redis的配置和使用、redis的数据结构以及缓存遇见的常见问题
目录
1.缓存
2.redis不仅仅可以做缓存,只不过说他的大部分场景,是做缓存。本地缓存重启后缓存里的东西就没有了,但是redis有。
3.redis有几个特性:查询快,但是是放到内存里的〈断电或者重启,数据就丢了),所以他有特定的持久化机制
4.服务器(centos)安装redis
5. redis在springboot中集成
6.使用场景
7.数据结构
a、String
b、Hash
c、List
d、Set
e、SortedSet
8.进阶篇:
①、Geospatial
②、BloomFilter(布隆过滤器)
9.redis的常用配置项
10.缓存常见问题:
1.缓存
①、缓存:有缓存时会优先查询缓存中的数据,查询不到再去查询数据库,并且查询完数据库会将查询到的信息放入缓存
②、缓存存在的意义:
a、减轻数据库压力。(数据库的数据是在磁盘里的,而缓存是存在内存里的,内存的读取速率快)就比如说有1000个请求参数是一样的,如果说我不用缓存,就会访问1000次数据库,用缓存,可能就访问一次
b、提升接口性能(性能不够,缓存来凑)(缓存比硬盘快)
③、缓存分为三种:
a、本地缓存:存在客户端,比如说微信的聊天记录(非常适合用本地缓存)(打开聊天窗口时,肯定不是调接口去查,而是从本地读出来。用本地缓存应该注意安全性:需要把聊天记录做好加密)
b、服务器缓存:放到jvm堆里面,比如说hashmap,key-value形式
c、分布式缓存:集群缓存中用的是各自单独的redis,每个缓存单独存储,而分布式缓存中会将这些缓存放到一个redis中
2.redis不仅仅可以做缓存,只不过说他的大部分场景,是做缓存。本地缓存重启后缓存里的东西就没有了,但是redis有。
3.redis有几个特性:查询快,但是是放到内存里的〈断电或者重启,数据就丢了),所以他有特定的持久化机制
①、快照形式:定时快照将数据备份到硬盘里。(比较耗费性能)不适合频繁的去备份
②、日志形式:(将日志存到硬盘)类似于mysql的binlog.(恢复的时候比较慢,每次恢复需要查询重现很多条日志),不适合长时间的备份 例:aa--bb aa--cc aa--dd aa
③、生产环境环境当中,往往两种机制相结合。大约平均每一分钟生成快照,剩下的生成日志,1分钟之后快照删除生成日志
4.服务器(centos)安装redis
①、finalshell连接上服务器
②、安装docker和redis
- 更新yum包:yum -y update
- yum remove docker docker-common docker-selinux docker-engine
- yum install -y yum-utils device-mapper-persistent-data lvm2
- yum-config-manager --add-repo http://mirrors.aliyun.com/docker-ce/linux/centos/docker-ce.repo
- yum -y install docker-ce-18.03.1.ce
- systemctl start docker
- docker pull redis:latest
- docker run -d -p 6379:6379 --name="myredis1" redis
- docker exec -it myredis1 redis-cli
5. redis在springboot中集成
①、添加依赖
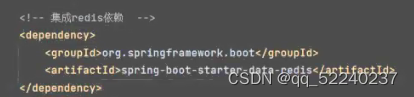
(IP+端口号+有密码的加上密码)

②、实现
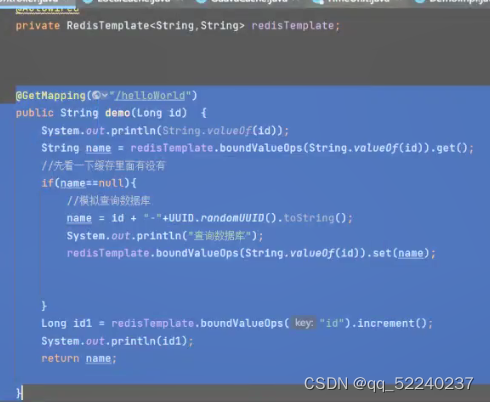
6.使用场景
①、在大型的秒杀库存扣减,app首页流量高峰,很容易将传统的关系型数据库(mysql,oracle等)给压垮
②、还有很多没必要持久化的数据,比如说短信验证码,点赞数等
③、分布式锁
④、 分布式缓存(session共享)
7.数据结构
①、redis的存储是以key-value的键值对的形式存储的,其中key都是String类型,value常见的就是以下的5种。
a、String
字符串类型,可以包含任何数据,最大可以是512MB,内部的实现结构和ArrayList类似,采用内分配冗余的形式,来减少内存的频繁分配(降低CPU压力)
struct SDS {
// 数组容量
T capacity;
// 数组长度
T len;
// 特殊标识位
byte flags;
// 数组内容
byte[ ] buf;
}
即在创建字符串的时候,len 的长度就是capacity,当需要修改时,如果存储容量不够的话,就会进行扩容,当字符串的容量小于1mb时,就会执行加倍扩容,即扩容到2*capacity,当容量大于1MB时,每次多增加1MB。
常见的指令
set name zhencong --存放字符串键值对
mset name zhencong age 18 --批量存放键值对
SETNX name zhencong --如果不存在key为name,那么就设置value(分布式锁的原理)
get name -- 获取key
mget name age --批量获取key
DEL key -- 删除key
expire key 60 --设置过期时间,单位为秒
INCR (23.890, 0.570, 2.44%) key -- 将key中存储的数字加1
DECR key -- 将key中存储的数字减1
INCRBY key 2 --将key中存储的值都加上2
DECRBY key 2 --将key中存储的值都减去2
需要注意的是,尽量避免同时操作大批量的key,比如给所有的key设置过期时间,因为redis是单线程的,如果操作耗费太多时间,会造成redis的假死(暂时不对外提供服务)
使用场景
i、不需要持久化的数据或者频繁更新的数据,比如验证码,点赞数
ii、对象缓存:可以通过序列化工具类,来缓存java对象,比如将某个对象序列化为json,需要用的时候再取出来,反序列化。常见的使用方式有mybatis二级缓存,接口级别缓存等等。
iii、使用setnx来实现分布式锁,(使用分布式锁时一定要设置过期时间,防止不能释放锁,造成死锁)
iv、可以用incr,decr来实现点赞数
v、分布式全局id:在一个大型的系统下,如果涉及到分库分表后,mysql 的自增id,肯定满足不了需要,如果用户量不大,可以每次从redis 这里通过自增获取id,但是如果用户量大,每次都拿肯定会给redis造成压力,可以一次取1000个,放本地缓存里,等用完了再去取。
b、Hash
是一个key-value的键值对,和java里的hashMap相似,当数据量较小是采用的是ziphash(默认),当数据量较大时采用hashtable。至于什么转换可以在配置文件进行配置。
hash-max-ziplist-entries 512 //配置当field-value超过512时(合起来1024),使用hashtable编码
hash-max-ziplist-value 64 //配置当key的单个field或value长度超过64时,使用hashtable编码
常用指令
hset hash name zhencong --设置值,
hget hash name -- 获取值
hmset hash name zhencong age 18 --批量设置
hmget hash name age --批量获取
hgetall hash 获取key的所有值
hkeys hash 获取hashmap中所有的key
hvals hash 获取hashmap中所有的value
应用场景
i、可以用于存储系统中对象的数据。
ii、也可以用于做缓存,来解决数据一致性的问题(不推荐)。
c、List
redis的list为quickList(快速链表)即多个ziplist(压缩链表)组合起来的。如图所示:ziplist;当数组容量较小的时候,会开辟一个连续的内存空间,只有当数组容量过多的时候,才会改为quickList,这样做的好处就是,如果采用普通的链表,当我们节点只存int类型的数据,还需要开辟两个指针,连接节点的上一个元素和下一个元素,会比较浪费空间。所以采用了quickList的方式,既能满足快速插入删除性能,又不会出现太大的空间浪费。
这么做也有缺点,就是当我们的list要变动时,肯定会涉及到内存重新分配和数据拷贝,这个是很影响性能的,list越大,修改元素的代价越大,所以一般我们不会存储过多元素。
redis的list是按插入顺序排序的,可以添加的一个节点到链表的头部(头插)或者尾部(尾插),是一个双向链表,对两端的操作性能会比较高,对中间节点的操作性能相对来说较差(因为得通过指针对遍历对应的节点)。
常用指令
rpush myList valu5e1 --向 list 的头部(右边)添加元素
rpush myList value2 value3 --向list的头部(最右边)添加多个元素
lpop myList # 将 list的尾部(最左边)元素取出
lpush myList2 value1 --尾插
使用场景
可以实现栈和队列,需要注意的是,push和pop的操作是原子性的,所以操作redis的时候,直接用就行了,不要把list读出来,通过java修改,再放回去,这样不能保证数据一致性。(先读先写或先读后写)
d、Set
redis的set和list相似,只不过可以自动去重。(java的set也可以自动去重)。
当你需要存储一个没有重复数据的列表时就可以选择set,同时set也可以判断某个数据在不在集合里面。
set的底层结构是一个value为null的哈希表,也就意味着他的时间复杂度为O(1),也就意味着即使数据再多,查找的时间也是一样的。
使用场景
可以用来计算多个数据源的交集或并集
e、SortedSet
和set很相似,sortedSet是一个有序不重复的列表。SortedSet里面的每个节点都关联了一个权重,用来排序。(集合里的每个节点是唯一的,但是评分却可以是相同的),利用这个特性我们可以利用redis来实现排行榜。也可以很快速的获取到一个区间内的节点。
SortedSet的底层是hash和跳表(一个很典型的数据机构,牺牲空间来换取时间)。hash的作用是存储每个节点和权重,跳表的作用是用来快速获取一个区间里的节点。
redis常用的数据机构就是以上五种,还有一些不常用的(加分项)
使用场景
直播系统的实时排行榜
8.进阶篇:
①、Geospatial
地理位置的缩写,可以表示一个区域的二维坐标,redis提供了经纬度设置,查询,范围查询,距离查询,经纬度hash等操作。
使用场景
可以用来计算距离最近的门店
②、BloomFilter(布隆过滤器)
布隆过滤器是一段很长的二进制向量和一系列随机映射函数,用来快速检索一个元素是否在一个集合里。但是他的准确率不是百分之百,有可能判断失误。因此他不适合零失误的场景。
优点:i,支持海量数据 (19.04, -0.70, -3.55%)场景下,判断元素是否存在。
ii,存储空间占用量小,不存储数据本身,存储的是hash值
iii,不存储数据本身,可以用来存储加密数据
缺点:不支持计数,同一个元素可以多次插入,而且效果是相同的。
使用场景:i、用来解决缓存穿透问题;
ii、可以判断用户是否阅读过某篇文章,防止重复推送,比如说抖音。
9.redis的常用配置项
| port | 端口号,默认6379 |
| bind | 主机地址,可以访问redis的ip |
| timeout | 连接空闲多长要关闭连接,表示客户端闲置一段时间后要关闭连接。如果指定为0,就表示连接的时长不限制。这个选项的默认值为0,表示默认不限制连接的空闲时长。 |
| dbfilename | 指定保存缓存数据的本地文件名,默认值为dump.rdb。 |
| dir | 指定保存缓存数据的本地文件所存放的目录,默认值为安装目录 |
| rdbcompression | 指定存储缓存数据至本地文件时是否压缩数据,默认为yes。Redis采用LZF压缩。为了节省CPU时间,可以关闭该选项,但会导致本地文件变得巨大。 |
| requirepass | 设置Redis连接密码 |
| slaveof | 在主从复制模式下,如果当前节点为Slave(从)节点,就设置为Master(主)节点的IP地址及端口,在Redis启动时自动从Master(主)节点进行数据同步。如果已经是Slave(从)服务器,则会丢掉旧数据集,从新的Master主服务器同步缓存数据。 |
| masterauth | 在主从复制模式下,当Master(主)服务器节点设置了密码保护时,Slave(从)服务器用此命令设置连接Master(主)服务器的密码。设置Master服务器节点密码的命令格式为: |
10.缓存常见问题:
①、什么是缓存穿透,缓存穿透带来的问题,如何解决缓存穿透?
a、缓存穿透:比如说我的key是数字(123),但是网络攻击者频繁的用字符串(abc)去获取缓存。导致永远无法命中缓存,直接查取的数据库。缓存的意义就是为了减少数据库压力。
b、解决方法:布隆过滤器
②、什么是缓存击穿,缓存击穿带来的问题,如何解决缓存击穿?
a、缓存击穿:比如说我的官网数据是热点数据,在并发非常高的时候,比如说高考报名的时候,官网数据缓存过期了。这时会直接查询数据库,丢失了缓存的意义
b、解决方案:一些非常高频的热点数据,不设置过期时间。并且开启定时任务定期查看缓存有没有被删除,如果缓存不存在了,更新缓存。不设置过期时间只能保证redis不会删,但是不能保证其他服务有没有可能删,所以需要开启定时任务,在缓存被别的删除的时候更新缓存。
③、什么是缓存雪崩,缓存雪崩带来的问题,如何解决缓存雪崩?
a、缓存雪崩:大批量的key在同一时刻同时失效,导致请求都打到了数据库
b、解决方案:key的过期时间做合理的规划,对于高频数据(自己定义的,你觉得这个数据是不是高频的),不设置过期时间
相关文章:
redis的配置和使用、redis的数据结构以及缓存遇见的常见问题
目录 1.缓存 2.redis不仅仅可以做缓存,只不过说他的大部分场景,是做缓存。本地缓存重启后缓存里的东西就没有了,但是redis有。 3.redis有几个特性:查询快,但是是放到内存里的〈断电或者重启,数据就丢了),…...

在Ubuntu系统下修改limits.conf不生效
文章目录 前言尝试过程总结 前言 最近遇到的一个问题,在Ubuntu系统下修改/etc/security/limits.conf不生效,查了多种资料都说不用重启,但是我改完就是不生效,多次尝试之后发现Ubuntu系统有毒。 尝试过程 通过 ulimit -n 命令可…...

selenium 选项 chrome_options
当前环境: Windows 10 Python 3.7 selenium 3.141.0 Google Chrome 115.0.5790.110 (64 位) 一种方法: from selenium import webdriverif __name__ __main__:# chrome 选项配置chrome_options webdriver.ChromeOptions(…...
)
自然语言处理(Natural Language Processing,NLP)
自然语言处理(Natural Language Processing,NLP)是人工智能领域的一个重要分支,旨在使计算机能够理解、处理和生成人类自然语言。NLP 的目标是让计算机能够像人类一样有效地理解和交流,从而实现更自然、更智能的人机交互。 NLP的理解概括&…...
基于机器学习的库存需求预测 -- 机器学习项目基础篇(12)
在本文中,我们将尝试实现一个机器学习模型,该模型可以预测在不同商店销售的不同产品的库存量。 导入库和数据集 Python库使我们可以轻松地处理数据,并通过一行代码执行典型和复杂的任务。 Pandas -此库有助于以2D阵列格式加载数据帧&#…...
【D3S】集成smart-doc并同步配置到Torna
目录 一、引言二、maven插件三、smart-doc.json配置四、smart-doc-maven-plugin相关命令五、推送文档到Torna六、通过Maven Profile简化构建 一、引言 D3S(DDD with SpringBoot)为本作者使用DDD过程中开发的框架,目前已可公开查看源码&#…...
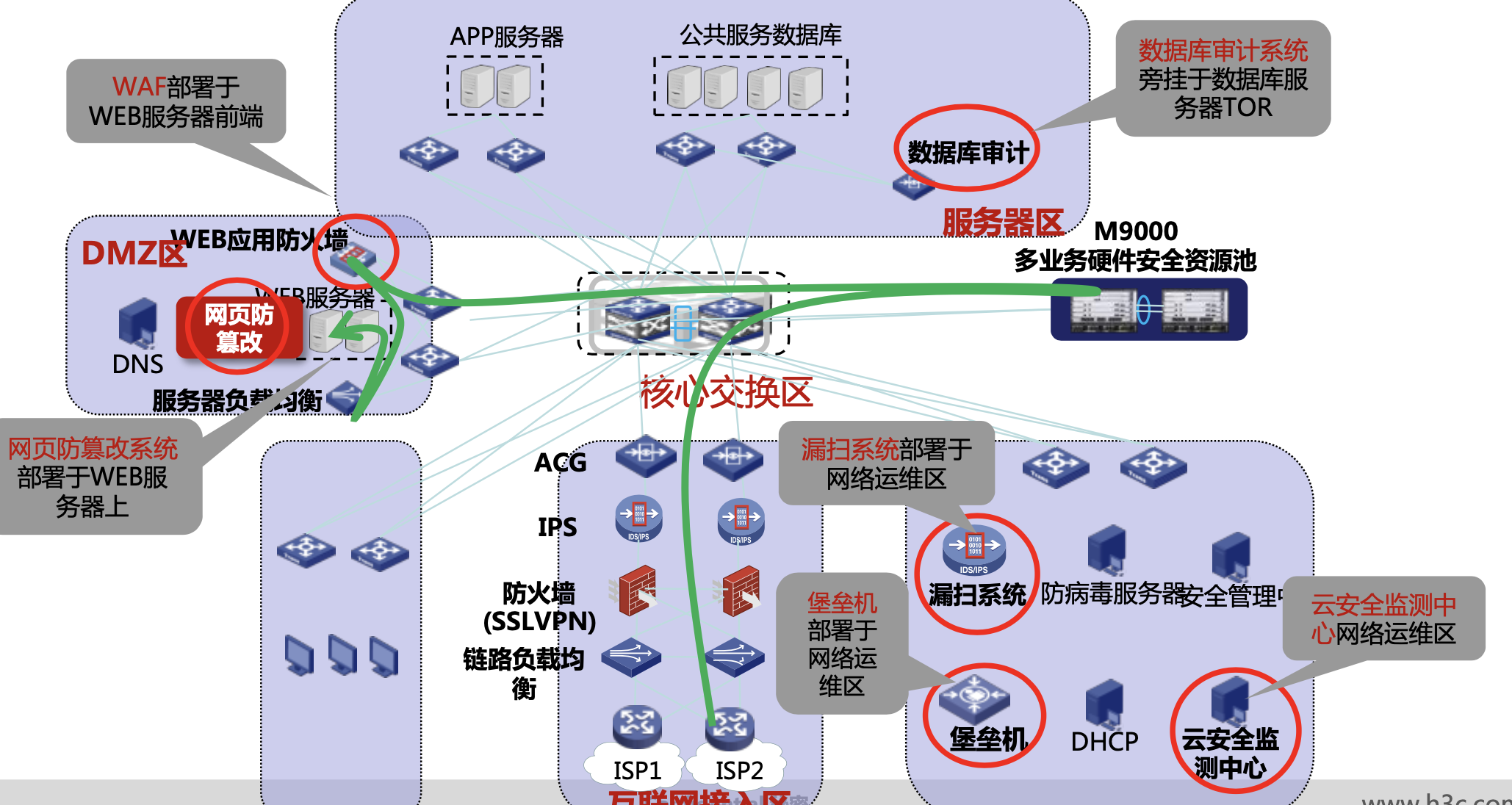
网络安全设备及部署
什么是等保定级? 之前了解了下等保定级,接下里做更加深入的探讨 文章目录 一、网路安全大事件1.1 震网病毒1.2 海康威视弱口令1.3 物联网Mirai病毒1.4 专网 黑天安 事件1.5 乌克兰停电1.6 委内瑞拉电网1.7 棱镜门事件1.8 熊猫烧香 二、法律法规解读三、安…...
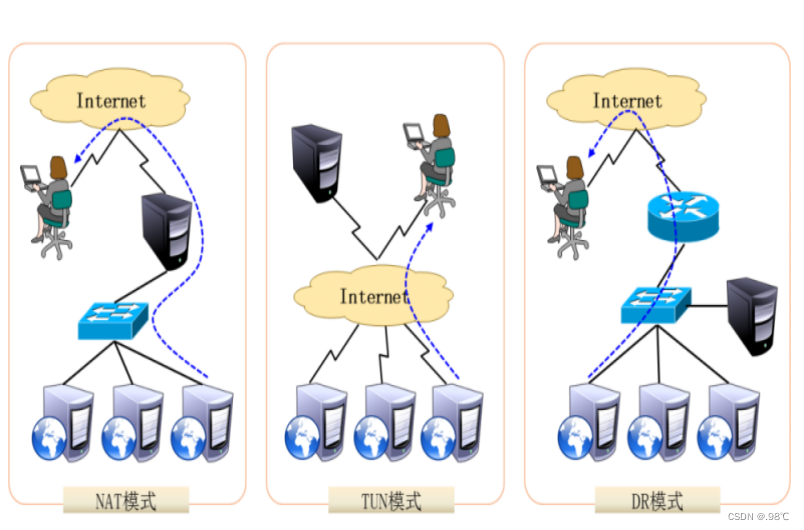
LVS集群
目录 1、lvs简介: 2、lvs架构图: 3、 lvs的工作模式: 1) VS/NAT: 即(Virtual Server via Network Address Translation) 2)VS/TUN :即(Virtual Server v…...
从入门到精通系列之十二:安装和设置 kubectl)
Kubernetes(K8s)从入门到精通系列之十二:安装和设置 kubectl
Kubernetes K8s从入门到精通系列之十二:安装和设置 kubectl 一、kubectl二、在 Linux 系统中安装并设置 kubectl1.准备工作2.用 curl 在 Linux 系统中安装 kubectl3.用原生包管理工具安装 三、验证 kubectl 配置四、kubectl 的可选配置和插件1.启用 shell 自动补全功…...
探索 TypeScript 元组的用例
元组扩展了数组数据类型的功能。使用元组,我们可以轻松构造特殊类型的数组,其中元素相对于索引或位置是固定类型的。由于 TypeScript 的性质,这些元素类型在初始化时是已知的。使用元组,我们可以定义可以存储在数组中每个位置的数…...

Pytorch使用NN神经网络模型实现经典波士顿boston房价预测问题
Pytorch使用多层神经网络模型实现经典波士顿boston房价预测问题 波士顿房价数据集介绍 波士顿房价数据集是一个经典的机器学习数据集,用于预测波士顿地区房屋的中位数价格。该数据集包含了506个样本,每个样本有13个特征,包括城镇的各种指标&…...
微服务间消息传递
微服务间消息传递 微服务是一种软件开发架构,它将一个大型应用程序拆分为一系列小型、独立的服务。每个服务都可以独立开发、部署和扩展,并通过轻量级的通信机制进行交互。 应用开发 common模块中包含服务提供者和服务消费者共享的内容provider模块是…...
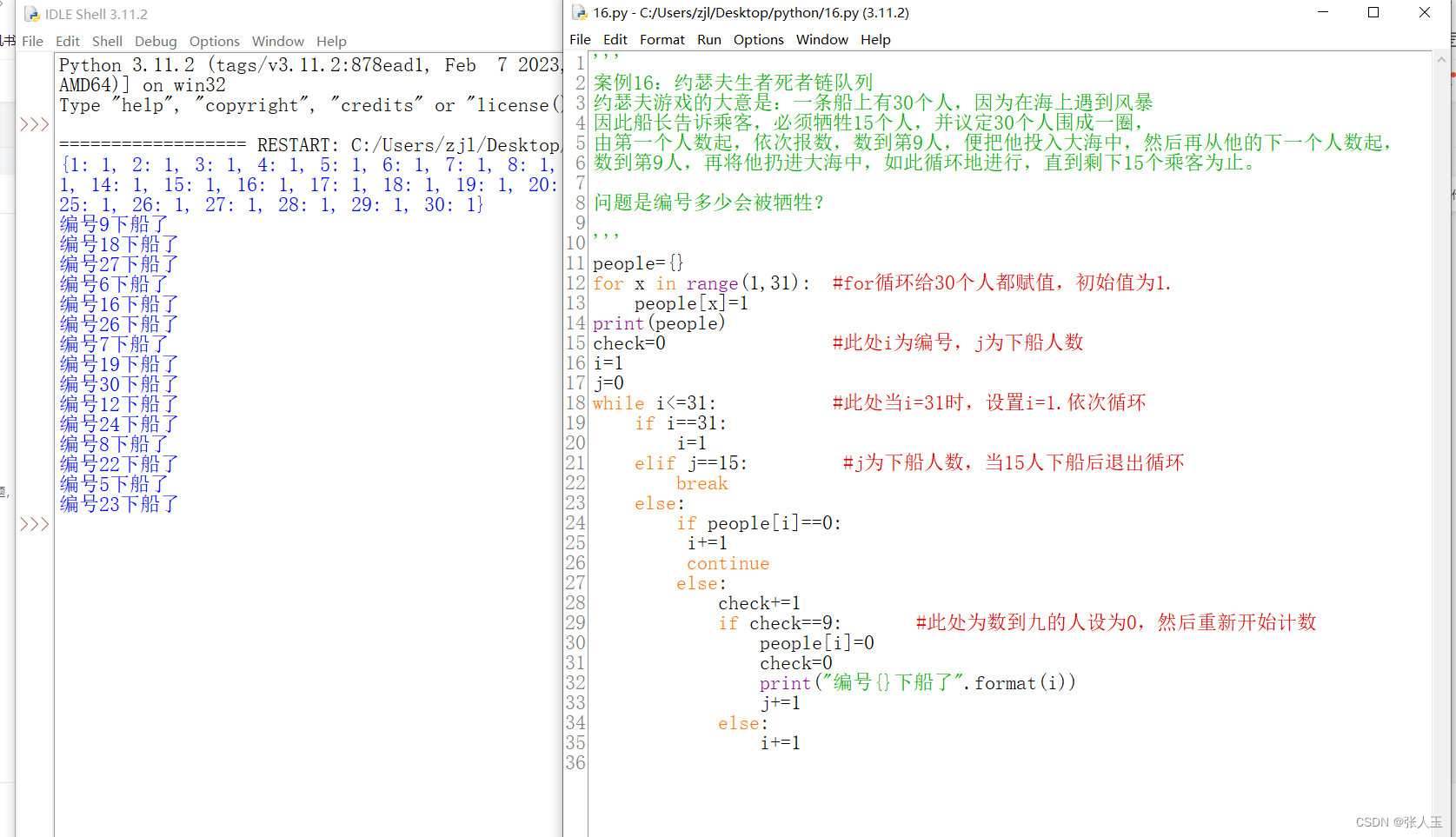
python——案例16:约瑟夫生者死者链队列
约瑟夫游戏的大意是:一条船上有30个人,因为在海上遇到风暴 因此船长告诉乘客,必须牺牲15个人,并议定30个人围成一圈, 由第一个人数起,依次报数,数到第9人,便把他投入大海中ÿ…...

【人工智能前沿弄潮】—— 玩转SAM(Segment Anything)
玩转SAM(Segment Anything) 官网链接: Segment Anything | Meta AI (segment-anything.com) github链接: facebookresearch/segment-anything: The repository provides code for running inference with the SegmentAnything Model (SAM), links fo…...

每日一题——合并两个有序的数组
题目 给出一个有序的整数数组 A 和有序的整数数组 B ,请将数组 B 合并到数组 A 中,变成一个有序的升序数组 数据范围:0≤n,m≤100,∣Ai∣<100,∣Bi∣<100 注意: 1.保证 A 数组有足够的空间存放 B …...
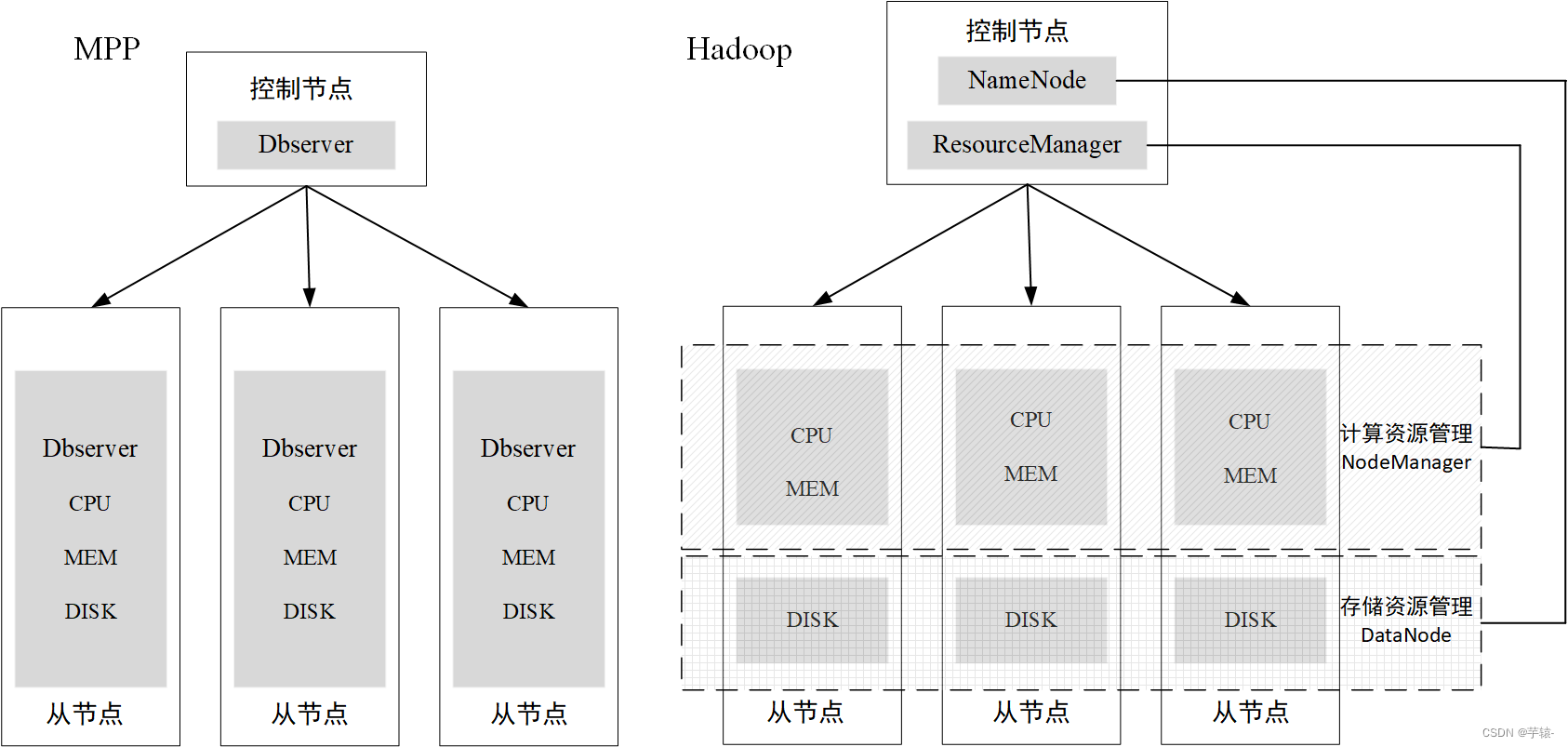
MPP架构和Hadoop架构的区别
1. 架构的介绍 mpp架构是将许多数据库通过网络连接起来,相当于将一个个垂直系统横向连接,形成一个统一对外的服务的分布式数据库系统。每个节点由一个单机数据库系统独立管理和操作该物理机上的的所有资源(CPU,内存等)…...
Java02-迭代器,数据结构,List,Set ,Map,Collections工具类
目录 什么是遍历? 一、Collection集合的遍历方式 1.迭代器遍历 方法 流程 案例 2. foreach(增强for循环)遍历 案例 3.Lamdba表达式遍历 案例 二、数据结构 数据结构介绍 常见数据结构 栈(Stack) 队列&a…...

福布斯发布2023云计算100强榜单,全球流程挖掘领导者Celonis排名17
近日,全球流程挖掘领导者Celonis入选福布斯2023 年云计算 100 强榜单,估值130亿美元,排名第17,Celonis已经是连续三年跻身榜单前20名。 本次榜单由福布斯与Bessemer Venture Partners和Salesforce Ventures联合发布,旨…...

计算机网络 MAC地址
...

Jay17 2023.8.10日报
笔记 【python反序列化】 序列化 类对象->字节流(字符串) 反序列化 字节流->对象 python反序列化没PHP这么灵活,没这么多魔术方法。 import pickle import os class ctfshow(): def init(self): self.username0 self.password0 d…...

CAN设备选型避坑指南:如何通过“接收压力测试”判断USB-CAN适配器会不会丢帧?
CAN设备选型实战:如何用接收压力测试避开数据丢帧陷阱 当你在自动驾驶原型车的CAN总线监控系统中发现关键故障码丢失,或工业网关的实时数据出现断片时,问题往往出在CAN接口设备的选型失误上。我见过太多团队在项目后期被频繁的丢帧问题困扰&a…...

C#中SetProperty的5个高级用法:从基础到回调函数实战
C#中SetProperty的5个高级用法:从基础到回调函数实战 在C#开发中,SetProperty方法早已超越了简单的属性赋值功能,成为MVVM架构中不可或缺的瑞士军刀。对于已经掌握基础用法的开发者来说,深入挖掘其高级特性能够显著提升代码的灵活…...

Vivado综合时信号被优化?手把手教你用DONT_TOUCH保留关键状态信号
Vivado综合优化陷阱:如何用DONT_TOUCH守住关键状态信号 在FPGA开发的世界里,Vivado的综合优化就像一把双刃剑。它能帮我们精简设计、提升性能,但有时也会"过度热心"地优化掉我们真正需要的关键信号。特别是状态机中的状态信号&…...

iOS开发中.p12证书密码丢失的应急处理与安全导出指南
1. 当.p12证书密码丢失时,开发者该怎么办? 遇到.p12证书密码丢失的情况,很多iOS开发者会感到手足无措。这种情况在实际开发中并不少见,特别是当项目交接或长时间未使用证书时。我曾经接手过一个老项目,就遇到过前任开发…...

Nunchaku FLUX.1-dev 操作系统兼容性指南:Windows系统部署要点
Nunchaku FLUX.1-dev 操作系统兼容性指南:Windows系统部署要点 如果你是一名Windows开发者,想在自己的电脑上跑起来Nunchaku FLUX.1-dev,那你来对地方了。我知道,很多AI模型和工具的教程,默认都是给Linux或者macOS用户…...

ESP32-CAM与WebSocket:构建低延迟远程监控系统的实战指南
1. 为什么选择WebSocket而不是HTTP轮询? 刚开始接触ESP32-CAM远程监控项目时,我和大多数开发者一样,首先想到的是用HTTP轮询方案。毕竟HTTP协议大家都熟悉,实现起来也简单。但实际测试后发现,这种方式在实时视频传输场…...
)
胶片背后的科学:揭秘溴化银如何捕捉光影(含现代数码摄影对比)
胶片背后的科学:揭秘溴化银如何捕捉光影(含现代数码摄影对比) 当光线穿过镜头,在胶片表面留下潜影的那一刻,一场精妙的化学反应便悄然启动。这种用银盐捕捉光影的技术,曾统治影像记录领域长达一个多世纪&am…...

终极指南:5步让老款Mac安装最新macOS系统
终极指南:5步让老款Mac安装最新macOS系统 【免费下载链接】OpenCore-Legacy-Patcher Experience macOS just like before 项目地址: https://gitcode.com/GitHub_Trending/op/OpenCore-Legacy-Patcher 想让2008年甚至更早的MacBook也能运行最新的macOS Sequo…...

移动应用安全新规下,APK加固如何满足等保2.0与个人信息保护法?
随着《网络安全法》、等保2.0标准以及《个人信息保护法》的全面实施,移动应用安全已经从单纯的技术问题,上升为法律层面的硬性要求。APP运营者而言,不满足合规要求,轻则应用下架,重则面临巨额罚款和法律责任。而在所有…...

第十六届 蓝桥杯嵌入式设计与开发 省赛 客观题
不定项选择,共10题 01.关于STM32时钟源的说法,错误的是() A.HSI精度高于HSE B.LSE常用于RTC模块 C.PLL可将外部或内部时钟倍频 D.切换系统时钟源或修改主频时,必须先进入停机模式 答案:AD A:HSI(内部高速时钟ÿ…...