MySQL索引1——索引基本概念与索引结构(B树、R树、Hash等)
目录
索引(INDEX)基本概念
索引结构分类
B+Tree树索引结构
Hash索引结构
Full-Text索引
R-Tree索引
索引(INDEX)基本概念
什么是索引
索引是帮助MySQL高效获取数据的有序数据结构
为数据库表中的某些列创建索引,就是对数据库表中某些列的值通过不同的数据结构进行排序
为列建立索引之后,数据库除了维护数据之外,还会维护满足特定查找算法的数据结构,这些数据结构以某种方式指向数据,这样就可以在这些数据结构上实现快速查询,这种数据结构就是索引
索引的作用
通过索引可以将无序的数据变为有序的数据,能够实现快速访问数据库表中的特定信息
优缺点
优点
提高数据检索的效率,降低数据库的IO成本
通过索引对数据进行排序,降低数据排序的成本,降低CPU的消耗
缺点
索引会占用空间
索引提高了表的查询效率,但是却降低了更新表的速度(Insert、Update、Delete)
索引只是一个提高效率的因素,如果MySQL有大数据量的表,就需要花时间研究最优秀的索引(即需要研究为哪些字段建立索引能够使得效率提升到最大化,因为一条查询语句只会引用到一种索引,并且一般建议一个表建立的索引数量不要超过5个)
索引结构分类
索引结构主要分为四大类
B+Tree索引-(B+树)
最常见的索引类型,大部分的存储引擎都支持此索引
Hash索引-(Hash表)
底层的数据结构是用哈希表实现的,只有精确匹配索引列的查询才有效,不支持范围查询
Full-Text索引-(倒排索引)
又名全文索引,是一种通过建立倒排索引,快速匹配文档的方式
R-Tree索引(R-Tree树)
又名空间索引,是MyISAM引擎的一个特殊索引类型,主要用于地理位置数据,使用较少
存储引擎对不同索引的支持情况(默认B+Tree索引)
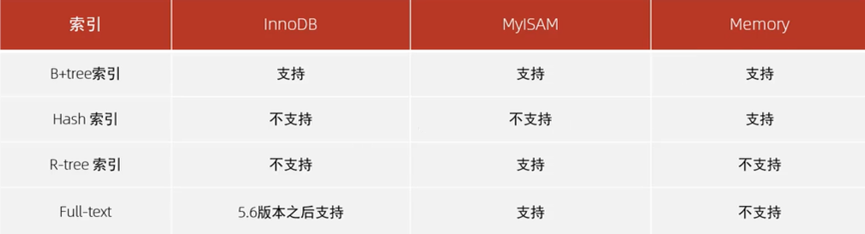
在MySQL数据库中,支持Hash索引的是Memory引擎;而InnoDB中具有自适应Hash的功能,根据B+tree索引在指定条件下自动构建的
B+Tree树索引结构
B+Tree树是由二叉树 → 红黑树(自平衡二叉树) → B-Tree树烟花而来的,我们在介绍B+Tree树之前先介绍这三种数据结构
二叉树
二叉树的每个节点最多有两个子节点(两颗子树);并且两个子节点是有序的
以单个节点为例:左边子节点是比自身小的,右边子节点是比自身大的
缺点
- 大数据量的情况下,层级较深,检索速度慢
- 容易形成倾斜树(左倾斜或右倾斜)
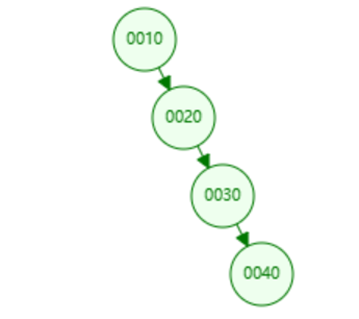
二叉树的工作原理
二叉树的数据插入(依次插入30、40、20、19、21、39、35)

二叉树的数据遍历

二叉树的数据查找(查找39 、21、25)
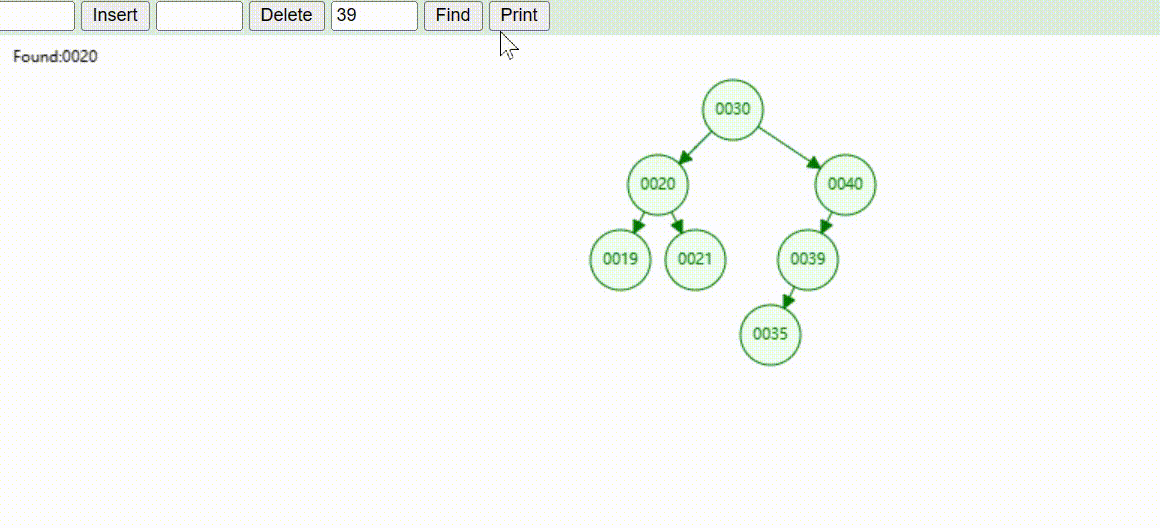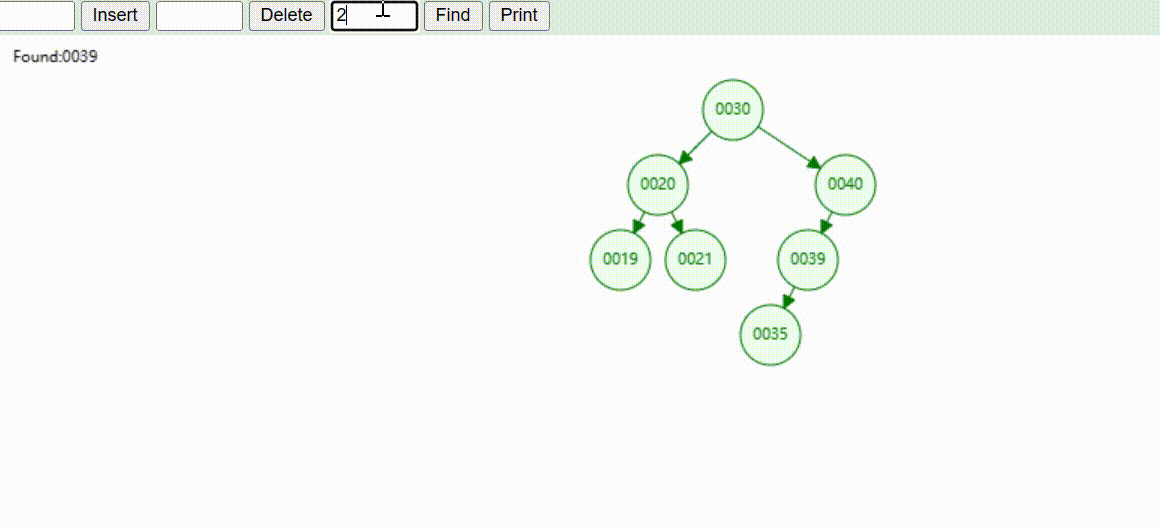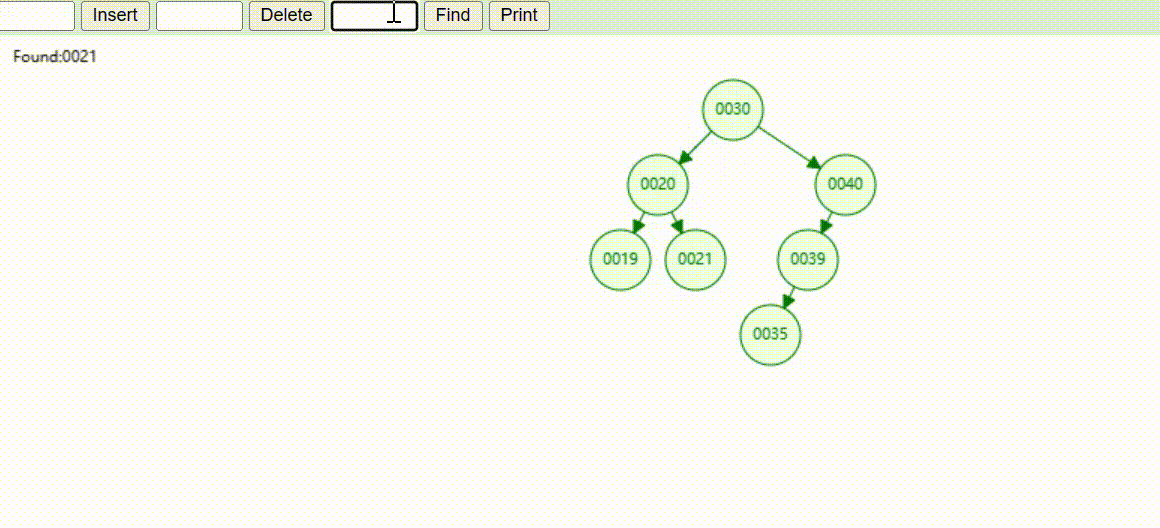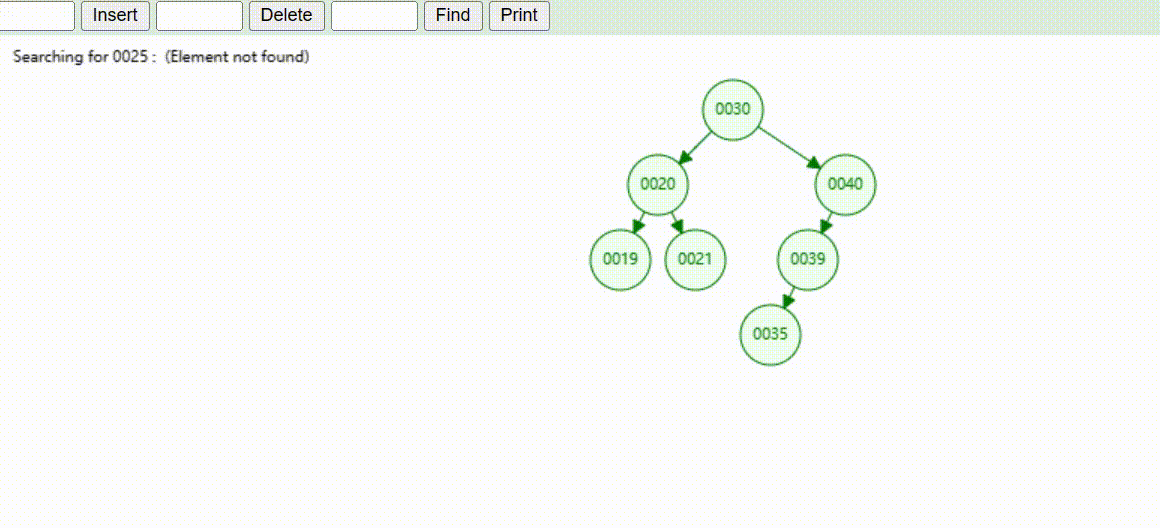
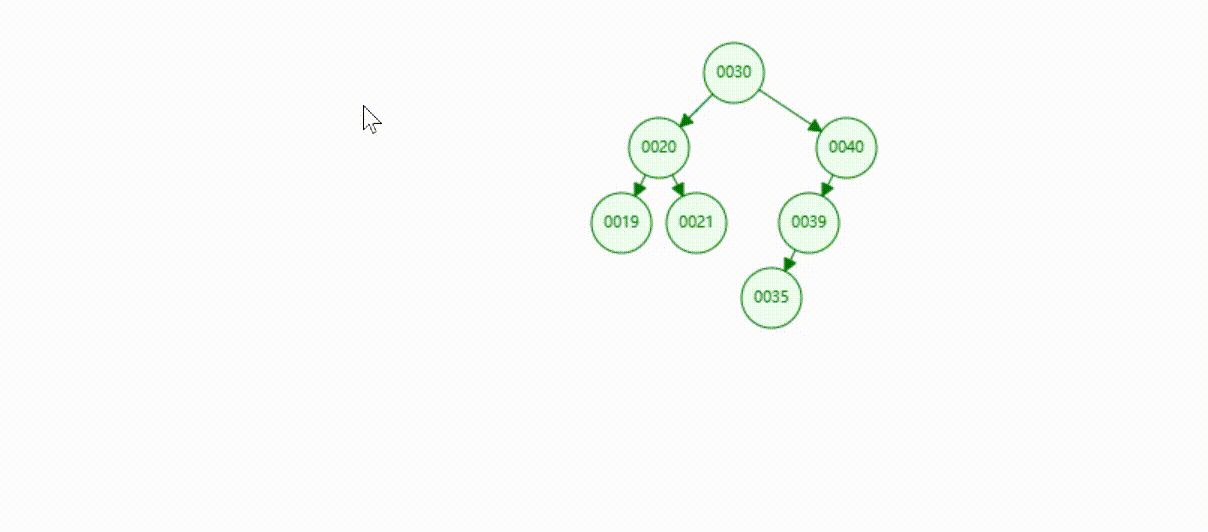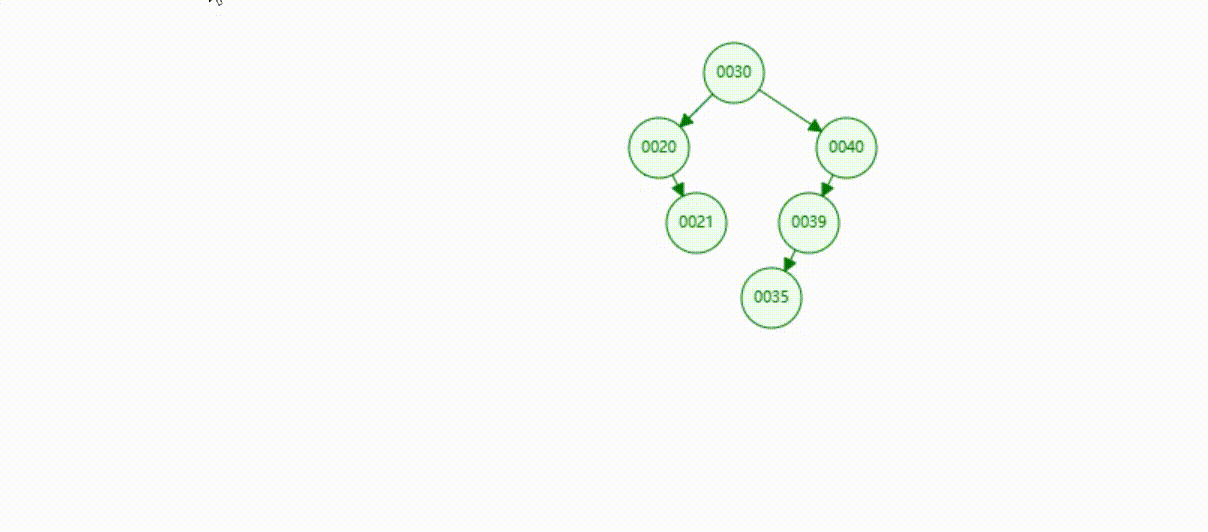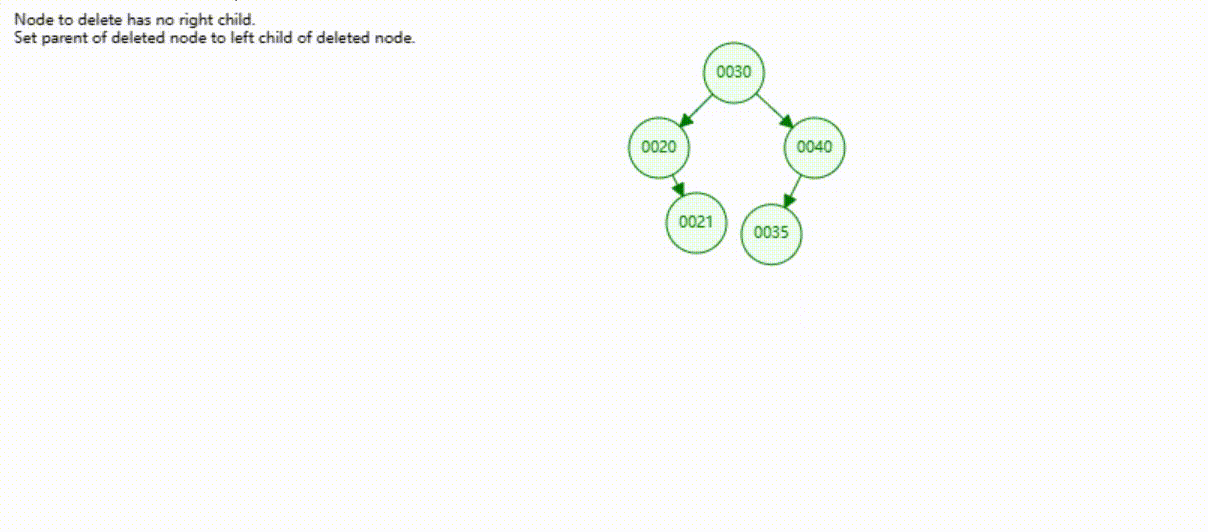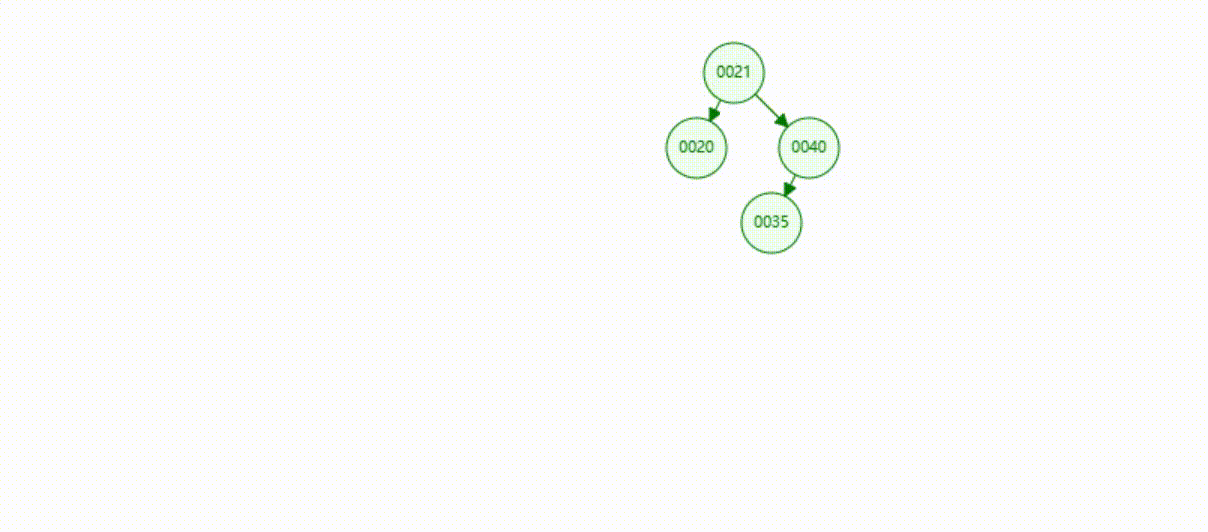
二叉树的数据删除(依次删除19、39、30)
红黑树(自平衡二叉树)
红黑树时二叉树的变种,可以解决二叉树插入数值时产生斜树的问题
任何一个节点都有颜色(红色或黑色),通过颜色来确保树在插入和删除时的平衡
根节点一定是黑色的;Null节点被认为是黑色的;每个红色节点的两个叶子节点都是黑色
每个叶子节点到根的路径上不能出现连续的红色节点
任何一个节点到达叶子节点所经过的黑节点个数必须相等
当在红黑树中进行插入和删除操作时,会通过左旋、右旋、重新着色来修复树结构,保持树的平衡
缺点
- 在进行大量插入和删除操作的情况下,可能会造成频繁的树重构,影响性能
- 红黑树的实现比较复杂,需要维护节点的颜色和平衡
- 红黑树本质也是二叉树,在大数据量的情况下,层级较深,检索速度会下降
红黑树的工作原理
红黑树的数据插入(依次插入30、40、20、19、21、39、35) 使用到了右旋

红黑树的数据遍历
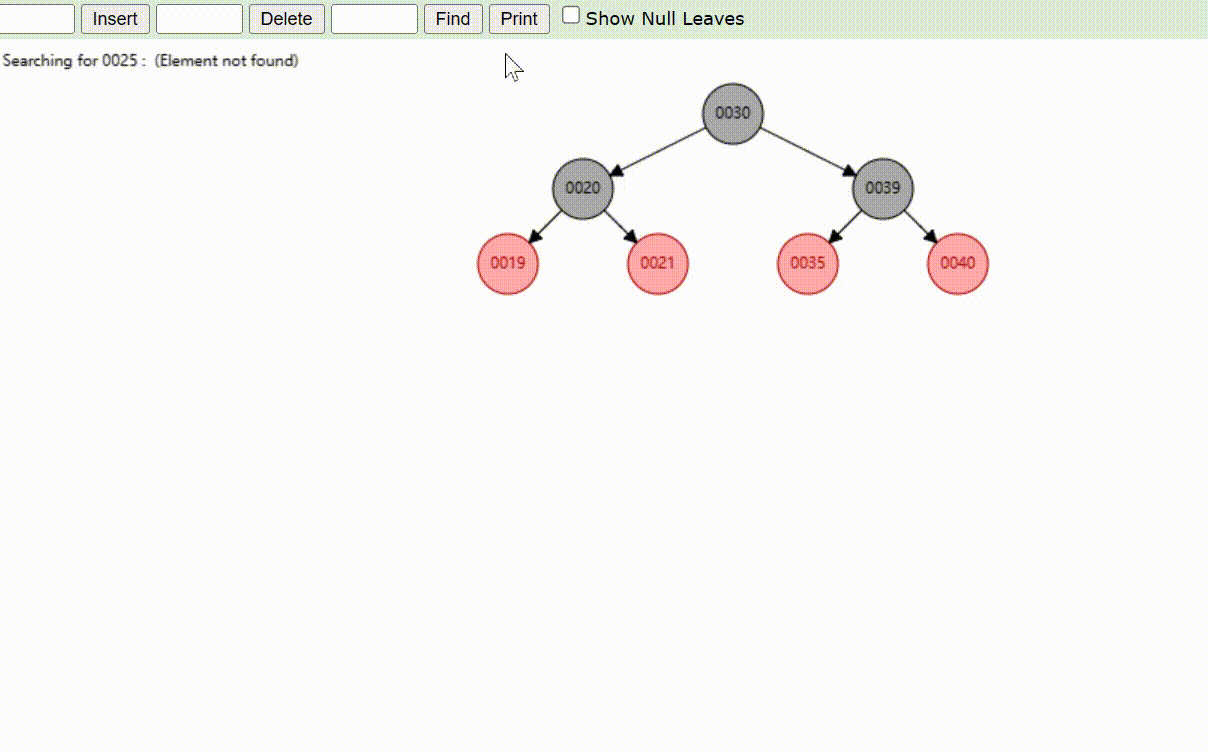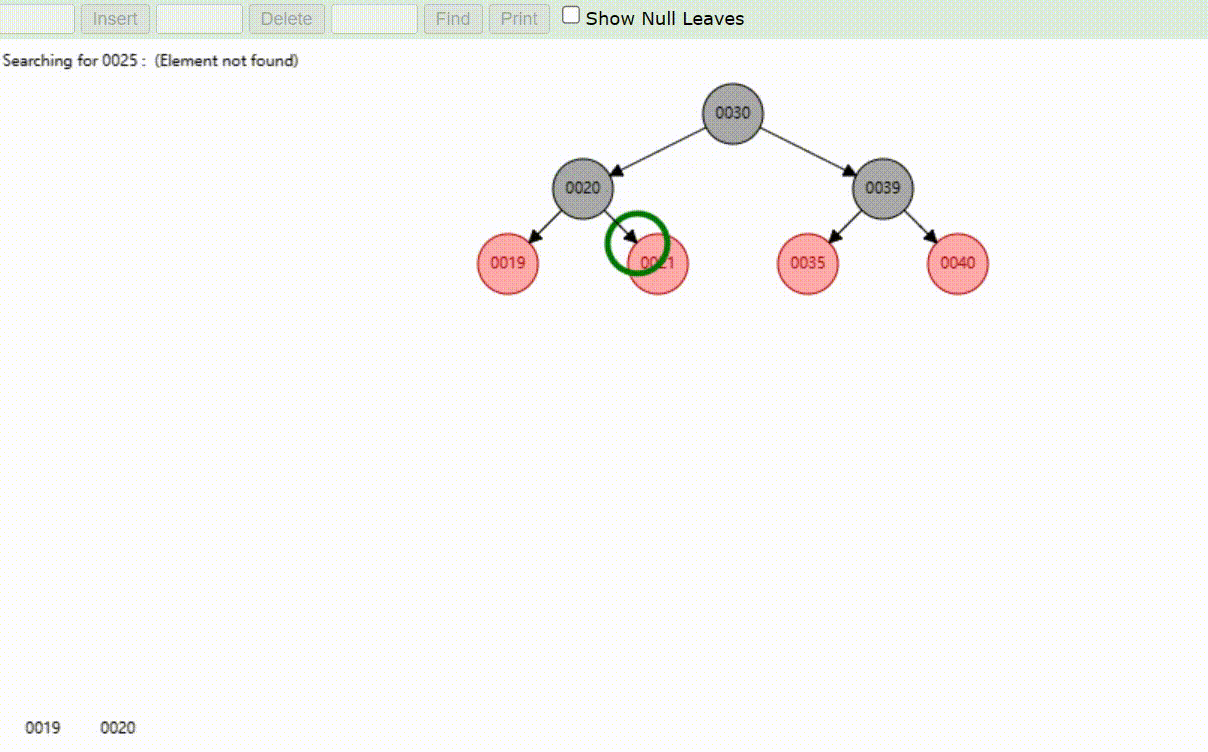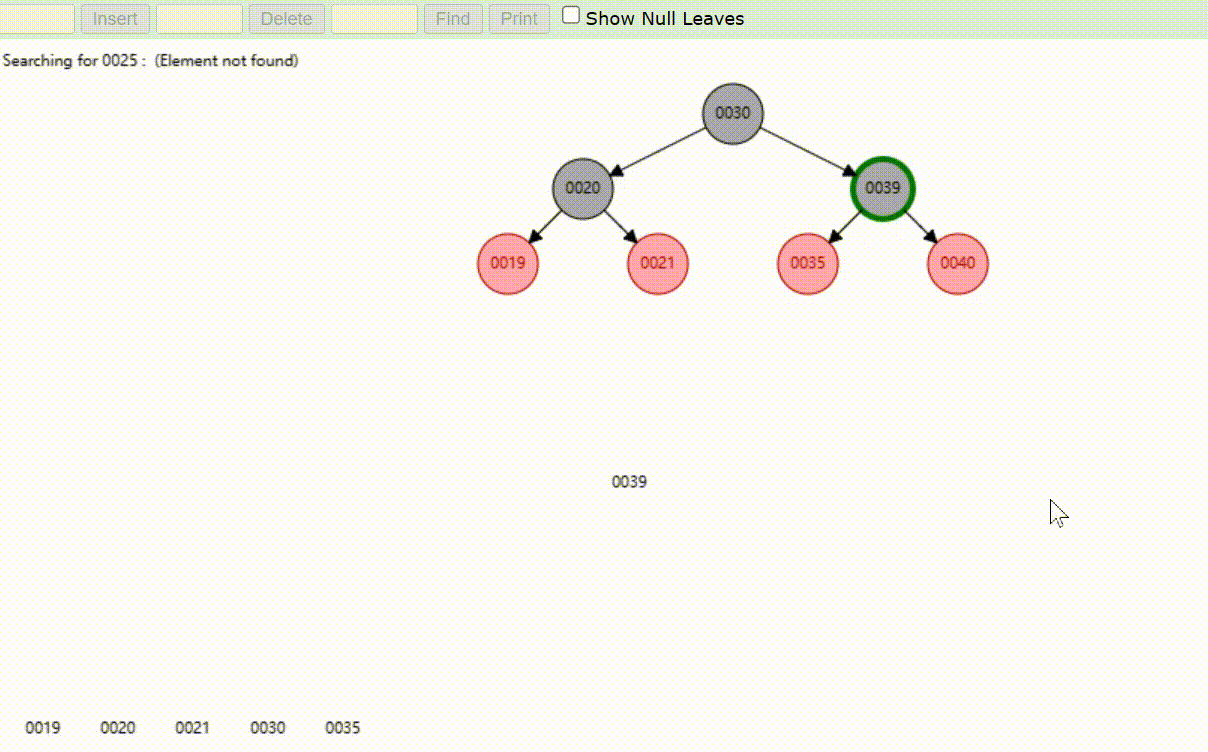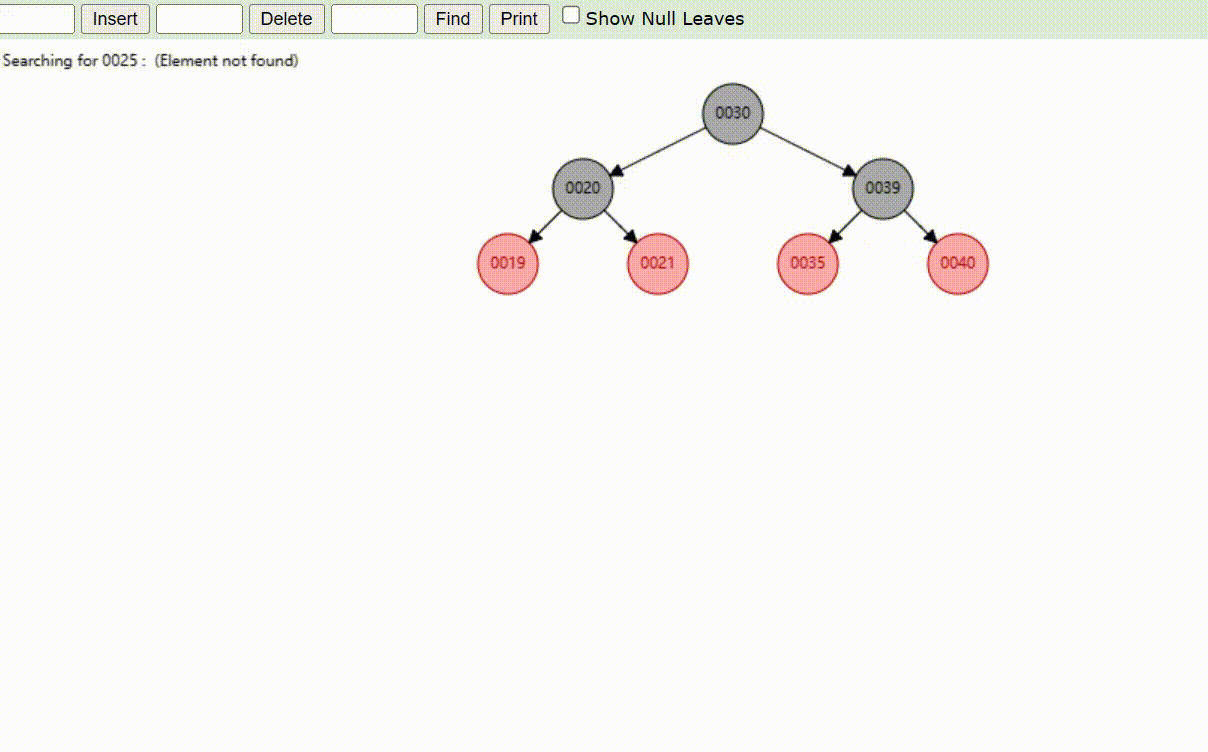
红黑树的数据查找(查找39 、21、25)
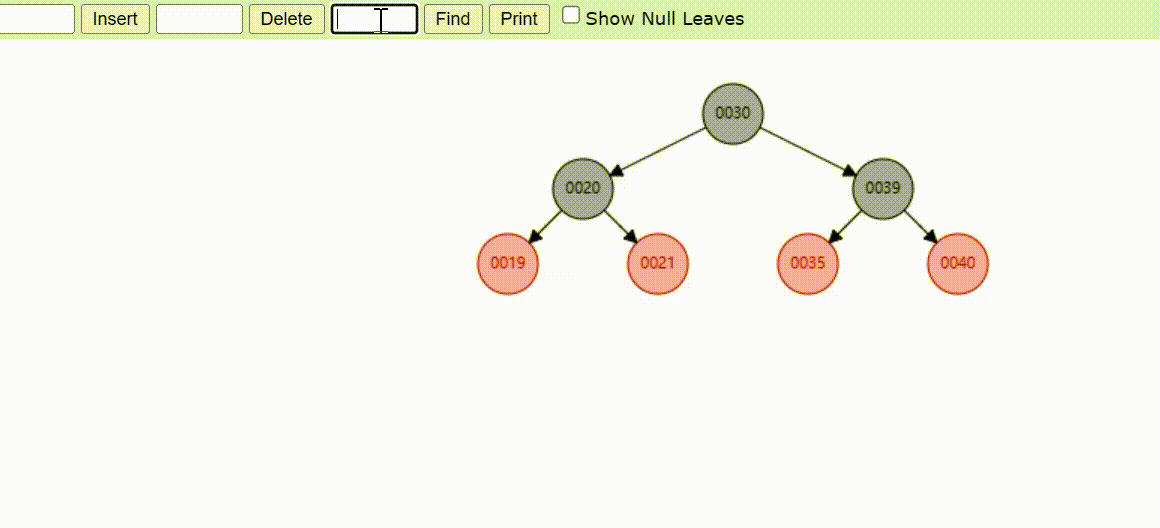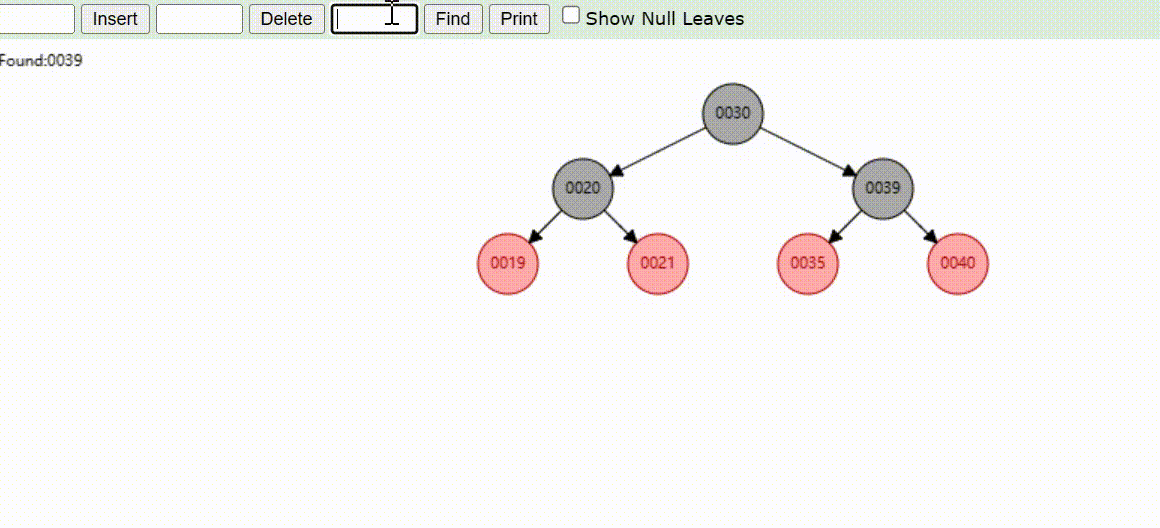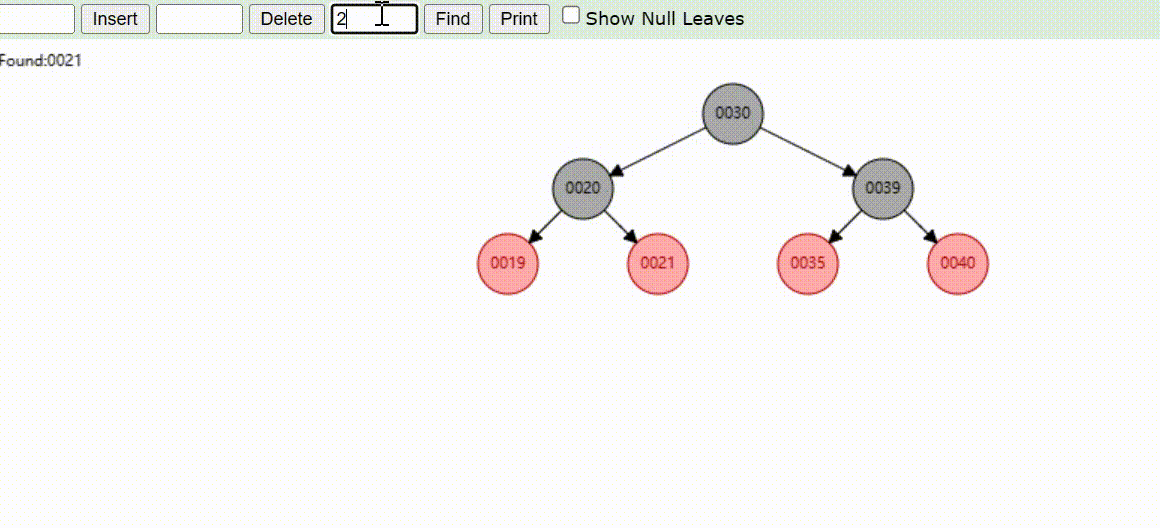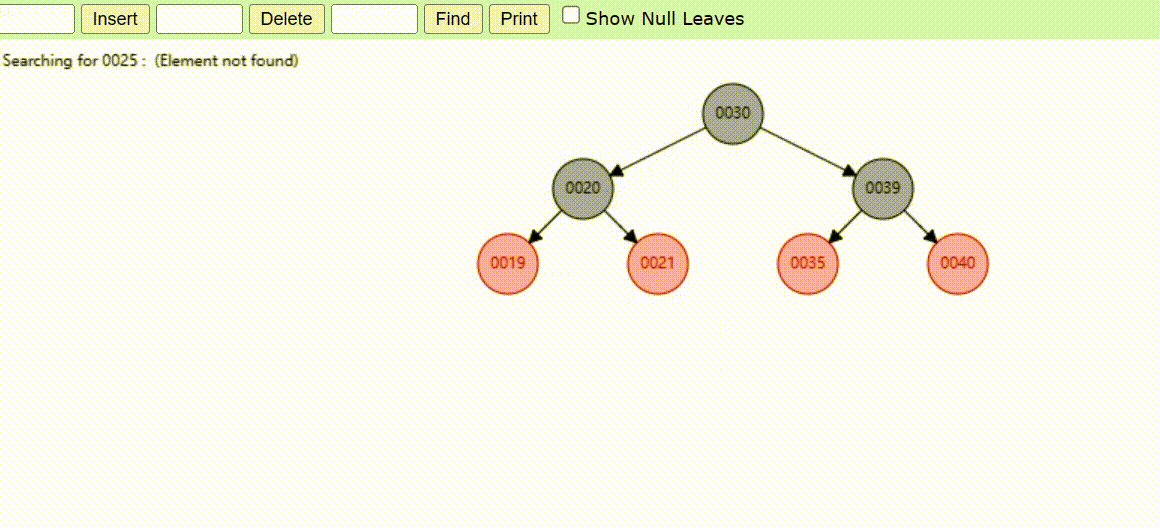
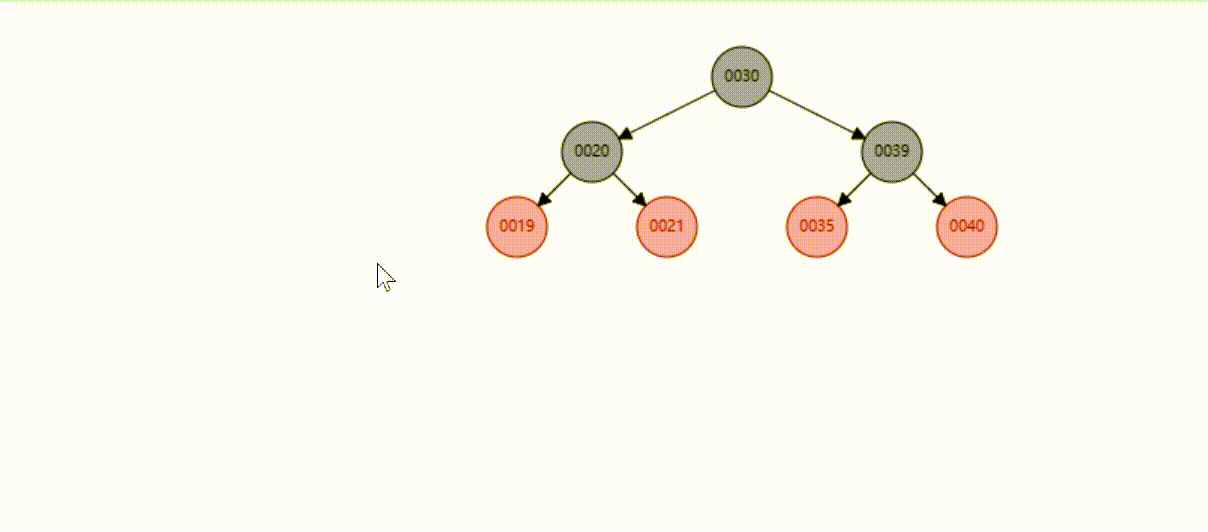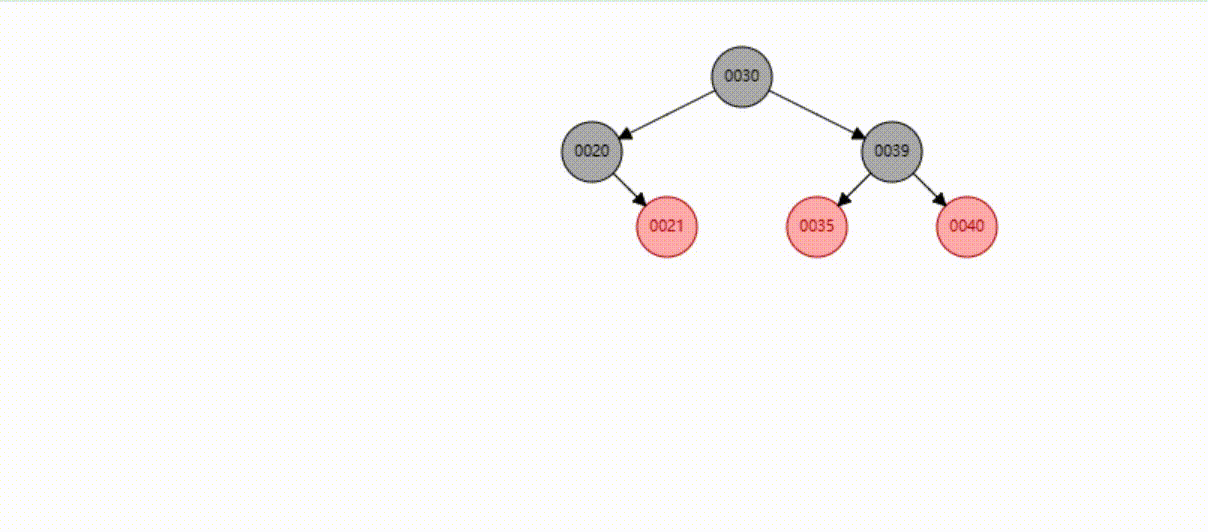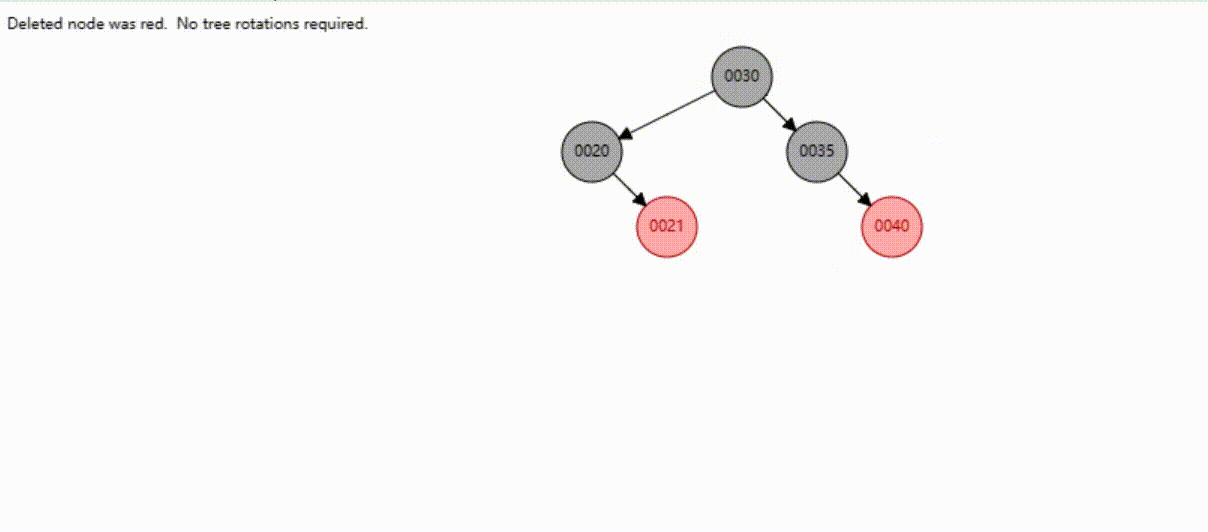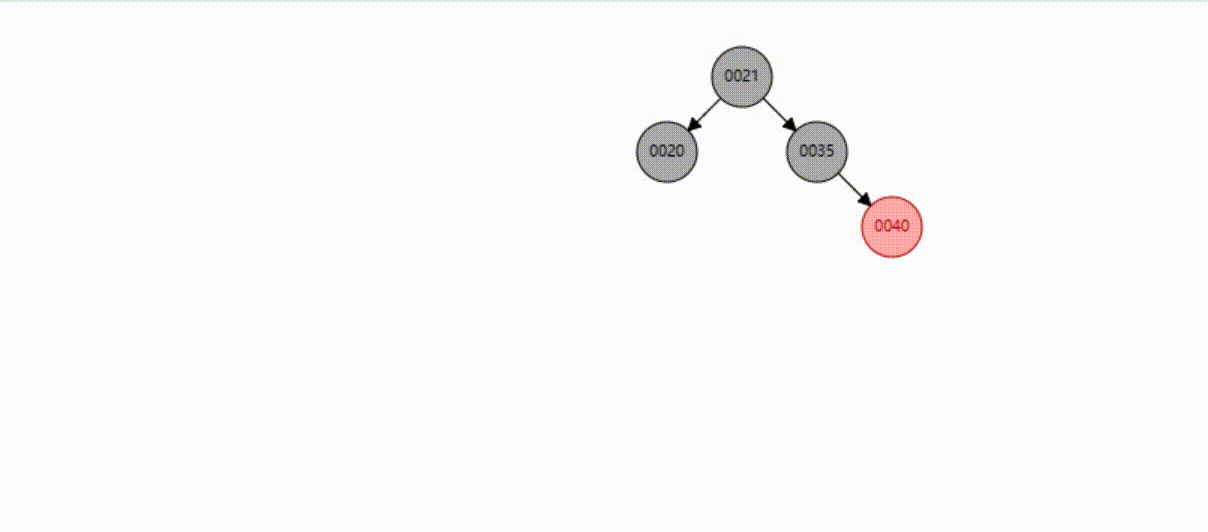
红黑树的数据删除(依次删除19、39、30)
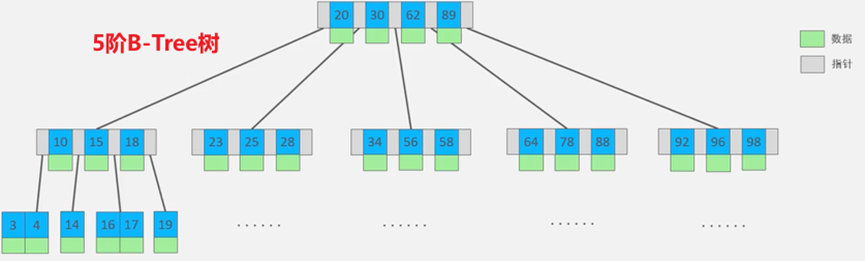
B-Tree树(多路平衡查找树)
二叉树一个Node节点只能够存储一个Key和一个Value,并且只有两个子节点;而多路树相比较而言一个Node节点能够存储更多的Key和Value,能够携带更多的子节点,建树高度会比二叉树要低
B-Tree树的一个节点能够存储多少Key和Value,可以有多少个子节点通过最大度数(MAX-Degree 也称为阶数)决定
一个m阶的B-Tree树
树中的每个节点最多有m个子节点,m-1个Key和Value(两个子树的指针夹着一个Key和Value)
树的根节点至少有一个Key和Value,至少两个子节点
缺点
B树的叶子节点和非叶子节点都会保存数据,使得非叶子节点保存的指针量变小
如果存储大量的数据,需要增加树的高度,导致IO操作变多,查询性能变低
B-Tree树的工作原理
B-Tree树的数据插入Max-Degree为3(依次插入30、40、20、19、21、39、35)

B-Tree树的数据遍历
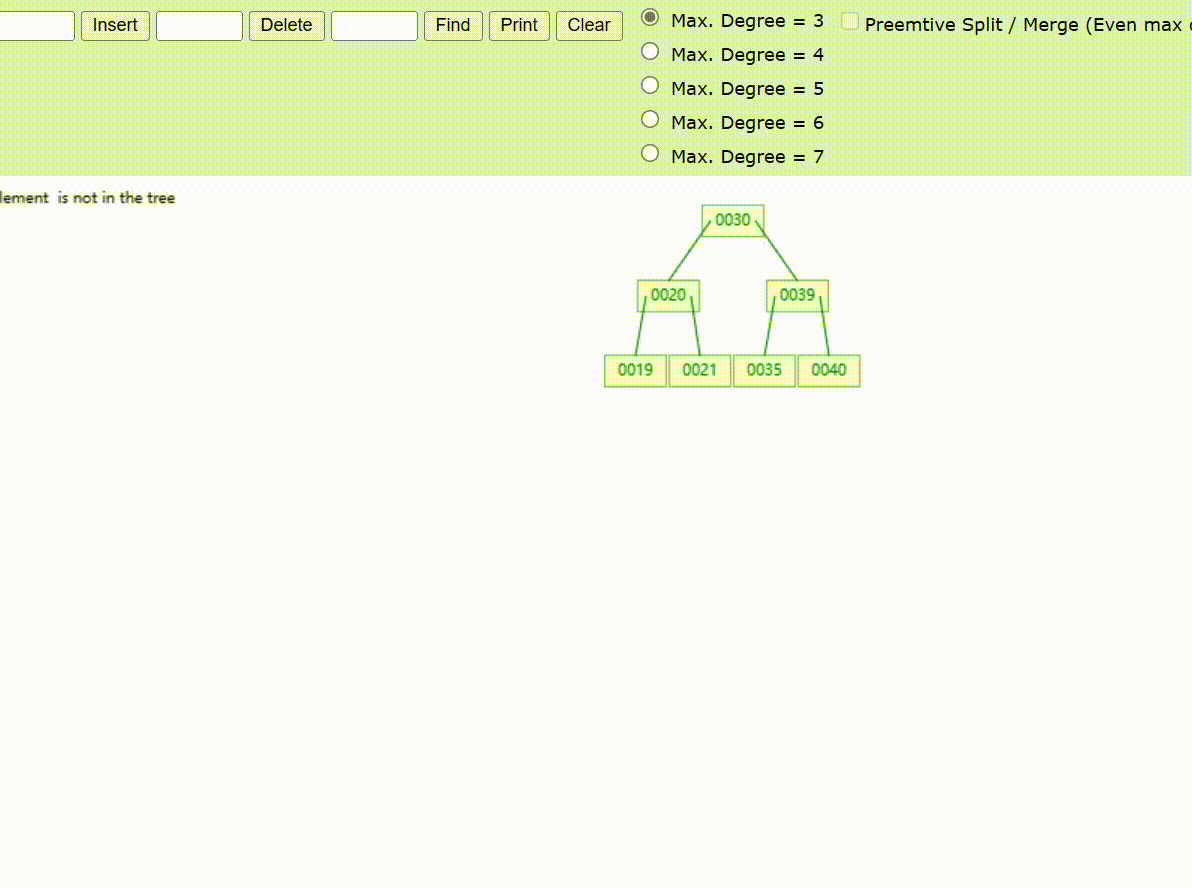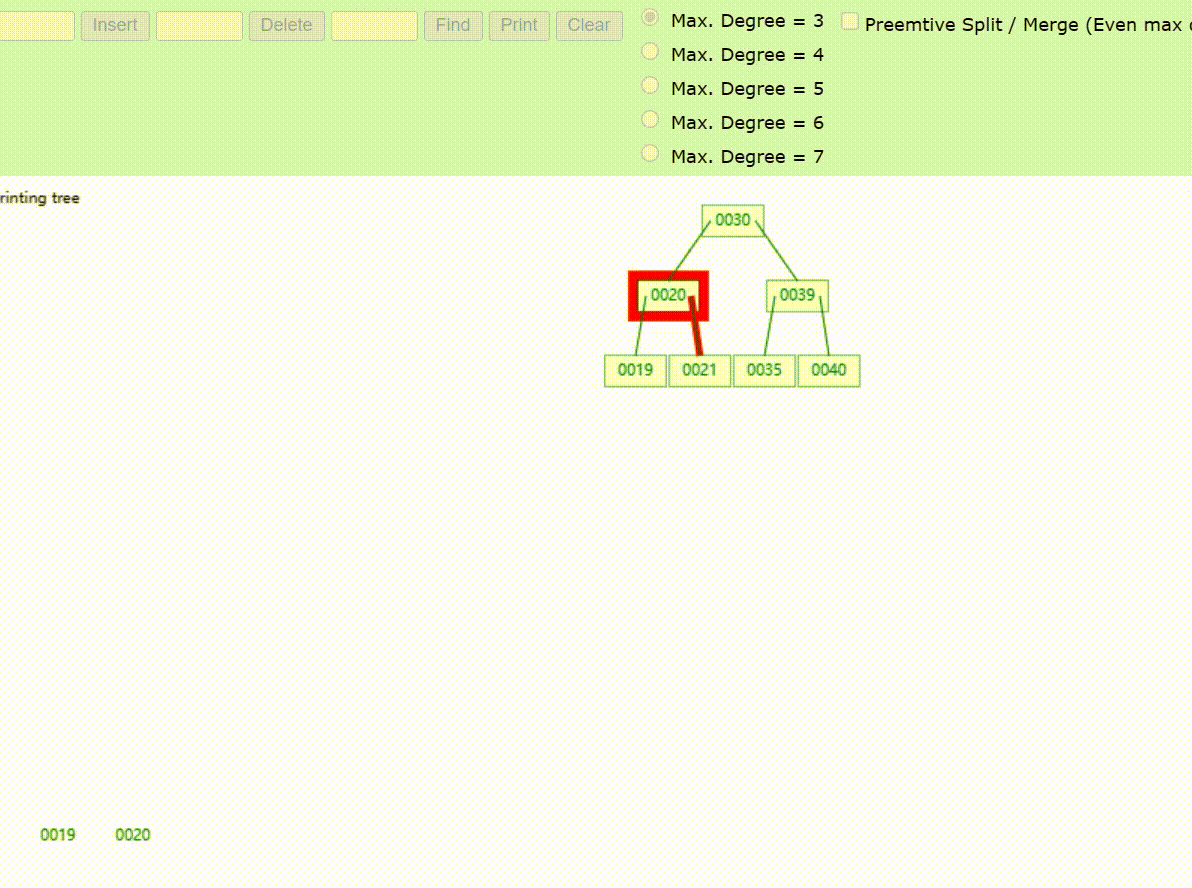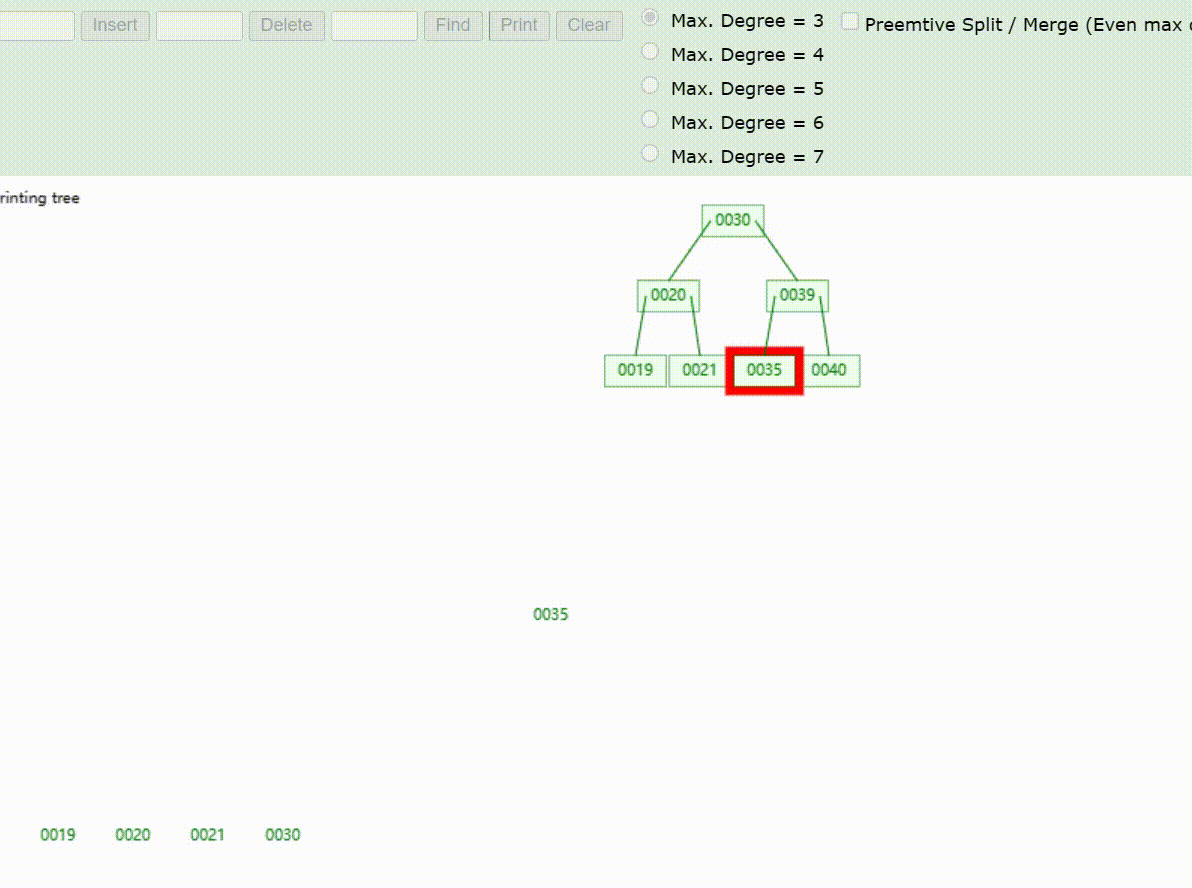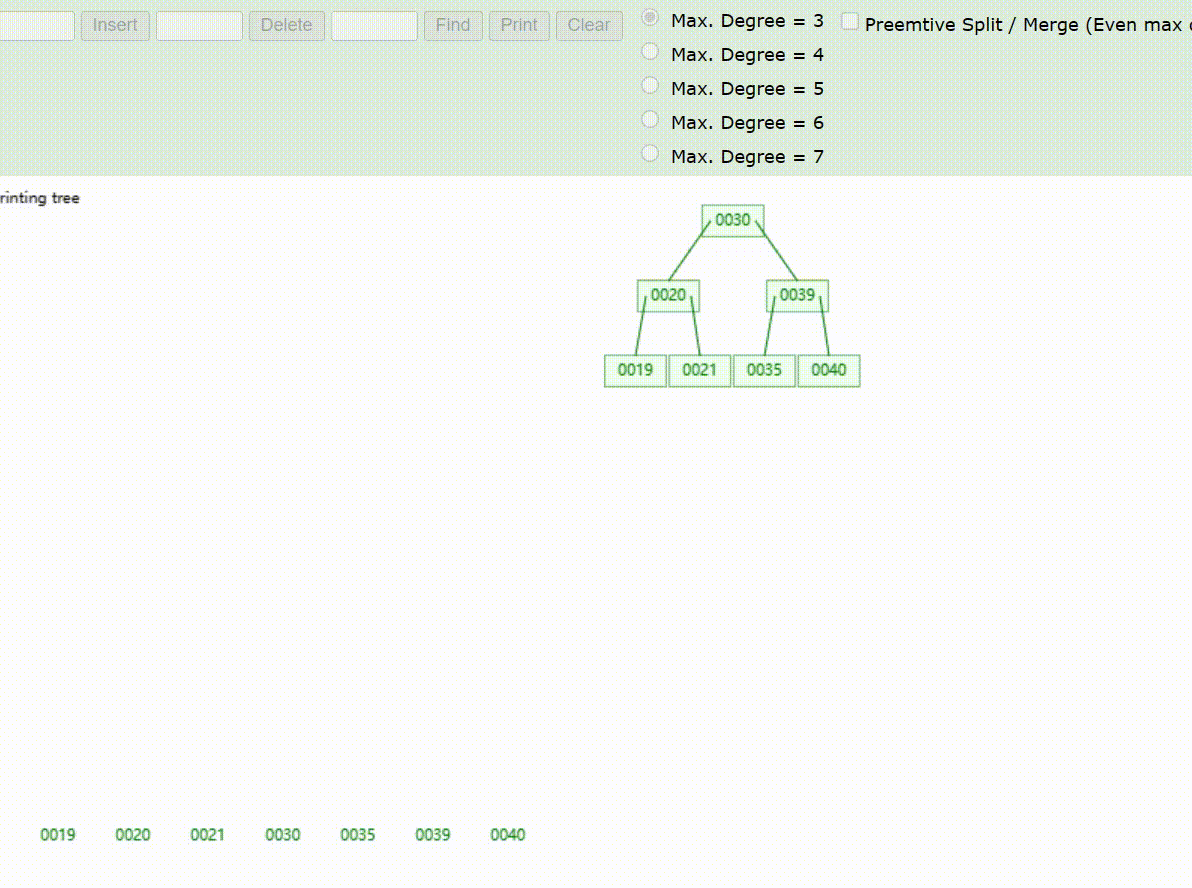
B-Tree树的数据查找(查找39 、21、25)
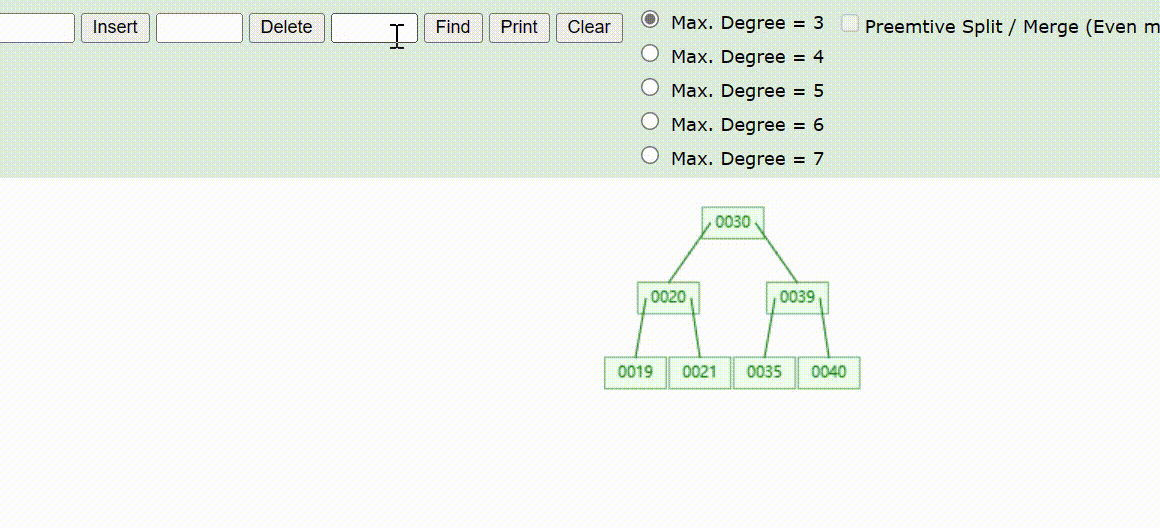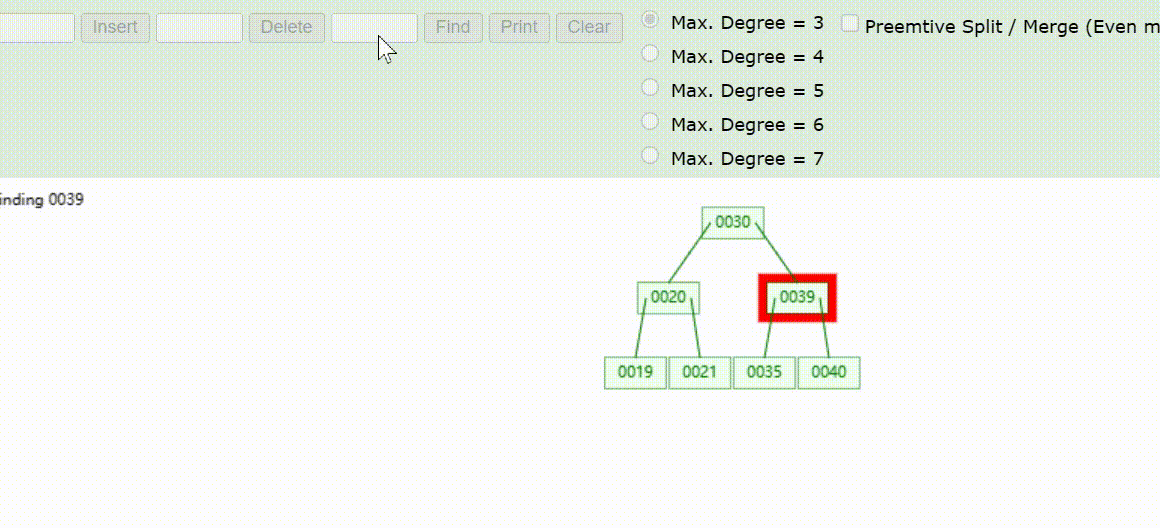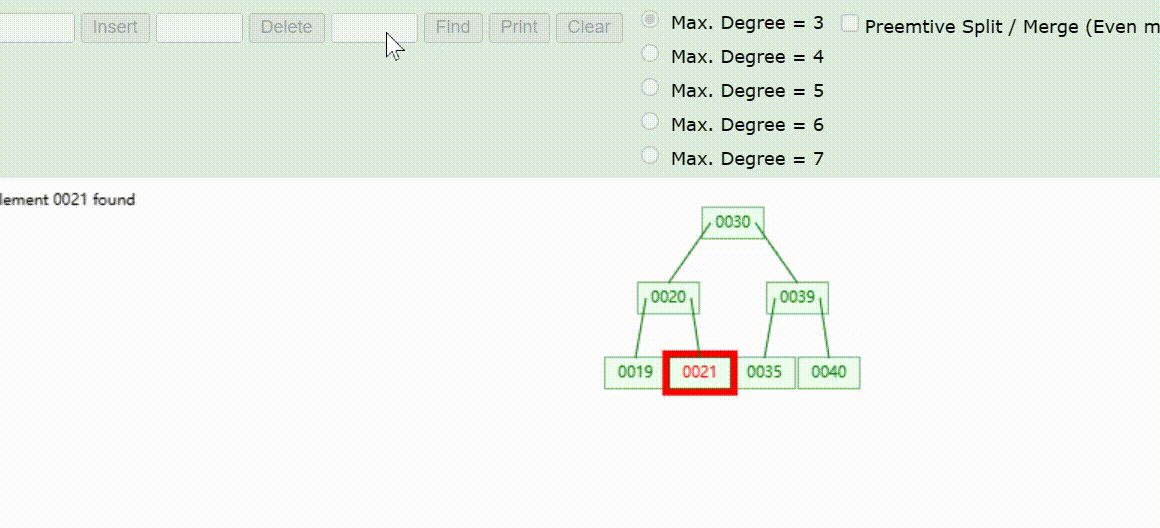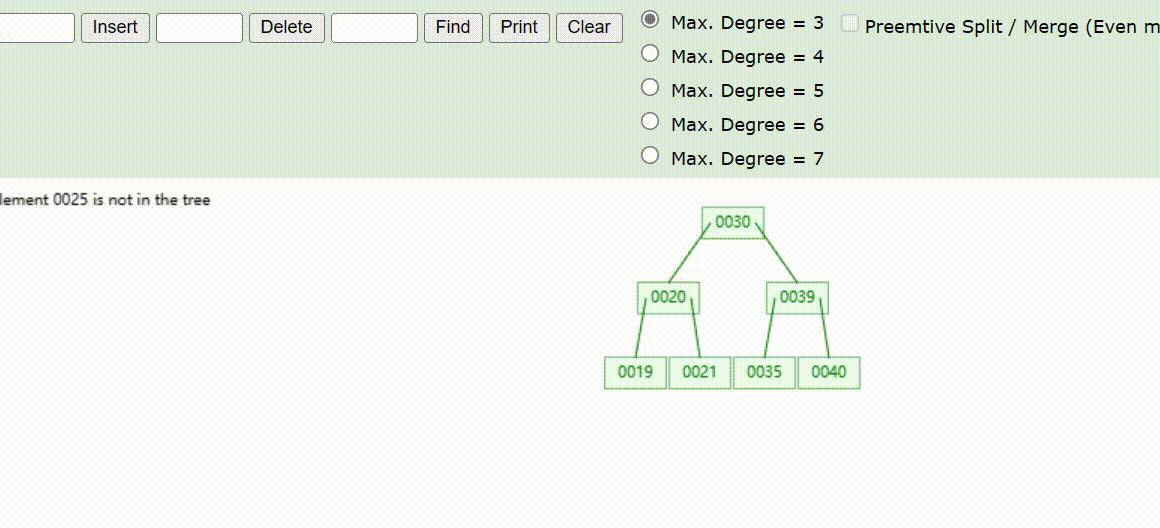
B-Tree树的数据删除(依次删除19、39、30)

B+Tree树
B+Tree树是B-Tree树的变种,也是一种多路搜索树,定义基本与B-Tree相同
B+Tree只有叶子节点存储数据,并且所有的元素都会出现在叶子节点中,所有叶子节点形成了一个单向链表;叶子节点将数据按照大小排列,并且相邻叶子节点之间按照大小排列
非叶子节点不存储数据,只存储Key,只是起到索引的作用,在相同的数据量下,B+Tree树更加矮壮
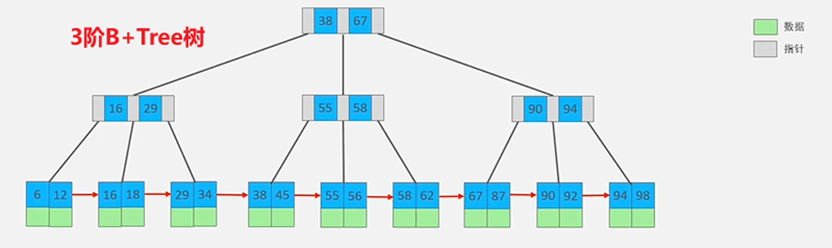
B-Tree树的工作原理
B+Tree树的数据插入Max-Degree为3(依次插入30、40、20、19、21、39、35)

B+Tree树的数据遍历
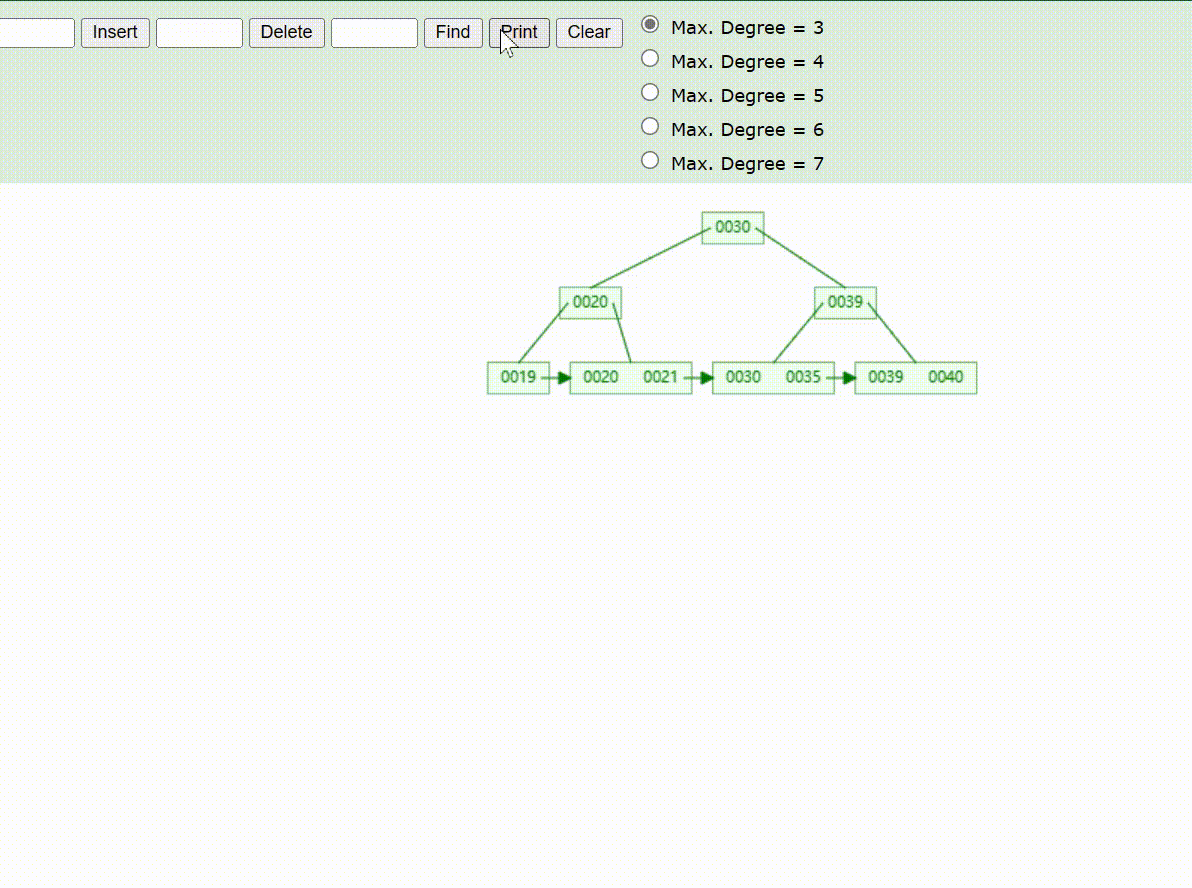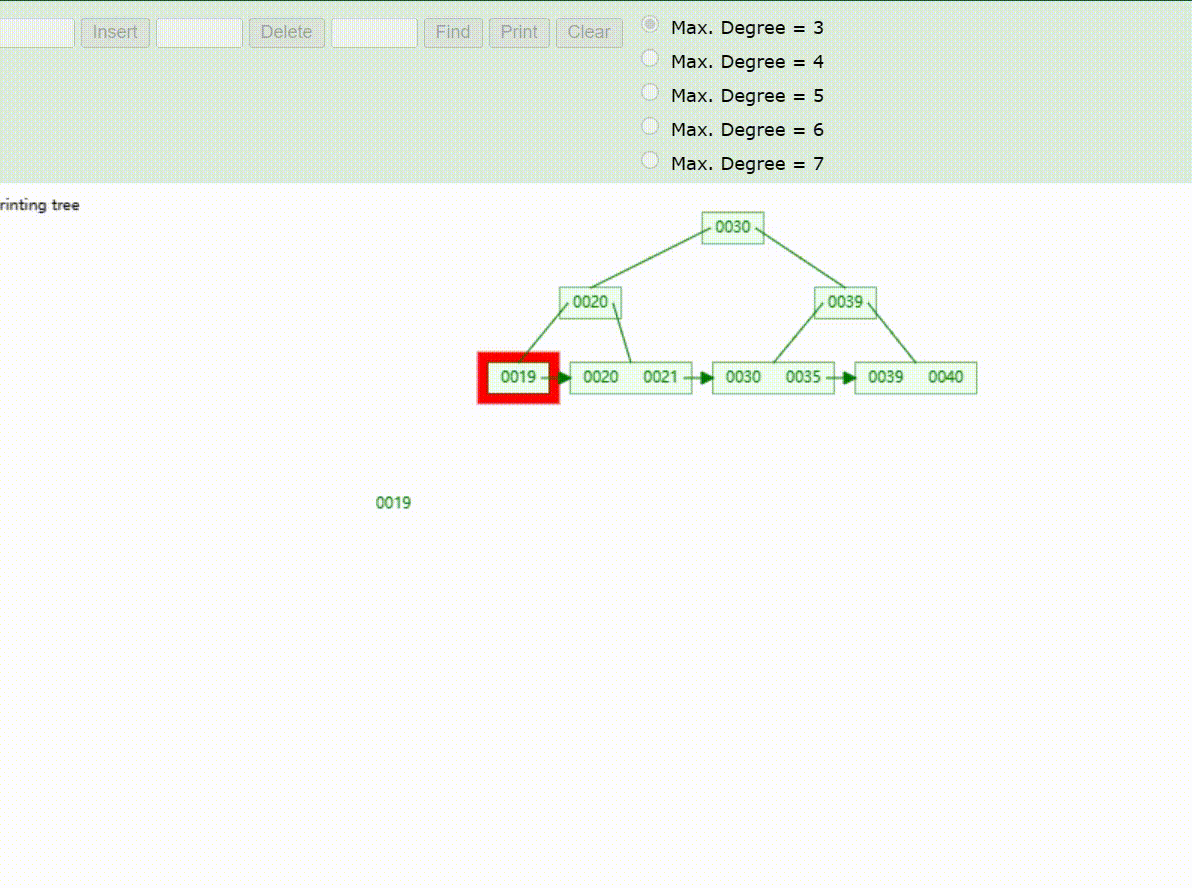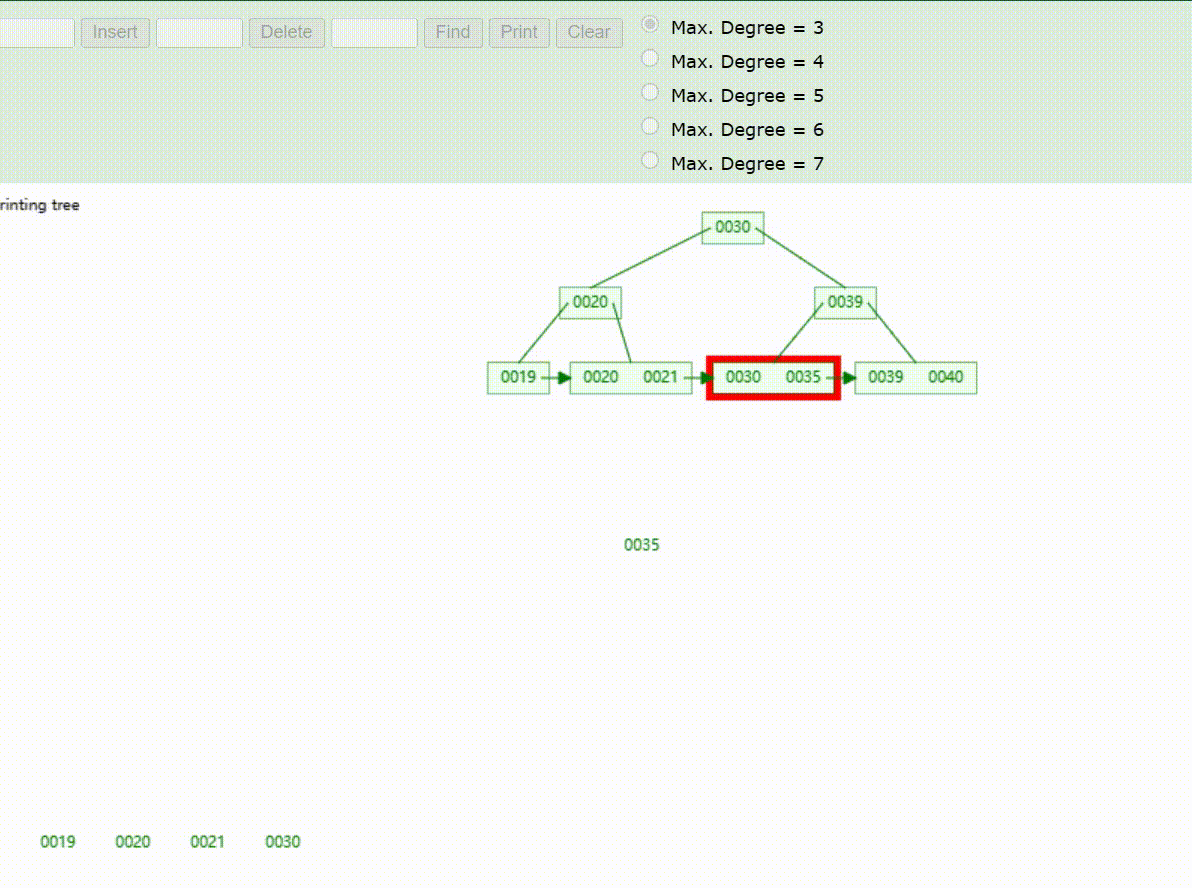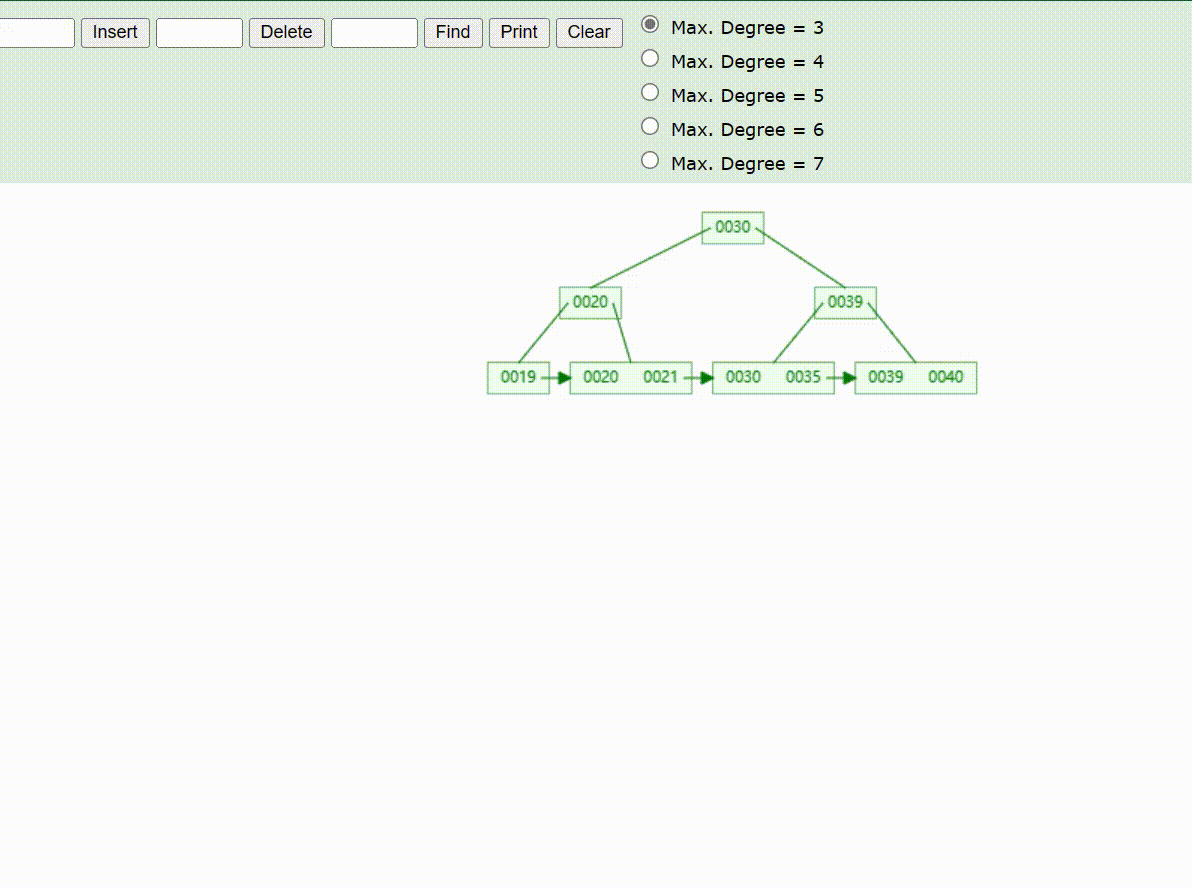
B+Tree树的数据查找(查找39 、21、25)
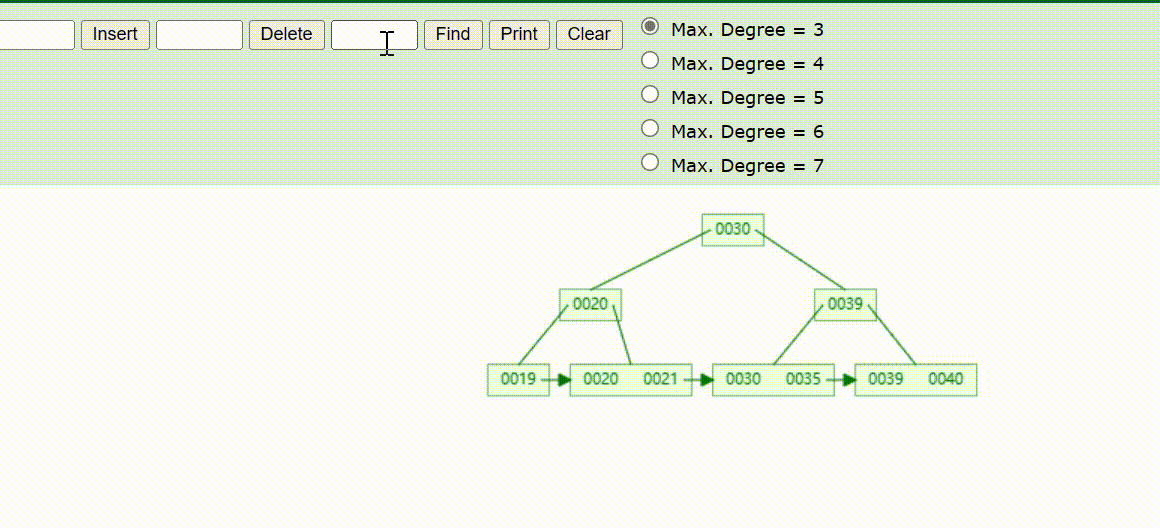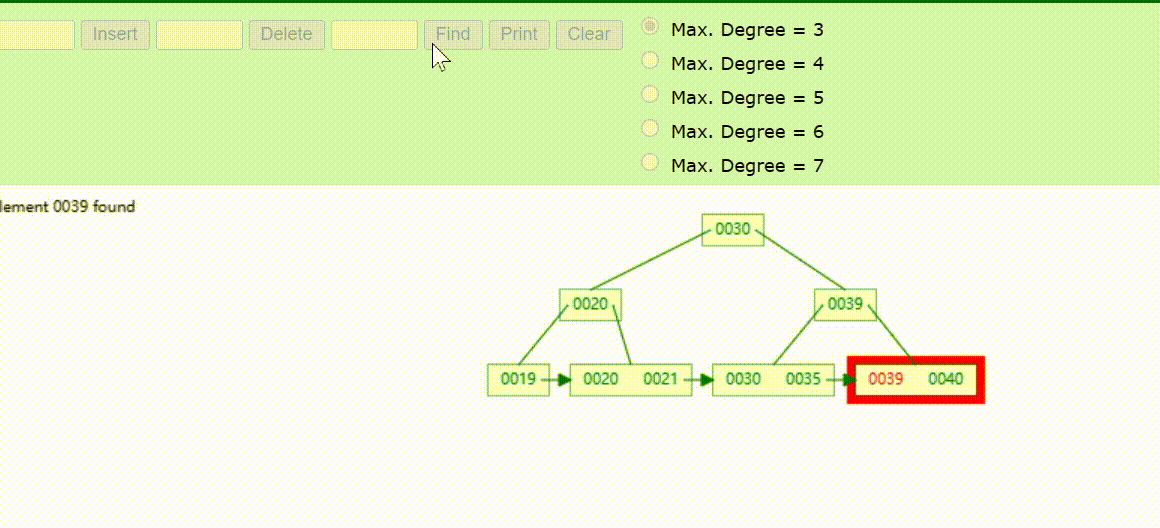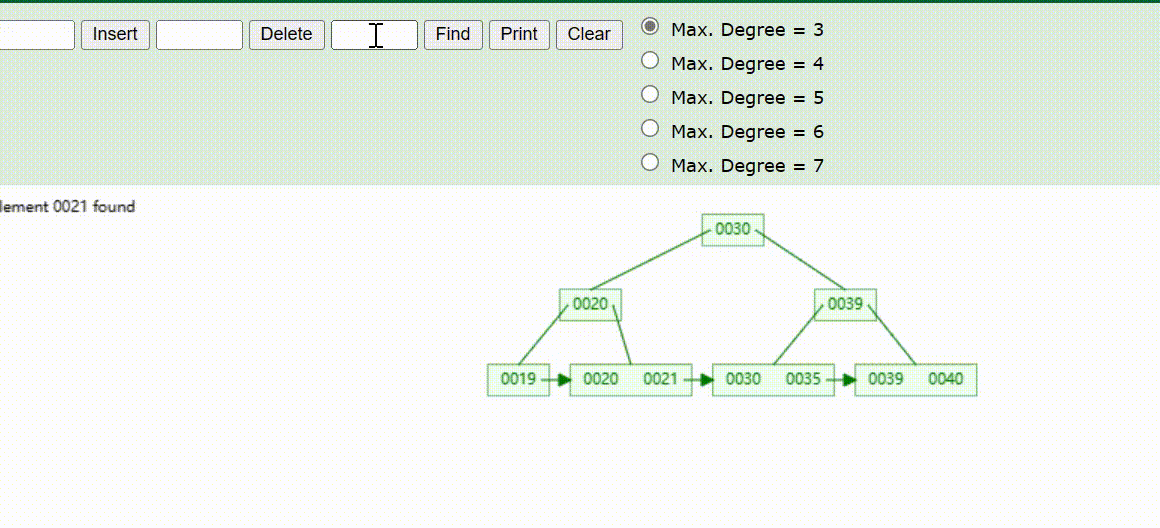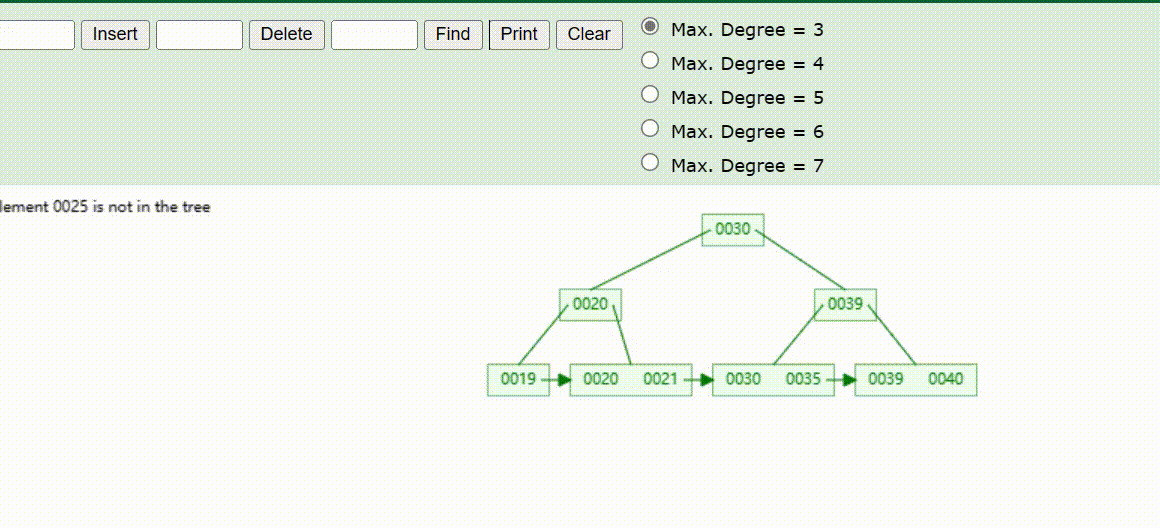
B+Tree树的数据删除(依次删除19、39、30)
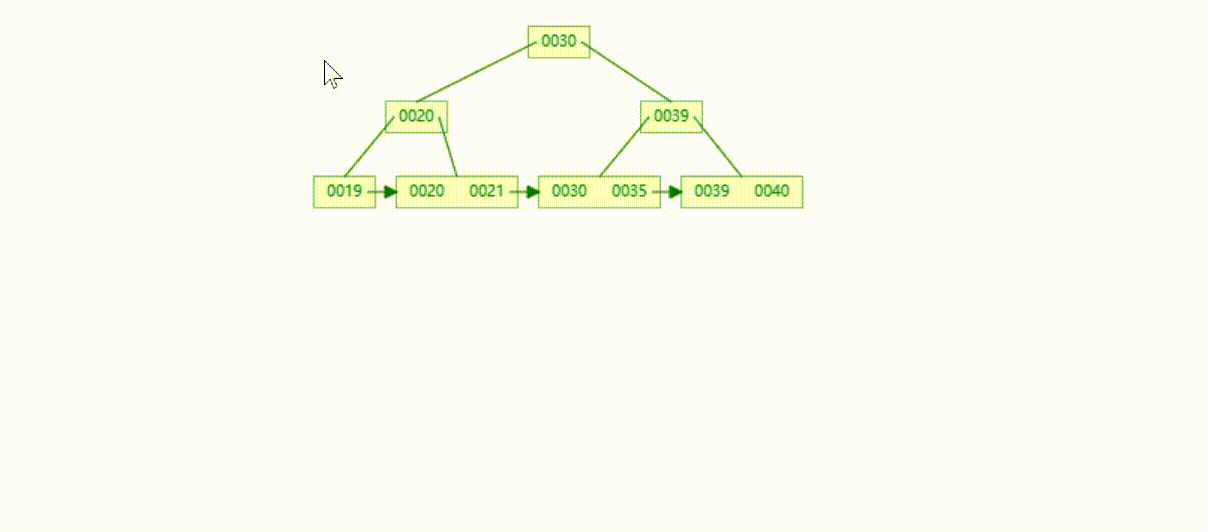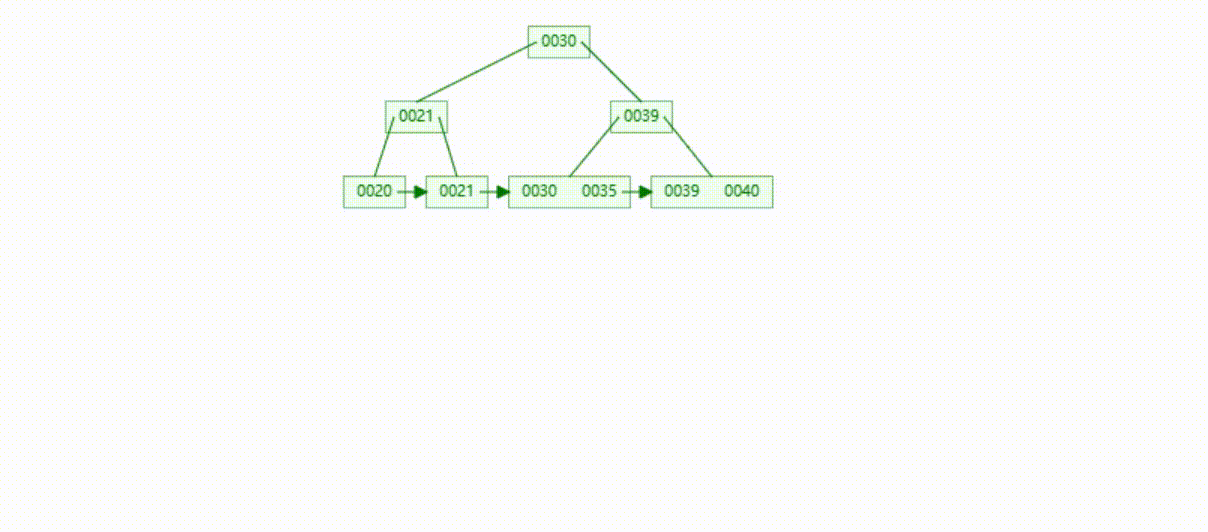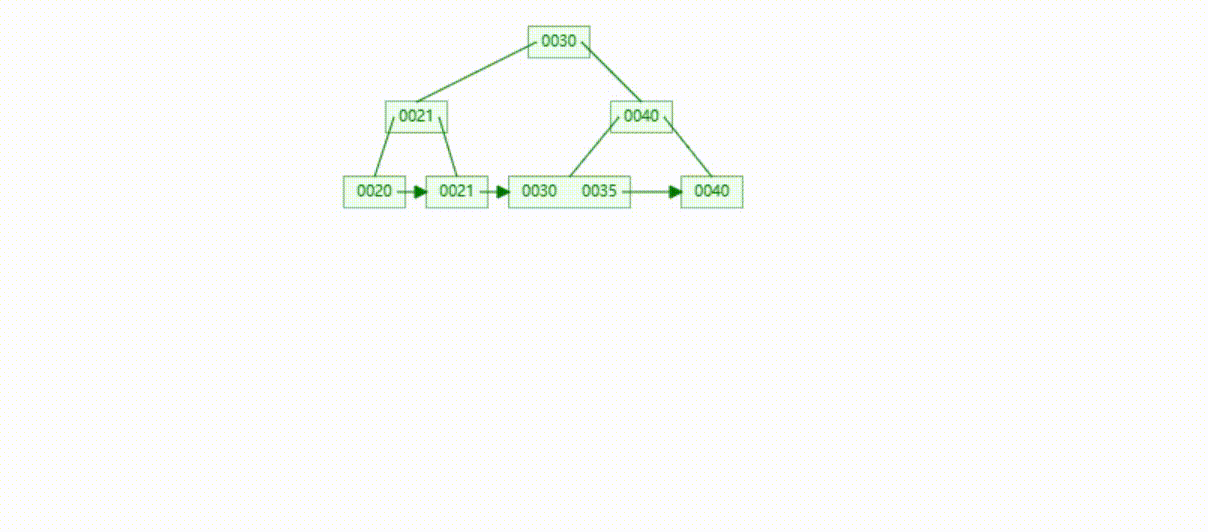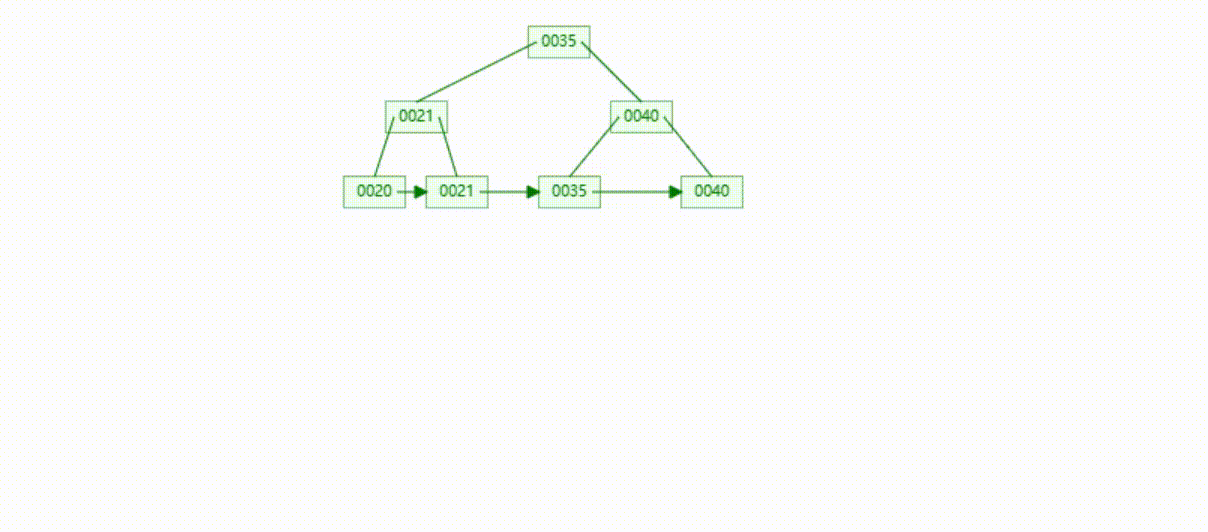
MySQL的B+Tree索引结构
MySQL的索引数据结构对经典的B+Tree进行了优化,在原B+Tree的基础上,增加了一个指向相邻叶子节点的链表指针,所有叶子节点形成了一个双向链表,提高了遍历速度
MySQL在查询是根据查询条件查询对应的键值(Key),然后将键值对应数据(Value)提取出来
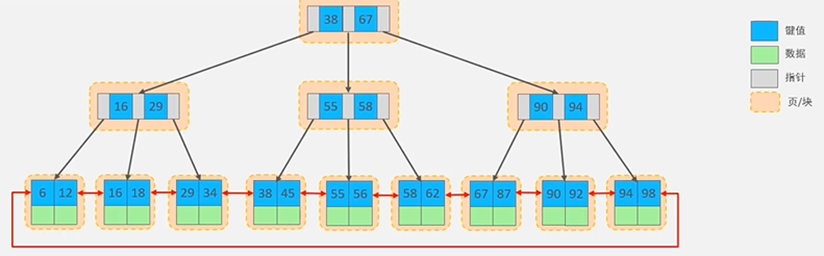
Hash索引结构
哈希索引就是采用一定的hash算法,将键值换算成新的Hash值,将哈希值映射到一个桶中,桶中存储了所有哈希值相同的数据行的指针,然后存储在Hash表中;
当查询时,MySQL会先通过哈希函数计算出查询条件的哈希值,在Hash表中查找对应的桶,然后在对应的桶中查找相应的数据行
哈希冲突
如果两个或多个键值,映射到同一个相同的槽位(桶),则他们就产生了hash冲突,通过链表解决
特点
- Hash索引只能够用于对等比较(=,in等),不支持范围查询(between,>,<等)
- 无法利用Hash索引完成排序操作;因为Hash索引中存放的是经过Hash计算后的Hash值,此值的大小并不一定和Hash运算之前的键值完全一样
- Hash索引无法避免表扫描,即每次都要全表扫描;因为Hash索引是将键值通过Hash运算之后,将其结果和对应的行指针信息存放在一个Hash表中,由于不同的索引键可能存在相同的Hash值,也就是哈希冲突,所以满足某个Hash键值的数据的记录跳数,无法直接从Hash索引中直接完成查询,还是要通过访问表中的实际数据进行比较,并得到相应的结果
- 对于联合索引,Hash不能使用部分索引键查询(要么全部使用,要么全部不使用)
- Hash只需要做一次运算,就可以找到该数据所在的桶;不像树结构那样从根、叶子节点的顺序来查找;所以Hash索引的查询效率理论上是要高于B+Tree的;不过对于存在大量Hash值相同的情况下,性能不一定比B+Tree高
Full-Text索引
通过建立倒排索引(Inverted Index)构建Full-Text索引,提高数据的检索效率
倒排索引是一种将文档中的单词/汉字映射到其出现位置的数据结构,主要用来解决判断字段的值中 是否包含 某字符/汉字的问题
我们对于简单业务或者数据量小的业务,可以通过Like()关键字来判断;但是对于大数据量业务,使用Like效率会大大降低
不同存储索引对Full-Text索引的支持
在MySQL5.6版本之前,只有MYISAM存储引擎支持全文索引
在MySQL5.6版本之后,InnoDB能够支持全文索引;不过只支持对英文的全文索引,不支持中文的全文索引;后续通过内置分词器(ngram)来支持中文索引
配置ngram的最小长度
在MySQL的配置文件中添加以下字段
ft_min_word_len = 2 #此最小长度就是分词的最小长度,默认为2
即:对于一段语句,可以分为多个汉字组,每个汉字组最少都有2个汉字
我想学习数据库 可以分词为: 我想 学习 数据库 三个组
一般不会将ngram设置的很小,如果很小的话会占用大量的空间,因此我们一般都不修改此最小长度,就默认为2
全文索引的流程
用户输入要查找的内容 → SQL执行引擎 → ngram对查找的内容进行分词 → 把分词后的词依次的去倒排索引中去查找 → 将相应的记录返回
分词器ngram在建立索引时会对字段中的值进行分词;在进行查询时也会对要查找的内容分词
R-Tree索引
构建空间索引有多种数据结构,例如四叉树、R-Tree树
在MySQL中是通过R-Tree树来构建空间索引的,是一种加快空间数据查询速度的技术
R-tree将空间数据分割成一系列矩形区域,每个节点可以表示一个矩形区域,同时可以包含其他节点或数据项。这种层级结构允许MySQL在空间查询中更快地定位所需的数据,减少搜索范围,从而提高查询性能
例如:
一个表中的某字段存储着一个地方餐馆的经纬度位置信息,现在我们需要根据我们的位置,找附近1公里的餐馆
我们可以通过计算我们的位置,找到附近1公里范围内的经纬度范围,然后查询表中的满足此经纬度的值;为了加快检索效率,我们就可以对存储经纬度位置信息的字段建立空间索引
R-Tree的构建过程——R树是把B树的思想扩展到了多维空间
1、数据划分
所有的数据项也成为对象(点、线或面)都被视为一个单独的矩形
2、构建叶子节点(叶子节点是R树的底层节点)
将划分好的矩形进行分组,并构建叶子节点;每个叶子节点包含多个对象及其对应的矩形
3、合并叶子节点
当叶子节点的数目超过了R-Tree规定的最大容量,此时R树会尝试合并相邻的叶子节点来减少树的高度和提高查询效率
4、构建非叶子节点
将合并后叶子构建为新的非叶子节点;非叶子节点也是一个矩形,包含了其所有子节点的矩形范围
5、递归构建
重复上述的操作,知道构建出整个R树的根节点(R树的最顶层节点,将包含所有的数据范围)
具体R树的构建方式可以参考以下文章
从B树、B+树、B*树谈到R 树_v_JULY_v的博客-CSDN博客![]() https://blog.csdn.net/v_JULY_v/article/details/6530142
https://blog.csdn.net/v_JULY_v/article/details/6530142
相关文章:
MySQL索引1——索引基本概念与索引结构(B树、R树、Hash等)
目录 索引(INDEX)基本概念 索引结构分类 BTree树索引结构 Hash索引结构 Full-Text索引 R-Tree索引 索引(INDEX)基本概念 什么是索引 索引是帮助MySQL高效获取数据的有序数据结构 为数据库表中的某些列创建索引,就是对数据库表中某些列的值通过不同的数据结…...

2023-08-06力扣今日四题
链接: 剑指 Offer 59 - II. 队列的最大值 题意: 如题,要求O1给出数列的最大值 解: 类似滑动窗口 1 1 2 1 2用双端队列存储成2 2(每次从前面获取最大值,后面插入新数字)也就是第一个2覆盖了…...

Kubernetes入门 三、命令行工具 kubectl
目录 语法操作示例资源操作Pod 与集群资源类型与别名格式化输出 kubectl 是 Kubernetes 集群的命令行工具,通过它能够对集群本身进行管理,并能够在集群上进行容器化应用的安装和部署。 语法 使用以下语法从终端窗口运行 kubectl 命令: kub…...
18 | 基于DDD的微服务设计实例
为了更好地理解 DDD 的设计流程,这篇文章会用一个项目来带你了解 DDD 的战略设计和战术设计,走一遍从领域建模到微服务设计的全过程,一起掌握 DDD 的主要设计流程和关键点。 项目基本信息 项目的目标是实现在线请假和考勤管理。功能描述如下…...
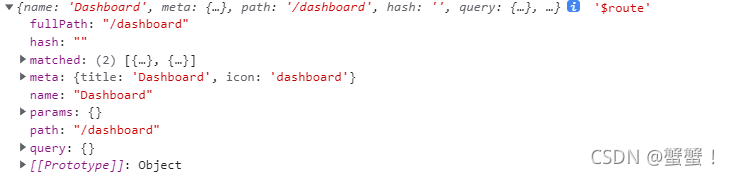
router和route的区别
简单理解为,route是用来获取路由信息的,router是用来操作路由的。 一、router router是VueRouter的实例,通过Vue.use(VueRouter)和VueRouter构造函数得到一个router的实例对象,这个对象中是一个全局的对象,他包含了所…...

每日后端面试5题 第五天
一、Redis的常用数据类型有哪些,简单说一下常用数据类型特点 1.字符串string 最基本的数据存储类型,普通字符串 SET key value 2.哈希hash 类似于Java中HashMap的结构 HSET key field value 3.列表list 按照插入顺序排序,操作左边或右…...

BGP基础实验
题目 IP地址配置 R1 R2 R3 R4 R5 AS2内全网通 R2: ospf 1 router-id 2.2.2.2 area 0.0.0.0 network 2.2.2.0 0.0.0.255 network 23.1.1.0 0.0.0.255 R3: ospf 1 router-id 3.3.3.3 area 0.0.0.0 network 3.3.3.0 0.0.0.255 network 23.…...
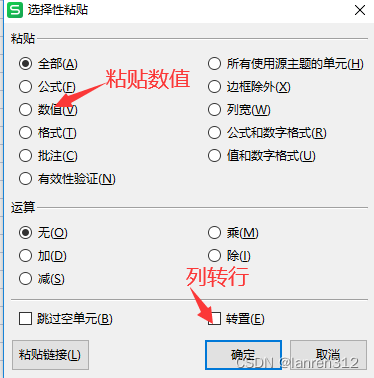
在excel中整理sql语句
数据准备 CREATE TABLE t_test (id varchar(32) NOT NULL,title varchar(255) DEFAULT NULL,date datetime DEFAULT NULL ) ENGINEInnoDB DEFAULT CHARSETutf8mb4; INSERT INTO t_test VALUES (87896cf20b5a4043b841351c2fd9271f,张三1,2023/6/8 14:06); INSERT INTO t_test …...

Vue中下载不同文件的几种方式
当在Vue中需要实现文件下载功能时,我们可以有多种方式来完成。下面将介绍五种常用的方法。 1. 使用window.open方法下载文件 <template><div><button click"downloadFile(file1.pdf)">下载文件1</button><button click"…...

Ethernet/ip协议开发记录
目录 简介 一:EtherNet/IP 二:CIP 1. CIP 对象模型 2. CIP 服务 3. CIP 对象库...

Spring系列三:基于注解配置bean
文章目录 💗通过注解配置bean🍝基本介绍🍝快速入门🍝注意事项和细节 💗自己实现Spring注解配置Bean机制🍝思路分析🍝注意事项和细节 💗自动装配 Autowired🍝案例1: Autow…...
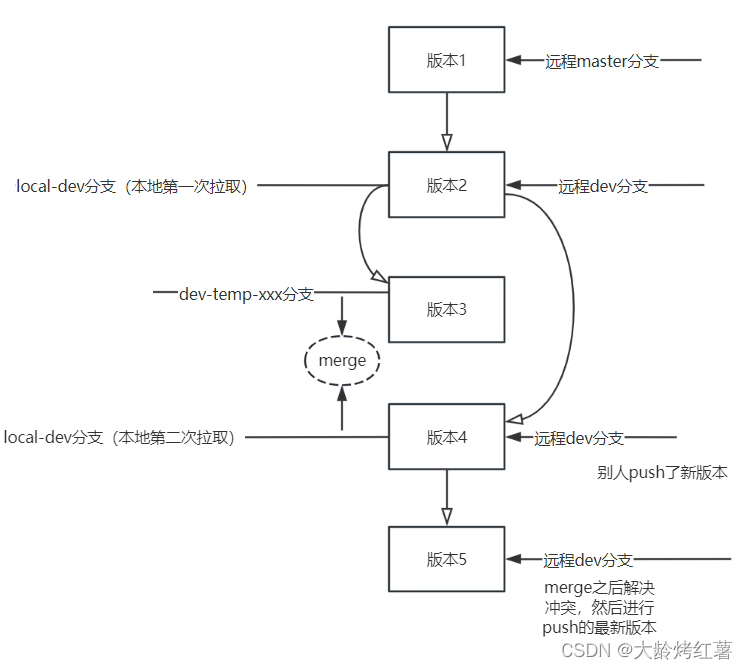
git的简单介绍和使用
git学习 1. 概念git和svn的区别和优势1.1 区别1.2 git优势 2. git的三个状态和三个阶段2.1 三个状态:2.2 三个阶段: 3. 常用的git命令3.1 下面是最常用的命令3.2 git命令操作流程图如下: 4. 分支内容学习4.1 项目远程仓库4.2 项目本地仓库4.3…...
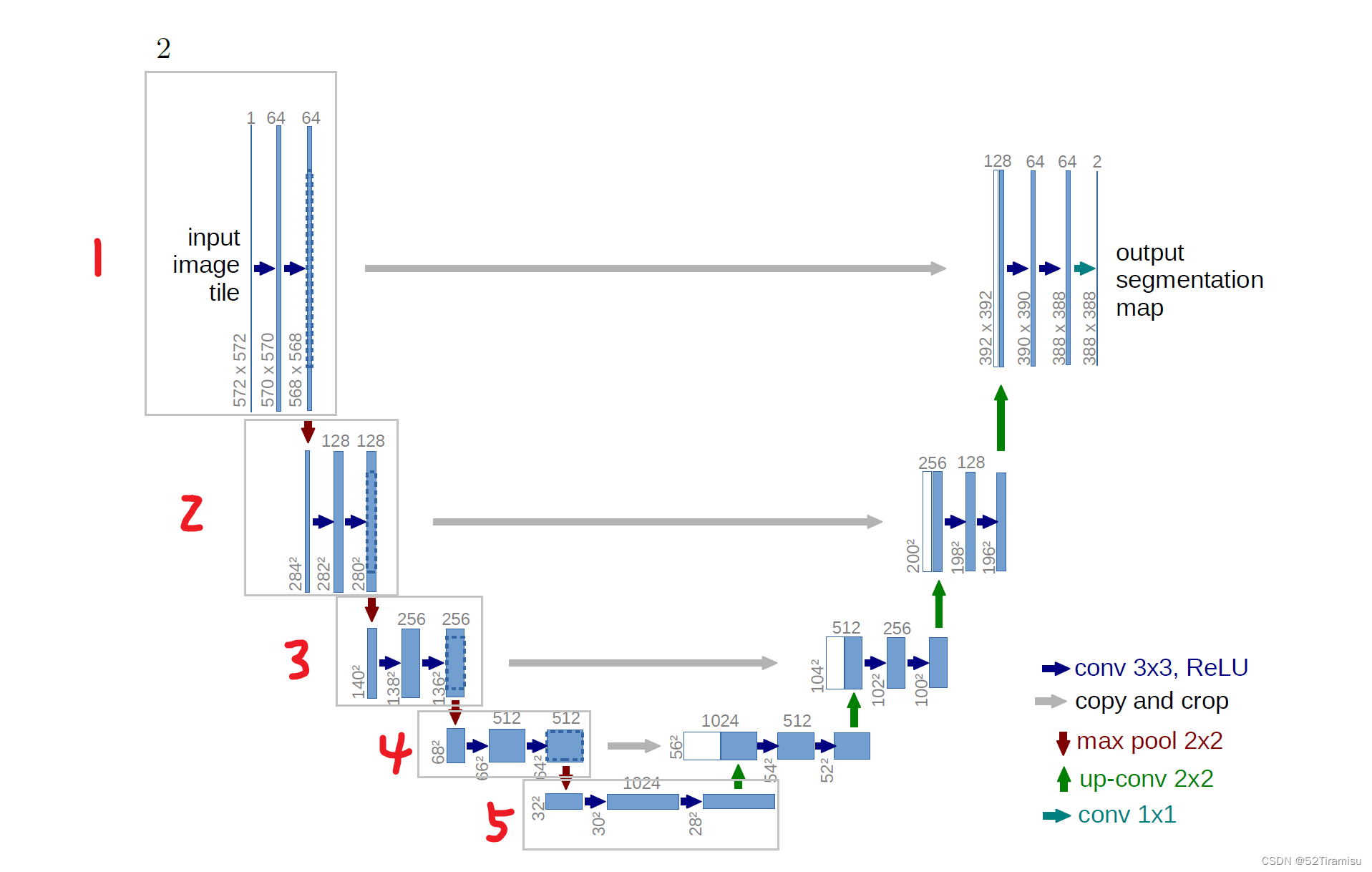
UNet Model
论文地址 第一阶段 conv2d(33) first conv:5725721 → 57057064 second conv:57057064 → 56856864 代码 # first 33 convolutional layer self.first nn.Conv2d(in_channels, out_channels, kernel_size3, padding1) self.act1 nn.ReLU() # Seco…...

vue+iviewUi+oss直传阿里云上传文件
前端实现文件上传到oss(阿里云)适用于vue、react、uni-app,获取视频第一帧图片 用户获取oss配置信息将文件上传到阿里云,保证了安全性和减轻服务器负担。一般文件资源很多直接上传到服务器会加重服务器负担此时可以选择上传到oss&…...
)
算法leetcode|68. 文本左右对齐(rust重拳出击)
文章目录 68. 文本左右对齐:样例 1:样例 2:样例 3:提示: 分析:题解:rust:go:c:python:java: 68. 文本左右对齐: 给定一个…...
)
基于MATLAB实现小波算法仿真(附上多个完整源码+数据集)
小波变换是一种常用的信号处理技术,广泛应用于图像处理、音频处理、压缩等领域。本文将介绍MATLAB中小波变换的基本原理和实现方法,并给出一个示例来说明如何使用MATLAB进行小波变换和逆变换。 文章目录 1. 引言2. 小波变换的基本原理3. MATLAB中的小波变…...
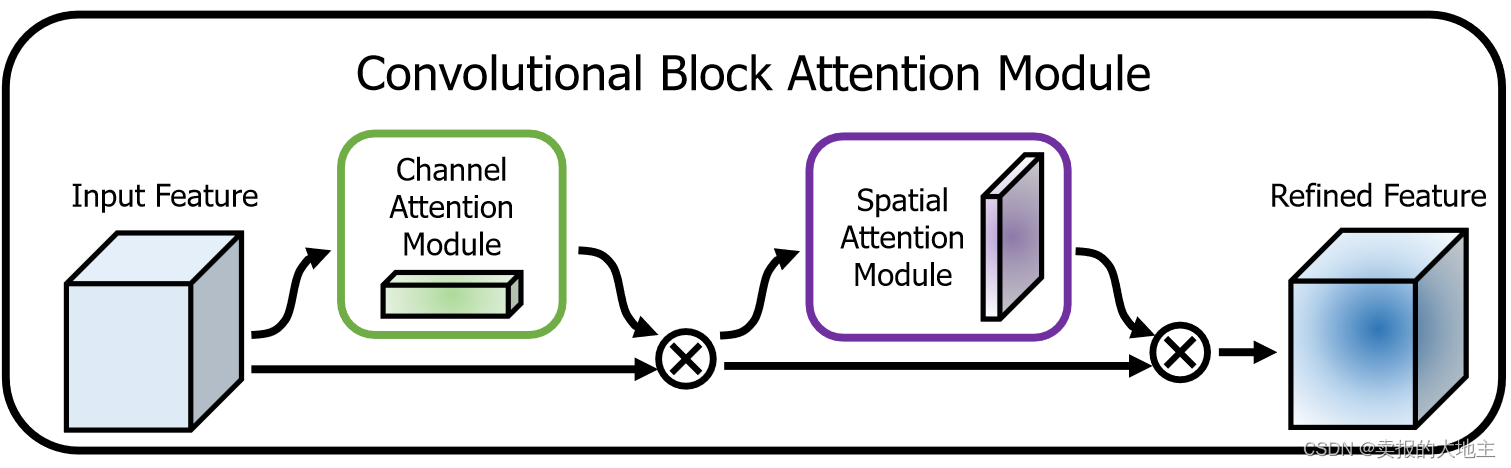
【深度学习注意力机制系列】—— CBAM注意力机制(附pytorch实现)
CBAM(Convolutional Block Attention Module)是一种用于增强卷积神经网络(CNN)性能的注意力机制模块。它由Sanghyun Woo等人在2018年的论文[1807.06521] CBAM: Convolutional Block Attention Module (arxiv.org)中提出。CBAM的主…...
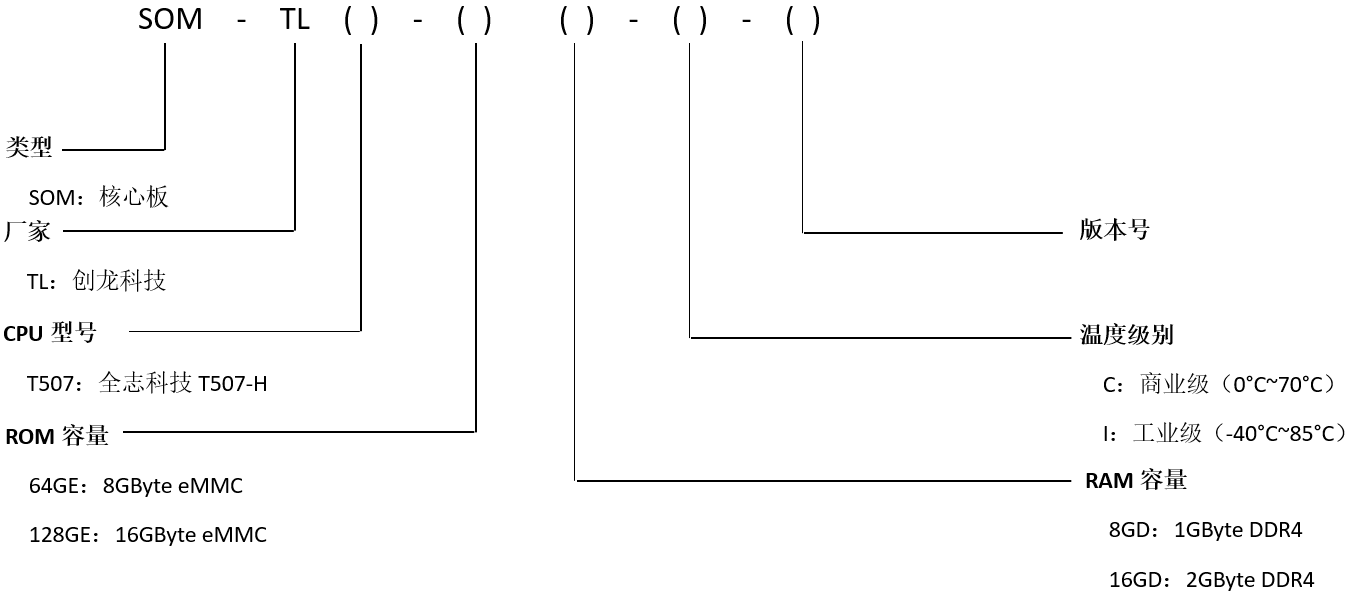
【资料分享】全志科技T507-H工业核心板规格书
1 核心板简介 创龙科技SOM-TLT507是一款基于全志科技T507-H处理器设计的4核ARM Cortex-A53全国产工业核心板,主频高达1.416GHz。核心板CPU、ROM、RAM、电源、晶振等所有元器件均采用国产工业级方案,国产化率100%。 核心板通过邮票孔连接方式引出MIPI C…...
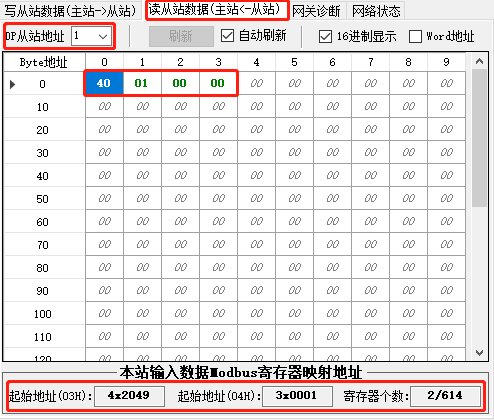
Profibus-DP转modbus RTU网关modbus rtu和tcp的区别
捷米JM-DPM-RTU网关在Profibus总线侧实现主站功能,在Modbus串口侧实现从站功能。可将ProfibusDP协议的设备(如:EH流量计、倍福编码器等)接入到Modbus网络中;通过增加DP/PA耦合器,也可将Profibus PA从站接入…...

Flash浏览器终极指南:一键解决Flash内容播放难题,免费重温经典游戏
Flash浏览器终极指南:一键解决Flash内容播放难题,免费重温经典游戏 【免费下载链接】CefFlashBrowser Flash浏览器 / Flash Browser 项目地址: https://gitcode.com/gh_mirrors/ce/CefFlashBrowser 还在为无法播放网页Flash内容而烦恼吗ÿ…...

Digital_Life_Server高级功能开发:自定义角色与语音风格定制
Digital_Life_Server高级功能开发:自定义角色与语音风格定制 【免费下载链接】Digital_Life_Server Yet another voice assistant, but alive. 项目地址: https://gitcode.com/gh_mirrors/di/Digital_Life_Server Digital_Life_Server是一款强大的语音助手框…...

终极指南:如何用Bloxstrap重新定义你的Roblox游戏启动体验
终极指南:如何用Bloxstrap重新定义你的Roblox游戏启动体验 【免费下载链接】bloxstrap An alternative bootstrapper for Roblox with a bunch of extra features. 项目地址: https://gitcode.com/GitHub_Trending/bl/bloxstrap Bloxstrap是一款功能强大的第…...

MDCSwipeToChoose快速入门:5步创建你的第一个滑动卡片应用
MDCSwipeToChoose快速入门:5步创建你的第一个滑动卡片应用 【免费下载链接】MDCSwipeToChoose Swipe to "like" or "dislike" any view, just like Tinder.app. Build a flashcard app, a photo viewer, and more, in minutes, not hours! 项…...
)
AI驱动的软件文档闭环:从代码提交到API文档/PRD/测试用例自动生成(实测准确率92.6%,已交付37个生产系统)
第一章:AI原生软件研发文档自动化生成方案 2026奇点智能技术大会(https://ml-summit.org) AI原生软件研发正面临文档滞后、语义割裂与维护成本激增的三重挑战。传统文档生成依赖人工补全或静态模板,难以响应代码逻辑的实时演进;而AI驱动的文…...

东南亚电商支付方式有哪些?2026最新整
东南亚电商支付方式以电子钱包、信用卡支付、实时转账和国家统一二维码为核心。印尼常用GoPay、DANA、QRIS,泰国 以PromptPay和TrueMoney为主,马来西亚主流是DuitNow和TouchnGo,新加坡则以PayNow和GrabPay覆盖核心场景。 对于独立站卖家而言…...

云厂商集体涨价实录:AWS/阿里云/腾讯云2026年Q1成本变化全解析与应对方案
前言2026年4月,亚马逊股东信正式披露:AWS AI服务年化收入突破150亿美元,自研芯片业务年化收入超200亿美元。与此同时,腾讯云宣布年内第二次调价,这已经是今年Q1以来全球主要云厂商的第N次集体涨价动作了。本文整理了各…...

SolidEdge许可证分点典型成功案例深度解析
SolidEdge许可证分点典型成功案例深度解析记得上个月,项目组又是因为SolidEdge许可抢不到耽误了两天出图。工程师抓狂,IT部门也跟着着急。可巧的是,查账截图里显示,公司每年在软件授权上的投入早就超过千万,可也是&…...

别再死记硬背VAE公式了!用PyTorch手把手带你理解‘重参数化’这个核心技巧
从代码实践理解VAE重参数化:为什么这个技巧让生成模型真正"可训练" 在深度学习领域,变分自编码器(VAE)作为生成模型的经典代表,其核心思想是通过学习数据的潜在分布来生成新样本。但许多初学者在理解VAE时&a…...

Windows/Mac双平台实测:Caption滚动字幕软件如何5分钟打造高逼格桌面特效
Windows/Mac双平台实测:Caption滚动字幕软件如何5分钟打造高逼格桌面特效 在数字内容创作领域,视觉冲击力往往决定着作品的传播效果。无论是自媒体博主的视频包装,还是创意工作者的项目展示,动态文字元素总能成为吸引眼球的利器。…...