小研究 - 微服务系统服务依赖发现技术综述(一)
微服务架构得到了广泛的部署与应用, 提升了软件系统开发的效率, 降低了系统更新与维护的成本, 提高了系统的可扩展性. 但微服务变更频繁、异构融合等特点使得微服务故障频发、其故障传播快且影响大, 同时微服务间复杂的调用依赖关系或逻辑依赖关系又使得其故障难以被及时、准确地定位与诊断, 对微服务架构系统的智能运维提出了挑战. 服务依赖发现技术从系统运行时数据中识别并推断服务之间的调用依赖关系或逻辑依赖关系, 构建服务依赖关系图, 有助于在系统运行时及时、精准地发现与定位故障并诊断根因, 也有利于如资源调度、变更管理等智能运维需求. 首先就微服务系统中服务依赖发现问题进行分析, 其次, 从基于监控数据、系统日志数据、追踪数据等 3 类运行时数据的角度总结分析了服务依赖发现技术的技术现状; 然后, 以基于服务依赖关系图的故障根因定位、资源调度与变更管理等为例, 讨论了服务依赖发现技术应用于智能运维的相关研究. 最后, 对服务依赖发现技术如何准确地发现调用依赖关系和逻辑依赖关系, 如何利用服务依赖关系图进行变更治理进行了探讨并对未来的研究方向进行了展望.
目录
1 问题描述
2 服务依赖发现
2.1 基于监控数据的服务依赖发现
2.1.1 基于网络通信包数据的服务依赖发现
2.1.2 基于资源使用数据的服务依赖发现
2.1.3 基于统计指标的服务依赖发现
2.2 基于系统日志的服务依赖发现
2.2.1 依据统一标识的服务依赖发现
2.2.2 基于共现概率的服务依赖发现
2.2.3 基于日志频率的服务依赖发现
2.3 基于追踪数据的服务依赖发现
1 问题描述
● 服务. 在微服务架构软件系统中, 服务即指微服务. 但在已有的服务依赖发现相关研究工作中, 并没有一个通用且标准的关于服务的定义, 所以在不同的研究工作中, 服务依赖发现中的“服务”的具体含义可能有所不同, 但基本可以划分为 3 类: 由 IP 和 Port 代表的服务, 组件或者应用, 虚拟机. 在文献中, 服务或被定义为<IP,Port> 这样的二元组, 或被定义为<IP, Port, Protocol> 的三元组. 在文献中, 服务即组件/应用, 组件是分布式软件系统中可被独立部署的最小单元. 而将虚拟机作为服务依赖发现的研究对象时, 通常是基于假设: 每个虚拟机中仅部署一个服务, 因此虚拟机之间的依赖关系也就代表服务之间的依赖关系. 在一对服务依赖关系中, 服务按照是依赖的一方还是被依赖的一方可以划分为依赖服务 (depending service) 和被依赖服务 (depended service).
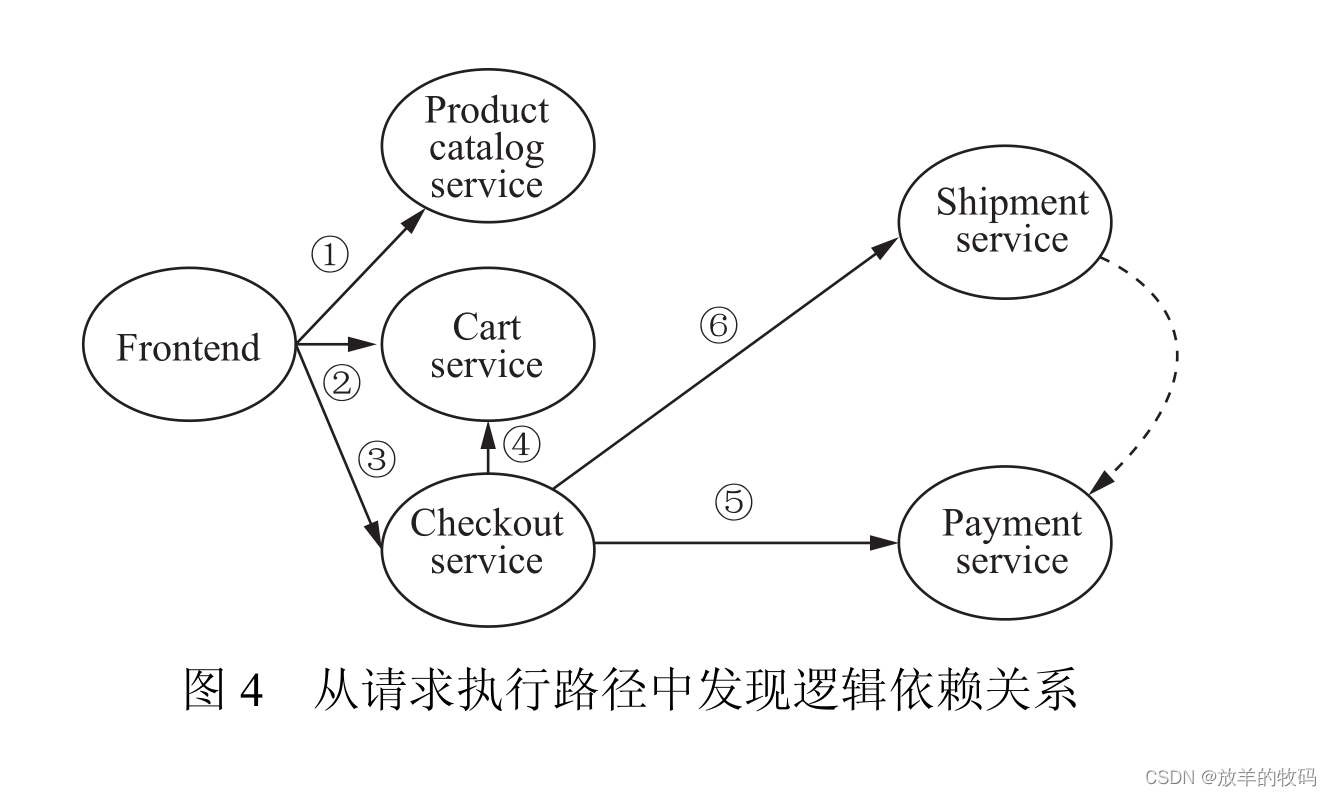
● 依赖. 服务依赖发现中的依赖关系有两种, 调用依赖关系 (local-remote dependency) 和逻辑依赖关系 (remote-remote dependency). 调用依赖关系指一个服务 为完成对该服务的请求的响应, 对其他服务如 的调用关系,是微服务系统中最常见的依赖关系. 如图 2 所示在一个典型的开源微服务系统中所发现的部分服务依赖关系中, CheckoutService 为完成结账服务, 会分别调用CartService、PaymentService 和 ShipmentService 完成下单、支付和邮寄功能, 那么CheckoutService 依赖于 CartService、PaymentService 以及 ShipmentService, 依赖类型为调用依赖. 逻辑依赖关系是指一个服务 完成对该服务的请求响应是以另一个服务 完成对指定请响应为前提的逻辑先后关系. 如图 2 所示的服务依赖关系中, ShipmentService 为完成邮寄服务, CheckoutService 首先需要调用PaymentService 完成支付, 那么 ShipmentService 依赖 PaymentService, 依赖类型为逻辑依赖. 依赖关系是可以传递的, 即 , 根据依赖关系是否是由其他依赖关系的传递而衍生, 又可将依赖关系分为直接依赖 (direct dependency) 关系与间接依赖 (indirect dependency) 关系, 所有间接依赖关系都可以通过直接依赖关系传递获得, 因此为了保持服务依赖图的统一与简洁, 服务依赖图中依赖关系视为直接依赖关系. 除此之外,服务依赖发现方法通常会基于不同算法赋予依赖关系一个数值来衡量依赖关系的强弱或依赖关系存在的置信度.

2 服务依赖发现
从多源运行时数据角度对服务依赖发现方法进行综述分析. 系统运行时数据可以分为 3 类: 监控数据、系统日志数据与追踪数据. 监控数据是由监控工具在系统运行时获取的用以表征系统运行状况的数据, 包括网络通信包 (packet) 数据、资源使用数据如 CPU/内存等的使用量、业务统计指标如请求响应时间与吞吐量等. 系统日志数据是由开发人员在开发时添加的日志打印语句在系统运行时产生的用以记录程序运行状态及相关变量信息的半结构化文本数据. 追踪数据是由分布式追踪技术产生的用以刻画请求在分布式软件系统中端到端的处理过程的数据. 展示了服务依赖发现的基本流程. 首先, 多数服务依赖发现方法依赖于运行时数据的分布变化相关性, 为加速和加剧分布变化, 需要利用故障或干扰注入工具对微服务系统进行故障和干扰注入. 然后, 收集微服务系统产生的监控、系统日志和追踪数据并利用这些数据发现微服务实例和微服务依赖关系. 最后, 根据服务依赖关系构建服务依赖关系图. 相关研究工作分别基于 3 类不同运行时数据, 提出了不同自动化构建服务依赖关系图的方法.
2.1 基于监控数据的服务依赖发现
2.1.1 基于网络通信包数据的服务依赖发现
基于网络通信包数据的服务依赖发现方法利用存在依赖关系的两个微服务的网络通信消息中存在特定交互模式与时空上相关性的特点, 通过监听与解析网络传输层网络包数据, 使用统计方法从中推断服务之间的依赖关系.
基于网络通信包数据的服务依赖发现首先利用网络包监控工具获取每个节点上所有 TCP packets 与 UDPpackets, 从每个 packet 中提取一个五元组<SrcIP, SrcPort, DestIP, DestPort, Protocol>, 其中 SrcIP, SrcPort, DestIP,DestPort, Protocol 分别表示一个 packet 的源端 IP, 源端端口, 目标 IP, 目标端口与传输层协议; 然后根据五元组将在一定时间窗口内所有拦截到的 packets 划分为不同流 (flow)/通道 (channel)/会话 (session), 同一个流中 SrcIP,SrcPort, DestIP, DestPort 是相同的 (或者源端 IP 和源端端口与目标 IP 和目标端口交换), 进而得到表征每一个流的七元组<SrcIP, SrcPort, DestIP, DestPort, Protocol, startTime, endTime>, TCP 流的 startTime 是建立 TCP 连接 3 次握手时第 1 个 packet 的时间戳, endTime 是关闭 TCP 连接 4 次握手时最后一个 packet 的时间戳, UDP 流的startTime 是最早出现该五元组 pakcet 的时间戳, endTime 是在大于指定的时间间隔内不再出现该五元组 packet 的最后一个 packet 的时间戳; 构建系统中每个节点的所有流之后, 不同文献采用不同方法计算两个由<IP1, Port1> 和<IP2, Port2> 代表的两个服务是否存在依赖关系以及依赖关系成立的概率.
2.1.2 基于资源使用数据的服务依赖发现
基于资源使用数据的服务依赖发现技术利用存在依赖关系的两个服务之间资源使用在时间序列存在相似性的特点, 通过不同算法计算不同服务在一维或多维的资源使用时间序列数据上的相似度, 推断任意两个服务之间的相似度即服务依赖的强弱.
2.1.3 基于统计指标的服务依赖发现
基于统计指标的服务依赖发现方法利用存在依赖关系的两个服务执行时间差 (delay) 与响应时间 (responsetime) 存在一定规律的特点, 通过分析两个服务间的执行与响应时间关系, 进而推断两个服务之间的依赖关系.其通过拦截每个服务在一定时间窗口内的所有网络包, 使其延迟传递一定的时间并监控其他所有服务的响应时间, 根据服务的响应时间是否受影响, 以及响应时间受影响的程度, 来判断每个服务与被拦截网络包的服务依赖关系及强弱. 其反应在响应时间上的相关性特征不同, 通过学习利用被依赖服务响应时间来预测依赖服务响应时间的模型, 可以判断服务之间是否存在依赖关系, 以及存在的调用依赖关系的类型. 将服务之间的调用关系分为 4 类: 单调依赖 (single dependency)、组合依赖 (composite dependency)、并行依赖 (concurrent dependency)和分流依赖 (distrbuted dpendency), 分别表示两个服务之间的直接调用关系、一个服务依赖多个服务的串行调用,一个服务依赖多个服务的并行调用以及一个服务在负载均衡场景下对多个服务的调用. 针对 4 类调用关系, 作者分别分析了被依赖服务响应时间与依赖服务响应时间的关系, 给出了预测模型. 通过利用历史数据训练预测模型,可以预测某个服务的响应时间, 通过对比预测的响应时间符合哪类调用关系, 可以判断服务之间的调用依赖关系的类型.
2.2 基于系统日志的服务依赖发现
基于系统日志数据的微服务依赖关系发现利用不同日志数据内容或特征, 发现或推断不同微服务的调用路径、逻辑依赖或关联关系. 根据所依赖的日志内容或特征, 相关研究工作可以分为 3 种: 依据统一标识的服务依赖发现, 基于共现概率的服务依赖发现和基于日志频率的服务依赖发现. 依据统一标识的服务依赖发现假设日志文本中存在对不同微服务的标识信息 (例如 IP 等) 或请求的标识信息 (例如 Request ID, Block ID 等), 通过解析日志文本, 提取标识信息然后通过表示标识关联不同微服务. 基于共现概率的服务依赖发现假设如果两个微服务输出的一些日志存在频繁共现关系, 则两个微服务之间存在服务依赖. 基于日志频率的服务依赖发现统计连续时间窗口内不同微服务输出的日志频率, 将日志频率作为一个核心指标, 通过挖掘不同微服务的该指标之间的分布关系, 挖掘其中因果和关联关系, 最终获取微服务服务依赖.
2.2.1 依据统一标识的服务依赖发现
依据统一标识的服务依赖发现是基于系统日志数据的微服务依赖发现的主流方法. 本方法假设日志文本中包含能够表征请求的标识信息, 如果两个微服务输出日志的标识信息相同且具有先后序列关系, 则说明两个微服务在请求执行过程中存在调用关系, 即存在依赖关系. 文献 [36] 使用日志中 resource ID 和 request ID 关联不同微服务的日志, 构建请求执行路径. HDFS 日志文本中提取 block ID 和 IP 信息, IP 信息用以发现并标识各个微服务, block ID 用于构建请求执行路径,并通过关联执行路径中的连续日志, 发现微服务依赖. 在很多情况下, 日志文本中不存在一个特殊标识能够标识一个请求执行路径. 为解决这个问题, 文献 [37,38] 假设日志文本中包含多种 ID 信息, 通过多种 ID 信息串联请求执行路径, 最终发现微服务间的依赖关系. 文献 [39] 的主要贡献在于从系统源代码中找到最关键的 ID, 并最终使用这些 ID 对微服务进行依赖关系发现. 具体而言, 首先通过静态代码分析方法, 挖掘出绝对精确的日志之间的转移关系和日志中的关键标识. 然后, 这些关键标识被用于连接跨越不同组件却属于同一个请求的日志, 进而形成了一个跨服务的完整的以日志为节点的请求执行路径.
2.2.2 基于共现概率的服务依赖发现
基于共现概率的服务依赖发现的核心思想是依据单条日志之间的共现概率, 判断输出日志的服务间的依赖关系. 本方法假设如果不同微服务输出的两条日志之间存在着频繁先后共现关系, 则说明两个微服务可能存在逻辑上的因果或关联关系, 并依据此发现服务间依赖关系.
2.2.3 基于日志频率的服务依赖发现
基于日志频率的服务依赖发现的核心思想是将日志转换成为数值型的指标, 通过分析指标的分布差异或变化趋势, 发现微服务间的依赖关系. 本方法假设伴随着负载变化, 不同微服务输出的日志数量或频率也随之变化, 如果两个微服务输出的日志数量或频率之间存在相关性, 则说明两个微服务有可能共同协作处理相同请求, 因此两者之间存在一些因果或关联关系, 并依据此发现服务依赖关系.
2.3 基于追踪数据的服务依赖发现
基于追踪数据的服务依赖发现技术以分布式追踪技术作为支撑, 通过分布式追踪技术生成一次服务请求在分布式软件系统中的请求执行路径, 请求执行路径中的事件之间存在因果关系, 当事件的粒度为方法/服务时, 事件之间的因果关系即方法/服务之间的调用关系, 每一个请求执行路径中都包含了部分的服务依赖 (事件之间的因果关系) 信息, 而将多个请求执行路径中的服务依赖信息进行合并便能直接且准确地获取分布式软件系统完整的服务之间的调用依赖信息. 当请求执行路径中事件为细粒度的系统调用、方法调用时, 从请求执行路径中构建服务依赖关系图需要首先对请求执行路径进行抽象, 将细粒度的事件聚合为服务, 然后根据服务之间的因果关系判断服务之间调用依赖关系.
虽然请求执行路径中仅直接体现了服务调用依赖关系, 但服务之间的逻辑依赖关系同样可以从请求执行路径中较为直接地获取. 例如在图 4 所示的请求执行路径中, 事件之间的因果关系即服务之间的调用依赖关系, 服务之间的调用顺序可以根据各个服务调用的时间戳决定, 为从请求执行路径中发现 ShipmentService 对 PaymentService的逻辑依赖关系, 首先需要判断在所有此类请求执行路径中, PaymentService 是否先于 ShipmentSerice 被调用; 进而判断调用 PaymentService 的失效是否会导致 ShipmentService 的调用同样失效, 如果 PaymentService 的失效同样会导致 ShipmentService 的失效 (或者失效的概率超过一定阈值), 那么则可以判断 ShipmentService 与 PaymentService之间存在逻辑依赖关系.
相关文章:
小研究 - 微服务系统服务依赖发现技术综述(一)
微服务架构得到了广泛的部署与应用, 提升了软件系统开发的效率, 降低了系统更新与维护的成本, 提高了系统的可扩展性. 但微服务变更频繁、异构融合等特点使得微服务故障频发、其故障传播快且影响大, 同时微服务间复杂的调用依赖关系或逻辑依赖关系又使得其故障难以被及时、准确…...

2023-08-07力扣今日八题
链接: 剑指 Offer 50. 第一个只出现一次的字符 题意: 如题 解: map存下标,由于存在下标0,所以用find,或者记录下标1也可以 实际代码: #include<bits/stdc.h> using namespace std;…...

Segment Anything【论文翻译】
文章目录 论文基础信息如下Abstract1. Introduction2. Segment Anything Task3. Segment Anything Model4. Segment Anything Data Engine5. Segment Anything Dataset6. Segment Anything RAI Analysis7. Zero-Shot Transfer Experiments7.1. Zero-Shot Single Point Valid Ma…...

银河麒麟QT连接DM8数据库
1. 安装达梦8 官网下载, 按照官方文档进行安装即可. 2. 安装unixodbc 1> 下载odbc安装包 unixODBC-2.3.7pre.tar.gz 2> 解压 tar -xvf unixODBC-2.3.7pre.tar.gz3> 编译 ./configure -prefix /usr/local make && make install4> 查找配置 odbcinst -j5…...

并发编程1:线程安全性概述
目录 1、什么是线程安全性? 2、操作的原子性:避免竞态条件 3、锁机制:内置锁和可重入 4、如何用锁来保护状态? 5、同步机制中的活跃性与性能问题 编写线程安全的代码,其核心在于对状态访问操作进行管理࿰…...
(论文复现)DeepAnt模型复现及应用
DeepAnt论文如下,其主要是用于时间序列的无监督粗差探测。 其提出的模型架构如下: 该文提出了一个无监督的时间序列粗差探测模型,其主要有预测模块和探测模块组成,其中预测模块的网络结构如下。 预测结构是将时间序列数据组…...
【机器学习】在 MLOps构建项目 ( MLOps2)
My MLOps tutorials: Tutorial 1: A Beginner-Friendly Introduction to MLOps教程 2:使用 MLOps 构建机器学习项目 一、说明 如果你希望将机器学习项目提升到一个新的水平,MLOps 是该过程的重要组成部分。在本文中,我们将以经典手写数字分类…...
【MySQL】聚合函数与分组查询
文章目录 一、聚合函数1.1 count 返回查询到的数据的数量1.2 sum 返回查询到的数据的总和1.3 avg 返回查询到的数据的平均值1.4 max 返回查询到的数据的最大值1.5 min 返回查询到的数据的最小值 二、分组查询group by2.1 导入雇员信息表2.2 找到最高薪资和员工平均薪资2.3 显示…...
conda 环境 numpy 安装报错需要 Microsoft Visual C++ 14.0
到公司装深度学校环境。项目较旧,安装依赖,一堆报错(基于 conda 环境): numpy 安装报需要 C 14.0 No module named numpy.distutils._msvccompiler in numpy.distutils; trying from distutilserror: Microsoft Visu…...
)
算法工程师-机器学习面试题总结(5)
什么是信息熵? 信息熵是信息理论中用来衡量一个随机变量的不确定度或者信息量的概念。它是在给定一组可能的事件中,对每个事件发生的概率进行加权平均得到的值。 在信息熵的计算中,概率越大的事件所带来的信息量越小,概率越小的事…...
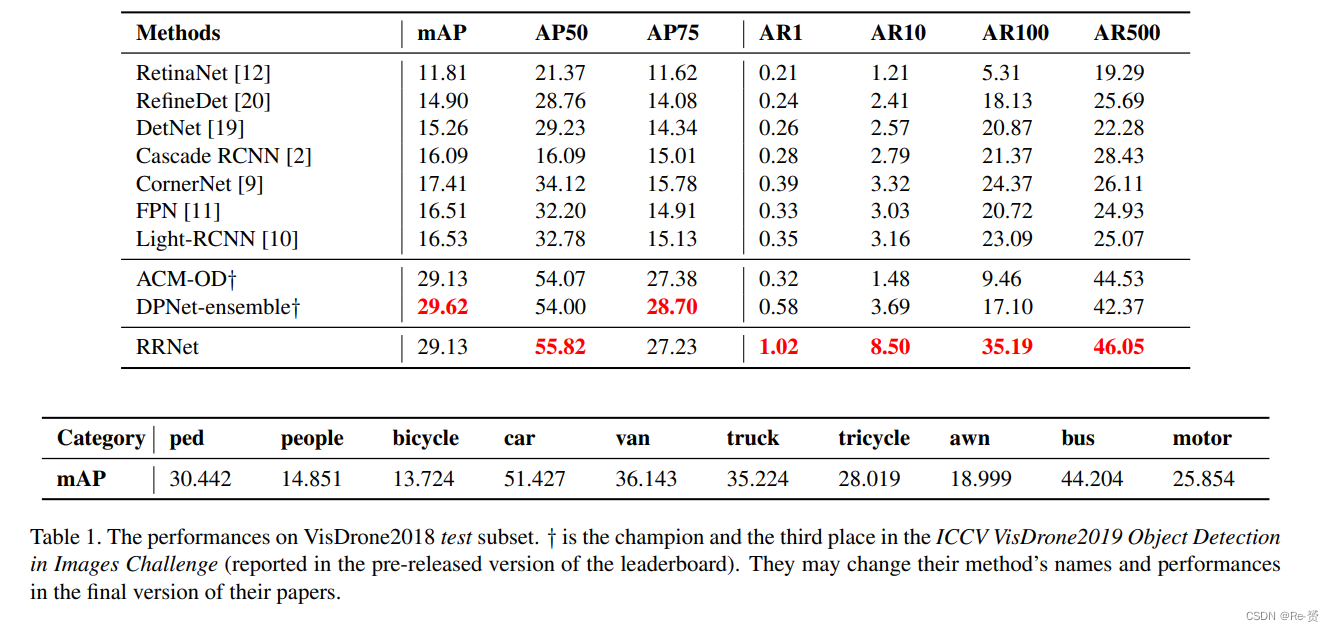
论文阅读 RRNet: A Hybrid Detector for Object Detection in Drone-captured Images
文章目录 RRNet: A Hybrid Detector for Object Detection in Drone-captured ImagesAbstract1. Introduction2. Related work3. AdaResampling4. Re-Regression Net4.1. Coarse detector4.2. Re-Regression 5. Experiments5.1. Data augmentation5.2. Network details5.3. Tra…...

js执行机制
JavaScript 的执行机制是基于单线程的事件循环模型。这意味着 JavaScript 代码会按照顺序一行一行地执行,同时只能执行一个任务。让我们更详细地了解 JavaScript 的执行机制: 调用栈(Call Stack): JavaScript 使用调用…...

关于策略模式的注入问题
上面抄别人的 当在实现策略方法时,报null,排查后发现是接口实现有多个,需要添加别名 注入时添加Qeualifier,指定名称,如下图;如图上修改, 测试类中不用new具体行为策略了,注入别名即…...

通用Mapper的四个常见注解
四个常见注解 1、Table 作用:建立实体类和数据库表之间的对应关系。 默认规则:实体类类名首字母小写作为表名,如 Employee -> employee 表 用法:在 Table 注解的 name 属性中指定目标数据库的表名; 案例&#…...

二进制安装K8S(单Master集群架构)
目录 一:操作系统初始化配置 1、项目拓扑图 2、服务器 3、初始化操作 二: 部署 etcd 集群 1、etcd 介绍 2、准备签发证书环境 3、master01 节点上操作 (1)生成Etcd证书 (2)创建用于存放 etcd 配置文…...

基于java汽车销售分析与管理系统设计与实现
摘 要 计算机现在已成为人们办公和生活不可或缺的组成部分,在工作范畴计算机成熟运用大大提升了工作人员的工作效率,化繁为简,加速社会经济发展。在生活上,人们可以通过计算机互联网更快的了解到全球时事要闻、听到最新潮流音乐、…...
Glass指纹识别工具,多线程Web指纹识别工具-Chunsou
Glass指纹识别工具,多线程Web指纹识别工具-Chunsou。 Glass指纹识别工具 Glass一款针对资产列表的快速指纹识别工具,通过调用Fofa/ZoomEye/Shodan/360等api接口快速查询资产信息并识别重点资产的指纹,也可针对IP/IP段或资产列表进行快速的指…...
BIO,NIO,AIO总结
文章目录 1. BIO (Blocking I/O)1.1 传统 BIO1.2 伪异步 IO1.3 代码示例 1.4 总结2. NIO (New I/O)2.1 NIO 简介2.2 NIO的特性/NIO与IO区别1)Non-blocking IO(非阻塞IO)2)Buffer(缓冲区)3)Channel (通道)4)Selector (选择器) 2.3 NIO 读数据和写数据方式…...
[腾讯云Cloud Studio实战训练营]基于Cloud Studio完成图书管理系统
[腾讯云Cloud Studio实战训练营]基于Cloud Studio完成图书管理系统 ⭐前言🌜Cloud Studio产品介绍1.登录2.创建工作空间3.工作空间界面简介4.环境的使用 ⭐实验实操🌜Cloud Studio实现图书管理系统1.实验目的 2. 实验过程2.实验环境3.源码讲解3.1添加数据…...
Node.js 基础模块)
(二)Node.js 基础模块
(二)Node.js 基础模块 1. fs文件系统模块1.1 什么是fs文件系统模块1.2 读取指定文件中的内容1. fs.readFile()的语法格式2. fs.readFile()的示例代码 1.3 向指定的文件中写入内容1. fs.writeFile()的语法格式2. fs.writeFile()的实例代码 1.4 __dirname …...

HS2-HF Patch:为《Honey Select 2》注入新生命的魔法补丁
HS2-HF Patch:为《Honey Select 2》注入新生命的魔法补丁 【免费下载链接】HS2-HF_Patch Automatically translate, uncensor and update HoneySelect2! 项目地址: https://gitcode.com/gh_mirrors/hs/HS2-HF_Patch 你是不是曾经打开《Honey Select 2》时&am…...

将HermesAgent项目接入Taotoken的详细配置步骤与注意事项
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 将HermesAgent项目接入Taotoken的详细配置步骤与注意事项 本文旨在为开发者提供一份清晰的指南,帮助你将HermesAgent项…...

VHD2VL终极指南:5分钟快速将VHDL转换为Verilog的免费工具
VHD2VL终极指南:5分钟快速将VHDL转换为Verilog的免费工具 【免费下载链接】vhd2vl 项目地址: https://gitcode.com/gh_mirrors/vh/vhd2vl 在FPGA和ASIC设计领域,VHDL转Verilog是许多工程师面临的共同挑战。手动转换不仅耗时费力,还容…...

快速免费解锁网易云音乐NCM格式:ncmdumpGUI完整使用指南
快速免费解锁网易云音乐NCM格式:ncmdumpGUI完整使用指南 【免费下载链接】ncmdumpGUI C#版本网易云音乐ncm文件格式转换,Windows图形界面版本 项目地址: https://gitcode.com/gh_mirrors/nc/ncmdumpGUI 你是否曾在网易云音乐下载了心爱的歌曲&am…...

AutoCut终极指南:如何用文本编辑器快速剪辑100个视频
AutoCut终极指南:如何用文本编辑器快速剪辑100个视频 【免费下载链接】autocut 用文本编辑器剪视频 项目地址: https://gitcode.com/GitHub_Trending/au/autocut 还在为手动剪辑视频而烦恼吗?AutoCut项目让你告别复杂的视频编辑软件,通…...

迪拜塔幕墙设计
迪拜塔幕墙设计 【作 者】:罗永增 【关键词】:迪拜塔,幕墙,设计,系统。 前言:...

Qdrant Python客户端全解析:从向量数据库连接到AI应用开发实战
1. 项目概述:从向量数据库到客户端,现代AI应用落地的关键拼图如果你最近在折腾大语言模型应用,或者想给自己的产品加上一个“智能大脑”,那你大概率已经听过“向量数据库”这个词了。简单来说,它就像一个专门为AI模型设…...

如何用Sunshine打造个人游戏云:终极自托管游戏串流解决方案
如何用Sunshine打造个人游戏云:终极自托管游戏串流解决方案 【免费下载链接】Sunshine Self-hosted game stream host for Moonlight. 项目地址: https://gitcode.com/GitHub_Trending/su/Sunshine 你是否曾经梦想在任何设备上畅玩PC游戏?无论是想…...
技术解析与应用前景)
量子私有信息检索(QPIR)技术解析与应用前景
1. 量子私有信息检索技术概述量子私有信息检索(Quantum Private Information Retrieval, QPIR)是密码学领域的一项突破性技术,它允许用户从数据库中检索特定条目而不泄露被查询的是哪个条目。这项技术的核心价值在于解决了隐私保护与数据获取…...

ARM Cortex-X4/X925处理器仿真模型与指令集详解
1. ARM Cortex-X4/X925处理器仿真模型概述处理器仿真模型在现代芯片设计中扮演着至关重要的角色,特别是在Arm架构的生态系统中。作为Arm最新一代高性能核心,Cortex-X4和X925的Iris仿真组件提供了完整的指令集和微架构行为建模,使开发者能够在…...