使用langchain与你自己的数据对话(五):聊天机器人

之前我已经完成了使用langchain与你自己的数据对话的前四篇博客,还没有阅读这四篇博客的朋友可以先阅读一下:
- 使用langchain与你自己的数据对话(一):文档加载与切割
- 使用langchain与你自己的数据对话(二):向量存储与嵌入
- 使用langchain与你自己的数据对话(三):检索(Retrieval)
- 使用langchain与你自己的数据对话(四):问答(question answering)
今天我们来继续讲解deepleaning.AI的在线课程“LangChain: Chat with Your Data”的第六门课:chat。
Langchain在实现与外部数据对话的功能时需要经历下面的5个阶段,它们分别是:Document Loading->Splitting->Storage->Retrieval->Output,如下图所示:
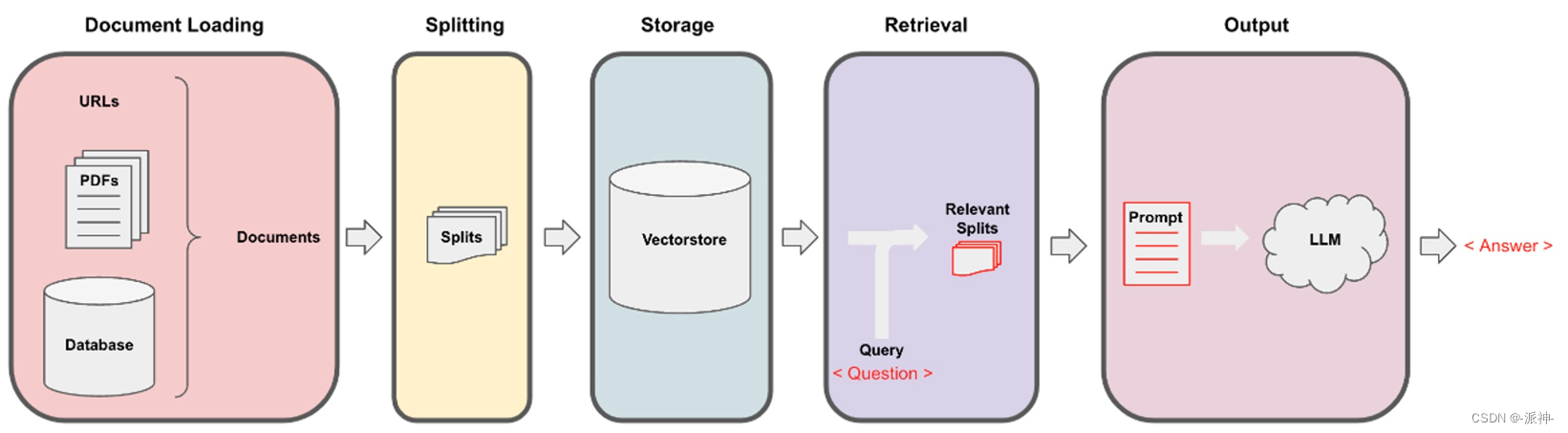
在前面的四篇博客中我们以及完成了这5给阶段所有的内容介绍,并在第四篇博客中我们还创建了RetrievalQA实现了对数据的问答功能,但是这里有一个小小的缺陷,那就是通过RetrievalQA实现的问答功能只能针对当前问题进行回答,它无法参考上下文来来回答问题,也就是说它没有记忆能力,无法实现连贯性聊。今天我们就来解决这个问题,我们会创建一个真正的个性化聊天机器人,它会学习用户提供的数据,并解答任何关于数据内容的问题,并且它具有记忆能力,能够实现真正的连贯性聊天。
在讨论聊天机器人之前之前,先让我们完成一些基础性工作,比如设置一下openai的api key:
import os
import openai
import sys
sys.path.append('../..')import panel as pn # GUI
pn.extension()from dotenv import load_dotenv, find_dotenv
_ = load_dotenv(find_dotenv()) # read local .env fileopenai.api_key = os.environ['OPENAI_API_KEY']先前内容回顾
之前我们介绍了Langchain在实现与外部数据对话的功能时需要经历下面的5个阶段,它们分别是:Document Loading->Splitting->Storage->Retrieval->Output。下面我们通过代码来简单实现一下这5个阶段的功能:
from langchain.vectorstores import Chroma
from langchain.embeddings.openai import OpenAIEmbeddings#加载本地向量数据库
persist_directory = 'docs/chroma/'
embedding = OpenAIEmbeddings()
vectordb = Chroma(persist_directory=persist_directory, embedding_function=embedding)#搜索与问题相关的文档
question = "What are major topics for this class?"
docs = vectordb.similarity_search(question,k=3)#查看搜索结果中的文档数量
len(docs)
这里我们在向量数据库中搜索到3篇与问题相关的文档,下面我们查看一下这3篇文档:
docs 下面我们来创建RetrievalQA,同时我们加入一个prompt的模板,在该prompt我们要求llm尽量用简洁的语言来回答问题,并且不能编造答案,最后我们还要求llm在答案的结语上加上“thanks for asking!”,通过这个prompt模板llm能给出简洁的格式化的答案:
下面我们来创建RetrievalQA,同时我们加入一个prompt的模板,在该prompt我们要求llm尽量用简洁的语言来回答问题,并且不能编造答案,最后我们还要求llm在答案的结语上加上“thanks for asking!”,通过这个prompt模板llm能给出简洁的格式化的答案:
from langchain.chat_models import ChatOpenAI
from langchain.prompts import PromptTemplate# Build prompt
template = """Use the following pieces of context to answer the question at the end. \
If you don't know the answer, just say that you don't know, don't try to make up an answer. \
Use three sentences maximum. Keep the answer as concise as possible. \
Always say "thanks for asking!" at the end of the answer. {context}
Question: {question}
Helpful Answer:"""
QA_CHAIN_PROMPT = PromptTemplate(input_variables=["context", "question"],template=template,)# Run chain
from langchain.chains import RetrievalQA
question = "Is probability a class topic?"
qa_chain = RetrievalQA.from_chain_type(llm=ChatOpenAI(temperature=0),retriever=vectordb.as_retriever(),return_source_documents=True,chain_type_kwargs={"prompt": QA_CHAIN_PROMPT})result = qa_chain({"query": question})
result["result"] 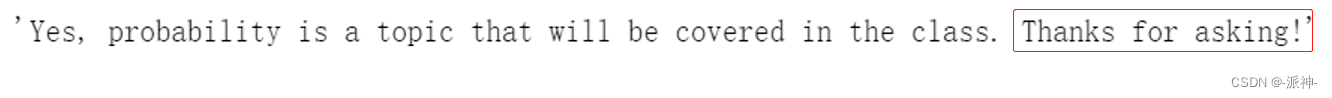
这里我们看到RetrievalQA返回了一个很简洁的答案,并在最后附加了“thanks for asking!”,这符合我们对它的要求。
ConversationalRetrievalChain
到目前为止我们已经创建好了RetrievalQA,可以实现对数据内容的问答,不过这里会有一个问题,就是通过RetrievalQA创建的检索问答链,它没有记忆功能,它无法记住之前用户已经提出过问题,所以RetrievalQA不能实现连贯性的聊天问答。为了解决这个功能,我们可以通过创建ConversationalRetrievalChain,它会存储每次聊天的历史记录,当LLM在回答当前问题的时候都会参考历史聊天记录,这样就可以实现连贯性的聊天:
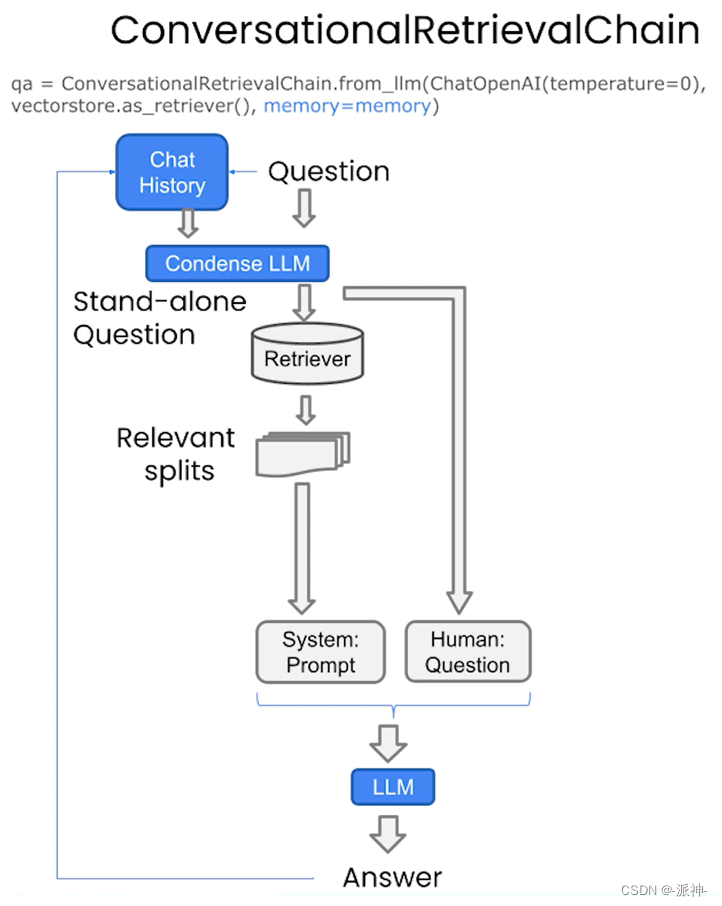
为了保存么此用户和LLM之间的聊天记录,我们需要创建一个ConversationBufferMemory组件,该组件会自动保存每一次用户和LLM之间对话记录。ConversationalRetrievalChain包含3给主要的参数:
- llm: 语言模型,这里我们使用openai的“gpt-3.5-turbo”模型
- retriever:检索器,这里我们由向量数据库来创建检索器
- memory:记忆力组件,这里我们使用ConversationBufferMemory
from langchain.chat_models import ChatOpenAI
from langchain.memory import ConversationBufferMemory
from langchain.chains import ConversationalRetrievalChain#创建memory
memory = ConversationBufferMemory(memory_key="chat_history",return_messages=True
)#创建ConversationalRetrievalChain
qa = ConversationalRetrievalChain.from_llm(llm=ChatOpenAI(temperature=0),retriever=vectordb.as_retriever(),memory=memory
)这里我们创建了ConversationalRetrievalChain的实例qa,接下来我们来实现连贯性的聊天,我们首先向LLM提出一个问题:概率是这门课的主题吗?
question1="概率是这门课的主题吗?"
result = qa({"question": question1})
print(result['answer'])
接下来我们第二给问题:为什么需要先修课程呢?,这里需要说明的是该问题其实是衔接第一个问题的答案,如果我们的ConversationalRetrievalChain有记忆功能,那么它一定会知道这里的先修课程是指哪些课程,并且给出正确的回答:
question2 = "为什么需要先修课程呢?"
result = qa({"question": question2})
print(result['answer'])
这里我们向LLM提出了2个问题,第一个问题是:概率是这门课的主题吗?我们知道,我们的向量数据库中存储的是吴恩达老师著名的机器学习课程cs229的课程讲义,因此课程中涉及到了一些概率的基础知识,那么接下来提出的第二给问题:为什么需要先修课程呢?该问题其实是衔接第一个问题的答案,要回答该问题必须要知道这里的先修课程是指哪些课程,因为LLM在回答第一个问题的时候已经明确告知用户概率是这门课的一个主题,那么概率也就是这门课的先修课程,这里我们看到ConversationalRetrievalChain在回答第二给问题的时候已经参考了之前的历史聊天记录,因此它给出了合理的答案。
创建聊天机器人
下面我们把Langchain在实现与外部数据对话的功能的5个阶段所有的内容整合起来,然后建一个真正意义上的聊天机器人,这里我们在jupyter notebook中使用panel组件来创建一个GUI的聊天对话界面:
from langchain.embeddings.openai import OpenAIEmbeddings
from langchain.text_splitter import CharacterTextSplitter, RecursiveCharacterTextSplitter
from langchain.vectorstores import DocArrayInMemorySearch
from langchain.document_loaders import TextLoader
from langchain.chains import RetrievalQA, ConversationalRetrievalChain
from langchain.memory import ConversationBufferMemory
from langchain.chat_models import ChatOpenAI
from langchain.document_loaders import TextLoader
from langchain.document_loaders import PyPDFLoader
import panel as pn
import paramdef load_db(file, chain_type, k):# load documentsloader = PyPDFLoader(file)documents = loader.load()# split documentstext_splitter = RecursiveCharacterTextSplitter(chunk_size=1000, chunk_overlap=150)docs = text_splitter.split_documents(documents)# define embeddingembeddings = OpenAIEmbeddings()# create vector database from datadb = DocArrayInMemorySearch.from_documents(docs, embeddings)# define retrieverretriever = db.as_retriever(search_type="similarity", search_kwargs={"k": k})# create a chatbot chain. Memory is managed externally.qa = ConversationalRetrievalChain.from_llm(llm=ChatOpenAI(temperature=0), chain_type=chain_type, retriever=retriever, return_source_documents=True,return_generated_question=True,)return qa class cbfs(param.Parameterized):chat_history = param.List([])answer = param.String("")db_query = param.String("")db_response = param.List([])def __init__(self, **params):super(cbfs, self).__init__( **params)self.panels = []self.loaded_file = "docs/cs229_lectures/MachineLearning-Lecture01.pdf"self.qa = load_db(self.loaded_file,"stuff", 4)def call_load_db(self, count):if count == 0 or file_input.value is None: # init or no file specified :return pn.pane.Markdown(f"Loaded File: {self.loaded_file}")else:file_input.save("temp.pdf") # local copyself.loaded_file = file_input.filenamebutton_load.button_style="outline"self.qa = load_db("temp.pdf", "stuff", 4)button_load.button_style="solid"self.clr_history()return pn.pane.Markdown(f"Loaded File: {self.loaded_file}")def convchain(self, query):if not query:return pn.WidgetBox(pn.Row('User:', pn.pane.Markdown("", width=600)), scroll=True)result = self.qa({"question": query, "chat_history": self.chat_history})self.chat_history.extend([(query, result["answer"])])self.db_query = result["generated_question"]self.db_response = result["source_documents"]self.answer = result['answer'] self.panels.extend([pn.Row('User:', pn.pane.Markdown(query, width=600)),pn.Row('ChatBot:', pn.pane.Markdown(self.answer, width=600, style={'background-color': '#F6F6F6'}))])inp.value = '' #clears loading indicator when clearedreturn pn.WidgetBox(*self.panels,scroll=True)@param.depends('db_query ', )def get_lquest(self):if not self.db_query :return pn.Column(pn.Row(pn.pane.Markdown(f"Last question to DB:", styles={'background-color': '#F6F6F6'})),pn.Row(pn.pane.Str("no DB accesses so far")))return pn.Column(pn.Row(pn.pane.Markdown(f"DB query:", styles={'background-color': '#F6F6F6'})),pn.pane.Str(self.db_query ))@param.depends('db_response', )def get_sources(self):if not self.db_response:return rlist=[pn.Row(pn.pane.Markdown(f"Result of DB lookup:", styles={'background-color': '#F6F6F6'}))]for doc in self.db_response:rlist.append(pn.Row(pn.pane.Str(doc)))return pn.WidgetBox(*rlist, width=600, scroll=True)@param.depends('convchain', 'clr_history') def get_chats(self):if not self.chat_history:return pn.WidgetBox(pn.Row(pn.pane.Str("No History Yet")), width=600, scroll=True)rlist=[pn.Row(pn.pane.Markdown(f"Current Chat History variable", styles={'background-color': '#F6F6F6'}))]for exchange in self.chat_history:rlist.append(pn.Row(pn.pane.Str(exchange)))return pn.WidgetBox(*rlist, width=600, scroll=True)def clr_history(self,count=0):self.chat_history = []return cb = cbfs()file_input = pn.widgets.FileInput(accept='.pdf')
button_load = pn.widgets.Button(name="Load DB", button_type='primary')
button_clearhistory = pn.widgets.Button(name="Clear History", button_type='warning')
button_clearhistory.on_click(cb.clr_history)
inp = pn.widgets.TextInput( placeholder='Enter text here…')bound_button_load = pn.bind(cb.call_load_db, button_load.param.clicks)
conversation = pn.bind(cb.convchain, inp) jpg_pane = pn.pane.Image( './img/convchain.jpg')tab1 = pn.Column(pn.Row(inp),pn.layout.Divider(),pn.panel(conversation, loading_indicator=True, height=300),pn.layout.Divider(),
)
tab2= pn.Column(pn.panel(cb.get_lquest),pn.layout.Divider(),pn.panel(cb.get_sources ),
)
tab3= pn.Column(pn.panel(cb.get_chats),pn.layout.Divider(),
)
tab4=pn.Column(pn.Row( file_input, button_load, bound_button_load),pn.Row( button_clearhistory, pn.pane.Markdown("Clears chat history. Can use to start a new topic" )),pn.layout.Divider(),pn.Row(jpg_pane.clone(width=400))
)
dashboard = pn.Column(pn.Row(pn.pane.Markdown('# ChatWithYourData_Bot')),pn.Tabs(('Conversation', tab1), ('Database', tab2), ('Chat History', tab3),('Configure', tab4))
)#启动聊天应用程序
dashboard


总结
今天我们学习了如何开发一个具有记忆能力的个性化问答机器人,所谓个性化是指该机器人可以针对用户数据的内容进行问答,我们在实现该机器人时使用了ConversationalRetrievalChain组件,它是一个具有记忆能力的检索链,也是机器人的核心组件。希望今天的内容对大家有所帮助!
参考资料
Overview — Panel v1.2.1
Welcome to Param! — param v1.13.0
https://github.com/sophiamyang/tutorials-LangChain
相关文章:
使用langchain与你自己的数据对话(五):聊天机器人
之前我已经完成了使用langchain与你自己的数据对话的前四篇博客,还没有阅读这四篇博客的朋友可以先阅读一下: 使用langchain与你自己的数据对话(一):文档加载与切割使用langchain与你自己的数据对话(二):向量存储与嵌入使用langc…...

爬虫与搜索引擎优化:通过Python爬虫提升网站搜索排名
作为一名专业的爬虫程序员,我深知网站的搜索排名对于业务的重要性。在如今竞争激烈的网络世界中,如何让自己的网站在搜索引擎结果中脱颖而出,成为关键。今天,和大家分享一些关于如何通过Python爬虫来提升网站的搜索排名的技巧和实…...

2024软考系统架构设计师论文写作要点
一、写作注意事项 系统架构设计师的论文题目对于考生来说,是相对较难的题目。一方面,考生需要掌握论文题目中的系统架构设计的专业知识;另一方面,论文的撰写需要结合考生自身的项目经历。因此,如何将自己的项目经历和专业知识有机…...

【Maven】依赖范围、依赖传递、依赖排除、依赖原则、依赖继承
【Maven】依赖范围、依赖传递、依赖排除、依赖原则、依赖继承 依赖范围 依赖传递 依赖排除 依赖原则 依赖继承 依赖范围 在Maven中,依赖范围(Dependency Scope)用于控制依赖项在编译、测试和运行时的可见性和可用性。通过指定适当的依赖…...
数组slice、splice字符串substr、split
一、定义 这篇文章主要对数组操作的两种方法进行介绍和使用,包括:slice、splice。对字符串操作的两种方法进行介绍和使用,包括:substr、split (一)、数组 slice:可以操作的数据类型有:数组字符串 splice:数组 操作数组…...

程序漏洞:安全威胁的隐患
在当今数字化时代,计算机程序是现代社会的核心基石。然而,随着技术的进步,程序漏洞也成为了一个不可忽视的问题。程序漏洞可能导致数据泄露、系统崩溃、恶意攻击和经济损失等一系列问题。本文将深入探讨程序漏洞的定义、分类、影响和预防措施…...

0基础学C#笔记09:希尔排序法
文章目录 前言一、希尔排序的思想二、使用步骤总结 前言 希尔排序可以说是插入排序的一种变种。无论是插入排序还是冒泡排序,如果数组的最大值刚好是在第一位,要将它挪到正确的位置就需要 n - 1 次移动。也就是说,原数组的一个元素如果距离它…...

DOCKER的容器
1. 什么是Container(容器) 要有Container首先要有Image,也就是说Container是通过image创建的。 Container是在原先的Image之上新加的一层,称作Container layer,这一层是可读可写的(Image是只读的࿰…...
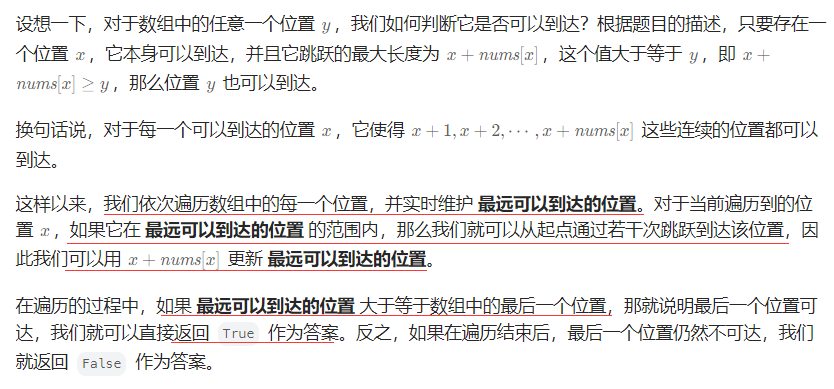
跳跃游戏——力扣55
文章目录 题目描述解法一 贪心题目描述 解法一 贪心 bool canJump(vector<int>& nums){int n=nums....
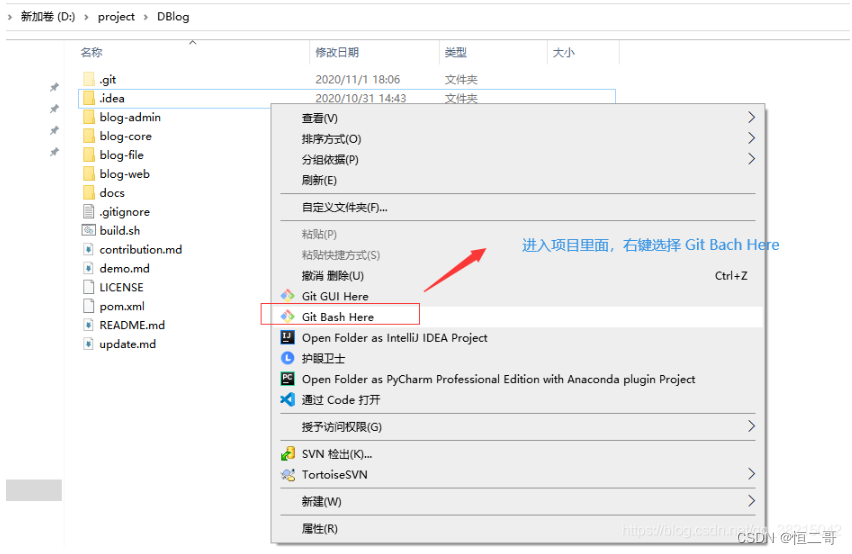
将本地项目上传至gitee的详细步骤
将本地项目上传至gitee的详细步骤 1.在gitee上创建以自己项目名称命名的空项目2.进入想上传的项目的文件夹,然后右键点击3. 初始化本地环境,把该项目变成可被git管理的仓库4.添加该项目下的所有文件5.使用如下命令将文件添加到仓库中去6.将本地代码库与远…...

iOS开发-导航栏UINavigationBar隐藏底部线及透明度
iOS 导航栏UINavigationBar隐藏底部线及透明度 苹果官方给出的解释: 如果你不调用方法设置一张背景图片的话,那就给你默认一张,然后同时还有一张阴影图片被默认设置上去,这就是导航栏上1px黑线的由来。 解决办法: 方…...

题目:2520.统计能整除数字的位数
题目来源: leetcode题目,网址:2520. 统计能整除数字的位数 - 力扣(LeetCode) 解题思路: 逐位判断即可。 解题代码: class Solution {public int countDigits(int num) {int res0;int ori…...
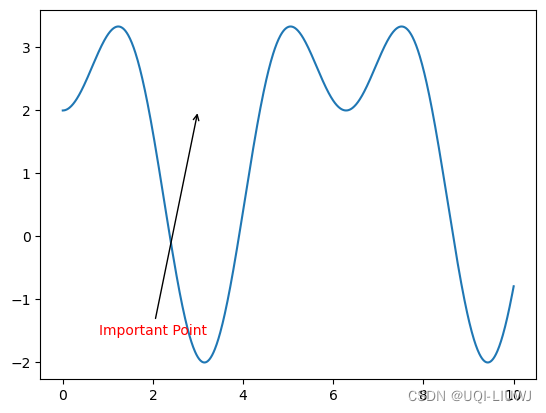
matplotlib 笔记 注释annotate
在图中的特定位置添加文本注释、箭头和连接线,以便更清晰地解释图形中的数据或信息 主要参数 text文本内容xy箭头指向的目标点的坐标xytext注释文本的坐标arrowprops 一个字典,指定注释箭头的属性,如颜色、箭头样式等 没有arrowprops的时候…...

Windows 无法安装到这个硬盘。选中的磁盘具有MBR分区。在EFI系统上,Windows只能安装到GPT磁盘
Windows无法安装到这个磁盘,选中的磁盘具有MBR分区表的解决方法 - 知乎 (zhihu.com) Windows无法安装到这个磁盘 选中的磁盘具有MBR分区表 - 知乎 (zhihu.com) 选中的磁盘具有MBR分区表,在EFI系统上,windows只能安装到GPT磁盘_选中的磁盘具有mbr分区表…...
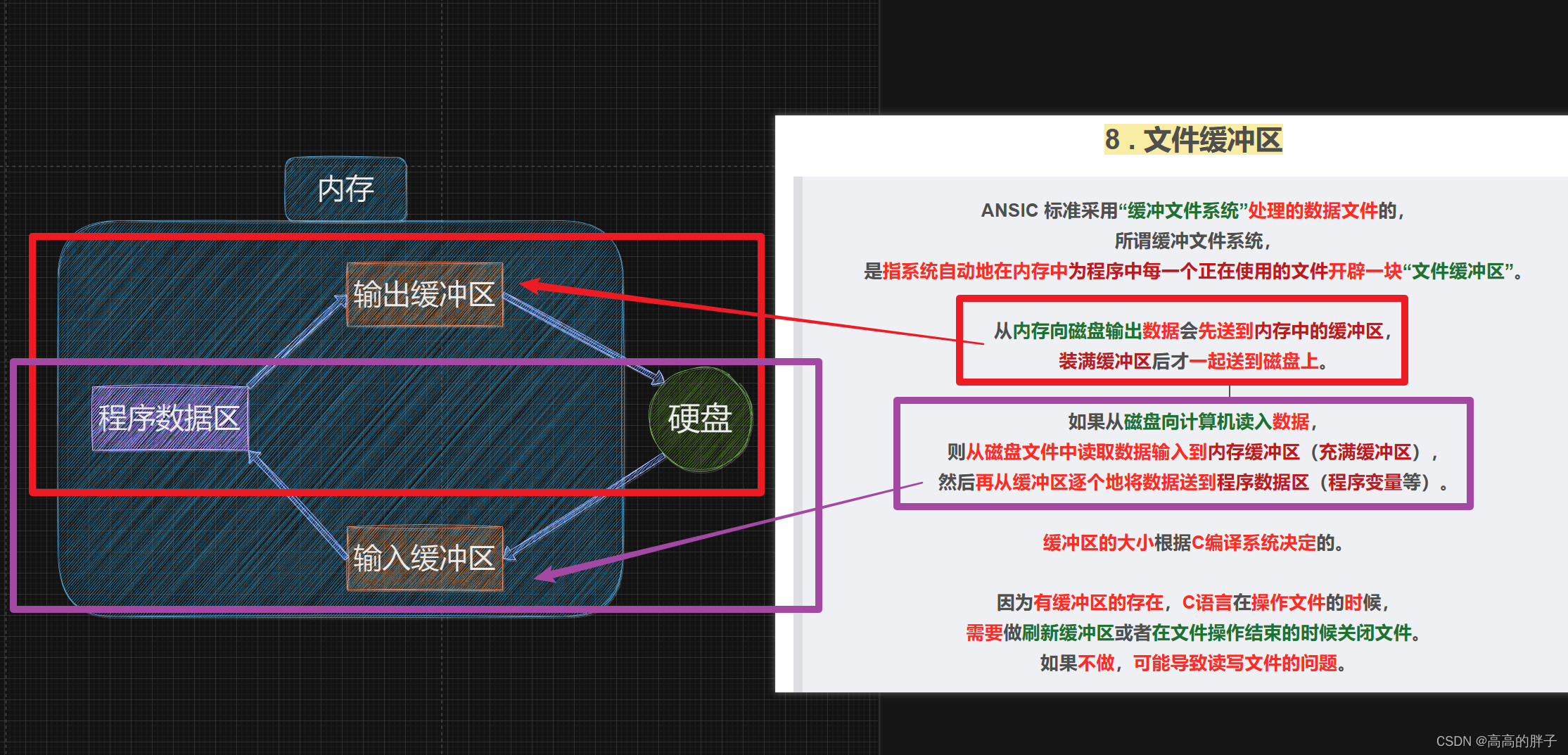
学C的第三十三天【C语言文件操作】
相关代码gitee自取: C语言学习日记: 加油努力 (gitee.com) 接上期: 学C的第三十二天【动态内存管理】_高高的胖子的博客-CSDN博客 1 . 为什么要使用文件 以前面写的通讯录为例,当通讯录运行起来的时候,可以给通讯录中增加、删…...

线性表的基本操作及在顺序存储及链式存储的实现
目录 线性表的基本操作:线性表的在顺序存储上的实现 线性表的基本操作: 一个数据结构的基本操作是指其最核心、最基本的操作。其他较复杂的操作可通过其基本操作来实现。线性表的主要操作如下 - InitList(&L):初始化表。构造一个空的线性表- Length…...

合宙Air724UG LuatOS-Air script lib API--nvm
nvm Table of Contents nvm nvm.init(defaultCfgFile, burnSave) nvm.set(k, v, r, s) nvm.sett(k, kk, v, r, s) nvm.flush() nvm.get(k) nvm.gett(k, kk) nvm.restore() nvm.remove() nvm 模块功能:参数管理 nvm.init(defaultCfgFile, burnSave) 初始化参数存储管…...

springboot单元测试的详细介绍
当开发一个复杂的应用程序时,确保代码的正确性和稳定性至关重要。在这方面,单元测试是一个不可或缺的工具,它可以帮助开发人员验证代码的各个部分是否按预期工作。Spring Boot提供了丰富的测试支持,使编写和执行单元测试变得更加容…...

Apache Doris 入门教程26:资源管理
为了节省Doris集群内的计算、存储资源,Doris需要引入一些其他外部资源来完成相关的工作,如Spark/GPU用于查询,HDFS/S3用于外部存储,Spark/MapReduce用于ETL, 通过ODBC连接外部存储等,因此我们引入资源管理机制来管理Do…...

【金融量化】Python实现根据收益率计算累计收益率并可视化
1 理论 理财产品(本金100元) 第1天:3% :(13%) ✖ 100 103 第2天:2% :(12%)✖ 以上 103 2.06 第3天:5% : (15%)✖ 以上…...

【实战】Hermes Agent 深度体验:会自我进化的 AI 智能体,3大核心机制拆解与上手指南
本文从实际使用角度出发,拆解 Hermes Agent 的自动 Skill 生成、三层记忆架构和多平台网关三大核心机制,并附完整的安装部署指南和踩坑记录。适合想要搭建长期运行的个人 AI Agent 的开发者阅读。 目录前言一、Hermes Agent 是什么1.1 项目背景1.2 核心定…...
)
STK实战:用6颗低轨+6颗高轨卫星实现全球覆盖(含波束优化技巧)
STK实战:高低轨卫星协同设计与全球覆盖优化 当我们需要为偏远地区提供通信服务或实现全球环境监测时,卫星星座的覆盖性能直接决定了系统可用性。传统单一轨道高度的卫星星座往往难以兼顾覆盖连续性和系统成本,而高低轨卫星协同设计则提供了一…...

Harpy与Swift项目集成:从Objective-C到现代开发的平滑过渡终极指南
Harpy与Swift项目集成:从Objective-C到现代开发的平滑过渡终极指南 【免费下载链接】Harpy Notify users when a new version of your app is available and prompt them to upgrade. 项目地址: https://gitcode.com/gh_mirrors/ha/Harpy 在iOS应用开发中&am…...

MVT协议深度解析:从Protobuf编码到GISBox实战,看它如何碾压传统栅格瓦片
MVT协议技术内幕:从二进制编码到百万级数据渲染实战 当我们打开手机地图App,双指放大查看小区楼栋轮廓时,很少有人会思考这流畅体验背后的技术革命。传统栅格瓦片就像打印在纸上的地图,放大后必然出现马赛克;而MVT协议…...

408计算机考研-计算机操作系统笔记-王道
计算机操作系统笔记-王道1.1.11.1.2操作系统的概念与功能操作系统的概念(定义)操作系统的功能和目标--向上提供方便易用的服务总结1.1.3 操作系统的特性并发与共享虚拟异步总结1.2_操作系统的发展和分类手工阶段批处理阶段--单道批处理系统多道批处理系统…...

Qwen3-Reranker完整指南:支持Markdown/HTML文档解析的增强版方案
Qwen3-Reranker完整指南:支持Markdown/HTML文档解析的增强版方案 1. 引言:重新定义文档检索的精准度 在日常工作中,你是否遇到过这样的困扰:用关键词搜索文档时,系统返回的结果看似相关,实际上却偏离了你…...

YOLO-v8.3镜像5分钟快速部署:告别手动配置,一键开启目标检测
YOLO-v8.3镜像5分钟快速部署:告别手动配置,一键开启目标检测 如果你正在寻找一个快速部署YOLOv8目标检测模型的方法,那么这篇文章就是为你准备的。传统的手动部署方式需要花费数小时配置环境、安装依赖和调试问题,而使用YOLO-v8.…...

保姆级指南:Mac上如何一键部署GLM-4.6V-Flash-WEB,实现图片智能问答
保姆级指南:Mac上如何一键部署GLM-4.6V-Flash-WEB,实现图片智能问答 1. 为什么选择GLM-4.6V-Flash-WEB? 在当今AI技术快速发展的时代,能够"看懂"图片并回答问题的多模态模型变得越来越重要。GLM-4.6V-Flash-WEB是智谱…...
)
从沙漏到矿机:聊聊离散元法DEM是怎么‘算’出颗粒世界的(附Rocky/EDEM软件对比与学习资源)
从沙漏到矿机:离散元法DEM如何重构颗粒世界的数字镜像 沙漏里的细沙流淌时,每一粒沙子都在重力和碰撞中演绎着独特的运动轨迹。这种看似简单的物理现象背后,隐藏着一个复杂的多体动力学问题——如何精确描述成千上万颗粒之间的相互作用&#…...

Wan2.2-I2V-A14B镜像免配置:内置模型权重42GB,节省下载与校验时间
Wan2.2-I2V-A14B镜像免配置:内置模型权重42GB,节省下载与校验时间 1. 镜像概述与核心优势 Wan2.2-I2V-A14B是一款专为文生视频任务优化的私有部署镜像,针对RTX 4090D 24GB显存显卡进行了深度优化。这个镜像最大的特点是内置了完整的42GB模型…...