原型模式与享元模式:提升系统性能的利器
原型模式和享元模式,前者是在创建多个实例时,对创建过程的性能进行调优;后者是用减
少创建实例的方式,来调优系统性能。这么看,你会不会觉得两个模式有点相互矛盾呢?
在有些场景下,我们需要重复创建多个实例,例如在循环体中赋值一个对象,此时我们就可以采用原型模式来优化对象的创建过程;而在有些场景下,我们则可以避免重复创建多个实例,在内存中共享对象就好了
原型模型
原型模型的实现
原型模式是通过给出一个原型对象来指明所创建的对象的类型,然后使用自身实现的克隆接口来复制这个原型对象,该模式就是用这种方式来创建出更多同类型的对象。
使用这种方式创建新的对象的话,就无需再通过 new 实例化来创建对象了。这是因为Object 类的 clone 方法是一个本地方法,它可以直接操作内存中的二进制流,所以性能相对 new 实例化来说,更佳
new一个对象和clone一个对象,性能差在哪里呢?上边提到直接从内存复制二进制怎末理解?
答: 一个对象通过new创建的过程为:
1、在内存中开辟一块空间;
2、在开辟的内存空间中创建对象;
3、调用对象的构造函数进行初始化对象。
而一个对象通过clone创建的过程为:
1、根据原对象内存大小开辟一块内存空间;
2、复制已有对象,克隆对象中所有属性值。
相对new来说,clone少了调用构造函数。如果构造函数中存在大量属性初始化或大对象,则使用clone的复制对象的方式性能会好一些。
首先先看一段原型模式的代码

要实现一个原型类,需要具备三个条件:
实现 Cloneable 接口:Cloneable 接口与序列化接口的作用类似,它只是告诉虚拟机可
以安全地在实现了这个接口的类上使用 clone 方法。在 JVM 中,只有实现了 Cloneable
接口的类才可以被拷贝,否则会抛出 CloneNotSupportedException 异常。
重写 Object 类中的 clone 方法:在 Java 中,所有类的父类都是 Object 类,而 Object
类中有一个 clone 方法,作用是返回对象的一个拷贝。
在重写的 clone 方法中调用 super.clone():默认情况下,类不具备复制对象的能力,需
要调用 super.clone() 来实现
从上面我们可以看出,原型模式的主要特征就是使用 clone 方法复制一个对象。通常,有
些人会误以为 Object a=new Object();Object b=a; 这种形式就是一种对象复制的过程,
然而这种复制只是对象引用的复制,也就是 a 和 b 对象指向了同一个内存地址,如果 b 修
改了,a 的值也就跟着被修改了。我们可以通过一个简单的例子来看看普通的对象复制问题:

如果是复制对象,此时打印的日志应该为:

然而,实际上是:
学生 1: test2
学生 2 :test2
通过 clone 方法复制的对象才是真正的对象复制,clone 方法赋值的对象完全是一个独立
的对象。Object 类的 clone 方法是一个本地方法,它直接操作内存中的二进
制流,特别是复制大对象时,性能的差别非常明显。我们可以用 clone 方法再实现一遍以
上例子
// 学生类实现 Cloneable 接口
class Student implements Cloneable{
private String name; // 姓名
public String getName() {
return name;
}
public void setName(String name) {
this.name= name;
}
// 重写 clone 方法
public Student clone() {
Student student = null;
try {
student = (Student) super.clone();
} catch (CloneNotSupportedException e) {
e.printStackTrace();
}
return student;
}
}
public class Test {
public static void main(String args[]) {
Student stu1 = new Student(); // 创建学生 1
stu1.setName("test1");
Student stu2 = stu1.clone(); // 通过克隆创建学生 2
stu2.setName("test2");
System.out.println(" 学生 1:" + stu1.getName());
System.out.println(" 学生 2:" + stu2.getName());
}
}运行结果:
学生 1:test1
学生 2:test2
深拷贝和浅拷贝
在调用 super.clone() 方法之后,首先会检查当前对象所属的类是否支持 clone,也就是看
该类是否实现了 Cloneable 接口
如果支持,则创建当前对象所属类的一个新对象,并对该对象进行初始化,使得新对象的成
员变量的值与当前对象的成员变量的值一模一样,但对于其它对象的引用以及 List 等类型
的成员属性,则只能复制这些对象的引用了。所以简单调用 super.clone() 这种克隆对象方
式,就是一种浅拷贝。
所以,当我们在使用 clone() 方法实现对象的克隆时,就需要注意浅拷贝带来的问题。我们
再通过一个例子来看看浅拷贝。
// 定义学生类
class Student implements Cloneable{
private String name; // 学生姓名
private Teacher teacher; // 定义老师类
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public Teacher getTeacher() {
return teacher;
}
public void setName(Teacher teacher) {
this.teacher = teacher;
}
//重写克隆方法
public Student clone() {
Student student = null;
try {
student = (Student) super.clone();
} catch (CloneNotSupportedException e) {
e.printStackTrace();
}
return student;
}
}
// 定义老师类
class Teacher implements Cloneable{
private String name; // 老师姓名
public String getName() {
return name;
}
public void setName(String name) {
this.name= name;
}
// 重写克隆方法,堆老师类进行克隆
public Teacher clone() {
Teacher teacher= null;
try {
teacher= (Teacher) super.clone();
} catch (CloneNotSupportedException e) {
e.printStackTrace();
}
return student;
}
}
public class Test {
public static void main(String args[]) {
Teacher teacher = new Teacher (); // 定义老师 1
teacher.setName(" 刘老师 ");
Student stu1 = new Student(); // 定义学生 1
stu1.setName("test1");
stu1.setTeacher(teacher);
Student stu2 = stu1.clone(); // 定义学生 2
stu2.setName("test2");
stu2.getTeacher().setName(" 王老师 ");// 修改老师
System.out.println(" 学生 " + stu1.getName + " 的老师是:" + stu1.getTeacher().get
System.out.println(" 学生 " + stu1.getName + " 的老师是:" + stu2.getTeacher().get
}
}运行结果:

观察以上运行结果,我们可以发现:在我们给学生 2 修改老师的时候,学生 1 的老师也跟
着被修改了。这就是浅拷贝带来的问题。
我们可以通过深拷贝来解决这种问题,其实深拷贝就是基于浅拷贝来递归实现具体的每个对
象,代码如下:

适用场景
在一些重复创建对象的场景下,我们就可以使用原型模式来提高对象的创建性能。例如,在开头提到的,循环体内创建对象时,我们就可以考虑用 clone 的方式来实现。
例如:

可以优化为 :

除此之外,原型模式在开源框架中的应用也非常广泛。例如 Spring 中,@Service 默认都
是单例的。用了私有全局变量,若不想影响下次注入或每次上下文获取 bean,就需要用到
原型模式,我们可以通过以下注解来实现,@Scope(“prototype”)。
以上可能会有这个哥们们不理解比如这个问题
文中说的,@service默认是单例模式,若不想影响下次请求,就要使用原型模式?
回复:纠正下,不是每次请求,而是每次bean注入或通过上下文获取bean时。
如果我们使用的是单例,假设有一个全局变量private int a=1,我们通过上下文获取到实例,调用A方法修改了变量a=2,此时下一个通过上下文获取到实例调用B方法获取变量,则a=2。
如果我们使用的是原型模式,假设有一个全局变量private int a=1,我们通过上下文获取到实
例,调用A方法修改了变量a=2,此时下一个通过上下文获取到实例调用B方法获取变量,则还是a=1。
享元模式
享元模式是运用共享技术有效地最大限度地复用细粒度对象的一种模式。该模式中,以对象
的信息状态划分,可以分为内部数据和外部数据。内部数据是对象可以共享出来的信息,这
些信息不会随着系统的运行而改变;外部数据则是在不同运行时被标记了不同的值。
享元模式一般可以分为三个角色,分别为 Flyweight(抽象享元类)、
ConcreteFlyweight(具体享元类)和 FlyweightFactory(享元工厂类)。抽象享元类通
常是一个接口或抽象类,向外界提供享元对象的内部数据或外部数据;具体享元类是指具体
实现内部数据共享的类;享元工厂类则是主要用于创建和管理享元对象的工厂类




这里注意内在数据,也就是线程共享的,这里咱们定义的是私有的String,大家会有欸他不是静态的怎末共享啊。???????????????????????

观察以上代码运行结果,我们可以发现:如果对象已经存在于享元池中,则不会再创建该对
象了,而是共用享元池中内部数据一致的对象。这样就减少了对象的创建,同时也节省了同
样内部数据的对象所占用的内存空间。
适用场景
享元模式在实际开发中的应用也非常广泛。例如 Java 的 String 字符串,在一些字符串常
量中,会共享常量池中字符串对象,从而减少重复创建相同值对象,占用内存空间。代码如
下:


在日常开发中的应用。例如,线程池就是享元模式的一种实现;将商品存储在应用服
务的缓存中,那么每当用户获取商品信息时,则不需要每次都从 redis 缓存或者数据库中获
取商品信息,并在内存中重复创建商品信息了。
-
总结
在不得已需要重复创建大量同一对象时,我们可以使用原型模式,通过 clone 方法复制对
象,这种方式比用 new 和序列化创建对象的效率要高;在创建对象时,如果我们可以共用
对象的内部数据,那么通过享元模式共享相同的内部数据的对象,就可以减少对象的创建,
实现系统调优
一些杂谈
- 线上短信业务被轰炸,流量费倍增……求推荐个解决思路,监测发现是爬虫程序
建议加一个图片验证码
- 这里需要考虑一个问题就是享元模式,在工厂哪用的那个hashmap的方式
相关文章:
原型模式与享元模式:提升系统性能的利器
原型模式和享元模式,前者是在创建多个实例时,对创建过程的性能进行调优;后者是用减 少创建实例的方式,来调优系统性能。这么看,你会不会觉得两个模式有点相互矛盾呢? 在有些场景下,我们需要重复…...

uniapp封装手写签名
组件代码 cat-signature <template><view v-if"visibleSync" class"cat-signature" :class"{visible:show}" touchmove.stop.prevent"moveHandle"><view class"mask" tap"close" /><view c…...

掌握 JVM 调优命令
常用命令 1、jps查看当前 java 进程2、jinfo实时查看和调整 JVM 配置参数3、jstat查看虚拟机统计信息4、jstack查看线程堆栈信息5、jmap查看堆内存的快照信息 JVM 日常调优总结起来就是:首先通过 jps 命令查看当前进程,然后根据 pid 通过 jinfo 命令查看…...
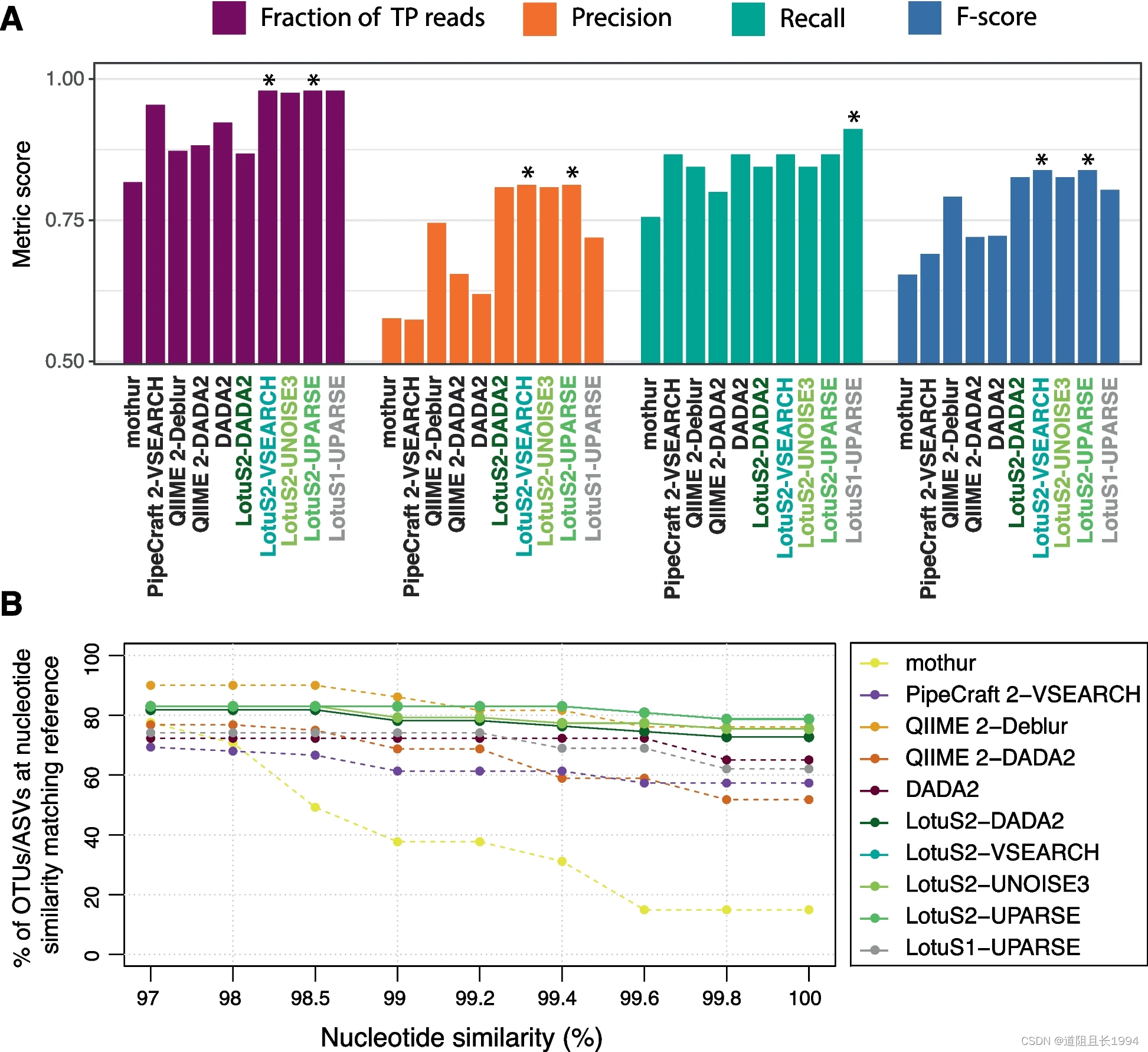
扩增子分析流程——Lotus2: 一行命令完成所有分析
为什么介绍lotus2 因为快,作者比较了lotus2流程和qiime2、dada2、vsearch等,lotus2的速度最快、占用内存最小。 因为方便,只需要一行代码,即可完成全部分析。 lotus2 -i Example/ -m Example/miSeqMap.sm.txt -o myTestRun而且分…...

微服务 云原生:搭建 Harbor 私有镜像仓库
Harbor官网 写在文前: 本文中用到机器均为虚拟机 CentOS-7-x86_64-Minimal-2009 镜像。 基础设施要求 虚拟机配置达到最低要求即可,本次系统中使用 docker 24.0.4、docker-compose 1.29.2。docker 及 docker-compose 的安装可以参考上篇文章 微服务 &am…...

Ceph入门到精通-远程开发Windows下使用SSH密钥实现免密登陆Linux服务器
工具: win10、WinSCP 服务器生成ssh密钥: 打开终端,使账号密码登录,输入命令 ssh-keygen -t rsa Winscp下载 Downloading WinSCP-6.1.1-Setup.exe :: WinSCP window 生成密钥 打开powershell ssh-keygen -t rsa 注意路径 …...
APP外包开发的开发语言对比
在开发iOS APP时有两种语言可以选择,Swift(Swift Programming Language)和 Objective-C(Objective-C Programming Language),它们是两种不同的编程语言,都被用于iOS和macOS等苹果平台的软件开发…...
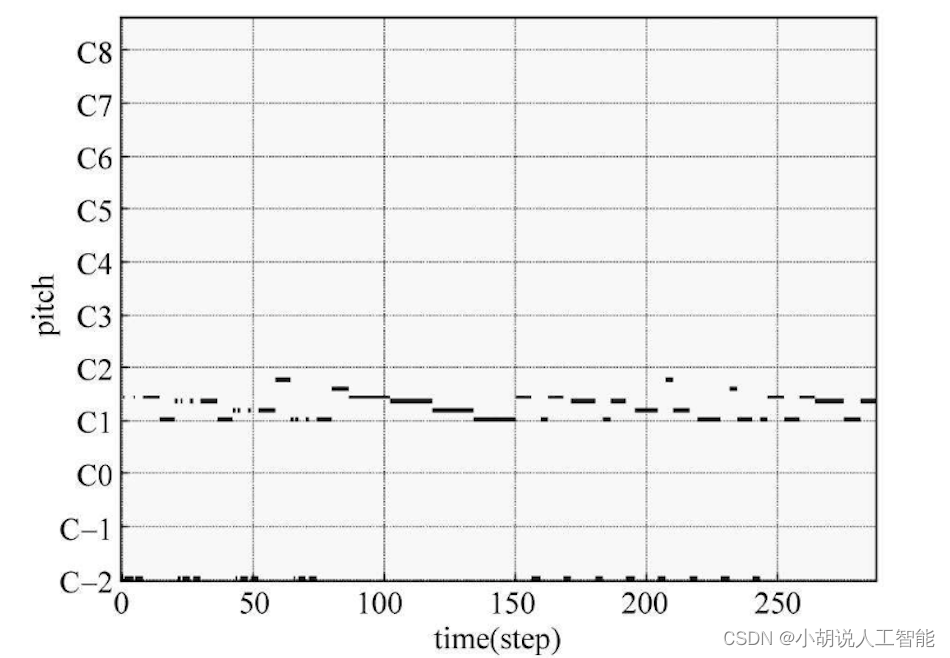
基于Python++PyQt5马尔科夫模型的智能AI即兴作曲—深度学习算法应用(含全部工程源码+测试数据)
目录 前言总体设计系统整体结构图系统流程图 运行环境Python 环境PC环境配置 模块实现1. 钢琴伴奏制作1)和弦的实现2)和弦级数转为当前调式音阶3)根据预置节奏生成伴奏 2. 乐句生成1)添加音符2)旋律生成3)节…...

Android中简单封装Livedata工具类
Android中简单封装Livedata工具类 前言: 之前讲解过livedata和viewmodel的简单使用,也封装过room工具类,本文是对livedata的简单封装和使用,先是封装了一个简单的工具类,然后实现了一个倒计时工具类的封装. 1.LiveD…...
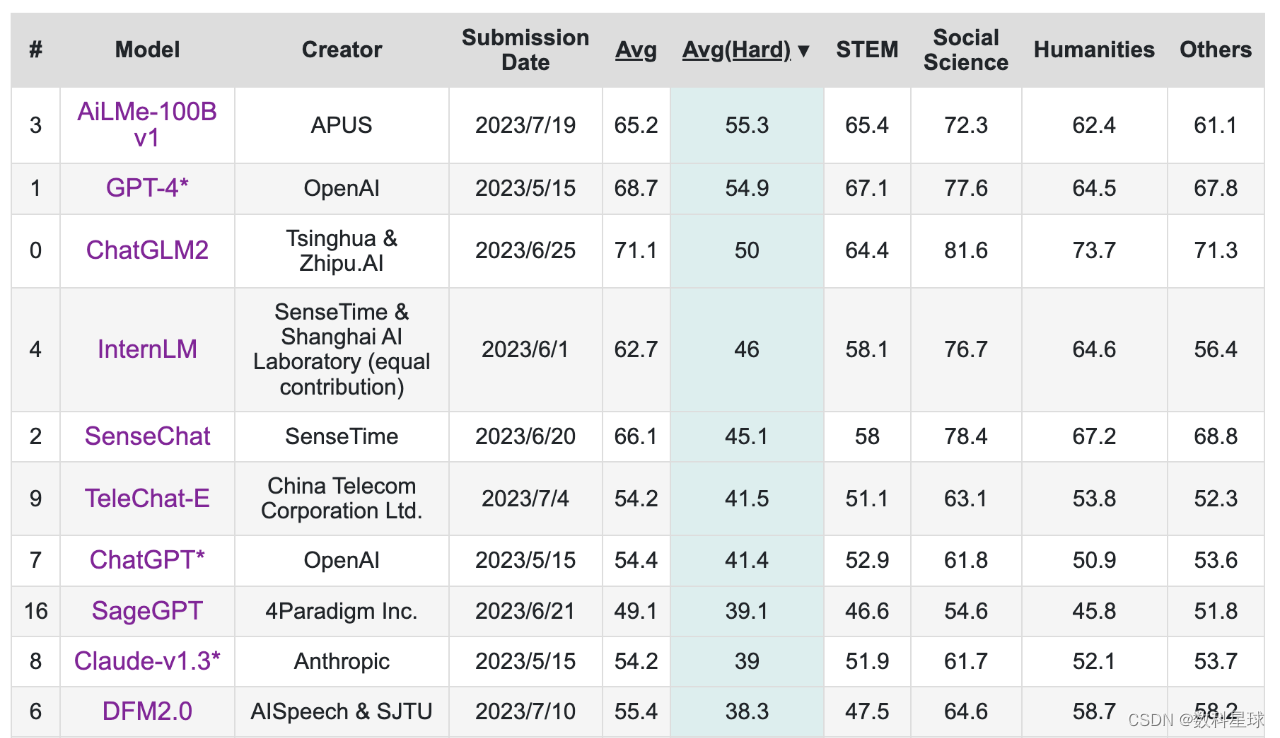
国内大模型在局部能力上已超ChatGPT
中文大模型正在后来居上,也必须后来居上。 数科星球原创 作者丨苑晶 编辑丨大兔 从GPT3.5彻底出圈后,大模型的影响力开始蜚声国际。一段时间内,国内科技公司可谓被ChatGPT按在地上打,毫无还手之力。 彼时,很多企业…...

监控设置ip地址怎么设置
监控设备的IP地址设置是保障监控系统正常工作的基础。通过设置IP地址,我们可以确定监控设备在局域网内的位置,并远程访问监控设备进行实时查看、存储视频等操作。下面虎观代理小二二将介绍具体步骤。 方法一: 和电脑连接在一起,…...
)
力扣:56. 合并区间(Python3)
题目: 以数组 intervals 表示若干个区间的集合,其中单个区间为 intervals[i] [starti, endi] 。请你合并所有重叠的区间,并返回 一个不重叠的区间数组,该数组需恰好覆盖输入中的所有区间 。 来源:力扣(Lee…...

最小二乘问题和非线性优化
最小二乘问题和非线性优化 0.引言1.最小二乘问题2.迭代下降法3.最速下降法4.牛顿法5.阻尼法6.高斯牛顿(GN)法7.莱文贝格马夸特(LM)法8.鲁棒核函数 0.引言 转载自此处,修正了一点小错误。 1.最小二乘问题 在求解 SLAM 中的最优状态估计问题时,我们一般…...

Selenium/webdriver原理解析
最近在看一些底层的东西。driver翻译过来是驱动,司机的意思。如果将webdriver比做成司机,竟然非常恰当。 我们可以把WebDriver驱动浏览器类比成出租车司机开出租车。在开出租车时有三个角色: 乘客:他/她告诉出租车司机去哪里&…...
多用户跨境B2B2C商城后台管理系统快速搭建
搭建一个多用户跨境B2B2C商城后台管理系统需要考虑多个方面,包括系统架构设计、用户权限管理、商品管理、订单管理、支付管理、物流管理等。搭建步骤如下: 1. 系统架构设计 首先,需要设计一个稳定可靠的系统架构。选择一个适合B2B2C商城的商…...

MySQL 优化
问题描述 MySQL 的性能优化分为四个部分: 硬件和操作系统层面的优化架构设计层面的优化MySQL 程序配置优SQL 优化 一、硬件及操作系统层面优化 从硬件层面来说,影响 Mysql 性能的因素有,CPU、可用内存大小、磁盘读写速度、 网络带宽。 从操作…...

VMware Workstation及CentOS-7虚机安装
创建新的虚机: 选择安装软件(这里选的是桌面版,也可以根据实际情况进行选择) 等待检查软件依赖关系 选择安装位置,自主配置分区 创建一个普通用户 安装完成后重启 点击完成配置,进入登陆界面…...
双向带头循环链表+OJ题讲解
💓博主个人主页:不是笨小孩👀 ⏩专栏分类:数据结构与算法👀 刷题专栏👀 C语言👀 🚚代码仓库:笨小孩的代码库👀 ⏩社区:不是笨小孩👀 🌹欢迎大家三连关注&…...

电脑开不了机如何解锁BitLocker硬盘锁
事情从这里说起,不想看直接跳过 早上闲着无聊,闲着没事干,将win11的用户名称改成了含有中文字符的用户名,然后恐怖的事情发生了,蓝屏了… 然后就是蓝屏收集错误信息,重启,蓝屏收集错误信息&…...
Python Web开发 Jinja2模板引擎
在之前的文章中,简单介绍了Python Web开发框架Flask,知道了如何写个Hello World,但是距离用Flask开发真正的项目,还有段距离,现在我们目标更靠近一些 —— 学习下Jinja2模板。 模板的作用 模板是用来做什么的呢&…...

从零构建Cursor编辑器编码统计插件:量化开发行为与性能优化实践
1. 项目概述:一个为开发者定制的代码编辑器洞察工具如果你和我一样,每天大部分时间都泡在代码编辑器里,尤其是像 Cursor 这样集成了 AI 能力的新锐工具,那你可能也会好奇:我到底写了多少行代码?删除了多少行…...

通达信缠论插件ChanlunX:3分钟实现专业缠论分析的完整解决方案
通达信缠论插件ChanlunX:3分钟实现专业缠论分析的完整解决方案 【免费下载链接】ChanlunX 缠中说禅炒股缠论可视化插件 项目地址: https://gitcode.com/gh_mirrors/ch/ChanlunX 你是否曾经面对复杂的K线图感到无从下手?是否因为缠论的手工绘制耗时…...
)
ssm基于Java的试题库管理系统(10030)
有需要的同学,源代码和配套文档领取,加文章最下方的名片哦 一、项目演示 项目演示视频 二、资料介绍 完整源代码(前后端源代码SQL脚本)配套文档(LWPPT开题报告/任务书)远程调试控屏包运行一键启动项目&…...

如何彻底解决Windows系统DLL缺失问题:Visual C++运行库一键修复终极指南
如何彻底解决Windows系统DLL缺失问题:Visual C运行库一键修复终极指南 【免费下载链接】vcredist AIO Repack for latest Microsoft Visual C Redistributable Runtimes 项目地址: https://gitcode.com/gh_mirrors/vc/vcredist 你是否曾经遇到过打开软件时突…...

深度实战:在Linux系统上免费运行Adobe Illustrator CC的高效开源方案
深度实战:在Linux系统上免费运行Adobe Illustrator CC的高效开源方案 【免费下载链接】illustratorCClinux Illustrator CC v17 installer for Gnu/Linux 项目地址: https://gitcode.com/gh_mirrors/il/illustratorCClinux 对于Linux用户而言,专业…...

Live Server深度解析:如何用实时重载技术提升前端开发效率300%
Live Server深度解析:如何用实时重载技术提升前端开发效率300% 【免费下载链接】vscode-live-server Launch a development local Server with live reload feature for static & dynamic pages. 项目地址: https://gitcode.com/gh_mirrors/vs/vscode-live-se…...

如何在Mac上免费一键解锁CrossOver游戏兼容性:CXPatcher完全指南
如何在Mac上免费一键解锁CrossOver游戏兼容性:CXPatcher完全指南 【免费下载链接】CXPatcher A patcher to upgrade Crossover dependencies and improve compatibility 项目地址: https://gitcode.com/gh_mirrors/cx/CXPatcher 想在Mac上流畅运行Windows游戏…...

MCP协议实战:为AI智能体构建标准化地址查询工具
1. 项目概述与核心价值最近在折腾AI应用开发,特别是想给大语言模型(LLM)装上“手”和“眼睛”,让它能主动去操作外部系统、查询实时数据。在这个过程中,一个绕不开的概念就是“工具调用”(Tool Calling&…...

揭秘macOS独立滚动控制:Scroll Reverser如何巧妙解决输入设备冲突
揭秘macOS独立滚动控制:Scroll Reverser如何巧妙解决输入设备冲突 【免费下载链接】Scroll-Reverser Per-device scrolling prefs on macOS. 项目地址: https://gitcode.com/gh_mirrors/sc/Scroll-Reverser 你是否曾经为macOS系统的滚动方向设置感到困扰&…...

从自动化到智能代理:构建家庭智能中枢的架构与实践
1. 项目概述与核心价值最近在折腾智能家居和自动化流程,发现市面上的很多方案要么太“重”,需要依赖特定品牌的生态闭环;要么太“散”,各种工具和脚本堆在一起,管理起来一团乱麻。直到我遇到了一个名为“Home-agent-as…...