Diffusion扩散模型学习4——Stable Diffusion原理解析-inpaint修复图片为例
Diffusion扩散模型学习4——Stable Diffusion原理解析-inpaint修复图片为例
- 学习前言
- 源码下载地址
- 原理解析
- 一、先验知识
- 二、什么是inpaint
- 三、Stable Diffusion中的inpaint
- 1、开源的inpaint模型
- 2、基于base模型inpaint
- 四、inpaint流程
- 1、输入图片到隐空间的编码
- 2、文本编码
- 3、采样流程
- a、生成初始噪声
- b、对噪声进行N次采样
- c、如何引入denoise
- i、加噪的逻辑
- ii、mask处理
- iii、采样处理
- 4、隐空间解码生成图片
- Inpaint预测过程代码
学习前言
Inpaint是Stable Diffusion中的常用方法,一起简单学习一下。

源码下载地址
https://github.com/bubbliiiing/stable-diffusion
喜欢的可以点个star噢。
原理解析
一、先验知识
txt2img的原理如博文
Diffusion扩散模型学习2——Stable Diffusion结构解析-以文本生成图像(文生图,txt2img)为例
img2img的原理如博文
Diffusion扩散模型学习3——Stable Diffusion结构解析-以图像生成图像(图生图,img2img)为例
二、什么是inpaint
Inpaint是一项图片修复技术,可以从图片上去除不必要的物体,让您轻松摆脱照片上的水印、划痕、污渍、标志等瑕疵。
一般来讲,图片的inpaint过程可以理解为两步:
1、找到图片中的需要重绘的部分,比如上述提到的水印、划痕、污渍、标志等。
2、去掉水印、划痕、污渍、标志等,自动填充图片应该有的内容。
三、Stable Diffusion中的inpaint
Stable Diffusion中的inpaint的实现方式有两种:
1、开源的inpaint模型
参考链接:inpaint_st.py,该模型经过特定的训练。需要输入符合需求的图片才可以进行inpaint。
需要注意的是,该模型使用的config文件发生了改变,改为v1-inpainting-inference.yaml。其中最显著的区别就是unet_config的in_channels从4变成了9。相比于原来的4,我们增加了4+1(5)个通道的信息。

4+1(5)个通道的信息应该是什么呢?一个是被mask后的图像,对应其中的4;一个是mask的图像,对应其中的1。

- 1、我们首先把图片中需要inpaint的部分给置为0,获得被mask后的图像,然后利用VAE编码,VAE输出通道为4,假设被mask的图像是[512, 512, 3],此时我们获得了一个[4, 64, 64]的隐含层特征,对应其中的4。
- 2、然后需要对mask进行下采样,采样到和隐含层特征一样的高宽,即mask的shape为[1, 512, 512],利用下采样获得[1, 64, 64]的mask。本质上,我们获得了隐含层的mask。
- 3、然后我们将 下采样后的被mask的图像 和 隐含层的mask 在通道上做一个堆叠,获得一个[5, 64, 64]的特征,然后将此特征与随机初始化的高斯噪声堆叠,则获得了上述图片中的9通道特征。
此后采样的过程与常规采样方式一样,全部采样完成后,使用VAE解码,获得inpaint后的图像。
可以感受到上述的方式必须基于一个已经训练好的unet模型,这要求训练者需要有足够的算力去完成这一个工作,对大众开发者而言并不友好。因此该方法很少在实际中得到使用。
2、基于base模型inpaint
如果我们必须训练一个inpaint模型才能对当前的模型进行inpaint,那就太麻烦了,有没有什么方法可以不需要训练就能inpaint呢?
诶诶,当然有哈。
Stable Diffusion就是一个生成模型,如果我们可以做到让Stable Diffusion只生成指定区域,并且在生成指定区域的时候参考其它区域,那么它自身便是一个天然的inpaint模型。

如何做到这一点呢?我们需要结合img2img方法,我们首先考虑inpaint的两个输入:一个是原图,另外一个是mask图。
在img2img中,存在一个denoise参数,假设我们设置denoise数值为0.8,总步数为20步,那么我们会对输入图片进行0.8x20次的加噪声。如果我们可以在这个加噪声图片的基础上进行重建,那么网络必然会考虑加噪声图(也就对应了原始图片的特征)。
在图像重建的20步中,对隐含层特征,我们利用mask将不重建的地方都替换成 原图按照当前步数加噪后的隐含层特征。此时不重建的地方的特征都由输入图片决定。然后不替换需要重建的地方进行,利用unet计算噪声进行重建。
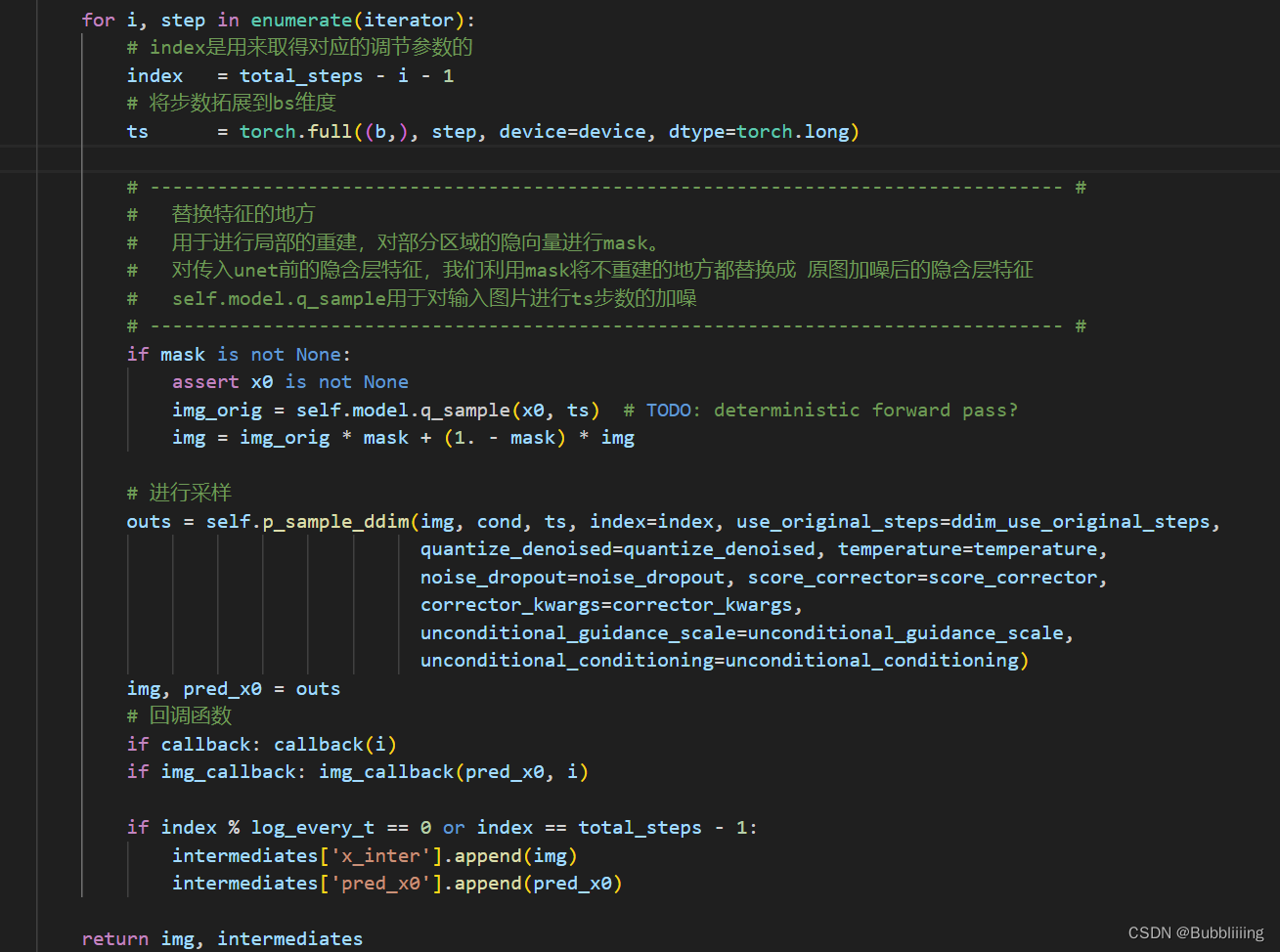
具体部分,可看下面的循环与代码,我已经标注出了 替换特征的地方,在这里mask等于1的地方保留原图,mask等于0的地方不断的重建。
- 将原图x0映射到VAE隐空间,得到img_orig;
- 初始化随机噪声img(也可以使用img_orig完全加噪后的噪声);
- 开始循环:
- 对于每一次时间步,根据时间步生成img_orig对应的噪声特征;
- 一个是基于上个时间步降噪后得到的img,一个是基于原图得到的img_orig。通过mask将两者融合, i m g = i m g _ o r i g ∗ m a s k + ( 1.0 − m a s k ) ∗ i m g img = img\_orig * mask + (1.0 - mask) * img img=img_orig∗mask+(1.0−mask)∗img。即,将原图中的非mask区域和噪声图中的mask区域进行融合,得到新的噪声图。
- 然后继续去噪声直到结束。
由于该方法不需要训练新模型,并且重建效果也不错,所以该方法比较通用。
for i, step in enumerate(iterator):# index是用来取得对应的调节参数的index = total_steps - i - 1# 将步数拓展到bs维度ts = torch.full((b,), step, device=device, dtype=torch.long)# --------------------------------------------------------------------------------- ## 替换特征的地方# 用于进行局部的重建,对部分区域的隐向量进行mask。# 对传入unet前的隐含层特征,我们利用mask将不重建的地方都替换成 原图加噪后的隐含层特征# self.model.q_sample用于对输入图片进行ts步数的加噪# --------------------------------------------------------------------------------- #if mask is not None:assert x0 is not Noneimg_orig = self.model.q_sample(x0, ts) # TODO: deterministic forward pass?img = img_orig * mask + (1. - mask) * img# 进行采样outs = self.p_sample_ddim(img, cond, ts, index=index, use_original_steps=ddim_use_original_steps,quantize_denoised=quantize_denoised, temperature=temperature,noise_dropout=noise_dropout, score_corrector=score_corrector,corrector_kwargs=corrector_kwargs,unconditional_guidance_scale=unconditional_guidance_scale,unconditional_conditioning=unconditional_conditioning)img, pred_x0 = outs# 回调函数if callback: callback(i)if img_callback: img_callback(pred_x0, i)if index % log_every_t == 0 or index == total_steps - 1:intermediates['x_inter'].append(img)intermediates['pred_x0'].append(pred_x0)
四、inpaint流程
根据通用性,本文主要以上述提到的基于base模型inpaint进行解析。
1、输入图片到隐空间的编码

inpaint技术衍生于图生图技术,所以同样需要指定一张参考的图像,然后在这个参考图像上开始工作。
利用VAE编码器对这张参考图像进行编码,使其进入隐空间,只有进入了隐空间,网络才知道这个图像是什么。
此时我们便获得在隐空间的图像,后续会在这个 隐空间加噪后的图像 的基础上进行采样。
2、文本编码
文本编码的思路比较简单,直接使用CLIP的文本编码器进行编码就可以了,在代码中定义了一个FrozenCLIPEmbedder类别,使用了transformers库的CLIPTokenizer和CLIPTextModel。
在前传过程中,我们对输入进来的文本首先利用CLIPTokenizer进行编码,然后使用CLIPTextModel进行特征提取,通过FrozenCLIPEmbedder,我们可以获得一个[batch_size, 77, 768]的特征向量。
class FrozenCLIPEmbedder(AbstractEncoder):"""Uses the CLIP transformer encoder for text (from huggingface)"""LAYERS = ["last","pooled","hidden"]def __init__(self, version="openai/clip-vit-large-patch14", device="cuda", max_length=77,freeze=True, layer="last", layer_idx=None): # clip-vit-base-patch32super().__init__()assert layer in self.LAYERS# 定义文本的tokenizer和transformerself.tokenizer = CLIPTokenizer.from_pretrained(version)self.transformer = CLIPTextModel.from_pretrained(version)self.device = deviceself.max_length = max_length# 冻结模型参数if freeze:self.freeze()self.layer = layerself.layer_idx = layer_idxif layer == "hidden":assert layer_idx is not Noneassert 0 <= abs(layer_idx) <= 12def freeze(self):self.transformer = self.transformer.eval()# self.train = disabled_trainfor param in self.parameters():param.requires_grad = Falsedef forward(self, text):# 对输入的图片进行分词并编码,padding直接padding到77的长度。batch_encoding = self.tokenizer(text, truncation=True, max_length=self.max_length, return_length=True,return_overflowing_tokens=False, padding="max_length", return_tensors="pt")# 拿出input_ids然后传入transformer进行特征提取。tokens = batch_encoding["input_ids"].to(self.device)outputs = self.transformer(input_ids=tokens, output_hidden_states=self.layer=="hidden")# 取出所有的tokenif self.layer == "last":z = outputs.last_hidden_stateelif self.layer == "pooled":z = outputs.pooler_output[:, None, :]else:z = outputs.hidden_states[self.layer_idx]return zdef encode(self, text):return self(text)
3、采样流程
a、生成初始噪声
在inpaint中,我们的初始噪声获取于参考图片,参考第一步获得Latent特征后,使用该Latent特征基于DDIM Sampler进行加噪,获得输入图片加噪后的特征。
此处先不引入denoise参数,所以直接20步噪声加到底。在该步,我们执行了下面两个操作:
- 将原图x0映射到VAE隐空间,得到img_orig;
- 初始化随机噪声img(也可以使用img_orig完全加噪后的噪声);
b、对噪声进行N次采样
我们便从上一步获得的初始特征开始去噪声。
我们会对ddim_timesteps的时间步取反,因为我们现在是去噪声而非加噪声,然后对其进行一个循环,循环的代码如下:
循环中有一个mask,它的作用是用于进行局部的重建,对部分区域的隐向量进行mask,在此前我们并未用到,这一次我们需要用到了。
- 对于每一次时间步,根据时间步生成img_orig对应的加噪声特征;
- 一个是基于上个时间步降噪后得到的img;一个是基于原图得到的img_orig。我们通过mask将两者融合, i m g = i m g _ o r i g ∗ m a s k + ( 1.0 − m a s k ) ∗ i m g img = img\_orig * mask + (1.0 - mask) * img img=img_orig∗mask+(1.0−mask)∗img。即,将原图中的非mask区域和噪声图中的mask区域进行融合,得到新的噪声图。
- 然后继续去噪声直到结束。
for i, step in enumerate(iterator):# index是用来取得对应的调节参数的index = total_steps - i - 1# 将步数拓展到bs维度ts = torch.full((b,), step, device=device, dtype=torch.long)# --------------------------------------------------------------------------------- ## 替换特征的地方# 用于进行局部的重建,对部分区域的隐向量进行mask。# 对传入unet前的隐含层特征,我们利用mask将不重建的地方都替换成 原图加噪后的隐含层特征# self.model.q_sample用于对输入图片进行ts步数的加噪# --------------------------------------------------------------------------------- #if mask is not None:assert x0 is not Noneimg_orig = self.model.q_sample(x0, ts) # TODO: deterministic forward pass?img = img_orig * mask + (1. - mask) * img# 进行采样outs = self.p_sample_ddim(img, cond, ts, index=index, use_original_steps=ddim_use_original_steps,quantize_denoised=quantize_denoised, temperature=temperature,noise_dropout=noise_dropout, score_corrector=score_corrector,corrector_kwargs=corrector_kwargs,unconditional_guidance_scale=unconditional_guidance_scale,unconditional_conditioning=unconditional_conditioning)img, pred_x0 = outs# 回调函数if callback: callback(i)if img_callback: img_callback(pred_x0, i)if index % log_every_t == 0 or index == total_steps - 1:intermediates['x_inter'].append(img)intermediates['pred_x0'].append(pred_x0)return img, intermediates
c、如何引入denoise
上述代码是官方自带的基于base模型的可用于inpaint的代码,但问题在于并未考虑denoise参数。
假设我们对生成图像的某一区域不满意,但是不满意的不多,其实我们不需要完全进行重建,只需要重建一点点就行了,那么此时我们便需要引入denoise参数,表示我们要重建的强度。
i、加噪的逻辑
同样,我们的初始噪声获取于参考图片,参考第一步获得Latent特征后,使用该Latent特征和denoise参数基于DDIM Sampler进行加噪,获得输入图片加噪后的特征。
加噪的逻辑如下:
- denoise可认为是重建的比例,1代表全部重建,0代表不重建;
- 假设我们设置denoise数值为0.8,总步数为20步;我们会对输入图片进行0.8x20次的加噪声,剩下4步不加,可理解为80%的特征,保留20%的特征;不过就算加完20步噪声,原始输入图片的信息还是有一点保留的,不是完全不保留。
with torch.no_grad():if seed == -1:seed = random.randint(0, 65535)seed_everything(seed)# ----------------------- ## 对输入图片进行编码并加噪# ----------------------- #if image_path is not None:img = HWC3(np.array(img, np.uint8))img = torch.from_numpy(img.copy()).float().cuda() / 127.0 - 1.0img = torch.stack([img for _ in range(num_samples)], dim=0)img = einops.rearrange(img, 'b h w c -> b c h w').clone()if vae_fp16:img = img.half()model.first_stage_model = model.first_stage_model.half()else:model.first_stage_model = model.first_stage_model.float()ddim_sampler.make_schedule(ddim_steps, ddim_eta=eta, verbose=True)t_enc = min(int(denoise_strength * ddim_steps), ddim_steps - 1)# 获得VAE编码后的隐含层向量z = model.get_first_stage_encoding(model.encode_first_stage(img))x0 = z# 获得加噪后的隐含层向量z_enc = ddim_sampler.stochastic_encode(z, torch.tensor([t_enc] * num_samples).to(model.device))z_enc = z_enc.half() if sd_fp16 else z_enc.float()
ii、mask处理
我们需要对mask进行下采样,使其和上述获得的加噪后的特征的shape一样。
if mask_path is not None:mask = torch.from_numpy(mask).to(model.device)mask = torch.nn.functional.interpolate(mask, size=z_enc.shape[-2:])
iii、采样处理
此时,因为使用到了denoise参数,我们要基于img2img中的decode方法进行采样。
由于decode方法中不存在mask与x0参数,我们补一下:
@torch.no_grad()
def decode(self, x_latent, cond, t_start, mask, x0, unconditional_guidance_scale=1.0, unconditional_conditioning=None,use_original_steps=False):# 使用ddim的时间步# 这里内容看起来很多,但是其实很少,本质上就是取了self.ddim_timesteps,然后把它reversed一下timesteps = np.arange(self.ddpm_num_timesteps) if use_original_steps else self.ddim_timestepstimesteps = timesteps[:t_start]time_range = np.flip(timesteps)total_steps = timesteps.shape[0]print(f"Running DDIM Sampling with {total_steps} timesteps")iterator = tqdm(time_range, desc='Decoding image', total=total_steps)x_dec = x_latentfor i, step in enumerate(iterator):index = total_steps - i - 1ts = torch.full((x_latent.shape[0],), step, device=x_latent.device, dtype=torch.long)# --------------------------------------------------------------------------------- ## 替换特征的地方# 用于进行局部的重建,对部分区域的隐向量进行mask。# 对传入unet前的隐含层特征,我们利用mask将不重建的地方都替换成 原图加噪后的隐含层特征# self.model.q_sample用于对输入图片进行ts步数的加噪# --------------------------------------------------------------------------------- #if mask is not None:assert x0 is not Noneimg_orig = self.model.q_sample(x0, ts) # TODO: deterministic forward pass?x_dec = img_orig * mask + (1. - mask) * x_dec# 进行单次采样x_dec, _ = self.p_sample_ddim(x_dec, cond, ts, index=index, use_original_steps=use_original_steps,unconditional_guidance_scale=unconditional_guidance_scale,unconditional_conditioning=unconditional_conditioning)return x_dec
4、隐空间解码生成图片
通过上述步骤,已经可以多次采样获得结果,然后我们便可以通过隐空间解码生成图片。
隐空间解码生成图片的过程非常简单,将上文多次采样后的结果,使用decode_first_stage方法即可生成图片。
在decode_first_stage方法中,网络调用VAE对获取到的64x64x3的隐向量进行解码,获得512x512x3的图片。
@torch.no_grad()
def decode_first_stage(self, z, predict_cids=False, force_not_quantize=False):if predict_cids:if z.dim() == 4:z = torch.argmax(z.exp(), dim=1).long()z = self.first_stage_model.quantize.get_codebook_entry(z, shape=None)z = rearrange(z, 'b h w c -> b c h w').contiguous()z = 1. / self.scale_factor * z# 一般无需分割输入,所以直接将x_noisy传入self.model中,在下面else进行if hasattr(self, "split_input_params"):......else:if isinstance(self.first_stage_model, VQModelInterface):return self.first_stage_model.decode(z, force_not_quantize=predict_cids or force_not_quantize)else:return self.first_stage_model.decode(z)
Inpaint预测过程代码
整体预测代码如下:
import os
import randomimport cv2
import einops
import numpy as np
import torch
from PIL import Image
from pytorch_lightning import seed_everythingfrom ldm_hacked import *# ----------------------- #
# 使用的参数
# ----------------------- #
# config的地址
config_path = "model_data/sd_v15.yaml"
# 模型的地址
model_path = "model_data/v1-5-pruned-emaonly.safetensors"
# fp16,可以加速与节省显存
sd_fp16 = True
vae_fp16 = True# ----------------------- #
# 生成图片的参数
# ----------------------- #
# 生成的图像大小为input_shape,对于img2img会进行Centter Crop
input_shape = [512, 768]
# 一次生成几张图像
num_samples = 1
# 采样的步数
ddim_steps = 20
# 采样的种子,为-1的话则随机。
seed = 12345
# eta
eta = 0
# denoise强度,for img2img
denoise_strength = 1.00# ----------------------- #
# 提示词相关参数
# ----------------------- #
# 提示词
prompt = "a cute dog, with yellow leaf, trees"
# 正面提示词
a_prompt = "best quality, extremely detailed"
# 负面提示词
n_prompt = "longbody, lowres, bad anatomy, bad hands, missing fingers, extra digit, fewer digits, cropped, worst quality, low quality"
# 正负扩大倍数
scale = 9
# img2img使用,如果不想img2img这设置为None。
image_path = "imgs/test_imgs/cat.jpg"
# inpaint使用,如果不想inpaint这设置为None;inpaint使用需要结合img2img。
# 注意mask图和原图需要一样大
mask_path = "imgs/test_imgs/cat_mask.jpg"# ----------------------- #
# 保存路径
# ----------------------- #
save_path = "imgs/outputs_imgs"# ----------------------- #
# 创建模型
# ----------------------- #
model = create_model(config_path).cpu()
model.load_state_dict(load_state_dict(model_path, location='cuda'), strict=False)
model = model.cuda()
ddim_sampler = DDIMSampler(model)
if sd_fp16:model = model.half()if image_path is not None:img = Image.open(image_path)img = crop_and_resize(img, input_shape[0], input_shape[1])if mask_path is not None:mask = Image.open(mask_path).convert("L")mask = crop_and_resize(mask, input_shape[0], input_shape[1])mask = np.array(mask)mask = mask.astype(np.float32) / 255.0mask = mask[None,None]mask[mask < 0.5] = 0mask[mask >= 0.5] = 1with torch.no_grad():if seed == -1:seed = random.randint(0, 65535)seed_everything(seed)# ----------------------- ## 对输入图片进行编码并加噪# ----------------------- #if image_path is not None:img = HWC3(np.array(img, np.uint8))img = torch.from_numpy(img.copy()).float().cuda() / 127.0 - 1.0img = torch.stack([img for _ in range(num_samples)], dim=0)img = einops.rearrange(img, 'b h w c -> b c h w').clone()if vae_fp16:img = img.half()model.first_stage_model = model.first_stage_model.half()else:model.first_stage_model = model.first_stage_model.float()ddim_sampler.make_schedule(ddim_steps, ddim_eta=eta, verbose=True)t_enc = min(int(denoise_strength * ddim_steps), ddim_steps - 1)# 获得VAE编码后的隐含层向量z = model.get_first_stage_encoding(model.encode_first_stage(img))x0 = z# 获得加噪后的隐含层向量z_enc = ddim_sampler.stochastic_encode(z, torch.tensor([t_enc] * num_samples).to(model.device))z_enc = z_enc.half() if sd_fp16 else z_enc.float()if mask_path is not None:mask = torch.from_numpy(mask).to(model.device)mask = torch.nn.functional.interpolate(mask, size=z_enc.shape[-2:])mask = 1 - mask# ----------------------- ## 获得编码后的prompt# ----------------------- #cond = {"c_crossattn": [model.get_learned_conditioning([prompt + ', ' + a_prompt] * num_samples)]}un_cond = {"c_crossattn": [model.get_learned_conditioning([n_prompt] * num_samples)]}H, W = input_shapeshape = (4, H // 8, W // 8)if image_path is not None:samples = ddim_sampler.decode(z_enc, cond, t_enc, mask, x0, unconditional_guidance_scale=scale, unconditional_conditioning=un_cond)else:# ----------------------- ## 进行采样# ----------------------- #samples, intermediates = ddim_sampler.sample(ddim_steps, num_samples,shape, cond, verbose=False, eta=eta,unconditional_guidance_scale=scale,unconditional_conditioning=un_cond)# ----------------------- ## 进行解码# ----------------------- #x_samples = model.decode_first_stage(samples.half() if vae_fp16 else samples.float())x_samples = (einops.rearrange(x_samples, 'b c h w -> b h w c') * 127.5 + 127.5).cpu().numpy().clip(0, 255).astype(np.uint8)# ----------------------- #
# 保存图片
# ----------------------- #
if not os.path.exists(save_path):os.makedirs(save_path)
for index, image in enumerate(x_samples):cv2.imwrite(os.path.join(save_path, str(index) + ".jpg"), cv2.cvtColor(image, cv2.COLOR_BGR2RGB))
相关文章:
Diffusion扩散模型学习4——Stable Diffusion原理解析-inpaint修复图片为例
Diffusion扩散模型学习4——Stable Diffusion原理解析-inpaint修复图片为例 学习前言源码下载地址原理解析一、先验知识二、什么是inpaint三、Stable Diffusion中的inpaint1、开源的inpaint模型2、基于base模型inpaint 四、inpaint流程1、输入图片到隐空间的编码2、文本编码3、…...

dns的负载分配是什么
DNS 负载分配是使用 DNS 系统对传入的网络流量进行分配的一种技术。这可以是基于多种策略来分配的,从简单的轮询到更复杂的基于地理位置或服务器健康状况的分配。下面是 DNS 负载分配的几种常见形式: 轮询(Round Robin)࿱…...
adb 通过wifi连接手机
adb 通过wifi连接手机 1. 电脑通过USB线连接手机2. 手机开启USB调试模式,开启手机开发者模式3.手机开启USB调试模式 更多设置-》开发者选项-》USB调试4.点击Wi-Fi 高级设置,可以查看到手机Wi-Fi的IP地址,此IP地址adb命令后面的ip地址…...
将应用设置成系统App/获取Android设备SN号
1,和系统签名一致;(签名设置签名文件) 2,配置Manifest 至此你的App就是一个系统App了,可以执行一些系统App才能有的操作,如获取机器SN号: public String getSerialNumber() {Strin…...

2.CUDA 编程手册中文版---编程模型
2.编程模型 更多精彩内容,请扫描下方二维码或者访问https://developer.nvidia.com/zh-cn/developer-program 来加入NVIDIA开发者计划 本章通过概述CUDA编程模型是如何在c中公开的,来介绍CUDA的主要概念。 编程接口中给出了对 CUDA C 的广泛描述。 本章…...
Claude 2、ChatGPT、Google Bard优劣势比较
Claude 2: 优势:Claude 2能够一次性处理多达10万个tokens(约7.5万个单词)。 tokens数量反映了模型可以处理的文本长度和上下文数量。tokens越多,模型理解语义的能力就越强)。它在法律、数学和编码等多个…...
Docker安装Hadoop分布式集群
一、准备环境 docker search hadoop docker pull sequenceiq/hadoop-docker docker images二、Hadoop集群搭建 1. 运行hadoop102容器 docker run --name hadoop102 -d -h hadoop102 -p 9870:9870 -p 19888:19888 -v /opt/data/hadoop:/opt/data/hadoop sequenceiq/hadoop-do…...
文盘 Rust -- tokio 绑定 cpu 实践
tokio 是 rust 生态中流行的异步运行时框架。在实际生产中我们如果希望 tokio 应用程序与特定的 cpu core 绑定该怎么处理呢?这次我们来聊聊这个话题。 首先我们先写一段简单的多任务程序。 use tokio::runtime; pub fn main() {let rt runtime::Builder::new_mu…...
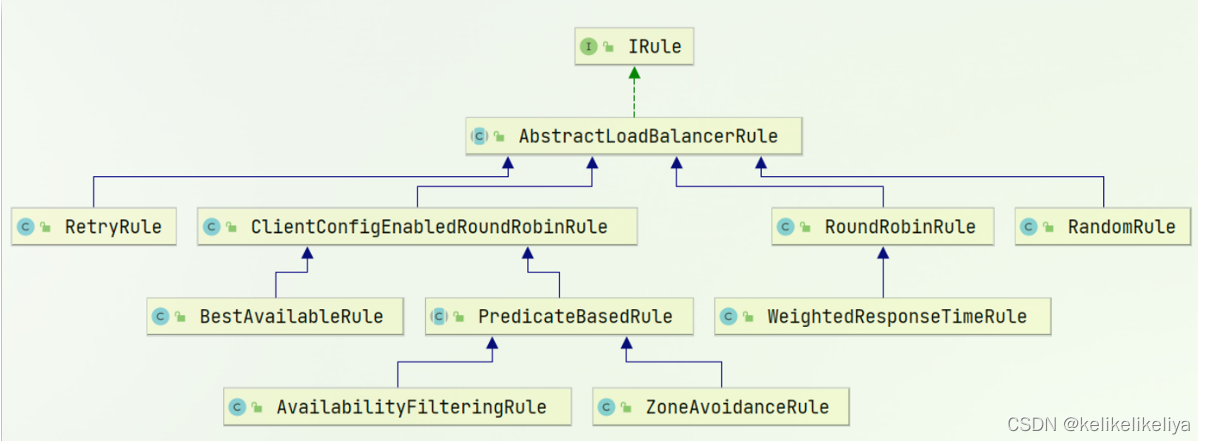
微服务Ribbon-负载均衡策略和饥饿加载
目录 一、负载均衡策略 1.1 负载均衡策略介绍 1.2 自定义负载均衡策略 二、饥饿加载 (笔记整理自bilibili黑马程序员课程) 一、负载均衡策略 1.1 负载均衡策略介绍 负载均衡的规则都定义在IRule接口中,而IRule有很多不同的实现类&…...

uni-app 运行时报错“本应用使用HBuilderX x.x.x 或对应的cli版本编译,而手机端SDK版本是x.x.x。不匹配的版本可能造成应用异常”
uni-app 运行时报错“本应用使用HBuilderX x.x.x 或对应的cli版本编译,而手机端SDK版本是x.x.x。不匹配的版本可能造成应用异常” 出现原因 手机端SDK版本和HBuilderX版本不一致。 解决办法 方法一 项目根目录下找到 manifest.json 配置文件,选择源码…...
Windows使用docker desktop 安装kafka、zookeeper集群
docker-compose安装zookeeper集群 参考文章:http://t.csdn.cn/TtTYI https://blog.csdn.net/u010416101/article/details/122803105?spm1001.2014.3001.5501 准备工作: 在开始新建集群之前,新建好文件夹,用来挂载kafka、z…...

11 | 苹果十年财报分析
在本文中,我们将对苹果公司的财务报告进行深入分析,关注其销售收入、利润情况以及关键产品线的表现。我们将研究财报中的数据,挖掘背后的商业策略和市场动态,以便更好地了解苹果公司在不同市场环境下的业绩表现。通过对财报数据的解读和分析,我们将探讨苹果公司在竞争激烈…...

Zookeeper与Redis 对比
1. 为什么使用分布式锁? 使用分布式锁的目的,是为了保证同一时间只有一个 JVM 进程可以对共享资源进行操作。 根据锁的用途可以细分为以下两类: 1、 允许多个客户端操作共享资源,我们称为共享锁。 这种锁的一般是对共享资源具有幂…...
跨境商城服务平台搭建与开发(金融服务+税务管理)
随着全球电子商务的快速发展,跨境贸易已经成为一种新的商业趋势。在这个背景下,搭建一个跨境商城服务平台,提供金融服务、税务管理等一系列服务,可以极大地促进跨境贸易的发展。本文将详细阐述跨境商城服务平台搭建与开发的步骤。…...

docker配置文件
/etc/docker/daemon.json 文件作用 /etc/docker/daemon.json 文件是 Docker 配置文件,用于配置 Docker 守护进程的行为和参数。Docker 守护进程是负责管理和运行 Docker 容器的后台进程,通过修改 daemon.json 文件,可以对 Docker 守护进程进…...

Mysql数据库之单表查询
目录 一、练习时先导入数据如下: 二、查询验证导入是否成功 三、单表查询 四、where和having的区别 一、练习时先导入数据如下: 素材: 表名:worker-- 表中字段均为中文,比如 部门号 工资 职工号 参加工作 等 CRE…...

macos搭建appium-iOS自动化测试环境
目录 准备工作 安装必需的软件 安装appium 安装XCode 下载WDA工程 配置WDA工程 搭建appiumwda自动化环境 第一步:启动通过xcodebuild命令启动wda服务 分享一下如何在mac电脑上搭建一个完整的appium自动化测试环境 准备工作 前期需要准备的设备和账号&…...
日常工具 之 一些 / 方便好用 / 免费 / 在线 / 工具整理
日常工具 之 一些 / 方便好用 / 免费 / 在线 / 工具整理 目录 日常工具 之 一些 / 方便好用 / 免费 / 在线 / 工具整理 1、在线Json ,可以在线进行json 格式验证,解析转义等操作 2、Gif动图分解,在线把 gif 图分解成一张张单图 3、在线P…...
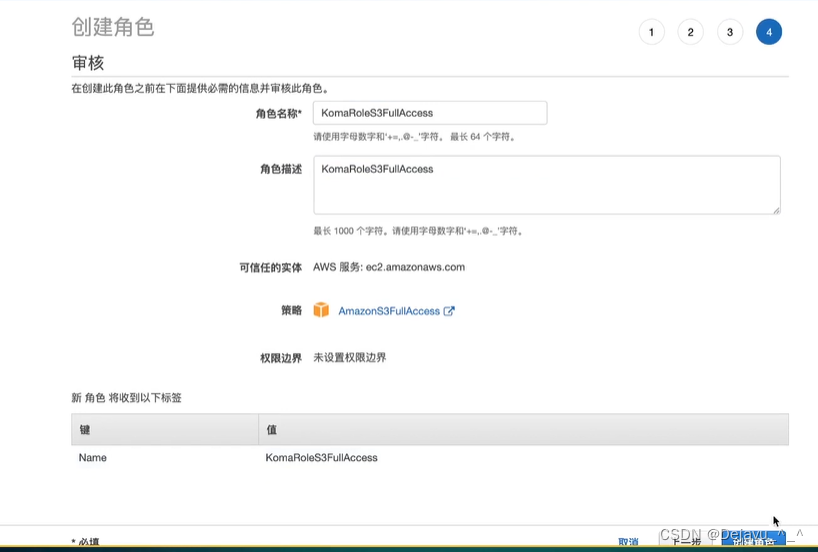
AWS 中文入门开发教学 50- S3 - 网关终端节点 - 私有网络访问S3的捷径
知识点 通过设置网关终端节点,使私有网段中的EC2也可以访问到S3服务官网 https://docs.aws.amazon.com/zh_cn/codeartifact/latest/ug/create-s3-gateway-endpoint.html 实战演习 通过网关访问S3 看图说话"> 实战步骤 创建一个可以访问S3的角色 KomaRoleS3FullAcc…...

windows使用/服务(13)戴尔电脑怎么设置通电自动开机
戴尔pc机器通电自启动 1、将主机显示器键盘鼠标连接好后,按主机电源键开机 2、在开机过程中按键盘"F12",进入如下界面,选择“BIOS SETUP” 3、选择“Power Management” 4、选择“AC Recovery”,点选“Power On”,点击“…...

OpenClaw硬件配置建议:流畅运行Qwen2.5-VL-7B的电脑要求
OpenClaw硬件配置建议:流畅运行Qwen2.5-VL-7B的电脑要求 1. 为什么需要关注硬件配置? 去年夏天,我第一次尝试在MacBook Pro上部署OpenClaw对接Qwen2.5-VL-7B模型时,经历了长达3小时的"烤机"体验——风扇狂转、机身发烫…...

常见的服务器
常见的服务器 目录 [ 一、塔式服务器(Tower Server)](#%E4%B8%80%E3%80%81%E5%A1%94%E5%BC%8F%E6%9C%8D%E5%8A%A1%E5%99%A8%EF%BC%88Tower%20Server%EF%BC%89) [ 二、机架式服务器(Rack Server)](#%E4%BA%8C%E3%80%81%E6%9C%BA%E6…...

【Spring Boot 4.0 Agent-Ready 架构权威白皮书】:20年资深架构师亲授企业级落地避坑指南
第一章:Spring Boot 4.0 Agent-Ready 架构全景认知Spring Boot 4.0 正式引入 Agent-Ready 架构范式,标志着其从“开发友好”迈向“运行时可观测、可干预、可演进”的新阶段。该架构并非简单叠加 Java Agent 支持,而是将字节码增强、生命周期钩…...

阿联酋科技创新研究院:单模型实现多视觉任务统一解决突破
这项由阿联酋科技创新研究院(Technology Innovation Institute,TII)Falcon Vision团队主导的研究发表于2026年3月,论文编号为arXiv:2603.27365v1。有兴趣深入了解的读者可以通过该编号在相关学术平台查询完整论文内容。传统的计算…...

MCP3221 12位I²C ADC驱动设计与精度优化实战
1. MCP3221 12位IC模数转换器底层驱动技术解析MCP3221是Microchip公司推出的超低功耗、单通道、12位分辨率的串行模数转换器(ADC),采用标准IC总线接口,工作电压范围宽达2.7V至5.0V,静态电流典型值仅仅为1.5μA…...

AI时代的算法思维:大经典排序学习弥
引言 在现代软件开发中,性能始终是衡量应用质量的重要指标之一。无论是企业级应用、云服务还是桌面程序,性能优化都能显著提升用户体验、降低基础设施成本并增强系统的可扩展性。对于使用 C# 开发的应用程序而言,性能优化涉及多个层面&#x…...

OpenClaw模型量化指南:压缩Qwen2.5-VL-7B提升本地运行效率
OpenClaw模型量化指南:压缩Qwen2.5-VL-7B提升本地运行效率 1. 为什么需要量化多模态大模型 当我第一次在本地MacBook Pro上尝试运行Qwen2.5-VL-7B时,风扇立刻开始狂转,16GB内存几乎被吃满,模型加载就花了近3分钟。这种体验让我意…...

大模型时代,这5大热门职业让你月入50K!错过等一年!
在数字技术迭代速度不断加快的当下,人工智能领域的大模型(Large Models) 已从实验室走向产业落地,成为重构各行业生产模式、驱动创新升级的核心引擎。凭借在数据处理、模式识别、复杂任务决策等方面的超强能力,大模型不…...

跨平台文件同步:OpenClaw调用Qwen3-32B实现智能归档
跨平台文件同步:OpenClaw调用Qwen3-32B实现智能归档 1. 为什么需要智能文件同步工具 作为一个长期被数字资产混乱困扰的技术从业者,我电脑里的文件就像一座无人管理的图书馆。下载的论文、会议录音、代码片段、临时截图散落在十几个文件夹中࿰…...
)
为什么你的PHP异步服务越写越慢?——深入内核级I/O多路复用原理、内存泄漏陷阱与CPU亲和性配置(生产环境血泪复盘)
第一章:为什么你的PHP异步服务越写越慢?——问题现象与根因定位全景图当 PHP 项目引入 ReactPHP、Amp 或 Swoole 实现异步 I/O 后,开发者常预期性能线性提升,但实际却遭遇响应延迟加剧、内存持续增长、协程堆积甚至进程僵死等反直…...