MyBatis缓存
文章目录
- MyBatis的缓存
- 1、缓存概述
- 2、MyBatis的一级缓存
- 2.1 一级缓存的使用
- 2.2 一级缓存的失效
- 3、MyBatis的二级缓存
- 3.1 二级缓存的开启
- 3.2 二级缓存的失效
- 3.2 二级缓存相关配置
- 4、系统缓存的查询顺序
- 5、EHCache的使用
- 5.1 EHCache基本介绍
- 5.2 EHCache的基本使用
- 5.3 EHCache配置文件参数详解
MyBatis的缓存
1、缓存概述
-
什么是缓存?
缓存:存储在计算机上的一个原始数据复制集,就是数据交换的缓冲区(称作Cache),是存贮数据(使用频繁的数据)的临时地方。当用户查询数据,首先在缓存中寻找,如果找到了则直接执行。如果找不到,则去数据库中查找。
-
缓存有什么用?
缓存的本质就是用空间换时间,牺牲数据的实时性,以服务器内存中的数据暂时代替从数据库读取最新的数据,减少数据库IO,减轻服务器压力,减少网络延迟,加快页面打开速度。
-
缓存的分类:
- 文件缓存:文件缓存是把一些需要高速存取的变量缓存在内存中。模板引擎用的就是文件缓存机制,把动态代码编译成静态文件放入硬盘,不用每次访问都编译,直接读出即可。
- 浏览器缓存:浏览器缓存根据一套与服务器约定的规则进行工作,在同一个会话过程中会检查一次并确定缓存的副本足够新。如果在浏览过程中前进或后退时访问到同一个图片,这些图片可以从浏览器缓存中调出而即时显示。
- 数据库缓存:常用的缓存方案有memcached、redis等。把经常需要从数据库查询的数据、或经常更新的数据放入到缓存中,这样下次查询时,直接从缓存直接返回,减轻数据库压力,提升数据库性能。
- Web应用层缓存:应用层缓存指的是从代码层面上,通过代码逻辑和缓存策略,实现对数据、页面、图片等资源的缓存,可以根据实际情况选择将数据存在文件系统或者内存中,减少数据库查询或者读写瓶颈,提高响应效率。
- 服务器缓存:包括代理服务器缓存和CDN缓存。
- 代理服务器缓存:代理服务器是浏览器和源服务器之间的中间服务器,浏览器先向这个中间服务器发起Web请求,经过处理后(比如权限验证,缓存匹配等),再将请求转发到源服务器。
- CDN缓存:也叫网关缓存、反向代理缓存。CDN缓存一般是由网站管理员自己部署,为了让他们的网站更容易扩展并获得更好的性能。
MyBatis的缓存属于Web应用层缓存,在MyBatis中缓存被分为两大类:系统缓存和自定义缓存
- 系统缓存:是MyBatis中自带的缓存,这些缓存都是MyBatis帮我们设计好了的,直接就能用,主要包含一级缓存和二级缓存
- 自定义缓存:顾名思义,就是自己定义的缓存,需要自己手动去设计,当然一般而言我们并不会真正的区设计一个缓存,而是直接使用第三方设计的缓存,比如:Redis、Enhance等
2、MyBatis的一级缓存
一级缓存:一级缓存是默认开启的,它的范围是
SqlSession级别的,当我们用SqlSession来查询数据的时候,如果下一次再使用相同的SqlSession进行查询的时候,就会直接从缓存中取数据,如果没有才从数据库中取数据,缓存只针对查询功能有效
2.1 一级缓存的使用
示例:
import com.hhxy.mapper.CacheMapper;
import com.hhxy.pojo.Emp;
import com.hhxy.utils.SqlSessionFactoryUtil;
import org.apache.ibatis.session.SqlSession;
import org.apache.ibatis.session.SqlSessionFactory;
import org.junit.Test;/*** @author ghp* @date 2022/9/9*/
public class CacheMapperTest {@Testpublic void cacheMapperTest(){//1、获取SqlSessionFactory对象SqlSessionFactory sqlSF = SqlSessionFactoryUtil.getSqlSF();//2、获取SqlSession对象SqlSession sqlS1 = sqlSF.openSession();SqlSession sqlS2 = sqlSF.openSession();//3、获取Mapper接口对象CacheMapper mapper1 = sqlS1.getMapper(CacheMapper.class);CacheMapper mapper2 = sqlS2.getMapper(CacheMapper.class);//4、执行SQLint empId = 20;/*使用SqlSession1执行SQL*/Emp emp1 = mapper1.getEmpById(empId);System.out.println("emp1 = " + emp1);Emp emp2 = mapper1.getEmpById(empId);System.out.println("emp2 = " + emp2);/*使用SqlSession2执行SQL*/Emp emp3 = mapper2.getEmpById(empId);System.out.println("emp3 = " + emp3);//5、释放资源}
}
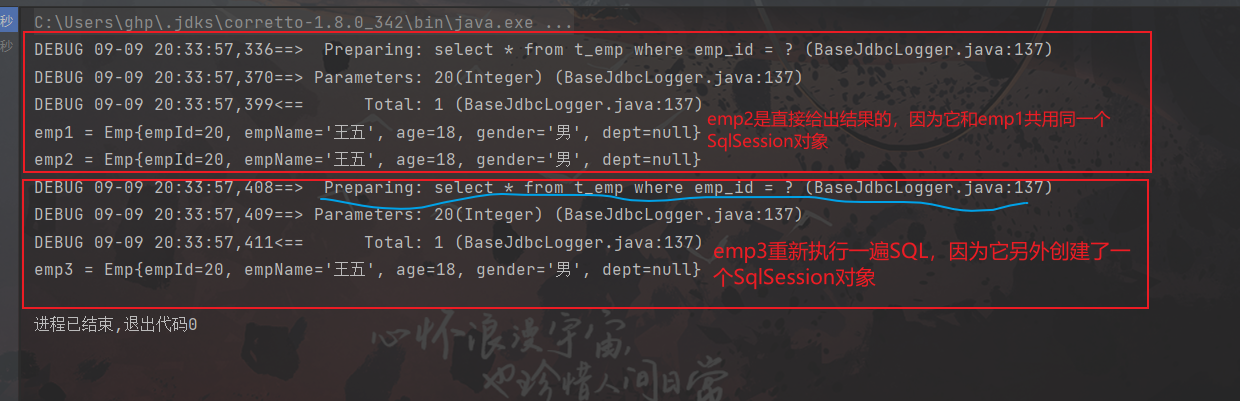
2.2 一级缓存的失效
使一级缓存失效的四种情况:
-
不同的SqlSession对应不同的一级缓存
这是由一级缓存的级别决定的,详情见上面的示例,不在赘述
-
同一个SqlSession但是查询条件不同
这个也很好理解,不同条件查询得到的数据是不一致的
-
同一个SqlSession两次查询期间执行了任何一次增删改操作
因为增、删、改会清空一级缓存,原因:缓存中的数据毕竟不是数据库中的即时数据,在执行增删改操作后,可能会影响到我们上一次刚查询的数据(此时缓存中的数据就已经过时了,比如:进行第一次查询,数据进入缓存,但进行一个删除操作后将这条进入缓存的数据从数据库中删除了,第二次查询这条数据已经不存在了,直接使用缓存中的数据显然的错误的),所以MyBatis干脆就规定了增删改后,直接清空一级缓存,这样就能保证二次查询的正确性
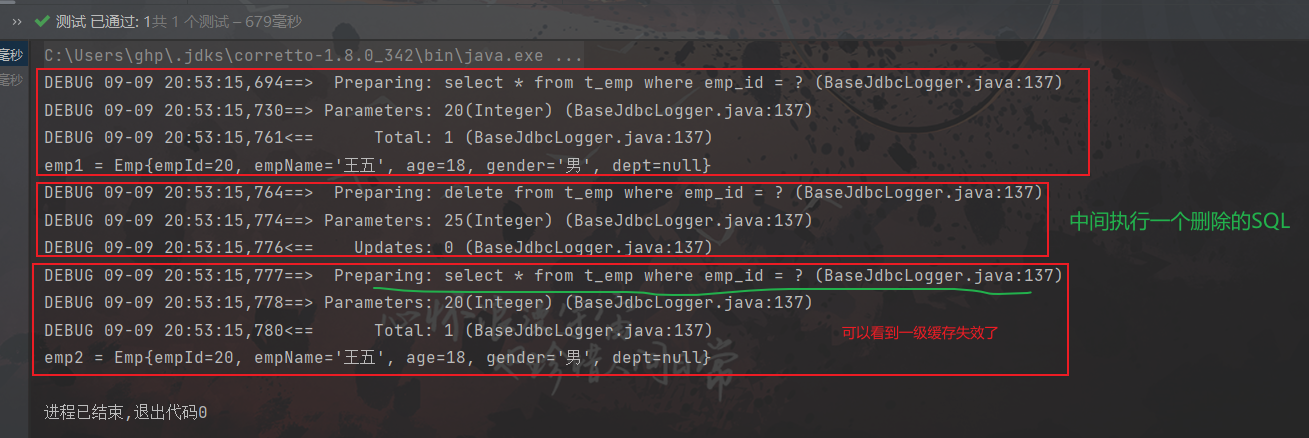
-
同一个SqlSession两次查询期间手动清空了缓存
//清空一级缓存的代码 sqlSession.clearCache();
3、MyBatis的二级缓存
二级缓存:二级缓存需要手动开启,它的范围是
SqlSessionFactory级别的,通过同一个SqlSessionFactory创建的SqlSession查询的结果会被缓存;此后若再次执行相同的查询语句,结果就会从缓存中获取
3.1 二级缓存的开启
-
二级缓存的开启条件:
-
在核心配置文件中,设置全局配置属性
cacheEnabled="true",默认为true,不需要设置<setting name="cacheEnabled" value="true"/> -
在映射文件中设置标签
<cache/>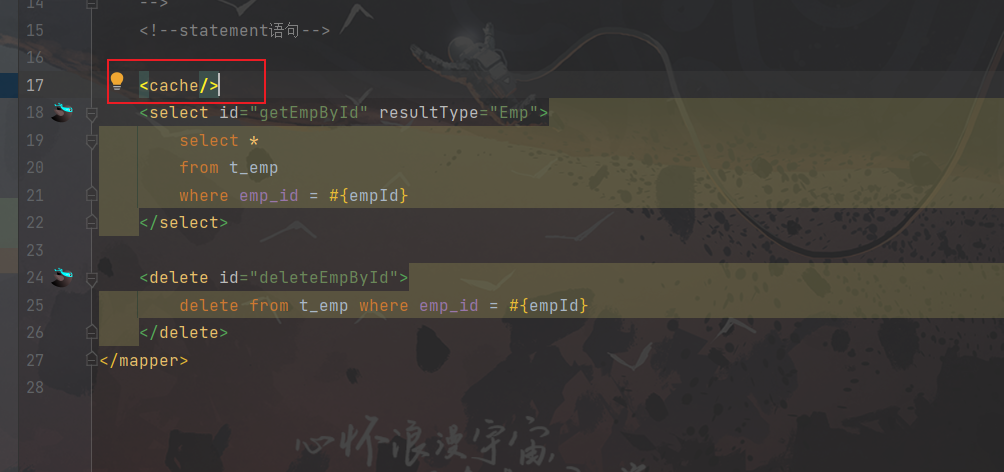
-
二级缓存必须在SqlSession关闭或提交之后有效,不进行关闭或提交,则查询的数据会自动进入一级缓存
-
查询的数据所转换的实体类类型必须实现序列化的接口,否则报
java.io.NotSerializableException: com.hhxy.pojo.Emp异常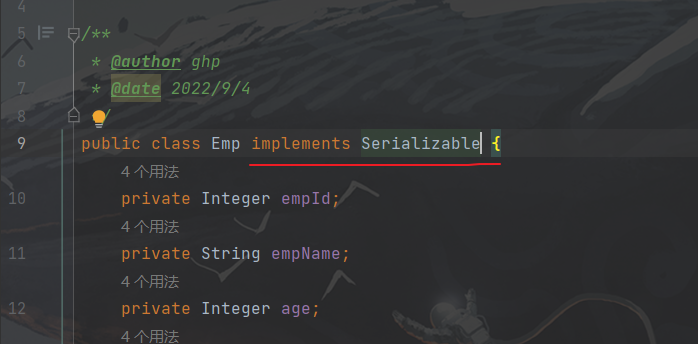
-
示例:
二级缓存测试代码:
import com.hhxy.mapper.CacheMapper;
import com.hhxy.pojo.Emp;
import com.hhxy.utils.SqlSessionFactoryUtil;
import org.apache.ibatis.session.SqlSession;
import org.apache.ibatis.session.SqlSessionFactory;
import org.junit.Test;/*** @author ghp* @date 2022/9/9*/
public class CacheMapperTest {@Testpublic void cacheMapperTest(){//1、获取SqlSessionFactory对象SqlSessionFactory sqlSF = SqlSessionFactoryUtil.getSqlSF();//2、获取SqlSession对象SqlSession sqlS1 = sqlSF.openSession();SqlSession sqlS2 = sqlSF.openSession();//3、获取Mapper接口对象CacheMapper mapper1 = sqlS1.getMapper(CacheMapper.class);CacheMapper mapper2 = sqlS2.getMapper(CacheMapper.class);//4、执行SQLint empId = 20;/*使用SqlSession1执行SQL*/Emp emp1 = mapper1.getEmpById(empId);System.out.println("emp1 = " + emp1);sqlS1.close();//如果去掉这句话,就会执行两遍SQL/*使用SqlSession2执行SQL*/Emp emp2 = mapper2.getEmpById(empId);System.out.println("emp3 = " + emp2);//5、释放资源}
}
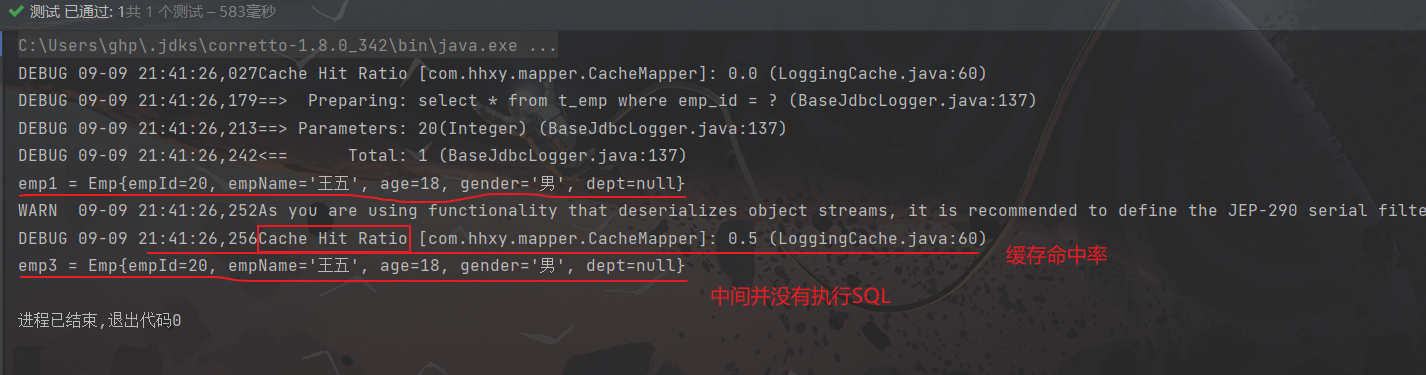
备注:只有二级缓存才会输出缓存命中率
3.2 二级缓存的失效
-
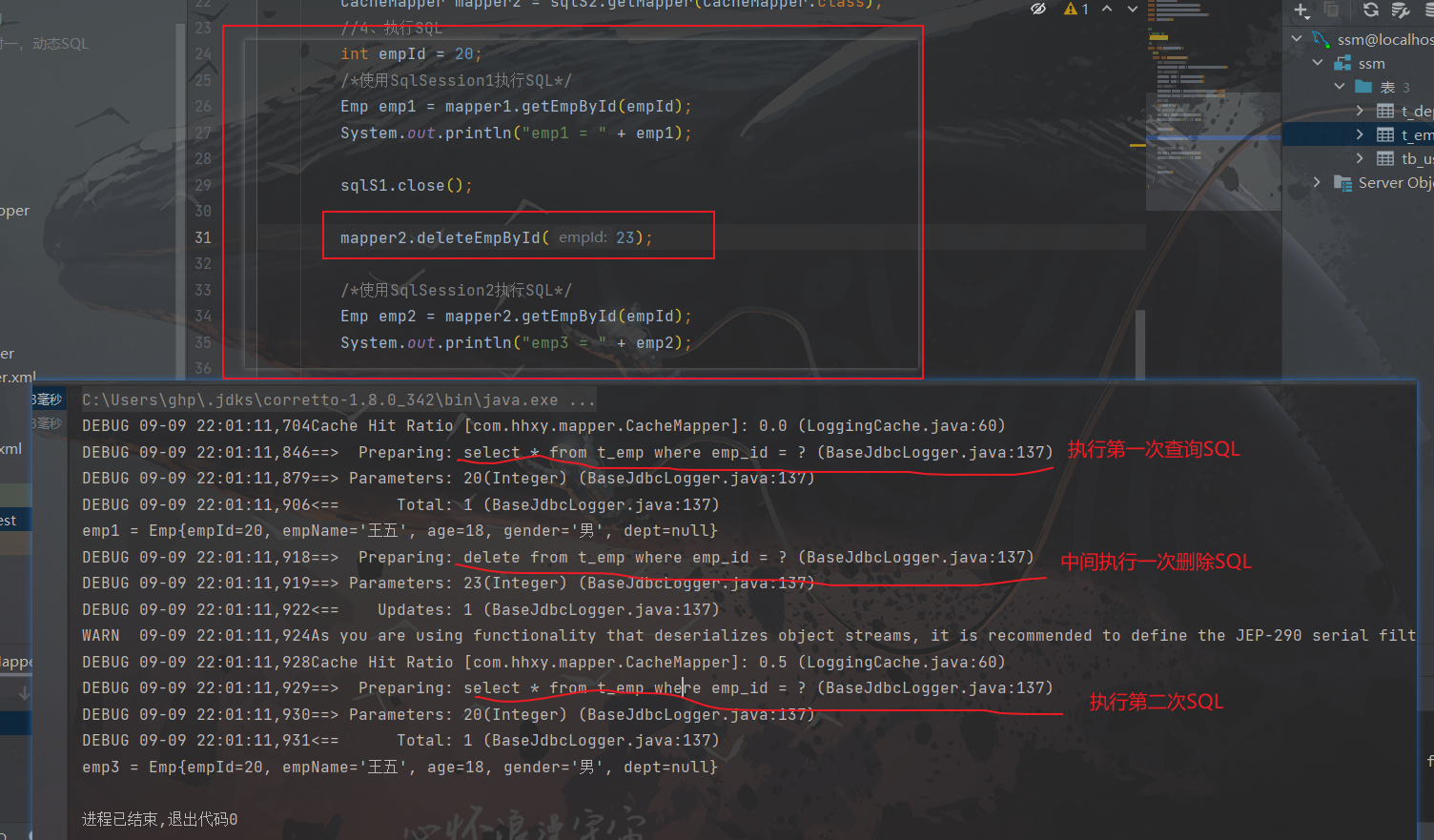
使二级缓存失效的情况: 两次查询之间执行了任意的增、删、改,会使一级和二级缓存同时失效
因为增、删、改清除了二级缓存,当第二次进行查询时,先到缓存区中寻找是否具有所需数据,结果由于缓存区被清空了,所以重新执行SQL语句到数据库中查询并获取数据
3.2 二级缓存相关配置
-
在mapper配置文件中添加的
cache标签可以设置一些属性:eviction属性:缓存回收策略,默认的是 LRU- LRU(Least Recently Used):最近最少使用的,移除最长时间不被使用的对象
- FIFO(First in First out):先进先出,按对象进入缓存的顺序来移除它们
- SOFT :软引用1,内存不足时回收,JVM会根据当前堆的使用情况来判断何时回收(一般当缓存溢出时,就会回收软引用的对象)
- WEAKReference:弱引用,GC触发就回收,JVM一旦发现使用弱引用规则指向的对象就会直接回收
- StrongReference:强引用,不会被回收,JVM宁愿抛出异常也不会回收使用强引用规则指向的对象(这是Java中最普遍的引用)
- PhantomReference:虚引用,虚引用主要用来跟踪对象的回收,并不影响对象的生命周期,使用虚引用规则指向的对象可能随时被回收
推荐阅读:
-
页面置换算法相关概念和计算:详细解说LRU算法和FIFO算法
-
强、软、弱、虚引用的区别和使用 - 知乎 (zhihu.com)
-
Java:强引用,软引用,弱引用和虚引用
-
flushInterval属性:刷新间隔,单位为毫秒。默认是不设置(也就是没有刷新间隔),只有缓存被调用时进行刷新 -
size属性:引用数目,为正整数。代表缓存最多可以存储多少个对象(太大容易导致内存溢出,太小缓存没什么意义,所以一般使用默认的) -
readOnly属性:只读,取值为boolean类型,默认是false-
true:只读缓存,会给所有调用者返回缓存对象的相同实例。因此这些对象不能被修改。这提供了很重要的性能优势。
因为返回缓存对象的相同实例,所以才会将他设置成只读,因为返回缓存对象的相同实例时,如果调用者对这个对象进行修改,会导致直接修改掉缓存中的对象,存在安全隐患(只读就能解决这种安全隐患);性能优势是相较于取值时false的状态而言的,
因为读写缓存,是返回一个缓存对象的拷贝(准确来说是深拷贝),拷贝是需要耗费时间、以及资源的
-
false:读写缓存,会返回缓存对象的拷贝(通过序列化)。这会慢一些,但是安全,因此默认是 false。
这种方式能进行读写缓存的原因,是因为返回的对象是缓存对象的拷贝,当我们对缓存对象进行修改时,由于是深拷贝,返回的缓存对象的修改并不会影响到缓存中的对象,所以更安全,但是相较于只读缓存性能更低
-
4、系统缓存的查询顺序
二级缓存→一级缓存二级缓存 \to 一级缓存二级缓存→一级缓存
-
先查询二级缓存
原因:二级缓存的范围更大,二级缓存是SqlSessionFactory级别的,而一级缓存是SqlSession级别的,二级缓存中可能会有其他程序已经查出来的数据,可以拿来直接使用
-
如果二级缓存没有命中,再查询一级缓存
原因:一级缓存有二级缓存中没有的数据,二级缓存虽然范围比一级缓存大,但并不包含所有的一级缓存,二级缓存必须使用
close()方法后才能将数据读取到二级缓存中,有一些没有使用close()方法的查询结果只在一级缓存中 -
如果一级缓存也没有命中,则查询数据库 SqlSession关闭之后,一级缓存中的数据会写入二级缓
5、EHCache的使用

5.1 EHCache基本介绍
-
EHCache是什么?
EhCache 是一个纯Java的进程内缓存框架,具有快速、精干等特点,是Hibernate2中默认的CacheProvider3。
Ehcache是一种广泛使用的开源Java分布式缓存。主要面向通用缓存,Java EE和轻量级容器。它具有内存和磁盘存储,缓存加载器,缓存扩展,缓存异常处理程序,一个gzip缓存servlet过滤器,支持REST和SOAP api等特点。
EHCache官网:EHCache
Hibernate介绍:Hibernate 中文文档 | Hibernate 中文网
-
EHCache的作用?
EHCache是SqlSessionFactory级别,提供二级缓存的功能,相较MyBatis自带的二级缓存具有更加优秀的性能。
-
EHCache的特点:
- 使用起来快速、简单、灵活。因为是框架嘛,当然具有框架的一般特点,使用简单,灵活性是EHCache具有多种缓存策略,同时缓存数据有两级:内存和磁盘,因此无需担心容量问题
- 健壮性、扩展性。
- 分布式。可以通过RMI、可插入API等方式进行分布式缓存
- 支持多缓存管理器实例,以及一个实例的多个缓存区域
……
PS:这些所谓的特点只需要了解即可,重点还是会使用,当你能够熟练使用多个缓存时,你就能自然而然地明白它的特点了
5.2 EHCache的基本使用
-
Step1:创建Maven工程
目录结构:
-
Step2:导入依赖
EHCache所需依赖:
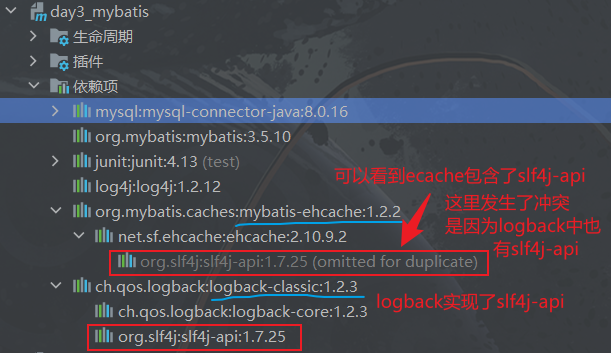
<!--mysql驱动--><dependency><groupId>mysql</groupId><artifactId>mysql-connector-java</artifactId><version>8.0.16</version></dependency><!--mybatis--><dependency><groupId>org.mybatis</groupId><artifactId>mybatis</artifactId><version>3.5.10</version></dependency><!-- Mybatis EHCache整合包 --><dependency><groupId>org.mybatis.caches</groupId><artifactId>mybatis-ehcache</artifactId><version>1.2.2</version></dependency><!-- slf4j日志门面的一个具体实现 --><dependency><groupId>ch.qos.logback</groupId><artifactId>logback-classic</artifactId><version>1.2.3</version></dependency>备注:日志门面就是日志提供的接口(这里说的就是
slf4j-api),即要使用EHCache必须先实现slf4j-api(slf4j日志门面),但是EHCache却没有实现slf4j-api,所以需要我们导入第三方slf4j-api的实现,也就是logback-classic这个可以在Maven中看到,EHCache中是有slf4j的:
推荐阅读:浅谈日志门面
-
Step3:编写MyBatis配置文件
略……
推荐阅读:快速上手MyBatis(该文通俗易懂,步骤说明详细,是很适合快速上手MyBatis的不二之选)
-
Step4:编写ehcache配置文件
ehcache.xml:
<?xml version="1.0" encoding="utf-8" ?> <ehcache xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"xsi:noNamespaceSchemaLocation="../config/ehcache.xsd"><!-- 磁盘保存路径 --><diskStore path="D:\Test\ehcache"/><defaultCachemaxElementsInMemory="1000"maxElementsOnDisk="10000000"eternal="false"overflowToDisk="true"timeToIdleSeconds="120"timeToLiveSeconds="120"diskExpiryThreadIntervalSeconds="120"memoryStoreEvictionPolicy="LRU"></defaultCache> </ehcache> -
Step5:编写logback配置文件
logback.xml:
<?xml version="1.0" encoding="UTF-8"?> <configuration debug="true"><!-- 指定日志输出的位置 --><appender name="STDOUT" class="ch.qos.logback.core.ConsoleAppender"><encoder><!-- 日志输出的格式 --><!-- 按照顺序分别是: 时间、日志级别、线程名称、打印日志的类、日志主体内容、换行--><pattern>[%d{HH:mm:ss.SSS}] [%-5level] [%thread] [%logger][%msg]%n</pattern></encoder></appender><!-- 设置全局日志级别。日志级别按顺序分别是: DEBUG、INFO、WARN、ERROR --><!-- 指定任何一个日志级别都只打印当前级别和后面级别的日志。 --><root level="DEBUG"><!-- 指定打印日志的appender,这里通过“STDOUT”引用了前面配置的appender --><appender-ref ref="STDOUT" /></root><!-- 根据特殊需求指定局部日志级别 --><logger name="com.atguigu.crowd.mapper" level="DEBUG"/> </configuration> -
Step6:编写Java代码
这里可以直接使用前面测试二级缓存的代码,因为他们都是属于二级缓存,所以我们就直接看测试结果吧(●’◡’●)
1)不在中间使用删除方法
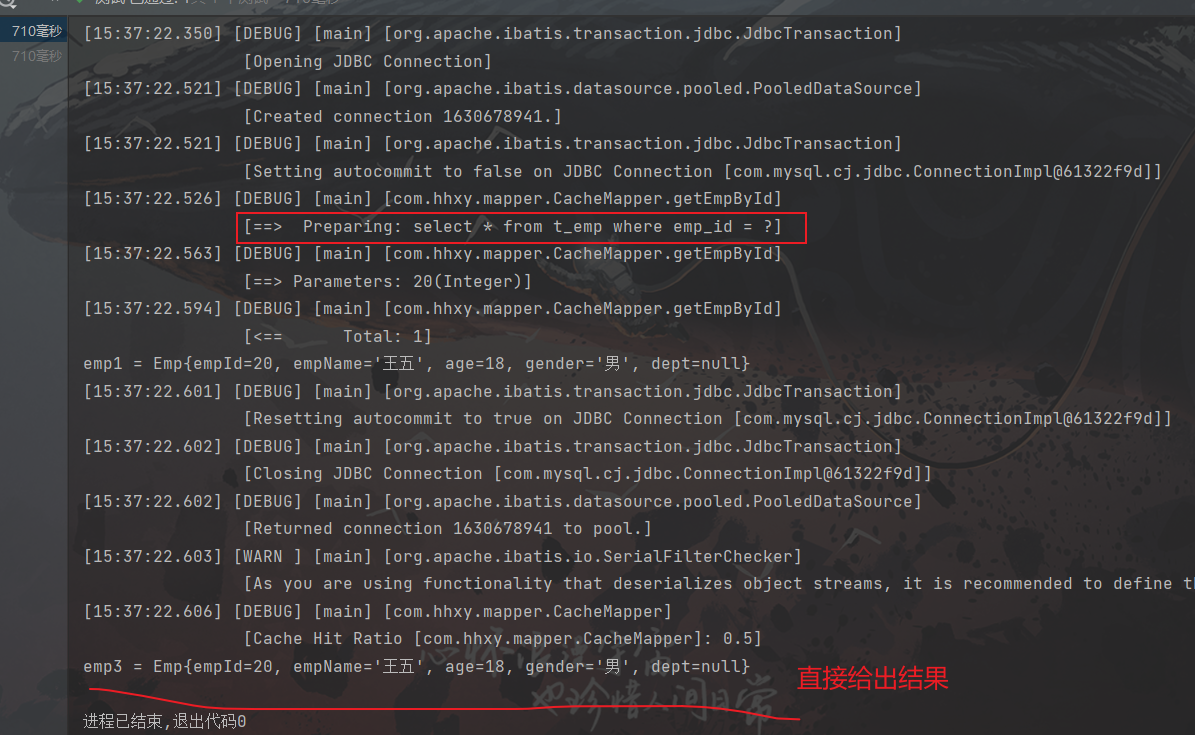
2)在中间使用删除方法:
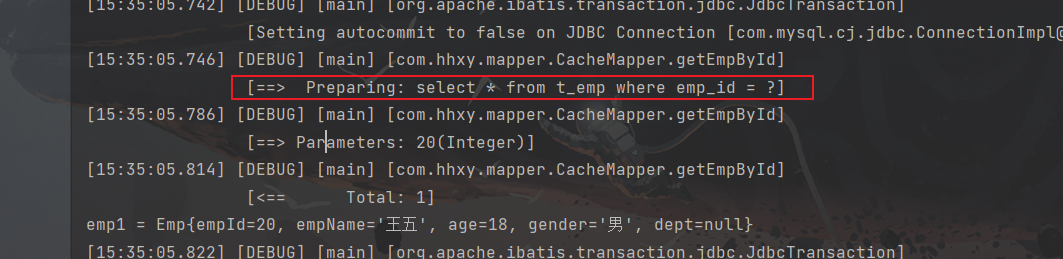
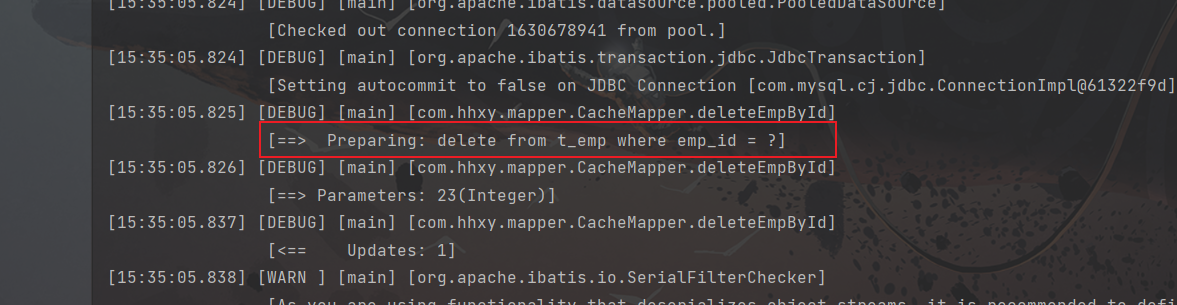
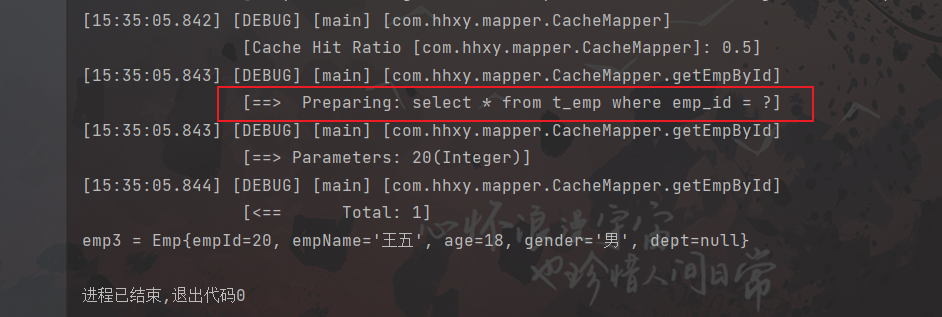
5.3 EHCache配置文件参数详解
| 参数名 | 作用 |
|---|---|
maxElementsInMemory | 设置在内存中缓存的element的最大数目 |
maxElementsOnDisk | 设置在磁盘上缓存的element的最大数目,其中0表示无穷大 |
etenrnal | 设定缓存的elements是否永远不过期。 如果为 true,则缓存的数据始终有效, 如果为false那么还 要根据timeToIdleSeconds、timeToLiveSeconds 判断 |
overflowToDisk | 设定当内存缓存溢出的时候是否将过期的element 缓存到磁盘上 |
timeToIdleSeconds | 当缓存在EhCache中的数据前后两次访问的时间超 过timeToIdleSeconds的属性取值时, 这些数据便 会删除,默认值是0,也就是可闲置时间无穷大 |
timeToLiveSeconds | 缓存element的有效生命期,默认是0.,也就是 element存活时间无穷大 |
diskSpoolBuffer | DiskStore(磁盘缓存)的缓存区大小。默认是 30MB。每个Cache都应该有自己的一个缓冲区 |
diskPersistend | 在VM重启的时候是否启用磁盘保存EhCache中的数 据,默认是false |
diskExpiryThreadIntervalSeconds | 磁盘缓存的清理线程运行间隔,默认是120秒。每 个120s, 相应的线程会进行一次EhCache中数据的 清理工作 |
memoryStoreEvictionPolicy | 当内存缓存达到最大,有新的element加入的时 候, 移除缓存中element的策略。 默认是LRU (最 近最少使用),可选的有LFU (最不常使用)和 FIFO (先进先出) |
备注:颜色加深的是必须参数
推荐阅读:页面置换算法相关概念和计算:含LRU、LFU和FIFO三个算法的详解

参考文章:
- 究竟什么是缓存? - 知乎 (zhihu.com)
- 架构成长系列:缓存的分类 - 知乎 (zhihu.com)
- 缓存及其分类
- 页面置换算法相关概念和计算
- 强、软、弱、虚引用的区别和使用 - 知乎 (zhihu.com)
- Ehcache 入门详解
- MyBatis的基本使用
- 浅谈日志门面
- 页面置换算法相关概念和计算
- (4条消息) Java:强引用,软引用,弱引用和虚引用_瞧德的博客-CSDN博客_强引用弱引用软引用和虚引用
Java中的引用一般是指变量对对象的引用,栈中的变量引用堆中的对象,让变量拥有对象的属性和行为,这个变量和对象的这种关系叫做引用 ↩︎
Hibernate和MyBatis一样都是ORM框架,同属于持久层(也叫数据访问层)的框架 ↩︎
CacheProvider(缓存提供者)是Java缓存中的一个提供缓存技术的角色,主要用来提供缓存功能 ↩︎
相关文章:
MyBatis缓存
文章目录MyBatis的缓存1、缓存概述2、MyBatis的一级缓存2.1 一级缓存的使用2.2 一级缓存的失效3、MyBatis的二级缓存3.1 二级缓存的开启3.2 二级缓存的失效3.2 二级缓存相关配置4、系统缓存的查询顺序5、EHCache的使用5.1 EHCache基本介绍5.2 EHCache的基本使用5.3 EHCache配置…...
Linux环境下(CentOS 7)安装Java(JDK8)
Linux环境下(CentOS 7)安装Java(JDK8) 一、安装教程 1.1 首先,进入oracle官网下载jdk8的安装包,下载地址如下,这里以 jdk-8u121-linux-x64.tar.gz安装包为例。 http://www.oracle.com/technetwork/java/javase/downloads/jdk8-downloads-21…...
基于STM32L431+Liteos的串口空闲中断加DMA循环接收
①MCU为STM32L431,使用串口2。 ②Liteos采用接管中断的方式。 STM32CubeMX配置生成串口代码: 串口DMA接收和发送配置区别是接收采用循环模式,发送为正常模式。 将生成的代码移植到liteos工程中,由于使用的接管中断的方式&#…...

BZOJ4403 序列统计
题目描述 给定三个正整数N、L和R,统计长度在1到N之间,元素大小都在L到R之间的单调不降序列的数量。输出答案对106310^631063取模的结果。 输入 输入第一行包含一个整数T,表示数据组数。 第2到第T1行每行包含三个整数N、L和R,N、…...
如何正确使用 钳位二极管
在电路设计中,经常遇到需要IO保护的场景,比如ADC采样,GPIO接收电平信号等。 常见的保护方法有分压,限幅,限流等。本次我们讨论限幅方法中的 钳位二极管。 我们以BAT54S为例,它的符号是这样的, 而在很多手册里,我们可以看到,一般是这样使用的: 因此,我设计了简化…...
【C语言进阶】动态内存管理
👦个人主页:Weraphael ✍🏻作者简介:目前是C语言学习者 ✈️专栏:C语言航路 🐋 希望大家多多支持,咱一起进步!😁 如果文章对你有帮助的话 欢迎 评论💬 点赞&a…...

第一批因ChatGPT坐牢的人,已经上路了
大家好,我是 Jack。 ChatGPT 的火爆有目共睹,有人靠着它赚了第一桶金,也有人靠着它即将吃上第一顿牢饭。 任何一件东西的火爆,总会给一些聪明人带来机会。 艾尔登法环火的时候,一堆淘宝卖魂的;羊了个羊火…...

Eclipse下Maven的集成
Eclipse下Maven的集成 2.1指定本地maven环境 参考:Eclipse的Maven创建_叶书文的博客-CSDN博客_eclipse创建maven项目 指定用本地maven指定maven仓库设置和地址2.2创建maven项目 1.新建 2.目录设置 3.坐标设置(随便写就行) 4.目录结构 2.3配置…...

Elasticsearch7学习笔记(尚硅谷)
文章目录一、ElasticSearch概述1、ElasticSearch是什么2、全文搜索引擎3、ElasticSearch 和 Solr3.1 概述3.2 比较总结二、Elasticsearch入门1、Elasticsearch安装1.1 下载使用1.2 数据格式2、索引操作3、文档操作(了解)3.1 创建文档3.2 文档查询3.3 文档…...

前端学习第一阶段-第7章 品优购电商项目
7-1 品优购项目介绍及准备工作 01-品优购项目导读 02-网站制作流程 03-品优购项目规划 04-品优购项目搭建 05-品优购项目-样式的模块化开发 06-品优购项目-favicon图标制作 07-品优购项目-TDK三大标签SEO优化 7-2 首页Header区域实现 08-品优购首页-快捷导航shortcut结构搭建 0…...

cocos2dx 4.0 - cpp - pc版 环境搭建
开发环境vs2022 cocos2dx4.0 python2.7.18 cmake3.25安装教程(环境搭建)安装VS2022-Community, 勾选c进行安装安装cmake3.25, 勾选环境变量进行安装安装python2.7.18, 勾选环境变量进行安装下载cocos2dx4.0并解压配置cocos2dx:运行cmd,进入…...
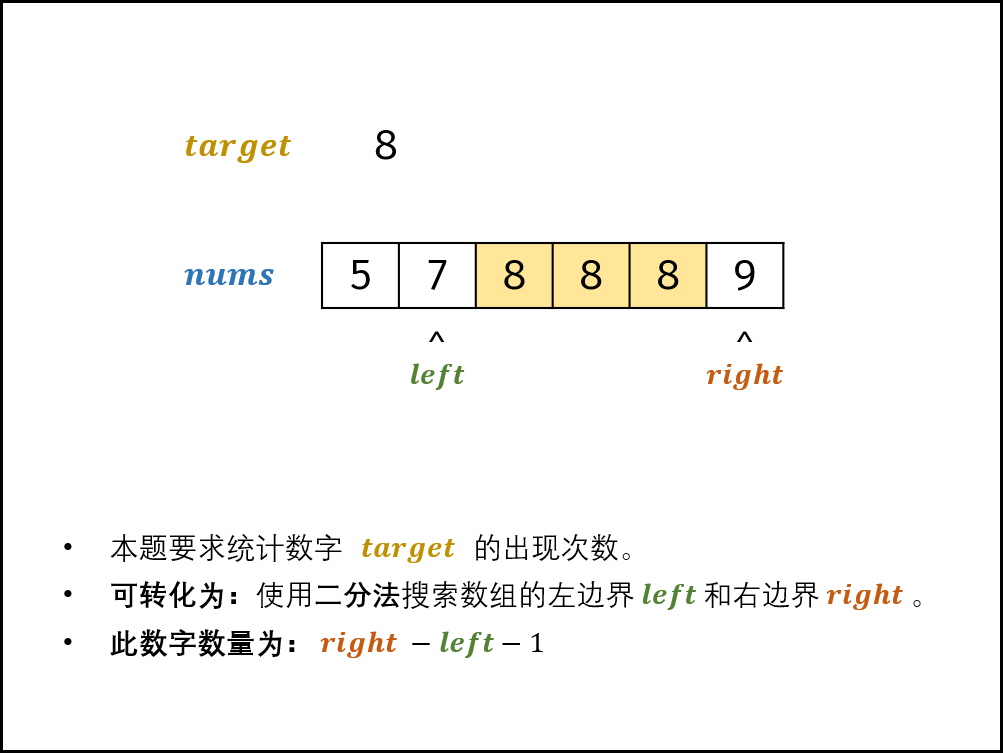
剑指 Offer 53 - I. 在排序数组中查找数字 I
原题链接 难度:easy\color{Green}{easy}easy 题目描述 统计一个数字在排序数组中出现的次数。 示例 1: 输入: nums [5,7,7,8,8,10], target 8 输出: 2示例 2: 输入: nums [5,7,7,8,8,10], target 6 输出: 0提示: 0<nums.length<1050 <…...
 | 机试题算法思路 【2023】)
华为OD机试 - 删除指定目录(Python) | 机试题算法思路 【2023】
最近更新的博客 华为OD机试 - 热点网络统计 | 备考思路,刷题要点,答疑 【新解法】 华为OD机试 - 查找单入口空闲区域 | 备考思路,刷题要点,答疑 【新解法】 华为OD机试 - 好朋友 | 备考思路,刷题要点,答疑 【新解法】 华为OD机试 - 找出同班小朋友 | 备考思路,刷题要点…...

PowerShell Install Office 2021 Pro Plus Viso Professional
前言 微软Office在很长一段时间内都是最常用和最受欢迎的软件。从小型创业公司到大公司,它的使用比例相当。它可以很容易地从微软的官方网站下载。但是,微软只提供安装程序,而不提供完整的软件供下载。这些安装文件通常比较小。下载并运行后,安装的文件将从后端服务器安装M…...

KubeSphere实战
文章目录一、KubeSphere平台安装1、Kubernetes上安装KubeSphere1.1 安装docker1.2 安装Kubernetes1.3 前置环境之nfs存储1.4 前置环境之metrics-server1.5 安装KubeSphere2、Linux单节点部署KubeSphere3、Linux多节点部署KubeSphere(推荐)二、KubeSphere实战1、多租户实战2、中…...

Linux 简介
Linux 内核最初只是由芬兰人林纳斯托瓦兹(Linus Torvalds)在赫尔辛基大学上学时出于个人爱好而编写的。 Linux 是一套免费使用和自由传播的类 Unix 操作系统,是一个基于 POSIX 和 UNIX 的多用户、多任务、支持多线程和多 CPU 的操作系统。 …...
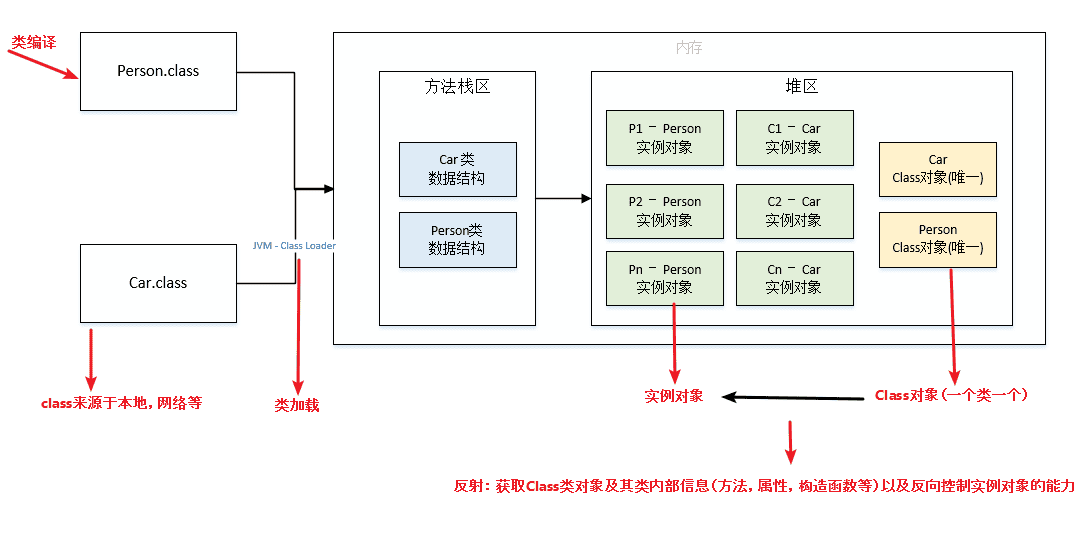
java面试题-泛型异常反射
泛型1.什么是泛型?Java是一种强类型语言,数据类型在编译时必须确定。如果我们想要在代码中使用不同类型的数据,那么就需要为每种类型分别写出相应的代码。这样会导致代码冗长、重复,也不便于维护。为了解决这个问题,Ja…...

详细解读ChatGPT:如何调用ChatGPT的API接口到官方例子的说明以及GitHub上的源码应用和csdn集成的ChatGPT
文章目录1. 解读ChatGPT1.1 词语解释1.2 功能解读2. GitHub上ChatGPT的应用源码3. 调用ChatGPT的API4. 官方例子说明5. 集成ChatGPT自ChatGPT出来到如今,始终走在火热的道路上,如今日活用户破亿,他为何有如此大的魅力,深受广大用户…...

九龙证券|最新评级情况出炉,机构扎堆这一板块!聚氨酯龙头获得最多关注
本周算计254家上市公司获组织“买入型”评级。 电子板块评级组织扎堆 证券时报数据宝计算,2月13日至17日,A股市场53家组织算计进行347次评级,254家上市公司获“买入型”评级(包含买入、增持、强烈推荐、推荐)。 从申…...
考研复试机试 | C++ | 尽量不要用python,很多学校不支持
目录1.1打印日期 (清华大学上机题)题目:代码:1.2改一改:上一题反过来问题代码:2.Day of Week (上交&&清华机试题)题目:代码:3.剩下的树(清…...

基于React与Docker构建可定制个人仪表盘:homepage项目实战指南
1. 项目概述:一个现代、轻量的个人仪表盘如果你和我一样,每天上班第一件事就是打开十几个浏览器标签页,在邮箱、项目管理工具、服务器监控、待办清单、常用文档之间来回切换,那么你一定能理解那种“数字工作台”杂乱无章带来的烦躁…...

ModTheSpire终极指南:为《杀戮尖塔》构建安全高效的模组生态
ModTheSpire终极指南:为《杀戮尖塔》构建安全高效的模组生态 【免费下载链接】ModTheSpire External mod loader for Slay The Spire 项目地址: https://gitcode.com/gh_mirrors/mo/ModTheSpire 在游戏模组开发领域,安全性与扩展性往往难以兼得。…...

USGv6新规驱动IPv6单栈部署:从协议原理到实战测试的全面指南
1. 从USGv6新版规范看IPv6单栈部署的必然性与实战准备最近,行业里关于IPv6单栈网络(IPv6-Only)的讨论又热了起来。这阵风潮的源头,是美国国家标准与技术研究院(NIST)近期更新了其“美国政府IPv6配置文件”&…...

兔子需要通风吗?关键不是风,而是空气路径
养兔子的朋友,大概率都有一个共识:要给兔子控温,夏天防中暑、冬天防受冻。但很多人都忽略了一个和温度同等重要的点——空气流动。 从环境工程的角度来说,兔子的舒适生活环境,离不开三个核心因素:温度、湿度…...

高效视频下载方案:VideoDownloadHelper插件一站式实战指南
高效视频下载方案:VideoDownloadHelper插件一站式实战指南 【免费下载链接】VideoDownloadHelper Chrome Extension to Help Download Video for Some Video Sites. 项目地址: https://gitcode.com/gh_mirrors/vi/VideoDownloadHelper 你是否曾在浏览网页时遇…...
)
【限时开放】ChatGPT-Sora 2联合推理链搭建教程:含Prompt模板库、错误码速查表与延迟压测数据(仅存96小时)
更多请点击: https://intelliparadigm.com 第一章:ChatGPT-Sora 2联合推理链的核心架构与演进逻辑 ChatGPT-Sora 2联合推理链代表了多模态大模型协同推理范式的重大跃迁——它并非简单地将语言模型与视频生成模型并联调用,而是构建了语义对齐…...

AgentDock:构建可控AI智能体的开源框架与工程实践
1. 项目概述:构建可控的智能体应用框架如果你正在寻找一个既能利用大语言模型(LLM)的创造力,又能确保关键业务流程稳定可靠的开发框架,那么 AgentDock 的出现可能正合你意。我最近深度体验了这个开源项目,它…...

3步解锁SWF逆向工程:JPEXS开源工具深度解析
3步解锁SWF逆向工程:JPEXS开源工具深度解析 【免费下载链接】jpexs-decompiler JPEXS Free Flash Decompiler 项目地址: https://gitcode.com/gh_mirrors/jp/jpexs-decompiler 你是否曾面对一个陈旧的SWF文件束手无策?当Flash技术逐渐退出历史舞台…...

基于Apify与NLP的大麻监管情报系统架构与MCP集成实践
1. 项目概述:当AI遇见大麻监管情报如果你在合规、法律科技或者生命科学领域工作,最近可能听过“监管情报”这个词。简单说,它就是利用技术手段,从海量的、不断变化的法规文件中,自动提取、分析和监控关键信息ÿ…...

Pearcleaner:macOS终极免费应用清理工具,彻底告别数字残留
Pearcleaner:macOS终极免费应用清理工具,彻底告别数字残留 【免费下载链接】Pearcleaner A free, source-available and fair-code licensed mac app cleaner 项目地址: https://gitcode.com/gh_mirrors/pe/Pearcleaner 你是否曾经在macOS上删除应…...