微服务——es数据聚合+RestClient实现聚合
数据聚合
聚合的种类

DSL实现Bucket聚合

 如图所示,设置了10个桶,那么就显示了数量最多的前10个桶,品牌含有7天酒店的有30家,
如图所示,设置了10个桶,那么就显示了数量最多的前10个桶,品牌含有7天酒店的有30家,
品牌含有如家的也有30家。
修改排序规则

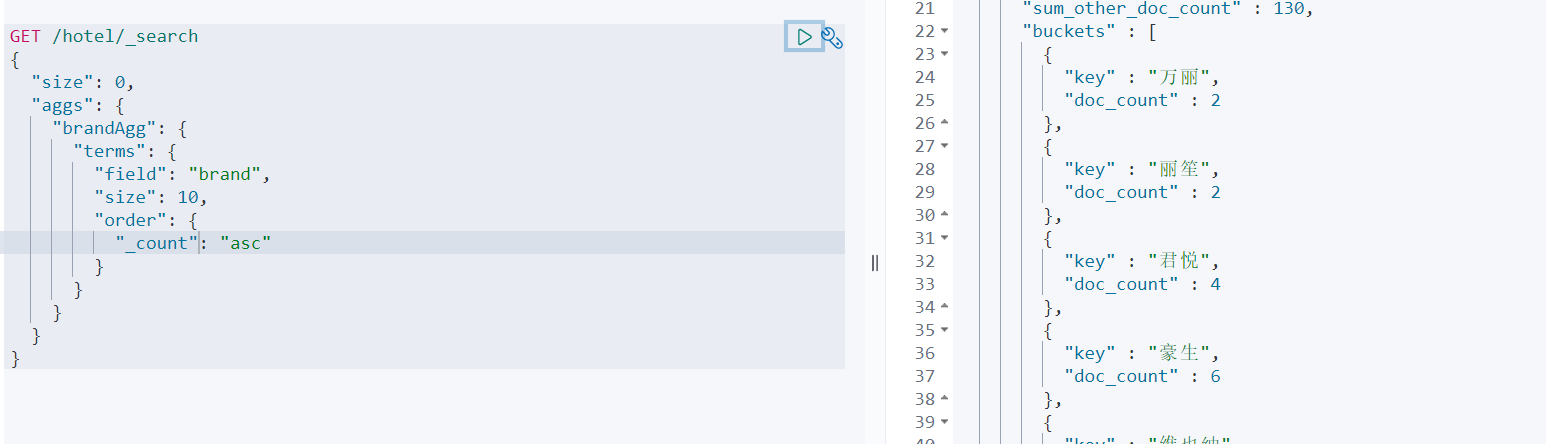 限定聚合范围
限定聚合范围

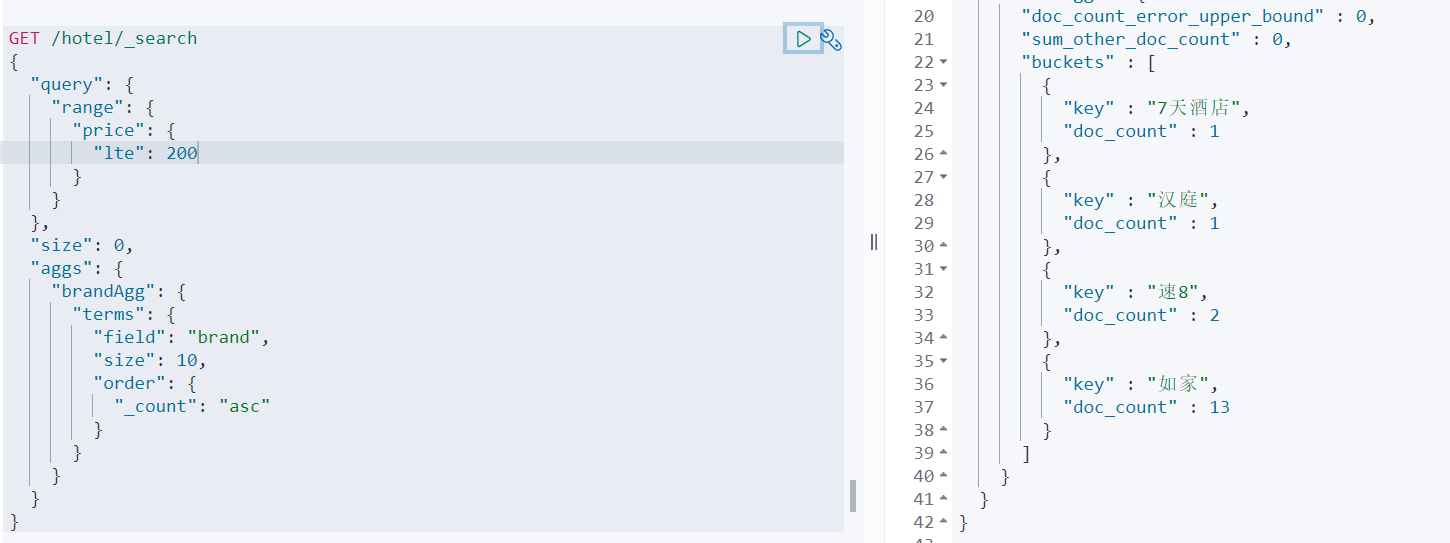 DSL实现Metrics聚合
DSL实现Metrics聚合
如下案例要求对不同的品牌进行统计,所以要进行分组。

如图所示,要对桶的平均评分做排序,要使用不同桶的平均评分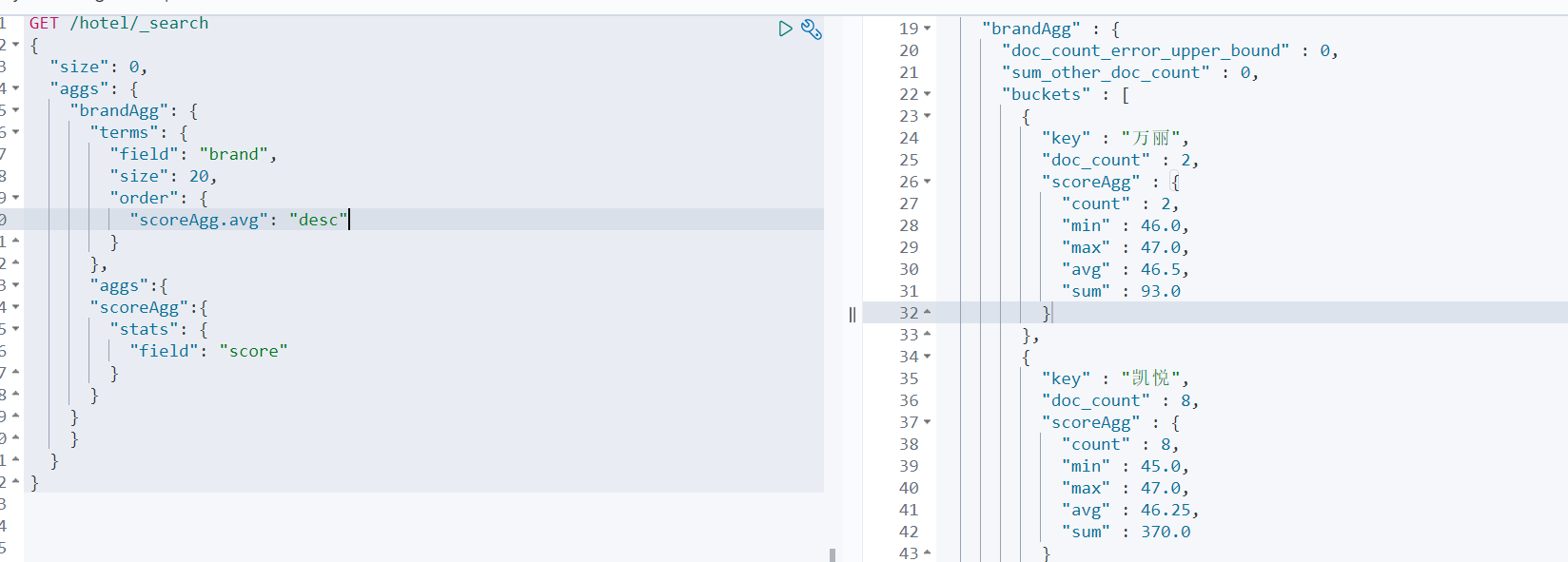
RestClient实现聚合
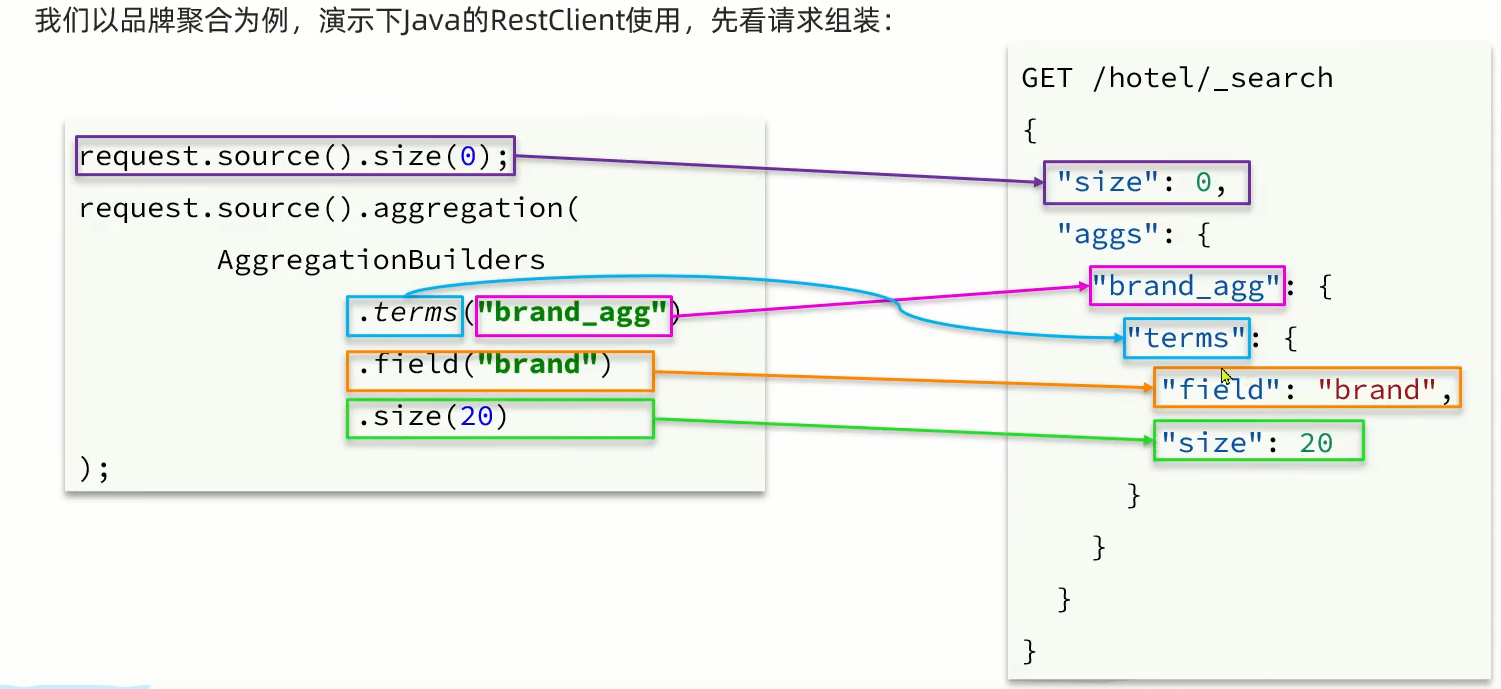
请求组装
@Testvoid testAggregation() throws IOException {//1.准备RequestSearchRequest request = new SearchRequest("hotel");//2.准备DSl//2.1设置sizerequest.source().size(0);//2.2聚合request.source().aggregation(AggregationBuilders.terms("brandAgg").field("brand").size(10));//3.发出请求SearchResponse response = client.search(request, RequestOptions.DEFAULT);//4.解析结果System.out.println(response);} 
结果解析

@Testvoid testAggregation() throws IOException {//1.准备RequestSearchRequest request = new SearchRequest("hotel");//2.准备DSl//2.1设置sizerequest.source().size(0);//2.2聚合request.source().aggregation(AggregationBuilders.terms("brandAgg").field("brand").size(10));//3.发出请求SearchResponse response = client.search(request, RequestOptions.DEFAULT);//4.解析结果Aggregations aggregations = response.getAggregations();//4.1根据聚合名称获取聚合结果Terms brandTerms = aggregations.get("brandAgg");//4.2获取bucketsList<? extends Terms.Bucket> buckets = brandTerms.getBuckets();//4.3遍历for (Terms.Bucket bucket : buckets) {//4.4获取keyString key = bucket.getKeyAsString();System.out.println(key);}} 
多条件聚合
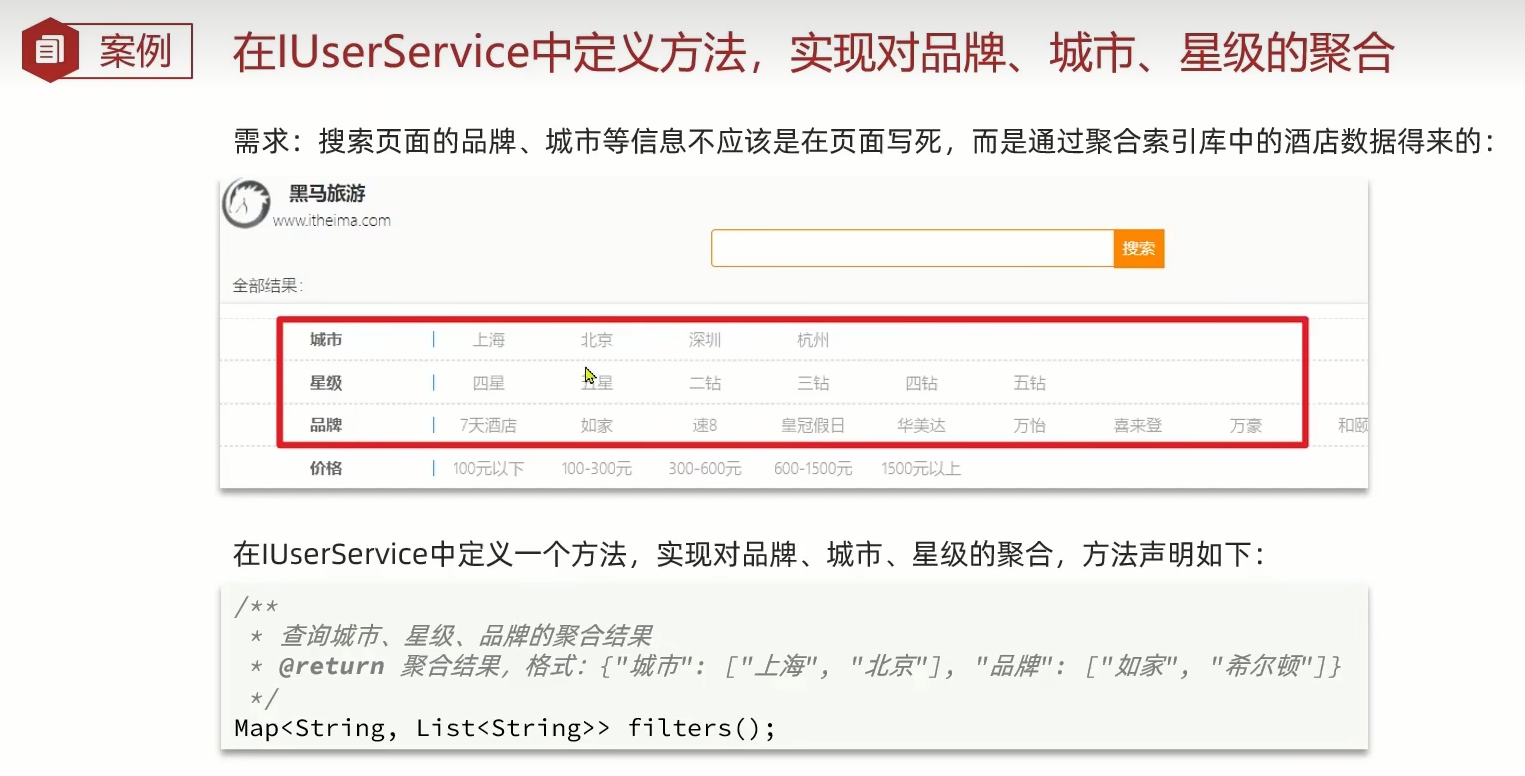
在Service中
将公共代码抽取出来,提高复用性
@Overridepublic Map<String, List<String>> filters() {try {//1.准备RequestSearchRequest request = new SearchRequest("hotel");//2.准备DSl//2.1设置sizerequest.source().size(0);//2.2聚合buildAggregation(request);//3.发出请求SearchResponse response = client.search(request, RequestOptions.DEFAULT);//4.解析结果Map<String, List<String>>result=new HashMap<>();Aggregations aggregations = response.getAggregations();//5.1根据品牌名称获取品牌结果List<String> brandList = getAggByName(aggregations,"brandAgg");result.put("品牌",brandList);//5.2根据品牌名称获取品牌结果List<String> cityList = getAggByName(aggregations,"cityAgg");result.put("城市",cityList);//5.3根据品牌名称获取品牌结果List<String> starList = getAggByName(aggregations,"starAgg");result.put("星级",starList);return result;} catch (IOException e) {throw new RuntimeException(e);}}private static List<String> getAggByName(Aggregations aggregations,String aggName) {//4.1根据聚合名称获取聚合结果Terms brandTerms = aggregations.get(aggName);//4.2获取bucketsList<? extends Terms.Bucket> buckets = brandTerms.getBuckets();//4.3遍历List<String>brandList=new ArrayList<>();for (Terms.Bucket bucket : buckets) {//4.4获取keyString key = bucket.getKeyAsString();brandList.add(key);}return brandList;}
在一个测试类中
@SpringBootTest
class HotelDemoApplicationTests {@Autowiredprivate IHotelService hotelService;@Testvoid contextLoads() {Map<String, List<String>> filters = hotelService.filters();System.out.println(filters);}}运行得到

带过滤条件的聚合
在查询的时候要在查询结果上做聚合,不应该直接将所有数据的聚合结果返回。
所以就是加上query参数。
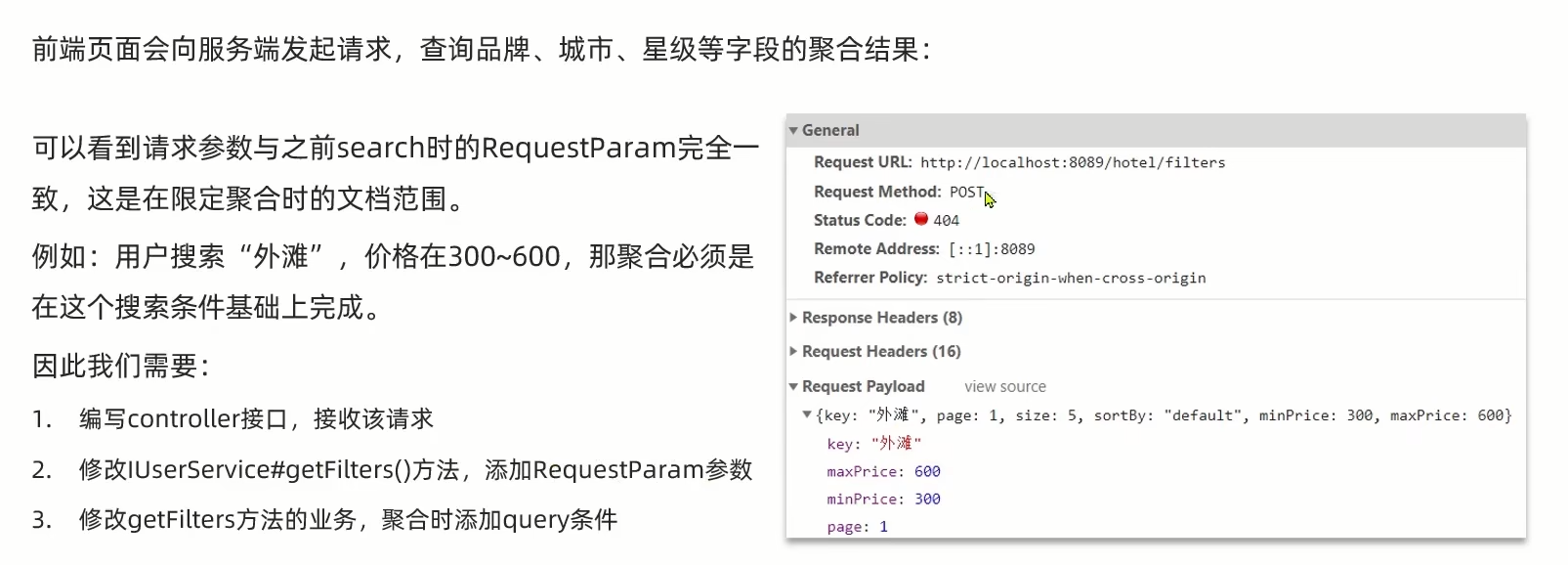
Controller中
传递的参数和正常参数一模一样
@PostMapping("filters")public Map<String, List<String>> getFilters(@RequestBody RequestParams Params){return hotelService.filters(Params);}Service中
添加传递参数,并且新设置了2.3query,使用搜索时同款的query设置方法
@Overridepublic Map<String, List<String>> filters(RequestParams Params) {try {//1.准备RequestSearchRequest request = new SearchRequest("hotel");//2.准备DSl//2.1设置sizerequest.source().size(0);//2.2聚合buildAggregation(request);//2.3querybuildBasicQuery(Params, request);//3.发出请求SearchResponse response = client.search(request, RequestOptions.DEFAULT);//4.解析结果Map<String, List<String>>result=new HashMap<>();Aggregations aggregations = response.getAggregations();//5.1根据品牌名称获取品牌结果List<String> brandList = getAggByName(aggregations,"brandAgg");result.put("品牌",brandList);//5.2根据品牌名称获取品牌结果List<String> cityList = getAggByName(aggregations,"cityAgg");result.put("城市",cityList);//5.3根据品牌名称获取品牌结果List<String> starList = getAggByName(aggregations,"starAgg");result.put("星级",starList);return result;} catch (IOException e) {throw new RuntimeException(e);}}结果测试
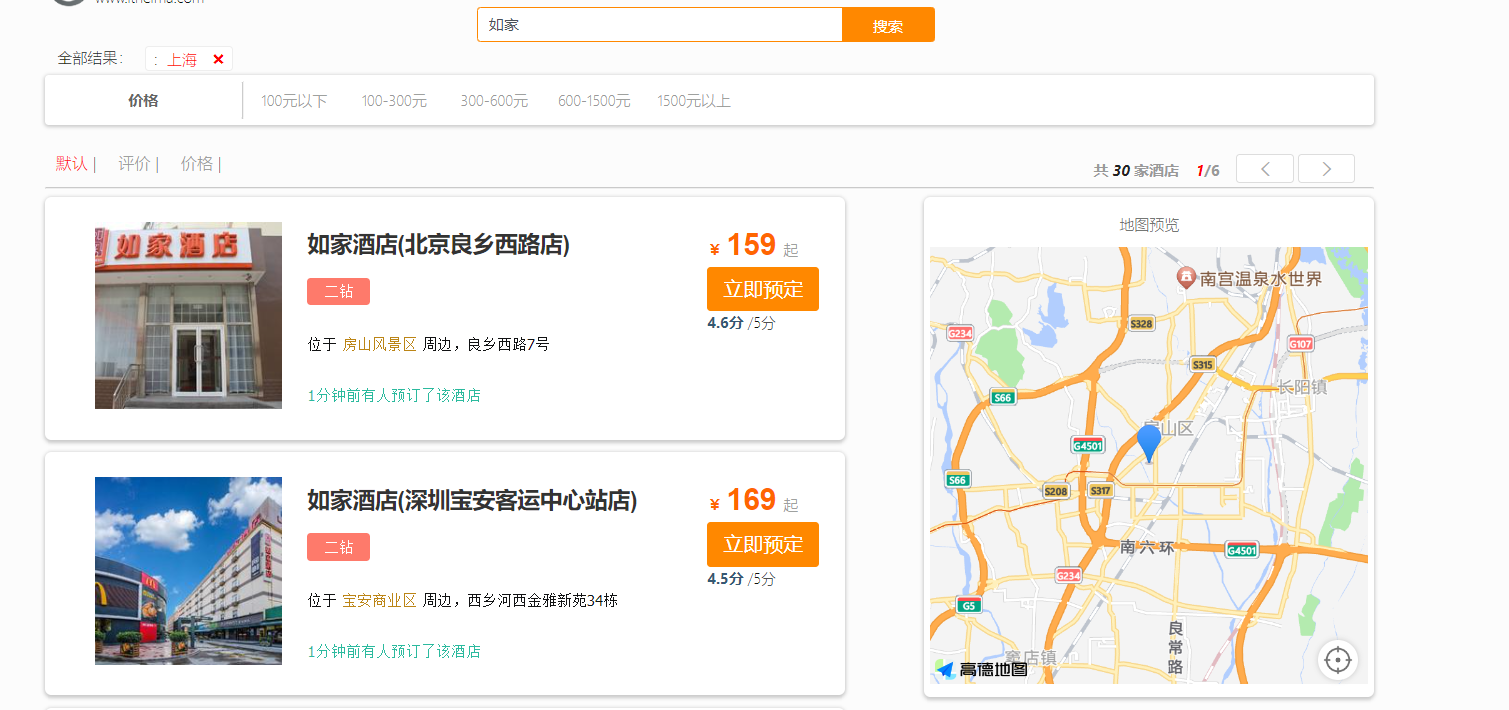
根据搜索框和过滤条件成功过滤
相关文章:
微服务——es数据聚合+RestClient实现聚合
数据聚合 聚合的种类 DSL实现Bucket聚合 如图所示,设置了10个桶,那么就显示了数量最多的前10个桶,品牌含有7天酒店的有30家, 品牌含有如家的也有30家。 修改排序规则 限定聚合范围 DSL实现Metrics聚合 如下案例要求对不同的品…...
代码分析Java中的BIO与NIO
开发环境 OS:Win10(需要开启telnet服务,或使用第三方远程工具) Java版本:8 BIO 概念 BIO(Block IO),即同步阻塞IO,特点为当客户端发起请求后,在服务端未处理完该请求之前ÿ…...
网络安全(黑客)工作篇
一、网络安全行业的就业前景如何? 网络安全行业的就业前景非常广阔和有吸引力。随着数字化、云计算、物联网和人工智能等技术的迅速发展,网络安全的需求持续增长。以下是网络安全行业就业前景的一些关键因素: 高需求:随着互联网的…...
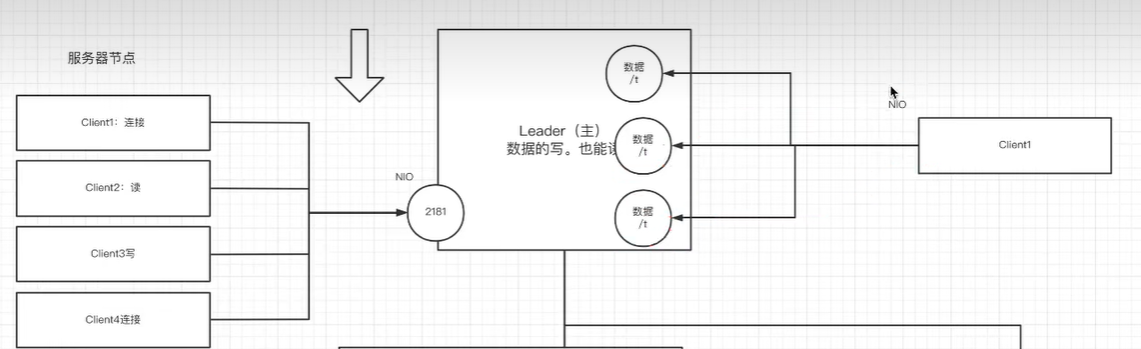
zookeeper入门学习
zookeeper入门学习 zookeeper应用场景 分布式协调组件 客户端第一次请求发给服务器2,将flag值修改为false,第二次请求被负载均衡到服务器1,访问到的flag也会是false 一旦有节点发生改变,就会通知所有监听方改变自己的值&#…...

VirtualEnv 20.24.0 发布
导读VirtualEnv 20.24.0 现已发布,VirtualEnv 用于在一台机器上创建多个独立的 Python 运行环境,可隔离项目之间的第三方包依赖,为部署应用提供方便,把开发环境的虚拟环境打包到生产环境即可,不需要在服务器上再折腾一…...
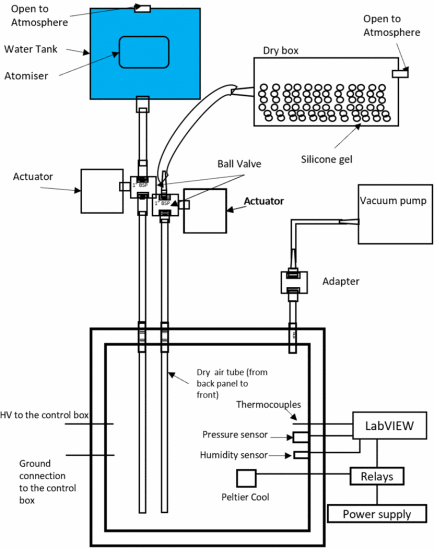
LabVIEW开发高压航空航天动力系统爬电距离的测试
LabVIEW开发高压航空航天动力系统爬电距离的测试 更多电动飞机MEA技术将发电,配电和用电集成到一个统一的系统中,提高了飞机的可靠性和可维护性。更多的电动飞机使用更多的电能来用电动替代品取代液压和气动系统。对车载电力的需求不断增加,…...
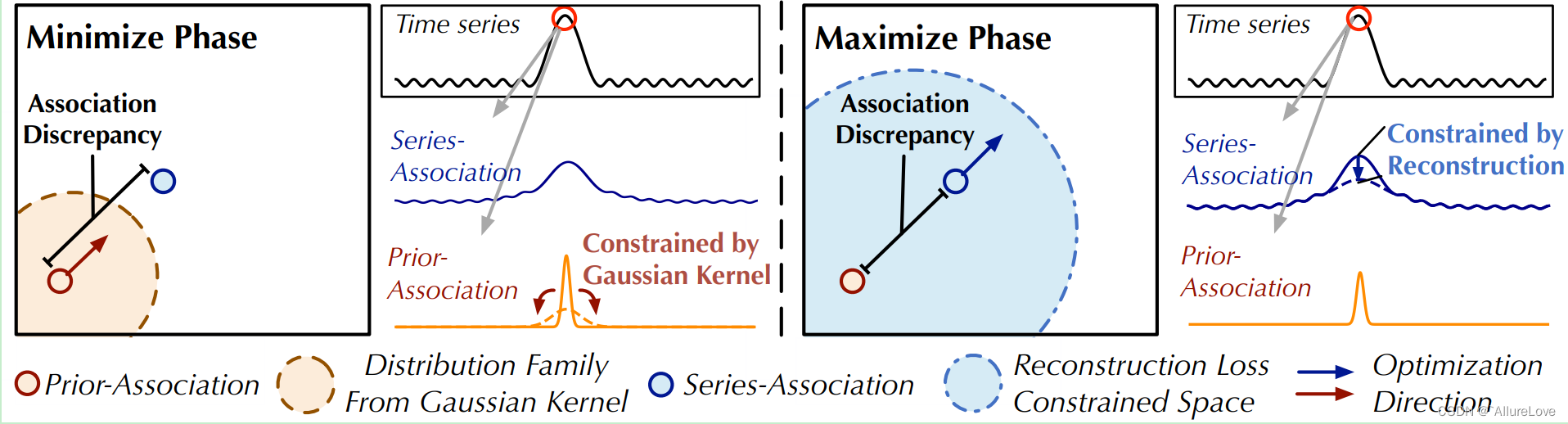
【论文阅读】基于深度学习的时序异常检测——Anomaly Transformer
系列文章链接 数据基础:多维时序数据集简介 论文一:2022 Anomaly Transformer:异常分数预测 论文二:2022 TransAD:异常分数预测 论文链接:Anomaly Transformer.pdf 代码链接:https://github.co…...

Java并发总结
1.创建线程三种方式 Runnable.Callable接口使用继承Thread类的方式创建多线程Runnable 和Callable区别 Callable规定(重写)的方法是call(),Runnable规定(重写)的方法是run()。Callable的任务执行后可返回值࿰…...
视频汇聚平台EasyCVR视频广场侧边栏支持拖拽
为了提升用户体验以及让平台的操作更加符合用户使用习惯,我们在EasyCVR v3.3版本中,支持面包屑侧边栏的广场视频、分组列表、收藏这三个模块拖拽排序,并且该操作在视频广场、视频调阅、电子地图、录像回放等页面均能支持。 TSINGSEE青犀视频…...

MyCat分片规则——范围分片、取模分片、一致性hash、枚举分片
1.范围分片 2.取模分片 范围分片和取模分片针对数字类型的字段可以,但是针对于字符串类型的字段时。这两种就不适用了。 3.一致性hash 4.枚举分片 默认节点指的是,如果我们向数据库表插入数据的时候,超出了这个枚举值,那么默认向…...
设计模式行为型——备忘录模式
目录 什么是备忘录模式 备忘录模式的实现 备忘录模式角色 备忘录模式类图 备忘录模式举例 备忘录模式代码实现 备忘录模式的特点 优点 缺点 使用场景 注意事项 实际应用 什么是备忘录模式 备忘录模式(Memento Pattern)又叫做快照模式&#x…...
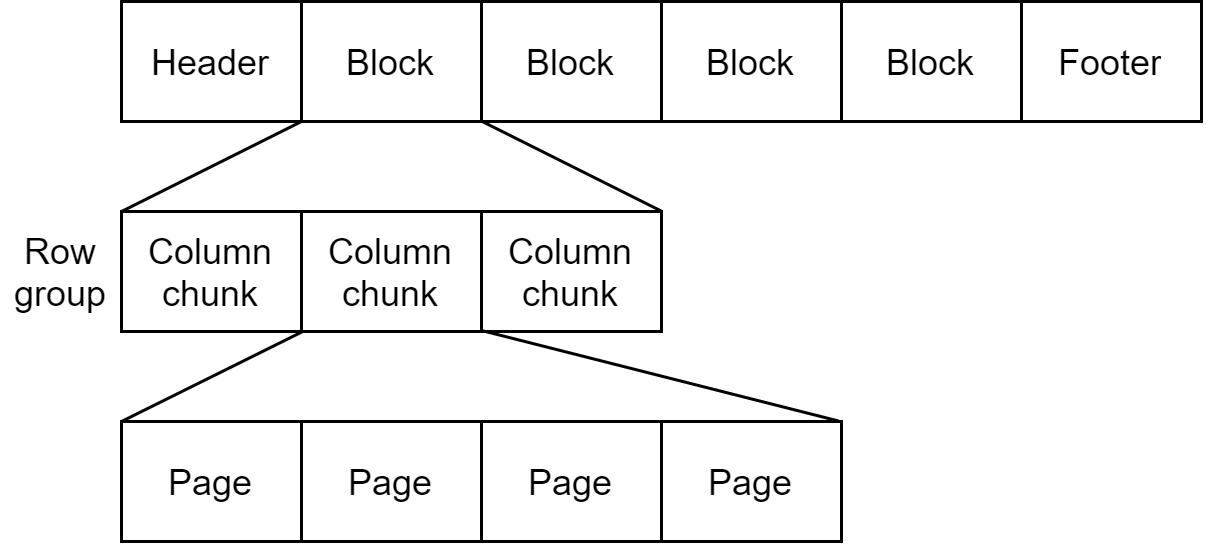
Parquet存储的数据模型以及文件格式
文章目录 数据模型Parquet 的原子类型Parquet 的逻辑类型嵌套编码 Parquet文件格式 本文主要参考文献:Tom White. Hadoop权威指南. 第4版. 清华大学出版社, 2017.pages 363. Aapche Parquet是一种能有效存储嵌套数据的列式存储格式,在Spark中应用较多。 …...

Go和Java实现访问者模式
Go和Java实现访问者模式 我们下面通过一个解压和压缩各种类型的文件的案例来说明访问者模式的使用。 1、访问者模式 在访问者模式中,我们使用了一个访问者类,它改变了元素类的执行算法。通过这种方式,元素的执行算法可以随 着访问者改变而…...

想要通过软件测试的面试,都需要学习哪些知识
很多人认为,软件测试是一个简单的职位,职业生涯走向也不会太好,但是随着时间的推移,软件测试行业的变化,人们开始对软件测试行业的认知有了新的高度,越来越多的人开始关注这个行业,开始重视这个…...
MySQL的索引使用的数据结构,事务知识
一、索引的数据结构🌸 索引的数据结构(非常重要) mysql的索引的数据结构,并非定式!!!取决于MySQL使用哪个存储引擎 数据库这块组织数据使用的数据结构是在硬盘上的。我们平时写的代码是存在内存…...
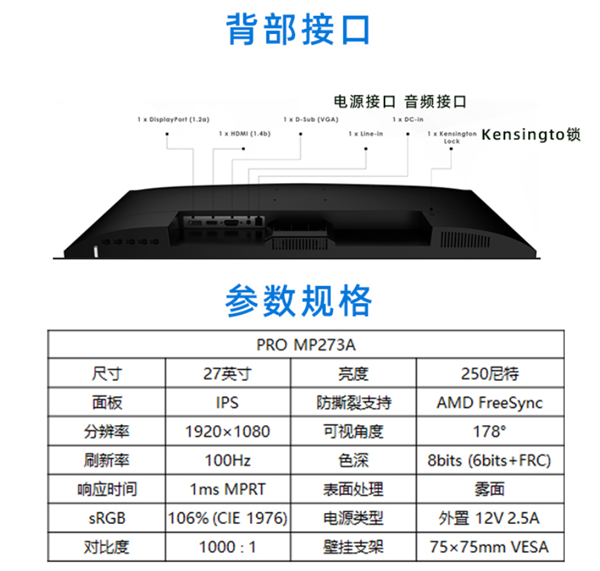
普及100Hz高刷+1ms响应 微星发布27寸显示器:仅售799元
不论办公还是游戏,高刷及低响应时间都很重要,微星现在推出了一款27寸显示器PRO MP273A, 售价只有799元,但支持100Hz高刷、1ms响应时间,还有FreeSync技术减少撕裂。 PRO MP273A的100Hz高刷新率是其最大的卖点之一&#…...
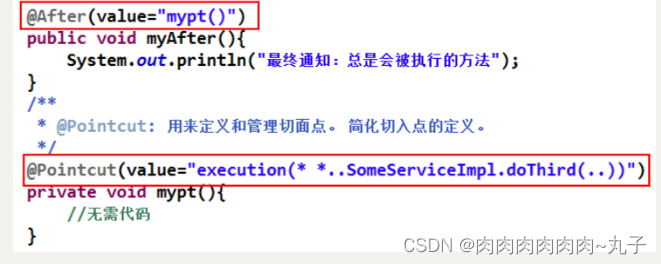
Java课题笔记~6个重要注解参数含义
1、[掌握]Before 前置通知-方法有 JoinPoint 参数 在目标方法执行之前执行。被注解为前置通知的方法,可以包含一个 JoinPoint 类型参数。 该类型的对象本身就是切入点表达式。通过该参数,可获取切入点表达式、方法签名、目标对象等。 不光前置通知的方…...

Windows Docker Desk环境时区问题导致的时间问题解决?
大多docker镜像为了保持镜像大小,采用了alpine linux。 但经常由于时区问题导致时间不准确,解决也很简单。 1.查看事件文件 cd /usr/share/zoneinfo 2.复制时区文件 将文件copy到 /etc/localtime 路径下即可(重庆时区,上海也…...
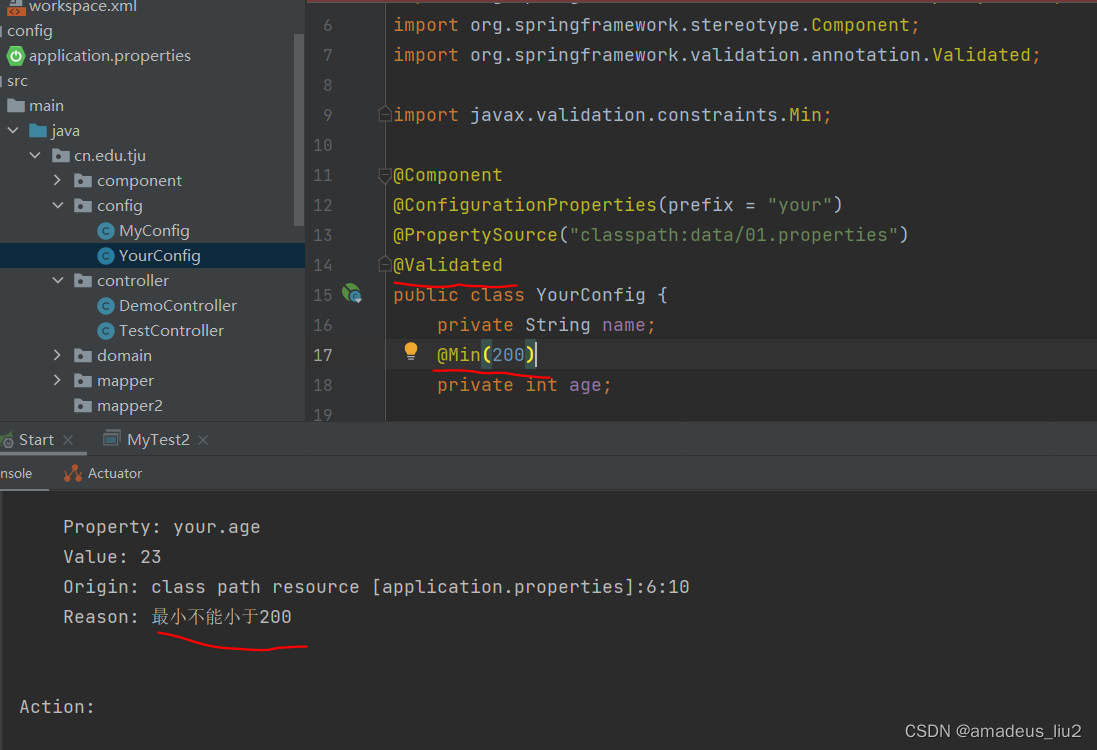
SpringBoot复习:(22)ConfigurationProperties和@PropertySource配合使用及JSR303校验
一、配置类 package cn.edu.tju.config;import org.springframework.boot.context.properties.ConfigurationProperties; import org.springframework.context.annotation.PropertySource; import org.springframework.stereotype.Component;Component ConfigurationPropertie…...
)
Spring IoC (控制反转)
IoC 是 Inversion of Control 的简写,译为“控制反转”,它不是一门技术,而是一种设计思想,是一个重要的面向对象编程法则。 Spring 通过 IoC 容器来管理所有 Java 对象的实例化和初始化,控制对象与对象之间的依赖关系。…...

SpringBatch学习
/*** 示例一:Tasklet 方式*/ Configuration EnableBatchProcessing public class TaskletBatchConfig {private static final Logger logger LoggerFactory.getLogger(TaskletBatchConfig.class);Autowiredprivate JobBuilderFactory jobBuilderFactory;Autowiredp…...

保姆级教程:用LabVIEW 2023给CANoe做个外挂,实现硬件数据采集与自动化测试
保姆级教程:用LabVIEW 2023给CANoe做个外挂,实现硬件数据采集与自动化测试 在汽车电子测试领域,工程师们常常面临一个核心矛盾:CANoe作为行业标准的总线仿真工具提供了强大的协议分析和测试管理能力,但在面对非标硬件接…...

AI智能体技能开发实战:从工具调用到安全部署全解析
1. 项目概述:当AI学会“上网”与“思考”最近在折腾AI应用开发的朋友,估计都绕不开一个核心问题:如何让大语言模型(LLM)不只是个“聊天高手”,更能成为一个能独立完成复杂任务的“智能体”。你肯定遇到过&a…...

MPICH2并行计算环境搭建:从“目标计算机积极拒绝”到畅通无阻的实战排错指南
1. 遇到"目标计算机积极拒绝"时别慌 第一次在MPICH2环境里看到"目标计算机积极拒绝"这个报错时,我正急着跑一个分布式计算任务。命令行里突然蹦出的ERROR:Error while connecting to host让我瞬间头皮发麻——明明昨天还能正常运行的集群&#…...
)
SketchUp 2021照片匹配实战:手把手教你用一张床头柜照片快速建模(含尺寸校准技巧)
SketchUp 2021照片匹配实战:从单张照片到精准3D模型的完整工作流 在室内设计和家具建模领域,时间就是金钱。当你手头只有一张产品照片——可能是电商平台的商品图,或是客户发来的参考图片——如何快速将其转化为可编辑的3D模型?Sk…...

动态路由协议与BGP路径属性:网络工程师的核心必修课
1. 从“路标”到“地图”:动态路由协议的核心价值 在网络世界里,路由器就像一个个十字路口的交通警察。如果每个路口都需要手动设置去往所有目的地的路牌,那不仅工作量巨大,一旦某条路临时施工或封闭,整个城市的交通都…...

嵌入式UI开发提速秘籍:用GUI Guider+NXP工具链为LVGL 8.3.2快速设计界面并集成到Keil工程
嵌入式UI开发效率革命:GUI Guider与Keil工程的无缝整合实战 在嵌入式系统开发中,用户界面(UI)的设计与实现往往是最耗时的环节之一。传统的手写代码方式不仅效率低下,而且难以快速迭代和调整。本文将介绍如何利用NXP的GUI Guider工具与Keil开…...

Wonder3D:用一张照片开启3D建模新纪元
Wonder3D:用一张照片开启3D建模新纪元 【免费下载链接】Wonder3D Single Image to 3D using Cross-Domain Diffusion for 3D Generation 项目地址: https://gitcode.com/gh_mirrors/wo/Wonder3D 还在为复杂的3D建模软件头疼吗?今天我要向你介绍一…...

【紧急预警】NotebookLM在广义相对论语境下的概念漂移现象:基于57篇PRL论文的偏差审计报告
更多请点击: https://intelliparadigm.com 第一章:【紧急预警】NotebookLM在广义相对论语境下的概念漂移现象:基于57篇PRL论文的偏差审计报告 现象复现与基准测试协议 我们在标准LIGO-PRL语料集(v2.3)上对NotebookLM…...

PearProject梨子项目:如何快速搭建轻量级远程协作系统的完整指南
PearProject梨子项目:如何快速搭建轻量级远程协作系统的完整指南 【免费下载链接】pearProject pear,梨子,轻量级的在线项目/任务协作系统,远程办公协作 项目地址: https://gitcode.com/gh_mirrors/pe/pearProject PearPro…...