torch.multiprocessing
文章目录
- 张量共享
- torch.multiprocessing.spawn
- multiprocessing.Pool与torch.multiprocessing.Pool
- 阻塞
- 非阻塞
- map
- 阻塞
- 非阻塞
- starmap
torch.multiprocessing是具有额外功能的multiprocessing,其 API 与multiprocessing完全兼容,因此我们可以将其用作直接替代品。
multiprocessing支持 3 种进程启动方法:fork(Unix 上默认)、spawn(Windows 和 MacOS 上默认)和forkserver。要在子进程中使用 CUDA,必须使用forkserver或spawn。启动方法应该通过set_start_method()在if name == 'main’主模块的子句中使用来设置一次:
import torch.multiprocessing as mpif __name__ == '__main__':mp.set_start_method('forkserver')...
张量共享
import torch.multiprocessing as mp
import timemat = torch.randn((200, 200))
print(mat.is_shared())queue = mp.Queue()
q.put(a)
print(a.is_shared())
#False
#True
import torch
import torch.multiprocessing as mp
import timedef foo(q):q.put(torch.randn(20, 20))q.put(torch.randn(10, 10))time.sleep(3)def bar(q):t1 = q.get()print(f"Received {t1.size()}")time.sleep(1) # 注意这里不能等待超过3,会导致foo结束,无法获取t2 = q.get()print(f"Received {t2.size()}")if __name__ == "__main__":mp.set_start_method('spawn')queue = mp.Queue()p1 = mp.Process(target=foo, args=(queue,))p2 = mp.Process(target=bar, args=(queue,))p1.start()p2.start()p1.join()p2.join()
仅在Python 3中使用spawn或forkserver启动方法才支持在进程之间共享CUDA张量。
torch.multiprocessing.spawn
torch.multiprocessing.spawn(fn,args=(),nprocs=1,join=True, # join (bool) – 执行一个阻塞的join对于所有进程.daemon=False, # daemon (bool) – 派生进程守护进程标志。如果设置为True,将创建守护进程.start_method="spawn",
)
其中,fn 是要在子进程中运行的函数,args 是传递给该函数的参数,nprocs 是要启动的进程数。当 nprocs 大于 1 时,会创建多个子进程,并在每个子进程中调用 fn 函数,每个子进程都会使用不同的进程 ID 进行标识。当 nprocs 等于 1 时,会在当前进程中直接调用 fn 函数,而不会创建新的子进程。
join=true时,主进程等待所有子进程完成执行并退出,然后继续执行后续的代码。在这个过程中,主进程会被阻塞,也就是说,主进程会暂停执行,直到所有子进程都完成了它们的任务。
torch.multiprocessing.spawn 函数会自动将数据分布到各个进程中,并在所有进程执行完成后进行同步,以确保各个进程之间的数据一致性。同时,该函数还支持多种进程间通信方式,如共享内存(Shared Memory)、管道(Pipe)等,可以根据具体的需求进行选择。
比如下面的fn
def main_worker(gpu, args): # gpu参数控制进程号args.rank = gpu # 用rank记录进程id号dist.init_process_group(backend='nccl', init_method=args.dist_url, world_size=args.num_gpus,rank=args.rank)torch.cuda.set_device(gpu) # 设置默认GPU 最好方法哦init之后,这样你使用.cuda(),数据就是去指定的gpu上了# 定义模型, 转同步BNmodel = xxxmodel = nn.SyncBatchNorm.convert_sync_batchnorm(model)model.cuda()model = torch.nn.parallel.DistributedDataParallel(model, device_ids=[gpu],find_unused_parameters=True )#定义数据集train_dataset = xxxx# 注意这一步,和单卡的唯一区别。这个sample能保证多个进程不会取重复的数据。shuffle必须设置为False(默认)train_sampler = torch.utils.data.distributed.DistributedSampler(train_dataset)train_loader = torch.utils.data.DataLoader(train_dataset,batch_size=args.batch_size,num_workers=args.workers, pin_memory=True, sampler=train_sampler)...if args.rank == 0 : # 主进程torch.save(xx)print(log)启动代码
import torch.multiprocessing as mp
import torch.distributed as distif __name__ == '__main__':# import configuration file# load json or yaml, argsparseargs = xxxxx# 接下来是设置多进程启动的代码# 1.首先设置端口,采用随机的办法,被占用的概率几乎很低.port_id = 29999args.dist_url = 'tcp://127.0.0.1:' + str(port_id)# 2. 然后统计能使用的GPU,决定我们要开几个进程,也被称为world sizeargs.num_gpus = torch.cuda.device_count()# 3. 多进程的启动torch.multiprocessing.set_start_method('spawn')mp.spawn(main_worker, nprocs=args.num_gpus, args=(args,))multiprocessing.Pool与torch.multiprocessing.Pool
multiprocessing.Pool创建一个进程池,每个进程都分配一个单独的内存空间。它是一个上下文管理器,因此可以在语句中使用with
with mp.Pool(processes=num_workers) as pool:
等价于
pool = mp.Pool(processes=num_workers)
# do something
pool.close()
pool.join()
阻塞
import time
import multiprocessing as mpdef foo(x, y):time.sleep(3)return x + ywith mp.Pool(processes=4) as pool:a = pool.apply(foo, (1, 2))b = pool.apply(foo, (3, 4))print(a, b)
# 3 7
#---
#Runtime: 6.0 seconds
创建一个包含 4 个工作进程的池,然后向池中提交两个任务来运行。由于apply是阻塞调用,因此主进程将等到第一个任务完成后再提交第二个任务。这基本上是无用的,因为这里没有实现并行性。
with mp.Pool(processes=4) as pool:handle1 = pool.apply_async(foo, (1, 2))handle2 = pool.apply_async(foo, (3, 4))a = handle1.get()b = handle2.get()print(a, b)
# 3 7
#---
#Runtime: 3.0 seconds
非阻塞
apply_async是非阻塞的并AsyncResult立即返回一个对象。然后我们可以使用它get来获取任务的结果。
注意get会阻塞直到任务完成;apply(fn, args, kwargs)相当于apply_async(fn, args, kwargs).get().
还可以加回调函数
def callback(result):print(f"Got result: {result}")with mp.Pool(processes=4) as pool:handle1 = pool.apply_async(foo, (1, 2), callback=callback)handle2 = pool.apply_async(foo, (3, 4), callback=callback)
#Got result: 3
#Got result: 7
#---
#Runtime: 3.0 seconds
map
map将输入的可迭代对象划分为块,并将每个块作为单独的任务提交到池中。然后收集任务的结果并以列表的形式返回。
阻塞
import multiprocessing as mp
import timedef foo(x):print(f"Starting foo({x})")time.sleep(2)return xwith mp.Pool(processes=2) as pool:result = pool.map(foo, range(10), chunksize=None)print(result)
Starting foo(0)
Starting foo(2)
Starting foo(1)
Starting foo(3)
Starting foo(4)
Starting foo(6)
Starting foo(5)
Starting foo(7)
Starting foo(8)
Starting foo(9)
[0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
---
Runtime: 12.0 seconds
在这种情况下,chunksize 自动计算为 2。这意味着可迭代对象被分为 5 个大小为 2: 的块[0, 1], [2, 3], [4, 5], [6, 7], [8, 9]。
map是一个阻塞调用,因此它将等待所有任务完成后再返回。与 apply类似
首先,前两个块[0, 1], [2, 3]分别被提交给2个worker,此时worker0执行0worker1执行2,然后worker0执行1worker1执行3;
然后接下来的两个块[4, 5], [6, 7]被提交。最后,最后一个块[8, 9]被提交给任一worker。
三次提交,每次提交运行2*2秒,共计12s,这不是最优的。在这种情况下,如果我们显式地将 chunksize 设置为 1 或 5,则运行时间将为 10 秒,这已经是最好的了。
非阻塞
with mp.Pool(processes=2) as pool:handle = pool.map_async(foo, range(10), chunksize=None)# do something elseresult = handle.get()print(result)
starmap
map只是将可迭代的元素传递给函数。如果想应用一个多参数函数,我们要么必须传入一个列表并将其解压到函数内。
使用starmap. 对于可迭代的每个元素,starmap将其解压到函数的参数中。
def bar(x, y):print(f"Starting bar({x}, {y})")time.sleep(2)return x + ywith mp.Pool(processes=2) as pool:pool.starmap(bar, [(1, 2), (3, 4), (5, 6)])
starmap是同步的,异步用starmap_async
https://tokudayo.github.io/multiprocessing-in-python-and-torch/#torchmultiprocessing
https://docs.python.org/zh-cn/3.7/library/multiprocessing.html
相关文章:

torch.multiprocessing
文章目录 张量共享torch.multiprocessing.spawnmultiprocessing.Pool与torch.multiprocessing.Pool阻塞非阻塞map阻塞非阻塞 starmap torch.multiprocessing是具有额外功能的multiprocessing,其 API 与multiprocessing完全兼容,因此我们可以将其用作直接…...

解决本地代码commit后发现远程分支被更新的烦恼!
解决本地代码commit后远程分支更新的烦恼! 在进行代码开发过程中,当我们准备将本地代码推送到远程分支时,有时会遇到远程分支已经被更新的情况。这给我们的开发工作带来了一些挑战,因为我们需要确保我们的修改与远程分支的更新保持…...
最新AI创作系统ChatGPT程序源码+详细搭建部署教程+微信公众号版+H5源码/支持GPT4.0+GPT联网提问/支持ai绘画+MJ以图生图+思维导图生成!
使用Nestjs和Vue3框架技术,持续集成AI能力到系统! 新增 MJ 官方图片重新生成指令功能同步官方 Vary 指令 单张图片对比加强 Vary(Strong) | Vary(Subtle)同步官方 Zoom 指令 单张图片无限缩放 Zoom out 2x | Zoom out 1.5x新增GPT联网提问功能、手机号注…...
)
910数据结构(2014年真题)
算法设计题 问题1 已知一个带头结点的单链表head,假设结点中的元素为整数,试编写算法:按递增次序输出单链表中各个结点的数据元素,并释放结点所占的存储空间。要求:(1)用文字给出你的算法思想;(2)不允许使…...
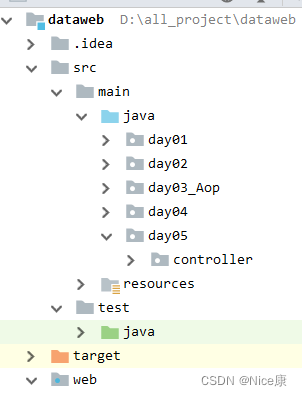
Idea创建maven管理的web项目
如果你想在项目中添加一个传统的 src 目录来存放源代码,可以按照以下步骤操作: 1. 在项目视图中,右键单击项目名称,选择 “New” -> “Directory”。 2. 在弹出的对话框中,输入目录名称为 “src”,然后…...
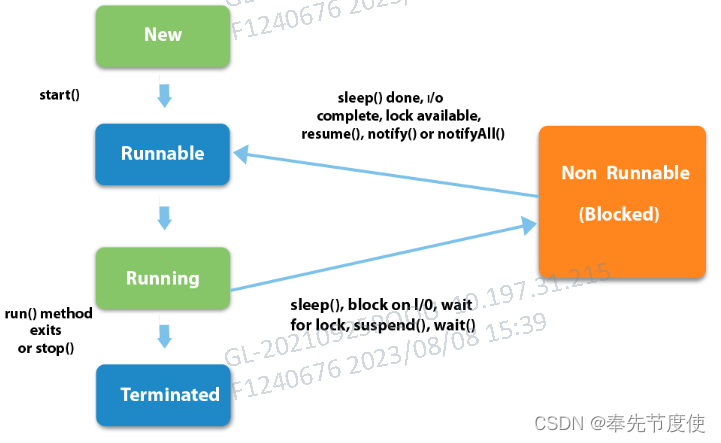
Java并发编程(一)多线程基础概念
概述 多线程技术:基于软件或者硬件实现多个线程并发执行的技术 线程可以理解为轻量级进程,切换开销远远小于进程 在多核CPU的计算机下,使用多线程可以更好的利用计算机资源从而提高计算机利用率和效率来应对现如今的高并发网络环境 并发编程…...
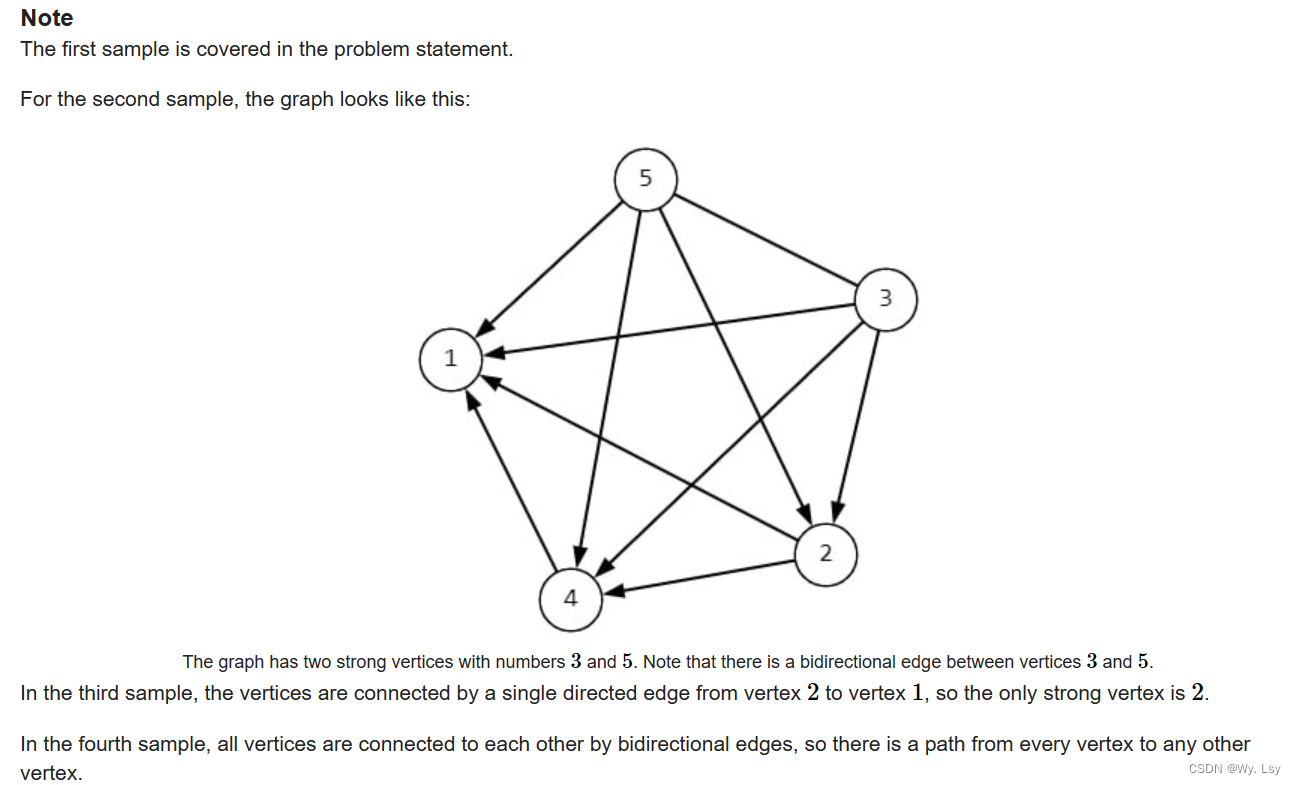
D. Strong Vertices - 思维 + 二分
分析: 首先找到边的指向很容易,但是暴力是o(n2),超时,可以将给定的式子变形,au - av > bu - bv即au - bu > av - bv,可以将两个数组转变为一个数组中的任意两个值之间的关系,因…...

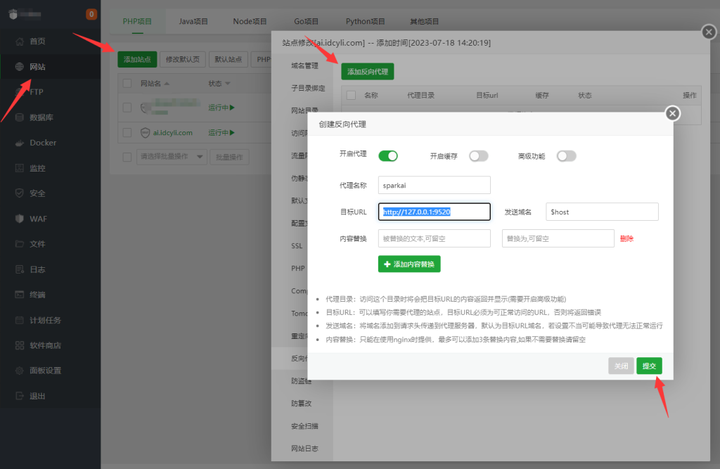
8月9日上课内容 nginx负载均衡
负载均衡工作当中用的很多的,也是面试会问的很重要的一个点 负载均衡:通过反向代理来实现(nginx只有反向代理才能做负载均衡) 正向代理的配置方法(用的较少) 反向代理的方式:四层代理与七层代…...

为何我们都应关心算法备案?
随着技术的日新月异,算法成为现代生活的核心组成部分,从社交媒体推荐、在线广告到智能交通管理,几乎无处不在。然而,如此普及的技术给我们带来了一个新的挑战:如何确保算法的透明度、公正性和道德性?答案可…...
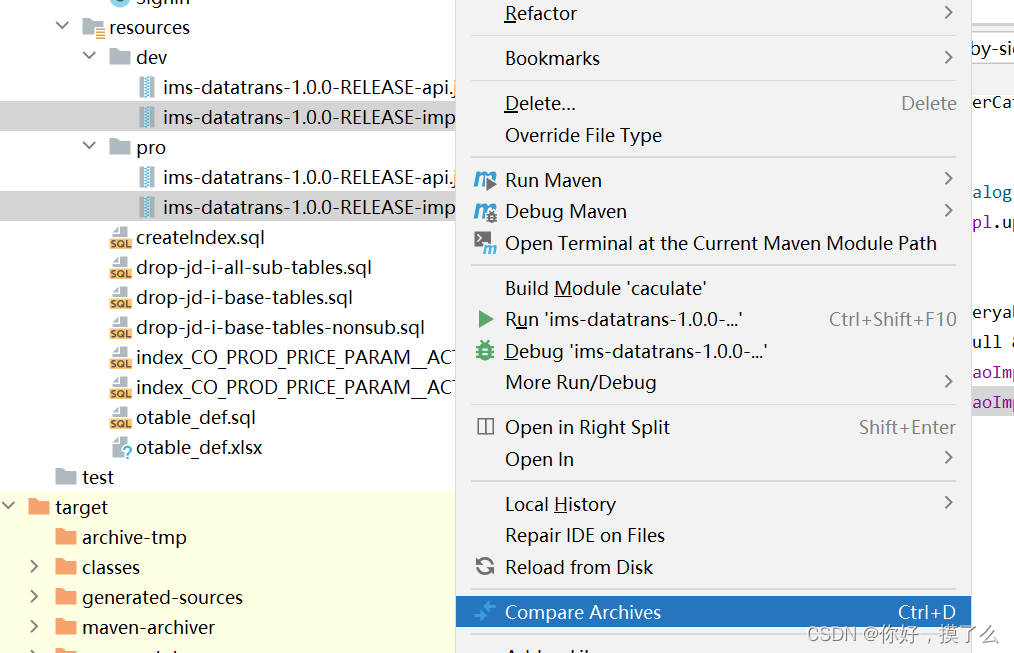
[IDEA]使用idea比较两个jar包的差异
除了一些小工具外,idea自带了jar包比较的功能。 把需要比对的jar包放到任意目录下,然后选中两个需要比较的jar包,右键,选择Compare Archives,然后就可以比较了。 这次疏忽了,每次打包前需要commit界面看一下…...

HTML笔记(2)
列表标签 项目标识符(项目符号)一般是不需要的 代码演示 改变符号样式,type属性 表格标签 代码演示 练习案例 布局标签 div是块儿级标签,占一整行; span标签不会占一整行,它只占包裹内容的那块儿区域&a…...

前端大屏自适应缩放
简介 前端中大屏往往用于展示各种炫酷的界面和特效,因此特别受用好欢迎。 但是在开发过程中,常常也会出现各种问题,与一般的页面相比, 最让人头疼的是大屏的自适应问题。使用CSS中transform属性和js获取缩放比例方法 先简单写一下…...

【Express.js】全面鉴权
全面鉴权 这一节我们来介绍一下 Passport.js,这是一个强大的 NodeJS 的认证中间件 Passport.js 提供了多种认证方式,账号密码、OpenID、ApiKey、JWT、OAuth、三方登录等等。 使用 Passport.js 认证要配置三个部分: 认证策略中间件会话 接…...

了解华为(H3C)网络设备和OSI模型基本概念
目录 一,认识华为 1.华为发展史 2.华为网络设备介绍 3.VRP概述 二,OSI七层模型 1.七层模型详细表格 2.各层的作用 3.数据在各层之间的传递过程 4.OSI四层网络模型 一,认识华为 官网:https://www.huawei.com/cn/ 1.华为发…...

Web3到底是个啥?
Web3是近两年来科技领域最火热的概念之一,但是目前对于Web3的定义却仍然没有形成标准答案,相当多对于Web3的理解,都是建立在虚拟货币行业(即俗称的“币圈”)的逻辑基础之上的。 区块链服务网络(BSN&#x…...

山东高校的专利申请人经常掉进的误区2
02、专利技术交底书只提供简单思路 一些高校科研人员在申请专利时,给专利代理人的技术交底书往往只给出了思路,或者技术方案不够详细,或者根本不会有实验验证过程和数据。 事实上,专利技术交底书的详尽程度将直接影响代理人对技…...

关于webpack的基本配置
文章目录 前言一、webpack基本配置1.配置拆分和merge2. 启动服务3、处理es6,配置babel4、处理样式5、处理图片 前言 为什么要有webpack构建和打包? 更好的模块化管理。webpack支持模块化规范:代码分割成独立模块,并管理模块之间…...

SpringBoot WebSocket配合react 使用消息通信
引入websocket依赖 <dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-websocket</artifactId></dependency>配置websocket import org.springframework.context.annotation.Bean; import org.spr…...

【积水成渊】uniapp高级玩法分享
大家好,我是csdn的博主:lqj_本人 这是我的个人博客主页: lqj_本人_python人工智能视觉(opencv)从入门到实战,前端,微信小程序-CSDN博客 最新的uniapp毕业设计专栏也放在下方了: https://blog.csdn.net/lbcy…...
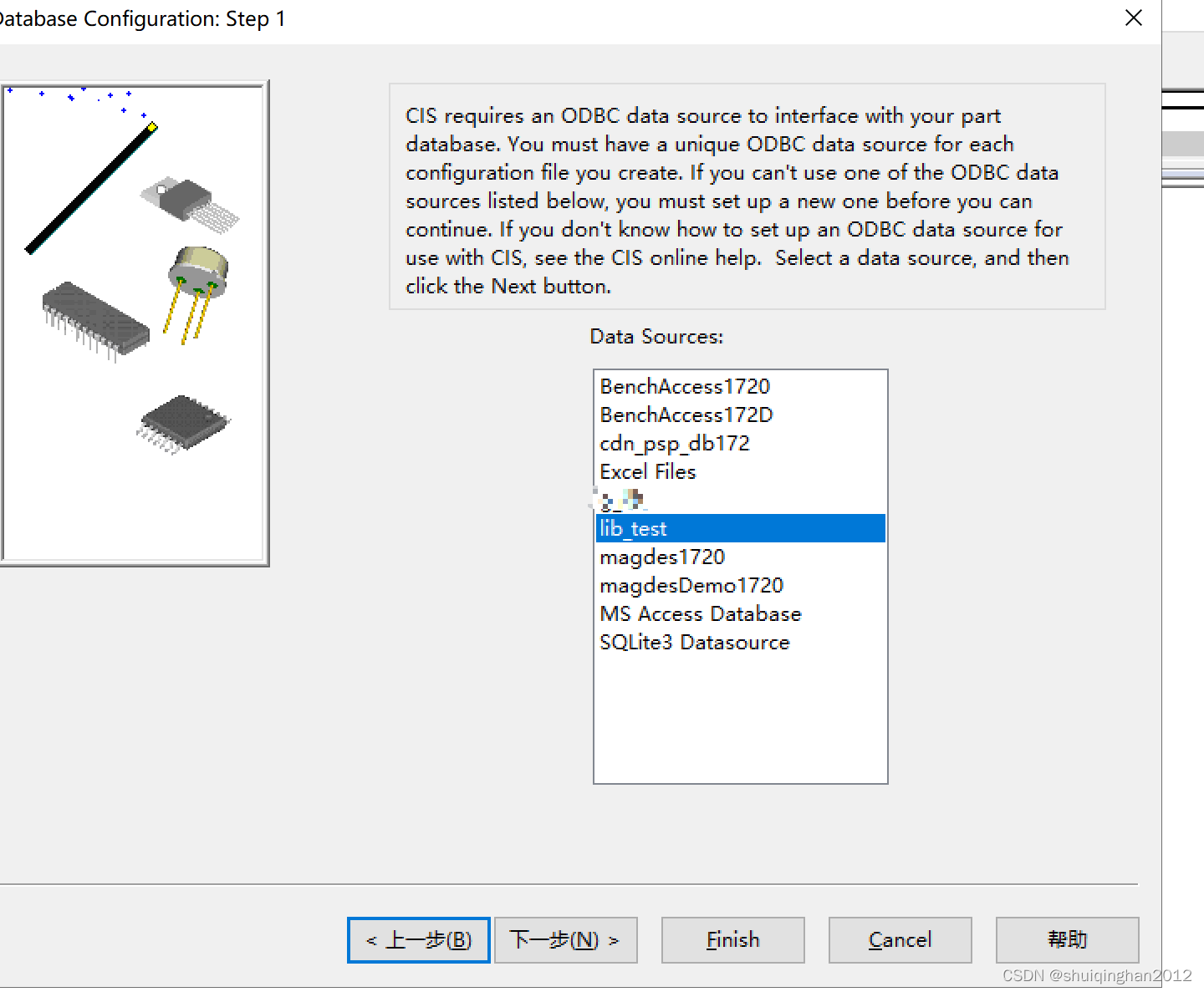
在指定的 DSN 中,驱动程序和应用程序之间的体系结构不匹配
1.Cadence 17.2 配置CIS数据库报:ERROR(ORCIS-6245): Database Operation Failed 安装cadance17.2以上版本时,ERROR(ORCIS-6245): Database Operation Failed_收湾湾的博客-CSDN博客 原因是ODBC数据库没有配置,或者没有驱动, 驱…...

终极进阶指南:3大维度深度优化ControlNet-v1-1_fp16_safetensors性能瓶颈
终极进阶指南:3大维度深度优化ControlNet-v1-1_fp16_safetensors性能瓶颈 【免费下载链接】ControlNet-v1-1_fp16_safetensors 项目地址: https://ai.gitcode.com/hf_mirrors/comfyanonymous/ControlNet-v1-1_fp16_safetensors ControlNet-v1-1_fp16_safete…...

Python的asyncio事件循环与不同事件循环策略的性能影响分析
Python的asyncio事件循环与不同事件循环策略的性能影响分析 Python的asyncio模块为异步编程提供了强大的支持,其核心是事件循环机制。事件循环负责调度和执行异步任务,而不同的循环策略可能对性能产生显著影响。随着高并发应用需求的增长,理…...

C++模板元编程理论基础简介
C模板元编程理论基础简介 一、数学理论基础 1.1 λ演算与函数式编程 模板元编程本质上是编译时的函数式编程,其理论基础源于λ演算:纯函数性:模板实例化是纯函数过程 相同输入总是产生相同输出无副作用(在编译时环境中)…...

Xilinx DSP48 Macro流水线深度怎么调?一个配置项让你的设计频率翻倍
Xilinx DSP48 Macro流水线深度优化实战:突破性能瓶颈的关键策略 在高速数字信号处理领域,FPGA设计者经常面临一个经典难题——如何在有限的硬件资源下实现更高的运算频率。当我们使用Xilinx DSP48 Macro进行复杂运算时,默认的"Auto"…...

世界第一个开源可商用 .NET Office 转 PDF 工具/库 - MiniPdf僬
1. 智能软件工程的范式转移:从库集成到原生框架演进 在生成式人工智能(Generative AI)从单纯的文本生成向具备自主规划与执行能力的“代理化(Agentic)”系统跨越的过程中,.NET 生态系统正在经历一场自该平台…...

Neeshck-Z-lmage_LYX_v2问题解决:常见报错与参数调节技巧
Neeshck-Z-lmage_LYX_v2问题解决:常见报错与参数调节技巧 1. 引言:为什么需要这份指南? 当你第一次打开Neeshck-Z-lmage_LYX_v2这个本地AI绘画工具时,可能会被它简洁的界面所迷惑——几个滑块、一个输入框和一个生成按钮&#x…...

从零到一:手把手教你构建专属Pikachu漏洞演练场
1. 为什么需要搭建Pikachu漏洞演练场 刚开始学习网络安全时,很多人都会遇到一个尴尬的问题:学了很多理论,但找不到合适的实战环境。直接拿真实网站练手既不道德也不合法,这时候就需要一个安全、可控的漏洞演练平台。Pikachu就是这…...

FPGA 实现 YCbCr 到 RGB 色彩空间转换的定点化设计
1. 色彩空间转换的基础原理 第一次接触YCbCr和RGB转换时,我完全被那些小数系数搞晕了。后来才发现,这其实就是把颜色信息用不同方式"打包"的过程。想象你有一套乐高积木,RGB是按红绿蓝三种基础积木的数量来记录,而YCbCr…...
PixelMentor:一个开源网站 · 调用AI视觉能力分析图片 · 提供影视后期修改意见雀
1. 前言 本文详细介绍如何使用 kylin v10 iso 文件构建出 docker image,docker 版本为 20.10.7。 2. 构建 yum 离线源 2.1. 挂载 ISO 文件 mount Kylin-Server-V10-GFB-Release-030-ARM64.iso /media 2.2. 添加离线 repo 文件 在/etc/yum.repos.d/下创建kylin-local…...

忍者像素绘卷:天界画坊LSTM时间序列分析应用:预测用户绘画风格偏好
忍者像素绘卷:天界画坊LSTM时间序列分析应用 1. 场景痛点:AI绘画平台的用户偏好捕捉难题 在AI绘画平台"天界画坊"的运营过程中,我们发现一个普遍存在的痛点:用户风格偏好的动态变化难以捕捉。传统推荐系统主要基于静态…...