竞赛项目 深度学习的智能中文对话问答机器人
文章目录
- 0 简介
- 1 项目架构
- 2 项目的主要过程
- 2.1 数据清洗、预处理
- 2.2 分桶
- 2.3 训练
- 3 项目的整体结构
- 4 重要的API
- 4.1 LSTM cells部分:
- 4.2 损失函数:
- 4.3 搭建seq2seq框架:
- 4.4 测试部分:
- 4.5 评价NLP测试效果:
- 4.6 梯度截断,防止梯度爆炸
- 4.7 模型保存
- 5 重点和难点
- 5.1 函数
- 5.2 变量
- 6 相关参数
- 7 桶机制
- 7.1 处理数据集
- 7.2 词向量处理seq2seq
- 7.3 处理问答及答案权重
- 7.4 训练&保存模型
- 7.5 载入模型&测试
- 8 最后
0 简介
🔥 优质竞赛项目系列,今天要分享的是
基于深度学习的中文对话问答机器人
该项目较为新颖,适合作为竞赛课题方向,学长非常推荐!
🧿 更多资料, 项目分享:
https://gitee.com/dancheng-senior/postgraduate
1 项目架构
整个项目分为 数据清洗 和 建立模型两个部分。
(1)主要定义了seq2seq这样一个模型。
首先是一个构造函数,在构造函数中定义了这个模型的参数。
以及构成seq2seq的基本单元的LSTM单元是怎么构建的。
(2)接着在把这个LSTM间单元构建好之后,加入模型的损失函数。
我们这边用的损失函数叫sampled_softmax_loss,这个实际上就是我们的采样损失。做softmax的时候,我们是从这个6000多维里边找512个出来做采样。
损失函数做训练的时候需要,测试的时候不需要。训练的时候,y值是one_hot向量
(3)然后再把你定义好的整个的w[512*6000]、b[6000多维],还有我们的这个cell本身,以及我们的这个损失函数一同代到我们这个seq2seq模型里边。然后呢,这样的话就构成了我们这样一个seq2seq模型。
函数是tf.contrib.legacy_seq2seq.embedding_attention_seq2seq()
(4)最后再将我们传入的实参,也就是三个序列,经过这个桶的筛选。然后放到这个模型去训练啊,那么这个模型就会被训练好。到后面,我们可以把我们这个模型保存在model里面去。模型参数195M。做桶的目的就是节约计算资源。
2 项目的主要过程
前提是一问一答,情景对话,不是多轮对话(比较难,但是热门领域)
整个框架第一步:做语料
先拿到一个文件,命名为.conv(只要不命名那几个特殊的,word等)。输入目录是db,输出目录是bucket_dbs,不存在则新建目录。
测试的时候,先在控制台输入一句话,然后将这句话通过正反向字典Ids化,然后去桶里面找对应的回答的每一个字,然后将输出通过反向字典转化为汉字。
2.1 数据清洗、预处理
读取整个语料库,去掉E、M和空格,还原成原始文本。创建conversion.db,conversion表,两个字段。每取完1000组对话,插入依次数据库,批量提交,通过cursor.commit.
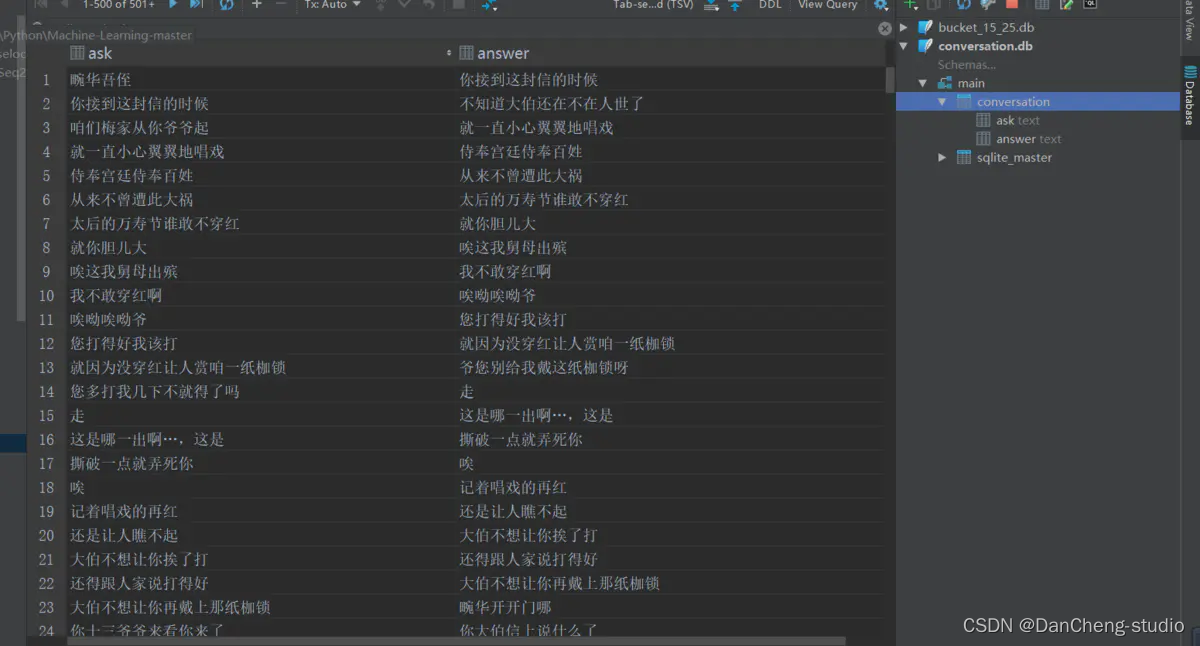
2.2 分桶
从总的conversion.db中分桶,指定输入目录db, 输出目录bucket_dbs.
检测文字有效性,循环遍历,依次记录问题答案,每积累到1000次,就写入数据库。
for ask, answer in tqdm(ret, total=total):if is_valid(ask) and is_valid(answer):for i in range(len(buckets)):encoder_size, decoder_size = buckets[i]if len(ask) <= encoder_size and len(answer) < decoder_size:word_count.update(list(ask))word_count.update(list(answer))wait_insert.append((encoder_size, decoder_size, ask, answer))if len(wait_insert) > 10000000:wait_insert = _insert(wait_insert)break
将字典维度6865未,投影到100维,也就是每个字是由100维的向量组成的。后面的隐藏层的神经元的个数是512,也就是维度。
句子长度超过桶长,就截断或直接丢弃。
四个桶是在read_bucket_dbs()读取的方法中创建的,读桶文件的时候,实例化四个桶对象。
2.3 训练
先读取json字典,加上pad等四个标记。
lstm有两层,attention在解码器的第二层,因为第二层才是lstm的输出,用两层提取到的特征越好。
num_sampled=512, 分批softmax的样本量(
训练和测试差不多,测试只前向传播,不反向更新
3 项目的整体结构
s2s.py:相当于main函数,让代码运行起来
里面有train()、test()、test_bleu()和create_model()四个方法,还有FLAGS成员变量,
相当于静态成员变量 public static final string
decode_conv.py和data_utils.py:是数据处理
s2s_model.py:
里面放的是模型
里面有init()、step()、get_batch_data()和get_batch()四个方法。构造方法传入构造方法的参数,搭建S2SModel框架,然后sampled_loss()和seq2seq_f()两个方法
data_utils.py:
读取数据库中的文件,并且构造正反向字典。把语料分成四个桶,目的是节约计算资源。先转换为db\conversation.db大的桶,再分成四个小的桶。buckets
= [ (5, 15), (10, 20), (15, 25), (20, 30)]
比如buckets[1]指的就是(10, 20),buckets[1][0]指的就是10。
bucket_id指的就是0,1,2,3
dictionary.json:
是所有数字、字母、标点符号、汉字的字典,加上生僻字,以及PAD、EOS、GO、UNK 共6865维度,输入的时候会进行词嵌入word
embedding成512维,输出时,再转化为6865维。
model:
文件夹下装的是训练好的模型。
也就是model3.data-00000-of-00001,这个里面装的就是模型的参数
执行model.saver.restore(sess, os.path.join(FLAGS.model_dir,
FLAGS.model_name))的时候,才是加载目录本地的保存的模型参数的过程,上面建立的模型是个架子,
model = create_model(sess, True),这里加载模型比较耗时,时间复杂度最高
dgk_shooter_min.conv:
是语料,形如: E
M 畹/华/吾/侄/
M 你/接/到/这/封/信/的/时/候/
decode_conv.py: 对语料数据进行预处理
config.json:是配置文件,自动生成的
4 重要的API
4.1 LSTM cells部分:
cell = tf.contrib.rnn.BasicLSTMCell(size)cell = tf.contrib.rnn.DropoutWrapper(cell, output_keep_prob=dropout)cell = tf.contrib.rnn.MultiRNNCell([cell] * num_layers)对上一行的cell去做Dropout的,在外面裹一层DropoutWrapper
构建双层lstm网络,只是一个双层的lstm,不是双层的seq2seq
4.2 损失函数:
tf.nn.sampled_softmax_loss( weights=local_w_t,
b labels=labels, #真实序列值,每次一个
inputs=loiases=local_b,
cal_inputs, #预测出来的值,y^,每次一个
num_sampled=num_samples, #512
num_classes=self.target_vocab_size # 原始字典维度6865)
4.3 搭建seq2seq框架:
tf.contrib.legacy_seq2seq.embedding_attention_seq2seq(encoder_inputs, # tensor of input seq 30decoder_inputs, # tensor of decoder seq 30tmp_cell, #自定义的cell,可以是GRU/LSTM, 设置multilayer等num_encoder_symbols=source_vocab_size,# 编码阶段字典的维度6865num_decoder_symbols=target_vocab_size, # 解码阶段字典的维度 6865embedding_size=size, # embedding 维度,512num_heads=20, #选20个也可以,精确度会高点,num_heads就是attention机制,选一个就是一个head去连,5个就是5个头去连output_projection=output_projection,# 输出层。不设定的话输出维数可能很大(取决于词表大小),设定的话投影到一个低维向量feed_previous=do_decode,# 是否执行的EOS,是否允许输入中间cdtype=dtype)4.4 测试部分:
self.outputs, self.losses = tf.contrib.legacy_seq2seq.model_with_buckets(
self.encoder_inputs,
self.decoder_inputs,
targets,
self.decoder_weights,
buckets,
lambda x, y: seq2seq_f(x, y, True),
softmax_loss_function=softmax_loss_function
)
4.5 评价NLP测试效果:
在nltk包里,有个接口叫bleu,可以评估测试结果,NITK是个框架
from nltk.translate.bleu_score import sentence_bleu
score = sentence_bleu(
references,#y值
list(ret),#y^
weights=(1.0,)#权重为1
)
4.6 梯度截断,防止梯度爆炸
clipped_gradients, norm = tf.clip_by_global_norm(gradients,max_gradient_norm)
tf.clip_by_global_norm(t_list, clip_norm, use_norm=None, name=None)
通过权重梯度的总和的比率来截取多个张量的值。t_list是梯度张量, clip_norm是截取的比率,这个函数返回截取过的梯度张量和一个所有张量的全局范数
4.7 模型保存
tf.train.Saver(tf.global_variables(), write_version=tf.train.SaverDef.V2)
5 重点和难点
5.1 函数
def get_batch_data(self, bucket_dbs, bucket_id):
def get_batch(self, bucket_dbs, bucket_id, data):
def step(self,session,encoder_inputs,decoder_inputs,decoder_weights,bucket_id):
5.2 变量
batch_encoder_inputs, batch_decoder_inputs, batch_weights = [], [], []
6 相关参数
model = s2s_model.S2SModel(data_utils.dim, # 6865,编码器输入的语料长度data_utils.dim, # 6865,解码器输出的语料长度buckets, # buckets就是那四个桶,data_utils.buckets,直接在data_utils写的一个变量,就能直接被点出来FLAGS.size, # 隐层神经元的个数512FLAGS.dropout, # 隐层dropout率,dropout不是lstm中的,lstm的几个门里面不需要dropout,没有那么复杂。是隐层的dropoutFLAGS.num_layers, # lstm的层数,这里写的是2FLAGS.max_gradient_norm, # 5,截断梯度,防止梯度爆炸FLAGS.batch_size, # 64,等下要重新赋值,预测就是1,训练就是64FLAGS.learning_rate, # 0.003FLAGS.num_samples, # 512,用作负采样forward_only, #只传一次dtype){"__author__": "qhduan@memect.co","buckets": [[5, 15],[10, 20],[20, 30],[40, 50]],"size": 512,/*s2s lstm单元出来之后的,连的隐层的number unit是512*/"depth": 4,"dropout": 0.8,"batch_size": 512,/*每次往里面放多少组对话对,这个是比较灵活的。如果找一句话之间的相关性,batch_size就是这句话里面的字有多少个,如果要找上下文之间的对话,batch_size就是多少组对话*/"random_state": 0,"learning_rate": 0.0003,/*总共循环20次*/"epoch": 20,"train_device": "/gpu:0","test_device": "/cpu:0"}7 桶机制
7.1 处理数据集
语料库长度桶结构
(5, 10): 5问题长度,10回答长度
每个桶中对话数量,一问一答为一次完整对话
Analysis
(1) 设定4个桶结构,即将问答分成4个部分,每个同种存放对应的问答数据集[87, 69, 36,
8]四个桶中分别有87组对话,69组对话,36组对话,8组对话;
(2) 训练词数据集符合桶长度则输入对应值,不符合桶长度,则为空;
(3) 对话数量占比:[0.435, 0.78, 0.96, 1.0];
7.2 词向量处理seq2seq
获取问答及答案权重
参数:
- data: 词向量列表,如[[[4,4],[5,6,8]]]
- bucket_id: 桶编号,值取自桶对话占比
步骤:
- 问题和答案的数据量:桶的话数buckets = [(5, 10), (10, 15), (20, 25), (40, 50)]
- 生成问题和答案的存储器
- 从问答数据集中随机选取问答
- 问题末尾添加PAD_ID并反向排序
- 答案添加GO_ID和PAD_ID
- 问题,答案,权重批量数据
- 批量问题
- 批量答案
- 答案权重即Attention机制
- 若答案为PAD则权重设置为0,因为是添加的ID,其他的设置为1
Analysis
-
(1) 对问题和答案的向量重新整理,符合桶尺寸则保持对话尺寸,若不符合桶设定尺寸,则进行填充处理,
问题使用PAD_ID填充,答案使用GO_ID和PAD_ID填充; -
(2) 对问题和答案向量填充整理后,使用Attention机制,对答案进行权重分配,答案中的PAD_ID权重为0,其他对应的为1;
-
(3) get_batch()处理词向量;返回问题、答案、答案权重数据;
返回结果如上结果:encoder_inputs, decoder_inputs, answer_weights.
7.3 处理问答及答案权重
参数:session: tensorflow 会话.encoder_inputs: 问题向量列表decoder_inputs: 回答向量列表answer_weights: 答案权重列表bucket_id: 桶编号which bucket of the model to use.forward_only: 前向或反向运算标志位
返回:一个由梯度范数组成的三重范数(如果不使用反向传播,则为无)。平均困惑度和输出
Analysis
-
(1) 根据输入的问答向量列表,分配语料桶,处理问答向量列表,并生成新的输入字典(dict), input_feed = {};
-
(2) 输出字典(dict), ouput_feed = {},根据是否使用反向传播获得参数,使用反向传播,
output_feed存储更新的梯度范数,损失,不使用反向传播,则只存储损失; -
(3) 最终的输出为分两种情况,使用反向传播,返回梯度范数,损失,如反向传播不使用反向传播,
返回损失和输出的向量(用于加载模型,测试效果),如前向传播;
7.4 训练&保存模型
步骤:
-
检查是否有已存在的训练模型
-
有模型则获取模型轮数,接着训练
-
没有模型则从开始训练
-
一直训练,每过一段时间保存一次模型
-
如果模型没有得到提升,减小learning rate
-
保存模型
-
使用测试数据评估模型
global step: 500, learning rate: 0.5, loss: 2.574068747580052 bucket id: 0, eval ppx: 14176.588030763274 bucket id: 1, eval ppx: 3650.0026667220773 bucket id: 2, eval ppx: 4458.454110999805 bucket id: 3, eval ppx: 5290.083583183104
7.5 载入模型&测试
(1) 该聊天机器人使用bucket桶结构,即指定问答数据的长度,匹配符合的桶,在桶中进行存取数据;
(2) 该seq2seq模型使用Tensorflow时,未能建立独立标识的图结构,在进行后台封装过程中出现图为空的现象;
从main函数进入test()方法。先去内存中加载训练好的模型model,这部分最耗时,改batch_size为1,传入相关的参数。开始输入一个句子,并将它读进来,读进来之后,按照桶将句子分,按照模型输出,然后去查字典。接着在循环中输入上句话,找对应的桶。然后拿到的下句话的每个字,找概率最大的那个字的index的id输出。get_batch_data(),获取data [('天气\n', '')],也就是问答对,但是现在只有问,没有答get_batch()获取encoder_inputs=1*10,decoder_inputs=1*20 decoder_weights=1*20step()获取预测值output_logits,

8 最后
🧿 更多资料, 项目分享:
https://gitee.com/dancheng-senior/postgraduate
相关文章:
竞赛项目 深度学习的智能中文对话问答机器人
文章目录 0 简介1 项目架构2 项目的主要过程2.1 数据清洗、预处理2.2 分桶2.3 训练 3 项目的整体结构4 重要的API4.1 LSTM cells部分:4.2 损失函数:4.3 搭建seq2seq框架:4.4 测试部分:4.5 评价NLP测试效果:4.6 梯度截断…...

【剑指 の 精选】热门状态机 DP 运用题
题目描述 这是 LeetCode 上的 「剑指 Offer II 091. 粉刷房子」 ,难度为 「中等」。 Tag : 「状态机 DP」、「动态规划」 假如有一排房子,共 n 个,每个房子可以被粉刷成红色、蓝色或者绿色这三种颜色中的一种,你需要粉刷所有的房子…...
自动化实践-全量Json对比在技改需求提效实践
1 背景 随着自动化测试左移实践深入,越来越多不同类型的需求开始用自动化测试左移来实践,在实践的过程中也有了新的提效诉求,比如技改类的服务拆分项目或者BC流量拆分的项目,在实践过程中,这类需求会期望不同染色环境…...
【Matlab】PSO优化(单隐层)BP神经网络
上一篇博客介绍了BP-GA:BP神经网络遗传算法(BP-GA)函数极值寻优——非线性函数求极值,本篇博客将介绍用PSO(粒子群优化算法)优化BP神经网络。 1.优化思路 BP神经网络的隐藏节点通常由重复的前向传递和反向传播的方式来决定&#…...

创建型模式-原型模式
文章目录 一、原型模式1. 概述2. 结构3. 实现4. 案例1.5 使用场景1.6 扩展(深克隆) 一、原型模式 1. 概述 用一个已经创建的实例作为原型,通过复制该原型对象来创建一个和原型对象相同的新对象。 2. 结构 原型模式包含如下角色: …...
JS逆向系列之猿人学爬虫第11题 - app抓取 - so文件协议破解
题目地址 http://match.yuanrenxue.com/match/11这是个app题目,先下载下来安装到测试手机上 安装完成后的app界面长这样 打开之后是这样的: 要求已经简单明了了。 二话不说先反编译app 不出意外的是没出意外,源代码里面没啥混淆,所有东西都展示的明明白白的。 "…...
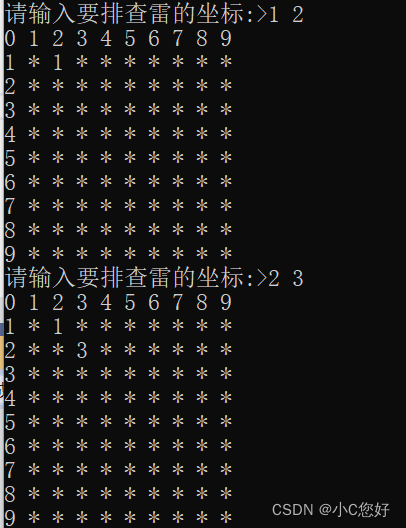
c基础扫雷
和三子棋一样,主函数先设计游戏菜单界面,这里就不做展示了。 初始化棋盘 初级扫雷大小为9*9的棋盘,但排雷是周围一圈进行排雷(8格),而边界可能会越界。数组扩大了一圈,行和列都加了2,所以我们用一个11*11的数组来初始化…...

端点中心(Endpoint Central)的软件许可证管理
软件许可证管理 (SLM) 是从单个控制台管理整个组织中使用的软件许可证的过程。软件许可证是由软件发行商或分销商制作的法律文件,提供有关软件使用和分发的规则和指南,本文档通常包含条款和条件、限制和免责声明。 软件许可证管理…...
SpringCloud源码探析(九)- Sentinel概念及使用
1.概述 在微服务的依赖调用中,若被调用方出现故障,出于自我保护的目的,调用方会主动停止调用,并根据业务需要进行对应处理,这种方式叫做熔断,是微服务的一种保护方式。为了保证服务的高可用性,…...
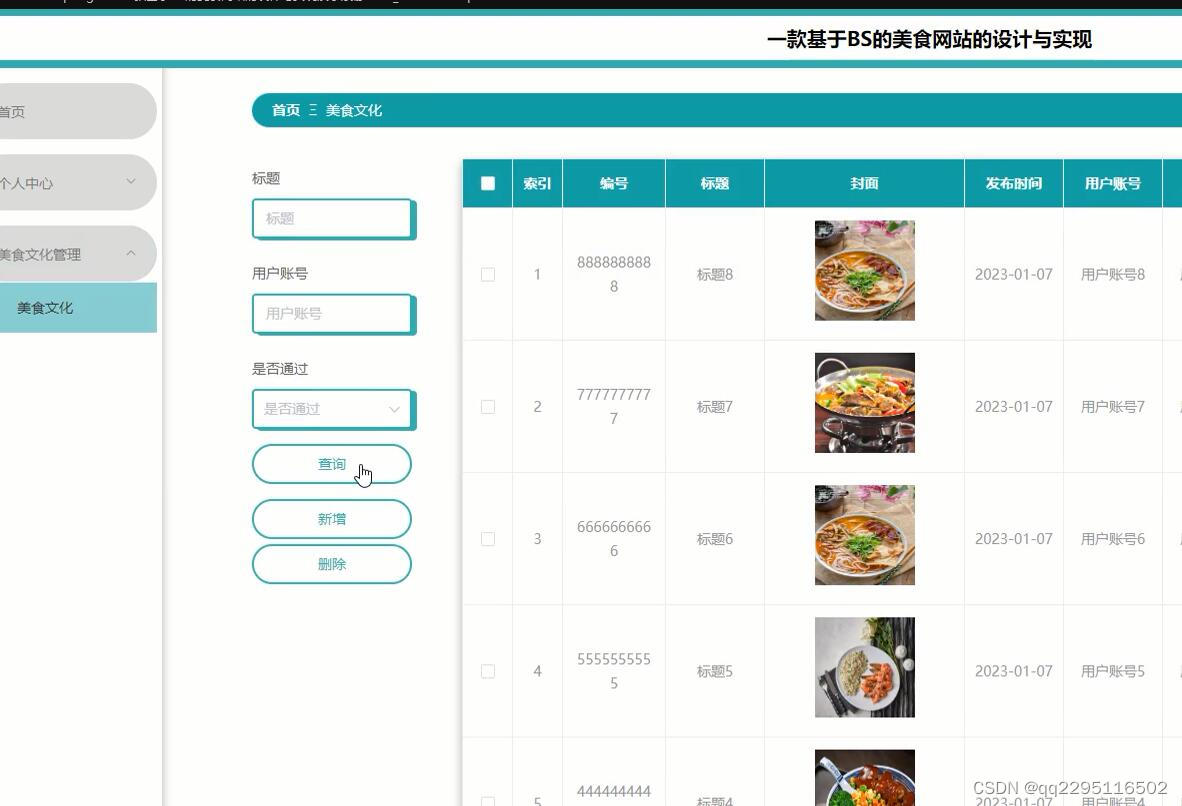
nodejs+vue+elementui美食网站的设计与实现演示录像2023_0fh04
本次的毕业设计主要就是设计并开发一个美食网站软件。运用当前Google提供的nodejs 框架来实现对美食信息查询功能。当然使用的数据库是mysql。系统主要包括个人信息修改,对餐厅管理、用户管理、餐厅信息管理、菜系分类管理、美食信息管理、美食文化管理、系统管理、…...

Mysql 数据库增删改查
MySQL是目前最流行的关系型数据库。以下是MySQL数据库的增删改查操作。 1.数据库连接 在进行增删改查操作之前,需要先连接MySQL数据库。使用以下命令进行连接: import mysql.connectormydb mysql.connector.connect(host"localhost",user&…...
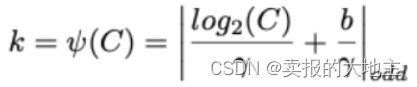
【深度学习注意力机制系列】—— ECANet注意力机制(附pytorch实现)
ECANet(Efficient Channel Attention Network)是一种用于图像处理任务的神经网络架构,它在保持高效性的同时,有效地捕捉图像中的通道间关系,从而提升了特征表示的能力。ECANet通过引入通道注意力机制,以及在…...

python爬虫的简单实现
当涉及网络爬虫时,Python中最常用的库之一是requests。它能够发送HTTP请求并获取网页内容。下面是一个简单的示例,展示如何使用requests库来获取一个网页的内容: import requests 指定要爬取的网页的URL url ‘https://example.com’ 发…...

如何正确的向chatgpt提问?
有没有发现,在使用ChatGPT的时候,他回答的一些问题并不是我们想要的甚至有的时候出现牛头不对马嘴的情况。 这时候就会感慨一句,人工智能也不怎么样嘛! 但是,有没有想过,是自己问的问题太宽泛,没有问到点上…...
一键部署 Umami 统计个人网站访问数据
谈到网站统计,大家第一时间想到的肯定是 Google Analytics。然而,我们都知道 Google Analytics 会收集所有用户的信息,对数据没有任何控制和隐私保护。 Google Analytics 收集的指标实在是太多了,有很多都是不必要的,…...

java种的hutool库接口说明和整理
1. Hutool库基本介绍 1.1. 地址 官网地址:https://www.hutool.cn/ 1.2. 基本介绍 Hutool是一个小而全的Java工具类库,通过静态方法封装,降低相关API的学习成本,提高工作效率,使Java拥有函数式语言般的优雅…...

控制国外各类电液伺服阀放大器
控制通用型不带反馈信号输入的伺服阀放大器,对射流管式电液伺服阀、喷嘴挡板式电液伺服阀及国外各类电液伺服阀进行控制。 通过系统参数有10V和4~20mA输入指令信号选择; 供电电源: 24VDC(标准) 输出电流:最大可达10…...

【go语言基础】go中的方法
先思考一个问题,什么是方法,什么是函数? 方法是从属于某个结构体或者非结构体的。在func这个关键字和方法名中间加了一个特殊的接收器类型,这个接收器可以是结构体类型的或者是非结构体类型的。从属的结构体获取该方法。 函数则…...

Go 语言并发编程 及 进阶与依赖管理
1.0 从并发编程本质了解Go高性能的本质 1.1 Goroutine 协程可以理解为轻量级线程; Go更适合高并发场景原因之一:Go语言一次可以创建上万协成; “快速”:开多个协成 打印。 go func(): 在函数前加 go 代表 创建协程; time.Sleep():…...
绽放趋势:Python折线图数据可视化艺术
文章目录 一 json数据格式1.1 json数据格式认识1.2 Python数据和Json数据的相互转换 二 pyecharts模块2.1 pyecharts概述2.2 pyecharts模块安装 三 pyecharts快速入门3.1 基础折线图3.2 pyecharts配置选项3.2.1 全局配置选项 3.4 折线图相关配置3.4.1 .add_yaxis相关配置选项3.…...

Sunshine游戏串流完全指南:从零开始搭建自托管游戏服务器
Sunshine游戏串流完全指南:从零开始搭建自托管游戏服务器 【免费下载链接】Sunshine Self-hosted game stream host for Moonlight. 项目地址: https://gitcode.com/GitHub_Trending/su/Sunshine Sunshine是一款强大的自托管游戏串流服务器,专为M…...

【收藏备用|2026年版】程序员小白必看:AI大模型不是抢饭碗,是帮你涨薪的神器!
这两年,技术圈流传着一句扎心的话,相信每个程序员和刚入行的小白都听过,听完难免心头一紧: “这个岗位,可以用AI替代。” 我身边做技术的朋友,不管是刚入门、还在啃基础代码的小白,还是工作三…...
)
别再乱选求解器了!CST MWS 2021版6大求解器保姆级选择指南(附应用场景)
CST MWS 2021求解器选择全攻略:从原理到实战的黄金法则 在电磁仿真领域,CST Microwave Studio(MWS)就像一位拥有六把不同钥匙的开锁专家——每把钥匙(求解器)对应特定类型的锁(电磁问题…...

LabVIEW TCP通讯实现三菱PLC FX3U的MC协议网络交互:命令帧读写、批量数据传输...
LabVIEW网络网口TCP通讯三菱PLC FX3U ENET-ADP,MC协议网络通讯FX3U网络通讯。 官方MC协议,报文读取,安全稳定。 程序代开发,代写程序。 通讯配置,辅助测试。 FX3U无程序网络通讯实现。 常用功能一网打尽。 1.命令帧读写…...
别再瞎调参数了!手把手教你用Hugging Face Transformers设置大模型temperature、top_p等核心参数
别再瞎调参数了!手把手教你用Hugging Face Transformers设置大模型核心参数 刚接触大模型调参的开发者常陷入两个极端:要么保守地使用默认参数导致输出平庸,要么盲目调整参数组合让结果失控。本文将用代码实例展示如何像专业炼丹师一样精准控…...

路由选择协议技术
引言 在当今互联互通的网络世界中,数据包如何从源设备高效、准确地到达目的地,离不开路由选择协议的支撑。作为TCP/IP体系架构中的核心组成部分,路由选择协议负责动态维护网络中的路由表,确保数据能够沿着最优路径传输。本文将系统…...

STM32CubeMX最新版安装避坑指南:从注册账号到固件包下载,手把手解决网络报错
STM32CubeMX最新版安装避坑指南:从注册账号到固件包下载,手把手解决网络报错 第一次接触STM32开发的朋友们,十有八九会在CubeMX安装环节踩坑。作为ST官方推出的图形化配置工具,CubeMX能大幅降低开发门槛,但它的安装过程…...

CoCo框架:代码驱动的文本到图像生成技术解析
1. 项目概述CoCo(Code-as-CoT)是一种创新的文本到图像(T2I)生成框架,它将传统的自然语言链式思考(CoT)推理过程转化为可执行代码,从而实现对生成图像结构化布局的精确控制。该框架由…...
)
保姆级教程:在Ubuntu 22.04上从零安装ROS Humble(含虚拟机配置与常见报错解决)
零基础实战:Ubuntu 22.04虚拟机环境下的ROS Humble完整安装指南 当机器人操作系统(ROS)遇上Ubuntu长期支持版,会碰撞出怎样的开发火花?本指南专为从未接触过Linux环境的开发者设计,从虚拟机配置到ROS Humbl…...

深度评测:Seedance 2.0 vs Runway Gen-3在复杂动作生成上的优劣
引言 当前AI视频生成赛道竞争白热化,复杂人体动作、物理交互、连续运镜、多物体动态协同,是区分模型实力的核心分水岭,也是短视频创作、影视分镜、广告实拍替代的核心刚需。目前主流商用模型中,字节 Seedance 2.0 与 Runway Gen-3 是最具代表性的两大标杆。本文基于统一测试…...