springBoot集成caffeine,自定义缓存配置 CacheManager
目录
springboot集成caffeine
Maven依赖
配置信息:properties文件
config配置
使用案例
Caffeine定制化配置多个cachemanager
springboot集成redis并且定制化配置cachemanager
springboot集成caffeine
Caffeine是一种基于服务器内存的缓存库。它将数据存储在应用程序的内存中,以实现快速的数据访问和高性能。
由于Caffeine缓存在服务器内存中存储数据,因此它适用于需要快速读取和频繁访问的数据,比如一些热门数据、配置信息、常用查询的结果等。但是它不适用于大规模数据或需要持久化存储的数据,因为服务器内存有限,无法存储大量数据,并且缓存数据在应用程序重启后会丢失。
Maven依赖
<parent><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-parent</artifactId><version>2.5.2</version><relativePath/>
</parent><dependencies><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter</artifactId></dependency><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-web</artifactId></dependency><!-- caffeine服务器本地缓存 --><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-cache</artifactId></dependency><!-- caffeine --><dependency><groupId>com.github.ben-manes.caffeine</groupId><artifactId>caffeine</artifactId><version>2.8.1</version></dependency><!-- 可以对自定义配置的信息进行提示 --><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-configuration-processor</artifactId></dependency>
</dependencies>
配置信息:properties文件
/*** Caffeine Cache自定义配置属性类*/
@Data //lombok插件的 看自己需求是否引入
@Component
@ConfigurationProperties(prefix = "com.common.caffeine")
//这个ConfigurationProperties是为了方便配置yaml文件,
//如果有需要的话可以在yaml文件中进行配置,需要与spring-boot-configuration-processor
//这个依赖搭配使用,
//然后再在resources目录下创建一个META-INF文件夹,该文件夹下存放一个配置文件提升信息(下面会贴出来的),
//这样的话在yaml文件中进行书写的时候就会有提升信息了
public class CaffeineCacheProperties {/*** 缓存初始容量 映射的话会很灵活 羊肉串写法与驼峰命名都可以和下面的属性进行映射* com.ifi.performance.common.caffeine.init-cache-capacity*/private Integer initCacheCapacity = 256;/*** 缓存最大容量,超过之后会按照recently or very often(最近最少)策略进行缓存剔除* com.ifi.performance.common.caffeine.max-cache-capacity*/private Long maxCacheCapacity = 10000L;/*** 是否允许空值null作为缓存的value* com.ifi.performance.common.caffeine.allow-null-value*/private Boolean allowNullValue = Boolean.TRUE;}配置yaml文件提升信息:additional-spring-configuration-metadata.json
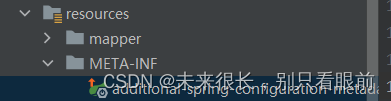
{"properties": [{"name": "com.ifi.performance.common.caffeine.init-cache-capacity","type": "java.lang.Integer","description": "Caffeine缓存的初始容量","defaultValue": 256},{"name": "com.ifi.performance.common.caffeine.max-cache-capacity","type": "java.lang.Long","description": "Caffeine缓存的最大容量","defaultValue": "10000L"},{"name": "com.ifi.performance.common.caffeine.allow-null-value","type": "java.lang.Boolean","description": "Caffeine缓存是否允许null作为value的属性","defaultValue": "true"}]
}这样在yaml文件中输入com.common.caffeine的时候就会有提示信息了。
config配置
/*** 服务端公用缓存常量类*/
public interface CacheConstants {/*** 系统服务端公用缓存名称 默认缓存*/String CACHE_NAME = "server_cache";
} 编写config配置文件:CaffeineCacheConfig.java
@SpringBootConfiguration
@EnableCaching //开启注解扫描
@Slf4j
public class CaffeineCacheConfig {//刚刚编写的properties配置文件@Autowiredprivate CaffeineCacheProperties properties;/*** 默认的全局缓存管理器* @return*/@Bean("defaultCacheManager")public CaffeineCacheManager defaultCacheManager() {CaffeineCacheManager defaultCacheManager = new CaffeineCacheManager(CacheConstants.CACHE_NAME); //指定这个缓存的命名,这里我是使用了一个常量类defaultCacheManager.setAllowNullValues(properties.getAllowNullValue());Caffeine<Object, Object> caffeineBuilder = Caffeine.newBuilder().initialCapacity(properties.getInitCacheCapacity()).maximumSize(properties.getMaxCacheCapacity()) //从配置文件中获取最大容量.expireAfterWrite(7, TimeUnit.DAYS); //过期时间defaultCacheManager.setCaffeine(caffeineBuilder);log.info("the caffeine cache manager is loaded successfully!");return defaultCacheManager;}
}使用案例
这样配置好了之后就可以在controller、service中使用配置好的缓存了。
比如说我们要在service中进行使用,案例如下:
@Autowired
@Qualifier(value = "defaultCacheManager") //这里可以直接使用Autowired就行,Autowired默认是按照对象类型进行依赖注入,如果容器中有两个及以上的同一种类型的bean,那么就会报bean冲突的错误,后面的定制化配置会用到这个Autowired
private CaffeineCacheManager defaultCacheManager;Cache cache = defaultCacheManager.getCache(CacheConstants.CACHE_NAME); //配置类中对这个cachemanager设置的缓存名称
//下面就可以通过cache操作数据:存入缓存或者是从缓存中获取数据、删除数据了。
//存入缓存的数据是key-value形式的,key最好是一个唯一的标识,不然可能会出现缓存覆盖的情况,value可以是一个字符串也可以是自定义的对象,这里我是自定义了一个对象,比如UserCache对象,这个对象中有我需要缓存的数据,比如userid等自己需要的数据
UserCache usercache = new UserCache();
usercache.setuserId = "123456"; //实际业务场景中,比如用户登录成功,可以把用户id设置进来,方便其他业务进行获取 LOGIN_INFO 常量为自定义的一个标识符,方便在查询辨别缓存数据
cache.put(userId+CacheConstants.LOGIN_INFO,usercache);//特别注意:get缓存数据的时候,很大可能获取到的是null对象,因为比如有一些业务没有被触发从而导致没有填充你需要的数据到缓存,所以这里一定要加一个空指针判断!!!
UserCache usercache = cache.get( userId + CacheConstants.LOGIN_INFO, UserCache.class);
if(usercache == null){return null;
}//清除缓存中指定的数据 通过key来清除缓存中的数据,比如用户退出登录了可以把他的一些缓存信息给清除
cache.evict(userId + CacheConstants.LOGIN_INFO);因为我们使用的缓存管理接口是spring-cache的,spring-cache中的操作api中并没有提供设置数据缓存的过期时间的,所以如果我们有这种业务需要(比如验证码信息需要5分钟才过期,用户登录信息30天才过期),那么就需要定制化配置cachemanager了,这样从源头上解决问题。
Caffeine定制化配置多个cachemanager
依赖与上面一致,只需要修改CaffeineCacheConfig类与使用方式就行。
@SpringBootConfiguration
@EnableCaching //开启注解扫描
@Slf4j
public class CaffeineCacheConfig {@Autowiredprivate CaffeineCacheProperties properties;/*** 默认的全局缓存管理器* @return*/@Primary //必须要加这个注解,用于标识一个Bean(组件)是首选的候选者。当有多个同类型的Bean(组件)时,使用了@Primary注解的Bean将会成为默认选择,如果没有其他限定符(如@Qualifier)指定具体要使用的Bean,则会优先选择带有@Primary注解的Bean。@Bean("defaultCacheManager")public CaffeineCacheManager defaultCacheManager() {CaffeineCacheManager defaultCacheManager = new CaffeineCacheManager(CacheConstants.ACHE_NAME);defaultCacheManager.setAllowNullValues(properties.getAllowNullValue());Caffeine<Object, Object> caffeineBuilder = Caffeine.newBuilder().initialCapacity(properties.getInitCacheCapacity()).maximumSize(properties.getMaxCacheCapacity()).expireAfterWrite(7, TimeUnit.DAYS);defaultCacheManager.setCaffeine(caffeineBuilder);log.info("the caffeine cache manager is loaded successfully!");return defaultCacheManager;}/*** 用于管理验证码缓存,设置过期时间为300秒*/@Bean("verificationCodeCacheManager")public CaffeineCacheManager verificationCodeCacheManager() {CaffeineCacheManager verificationCodeCacheManager = new CaffeineCacheManager(CacheConstants.CODE_CACHE_NAME);verificationCodeCacheManager.setCaffeine(Caffeine.newBuilder().initialCapacity(properties.getInitCacheCapacity()).maximumSize(properties.getMaxCacheCapacity()).expireAfterWrite(300, TimeUnit.SECONDS));log.info("the verificationCodeCacheManager cache manager is loaded successfully!");return verificationCodeCacheManager;}}使用方式,和上面的案例一致,不过这个时候就必须使用@Qualifier来指定相关的bean。其他使用方式都是一致的。
@Autowired
@Qualifier(value = "defaultCacheManager")
private CaffeineCacheManager defaultCacheManager;@Autowired
@Qualifier(value = "verificationCodeCacheManager")
private CaffeineCacheManager verificationCodeCacheManager;springboot集成redis并且定制化配置cachemanager
缓存使用到的Maven依赖:
<!-- 集成redis依赖 -->
<dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-data-redis</artifactId>
</dependency>
<!-- 提供Redis连接池 -->
<dependency><groupId>org.apache.commons</groupId><artifactId>commons-pool2</artifactId>
</dependency>yaml文件:Redis部分的配置
spring:redis:database: 0host: localhostport: 6379password: abc123456 #这个看你的Redis版本,一些老的Redis用的是auth,一些比较新的用的是password配置timeout: 10slettuce:pool:# 连接池最大连接数max-active: 200# 连接池最大阻塞等待时间(使用负值表示没有限制)max-wait: -1ms# 连接池中的最大空闲连接max-idle: 10# 连接池中的最小空闲连接min-idle: 3config配置类:
@SpringBootConfiguration
@EnableCaching
@Slf4j
public class RedisCacheConfig {/*** 定制链接和操作Redis的客户端工具 配置一些序列化器,这样通过缓存管理工具看到的缓存数据就不是乱码了* @param redisConnectionFactory* @return*/@Beanpublic RedisTemplate<String, Object> redisTemplate(RedisConnectionFactory redisConnectionFactory) {RedisTemplate<String, Object> redisTemplate = new RedisTemplate<>();redisTemplate.setConnectionFactory(redisConnectionFactory);//配置序列化器Jackson2JsonRedisSerializer<Object> jackson2JsonRedisSerializer = new Jackson2JsonRedisSerializer<>(Object.class);ObjectMapper objectMapper = new ObjectMapper();GenericJackson2JsonRedisSerializer genericJackson2JsonRedisSerializer = new GenericJackson2JsonRedisSerializer();redisTemplate.setDefaultSerializer(genericJackson2JsonRedisSerializer);objectMapper.setVisibility(PropertyAccessor.ALL, JsonAutoDetect.Visibility.ANY);objectMapper.enableDefaultTyping(ObjectMapper.DefaultTyping.NON_FINAL);jackson2JsonRedisSerializer.setObjectMapper(objectMapper);redisTemplate.setKeySerializer(new StringRedisSerializer());redisTemplate.setHashKeySerializer(new StringRedisSerializer());redisTemplate.setHashValueSerializer(genericJackson2JsonRedisSerializer);redisTemplate.setValueSerializer(genericJackson2JsonRedisSerializer);redisTemplate.afterPropertiesSet();return redisTemplate;}/*** 默认的全局缓存管理器 配置一些序列化器,这样通过缓存管理工具看到的缓存数据就不是乱码了* @return*/@Primary //关于这个相关的解释,上面的caffeine配置中都有说明,这里就不额外说明了@Bean("defaultCacheManager")public RedisCacheManager defaultCacheManager(RedisConnectionFactory redisConnectionFactory) {GenericJackson2JsonRedisSerializer genericJackson2JsonRedisSerializer = new GenericJackson2JsonRedisSerializer();StringRedisSerializer stringRedisSerializer = new StringRedisSerializer();RedisCacheConfiguration config = RedisCacheConfiguration.defaultCacheConfig().serializeKeysWith(RedisSerializationContext.SerializationPair.fromSerializer(stringRedisSerializer)).serializeValuesWith(RedisSerializationContext.SerializationPair.fromSerializer(genericJackson2JsonRedisSerializer));RedisCacheManager defaultCacheManager = RedisCacheManager.builder(redisConnectionFactory).cacheDefaults(config).build();log.info("the redis defaultCacheManager is loaded successfully!");return defaultCacheManager;}/*** 用于管理验证码缓存,设置过期时间为300秒*/@Bean("verificationCodeCacheManager")public RedisCacheManager verificationCodeCacheManager(RedisConnectionFactory redisConnectionFactory) {GenericJackson2JsonRedisSerializer genericJackson2JsonRedisSerializer = new GenericJackson2JsonRedisSerializer();StringRedisSerializer stringRedisSerializer = new StringRedisSerializer();RedisCacheConfiguration config = RedisCacheConfiguration.defaultCacheConfig().entryTtl(Duration.ofMinutes(5)).serializeKeysWith(RedisSerializationContext.SerializationPair.fromSerializer(stringRedisSerializer)).serializeValuesWith(RedisSerializationContext.SerializationPair.fromSerializer(genericJackson2JsonRedisSerializer));RedisCacheManager verificationCodeCacheManager = RedisCacheManager.builder(redisConnectionFactory).cacheDefaults(config).build();log.info("the verificationCodeCacheManager cache manager is loaded successfully!");return verificationCodeCacheManager;}}使用方式,和上面的一致:
@Autowired
@Qualifier(value = "defaultCacheManager")
private CaffeineCacheManager defaultCacheManager;Cache cache = defaultCacheManager.getCache(CacheConstants.CACHE_NAME); //配置类中对这个cachemanager设置的缓存名称UserCache usercache = new UserCache();
usercache.setuserId = "123456";
//实际业务场景中,比如用户登录成功,可以把用户id设置进来,方便其他业务进行获取 LOGIN_INFO 常量为自定义的一个标识符,方便在查询辨别缓存数据
cache.put(userId+CacheConstants.LOGIN_INFO,usercache);//特别注意:get缓存数据的时候,很大可能获取到的是null对象
UserCache usercache = cache.get( userId + CacheConstants.LOGIN_INFO, UserCache.class);
if(usercache == null){return null;
}//清除缓存中指定的数据 通过key来清除缓存中的数据
cache.evict(userId + CacheConstants.LOGIN_INFO);相关文章:
springBoot集成caffeine,自定义缓存配置 CacheManager
目录 springboot集成caffeine Maven依赖 配置信息:properties文件 config配置 使用案例 Caffeine定制化配置多个cachemanager springboot集成redis并且定制化配置cachemanager springboot集成caffeine Caffeine是一种基于服务器内存的缓存库。它将数据存储在…...
【瑞吉外卖】Git部分学习
Git简介 Git是一个分布式版本控制工具,通常用来对软件开发过程中的源代码文件进行管理。通过Git仓库来存储和管理这些文件,Git仓库分为两种: 本地仓库:开发人员自己电脑上的Git仓库 远程仓库:远程服务器上的Git仓库…...

如何阐述自己做了一个什么样的东西
线上qps2000,主要的性能瓶颈在于出现在数据库I/O上。另外,如果是一个正常部署的容器,qps能达到几百就不错了。资讯服务现在做了静态的底层页,所以热点新闻多数会命中底层页,即便没有命中底层页,也会走多层的…...
:QSPI 同步与异步 Mcal配置及代码实战)
TC3XX - MCAL知识点(二十二):QSPI 同步与异步 Mcal配置及代码实战
目录 1、MCAL配置 1.1、配置目标 1.2、同步QSPI配置 1.2.1、SpiGeneral 1.2.2、SpiMaxChannel 1.2.3、SpiMaxJob...

led台灯哪些牌子性价比高?推荐几款性价比高的护眼台灯
作为学龄期儿童的家长,最担心的就是孩子长时间学习影响视力健康。无论是上网课、写作业、玩桌游还是陪伴孩子读绘本,都需要一个足够明亮的照明环境,因此选购一款为孩子视力发展保驾护航的台灯非常重要。为大家推荐几款性价比高的护眼台灯。 …...

什么情况下容易发生锁表及如何处理
目录 什么情况下容易发生锁表发生锁表怎么解决 什么情况下容易发生锁表 在数据库中,当多个事务同时竞争访问同一个表的资源时,可能会发生锁表现象,导致性能下降甚至阻塞。以下情况容易导致锁表问题: 大事务操作:如果一…...
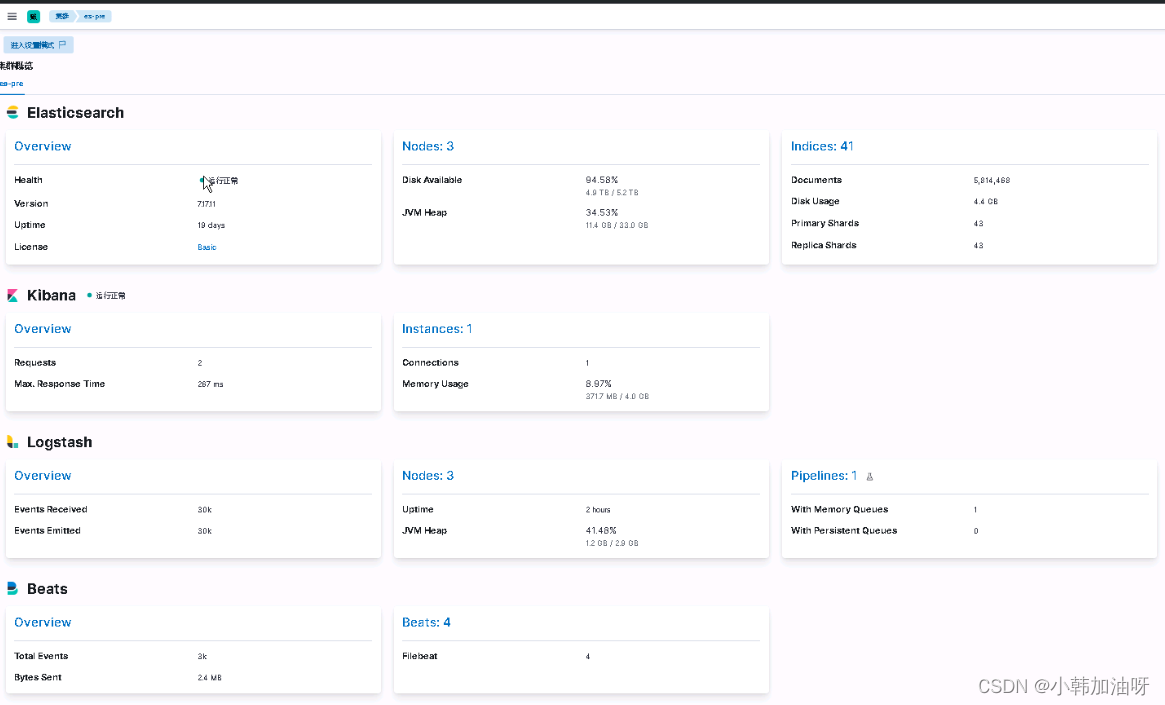
elk开启组件监控
elk开启组件监控 效果: logstash配置 /etc/logstash/logstash.yml rootnode1:~# grep -Ev "^#|^$" /etc/logstash/logstash.yml path.data: /var/lib/logstash path.logs: /var/log/logstash xpack.monitoring.enabled: true xpack.monitoring.elasti…...

Java Random 类的使用
Java中的Random类是用来生成伪随机数的工具类。它可以用来生成随机的整数、浮点数和布尔值。以下是Java Random类的一些常见用法: 创建Random对象: Random random new Random();生成随机整数: int randomNumber random.nextInt(); // 生…...

完美的分布式监控系统——Prometheus(普罗米修斯)与优雅的开源可视化平台——Grafana(格鲁夫娜)
一、基本概念 1、之间的关系 prometheus与grafana之间是相辅相成的关系。作为完美的分布式监控系统的Prometheus,就想布加迪威龙一样示例和动力强劲。在猛的车也少不了仪表盘来观察。于是优雅的可视化平台Grafana出现了。 简而言之Grafana作为可视化的平台ÿ…...
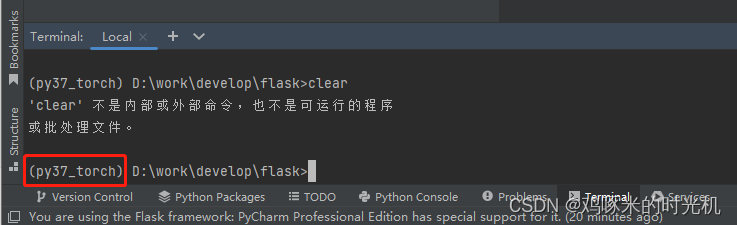
pycharm的Terminal中如何设置打开anaconda3的虚拟环境
在pycharm的File -> Settings -> Tools -> Terminal下面,如下图所示 修改为红框中内容,然后关闭终端在重新打开终端,即可看到anaconda3的虚拟环境就已经会被更新...

Jmeter(四) - 从入门到精通 - 创建网络测试计划(详解教程)
1.简介 在本节中,您将学习如何创建基本的 测试计划来测试网站。您将创建五个用户,这些用户将请求发送到JMeter网站上的两个页面。另外,您将告诉用户两次运行测试。因此,请求总数为(5个用户)x(2…...

Flowable-结束事件-空结束事件
目录 定义图形标记XML内容 定义 空结束事件是最常见的一种结束事件,也是最简单的一种结束事件,只要把结束任务置于流程 或分支的最后节点,流程实例运行到该节点的时候,流程引擎就会结束该流程实例或分支。前面提 到,结…...

Elasticsearch:如何创建 Elasticsearch PEM 和/或 P12 证书?
你是否希望使用 SSL/TLS 证书来保护你的 Elasticsearch 部署? 在本文中,我们将指导你完成为 Elasticsearch 创建 PEM 和 P12 证书的过程。 这些证书在建立安全连接和确保 Elasticsearch 集群的完整性方面发挥着至关重要的作用。 友情提示:你可…...

数仓架构模型设计参考
1、数据技术架构 1.1、技术架构 1.2、数据分层 将数据仓库分为三层,自下而上为:数据引入层(ODS,Operation Data Store)、数据公共层(CDM,Common Data Model)和数据应用层ÿ…...
用法简介并举例)
RedisTemplate.opsForGeo()用法简介并举例
RedisTemplate.opsForGeo()是RedisTemplate类提供的用于操作Geo类型(地理位置)的方法。它可以用于对Redis中的Geo数据结构进行各种操作,如添加地理位置、获取距离、获取位置信息等。 下面是一些常用的RedisTemplate.opsForGeo()方法及其用法…...
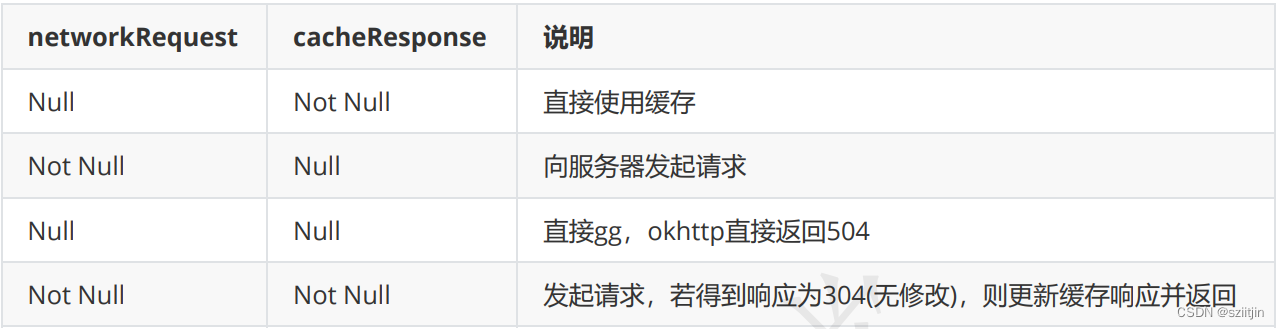
Android OkHttp源码分析--拦截器
拦截器责任链: OkHttp最核心的工作是在 getResponseWithInterceptorChain() 中进行,在进入这个方法分析之前,我们先来了 解什么是责任链模式,因为此方法就是利用的责任链模式完成一步步的请求。 拦截器流程: OkHtt…...

docker:如何传环境变量给entrypoint
使用shell,不带中括号 ENTRYPOINT .\main -web -c $CONFIGENTRYPOINT [sh, -c, ".\main -web -c $CONFIG"]docker build --build-arg ENVIROMENTintegration // 覆盖ENTRYPOINT命令 使用shell脚本 ENTRYPOINT ["./entrypoint.sh"]entrypoint.sh 镜像是a…...
kuboard安装和使用
windows平台下使用docker和docker-compose部署Kuboard,并添加Docker Desktop for windows的k8s单机集群 使用docker安装 docker run -d \--restartunless-stopped \--namekuboard \-p 80:80/tcp \-p 10081:10081/tcp \-e KUBOARD_ENDPOINT"http://内网IP:80&…...
海外直播种草短视频购物网站巴西独立站搭建
一、市场调研 在搭建网站之前,需要进行充分的市场调研,了解巴西市场的消费者需求、购物习惯和竞争情况。可以通过以下途径进行市场调研: 调查问卷:可以在巴西市场上发放调查问卷,了解消费者的购物习惯、偏好、购买力…...

C#图像均值和方差计算实例
本文展示图像均值和方差计算实例,分别实现RGB图像和8位单通道图像的计算方法 实现代码如下: #region 方法 RGB图像均值 直接操作内存快/// <summary>/// 定义RGB图像均值函数/// </summary>/// <param name="bmp"></param>/// <retur…...
Windows平台RTSP/RTMP直播播放SDK集成说明(C#版))
大牛直播SDK(SmartMediaKit)Windows平台RTSP/RTMP直播播放SDK集成说明(C#版)
文档概述 本文介绍大牛直播SDK(SmartMediaKit)在 Windows 平台下 RTSP、RTMP 直播播放模块的集成方法,面向 Windows Forms、WPF 等 C# 客户端应用场景,重点说明 SDK 集成准备、播放器初始化、RTSP/RTMP 播放、播放参数配置、事件…...

百度网盘下载加速终极指南:3步实现高速下载的完整教程
百度网盘下载加速终极指南:3步实现高速下载的完整教程 【免费下载链接】baidu-wangpan-parse 获取百度网盘分享文件的下载地址 项目地址: https://gitcode.com/gh_mirrors/ba/baidu-wangpan-parse 还在为百度网盘几十KB/s的龟速下载而烦恼吗?作为…...

职场痛点|同事甩锅、摸鱼划水,干活全靠自己?3步破局不内耗
职场痛点|同事甩锅、摸鱼划水,干活全靠自己?3步破局不内耗相信很多职场人都有过这样的崩溃瞬间:明明是团队协作的任务,同事要么全程摸鱼划水,不干活、不配合,要么出了问题就第一时间甩锅&#x…...

Input Overlay 完整指南:实时显示键盘、游戏手柄和鼠标输入的终极工具
Input Overlay 完整指南:实时显示键盘、游戏手柄和鼠标输入的终极工具 【免费下载链接】input-overlay Show keyboard, gamepad and mouse input on stream 项目地址: https://gitcode.com/gh_mirrors/in/input-overlay Input Overlay 是一款功能强大的开源输…...
,限免领取仅剩200份)
ElevenLabs海南话语音部署避坑清单(含IPA音标对齐表+海口话声调模板),限免领取仅剩200份
更多请点击: https://intelliparadigm.com 第一章:ElevenLabs海南话语音部署避坑清单(含IPA音标对齐表海口话声调模板),限免领取仅剩200份 部署ElevenLabs模型支持海口话(海南闽语)语音合成时&…...

如何用Python快速接入Taotoken平台调用多款大模型
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 如何用Python快速接入Taotoken平台调用多款大模型 对于希望便捷使用多种大语言模型的开发者而言,逐一对接不同厂商的AP…...

如何用Akagi打造实时麻将AI辅助系统:从新手到高手的完整指南
如何用Akagi打造实时麻将AI辅助系统:从新手到高手的完整指南 【免费下载链接】Akagi 支持雀魂、天鳳、麻雀一番街、天月麻將,能夠使用自定義的AI模型實時分析對局並給出建議,內建Mortal AI作為示例。 Supports Majsoul, Tenhou, Riichi City,…...

长期使用 Taotoken Token Plan 套餐在成本控制方面的实际感受
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 长期使用 Taotoken Token Plan 套餐在成本控制方面的实际感受 1. 从按需付费到计划订阅的转变 最初接触 Taotoken 时,…...

PrismLauncher-Cracked:如何通过代码修改实现Minecraft完全离线启动?
PrismLauncher-Cracked:如何通过代码修改实现Minecraft完全离线启动? 【免费下载链接】PrismLauncher-Cracked This project is a Fork of Prism Launcher, which aims to unblock the use of Offline Accounts, disabling the restriction of having a …...

获 800 万美元融资,MAU 超 40 万!「shapes」AI 社交能否成下一代聊天应用?
《「shapes」获 800 万美元种子轮融资,AI 助力社交“入场”,能否成下一代聊天应用?》这几天,我在「shapes」随机进了个陌生群聊,发了句 "hello",三秒内就有 AI 角色接上,回了串热情有…...