pytorch Stream 多流处理
CUD Stream
- https://docs.nvidia.com/cuda/cuda-c-programming-guide/index.html#c-language-extensions
中指出在kenel的调用函数中最后一个可选参数表示该核函数处在哪个流之中。

- 参数Dg用于定义整个grid的维度和尺寸,即一个grid有多少个block。为dim3类型。Dim3 Dg(Dg.x, Dg.y, 1)表示grid中每行有Dg.x个block,每列有Dg.y个block,第三维恒为1(目前一个核函数只有一个grid)。整个grid中共有Dg.x*Dg.y个block,其中Dg.x和Dg.y最大值为65535。
- 参数Db用于定义一个block的维度和尺寸,即一个block有多少个thread。为dim3类型。Dim3 Db(Db.x, Db.y, Db.z)表示整个block中每行有Db.x个thread,每列有Db.y个thread,高度为Db.z。Db.x和Db.y最大值为512,Db.z最大值为62。 一个block中共有Db.x*Db.y*Db.z个thread。计算能力为1.0,1.1的硬件该乘积的最大值为768,计算能力为1.2,1.3的硬件支持的最大值为1024。
- Ns 的类型为 size_t,用于设置每个block除了静态分配的shared Memory以外,最多能动态分配的shared memory大小,单位为byte。不需要动态分配时该值为0或省略不写。如[__shared__](https://docs.nvidia.com/cuda/cuda-c-programming-guide/index.html#shared)中所述,此动态分配的内存由声明为外部数组的任何变量使用;
- 参数S是一个cudaStream_t类型的可选参数,初始值为零,表示该核函数处在哪个流之中。
-
CUDA编程中,默认使用默认流非并行执行kernel,每个kernel由许多thread并行的执行在GPU上。Stream的概念是相对Grid level来说的,使得kernel在一个device上同时执行。
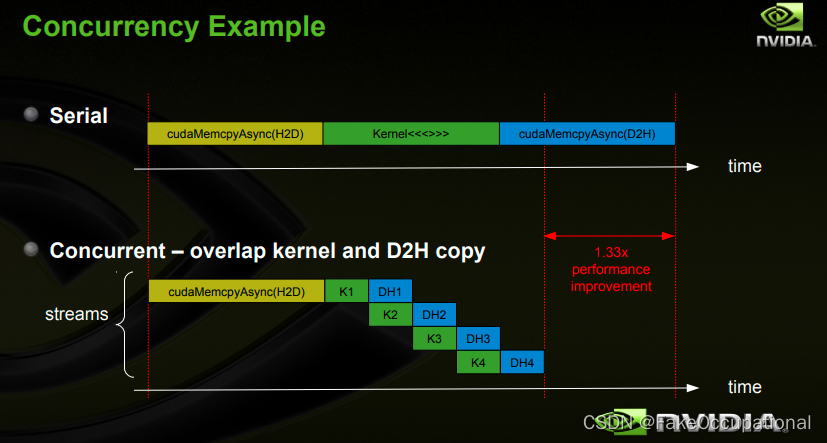
-
官方提供的用例
// https://docs.nvidia.com/cuda/cuda-c-programming-guide/index.html#streams
cudaStream_t stream[2];
for (int i = 0; i < 2; ++i)cudaStreamCreate(&stream[i]);
float* hostPtr;
cudaMallocHost(&hostPtr, 2 * size);
// 以下代码示例将其中每个流定义为从主机到设备的一个内存副本、一个内核启动和一个从设备到主机的内存副本的序列:
for (int i = 0; i < 2; ++i) {cudaMemcpyAsync(inputDevPtr + i * size, hostPtr + i * size,size, cudaMemcpyHostToDevice, stream[i]);MyKernel <<<100, 512, 0, stream[i]>>>(outputDevPtr + i * size, inputDevPtr + i * size, size);cudaMemcpyAsync(hostPtr + i * size, outputDevPtr + i * size,size, cudaMemcpyDeviceToHost, stream[i]);
}
// 通过调用 释放流
for (int i = 0; i < 2; ++i)cudaStreamDestroy(stream[i]);
PyTorch Stream
-
在PyTorch中,默认情况下,GPU上的操作是在默认流(default stream)中执行的。默认流是一个序列化的流,其中的操作按照它们出现的顺序逐个执行。这意味着在没有显式指定其他流的情况下,所有的操作都会在默认流中执行。
-
然而,PyTorch还提供了功能可以将操作提交到其他流中执行,以充分利用GPU的并行性。这对于并行处理多个任务或同时执行多个独立操作非常有用。
-
您可以使用
torch.cuda.Stream()来创建其他流,并使用torch.cuda.current_stream()来获取当前流。然后,您可以将操作提交到指定的流中执行,例如:
import torchdevice = torch.device('cuda')# 创建一个默认流
default_stream = torch.cuda.current_stream()# 创建一个自定义流
custom_stream = torch.cuda.Stream()# 在默认流中执行操作
with torch.cuda.stream(default_stream):# 执行操作...# 在自定义流中执行操作
with torch.cuda.stream(custom_stream):# 执行操作...
例子
import torch
s1 = torch.cuda.Stream()
s2 = torch.cuda.Stream()
# Initialise cuda tensors here. E.g.:
A = torch.rand(1000, 1000, device = 'cuda')
B = torch.rand(1000, 1000, device = 'cuda')
# Wait for the above tensors to initialise.
torch.cuda.synchronize()
with torch.cuda.stream(s1):C = torch.mm(A, A)
with torch.cuda.stream(s2):D = torch.mm(B, B)
# Wait for C and D to be computed.
torch.cuda.synchronize()
# Do stuff with C and D.
print(C)
print(D)
// https://stackoverflow.com/questions/70128833/why-and-when-to-use-torch-cuda-stream
这样可以利用多个流来并行执行计算,并在计算和数据传输之间实现重叠。这对于提高GPU利用率和加速训练或推理过程非常有帮助。
错误示例
- 没有使用 synchronize() 或者 wait_stream()进行同步,可能导致再未完成归一化前执行求和
// https://pytorch.org/docs/stable/notes/cuda.html
cuda = torch.device('cuda')
s = torch.cuda.Stream() # Create a new stream.
A = torch.empty((100, 100), device=cuda).normal_(0.0, 1.0)
with torch.cuda.stream(s):# sum() may start execution before normal_() finishes!B = torch.sum(A)
CG
-
https://docs.nvidia.com/cuda/cuda-c-programming-guide/index.html#streams
-
https://pytorch.org/docs/stable/notes/cuda.html#multistream-capture
-
https://pytorch.org/cppdocs/notes/tensor_cuda_stream.html
-
https://pypi.org/project/pytorch-stream/
-
CUDA 的 Stream and Event https://zhuanlan.zhihu.com/p/369367933
-
GITHUBGIST Gist就是小型代码片段的分享https://www.cnblogs.com/leader755/p/14284716.html
-
[JIT] 在 TorchScript 中支持 CUDA 流 https://github.com/pytorch/pytorch/issues/41355
-
https://pytorch.org/docs/stable/notes/cuda.html#cuda-semantics
-
https://github.com/pytorch/pytorch/issues/41355
多设备
// https://pytorch.org/docs/stable/notes/cuda.html#cuda-semantics
cuda = torch.device('cuda') # Default CUDA device
cuda0 = torch.device('cuda:0')
cuda2 = torch.device('cuda:2') # GPU 2 (these are 0-indexed)x = torch.tensor([1., 2.], device=cuda0)
# x.device is device(type='cuda', index=0)
y = torch.tensor([1., 2.]).cuda()
# y.device is device(type='cuda', index=0)with torch.cuda.device(1):# allocates a tensor on GPU 1a = torch.tensor([1., 2.], device=cuda)# transfers a tensor from CPU to GPU 1b = torch.tensor([1., 2.]).cuda()# a.device and b.device are device(type='cuda', index=1)# You can also use ``Tensor.to`` to transfer a tensor:b2 = torch.tensor([1., 2.]).to(device=cuda)# b.device and b2.device are device(type='cuda', index=1)c = a + b# c.device is device(type='cuda', index=1)z = x + y# z.device is device(type='cuda', index=0)# even within a context, you can specify the device# (or give a GPU index to the .cuda call)d = torch.randn(2, device=cuda2)e = torch.randn(2).to(cuda2)f = torch.randn(2).cuda(cuda2)# d.device, e.device, and f.device are all device(type='cuda', index=2)
相关文章:
pytorch Stream 多流处理
CUD Stream https://docs.nvidia.com/cuda/cuda-c-programming-guide/index.html#c-language-extensions 中指出在kenel的调用函数中最后一个可选参数表示该核函数处在哪个流之中。 - 参数Dg用于定义整个grid的维度和尺寸,即一个grid有多少个block。为dim3类型。…...

微信小程序选项卡切换(滑动切换,点击切换)
效果如下:可点击切换,滑动切换 代码如下 这个可以在项目用 index.wxml <view classtopTabSwiper><view classtab {{currentData 0 ? "tabBorer" : ""}} data-current "0" bindtapcheckCurrent>选项一&…...

安路FPGA的赋值报错——移位处理,加括号
authordaisy.skye的博客_CSDN博客-嵌入式,Qt,Linux领域博主 在使用移位符号用来当作除以号使用时,发现如下问题 其中 cnt_8K 为偶数和奇数时输出的数据不一样 reg [10:0] cnt_8K; reg [10:0] ram1_addra; always(posedge clk_16M) begin if(ram_out_flag )begin if(…...
)
GO学习之 接口(Interface)
GO系列 1、GO学习之Hello World 2、GO学习之入门语法 3、GO学习之切片操作 4、GO学习之 Map 操作 5、GO学习之 结构体 操作 6、GO学习之 通道(Channel) 7、GO学习之 多线程(goroutine) 8、GO学习之 函数(Function) 9、GO学习之 接口(Interface) 文章目录 GO系列前言一、什么是…...
ansible常见模块的运用
ansible常见模块的运用 一:Ansible简介二:ansible 环境安装部署管理端安装 ansibleansible 目录结构配置主机清单配置密钥对验证 三:ansible 命令行模块1.command 模块在远程主机执行命令,不支持管道,重定向…...

合宙Air724UG LuatOS-Air script lib API--patch
patch Table of Contents patch patch.safeJsonDecode(s) (local函数 无法被外部调用) patch 模块功能:Lua补丁 patch.safeJsonDecode(s) (local函数 无法被外部调用) 封装自定义的json.decode接口 参数 名称 传入值类型 释义 s string json格式的字符串 返回值 t…...

pytorch求导
pytorch求导的初步认识 requires_grad tensor(data, dtypeNone, deviceNone, requires_gradFalse)requires_grad是torch.tensor类的一个属性。如果设置为True,它会告诉PyTorch跟踪对该张量的操作,允许在反向传播期间计算梯度。 x.requires_grad 判…...

Java基础异常详解
Java基础异常详解 文章目录 Java基础异常详解编译时异常(Checked Exception):运行时异常(Unchecked Exception): Java中的异常是用于处理程序运行时出现的错误或异常情况的一种机制。 异常本身也是一个类。 异常分为…...

vue3+vue-i18n 监听语言的切换
最近在用 vue3 做一个后台管理系统,之前是只考虑中文,现在加了个需求是多语言。 本来也不是太难的需求,但是我用的并不熟悉,并且除了页面展示不同的语言,需求是在切换语言的时候在几个页面中需要做出一些自定义的行为&…...

【考研复习】24王道数据结构课后习题代码|2.3线性表的链式表示
文章目录 总结01 递归删除结点02 删除结点03 反向输出04 删除最小值05 逆置06 链表递增排序07 删除区间值08 找公共结点09 增序输出链表10 拆分链表--尾插11 拆分链表--头插12 删除相同元素13 合并链表14 生成含有公共元素的链表C15 求并集16 判断子序列17 判断循环链表是否对称…...
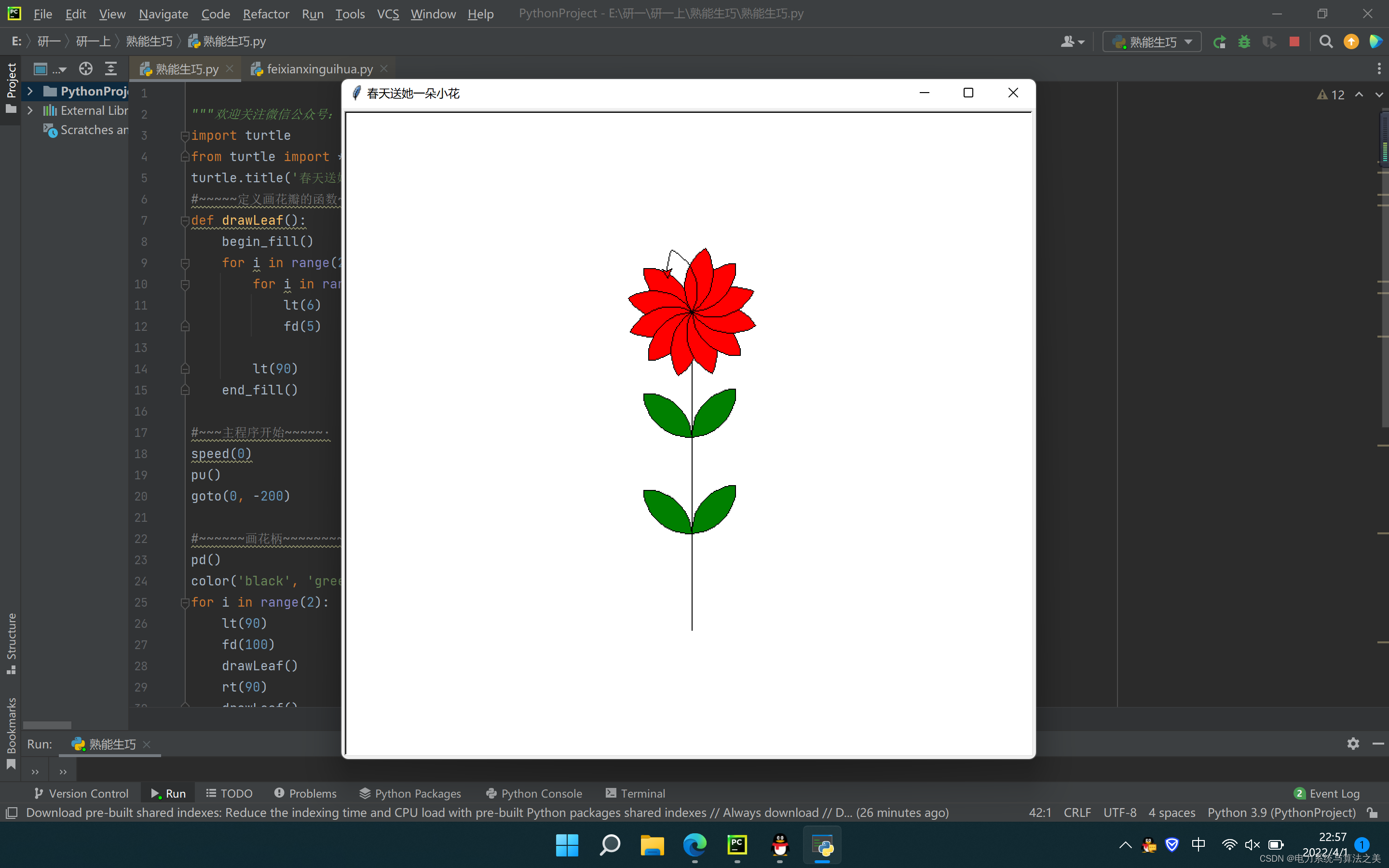
娇滴滴的一朵花(Python实现)
目录 1 娇滴滴的她 2 Python代码实现 1 娇滴滴的她 娇滴滴。双眉敛破春山色。春山色。 为君含笑,为君愁蹙。多情别後无消息。 此时更有谁知得。谁知得。夜深无寐,度江横笛。 2 Python代码实现 import turtle from turtle import * turtle.title(春天送她一朵小花)…...

Android AccessibilityService研究
AccessibilityService流程分析 AccessibilityService开启方式AccessibilityService 开启原理 AccessibilityService开启方式 . 在Framework里直接添加对应用app 服务component。 loadSetting(stmt, Settings.Secure.ACCESSIBILITY_ENABLED,1); loadSetting(stmt, Settings.Se…...

华为OD机试(含B卷)真题2023 算法分类版,58道20个算法分类,如果距离机考时间不多了,就看这个吧,稳稳的
目录 一、数据结构1、线性表2、优先队列3、滑动窗口4、二叉树5、并查集6、栈 二、算法1、基础算法2、字符串3、图4、动态规划5、数学 三、漫画算法2:小灰的算法进阶参与方式 很多小伙伴问我,华为OD机试算法题太多了,知识点繁杂,如…...
JMeter命令行执行+生成HTML报告
1、为什么用命令行模式 使用GUI方式启动jmeter,运行线程较多的测试时,会造成内存和CPU的大量消耗,导致客户机卡死; 所以一般采用的方式是在GUI模式下调整测试脚本,再用命令行模式执行; 命令行方式支持在…...

学习Boost二:从附录3来看编码习惯
附录C 关键字浅谈 在C11标准中(C11.2.12)总共定义了73个关键字(keyword)、2个“准”关键字(identifiers with special meaning)和11个操作符替代字(alternative representation)[1]。…...
STM32基础入门学习笔记:核心板 电路原理与驱动编程
文章目录: 一:LED灯操作 1.LED灯的点亮和熄灭 延迟闪烁 main.c led.c led.h BitAction枚举 2.LED呼吸灯(灯的强弱交替变化) main.c delay.c 3.按键控制LED灯 key.h key.c main.c 二:FLASH读写程序(有…...
最后一次模拟考试题解
哦我想这不用看都知道是为了水任务 T1 黑白染色 其实这题有原 什么手写体 md (指 markdown) 分析 首先这题如果你题目没看错的话 ,会发现其实他是 n m n \times m nm 让你求 n n n \times n nn 的区域内的点(不会只有我一个人题目看错了罢 然后我们会发现…...
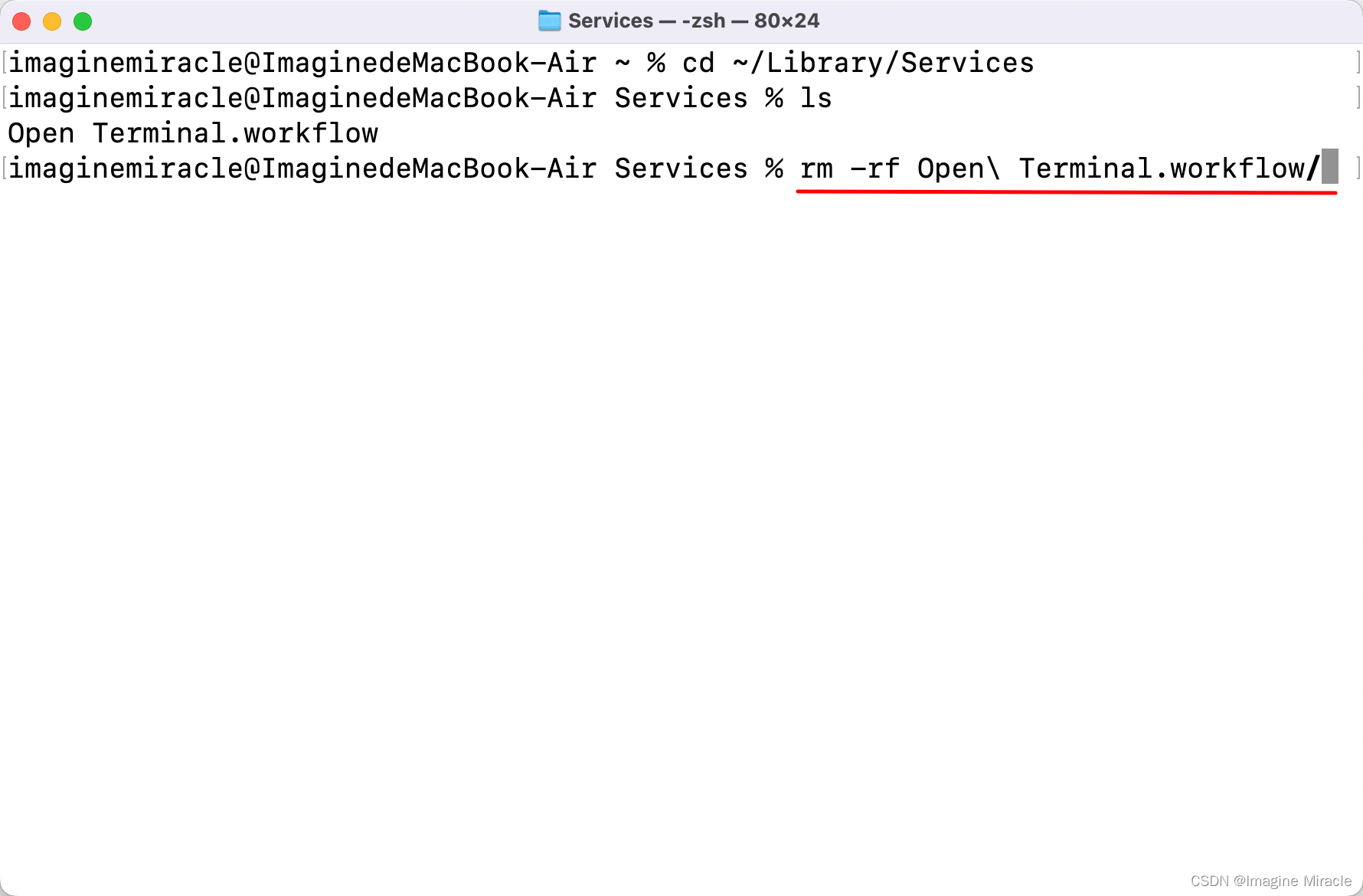
Mac 创建和删除 Automator 工作流程,设置 Terminal 快捷键
1. 创建 Automator 流程 本文以创建一个快捷键启动 Terminal 的自动操作为示例。 点击打开 自动操作; 点击 新建文稿 点击 快速操作 选择 运行 AppleScript 填入以下内容 保存名为 “Open Terminal” 打开 设置 > 键盘,选择 键盘快捷键 以此选择 服…...

2023华为OD机试真题B卷 Java 实现【最长的元音串】
前言 本题使用Java解答,如果需要Python代码,链接 题目 给定一个只由英文字母(a-z, A-Z)组成的字符串,找出其中最长的只包含元音字母(a, e, i, o, u, A, E, I, O, U)的子串,并返回其长度。如果不存在元音子串,则返回0。 输入: 一个由英文字母组成的字符串,长度大…...

网络防御之传输安全
1.什么是数据认证,有什么作用,有哪些实现的技术手段? 数据认证是一种权威的电子文档 作用:它能保证数据的完整性、可靠性、真实性 技术手段有数字签名、加密算法、哈希函数等 2.什么是身份认证,有什么作用,有哪些…...

基于TRRS Trinkey的辅助技术设备开发:从接口转换到可编程交互
1. 项目概述:当辅助技术遇上可编程硬件如果你接触过辅助技术(Assistive Technology, AT),或者身边有朋友需要借助特殊设备与数字世界交互,你可能会发现,市面上很多现成的开关、控制器要么功能单一ÿ…...

用AI工具做技术课程:一个人完成录课、剪辑、上架全流程
软件测试从业者的知识变现新路径作为一名软件测试工程师,你手里握着大量值钱的东西——接口自动化怎么搭、性能瓶颈怎么定位、测试用例怎么设计才不漏测。这些东西在你的团队里可能是常识,但放到整个行业,就是别人愿意付费学习的硬通货。但一…...

VSCode性能优化实战:回归轻量编辑器,提升开发效率
1. 项目概述:为什么我们需要一个“经典体验”的VSCode? 如果你是一个从Sublime Text、Notepad或者更早的编辑器时代走过来的开发者,最近打开Visual Studio Code时,可能会感到一丝陌生。没错,VSCode变得越来越强大&…...

声明式应用编排框架Planifest:云原生时代应用交付新范式
1. 项目概述:一个面向未来的声明式应用编排框架如果你和我一样,在云原生和自动化运维领域摸爬滚打了几年,就会深刻体会到“编排”这个词的分量。从早期的Shell脚本,到Ansible、Terraform,再到Kubernetes的YAML海洋&…...

从LLM到智能体:基于推理循环的AI应用开发框架解析
1. 项目概述:一个面向推理任务的智能体框架最近在探索如何让AI模型更“聪明”地处理复杂任务时,我注意到了GitHub上一个名为“zyron-reasoning”的项目。这个由kaiogs07维护的仓库,其核心定位是一个用于构建和运行“推理智能体”的框架。简单…...

UltraScale架构FPGA功耗优化技术与工程实践
1. UltraScale架构的功耗优化技术全景解析在当今高性能计算和通信领域,功耗已成为FPGA选型的决定性因素之一。Xilinx UltraScale架构通过多层次的创新,在20nm工艺节点上实现了显著的功耗降低。作为深耕FPGA设计十余年的工程师,我将从实际应用…...

NewLife.Core配置系统深度解析:XML/JSON/HTTP多源配置实战
NewLife.Core配置系统深度解析:XML/JSON/HTTP多源配置实战 【免费下载链接】X Core basic components: log (file / network), configuration (XML / JSON / HTTP), cache (memory / redis), network (TCP / UDP / HTTP), RPC framework, serialization (binary / X…...

Zotero插件市场:告别繁琐安装,开启高效学术插件管理新时代
Zotero插件市场:告别繁琐安装,开启高效学术插件管理新时代 【免费下载链接】zotero-addons Zotero Add-on Market | Zotero插件市场 | Browsing, installing, and reviewing plugins within Zotero 项目地址: https://gitcode.com/gh_mirrors/zo/zoter…...
从零实现大语言模型:Transformer架构、自注意力机制与PyTorch实战
1. 项目概述:从零构建大语言模型的实践指南 最近几年,大语言模型(LLM)无疑是技术领域最耀眼的存在。从ChatGPT的横空出世到各类开源模型的百花齐放,它们展现出的理解和生成能力令人惊叹。然而,对于许多开发…...

AI编程助手My_CoPaw:从代码补全到智能协作者的架构演进
1. 项目概述:当你的代码有了“猫爪”伙伴最近在GitHub上闲逛,发现一个挺有意思的项目,叫haozhuoyuan/My_CoPaw。光看名字,CoPaw——协作的爪子,是不是立刻联想到“猫爪”(Cat‘s Paw)和“协作”…...