(论文复现)DeepAnt模型复现及应用
DeepAnt论文如下,其主要是用于时间序列的无监督粗差探测。

其提出的模型架构如下:
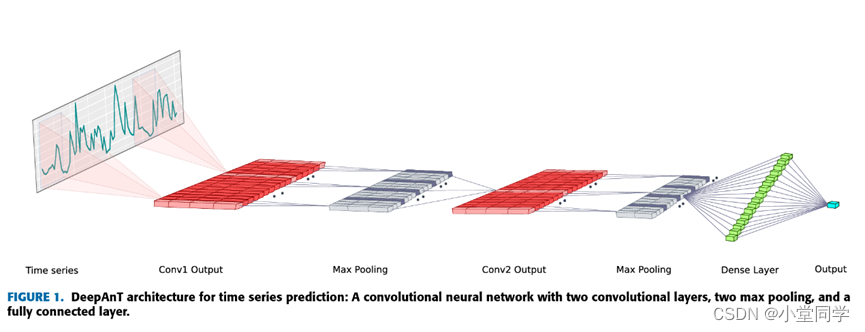
该文提出了一个无监督的时间序列粗差探测模型,其主要有预测模块和探测模块组成,其中预测模块的网络结构如下。
预测结构是将时间序列数据组织成数据集之后经过两次的卷积和最大池化,最后将卷积结果通过一个全连接层转换为一个输出数据(若是单步预测则输出单元个数为1)
探测模块是将模型的时序预测结果与该时刻的观测数据相比来计算欧氏距离,以此来作为当前时间点距离的异常分数。以此来作为数据粗差探测的标准。
(本博客主要是分享复现代码,论文中的细节原理可自行下载学习)
复现代码(数据不便分享):
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import torch
import torch.nn as nn
import torch.nn.functional as F
from torch.utils.data import Dataset,DataLoader,TensorDataset
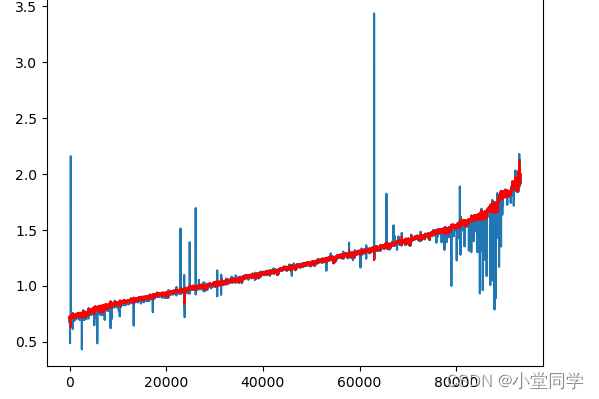
from sklearn.preprocessing import MinMaxScaler,StandardScalerdef MSE(arr1,arr2):arr1,arr2 = np.array(arr1).flatten(),np.array(arr2).flatten()assert arr1.shape[0] == arr2.shape[0]return np.sum(np.power(arr1-arr2,2)) / arr1.shape[0]def MAE(arr1,arr2):arr1,arr2 = np.array(arr1).flatten(),np.array(arr2).flatten()assert arr1.shape[0] == arr2.shape[0]return np.sum(np.abs(arr1-arr2)) / arr1.shape[0]class MyData(Dataset):def __init__(self,arr,history_window,predict_len) -> None:self.length = arr.flatten().shape[0]self.history_window = history_windowself.dataset_x,self.dataset_y = self.get_dataset(arr,history_window,predict_len)def get_dataset(self,arr,history_window,predict_len):arr = np.array(arr).flatten()N = history_windowM = predict_lendataset_x = np.zeros((arr.shape[0] - N,N))dataset_y = np.zeros((arr.shape[0] - N,M))for i in range(arr.shape[0] - N):dataset_x[i] = arr[i:i+N]dataset_y[i] = arr[i+N:i+N+M]dataset_x = torch.from_numpy(dataset_x).to(torch.float)dataset_y = torch.from_numpy(dataset_y).to(torch.float)return (dataset_x,dataset_y)def __getitem__(self, index): # 定义方法 data[i] 的返回值return (self.dataset_x[index,:],self.dataset_y[index,:])def __len__(self): # 获取数据集样本个数return self.length - self.history_windowclass DeepAnt(nn.Module):def __init__(self,lag,p_w):super().__init__()self.convblock1 = nn.Sequential(nn.Conv1d(in_channels=1, out_channels=32, kernel_size=3, padding='valid'),nn.ReLU(inplace=True),nn.MaxPool1d(kernel_size=2))self.convblock2 = nn.Sequential(nn.Conv1d(in_channels=32, out_channels=32, kernel_size=3, padding='valid'),nn.ReLU(inplace=True),nn.MaxPool1d(kernel_size=2))self.flatten = nn.Flatten()self.denseblock = nn.Sequential(nn.Linear(32, 40), # for lag = 10#nn.Linear(96, 40), # for lag = 20#nn.Linear(192, 40), # for lag = 30nn.ReLU(inplace=True),nn.Dropout(p=0.25),)self.out = nn.Linear(40, p_w)def forward(self, x):x = x.view(-1,1,lag)x = self.convblock1(x)x = self.convblock2(x)x = self.flatten(x)x = self.denseblock(x)x = self.out(x)return xdef Train(model,data_set,EPOCH,task_id):if torch.cuda.is_available():device = torch.device('cuda')print('cuda is used...')else:torch.device('cpu')print('cpu is used...')scale = StandardScaler()loss_fn = nn.MSELoss()model.to(device)loss_fn.to(device)train_x,train_y = data_set.dataset_x,data_set.dataset_ytrain_x = scale.fit_transform(train_x)train_x = torch.from_numpy(train_x).to(torch.float).to(device)train_y = train_y.to(device).to(torch.float)torch_dataset = TensorDataset(train_x,train_y)optimizer = torch.optim.Adam(model.parameters())BATCH_SIZE = 100model = model.train()train_loss = []print('======Start training...=======')print(f'Epoch is {EPOCH}\ntrain_x shape is {train_x.shape}\nBATCH_SIZE is {BATCH_SIZE}')for i in range(EPOCH):loader = DataLoader(dataset=torch_dataset,batch_size=BATCH_SIZE,shuffle=True)temp_1 = []for step,(batch_x,batch_y) in enumerate(loader):out = model(batch_x)optimizer.zero_grad()loss = loss_fn(out,batch_y)temp_1.append(loss.item())loss.backward()optimizer.step()torch.cuda.empty_cache()train_loss.append(np.mean(np.array(temp_1)))if i % 10 == 0:print(f"The {i}/{EPOCH} is end, loss is {np.round(np.mean(np.array(temp_1)),6)}.")print('========Training end...=======')model = model.eval()plt.plot(train_loss)pred = model(train_x).cpu().data.numpy()print(f'pred shape {pred.shape}')plt.figure()y = train_y.cpu().data.numpy().flatten()print(f'y shape {y.shape}')plt.plot(y,c='b',label='True')plt.plot(pred,'r',label='pred')plt.legend()plt.title('Train_result')plt.show()return predif __name__ == "__main__":data_f = pd.read_csv('HF05_processed.csv')data = np.array(pd.DataFrame(data_f)['OT'])lag = 10dataset = MyData(data,lag,1)model = DeepAnt(lag,1)res = Train(model,dataset,200,'1')data = data[lag:].flatten() plt.plot(data)plt.plot(res,c='r')err = data - res.flatten()anomaly_score = np.sqrt(np.power(err,2))plt.figure()plt.plot(anomaly_score)error_list = []threshold = 0.04for i in range(anomaly_score.shape[0]):if anomaly_score[i] > threshold:error_list.append(i)print(len(error_list))plt.figure()plt.plot(data)plt.plot(error_list,[data[i] for i in error_list],ls='',marker='x',c='r',markersize=4)plt.show()运行结果:

才疏学浅,敬请指正!
欢迎交流:
邮箱:rton.xu@qq.com
QQ:2264787072
相关文章:
(论文复现)DeepAnt模型复现及应用
DeepAnt论文如下,其主要是用于时间序列的无监督粗差探测。 其提出的模型架构如下: 该文提出了一个无监督的时间序列粗差探测模型,其主要有预测模块和探测模块组成,其中预测模块的网络结构如下。 预测结构是将时间序列数据组…...
【机器学习】在 MLOps构建项目 ( MLOps2)
My MLOps tutorials: Tutorial 1: A Beginner-Friendly Introduction to MLOps教程 2:使用 MLOps 构建机器学习项目 一、说明 如果你希望将机器学习项目提升到一个新的水平,MLOps 是该过程的重要组成部分。在本文中,我们将以经典手写数字分类…...
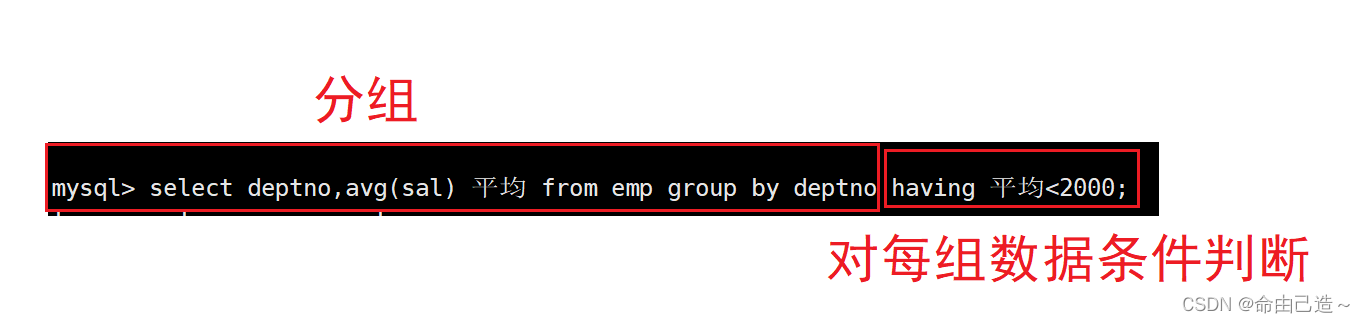
【MySQL】聚合函数与分组查询
文章目录 一、聚合函数1.1 count 返回查询到的数据的数量1.2 sum 返回查询到的数据的总和1.3 avg 返回查询到的数据的平均值1.4 max 返回查询到的数据的最大值1.5 min 返回查询到的数据的最小值 二、分组查询group by2.1 导入雇员信息表2.2 找到最高薪资和员工平均薪资2.3 显示…...
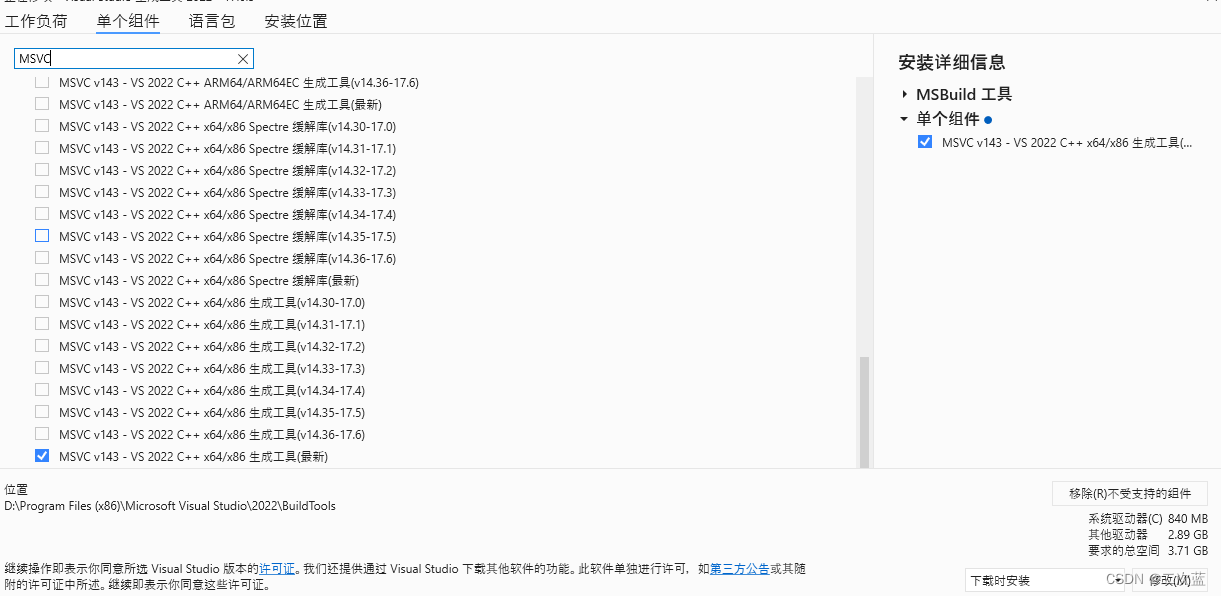
conda 环境 numpy 安装报错需要 Microsoft Visual C++ 14.0
到公司装深度学校环境。项目较旧,安装依赖,一堆报错(基于 conda 环境): numpy 安装报需要 C 14.0 No module named numpy.distutils._msvccompiler in numpy.distutils; trying from distutilserror: Microsoft Visu…...
)
算法工程师-机器学习面试题总结(5)
什么是信息熵? 信息熵是信息理论中用来衡量一个随机变量的不确定度或者信息量的概念。它是在给定一组可能的事件中,对每个事件发生的概率进行加权平均得到的值。 在信息熵的计算中,概率越大的事件所带来的信息量越小,概率越小的事…...
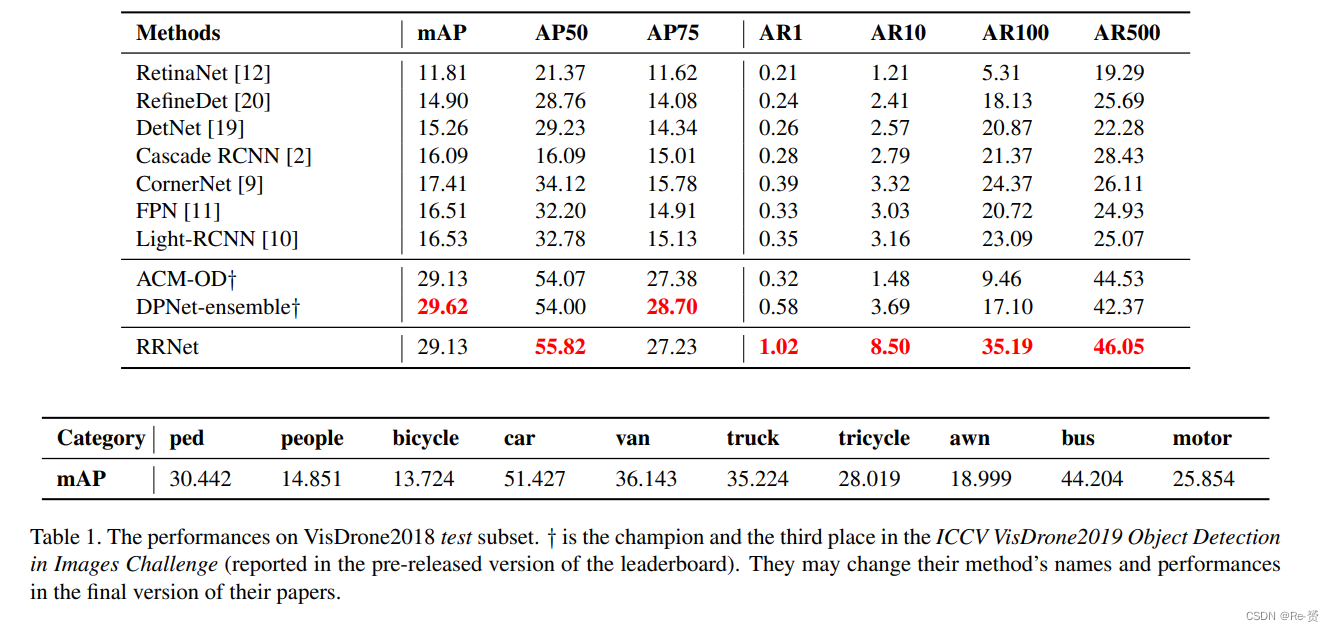
论文阅读 RRNet: A Hybrid Detector for Object Detection in Drone-captured Images
文章目录 RRNet: A Hybrid Detector for Object Detection in Drone-captured ImagesAbstract1. Introduction2. Related work3. AdaResampling4. Re-Regression Net4.1. Coarse detector4.2. Re-Regression 5. Experiments5.1. Data augmentation5.2. Network details5.3. Tra…...

js执行机制
JavaScript 的执行机制是基于单线程的事件循环模型。这意味着 JavaScript 代码会按照顺序一行一行地执行,同时只能执行一个任务。让我们更详细地了解 JavaScript 的执行机制: 调用栈(Call Stack): JavaScript 使用调用…...

关于策略模式的注入问题
上面抄别人的 当在实现策略方法时,报null,排查后发现是接口实现有多个,需要添加别名 注入时添加Qeualifier,指定名称,如下图;如图上修改, 测试类中不用new具体行为策略了,注入别名即…...

通用Mapper的四个常见注解
四个常见注解 1、Table 作用:建立实体类和数据库表之间的对应关系。 默认规则:实体类类名首字母小写作为表名,如 Employee -> employee 表 用法:在 Table 注解的 name 属性中指定目标数据库的表名; 案例&#…...

二进制安装K8S(单Master集群架构)
目录 一:操作系统初始化配置 1、项目拓扑图 2、服务器 3、初始化操作 二: 部署 etcd 集群 1、etcd 介绍 2、准备签发证书环境 3、master01 节点上操作 (1)生成Etcd证书 (2)创建用于存放 etcd 配置文…...

基于java汽车销售分析与管理系统设计与实现
摘 要 计算机现在已成为人们办公和生活不可或缺的组成部分,在工作范畴计算机成熟运用大大提升了工作人员的工作效率,化繁为简,加速社会经济发展。在生活上,人们可以通过计算机互联网更快的了解到全球时事要闻、听到最新潮流音乐、…...
Glass指纹识别工具,多线程Web指纹识别工具-Chunsou
Glass指纹识别工具,多线程Web指纹识别工具-Chunsou。 Glass指纹识别工具 Glass一款针对资产列表的快速指纹识别工具,通过调用Fofa/ZoomEye/Shodan/360等api接口快速查询资产信息并识别重点资产的指纹,也可针对IP/IP段或资产列表进行快速的指…...
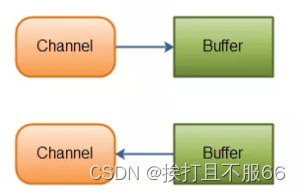
BIO,NIO,AIO总结
文章目录 1. BIO (Blocking I/O)1.1 传统 BIO1.2 伪异步 IO1.3 代码示例 1.4 总结2. NIO (New I/O)2.1 NIO 简介2.2 NIO的特性/NIO与IO区别1)Non-blocking IO(非阻塞IO)2)Buffer(缓冲区)3)Channel (通道)4)Selector (选择器) 2.3 NIO 读数据和写数据方式…...
[腾讯云Cloud Studio实战训练营]基于Cloud Studio完成图书管理系统
[腾讯云Cloud Studio实战训练营]基于Cloud Studio完成图书管理系统 ⭐前言🌜Cloud Studio产品介绍1.登录2.创建工作空间3.工作空间界面简介4.环境的使用 ⭐实验实操🌜Cloud Studio实现图书管理系统1.实验目的 2. 实验过程2.实验环境3.源码讲解3.1添加数据…...
Node.js 基础模块)
(二)Node.js 基础模块
(二)Node.js 基础模块 1. fs文件系统模块1.1 什么是fs文件系统模块1.2 读取指定文件中的内容1. fs.readFile()的语法格式2. fs.readFile()的示例代码 1.3 向指定的文件中写入内容1. fs.writeFile()的语法格式2. fs.writeFile()的实例代码 1.4 __dirname …...

AUC及其拓展GAUC
AUC及其拓展GAUC auc的定义 auc用来评估一个分类器的排序质量,它的物理含义:给定一堆正负样本,随机取一个正样本,一个负样本,学习器将正样本排在负样本前面的概率 auc的计算 具体计算方法:给定m个正样本…...

【CSS】CSS 选择器
CSS 选择器 1.基础选择器 1.1 元素选择器 语法:标签名{...} 元素选择器会选中对应标签名的HTML元素,例如:p{...},div{...},span{...}等 1.2 类选择器 语法:.类名{...} 类选择器会选中class属性为指定…...

2023-08-07力扣今日四题-好题
链接: 剑指 Offer 03. 数组中重复的数字 题意: 如题 解: 看到一个很牛的时间复杂度O(n)的原地算法:由于数组长度n,数组内只有0到n-1,那么,我们用对应-n到-1表示nums[index]出现过一次&…...
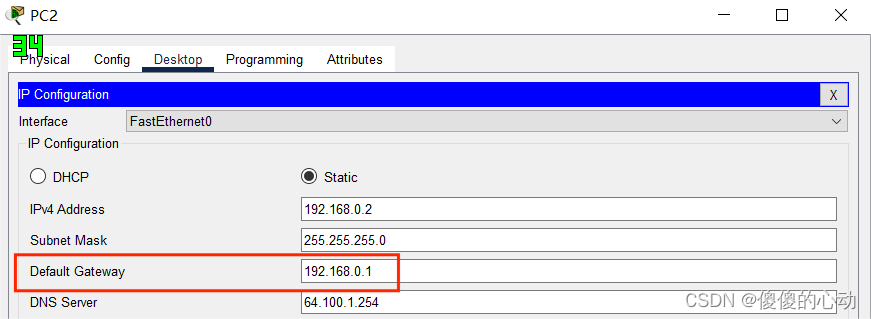
Packet Tracer - IPv4 和 IPv6 编址故障排除
Packet Tracer - IPv4 和 IPv6 编址故障排除 地址分配表 设备 接口 IPv4 地址 子网掩码 默认网关 IPv6 地址/前缀 R1 G0/0 10.10.1.1 255.255.255.0 N/A G0/1 192.168.0.1 255.255.255.0 N/A 2001:DB8:1:1::1/64 N/A G0/2 2001:DB8:1:2::1/64 N/A S0/0/0 …...
PHP国外在线教育系统源码 在线课程系统源码 直播课程系统源码提供在线课程,现场课程,测验
Proacademy是在线教育一体化的解决方案,用于创建类似于Udemy、Skillshare、Coursera这种在线教育市场。 这个平台提供在线课程,现场课程,测验等等,并有一个基于实际业务需要的高级认证插件,程序基于Laravel强大的安全框…...

163MusicLyrics:一键获取网易云QQ音乐歌词的专业工具
163MusicLyrics:一键获取网易云QQ音乐歌词的专业工具 【免费下载链接】163MusicLyrics 云音乐歌词获取处理工具【网易云、QQ音乐】 项目地址: https://gitcode.com/GitHub_Trending/16/163MusicLyrics 还在为找不到高质量歌词而烦恼吗?163MusicLy…...

如何为《欧洲卡车模拟2》实现完整智能驾驶体验?ETS2LA自动驾驶插件终极指南
如何为《欧洲卡车模拟2》实现完整智能驾驶体验?ETS2LA自动驾驶插件终极指南 【免费下载链接】Euro-Truck-Simulator-2-Lane-Assist Plugin based interface program for ETS2/ATS. 项目地址: https://gitcode.com/gh_mirrors/eur/Euro-Truck-Simulator-2-Lane-Ass…...

智能路由器项目解析:基于策略路由实现多线路流量智能调度
1. 项目概述:一个“聪明”的路由器能做什么?最近在GitHub上看到一个挺有意思的项目,叫smart-router,作者是c0nSpIc0uS7uRk3r。光看名字,你可能会觉得这又是一个关于家庭网络优化的工具,但点进去仔细研究后&…...

QMCFLAC2MP3终极指南:免费快速解锁QQ音乐格式限制
QMCFLAC2MP3终极指南:免费快速解锁QQ音乐格式限制 【免费下载链接】qmcflac2mp3 直接将qmcflac文件转换成mp3文件,突破QQ音乐的格式限制 项目地址: https://gitcode.com/gh_mirrors/qm/qmcflac2mp3 你是否曾经在QQ音乐下载了心爱的歌曲࿰…...

Hitboxer终极指南:专业级游戏键盘重映射与SOCD清理工具完全教程
Hitboxer终极指南:专业级游戏键盘重映射与SOCD清理工具完全教程 【免费下载链接】socd Key remapper for epic gamers 项目地址: https://gitcode.com/gh_mirrors/so/socd Hitboxer是一款专为竞技游戏玩家设计的专业级键盘按键重映射和SOCD清理工具ÿ…...

攻克R与Python的壁垒:Giotto空间转录组分析环境一站式搭建指南
1. 为什么你的Giotto安装总是失败? 每次看到空间转录组数据就手痒想用Giotto分析,结果安装环节就被劝退?这可能是大多数生物信息学新手都会遇到的尴尬。作为一个在生信领域摸爬滚打多年的"环境配置工程师",我太理解这种…...

终极指南:如何为PotPlayer配置百度翻译插件实现实时字幕翻译
终极指南:如何为PotPlayer配置百度翻译插件实现实时字幕翻译 【免费下载链接】PotPlayer_Subtitle_Translate_Baidu PotPlayer 字幕在线翻译插件 - 百度平台 项目地址: https://gitcode.com/gh_mirrors/po/PotPlayer_Subtitle_Translate_Baidu PotPlayer_Sub…...

Arm Neoverse CMN-700 HN-F寄存器架构与缓存一致性配置详解
1. Arm Neoverse CMN-700 HN-F寄存器架构概述在现代SoC设计中,一致性互连网络(Coherent Mesh Network)是实现多核处理器高效协同工作的核心基础设施。作为Arm Neoverse平台的关键组件,CMN-700通过其独特的网格拓扑结构和分布式节点…...

全域态势数字孪生,筑牢楼宇长效安全透明防护屏障
全域态势数字孪生,筑牢楼宇长效安全透明防护屏障副标题:全要素三维动态实时复刻楼宇实景,依托无感全域人员感知、多机位跨镜联动追踪、身体指纹唯一身份归档,异常行为、区域滞留、安全隐患提前透明预警处置一、方案概述伴随城市高…...
)
【Midjourney数字艺术风格终极指南】:20年AI视觉专家亲授7大核心风格参数调优法则(含V6.1新增Realism Mode实测数据)
更多请点击: https://intelliparadigm.com 第一章:Midjourney数字艺术风格演进与V6.1核心变革 Midjourney自V1发布以来,其图像生成范式经历了从纹理模拟到语义理解、从风格模仿到跨模态协同的深层跃迁。V6.1标志着模型首次在原生架构中集成…...