【JavaEE初阶】了解JVM
文章目录
- 一. JVM内存区域划分
- 二. JVM类加载机制
- 2.1 类加载整体流程
- 2.2 类加载的时机
- 2.3 双亲委派模型(经典)
- 三. JVM垃圾回收机制(GC)
- 3.1 GC实际工作过程
- 3.1.1 找到垃圾/判定垃圾
- 1. 引用计数(不是java的做法,Python/PHP)
- 2. 可达性分析(Java的做法)
- 3.1.2 清理垃圾
- 1. 标记清除
- 2. 复制算法
- 3. 标记整理
- 4. 分代回收
一. JVM内存区域划分
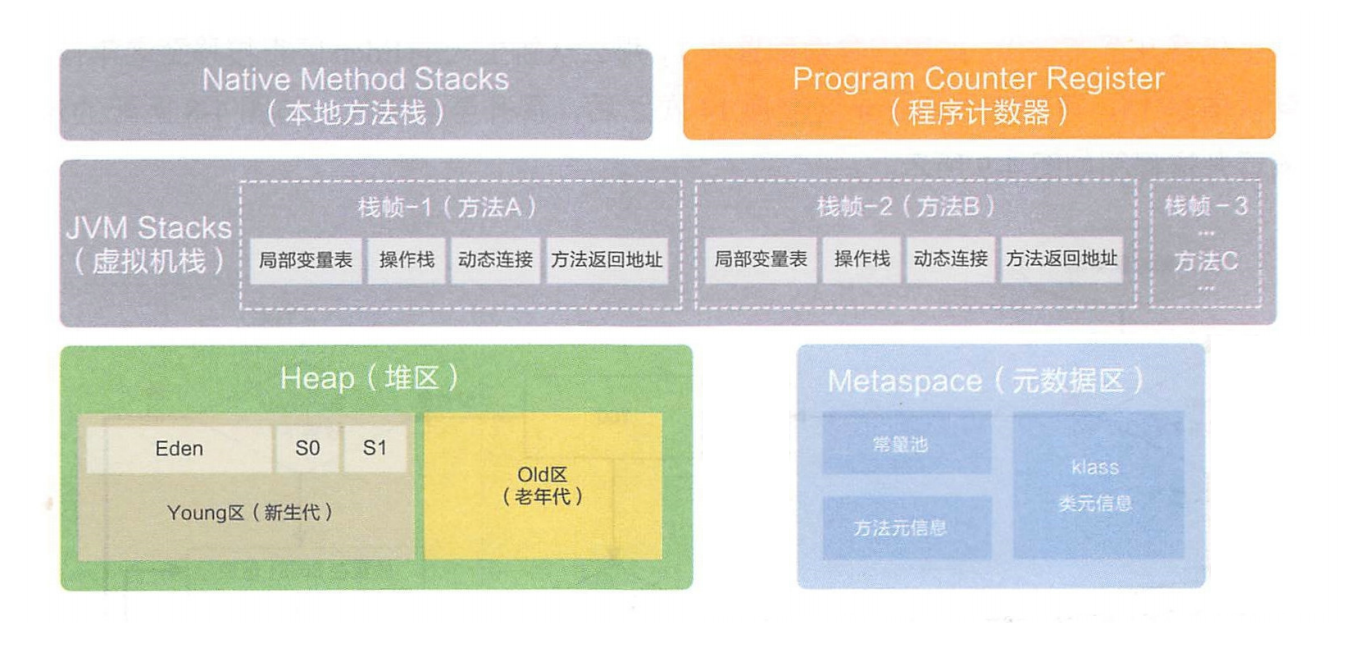
JVM启动的时候,会申请到一整个很大的内存区域.JVM是一个应用程序,要从操作系统里申请内存.JVM就根据需要,把空间分为几个部分,每个部分各自有不同的功能.具体划分如下:
-
Native Method Stacks(本地方法栈):native表示是JVM内部的C++代码.就是给调用native方法(JVM内部的方法)准备的栈空间. -
Program Counter Register(程序计数器):记录当前线程执行到那个命令.(很小的一块存一个地址)每个线程有一份. -
JVM Stack(虚拟机栈):虚拟机栈是给Java代码使用的栈. 此栈是JVM中一个特定的空间,对于 JVM虚拟机栈
,这里存储的是方法之间的调用关系.整个栈空间内部,可以认为是包含很多个元素(每个元素表示一个方法),把这里的每个元素称为**“栈帧”,这一个栈帧里,会包含这个方法的入口地址,方法的参数,返回地址,局部变量等.
而对于 本地方法栈 , 存储的是native方法之间的调用关系**.
虚拟机栈,不是只有一个,而是有很多个,每个线程都有一个.

由于函数调用,是有先进后出特点的.此处的栈,也是先进后出的.
栈空间整体一般都不会很大,但是每个栈帧其实占得空间比较小,一般代码无限递归才会出现栈溢出情况. -
Heap(堆):整个JVM空间最大的区域.new出来的对象,类的成员变量,都在堆上.**堆是一个进程只有一份,栈是每个线程有一份.**一个进程里有多个线程.所以一个进程有多个栈.每个jvm就是一个java进程.
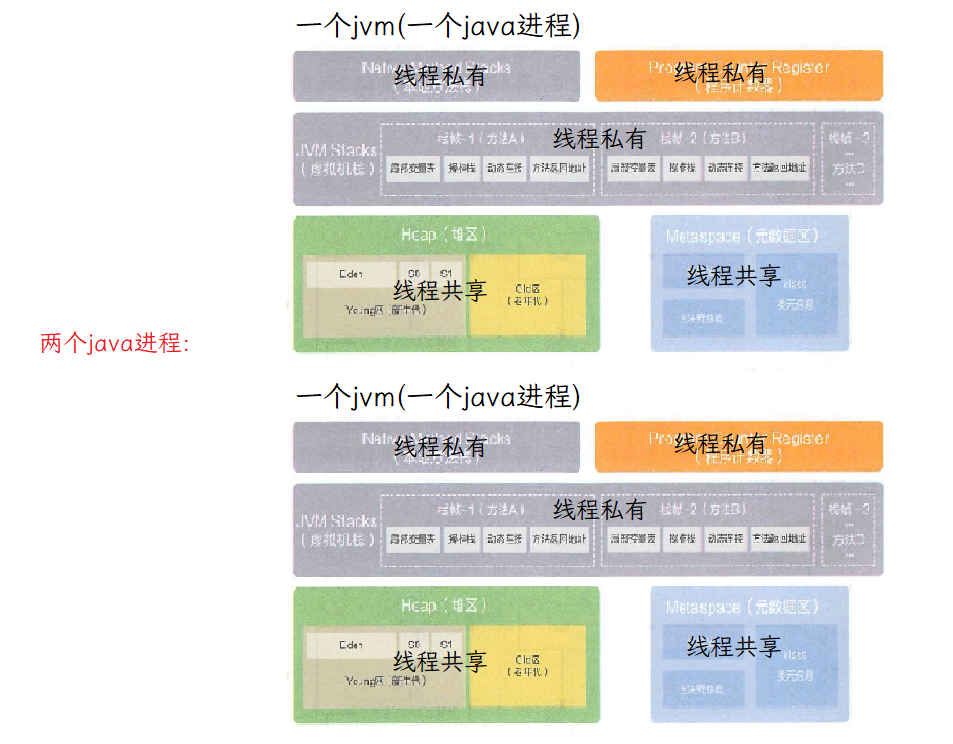
注意这里的常见说法:栈是线程私有的.(此说法不完全对).私有的意思是我的你用不了.实际上,一个线程栈上的内容,可以被另一个线程使用.比如通过变量捕获,一个线程可以访问到另一个线程的局部变量.
-
Metaspace(元数据区):即方法区.一个进程里只有一块,多个线程共用一块. -
小结: -
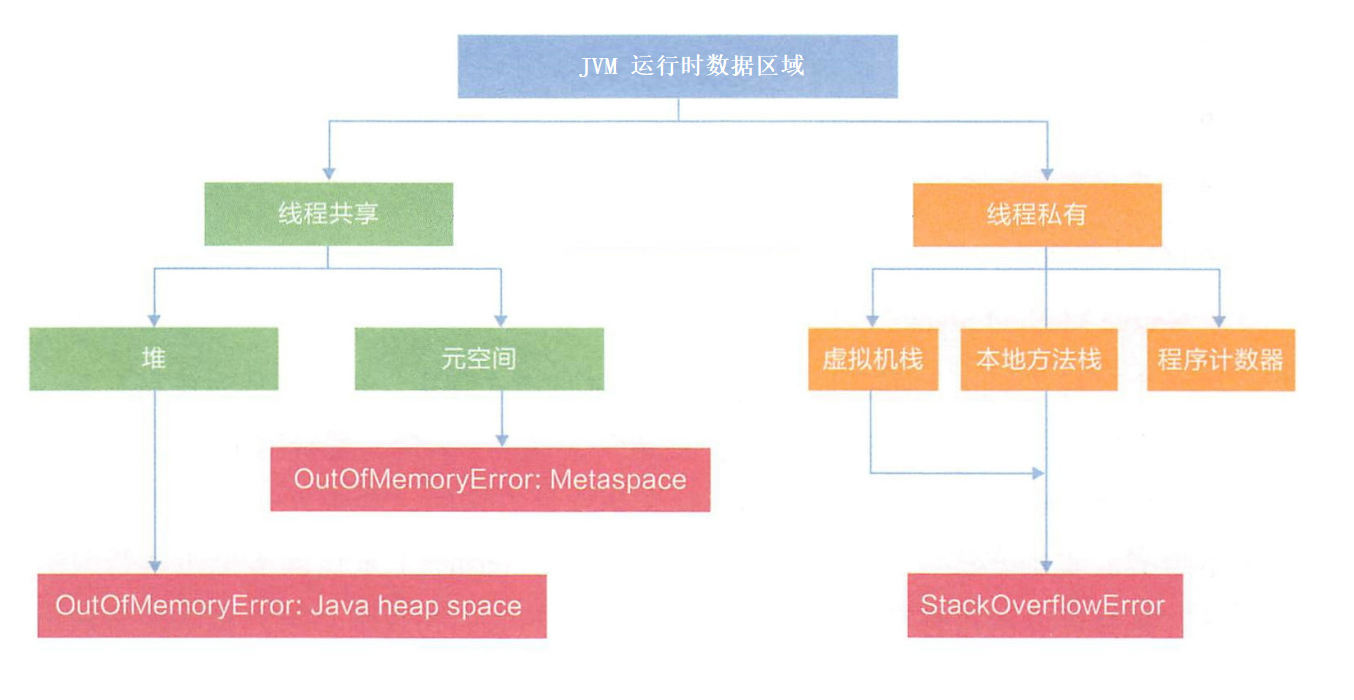
局部变量 在 栈
-
普通成员变量 在 堆
-
静态成员变量 在 方法区/元数据区
二. JVM类加载机制
2.1 类加载整体流程
类加载,准确的说,类加载就是.class文件,从文件(硬盘)被加载到内存中(元数据区)这样的过程.这个过程是非常复杂的.
.class文件可以有多个类对象
.class文件是编译后的Java源代码,它包含了编译后的字节码指令.
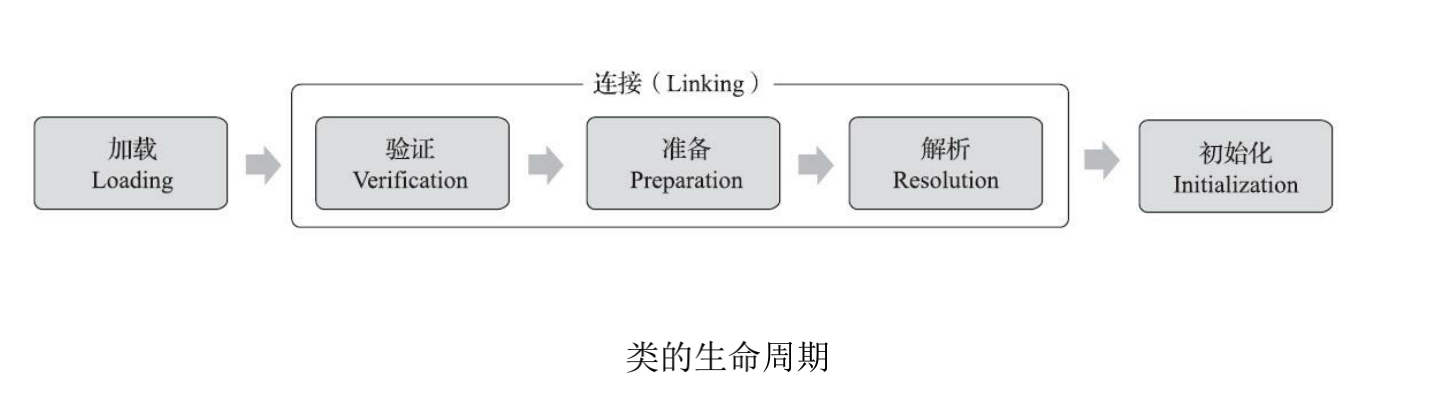
类加载主要分为以下几个过程:
-
加载:把.class文件找到(找的过程),打开文件,地文件,把文件内容读到内存中. -
验证:检查.class文件格式是否正确..class文件是一个二进制文件,这里的格式是有严格说明的,官方提供了JVM虚拟机规范.规范文档上描述了.class的格式:
java代码中写的类的所有信息,都会包含在上述.class文件中.使用二进制的方式重新组织. -
准备:给类对象分配内存空间(此时内存初始化为全0) -
解析:针对字符串常量进行初始化,把符号引用转为直接引用.
字符串常量,得有一块内存空间,存这个字符的实际内容,还得有一个引用,用来保存这个内存空间的起始地址.
在类加载之前,字符串常量,此时是处在.class文件中的,此时这个"引用"记录的并非是字符串常量的真正地址,而是它在文件中的"偏移量".(或者是占位符)(符号引用)
类加载之后,才真正在把这个字符串常量放到内存中,此时才有"内存地址",这个引用才能被真正赋予成指定内存地址.(直接引用)举个🌰: 小学的时候,学校组织以班为单位大家看电影,
但是到电影院之前我不知道自己的真实地址(真实座位),但是我知道我前面是A,后面是B,此时到了电影院,我们仨也是挨着的.(符号引用)
此时我只知道自己的相对位置. 到了电影院之后,老师组织同学们坐下.我坐下之后才知道我们的真正位置.(直接引用) -
初始化:调用构造方法,进行成员初始化,执行代码块,静态代码块,加载父类.
2.2 类加载的时机
一个类,不是java程序已运行,就把所有的类都加载了.而是真正使用的时候才加载(懒汉模式)
在以下场景中会触发类加载:
- 构造类的实例
- 调用这个类的静态方法/使用静态属性
- 加载子类,就会先加载其父类
以上都是用到了再加载,一旦加载过后,后续使用就不用再加载.
2.3 双亲委派模型(经典)
此过程发生在加载阶段.
双亲委派模型:描述的是加载 找.class文件的基本过程.
JVM默认提供了三个类加载器:
启动类加载器(BootStrap ClassLoader):负责加载Java标准库中的类(无论是哪种JVM的实现,都会提供这些一样的类)扩展类加载器(Extension ClassLoader):负责加载JVM扩展库中的类.(由实现JVM的厂商/组织提供的额外功能)应用程序类加载器(Application ClassLoader):负责加载项目中自己写的类以及第三方库中的.
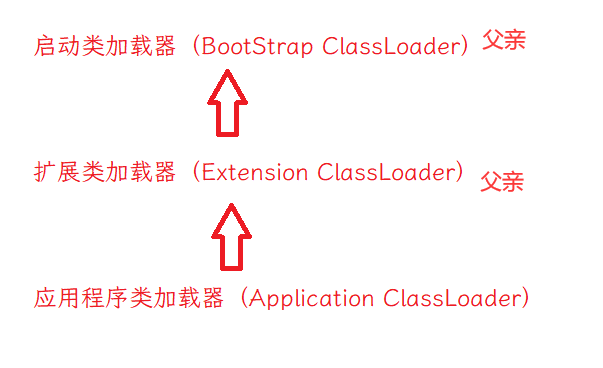
上述三个类,存在"父子关系"(不是父类子类,相当于每个class loader有一个parent属性,指向自己的父 类加载器).
那么上述类加载器如何配合工作呢?
首先加载一个类的时候,实现从ApplicationClassLoader开始.但是ApplicationClassLoader会把家在任务交给父亲,让父亲去进行.于是ExtensionClassLoader要去加载了,但是也不是真的加载,而是再委托给自己的父亲.于是BootstrapClassLoader要去加载了,也是想委托给自己的父亲,结果发现,自己的父亲是null. 没有父亲/父亲加载完了,没找着类,才由自己进行加载,此时BootstrapClassLoader就会搜索自己负责的标准库目录的相关的类,如果找到就加载,如果没找到,就继续由子类加载器进行加载.然后由ExtensionClassLoader真正搜索扩展库相关的目录,如果找到了就加载,如果没找到就由子类加载器进行加载.然后由ApplicationClassLoader真正搜索用户项目相关的目录,如果找到就加载,如果没找到就由子类加载器进行加载(由于当前没有子了,只能抛出 类找不到这样的异常)
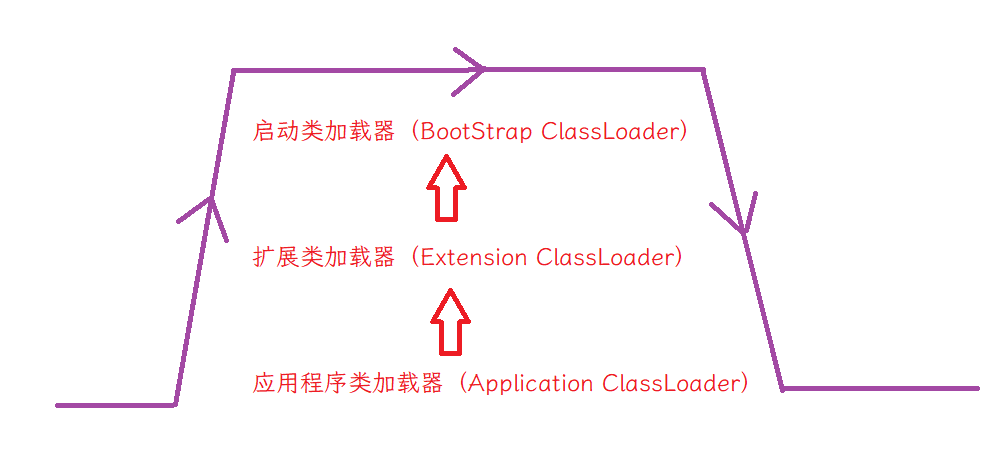
那么为什么要有上述顺序呢?
上述这套顺序其实是出自于JVM实现代码的逻辑,这段代码大概是使用递归的方式写的.但这个顺序,最主要的目的就是为了保证Bootstrap能够先加载,Application能够后加载.这样就可以避免说因为用户创建了一些奇怪的类,引起不必要的bug.
假设用户在自己的代码中写了个java.lang.String按照上述加载流程,此时JVM加载的还是标准库的类,不会加载到用户自己写的这个类. 这样就能保证,即使出现上述问题,也不会让jvm已有代码混乱,最多是用户自己写的类不生效.
另一方面,类加载器,其实是可以用户自定义的.上述三个类加载器是jvm自带的.用户自定义的类加载器,也可以加入到上述流程中,就可以和现有的加载器配合使用,
三. JVM垃圾回收机制(GC)
垃圾:指的是不再使用的内存空间.垃圾回收,就是把不用的内存帮我们自动释放.
在执行程序时,要在堆上申请一块内存空间.在C/C++中,上述内存空间需要手动方式进行释放.如果不手动释放的话,这块内存的空间就会持续存在,一直存在到进程结束(堆上的内存生命周期比较长.不像栈,栈的空间会随着方法执行结束,栈帧销毁而自动释放,堆则默认不能自动释放.)那么这就可能会导致一个严重的问题—内存泄漏.如果内存一直占着不用,又不释放,就会导致剩余空间越来越少.进一步导致后续的内存申请操作失败.因此,大佬们想了一些办法,来解决内存泄漏的问题.
GC是其中最为主流的方式.(Java Go Python PHP JS大部分的主流语言都是使用GC解决内存泄漏的问题的)
但GC中有一个比较关键的问题:STW问题(stop the world)
如果有时候,内存中的垃圾已经非常多了,此时触发一次GC操作,开销可能非常大,大到可能把系统资源吃了很多.另一方面GC回收垃圾的时候可能会涉及到一些锁操作.导致业务代码无法正常执行.这样的卡顿,极端情况下,可能是出现即使毫秒甚至上百毫秒.
JVM中有很多内存区域:
- 堆
- 栈
- 程序计数器
- 元数据区
- …
GC主要是针对堆进行释放的.
GC是以"对象"为基本单位,进行回收的.而不是字节!
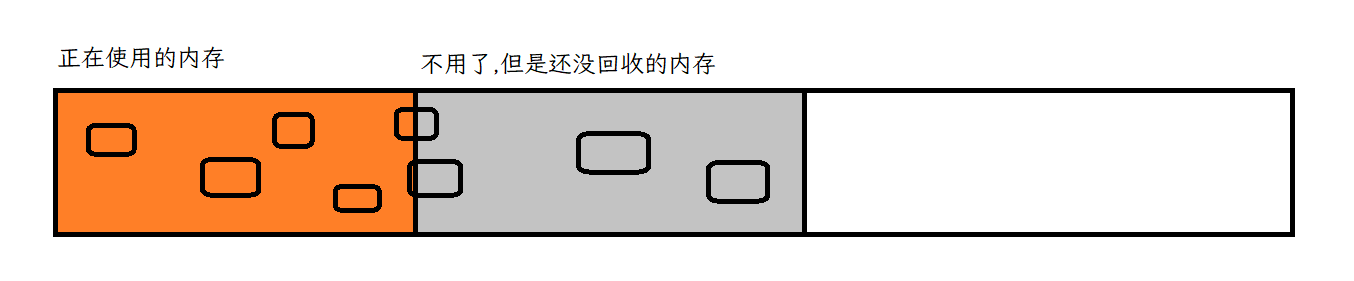
GC回收的是整个对象都不再使用的情况.而一部分使用一部分不使用的对象,暂且不回收.
3.1 GC实际工作过程
- 找到垃圾/判定垃圾
- 再进行对象的释放
3.1.1 找到垃圾/判定垃圾
找到垃圾/判定垃圾的关键就是看到底有没有"引用"指向它.如果一个对象,有引用指向它,就可能被使用到;如果一个对象,没有引用指向了,就不会再被使用了.
具体如何知道对象是否有引用指向呢?
1. 引用计数(不是java的做法,Python/PHP)
给每个对象分配了一个计数器(整数).每次创建一个引用指向该对象,计数器就+1,每次该引用被销毁,计数器就-1.
{Test t = new Test();//Test对象的引用计数1Test t2 = t;//t2也指向了t,引用计数2Test t3 = t;//引用计数就是3
}
//大括号结束,上述三个引用超出作用域失效.此时引用计数就是0了,此时new Test()对象就是垃圾了.
这个办法简单有效,但是java没有采用.但是这个办法也有一定的缺点:
1. 内存空间浪费的多(利用率低)
每个对象都要分配一个计数器,如果按四个字节计算.代码中的对象非常少就无所谓.但是如果对象特别多,占用的额外空间就会很多,尤其是每个对象都比较小的情 况.例如:一个对象体积1k,此时多4个字节,无所谓.一个对象体积事4字节,此时多4个字节,相当于体积扩大一倍.
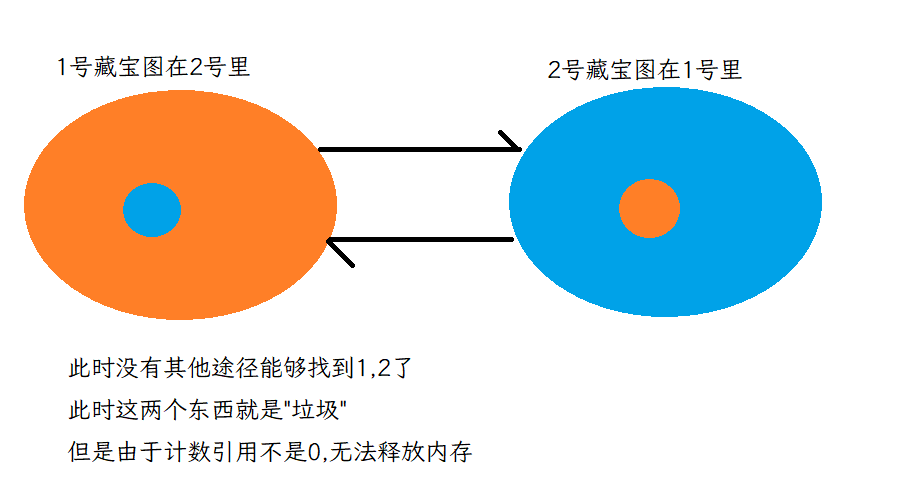
2. 存在循环引用的问题
class Test{Test t = null;
}
Test a = new Test();//1号对象,引用计数是1
Test b = new Test();//2号对象,引用计数是1
a.t = b;//a.t也指向2号对象了,2号对象的引用是2
b.t = a;//b.t也指向1号对象了,1号对象的引用是2
接下来,a和b引用销毁,此时a和b计数-1,但引用计数结果还都是1,不能释放资源,但实际这两个对象已经无法访问了。python/php使用引用计数,需要搭配其他机制来避免循环引用.
举个🌰:
2. 可达性分析(Java的做法)
把对象之间的引用关系理解成了一个树形结构,从一些特殊的起点出发,进行遍历,只要能遍历访问到的对象,就是"可达的",再把"不可达的"当作垃圾即可.
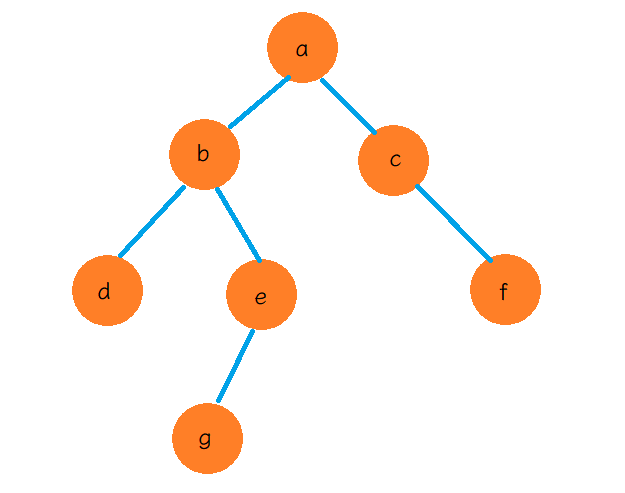
就像上述的二叉树,root指向根节点a.
如果root.right.right = null ,此时就表示f不可达
如果root.right = null此时就表示c不可达,f也不可达了。
可达性分析的关键要点,进行上述遍历,需要有"起点"被称为gcroots.以下常做为根起点:
- 栈上的局部变量(每个栈的每个局部变量,都是起点)
- 常量池中引用的对象
- 方法区中,静态成员引用的对象
可达性分析,总的来所,就是从所有的gcroots的起点出发,看看该对象里又通过引用能访问那些对象,依次遍历,把所有可以访问的对象都给遍历一遍(遍历的同时把对象标记成"可达"),剩下的遍历不到的对象就是"不可达".
可达性分析的特点:可达性分析克服了引用计数的两个缺点,但是也有自己的缺点:
- 消耗的时间更多,因此某个对象成了垃圾,也不一定能第一时间发现,因为扫描的过程,需要消耗时间
- 在进行可达性分析的时候,依次遍历,一旦这个过程中,当前代码中的对象引用关系发生了变化,这就会使情况变得更加复杂。比如,当一个对象指向下一个对象,刚遍历完这个对象,这个对象的引用变了。因此,我们为了更准确的遍历,需要让其他的业务线程暂停工作(STW问题)。
3.1.2 清理垃圾
主要有三种基本做法:
1. 标记清除
这种策略,就是直接把垃圾对象的内存释放,但是这个方式的缺点就是会产生内存碎片.
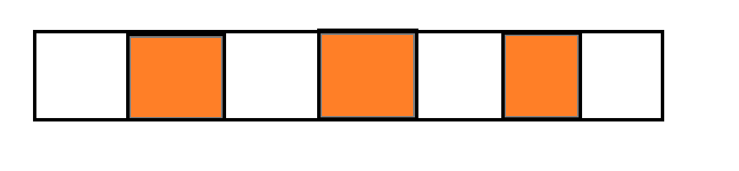
我们从内存中申请空间的时候,都是整块的连续的空间,现在这里空闲的空间是离散的,独立的空间,总的空间可能很大.假如总的空闲的空间可能超过了1G,但是你想申请500MB可能都不一定申请到。
2. 复制算法
为了解决内存碎片的问题,又引入了复制算法.复制算法,是把整个内存空间,分成两半,一次只用一半.
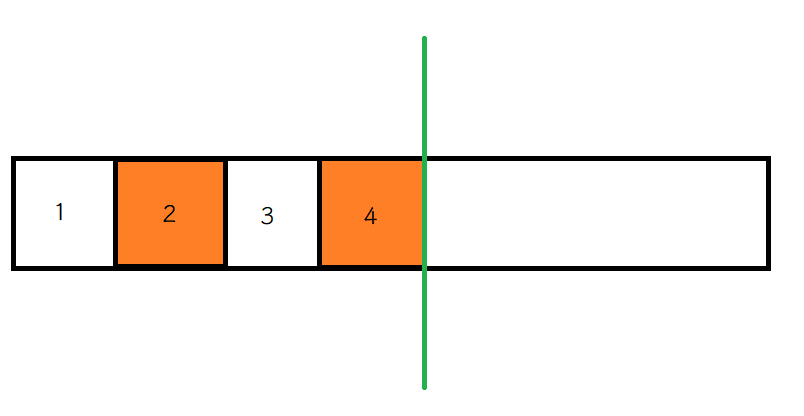
现在将2和4标记为垃圾,要释放垃圾,复制算法会将左边不需要释放内存的空间复制到右边的空间中,然后整体释放左边空间的内存.
复制算法,就是把"不是垃圾"的对象复制到另外一半,然后把整个空间删除掉.
每次触发复制算法,都是向另外─侧进行复制,内存中的数据拷贝过去.
缺点:
- 空间利用率低
- 如果要是垃圾少,有效对象多,复制成本就比较大了~~
3. 标记整理
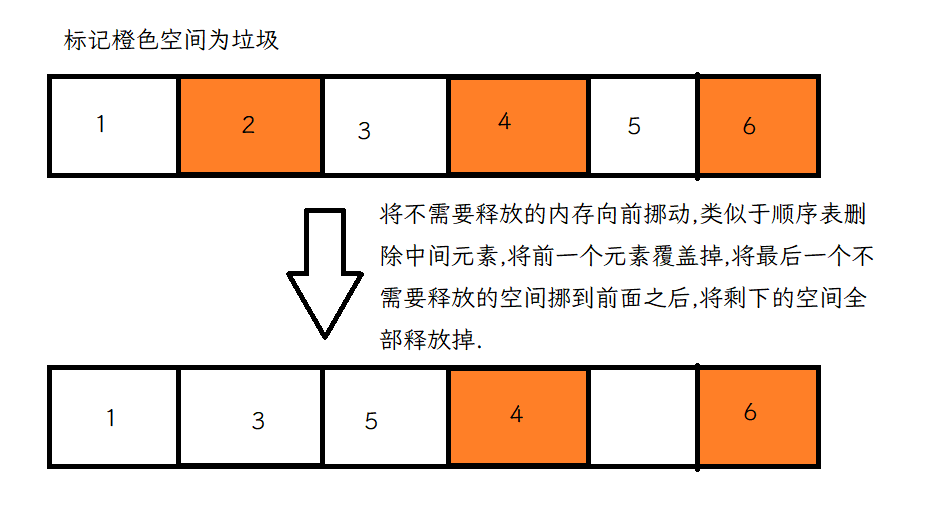
这种方法,保证了空间利用率,同时也解决了内存碎片问题
但是这种做法的缺点:
- 效率不高如果要搬运的空间比较大,此时开销也很大
4. 分代回收
基于上述这些基本策略,搞了一个复合策略"分代回收"
把垃圾回收,分成不同的场景,有的场景有这个算法,有的场景有那个,各展所长.
分代是怎么分的?
基于一个经验规律:如果一个东西,存在的时间比较长了,那么大概率还会继续的长时间持续存在下去.(要没早就没了,既然存在,肯定有点用)
规律不等于"定律",允许例外,针对大部分情况有效的.
上述规律,对于Java的对象也是有效的.(是有一系列的实验和论证过程)
java的对象要么就是生命周期特别短,要么就是特别长.根据生命周期的长短,分别使用不同的算法.
给对象引入一个概念,年龄.(单位不是年,而是熬过GC的轮次)(经过了这一轮可达性分析的遍历,发现这个对象还不是垃圾.这就是"熬过一轮GC") 年龄越大,这个对象存在的时间就越久.
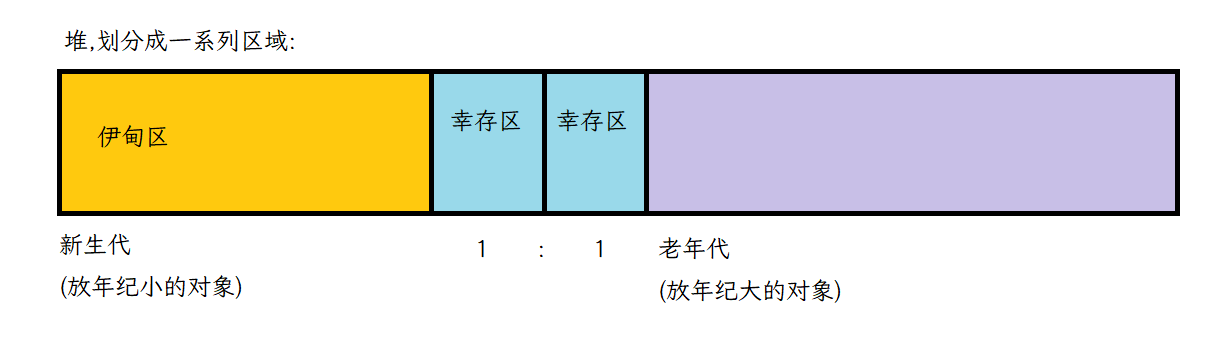
刚new 出来的,年龄是0的对象,放到伊甸区.(出自圣经,上帝在伊甸园造小人)
熬过一轮GC,对象就要被放到幸存区了.虽然看起来幸存区很小,伊甸区很大,一般够放.
伊甸区到幸存区,采用的是复制算法.
幸存区之后,也要周期性的接受GC的考验.
如果变成垃圾,就要被释放.如果不是垃圾,拷贝到另外一个幸存区(这俩幸存区同一时刻只用一个),在两者之间来回拷贝(复制算法),由于幸存区体积不大, 此处的空间浪费也能接受.如果这个对象已经再两个幸存区中来回拷贝很多次了这个时候就要进入老年代了·
老年代都是年纪大的对象.生命周期普遍更长.针对老年代,也要周期性GC扫描,但是频率更低了
如果老年代的对象是垃圾了,使用标记整理的方式进行释放.
相关文章:
【JavaEE初阶】了解JVM
文章目录 一. JVM内存区域划分二. JVM类加载机制2.1 类加载整体流程2.2 类加载的时机2.3 双亲委派模型(经典) 三. JVM垃圾回收机制(GC)3.1 GC实际工作过程3.1.1 找到垃圾/判定垃圾1. 引用计数(不是java的做法,Python/PHP)2. 可达性分析(Java的做法) 3.1.2 清理垃圾1. 标记清除2…...
)
基于vue2.0和elementUi的vue农历日期组件vue-jlunar-datepicker(插件)
vue-jlunar-datepicker(插件) vue实现农历日历插件——vue-jlunar-datepicker插件 这个插件本身是基于vue2.0和elementUi框架来实现的。 安装 vue-jlunar-datepicker 插件 npm install vue-jlunar-datepicker --save // 如果安装过程中,出现…...

Python爬虫——selenium_元素定位
元素定位:自动化要做的就是模拟鼠标和键盘来操作这些元素,点击,输入等等。操作这些元素前首先要找到它们,WebDriver提供很多定位元素的方法 from selenium import webdriver# 创建浏览器对象 path files/chromedriver.exe brows…...

短视频内容平台(如TikTok、Instagram Reel、YouTube Shorts)的系统设计
现在,短视频内容已成为新趋势,每个人都在从TikTok、Instagram、YouTube等平台上消费这些内容。让我们看看如何为TikTok创建一个系统。 这样的应用程序看起来很小,但在后台有很多事情正在进行。以下是相关的挑战: •由于该应用程序…...

【git】Git 回退到指定版本:
文章目录 方法一: 使用 git reset 命令方法二:使用 git revert 命令方法三:使用 git checkout 命令常见的错误及其解决办法如下: 方法一: 使用 git reset 命令 命令可以将当前分支的 HEAD 指针指向指定的提交,从而回退代码到指定版…...

kibana+nginx配置密码 ubuntu
JAVA进阶之路-nginx设置密码 Kibana——通过Nginx代理Kibana并实现登陆认证 需要配置一下nginx文件 nginx配置文件详解 密码生成安装软件 apt install apache2-utils...
Git仓关联多个远程仓路径
前言 Git仓如果需要将代码push到多个仓,常用的做法是添加多个远程仓路径,然后分别push。这样虽然可以实现目的,但是需要多次执行push指令,很麻烦。 本文介绍关联多个远程仓路径且执行一次push指令的方法:git remote …...
使用ffmpeg将m4a及wav等文件转换为MP3格式
要使用ffmpeg将m4a及wav等文件转换为MP3格式,您可以按照以下步骤进行操作: 安装 ffmpeg 确保您已经安装了ffmpeg软件。如果没有安装,请访问ffmpeg的官方网站https://ffmpeg.org/ 并按照说明进行安装。 Win10 / Win11 可以通过 winget 命令…...

【CI/CD】Git Flow 分支模型
Git Flow 分支模型 1.前言 Git Flow 模型(本文所阐述的分支模型)构思于 2010 年,也就是 Git 诞生后不久,距今已有 10 多年。在这 10 多年中,Git Flow 在许多软件团队中大受欢迎。 在这 10 多年里,Git 本身…...
SpringBoot Thymeleaf模板引擎
Thymeleaf 模板引擎 前端交给我们的页面,是html页面。如果是我们以前开发,我们需要把他们转成jsp页面,jsp好处就是当我们查出一些数据转发到JSP页面以后,我们可以用jsp轻松实现数据的显示,及交互等。 jsp支持非常强大…...

prometheus部署
一、前言 Prometheus 是一个开源的系统监控和警报工具,用于收集、存储和查询时间序列数据。它旨在提供高效的多维数据收集和查询功能,帮助用户监控其应用程序和基础设施的性能,并在出现问题时触发警报,总来得说prometheus是用来收…...

Flink-Window详细讲解-countWindow
一.countWindow和countWindowall区别 1.countWindow: 如果您使用 countWindow(5),这意味着您将数据流划分成多个大小为 5 的窗口。划分后的窗口如下: 窗口 1: [1, 2, 3, 4, 5]窗口 2: [6, 7, 8, 9, 10] 当每个窗口中的元素数量达到 5 时&…...

React 18 state 如同一张快照
参考文章 state 如同一张快照 也许 state 变量看起来和一般的可读写的 JavaScript 变量类似。但 state 在其表现出的特性上更像是一张快照。设置它不会更改已有的 state 变量,但会触发重新渲染。 设置 state 会触发渲染 可能会认为用户界面会直接对点击之类的用…...
EasyPoi导出 导入(带校验)简单示例 EasyExcel
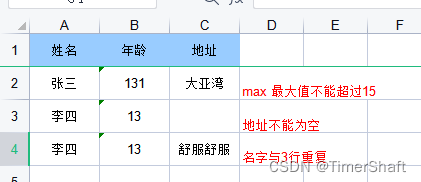
官方文档 : http://doc.wupaas.com/docs/easypoi pom的引入: <!-- easyPoi--><dependency><groupId>cn.afterturn</groupId><artifactId>easypoi-spring-boot-starter</artifactId><version>4.0.0</version></dep…...
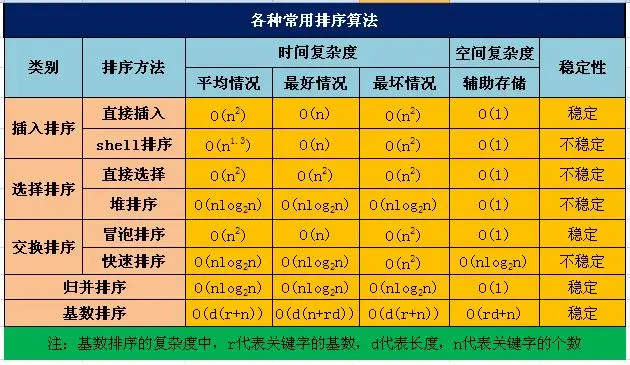
八大排序
目录 选择排序-直接插入排序 插入排序-希尔排序 选择排序-简单选择排序 选择排序-堆排序 交换排序-冒泡排序 交换排序-快速排序 归并排序 基数排序 选择排序-直接插入排序 基本思想: 如果碰见一个和插入元素相等的,那么插入元素把想插入的元素放在相等元素…...

网络安全【黑客技术】自学
1.网络安全是什么 网络安全可以基于攻击和防御视角来分类,我们经常听到的 “红队”、“渗透测试” 等就是研究攻击技术,而“蓝队”、“安全运营”、“安全运维”则研究防御技术。 掌握技术的听说也需要心怀正义,不要利用技术行不轨之事&…...

【网络通信】socket编程——TCP套接字
TCP依旧使用代码来熟悉对应的套接字,很多接口都是在udp中使用过的 所以就不会单独把他们拿出来作为标题了,只会把第一次出现的接口作为标题 文章目录 服务端 tcp_servertcpserver.hpp(封装)初始化 initServer1. 创建socket2. 绑定 bindhtons —— 主机序…...

ROS2系统学习番外篇2---用VSCode开发ROS2程序
在ROS2系统学习3—第一个“Hello World”程序—即工作空间创建与包创建中已经介绍了如何创建ROS的工作空间以及包。在开发大型工程时,往往需要在IDE下面进行开发,因此本篇介绍使用VSCode来搭建ROS2开发环境的方法。 首先用VSCode打开ROS2的工作空间。 使用快捷键编译ROS2 …...

06 - Stream如何提高遍历集合效率?
前面我们讲过 List 集合类,那我想你一定也知道集合的顶端接口 Collection。 在 Java8 中,Collection 新增了两个流方法,分别是 Stream() 和 parallelStream()。 1、什么是 Stream? 现在很多大数据量系统中都存在分表分库的情况…...
【Spring】使用注解的方式获取Bean对象(对象装配)
目录 一、了解对象装配 1、属性注入 1.1、属性注入的优缺点分析 2、setter注入 2.1、setter注入的优缺点分析 3、构造方法注入 3.1、构造方法注入的优缺点 二、Resource注解 三、综合练习 上一个博客中,我们了解了使用注解快速的将对象存储到Spring中&#x…...

CSS如何实现卡片式布局_掌握盒模型阴影与间距设置
box-shadow 要清晰自然需控制偏移与模糊比例,避免与 border 冲突;文字不被遮挡需确保无误设 z-index 或 overflow: hidden;padding 管内距、margin 管外距;Flex 中用 flex: 1 0 300px 防缩窄;border-radius 与 shadow …...

Argo Events 高级过滤技巧:数据过滤、上下文过滤和时间过滤的完整指南
Argo Events 高级过滤技巧:数据过滤、上下文过滤和时间过滤的完整指南 【免费下载链接】argo-events Event-driven Automation Framework for Kubernetes 项目地址: https://gitcode.com/gh_mirrors/ar/argo-events Argo Events 是 Kubernetes 生态系统中强大…...

猫抓Cat-Catch:三步搞定网页视频音频下载的终极指南
猫抓Cat-Catch:三步搞定网页视频音频下载的终极指南 【免费下载链接】cat-catch 猫抓 浏览器资源嗅探扩展 / cat-catch Browser Resource Sniffing Extension 项目地址: https://gitcode.com/GitHub_Trending/ca/cat-catch 还在为无法保存喜欢的在线视频而烦…...

课题申请:如何预判评审潜台词并从容应对?
在基金申报的激烈竞争中,许多科研人员常常陷入一个误区:将申请书单纯地视为一份“任务说明书”。我们习惯于在文中详细罗列“要做什么”、“打算怎么做”,却往往忽略了评审专家在阅读时的心理活动。当一份申请书只停留在陈述层面,…...

智元GO-2:具身基座大模型新突破
智元机器人正式推出新一代具身基座大模型Genie Operator-2(GO-2),它在GO-1基础上进化,弥合语义‑运动鸿沟,在多个基准测试中刷新行业SOTA。进化亮点:弥合语义‑运动鸿沟GO-2在GO-1基础上进化,致…...

产品经理年度述职全攻略:从职责梳理到未来规划的完整指南
1. 年度述职的核心价值与准备要点 每到年底,产品经理们都会面临一场"年终大考"——述职报告。这不仅是展示个人价值的舞台,更是系统复盘工作、规划未来的重要契机。我经历过7次年度述职,从最初的照本宣科到现在的游刃有余ÿ…...

Fan Control:Windows风扇控制终极指南,告别噪音与高温烦恼![特殊字符]
Fan Control:Windows风扇控制终极指南,告别噪音与高温烦恼!🔥 【免费下载链接】FanControl.Releases This is the release repository for Fan Control, a highly customizable fan controlling software for Windows. 项目地址…...

如何快速获取百度网盘提取码:开源工具的终极实战指南
如何快速获取百度网盘提取码:开源工具的终极实战指南 【免费下载链接】baidupankey 项目地址: https://gitcode.com/gh_mirrors/ba/baidupankey 还在为百度网盘分享链接的提取码而烦恼吗?每次遇到需要密码的资源,你都要在多个网页间来…...

PotPlayer字幕翻译终极指南:5步实现外语视频无障碍实时翻译
PotPlayer字幕翻译终极指南:5步实现外语视频无障碍实时翻译 【免费下载链接】PotPlayer_Subtitle_Translate_Baidu PotPlayer 字幕在线翻译插件 - 百度平台 项目地址: https://gitcode.com/gh_mirrors/po/PotPlayer_Subtitle_Translate_Baidu 还在为观看外语…...

#50_基尔霍夫两大定律
50_基尔霍夫两大定律 50_基尔霍夫两大定律0. 引言0.1 基尔霍夫定律的历史背景0.2 基尔霍夫定律在电路分析中的地位0.3 两大定律的适用条件1. 基本概念1.1 电路的基本术语a. 支路b. 节点c. 回路d. 网孔1.2 电流的参考方向1.3 电压的参考极性2. 基尔霍夫电流定律(KCL&…...