【MySQL】聚合函数与分组查询
文章目录
- 一、聚合函数
- 1.1 count 返回查询到的数据的数量
- 1.2 sum 返回查询到的数据的总和
- 1.3 avg 返回查询到的数据的平均值
- 1.4 max 返回查询到的数据的最大值
- 1.5 min 返回查询到的数据的最小值
- 二、分组查询group by
- 2.1 导入雇员信息表
- 2.2 找到最高薪资和员工平均薪资
- 2.3 显示每个部门的平均工资和最高工资
- 2.4 显示每个部门不同岗位的平均工资和最低工资
- 2.5 显示平均工资低于2000的部门和它的平均工资
一、聚合函数
MySQL中的聚合函数用于对数据进行计算和统计,常见的聚合函数包括下面列举出来的聚合函数:
函数 说明
COUNT([DISTINCT] expr) 返回查询到的数据的数量
SUM([DISTINCT] expr) 返回查询到的数据的总和,不是数字没有意义
AVG([DISTINCT] expr) 返回查询到的数据的平均值,不是数字没有意义
MAX([DISTINCT] expr) 返回查询到的数据的最大值,不是数字没有意义
MIN([DISTINCT] expr) 返回查询到的数据的最小值,不是数字没有意义
1.1 count 返回查询到的数据的数量
- 查看班级有多少同学
mysql> select * from exam_result;
+----+-----------+---------+------+---------+
| id | name | chinese | math | english |
+----+-----------+---------+------+---------+
| 1 | 张三 | 134 | 98 | 56 |
| 2 | 李四 | 120 | 80 | 77 |
| 4 | 赵六 | 164 | 84 | 67 |
| 5 | 田七 | 110 | 115 | 45 |
| 6 | 孙八 | 140 | 84 | 78 |
| 8 | 张翼德 | 90 | 128 | 66 |
+----+-----------+---------+------+---------+
6 rows in set (0.00 sec)mysql> select count(*) 总数 from exam_result;
+--------+
| 总数 |
+--------+
| 6 |
+--------+
1 row in set (0.00 sec)mysql> select count(1) 总数 from exam_result;
+--------+
| 总数 |
+--------+
| 6 |
+--------+
1 row in set (0.00 sec)
- 统计数学成绩有多少个
# 统计全部
mysql> select count(math) from exam_result;
+-------------+
| count(math) |
+-------------+
| 6 |
+-------------+
1 row in set (0.00 sec)# 统计有效的(去重)
mysql> select count(distinct math) as res from exam_result;
+-----+
| res |
+-----+
| 5 |
+-----+
1 row in set (0.00 sec)
- 统计英语不及格的人数
mysql> select count(*) from exam_result where english<60;
+----------+
| count(*) |
+----------+
| 2 |
+----------+
1 row in set (0.00 sec)
1.2 sum 返回查询到的数据的总和
- 查看数学成绩的总和
mysql> select sum(math) from exam_result;
+-----------+
| sum(math) |
+-----------+
| 589 |
+-----------+
1 row in set (0.00 sec)
- 统计英语不及格的分数总和
mysql> select sum(english) from exam_result where english<60;
+--------------+
| sum(english) |
+--------------+
| 101 |
+--------------+
1 row in set (0.00 sec)# 也可以统计不及格的平均分
mysql> select sum(english)/count(english) from exam_result where english<60;
+-----------------------------+
| sum(english)/count(english) |
+-----------------------------+
| 50.5 |
+-----------------------------+
1 row in set (0.00 sec)
1.3 avg 返回查询到的数据的平均值
统计不及格的英语的平均分不需要上面那么麻烦自己手动除:
mysql> select avg(english) from exam_result where english<60;
+--------------+
| avg(english) |
+--------------+
| 50.5 |
+--------------+
1 row in set (0.01 sec)
- 统计总分的平均分
mysql> select avg(chinese+math+english) from exam_result;
+---------------------------+
| avg(chinese+math+english) |
+---------------------------+
| 289.3333333333333 |
+---------------------------+
1 row in set (0.00 sec)
1.4 max 返回查询到的数据的最大值
- 查询数学成绩的最大值
mysql> select max(math) from exam_result;
+-----------+
| max(math) |
+-----------+
| 128 |
+-----------+
1 row in set (0.00 sec)
这里要注意聚合必须分组,不能这么使用:
mysql> select name, max(math) from exam_result;
1.5 min 返回查询到的数据的最小值
# 查看数学成绩的最小值
mysql> select min(math) from exam_result;
+-----------+
| min(math) |
+-----------+
| 80 |
+-----------+
1 row in set (0.00 sec)# 查看数学成绩大于100的最小值
mysql> select min(math) from exam_result where math>100;
+-----------+
| min(math) |
+-----------+
| 115 |
+-----------+
1 row in set (0.00 sec)
二、分组查询group by
分组的目的是为了进行分组之后,方便进行聚合统计
在select中使用group by 子句可以对指定列进行分组查询
语法:
select column1, column2, .. from table group by column;
2.1 导入雇员信息表
# 将linux目录下的sql表导入MySQL
mysql> source /home/yyh/scott_data.sql
Query OK, 0 rows affected, 1 warning (0.00 sec)mysql> use scott;
Database changedmysql> show tables;
+-----------------+
| Tables_in_scott |
+-----------------+
| dept |
| emp |
| salgrade |
+-----------------+
3 rows in set (0.00 sec)
emp员工表
dept部门表
salgrade工资等级表
2.2 找到最高薪资和员工平均薪资
# 查看员工表
mysql> select * from emp;
+--------+--------+-----------+------+---------------------+---------+---------+--------+
| empno | ename | job | mgr | hiredate | sal | comm | deptno |
+--------+--------+-----------+------+---------------------+---------+---------+--------+
| 007369 | SMITH | CLERK | 7902 | 1980-12-17 00:00:00 | 800.00 | NULL | 20 |
| 007499 | ALLEN | SALESMAN | 7698 | 1981-02-20 00:00:00 | 1600.00 | 300.00 | 30 |
| 007521 | WARD | SALESMAN | 7698 | 1981-02-22 00:00:00 | 1250.00 | 500.00 | 30 |
| 007566 | JONES | MANAGER | 7839 | 1981-04-02 00:00:00 | 2975.00 | NULL | 20 |
| 007654 | MARTIN | SALESMAN | 7698 | 1981-09-28 00:00:00 | 1250.00 | 1400.00 | 30 |
| 007698 | BLAKE | MANAGER | 7839 | 1981-05-01 00:00:00 | 2850.00 | NULL | 30 |
| 007782 | CLARK | MANAGER | 7839 | 1981-06-09 00:00:00 | 2450.00 | NULL | 10 |
| 007788 | SCOTT | ANALYST | 7566 | 1987-04-19 00:00:00 | 3000.00 | NULL | 20 |
| 007839 | KING | PRESIDENT | NULL | 1981-11-17 00:00:00 | 5000.00 | NULL | 10 |
| 007844 | TURNER | SALESMAN | 7698 | 1981-09-08 00:00:00 | 1500.00 | 0.00 | 30 |
| 007876 | ADAMS | CLERK | 7788 | 1987-05-23 00:00:00 | 1100.00 | NULL | 20 |
| 007900 | JAMES | CLERK | 7698 | 1981-12-03 00:00:00 | 950.00 | NULL | 30 |
| 007902 | FORD | ANALYST | 7566 | 1981-12-03 00:00:00 | 3000.00 | NULL | 20 |
| 007934 | MILLER | CLERK | 7782 | 1982-01-23 00:00:00 | 1300.00 | NULL | 10 |
+--------+--------+-----------+------+---------------------+---------+---------+--------+
14 rows in set (0.00 sec)# 聚合函数
mysql> select max(sal) 最高, avg(sal) 平均 from emp;
+---------+-------------+
| 最高 | 平均 |
+---------+-------------+
| 5000.00 | 2073.214286 |
+---------+-------------+
1 row in set (0.00 sec)
2.3 显示每个部门的平均工资和最高工资
这里就需要进行分组。
# 通过列分组
group by 列名
# 用该列的不同数据进行分组
mysql> select deptno,max(sal) 最高, avg(sal) 平均 from emp group by deptno;
+--------+---------+-------------+
| deptno | 最高 | 平均 |
+--------+---------+-------------+
| 10 | 5000.00 | 2916.666667 |
| 20 | 3000.00 | 2175.000000 |
| 30 | 2850.00 | 1566.666667 |
+--------+---------+-------------+
3 rows in set (0.00 sec)
这里分组条件用的是deptno,所以每个组内的deptno一定是相同的。
分组就是把一张表按照条件在逻辑上拆成了多个子表,然后分别对每个子表进行聚合统计。
2.4 显示每个部门不同岗位的平均工资和最低工资
这里既然要每个部门和不同岗位,那么就注定要分组。
先分组再聚合
group by deptno, job;
mysql> select deptno,job,max(sal) 最高,avg(sal) 平均 from emp group by deptno,job;
+--------+-----------+---------+-------------+
| deptno | job | 最高 | 平均 |
+--------+-----------+---------+-------------+
| 10 | CLERK | 1300.00 | 1300.000000 |
| 10 | MANAGER | 2450.00 | 2450.000000 |
| 10 | PRESIDENT | 5000.00 | 5000.000000 |
| 20 | ANALYST | 3000.00 | 3000.000000 |
| 20 | CLERK | 1100.00 | 950.000000 |
| 20 | MANAGER | 2975.00 | 2975.000000 |
| 30 | CLERK | 950.00 | 950.000000 |
| 30 | MANAGER | 2850.00 | 2850.000000 |
| 30 | SALESMAN | 1600.00 | 1400.000000 |
+--------+-----------+---------+-------------+
9 rows in set (0.00 sec)
这里要注意一般select后边的字段必须在group by中出现
比如说select 后边加个ename就会报错,因为同一个分组可能会有不同的ename。
2.5 显示平均工资低于2000的部门和它的平均工资
分成两步:
先统计每一个部门的平均工资(先按部门对平均工资进行分组聚合)
再对聚合的结果进行条件判断
- 如何对聚合的结果条件判断?
通过having搭配group by
having就是对聚合后的数据统计进行条件筛选
mysql> select deptno,avg(sal) 平均 from emp group by deptno having 平均<2000;
+--------+-------------+
| deptno | 平均 |
+--------+-------------+
| 30 | 1566.666667 |
+--------+-------------+
1 row in set (0.00 sec)
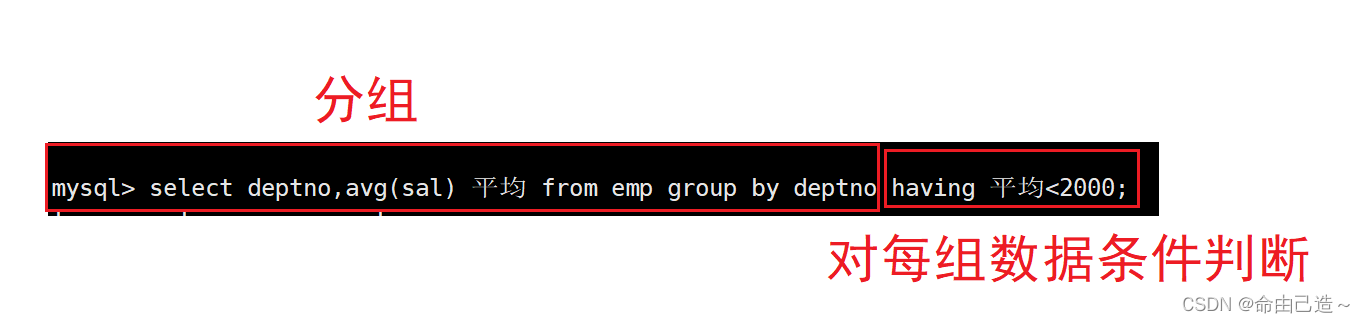
- having和where区别理解,执行顺序
先来看个样例:
SMITH不参与统计,显示每个部门、每种岗位的平均工资低于2000的工种。
mysql> select deptno,job,avg(sal) 平均 from emp where ename!='SMITH' group by deptno,job having 平均<2000;
+--------+----------+-------------+
| deptno | job | 平均 |
+--------+----------+-------------+
| 10 | CLERK | 1300.000000 |
| 20 | CLERK | 1100.000000 |
| 30 | CLERK | 950.000000 |
| 30 | SALESMAN | 1400.000000 |
+--------+----------+-------------+
4 rows in set (0.00 sec)
where 是对任意列进行条件筛选(筛选之后才会进行分组)
having 是对分组聚合之后的结果进行条件筛选
执行顺序:
先要知道从哪个表中取数据(from),再看拿数据过程中的筛选条件(where),然后对拿到的数据分组(group by),在按照分组之后的结果进行聚合统计并且重命名(select),最后再对结果做条件筛选(having)
相关文章:
【MySQL】聚合函数与分组查询
文章目录 一、聚合函数1.1 count 返回查询到的数据的数量1.2 sum 返回查询到的数据的总和1.3 avg 返回查询到的数据的平均值1.4 max 返回查询到的数据的最大值1.5 min 返回查询到的数据的最小值 二、分组查询group by2.1 导入雇员信息表2.2 找到最高薪资和员工平均薪资2.3 显示…...
conda 环境 numpy 安装报错需要 Microsoft Visual C++ 14.0
到公司装深度学校环境。项目较旧,安装依赖,一堆报错(基于 conda 环境): numpy 安装报需要 C 14.0 No module named numpy.distutils._msvccompiler in numpy.distutils; trying from distutilserror: Microsoft Visu…...
)
算法工程师-机器学习面试题总结(5)
什么是信息熵? 信息熵是信息理论中用来衡量一个随机变量的不确定度或者信息量的概念。它是在给定一组可能的事件中,对每个事件发生的概率进行加权平均得到的值。 在信息熵的计算中,概率越大的事件所带来的信息量越小,概率越小的事…...
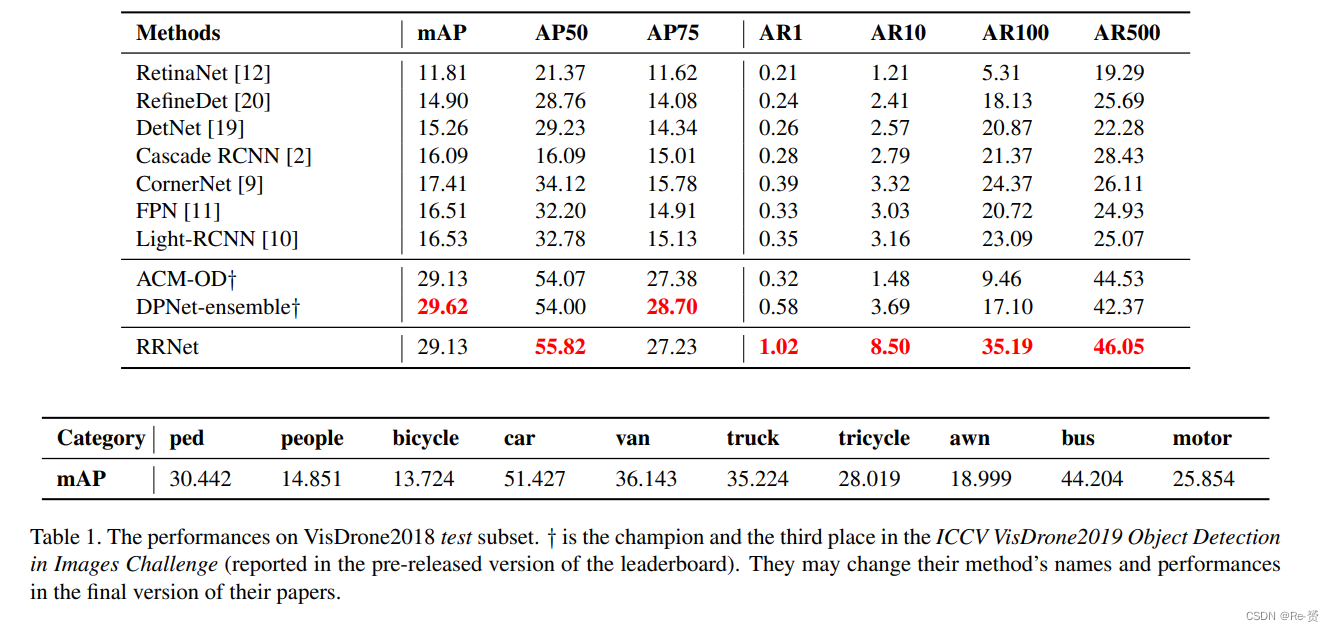
论文阅读 RRNet: A Hybrid Detector for Object Detection in Drone-captured Images
文章目录 RRNet: A Hybrid Detector for Object Detection in Drone-captured ImagesAbstract1. Introduction2. Related work3. AdaResampling4. Re-Regression Net4.1. Coarse detector4.2. Re-Regression 5. Experiments5.1. Data augmentation5.2. Network details5.3. Tra…...

js执行机制
JavaScript 的执行机制是基于单线程的事件循环模型。这意味着 JavaScript 代码会按照顺序一行一行地执行,同时只能执行一个任务。让我们更详细地了解 JavaScript 的执行机制: 调用栈(Call Stack): JavaScript 使用调用…...

关于策略模式的注入问题
上面抄别人的 当在实现策略方法时,报null,排查后发现是接口实现有多个,需要添加别名 注入时添加Qeualifier,指定名称,如下图;如图上修改, 测试类中不用new具体行为策略了,注入别名即…...

通用Mapper的四个常见注解
四个常见注解 1、Table 作用:建立实体类和数据库表之间的对应关系。 默认规则:实体类类名首字母小写作为表名,如 Employee -> employee 表 用法:在 Table 注解的 name 属性中指定目标数据库的表名; 案例&#…...

二进制安装K8S(单Master集群架构)
目录 一:操作系统初始化配置 1、项目拓扑图 2、服务器 3、初始化操作 二: 部署 etcd 集群 1、etcd 介绍 2、准备签发证书环境 3、master01 节点上操作 (1)生成Etcd证书 (2)创建用于存放 etcd 配置文…...

基于java汽车销售分析与管理系统设计与实现
摘 要 计算机现在已成为人们办公和生活不可或缺的组成部分,在工作范畴计算机成熟运用大大提升了工作人员的工作效率,化繁为简,加速社会经济发展。在生活上,人们可以通过计算机互联网更快的了解到全球时事要闻、听到最新潮流音乐、…...
Glass指纹识别工具,多线程Web指纹识别工具-Chunsou
Glass指纹识别工具,多线程Web指纹识别工具-Chunsou。 Glass指纹识别工具 Glass一款针对资产列表的快速指纹识别工具,通过调用Fofa/ZoomEye/Shodan/360等api接口快速查询资产信息并识别重点资产的指纹,也可针对IP/IP段或资产列表进行快速的指…...
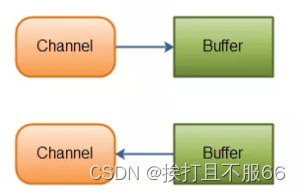
BIO,NIO,AIO总结
文章目录 1. BIO (Blocking I/O)1.1 传统 BIO1.2 伪异步 IO1.3 代码示例 1.4 总结2. NIO (New I/O)2.1 NIO 简介2.2 NIO的特性/NIO与IO区别1)Non-blocking IO(非阻塞IO)2)Buffer(缓冲区)3)Channel (通道)4)Selector (选择器) 2.3 NIO 读数据和写数据方式…...
[腾讯云Cloud Studio实战训练营]基于Cloud Studio完成图书管理系统
[腾讯云Cloud Studio实战训练营]基于Cloud Studio完成图书管理系统 ⭐前言🌜Cloud Studio产品介绍1.登录2.创建工作空间3.工作空间界面简介4.环境的使用 ⭐实验实操🌜Cloud Studio实现图书管理系统1.实验目的 2. 实验过程2.实验环境3.源码讲解3.1添加数据…...
Node.js 基础模块)
(二)Node.js 基础模块
(二)Node.js 基础模块 1. fs文件系统模块1.1 什么是fs文件系统模块1.2 读取指定文件中的内容1. fs.readFile()的语法格式2. fs.readFile()的示例代码 1.3 向指定的文件中写入内容1. fs.writeFile()的语法格式2. fs.writeFile()的实例代码 1.4 __dirname …...

AUC及其拓展GAUC
AUC及其拓展GAUC auc的定义 auc用来评估一个分类器的排序质量,它的物理含义:给定一堆正负样本,随机取一个正样本,一个负样本,学习器将正样本排在负样本前面的概率 auc的计算 具体计算方法:给定m个正样本…...

【CSS】CSS 选择器
CSS 选择器 1.基础选择器 1.1 元素选择器 语法:标签名{...} 元素选择器会选中对应标签名的HTML元素,例如:p{...},div{...},span{...}等 1.2 类选择器 语法:.类名{...} 类选择器会选中class属性为指定…...

2023-08-07力扣今日四题-好题
链接: 剑指 Offer 03. 数组中重复的数字 题意: 如题 解: 看到一个很牛的时间复杂度O(n)的原地算法:由于数组长度n,数组内只有0到n-1,那么,我们用对应-n到-1表示nums[index]出现过一次&…...
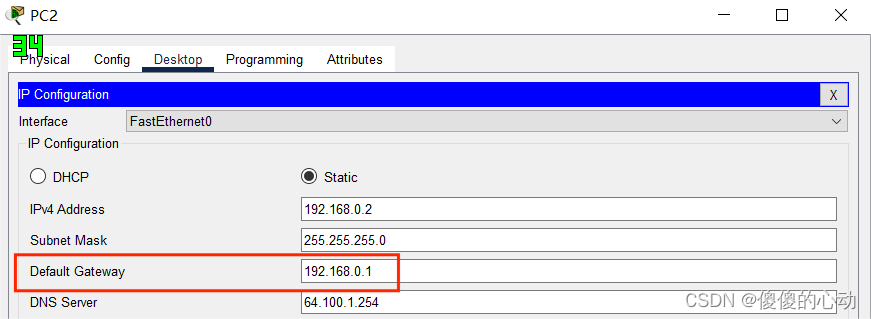
Packet Tracer - IPv4 和 IPv6 编址故障排除
Packet Tracer - IPv4 和 IPv6 编址故障排除 地址分配表 设备 接口 IPv4 地址 子网掩码 默认网关 IPv6 地址/前缀 R1 G0/0 10.10.1.1 255.255.255.0 N/A G0/1 192.168.0.1 255.255.255.0 N/A 2001:DB8:1:1::1/64 N/A G0/2 2001:DB8:1:2::1/64 N/A S0/0/0 …...
PHP国外在线教育系统源码 在线课程系统源码 直播课程系统源码提供在线课程,现场课程,测验
Proacademy是在线教育一体化的解决方案,用于创建类似于Udemy、Skillshare、Coursera这种在线教育市场。 这个平台提供在线课程,现场课程,测验等等,并有一个基于实际业务需要的高级认证插件,程序基于Laravel强大的安全框…...

Abaqus 中最常用的子程序有哪些 硕迪科技
在ABAQUS中,用户定义的子程序是一种重要的构件,可以将其插入到Abaqus分析中以增强该软件的功能和灵活性。这些子程序允许用户在分析过程中添加自定义材料模型、边界条件、初始化、加载等特定操作,以便更精准地模拟分析中的现象和现象。ABAQUS…...

容器——3.Collection 子接口之 Set
文章目录 3.1. comparable 和 Comparator 的区别3.1.1. Comparator 定制排序3.1.2. 重写 compareTo 方法实现按年龄来排序 3.2. 无序性和不可重复性的含义是什么3.3. 比较 HashSet、LinkedHashSet 和 TreeSet 三者的异同 3.1. comparable 和 Comparator 的区别 comparable 接口…...

终极指南:如何免费解锁Cursor Pro完整功能 - 突破AI编辑器限制的完整方案
终极指南:如何免费解锁Cursor Pro完整功能 - 突破AI编辑器限制的完整方案 【免费下载链接】cursor-free-vip [Support 0.45](Multi Language 多语言)自动注册 Cursor Ai ,自动重置机器ID , 免费升级使用Pro 功能: Youv…...

如何免费解锁WeMod专业版:2026年终极完整指南
如何免费解锁WeMod专业版:2026年终极完整指南 【免费下载链接】Wand-Enhancer Advanced UX and interoperability extension for Wand (WeMod) app 项目地址: https://gitcode.com/gh_mirrors/we/Wand-Enhancer 还在为WeMod专业版的高昂费用而烦恼吗…...

地下态势智能研判,拔高硐室深部安全透明管控等级技术白皮书
地下态势智能研判,拔高硐室深部安全透明管控等级技术白皮书 副标题:全要素三维动态重建井下场景,融合井下无感坐标解算、跨断面跨镜轨迹串联、身体指纹人员轨迹存档,井下风险前置感知、动态全程透明追溯 前言 矿山井下深部硐室与纵…...

终极指南:如何在Mac上免费快速导出微信聊天记录
终极指南:如何在Mac上免费快速导出微信聊天记录 【免费下载链接】WeChatExporter 一个可以快速导出、查看你的微信聊天记录的工具 项目地址: https://gitcode.com/gh_mirrors/wec/WeChatExporter 你是否曾因误删重要微信聊天记录而焦虑?或需要查找…...

Docker化OpenOffice部署:文档自动化转换服务实战指南
1. 项目概述与核心价值最近在折腾一个老项目,需要处理一批.odt格式的文档,这让我想起了那个曾经在开源办公软件领域与微软Office分庭抗礼的“老将”——OpenOffice。虽然现在LibreOffice的风头更盛,但OpenOffice依然有其独特的生态位和用户群…...

利用OCI免费套餐构建高可用Kubernetes集群实战指南
1. 项目概述:在免费云上构建企业级K8s集群最近在技术社区里,一个名为“nce/oci-free-cloud-k8s”的项目引起了我的注意。这个标题乍一看有点“黑话”的味道,但拆解开来,它指向了一个非常具体且极具吸引力的场景:利用Or…...

基于AutoHotkey的Windows桌面自动化工具开发实战
1. 项目概述与核心价值最近在整理个人项目库时,翻到了一个挺有意思的“老伙计”——cua_desktop_operator_skill。这个项目名听起来有点拗口,直译过来是“CUA桌面操作员技能”。乍一看,可能会让人联想到某种工业控制台的专用软件。但实际上&a…...

怎么找到一个行业的源头工厂、绕开中间商?一套五步识别流程
你下了单,货到了,质量也还行。但心里一直有个疙瘩:这家供应商到底是自己在生产,还是从别处转手赚了你一道差价? 这个问题对采购方和跨境卖家不是洁癖,是真金白银。同一款产品,源头工厂和中间商的…...

Helm-Intellisense:VS Code智能补全插件,提升values.yaml编写效率
1. 项目概述:为什么我们需要一个Helm智能补全工具?如果你和我一样,日常工作中大量使用Helm来管理Kubernetes应用,那你一定对编写values.yaml文件时那种“盲人摸象”的感觉深有体会。面对一个动辄几十上百行配置的Helm Chart&#…...

飞书自动化工具feishu-atuo:Python积木式开发与实战指南
1. 项目概述:飞书自动化,从零到一的效率革命 如果你和我一样,每天的工作流里都离不开飞书,那你肯定也经历过这些时刻:手动把日报、周报从文档复制到表格里归档;在多个群里重复发送同样的通知;为…...