格式而烦恼吗&…...