batch_softmax_loss
每个用户抽取一定数量的困难负样本,然后ssm
def batch_softmax_loss_neg(self, user_idx, rec_user_emb, pos_idx, item_emb):user_emb = rec_user_emb[user_idx]product_scores = torch.matmul(F.normalize(user_emb, dim=1), F.normalize(item_emb, dim=1).transpose(0, 1))pos_score = (rec_user_emb[user_idx] * item_emb[pos_idx]).sum(dim=-1)pos_score = torch.exp(pos_score / self.temp2)train_mask = self.data.ui_adj[user_idx, self.data.user_num:].toarray()train_mask = torch.tensor(train_mask).cuda()product_scores = product_scores * (1 - train_mask)neg_score, indices = product_scores.topk(500, dim=1, largest=True, sorted=True)neg_score = torch.exp(neg_score[:,400:] / self.temp2).sum(dim=-1)loss = -torch.log(pos_score / (pos_score + neg_score + 10e-6))return torch.mean(loss)
def batch_softmax_loss_neg(user_emb, pos_item_emb, neg_item_emb, temperature):user_emb, pos_item_emb, neg_item_emb = F.normalize(user_emb, dim=1), F.normalize(pos_item_emb, dim=1), F.normalize(neg_item_emb, dim=1)pos_score = (user_emb * pos_item_emb).sum(dim=-1)pos_score = torch.exp(pos_score / temperature)user_emb = user_emb.unsqueeze(1).expand(user_emb.shape[0],neg_item_emb.shape[1],user_emb.shape[1])neg_score = (user_emb * neg_item_emb).sum(dim=-1) # user_emb(n*1*d) neg_item_emb = (n*m*d)neg_score = torch.exp(neg_score / temperature).sum(dim=-1)loss = -torch.log(pos_score / (pos_score + neg_score + 10e-6))return torch.mean(loss)
均匀性损失(错误案例)
# def cal_uniform_loss(user_emb, item_emb):
# user_emb, item_emb = F.normalize(user_emb, dim=1), F.normalize(item_emb, dim=1)
# distance = user_emb - item_emb # n*d
# gaussian_potential = torch.exp(-2 * torch.norm(distance,p=2,dim=1))
# E_gaussian_potential = gaussian_potential.mean()
# return torch.log(E_gaussian_potential)
DNS
def DNSbpr(user_emb, pos_item_emb, neg_item_emb):pos_score = torch.mul(user_emb, pos_item_emb).sum(dim=1)user_emb = user_emb.unsqueeze(1).expand(user_emb.shape[0], neg_item_emb.shape[1], user_emb.shape[1])ttl_socre = (user_emb * neg_item_emb).sum(dim=-1)neg_score = torch.max(ttl_socre, dim=1).valuesloss = -torch.log(10e-6 + torch.sigmoid(pos_score - neg_score))return torch.mean(loss)
带margin的infonce
def InfoNCE_margin(view1, view2, temperature, margin, b_cos = True):if b_cos:view1, view2 = F.normalize(view1, dim=1), F.normalize(view2, dim=1)pos_score = (view1 * view2).sum(dim=-1)pos_score = torch.exp(pos_score / temperature)margin = margin * torch.eye(view1.shape[0])ttl_score = torch.matmul(view1, view2.transpose(0, 1))ttl_score += margin.cuda(0)ttl_score = torch.exp(ttl_score / temperature).sum(dim=1)cl_loss = -torch.log(pos_score / ttl_score+10e-6)return torch.mean(cl_loss)def InfoNCE_tau(view1, view2, temperature):view1, view2 = F.normalize(view1, dim=1), F.normalize(view2, dim=1)pos_score = (view1 * view2).sum(dim=-1)pos_score = torch.exp(pos_score / temperature)ttl_score = torch.matmul(view1, view2.transpose(0, 1))ttl_score = torch.exp(ttl_score / temperature).sum(dim=1)cl_loss = -torch.log(pos_score / ttl_score+10e-6)return torch.mean(cl_loss)def batch_bpr_loss(user_emb, item_emb):pos_score = torch.mul(user_emb, item_emb).sum(dim=1)neg_score = torch.matmul(user_emb, item_emb.transpose(0, 1)).mean(dim=1)loss = -torch.log(10e-6 + torch.sigmoid(pos_score - neg_score))return torch.mean(loss)def Dis_softmax(view1, view2, temperature, b_cos = True):if b_cos:view1, view2 = F.normalize(view1, dim=1), F.normalize(view2, dim=1)N,M = view1.shapepos_score = (view1 - view2).norm(p=2, dim=1)pos_score = torch.exp(pos_score / temperature)view1 = view1.unsqueeze(1).expand(N,N,M)view2 = view2.unsqueeze(0).expand(N,N,M)ttl_score = (view1 - view2).norm(p=2, dim=-1)ttl_score = torch.exp(ttl_score / temperature).sum(dim=1)cl_loss = torch.log(pos_score / ttl_score+10e-6)return torch.mean(cl_loss)
LightGCN+对比学习
def forward(self, perturbed=False):ego_embeddings = torch.cat([self.embedding_dict['user_emb'], self.embedding_dict['item_emb']], 0)all_embeddings = []all_embeddings_cl = ego_embeddingsfor k in range(self.n_layers):ego_embeddings = torch.sparse.mm(self.sparse_norm_adj, ego_embeddings)if perturbed:random_noise = torch.rand_like(ego_embeddings).cuda()ego_embeddings += torch.sign(ego_embeddings) * F.normalize(random_noise, dim=-1) * self.epsall_embeddings.append(ego_embeddings)if k==self.layer_cl-1:all_embeddings_cl += F.normalize(all_embeddings[1]-all_embeddings[0], dim=-1) * self.epsfinal_embeddings = torch.stack(all_embeddings, dim=1)final_embeddings = torch.mean(final_embeddings, dim=1)user_all_embeddings, item_all_embeddings = torch.split(final_embeddings, [self.data.user_num, self.data.item_num])user_all_embeddings_cl, item_all_embeddings_cl = torch.split(all_embeddings_cl, [self.data.user_num, self.data.item_num])if perturbed:return user_all_embeddings, item_all_embeddings,user_all_embeddings_cl, item_all_embeddings_clreturn user_all_embeddings, item_all_embeddings
def train(self):model = self.model.cuda()optimizer = torch.optim.Adam(model.parameters(), lr=self.lRate)hot_uidx, hot_iidx = self.select_ui_idx(500, mode='hot')cold_uidx, cold_iidx = self.select_ui_idx(500, mode='cold')norm_uidx, norm_iidx = self.select_ui_idx(500, mode='norm')iters = 10alphas_init = torch.tensor([1, 2], dtype=torch.float64).to(device)betas_init = torch.tensor([2, 1], dtype=torch.float64).to(device)weights_init = torch.tensor([1 - 0.05, 0.05], dtype=torch.float64).to(device)for epoch in range(self.maxEpoch):# epoch_rec_loss = []bmm_model = BetaMixture1D(iters, alphas_init, betas_init, weights_init)rec_user_emb, rec_item_emb, cl_user_emb, cl_item_emb = model(True)self.bmm_fit(rec_user_emb, rec_item_emb,torch.arange(self.data.user_num),np.random.randint(0,self.data.item_num, 100),bmm_model)for n, batch in enumerate(next_batch_pairwise(self.data, self.batch_size)):user_idx, pos_idx, rec_neg_idx = batchrec_user_emb, rec_item_emb, cl_user_emb, cl_item_emb = model(True)user_emb, pos_item_emb= rec_user_emb[user_idx], rec_item_emb[pos_idx]# rec_loss = self.batch_softmax_loss_neg(user_idx, rec_user_emb, pos_idx, rec_item_emb)# rec_neg_idx = torch.tensor(rec_neg_idx,dtype=torch.int64)# rec_neg_item_emb = rec_item_emb[rec_neg_idx]weight = self.getWeightSim(user_emb, pos_item_emb, bmm_model)rec_loss = weighted_SSM(user_emb,pos_item_emb,self.temp2,weight)cl_loss = self.cl_rate * self.cal_cl_loss([user_idx,pos_idx],rec_user_emb,cl_user_emb,rec_item_emb,cl_item_emb)batch_loss = rec_loss + l2_reg_loss(self.reg, user_emb, pos_item_emb) + cl_loss# epoch_rec_loss.append(rec_loss.item()), epoch_cl_loss.append(cl_loss.item())# Backward and optimizeoptimizer.zero_grad()batch_loss.backward()optimizer.step()if n % 100==0 and n>0:print('training:', epoch + 1, 'batch', n, 'rec_loss:', rec_loss.item(), 'cl_loss', cl_loss.item())with torch.no_grad():self.user_emb, self.item_emb = self.model()hot_emb = torch.cat([self.user_emb[hot_uidx],self.item_emb[hot_iidx]],0)cold_emb = torch.cat([self.user_emb[cold_uidx],self.item_emb[cold_iidx]],0)self.eval_uniform(epoch, hot_emb, cold_emb)hot_user_mag = self.cal_sim(epoch, hot_uidx, self.user_emb, self.item_emb,mode='hot')self.cal_sim(epoch, norm_uidx, self.user_emb, self.item_emb, mode='norm')cold_user_mag= self.cal_sim(epoch, cold_uidx, self.user_emb, self.item_emb, mode='cold')hot_item_mag = self.item_magnitude(epoch, hot_iidx, self.item_emb,mode='hot')self.item_magnitude(epoch, norm_iidx, self.item_emb, mode='norm')cold_item_mag = self.item_magnitude(epoch, cold_iidx, self.item_emb, mode='cold')print('training:',epoch + 1,'U_mag_ratio:',hot_user_mag/cold_user_mag, 'I_mag_ratio:',hot_item_mag/cold_item_mag)# self.getTopSimNeg(hot_uidx, self.user_emb,self.item_emb, 100)# self.getTopSimNeg(norm_uidx,self.user_emb,self.item_emb, 100)# self.getTopSimNeg(cold_uidx,self.user_emb,self.item_emb, 100)# epoch_rec_loss = np.array(epoch_rec_loss).mean()# self.loss.extend([epoch_rec_loss,epoch_cl_loss,hot_pair_uniform_loss.item(),random_item_uniform_loss.item()])# if epoch%5==0:# self.save_emb(epoch, hot_emb, mode='hot')# self.save_emb(epoch, random_emb, mode='random')self.fast_evaluation(epoch)# self.save_loss()self.user_emb, self.item_emb = self.best_user_emb, self.best_item_emb# self.save_emb(self.bestPerformance[0], hot_emb, mode='best_hot')# self.save_emb(self.bestPerformance[0], random_emb, mode='best_random')
hard_neg buffer
def getHardNeg(self, user_idx, pos_idx, rec_user_emb, rec_item_emb,temperature):u_emb,i_emb = F.normalize(rec_user_emb[user_idx], dim=1),F.normalize(rec_item_emb[pos_idx], dim=1)pos_score = (u_emb * i_emb).sum(dim=-1)pos_score = torch.exp(pos_score / temperature)i_emb = i_emb.unsqueeze(0).expand(u_emb.size(0), -1, -1)neg_idx = torch.LongTensor(pos_idx).unsqueeze(0).expand(u_emb.size(0), -1).to(device)# if torch.all(self.hardNeg[user_idx])!=0:# preNeg = self.hardNeg[user_idx]# preNeg_emb = F.normalize(rec_item_emb[preNeg], dim=1)# neg_idx = torch.cat([neg_idx,preNeg],1)# i_emb = torch.cat([i_emb, preNeg_emb],1)ttl_score = (u_emb.unsqueeze(1) * i_emb).sum(dim=-1)indices = torch.topk(ttl_score, k=100)[1].detach()ttl_score = torch.exp(ttl_score / temperature).sum(dim=1)rec_loss = -torch.log(pos_score / ttl_score + 10e-6)chosen_hardNeg = neg_idx[torch.arange(i_emb.size(0)).unsqueeze(1), indices]self.hardNeg[user_idx] = chosen_hardNegreturn torch.mean(rec_loss)
相关文章:

batch_softmax_loss
每个用户抽取一定数量的困难负样本,然后ssm def batch_softmax_loss_neg(self, user_idx, rec_user_emb, pos_idx, item_emb):user_emb rec_user_emb[user_idx]product_scores torch.matmul(F.normalize(user_emb, dim1), F.normalize(item_emb, dim1).transpose(…...

刘汉清:从生活到画布,宠物成为灵感源泉
出生于中国镇江的艺术家刘汉清,其作品展现出他对日常生活的深入洞察力,以及对美的独特理解。他的作品通常没有视觉参考,而是通过对他周围环境的理解,尤其是他的宠物,来进行创作。 在刘汉清的创作过程中,他…...
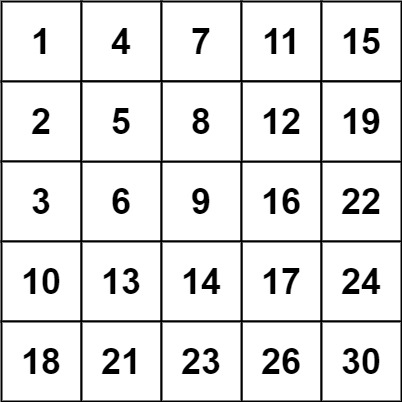
【LeetCode】240.搜索二维矩阵Ⅱ
题目 编写一个高效的算法来搜索 m x n 矩阵 matrix 中的一个目标值 target 。该矩阵具有以下特性: 每行的元素从左到右升序排列。每列的元素从上到下升序排列。 示例 1: 输入:matrix [[1,4,7,11,15],[2,5,8,12,19],[3,6,9,16,22],[10,13,…...

SED正则表达式中[方括号]的特殊处理
今天被这个方括号懵晕了,特此记录 例如: 去除输入字符串“1[2.3]4[ab,c]”中的所有方括号和逗号: $ echo "1[2.3]4[ab,c]"|sed -e "s/[,\]\[]//g" 1[2.3]4[ab,c] It doesnt work! 原因:Regular Expressi…...

Android 音频开发
在Android平台上进行音频开发,您需要掌握以下关键知识点: Android平台基础知识:熟悉Android操作系统的基本架构、组件和应用开发的基本概念。 音频API:了解Android提供的音频相关API,主要包括android.media.AudioReco…...

Java8新特性,Lambda,Stream流
Java8新特性,Lambda,Stream流 Java8版本在2014年3月18日发布,为Java语言添加了很多重要的新特性。新特性包括:Lambda表达式、方法引用、默认方法、新的时间日期API、Stream API、Optional类等等。这些新特性大大增强了Java语言的表达能力,使…...

模型训练之train.py代码解析
题目 作者:安静到无声 个人主页 from __future__ import absolute_import from __future__ import division from __future__ import print_function这段代码使用了Python 2.x的__future__模块来导入Python 3.x的一些特性。在Python 2.x中,使用print语句来输出内容,而在Py…...

linux 复习
vim 使用 一般模式 、 命令模式、编辑模式 esc 进入一般模式 i 进入编辑模式 shift: 进入命令模式 yy p 复制粘贴 5yy 复制当前开始的5行 dd 删除 5dd 删除当前开始的5行 u撤销操作 ctrlr 恢复 shiftg 滚动最底部 gg 滚动最顶 输入数字 然后shiftg 跳转到指定行 用户操作…...

C语言刷题------(2)
C语言刷题——————(2) 刷题网站:题库 - 蓝桥云课 (lanqiao.cn) First Question:时间显示 题目描述 小蓝要和朋友合作开发一个时间显示的网站。 在服务器上,朋友已经获取了当前的时间,用一个整数表…...

JVM 之 OopMap 和 RememberedSet
前几天看周志明的《深入 Java 虚拟机》,感觉对 OopMap 和 RememberedSet 的介绍,看起来不太容易理解清楚。今天查了一些资料,并结合自己的一些猜想,把对这两种数据结构的理解写出来。目的只是为了简单易懂,而且多有推测…...

Original error: gsmCall method is only available for emulators
在夜神模拟器执行报错 self.driver.make_gsm_call(5551234567, GsmCallActions.CALL)意思是gsmCall这个命令不支持,只支持下面这些命令 selenium.common.exceptions.UnknownMethodException: Message: Unknown mobile command "gsmCall". Only shell,exe…...
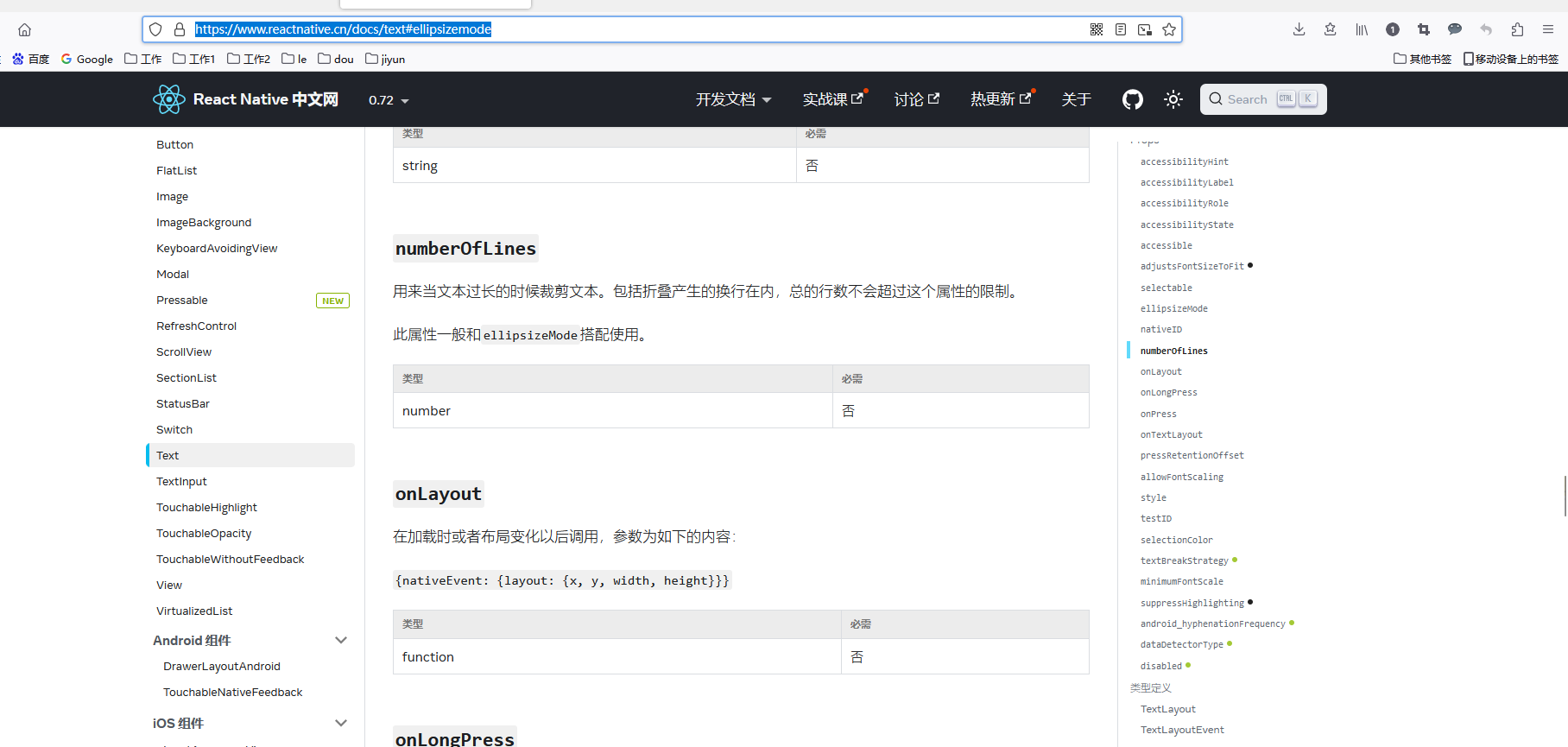
React Native从文本内容尾部截取显示省略号
<Textstyle{styles.mMeNickname}ellipsizeMode"tail"numberOfLines{1}>{userInfo.nickname}</Text> 参考链接: https://www.reactnative.cn/docs/text#ellipsizemode https://chat.xutongbao.top/...

机器学习笔记之优化算法(十一)凸函数铺垫:梯度与方向导数
机器学习笔记之优化算法——凸函数铺垫:梯度与方向导数 引言回顾:偏导数方向余弦方向导数方向导数的几何意义方向导数的定义 方向导数与偏导数之间的关联关系证明过程 梯度 ( Gradient ) (\text{Gradient}) (Gradient) 引言 本节作为介绍凸函数的铺垫&a…...
探究Vue源码:mustache模板引擎(11) 递归处理循环逻辑并收尾算法处理
好 在上文 探究Vue源码:mustache模板引擎(10) 解决不能用连续点符号找到多层对象问题,为编译循环结构做铺垫 我们解决了js字符串没办法通过 什么点什么拿到对象中的值的问题 这个大家需要记住 因为这个方法的编写之前是当做面试题出现过的 那么 本文 我们就要去写上…...
STM32 CubeMX USB_CDC(USB_转串口)
STM32 CubeMX STM32 CubeMX 定时器(普通模式和PWM模式) STM32 CubeMX一、STM32 CubeMX 设置USB时钟设置USB使能UBS功能选择 二、代码部分添加代码实验效果 printf发…...
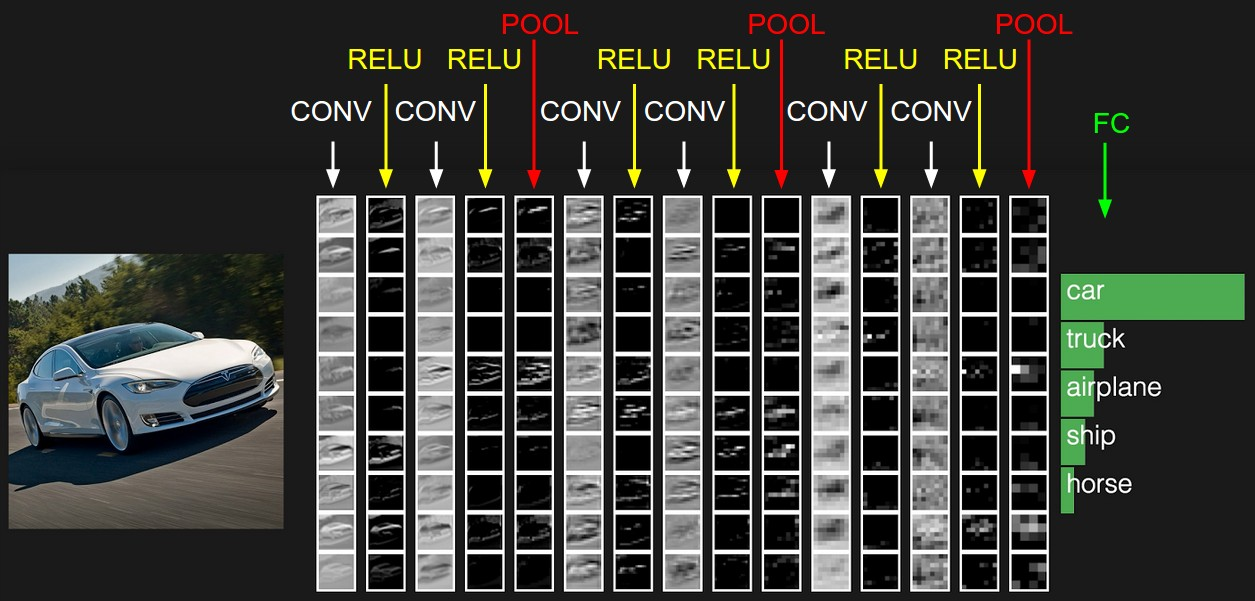
机器学习——卷积神经网络基础
卷积神经网络(Convolutional Neural Network:CNN) 卷积神经网络是人工神经网络的一种,是一种前馈神经网络。最早提出时的灵感来源于人类的神经元。 通俗来讲,其主要的操作就是:接受输入层的输入信息&…...
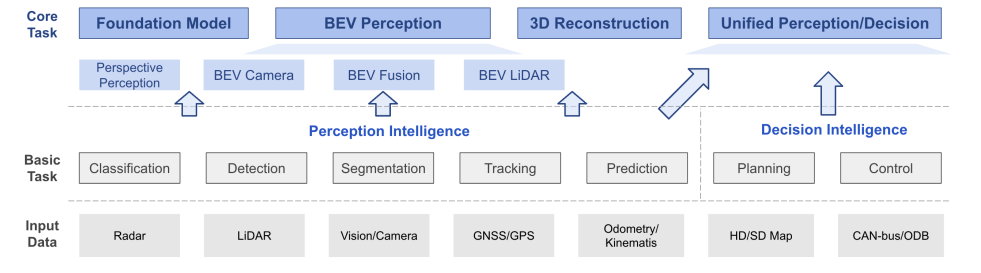
端到端自动驾驶前沿论文盘点(pdf+代码)
现在的自动驾驶,大多数还是采用的模块化架构,但这种架构的缺陷十分明显:在一个自动驾驶系统里,可能会包含很多个模型,每个模型都要专门进行训练、优化、迭代,随着模型的不断进化,参数量不断提高…...
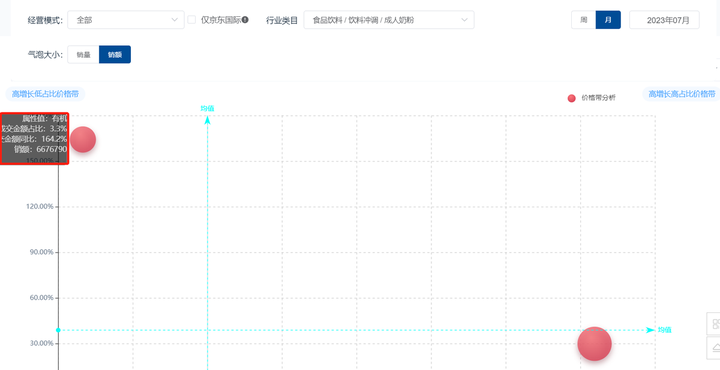
2023年中期奶粉行业分析报告(京东数据开放平台)
根据国家统计局和民政部数据公布,2022年中国结婚登记数创造了1980年(有数据公布)以来的历史新低,共计683.3万对。相较于2013年巅峰时期的数据,2022年全国结婚登记对数已接近“腰斩”。 2023年“520”期间的结婚登记数…...

web集群学习:基于CentOS 7构建 LVS-DR 群集并配置服务启动脚本
目录 1、环境准备 2、配置lvs服务启动脚本 1、在RS上分别配置服务启动脚本 2、在lvs director上配置服务启动脚本 3、客户端测试 配置LVS-DR模式主要注意的有 1、vip绑定在RS的lo接口; 2、RS做arp抑制; 1、环境准备 VIP192.168.95.10 RS1192.168…...

Flask 高级应用:使用蓝图模块化应用和 JWT 实现安全认证
本文将探讨 Flask 的两个高级特性:蓝图(Blueprints)和 JSON Web Token(JWT)认证。蓝图让我们可以将应用模块化,以便更好地组织代码;而 JWT 认证是现代 Web 应用中常见的一种安全机制。 一、使用…...

如何在Windows系统上一键部署终极包管理器:winget安装工具完全指南
如何在Windows系统上一键部署终极包管理器:winget安装工具完全指南 【免费下载链接】winget-install Install WinGet using PowerShell! Prerequisites automatically installed. Works on Windows 10/11 and Server 2019/2022. 项目地址: https://gitcode.com/gh…...

Polymarket套利机器人:DeFi预测市场的自动化交易策略与实现
1. 项目概述:一个捕捉Polymarket预测市场套利机会的自动化交易机器人 最近在DeFi和预测市场领域,Polymarket这个基于Polygon链的平台热度持续攀升。它本质上是一个事件预测市场,用户可以就各类现实世界事件(比如“某球队能否赢得冠…...

从AwesomeCursorPrompt看提示工程:如何设计高效AI编程指令
1. 项目概述:从“AwesomeCursorPrompt”看提示工程的工程化实践最近在折腾AI编程助手,特别是Cursor这个工具,发现一个挺有意思的现象:很多人觉得它“不够聪明”,或者用起来效果时好时坏。其实,这背后往往不…...

ARM GIC中断控制器架构与寄存器编程详解
1. ARM GIC中断控制器架构概述 中断控制器是现代处理器系统中至关重要的组件,它负责协调和管理来自各种外设的中断请求。ARM架构的通用中断控制器(GIC)经过多代演进,目前GICv3/GICv4已成为主流实现。GIC的核心功能包括中断优先级管理、中断分发、虚拟化支…...

AI智能体协作命令行工具squads-cli:多智能体编排与自动化实战
1. 项目概述:一个面向AI智能体协作的命令行工具如果你最近在关注AI智能体(Agent)的开发,尤其是多智能体协作(Multi-Agent Collaboration)这个方向,那你很可能已经听说过或接触过一些相关的框架。…...

为什么你的v8出图突然“高级感崩塌”?3分钟定位色彩语义锚点失效+实时修复模板
更多请点击: https://intelliparadigm.com 第一章:为什么你的v8出图突然“高级感崩塌”? V8 引擎本身并不直接“出图”——这一表述实为开发者对前端渲染链路中某环节异常的戏谑指代。真正崩塌的,往往是基于 V8 驱动的 Canvas/We…...

ChatGPT插件开发者签证通道开放?深度解析2026年美国USCIS新增O-1B“AI原生应用架构师”认证路径
更多请点击: https://intelliparadigm.com 第一章:ChatGPT插件生态系统的演进脉络与O-1B新政战略定位 ChatGPT插件系统自2023年3月开放以来,经历了从封闭API集成到开放开发者协议、再到平台化治理的三阶段跃迁。早期插件依赖硬编码函数调用&…...

基于CRICKIT与CPX的交互式电子展板:从传感器到执行器的完整原型开发指南
1. 项目概述:打造一个会“思考”和“反应”的电子展板如果你对Arduino或树莓派这类微控制器项目感兴趣,但又觉得从零开始连接电机、灯带、传感器,还要处理复杂的电源和信号问题,过程太过繁琐和容易出错,那么这个项目可…...

紧急通知:v8.1即将关闭旧版审美缓存——72小时内必须完成的3步风格校准清单
更多请点击: https://intelliparadigm.com 第一章:v8.1旧版审美缓存关停的技术动因与全局影响 核心架构演进压力 V8.1 引擎中长期运行的“审美缓存”(Aesthetic Cache)模块,本质上是一套基于 DOM 树节点样式偏好建模…...
)
从命令行到自动化:用xrandr和Bash脚本打造你的Linux多屏工作流(附常用场景脚本)
从命令行到自动化:用xrandr和Bash脚本打造你的Linux多屏工作流 在Linux系统中管理多显示器配置,xrandr无疑是最强大的命令行工具之一。但每次手动输入复杂的xrandr命令来调整显示器布局,对于追求效率的高级用户来说,无疑是一种时间…...