Django路由Router
文章目录
- 一、路由router
- 路由匹配
- 命名空间
- 反向解析
- 二、实践
- 创建用户模型Model
- 添加子路由 - 创建用户首页
- 页面跳转 - 使用反向解析和命名空间
- 1. 不使用命名空间的效果
- 2. 使用命名空间的效果
- 用户详情页面跳转 - 路由传参
- 路由传递多个参数
- re_path 以前写法,了解即可
- 重定向Redirect
- 1. 重定向别的地址
- 2.重定向到自己路由(带参数)
- 3.重定向 反向解析: 位置参数传参
- 4. 重定向 反向解析:关键字传参
一、路由router
在实际开发过程中,一个Djaqgo 项目会包含很多的 app,这时候如果我们只在主路由里进行配置就会显得杂乱无章,所以通常会在每个app 里,创建各自的 urls.py 路由模块,然后从根路由出发,将 app 所属的 url 请求,全部转发到相应的 urls.py模块中。而这个从主路由转发到各个应用路由的过程叫做路由的分发。
路由匹配
# 使用ur1给视图函数传参数
path('index/', index)
path('detail/<int:id>/', detail)# 给ur1取别名,那么在使用此ur1的地方可以使用别名。比如:
path('index/', index, name='index')
path('detail/<int:id>/', detail, name='detail')
<int:id> 整数
<str:id> 字符串
命名空间
在实际应用中,Diango中可能存在多个应用程序,每个应用程序都可能有自己的路由模块。为了防止路由冲突,Django提供了命名空间(namespace)的概念。命名空间是一种将路由命名为层次结构的方式,使得在查询路由时可以限定在该命名空间内。
# 在根路由中可以设置命名空间path('app/', include(('App.urls',"App",namespace='App')
反向解析
Django路由反向解析是一个非常重要的功能,它可以让我们在代码中使用路由别名替代URL路径,在修改URL时避免代码中的硬编码依赖,同时也可以提高可读性和可维护性。
- redirect 叫重定向
- 我们在做跳转的时候,其实就是做一个页面跳转,在我们后台相当于是一个视图函数之间的跳转,从这个视图函数直接跳到另一个视图函数
- reverse 是反向解析
- reverse(路由name) 得到的是name所对应的路由路径 (字符串)。
- reverse( ‘index’) ==> ‘index/’
- redirect(reverse( ‘index’)) 相当于==> redirect( ‘index/’ ) 也是可以跳转的。
- args= 位置传参
- kwargs= 关键字参数传参
# 在视图函数中,反向解析ur1:from django.shortcuts import render,redirect,reversedef buy(request):return redirect(reverse( 'index')) # 重定向return redirect(reverse( 'detail',args=[2])) # 重定向 参数传递return redirect(reverse('detail', kwargs={"id": 2})) # 重定向 关键字传参# 在templates中,使用别名{% url 'detail' stu.id %)# 使用命名空间:
# 指定命令空间后,使用反向解析时需要加上命名空间,比如:
# 1.在视图函数中:return redirect(reverse('App:index'))
# 2.在templates中:{% url 'App:index' %}{% url 'App:detail' 2 %}
如果用了命名空间,后面的反向解析(包括视图函数和模板中)都要使用命名空间
二、实践
新建一个新项目Day02MyDjangoPro01
创建用户模型Model
App\models.py
from django.db import modelsclass UserModel(models.Model):name = models.CharField(max_length=30)age = models.PositiveIntegerField() # 非负数生成迁移文件: python manage.py makemigrations
执行迁移: python manage.py migrate
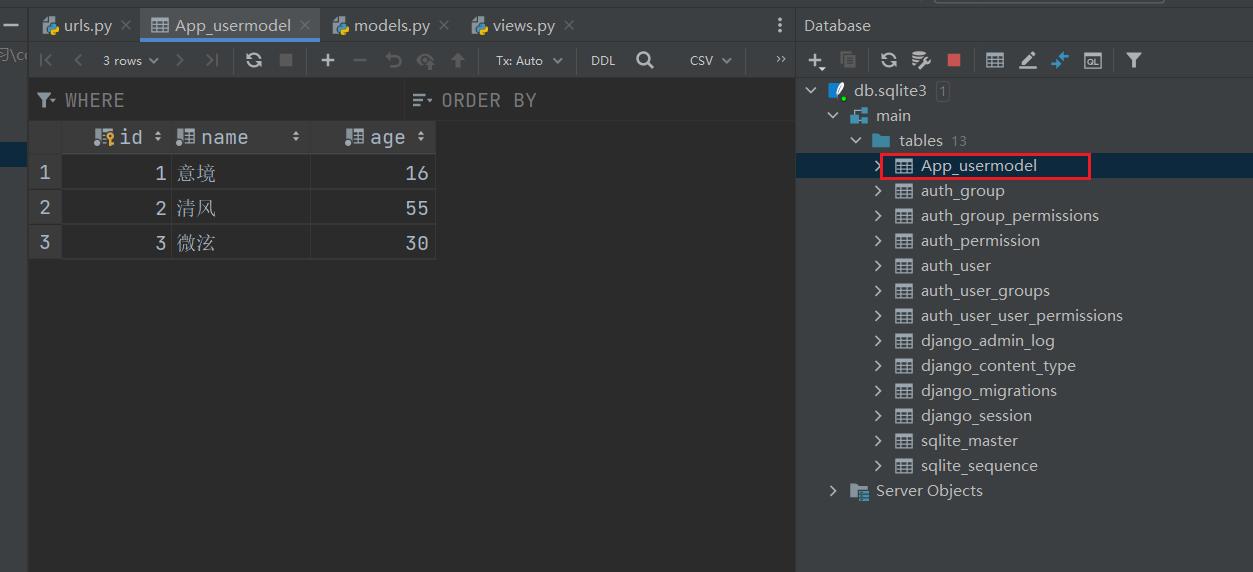
数据库:添加几条数据
添加子路由 - 创建用户首页
App\urls.py
from django.urls import path
from App.views import *urlpatterns = [path('index/', index), # 首页]
App\templates\index.html
<!DOCTYPE html>
<html lang="en">
<head><meta charset="UTF-8"><title>首页</title>
</head>
<body><h2>首页</h2><hr></body>
</html>
App\views.py
from django.shortcuts import renderdef index(request):return render(request, "index.html")
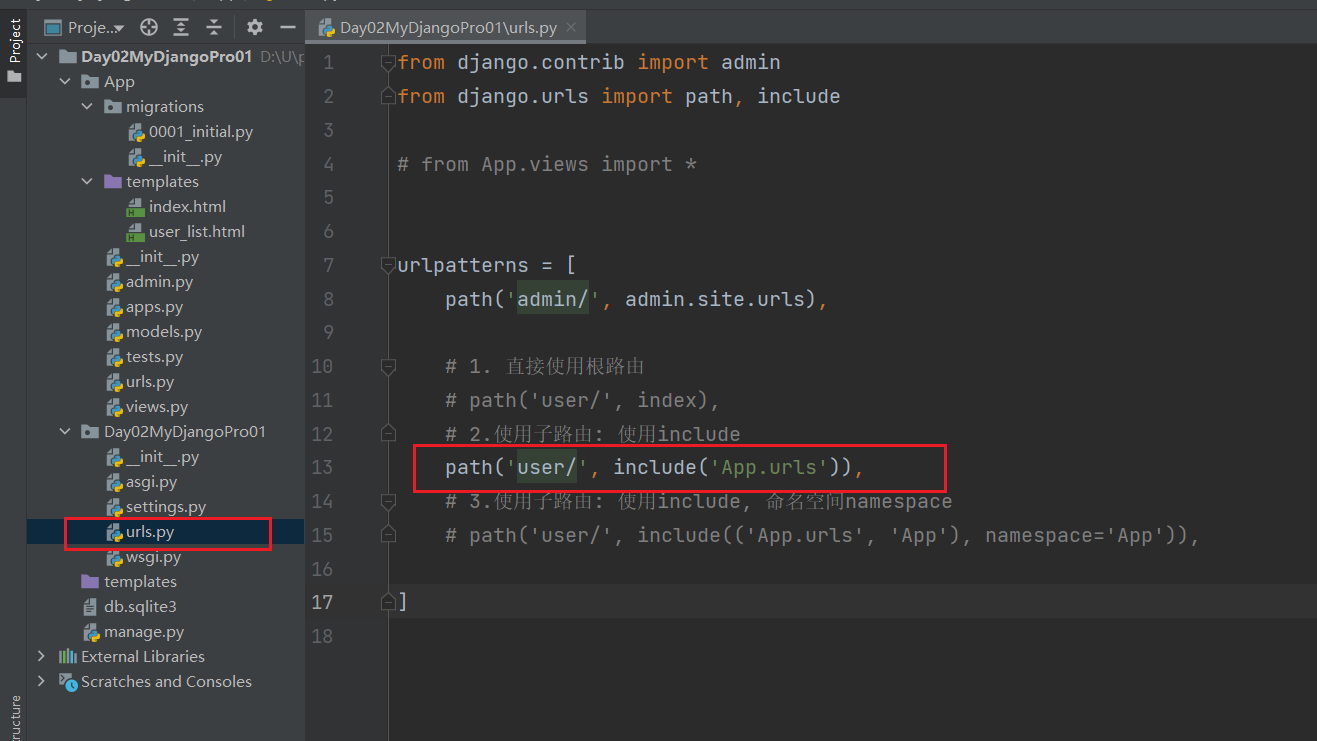
根路由 Day02MyDjangoPro01\urls.py
from django.contrib import admin
from django.urls import path, include# from App.views import *urlpatterns = [path('admin/', admin.site.urls),# 1. 直接使用根路由# path('user/', index),# 2.使用子路由: 使用include# path('user/', include('App.urls')),# 3.使用子路由: 使用include, 命名空间namespacepath('user/', include(('App.urls', 'App'), namespace='App')),]
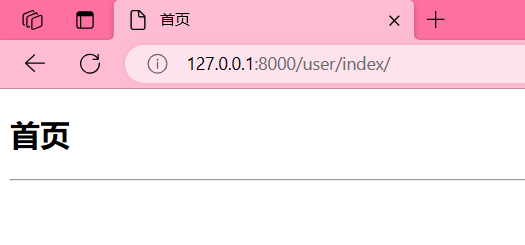
http://127.0.0.1:8000/user/index/
页面跳转 - 使用反向解析和命名空间
App\templates\user_list.html
<!DOCTYPE html>
<html lang="en">
<head><meta charset="UTF-8"><title>用户列表</title>
</head>
<body><h2>用户列表</h2><hr>
</body>
</html>
App\views.py 创建视图函数user_list
from django.shortcuts import render# 首页
def index(request):return render(request, "index.html")# 用户列表
def user_list(request):return render(request, "user_list.html")App\urls.py 写一个路由
from django.urls import path
from App.views import *urlpatterns = [path('index/', index), # 首页path('user_list/', user_list, name='user_list') # 用户列表
]
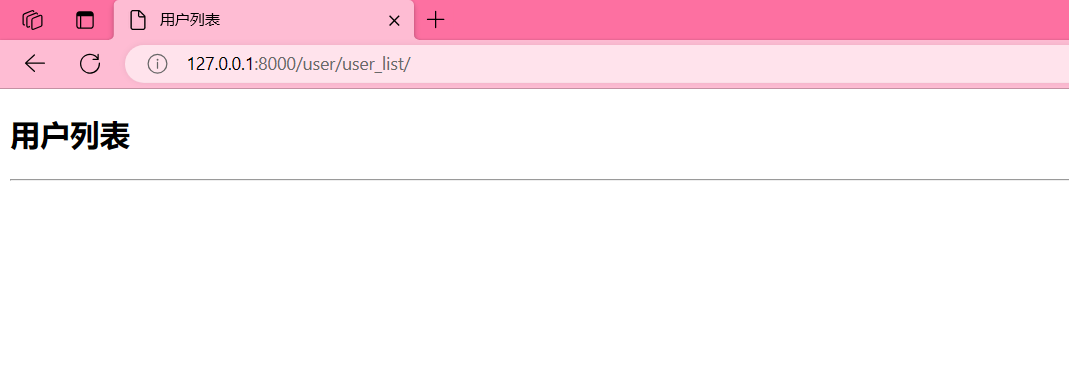
需求:在index页面跳转到user_list页面
1. 不使用命名空间的效果
根路由 Day02MyDjangoPro01\urls.py
App\templates\index.html
反向解析 {% url '定义路由后面name的名字' %}
<!DOCTYPE html>
<html lang="en">
<head><meta charset="UTF-8"><title>首页</title>
</head>
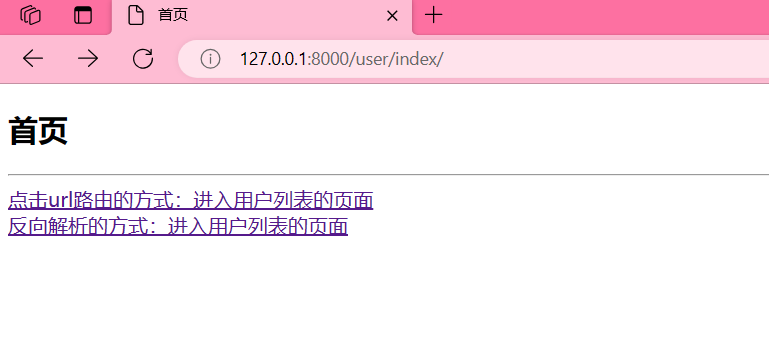
<body><h2>首页</h2><hr>{# url路由跳转 #}<a href="/user/user_list/">点击url路由的方式:进入用户列表的页面</a><br>{# 反向解析 {% url '定义路由后面name的名字' %} #}{# user_list 是path路由的name值 #}<a href="{% url 'user_list' %}">反向解析的方式:进入用户列表的页面</a><br></body>
</html>
点击是可以跳转的
2. 使用命名空间的效果
根路由 Day02MyDjangoPro01\urls.py
App\templates\index.html
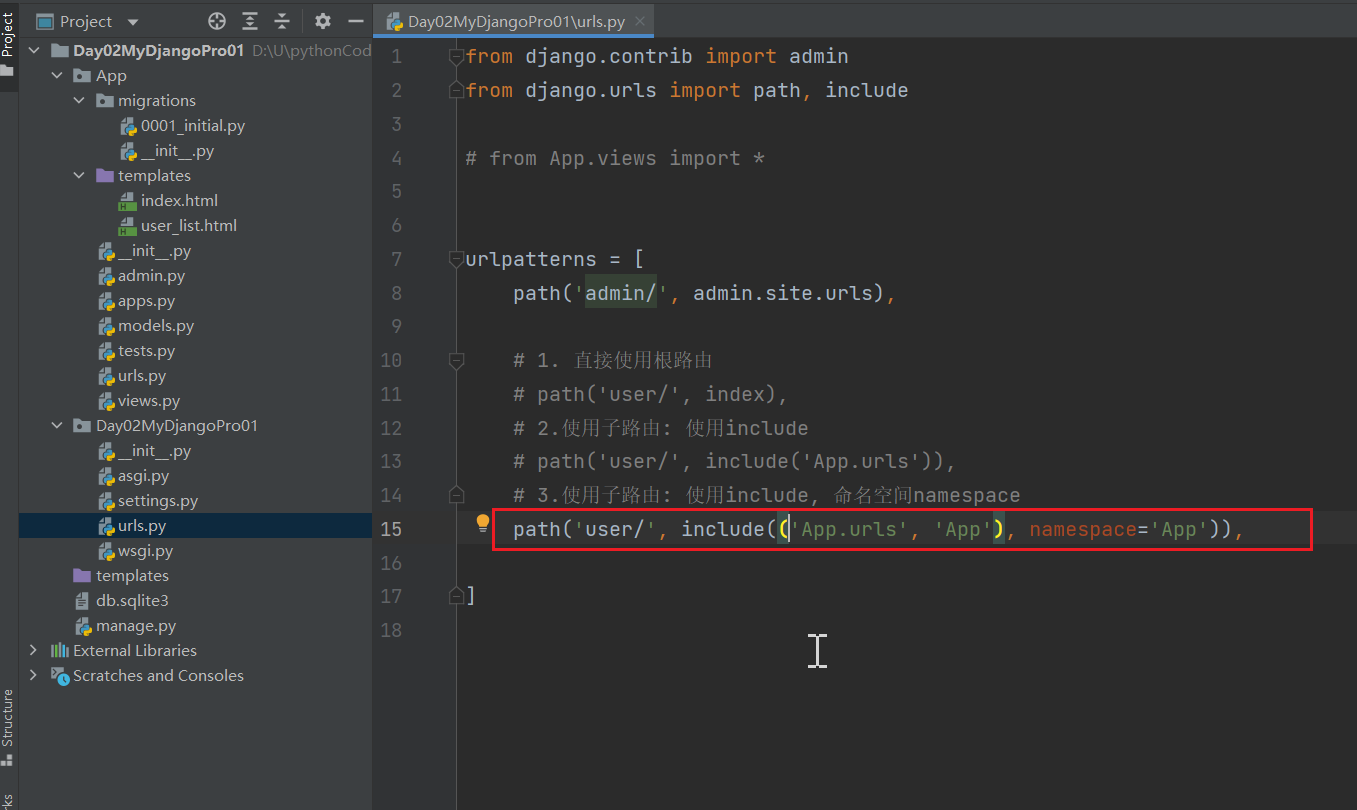
反向解析:带命名空间 {% url '命名空间的名称:定义路由后面name的名字' %}。namespace你可以理解为 一个子路由有一个命名空间。
这样做有什么用?一个命名空间表示一个应用,我们在写代码的时候,如果我们在不同应用中取相同name的话,那么可以通过应用空间namespace去区分他们。
如果是用子路由,就建议使用命名空间!!!
<!DOCTYPE html>
<html lang="en">
<head><meta charset="UTF-8"><title>首页</title>
</head>
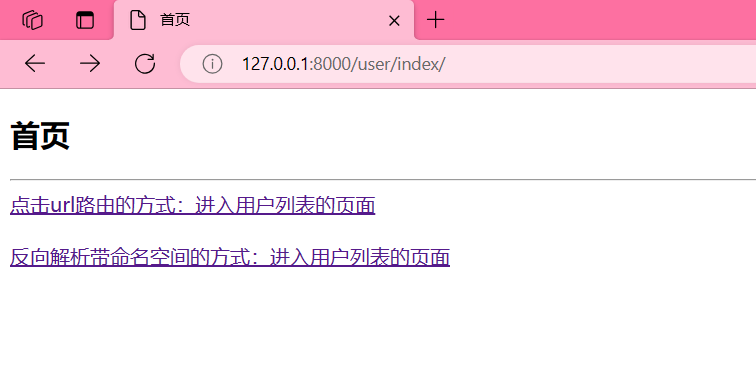
<body><h2>首页</h2><hr>{# url路由跳转 #}<a href="/user/user_list/">点击url路由的方式:进入用户列表的页面</a><br>{# 反向解析 {% url '定义路由后面name的名字' %} #}{# user_list 是path路由的name值 #}
{# <a href="{% url 'user_list' %}">反向解析的方式:进入用户列表的页面</a>#}<br>{# 反向解析:带命名空间 {% url '命名空间的名称:定义路由后面name的名字' %} #}<a href="{% url 'App:user_list' %}">反向解析带命名空间的方式:进入用户列表的页面</a>
</body>
</html>
点击是可以跳转的
用户详情页面跳转 - 路由传参
App\views.py ,user_list 传参、用户详情
from django.shortcuts import render
from App.models import *# 首页
def index(request):return render(request, "index.html")# 用户列表
def user_list(request):# 获取所有用户数据users = UserModel.objects.all()return render(request, "user_list.html", {"users": users})# 用户详情
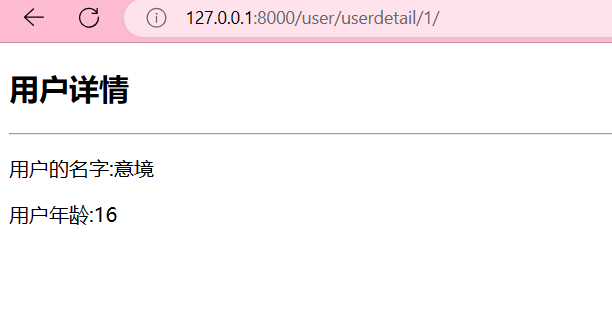
def user_detail(request, uid):# print("uid:", uid)user = UserModel.objects.get(pk=uid) # pk:primary key主键return render(request, "user_detail.html", {'user': user})增加一个页面,用户详情页面, App\templates\user_detail.html
<!DOCTYPE html>
<html lang="en">
<head><meta charset="UTF-8"><title>用户详情</title>
</head>
<body><h2>用户详情</h2><hr><p>用户的名字:{{ user.name }}</p><p>用户年龄:{{ user.age }}</p>
</body>
</html>
添加路由 App\urls.py
from django.urls import path
from App.views import *urlpatterns = [path('index/', index), # 首页path('user_list/', user_list, name='user_list'), # 用户列表path('userdetail/<int:uid>/', user_detail, name='userdetail'), # 用户详情
]App\templates\user_list.html ,将数据显示
<!DOCTYPE html>
<html lang="en">
<head><meta charset="UTF-8"><title>用户列表</title>
</head>
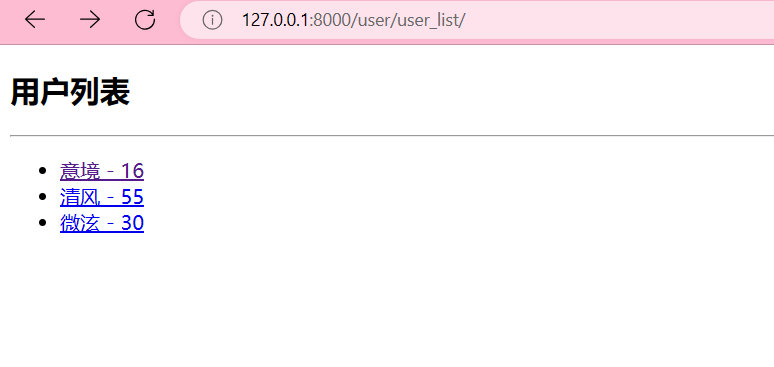
<body><h2>用户列表</h2><hr><ul>{% for user in users %}<li>{# 反向解析: 路由传参 #}<a href="{% url 'App:userdetail' user.id %}">{{ user.name }} - {{ user.age }}</a></li>{% endfor %}</ul></body>
</html>
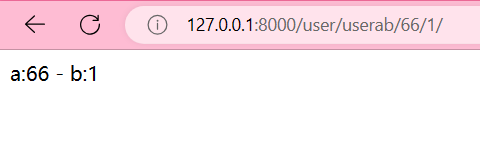
路由传递多个参数
App\views.py
from django.http import HttpResponse# 多个参数
def user_ab_view(request, a, b):return HttpResponse(f'a:{a} - b:{b}')
添加路由 App\urls.py
# 多个参数
path('userab/<int:a>/<int:b>/', user_ab_view, name='user_ab'),
但是如果我把视图函数参数顺序反过来 会怎么样呢?
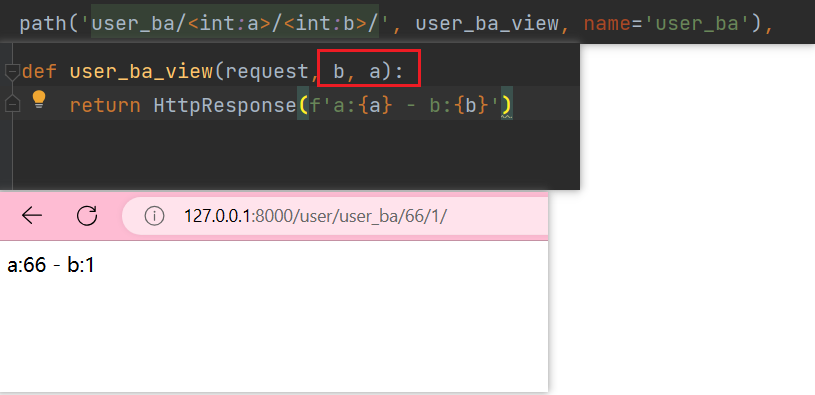
可以看到跟视图函数a,b顺序是没有关系的,a传给a,b传给b。
我们在用的时候,要和路由中的参数名一致,名字对应赋值,你可以理解为相当于关键字参数传值,a赋给a,b赋给b。
re_path 以前写法,了解即可
re 是正则的意思

第一个参数 得用正则,一般前面加一个r,字符串转义,这个跟正则没有太大关系,一般会写上r。有几个参数写上几个括号() ,整个字符串'user_ba/()/()/'会当做字符去处理的,
\d表示一个数字,\d+表示它可以是数字,表示这一块接收的是整数,+的意思就是一个整数多个整数都可以,但不能为零个整数。
a表示整数的名字,?P<a>这一串其实是给它命一个名字,给这个分组命名为a。
重定向Redirect
1. 重定向别的地址
App\views.py
from django.shortcuts import render, redirect, reverse# 重定向
def my_redirect(request):return redirect("https://blog.csdn.net/weixin_59633478/category_12401835.html")
添加路由 App\urls.py
path("myredirect/", my_redirect)
打开浏览器,输入http://127.0.0.1:8000/user/myredirect
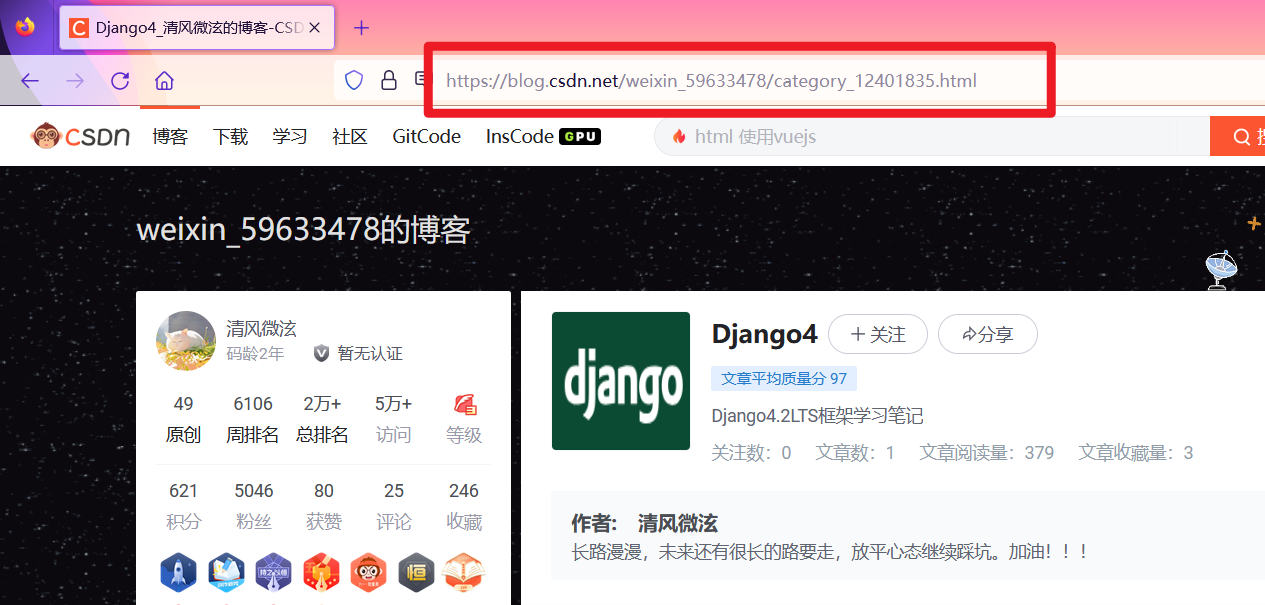
注意:自动跳到了https://blog.csdn.net/weixin_59633478/category_12401835.html,地址改变了
2.重定向到自己路由(带参数)
App\views.py
def my_redirect(request):# return redirect("/user/user_list")return redirect("/user/userdetail/2/") # 带参数:第一种写法
3.重定向 反向解析: 位置参数传参
def my_redirect(request):# return redirect("/user/userdetail/2/") # 带参数:第一种写法# 反向解析return redirect(reverse("App:userdetail", args=(2,))) # reverse("App:userdetail", args=(2,)) 相当于 '/user/userdetail/2/'
注意: 有命名空间一定要写命名空间,如果没有命名空间就不用写命名空间
# 不带命名空间
return redirect(reverse("userdetail", args=(2,)))
4. 重定向 反向解析:关键字传参
def my_redirect(request):# 反向解析# return redirect(reverse("App:userdetail", args=(2,))) # 反向解析: 关键字传参return redirect(reverse("App:userdetail", kwargs={'uid': 2}))
相关文章:
Django路由Router
文章目录 一、路由router路由匹配命名空间反向解析 二、实践创建用户模型Model添加子路由 - 创建用户首页页面跳转 - 使用反向解析和命名空间1. 不使用命名空间的效果2. 使用命名空间的效果 用户详情页面跳转 - 路由传参路由传递多个参数re_path 以前写法,了解即可重定向Redire…...
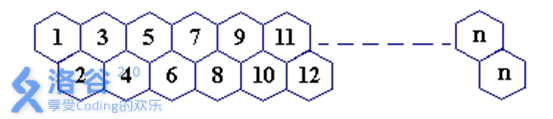
蜜蜂路线 P2437
蜜蜂路线 题目背景 无 题目描述 一只蜜蜂在下图所示的数字蜂房上爬动,已知它只能从标号小的蜂房爬到标号大的相邻蜂房,现在问你:蜜蜂从蜂房 m 开始爬到蜂房 n,m<n,有多少种爬行路线?(备注:题面有误&…...

无脑——010 复现yolov8 使用yolov8和rt detr 对比,并训练自己的数据集
1.配置环境 1. 首先去官网下载yolov8的zip https://github.com/ultralytics/ultralytics 存放在我的目录下G:\bsh\yolov8 然后使用conda创建新的环境 conda create -n yolov8 python3.8 #然后激活环境 conda activate yolov8然后安装pytorch,注意 ,py…...
如何给Google Chrome增加proxy
1. 先打开https://github.com/KaranGauswami/socks-to-http-proxy/releases 我的电脑是Liunx系统所以下载第一个 2. 下载完之后把这个文件变成可执行文件,可以是用这个命令 chmod x 文件名 3. 然后执行这个命令: ./sthp-linux -p 8080 -s 127.0.0.1:…...

设计模式——原型模式
原型模式就是有时我们需要多个类的实例,但是一个个创建,然后初始化,这样太麻烦了,此时可以使用克隆,来创建出克隆对象,就能大大的提高效率。具体就是要让此类实现Cloneable接口,然后重写Object类…...

Spring框架中的Bean生命周期
目录 Bean的实例化 BeanFactoryPostProcessor 属性赋值 循环依赖 初始化 处理各种Aware接口 执行BeanPostProcessor前置处理 执行InitializingBean初始化方法或执行init-method自定义初始化方法 执行BeanPostProcessor后置处理 销毁 Spring Bean 的生命周期总体分为…...

async和await修饰符
async和await是JavaScript中用来处理异步操作的关键字 。 async和await也是解决回调地域的终极方案,简单,而Promise链混杂难以看懂。 async关键字用于定义一个函数,使其返回一个Promise对象。这意味着该函数可以通过await关键字来暂停执行&…...
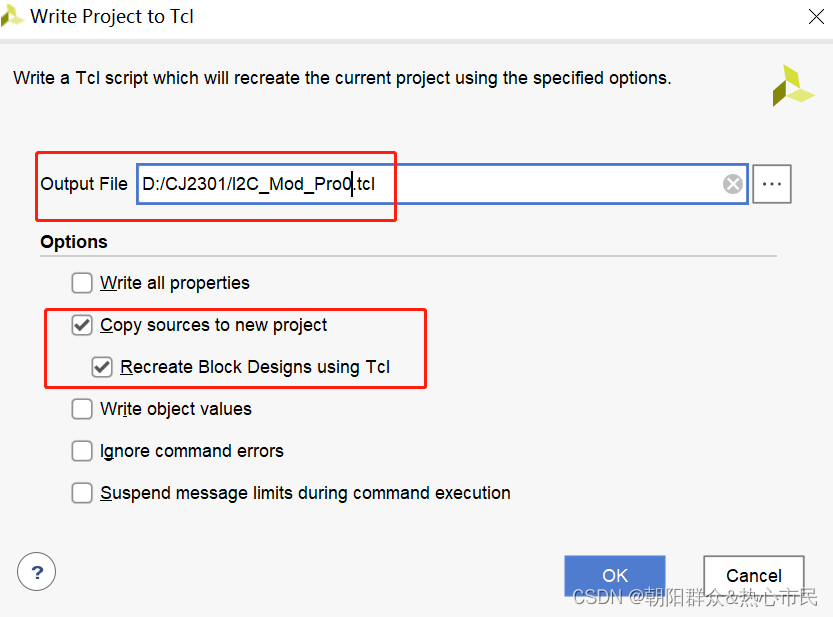
vivado tcl创建工程和Git管理
一、Tcl工程创建 二、Git版本管理 对于创建完成的工程需要Git备份时,不需要上传完整几百或上G的工程,使用tcl指令创建脚本,并只将Tcl脚本上传,克隆时,只需要克隆tcl脚本,使用vivado导入新建工程即可。 优…...

田间农业数字管理系统-高标准农田建设
政策背景 2019年11月,国务院办公厅印发的《国务院办公厅关于切实加强高标准农田建设提升粮食安全保障能力的意见》明确提出,到2022年,全国要建成10亿亩高标准农田。 2021年9月16日,由农业农村部印发的《全国高标准农田建设规划&a…...
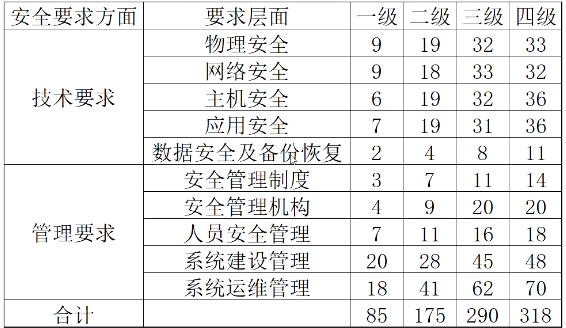
【网络安全】等保测评系列预热
【网络安全】等保测评系列预热 前言1. 什么是等级保护?2. 为什么要做等保?3. 路人甲疑问? 一、等保测试1. 渗透测试流程1.1 明确目标1.2 信息搜集1.3 漏洞探索1.4 漏洞验证1.5 信息分析1.6 获取所需1.7 信息整理1.8 形成报告 2. 等保概述2.1 …...
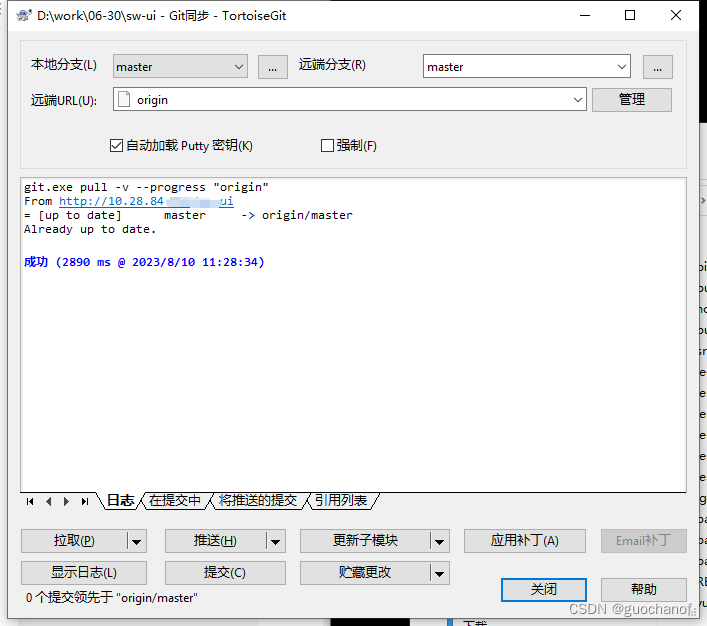
解决: git拉取报错 git 未能顺利结束 (退出码 1)
拉取代码失败信息 解决方法: 执行一下"git push -f origin master"命令即可 步骤: 1.项目文件夹右击选择"Git Bash Here",打开命令窗口 2. 输入"git push -f origin master"后,回画 执行结束 3.再拉取代码,成功...

【深度学习中的批量归一化BN和层归一化LN】BN层(Batch Normalization)和LN层(Layer Normalization)的区别
文章目录 1、概述2、BN层3、LN层4、Pytorch的实现5、BN层和LN层的对比 1、概述 归一化(Normalization) 方法:指的是把不同维度的特征(例如序列特征或者图像的特征图等)转换为相同或相似的尺度范围内的方法,比如把数据特征映射到[…...
开发一个RISC-V上的操作系统(六)—— 中断(interrupt)和异常(exception)
目录 往期文章传送门 一、控制流 (Control Flow)和 Trap 二、Exceptions, Traps, and Interrupts Contained Trap Requested Trap Invisible Trap Fatal Trap 异常和中断的异同 三、RISC-V的异常处理 mtvec(Machine Trap-Vector Ba…...
心跳跟随的心形灯(STM32(HAL)+WS2812+MAX30102)
文章目录 前言介绍系统框架原项目地址本项目开发开源地址硬件PCB软件功能 详细内容硬件外壳制作WS2812级联及控制MAX30102血氧传感器0.96OLEDFreeRTOS 效果视频总结 前言 在好几年前,我好像就看到了焊武帝 jiripraus在纪念结婚五周年时,制作的一个心跳跟…...
5. 服务发现
当主机较少时,在抓取配置中手动列出它们的IP地址和端口是常见的做法,但不适用于较大规模的集群。尤其不适用使用容器和基于云的实例的动态集群,这些实例经常会变化、创建或销毁的情况。 Prometheus通过使用服务发现解决了这个问题࿱…...

算法备案背后的原因:确保技术透明度与公正
随着现代技术的发展,算法逐渐渗透到我们日常生活的各个方面,从金融决策到个性化的商品推荐,再到医疗诊断和司法系统。然而,这种无所不在的应用也带来了一系列的社会和伦理问题,尤其是在算法的透明度和公正性上。这正是…...
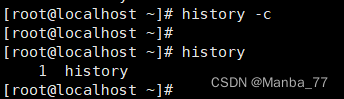
Linux centos 常用命令 【持续更新】
一、查看文件信息 indoe和目录项 # df命令查看每个硬盘分区的inode总数和已经使用的数量 df -i# 查看inode的大学 xfs_growfs /dev/sda1|grep "isize"# 查看文件的indoe号码 ls -istat查看文件信息 # 文件的详细信息 stat anaconda-ks.cfg # -t参数是在一行内输出…...

《使用 VMware 在 Windows 上搭建 Linux 系统的完整指南》
《使用 VMware 在 Windows 上搭建 Linux 系统的完整指南》 1、准备工作1.1 安装 VMware 软件1.2 下载 Linux 发行版镜像文件1.3 安装SSH工具 2、创建新的虚拟机2.1 VMware页面2.2 打开VMware页面并点击创建新的虚拟机,选择自定义2.3 选择系统兼容性,默认…...

大数据Flink(六十):Flink 数据流和分层 API介绍
文章目录 Flink 数据流和分层 API介绍 一、Flink 数据流...

软件测试面试题——如何测试App性能?
为什么要做App性能测试? 如果APP总是出现卡顿或网络延迟的情况,降低了用户的好感,用户可能会抛弃该App,换同类型的其他应用。如果APP的性能较好,用户体验高,使用起来丝滑顺畅,那该应用的用户粘…...

[具身智能-458]:从手工单张图片标注进化到自动生成海量、多样化数据,本质上是数据生产模式的一次工业革命。
从手工单张图片标注进化到自动生成海量、多样化数据,本质上是数据生产模式的一次工业革命。这不再是简单的工具升级,而是构建一个集“生成、标注、筛选”于一体的自动化“数据工厂”。整个演进路径可以清晰地分为三个阶段:自动化辅助标注、AI…...

windows在使用ping 127.0.0.1时出现一般故障的解决方案
大家好,我是爱编程的喵喵。双985硕士毕业,现担任全栈工程师一职,热衷于将数据思维应用到工作与生活中。从事机器学习以及相关的前后端开发工作。曾在阿里云、科大讯飞、CCF等比赛获得多次Top名次。现为CSDN博客专家、人工智能领域优质创作者。喜欢通过博客创作的方式对所学的…...

象棋AI连线工具VinXiangQi:让深度学习成为你的专属象棋教练
象棋AI连线工具VinXiangQi:让深度学习成为你的专属象棋教练 【免费下载链接】VinXiangQi Xiangqi syncing tool based on Yolov5 / 基于Yolov5的中国象棋连线工具 项目地址: https://gitcode.com/gh_mirrors/vi/VinXiangQi 想在下棋时获得职业选手级别的AI指…...

星穹铁道跃迁记录导出工具:3分钟掌握免费抽卡数据分析秘籍
星穹铁道跃迁记录导出工具:3分钟掌握免费抽卡数据分析秘籍 【免费下载链接】star-rail-warp-export Honkai: Star Rail Warp History Exporter 项目地址: https://gitcode.com/gh_mirrors/st/star-rail-warp-export 你是一个文章写手,你负责为开源…...

从电影《电力之战》到真实技术史:聊聊爱迪生、特斯拉与西屋电气的商业与技术博弈
电流战争背后的商业智慧:爱迪生、特斯拉与西屋电气的世纪博弈 1882年9月4日下午3点,托马斯爱迪生在纽约珍珠街发电站推上了电闸,400盏白炽灯瞬间点亮了曼哈顿下城的金融区。这个被后世称为"曼哈顿奇迹"的时刻,标志着电力…...

微服务可观测性实战:分布式链路追踪从入门到精通
前言微服务架构已经成了现代后端系统的主流选择。把一个单体应用拆成几十甚至上百个服务之后,每个服务的开发和部署确实灵活了,但排查问题变得异常困难——一个请求从网关进入,经过订单服务、库存服务、支付服务、积分服务,调用链…...

在Windows上解锁苹果触控板的原生体验:mac-precision-touchpad完全指南
在Windows上解锁苹果触控板的原生体验:mac-precision-touchpad完全指南 【免费下载链接】mac-precision-touchpad Windows Precision Touchpad Driver Implementation for Apple MacBook / Magic Trackpad 项目地址: https://gitcode.com/gh_mirrors/ma/mac-preci…...

Reference Extractor终极指南:三步快速恢复丢失的文献引用数据
Reference Extractor终极指南:三步快速恢复丢失的文献引用数据 【免费下载链接】ref-extractor Reference Extractor - Extract Zotero/Mendeley references from Microsoft Word files 项目地址: https://gitcode.com/gh_mirrors/re/ref-extractor Referenc…...

5步掌握Akagi:免费开源的雀魂AI助手实战指南
5步掌握Akagi:免费开源的雀魂AI助手实战指南 【免费下载链接】Akagi 支持雀魂、天鳳、麻雀一番街、天月麻將,能夠使用自定義的AI模型實時分析對局並給出建議,內建Mortal AI作為示例。 Supports Majsoul, Tenhou, Riichi City, Amatsuki, with…...

Zotero SciPDF插件:如何实现学术文献PDF自动下载的完整免费解决方案
Zotero SciPDF插件:如何实现学术文献PDF自动下载的完整免费解决方案 【免费下载链接】zotero-scipdf Download PDF from Sci-Hub automatically For Zotero7 项目地址: https://gitcode.com/gh_mirrors/zo/zotero-scipdf 还在为手动下载学术论文PDF而烦恼吗&…...