【办公自动化】使用Python一键提取PDF中的表格到Excel

🤵♂️ 个人主页:@艾派森的个人主页
✍🏻作者简介:Python学习者
🐋 希望大家多多支持,我们一起进步!😄
如果文章对你有帮助的话,
欢迎评论 💬点赞👍🏻 收藏 📂加关注+
目录
一、Python处理Excel
二、提取PDF表格到excel
三、往期推荐
文末推荐
文末福利
一、Python处理Excel
-
Python处理Excel的好处
1.批量操作:当要处理众多Excel文件时,例如出现重复性的手工劳动,那么使用Python就可以实现批量扫描文件、自动化进行处理,利用代码代替手工重复劳动,实现自动化,是Python第一个比Excel强大的地方
2.大型文件,当Excel文件超过几十兆、甚至上百兆时,打开文件很慢、处理文件更加慢,这时候若使用Python,会发现处理几十兆、几百兆甚至几GB都是没有问题的
3.当使用Excel进行复杂的计算时,会使用VBA,但是VBA本身是过时并且复杂的语言,Python是当前最简单且容易实现的一门语言,用Python能够处理比VBA难度更高的业务逻辑
4.Python是通用语言,不仅可以处理Excel,使用Python就可以得到很多额外的功能,例如:爬虫、发布网页的Web服务、与数据库进行连接、同时结合word和PPT进行处理、加入定时任务处理、人工智能分析等,各种额外的功能,这是Excel和VBA所不具备的
-
Python处理Excel主要有三大类库
1.pandas:是Python领域非常重要的,用于数据分析和可视化的类库,在处理Excel中,90%可以利用pandas类库就可以搞掂,利用pandas就可以读取Excel、处理Excel和输出Excel,但是pandas也有缺点,就是无法做到格式类,例如Excel中合并单元、大量复杂的样式(看起来很精美)的时候,用pandas无法搞掂,此时,依然是使用pandas结合openyxl、xlwings来搞掂需求
2.openpyxl:若电脑上未安装office时,也可以使用openpyxl,这个类型可以运行在linux上,并且也可以实现操作大部分Excel格式和样式的功能,使用它配合pandas,也可以完成大部分场景的需求
3.xlwings:比openyxl更加强大,只能运行在Windows或者Mac系统,并且该系统中必须安装了office才能运行,xlwings的原理,就是基于当前系统已经安装好的office软件,来进行功能的拓展来操作Excel
-
使用pandas的时候,经常会结合其他类库,来完成更加复杂的功能
-
requests, bs4:可以完成爬虫的功能
-
flask:可以做网页,把表格展示在网页上
-
Matplotlib:读取表格后,进行可视化
-
sklearn:进行复杂的数据分析时,也可以结合机器学习Sklearn把读取的Excel数据,进行数据分析和机器学习
-
Python-docx:也可以结合Python-docx类库,实现Excel和word的互通
-
smtplib:也可以使用smtplib,讲Excel数据发送邮件出去
-
-
开发环境
操作系统:使用windows, mac都可以
Python版本:系统中需要安装Python3.6以上的版本,Python2已经过期不建议使用,Python3.6以前的版本功能相对弱,最好就是采用Python3.6以上的版本
开发工具:有两个可以选择,jupyter notebook,是个网页编辑器,可以运行Python,常常用于交互性、探索性的开发;pycharm,用于成熟脚本,或者web服务的一些开发;这两个工具可以随意选择
重要类库:xlwings, pandas, matplotlib等
二、提取PDF表格到excel
从PDF文件获取表格中的数据,也是日常办公容易涉及到的一项工作。一个一个复制吧,效率确实太低了。用Python从PDF文档中提取表格数据,并写入Excel文件,灰常灰常高效。上市公司的年报往往包含几百张表格,用它作为例子再合适不过,搞定这个,其他含表格的PDF都是小儿科了。今天以"保利地产年报"为例,这个PDF文档中有321页含有表格,总表格数超过这个数了。
先导入PDF读取模块`pdfplumber`,随便挑一页看下表格数据的结构。如下,我们挑了第4页`pages[3]`来读取其中的表格,并显示。这里读取表格,用到了`extract_tables()`,即默认每页有多个表格。它会将单个表格的数据按行读取存入列表,再将每个表格的所有数据汇总存到一个上一级列表,最后将所有表格的数据汇总到一个大列表。而`extract_table()`方法则只能读一张表,当一个页面有多张表,就默认选第一个,因此会漏掉后面的。而且它们的数据结构也不同,差异如下。

“保利地产年报”第四页如图所示,读取的结果存到列表`table`,显示如下:
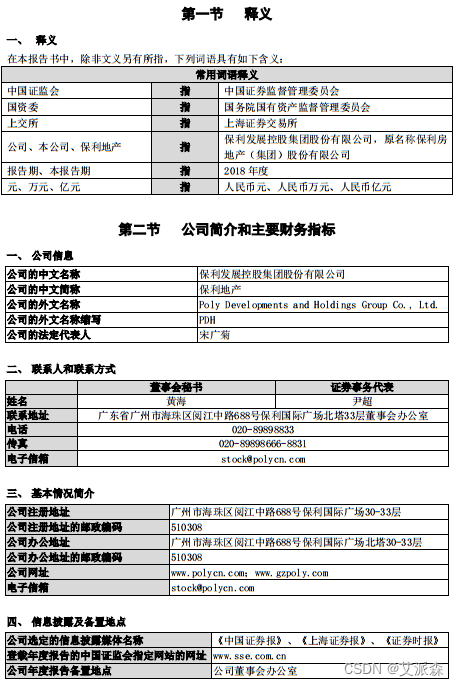
#观察读取出来的表格的数据结构
import pdfplumber
with pdfplumber.open("保利地产年报.pdf") as p:page = p.pages[3] #选取第4页(起始页为0)table = page.extract_tables() #多表格读取,存为嵌套列表print(table)[[['', '常用词语释义', None, None, None, None, None, ''], ['中国证监会', None, '', '指', '', '', '中国证券监督管理委员会', ''], ['国资委', None, '', '指', '', '', '国务院国有资产监督管理委员会', ''], ['上交所', None, '', '指', '', '上海证券交易所', None, None], ['公司、本公司、保利地产', None, '指', None, None, '保利发展控股集团股份有限公司,原名称保利房\n地产(集团)股份有限公司', None, None], ['报告期、本报告期', None, '', '指', '', '2018年度', None, None], ['元、万元、亿元', None, '', '指', '', '人民币元、人民币万元、人民币亿元', None, None]], [['公司的中文名称', '保利发展控股集团股份有限公司'], ['公司的中文简称', '保利地产'], ['公司的外文名称', 'Poly Developments and Holdings Group Co., Ltd.'], ['公司的外文名称缩写', 'PDH'], ['公司的法定代表人', '宋广菊']], [['', '董事会秘书', '证券事务代表'], ['姓名', '黄海', '尹超'], ['联系地址', '广东省广州市海珠区阅江中路688号保利国际广场北塔33层董事会办公室', None], ['电话', '020-89898833', None], ['传真', '020-89898666-8831', None], ['电子信箱', 'stock@polycn.com', None]], [['公司注册地址', '广州市海珠区阅江中路688号保利国际广场30-33层'], ['公司注册地址的邮政编码', '510308'], ['公司办公地址', '广州市海珠区阅江中路688号保利国际广场北塔30-33层'], ['公司办公地址的邮政编码', '510308'], ['公司网址', 'www.polycn.com;www.gzpoly.com'], ['电子信箱', 'stock@polycn.com']], [['公司选定的信息披露媒体名称', '《中国证券报》、《上海证券报》、《证券时报》'], ['登载年度报告的中国证监会指定网站的网址', 'www.sse.com.cn'], ['公司年度报告备置地点', '公司董事会办公室']]]确保可正常读取表格,以及了解读取出来的表格的数据结构,下面就可以一次性读取出所有表格,并存入Excel文件中了。导入相应模块,然后使用`pdfplumber`打开PDF文件。使用`Workbook()`新建Excel工作簿,然后使用`remove()`将其自带的工作表删除。因为我们想用PDF文件中表格所在的页码给相应的Excel工作表命名,以便二者的编号一致,方便后续查询。所以需要使用`enumerate()`给PDF的页从1开始编号。然后使用`extract_tables()`获取表格数据。
当然,如果当页没有表格,则`extract_tables()`获得的是空值`None`。在后续的操作中,空值会报错,所以加入`if`语句来做个判断。只有当列表`tables`不为空,即里面有货的时候,才建新的Excel表格,并执行后续的写入操作。列表`tables`若为空(即当页没有表格),则直接跳到下一页。
当发现当页有表格后,新建一个Excel表,以“Sheet”加上此时PDF的页码(比如“Sheet3”)命名。在写入数据时,先用一个`for`循环获得单个表格的数据,再用第二个`for`循环获得表格中一行的数据,然后写入Excel表。最后保存数据。由于表格太多,程序运行时间较长,大约需要3分钟。
import pdfplumber
from openpyxl import Workbook
with pdfplumber.open("保利地产年报.pdf") as p:wb = Workbook() #新建excel工作簿wb.remove(wb.worksheets[0])#删除工作簿自带的工作表for index,page in enumerate(p.pages,start = 1): #从1开始给所有页编号tables = page.extract_tables() #读取表格if tables: #判断是否存在表格,若不存在,则不执行下面的语句ws = wb.create_sheet(f"Sheet{index}") #新建工作表,表名的编号与表在PDF中的页码一致for table in tables: #遍历所有列表for row in table: #遍历列表中的所有子列表,里面保存着行数据ws.append(row) #写入excel表wb.save("保利地产年报表格.xlsx")数百个表格就这样潇洒地复制到Excel表格中了。
如果想要指定某个表格,在提取数据的时候指定页码即可。但如果想批量导出大量不同公司的年报的指定表格,则需要使用关键词定位了。还好,无论深圳市场还是上海市场,公司的年报中的标题基本都是唯一的,这给我们用标题做关键词提供了方便。假设我们需要提取公司“主要会计数据”下面的表格,则用关键词“主要会计数据”定位即可。如下以此为例进行操作。
import os
import pdfplumber
from openpyxl import Workbook path='PDF' #文件所在文件夹
files = [path+"\\"+i for i in os.listdir(path)] #获取文件夹下的文件名,并拼接完整路径
key_words = "主要会计数据"for file in files:with pdfplumber.open(file) as p:wb = Workbook() #新建excel工作簿wb.remove(wb.worksheets[0])#删除工作簿自带的工作表#获取关键词所在页及下一页的页码pages_wanted = []for index,page in enumerate(p.pages): #从0开始给所有页编号if key_words in page.extract_text():pages_wanted.append(index)pages_wanted.append(index+1)break#提取指定页码里的表格for i in pages_wanted: page = p.pages[i]tables = page.extract_tables() #读取表格if tables: #判断是否存在表格,若不存在,则不执行下面的语句ws = wb.create_sheet(f"Sheet{i+1}") #新建工作表,表名的编号与表在PDF中的页码一致for table in tables: #遍历所有列表for row in table: #遍历列表中的所有子列表,里面保存着行数据ws.append(row) #写入excel表wb.save("Excel\\{}.xlsx".format(file.split("\\")[1].split(".")[0]))以上,增加了一段获取关键词所在页码及下一页的页码的程序。之所以要获取关键词下一页页码,是因为有些表格会跨页,为了不遗漏数据,宁愿多获取一点。一旦找到关键词所在页,马上用`break`停止`for`循环。后面再遍历`pages_wanted`里面储存的页码,提取表格并写入Excel文件,并保存即可。批量获取的指定内容保存在`Excel`文件夹下。

三、往期推荐
Python提取pdf中的表格数据(附实战案例)
使用Python自动发送邮件
Python操作ppt和pdf基础
Python操作word基础
Python操作excel基础
文末推荐
AI时代Excel数据分析提升之道:知识精进+学习答疑+上机实训+综合实战+ChatGPT应用,零基础入门,极速提升数据分析效率!
内容简介:
本书在理论方面和实践方面都讲解得浅显易懂,能够让读者快速上手,一步步学会使用Python与Excel相结合进行数据处理与分析。
全书内容分3个部分共12章。第1~4章为入门部分,主要介绍什么是数据分析,以及Python的编程环境和基础语法知识。第5~9章为进阶部分,主要介绍数据处理和分析的各种方法。第10~12章为实战部分,这部分的3个实例综合了本书前面部分的知识点,介绍了如何结合Python与Excel在实际工作中进行数据处理与分析操作。
本书内容由浅入深,且配有案例的素材文件和代码文件,便于读者边学边练。本书还创新性地将ChatGPT引入教学当中,给读者带来全新的学习方式。本书既适合Python和数据分析的初学者学习,也适合希望从事数据分析相关行业的读者学习,还可作为广大职业院校数据分析培训相关专业的教材参考用书。
编辑推荐:
(1)零基础入门宝典,由浅入深讲解,无须额外的背景知识即可学习掌握。
(2)内容系统全面,可帮助读者快速了解使用Python进行Excel数据分析的基本语法并掌握开发能力。
(3)理论与实践相结合,每个理论都有对应的代码示例,读者参考代码示例完成编写,就可以看到实践效果。
(4)本书配有实训与问答,方便读者阅读后尽快巩固知识点,做到举一反三、学以致用。
(5)AI前沿产品ChatGPT+Python进行Excel数据分析,大幅学习和分析的效率

文末福利
《码上行动》和《Python自动化办公应用大全》二选一免费包邮送出5本!
- 抽奖方式:评论区随机抽取5位小伙伴免费送出!
- 参与方式:关注博主、点赞、收藏、评论区评论“人生苦短,拒绝内卷!”(切记要点赞+收藏,否则抽奖无效,每个人最多评论三次!)
- 活动截止时间:2023-08-08 20:00:00
《码上行动》京东链接:https://item.jd.com/14069538.html
《Python自动化大全》京东链接:https://item.jd.com/13953308.html
名单公布时间:2023-08-08 21:00:00
相关文章:

【办公自动化】使用Python一键提取PDF中的表格到Excel
🤵♂️ 个人主页:艾派森的个人主页 ✍🏻作者简介:Python学习者 🐋 希望大家多多支持,我们一起进步!😄 如果文章对你有帮助的话, 欢迎评论 💬点赞Ǵ…...
【基础类】—原型链系统性知识
一、创建对象有几种方法 字面量创建对象 1-1. 什么是字面量 字面量就是所见即所,指的是常量;用来为变量赋值时的常数量 代码例子:123;‘ABC’, {name: ‘张三’}, undefined , true 生活例子:门店的招牌&a…...
ddia(3)----Chapter3. Storage and Retrieval
However, first we’ll start this chapter by talking about storage engines that are used in the kinds of databases that you’re probably familiar with: traditional relational databases, and also most so-called NoSQL databases. We will examine two families o…...

SpringBoot自定义拦截器interceptor使用详解
Spring Boot拦截器Intercepter详解 Intercepter是由Spring提供的Intercepter拦截器,主要应用在日志记录、权限校验等安全管理方便。 使用过程 1.创建自定义拦截器,实现HandlerInterceptor接口,并按照要求重写指定方法 HandlerInterceptor接口源码&am…...

AI抠图使用指南:Stable Diffusion WebUI Rembg实用技巧
抠图是图像处理工具的一项必备能力,可以用在重绘、重组、更换背景等场景。最近我一直在探索 Stable Diffusion WebUI 的各项能力,那么 SD WebUI 的抠图能力表现如何呢?这篇文章就给大家分享一下。 安装插件 作为一个生成式AI,SD…...
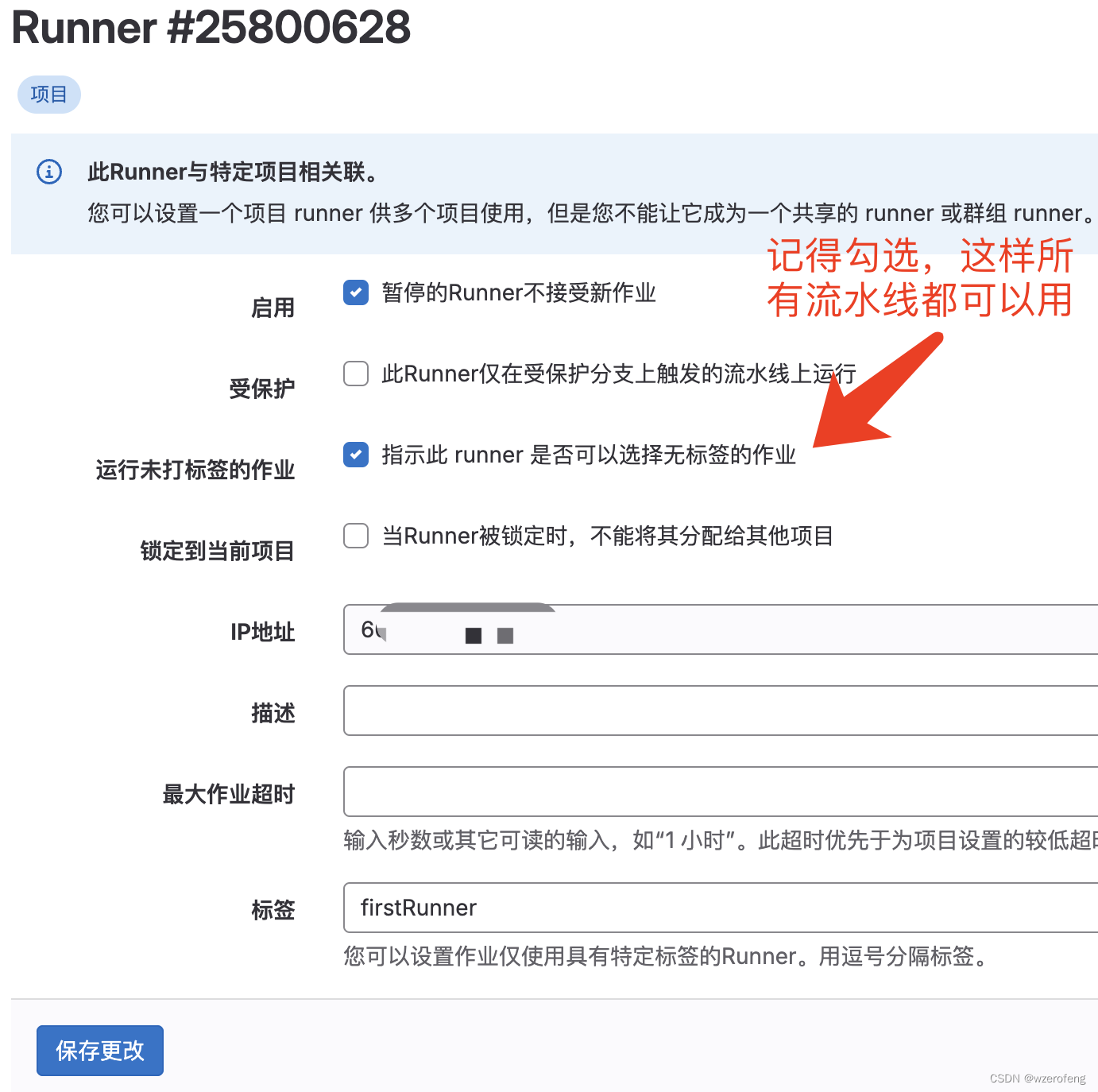
gitlab-Runner搭建
root wget https://packages.gitlab.com/runner/gitlab-runner/packages/fedora/29/gitlab-runner-12.6.0-1.x86_64.rpm/download.rpm rpm -ivh download.rpm ---- 安装 rpm -Uvh download.rpm -----更新升级 然后运行: gitlab-runner register --url https://git…...

【ChatGPT 指令大全】销售怎么借力ChatGPT提高效率
目录 销售演说 电话销售 产出潜在客户清单 销售领域计划 销售培训计划 总结 随着人工智能技术的不断进步,我们现在有机会利用ChatGPT这样的智能助手来改进我们的销售工作。在接下来的时间里,我将为大家介绍如何运用ChatGPT提高销售效率并取得更好的…...

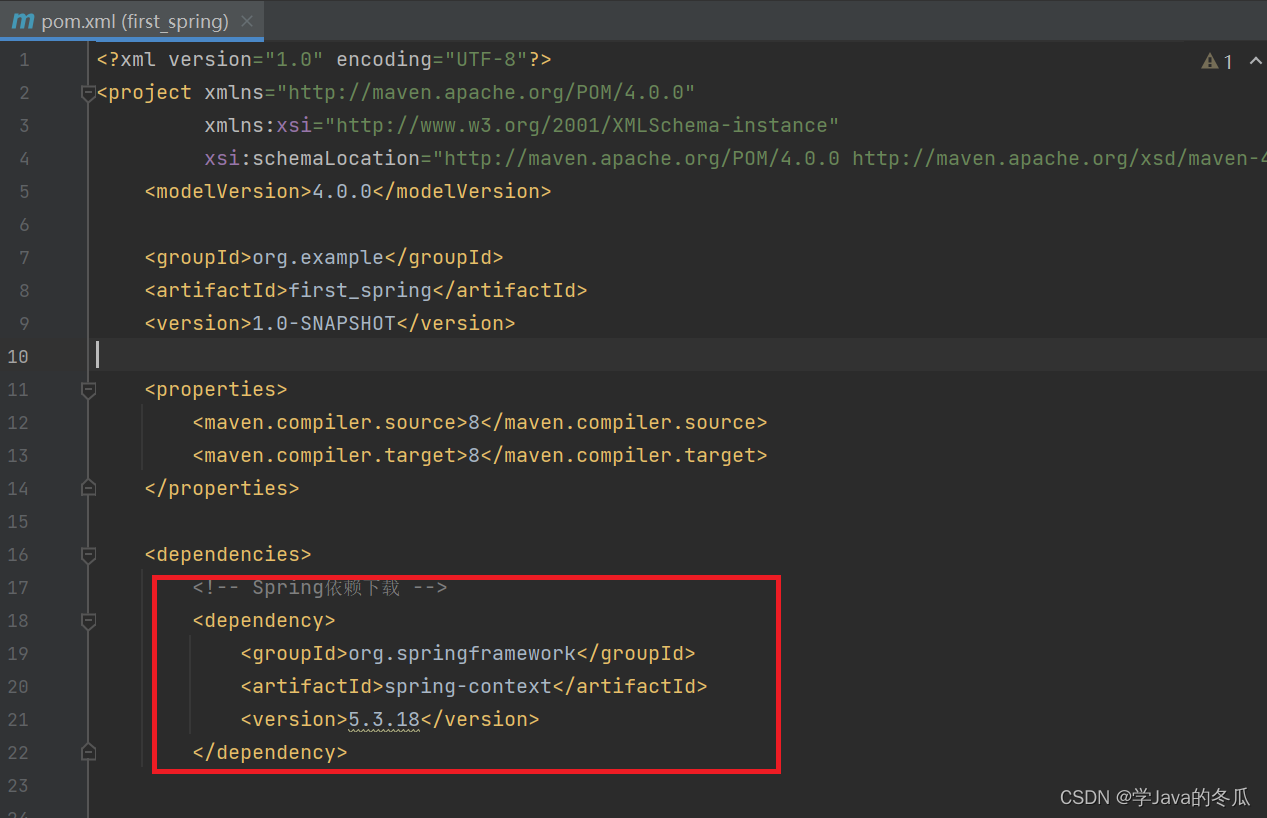
【Spring】-Spring项目的创建
作者:学Java的冬瓜 博客主页:☀冬瓜的主页🌙 专栏:【Framework】 主要内容:创建spring项目的步骤:先创建一个maven项目,再在pom.xml中添加spring框架支持,最后写一个启动类。 文章目…...

SQL | 使用通配符进行过滤
6-使用通配符进行过滤 6.1-LIKE操作符 前面介绍的所有操作符都是通过已知的值进行过滤,或者检查某个范围的值。但是如果我们想要查找产品名字中含有bag的数据,就不能使用前面那种过滤情况。 利用通配符,可以创建比较特定数据的搜索模式。 …...

make: *** [Makefile:719: ext/openssl/openssl.lo] Error 1
在ubuntu系统上编译安装PHP7.4.33时,会报错如下 make: *** [Makefile:719: ext/openssl/openssl.lo] Error 1 原因分析:这个错误提示的意思是PHP配置过程中缺少OpenSSL库文件,因此在编译过程中出现了问题;Ubuntu 22.04 中openss…...
Android Studio实现简单ListView
效果图 MainActivity package com.example.listviewtest;import androidx.appcompat.app.AppCompatActivity;import android.os.Bundle; import android.widget.ListView;import com.example.listviewtest.adapter.PartAdapter; import com.example.listviewtest.bean.PartB…...

【设计模式】模板模式
什么是模板模式? 模板方法模式(Template Method Pattern),又叫模板模式(Template Pattern),在一个抽象类公开定义了执行它的方法的模板。它的子类可以按需要重写方法实现,但调用将以抽象类中定义的方式进行…...
配置docker和复现
1.Nginx环境搭建 选择centos7来进行安装 1.1 创建Nginx的目录并进入 mkdir /soft && mkdir /soft/nginx/ cd /soft/nginx/ 1.2 下载Nginx的安装包,可以通过FTP工具上传离线环境包,或者通过wget命令在线获取安装包 wget https://nginx.org/down…...

Qt应用开发(基础篇)——工具箱 QToolBox
一、前言 QToolBox类继承于QFrame,QFrame继承于QWidget,是Qt常用的基础工具部件。 框架类QFrame介绍 QToolBox工具箱类提供了一列选项卡窗口,当前项显示在当前选项卡下面,适用于分类浏览、内容展示、操作指引这一类的使用场景。 二…...
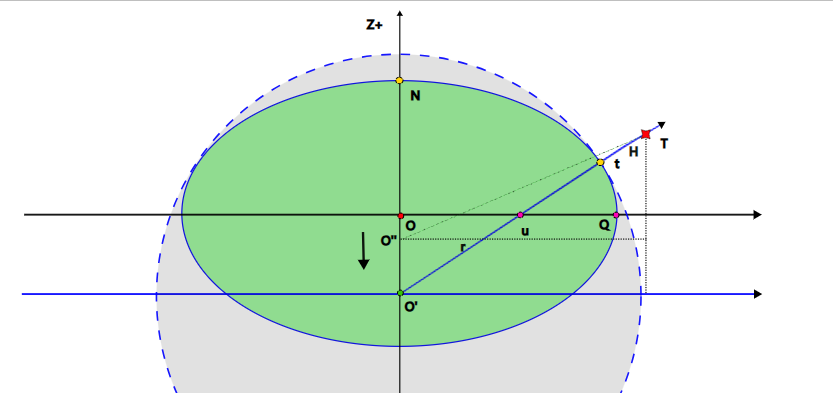
地理测绘基础知识(1) 坐标系经纬度与ECEF直角坐标的基本换算
经纬度与ECEF直角坐标的基本换算 我们目前最常用的全球坐标系是WGS-84坐标系,各种手机、地图基本用经纬度来标记位置。然而,经纬度对于空间的计算是很复杂的,需要很多三角函数操作。平面直角坐标系利用向量的运算,可以非常方便的…...
【UE4 RTS】08-Setting up Game Clock
前言 本篇实现的效果是在游戏运行后能够记录当前的游戏时间(年月日时分秒),并且可以通过修改变量从而改变游戏时间进行的快慢。 效果 步骤 1. 在Blueprints文件夹中新建如下两个文件夹,分别命名为“GameSettings”、“Player”…...
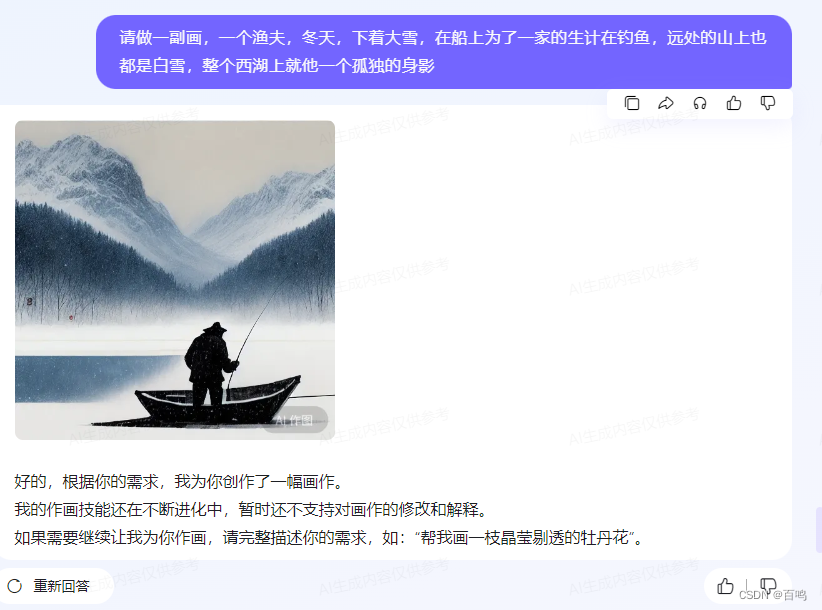
百度chatgpt内测版
搜索AI伙伴 申请到了百度的chatgpt: 完整的窗口布局: 三个哲学问题: 灵感中心: 请做一副画,一个渔夫,冬天,下着大雪,在船上为了一家的生计在钓鱼,远处的山上也都是白雪&a…...

[GAN] 使用GAN网络进行图片生成的“调参人”入门指南——生成向日葵图片
[GAN] 使用GAN网络进行图片生成的“炼丹人”日志——生成向日葵图片 文章目录 [GAN] 使用GAN网络进行图片生成的“炼丹人”日志——生成向日葵图片1. 写在前面:1.1 应用场景:1.2 数据集情况:1.3 实验原理讲解和分析(简化版&#x…...

(十)人工智能应用--深度学习原理与实战--模型的保存与加载使用
目的:将训练好的模型保存为文件,下次使用时直接加载即可,不必重复建模训练。 神经网络模型训练好之后,可以保存为文件以持久存储,这样下次使用时就不重新建模训练,直接加载就可以。TensorfLow提供了灵活的模型保存方案,既可以同时保存网络结构和权重(即保存全模型),也可…...

Ryujinx模拟器终极指南:在PC上畅玩Switch游戏的5个核心技巧
Ryujinx模拟器终极指南:在PC上畅玩Switch游戏的5个核心技巧 【免费下载链接】Ryujinx 用 C# 编写的实验性 Nintendo Switch 模拟器 项目地址: https://gitcode.com/GitHub_Trending/ry/Ryujinx 想在电脑上体验《塞尔达传说:旷野之息》的广阔世界&…...

PyVista三维可视化完整指南:从科学计算到工程应用的Python利器
PyVista三维可视化完整指南:从科学计算到工程应用的Python利器 【免费下载链接】pyvista 3D plotting and mesh analysis through a streamlined interface for the Visualization Toolkit (VTK) 项目地址: https://gitcode.com/gh_mirrors/py/pyvista PyVis…...

微服务可观测性实战:分布式链路追踪从入门到精通
前言微服务架构已经成了现代后端系统的主流选择。把一个单体应用拆成几十甚至上百个服务之后,每个服务的开发和部署确实灵活了,但排查问题变得异常困难——一个请求从网关进入,经过订单服务、库存服务、支付服务、积分服务,调用链…...

Ubuntu 20.04上从源码编译Geth 1.10.5:避开Go版本不匹配的坑
Ubuntu 20.04源码编译Geth 1.10.5全流程指南:从环境准备到实战部署 在区块链开发领域,Geth作为以太坊网络的官方客户端实现,其源码编译能力是开发者必须掌握的核心技能。不同于简单的apt-get安装,源码编译不仅能让你获得最新功能&…...

为什么92%的MCP 2026升级失败源于配置漂移?——5个被忽略的systemd服务依赖陷阱及修复checklist
更多请点击: https://intelliparadigm.com 第一章:MCP 2026安全漏洞修复教程导论 MCP(Modular Control Protocol)2026 是工业物联网(IIoT)场景中广泛部署的轻量级设备通信协议,其设计目标为低功…...

FSearch:Linux用户的极速文件搜索神器,告别等待的终极指南
FSearch:Linux用户的极速文件搜索神器,告别等待的终极指南 【免费下载链接】fsearch A fast file search utility for Unix-like systems based on GTK3 项目地址: https://gitcode.com/gh_mirrors/fs/fsearch 还在为Linux系统中查找文件而烦恼吗…...
)
告别版本混乱:在Ubuntu上用Tar包管理多版本TensorRT(附CUDA 11.0+cuDNN 8.0.5环境)
告别版本混乱:在Ubuntu上用Tar包管理多版本TensorRT(附CUDA 11.0cuDNN 8.0.5环境) 深度学习工程师经常面临一个棘手问题:如何在单台开发机上同时维护多个TensorRT版本?当项目A需要TensorRT 7.x而项目B依赖TensorRT 8.x…...
、.data和with torch.no_grad()的详细对比与选择指南)
别再混淆了!PyTorch中detach()、.data和with torch.no_grad()的详细对比与选择指南
PyTorch梯度控制三剑客:detach()、.data与no_grad()的深度抉择 在PyTorch的动态图机制中,梯度计算的高效控制是每个开发者必须掌握的技能。当你在模型推理时发现内存溢出,或在参数更新时遭遇意外梯度回传,问题的根源往往在于对计算…...

代理技能集合:涵盖规划、开发、工具使用等多方面扩展能力
代理技能 这是一系列代理技能的集合,可在规划、开发和工具使用等方面扩展能力。 规划与设计 这些技能能帮助你在编写代码前深入思考问题。 to - prd:将当前对话上下文转化为产品需求文档(PRD),并作为 GitHub 问题提交。…...

LazyLLM:低代码多智能体应用框架,简化AI开发与部署
1. 项目概述:LazyLLM,为“懒人”而生的多智能体应用构建框架如果你和我一样,在尝试构建一个像样的AI应用时,感到无比头疼——不是被各种框架的API调用、服务部署、模型切换、数据流编排搞得焦头烂额,就是被“快速迭代”…...