01-Hadoop集群部署(普通用户)
Hadoop集群部署(普通用户)
环境准备
1)准备3台客户机(关闭防火墙、静态IP、主机名称)
如果这一步已经配置过了,可以忽略
# 1 关闭防火墙
systemctl stop firewalld.service # 关闭当前防火墙
systemctl disable firewalld.service # 关闭防火墙开机自启动# 2.配置静态ip
vim /etc/sysconfig/network-scripts/ifcfg-ens33
# 做出如下修改
BOOTPROTO=static # 改为静态
# 末尾添加如下内容
IPADDR=192.168.188.128
GATEWAY=192.168.188.2
NETMASK=255.255.255.0
DNS1=192.168.188.2# 重启网卡
systemctl restart network.service# 3.修改主机名
vim /etc/hostname
# 配置hosts映射
vim /etc/hosts
192.168.188.128 kk01
192.168.188.129 kk02
192.168.188.130 kk03# 修改window的主机映射文件(hosts)
# 进入C:\Windows\System32\drivers\etc
# 添加如下内容
192.168.188.128 kk01
192.168.188.129 kk02
192.168.188.130 kk03
2)安装JDK,并配置JDK环境变量
扩展部分(可选)
# 如果安装的linux是最小版的,则需要安装net-tool工具包、vim编辑器等
yum install -y net-tools # 工具包中包含ifconfig等命令
yum install -y vim# 安装epel-release(Extra Packages for Enterprise Linux)与rpm相似,但是可以下载到官方repository中是找不到的rpm包
yum install -y epel-release
3)创建普通用户,并让其具有root权限
配置nhk用户具有root权限,方便后期加sudo执行root权限的命令(如果使用root用户可以忽略该步骤)
# 创建用户 (如果安装Linux时已经创建了,这一步骤可以忽略)
useradd nhk
passwd 123456# 配置普通用户(nhk)具有root权限,方便后期加sudo执行root权限的命令
vim /etc/sudoers# 在%wheel这行下面添加一行 (大概是在100行左右位置)## Allow root to run any commands anywhere
root ALL=(ALL) ALL ## Allows members of the 'sys' group to run networking, software,
## service management apps and more.
# %sys ALL = NETWORKING, SOFTWARE, SERVICES, STORAGE, DELEGATING, PROCESSES, LOCATE, DRIVERS## Allows people in group wheel to run all commands
%wheel ALL=(ALL) ALL ## Same thing without a password
# %wheel ALL=(ALL) NOPASSWD: ALL
nhk ALL=(ALL) NOPASSWD: ALL
注意:
nhk ALL=(ALL) NOPASSWD: ALL 这一行不要直接放到root行下面,因为所有用户都属于wheel组,你先配置了nhk具有免密功能,但是程序执行到%wheel行时,该功能又被覆盖回需要密码。所以nhk要放到%wheel这行下面。
4)创建统一工作目录
(后续在集群的多台机器之间都需要创建)
# 个人习惯
mkdir -p /opt/software/ # 软件安装目录、安装包存放目录
mkdir -p /opt/data/ # 数据存储路径# 修改文件夹所有者和所属组 (如果是使用root用户搭建集群可以忽略)
chown nhk:nhk /opt/software
chown nhk:nhk /opt/data# 黑马推荐
mkdir -p /export/server/ # 软件安装目录
mkdir -p /export/data/ # 数据存储路径
mkdir -p /export/software/ # 安装包存放目录# 尚硅谷推荐
mkdir /opt/module
mkdir /opt/software
5)集群时间同步
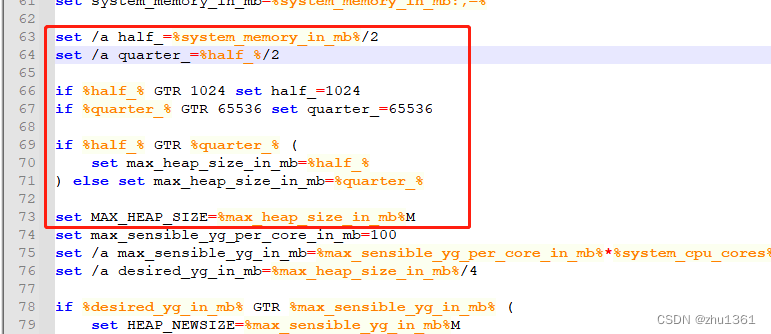
# 在集群的每台集群
yum -y install ntpdate $ sudo ntpdate ntp4.aliyun.com
16 Jun 20:04:19 ntpdate[3549]: adjust time server 203.107.6.88 offset 0.213857 sec
# 或
$ sudo ntpdate ntp5.aliyum.com# 查看时间
date
集群部署
1)集群部署规划
注意:NameNode 和 SecondaryNameNode 不要安装在同一台服务器
注意:ResourceManager 也很消耗内存,不要和 NameNode、SecondaryNameNode 配置在同一台机器上。
| kk01 | kk02 | kk03 | |
|---|---|---|---|
| HDFS | NameNode DataNode | DataNode | SecondaryNameNode DataNode |
| YARN | NodeManager | ResourceManager NodeManager | NodeManager |
2)上传Hadoop压缩包
上传压缩包至 /opt/software目录下
[nhk@kk01 software]$ ll
total 849736
-rw-rw-r--. 1 nhk nhk 338075860 Jun 16 20:10 hadoop-3.1.3.tar.gz
drwxr-xr-x. 8 nhk nhk 255 Sep 14 2017 jdk1.8.0_152
-rw-rw-r--. 1 nhk nhk 531056640 Jun 16 19:27 mysql-5.7.27-1.el7.x86_64.rpm-bundle.tar
-rw-r--r--. 1 nhk nhk 985600 Apr 28 2022 mysql-connector-java-5.1.37.jar
drwxrwxr-x. 2 nhk nhk 4096 Jun 16 19:30 mysql_lib
3)解压压缩包
[nhk@kk01 software]$ tar -zxvf hadoop-3.1.3.tar.gz -C /opt/software/
4)配置环境变量
进入 /etc/profile.d/my_env.sh 文件
[nhk@kk01 software]$ sudo vim /etc/profile.d/my_env.sh
在profile文件末尾添加JDK路径:(shitf+g)
#HADOOP_HOME
export HADOOP_HOME=/opt/software/hadoop-3.1.3
export PATH=$PATH:$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
刷新环境变量
[nhk@kk01 software]$ source /etc/profile.d/my_env.sh
配置集群
1)core配置文件
配置core-site.xml
[nhk@kk01 hadoop]$ pwd
/opt/software/hadoop-3.1.3/etc/hadoop
[nhk@kk01 hadoop]$ vim core-site.xml
参考的配置文件如下
<configuration><!-- 指定NameNode的地址 --><property><name>fs.defaultFS</name><value>hdfs://kk01:8020</value></property><!-- 指定hadoop数据的存储目录(默认存储在/tmp,这会导致数据丢失) --><property><name>hadoop.tmp.dir</name><value>/opt/software/hadoop-3.1.3/data</value></property><!-- 配置HDFS网页登录使用的静态用户为nhk(用哪个用户启动Hadoop就配置哪个用户) --><property><name>hadoop.http.staticuser.user</name><value>nhk</value></property><!-- 下面三个参数在Hadoop与 hive 整合时会用到 --><!-- 配置该nhk(superUser)允许通过代理访问的主机节点 --><property><name>hadoop.proxyuser.nhk.hosts</name><value>*</value></property><!-- 配置该nhk(superUser)允许通过代理用户所属组 --><property><name>hadoop.proxyuser.nhk.groups</name><value>*</value></property><!-- 配置该nhk(superUser)允许通过代理的用户--><property><name>hadoop.proxyuser.nhk.users</name><value>*</value></property><!-- 缓冲区大小,实际工作中根据服务器性能动态调整 --><property><name>io.file.buffer.size</name><value>4096</value></property></configuration>
注意
<property><name>fs.defaultFS</name><value>hdfs://kk01:8020</value>
</property>在 Hadoop 1.x 版本 为 8020
在 Hadoop 2.x 版本 为 9000
在 Hadoop 3.0.x 版本 为 9020
在 Hadoop 3.1.x 版本 为 8020
2)HDFS配置文件
配置hdfs-site.xml
[nhk@kk01 hadoop]$ pwd
/opt/software/hadoop-3.1.3/etc/hadoop
[nhk@kk01 hadoop]$ vim hdfs-site.xml
参考的配置文件如下
<configuration><!-- nn web端访问地址--><property><name>dfs.namenode.http-address</name><value>kk01:9870</value></property><!-- 2nn web端访问地址--><property><name>dfs.namenode.secondary.http-address</name><value>kk03:9868</value></property><!-- 测试环境指定HDFS副本的数量1,生成环境一定要配置成3 --><property><name>dfs.replication</name><value>3</value></property><!-- 关闭 hdfs 文件权限检查,方便学习使用 --><property><name>dfs.permissions</name><value>false</value></property>
</configuration>
注意
<!-- nn web端访问地址-->
<property><name>dfs.namenode.http-address</name><value>kk01:9870</value>
</property>在 Hadoop 1.x 版本 为 50070
在 Hadoop 2.x 版本 为 50070
在 Hadoop 3.x 版本 为 9780<!-- 2nn web端访问地址-->
<property><name>dfs.namenode.secondary.http-address</name><value>kk03:9868</value>
</property>在 Hadoop 2.x 版本 为 50090
3)YARN配置文件
配置yarn-site.xml
[nhk@kk01 hadoop]$ pwd
/opt/software/hadoop-3.1.3/etc/hadoop
[nhk@kk01 hadoop]$ vim yarn-site.xml
参考的配置文件如下
<configuration><!-- 指定MR走shuffle --><property><name>yarn.nodemanager.aux-services</name><value>mapreduce_shuffle</value></property><!-- 指定ResourceManager的地址--><property><name>yarn.resourcemanager.hostname</name><value>kk02</value></property><!-- 环境变量的继承 (在2.x版本不需要显式配置)--><property><name>yarn.nodemanager.env-whitelist</name>
<value>JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CONF_DIR,CLASSPATH_PREPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_MAPRED_HOME</value></property><!-- 以下三个参数,在生产环境中需要每台单独配置,以契合机器的内存大小--><!--yarn单个容器允许分配的最大最小内存(默认8g)--><property><name>yarn.scheduler.minimum-allocation-mb</name><value>512</value></property><property><name>yarn.scheduler.maximum-allocation-mb</name><value>4096</value></property><!-- yarn容器允许管理的物理内存大小(默认8g) --><property><name>yarn.nodemanager.resource.memory-mb</name><value>4096</value></property><!-- 关闭yarn对虚拟内存的限制检查 --><!-- 以下两个参数默认都为 true --><property><name>yarn.nodemanager.pmem-check-enabled</name><value>true</value></property><property><name>yarn.nodemanager.vmem-check-enabled</name><value>false</value></property>
</configuration>
4)MapReduce配置文件
配置mapred-site.xml
[nhk@kk01 hadoop]$ pwd
/opt/software/hadoop-3.1.3/etc/hadoop
[nhk@kk01 hadoop]$ vim mapred-site.xml
参考的配置文件如下
<configuration><!-- 指定MapReduce程序运行在Yarn上 --><property><name>mapreduce.framework.name</name><value>yarn</value></property>
</configuration>
5)workers
该文件用于指定 NodeManage、DataNode启动的节点
[nhk@kk01 hadoop]$ pwd
[nhk@kk01 hadoop]$ vim workers
[nhk@kk01 hadoop]$ cat workers
kk01
kk02
kk03
注意:
该文件中添加的内容结尾不允许有空格,文件中不允许有空行。
配置历史服务器
为了查看程序的历史运行情况,需要配置一下历史服务器。具体配置步骤如下:
1)配置 mapred-site.xml
[nhk@kk01 hadoop]$ pwd
/opt/software/hadoop-3.1.3/etc/hadoop
[nhk@kk01 hadoop]$ vim mapred-site.xml
在文件中增加如下配置
<!-- MR程序历史服务地址-->
<property><name>mapreduce.jobhistory.address</name><value>kk01:10020</value>
</property>
<!-- MR程序历史服务器web端地址-->
<property><name>mapreduce.jobhistory.webapp.address</name><value>kk01:19888</value>
</property>
配置日志的聚集
日志聚集概念:应用运行完成以后,将程序运行日志信息上传到HDFS系统上。
日志聚集功能好处:可以方便的查看到程序运行详情,方便开发调试。
注意:
开启日志聚集功能,需要重新启动NodeManager 、ResourceManager和HistoryManager。
开启日志聚集功能具体步骤如下:
1)配置 yarn-site.xml
[nhk@kk01 hadoop]$ pwd
/opt/software/hadoop-3.1.3/etc/hadoop
[nhk@kk01 hadoop]$ vim yarn-site.xml
在文件中增加如下配置
<!-- 开启日志聚集功能 -->
<property><name>yarn.log-aggregation-enable</name><value>true</value>
</property><!-- 设置日志聚集服务器地址 -->
<!-- 设置yarn历史服务器地址-->
<property> <name>yarn.log.server.url</name> <value>http://kk01:19888/jobhistory/logs</value>
</property><!-- 设置日志保留时间为7天 -->
<!-- 历史日志保存的时间 7天-->
<property><name>yarn.log-aggregation.retain-seconds</name><value>604800</value>
</property>
分发Hadoop及其环境变量
1)分发Hadoop
# 使用自定义分发脚本
[nhk@kk01 hadoop-3.1.3]$ xsync /opt/software/hadoop-3.1.3/# 如果没有脚本,也可以使用 scp 或 rsync 命令
scp -r /opt/software/hadoop-3.1.3/ nhk@kk02:/opt/software/
scp -r /opt/software/hadoop-3.1.3/ nhk@kk03:/opt/software/
2)分发环境变量
# 使用自定义分发脚本(分发环境变量xsync必须使用绝对路径)
[nhk@kk01 hadoop-3.1.3]$ sudo /home/nhk/bin/xsync /etc/profile.d/my_env.sh# 如果没有脚本,也可以使用 scp 或 rsync 命令
scp -r /etc/profile.d/my_env.sh nhk@kk02:/etc/profile.d/my_env.sh
scp -r /etc/profile.d/my_env.sh nhk@kk03:/etc/profile.d/my_env.sh
3)刷新环境变量
[nhk@kk01 hadoop-3.1.3]$ source /etc/profile.d/my_env.sh
[nhk@kk02 hadoop-3.1.3]$ source /etc/profile.d/my_env.sh
[nhk@kk03 hadoop-3.1.3]$ source /etc/profile.d/my_env.sh
群起集群
1)格式化
如果集群是第一次启动,需要在kk01节点格式化NameNode(注意格式化之前,一定要先停止上次启动的所有namenode 和 datanode进程,然后再删除 data 和 log 数据,后续如果集群出错,也是这样重新进行格式化)
[nhk@kk01 hadoop-3.1.3]$ bin/hdfs namenode -format# 若出现 successfully formatted 字样则说明格式化成功
2)启动HDFS
[nhk@kk01 hadoop-3.1.3]$ sbin/start-dfs.sh # 第一次启动,有这些警告是正常的
Starting namenodes on [kk01]
Starting datanodes
kk02: WARNING: /opt/software/hadoop-3.1.3/logs does not exist. Creating.
kk03: WARNING: /opt/software/hadoop-3.1.3/logs does not exist. Creating.
Starting secondary namenodes [kk03]
3)启动 yarn
需要在配置了ResourceManager的节点(kk02)启动YARN
[nhk@kk02 hadoop-3.1.3]$ sbin/start-yarn.sh
Starting resourcemanager
Starting nodemanagers在kk01上查看集群进程
[nhk@kk01 hadoop-3.1.3]$ xcall jps
------------ kk01 ------------
5125 Jps
4648 DataNode
4987 NodeManager
4477 NameNode
------------ kk02 ------------
3578 DataNode
4330 Jps
3820 ResourceManager
3950 NodeManager
------------ kk03 ------------
3890 NodeManager
4025 Jps
3724 SecondaryNameNode
3630 DataNode
4)web端查看HDFS
Web端查看HDFS的Web页面:http://kk01:9870/
5)web端查看 SecondaryNameNode
Web端查看SecondaryNameNode的Web页面:http://kk03:9868/status.html
我们发现查看了,但是啥也不显示,查看浏览器开发者页面发现如下报错
Uncaught ReferenceError: moment is not definedat Object.date_tostring (dfs-dust.js:61:7)
....
下面来解决这个bug
(1)进入SNN节点所在的机器
[nhk@kk03 static]$ pwd
/opt/software/hadoop-3.1.3/share/hadoop/hdfs/webapps/static
[nhk@kk03 static]$ vim dfs-dust.js
将如下函数
'date_tostring' : function (v) {return moment(Number(v)).format('ddd MMM DD HH:mm:ss ZZ YYYY');
},
修改为
'date_tostring' : function (v) {return Number(v).toLocaleString();
},
接着,我们删除浏览器缓存,再次查看SecondaryNameNode的Web页面即可正常查看
Hadoop群起脚本
如果我们每次要启动Hadoop都要现在kk01节点上启动hdfs、在kk02上启动yarn,这样岂不是很麻烦,所有我们编写了Hadoop群起停的脚本,如下
[nhk@kk01 bin]$ pwd
/home/nhk/bin
[nhk@kk01 bin]$ vim hdp.sh
脚本内容如下
#!/bin/bash
if [ $# -lt 1 ]
thenecho "No Args Input..."exit ;
fi
case $1 in
"start")echo " =================== 启动 hadoop集群 ==================="echo " --------------- 启动 hdfs ---------------"ssh kk01 "/opt/software/hadoop-3.1.3/sbin/start-dfs.sh"echo " --------------- 启动 yarn ---------------"ssh kk02 "/opt/software/hadoop-3.1.3/sbin/start-yarn.sh"echo " --------------- 启动 historyserver ---------------"ssh kk01 "/opt/software/hadoop-3.1.3/bin/mapred --daemon start historyserver"
;;
"stop")echo " =================== 关闭 hadoop集群 ==================="echo " --------------- 关闭 historyserver ---------------"ssh kk01 "/opt/software/hadoop-3.1.3/bin/mapred --daemon stop historyserver"echo " --------------- 关闭 yarn ---------------"ssh kk02 "/opt/software/hadoop-3.1.3/sbin/stop-yarn.sh"echo " --------------- 关闭 hdfs ---------------"ssh kk01 "/opt/software/hadoop-3.1.3/sbin/stop-dfs.sh"
;;
*)echo "Input Args Error..."
;;
esac
给脚本赋予执行权限
[nhk@kk01 bin]$ chmod 777 hdp.sh
集群时间同步
时间同步的方式:找一个机器,作为时间服务器,所有的机器与这台集群时间进行定时的同步,比如,每隔十分钟,同步一次时间。
1)时间服务器配置(必须root用户)
(0)查看所有节点ntpd服务状态和开机自启动状态
[nhk@kk01 ~]$ sudo systemctl status ntpd
[nhk@kk01 ~]$ sudo systemctl is-enabled ntpd[nhk@kk02 ~]$ sudo systemctl status ntpd
[nhk@kk02 ~]$ sudo systemctl is-enabled ntpd[nhk@kk03 ~]$ sudo systemctl status ntpd
[nhk@kk03 ~]$ sudo systemctl is-enabled ntpd
(1)在所有节点关闭ntp服务和自启动
[nhk@kk01 ~]$ sudo systemctl stop ntpd
[nhk@kk01 ~]$ sudo systemctl disable ntpd[nhk@kk02 ~]$ sudo systemctl stop ntpd
[nhk@kk02 ~]$ sudo systemctl disable ntpd[nhk@kk03 ~]$ sudo systemctl stop ntpd
[nhk@kk03 ~]$ sudo systemctl disable ntpd
(2)修改hadoop102的ntp.conf配置文件
[nhk@kk01 ~]$ sudo vim /etc/ntp.conf
修改内容如下
修改1(授权192.168.188.0-192.168.188.255网段上的所有机器可以从这台机器上查询和同步时间)
#restrict 192.168.188.0 mask 255.255.255.0 nomodify notrap
为
restrict 192.168.188.0 mask 255.255.255.0 nomodify notrap
修改2(集群在局域网中,不使用其他互联网上的时间)
server 0.centos.pool.ntp.org iburst
server 1.centos.pool.ntp.org iburst
server 2.centos.pool.ntp.org iburst
server 3.centos.pool.ntp.org iburst
为
#server 0.centos.pool.ntp.org iburst
#server 1.centos.pool.ntp.org iburst
#server 2.centos.pool.ntp.org iburst
#server 3.centos.pool.ntp.org iburst
c)添加3(当该节点丢失网络连接,依然可以采用本地时间作为时间服务器为集群中的其他节点提供时间同步)
server 127.127.1.0
fudge 127.127.1.0 stratum 10
(3)修改kk01的/etc/sysconfig/ntpd 文件
[nhk@kk01 ~]$ sudo vim /etc/sysconfig/ntpd
增加内容如下(让硬件时间与系统时间一起同步)
SYNC_HWCLOCK=yes
(4)重新启动ntpd服务
[nhk@kk01 ~]$ sudo systemctl start ntpd
(5)设置ntpd服务开机启动
[nhk@kk01 ~]$ sudo systemctl enable ntpd
2)其他机器配置(必须root用户)
(1)在其他机器配置10分钟与时间服务器同步一次
[nhk@kk02 ~]$ sudo crontab -e[nhk@kk03 ~]$ sudo crontab -e
编写定时任务如下:
*/10 * * * * /usr/sbin/ntpdate kk01
(2)修改任意机器时间
[nhk@kk02 ~]$ sudo date -s "2017-9-11 11:11:11"
(3)十分钟后查看机器是否与时间服务器同步
[nhk@kk02 ~]$ sudo date
说明:测试的时候可以将10分钟调整为1分钟,节省时间。
相关文章:
)
01-Hadoop集群部署(普通用户)
Hadoop集群部署(普通用户) 环境准备 1)准备3台客户机(关闭防火墙、静态IP、主机名称) 如果这一步已经配置过了,可以忽略 # 1 关闭防火墙 systemctl stop firewalld.service # 关闭当前防火墙 systemctl…...

DC电源模块关于的电路布局设计
BOSHIDA DC电源模块关于的电路布局设计 DC电源模块是现代电子设备中常用的电源模块之一,其功能是将市电或其他输入电源转换成定电压、定电流的直流电源输出,以满足电子设备的供电需求。电路布局的设计是DC电源模块的重要组成部分,它直接影响…...
)
MATLAB实现免疫优化算法(附上多个完整仿真源码)
免疫优化算法是一种基于免疫学原理的优化算法。该算法的基本思想是通过模拟人类免疫系统的功能,来寻找最优解。 MATLAB是一种专门用于数学计算和数据处理的软件工具,它具有强大的数学计算和数据分析能力,可以方便地实现各种优化算法。 本文…...
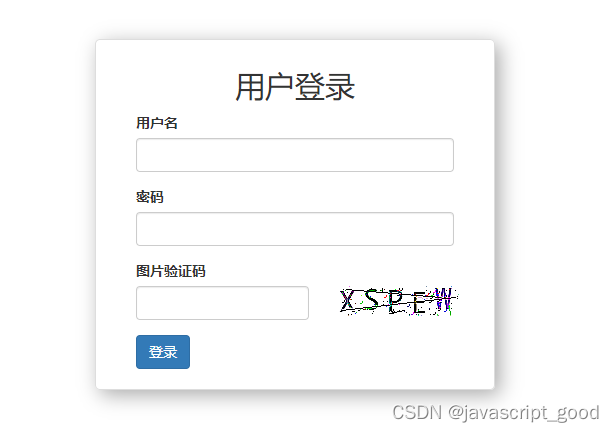
登录界面中图片验证码的生成和校验
一、用pillpw生成图片验证码 1、安装pillow pip install pip install pillow2、下载字体 比如:Monaco.ttf 3、实现生成验证码的方法 该方法返回一个img ,可以把这个img图片保存到内存中,也可以以文件形式保存到磁盘,还返回了验证码的文字…...

go的make使用
在 Go 语言中,make 是一个用于创建切片、映射(map)和通道(channel)的内建函数。它提供了一种初始化和分配内存的方式,用于创建具有特定长度和容量的数据结构。下面将详细介绍 make 函数的使用方法和各种情况…...
竞赛项目 深度学习实现语义分割算法系统 - 机器视觉
文章目录 1 前言2 概念介绍2.1 什么是图像语义分割 3 条件随机场的深度学习模型3\. 1 多尺度特征融合 4 语义分割开发过程4.1 建立4.2 下载CamVid数据集4.3 加载CamVid图像4.4 加载CamVid像素标签图像 5 PyTorch 实现语义分割5.1 数据集准备5.2 训练基准模型5.3 损失函数5.4 归…...
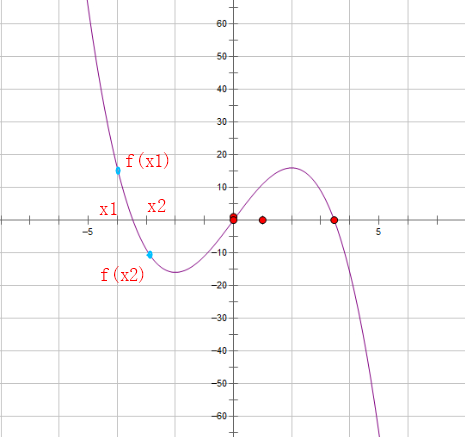
一元三次方程求解
一元三次方程求解 题目描述提示输入输出格式输入格式输出格式 输入输出样例输入样例输出样例 算法分析A C 代码 题目描述 有形如: a x 3 b x 2 c x d 0 ax^3bx^2c^xd0 ax3bx2cxd0一元三次方程。给出该方程中各项的系数 ( a a a, b b b,…...

基于java在线音乐网站设计与实现
在线音乐网站的设计与实现 摘 要 随着互联网趋势的到来,各行各业都在考虑利用互联网将自己推广出去,最好方式就是建立自己的互联网系统,并对其进行维护和管理。在现实运用中,应用软件的工作规则和开发步骤,采用SSM框架…...

Python爬虫如何更换ip防封
作为一名长期扎根在爬虫行业动态ip解决方案的技术员,我发现很多人常常在使用Python爬虫时遇到一个困扰,那就是如何更换IP地址。别担心,今天我就来教你如何在Python爬虫中更换IP,让你的爬虫不再受到IP封锁的困扰。废话不多说&#…...

涛思数据联合长虹佳华、阿里云 Marketplace 正式发布 TDengine Cloud
近日,涛思数据联合长虹佳华,正式在阿里云 Marketplace 发布全托管的时序数据云平台 TDengine Cloud,为用户提供更加丰富的订购渠道。目前用户可通过阿里云 Marketplace 轻松实现 TDengine Cloud 的订阅与部署,以最低的成本搭建最高…...
特殊符号的制作 台风 示例 使用第三方工具 Photoshop 地理信息系统空间分析实验教程 第三版
特殊符号的制作 首先这是一个含有字符的,使用arcgis自带的符号编辑器制作比较困难。所以我们准备采用Adobe Photoshop 来进行制作符号,然后直接导入符号的图片文件作为符号 我们打开ps,根据上面的图片的像素长宽比,设定合适的高度…...
IoTDB1.X windows运行失败问题的处理
在windows运行 IoTDB1.x时 会出现如图所示的问题 为什么会出现这样的问题?java没有安装还是未调用成功,我是JAVA8~11~17各种更换都未能解决问题,最后对其bat文件进行查看,发现在conf\datanode-env.bat、conf\confignode-env.bat这…...

pdf转图片【java版实现】
一、引入依赖 引入需要导入到项目中的依赖,如下所示: <!-- pdf转图片 --><dependency><groupId>net.sf.cssbox</groupId><artifactId>pdf2dom</artifactId><version>1.7</version></dependency>…...

python3.6 安装pillow失败
问题描述 python3 安装 pillow 失败 错误原因 python3.6 不支持 pillow9.0 以上的版本 解决方法: 指定版本安装 e.g., pillow8.0 pip3 install pillow8.0...

巨人互动|Meta海外户Meta的业务工具转化API
Meta的业务工具转化API是一项创新技术,它可以帮助企业实现更高效的业务工具转化和集成。通过这个API,企业可以将不同的业务工具整合到一个统一的平台上,提高工作效率和协作能力。本文小编将介绍Meta的业务工具转化API的功能和优势。 巨人互动…...

【JAVA】包、权限修饰符、final关键字、常量、枚举、抽象类、接口
1 包 包是用来分门别类的管理各种不同类的,类似于文件夹、建包利于程序的管理和维护。建包语句必须在第一行建包的语法格式:package 公司域名倒写.项目名称。包名建议全部小写相同包下的类可以直接访问,不同包下的类必须导包,才可…...
6.s081/6.1810(Fall 2022)Lab5: Copy-on-Write Fork for xv6
前言 本来往年这里还有个Lazy Allocation的,今年不知道为啥直接给跳过去了。. 其他篇章 环境搭建 Lab1: Utilities Lab2: System calls Lab3: Page tables Lab4: Traps Lab5: Copy-on-Write Fork for xv6 参考链接 官网链接 xv6手册链接,这个挺重要…...
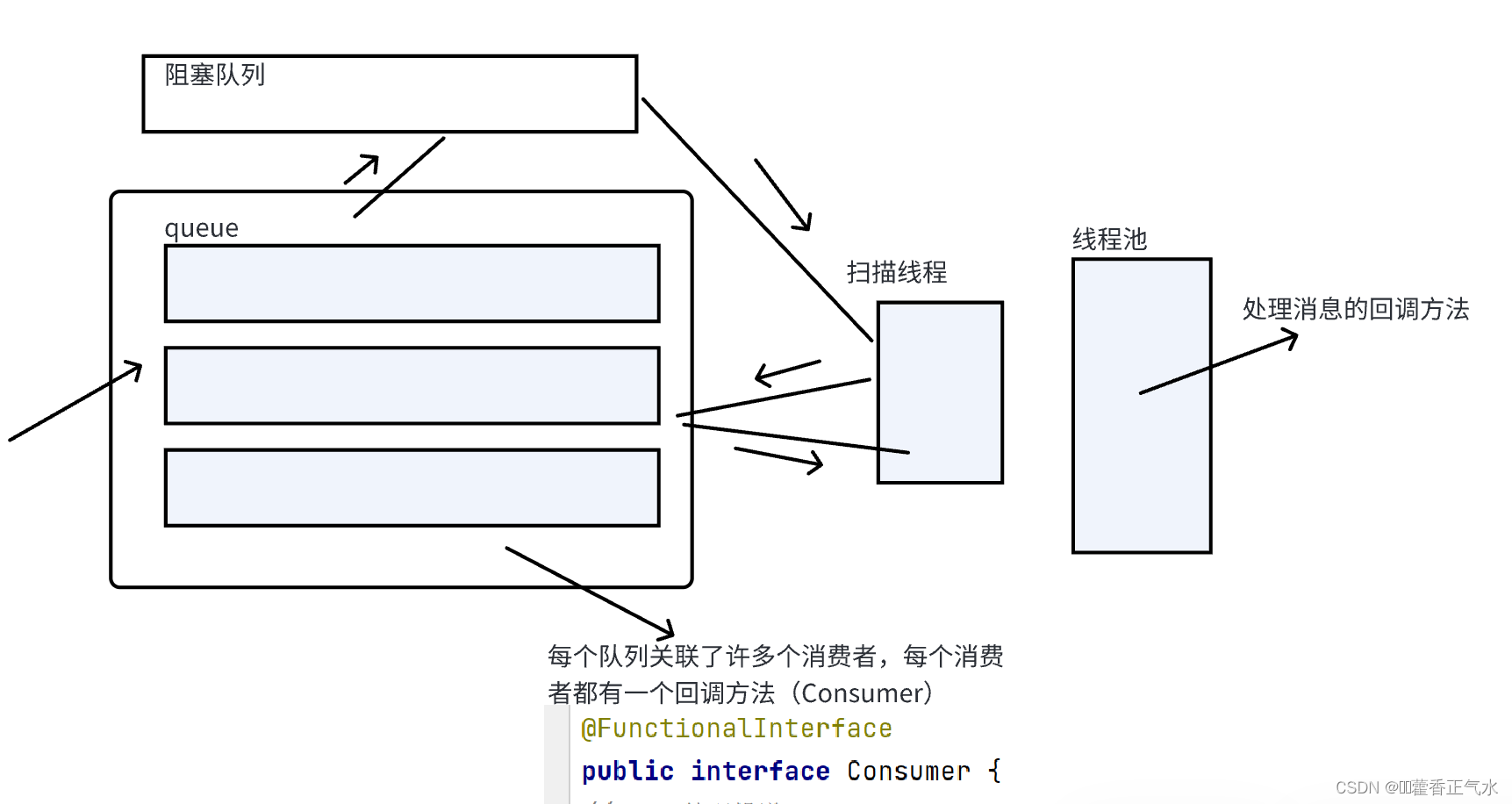
项目实战 — 消息队列(7){虚拟主机设计(2)}
目录 一、消费消息的规则 二、消费消息的具体实现方法 🍅 1、编写消费者类(ConsumerEnv) 🍅 2、编写Consumer函数式接口(回调函数) 🍅 3、编写ConsumeerManager类 🎄定义成员变…...
手把手教你快速实现内网穿透
快速内网穿透教程 文章目录 快速内网穿透教程前言*cpolar内网穿透使用教程*1. 安装cpolar内网穿透工具1.1 Windows系统1.2 Linux系统1.2.1 安装1.2.2 向系统添加服务1.2.3 启动服务1.2.4 查看服务状态 2. 创建隧道映射内网端口3. 获取公网地址 前言 要想实现在公网访问到本地的…...

【Linux取经路】揭秘进程的父与子
文章目录 1、进程PID1.1 通过系统调用接口查看进程PID1.2 父进程与子进程 2、通过系统调用创建进程-fork初始2.1 调用fork函数后的现象2.2 为什么fork给子进程返回0,给父进程返回pid?2.3 fork函数是如何做到返回两次的?2.4 一个变量怎么会有不…...

Docker AI Toolkit 2026正式发布:5大颠覆性功能+3层安全沙箱设计,AI工程师必须立即升级的7个理由
更多请点击: https://intelliparadigm.com 第一章:Docker AI Toolkit 2026:重新定义AI工程化交付范式 Docker AI Toolkit 2026 是面向生产级 AI 应用的一体化容器化工程套件,深度融合模型训练、推理优化、可观测性与合规审计能力…...

避坑指南:Signal, Image and Video Processing 投稿前,你必须搞懂的OA与非OA选择策略
信号图像处理领域投稿策略:OA与非OA期刊的深度权衡指南 刚完成一篇信号图像处理领域的研究论文时,许多研究者会面临一个关键抉择:该选择开源(OA)期刊还是传统非OA期刊?这个看似简单的选择背后,隐藏着学术影响力、发表速…...
)
从‘线性可分’到‘支持向量机’:感知机算法没告诉你的那些事儿(附避坑指南)
从‘线性可分’到‘支持向量机’:感知机算法没告诉你的那些事儿(附避坑指南) 当你第一次接触感知机时,可能会被它的简洁美所吸引——一个简单的线性分类器,用超平面将数据一分为二。但当你真正开始用它解决实际问题时&…...

5分钟搞定 小龙虾 AI OpenClaw v2.6.6 一键安装|办公自动化神器
Windows 一键部署 OpenClaw 教程|5 分钟搞定本地 AI 智能体,告别复杂配置【含最新安装包】 2026 年开源圈备受关注的「数字员工」OpenClaw(昵称小龙虾),GitHub 星标突破 28 万 ,凭借本地运行 零代码操作 …...

ARMv9内存管理:TCR2寄存器详解与优化实践
1. ARMv9内存管理架构概述在ARMv9架构中,内存管理单元(MMU)作为处理器核心组件,负责虚拟地址到物理地址的转换。与ARMv8相比,ARMv9在内存管理方面引入了多项增强特性,其中最重要的变化之一就是新增了TCR2扩展寄存器系列。这些寄存…...

面试场景:互联网大厂Java求职者挑战与学习
面试场景:互联网大厂Java求职者挑战与学习 场景设定: 谢飞机是一位程序员,正在挑战一家互联网大厂的Java岗位面试。面试官严肃认真,谢飞机有点紧张不自信。他对简单的问题能够侃侃而谈,但面对复杂问题却有些词不达意。…...

从GB/T到ECE R131:一份给智能驾驶测试工程师的AEB标准对照手册
从GB/T到ECE R131:智能驾驶测试工程师的AEB标准实战指南 当你在测试场盯着屏幕上跳动的刹车曲线时,是否曾困惑过为什么同一套AEB系统在不同标准下的表现差异如此之大?去年我们在某重型卡车项目上就踩过这样的坑——按照GB/T 38186测试完美的系…...

Win11Debloat:三步清理Windows 11臃肿问题,让你的电脑焕然一新
Win11Debloat:三步清理Windows 11臃肿问题,让你的电脑焕然一新 【免费下载链接】Win11Debloat A simple, lightweight PowerShell script that allows you to remove pre-installed apps, disable telemetry, as well as perform various other changes …...

11111111123
33333333311...

探秘 NaN 隐秘世界:IEEE 754 标准下的特殊值应用及 JavaScriptCore 案例
NaN 的隐秘世界 2018 年 3 月,浮点标准定义了非数字(Not-a-Number,NaN),用于表示非数字的值。双精度 NaN 有 51 位有效负载,可在动态类型语言运行时表示其他非浮点数值及其类型。2019 年 4 月更新ÿ…...