RabbitMQ相关问题
文章目录
- 避免重复消费(保证消息幂等性)
- 消息积压
- 上线更多的消费者,进行正常消费
- 惰性队列
- 消息缓存
- 延时队列
- RabbitMQ如何保证消息的有序性?
- RabbitMQ消息的可靠性、延时队列
- 如何实现数据库与缓存数据一致?
- 开启消费者多线程消费
避免重复消费(保证消息幂等性)
-
方式1: 消息全局ID或者写个唯一标识(如时间戳、UUID等) :每次消费消息之前根据消息id去判断该消息是否已消费过,如果已经消费过,则不处理这条消息,否则正常消费消息,并且进行入库操作。(消息全局ID作为数据库表的主键,防止重复)
-
方式2: 利用Redis的setnx 命令:给消息分配一个全局ID,只要消费过该消息,将 < id,message>以K-V键值对形式写入redis,消费者开始消费前,先去redis中查询有没消费记录即可
-
方式3: rabbitMQ的每一个消息都有
redelivered字段,可以获取是否是被重新投递过来的,而不是第一次投递过来的

发送消息
@Autowiredprivate RabbitTemplate rabbitTemplate;/*** 发送消息*/public void sendMessage() {// 创建消费对象,并指定 全局唯一ID(这里使用UUID,也可以根据业务规则生成,只要保证全局唯一即可)MessageProperties messageProperties = new MessageProperties ();messageProperties.setMessageId (UUID.randomUUID ().toString ());messageProperties.setContentType ("text/plain");messageProperties.setContentEncoding ("utf-8");Message message = new Message ("hello,message idempotent!".getBytes (), messageProperties);System.out.println ("生产消息:" + message.toString ());rabbitTemplate.convertAndSend (EXCHANGE_NAME, ROUTE_KEY, message);}
消费消息
/*** 消费消息** @param message* @param channel* @throws IOException*/@RabbitHandler//org.springframework.amqp.AmqpException: No method found for class [B 这个异常,并且还无限循环抛出这个异常。//注意@RabbitListener位置,笔者踩坑,无限报上面的错,还有另外一种解决方案: 配置转换器@RabbitListener(queues = "message_idempotent_queue")@Transactionalpublic void handler(Message message, Channel channel) throws IOException {/*** 发送消息之前,根据消息全局ID去数据库中查询该条消息是否已经消费过,如果已经消费过,则不再进行消费。*/// 获取消息IdString messageId = message.getMessageProperties ().getMessageId ();if (StringUtils.isBlank (messageId)) {logger.info ("获取消费ID为空!");return;}MessageIdempotent messageIdempotent = null;Optional<MessageIdempotent> list = messageIdempotentRepository.findById (messageId);if (list.isPresent ()) {messageIdempotent = list.get ();}// 如果找不到,则进行消费此消息if (null == messageIdempotent) {//获取消费内容String msg = new String (message.getBody (), StandardCharsets.UTF_8);logger.info ("-----获取生产者消息-------------------->" + "messageId:" + messageId + ",消息内容:" + msg);//手动ACKchannel.basicAck (message.getMessageProperties ().getDeliveryTag (), false);//存入到表中,标识该消息已消费MessageIdempotent idempotent = new MessageIdempotent ();idempotent.setMessageId (messageId);idempotent.setMessageContent (msg);messageIdempotentRepository.save (idempotent);} else {//如果根据消息ID(作为主键)查询出有已经消费过的消息,那么则不进行消费;logger.error ("该消息已消费,无须重复消费!");}}
消息积压
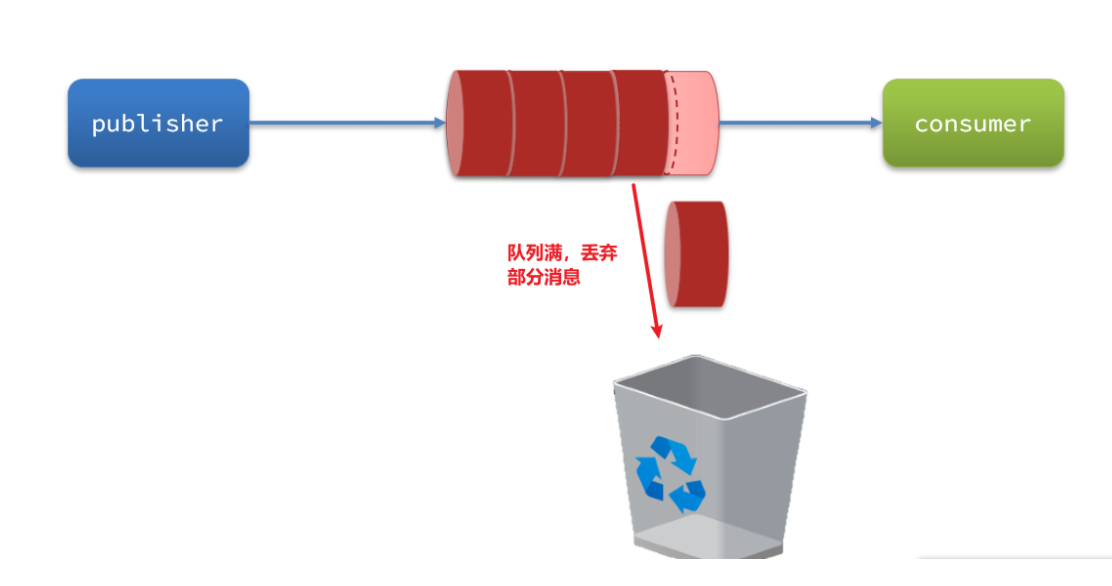
上线更多的消费者,进行正常消费
线上突发问题,要临时扩容,增加消费端的数量
考虑到
消费者的处理能力,增加配置!!!
spring:rabbitmq:listener:simple:prefetch: 1 # 每次只能获取一条消息,处理完成才能获取下一个消息
simple代表简单队列模型
惰性队列
//基于@Bean声明lazy-queue@Beanpublic Queue lazyQueue() {return QueueBuilder.durable("lazy.queue").lazy() //开启x-queue-mode为lazy.build();}//基于@RabbitListener声明LazyQueue@RabbitListener(queuesToDeclare = {@Queue(name = "lazy.queue",durable = "true",arguments = @Argument(name = "x-queue-mode", value = "lazy"))})public void listenLazyQueue(String msg) {System.out.println("接收到lazy.queue的消息:【" + msg + "】");}惰性队列的优点有哪些?
- 基于磁盘存储,消息上限高
- 没有间歇性的
page-out,性能比较稳定
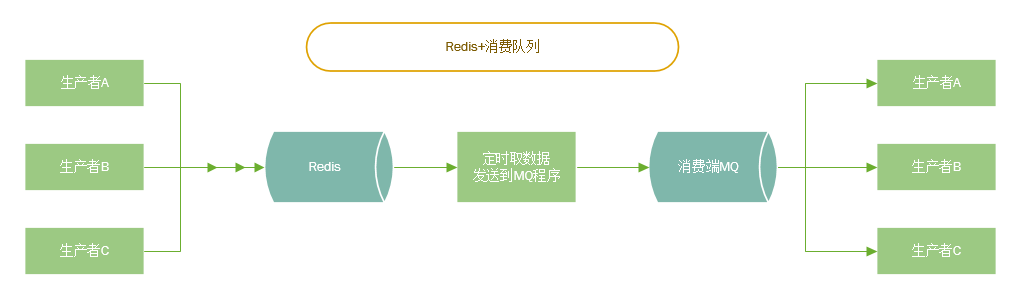
消息缓存
使用Redis的List或ZSET做接收消息缓存,写一个程序 按照消费者处理时间定时从Redis取消息发送到MQ
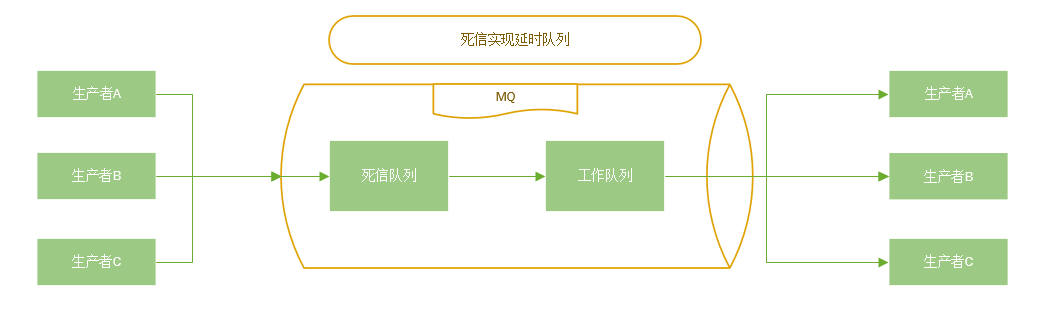
延时队列
设置消息过期时间,过期后转入死信队列,写一个程序 处理死信消息(重新如队列或者 即使处理或记录到数据库延后处理)
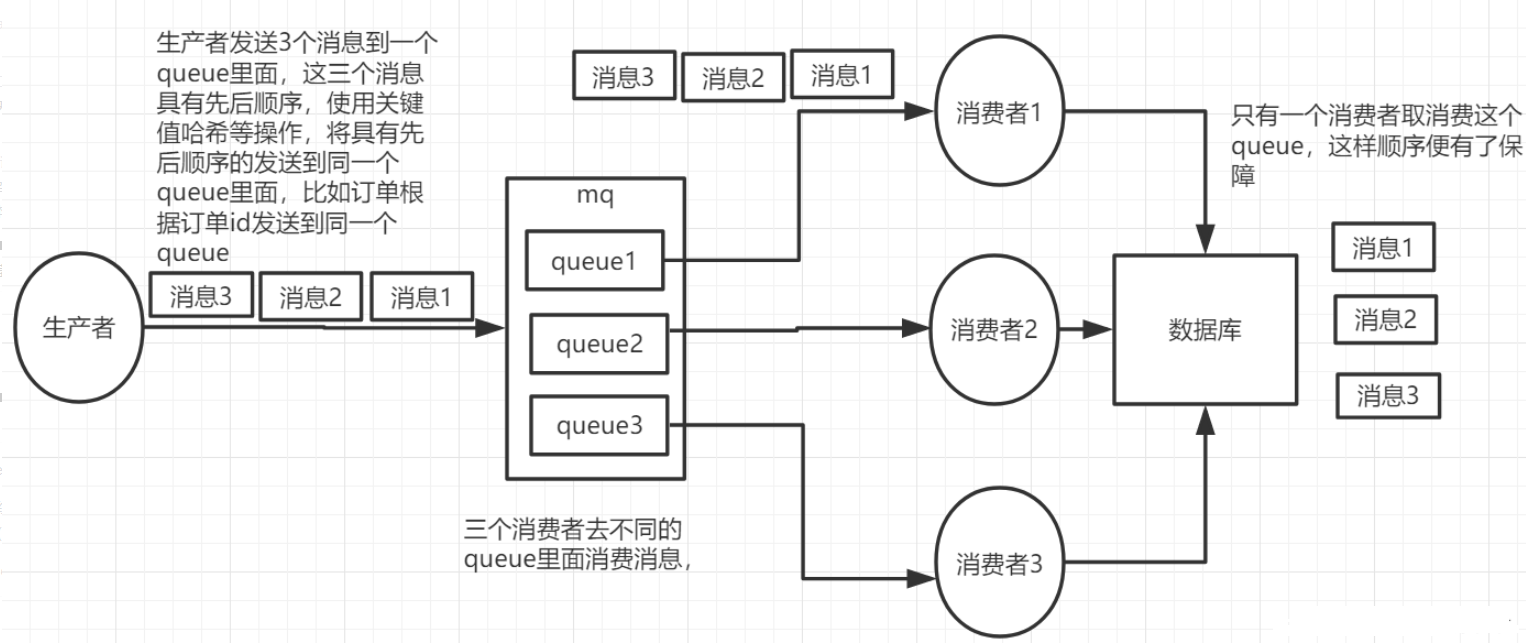
RabbitMQ如何保证消息的有序性?
RabbitMQ是队列存储,天然具备先进先出的特点,只要消息的发送是有序的,那么理论上接收也是有序的。不过当一个队列绑定了多个消费者时,可能出现消息轮询投递给消费者的情况,而消费者的处理顺序就无法保证
因此,要保证消息的有序性,需要做的下面几点:
- 保证消息发送的有序性
- 保证一组有序的消息都发送到同一个队列
- 保证一个队列只包含一个消费者
这样也会造成吞吐量下降,可以
在消费者内部采用多线程的方式消费
RabbitMQ消息的可靠性、延时队列
RabbitMQ消息可靠性、延时队列
如何实现数据库与缓存数据一致?
实现方案有下面几种:
- 本地缓存同步:当前微服务的数据库数据与缓存数据同步,可以直接在数据库修改时加入对Redis的修改逻辑,保证一致。
- 跨服务缓存同步:服务A调用了服务B,并对查询结果缓存。服务B数据库修改,可以
通过MQ通知服务A,服务A修改Redis缓存数据 - 通用方案:使用
Canal框架,伪装成MySQL的salve节点,监听MySQL的binLog变化,然后修改Redis缓存数据
开启消费者多线程消费
import lombok.extern.slf4j.Slf4j;
import org.springframework.amqp.core.Message;
import org.springframework.amqp.rabbit.annotation.Exchange;
import org.springframework.amqp.rabbit.annotation.Queue;
import org.springframework.amqp.rabbit.annotation.QueueBinding;
import org.springframework.amqp.rabbit.annotation.RabbitListener;
import org.springframework.stereotype.Component;@Slf4j
@Component
public class SpringRabbitListener {/*** @RabbitListener:加了该注解的方法表示该方法是一个消费者 concurrency:并发数量。* 其他属性和注解想了解的话,自己按Ctrl点进去看*/@RabbitListener(bindings = @QueueBinding(value = @Queue(value = "Queue1"),exchange = @Exchange(value = "Exchange1"),key = "key1"),concurrency = "10")public void process1(Message message) throws Exception {System.out.println("Queue1:" + new String(message.getBody()));}}
import org.springframework.amqp.core.AcknowledgeMode;
import org.springframework.amqp.rabbit.config.SimpleRabbitListenerContainerFactory;
import org.springframework.amqp.rabbit.connection.ConnectionFactory;
import org.springframework.amqp.rabbit.listener.RabbitListenerContainerFactory;
import org.springframework.amqp.support.converter.Jackson2JsonMessageConverter;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.context.annotation.Primary;
import org.springframework.core.task.TaskExecutor;
import org.springframework.scheduling.concurrent.ThreadPoolTaskExecutor;@Configuration
public class RabbitmqConfig {@Bean("batchQueueRabbitListenerContainerFactory")public RabbitListenerContainerFactory<?> rabbitListenerContainerFactory(ConnectionFactory connectionFactory) {SimpleRabbitListenerContainerFactory factory = new SimpleRabbitListenerContainerFactory ();factory.setConnectionFactory (connectionFactory);factory.setMessageConverter (new Jackson2JsonMessageConverter ());//确认方式,manual为手动ack.factory.setAcknowledgeMode (AcknowledgeMode.MANUAL);//每次处理数据数量,提高并发量//factory.setPrefetchCount(250);//设置线程数//factory.setConcurrentConsumers(30);//最大线程数//factory.setMaxConcurrentConsumers(50);/* setConnectionFactory:设置spring-amqp的ConnectionFactory。 */factory.setConnectionFactory (connectionFactory);factory.setConcurrentConsumers (1);factory.setPrefetchCount (1);//factory.setDefaultRequeueRejected(true);//使用自定义线程池来启动消费者。factory.setTaskExecutor (taskExecutor ());return factory;}@Bean("correctTaskExecutor")@Primarypublic TaskExecutor taskExecutor() {ThreadPoolTaskExecutor executor = new ThreadPoolTaskExecutor ();// 设置核心线程数executor.setCorePoolSize (100);// 设置最大线程数executor.setMaxPoolSize (100);// 设置队列容量executor.setQueueCapacity (0);// 设置线程活跃时间(秒)executor.setKeepAliveSeconds (300);// 设置默认线程名称executor.setThreadNamePrefix ("thread-file-queue");// 设置拒绝策略rejection-policy:当pool已经达到max size的时候,丢弃// executor.setRejectedExecutionHandler(new ThreadPoolExecutor.DiscardPolicy());// 等待所有任务结束后再关闭线程池executor.setWaitForTasksToCompleteOnShutdown (true);return executor;}
}相关文章:
RabbitMQ相关问题
文章目录避免重复消费(保证消息幂等性)消息积压上线更多的消费者,进行正常消费惰性队列消息缓存延时队列RabbitMQ如何保证消息的有序性?RabbitMQ消息的可靠性、延时队列如何实现数据库与缓存数据一致?开启消费者多线程消费避免重复消费(保证消…...

操作系统 三(存储管理)
一、 存储系统的“金字塔”层次结构设计原理:cpu自身运算速度很快。内存、外存的访问速度受到限制各层次存储器的特点:1)主存储器(主存/内存/可执行存储器)保存进程运行时的程序和数据,内存的访问速度远低于…...

day34 贪心算法 | 860、柠檬水找零 406、根据身高重建队列 452、用最少数量的箭引爆气球
题目 860、柠檬水找零 在柠檬水摊上,每一杯柠檬水的售价为 5 美元。 顾客排队购买你的产品,(按账单 bills 支付的顺序)一次购买一杯。 每位顾客只买一杯柠檬水,然后向你付 5 美元、10 美元或 20 美元。你必须给每个…...

使用canvas给上传的整张图片添加平铺的水印
写在开头 哈喽,各位倔友们又见面了,本章我们继续来分享一个实用小技巧,给图片加水印功能,水印功能的目的是为了保护网站或作者版权,防止内容被别人利用或白嫖。 但是网络中,是没有绝对安全的,…...
[安装之4] 联想ThinkPad 加装固态硬盘教程
方案:保留原有的机械硬盘,再加装一个固态硬盘作为系统盘。由于X250没有光驱,这样就无法使用第二个2.5寸的硬盘。还好,X250留有一个M.2接口,这样,就可以使用NGFF M.2接口的固态硬盘。不过,这种接…...
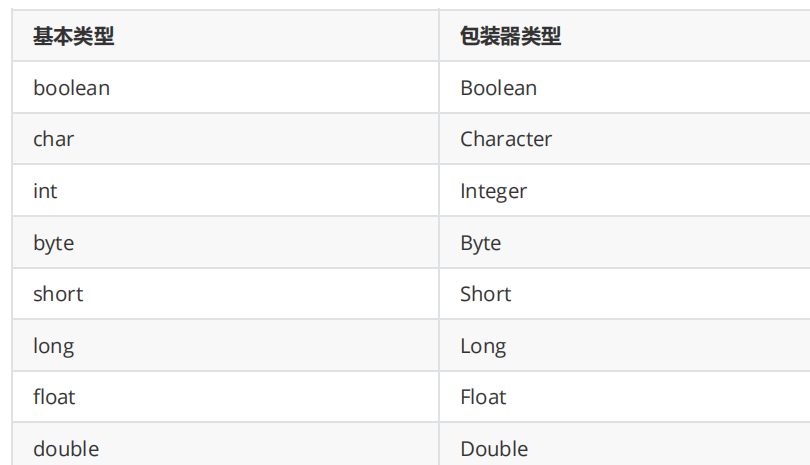
Java数据类型、基本与引用数据类型区别、装箱与拆箱、a=a+b与a+=b区别
文章目录1.Java有哪些数据类型2.Java中引用数据类型有哪些,它们与基本数据类型有什么区别?3.Java中的自动装箱与拆箱4.为什么要有包装类型?5.aab与ab有什么区别吗?1.Java有哪些数据类型 8种基本数据类型: 6种数字类型(4个整数型…...
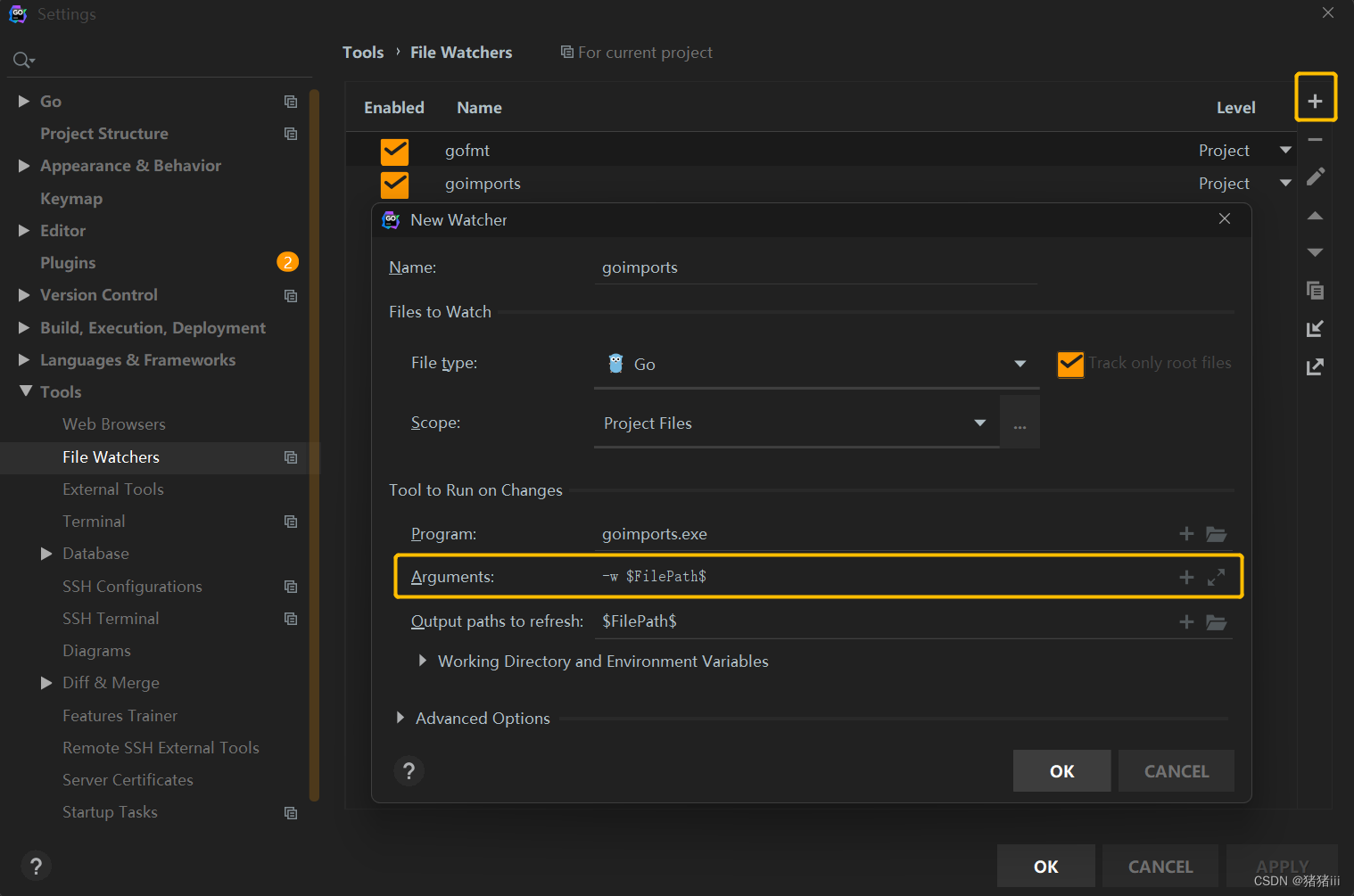
GoLang设置gofmt和goimports自动格式化
目录 设置gofmt gofmt介绍 配置gofmt 设置goimports goimports介绍 配置goimports 设置gofmt gofmt介绍 Go语言的开发团队制定了统一的官方代码风格,并且推出了 gofmt 工具(gofmt 或 go fmt)来帮助开发者格式化他们的代码到统一的风格…...

【k8s】如何搭建搭建k8s服务器集群(Kubernetes)
搭建k8s服务器集群 服务器搭建环境随手记 文章目录搭建k8s服务器集群前言:一、前期准备(所有节点)1.1所有节点,关闭防火墙规则,关闭selinux,关闭swap交换,打通所有服务器网络,进行p…...
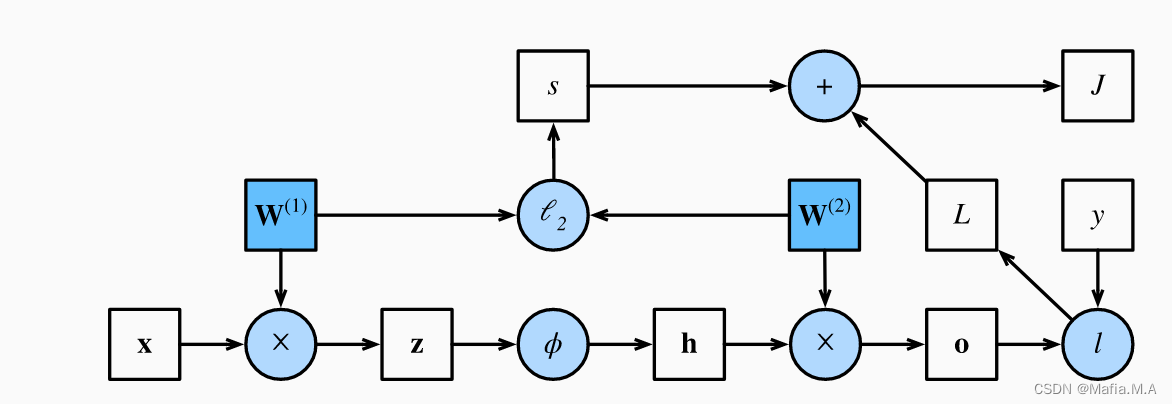
DIDL4_前向传播与反向传播(模型参数的更新)
前向传播与反向传播前向传播与反向传播的作用前向传播及公式前向传播范例反向传播及公式反向传播范例小结前向传播计算图前向传播与反向传播的作用 在训练神经网络时,前向传播和反向传播相互依赖。 对于前向传播,我们沿着依赖的方向遍历计算图并计算其路…...

链表学习之链表划分
链表解题技巧 额外的数据结构(哈希表);快慢指针;虚拟头节点; 链表划分 将单向链表值划分为左边小、中间相等、右边大的形式。中间值为pivot划分值。 要求:调整之后节点的相对次序不变,时间复…...
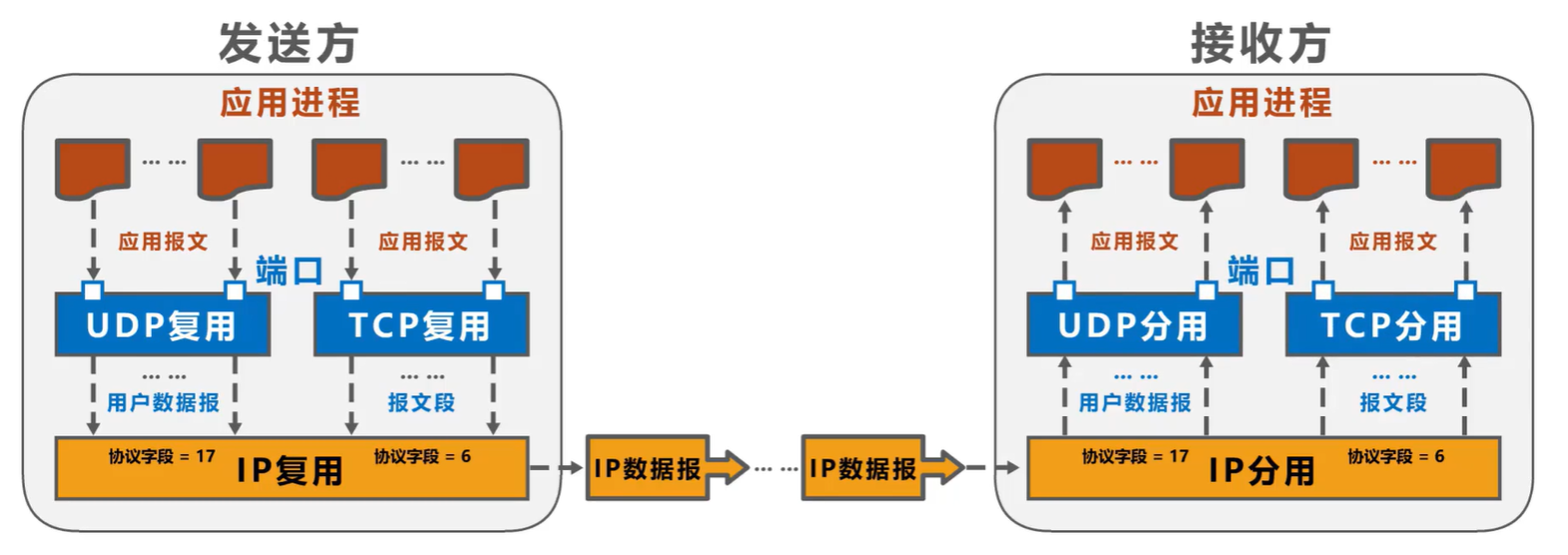
(考研湖科大教书匠计算机网络)第五章传输层-第一、二节:传输层概述及端口号、复用分用等概念
获取pdf:密码7281专栏目录首页:【专栏必读】考研湖科大教书匠计算机网络笔记导航 文章目录一:传输层概述(1)概述(2)从计算机网络体系结构角度看传输层(3)传输层意义二&am…...

C#:Krypton控件使用方法详解(第七讲) ——kryptonHeader
今天介绍的Krypton控件中的kryptonHeader,下面开始介绍这个控件的属性:控件的样子如上图所示,从上面控件外观来看,这个控件有三部分组成。第一部分是前面的图片,第二部分是kryptonHeader1文本,第三部分是控…...

5年软件测试工程师分享的自动化测试经验,一定要看
今天给大家分享一个华为的软件测试工程师分享的关于自动化测试的经验及干货。真的后悔太晚找他要了, 纯干货。一定要看完! 1.什么是自动化测试? 用程序测试程序,用代码取代思考,用脚本运行取代手工测试。自动化测试涵…...

什么是猜疑心理?小猫测试网科普小作文
什么是猜疑心理?猜疑心理是说一个人心中想法偏离了客观事实,牵强附会,往往是指不好的一面,对别人的一言一行都充满了不良的解读,认为这些对自己都有针对性,目的性,对自己都是不利的。猜疑心理重…...

Redis命令行对常用数据结构String、list、set、zset、hash等增删改查操作
1.Redis命令的小套路 - NX:not exist - EX:expire - M:multi 2.基本操作 ①切换数据库 Redis默认有16个数据库。 115 # Set the number of databases. The default database is DB 0, you can select 116 # a different one on a per-con…...

mycobot 使用教程
(1) 树莓派4B ubuntu系统调整swap空间与使SD卡快速扩容参考:https://www.bilibili.com/read/cv14825069https://blog.csdn.net/weixin_45824920/article/details/114381292?spm1001.2101.3001.6650.1&utm_mediumdistribute.pc_relevant.none-task-blog-2%7Edef…...
JVM学习总结,虚拟机性能监控、故障处理工具:jps、jstat、jinfo、jmap、Visual VM、jstack等
上篇:JVM学习总结,全面介绍运行时数据区域、各类垃圾收集器的原理使用、内存分配回收策略 参考资料:《深入理解Java虚拟机》第三版 文章目录三,虚拟机性能监控、故障处理工具1)jps:虚拟机进程状况工具2&…...

指针笔记(指针数组和指向数组的指针,数组中a和a的区别等)
指针数组和指向数组的指针 int *p[4]和int (*p)[4]有何区别? 前者是一个指针数组,数组大小为4,每一个元素都是一个指向int的指针 后者是指向int[4]类型数组的指针 以上代码若运行会报如下错误 main函数中定义的a数组本质是一个指向int[2]的…...

MySQL ---基础概念
目录 餐前小饮:什么是服务器?什么是数据库服务器? 一、数据库服务软件 1. 常见数据库产品 2.如何开启和停止MySQL服务 二、数据库术语及语法 1.数据库术语 2.SQL语法结构 3.SQL 语法要点 三、SQL分类 1.数据定义语言(D…...
【基础】Flink -- ProcessFunction
Flink -- ProcessFunction处理函数概述处理函数基本处理函数 ProcessFunction按键分区处理函数 KeyedProcessFunction定时器与定时服务基于处理时间的分区处理函数基于事件时间的分区处理函数窗口处理函数 ProcessWindowFunction应用案例 -- Top N处理函数概述 为了使代码拥有…...

初创公司如何利用Taotoken快速构建AI产品原型
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 初创公司如何利用Taotoken快速构建AI产品原型 对于资源有限的初创团队而言,验证产品想法、快速推出原型是生存和发展的…...

保姆级教程:用Intel官方工具搞定Realsense D435深度不准和黑点问题
深度视觉优化实战:Intel RealSense D435深度校准全流程解析 刚拆封的RealSense D435摄像头在深度模式下出现零星黑点?深度图某些区域数值明显失真?这些问题往往不是硬件缺陷,而是出厂校准参数与实际使用环境不匹配导致的。作为计算…...

为AI智能体构建可编程邮箱:mailbot实战指南
1. 项目概述:为AI智能体打造专属的“可编程邮箱”如果你正在开发一个AI智能体,无论是客服机器人、自动化工作流还是个人助理,让它具备收发邮件的能力往往是刚需。传统的做法是什么?要么去折腾Gmail的API,忍受OAuth授权…...

自然语言编写嵌入式软件之点亮LED灯
要实现的功能: 控制LED以10HZ的频率闪烁 传统实现过程:学C语言,看数据手册了解MCU,学教程,copy代码,学编译调试环境,学仿真,学用仪器测量 自然语言编程实现过程: 搭建…...

开源工具LMAO:通过浏览器自动化免费调用ChatGPT与Copilot API
1. 项目概述与核心价值如果你和我一样,是个喜欢折腾各种AI工具,但又对官方API的付费门槛、调用限制或者复杂的申请流程感到头疼的开发者,那么今天聊的这个项目,你一定会感兴趣。它叫LLM-API-Open,圈内朋友喜欢叫它LMAO…...
)
arXiv论文智能检索革命(Perplexity深度集成实战白皮书)
更多请点击: https://intelliparadigm.com 第一章:arXiv论文智能检索革命(Perplexity深度集成实战白皮书) 传统 arXiv 检索依赖关键词匹配与手动筛选,面对日均超 2000 篇新增论文,科研人员常陷入信息过载困…...

基于Node.js与Telegraf构建支持双历法的Telegram天气机器人
1. 项目概述:一个功能完备的Telegram天气机器人 最近在做一个需要集成天气信息的小项目,顺手就把之前写的一个Telegram天气机器人翻新重构了一遍。这个机器人不只是简单地查询温度,它融合了实时天气、24小时预报,并且特别加入了波…...

CREO 6.0装配实战:别再乱拖零件了,手把手教你用‘移动’和‘角度偏移’精准定位
CREO 6.0装配实战:从零件乱飞到精准定位的进阶技巧 刚接触CREO装配模块的新手设计师,最常遇到的挫败感莫过于:明明在脑海中构思好了零件位置,实际操作时却总是出现零件"乱飞"、"定位不准"的情况。这种体验就像…...

别再死记硬背截止、放大、饱和了!用Arduino+面包板,5分钟直观理解NPN/PNP三极管
用Arduino实验破解三极管的三大工作状态之谜 记得第一次翻开电子学教材看到三极管章节时,那些密密麻麻的曲线图和公式让我头皮发麻。"截止区"、"放大区"、"饱和区"——这些抽象概念就像天书一样难以理解。直到有一天,我拿…...

当AI学会“看”画质:用Python和PyTorch动手实现一个无参考图像质量评估模型
用Python和PyTorch构建无参考图像质量评估模型:从理论到实践 在数字图像爆炸式增长的时代,图像质量评估(IQA)技术正成为计算机视觉领域不可或缺的一环。无论是社交媒体平台的内容审核、医疗影像的自动分析,还是监控系统的实时画面处理&#x…...