Parquet存储的数据模型以及文件格式
文章目录
- 数据模型
- Parquet 的原子类型
- Parquet 的逻辑类型
- 嵌套编码
- Parquet文件格式
本文主要参考文献:Tom White. Hadoop权威指南. 第4版. 清华大学出版社, 2017.pages 363.
Aapche Parquet是一种能有效存储嵌套数据的列式存储格式,在Spark中应用较多。
列式存储格式在文件大小和查询性能上表现优秀,在列式存储格式下,同一列的数据连续保存。一般来说,这种做法可以允许更高效的编码方式,从而使列式存储格式的文件常常比行式存储格式的同等文件占用更少的空间。
例如:对于存储时间戳的列,采用的编码方式可以是存储第一个时间戳的值,尔后的值则只需要存储与前一个值之间的差,根据时间局部性原理(即同一时间前后的记录彼此相邻),这种编码方式更倾向于占用较小的空间。
查询引擎在执行时能够跳过对本次查询无用的行,提高查询性能。在Hadoop生态中还有其他的列式存储,如Hive项目中著名的ORCFile(Optimized Record Columnar File)。
Parquet的突出贡献在于能够以真正的列式存储格式来保存具有深度嵌套结构的数据。在显示世界中,具有多级嵌套模式的系统比较普通,所以这种能力非常重要。Parquet脱胎于Google发表的一篇关于Dremel的论文,它通过一种新颖的技术,以扁平的列式存储格式和很小的额外开销来存储嵌套的结构。有了这种技术,即使是嵌套的字段在读取时也不需求牵扯到其他字段,从而带来了性能上的极大提升。
Parquet的另一个特点是有很多工具都可以支持这种格式。作为Parquet的缔造者,Twitter和Cloudera的工程师们希望在尝试使用新工具来处理现有的数据时能够更加简化。为了达成这一目标,他们将该项目划分为两个部分,其一是以语言无关的方式来定义文件格式的Parquet规范(即Parquet-format),另一部分是不同语言(Java和C++)的规范实现,以便人们能够使用多种工具读/写Parquet文件。
事实上,大部分大数据处理组件都支持Parquet格式(包括MapReduce、Hive、Spark等)。这种灵活性同样也延伸至内存中的表示法:Java的实现并没有绑定某一种表示法,因而可以使用Avro、Thrift等多种内存数据表示法来讲数据写入Parquet文件或者从Parquet文件中读取数据。
数据模型
Parquet 的原子类型
Parquet定义了少数几个原子数据类型:
| 类型 | 描述 |
|---|---|
| boolean | 二进制值 |
| int32 | 32位有符号整数 |
| int64 | 64位有符号整数 |
| int96 | 96位有符号整数 |
| float | 单精度浮点数 |
| double | 双精度浮点数 |
| binary | 8位无符号字节序列 |
| fixed_len_byte_array | 固定数量的8位五符号字节 |
保存在Parquet文件中的数据通过模式进行描述,模式的根为message,message中包含一组字段,每个字段由一个重复数(required,optional或repeated,分别表示有且只有一次,0或1次,0或多次)、一个数据类型、一个字段名称构成。下面是一个简单的气象记录的Parquet模式:
message WhatherRecord {required int32 year;required int32 temperature;required binary stationId(UTF8);
}
请注意,Parquet的原子类型并不包括字符串类型。事实上,Parquet定义了一些逻辑类型,这些逻辑类型指出应当如何对原子类型进行解读,从而使得序列化的表示(即原子类型)与特定于应用的语义(即逻辑类型)相互独立。可以通过UTF8注解的binary原子类型表示字符串类型。
Parquet 的逻辑类型
下表列出了Parquet定义的一些逻辑类型,且每种逻辑类型都有一个具有代表性的模式范例。表中没有列出的类型包括有符号整数、无符号整数、其他一些日期或时间类型以及JSON和BSON文档类型。
| 逻辑类型注解 | 描述 | 模式示例 |
|---|---|---|
| UTF8 | 由UTF-8字符组成的字符串,可用于注解binary | message m { required binary a (UTF8); } |
| ENUM | 命名值的集合,可用于注解binary | message m { required binary a (ENUM); } |
| DECIMAL (precision,scala) | 任意精度的有符号小数,可用于注解int32、int64、binary或fixed_len_byte_array | message m { required int32 a (DECIMAL(5,2)); } |
| DATE | 不带时间的日期值,可用于注解int32。用Unix元年以来的天数表示 | message m { required binary a (DATE); } |
| LIST | 一组有序的值,可用于注解group | message m { required group a (LIST){ repeated group list{ required int32 element; } } } |
| MAP | 一组无序的键值对,可用于注解group | message m { required group a (MAP){ repeated group k_v{ required binary key (UTF8); optional int32 value; } } } |
Parquet 利用 group 类型来构造复杂类型,它可以增加一级嵌套。没有注解的group就是一个简单的嵌套记录。
可以用一种特殊的两级嵌套group结构构造list和map。list是通过LIST注解的group来表示,其中又嵌套了一个重复的group(命名为list),元素字段包含在这个内层group中。一个32位整数的list由数据类型为int32且重复数为required(必须出现一次)的元素字段构成。对map来说,外层的group a(使用MAP注解)嵌套了一个可重复的内层group(命名为k_v),其中包含key和value两个字段。
嵌套编码
使用面向列式的存储格式时,同一列数据连续存储。对于气象记录模式这种既无嵌套也无重复的扁平表而言,非常简单。 由于每一列都含有相同数量的值,因此可以直观地判断出每个值属于哪一行。
当過到嵌套和重复时,比如map 模式,事情一般会变得有些复杂,因为还需要对嵌套的结构进行编码。有些列式存储格式通过將嵌套结构扁平化来回避这个问题,使得只有位于最上层的列才能以列主(column-major)方式存储,例如 Hive 的RCFile 就采取了这种方式。这样,具有嵌套列的 map 中的键和值将会交错存储,也就是说,虽然你只想读取键,却不得不把值也读取到内存中。
Parquet 使用的是 Dremel 编码方法,即模式中的每个原子类型的字段都单独存储为一列,且每个值都要通过使用两个整数来对其结构进行编码,这两个整数分别是列定义深度(definition level和列元素重复次数(repetition level)。这种编码方式的细节错综复杂,不过你可以把列定义深度和列元素重复次数的存储想像成类似于用一个位字段来为扁平记录的空值进行编码,而非空值则一个紧挨一个地存储。
这种编码方式带来的好处是对任意一列(即使是嵌套列)数据的读取都不需要涉及到其他列。例如,在读取Parquet 的map 键-值对中的键时,不需要访问任何值,从而使其性能得到显著提升,尤其是当值非常大的时候,比如,包含很多字段的嵌套记录。
Parquet文件格式
Parauet 文件由一个文件头(header)、一个或多个紧随其后的文件块(block),以及一个用于结尾的文件尾(footer)构成。文件头中仅包含一个称为 PAR1 的 4 字节数字(Magic Number),它用来识别整个 Parquet 文件格式。文件的所有元数据都被保存在文件尾中。文件尾中的元数据包括文件格式的版本信息、模式信息、额外的健值对以及所有块的元数据信息。文件尾的最后两个字段分别是一个 4 字节字段(其中包含了文件尾中元数据长度的编码)和一个 PAR1(与文件头中的相同)。
由于元数据保存在文件尾中,因此在读 Parquet 文件时,首先要做的就是找到文件的结尾,然后(减去 8个字节)读取文件尾中的元数据长度,并根据元数据长度逆向读取文件尾中的元数据。顺序文件和 Avro 数据文件都是把元数据保存在文件头中,并且使用 sync marker 来分割文件块,而 Parquet 文件则不同,由于文件块之间的边界信息被保存在文件尾的元数据中,因此Parquet 文件不需要使用 sync marker。这种做法之所以可行,正是因为元数据要等到最后才写人,此时所有文件块都已写完,只要文件没有关闭,writer 就能在内存中保留这些文件块的边界位置。综上所述,由于通过读取文件尾可以定位文件块,因此Parquet 文件是可分割
且可并行处理的(例如通过 MapReduce 处理)。
Parquet 文件中的每个文件块负责存储一个行组(row group),行组由列块(column chunk)构成,且一个列块负责存储一列数据。每个列块中的数据以页(page)为单位存储,如图所示。
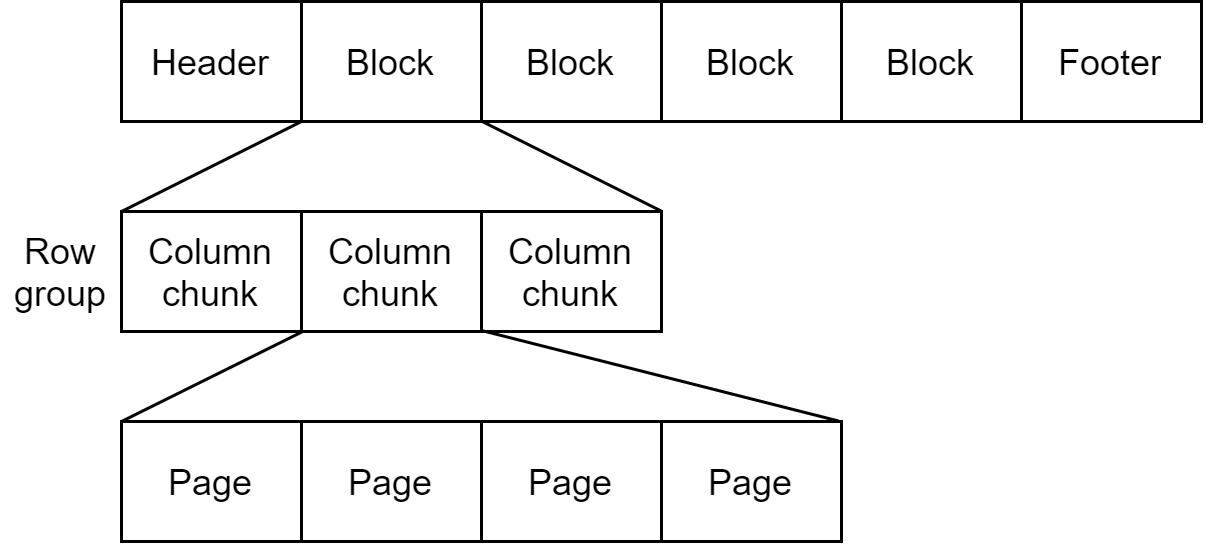
由于每页所包含的值都来自于同一列,因此极有可能这些值之间的差别并不大,那么使用页作为压缩单位是非常合适的。初级压缩来自编码方式,最简单的编码方式是无格式编码(plain encoding),即原封不动地存储一个值(例如使用 4 宇节的小端字节表示法来存储 int32 类型),然而,这种编码方式并没有提供任何程度的压缩。
Parquet 会使用一些带有压缩效果的编码方式,包括差分编码(保存值与值之间的差)、游程长度编码(将一连串相同的值编码为一个值以及重复次数)、字典编码(创建一个字典,对字典本身进行编码,然后使用代表字典索引的一个整数来表示值)。在大多数情况下,Parquet 还会使用其他一些技术,比如位紧缩法 (bit packing),它將多个较小的值保存在一个字节中以节省空间。
在写文件时,Parquet 会根据列的类型自动选择适当的编码方式。例如,在保存布尔类型时,Parquet 会结合游程长度编码与位紧缩法。大部分数据类型的默认编码方式是字典编码,但如果字典太大,就要退回到无格式编码。触发退回的阈值称为字典页大小(dictionary page size),其默认值等于页的大小(因此,倘若使用字典编码,那么这个字典页不得超过一页的范围)。请注意,实际采用的编码方式保存在文件的元数据中,这样才能确保reader 在读取数据时使用正确的编码方式。
除编码外,还可以以页为单位,利用标准压缩算法对编码后的数据进行第二次压缩。Parquet 的默认设置是不使用任何压缩算法,但它可以支持 Snappy、gzip 和LZ0 等压缩工具。
对于嵌套数据来说,每一页还需要存储该页所包含的值的列定义深度和列元素重复次数。由于这两个数都是很小的整数(最大值取快于模式指定的嵌套深度),因此使用位紧缩法与游程长度编码可以非常有效地进行编码。
相关文章:
Parquet存储的数据模型以及文件格式
文章目录 数据模型Parquet 的原子类型Parquet 的逻辑类型嵌套编码 Parquet文件格式 本文主要参考文献:Tom White. Hadoop权威指南. 第4版. 清华大学出版社, 2017.pages 363. Aapche Parquet是一种能有效存储嵌套数据的列式存储格式,在Spark中应用较多。 …...

Go和Java实现访问者模式
Go和Java实现访问者模式 我们下面通过一个解压和压缩各种类型的文件的案例来说明访问者模式的使用。 1、访问者模式 在访问者模式中,我们使用了一个访问者类,它改变了元素类的执行算法。通过这种方式,元素的执行算法可以随 着访问者改变而…...

想要通过软件测试的面试,都需要学习哪些知识
很多人认为,软件测试是一个简单的职位,职业生涯走向也不会太好,但是随着时间的推移,软件测试行业的变化,人们开始对软件测试行业的认知有了新的高度,越来越多的人开始关注这个行业,开始重视这个…...
MySQL的索引使用的数据结构,事务知识
一、索引的数据结构🌸 索引的数据结构(非常重要) mysql的索引的数据结构,并非定式!!!取决于MySQL使用哪个存储引擎 数据库这块组织数据使用的数据结构是在硬盘上的。我们平时写的代码是存在内存…...
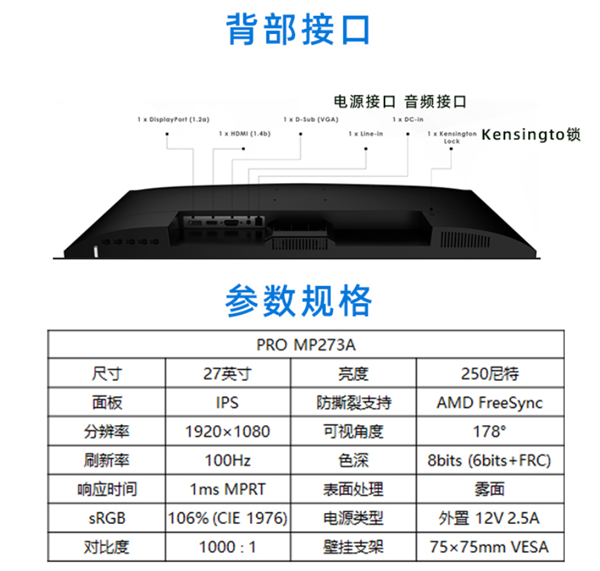
普及100Hz高刷+1ms响应 微星发布27寸显示器:仅售799元
不论办公还是游戏,高刷及低响应时间都很重要,微星现在推出了一款27寸显示器PRO MP273A, 售价只有799元,但支持100Hz高刷、1ms响应时间,还有FreeSync技术减少撕裂。 PRO MP273A的100Hz高刷新率是其最大的卖点之一&#…...
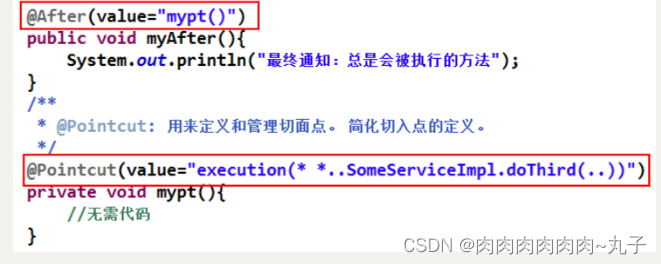
Java课题笔记~6个重要注解参数含义
1、[掌握]Before 前置通知-方法有 JoinPoint 参数 在目标方法执行之前执行。被注解为前置通知的方法,可以包含一个 JoinPoint 类型参数。 该类型的对象本身就是切入点表达式。通过该参数,可获取切入点表达式、方法签名、目标对象等。 不光前置通知的方…...

Windows Docker Desk环境时区问题导致的时间问题解决?
大多docker镜像为了保持镜像大小,采用了alpine linux。 但经常由于时区问题导致时间不准确,解决也很简单。 1.查看事件文件 cd /usr/share/zoneinfo 2.复制时区文件 将文件copy到 /etc/localtime 路径下即可(重庆时区,上海也…...
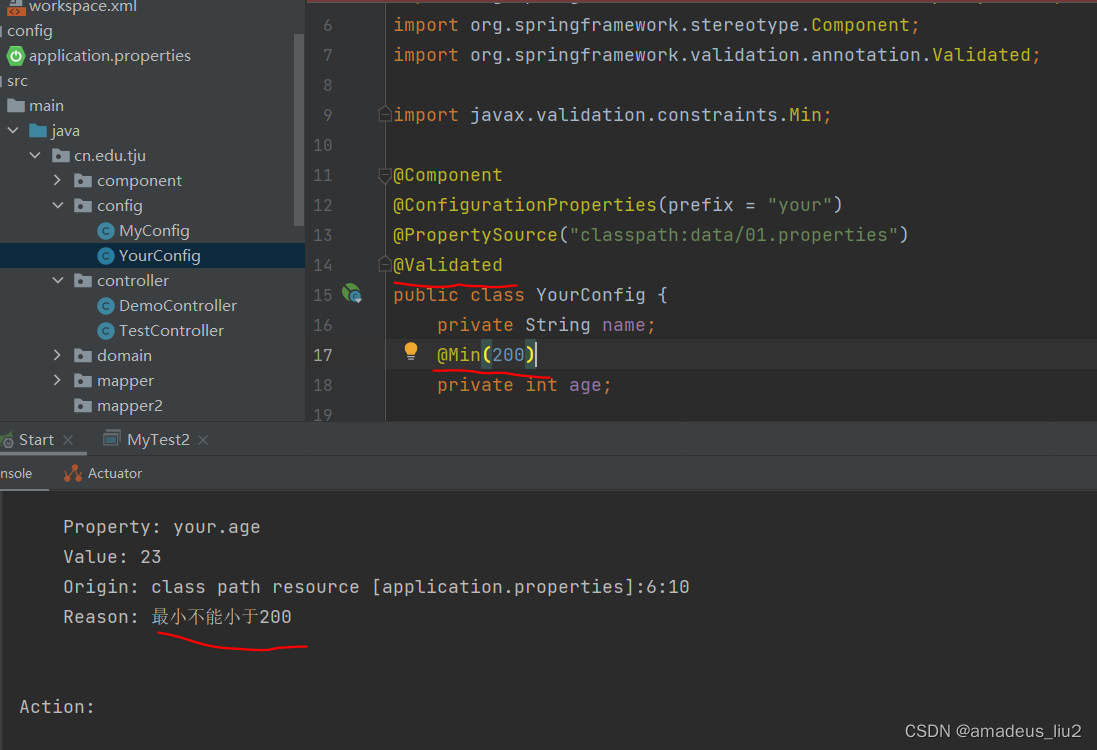
SpringBoot复习:(22)ConfigurationProperties和@PropertySource配合使用及JSR303校验
一、配置类 package cn.edu.tju.config;import org.springframework.boot.context.properties.ConfigurationProperties; import org.springframework.context.annotation.PropertySource; import org.springframework.stereotype.Component;Component ConfigurationPropertie…...
)
Spring IoC (控制反转)
IoC 是 Inversion of Control 的简写,译为“控制反转”,它不是一门技术,而是一种设计思想,是一个重要的面向对象编程法则。 Spring 通过 IoC 容器来管理所有 Java 对象的实例化和初始化,控制对象与对象之间的依赖关系。…...

安卓下模拟渲染EGLImageKHR
创建AHardwareBuffer并填充颜色 AHardwareBuffer_Desc desc = {static_cast<uint32_t>(screenW),static_cast<uint32_t>(screenH),...

Spring MVC 框架学习总结
文章目录 初步认识 Spring MVC 框架 一、初识 Spring MVC 框架 二、 三、 四、 五、 六、 七、 八、 九、...
2、简单上手+el挂载点+v-xx(v-text、v-html、v-on、v-show、v-if、v-bind、v-for)
官网: vue3:https://cn.vuejs.org/ vue2:https://v2.cn.vuejs.org/v2/guide/ 简单上手: 流程: 导入开发版本的Vue.js <!--开发环境版本,包含了有帮助的命令行警告--> <script src"https…...

C++初阶语法——命名空间
前言:C,即cplusplus,顾名思义,是C语言promax版本,C兼容C语言。 C的诞生是因为贝尔实验室的本贾尼等大佬认为C语言的语法坑实在太多,拥有许多不足之处(比如命名冲突,)&…...

Axwing.878 线性同余方程
题目 给定n组数据ai, bi , mi,对于每组数求出一个xi,使其满足ai * xibi (mod mi),如果无解则输出impossible。 输入格式 第一行包含整数n。 接下来n行,每行包含一组数据ai , bi , mi。 输出格式 输出共n行,每组数…...
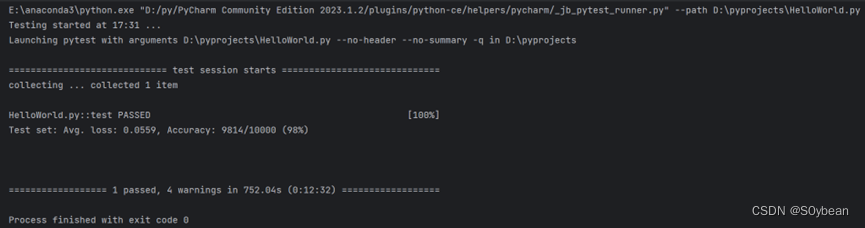
【Pytorch+torchvision】MNIST手写数字识别
深度学习入门项目,含代码详细解析 在本文中,我们将在PyTorch中构建一个简单的卷积神经网络,并使用MNIST数据集训练它识别手写数字。 MNIST包含70,000张手写数字图像: 60,000张用于培训,10,000张用于测试。图像是灰度(即…...

spring boot 集成rocketmq
集成Spring Boot和RocketMQ 在现代的微服务架构中,消息队列已经成为一种常见的异步处理模式,它能解决服务间的同步调用、耦合度高、流量高峰等问题。RocketMQ是阿里巴巴开源的一款消息中间件,性能优秀,功能齐全,被广泛…...

redis Hash类型命令
Redis中的Hash类型有多个常用命令可用于对Hash键进行操作。以下是一些常见的Redis Hash类型命令: HSET:设置Hash字段的值。 它将指定字段与相应的值关联起来,如果字段已经存在,则更新其值,如果字段不存在,…...

P1194 买礼物(最小生成树)(内附封面)
买礼物 题目描述 又到了一年一度的明明生日了,明明想要买 B B B 样东西,巧的是,这 B B B 样东西价格都是 A A A 元。 但是,商店老板说最近有促销活动,也就是: 如果你买了第 I I I 样东西࿰…...

oracle基础语法和备份恢复
Oracle总结 sql命令分类 1.DDL,数据定义语言,create创建/drop销毁 2.DCL,数据库控制语言,grant授权/revoke撤销 3.DML,数据操纵语言,insert/update/delete等sql语句 4.DQL,数据查询语言&am…...

【MATLAB第66期】#源码分享 | 基于MATLAB的PAWN全局敏感性分析模型(有条件参数和无条件参数)
【MATLAB第66期】#源码分享 | 基于MATLAB的PAWN全局敏感性分析模型(有条件参数和无条件参数) 文献参考 Pianosi, F., Wagener, T., 2015. A simple and efficient method for global sensitivity analysis based on cumulative distribution functions.…...
LunaTranslator:打破语言壁垒,让视觉小说触手可及
LunaTranslator:打破语言壁垒,让视觉小说触手可及 【免费下载链接】LunaTranslator 视觉小说翻译器 / Visual Novel Translator 项目地址: https://gitcode.com/GitHub_Trending/lu/LunaTranslator 还在为日文、英文的视觉小说而烦恼吗࿱…...

AIStoryBuilders:基于LangChain与向量数据库的智能故事创作框架解析
1. 项目概述:当AI成为你的故事合伙人如果你和我一样,既痴迷于天马行空的叙事,又时常被“灵感枯竭”或“情节卡壳”折磨,那么“AIStoryBuilders”这个项目,绝对值得你花时间深入了解。它不是一个简单的AI写作工具&#…...

Python小说爬虫框架NovelClaw:模块化设计与规则驱动实践
1. 项目概述:一个为小说爱好者打造的智能采集与整理工具如果你和我一样,是个重度小说爱好者,同时又有点技术背景,那你肯定遇到过这样的烦恼:追更的小说散落在十几个不同的网站,更新提醒全靠缘分;…...
)
基于YOLO26深度学习的钢铁腐蚀生锈识别检测系统(项目源码+数据集+模型权重+UI界面+python+深度学习+远程环境部署)
摘要 钢铁材料在工业基础设施中广泛应用,但其长期暴露于潮湿、氧化环境中极易发生腐蚀生锈现象,严重影响结构安全与使用寿命。为实现钢铁腐蚀区域的自动化检测,本研究基于YOLO26目标检测算法构建了一套钢铁腐蚀识别系统。系统采用单类别检测…...

基于 HarmonyOS 6.0 的校园闲置市集应用开发实战:从页面构建到跨端设计深度解析
基于 HarmonyOS 6.0 的校园闲置市集应用开发实战:从页面构建到跨端设计深度解析 前言 随着 HarmonyOS 生态不断完善,HarmonyOS 6.0 在分布式能力、跨端协同以及 ArkUI 声明式开发方面再次进行了大幅升级。相比传统 Android 页面开发模式,Harm…...

OpenAshare:本地化AI开发工具集,模块化集成Ollama与LangChain
1. 项目概述:一个为开发者打造的本地化AI工具集最近在GitHub上闲逛,发现了一个挺有意思的项目,叫“OpenAshare”。初看这个名字,你可能会联想到“开源分享”之类的概念,但点进去之后,我发现它的定位远比一个…...

在Gazebo中为Husky机器人集成Livox Mid-70传感器仿真
1. 环境准备与基础概念 在开始为Husky机器人集成Livox Mid-70传感器之前,我们需要先搭建好基础环境。Gazebo作为一款功能强大的机器人仿真工具,能够模拟真实物理环境中的传感器行为。Livox Mid-70是一款固态激光雷达,相比传统机械式雷达&…...

ARM GICv3中断控制器架构与ICC_CTLR_EL3寄存器解析
1. ARM GICv3中断控制器架构概述在现代处理器架构中,中断控制器是连接外设与CPU核心的关键枢纽。ARM的通用中断控制器(Generic Interrupt Controller, GIC)经过多代演进,GICv3架构在虚拟化支持、多安全域管理和扩展性方面实现了显著提升。作为GICv3的核心…...

【花雕动手做】几美元芯片就能跑的AI Agent:ESP-Claw如何用“聊天”重新定义硬件
当AI Agent突破虚拟世界的边界,开始直接控制物理设备,智能硬件的发展范式正被彻底改写。无需复杂编程,只需一句自然语言,就能让廉价硬件完成预设任务——这不是科幻场景,而是乐鑫科技开源项目ESP-Claw正在落地的现实。 作为一款开源项目,ESP-Claw在GitHub上线仅一个月便…...

基于MCP协议构建AI工具调用客户端:原理、实践与Node.js实现
1. 项目概述:MCP生态中的客户端实践最近在折腾AI智能体开发,发现一个挺有意思的现象:大家把大模型的能力吹得天花乱坠,但真要让它们去操作一个具体的系统、查询实时的数据,或者调用一个私有API,往往就卡壳了…...