基于机器学习的库存需求预测 -- 机器学习项目基础篇(12)
在本文中,我们将尝试实现一个机器学习模型,该模型可以预测在不同商店销售的不同产品的库存量。
导入库和数据集
Python库使我们可以轻松地处理数据,并通过一行代码执行典型和复杂的任务。
- Pandas -此库有助于以2D阵列格式加载数据帧,并具有多种功能,可一次性执行分析任务。
- Numpy - Numpy数组非常快,可以在很短的时间内执行大型计算。
- Matplotlib/Seaborn -这个库用于绘制可视化。
- Sklearn -此模块包含多个库,这些库具有预实现的功能,以执行从数据预处理到模型开发和评估的任务。
- XGBoost -这包含eXtreme Gradient Boosting机器学习算法,这是帮助我们实现高精度预测的算法之一。
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sb
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import LabelEncoder, StandardScaler
from sklearn import metrics
from sklearn.svm import SVC
from xgboost import XGBRegressor
from sklearn.linear_model import LinearRegression, Lasso, Ridge
from sklearn.ensemble import RandomForestRegressor
from sklearn.metrics import mean_absolute_error as maeimport warnings
warnings.filterwarnings('ignore')
现在,让我们将数据集加载到panda的数据框中,并打印它的前五行。
df = pd.read_csv('StoreDemand.csv')
display(df.head())
display(df.tail())
如我们所见,我们有10家商店和50种产品的5年数据,可以计算得,
(365 * 4 + 366) * 10 * 50 = 913000
现在让我们检查一下我们计算的数据大小是否正确。
df.shape
输出:
(913000, 4)
让我们检查数据集的每列包含哪种类型的数据。
df.info()
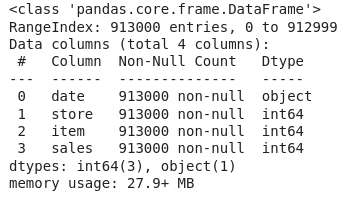
根据上面关于每列数据的信息,我们可以观察到没有空值。
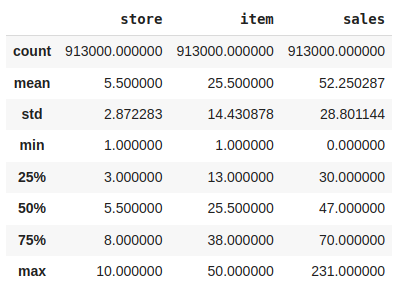
df.describe()
特征工程
有时候,同一个特征中提供了多个特征,或者我们必须从现有的特征中派生一些特征。我们还将尝试在数据集中包含一些额外的功能,以便我们可以从我们拥有的数据中获得一些有趣的见解。此外,如果导出的特征是有意义的,那么它们将成为显著提高模型准确性的决定性因素。
parts = df["date"].str.split("-", n = 3, expand = True)
df["year"]= parts[0].astype('int')
df["month"]= parts[1].astype('int')
df["day"]= parts[2].astype('int')
df.head()
无论是周末还是工作日,都必须对满足需求的要求产生一定的影响。
from datetime import datetime
import calendardef weekend_or_weekday(year,month,day):d = datetime(year,month,day)if d.weekday()>4:return 1else:return 0df['weekend'] = df.apply(lambda x:weekend_or_weekday(x['year'], x['month'], x['day']), axis=1)
df.head()
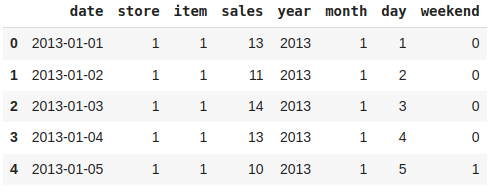
如果有一个列可以表明某一天是否有任何假期,那就太好了。
from datetime import date
import holidaysdef is_holiday(x):india_holidays = holidays.country_holidays('IN')if india_holidays.get(x):return 1else:return 0df['holidays'] = df['date'].apply(is_holiday)
df.head()
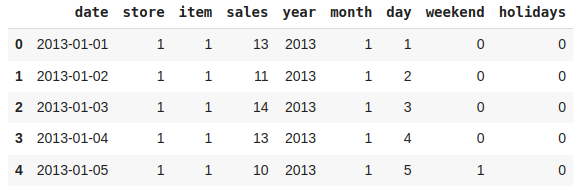
现在,让我们添加一些周期特性。
df['m1'] = np.sin(df['month'] * (2 * np.pi / 12))
df['m2'] = np.cos(df['month'] * (2 * np.pi / 12))
df.head()
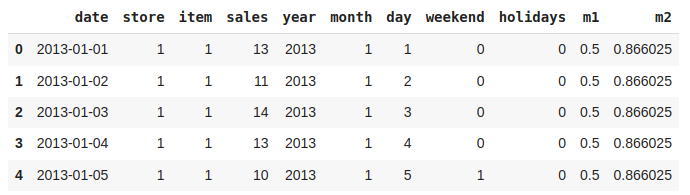
让我们有一个列,其值指示它是一周中的哪一天。
def which_day(year, month, day):d = datetime(year,month,day)return d.weekday()df['weekday'] = df.apply(lambda x: which_day(x['year'],x['month'],x['day']),axis=1)
df.head()
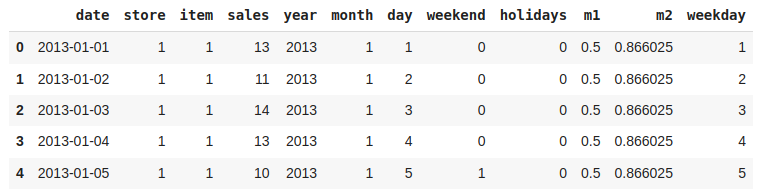
现在让我们删除对我们无用的列。
df.drop('date', axis=1, inplace=True)
可能还有一些其他相关的特征可以添加到这个数据集中,但是让我们尝试使用这些特征构建一个构建,并尝试提取一些见解。
探索性数据分析
EDA是一种使用可视化技术分析数据的方法。它用于发现趋势和模式,或在统计摘要和图形表示的帮助下检查假设。
我们使用一些假设向数据集添加了一些功能。现在让我们检查不同特征与目标特征之间的关系。
df['store'].nunique(), df['item'].nunique()
输出:
(10, 50)
从这里我们可以得出结论,有10个不同的商店,他们出售50种不同的产品。
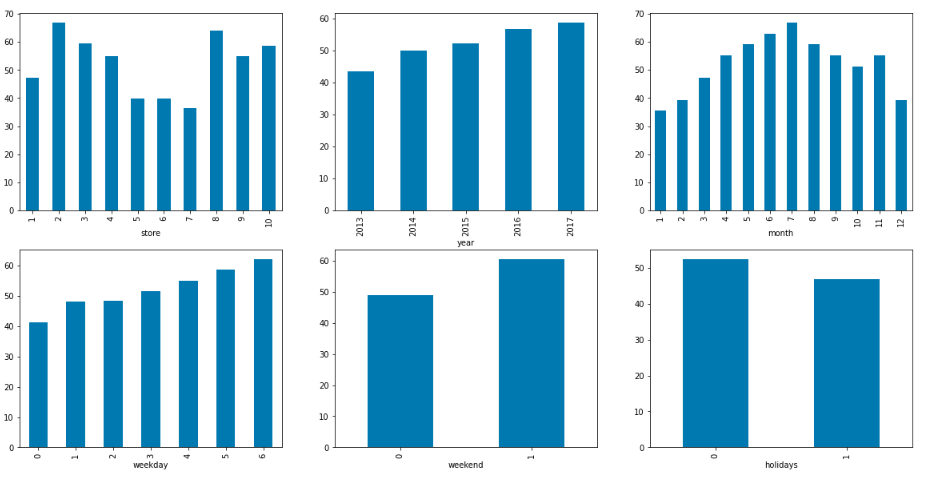
features = ['store', 'year', 'month',\'weekday', 'weekend', 'holidays']plt.subplots(figsize=(20, 10))
for i, col in enumerate(features):plt.subplot(2, 3, i + 1)df.groupby(col).mean()['sales'].plot.bar()
plt.show()
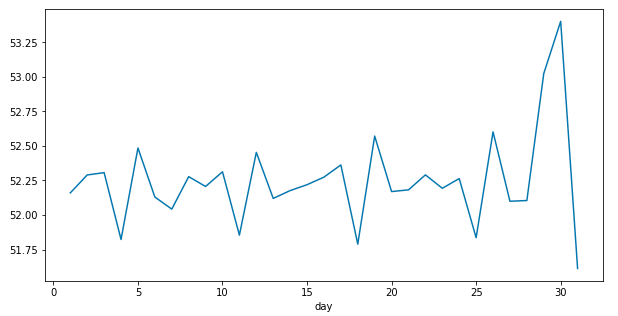
现在让我们来看看随着月末的临近,库存的变化情况.
plt.figure(figsize=(10,5))
df.groupby('day').mean()['sales'].plot()
plt.show()
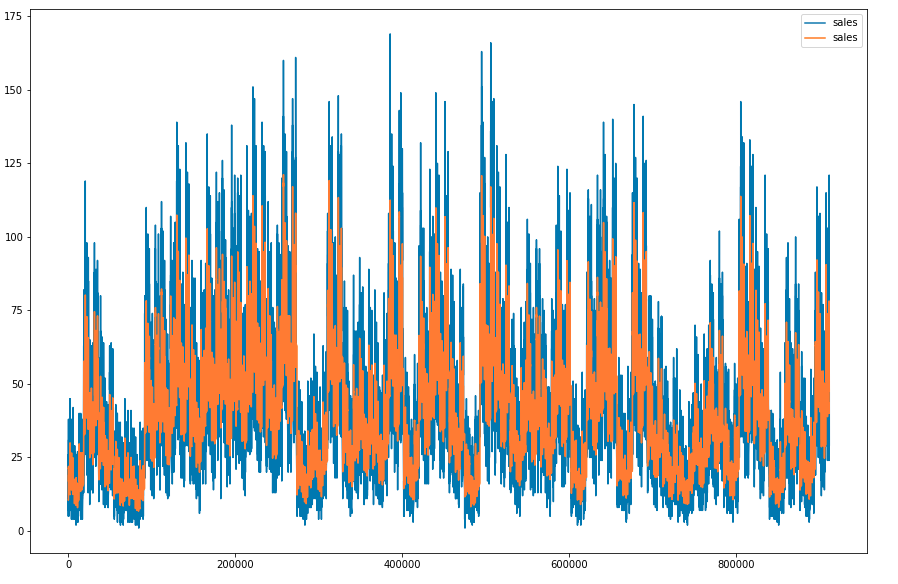
让我们画出30天的表现。
plt.figure(figsize=(15, 10))# Calculating Simple Moving Average
# for a window period of 30 days
window_size = 30
data = df[df['year']==2013]
windows = data['sales'].rolling(window_size)
sma = windows.mean()
sma = sma[window_size - 1:]data['sales'].plot()
sma.plot()
plt.legend()
plt.show()
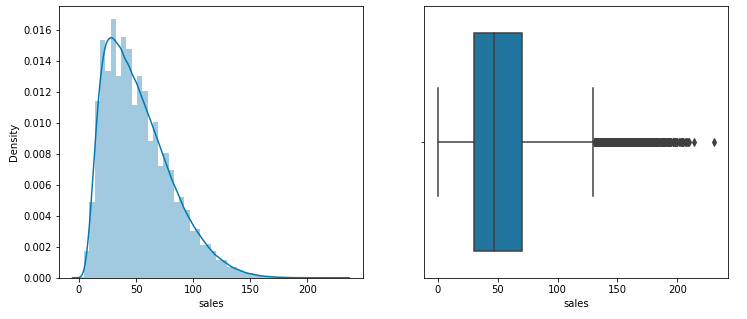
由于sales列中的数据是连续的,让我们检查它的分布,并检查该列中是否有一些离群值。
plt.subplots(figsize=(12, 5))
plt.subplot(1, 2, 1)
sb.distplot(df['sales'])plt.subplot(1, 2, 2)
sb.boxplot(df['sales'])
plt.show()
高度相关的特征
plt.figure(figsize=(10, 10))
sb.heatmap(df.corr() > 0.8,annot=True,cbar=False)
plt.show()
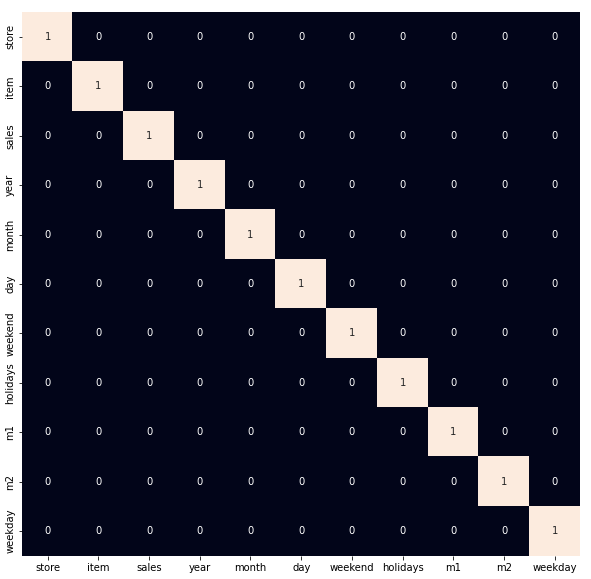
正如我们之前所观察到的,让我们删除数据中存在的离群值。
df = df[df['sales']<140]
模型训练
现在,我们将分离特征和目标变量,并将它们分为训练数据和测试数据,我们将使用这些数据来选择在验证数据上表现最好的模型。
features = df.drop(['sales', 'year'], axis=1)
target = df['sales'].valuesX_train, X_val, Y_train, Y_val = train_test_split(features, target,test_size = 0.05,random_state=22)
X_train.shape, X_val.shape
输出:
((861170, 9), (45325, 9))
在将数据输入机器学习模型之前对其进行标准化,有助于我们实现稳定和快速的训练。
# Normalizing the features for stable and fast training.
scaler = StandardScaler()
X_train = scaler.fit_transform(X_train)
X_val = scaler.transform(X_val)
我们将数据分为训练数据和验证数据,并对数据进行了归一化。现在,让我们训练一些最先进的机器学习模型,并使用验证数据集从中选择最佳模型。
models = [LinearRegression(), XGBRegressor(), Lasso(), Ridge()]for i in range(4):models[i].fit(X_train, Y_train)print(f'{models[i]} : ')train_preds = models[i].predict(X_train)print('Training Error : ', mae(Y_train, train_preds))val_preds = models[i].predict(X_val)print('Validation Error : ', mae(Y_val, val_preds))
输出:
LinearRegression() :
Training Error : 20.902897365994484
Validation Error : 20.97143554027027[08:31:23] WARNING: /workspace/src/objective/regression_obj.cu:152:
reg:linear is now deprecated in favor of reg:squarederror.
XGBRegressor() :
Training Error : 11.751541013057603
Validation Error : 11.790298395298885Lasso() :
Training Error : 21.015028699769758
Validation Error : 21.071517213774968Ridge() :
Training Error : 20.90289749951532
Validation Error : 20.971435731904066
相关文章:
基于机器学习的库存需求预测 -- 机器学习项目基础篇(12)
在本文中,我们将尝试实现一个机器学习模型,该模型可以预测在不同商店销售的不同产品的库存量。 导入库和数据集 Python库使我们可以轻松地处理数据,并通过一行代码执行典型和复杂的任务。 Pandas -此库有助于以2D阵列格式加载数据帧&#…...
【D3S】集成smart-doc并同步配置到Torna
目录 一、引言二、maven插件三、smart-doc.json配置四、smart-doc-maven-plugin相关命令五、推送文档到Torna六、通过Maven Profile简化构建 一、引言 D3S(DDD with SpringBoot)为本作者使用DDD过程中开发的框架,目前已可公开查看源码&#…...
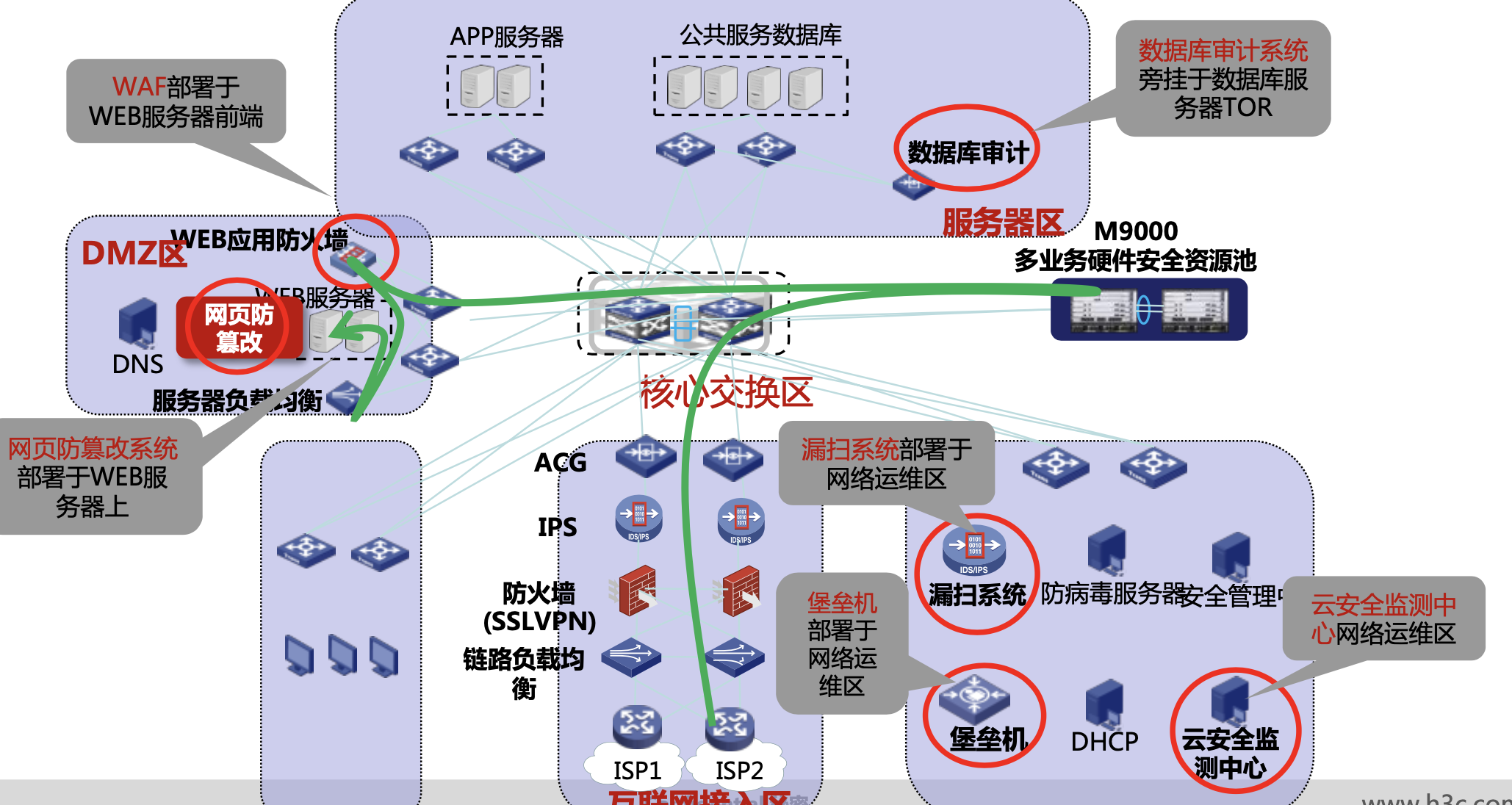
网络安全设备及部署
什么是等保定级? 之前了解了下等保定级,接下里做更加深入的探讨 文章目录 一、网路安全大事件1.1 震网病毒1.2 海康威视弱口令1.3 物联网Mirai病毒1.4 专网 黑天安 事件1.5 乌克兰停电1.6 委内瑞拉电网1.7 棱镜门事件1.8 熊猫烧香 二、法律法规解读三、安…...
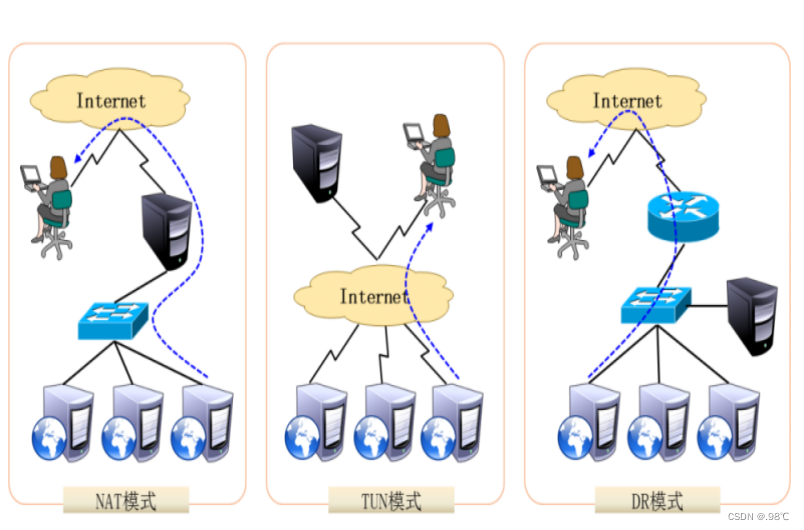
LVS集群
目录 1、lvs简介: 2、lvs架构图: 3、 lvs的工作模式: 1) VS/NAT: 即(Virtual Server via Network Address Translation) 2)VS/TUN :即(Virtual Server v…...
从入门到精通系列之十二:安装和设置 kubectl)
Kubernetes(K8s)从入门到精通系列之十二:安装和设置 kubectl
Kubernetes K8s从入门到精通系列之十二:安装和设置 kubectl 一、kubectl二、在 Linux 系统中安装并设置 kubectl1.准备工作2.用 curl 在 Linux 系统中安装 kubectl3.用原生包管理工具安装 三、验证 kubectl 配置四、kubectl 的可选配置和插件1.启用 shell 自动补全功…...
探索 TypeScript 元组的用例
元组扩展了数组数据类型的功能。使用元组,我们可以轻松构造特殊类型的数组,其中元素相对于索引或位置是固定类型的。由于 TypeScript 的性质,这些元素类型在初始化时是已知的。使用元组,我们可以定义可以存储在数组中每个位置的数…...

Pytorch使用NN神经网络模型实现经典波士顿boston房价预测问题
Pytorch使用多层神经网络模型实现经典波士顿boston房价预测问题 波士顿房价数据集介绍 波士顿房价数据集是一个经典的机器学习数据集,用于预测波士顿地区房屋的中位数价格。该数据集包含了506个样本,每个样本有13个特征,包括城镇的各种指标&…...
微服务间消息传递
微服务间消息传递 微服务是一种软件开发架构,它将一个大型应用程序拆分为一系列小型、独立的服务。每个服务都可以独立开发、部署和扩展,并通过轻量级的通信机制进行交互。 应用开发 common模块中包含服务提供者和服务消费者共享的内容provider模块是…...
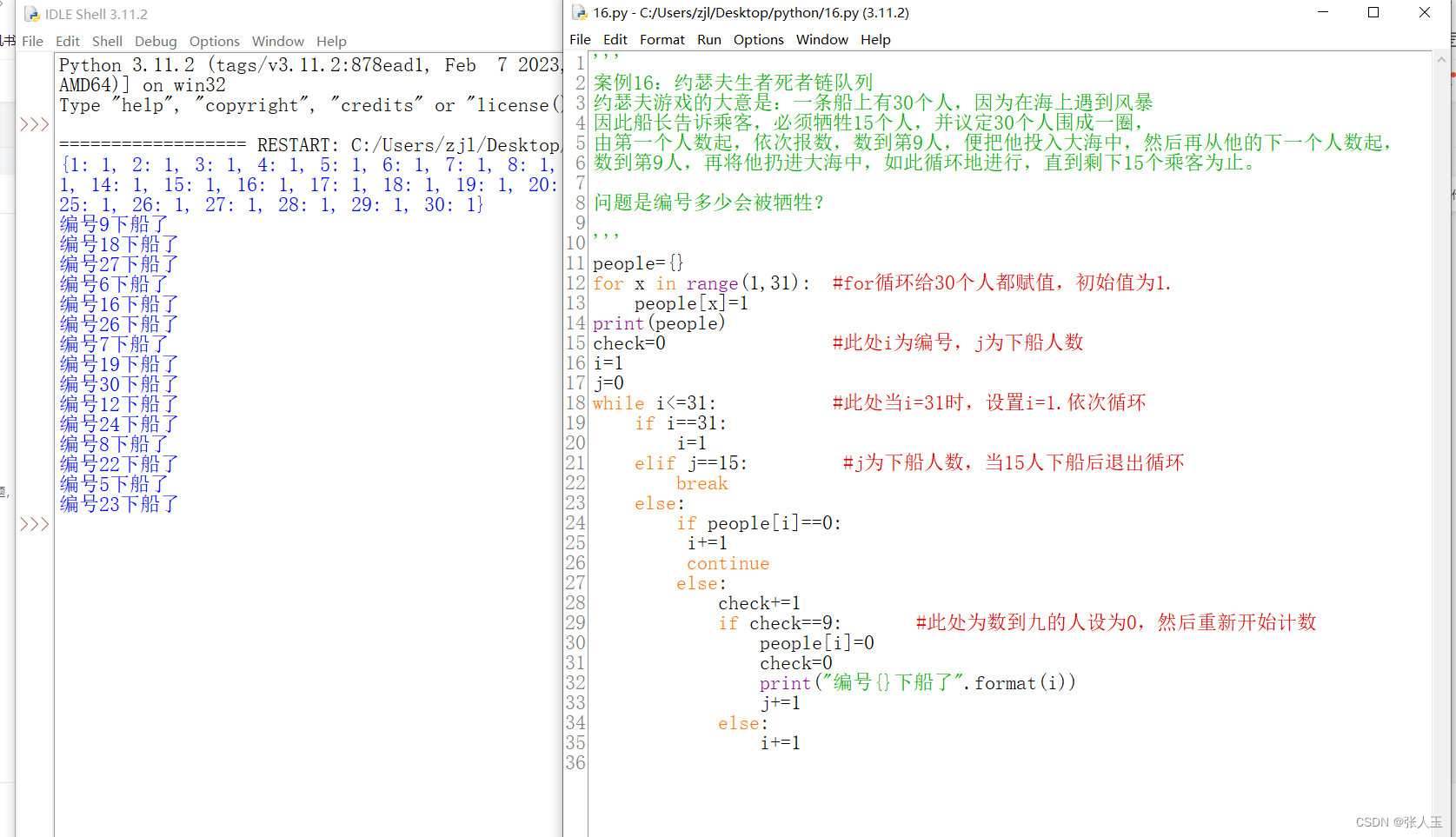
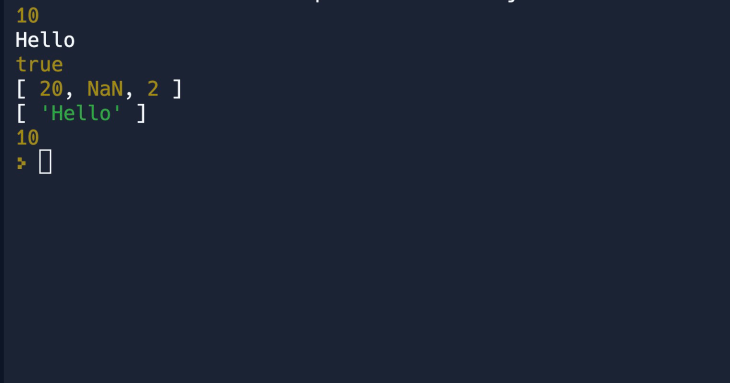
python——案例16:约瑟夫生者死者链队列
约瑟夫游戏的大意是:一条船上有30个人,因为在海上遇到风暴 因此船长告诉乘客,必须牺牲15个人,并议定30个人围成一圈, 由第一个人数起,依次报数,数到第9人,便把他投入大海中ÿ…...

【人工智能前沿弄潮】—— 玩转SAM(Segment Anything)
玩转SAM(Segment Anything) 官网链接: Segment Anything | Meta AI (segment-anything.com) github链接: facebookresearch/segment-anything: The repository provides code for running inference with the SegmentAnything Model (SAM), links fo…...

每日一题——合并两个有序的数组
题目 给出一个有序的整数数组 A 和有序的整数数组 B ,请将数组 B 合并到数组 A 中,变成一个有序的升序数组 数据范围:0≤n,m≤100,∣Ai∣<100,∣Bi∣<100 注意: 1.保证 A 数组有足够的空间存放 B …...
MPP架构和Hadoop架构的区别
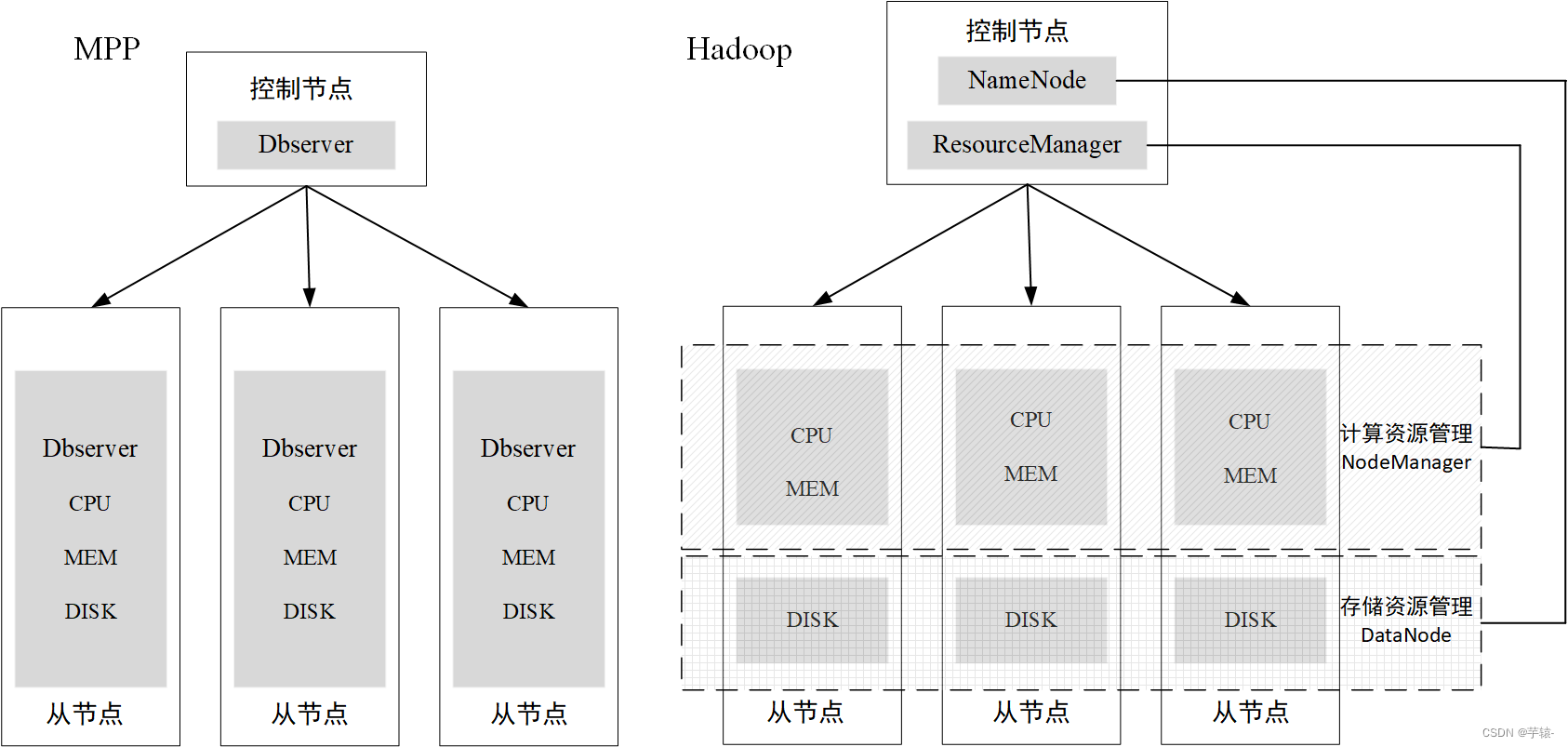
1. 架构的介绍 mpp架构是将许多数据库通过网络连接起来,相当于将一个个垂直系统横向连接,形成一个统一对外的服务的分布式数据库系统。每个节点由一个单机数据库系统独立管理和操作该物理机上的的所有资源(CPU,内存等)…...
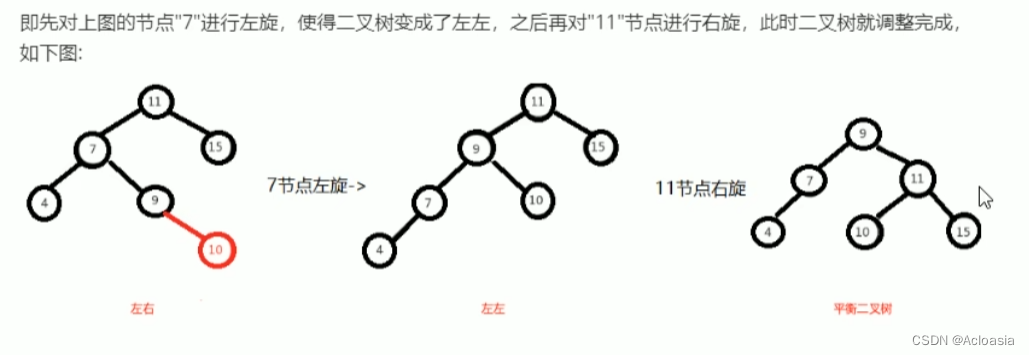
Java02-迭代器,数据结构,List,Set ,Map,Collections工具类
目录 什么是遍历? 一、Collection集合的遍历方式 1.迭代器遍历 方法 流程 案例 2. foreach(增强for循环)遍历 案例 3.Lamdba表达式遍历 案例 二、数据结构 数据结构介绍 常见数据结构 栈(Stack) 队列&a…...

福布斯发布2023云计算100强榜单,全球流程挖掘领导者Celonis排名17
近日,全球流程挖掘领导者Celonis入选福布斯2023 年云计算 100 强榜单,估值130亿美元,排名第17,Celonis已经是连续三年跻身榜单前20名。 本次榜单由福布斯与Bessemer Venture Partners和Salesforce Ventures联合发布,旨…...

计算机网络 MAC地址
...

Jay17 2023.8.10日报
笔记 【python反序列化】 序列化 类对象->字节流(字符串) 反序列化 字节流->对象 python反序列化没PHP这么灵活,没这么多魔术方法。 import pickle import os class ctfshow(): def init(self): self.username0 self.password0 d…...
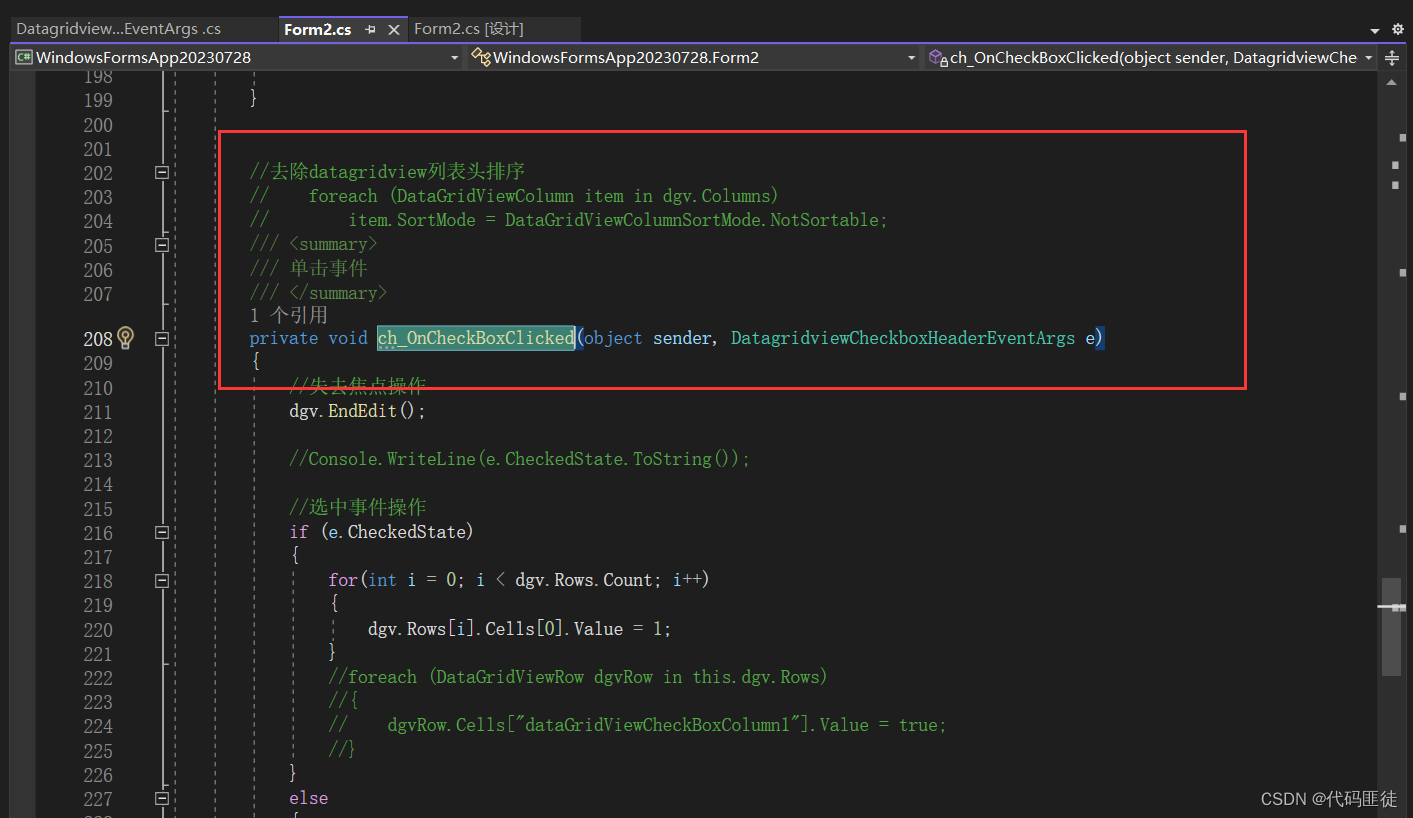
Winform中DatagridView 表头实现一个加上一个checkBox,实现全选选项功能
实现效果 点击checkBox1或者直接在第一列列表头点击即可实现 代码实现 我的datagridview叫dgv 我在datagridview已经默认添加了一个DataGridViewCheckBoxColumn,勾选时value为1,不勾选时value为0 第一种通过可视化拖动一个checkBox来实现 拖动组…...
rust基础
这是笔者学习rust的学习笔记(如有谬误,请君轻喷) 参考视频: https://www.bilibili.com/video/BV1hp4y1k7SV参考书籍:rust程序设计语言:https://rust.bootcss.com/title-page.htmlmarkdown地址:h…...

剑指offer39.数组中出现次数超过一半的数字
这个题非常简单,解法有很多种,我用的是HashMap记录每个元素出现的次数,只要次数大于数组长度的一半就返回。下面是我的代码: class Solution {public int majorityElement(int[] nums) {int len nums.length/2;HashMap<Integ…...

spring技术栈面试题
1 Spring支持的事务管理类型有哪些?你在项目中使用哪种方式? Spring支持两种类型的事务管理: 编程式事务管理:这意味你通过编程的方式管理事务,给你带来极大的灵活性,但是难维护。声明式事务管理&#x…...

使用 HTML + JavaScript 实现组织架构图
文章目录一、组织架构图二、效果演示三、系统分析1.页面结构1.1 操作区域1.2 组织结构图区域2 核心功能实现2.1 数据结构定义2.2 节点渲染逻辑2.3节点展开/收起功能2.4 全部展开/收起四、扩展建议五、完整代码一、组织架构图 在企业管理系统或团队协作平台中,组织结…...
)
用WPF和OpenCVSharp从零搭建一个Vision Master风格的视觉软件(附完整源码)
从零构建工业级视觉处理软件:WPFOpenCVSharp实战指南 工业视觉检测系统正逐渐成为智能制造的核心组件,但市面上成熟的商业软件往往价格昂贵且难以定制。作为一名长期从事工业自动化开发的工程师,我经常遇到需要快速开发定制化视觉解决方案的场…...

HsMod终极指南:如何通过开源插件将炉石传说个性化体验提升5倍
HsMod终极指南:如何通过开源插件将炉石传说个性化体验提升5倍 【免费下载链接】HsMod Hearthstone Modification Based on BepInEx 项目地址: https://gitcode.com/GitHub_Trending/hs/HsMod HsMod是一款基于BepInEx框架的开源炉石传说插件,为技术…...

文墨共鸣效果展示:当传统水墨美学遇上现代AI技术
文墨共鸣效果展示:当传统水墨美学遇上现代AI技术 1. 视觉与技术的完美融合 1.1 水墨美学的数字重生 在数字化浪潮中,"文墨共鸣"项目创造性地将中国传统水墨美学与现代AI技术相结合。这个独特的语义相似度分析工具摒弃了传统技术工具的冰冷界…...

CUDA driver error: invalid argument问题修改
训练qwen2时遇到了这个报错,只需要清理缓存即可。rm -rf ~/.cache/torch/kernels/...

Claude参数曝光,AI模型竞争格局再掀波澜
马斯克“手滑”,Claude参数浮出水面 马斯克在分享xAI的Colossus 2超算训练计划时,意外透露了Claude系列模型的参数规模。他表示Grok 4.2参数量为5000亿,是xAI目前在训最大10万亿参数模型的5%,同时指出Grok参数量是Sonnet的一半、O…...

【算法优化】基于网格划分的高效DBSCAN改进策略
1. 为什么需要优化DBSCAN算法? 第一次接触DBSCAN算法时,我被它的聚类能力惊艳到了——不需要预先指定簇数量,还能识别任意形状的簇。但当我用真实数据集测试时,电脑直接卡死,这才发现传统DBSCAN的O(n)时间复杂度有多可…...

Phi-3-vision-128k-instruct实战:构建基于卷积神经网络的图像增强预处理流水线
Phi-3-vision-128k-instruct实战:构建基于卷积神经网络的图像增强预处理流水线 1. 引言:当AI视觉遇上图像质量问题 你有没有遇到过这样的情况?好不容易拍了一张照片,结果因为光线不足、镜头抖动或者设备限制,图像质量…...

深入circe核心组件:Encoder、Decoder与Codec的完整解析
深入circe核心组件:Encoder、Decoder与Codec的完整解析 【免费下载链接】circe Yet another JSON library for Scala 项目地址: https://gitcode.com/gh_mirrors/ci/circe circe 是 Scala 生态中一款强大的 JSON 处理库,它通过类型安全的方式实现…...

2026年公考备战:呼和浩特这3家培训机构凭何领跑行业口碑榜?
呼和浩特这3家培训机构凭何领跑行业口碑榜?随着2026年公考备战季悄然拉开序幕,呼和浩特众多备考生的目光再次聚焦于如何选择一家靠谱的培训机构。近期,一份基于学员真实反馈、上岸数据及行业教研深度的本土公考机构口碑榜引发关注。榜单显示&…...