python爬虫之scrapy框架介绍
一、Scrapy框架简介
Scrapy 是一个开源的 Python 库和框架,用于从网站上提取数据。它为自从网站爬取数据而设计,也可以用于数据挖掘和信息处理。Scrapy 可以从互联网上自动爬取数据,并将其存储在本地或在 Internet 上进行处理。Scrapy 的目标是提供更简单、更快速、更强大的方式来从网站上提取数据。

二、Scrapy的基本构成
Scrapy 框架由以下五个主要组件构成:
1. Spiders:它是 Scrapy 框架的核心部分,主要用于定义从网站上提取数据的方式。Spider 是一个 Python 类,它定义了如何从特定的网站抓取数据。
2. Items:它用于定义爬取的数据结构,Scrapy 将在爬取过程中自动创建 Item 对象,它们将被进一步处理,例如存储到数据库中。
3. Item Pipeline:它是 Scrapy 框架用于处理 Item 对象的机制。它可以执行诸如数据清洗、验证和存储等操作。
4. Downloader:它是 Scrapy 框架用于下载页面的组件之一。它正在处理网络请求,从互联网上下载页面并将其回传到 Spider 中。
5. Middleware:它是 Scrapy 框架用于处理 Spider、Downloader 和 Item Pipeline 之间交互的组件之一。中间件在这个架构中扮演了一个交换件角色,可以添加、修改或删除请求、响应和 Item 对象。
三、Scrapy框架的运行流程
Scrapy 的运行流程可以分为以下几步:
1. 下载调度器:Scrapy 框架接收 URL 并将其传递给下载调度器。下载调度器负责队列管理和针对每个 URL 的下载请求的优先级。它还可以控制并发请求的总数,从而避免对服务器的过度负载。
2. 下载器:下载器使用 HTTP 请求从互联网上下载 HTML 或其他类型的页面内容。下载器可以通过中间件拦截处理、修改或过滤请求和响应。下载器还可以将下载的数据逐步传递到爬虫中。
3. 爬虫:Spider 接收下载器提供的页面数据,并从中提取有用的信息。Spider 可以通过规则来定义如何从页面中提取数据。Spider 可以将提取的数据传递给 Item Pipeline 进行处理。
4. Item Pipeline:Item Pipeline 进行数据的清洗、验证和存储等操作。它还可以将数据存储到数据库、JSON 或 CSV 文件中。
5. 输出:Scrapy 可以输出爬取的数据到命令行、文件或 JSON 格式。输出可以用于生成各种类型的报告或分析。
四、Scrapy框架的使用
下面我们将介绍如何使用 Scrapy 框架。
1. 安装 Scrapy
Scrapy 框架可以通过 pip 安装。使用以下命令安装 Scrapy:
pip install scrapy
2. 创建 Scrapy 项目
使用以下命令创建 Scrapy 项目:
scrapy startproject project_name
其中,project_name 是项目的名称。
3. 创建 Spider
使用以下命令创建 Spider:
scrapy genspider spider_name domain_name其中,spider_name 是 Spider 的名称,domain_name 是要爬取的域名。
在 Spider 中,我们可以定义如何从网站上提取数据。下面是一个简单的 Spider 的示例:
import scrapyclass MySpider(scrapy.Spider):name = 'myspider'start_urls = ['http://www.example.com']def parse(self, response):# 提取数据的代码pass在这个示例中,我们定义了一个 Spider,并指定了它的名称和要爬取的 URL。我们还实现了一个 parse 方法,用于提取页面上的数据。
4. 创建 Item
在 Scrapy 中,我们可以定义自己的数据结构,称为 Item。我们可以使用 Item 类来定义数据结构。下面是一个 Item 的示例:
import scrapyclass MyItem(scrapy.Item):title = scrapy.Field()author = scrapy.Field()content = scrapy.Field()在这个示例中,我们定义了一个 Item,并定义了三个字段:title、author 和 content。
5. 创建 Item Pipeline
在 Scrapy 中,我们可以定义 Item Pipeline 来处理 Item 对象。Item Pipeline 可以执行以下操作:
- 清洗 Item 数据
- 验证 Item 数据
- 存储 Item 数据
下面是一个简单的 Item Pipeline 的示例:
class MyItemPipeline(object):def process_item(self, item, spider):# 处理 Item 的代码return item
在这个示例中,我们定义了一个 Item Pipeline,并实现了 process_item 方法。
6. 配置 Scrapy
Scrapy 有几个重要的配置选项。其中,最常见的是 settings.py 文件中的选项。下面是一个 settings.py 文件的示例:
BOT_NAME = 'mybot'
SPIDER_MODULES = ['mybot.spiders']
NEWSPIDER_MODULE = 'mybot.spiders'ROBOTSTXT_OBEY = TrueDOWNLOADER_MIDDLEWARES = {'mybot.middlewares.MyCustomDownloaderMiddleware': 543,
}ITEM_PIPELINES = {'mybot.pipelines.MyCustomItemPipeline': 300,
}
在这个示例中,我们定义了一些重要的选项,包括 BOT_NAME、SPIDER_MODULES、NEWSPIDER_MODULE、ROBOTSTXT_OBEY、DOWNLOADER_MIDDLEWARES 和 ITEM_PIPELINES。
7. 运行 Scrapy
使用以下命令运行 Scrapy:
scrapy crawl spider_name
其中,spider_name 是要运行的 Spider 的名称。
五、Scrapy框架的案例
下面我们来实现一个简单的 Scrapy 框架的案例。
1. 创建 Scrapy 项目
使用以下命令创建 Scrapy 项目:
scrapy startproject quotes我们将项目名称设置为 quotes。
2. 创建 Spider
使用以下命令创建 Spider:
scrapy genspider quotes_spider quotes.toscrape.com其中,quotes_spider 是 Spider 的名称,quotes.toscrape.com 是要爬取的域名。
在 Spider 中,我们定义如何从网站上提取数据。下面是一个 quotes_spider.py 文件的示例:
import scrapyclass QuotesSpider(scrapy.Spider):name = "quotes"def start_requests(self):urls = ['http://quotes.toscrape.com/page/1/','http://quotes.toscrape.com/page/2/',]for url in urls:yield scrapy.Request(url=url, callback=self.parse)def parse(self, response):for quote in response.css('div.quote'):yield {'text': quote.css('span.text::text').get(),'author': quote.css('span small::text').get(),'tags': quote.css('div.tags a.tag::text').getall(),}next_page = response.css('li.next a::attr(href)').get()if next_page is not None:yield response.follow(next_page, self.parse)在这个示例中,我们定义了一个 Spider,并指定了它的名称。我们还实现了 start_requests 方法,用于定义要爬取的 URL。我们还实现了一个 parse 方法,用于提取页面上的所有引用。我们使用 response.css 方法选择要提取的元素,并使用 yield 语句返回一个字典对象。
3. 运行 Spider
使用以下命令运行 Spider:
scrapy crawl quotes这个示例将下载 quotes.toscrape.com 网站上的页面,并从中提取所有引用。它将引用的文本、作者和标签存储到 MongoDB 数据库中。
六、总结
Scrapy 是一个功能强大的 Python 库和框架,用于从网站上提取数据。它为自从网站爬取数据而设计,也可以用于数据挖掘和信息处理。Scrapy 的目标是提供更简单、更快速、更强大的方式来从网站上提取数据。Scrapy 框架由 Spiders、Items、Item Pipeline、Downloader 和 Middleware 等组件构成,并具有可定制和可扩展性强的特性。使用 Scrapy 框架可以大大减少开发人员在网络爬虫开发中的时间和精力,是一个非常优秀的爬虫框架。
相关文章:
python爬虫之scrapy框架介绍
一、Scrapy框架简介 Scrapy 是一个开源的 Python 库和框架,用于从网站上提取数据。它为自从网站爬取数据而设计,也可以用于数据挖掘和信息处理。Scrapy 可以从互联网上自动爬取数据,并将其存储在本地或在 Internet 上进行处理。Scrapy 的目标…...

winform中嵌入cefsharp, 并使用selenium控制
正常说, 需要安装的包 下面是所有的包 全部代码 using OpenQA.Selenium.Chrome; using OpenQA.Selenium; using System; using System.Windows.Forms; using CefSharp.WinForms; using CefSharp;namespace WindowsFormsApp2 {public partial class Form1 : Form{//…...
)
【leetcode】349. 两个数组的交集(easy)
给定两个数组 nums1 和 nums2 ,返回 它们的交集 。输出结果中的每个元素一定是 唯一 的。我们可以 不考虑输出结果的顺序 。 思路: 先遍历nums1将其元素不重复地添加到哈希表a中;建立哈希表dup用于存储b和a重复的元素;遍历nums2…...

leetcode 2616. 最小化数对的最大差值
在数组nums中找到p个数对,使差值绝对值的和最小。 思路: 最小差值应该是数值相近的一对数之间产生,让数值相近的数字尽量靠在一起方便计算,所以需要排序。 这里不去直接考虑一对对的数字,而是直接考虑差值的取值。 …...

npm install 安装慢的问题处理
原因 npm install 默认使用的安装镜像时国外的镜像,国内使用会受到网络的限制。 解决方案 更换网络更换npm的安装镜像为国内,比如: npm config set registry https://registry.npm.taobao.org...
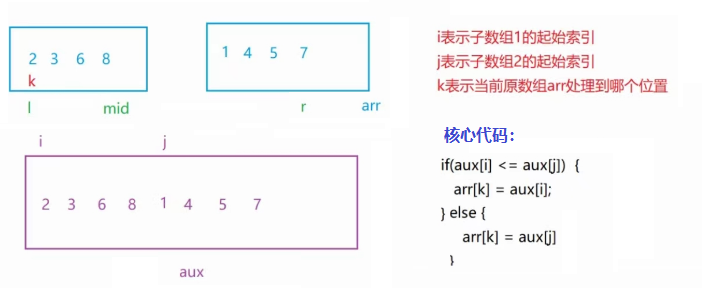
【JAVA】七大排序算法(图解)
稳定性: 待排序的序列中若存在值相同的元素,经过排序之后,相等元素的先后顺序不发生改变,称为排序的稳定性。 思维导图: (排序名称后面蓝色字体为时间复杂度和稳定性) 1.直接插入排序 核心思…...
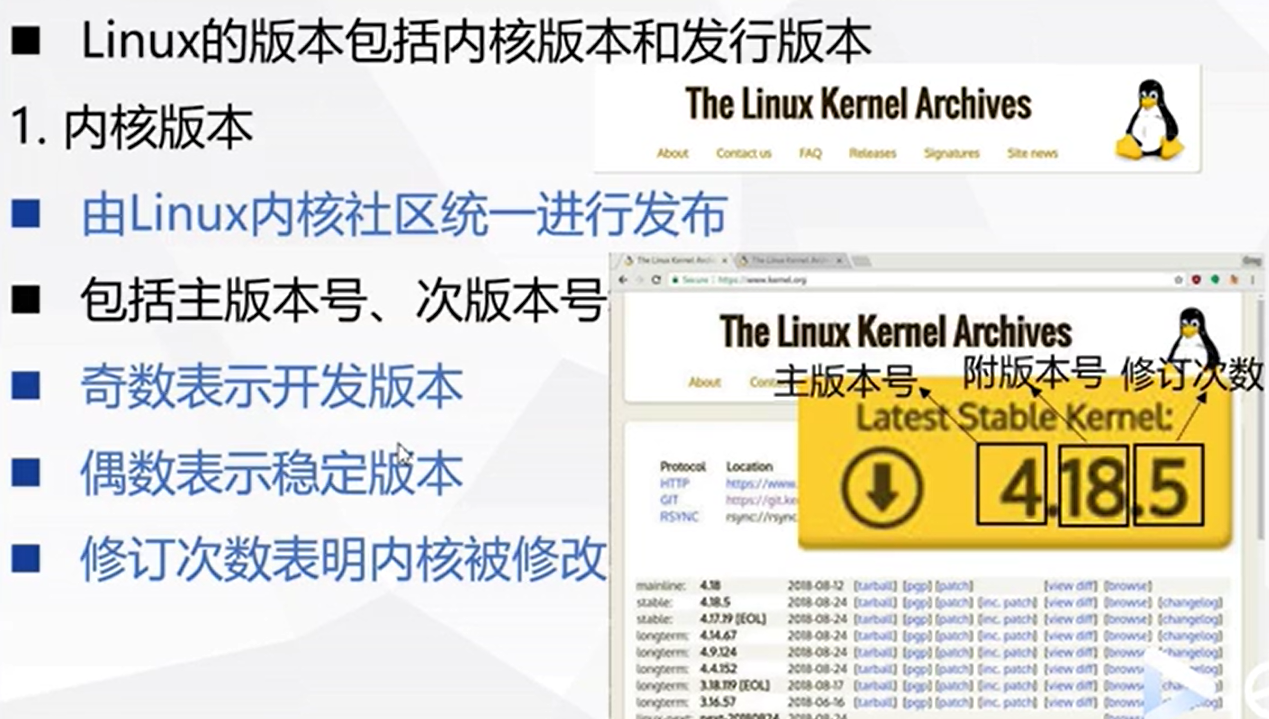
UNIX 系统概要
UNIX 家族UNIX 家谱家族后起之秀 LinuxUNIX vs LinuxUNIX/Linux 应用领域 UNIX 操作系统诞生与发展UNIX 操作系统概要内核常驻模块shell虚拟计算机特性 其他操作系统 LinuxRichard StallmanGNU 项目FSF 组织GPL 协议Linus Torvalds UNIX 家族 有人说,这个世界上只有…...
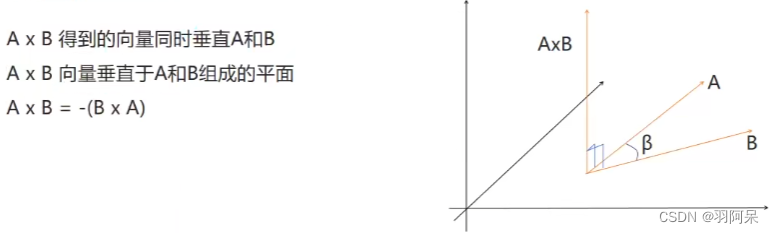
Unity 基础函数
Mathf: //1.π-PI print(Mathf.PI); //2.取绝对值-Abs print(Mathf.Abs(-10)); print(Mathf.Abs(-20)); print(Mathf.Abs(1)); //3.向上取整-Ce il To In t float f 1.3f; int i (int)f; …...
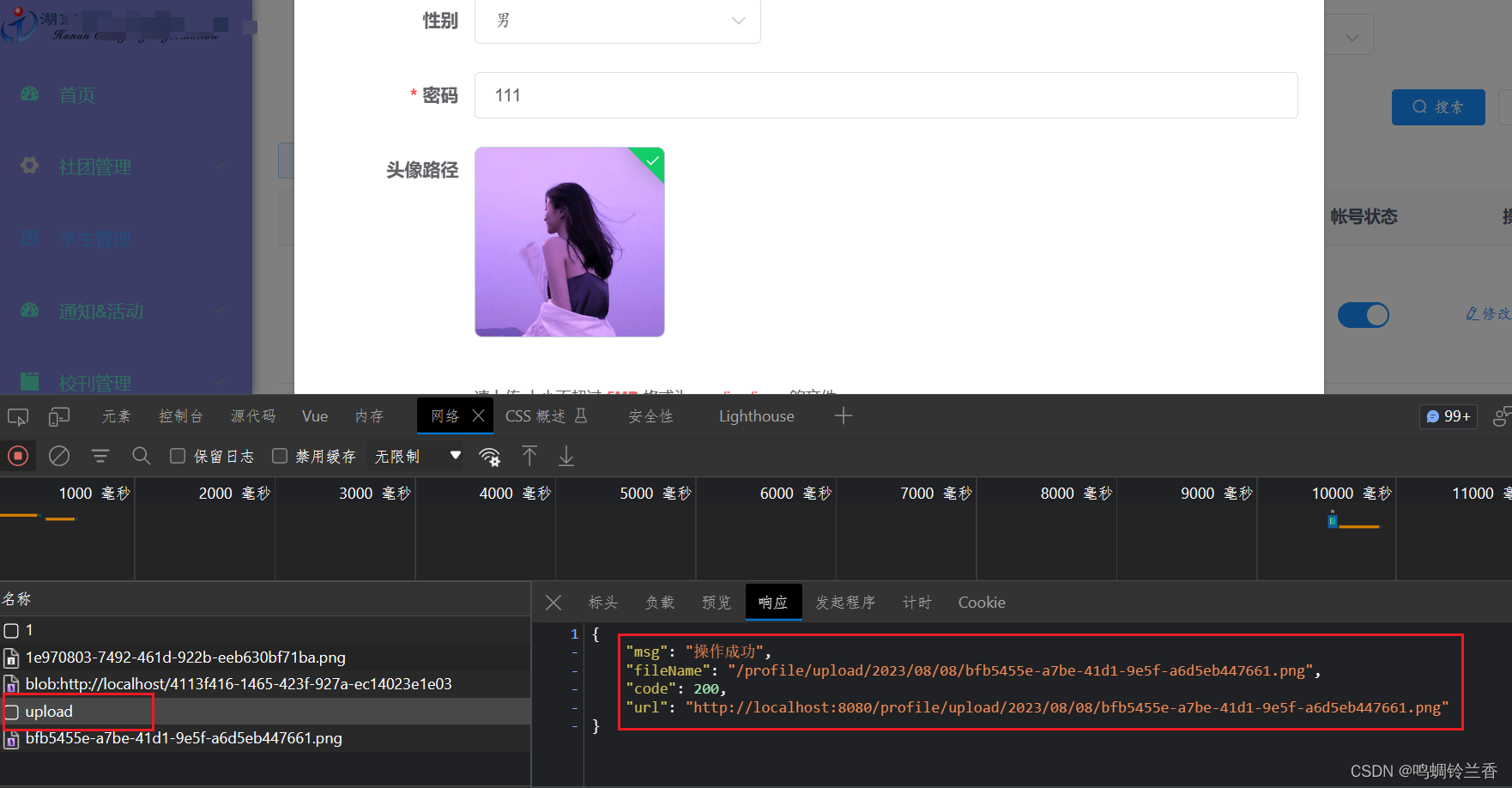
【学习】若依源码(前后端分离版)之 “ 上传图片功能实现”
大型纪录片:学习若依源码(前后端分离版)之 “ 上传图片功能实现” 前言前端部分后端部分结语 前言 图片上传也基本是一个项目的必备功能了,所以今天和大家分享一下我最近在使用若依前后端分离版本时,如何实现图片上传…...
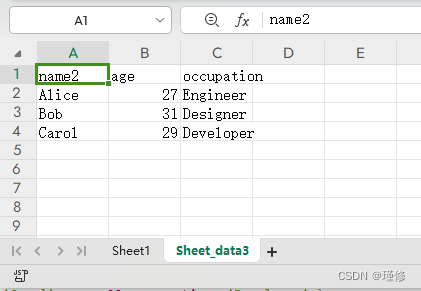
vue3 excel 导出功能
1.安装 xlsx 库 npm install xlsx2.创建导出函数 src/utils/excelUtils.js import * as XLSX from xlsx;const exportToExcel (fileName, datas, sheetNames) > {// 创建工作簿const wb XLSX.utils.book_new()for (let i 0; i < datas.length; i) {let data datas…...

python 相关框架事务开启方式
前言 对于框架而言,各式API接口少不了伴随着事务的场景,下面就列举常用框架的事务开启方法 一、Django import traceback from django.db import transaction from django.contrib.auth.models import User try:with transaction.atomic(): # 在with…...

vue使用ElementUI
1.安装 npm i element-ui -S 2.引入 2.1完整引入 import Vue from vue; import ElementUI from element-ui; import element-ui/lib/theme-chalk/index.css; import App from ./App.vue;Vue.use(ElementUI); 2.2按需引入 说明:为了输入时候有提示,建…...

Python做一个绘图系统3:从文本文件导入数据并绘图
文章目录 导入数据文件对话框修改绘图逻辑源代码 Python绘图系统系列:将matplotlib嵌入到tkinter 简单的绘图系统 导入数据 单纯从作图的角度来说,更多情况是已经有了一组数据,然后需要将其绘制。这组数据可能是txt格式的,也可能…...

flutter开发实战-获取Widget的大小及位置
flutter开发实战-获取Widget的大小及位置 最近开发过程中需要获取Widget的大小及位置,这时候就需要使用到了GlobalKey了和WidgetsBinding.instance.addPostFrameCallback了 一、addPostFrameCallback 该函数的作用: flutter中的界面组件Widget每一帧…...

软件测试工程师面试如何描述自动化测试是怎么实现的?
软件测试工程师面试的时候,但凡简历中有透露一点点自己会自动化测试的技能点的描述,都会被面试官问,那你结合你的测试项目说说自动化测试是怎么实现的?一到这里,很多网友,包括我的学生,也都一脸…...

Qt5兼容使用之前Qt4接口 intersect接口
1. 问题 项目卡中遇到编译报错, 错误 C2039 “intersect”: 不是“QRect”的成员 。 2. 排查过程 排查到依赖的第三方代码,使用 intersect 接口, 跟踪排查到头文件中使用了***#if QT_DEPRECATED_SINCE(5, 0)*** #if QT_DEPRECATED_SINCE…...

【云原生】Kubernetes节点亲和性分配 Pod
目录 1 给节点添加标签 2 根据选择节点标签指派 pod 到指定节点[nodeSelector] 3 根据节点名称指派 pod 到指定节点[nodeName] 4 根据 亲和性和反亲和性 指派 pod 到指定节点 5 节点亲和性权重 6 pod 间亲和性和反亲和性及权重 7 污点和容忍度 8 Pod 拓扑分布约束 官方…...
)
【Essential C++课后练习】纯代码(更新中)
文章目录 第一章 C编程基础1.41.51.61.71.8 第二章 面向过程的编程风格2.12.22.32.42.52.6 第一章 C编程基础 1.4 /*********************************************************************说明:试着扩充这个程序的内容:(1)要求用户同时输…...

C#仿热血江湖GClass
目录 1 C#仿热血江湖GClass 1.1 GClass32 1.2 method_4 1.3 smethod_0 C#仿热血江湖GClass public class GClass32 { private byte[] byte_0;...

[SQL智慧航行者] - 用户购买商品推荐
话不多说, 先看数据表信息. 数据表信息: employee 表, 包含所有员工信息, 每个员工有其对应的 id, salary 和 departmentid. --------------------------------- | id | name | salary | departmentid | --------------------------------- | 1 | Joe | 70000 | 1 …...

Windows Cleaner:终极C盘空间清理指南,告别系统卡顿与存储危机
Windows Cleaner:终极C盘空间清理指南,告别系统卡顿与存储危机 【免费下载链接】WindowsCleaner Windows Cleaner——专治C盘爆红及各种不服! 项目地址: https://gitcode.com/gh_mirrors/wi/WindowsCleaner 你是否曾因C盘爆红而焦虑&a…...

等保测评知多少?等保测评规定几年做一次
等保测评知多少?等保测评规定几年做一次 随着网络信息技术的快速发展,为了进一步规范对网站的管理,国家要求商家及企业进行等保测评。那等保测评是什么意思?下面,就跟龙翊信安一起来看看吧。 一、等保测评是什么含义 等…...
)
STM32F103片内Flash 存储器操作(FLASH页划分)
一、Flash 基础1.1 什么是 Flash?Flash Memory: 闪存存储器定义: 一种非易失性存储器,掉电后数据不丢失核心特性:非易失性: 掉电后数据不丢失 可擦写: 可以多次擦除和写入 块操作: 擦…...

Felgo框架在QmlBook中的应用:快速构建企业级应用
Felgo框架在QmlBook中的应用:快速构建企业级应用 【免费下载链接】qmlbook The source code for the upcoming qml book 项目地址: https://gitcode.com/gh_mirrors/qm/qmlbook Felgo框架是QmlBook中推荐的企业级应用开发解决方案,它基于Qt框架扩…...

终极Node.js最佳实践指南:2024年102个开发技巧大揭秘
终极Node.js最佳实践指南:2024年102个开发技巧大揭秘 【免费下载链接】nodebestpractices :white_check_mark: The Node.js best practices list (July 2024) 项目地址: https://gitcode.com/GitHub_Trending/no/nodebestpractices Node.js开发者在构建企业级…...

AI+3D视觉重塑金属圆棒自动化上下料:高精度、快节拍、降成本实战案例
在汽车、金属加工等核心制造领域,金属圆棒作为基础关键工件,其上下料环节的自动化水平直接决定产线效率与产品一致性。传统人工上下料存在强度大、效率低、精度波动、易损伤工件等痛点,而**AI3D视觉引导机器人**正成为破解该场景瓶颈的主流技…...

【K8S专题】深入浅出 Kubernetes 探针:存活、就绪与启动探针的原理与实战指南
深入浅出 Kubernetes 探针:存活、就绪与启动探针的原理与实战指南一、 引言:为什么我们需要探针?二、 核心概念详解:三大探针的角色定位1. 存活探针:看门狗2. 就绪探针:流量守门人3. 启动探针:慢…...

Phi-4-mini-reasoning辅助软件测试:智能生成测试用例与缺陷推理
Phi-4-mini-reasoning辅助软件测试:智能生成测试用例与缺陷推理 1. 引言:当AI遇见软件测试 "昨天又加班到凌晨,就为了赶测试用例..."这是测试工程师小王的日常吐槽。在软件测试领域,编写全面的测试用例和发现潜在缺陷…...

AIGlasses_for_navigation 与操作系统原理结合:实现高并发推理服务
AIGlasses_for_navigation 与操作系统原理结合:实现高并发推理服务 最近在折腾一个基于AIGlasses_for_navigation的实时导航服务,想法挺酷,但一上线就遇到了大麻烦。想象一下,成千上万的用户同时请求路线规划,你的服务…...

Qwen3-32B问题解决:常见部署错误及解决方法汇总
Qwen3-32B问题解决:常见部署错误及解决方法汇总 1. 引言:为什么部署Qwen3-32B会遇到问题? 部署320亿参数的大语言模型从来不是一件简单的事。即使Qwen3-32B在性能上已经做了大量优化,但在实际部署过程中,开发者仍会遇…...