密度峰值聚类算法(DPC)
密度峰值聚类算法
- 目录
- DPC算法
- 1.1 DPC算法的两个假设
- 1.2 DPC算法的两个重要概念
- 1.3 DPC算法的执行步骤
- 1.4 DPC算法的优缺点
- matlab代码
- 密度计算函数
- 计算delta
- 寻找聚类中心点
- 聚类算法
目录
DPC算法
1.1 DPC算法的两个假设
1)类簇中心被类簇中其他密度较低的数据点包围;
2)类簇中心间的距离相对较远。
1.2 DPC算法的两个重要概念
1)局部密度
设有数据集为 ,其中 ,N为样本个数,M为样本维数。
对于样本点i的局部密度,局部密度有两种计算方式,离散值采用截断核的计算方式,连续值则用高斯核的计算方式。

式中dij为数据点 i 与数据点 j 的欧氏距离,dc为数据点i的邻域截断距离。
采用截断核计算的局部密度ρi等于分布在样本点i的邻域截断距离范围内的样本点个数;而利用高斯计算的局部密度ρi等于所有样本点到样本点i的高斯距离之和。
DPC算法的原论文指出,对于较大规模的数据集,截断核的计算方式聚类效果较好;而对于小规模数据集,高斯核的计算方式聚类效果更为明显。

1.3 DPC算法的执行步骤

1.4 DPC算法的优缺点
优点:
1)不需要事先指定类簇数;
2)能够发现非球形类簇;
3)只有一个参数需要预先取值。
缺点:
1)当类簇间的数据密集程度差异较大时,DPC算法并不能获得较好的聚类效果;
2)DPC算法的样本分配策略存在分配连带错误。
matlab代码
密度计算函数
计算密度,利用截断核算法,pdist2是计算欧式距离的,对于每个idata_len进行计算所有的点的欧式距离,利用求和函数进行求取密度
function data_density=cal_density(data,cut_dist)%%利用截断核的方式进行计算data_len=size(data,1);%%size(data,1)是获取data的行数,size(data,2)是获取列数data_density=zeros(1,data_len);%%for idata_len=1:data_lentemp_dist=pdist2(data,data(idata_len,:));%计算第i行的点和data中所有点的欧式距离data_density(idata_len)=sum(temp_dist<=cut_dist);%%temp_dist中所有数据同cut_dist进行比较%%disp(data_density(idata_len))end
end
计算delta
两种情况:
对于密度最高的值,选取距离其最远的距离
对于密度最低的值,选取距离其最近的距离
function data_delta=cal_delta(data,data_density)data_len=size(data,1);data_delta=zeros(1,data_len);for idata_len=1:data_lenindex=data_density>data_density(idata_len);%%index中存的是所有大于idata_len密度值的下标if sum(index)~=0data_delta(idata_len)=min(pdist2(data(idata_len,:),data(index,:)));elsedata_delta(idata_len)=max(pdist2(data(idata_len,:),data));end%{两种情况:对于密度最高的值,选取距离其最远的距离对于密度最低的值,选取距离其最近的距离%}end
end
寻找聚类中心点
首先计算决策值,之后进行排序,选择前后项差值较大的点作为疑似中心点,然后对每个疑似中心点找出小于两倍截断距离的疑似中心点并选取其中具有最大密度的点,最后进行去重
function [center,center_index]=find_center(data,data_delta,data_density,cut_dist)R=data_density.*data_delta;%计算决策值figure;plot(R,'*','Color','red')[sort_R,R_index]=sort(R,"descend");%sort_R是排序好的序列,R_index是sort_R中元素在原来的R中的位置gama=abs(sort_R(1:end-1)-sort_R(2:end));%计算sort_R临近的两项之间的距离%disp(gama)[sort_gama,gama_idnex]=sort(gama,"descend");%对差值进行降序排列gmeans=mean(sort_gama(2:end));%求平均值%gmeans=mean(sort_gama);%寻找疑似聚类中心点,疑似聚类中心:第i项比第i+1项的差值大于平均差值,就认为第i项是疑似聚类中心temp_center=data(R_index(gama>gmeans),:);temp_center_index=R_index(gama>gmeans);%进一步筛选中心点temp_center_dist=pdist2(temp_center,temp_center); temp_center_len=size(temp_center,1);center=[];center_index=[];%判断中心点之间距离是否小于2倍截断距离并中心点去重for icenter_len=1:temp_center_lentemp_index=find(temp_center_dist(icenter_len,:)<2*cut_dist);%返回比2*截断距离小的下标[~,max_density_index]=max(data_density(temp_center_index(temp_index)));%找出符合条件的最大值的索引if sum(center_index==temp_center_index(temp_index(max_density_index)))==0%如果不在center_index中则加入center=[center;temp_center(temp_index(max_density_index),:)];%每个数据是坐标,因此垂直拼接center_index=[center_index,temp_center_index(temp_index(max_density_index))];%{if icenter_len<=1disp(center)end%}end%center(icenter_len,:)=temp_center(temp_index(max_density_index),:);end
end
%{
[A,B]相当于水平拼接A和B,即horzcat(A,B)
[A;B]相当于垂直拼接A和B,即vertcat(A,B)
%}
聚类算法
对于中心点:归于自身
对于非中心点:首先选择密度比自身大的点,然后不断选择其中密度最小的点,判断是否为中心点,是则归于此点,否则继续迭代
function cluster=Clustering(data,center,center_index,data_density)data_len=size(data,1);data_dist=pdist2(data,data);cluster=zeros(1,data_len);% 标记中心点序号for i=1:size(center_index,2)cluster(center_index(i))=i;end% 对数据密度进行降序排序[sort_density,sort_index]=sort(data_density,"descend");for idata_len=1:data_len%判断当前数据点是否被分类if cluster(sort_index(idata_len))==0near=sort_index(idata_len);while 1near_density=find(data_density>data_density(near));%找出密度比near大的点near_dist=data_dist(near,near_density);%选取其中最小值[~,min_index]=min(near_dist);if cluster(near_density(min_index))%若为中心点则可加入,否则不能,继续迭代查找cluster(sort_index(idata_len))=cluster(near_density(min_index));break;elsenear=near_density(min_index);endendendend
end
相关文章:
密度峰值聚类算法(DPC)
密度峰值聚类算法目录DPC算法1.1 DPC算法的两个假设1.2 DPC算法的两个重要概念1.3 DPC算法的执行步骤1.4 DPC算法的优缺点matlab代码密度计算函数计算delta寻找聚类中心点聚类算法目录 DPC算法 1.1 DPC算法的两个假设 1)类簇中心被类簇中其他密度较低的数据点包围…...
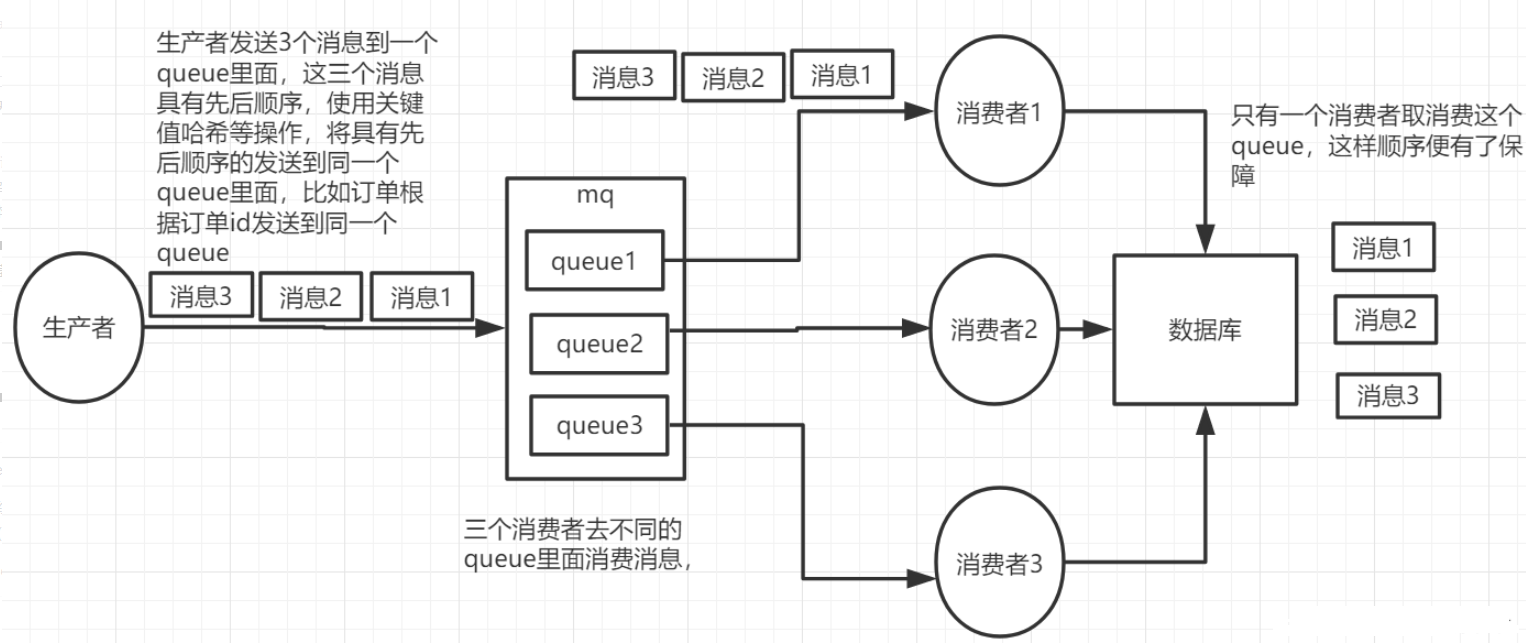
RabbitMQ相关问题
文章目录避免重复消费(保证消息幂等性)消息积压上线更多的消费者,进行正常消费惰性队列消息缓存延时队列RabbitMQ如何保证消息的有序性?RabbitMQ消息的可靠性、延时队列如何实现数据库与缓存数据一致?开启消费者多线程消费避免重复消费(保证消…...

操作系统 三(存储管理)
一、 存储系统的“金字塔”层次结构设计原理:cpu自身运算速度很快。内存、外存的访问速度受到限制各层次存储器的特点:1)主存储器(主存/内存/可执行存储器)保存进程运行时的程序和数据,内存的访问速度远低于…...

day34 贪心算法 | 860、柠檬水找零 406、根据身高重建队列 452、用最少数量的箭引爆气球
题目 860、柠檬水找零 在柠檬水摊上,每一杯柠檬水的售价为 5 美元。 顾客排队购买你的产品,(按账单 bills 支付的顺序)一次购买一杯。 每位顾客只买一杯柠檬水,然后向你付 5 美元、10 美元或 20 美元。你必须给每个…...

使用canvas给上传的整张图片添加平铺的水印
写在开头 哈喽,各位倔友们又见面了,本章我们继续来分享一个实用小技巧,给图片加水印功能,水印功能的目的是为了保护网站或作者版权,防止内容被别人利用或白嫖。 但是网络中,是没有绝对安全的,…...
[安装之4] 联想ThinkPad 加装固态硬盘教程
方案:保留原有的机械硬盘,再加装一个固态硬盘作为系统盘。由于X250没有光驱,这样就无法使用第二个2.5寸的硬盘。还好,X250留有一个M.2接口,这样,就可以使用NGFF M.2接口的固态硬盘。不过,这种接…...
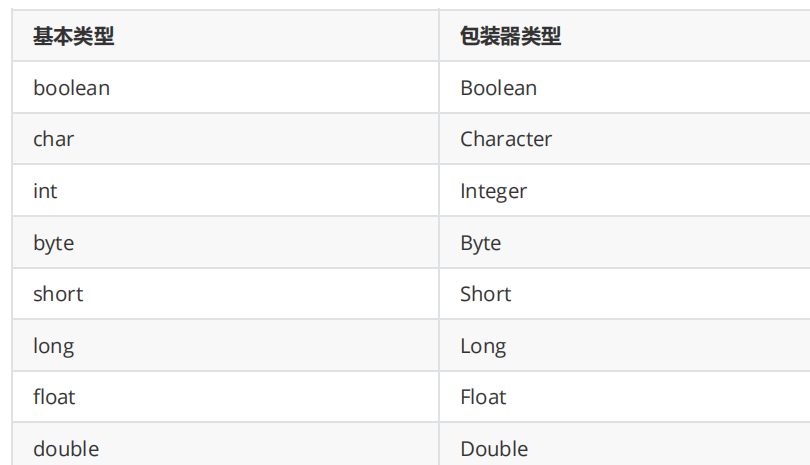
Java数据类型、基本与引用数据类型区别、装箱与拆箱、a=a+b与a+=b区别
文章目录1.Java有哪些数据类型2.Java中引用数据类型有哪些,它们与基本数据类型有什么区别?3.Java中的自动装箱与拆箱4.为什么要有包装类型?5.aab与ab有什么区别吗?1.Java有哪些数据类型 8种基本数据类型: 6种数字类型(4个整数型…...
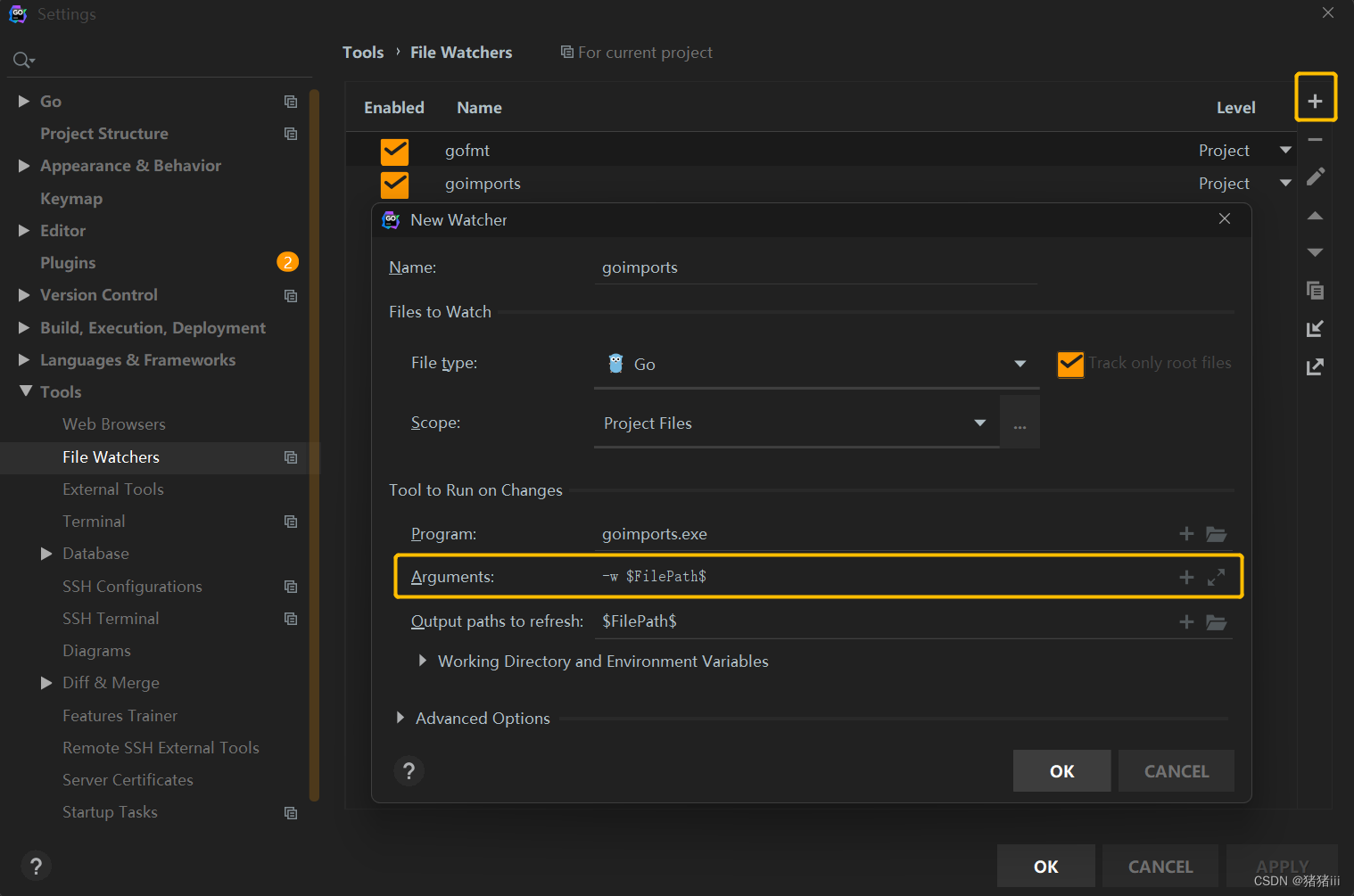
GoLang设置gofmt和goimports自动格式化
目录 设置gofmt gofmt介绍 配置gofmt 设置goimports goimports介绍 配置goimports 设置gofmt gofmt介绍 Go语言的开发团队制定了统一的官方代码风格,并且推出了 gofmt 工具(gofmt 或 go fmt)来帮助开发者格式化他们的代码到统一的风格…...

【k8s】如何搭建搭建k8s服务器集群(Kubernetes)
搭建k8s服务器集群 服务器搭建环境随手记 文章目录搭建k8s服务器集群前言:一、前期准备(所有节点)1.1所有节点,关闭防火墙规则,关闭selinux,关闭swap交换,打通所有服务器网络,进行p…...
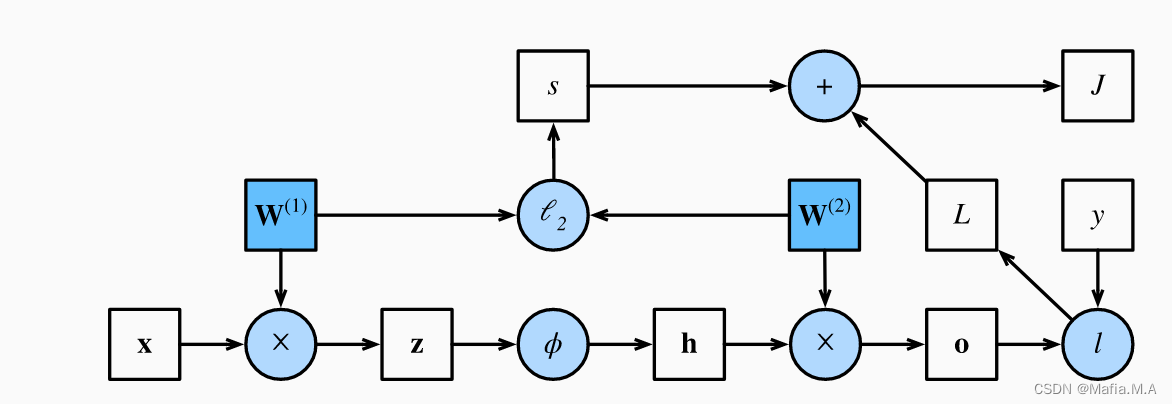
DIDL4_前向传播与反向传播(模型参数的更新)
前向传播与反向传播前向传播与反向传播的作用前向传播及公式前向传播范例反向传播及公式反向传播范例小结前向传播计算图前向传播与反向传播的作用 在训练神经网络时,前向传播和反向传播相互依赖。 对于前向传播,我们沿着依赖的方向遍历计算图并计算其路…...

链表学习之链表划分
链表解题技巧 额外的数据结构(哈希表);快慢指针;虚拟头节点; 链表划分 将单向链表值划分为左边小、中间相等、右边大的形式。中间值为pivot划分值。 要求:调整之后节点的相对次序不变,时间复…...
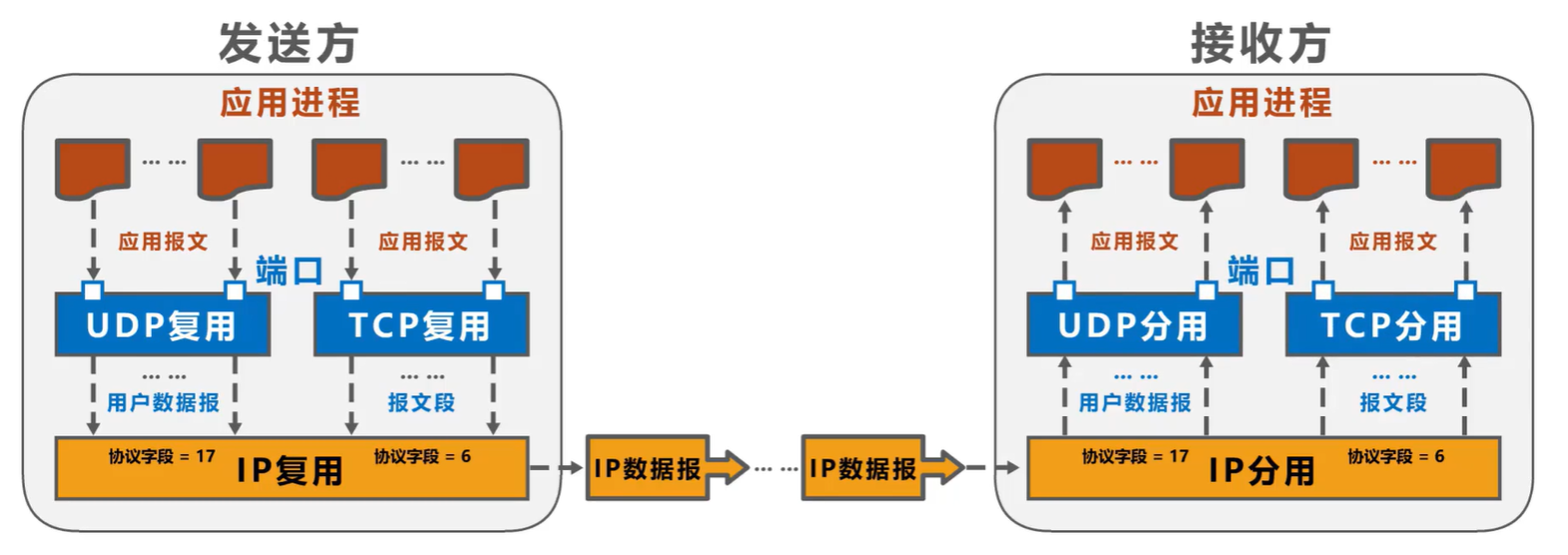
(考研湖科大教书匠计算机网络)第五章传输层-第一、二节:传输层概述及端口号、复用分用等概念
获取pdf:密码7281专栏目录首页:【专栏必读】考研湖科大教书匠计算机网络笔记导航 文章目录一:传输层概述(1)概述(2)从计算机网络体系结构角度看传输层(3)传输层意义二&am…...

C#:Krypton控件使用方法详解(第七讲) ——kryptonHeader
今天介绍的Krypton控件中的kryptonHeader,下面开始介绍这个控件的属性:控件的样子如上图所示,从上面控件外观来看,这个控件有三部分组成。第一部分是前面的图片,第二部分是kryptonHeader1文本,第三部分是控…...

5年软件测试工程师分享的自动化测试经验,一定要看
今天给大家分享一个华为的软件测试工程师分享的关于自动化测试的经验及干货。真的后悔太晚找他要了, 纯干货。一定要看完! 1.什么是自动化测试? 用程序测试程序,用代码取代思考,用脚本运行取代手工测试。自动化测试涵…...

什么是猜疑心理?小猫测试网科普小作文
什么是猜疑心理?猜疑心理是说一个人心中想法偏离了客观事实,牵强附会,往往是指不好的一面,对别人的一言一行都充满了不良的解读,认为这些对自己都有针对性,目的性,对自己都是不利的。猜疑心理重…...

Redis命令行对常用数据结构String、list、set、zset、hash等增删改查操作
1.Redis命令的小套路 - NX:not exist - EX:expire - M:multi 2.基本操作 ①切换数据库 Redis默认有16个数据库。 115 # Set the number of databases. The default database is DB 0, you can select 116 # a different one on a per-con…...

mycobot 使用教程
(1) 树莓派4B ubuntu系统调整swap空间与使SD卡快速扩容参考:https://www.bilibili.com/read/cv14825069https://blog.csdn.net/weixin_45824920/article/details/114381292?spm1001.2101.3001.6650.1&utm_mediumdistribute.pc_relevant.none-task-blog-2%7Edef…...
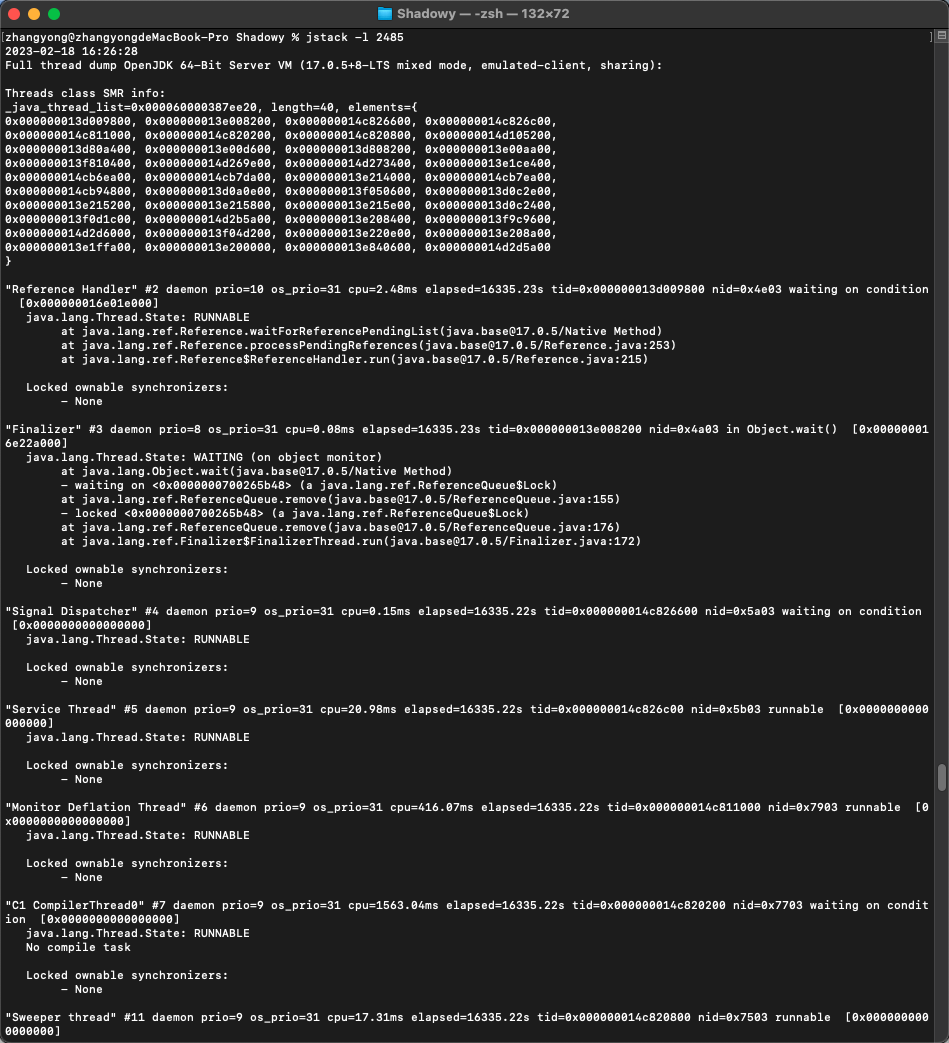
JVM学习总结,虚拟机性能监控、故障处理工具:jps、jstat、jinfo、jmap、Visual VM、jstack等
上篇:JVM学习总结,全面介绍运行时数据区域、各类垃圾收集器的原理使用、内存分配回收策略 参考资料:《深入理解Java虚拟机》第三版 文章目录三,虚拟机性能监控、故障处理工具1)jps:虚拟机进程状况工具2&…...

指针笔记(指针数组和指向数组的指针,数组中a和a的区别等)
指针数组和指向数组的指针 int *p[4]和int (*p)[4]有何区别? 前者是一个指针数组,数组大小为4,每一个元素都是一个指向int的指针 后者是指向int[4]类型数组的指针 以上代码若运行会报如下错误 main函数中定义的a数组本质是一个指向int[2]的…...

MySQL ---基础概念
目录 餐前小饮:什么是服务器?什么是数据库服务器? 一、数据库服务软件 1. 常见数据库产品 2.如何开启和停止MySQL服务 二、数据库术语及语法 1.数据库术语 2.SQL语法结构 3.SQL 语法要点 三、SQL分类 1.数据定义语言(D…...

网站国产化改造怎么做?深度解读国产化替代路径与CMS推荐
在近年来科技领域的舆论场中,“国产化”无疑是出现频率最高的关键词之一。从芯片到操作系统,从数据库到办公软件,再到企业对外展示的门户——网站,国产化替代已从“可选项”变成了很多行业的“必答题”。但国产化仅仅是“换个牌子…...

2026程序员危机:AI岗位暴涨12倍,传统开发即将“毕业”?转型AI大模型开发,才是破局关键!
2026年技术圈将面临巨大变革,AI岗位需求激增,传统编程岗位面临淘汰风险。企业更看重懂AI、能提效的复合型人才。程序员需转型AI大模型开发,掌握系统设计、代码审查及AI工具应用能力。北大青鸟推出AI大模型开发实战营,聚焦落地开发…...

智能产品系统架构分析 - 智能办公系统架构分层
方向:方案分析、架构设计、模块分解 智能产品系统架构分析:智能办公系统架构分层。 对智能办公系统进行架构分层分析,给出实例、UML建模、项目结构等。 “智能产品系统架构分析:智能办公系统架构分层”。 包含设备控制、预约管…...

稀疏结式与动作矩阵:视觉几何求解器中的等价性证明
1. 项目概述:从视觉几何到代数求解的桥梁 在计算机视觉领域,尤其是三维重建、相机标定、姿态估计这些核心任务中,我们常常会遇到一个看似简单、实则棘手的问题:求解一个由多个多项式方程构成的方程组。比如,从两幅图像…...

扩散模型如何重塑建筑设计流程:从概念生成到性能优化的AI协作
1. 项目概述:当AI成为建筑师的“副驾驶”几年前,当我在设计院通宵达旦地对着屏幕调整一个曲面屋顶的参数时,我就在想,有没有一种工具,能让我把脑子里那个模糊的意象,瞬间变成可供推敲的视觉草稿?…...

VisualCppRedist AIO 深度解析:从MSI自动化处理到系统注册表管理的完整解决方案
VisualCppRedist AIO 深度解析:从MSI自动化处理到系统注册表管理的完整解决方案 【免费下载链接】vcredist AIO Repack for latest Microsoft Visual C Redistributable Runtimes 项目地址: https://gitcode.com/gh_mirrors/vc/vcredist 在Windows系统开发和…...

Taotoken提供的官方价折扣与活动对于项目原型的成本友好度
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 Taotoken提供的官方价折扣与活动对于项目原型的成本友好度 对于启动新项目或开发原型的开发者而言,早期试错成本是需要…...

【2026实测】论文AI率从81%降至个位数?8款降AIGC工具深度横测
内容ai率检测数值太高,不得不熬夜改了一遍又一遍,润色到想吐,结果检测报告上数字还是不尽人意,截止日期越逼越近,真的是没办法了。 我花了整整三天,把2026全网热门的几十款降AI工具通通测了个遍࿰…...
)
毕设成品 深度学习安全帽佩戴检测(源码+论文)
文章目录 0 前言🔥这两年开始毕业设计和毕业答辩的要求和难度不断提升,传统的毕设题目缺少创新和亮点,往往达不到毕业答辩的要求,这两年不断有学弟学妹告诉学长自己做的项目系统达不到老师的要求。为了大家能够顺利以及最少的精力…...

VINS-Mono在EUROC数据集上的实战评测:从轨迹精度到运行耗时,我的避坑心得
VINS-Mono在EUROC数据集上的实战评测:从轨迹精度到运行耗时,我的避坑心得 当第一次在无人机上部署VINS-Mono时,我盯着实时轨迹和地面真值之间逐渐拉大的偏差,意识到论文里的漂亮曲线背后藏着太多未言明的细节。这次评测源于一个实…...