Pytorch量化之Post Train Static Quantization(训练后静态量化)
使用Pytorch训练出的模型权重为fp32,部署时,为了加快速度,一般会将模型量化至int8。与fp32相比,int8模型的大小为原来的1/4, 速度为2~4倍。
Pytorch支持三种量化方式:
- 动态量化(Dynamic Quantization): 只量化权重,激活在推理过程中进行量化
- 静态量化(Static Quantization): 量化权重和激活
- 量化感知训练(Quantization Aware Training,QAT): 插入量化算子后进行训练,主要在静态量化精度不满足需求时进行。
大多数情况下,我们只需要进行静态量化,少数情况下在量化感知训练不满足时使用QAT进行微调。所以本篇只重点讲静态量化,并且理论部分先略过(后面再专门总结),只关注实操。
注:下面的代码是在pytorch1.10下,后面Pytorch对量化的接口有调整
官方文档:Quantization — PyTorch 1.10 documentation
动态模式(Eager Mode)与静态模式(fx graph)
Pytorch支持用2种方式量化,一种是动态图模式,也是我们日常使用Pytorch训练所使用的方式,使用这种方式量化需要自己手动修改网络结构,在支持量化的算子前、后插入量化节点,优点是方便调试。静态模式则是由pytorch自动在计算图中插入量化节点,不需要手动修改网络。
网络上大部分的教程都是基于静态模式,这种方式比较大的问题就是需要手动修改网络结构,官方教程里的网络是属于demo型, 其中的QuantStub和DeQuantStub就分别是量化和反量化的节点:
# define a floating point model where some layers could be statically quantized
class M(torch.nn.Module):def __init__(self):super(M, self).__init__()# QuantStub converts tensors from floating point to quantizedself.quant = torch.quantization.QuantStub()self.conv = torch.nn.Conv2d(1, 1, 1)self.relu = torch.nn.ReLU()# DeQuantStub converts tensors from quantized to floating pointself.dequant = torch.quantization.DeQuantStub()def forward(self, x):# manually specify where tensors will be converted from floating# point to quantized in the quantized modelx = self.quant(x)x = self.conv(x)x = self.relu(x)# manually specify where tensors will be converted from quantized# to floating point in the quantized modelx = self.dequant(x)return x
Pytorch对于很多网络层是不支持量化的(比如很常用的Prelu),如果我们用这种方式,我们就必须在这些不支持的层前面插入DeQuantStub,然后在支持的层前面插入QuantStub。笔者体验下来,体验很差,个人觉得不太实用,会破坏原来的网络结构。
而静态图模式,我们只需要调用Pytorch提供的接口将原模型转换一下即可,不需要修改原来的网络结构文件,个人认为实用性更强。

静态模式量化
1. 载入fp32模型,并转成fx graph
其中量化参数有‘fbgemm’和‘qnnpack’两种,前者在x86运行,后者在arm运行。
model_fp32 = torch.load(xxx)
model_fp32_quantize = copy.deepcopy(model_fp32)
qconfig_dict = {"": torch.quantization.get_default_qconfig('fbgemm')}
model_fp32_quantize.eval()
# preparemodel_prepared = quantize_fx.prepare_fx(model_fp32_quantize, qconfig_dict)
model_prepared.eval()
2.读取量化数据,标定(Calibration)量化参数
标定的过程就是使用模型推理量化图片,然后统计权重和激活分布,从而得到量化参数。量化图片一般来源于训练集(几百张左右,根据测试情况调整)。量化图片可以通过Pytorch的Dataloader读取,也可以直接自行实现读图片然后送入网络。
### 使用dataloader读取
for i, (data, label) in enumerate(train_loader):data = data.to(torch.device("cpu:0"))outputs = model_prepared(data)print("calibrating {}".format(i))if i > 1000:break
3. 转换为量化模型并保存
quantized_model = quantize_fx.convert_fx(model_prepared)
torch.jit.save(torch.jit.script(quantized_model), "quantized_model.pt")
速度测试
量化后的模型使用方法与fp32模型一样:
import torch
import cv2
import numpy as np
torch.set_num_threads(1)fused_model = torch.jit.load("jit_model.pt")
fused_model.eval()
fused_model.to(torch.device("cpu:0"))img = cv2.imread("./1.png")
img_fp32 = img.astype(np.float32)
img_fp32 = (img_fp32-127.5) / 127.5
input = torch.from_numpy(img).permute(2, 0, 1).unsqueeze(0).float()def speed_test(model, input):# warm upfor i in range(10):model(input)import timestart = time.time()for i in range(100):model(input)end = time.time()print("model time: ", (end-start)/100)time.sleep(10)# quantized model
quantized_model= torch.jit.load("quantized_model.pt")
quantized_model.eval()
quantized_model.to(torch.device("cpu:0"))speed_test(fused_model, input)
speed_test(quantized_model, input)
实测fp32模型单核运行120ms, 量化后47ms
结语
本文介绍了fx graph模式下的Pytorch的PTSQ方法,并实测了一个模型,效果还比较不错。

相关文章:
Pytorch量化之Post Train Static Quantization(训练后静态量化)
使用Pytorch训练出的模型权重为fp32,部署时,为了加快速度,一般会将模型量化至int8。与fp32相比,int8模型的大小为原来的1/4, 速度为2~4倍。 Pytorch支持三种量化方式: 动态量化(Dynamic Quantization&…...

Sql奇技淫巧之EXIST实现分层过滤
在这样一个场景,我 left join 了很多张表,用这些表的不同列来过滤,看起来非常合理 但是出现的问题是 left join 其中一张或多张表出现了笛卡尔积,且无法消除 FUNCTION fun_get_xxx_helper(v_param_1 VARCHAR2,v_param_2 VARCHAR2…...

Linux下升级jdk1.8小版本
先输入java -version 查看是否安装了jdk java -version (1)如果没有返回值,直接安装新的jdk即可。 (2)如果有返回值,例如: java version "1.8.0_251" Java(TM) SE Runtime Enviro…...

【Mysql】数据库基础与基本操作
🌇个人主页:平凡的小苏 📚学习格言:命运给你一个低的起点,是想看你精彩的翻盘,而不是让你自甘堕落,脚下的路虽然难走,但我还能走,比起向阳而生,我更想尝试逆风…...

87 | Python人工智能篇 —— 机器学习算法 决策树
本教程将深入探讨决策树的基本原理,包括特征选择方法、树的构建过程以及剪枝技术,旨在帮助读者全面理解决策树算法的工作机制。同时,我们将使用 Python 和 scikit-learn 库演示如何轻松地实现和应用决策树,以及如何对结果进行可视化。无论您是初学者还是有一定机器学习经验…...
【计算机视觉】干货分享:Segmentation model PyTorch(快速搭建图像分割网络)
一、前言 如何快速搭建图像分割网络? 要手写把backbone ,手写decoder 吗? 介绍一个分割神器,分分钟搭建一个分割网络。 仓库的地址: https://github.com/qubvel/segmentation_models.pytorch该库的主要特点是&#…...
解析湖仓一体的支撑技术及实践路径
自2021年“湖仓一体”首次写入Gartner数据管理领域成熟度模型报告以来,随着企业数字化转型的不断深入,“湖仓一体”作为新型的技术受到了前所未有的关注,越来越多的企业视“湖仓一体” 为数字化转型的重要基础设施。 01 数据平台的发展历程…...
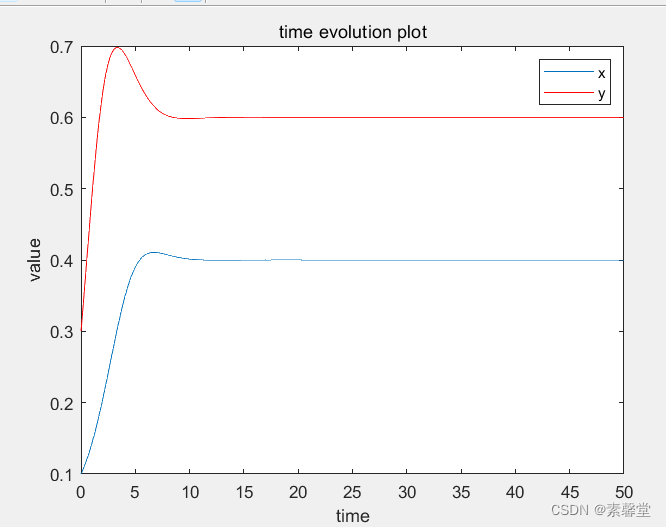
40.利用欧拉法求解微分方程组(matlab程序)
1.简述 求解微分方程的时候,如果不能将求出结果的表达式,则可以对利用数值积分对微分方程求解,获取数值解。欧拉方法是最简单的一种数值解法。前面介绍过MATLAB实例讲解欧拉法求解微分方程,今天实例讲解欧拉法求解一阶微分方程组。…...

OpenAI-Translator 实战总结
最近在极客时间学习《AI 大模型应用开发实战营》,自己一边跟着学一边开发了一个进阶版本的 OpenAI-Translator,在这里简单记录下开发过程和心得体会,供有兴趣的同学参考 功能概览 通过openai的chat API,实现一个pdf翻译器实现一个…...
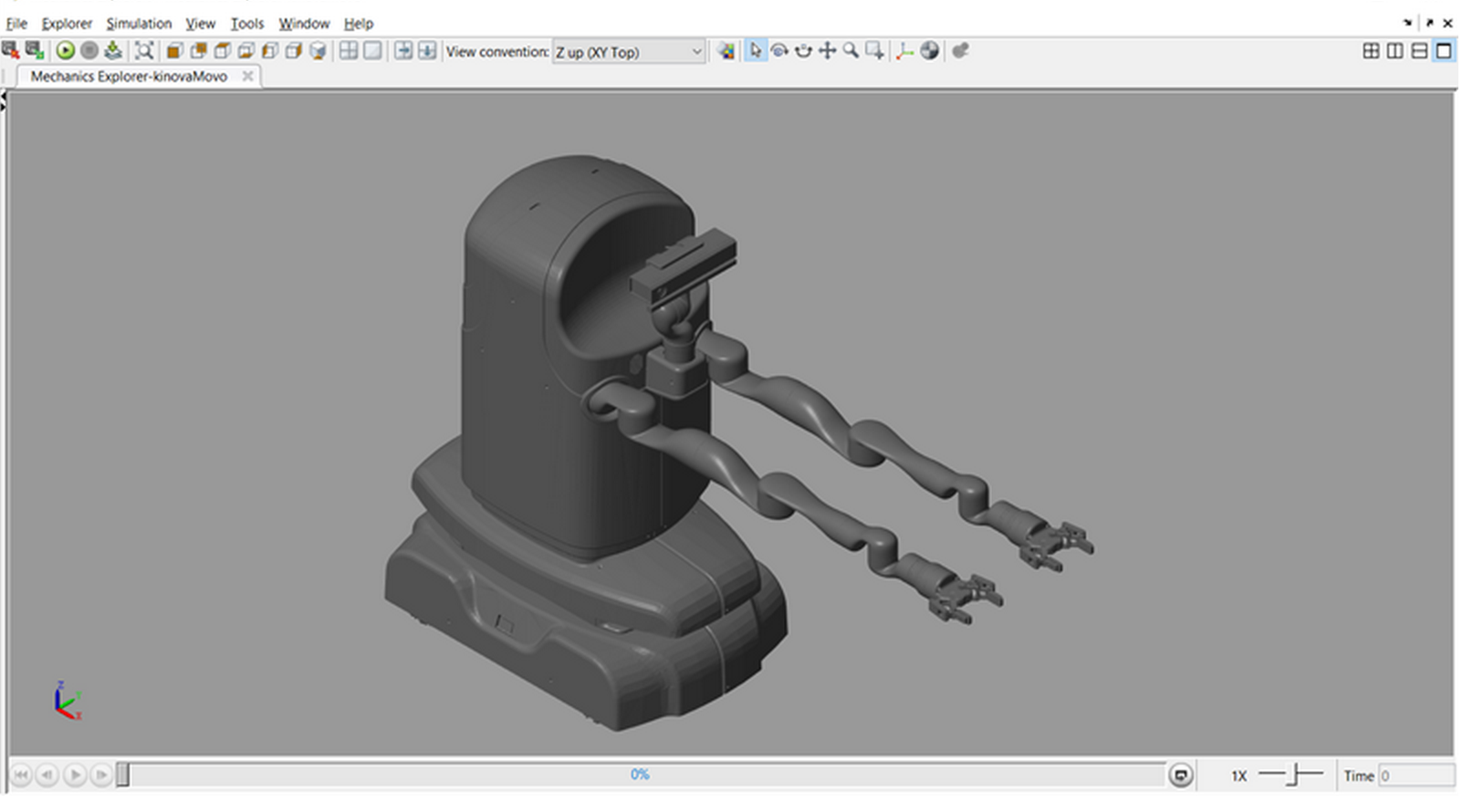
【工业机器人】用于轨迹规划和执行器分析的机械手和移动机器人模型(MatlabSimulink)
💥💥💞💞欢迎来到本博客❤️❤️💥💥 🏆博主优势:🌞🌞🌞博客内容尽量做到思维缜密,逻辑清晰,为了方便读者。 ⛳️座右铭&a…...

开源在线文档服务OnlyOffice
开源在线文档服务OnlyOffice应用启动与示例运行 - 掘金 ONLYOFFICE API 文档 - Example - IDEA运行Java示例 | ONLYOFFICE中文网 NEXTCLOUDonlyoffice的搭建和使用_nextcloud onlyoffice_莫冲的博客-CSDN博客 OnlyOffice java 部署使用,文件流方式 预览文件 | 言曌博…...

汽车基本常识
目录 电源KL30KL15 零部件简称 电源 KL30 KL15 零部件简称 VCU:整车控制器 直接网络管理节点 CDU:充电系统控制器 MCU:电机控制器 TCU:变速箱控制器 ABS:防抱死系统 EPS:助力转向 T-Box:远程…...

百度资深PMO阚洁受邀为第十二届中国PMO大会演讲嘉宾
百度在线网络技术(北京)有限公司资深PMO阚洁女士受邀为由PMO评论主办的2023第十二届中国PMO大会演讲嘉宾,演讲议题:运筹于股掌之间,决胜于千里之外 —— 360斡旋项目干系人。大会将于8月12-13日在北京举办,…...

为什么C++有多种整型?
C中有多种整型是为了满足不同的需求,提供更灵活和高效的整数表示方式。不同的整型具有不同的字节大小、范围和精度,可以根据应用的需求选择合适的整型类型。以下是一些原因解释为什么C有多种整型: 内存和性能优化:不同的整型在内存…...
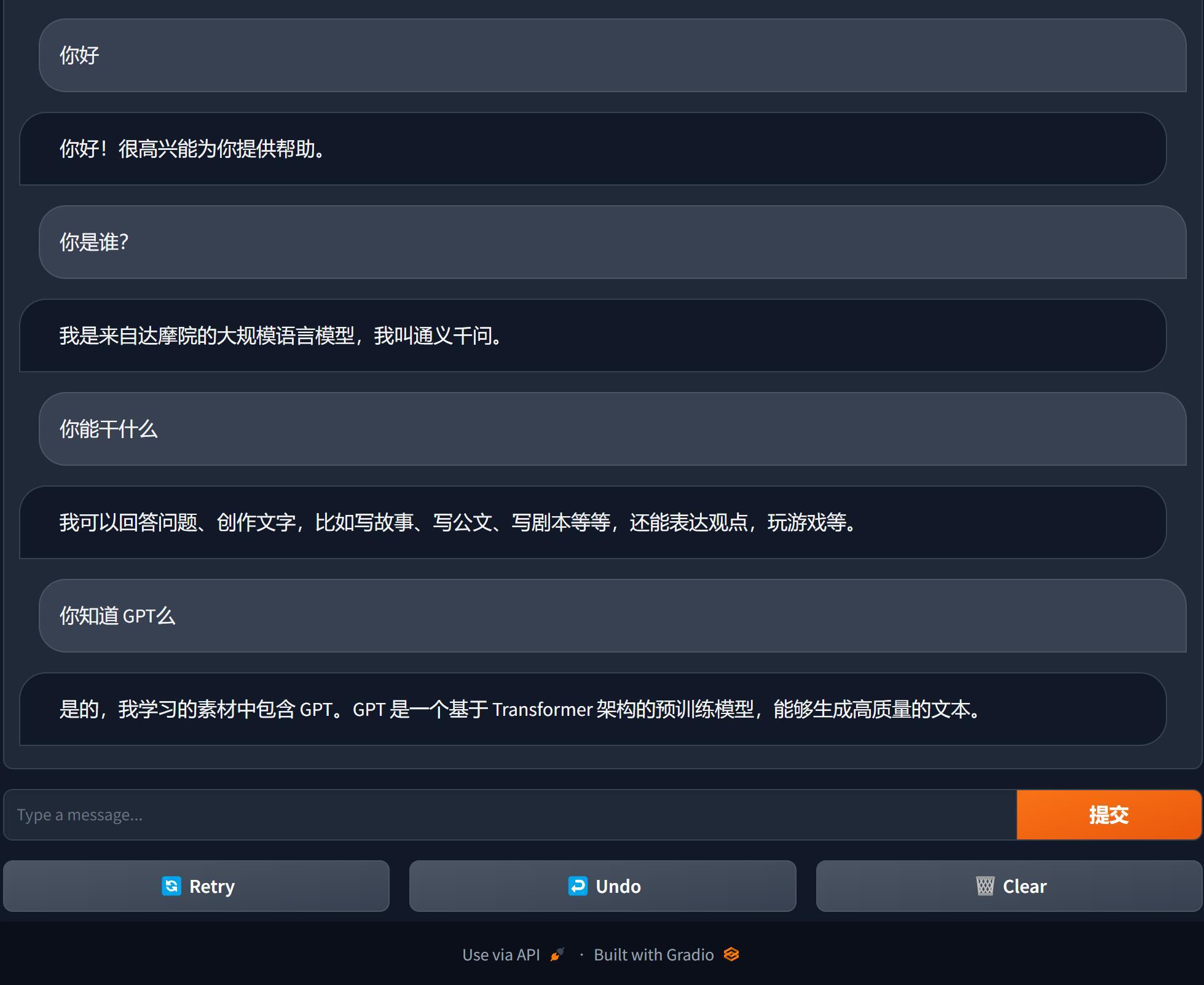
玩一玩通义千问Qwen开源版,Win11 RTX3060本地安装记录!
大概在两天前,阿里做了一件大事儿。 就是开源了一个低配版的通义千问模型--通义千问-7B-Chat。 这应该是国内第一个大厂开源的大语言模型吧。 虽然是低配版,但是在各类测试里面都非常能打。 官方介绍: Qwen-7B是基于Transformer的大语言模…...

oracle积累增量和差异增量
积累增量和差异增量: 对于 RMAN 来说,积累增量备份和差异增量备份都是增量备份的一种形式,它们之间的区别在于备份的范围和备份集的方式。 积累增量备份:在进行积累增量备份时,RMAN 会备份自最后一次完全备份或增量备…...
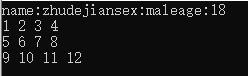
利用C++nlohmann库解析json文件
json文件示例: 代码运行环境VS2019 一、git下载nlohmann库文件源代码 源代码文件目录 二、利用VS2019新建工程,并配置项目属性 配置VC目录---包含目录 三、项目源代码 #include <iostream> #include <fstream> #include <nlohmann/jso…...

OpenCV 中的光流 (C++/Python)
什么是光流? 光流是一项视频中两个连续帧之间每像素运动估计的任务。基本上,光流任务意味着计算像素的位移矢量作为两个相邻图像之间的对象位移差。光流的主要思想是估计物体由其运动或相机运动引起的位移矢量。 理论基础 假设我们有一个灰度图像——具有像素强度的矩阵。我…...
第9集丨Vue 江湖 —— 监测数据原理
目录 一、修改数据时的一个问题1.1 现象一1.2 现象二 二、Vue监测数据原理2.1 模拟一个数据监测2.2 数据劫持2.3 Vue.set()/vm.$set()2.4 基本原理2.4.1 如何监测对象中的数据?2.4.2 如何监测数组中的数据?2.4.3 修改数组中的某个元素 2.5 案例2.5.1 需求功能2.5.2 实现 一、…...

【YOLO】替换骨干网络为轻量级网络MobileNet3
替换骨干网络为轻量级网络MobileNet_v3 上一章 模型网络结构解析&增加小目标检测 文章目录 替换骨干网络为轻量级网络MobileNet_v3前言一、MobileNetV3介绍二、MobileNetV2&MobileNetV3三、MobileNetV3网络结构1. 结构查看2. 查看每层featuremap大小三、YOLOV5替换骨干…...

背包问题避坑指南:为什么贪心算法有时会失效?
贪心算法的陷阱:为什么背包问题中局部最优不等于全局最优? 在算法设计的浩瀚海洋中,贪心算法以其简洁高效的特点备受青睐。它像一位精明的商人,每一步都做出当下看起来最有利的选择。然而,这种"目光短浅"的策…...

同花顺_策略解码_五彩K线实战指南
1. 五彩K线入门:从代码看市场语言 第一次打开同花顺的五彩K线功能时,我盯着屏幕上突然变得花花绿绿的走势图愣了半天。这些红红绿绿的标记背后,其实藏着程序员用代码翻译的市场密码。就像交通信号灯用颜色指挥车辆通行,五彩K线用颜…...
)
HC-05蓝牙模块AT模式配置全攻略:用STM32CubeIDE的串口调试功能搞定(免USB转TTL)
HC-05蓝牙模块AT模式配置全攻略:用STM32CubeIDE的串口调试功能搞定(免USB转TTL) 当你手头只有一块STM32开发板和HC-05蓝牙模块,却需要快速配置模块参数时,传统方法要求额外的USB转TTL工具往往成为绊脚石。本文将揭示如…...

Rust 内存分配与所有权管理
Rust 内存分配与所有权管理:安全与性能的完美平衡 在编程语言的世界中,内存管理一直是开发者面临的核心挑战之一。传统语言如 C/C 依赖手动管理内存,容易引发内存泄漏或悬垂指针;而 Java 等语言采用垃圾回收机制(GC&a…...

**图神经网络实战:用PyTorch Geometric构建社交关系预测模型**在当前人工智能飞速发展的背景下,**图神经网络(GN
图神经网络实战:用PyTorch Geometric构建社交关系预测模型 在当前人工智能飞速发展的背景下,图神经网络(GNN) 已成为处理复杂结构化数据的利器,尤其在社交网络分析、推荐系统和知识图谱等领域表现卓越。本文将带你从零…...

建立班级相册?超简单,保姆级教你在PPT里建立班级“小红书”,3步打造有温度的班级小世界!
边听边看收获更多! 班级相册超简单,保姆级教你在PPT里建立班级“小红书”社区!你有搞班级相册吗? 是不是早已 “名存实亡”? 每次班级活动拍了几十张照片,最后都散落在微信群、QQ 群的聊天记录里 —— 想找…...

[精品]基于微信小程序的校园二手书籍交易平台的设计与实现 UniApp
收藏关注不迷路!!需要的小伙伴可以发链接或者截图给我 这里写目录标题 项目介绍项目实现效果图所需技术栈文件解析微信开发者工具HBuilderXuniappmysql数据库与主流编程语言登录的业务流程的顺序是:毕设制作流程系统性能核心代码系统测试详细…...

PowerShell色彩魔法:利用ANSI转义序列打造个性化终端输出
1. 从黑白到彩色:PowerShell终端的美化革命 记得刚接触编程那会儿,最让我头疼的就是PowerShell那个黑漆漆的窗口。每次调试脚本,满屏的白色文字看得眼睛发酸,关键信息总是淹没在茫茫输出中。直到有一天,我在Linux终端看…...

Wan2.2-I2V-A14B效果对比:不同算法模型生成视频的质量评估
Wan2.2-I2V-A14B效果对比:不同算法模型生成视频的质量评估 1. 开场白:为什么需要关注视频生成质量 最近两年,从图片生成视频的技术发展迅猛,各种算法模型层出不穷。但作为实际使用者,我们最关心的还是:哪…...

从零构建基于Hadoop的网站流量日志分析平台:以搜狗搜索日志为例
1. 为什么需要网站流量日志分析平台 每天都有数以亿计的用户在互联网上浏览网页、搜索信息。这些行为产生的日志数据就像一座金矿,蕴含着用户偏好、市场趋势等宝贵信息。但处理这些数据可不容易——想象一下,你要从500万条杂乱无章的日志记录中找出最有…...