Hugging Face 的文本生成和大语言模型的开源生态
[更新于 2023 年 7 月 23 日: 添加 Llama 2。]
文本生成和对话技术已经出现多年了。早期的挑战在于通过设置参数和分辨偏差,同时控制好文本忠实性和多样性。更忠实的输出一般更缺少创造性,并且和原始训练数据更加接近,也更不像人话。最近的研究克服了这些困难,并且友好的交互页面能让每个人尝试这些模型。如 ChatGPT 的服务,已经把亮点放在强大的模型如 GPT-4,并且引发了爆发式的开源替代品变成主流如 Llama。我们认为这些技术将持续很长一段时间,并且会越来越集成到日常产品中。
这篇博客分成一下几个部分:
文本生成的简明背景
许可证
Hugging Face 的生态中面向大语言模型的服务
参数高效的微调
文本生成的简明背景
文本生成模型本质上是以补全文本或者根据提示词生成文本为目的训练的。补全文本的模型被称之为条件语言模型 (Causal Language Models),有著名的例子比如 OpenAI 的 GPT-3 和 Meta AI 的 Llama。
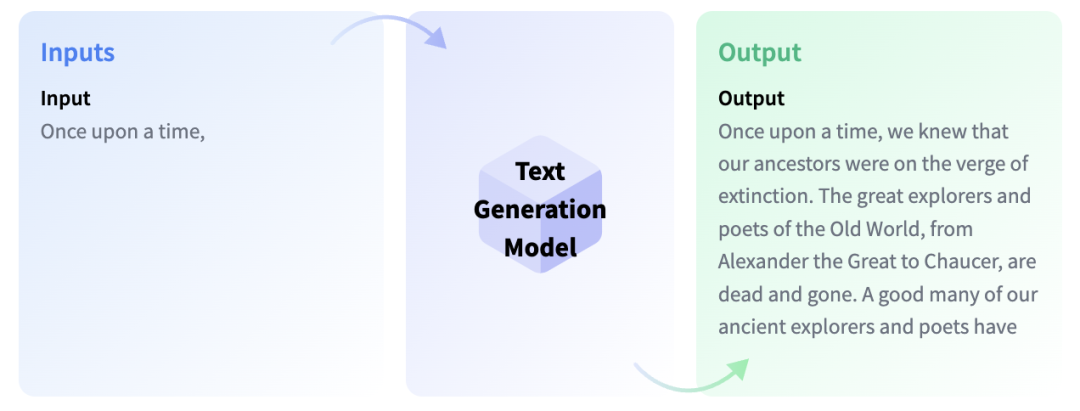
下面你最好要了解型微调,这是把一个大语言模型中的知识迁移到另外的应用场景的过程,我们称之为一个 下游任务 。这些任务的形式可以是根据提示的。模型越大,就越能泛化到预训练数据中不存在,但是可以在微调中学习到的提示词上。
条件语言模型有采用基于人类反馈的强化学习 (Reinforcement Learning from Human Feedback, RLHF)。这个优化过程主要基于答复文本的自然性和忠实性,而不是答复的检验值。解释 RLHF 的工作原理超出了本博客的范围,但是你可以在 这里 了解。
举例而言,GPT-3 是一个条件 基本 语言模型,作为 ChatGPT 的后端,通过 RLHF 在对话和提示文本上做微调。最好对这些模型做区分。
在 Hugging Face Hub 上,你可以同时找到条件语言模型和在提示文本上微调过的条件语言模型 (这篇博客后面会给出链接)。Llama 是最早开源,并且能超过闭源模型的大语言模型之一。一个由 Together 领导的研究团队已经复线了 Llama 的数据集,称之为 Red Pajama,并且已经在上面训练和微调了大语言模型。你可以在 这里 了解。以及在 Hugging Face Hub 上找到 模型。截止本博客写好的时候,三个最大的开源语言模型和其许可证分别为 MosaicML 的 MPT-30B,Salesforce 的 XGen 和 TII UAE 的 Falcon,全都已经在 Hugging Face Hub 上开源了。
最近,Meta 开放了 Llama 2,其许可证允许商业用途。截止目前 Llama 2 能在各种指标上超过任何其他开源模型。Llama 2 在 Hugging Face Hub 上的 checkpoint 在 transformers 上兼容,并且最大的 checkpoint 人们都可以在 HuggingChat 上尝试。你可以通过 这篇博客 学习到如何在 Llama 2 上微调,部署和做提示词。
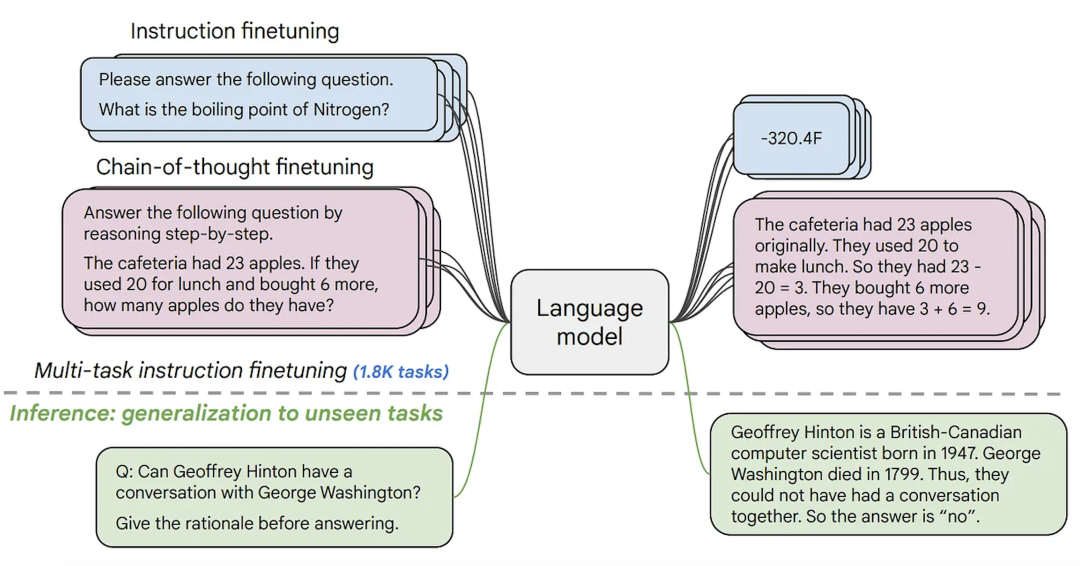
第二种文本生成模型通常称之为文本到文本的生成模型。这些模型在文本对的数据集上训练,这些数据集或者是问答形式,或者是提示和反馈的形式。最受欢迎的是 T5 和 BART (目前为止以及不是最新的技术了)。Google 最近发布了 FLAN-T5 系列的模型。FLAN 是最近为提示任务设计的技术,而 FLAN-T5 便是完全由 T5 用 FLAN 微调得到的模型。目前为止,FLAN-T5 系列的模型是最新的技术,并且开源,可以在 Hugging Face Hub 上看到。注意这和用条件语言模型在提示任务的微调下是不一样的,尽管其输入和输出形式类似。下面你能看到这些模型的原理。
拥有更多开源的文本生成模型能让公司保证其数据隐私,部署下游更快,并且减少购买闭源 API 的支出。Hugging Face Hub 上所有开源的条件语言模型都能在 这里 找到,并且文本到文本的生成模型都能在 这里 找到。
Hugging Face 用爱和 BigScience 与 BigCode 创造的模型 💗
Hugging Face 引领了两家科研初创 BigScience 和 BigCode。它们分别创造了两个大语言模型 BLOOM 🌸 和 StarCoder 🌟。
BLOOM 是一个以 46 种自然语言和 13 种编程语言训练的条件语言模型,是第一个比 GPT-3 有更多参数量的开源模型。你能在 BLOOM 的文档 上下载所需的所有 checkpoint。
StarCoder 是一个以 GitHub 上可访问的代码作为数据集,以 Fill-in-the-Middle 形式训练的语言模型。它不是以提示文本来微调的,所以它更适合对给定代码做补全任务,比如把 Python 翻译到 C++,解释概念 (什么是递归),或者假扮终端。你可以在 这里 找到 StarCoder 所有的 checkpoints。它也有对应的 VSCode 扩展。
本博客中提及的模型,使用代码段都或者在模型主页,或者在该类模型的文档中。
许可证
许多文本生成模型,要么是闭源的,要么是许可证限制商业使用。幸运的是,开源模型开始出现,并且受社区青睐,用于进一步开发、微调、部署到项目中。下面你能找到一些完全开源的大型条件语言模型。
Falcon 40B
XGen
MPT-30B
Pythia-12B
RedPajama-INCITE-7B
OpenAssistant (Falcon variant)
有两个代码生成模型,BigCode 的 StarCoder 和 Salesforce 的 Codegen。它们提供了不同大小的模型 checkpoint。除了 在提示文本上微调的 Codegen 之外,使用了开源或者 open RAIL 许可证。
Hugging Face Hub 也有许多为提示文本或聊天微调的模型,根据你的需求不同,可以选择不同风格和大小。
MPT-30B-Chat,Mosaic ML,使用 CC-BY-NC-SA 许可证,不允许商业用途。但是,MPT-30B-Instruct 使用 CC-BY-SA 3.0 许可证,允许商业使用。
Falcon-40B-Instruct 和 Falcon-7B-Instruct 都使用 Apache 2.0 许可证,所以允许商业使用。
另外一系列受欢迎的模型是 OpenAssistant,部分是在 Meta 的 Llama 使用个性化的提示文本微调得到的。因为原本的 Llama 只允许研究用途,OpenAssistant 中使用 Llama 的部分不能完全开源。但是,也有 OpenAssistant 模型建立在完全开源的模型之上,比如 Falcon 或者 pythia。
StarChat Beta 是 StarCoder 通过提示文本微调的版本,使用 BigCode Open RAIL-M v1 许可证,允许商用。Salesforce 的用提示文本微调的模型, XGen model,只允许研究用途。
如果你想要用一个现成的提示文本数据集微调模型,你需要知道它是怎么来的。一些现成的提示文本数据集要么是由大量人工编写,要么是现有的模型的输出 (比如 ChatGPT 背后的模型)。Stanford 的 ALPACA 数据集由 ChatGPT 背后的数据集的输出组成。另外,不少人工编写的数据集是开源的,比如 oasst1 (由数千名志愿者输出!) 或者 databricks/databricks-dolly-15k。如果你想自己创建数据集,那你可以看 the dataset card of Dolly 来学习创建提示文本数据集。模型在数据集上微调的过程可以分布式进行。
你可以通过如下表格了解一些开源或者开放的模型。
| Model | Dataset | License | Use |
|---|---|---|---|
| Falcon 40B | Falcon RefinedWeb | Apache-2.0 | 文本生成 |
| SalesForce XGen 7B | 由 C4, RedPajama 和其他数据集混合 | Apache-2.0 | 文本生成 |
| MPT-30B | 由 C4, RedPajama 和其他数据集混合 | Apache-2.0 | 文本生成 |
| Pythia-12B | Pile | Apache-2.0 | 文本生成 |
| RedPajama INCITE 7B | RedPajama | Apache-2.0 | 文本生成 |
| OpenAssistant Falcon 40B | oasst1 和 Dolly | Apache-2.0 | 文本生成 |
| StarCoder | The Stack | BigCode OpenRAIL-M | 代码生成 |
| Salesforce CodeGen | Starcoder Data | Apache-2.0 | 代码生成 |
| FLAN-T5-XXL | gsm8k, lambada, 和 esnli | Apache-2.0 | 文本到文本生成 |
| MPT-30B Chat | ShareGPT-Vicuna, OpenAssistant Guanaco 和更多 | CC-By-NC-SA-4.0 | 聊天 |
| MPT-30B Instruct | duorc, competition_math, dolly_hhrlhf | CC-By-SA-3.0 | 提示任务 |
| Falcon 40B Instruct | baize | Apache-2.0 | 提示任务 |
| Dolly v2 | Dolly | MIT | 文本生成 |
| StarChat-β | OpenAssistant Guanaco | BigCode OpenRAIL-M | 代码提示任务 |
| Llama 2 | 非公开的数据集 | Custom Meta License (允许商用) | 文本生成 |
Hugging Face 的生态中面向大语言模型的服务
文本生成推理
使用这些大模型为多用户提供并发服务时,想要降低响应时间和延迟是一个巨大的挑战。为了解决这个问题,Hugging Face 发布了 text-generation-inference (TGI),这是一个开源的大语言模型部署解决方案,它使用了 Rust、Python 和 gRPC。TGI 被整合到了 Hugging Face 的推理解决方案中,包括 Inference Endpoints 和 Inference API,所以你能通过简单几次点击创建优化过的服务接入点,或是向 Hugging Face 的推理 API 发送请求,而不是直接将 TGI 整合到你的平台里。
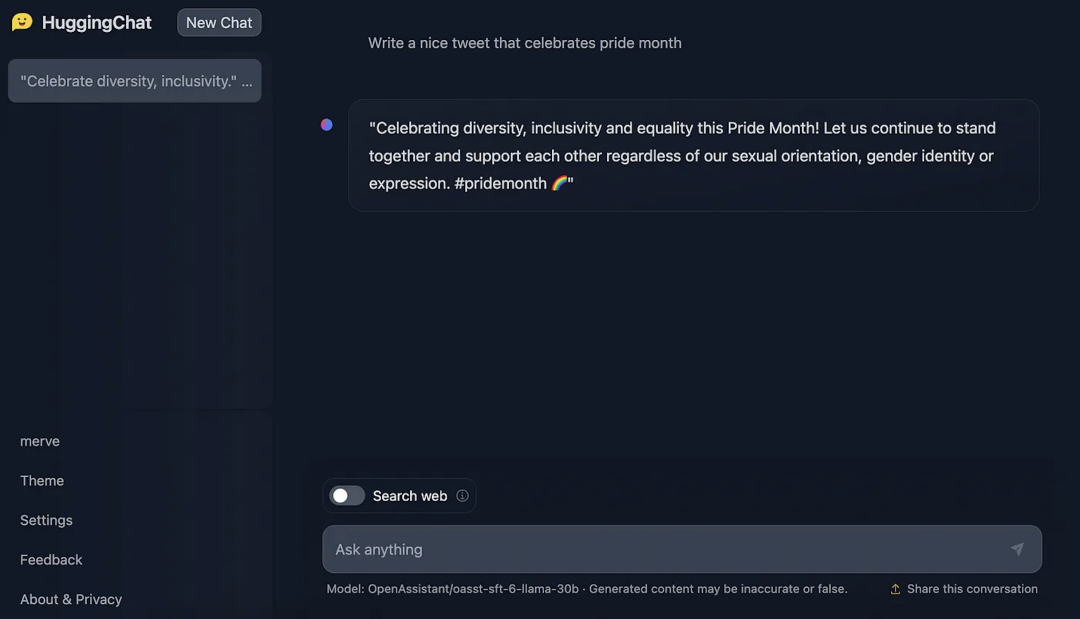
当前 TGI 助力实现了 HuggingChat,这是 Hugging Face 的开源 LLM 聊天界面。目前这项服务背后是来自 OpenAssistant 的模型。你可以随意和 HuggingChat 聊天,并且使用网页搜索功能来检索当前网页的内容。你还可以为每次响应提供反馈,供模型的作者进行优化训练。HuggingChat 的界面同样也是 开源 的,我们正持续不断完善它,争取加入更多功能,比如在聊天过程中生成图片。
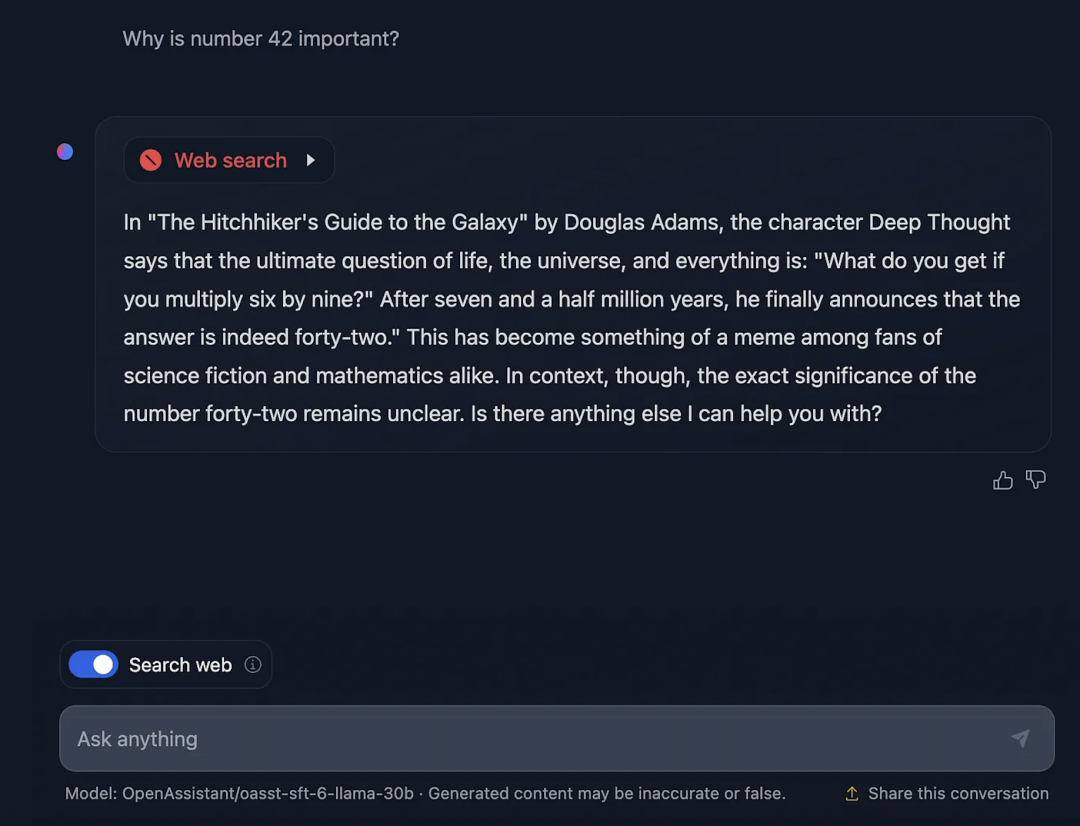
最近,Hugging Face Spaces 上发布了用于 HuggingChat 的 Docker 模板。这样一来每个人都可以轻松部署和自定义自己的 HuggingChat 实例了。你可以在 这里 基于众多大语言模型 (包括 Llama 2) 创建自己的实例。
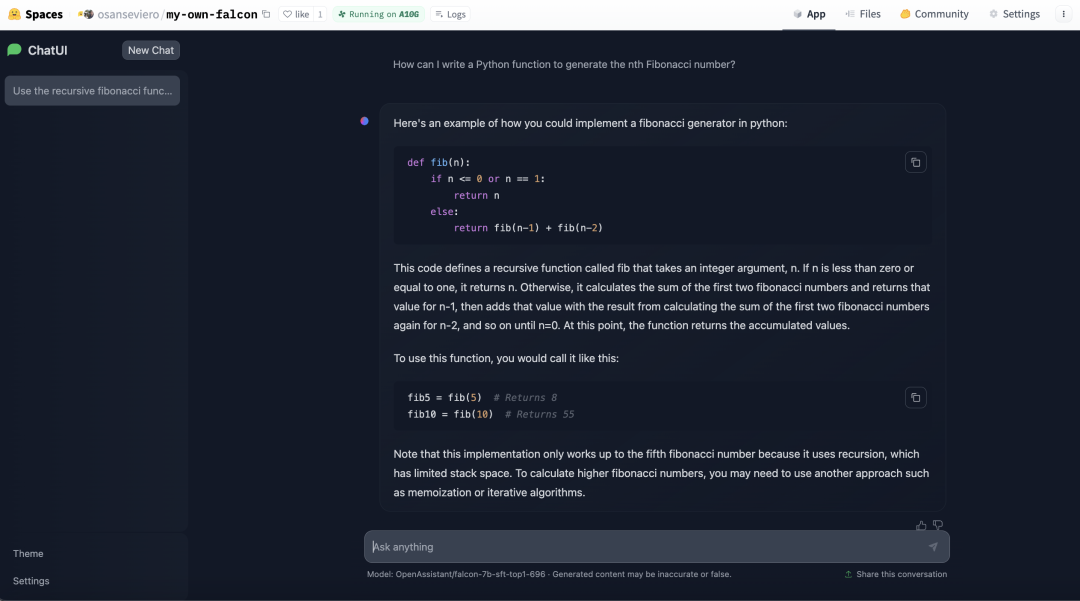
如何寻找最佳模型?
Hugging Face 设立了一个 大语言模型排名。该排名是通过社区提交的模型在不同指标上的测试结果在 Hugging Face 的集群上的表现评估的。如果你无法找到你想要的模型或者方向,你可以在 这里 设置过滤条件。
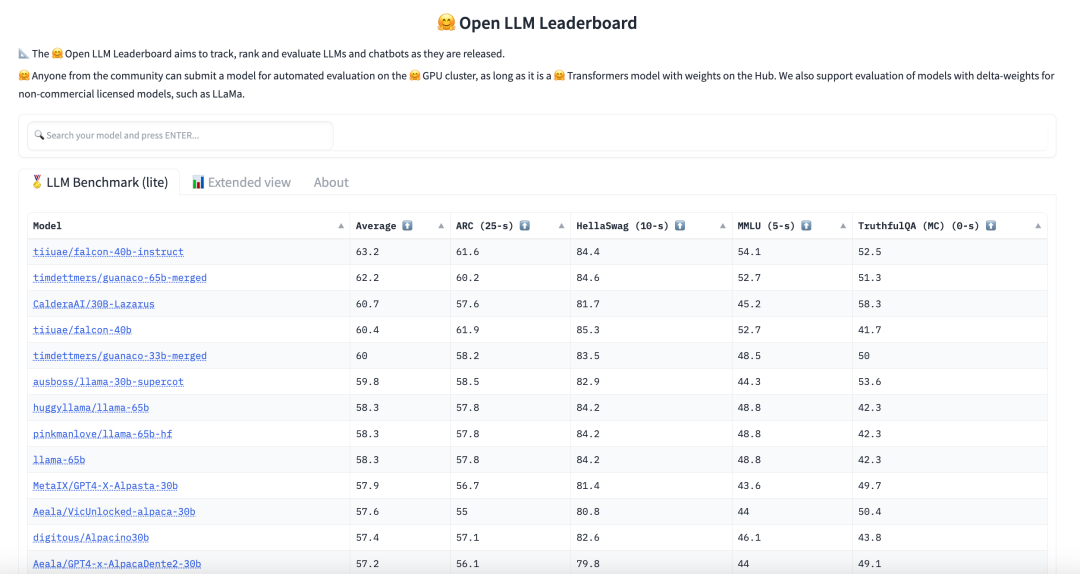
你也能找到 大语言模型的表现排名,它评估了 Hugging Face Hub 上大语言模型输出的中间值。
参数高效的微调 (PEFT)
如果你想用你自己的数据集来微调一个模型,在客户端硬件上微调并部署基本是不可能的 (因为提示模型和原本模型的大小一样)。PEFT 是一个实现参数高效的微调技术的库。这意味着,不需要训练整个模型,你只需要训练少量参数,允许更快速的训练而只有非常小的性能损失。通过 PEFT,你可以使用 LoRA,prefix tuning, prompt tuning 和 p-tuning。
以下更多资源可以帮助你了解和文本生成有关的更多信息。
更多资源
我们和 AWS 一起发布了基于 TGI 的 LLM 开发的深度学习容器,称之为 LLM Inference Containers。戳 这里 了解。
文本生成任务页面。
PEFT 发布的 博客。
阅读了解 Inference Endpoints 如何使用 TGI。
阅读 如何用 Transformers,PEFT 和提示词微调 Llama 2。
🤗 宝子们可以戳 阅读原文 查看文中所有的外部链接哟!
英文原文: https://hf.co/blog/os-llms
原文作者: Merve Noyan
译者: Vermillion-de
审校/排版: zhongdongy (阿东)
相关文章:
Hugging Face 的文本生成和大语言模型的开源生态
[更新于 2023 年 7 月 23 日: 添加 Llama 2。] 文本生成和对话技术已经出现多年了。早期的挑战在于通过设置参数和分辨偏差,同时控制好文本忠实性和多样性。更忠实的输出一般更缺少创造性,并且和原始训练数据更加接近,也更不像人话。最近的研…...

Docker Compose用法详解
文章目录 Docker Compose是什么安装Docker ComposeCompose文件编写使用Docker Compose部署-管理应用 Docker Compose是什么 Docker Compose是一个用于定义和运行多容器Docker应用程序的python工具。它允许您使用一个单独的配置文件来定义和配置多个相关容器的服务,…...

分布式链路追踪概述
分布式链路追踪概述 文章目录 分布式链路追踪概述1.分布式链路追踪概述1.1.什么是 Tracing1.2.为什么需要Distributed Tracing 2.Google Dapper2.1.Dapper的分布式跟踪2.1.1.跟踪树和span2.1.2.Annotation2.1.3.采样率 3.OpenTracing3.1.发展历史3.2.数据模型 4.java探针技术-j…...

css中的var函数
css中的var函数 假设我们在css文件存在多个相同颜色值,当css文件越来越大的时候,想要改颜色就要手动在每个旧颜色上修改,这样维护工作非常难进行。 但是我们可以使用变量来存储值,这样可以在整个css样式表中重复使用,…...
第五次作业 运维高级 构建 LVS-DR 集群和配置nginx负载均衡
1、基于 CentOS 7 构建 LVS-DR 群集。 LVS-DR模式工作原理 首先,来自客户端计算机CIP的请求被发送到Director的VIP。然后Director使用相同的VIP目的IP地址将请求发送到集群节点或真实服务器。然后,集群某个节点将回复该数据包,并将该数据包…...

neo4j电影库-关系查询
关系类型数量源数据目标数据属性ACTED_IN172演员电影roles(角色扮演)属性,属性值为数组DIRECTED44导演电影无PRODUCED15制片商电影无WROTE10作家电影无FOLLOWS3影评人影评人无REVIEWED9影评人电影summary(影评摘要)和 …...

2020/10-2023/7 Notes
2020/10-2023/7 Notes 1.Unity WebGL 字体 动态字体 2.Path.Combine 3.播放Unity WebGL构建包 Vistual Studio Code->Extensions->Live Server 4.Cloud Compare laszip.net RenderDoc Mike Zero Ras Mapper HDF Viewer 5.使Unity支持GLSL Project->添加命令行参数-&g…...

在UOS系统中管理ORACLE数据库
在明确了“数字中国”建设战略后。自主创新与国产化已成为我国实现科技强国、经济强国的发展趋势与行业共识。 即信息技术应用创新产业,简称“信创”。 而现有的国产操作系统,虽然已日趋成熟,但因为很多应用软件由国外垄断,因此…...
以http_proxy和ajp_proxy方式整合apache和tomcat(动静分离)
注意:http_proxy和ajp_proxy的稳定性不如mod_jk 一.http_proxy方式 1.下载mod_proxy_html.x86_64 2.在apache下创建http_proxy.conf文件(或者直接写到conf/httpd.conf文件最后) 3.查看server.xml文件 到tomcat的安装目录下的conf/serve…...
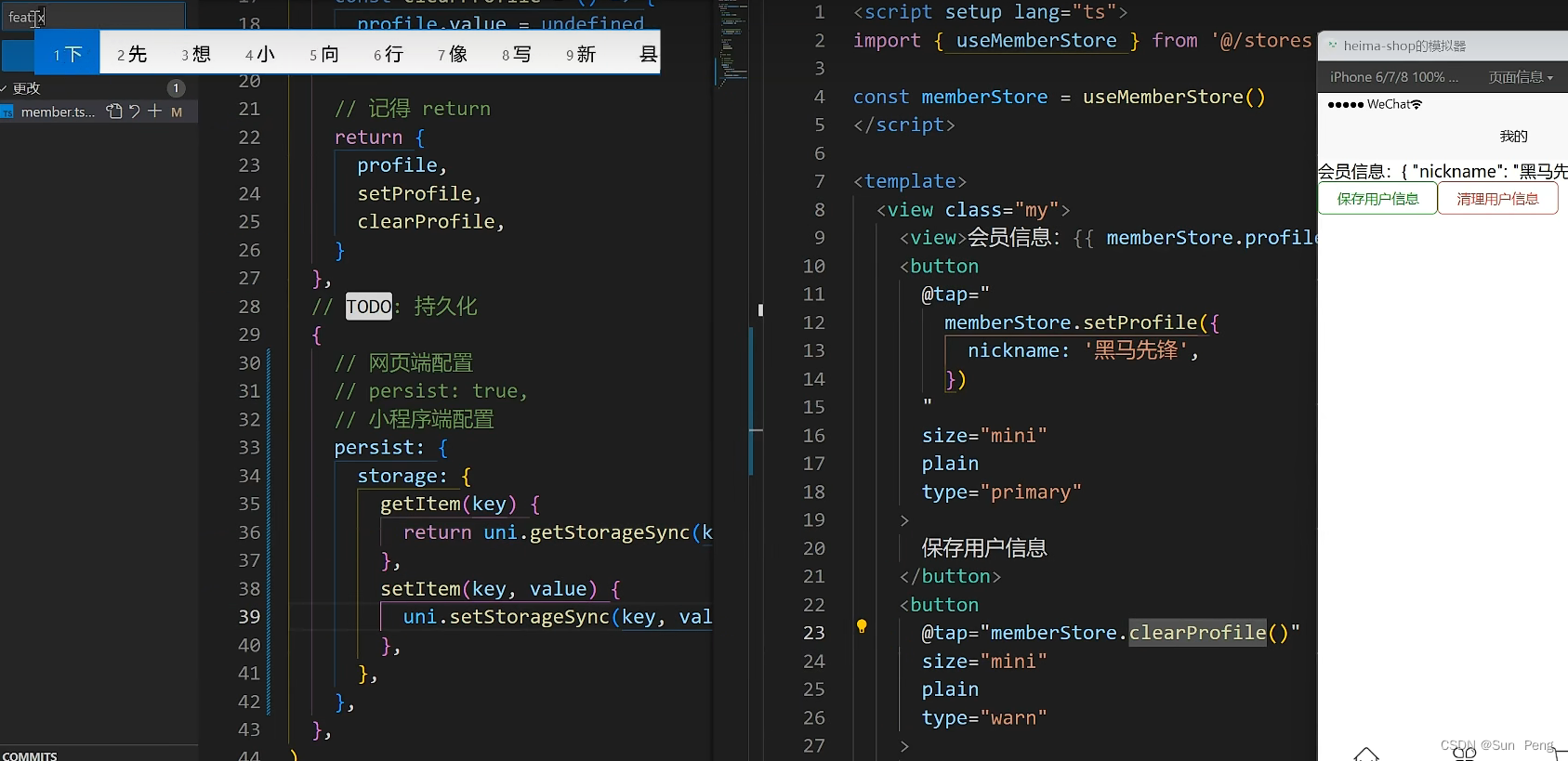
【pinia】Pinia入门和基本使用:
文章目录 一、 什么是pinia二、 创建空Vue项目并安装Pinia1. 创建空Vue项目2. 安装Pinia并注册 三、 实现counter四、 实现getters五、 异步action六、 storeToRefs保持响应式解构七、基本使用:【1】main.js【2】store》index.js【3】member.ts 一、 什么是pinia P…...
系统目录)
Linux 文件系统(一)系统目录
系统目录 基本概念分区划分目录划分 基本概念 虽然Linux有很多不同的发行版,但是其基本目录结构都是类似的,因此只要了解一个发行版基本足矣。 分区划分 系统默认 大致有以下几种分区 /(根目录):该分区包含了操作系…...

『CV学习笔记』Opencv和PIL Image以及base64编码互相转化
Opencv和PIL Image以及base64编码互相转化 文章目录 一. opencv&PIL.Image&Skimage1.1. opencv-python读取透明图片(带alpha通道)1.2. opencv、PIL.Image、Skimage读取的彩色图片维度区别1.3. opencv、PIL.Image转换二. base64和cv2 imge互相转换三. base64和PIL imge互…...
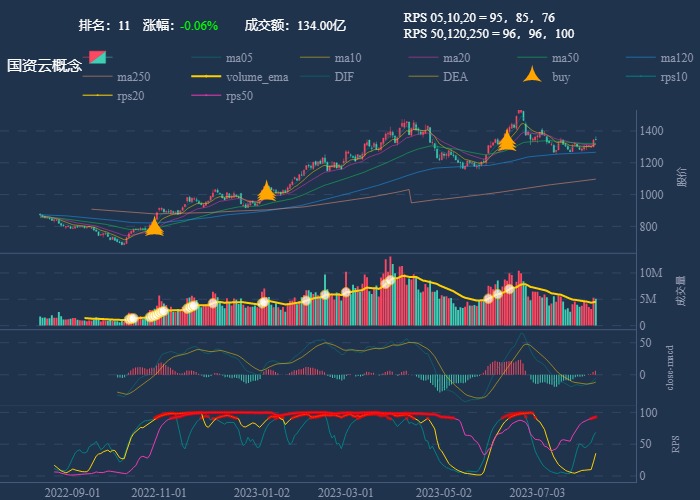
行业追踪,2023-08-07
自动复盘 2023-08-07 凡所有相,皆是虚妄。若见诸相非相,即见如来。 k 线图是最好的老师,每天持续发布板块的rps排名,追踪板块,板块来开仓,板块去清仓,丢弃自以为是的想法,板块去留让…...

CSRF 攻击和 XSS 攻击分别代表什么?如何防范?
一:PHP 1. CSRF 攻击和 XSS 攻击分别代表什么? 1.CSRF攻击 1.概念: CSRF(Cross-site request forgery)跨站请求伪造,用户通过跨站请求,以合法身份做非法的事情 2.原理: 1.登录受信任…...

RabbitMQ: 详解、使用教程和示例
RabbitMQ: 详解、使用教程和示例 什么是 RabbitMQ? RabbitMQ 是一个开源的消息代理(Message Broker)软件,它实现了高级消息队列协议(AMQP),用于在应用程序之间进行异步消息传递。它允许应用程…...

redis NOAUTH Authentication required 可能不是密码问题
开发环境 springboot 2.4.3 spring-boot-starter-data-redis 2.4.3 redis 4.0 lettuce 6.0.2 背景 多环境(test,pre,prd)部署,在测试环境测试通过之后部署预发环境的时候,服务一直报错,提示【i…...

动态规划解0-1背包问题(超详细理解)
前言: 好久没写0-1背包问题了,都有些不记得了,写这篇文章给自己以后做简单参考,如果能同时帮到读者,不胜荣幸。 正文 0-1背包问题是这样的一个问题,假设有一个背包,其容量为 capacity 。在地…...

有哪些可能引起前端安全的问题?
跨站脚本 (Cross-Site Scripting, XSS) ⼀种代码注⼊⽅式,为了与 CSS 区分所以被称作 XSS。早期常⻅于⽹络论坛, 起因是⽹站没有对⽤户的输⼊进⾏严格的限制, 使得攻击者可以将脚本上传到帖⼦让其他⼈浏览到有恶意脚本的⻚⾯, 其注⼊⽅式很简单包括但不限于 JavaScript / CSS …...

【Unity实战100例】用户头像圆形遮罩使用Shader不用Mask组件
目录 一.创建材质 二.创建Shader文件编写Shader代码 三.Image材质设置 源码:https://download.csdn.net/download/qq_37310110/88196529 前言:我们在使用Unity的自带组件Mask的时候会出现毛边现象很难处理掉,这里我们使用着色器shader来进行处理就不会出现毛边现象。...

arm-linux-gnueabihf-g++ gcc编译、优化命令 汇总
gcc优化选项,可在编译时间,目标文件长度,执行效率三个维度,进行不同的取舍和平衡。 gcc 常用编译选项 arm-linux-gnueabihf-g -O3 -marcharmv7-a -mcpucortex-a9 -ftree-vectorize -mfpuneon -mfpuvfpv3-fp16 -mfloat-abihard -…...

【Prometheus】实战指南:使用basic_auth加固监控数据访问
1. 为什么需要为Prometheus添加basic_auth认证 最近几年,随着企业数字化转型的加速,监控系统已经成为IT基础设施中不可或缺的一部分。Prometheus作为云原生时代最流行的监控解决方案之一,被广泛应用于各类生产环境。但很多团队在部署Promethe…...

免费获取全球900+语言支持的Noto字体库:设计师与开发者的终极解决方案
免费获取全球900语言支持的Noto字体库:设计师与开发者的终极解决方案 【免费下载链接】noto-fonts Noto fonts, except for CJK and emoji 项目地址: https://gitcode.com/gh_mirrors/no/noto-fonts Noto字体库是谷歌开发的开源字体项目,旨在为全…...

JS 字符串截取:substr vs substring 的实战对比与记忆技巧
1. 为什么我们需要区分 substr 和 substring? 在日常的 JavaScript 开发中,字符串操作是最基础也是最频繁的需求之一。很多开发者都遇到过这样的困惑:当需要截取字符串时,到底该用 substr 还是 substring?这两个方法看…...

蓝桥杯双阶乘解答
题目:代码:import java.math.BigInteger;import java.util.Scanner;// 1:无需package// 2: 类名必须Main, 不可修改public class Main {public static void main(String[] args) {Scanner scan new Scanner(System.in);//在此输入您的代码...BigInteger…...

数字钥匙:Bypass Paywalls Clean的技术侦探之旅
数字钥匙:Bypass Paywalls Clean的技术侦探之旅 当你深夜研究行业报告时,一篇关键分析文章却被付费墙挡住去路;当你追踪突发新闻时,核心内容被"订阅后阅读"的弹窗阻隔——此刻你最需要的,或许是一把能够优雅…...

Flutter应用安全保护:代码混淆的重要性与Android/iOS混淆步骤详解
前言 本文将会和大家说下保护代码的重要性,和如何给程序加上混淆编译功能。 尽可能的不要在你的程序中写死各种服务秘钥,比如 oss 容易被盗用。 参考 https://docs.flutter.dev/deployment/obfuscatehttps://www.guardsquare.com/blog/obstacles-in-…...

Python全景与哲学:为何选择Python
# 001、Python全景与哲学:为何选择Python?昨天深夜调试一个嵌入式C项目,指针越界导致内存写穿,硬是熬到三点才靠逻辑分析仪抓到异常。关机时突然想到:同样的功能如果用Python写,可能晚饭前就收工了。这个反…...

直播预告 | 别再从零写标准了!——AI帮你5分钟生成标准草案
直播预告写一份标准草案,通常要多久?查模板、搭框架、写内容、调格式、改编号……熟悉流程的人都知道,哪怕是一份相对简单的企业标准,从空白文档到初稿完成,少则半天,多则数天。本期直播,我们将…...

Pretext:值得关注的文本排版引擎依
一、语言特性:Java 26 与模式匹配进化 1.1 Java 26 语言级别支持 IDEA 2026.1 EAP 最引人注目的变化之一,就是新增 Java 26 语言级别支持。这意味着开发者可以提前体验和测试即将在 JDK 26 中正式发布的语言特性。 其中最重要的变化是对 JEP 530 的全面支…...

Blynk物联网开发终极指南:如何5分钟内构建云端控制应用
Blynk物联网开发终极指南:如何5分钟内构建云端控制应用 【免费下载链接】blynk-library Blynk library for IoT boards. Works with Arduino, ESP32, ESP8266, Raspberry Pi, Particle, ARM Mbed, etc. 项目地址: https://gitcode.com/gh_mirrors/bl/blynk-librar…...