【深度学习】在 MNIST实现自动编码器实践教程
一、说明
自动编码器是一种无监督学习的神经网络模型,主要用于降维或特征提取。常见的自动编码器包括基本的单层自动编码器、深度自动编码器、卷积自动编码器和变分自动编码器等。
其中,基本的单层自动编码器由一个编码器和一个解码器组成,编码器将输入数据压缩成低维数据,解码器将低维数据还原成原始数据。深度自动编码器是在单层自动编码器的基础上增加了多个隐藏层,可以实现更复杂的特征提取。卷积自动编码器则是针对图像等数据特征提取的一种自动编码器,它使用卷积神经网络进行特征提取和重建。变分自动编码器则是一种生成式模型,可以用于生成新的数据样本。
总的来说,不同类型的自动编码器适用于不同类型的数据和问题,选择合适的自动编码器可以提高模型的性能。
二、在Minist数据集实现自动编码器
2.1 概述
本文中的代码用于在 MNIST 数据集上训练自动编码器。自动编码器是一种旨在重建其输入的神经网络。在此脚本中,自动编码器由两个较小的网络组成:编码器和解码器。编码器获取输入图像,将其压缩为 64 个特征,并将编码表示传递给解码器,然后解码器重建输入图像。自动编码器通过最小化重建图像和原始图像之间的均方误差来训练。该脚本首先加载 MNIST 数据集并规范化像素值。然后,它将图像重塑为一维表示,以便可以将其输入神经网络。之后,使用tensorflow.keras库中的输入层和密集层创建编码器和解码器模型。自动编码器模型是通过链接编码器和解码器模型创建的。然后使用亚当优化器和均方误差损失函数编译自动编码器。最后,自动编码器在归一化和重塑的MNIST图像上训练25个epoch。通过绘制训练集和测试集在 epoch 上的损失来监控训练进度。训练后,脚本绘制一些测试图像及其相应的重建。此外,还计算了原始图像和重建图像之间的均方误差和结构相似性指数(SSIM)。
下图显示了模型的良好拟合,可以看到模型的良好拟合。
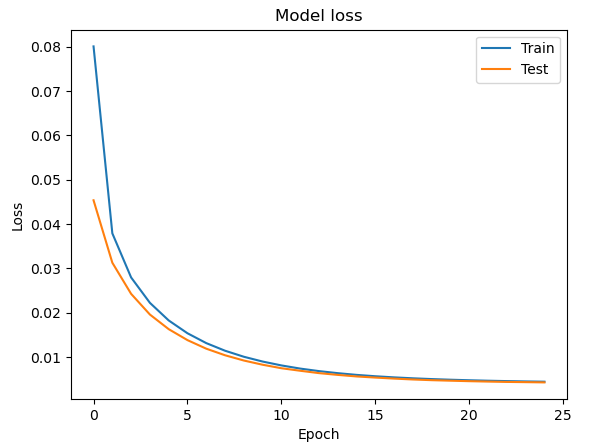
该代码比较两个图像,一个来自测试集的原始图像和一个由自动编码器生成的预测图像。它使用该函数计算两个图像之间的均方误差 (MSE),并使用 scikit-image 库中的函数计算两个图像之间的结构相似性指数 (SSIM)。根据 mse 和 ssim 代码检索test_labels以打印测试图像的值。msessim
2.2 代码实现
import numpy as np
import tensorflow
import tensorflow as tf
import matplotlib.pyplot as plt
from tensorflow.keras.models import Model
from tensorflow.keras.datasets import mnist
from tensorflow.keras.layers import Input, Dense, Flatten
from tensorflow.keras.layers import Layer
from skimage import metrics
## import os can be skipped if there is nocompatibility issue
## with the OpenMP library and TensorFlow
import os
os.environ["KMP_DUPLICATE_LIB_OK"]="TRUE"# Load the MNIST dataset
(x_train, train_labels), (x_test, test_labels) = mnist.load_data()# Normalize the data
x_train = x_train.astype('float32') / 255.
x_test = x_test.astype('float32') / 255.# Flatten the images
x_train = x_train.reshape((len(x_train), np.prod(x_train.shape[1:])))
x_test = x_test.reshape((len(x_test), np.prod(x_test.shape[1:])))# Randomize both the training and test
permutation = np.random.permutation(len(x_train))
x_train, train_labels = x_train[permutation], train_labels[permutation]
permutation = np.random.permutation(len(x_test))
x_test, test_labels = x_test[permutation], test_labels[permutation]
# Create the encoderlist_xtest = [ [x_test[i], test_labels[i]] for i in test_labels]
print(len(list_xtest)) encoder_input = Input(shape=(784,))
encoded = Dense(64, activation='relu')(encoder_input)
encoder = Model(encoder_input, encoded)# Create the decoder
decoder_input = Input(shape=(64,))
decoded = Dense(784, activation='sigmoid')(decoder_input)
decoder = Model(decoder_input, decoded)# Create the autoencoder
autoencoder = Model(encoder_input, decoder(encoder(encoder_input)))lr_schedule = tensorflow.keras.optimizers.schedules.ExponentialDecay(initial_learning_rate = 5e-01, decay_steps = 2500, decay_rate = 0.75,staircase=True)
tensorflow.keras.optimizers.Adam(learning_rate = lr_schedule,beta_1=0.95,beta_2=0.99,epsilon=1e-01)
autoencoder.compile(optimizer='adam', loss='mean_squared_error')# Train the autoencoder
history = autoencoder.fit(x_train, x_train,epochs=25,batch_size=512,shuffle=True,validation_data=(x_test, x_test))# Plot the training history
plt.plot(history.history['loss'])
plt.plot(history.history['val_loss'])
plt.title('Model loss')
plt.ylabel('Loss')
plt.xlabel('Epoch')
plt.legend(['Train', 'Test'], loc='upper right')
plt.show()# Plot the test figures vs. predicted figures
decoded_imgs = autoencoder.predict(x_test)def mse(imageA, imageB):err = np.sum((imageA.astype("float") - imageB.astype("float")) ** 2)err /= float(imageA.shape[0])return errdef ssim(imageA, imageB):return metrics.structural_similarity(imageA, imageB,channel_axis=None)decomser = []
decossimr = []
n = 10
list_xtestn = [ [x_test[i], test_labels[i]] for i in range(10)]
print([list_xtestn[i][1] for i in range(n)])
plt.figure(figsize=(20, 4))
for i in range(n):# Display originalax = plt.subplot(2, n, i + 1)plt.imshow(x_test[i].reshape(28, 28))plt.gray()ax.get_xaxis().set_visible(False)ax.get_yaxis().set_visible(False)# Display reconstructionax = plt.subplot(2, n, i + 1 + n)plt.imshow(decoded_imgs[i].reshape(28, 28))plt.gray()ax.get_xaxis().set_visible(False)ax.get_yaxis().set_visible(False)if mse(list_xtestn[i][0],decoded_imgs[i]) <= 0.01: msel = mse(list_xtestn[i][0],decoded_imgs[i])decomser.append(list_xtestn[i][1]) if ssim(list_xtestn[i][0],decoded_imgs[i]) > 0.85:ssiml = ssim(list_xtestn[i][0],decoded_imgs[i])decossimr.append(list_xtestn[i][1]) print("mse and ssim for image %s are %s and %s" %(i,msel,ssiml))
plt.show() print(decomser)
print(decossimr)
三、实验的部分结果示例
该模型可以预测手写数据,如下所示。

此外,使用MSE和ssim方法将预测图像与测试图像进行比较,可以访问test_labels并打印预测数据。

此代码演示如何使用自动编码器通过图像比较教程来训练和建立手写识别网络。一开始,训练和测试图像是随机的,因此每次运行的图像集都不同。
在另一篇文章中,我们将展示如何使用 Padé 近似值作为自动编码器 (link.medium.com/cqiP5bd9ixb) 的激活函数。
引用:
- 原始的MNIST数据集:LeCun,Y.,Cortes,C.和Burges,C.J.(2010)。MNIST手写数字数据库。AT&T 实验室 [在线]。可用: http://yann。莱昆。com/exdb/mnist/
- 自动编码器概念和应用:Hinton,G.E.和Salakhutdinov,R.R.(2006)。使用神经网络降低数据的维数。科学, 313(5786), 504–507.
- 使用自动编码器进行图像重建:Masci,J.,Meier,U.,Cireşan,D.和Schmidhuber,J.(2011年52月)。用于分层特征提取的堆叠卷积自动编码器。在人工神经网络国际会议(第 59-<> 页)中。施普林格,柏林,海德堡。
- The tensorflow.keras library: Chollet, F. (2018).使用 Python 进行深度学习。纽约州谢尔特岛:曼宁出版公司
- 均方误差损失函数和亚当优化器:Kingma,D.P.和Ba,J.(2014)。Adam:一种随机优化的方法。arXiv预印本arXiv:1412.6980。
- 结构相似性指数(SSIM):Wang,Z.,Bovik,A.C.,Sheikh,H.R.和Simoncelli,E.P.(2004)。图像质量评估:从错误可见性到结构相似性。IEEE图像处理事务,13(4),600-612。
-
弗朗西斯·贝尼斯坦特
·
相关文章:
【深度学习】在 MNIST实现自动编码器实践教程
一、说明 自动编码器是一种无监督学习的神经网络模型,主要用于降维或特征提取。常见的自动编码器包括基本的单层自动编码器、深度自动编码器、卷积自动编码器和变分自动编码器等。 其中,基本的单层自动编码器由一个编码器和一个解码器组成,编…...
SpringBoot3基础用法
技术和工具「!喜新厌旧」 一、背景 最近在一个轻量级的服务中,尝试了最新的技术和工具选型; 即SpringBoot3,JDK17,IDEA2023,Navicat16,虽然新的技术和工具都更加强大和高效,但是适应采坑的过程…...

6、移除链表元素
方法1:原链表删除元素 伪代码: 首先判断头节点是否是待删除元素。(头节点和其他节点的删除方法不一样) while(head ! null && head->value target) //如果链表为 1 1 1 1 1,要删除元素1时用if就会失效 {h…...
大厂容器云实践之路(一)
1-华为CCE容器云实践 华为企业云 | CCE容器引擎实践 ——从IaaS到PaaS到容器集群 容器部署时代的来临 IaaS服务如日中天 2014-2015年,大家都在安逸的使用IaaS服务; 亚马逊AWS的部署能力方面比所有竞争对手…...
《合成孔径雷达成像算法与实现》Figure3.1
代码复现如下: clc close all clear all%参数设置 B 5.80e6; %信号带宽 T 7.26e-6; %脉冲持续时间 K B/T; %线性调频频率 alpha 5; %过采样率 F alpha*B; %采样频率 N F*T; %采样点数 dt T/N; …...
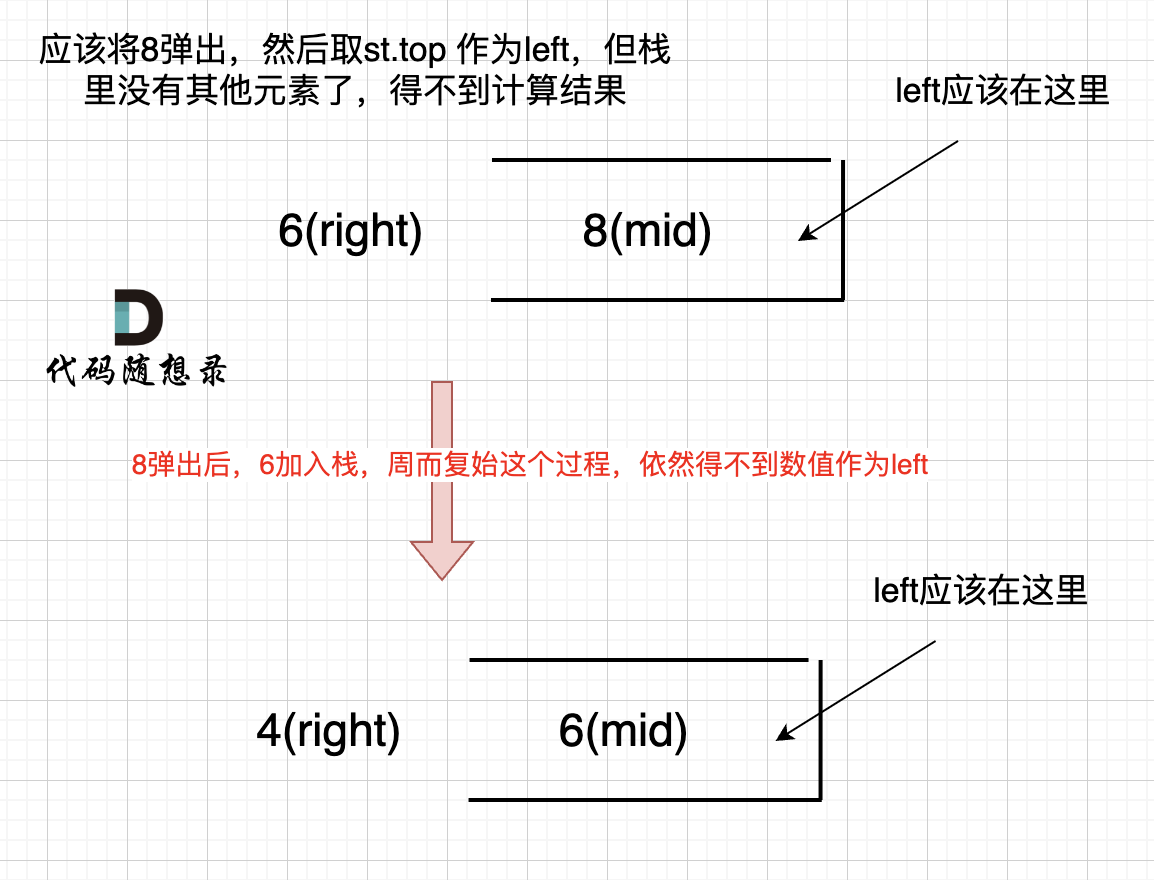
代码随想录算法训练营day60
文章目录 Day60 柱状图中最大的矩形题目思路代码 Day60 柱状图中最大的矩形 84. 柱状图中最大的矩形 - 力扣(LeetCode) 题目 给定 n 个非负整数,用来表示柱状图中各个柱子的高度。每个柱子彼此相邻,且宽度为 1 。 求在该柱状图…...
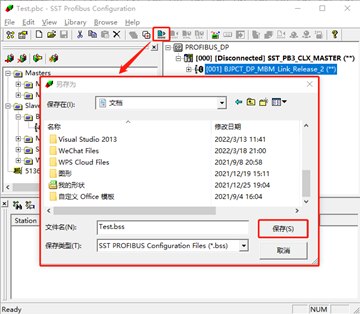
Modbus TCP转Profibus DP网关modbus tcp报文解析
捷米JM-DPM-TCP网关。在Profibus总线侧作为主站,在以太网侧作为ModbusTcp服务器功能, 下面是介绍捷米JM-DPM-TCP主站网关组态工具的配置方法 2, Profibus主站组态工具安装 执行资料光盘中的安装文件setup64.exe或setup.exe安装组态工具。安装过程中一直…...

对 Promise 的理解
Promise 是异步编程的一种解决方案,它是一个对象,可以获取异步 操作的消息,他的出现大大改善了异步编程的困境,避免了地狱回调, 它比传统的解决方案回调函数和事件更合理和更强大。 所谓 Promise,简单说就…...

Vuex:Vue.js应用程序的状态管理模式
介绍 在Vue.js应用程序中,随着项目复杂度的增加,组件之间的数据共享和管理变得困难。为了解决这个问题,Vue.js提供了一个名为Vuex的状态管理模式。Vuex可以帮助我们更有效地组织、管理和共享应用程序的状态。 什么是Vuex? Vuex…...
Unity之ShaderGraph 节点介绍 Utility节点
Utility 逻辑All(所有分量都不为零,返回 true)Any(任何分量不为零,返回 true)And(A 和 B 均为 true)Branch(动态分支)Comparison(两个输入值 A 和…...
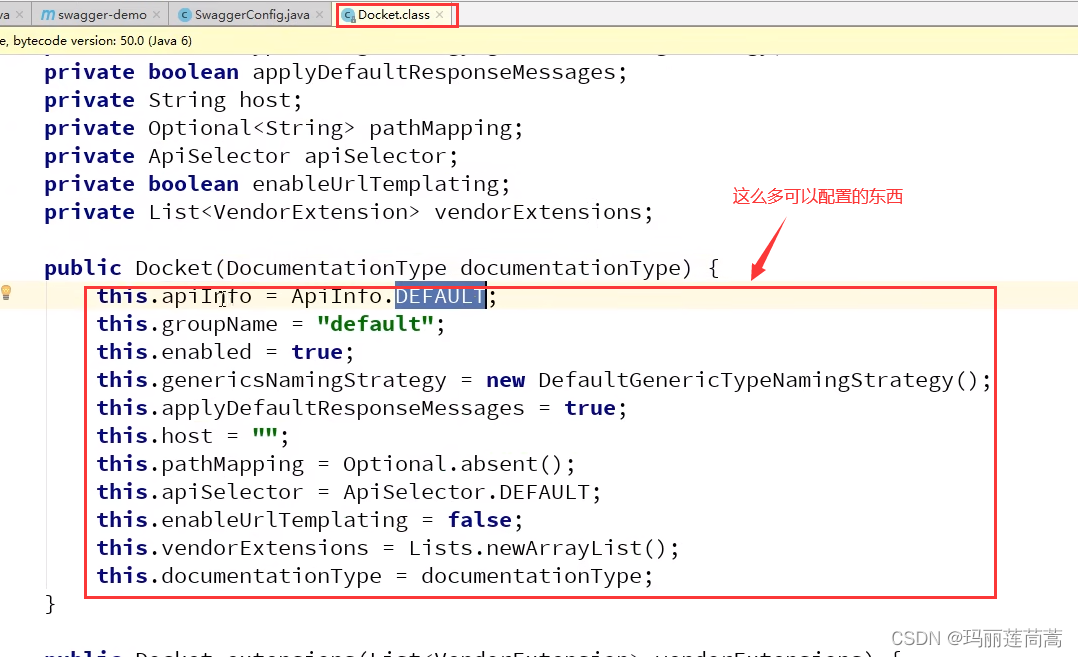
springboot()—— swagger
零、一张图读懂swagger 懂了,这玩意就是用swagger搞出来的! 就是一个后端开发自测的东西嘛! 一、概念 存在即合理,我们看一下swagger诞生的原因:在前后端分离的架构中,前端新增一个字段,后端就…...
Java课题笔记~ 关联映射
一、MyBatis关联查询 在关系型数据库中,表与表之间存在着3种关联映射关系,分别为一对一、一对多、多对多。 一对一:一个数据表中的一条记录最多可以与另一个数据表中的一条记录相关。列如学生与学号就属于一对一关系。 一对多:主…...

一零六七、JVM梳理
JVM? Java虚拟机,可以理解为Java程序的运行环境,可以执行Java字节码(Java bytecode)并提供了内存管理、垃圾回收、线程管理等功能 java内存区域划分?每块内存中都对应什么? 方法区:类的结构信息、常量池、…...

【CSS】网格布局(简单布局、网格合并、网格嵌套)
文章目录 CSS网格布局(Grid Layout)1. 简单布局2. 网格合并3. 网格嵌套4. 总结 CSS网格布局(Grid Layout) CSS网格布局(Grid Layout)是一种强大且灵活的CSS布局系统,允许开发者以网格形式组织和…...
06 Ubuntu22.04上的miniconda3安装、深度学习常用环境配置
下载脚本 我依然是在清华镜像当中寻找的脚本。这里找脚本真的十分方便,我十分推荐。 wget https://mirrors.tuna.tsinghua.edu.cn/anaconda/miniconda/Miniconda3-latest-Linux-x86_64.sh 下载十分快速,10秒解决问题 运行miniconda3安装脚本 赋予执…...
【CSS3】CSS3 动画 ② ( 动画序列 | 使用 from 和 to 定义动画序列 | 定义多个动画节点 | 代码示例 )
文章目录 一、动画序列二、代码示例 - 使用 from 和 to 定义动画序列三、代码示例 - 定义多个动画节点 一、动画序列 定义动画时 , 需要设置动画序列 , 下面的 0% 和 100% 设置的是 动画 在 运行到某个 百分比节点时 的 标签元素样式状态 ; keyframes element-move { 0% { tr…...
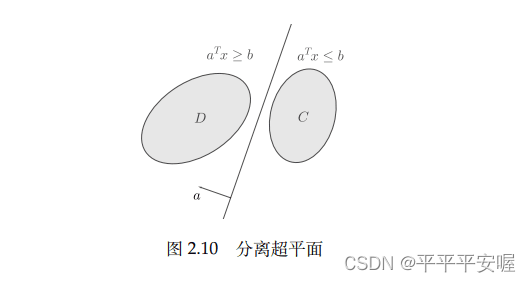
最优化:建模、算法与理论
最优化:建模、算法与理论 目前在学习 最优化:建模、算法与理论这本书,来此记录一下,顺便做一些笔记,在其中我也会加一些自己的理解,尽量写的不会那么的条条框框(当然最基础的还是要有ÿ…...
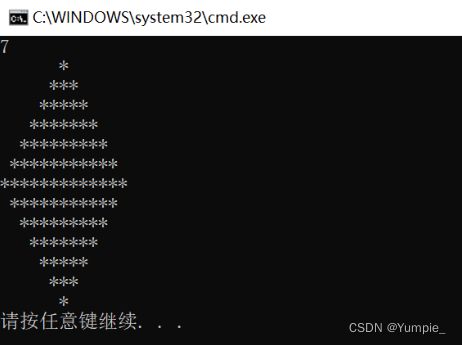
拿捏--->打印菱形
文章目录 题目描述算法思路代码示例 题目描述 在屏幕上输出以下图案: 算法思路 代码示例 #define _CRT_SECURE_NO_WARNINGS #include<stdio.h> int main() {int n;scanf("%d", &n);//上半部分菱形for (int i 0; i < n; i) //上半部分…...
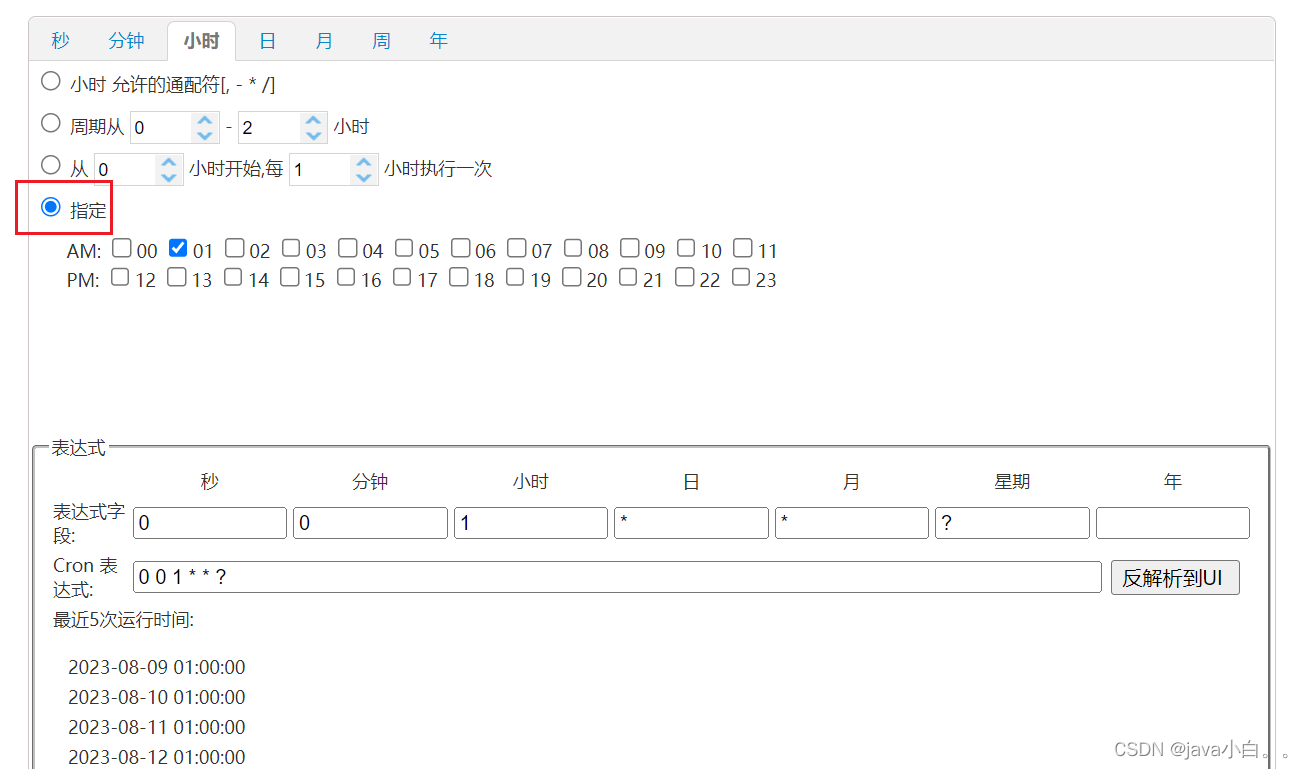
【SpringBoot笔记】定时任务(cron)
定时任务就是在固定的时间执行某个程序,闹钟的作用。 1.在启动类上添加注解 EnableScheduling 2.创建定时任务类 在这个类里面使用表达式设置什么时候执行 cron 表达式(也叫七子表达式),设置执行规则 package com.Lijibai.s…...
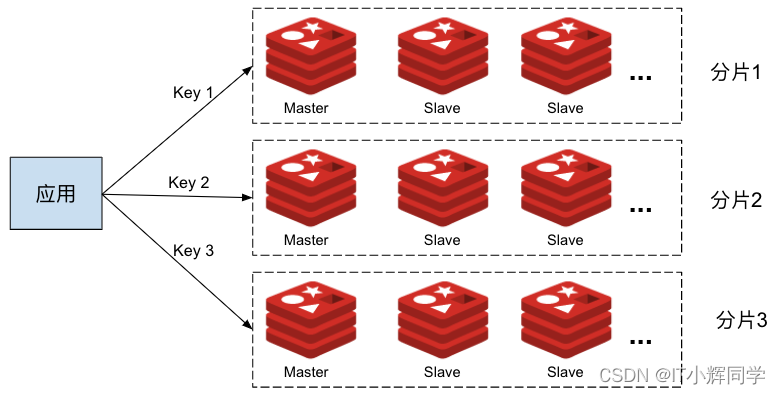
Redis单机,主从,哨兵,集群四大模式
Redis 单机模式 Redis 单机模式是指 Redis 数据库在单个服务器上以独立的、单一的进程运行的模式。在这种模式下,Redis 不涉及数据分片或集群配置,所有的数据和操作都在一个实例中进行。以下是关于 Redis 单机模式的详细介绍: 单一实例&#…...

为Claude Code寻找稳定替代方案,Taotoken接入配置指南
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 为Claude Code寻找稳定替代方案,Taotoken接入配置指南 当开发者依赖Claude Code这类编程助手工具进行日常开发时&#…...

3个创新视角:重新定义AMD平台内存监控的新范式
3个创新视角:重新定义AMD平台内存监控的新范式 【免费下载链接】ZenTimings 项目地址: https://gitcode.com/gh_mirrors/ze/ZenTimings 在AMD Ryzen平台的性能调优领域,内存时序监控一直是个技术门槛较高的领域。传统监控工具往往停留在表面参数…...

技术人的“薪资锚点”策略:第一个报价为什么至关重要?
被低估的“第一印象”在软件测试领域,技术人习惯于与代码、逻辑和数据打交道,往往将薪资谈判视为一种非理性的“讨价还价”。然而,从行为经济学的视角审视,谈判的开局瞬间,其实已经为最终结果划定了无形的边界。那个最…...

电子取证实战:利用FTK Imager与VMware实现DD/E01镜像的动态仿真与启动
1. 电子取证中的镜像仿真入门 第一次接触电子取证时,我被各种专业术语搞得晕头转向。直到有一次需要分析一个嫌疑人的硬盘镜像,才真正体会到动态仿真的重要性。简单来说,动态仿真就是让存储在DD或E01镜像中的操作系统"活"起来&…...
如何3分钟完成漫画翻译:BallonsTranslator AI智能工具完全指南
如何3分钟完成漫画翻译:BallonsTranslator AI智能工具完全指南 【免费下载链接】BallonsTranslator 深度学习辅助漫画翻译工具, 支持一键机翻和简单的图像/文本编辑 | Yet another computer-aided comic/manga translation tool powered by deeplearning 项目地址…...

环境配置与基础教程:保姆级教程:在 Mac M 芯片上利用 MPS 加速 YOLO 训练与推理的完整环境搭建
写在前面:为什么你的 Mac 也能跑深度学习? 几年前,如果有人告诉你用 MacBook 训练深度学习模型,你大概会笑出声。那时候 Mac 上的 PyTorch 只能依赖 CPU 吭哧吭哧地算,训练一个小模型都要等到天荒地老。但自从 Apple Silicon 芯片(M1、M2、M3、M4,以及最新的 M5)横空出…...

别再只会用StegSolve了!深入理解LSB隐写原理,手写Python脚本提取隐藏信息
从像素到秘密:手写Python脚本破解LSB隐写的核心技术 当你面对一张看似普通的图片,是否曾想过它可能隐藏着重要信息?在CTF竞赛和数字取证领域,LSB(最低有效位)隐写术是最基础却最常被忽视的技术之一。大多数…...

告别Arduino IDE:在Visual Studio Code中搭建高效Arduino开发环境
1. 为什么选择VS Code开发Arduino项目 第一次接触Arduino开发时,大多数人都是从官方Arduino IDE开始的。这个简单的开发环境确实能快速上手,但随着项目复杂度增加,它的局限性就越来越明显:代码补全功能弱、项目管理混乱、调试工具…...

2026届学术党必备的六大AI科研神器解析与推荐
Ai论文网站排名(开题报告、文献综述、降aigc率、降重综合对比) TOP1. 千笔AI TOP2. aipasspaper TOP3. 清北论文 TOP4. 豆包 TOP5. kimi TOP6. deepseek 于当下的学术语境里面,AI辅助论文写作已经变成了越来越多研究者采用的效率工具。…...

NLP知识图谱构建实战:从文本到结构化知识的完整流程
1. 项目概述:当NLP遇上知识图谱如果你在NLP(自然语言处理)领域摸爬滚打了一段时间,或者对知识图谱(Knowledge Graph)这个听起来就很有“智慧感”的东西感兴趣,那么你大概率在GitHub上见过或搜索…...