YOLOv5-7.0实例分割+TensorRT部署
一:介绍
将YOLOv5结合分割任务并进行TensorRT部署,是一项既具有挑战性又令人兴奋的任务。分割(Segmentation)任务要求模型不仅能够检测出目标的存在,还要精确地理解目标的边界和轮廓,为每个像素分配相应的类别标签,使得计算机能够对图像进行更深入的理解和解释。而TensorRT作为一种高性能的深度学习推理引擎,能够显著加速模型的推理过程,为实时应用提供了强大的支持。
在本文中,我们将探讨如何将YOLOv5与分割任务相结合,实现同时进行目标检测和像素级别的语义分割。我们将详细介绍模型融合的技术和步骤,并深入讨论如何利用TensorRT对模型进行优化,以实现在嵌入式设备和边缘计算环境中的高效部署。通过阐述实验结果和性能指标,我们将展示这一方法的有效性和潜力,为读者带来关于结合YOLOv5、分割任务和TensorRT部署的全面认识。
二:python
- 打开pycharm,终端输入pip install labelme
- 为了方便我们之后标注的工作,需要打开C盘->用户->用户名->.labelmerc文件
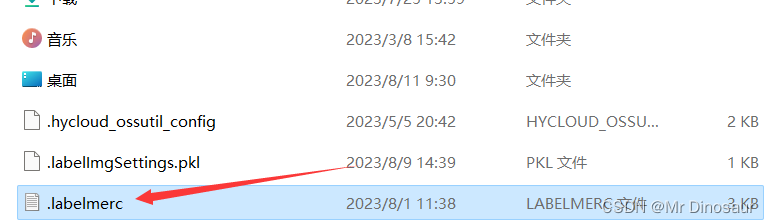 打开之后,将第一行的auto_save改为true,方便标框需要将create_polygon改为W,方便修改标注框将edit_polygon改为J
打开之后,将第一行的auto_save改为true,方便标框需要将create_polygon改为W,方便修改标注框将edit_polygon改为J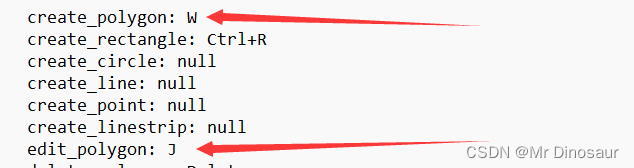
- 下载结束后,pycharm终端输入labelme,打开你数据集的文件夹,进行标注即可,这里不放图片演示了
- 标注完之后我们需要将json文件转换为txt文件,下面放上所需要的代码
import json import os import argparse from tqdm import tqdmdef convert_label_json(json_dir, save_dir, classes):json_paths = os.listdir(json_dir)classes = classes.split(',')for json_path in tqdm(json_paths):# for json_path in json_paths:path = os.path.join(json_dir, json_path)with open(path, 'r') as load_f:json_dict = json.load(load_f)h, w = json_dict['imageHeight'], json_dict['imageWidth']# save txt pathtxt_path = os.path.join(save_dir, json_path.replace('json', 'txt'))txt_file = open(txt_path, 'w')for shape_dict in json_dict['shapes']:label = shape_dict['label']label_index = classes.index(label)points = shape_dict['points']points_nor_list = []for point in points:points_nor_list.append(point[0] / w)points_nor_list.append(point[1] / h)points_nor_list = list(map(lambda x: str(x), points_nor_list))points_nor_str = ' '.join(points_nor_list)label_str = str(label_index) + ' ' + points_nor_str + '\n'txt_file.writelines(label_str)if __name__ == "__main__":"""python json2txt_nomalize.py --json-dir my_datasets/color_rings/jsons --save-dir my_datasets/color_ringsts --classes "cat,dogs""""parser = argparse.ArgumentParser(description='json convert to txt params')parser.add_argument('--json-dir', type=str, default=r'json', help='json path dir')parser.add_argument('--save-dir', type=str, default=r'txt',help='txt save dir')parser.add_argument('--classes', type=str,default="1", help='classes')args = parser.parse_args()json_dir = args.json_dirsave_dir = args.save_dirclasses = args.classesconvert_label_json(json_dir, save_dir, classes) -
转换为txt文件后,划分一下数据集,进行训练(此步骤有手就行,在此不演示了)
-
将你训练得到的best.pt通过gen_wts.py转换为wts文件,为了方便操作,将best.pt放入目录下,终端输入:python gen_wts.py -w best.pt

gen_wts.py的代码如下
import sys import argparse import os import struct import torch from utils.torch_utils import select_devicedef parse_args():parser = argparse.ArgumentParser(description='Convert .pt file to .wts')parser.add_argument('-w', '--weights', required=True,help='Input weights (.pt) file path (required)')parser.add_argument('-o', '--output', help='Output (.wts) file path (optional)')parser.add_argument('-t', '--type', type=str, default='detect', choices=['detect', 'cls'],help='determines the model is detection/classification')args = parser.parse_args()if not os.path.isfile(args.weights):raise SystemExit('Invalid input file')if not args.output:args.output = os.path.splitext(args.weights)[0] + '.wts'elif os.path.isdir(args.output):args.output = os.path.join(args.output,os.path.splitext(os.path.basename(args.weights))[0] + '.wts')return args.weights, args.output, args.typept_file, wts_file, m_type = parse_args() print(f'Generating .wts for {m_type} model')# Initialize device = select_device('cpu') # Load model print(f'Loading {pt_file}') model = torch.load(pt_file, map_location=device) # load to FP32 model = model['ema' if model.get('ema') else 'model'].float()if m_type == "detect":# update anchor_grid infoanchor_grid = model.model[-1].anchors * model.model[-1].stride[..., None, None]# model.model[-1].anchor_grid = anchor_griddelattr(model.model[-1], 'anchor_grid') # model.model[-1] is detect layer# The parameters are saved in the OrderDict through the "register_buffer" method, and then saved to the weight.model.model[-1].register_buffer("anchor_grid", anchor_grid)model.model[-1].register_buffer("strides", model.model[-1].stride)model.to(device).eval()print(f'Writing into {wts_file}') with open(wts_file, 'w') as f:f.write('{}\n'.format(len(model.state_dict().keys())))for k, v in model.state_dict().items():vr = v.reshape(-1).cpu().numpy()f.write('{} {} '.format(k, len(vr)))for vv in vr:f.write(' ')f.write(struct.pack('>f', float(vv)).hex())f.write('\n')
三、TensorRT
- 下载与YOLOv5-7.0对应的tensorrt分割版本wang-xinyu/tensorrtx: Implementation of popular deep learning networks with TensorRT network definition API (github.com)
- 使用cmake解压,嫌麻烦直接自己配置也行
- TensorRT的配置我之前文章里面有写,不清楚的可以去看一下Windows YOLOv5-TensorRT部署_tensorrt在windows部署_Mr Dinosaur的博客-CSDN博客
- 打开config.h,修改一下自己的检测类别和图片大小
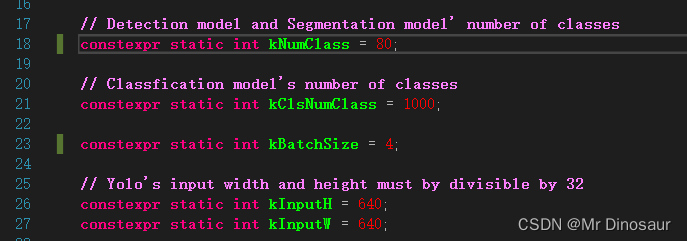
- 打开yolov5_seg.cpp,找到主函数进行文件路径修改

- 如果你显源码运行麻烦(我就是),当然也可以自行修改去生成它的engine引擎文件,引擎文件生成后即可进行分割测试

- 分割结果
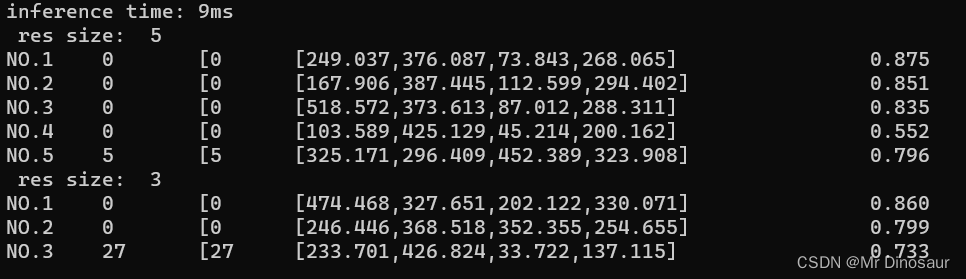 推理速度一般吧,比检测要慢一些
推理速度一般吧,比检测要慢一些


四、总结
- 部署的话基本就这些操作,可以将接口进行封装,方便之后调用,需要的话我之后再更新吧
- 分割的速度要比检测慢了快有10ms左右,对速度有要求的话需要三思
- 分割对大目标比较友好,如果你想检测小目标的话还是使用目标检测吧
半年多没更新了,对粉丝们说声抱歉,之后会不定时进行更新!
相关文章:
YOLOv5-7.0实例分割+TensorRT部署
一:介绍 将YOLOv5结合分割任务并进行TensorRT部署,是一项既具有挑战性又令人兴奋的任务。分割(Segmentation)任务要求模型不仅能够检测出目标的存在,还要精确地理解目标的边界和轮廓,为每个像素分配相应的…...
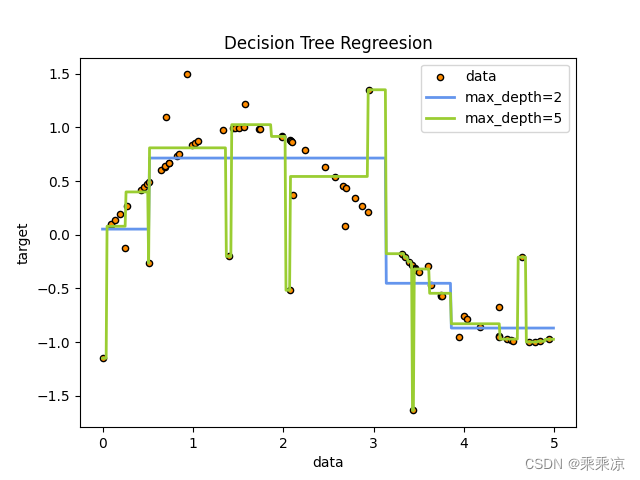
回归决策树模拟sin函数
# -*-coding:utf-8-*- import numpy as np from sklearn import tree import matplotlib.pyplot as pltplt.switch_backend("TkAgg") # 创建了一个随机数生成器对象 rng rngnp.random.RandomState(1) print("rng",rng) #5*rng.rand(80,1)生成一个80行、1列…...

NeRF基础代码解析
embedders 对position和view direction做embedding。 class FreqEmbedder(nn.Module):def __init__(self, in_dim3, multi_res10, use_log_bandsTrue, include_inputTrue):super().__init__()self.in_dim in_dimself.num_freqs multi_resself.max_freq_log2 multi_resself…...
职场新星:Java面试干货让你笑傲求职路(三)
职场新星:Java面试干货让你笑傲求职路 1、token 为什么存放在 redis 中?2、索引的底层原理是什么?3、Spring IOC和AOP的原理4、接口和抽象类有什么共同点和区别?5、为什么要使用线程池?直接new个线程不好吗?…...

获取指定收获地址的信息
目录 1 /// 获取指定收获地址的信息 2 /// 删除指定的收获地址信息 3 /// 取消订单 4 /// 确认订单收货 /// <summary> /// 获取指定收获地址的信息</...
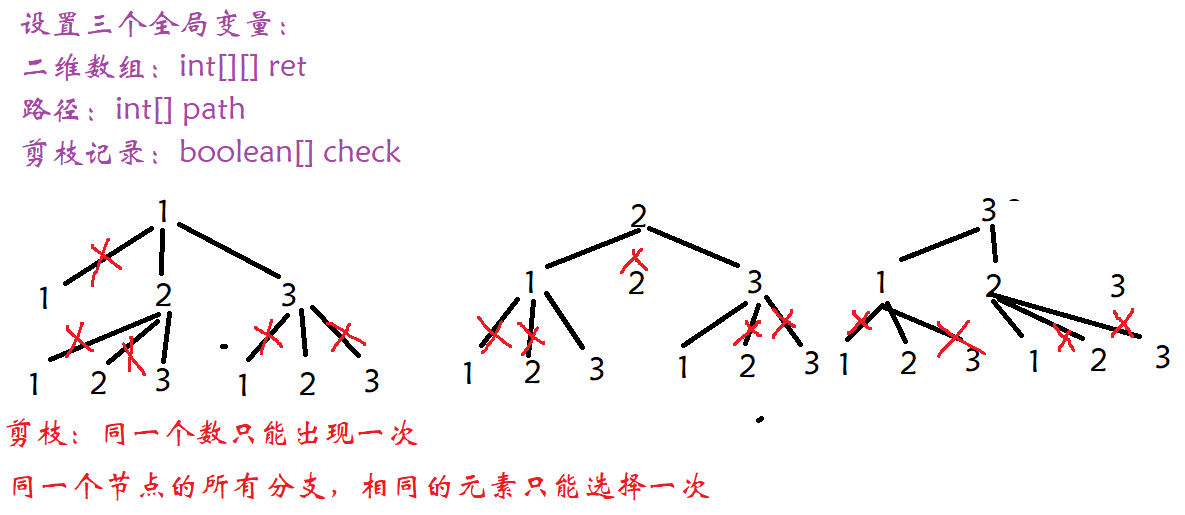
突破笔试:力扣全排列(medium)
1. 题目链接:46. 全排列 2. 题目描述:给定一个不含重复数字的数组 nums ,返回其 所有可能的全排列 。你可以 按任意顺序 返回答案。 示例 1: 输入:nums [1,2,3] 输出:[[1,2,3],[1,3,2],[2,1,3],[2,3,1],[…...
gitlab 503 错误的解决方案
首先使用 sudo gitlab-ctl status 命令查看哪些服务没用启动 sudo gitlab-ctl status 再用 gitlab-rake gitlab:check 命令检查 gitlab。根据发生的错误一步一步纠正。 gitlab-rake gitlab:check 查看日志 tail /var/log/gitlab/gitaly/current删除gitaly.pid rm /var/opt…...

智能离子风棒联网监控静电消除器的主要功能和特点
智能离子风棒联网监控静电消除器是一种集成了智能化和网络化监控功能的设备,用于监测和消除静电现象。它的工作原理是通过产生大量的正负离子,将空气中的静电中和和消除,从而达到防止静电积累和放电的目的。 智能离子风棒联网监控静电消除器的…...
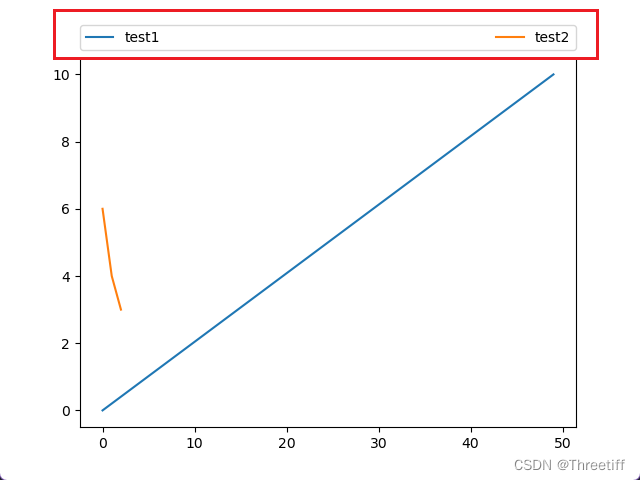
matplotlib 设置legend的位置在轴最上方,长度与图的长度相同
import matplotlib.pyplot as plt import numpy as npx1 np.linspace(0, 10, 50) x2 [6,4,3]ax plt.subplot() ax.plot(x1, label"test1") ax.plot(x2, label"test2") # 设置图例的位置 # 将左下角放置在【0, 1.02】位置处,横为1,…...

Docker-Compose 安装rabbitmq
【编写:docker-compose-rabbitmq.yml】创建数据目录: mkdir -p /opt/rabbitmq/data cd /opt/rabbitmq# 创建 docker-compose-rabbitmq.yml vim docker-compose-rabbitmq.yml 输入: version: "3.1" services:rabbitmq:image: rabbit…...

leetcode357- 2812. 找出最安全路径
这个题比较经典,可以用多个算法来求解,分别给出各个算法的求解方法,主要是分为第一部分的多源BFS求每个位置的距离和第二部分求(0,0)到(n-1,n-1)的最短路径(可以用多种方法求) 目录 多源BFS求最短路径枚举安全系数判断…...
Oracle连接数据库提示 ORA-12638:身份证明检索失败
ORA-12638 是一个 Oracle 数据库的错误代码,它表示身份验证(认证)检索失败。这通常与数据库连接相关,可能由于以下几个原因之一引起: 错误的用户名或密码: 提供的数据库用户名或密码不正确,导致…...

在 Linux 中使用 systemd 注册服务
Systemd 是一种现代的 Linux 系统初始化系统和服务管理器。它旨在管理系统服务的初始化、配置和控制。Systemd 的一个关键特性是它可以管理服务,这些服务是为系统提供特定功能的后台进程。在本指南中,我们将探讨如何使用 systemd 在 Linux 中注册服务。 …...

(03)Unity HTC VRTK 基于 URP 开发记录
1.简介 本篇主要内容为:URP如何与VRTK结合、URP需要注意的地方、VRTK的功能进行阐述。 因项目本身要求要渲染出比较好的画质,所以抛弃了Unity默认渲染管线Built-in,使用URP进行渲染,当然也可以选HDRP,但考虑到后期项目…...
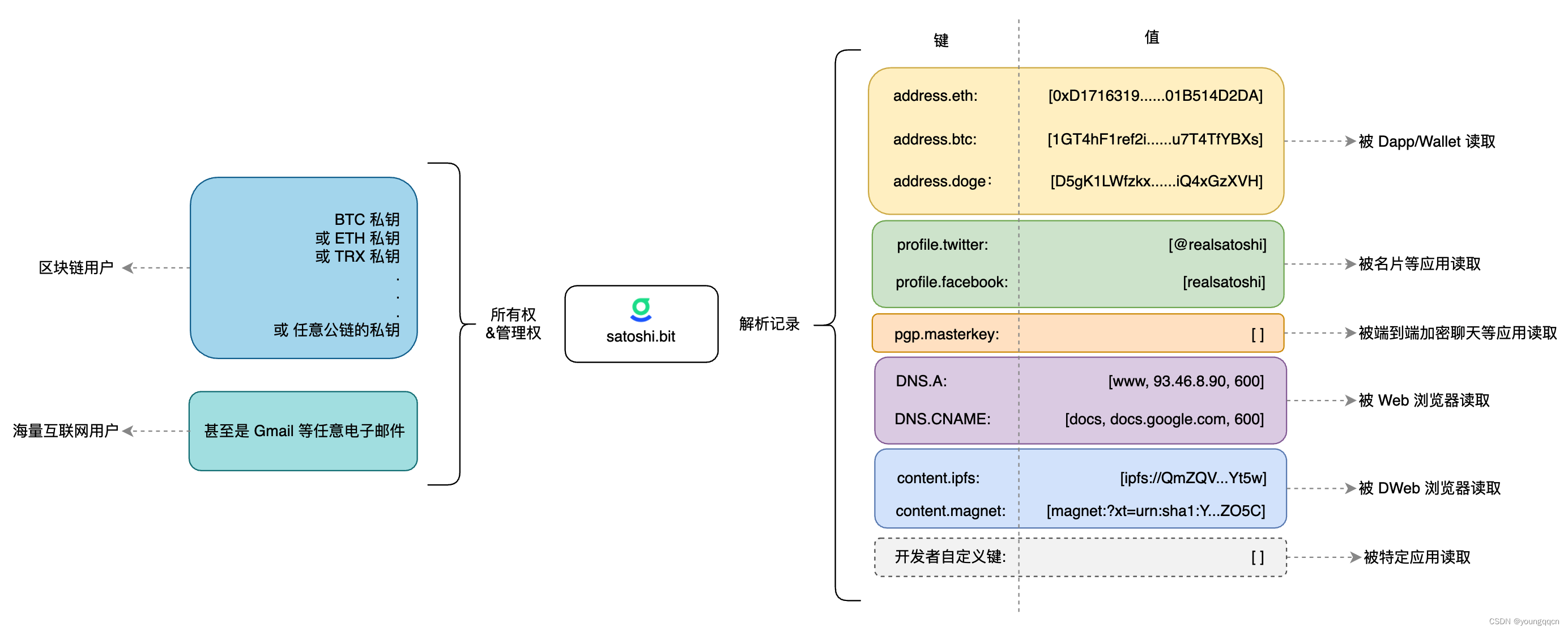
.bit域名调研
.bit域名研究 问题: .bit域名和ENS域名的相同点?不同点?有什么关系? .bit的定义 .bit 是基于区块链的,开源的,跨链去中心化账户系统.bit 提供了以 .bit 为后缀的全局唯一的命名体系,可用于加密…...
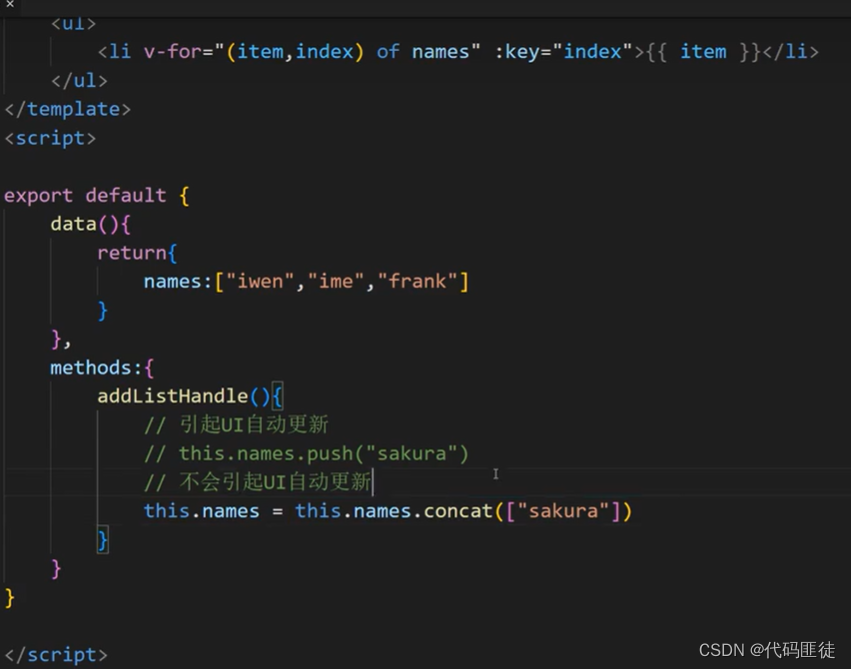
Vue数组变更方法和替换方法
一、可以引起UI界面变化 Vue 将被侦听的数组的变更方法进行了包裹,所以它们也将会触发视图更新。这些被包裹过的方法包括: push()pop()shift()unshift()splice()sort()reverse() 以上七个数组都会改变原数组,下面来分别讲解它们的区别&…...

Centos-6.3安装使用MongoDB
安装说明 系统环境:Centos-6.3 安装软件:mongodb-linux-x86_64-2.2.2.tgz 下载地址:http://www.mongodb.org/downloads 安装机器:192.168.15.237 上传位置:/usr/local/ 软件安装位置:/usr/local/mongodb 数…...

Mysql 复杂查询丨联表查询
💗wei_shuo的个人主页 💫wei_shuo的学习社区 🌐Hello World ! JOIN(联表查询) 联表查询(Join)是一种在数据库中使用多个表进行关联查询的操作。它通过使用 JOIN 关键字将多个表连接在…...
C语言进阶第二课-----------指针的进阶----------升级版
作者前言 🎂 ✨✨✨✨✨✨🍧🍧🍧🍧🍧🍧🍧🎂 🎂 作者介绍: 🎂🎂 🎂 🎉🎉🎉…...

若依vue -【 111 ~ 更 ~ 127 完 】
【更】111 3.5.0版本更新介绍 112 使用docker实现一键部署 1、安装docker yum install https://download.docker.com/linux/fedora/30/x86_64/stable/Packages/containerd.io-1.2.6-3.3.fc30.x86_64.rpm yum install -y yum-utils device-mapper-persistent-data lvm2 yum-c…...

M5Stack热成像模块开发与应用指南
1. M5Stack Thermal Camera 2 Unit 热成像模块深度解析作为一名长期从事嵌入式开发的工程师,我最近测试了M5Stack推出的Thermal Camera 2 Unit热成像模块。这款产品将ESP32芯片与MLX90640红外传感器相结合,为开发者提供了一个高性价比的热成像解决方案。…...
)
【稀缺实测数据集+可运行代码】:R语言实现LLM输出偏见量化评估(含chi2_residual_bias、KL-divergence_error等6种统计检验报错修复方案)
更多请点击: https://intelliparadigm.com 第一章:R语言在大语言模型偏见检测中的统计方法报错解决方法 在使用R语言对LLM输出进行偏见量化分析(如性别/种族倾向性卡方检验、嵌入空间KL散度计算)时,常见报错多源于数据…...

Phi-3.5-mini-instruct快速体验:免费开源的3.8B指令微调模型,中文问答实测
Phi-3.5-mini-instruct快速体验:免费开源的3.8B指令微调模型,中文问答实测 1. 模型简介 Phi-3.5-mini-instruct是微软推出的开源指令微调模型,参数规模为3.8B,支持128K超长上下文窗口。作为Phi-3系列中的轻量级成员,…...

技术返祖运动:软件测试中的传统智慧回归
在数字技术飞速发展的时代,软件测试从业者面临前所未有的挑战:系统复杂性剧增、数据过载和认知疲劳。技术返祖运动应运而生,它并非简单的历史倒退,而是战略性地回归传统方法,以应对现代测试生态的脆弱性。这场运动的核…...

免费开源AI搜索技能部署指南:基于FastAPI与DuckDuckGo构建自主可控的联网搜索方案
1. 项目概述:一个免费、开源的网络搜索技能实现最近在折腾一些自动化工具和智能助手,发现一个挺普遍的需求:让AI助手能直接联网搜索,获取最新的信息。市面上很多方案要么收费,要么依赖特定的闭源API,要么就…...

Hunyuan Custom模型参数调优与风格迁移实战
1. 探索Hunyuan Custom模型的潜力:单主题深度测试报告作为一名长期关注生成式AI技术的实践者,我最近对腾讯推出的Hunyuan Custom模型进行了系统性测试。这个模型虽然发布已久,却鲜少见到深度评测内容。与Wan VACE等热门模型相比,它…...

答辩前三天才做 PPT?Paperxie AI PPT,把毕业论文答辩的焦虑全碾碎
paperxie-免费查重复率aigc检测/开题报告/毕业论文/智能排版/文献综述/AI PPThttps://www.paperxie.cn/ppt/createhttps://www.paperxie.cn/ppt/create 凌晨三点的宿舍,电脑屏幕亮着刺眼的白光,你对着空白的 PPT 模板反复刷新。距离毕业论文答辩只剩三天…...
 实战:在YOLOv5中集成可变形卷积提升小目标检测精度)
Deformable ConvNets (DCN) 实战:在YOLOv5中集成可变形卷积提升小目标检测精度
可变形卷积在YOLOv5中的实战应用:突破小目标检测瓶颈 无人机航拍图像中的车辆和行人检测一直是计算机视觉领域的难点——目标尺寸小、分布密集、形态多变,传统卷积神经网络在这些场景下往往表现不佳。去年我们在处理某智慧城市项目时,发现标准…...

手把手教你用FPGA实现EnDat 2.2协议:从线路延时补偿到CRC校验的完整设计
FPGA实战:EnDat 2.2协议栈的硬件实现与工业级优化 当海德汉编码器的金属外壳与半导体运动台的精密导轨相遇时,工程师们往往会在协议栈开发环节陷入泥潭。EnDat 2.2协议手册里那些晦涩的时序图和电缆长度-频率曲线,就像一道无形的屏障挡在理想…...

IDM无限试用完整指南:彻底解决30天限制的终极方案
IDM无限试用完整指南:彻底解决30天限制的终极方案 【免费下载链接】idm-trial-reset Use IDM forever without cracking 项目地址: https://gitcode.com/gh_mirrors/id/idm-trial-reset 你是否正在为IDM(Internet Download Manager)的…...