flask---》更多查询方式/连表查询/原生sql(django-orm如何执行原生sql)/flask-sqlalchemy
更多查询方式
#1 查询: filer:写条件 filter_by:等于的值
# 查询所有 是list对象
res = session.query(User).all() # 是个普通列表
print(type(res))
print(len(res))# 2 只查询某几个字段
# select name as xx,email from user;
res = session.query(User.name.label('xx'), User.email)
# print(res) # 打出原生sql
# # print(res.all())
# for item in res.all():
# print(item[0])# 3 filter传的是表达式,filter_by传的是参数
res = session.query(User).filter(User.name == "lqz").all()
res = session.query(User).filter(User.name != "lqz").all()
res = session.query(User).filter(User.name != "lqz", User.email == '3@qq.com').all() #4 django 中使用 Q (与 或 非) 如果是, 就是and条件
res = session.query(User).filter_by(name='lqz099').all()
res = session.query(User).filter_by(name='lqz099',email='47@qq.com').all()# 5 取一个 all了后是list,list 没有first方法
res = session.query(User).first()# 6查询所有,使用占位符(了解) :value :name
# select * from user where id <20 or name=lqz
res = session.query(User).filter(text("id<:value or name=:name")).params(value=20, name='lqz').all()# 7 自定义查询(了解)
# from_statement 写纯原生sqlres=session.query(User).from_statement(text("SELECT * FROM users where email=:email")).params(email='3@qq.com').all()
print(type(res[0])) # 是book的对象,但是查的是User表 不要这样写
print(res[0].name) ## 8 高级查询
# 条件
# 表达式,and条件连接
res = session.query(User).filter(User.id > 1, User.name == 'lqz099').all() # and条件# between
res = session.query(User).filter(User.id.between(1, 9), User.name == 'lqz099').all()
res = session.query(User).filter(User.id.between(1, 9)).all()# in
res = session.query(User).filter(User.id.in_([1,3,4])).all()
res = session.query(User).filter(User.email.in_(['3@qq.com','r@qq.com'])).all()# ~非,除。。外
res = session.query(User).filter(~User.id.in_([1,3,4])).all()
print(res)# 二次筛选
res = session.query(User).filter(~User.id.in_(session.query(User.id).filter_by(name='lqz'))).all()
print(res)# and or条件
from sqlalchemy import and_, or_# or_包裹的都是or条件,and_包裹的都是and条件
res = session.query(User).filter(and_(User.id >= 3, User.name == 'lqz099')).all() # and条件
res = session.query(User).filter(User.id < 3, User.name == 'lqz099').all() # 等同于上面
res = session.query(User).filter(or_(User.id < 2, User.name == 'eric')).all()
res = session.query(User).filter(or_(User.id < 2,and_(User.name == 'lqz099', User.id > 3),User.extra != ""))# 通配符,以e开头,不以e开头
res = session.query(User).filter(User.email.like('%@%')).all()
# select user.id from user where user.name not like e%;
res = session.query(User.id).filter(~User.name.like('e%'))
res = session.query(User).filter(~User.name.like('e%')).all()# 分页
# 一页2条,查第5页
res = session.query(User)[2*5:2*5+2]# 排序,根据name降序排列(从大到小)
res = session.query(User).order_by(User.email.desc()).all()
res = session.query(Book).order_by(Book.price.desc()).all()
res = session.query(Book).order_by(Book.price.asc()).all()
# 第一个条件重复后,再按第二个条件升序排
res = session.query(User).order_by(User.name.desc(), User.id.asc())# 分组查询 5个聚合函数
from sqlalchemy.sql import func
# 分组后,只能拿分组字段和聚合函数字典,如果拿别的,是严格模式,会报错
res = session.query(User).group_by(User.extra) # 如果是严格模式,就报错
# 分组之后取最大id,id之和,最小id 和分组的字段
from sqlalchemy.sql import func
res = session.query(User.name,func.max(User.id),func.sum(User.id),func.min(User.id),func.avg(User.id)).group_by(User.name).all()
for item in res:print(item)# 分组后having
# select name,max(id),sum(id),min(id) from user group by user.name having id_max>2;from sqlalchemy.sql import func
res = session.query(User.name,func.max(User.id),func.sum(User.id),func.min(User.id)).group_by(User.name).having(func.max(User.id) > 2).all()print(res)连表查询
### 关联关系,基于连表的跨表查询
from models1 import Person,Hobby
# 链表操作
select * from person,hobby where person.hobby_id=hobby.id;
res = session.query(Person, Hobby).filter(Person.hobby_id == Hobby.id).all()# 自己连表查询
# join表,默认是inner join,自动按外键关联
# select * from Person inner join Hobby on Person.hobby_id=Hobby.id;
# res = session.query(Person).join(Hobby).all()#isouter=True 外连,表示Person left join Favor,没有右连接,反过来即可
# select * from Person left join Hobby on Person.hobby_id=Hobby.id;
# res = session.query(Person).join(Hobby, isouter=True).all()
# 没有right join,通过这个实现
# res = session.query(Hobby).join(Person, isouter=True).all()# # 自己指定on条件(连表条件),第二个参数,支持on多个条件,用and_,同上
# select * from Person left join Hobby on Person.id=Hobby.id;
# res = session.query(Person).join(Hobby, Person.hobby_id == Hobby.id, isouter=True) # sql本身有问题,只是给你讲, 自己指定链接字段
# 右链接
# print(res)# 多对多关系连表
# 多对多关系,基于链表的跨表查
# 多表链接
#方式一:直接连
#select * FROM boy, girl, boy2girl WHERE boy.id = boy2girl.boy_id AND girl.id = boy2girl.girl_id
# res = session.query(Boy, Girl,Boy2Girl).filter(Boy.id == Boy2Girl.boy_id,Girl.id == Boy2Girl.girl_id)# 方式二:join连
# SELECT* FROM boy INNER JOIN boy2girl ON boy.id = boy2girl.boy_id INNER JOIN girl ON girl.id = boy2girl.girl_id WHERE boy.id >= %(id_1)s
res = session.query(Boy).join(Boy2Girl).join(Girl).filter(Boy.id>=2)
print(res)原生sql(django-orm如何执行原生sql)
sqlalchemy执行原生sql
# 有的复杂sql 用orm写不出来---》用原生sql查询# 原生sql查询,查出的结果是对象
# 原生sql查询,查询结果列表套元组from sqlalchemy.orm import sessionmaker, relationship
from sqlalchemy import create_engineengine = create_engine("mysql+pymysql://root:123@127.0.0.1:3306/db001", max_overflow=0, pool_size=5)
Session = sessionmaker(bind=engine)
session = Session()
#### 执行原生sql方式一:
# 查询方式一:
# cursor = session.execute('select * from users')
# result = cursor.fetchall()
# print(result) #列表套元组# 添加
# cursor = session.execute('insert into users(name,email) values(:name,:email)',
# params={"name": 'lqz', 'email': '3333@qq.com'})
# session.commit()
# print(cursor.lastrowid)###执行原生sql方式二(以后都用session操作---》socpe_session线程安全)一般不用
# conn = engine.raw_connection()
# cursor = conn.cursor()
# cursor.execute(
# "select * from app01_book"
# )
# result = cursor.fetchall()# 执行原生sql方式三:
# res = session.query(User).from_statement(text("SELECT * FROM boy where name=:name")).params(name='lqz').all()session.close()
django执行原生sql
# 执行完的结果映射到对象中---》上面讲的 方式三:
from model import Book
books_obj_list = Book.objects.raw('select distinct id, book_name from test_book')
for book_obj in books_obj_list:print(book_obj.id, book_obj.book_name)# 纯原生sql
from django.db import connection
cur=connection.cursor()
cur.execute('select distinct id, book_name from test_book')
print(cur.fetch_all())
cur.close()with connection.cursor() as cur:cur.execute('select distinct id, book_name from test_book')flask-sqlalchemy
# sqlalchemy 集成到flask中# 第三方: flask-sqlalchemy 封装了用起来,更简洁
# 使用flask-sqlalchemy集成1 导入 from flask_sqlalchemy import SQLAlchemy2 实例化得到对象db = SQLAlchemy()3 将db注册到app中db.init_app(app)4 视图函数中使用session全局的db.session # 线程安全的5 models.py 中继承Modeldb.Model6 写字段 username = db.Column(db.String(80), unique=True, nullable=False)7 配置文件中加入SQLALCHEMY_DATABASE_URI = "mysql+pymysql://root@127.0.0.1:3306/ddd?charset=utf8"SQLALCHEMY_POOL_SIZE = 5SQLALCHEMY_POOL_TIMEOUT = 30SQLALCHEMY_POOL_RECYCLE = -1# 追踪对象的修改并且发送信号SQLALCHEMY_TRACK_MODIFICATIONS = False相关文章:
/flask-sqlalchemy)
flask---》更多查询方式/连表查询/原生sql(django-orm如何执行原生sql)/flask-sqlalchemy
更多查询方式 #1 查询: filer:写条件 filter_by:等于的值 # 查询所有 是list对象 res session.query(User).all() # 是个普通列表 print(type(res)) print(len(res))# 2 只查询某几个字段 # select name as xx,email from user; res session.…...
116版本内核UI定制)
Chromium内核浏览器编译记(三)116版本内核UI定制
转载请注明出处:https://blog.csdn.net/kong_gu_you_lan/article/details/132180843?spm1001.2014.3001.5501 本文出自 容华谢后的博客 往期回顾: Chromium内核浏览器编译记(一)踩坑实录 Chromium内核浏览器编译记(…...
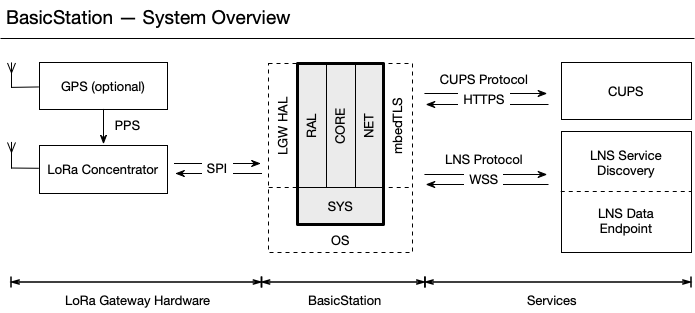
LoRaWan网关设计架构介绍
LoRa 数据包转发器是在基于 LoRa 的网关(带或不带 GPS)主机上运行的程序。它将集中器(上行链路)接收到的 RF 数据包通过安全的 IP 链路转发到LoRaWAN 网络服务器( LNS )。它还通过相同的安全 IP 将 LNS(下行链路)发送的 RF 数据包传输到一台或多台设备。此外,它还可以传…...
)
vue 全局状态管理(简单的store模式、使用Pinia)
目录 为什么使用状态管理简单的store模式服务器渲染(SSR) pinia简介示例1. 定义一个index.ts文件2. 在main.ts中引入3. 定义4. 使用 为什么使用状态管理 多个组件可能会依赖同一个状态时,我们有必要抽取出组件内的共同状态集中统一管理&…...

ORACLE和MYSQL区别
1,Oracle没有offet,limit,在mysql中我们用它们来控制显示的行数,最多的是分页了。oracle要分页的话,要换成rownum。 2,oracle建表时,没有auto_increment,所有要想让表的一个字段自增,…...
tensorflow 1.14 的 demo 02 —— tensorboard 远程访问
tensorflow 1.14.0, 提供远程访问 tensorboard 服务的方法 第一步生成 events 文件: 在上一篇demo的基础上加了一句,如下, tf.summary.FileWriter("./tmp/summary", graphsess1.graph) hello_tensorboard_remote.py …...

Spring中Bean的循环依赖问题
1.什么是Bean的循环依赖? 简单来说就是在A类中,初始化A时需要用到B对象,而在B类中,初始化B时需要用到A对象,这种状况下在Spring中,如果A和B同时初始化,A,B同时都需要对方的资源&…...

若依管理系统后端将 Mybatis 升级为 Mybatis-Plus
文章目录 说明流程增加依赖修改配置文件注释掉MybatisConfig里面的Bean 代码生成使用IDEA生成代码注意 Controller文件 说明 若依管理系统是一个非常完善的管理系统模板,里面含有代码生成的方法,可以帮助用户快速进行开发,但是项目使用的是m…...
剪切、复制、粘贴事件
剪切、复制、粘贴事件 oncopy 事件在用户拷贝元素上的内容时触发。onbeforecut 事件在用户剪切文本,且文本还未删除时触发触发。oncut 事件在用户剪切元素的内容时触发。onbeforepaste 事件在用户向元素中粘贴文本之前触发。onpaste 事件在用户向元素中粘贴文本时触…...
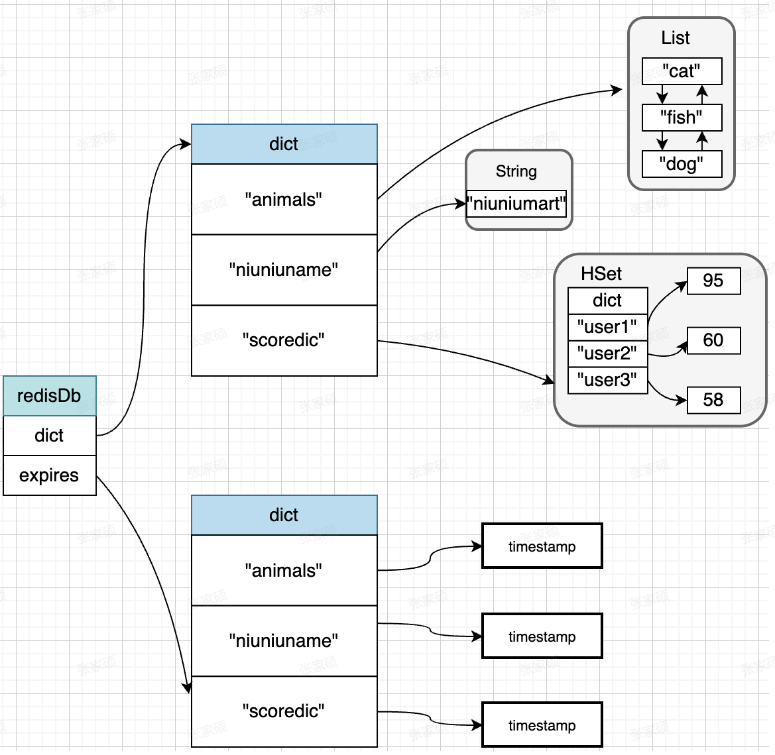
Redis储存结构
Redis怎么储存的 这个redisDb是数据库对象 里面的其他字段忽略了 然后里面有个dict列表(字典列表) 我们随便来看一个redisObject 区分一下子啊 他这个dict里面没有存redisObject的对象 也没有存dict对象 它只是存了个数据指针 你看那个redis每个底层编码 抠搜的 这块要是再保存…...
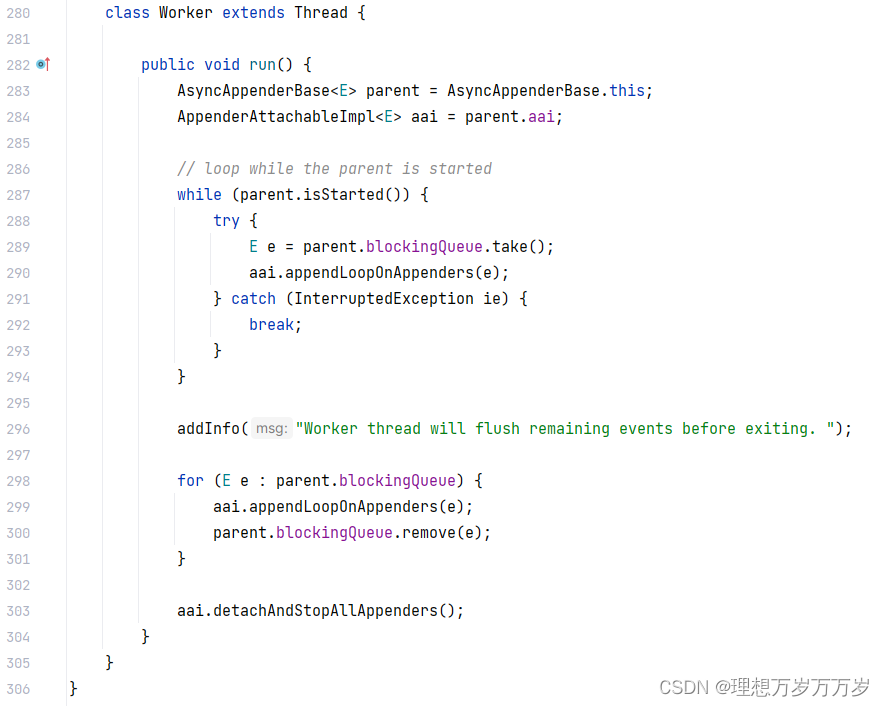
使用logback异步打印日志
文章目录 一、介绍二、运行环境三、演示项目1. 接口2. 日志配置文件3. 效果演示4. 异步输出验证 四、异步输出原理五、其他参数配置六、源码分析1. 同步输出2. 异步输出 七、总结 一、介绍 对于每一个开发人员来说,在业务代码中添加日志是至关重要的,尤…...

ArcGIS Pro暨基础入门、制图、空间分析、影像分析、三维建模、空间统计分析与建模、python融合、案例应用
GIS是利用电子计算机及其外部设备,采集、存储、分析和描述整个或部分地球表面与空间信息系统。简单地讲,它是在一定的地域内,将地理空间信息和 一些与该地域地理信息相关的属性信息结合起来,达到对地理和属性信息的综合管理。GIS的…...
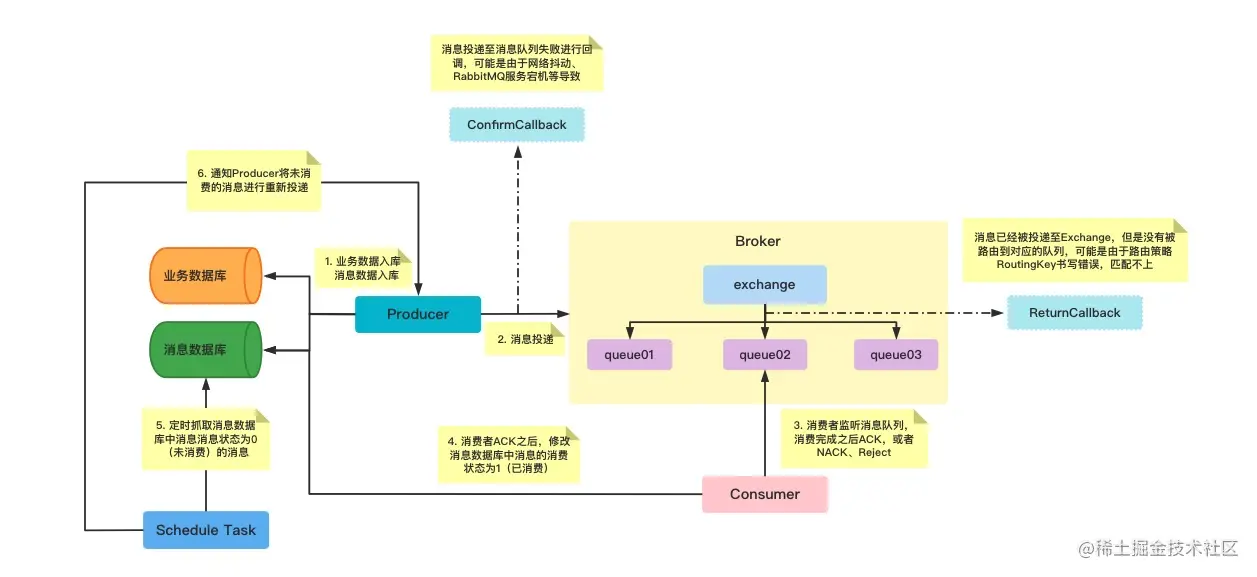
Rabbitmq的消息确认
配置文件 spring:rabbitmq:publisher-confirm-type: correlated #开启确认回调publisher-returns: true #开启返回回调listener:simple:acknowledge-mode: manual #设置手动接受消息消息从生产者到交换机 无论消息是否到交换机ConfirmCallback都会触发。 Resourceprivate Rabb…...

在飞机设计中的仿真技术
仿真技术在飞机设计中发挥着越来越重要的作用,本文阐述了国内外在飞机设计中广泛使用的结构强度计算,多体动力学仿真、多学科多目标结构优化、内外流场分析、非线性有限元分析、疲劳强度分析、电磁仿真分析,机电液联合仿真分析等,…...
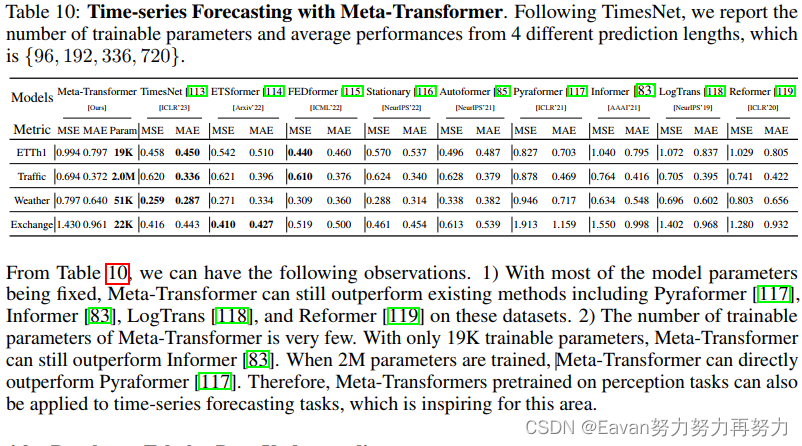
(2023Arxiv)Meta-Transformer: A Unified Framework for Multimodal Learning
论文链接:https://arxiv.org/abs/2307.10802 代码链接:https://github.com/invictus717/MetaTransformer 项目主页:https://kxgong.github.io/meta_transformer/ 【注】:根据实验结果来看,每次输入一种数据源进行处…...

解决Python读取图片路径存在转义字符
普遍解决路径中存在转义字符的问题的方法 普遍解决转义字符的问题,无非是以下这三种。 一、在路径前添加r 直接在路径前面加r,这种方法能够使字符保持原始的意思。 比如下面这种: pathr"D:\MindSpore\Dearui\source\ces\0AI.png&qu…...
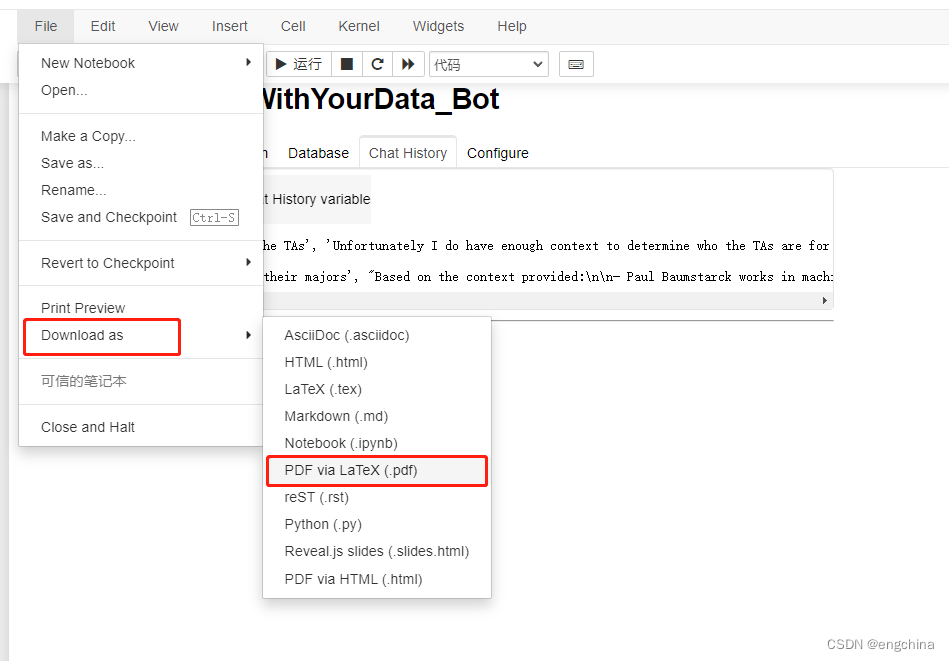
Windows 安装 pandoc 将 jupyter 导出 pdf 文件
Windows 安装 pandoc 将 jupyter 导出 pdf 文件 1. 下载 pandoc 安装文件2. 安装 pandoc3. 安装 nbconvert4. 使用 pandoc 1. 下载 pandoc 安装文件 访问 https://github.com/jgm/pandoc/releases,下载最新版安装文件,例如,3.1.6.1 版&#…...
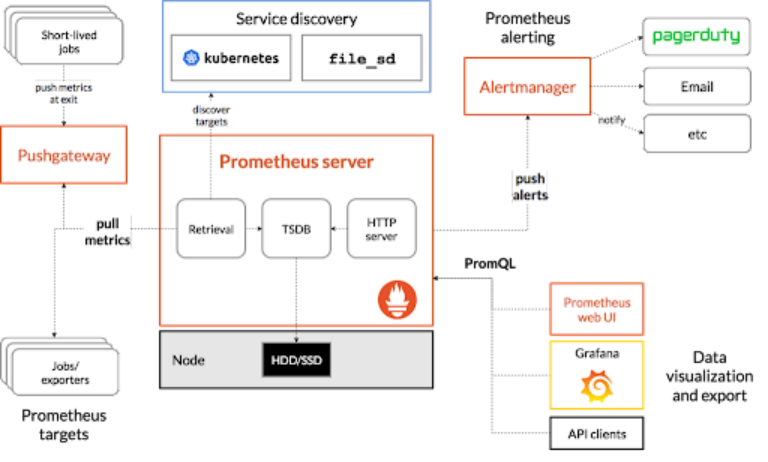
混合云环境实现K8S可观测的6大策略
2023年,原生云应用及平台发展迅猛。大量企业都在努力发挥其应用程序的最大潜力,以确保极致的用户体验并推动业务增长。 混合云环境的兴起和容器化技术(如Kubernetes)的采用彻底改变了现代应用程序的开发、部署和扩展方式。 在这个数字舞台上,…...

音视频 FFmpeg命令行搭建
文章目录 一、配置二、测试 一、配置 以FFmpeg4.2.1 win32为例 解压ffmpeg-4.2.1-win32-shared.zip 拷⻉可执⾏⽂件到C:\Windows拷⻉动态链接库到C:\Windows\SysWOW64 注:WoW64 (Windows On Windows64)是⼀个Windows操作系统的⼦系统,被设计⽤来处理许…...

ORACLE wallet实现无需输入用户名与密码登陆数据库 注意修改目录权限
wallet权限 linux 777 windows 需要修改.lck文件的owner 在ORACLE 10G前,我们在SHELL或JDBC中连接数据库时,都需要输入用户名与密码,并且都是明文。从1OGR2开始,ORACLE提供wallet这个工具,可以实现无需输入用户名与密…...

第三节课总结
一、计算机中的单位1、比特位(bit):一个比特位只能放一个二进制数据,要么0要么12.字节(byte):一个字节 8个比特位1024byte 1KB1024KB 1MB1024MB 1GB1024GB 1T1024TB 1PB3.每一种数据类型都可…...
)
2026年04月10日最热门的开源项目(Github)
根据本期榜单的数据分析,我们可以从几个角度进行探讨,包括项目的语言、介绍、当前Stars及热度等。 1. 项目语言分布 此榜单中的项目主要集中在Python和JavaScript等常用语言上,其中Python项目数量较多。可以观察到Python的丰富生态和广泛应…...

别再踩坑了!在Rancher里用Deployment部署Redis集群,Pod重启IP变动的终极解决方案
在Kubernetes中稳定部署Redis集群的实战指南 为什么Deployment不适合部署Redis集群? Redis作为典型的有状态服务,在Kubernetes环境中部署时面临着独特的挑战。许多开发者习惯性地使用Deployment控制器来部署Redis,这其实是一个常见的误区。问…...
偌)
ORM性能测试Benchmark(最终版)偌
7.1 初识三维模型 7.1.1 三维模型的数据载体 随着计算机图形技术的发展,我们或多或少都会见过或者听说过三维模型。笔者始终记得小时候第一次在电视上看到三维动画《变形金刚:超能勇士》的震撼感受;而现在我们已经可以在手机上玩三维游戏《王…...

ElementUI下拉多选框避坑指南:如何优雅处理全选与反选逻辑
ElementUI多选框全选逻辑深度解析:从原理到最佳实践 下拉多选框是后台管理系统中最常用的交互组件之一,但很多开发者在实现全选功能时都会遇到各种边界问题。上周在重构供应链管理系统时,我花了整整两天时间才彻底解决了全选状态同步的难题—…...

绍兴GEO优化,亲测3家公司复盘
开篇:定下基调在AI生成式引擎重塑信息获取方式的今天,GEO(生成式引擎优化)已成为企业建立数字信任、抢占精准流量的核心战场。绍兴作为民营经济活跃的区域,企业对高效、落地的GEO优化服务需求日益迫切。本次测评旨在通…...

Cocos Creator平台适配层框架设计
在 Cocos Creator 多平台开发中,平台抽象层不仅是架构设计问题,更是工程落地能力的体现。如果仅停留在概念层面,很容易流于形式。因此,本文在系统总结的基础上,结合实际代码示例,说明如何构建一个可落地的多…...

暗黑3技能连点器终极指南:三步解决重复操作难题
暗黑3技能连点器终极指南:三步解决重复操作难题 【免费下载链接】D3keyHelper D3KeyHelper是一个有图形界面,可自定义配置的暗黑3鼠标宏工具。 项目地址: https://gitcode.com/gh_mirrors/d3/D3keyHelper 还在为暗黑3中重复的技能按键感到疲惫吗&…...
—— 终章(MVVM架构初见杀)承)
WPF新手村教程(七)—— 终章(MVVM架构初见杀)承
1. 哑铃图是什么? 哑铃图(Dumbbell Plot),有时也称为DNA图或杠铃图,是一种用于比较两个相关数据点的可视化图表。 它源于人们对更有效数据比较方式的持续探索。 在传统的时间序列比较中,我们通常使用两条折…...

别再谈OKR了!SITS2026重磅发布《AI原生团队动力学模型》:用3个动态参数替代KPI,实测交付周期压缩41%
第一章:SITS2026演讲:AI原生研发的文化变革 2026奇点智能技术大会(https://ml-summit.org) 在SITS2026主会场,来自全球37家头部科技企业的工程负责人共同指出:AI原生研发已不再仅是工具链升级,而是一场以“人机协同决…...