Python实战之使用Python进行数据挖掘详解

一、Python数据挖掘
1.1 数据挖掘是什么?
数据挖掘是从大量的、不完全的、有噪声的、模糊的、随机的实际应用数据中,通过算法,找出其中的规律、知识、信息的过程。Python作为一门广泛应用的编程语言,拥有丰富的数据挖掘库,使得数据挖掘变得更加容易。
1.2 Python的优势
为什么我们要选择Python来进行数据挖掘呢?以下几点原因可能解答你的疑惑:
-
语法简洁,易学易用
-
丰富的数据挖掘库和工具
-
跨平台性,可在多种操作系统中运行
-
社区活跃,庞大的用户基础
二、Python数据挖掘的基本流程📚
接下来,我们将通过一个实际案例来揭示Python数据挖掘的基本流程。假设我们手头有一份销售数据,需要分析哪些产品最受欢迎,以便调整经营策略。
2.1 数据收集
首先,我们需要从各个渠道收集销售数据。在这个案例中,我们可以从数据库、API接口、Web爬虫等途径获取数据。这里我们使用pandas库来读取一个CSV文件中的数据。
import pandas as pd# 读取CSV文件
data = pd.read_csv("sales_data.csv")
文件内容形如:
日期,产品,销售额,销售量
2022-01-01,产品A,1000,10
2022-01-02,产品B,2000,20
2022-01-03,产品C,3000,30
2022-01-04,产品A,4000,40
2022-01-05,产品B,5000,50
2022-01-06,产品D,6000,60
2022-01-07,产品A,7000,70
2022-01-08,产品C,8000,80
2022-01-09,产品B,9000,90
2022-01-10,产品A,10000,100
2.2 数据预处理
收集到的数据很可能存在缺失值、重复值、异常值等问题,需要进行预处理。这里我们用pandas进行数据清洗。
# 去除重复值
data = data.drop_duplicates()# 填补缺失值
data = data.fillna(method="ffill")# 查找异常值并处理
data = data[data["销售额"] > 0]
2.3 数据分析
我们要根据业务需求进行数据分析。例如,我们可以分析不同产品的销售额、销售量等。这里我们使用pandas和matplotlib库进行数据分析和可视化。
import matplotlib.pyplot as plt# 按产品统计销售额
product_sales = data.groupby("产品")["销售额"].sum()# 绘制柱状图
plt.bar(product_sales.index, product_sales.values)
plt.xlabel("产品")
plt.ylabel("销售额")
plt.title("各产品销售额统计")
plt.show()
2.4 结果呈现
最后,我们将分析结果以表格、图表等形式呈现给决策者。这里我们使用pandas和matplotlib生成一个销售额排名的表格和柱状图。
# 排序
product_sales = product_sales.sort_values(ascending=False)# 输出销售额排名
print(product_sales)# 绘制柱状图
plt.bar(product_sales.index, product_sales.values)
plt.xlabel("产品")
plt.ylabel("销售额")
plt.title("各产品销售额排名")
plt.show()
三、Python数据挖掘实战:豆瓣电影评分分析🎬
3.1 项目背景
假如我们是一家电影制作公司,想要了解近年来观众喜欢的电影类型和特点,以便制定新电影的发展策略。我们将通过分析豆瓣电影评分数据,提取有价值的信息。
3.2 数据获取
我们使用Python的requests库和BeautifulSoup库爬取豆瓣电影榜单页面,抓取电影名称、类型、评分等信息。
import requests
from bs4 import BeautifulSoupurl = "https://movie.douban.com/top250"
headers = {'User-Agent': 'Mozilla/5.0'}
response = requests.get(url, headers=headers)
soup = BeautifulSoup(response.text, 'html.parser')movie_list = []
for item in soup.find_all('div', class_='item'):title = item.find('span', class_='title').textgenres = item.find('span', class_='genre').text.strip()rating = float(item.find('span', class_='rating_num').text)movie_list.append({'title': title, 'genres': genres, 'rating': rating})movies_df = pd.DataFrame(movie_list)
3.3 数据预处理
这里我们需要对数据进行简单的预处理,例如拆分电影类型字段,使得每个类型单独成列。
# 拆分电影类型字段
genres_df = movies_df['genres'].str.get_dummies(sep='/').add_prefix('genre_')
movies_df = pd.concat([movies_df, genres_df], axis=1)
3.4 数据分析
我们可以分析不同类型电影的平均评分、数量等,找出观众喜欢的电影类型。这里我们使用pandas和matplotlib库进行数据分析和可视化。
# 计算各类型电影的数量
genre_counts = genres_df.sum().sort_values(ascending=False)# 绘制饼图
plt.pie(genre_counts, labels=genre_counts.index, autopct='%1.1f%%')
plt.title("电影类型比例")
plt.show()# 计算各类型电影的平均评分
genre_ratings = movies_df.groupby('genres')['rating'].mean().sort_values(ascending=False)# 绘制柱状图
plt.bar(genre_ratings.index, genre_ratings.values)
plt.xlabel("类型")
plt.ylabel("平均评分")
plt.title("各类型电影平均评分")
plt.xticks(rotation=90)
plt.show()
3.5 结果呈现
根据分析结果,我们可以看出观众喜欢的电影类型,并制定相应的发展策略。例如,选择高评分的类型制作新电影,或者研究具有一定特点的电影,提高影片的吸引力。
四、技术总结
通过上述案例,我们了解了Python在数据挖掘领域的强大能力,探索了如何从海量数据中找到隐藏的价值。希望这篇文章能给你在数据挖掘之路上带来启发。
相关文章:
Python实战之使用Python进行数据挖掘详解
一、Python数据挖掘 1.1 数据挖掘是什么? 数据挖掘是从大量的、不完全的、有噪声的、模糊的、随机的实际应用数据中,通过算法,找出其中的规律、知识、信息的过程。Python作为一门广泛应用的编程语言,拥有丰富的数据挖掘库&#…...

scala 加载properties文件
利用java.util.Properties加载 import java.io.FileInputStream import java.util.Properties object LoadParameter {//动态获取properties文件可配置参数val props new Properties()def getParameter(s:String,filePath:String): String {props.load(new FileInputStream(f…...
备战秋招012(20230808)
文章目录 前言一、今天学习了什么?二、动态规划1.概念2.题目 总结 前言 提示:这里为每天自己的学习内容心情总结; Learn By Doing,Now or Never,Writing is organized thinking. 提示:以下是本篇文章正文…...

QT中定时器的使用
文章目录 概述步骤 概述 Qt中使用定时器大致有两种,本篇暂时仅描述使用QTimer实现定时器 步骤 // 1.创建定时器对象 QTimer *timer new QTimer(this);// 2.开启一个定时器,5秒触发一次 timer->start(5000); // 3.建立信号槽连接&am…...
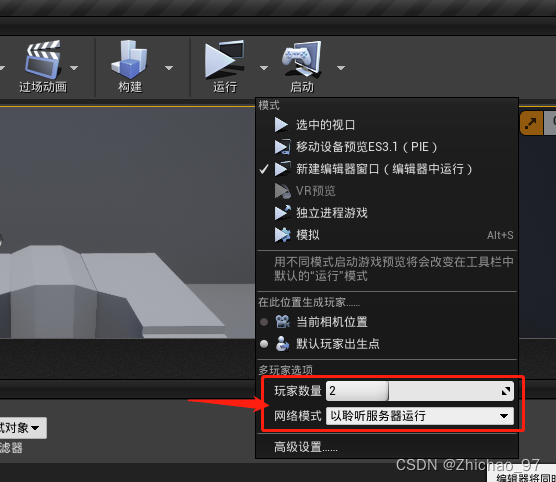
【UE4】多人联机教程(重点笔记)
效果 1. 创建房间、搜索房间功能 2. 根据指定IP和端口加入游戏 步骤 1. 新建一个第三人称角色模板工程 2. 创建一个空白关卡,这里命名为“InitMap” 3. 新建一个控件蓝图,这里命名为“UMG_ConnectMenu” 在关卡蓝图中显示该控件蓝图 打开“UMG_Connec…...

【go】GIN参数重复绑定报错EOF问题
文章目录 1 问题描述2 解决:替换为ShouldBindBodyWith 1 问题描述 在 Gin 框架中,当多次调用 ShouldBind() 或 ShouldBindJSON() 方法时,会导致请求体的数据流被读取多次,从而出现 “EOF” 错误。 例如在api层绑定了参数&#x…...
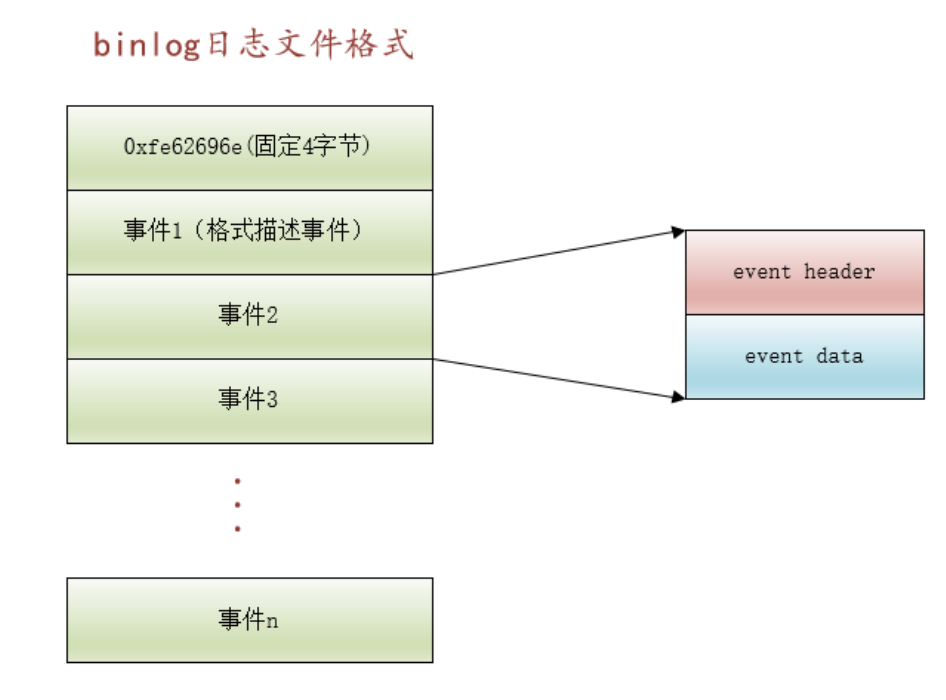
关于MySQL中的binlog
介绍 undo log 和 redo log是由Inno DB存储引擎生成的。 在MySQL服务器架构中,分为三层:连接层、服务层(server层)、执行层(存储引擎层) bin log 是 binary log的缩写,即二进制日志。 MySQL…...

我维护电脑的方法
无论是学习还是工作,电脑都是IT人必不可少的重要武器,一台好电脑除了自身配置要经得起考验,后期主人对它的维护也是决定它寿命的重要因素! 你日常是怎么维护你的“战友”的呢,维护电脑运行你有什么好的建议吗ÿ…...
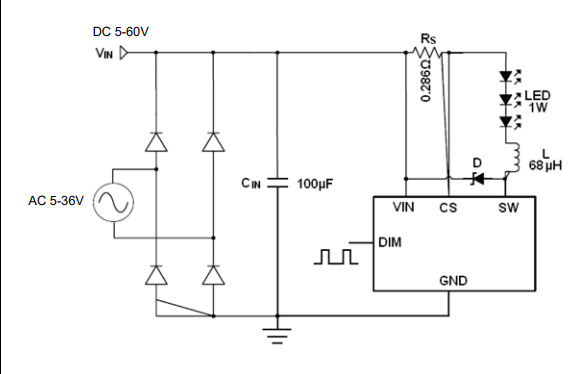
AP51656 电流采样降压恒流驱动IC RGB PWM深度调光 LED电源驱动
产品描述 AP51656是一款连续电感电流导通模式的降压恒流源,用于驱动一颗或多颗串联LED 输入电压范围从 5 V 到 60V,输出电流 可达 1.5A 。根据不同的输入电压和 外部器件, 可以驱动高达数十瓦的 LED。 内置功率开关,采用电流采样…...
Python爬虫的解析(学习于b站尚硅谷)
目录 一、xpath 1.xpath插件的安装 2. xpath的基本使用 (1)xpath的使用方法与基本语法(路径查询、谓词查询、内容查询(使用text查看标签内容)、属性查询、模糊查询、逻辑运算) (2&a…...
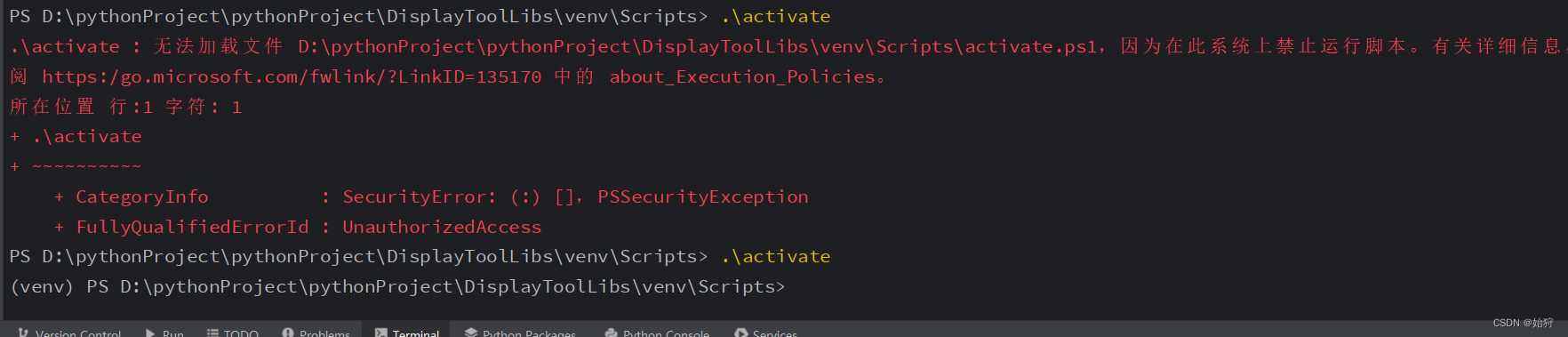
python的virtualenv虚拟环境无法激活activate
目录 问题描述: 解决办法: 解决结果: 问题描述: PS D:\pythonProject\pythonProject\DisplayToolLibs\venv\Scripts> .\activate .\activate : 无法加载文件 D:\pythonProject\pythonProject\DisplayToolLibs\venv\Scripts\…...

uniapp中token操作:存储、获取、失效处理。
实现代码 存储token:uni.setStorageSync(token, res.data.result);获取token:uni.getStorageSync(token);清除token:uni.setStorageSync(token, ); 应用场景 在登录操作中,保存token pwdLogin() {....this.$axios.request({url: .....,method: post,p…...

乐鑫科技 2022 笔试面试题
岗位:嵌入式软件实习生。 个人情况:本科双非电子信息工程,硕士华五软件工程研一在读;本科做过一些很水的项目 ,也拿项目搞了一些奖,相对来说嵌入式方向比较对口。 时间线及面试流程 2021.04.02 笔试 题目分为选择题和编程题,选择题二十题,编程题两题; 选择题基本…...
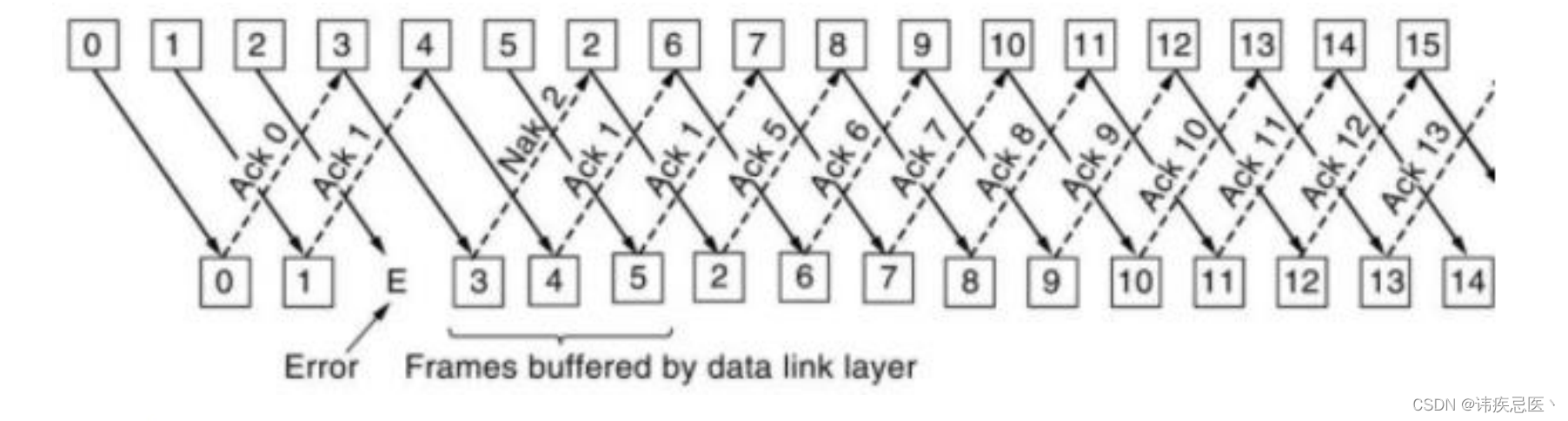
实现UDP可靠性传输
文章目录 1、TCP协议介绍1.1、ARQ协议1.2、停等式1.3、回退n帧1.4、选择性重传 1、TCP协议介绍 TCP协议是基于IP协议,面向连接,可靠基于字节流的传输层协议 1、基于IP协议:TCP协议是基于IP协议之上传输的,TCP协议报文中的源端口IP…...

Zebec Protocol 将进军尼泊尔市场,通过 Zebec Card 推动地区金融平等
流支付正在成为一种全新的支付形态,Zebec Protocol 作为流支付的主要推崇者,正在积极的推动该支付方案向更广泛的应用场景拓展。目前,Zebec Protocol 成功的将流支付应用在薪酬支付领域,并通过收购 WageLink 将其纳入旗下…...

Qt--动态链接库的创建和使用
写在前面 在Qt的实际开发中,免不了使用和创建动态链接库,因此熟悉Qt中动态链接库的创建和使用对后续的库开发或使用是非常用必要的。 在之前的文章https://blog.csdn.net/SNAKEpc12138/article/details/126189926?spm1001.2014.3001.5501中已经对导入…...
)
设计模式十二:享元模式(Flyweight Pattern)
当我们需要创建大量相似对象时,享元模式可以帮助我们节省内存空间和提高性能。该模式通过共享相同的数据来减少对象的数量。 在享元模式中,有两种类型的对象:享元(Flyweight)和非享元(Unshared Flyweight&a…...

【LeetCode】88. 合并两个有序数组 - 双指针
这里写自定义目录标题 2023-8-7 22:35:41 88. 合并两个有序数组 双指针 2023-8-7 22:35:41 class Solution {public void merge(int[] nums1, int m, int[] nums2, int n) {int last m n ;while(n > 0){if(m > 0 && nums2[n-1] > nums1[m-1]){nums1[las…...

HarmonyOS应用开发的新机遇与挑战
HarmonyOS 4已经于2023年8月4日在HDC2023大会上正式官宣。对广大HarmonyOS开发者而言,这次一次盛大的大会。截至目前,鸿蒙生态设备已达7亿台,HarmonyOS开发者人数超过220万。鸿蒙生态充满着新机遇,也必将带来新的挑战。 HarmonyO…...

Qt中qmake、构建、运行、清理的区别
Qt 中默认的执行顺序:qmake--- 编译 --- 运行。 一、qmake qmake: 根据之前项目指南创建的项目文件 .pro,并且运行 qmake [qmake xx.pro]生成调试 [build-ttt-***-Debug] 或者发布 [build-ttt-***-Release] 目录(这个是影子构建…...

C++/Qt 使用 Tushare 获取股票信息
探索数据之源:使用tushare为Qt/C学习项目获取股票数据在进行金融量化分析或学习金融市场行为时,获取高质量、结构化的股票数据是至关重要的第一步。作为一个计划将Qt/C用于金融数据可视化或策略模拟的学习者,我近期深入体验了使用Python库tus…...

终极指南:从NumPy到Pydantic的Claude-Code-Usage-Monitor依赖管理完整解析
终极指南:从NumPy到Pydantic的Claude-Code-Usage-Monitor依赖管理完整解析 【免费下载链接】Claude-Code-Usage-Monitor Real-time Claude Code usage monitor with predictions and warnings 项目地址: https://gitcode.com/gh_mirrors/cl/Claude-Code-Usage-Mon…...

Java高频面试题:RocketMQ有哪些使用场景?
大家好,我是锋哥。今天分享关于【Java高频面试题:RocketMQ有哪些使用场景?】面试题 。希望对大家有帮助;Java高频面试题:RocketMQ有哪些使用场景?RocketMQ 是阿里巴巴开源的一款分布式消息中间件࿰…...

逆向分析WhatsApp的GIF功能:用Frida抓取Tenor API的完整请求与响应数据
逆向工程实战:用Frida解密WhatsApp的GIF数据流 当你在WhatsApp中发送一个GIF表情时,是否好奇过这个动态图片是如何从服务器传输到你的手机上的?今天我们将深入WhatsApp客户端内部,通过动态插桩工具Frida来捕获和分析其背后的Tenor…...

2026微软SDE LeetCode高频题:208道,按频度排序,含备考建议
2026微软SDE LeetCode高频题:208道,按频度排序,含备考建议 微软SDE的LeetCode面试题,第一名不是反转链表,不是LRU缓存,而是—— 215. 数组中的第K个最大元素,出现14次。 我整理了基于真实面经…...
)
告别Makefile!用Zig 0.10.0自带的构建系统搞定ARM裸机开发(附完整项目配置)
用Zig构建系统重塑ARM裸机开发:告别Makefile的终极指南 当你在凌晨三点盯着第47个Makefile规则调试链接器错误时,是否想过——嵌入式开发必须这么痛苦吗?Zig 0.10.0带来的不仅是一门新语言,更是一套彻底革新裸机开发工作流的构建系…...

若依前后端分离系统生产环境部署:从零到上线的保姆级教程
若依前后端分离系统生产环境部署实战指南 引言:为什么选择若依框架? 对于刚接触企业级开发的新手来说,若依(RuoYi)框架无疑是一个绝佳的起点。这个基于Spring Boot和Vue.js的前后端分离架构,不仅提供了完善的权限管理、代码生成等…...

3分钟搞定网易云音乐加密文件:NCMD解密工具终极指南
3分钟搞定网易云音乐加密文件:NCMD解密工具终极指南 【免费下载链接】ncmdump 项目地址: https://gitcode.com/gh_mirrors/ncmd/ncmdump 还在为网易云音乐的NCM加密文件无法在其他播放器播放而烦恼吗?今天我要为你介绍一款简单高效的音频解密神器…...

如何在10分钟内实现AI助手与Figma的无缝协作?TalkToFigma Desktop完整指南
如何在10分钟内实现AI助手与Figma的无缝协作?TalkToFigma Desktop完整指南 【免费下载链接】cursor-talk-to-figma-mcp Cursor Talk To Figma MCP 项目地址: https://gitcode.com/GitHub_Trending/cu/cursor-talk-to-figma-mcp 您是否厌倦了在AI编程工具和Fi…...
)
YOLOv5实战:如何自定义COCO指标计算APtiny(附完整代码修改指南)
YOLOv5实战:深度解析COCO评估指标自定义与APtiny计算优化 在目标检测领域,COCO数据集的评估标准已成为衡量模型性能的黄金准则。但当我们面对特定场景——尤其是小目标检测任务时,标准的3232像素"small"类别划分往往难以满足精细化…...