ddia(3)----Chapter3. Storage and Retrieval
However, first we’ll start this chapter by talking about storage engines that are used in the kinds of databases that you’re probably familiar with: traditional relational databases, and also most so-called NoSQL databases. We will examine two families of storage engines: log-structured storage engines, and page-oriented storage engines such as B-trees.
Data Structures That Power Your Database
The simplest database in the world is two Bash functions:
#!/bin/bash
db_set () {echo "$1,$2" >> database
}db_get () {grep "^$1," database | sed -e "s/^$1,//" | tail -n 1
}
Every call to db_set appends to the end of a file, when you update a key, the old version is not overwritten–you need to look at the last occurrence of a key in a file to find the latest value. db_set has pretty good performance, because appending to a file is generally very efficient. Many databases internally use a log, just like db_set does. But it still has some shortages:
- its performance will be terrible if you have a large number of records in your database. Every time you want to look up a key,
db_gethas to scan the entire database file from beginning to end. - more issues to deal with (such as concurrency control, reclaiming disk space so that the log doesn’t grow forever, and handling errors and partially written records),
In order to efficiently find the value for a particular key in the database, we need a different data structure: an index.
Hash Indexes
The simplest possible indexing strategy is: keeping an in-memory hash map where every key is mapped to a byte offset in the data file----the location at which the value can be found. Whenever you append a new key-value pair to the file, you also update the hash map to reflect the offset of the data you just wrote(this works both for inserting new keys and for updating existing keys). When you want to look up a value, use the hash map to find the offset in the data file, seek to that location, and read the value.
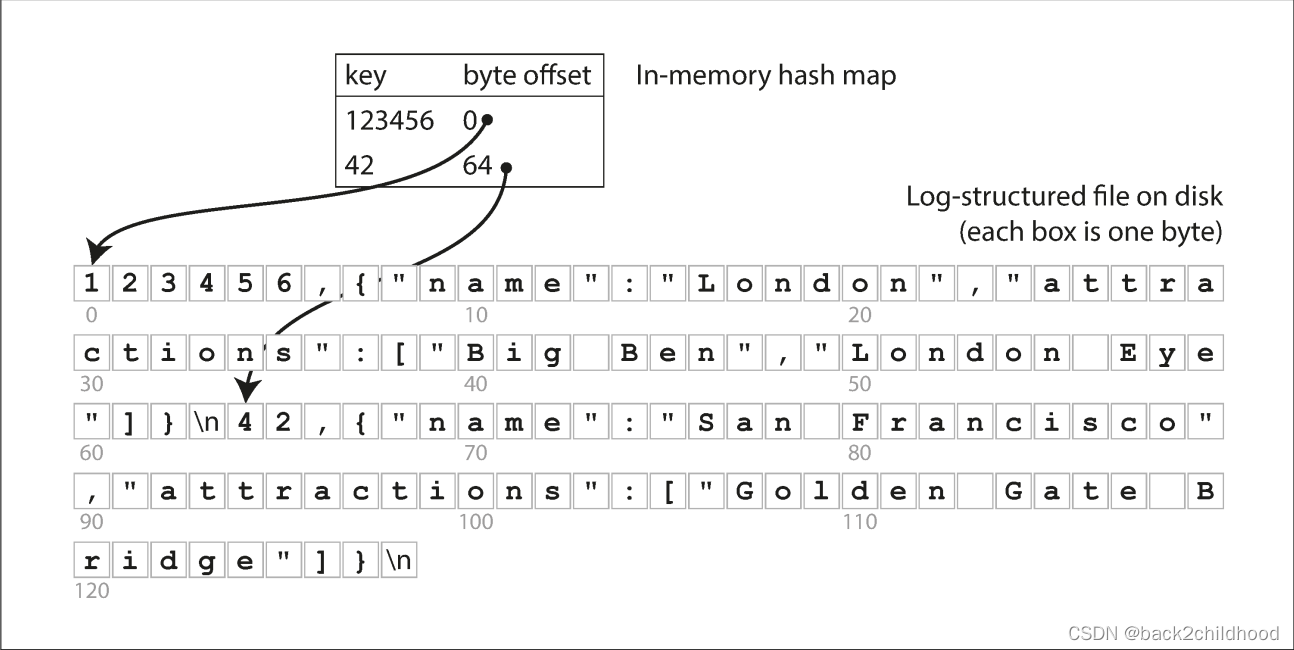
If you want to delete a key and its associated value, you have to append a special deletion record to the data file (sometimes called a tombstone).
We can break the log into segments of a certain size by closing segment file when it reaches a certain size to avoid eventally running out of disk space. Moreover, since compaction often makes segments much smaller (assuming that a key is overwritten several times on average within one segment), we can also merge several segments together at the same time as performing the compaction.

In order to achieve concurrency control, there is only one writer thread. Data file segments are append-only and otherwise immutable, so they can be read concurrently by multiple threads.
- Good
- Appending and segment merging are sequential write operations, which are generally much faster than random writes, especially on magnetic spinning-disk hard drives. To some extent, sequential writes are also preferable on flash-based
solid state drives(SSDs). - Merging old segments avoids the problem of data files getting fragmented over time.
- Concurrency and crash recovery are much simpler if segment files are append-only or immutable. For example, you don’t have to worry about the case where a crash happened while a value was being overwritten, leaving you with a file containing part of the old and part of the new value spliced together.
- Appending and segment merging are sequential write operations, which are generally much faster than random writes, especially on magnetic spinning-disk hard drives. To some extent, sequential writes are also preferable on flash-based
- Limitations
- Range queries are not efficient. you’d have to look up each key individually in the hash maps.
- The hash table must fit in memory, so the number of keys shouldn’t be too large or small.
SSTables and LSM-Trees
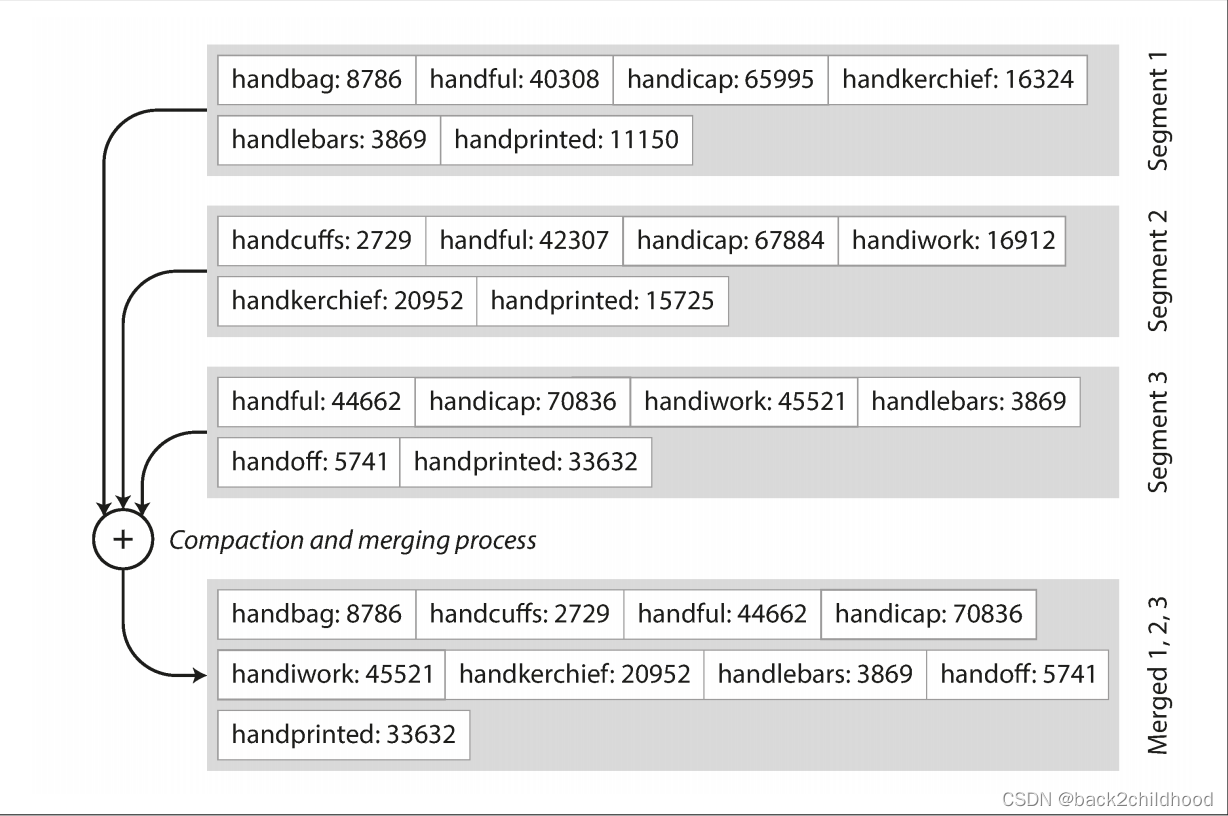
- Sorted String Table(SSTable): the sequence of key-value pairs is sorted by key.
- advantages:
- Merging segments is simple and efficient, even if the files are bigger than the available memory. This approach is like
mergesortalgorithm.
- In order to find a particular value, you no longer need to keep an index of all the keys in memory. If you are looking for the key
b, but don’t know the exact offset of that key in the segment file. However, you do know the offsets of the keysaandc, so you can jump to the offset foraand scan from there until you findb.
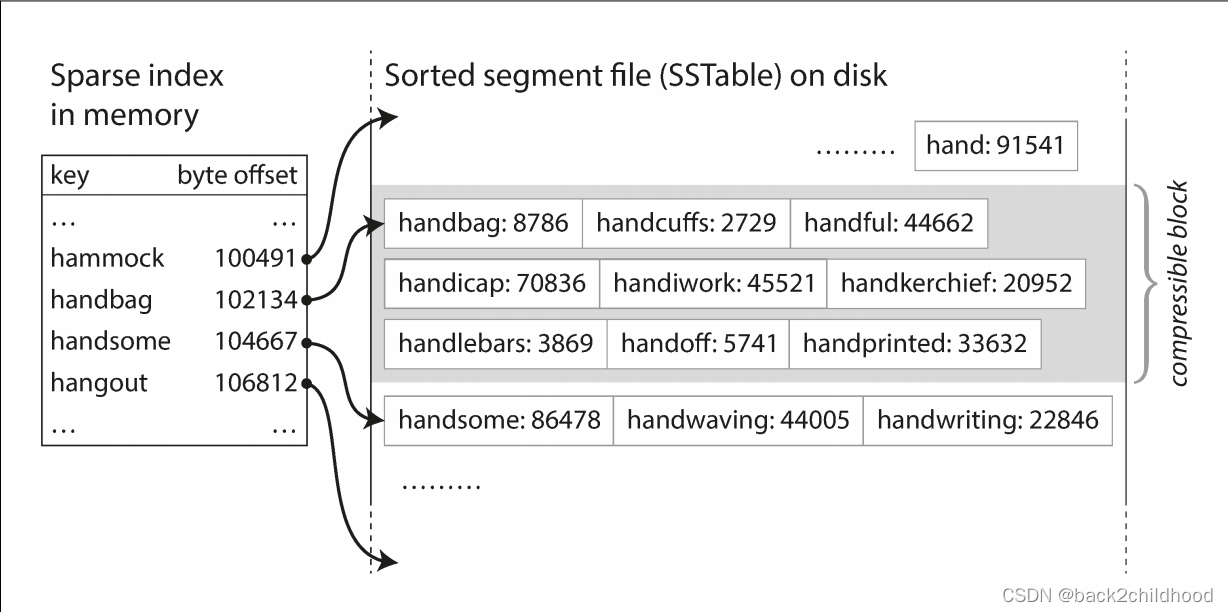
- Since read requests need to scan over several key-value pairs in the requested range anyway, it is possible to group those records into a block and compress it before writing it to disk.
- Merging segments is simple and efficient, even if the files are bigger than the available memory. This approach is like
Constructing and maintaining SSTables
- When a write comes in, add it to an in-memory balanced tree data structure (for example, a red-black tree). This in-memory tree is called a
memtable. - When the memtable is bigger than a threshold----typically a few megabytes----write it out to disk as an SSTable file. This can be done efficiently because the tree maintains sorted by key.
- In order to serve a read request, first try to find the key in the memtable, then in the most recent on-disk segment, then in the older segment.
- From time to time, run a merging and compaction process in the background to combine segment files and discard overwritten and deleted values.
- We can keep a separate log on disk to which every write is immediately appended, that log is not in sorted order, because its only purpose is to restore the memtable after a crash.
Making an LSM-tree out of SSTables
Performance optimizations
- If you want to look for a key do not exist in the database: you have to check the memtable, then the segments all the way back to the oldest(possibly having to read from disk for each one) before you can be sure that the key does not exist. In order to optimize, we can use
Bloom filters. - There are also different strategies to determine the order and timing of how SSTables are compacted and merged:
- size-tiered compaction: newer and smaller SSTables are successively merged into older and larger SSTables.
- leveled compaction: the key range is split up into smaller SSTables and older data is moved into separate “levels,” which allows the compaction to proceed more incrementally and use less disk space.
B-Trees
Like SSTables, B-trees keep key-value pairs sorted by key, which allows efficient key-value lookups and range queries. B-trees break the database down into fixed-size blocks or pages, traditionally 4KB in size, and read or write one page at a time.
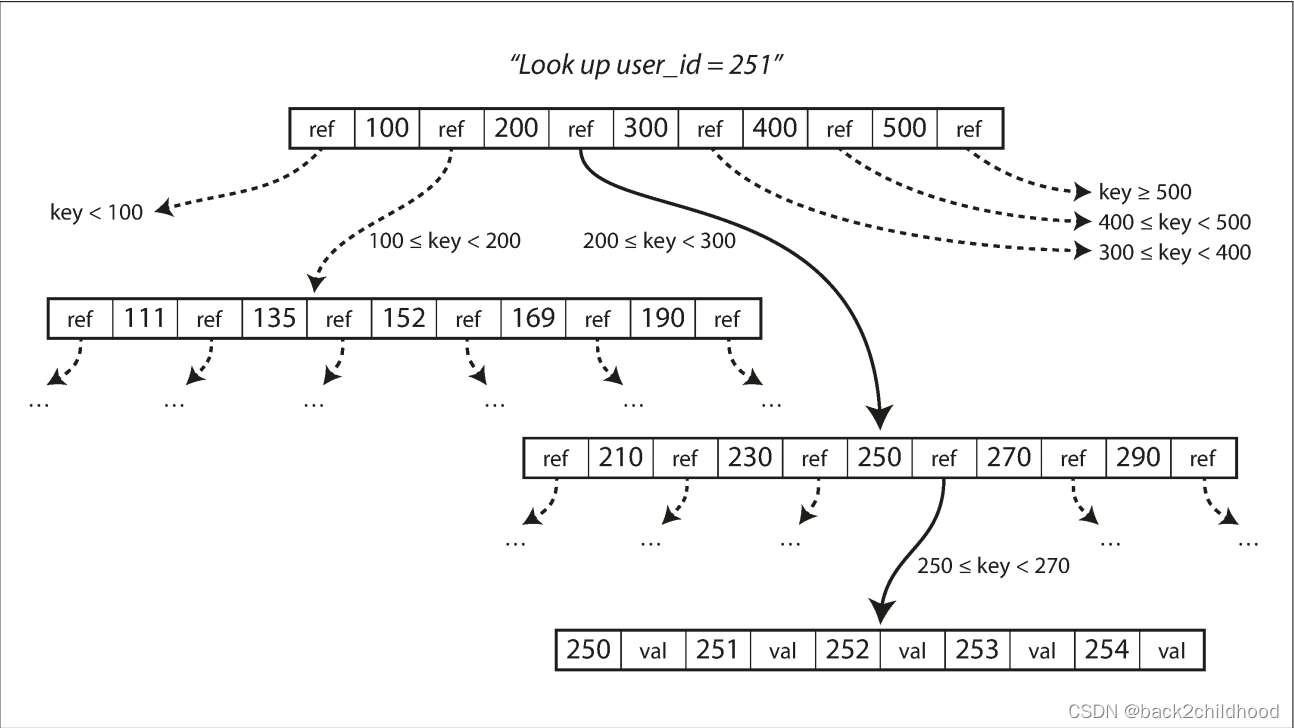
If you want to add a new key, you need to find the page whose range encompasses the new key and add it to that page. If there isn’t enough space in the page to accommodate the new key, it is split into two half-full pages, and the parent page is updated to account for the new subdivision of key ranges.
This algorithm ensures the tree remains balanced: a B-tree with n keys always has a depth of O(log n). Most databases can fit into a B-tree that is three or four levels deep, so you don’t need to follow many page references to find the page you are looking for. (A four-level tree of 4 KB pages with a branching factor of 500 can store up to 256 TB.)
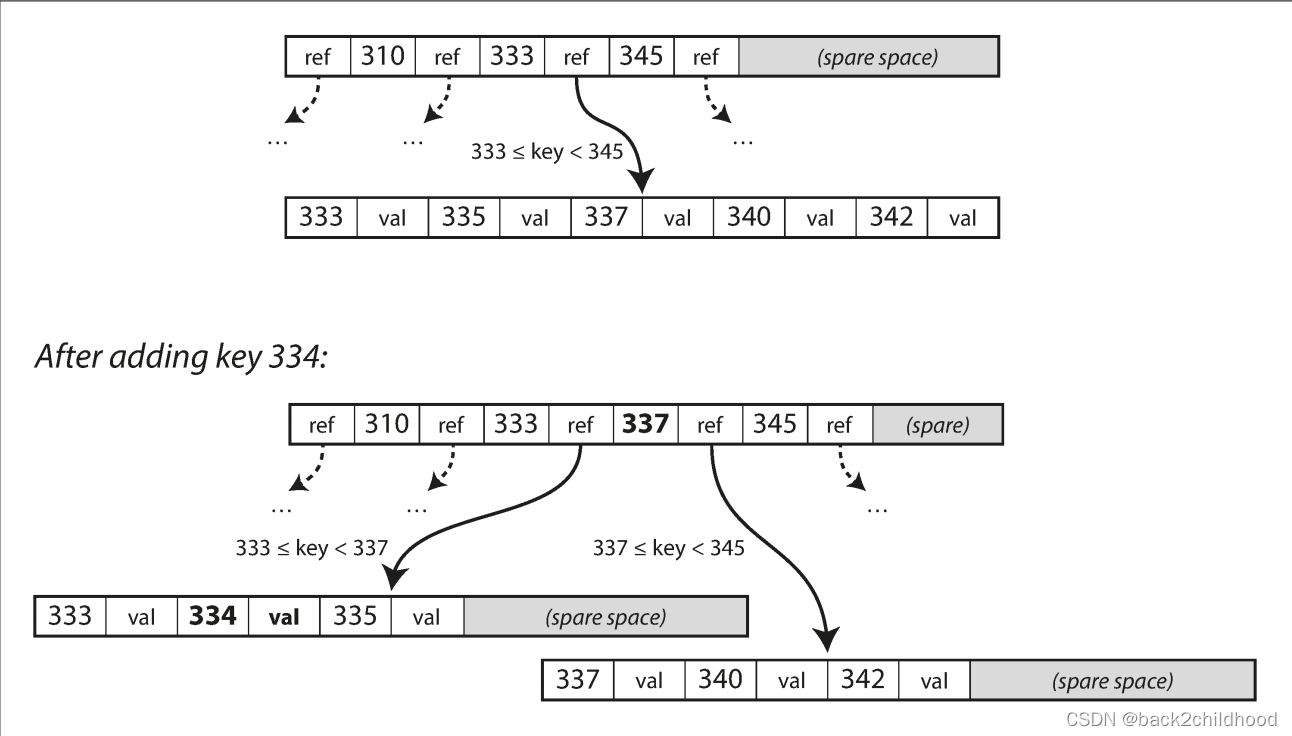
Making B-trees reliable
If you split a page because you want to insert a new key, this is a dangerous operation, because if the database crashes after only some of the pages be written, you end up with a corrupted index.
In order to make the database more reliable, there are two implementations:
- write-ahead log(WAL, also know as redo log). This is an append-only file to which every B-tree modification must be written before it can be written to the tree itself. When the database comes back up after a crash, this log is used to restore the B-tree back to a consistent state.
- Concurrency control is required if multiple threads are going to access the B-tree at the same time,
latches(lightweight locks)is used to protect the tree’s data structures.
B-tree optimizations
- Instead of overwriting pages and maintaining a WAL for crash recovery, some databases (like LMDB) use a copy-on-write scheme.
- We can save space in pages by not storing the entire key, but abbreviating it.
- Additional pointers have been added to the tree. For example, each leaf page may have references to its sibling pages to the left and right, which allows scanning keys in order without jumping back to parent pages.
Comparing B-Trees and LSM-Trees
Advantages of LSM-trees
- A B-tree index must write every piece of data at least twice: once to the write-ahead log, and once to the tree page itself (and perhaps again as pages are split).
- Log-structured indexes also rewrite data multiple times due to repeated compaction and merging of SSTables. This effect—one write to the database resulting in multiple writes to the disk over the course of the database’s lifetime—is known as write amplification. Moreover, LSM-trees are typically able to sustain higher write throughput than B-trees, partly because they sometimes have lower write amplification.
- LSM-trees can be compressed better, and thus often produce smaller files on disk than B-trees. B-tree storage engines leave some disk space unused due to fragmentation.
Downsides of LSM-trees
- A downside of log-structured storage is that the compaction process can sometimes interfere with the performance of ongoing reads and writes.
- Another issue with compaction arises at high write throughput: the disk’s finite write bandwidth needs to be shared between the initial write (logging and flushing a memtable to disk) and the compaction threads running in the background. If write throughput is high and compaction is not configured carefully, in this case, the number of unmerged segments on disk keeps growing until you run out of disk space, and reads also slow down because they need to check more segment files.
- An advantage of B-trees is that each key exists in exactly one place in the index, whereas a log-structured storage engine may have multiple copies of the same key in different segments.
Other Indexing Structures
So far we have only discussed key-value indexes, which are like a primary key index in the relational model.
It is also common to have secondary index, you can use CREATE INDEX to create a secondary index.
A secondary index can easily be constructed from a key-value index. The main difference is that keys are not unique.
Storing values within the index
Multi-column indexes
Keeping everything in memory
As RAM becomes cheaper, the cost-per-gigabyte argument is eroded. Many datasets are simply not that big, so it’s quite feasible to keep them entirely in memory.
Besides performance, in-memory databases also provide data models that are difficult to implement with disk-based indexes. For example, Redis offers a database-like interface to various data structures such as priority queues and sets. Because it keeps all data in memory, its implementation is comparatively simple.
Transaction Processing or Analytics?

There was a trend for companies to stop using their OLTP systems for analytics purposes, and to run the analytics on a separate database instead. This separate database was called a data warehouse.
Data Warehousing
A data warehouse, by contrast, is a separate database that analysts can query to their hearts’ content, without affecting OLTP operations. The data warehouse contains a read-only copy of the data in all the various OLTP systems in the company. Data is extracted from OLTP databases (using either a periodic data dump or a continuous stream of updates), transformed into an analysis-friendly schema, cleaned up, and then loaded into the data warehouse. This process of getting data into the warehouse is known as Extract–Transform–Load (ETL).

The divergence between OLTP databases and data warehouses
Stars and Snowflakes: Schemas for Analytics
- Star schema: The name “star schema” comes from the fact that when the table relationships are visualized, the fact table is in the middle, surrounded by its dimension tables.
- A variation of this template is known as the snowflake schema, where dimensions are further broken down into subdimensions.
In a typical data warehouse, tables are often very wide: fact tables often have over 100
columns, sometimes several hundred.

Column-Oriented Storage
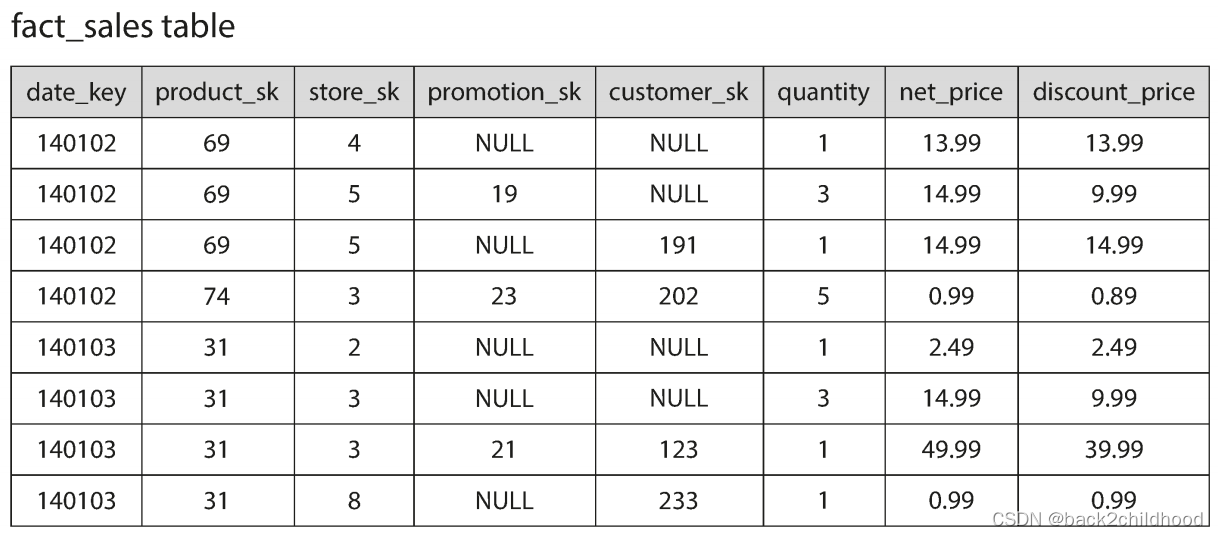
If we want to analyze whether people are more inclined to buy fresh fruit or candy, depending on the day of the week. It only needs access to three columns of the fact_sales table:daate_key, produck_sk, and quantity. The query ignores all other columns.
But in a row-oriented storage engine still needs to load all of those rows from disk to memory, parse them, and filter out those that don’t meet the required conditions.
The idea behind column-oriented storage is simple: don’t store all the values from one row together, but store all the values from each column together instead. If each column is stored in a separate file, a query only needs to read and parse those columns that are used in that query, which can save a lot of work.
Column Compression
Take a look at the sequences of values for each column, they look quite repetitive, the following are some approaches for compression.

One technique that is particularly effective in data warehouses is bitmap encoding.
But if the data is bigger, there will be a lot of zeros in most of the bitmaps (we say that they are sparse). In that case, the bitmaps can additionally be run-length encoded.

Bitmap indexes such as these are well suited for the kinds of queries that are common in a data warehouse.
WHERE product_sk IN (30, 68, 69)
Just need to load the three bitmaps for product_sk = 30, 68, 69 and calculate the bitwise OR of the three bitmaps.
Column-oriented storage and column families
Memory bandwidth and vectorized processing
Sort Order in Column Storage
The data needs to be sorted an entire row at a time, even though it is stored by column.
- Advantages:
- help with compression of columns. If the primary sort column does not have many distinct values, then after sorting, it will have long sequences where the same value is repeated many times in a row.
- That will help queries that need to group or filter sales by product within a certain date range.
Several different sort orders
The row-oriented store keeps every row in one place(in a heap file or a clustered index), and secondary indexes just contain pointers to the matching rows. In a column store, there normally aren’t any pointers to data elsewhere, only columns containing values.
Writing to Column-Oriented Storage
- If you wanted to insert a row in the middle of a sorted table, you would most likely have to rewrite all the column files.
- We can use LSM-tree to solve this problem: all writes first go to an in-memory store, where they are added to a sorted structure and prepared for writing to disk. Queries need to examine both the column data on disk and the recent writes in memory and combine the two.
Aggregation: Data Cubes and Materialized Views
Except for column-oriented storage, another aspect of data warehouses is materialized aggregates. As we all know, there are many aggregate functions in SQL, such as COUNT, SUM, MIN, etc. If the same aggregates are used by many different queries, we can cache the counts or sums that queries use most often. This cache is called materialized view.
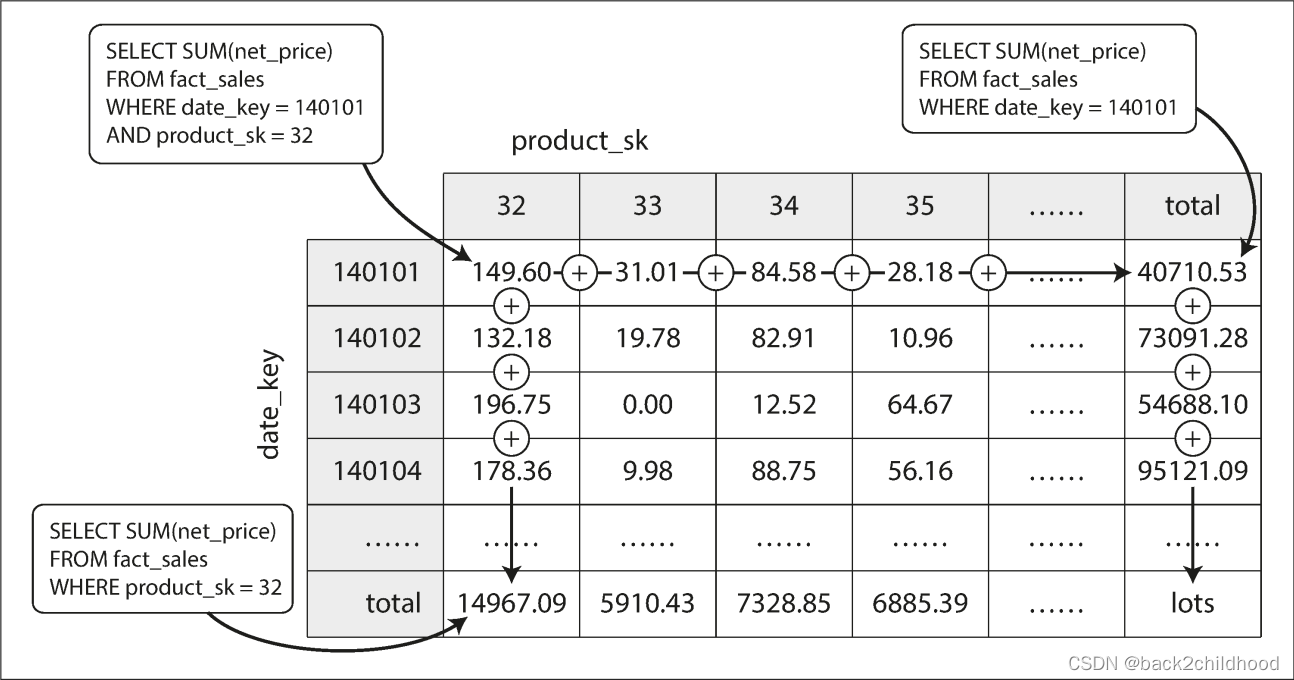
The advantage of a materialized data cube is that certain queries become very fast because they have effectively been precomputed.
The disadvantage is that a data cube doesn’t have the same flexibility as querying the raw data.
Summary
On a high level, we saw that storage engines fall into two broad categories: those optimized for transaction processing (OLTP), and those optimized for analytics (OLAP). There are big differences between the access patterns in those use cases:
- OLTP systems are typically user-facing, which means that they may see a huge volume of requests. In order to handle the load, applications usually only touch a small number of records in each query. The application requests records using some kind of key, and the storage engine uses an index to find the data for the requested key. Disk seek time is often the bottleneck here.
- OLAP and Data warehouses are less well known, because they are primarily used by business analysts, not by end users. They handle a much lower volume of queries than OLTP systems, but each query is typically very demanding, requiring many millions of records to be scanned in a short time. Disk bandwidth (not seek time) is often the bottleneck here, and
column-oriented storageis an increasingly popular solution for this kind of workload.
On the OLTP side, we saw storage engines from two main schools of thought:
- The log-structured school, which only permits appending to files and deleting obsolete files, but never updates a file that has been written. Bitcask, SSTables, LSM-trees, LevelDB, Cassandra, HBase, Lucene, and others belong to this group.
- The update-in-place school, which treats the disk as a set of fixed-size pages that can be overwritten. B-trees are the biggest example of this philosophy, being used in all major relational databases and also many nonrelational ones.
相关文章:
ddia(3)----Chapter3. Storage and Retrieval
However, first we’ll start this chapter by talking about storage engines that are used in the kinds of databases that you’re probably familiar with: traditional relational databases, and also most so-called NoSQL databases. We will examine two families o…...

SpringBoot自定义拦截器interceptor使用详解
Spring Boot拦截器Intercepter详解 Intercepter是由Spring提供的Intercepter拦截器,主要应用在日志记录、权限校验等安全管理方便。 使用过程 1.创建自定义拦截器,实现HandlerInterceptor接口,并按照要求重写指定方法 HandlerInterceptor接口源码&am…...

AI抠图使用指南:Stable Diffusion WebUI Rembg实用技巧
抠图是图像处理工具的一项必备能力,可以用在重绘、重组、更换背景等场景。最近我一直在探索 Stable Diffusion WebUI 的各项能力,那么 SD WebUI 的抠图能力表现如何呢?这篇文章就给大家分享一下。 安装插件 作为一个生成式AI,SD…...
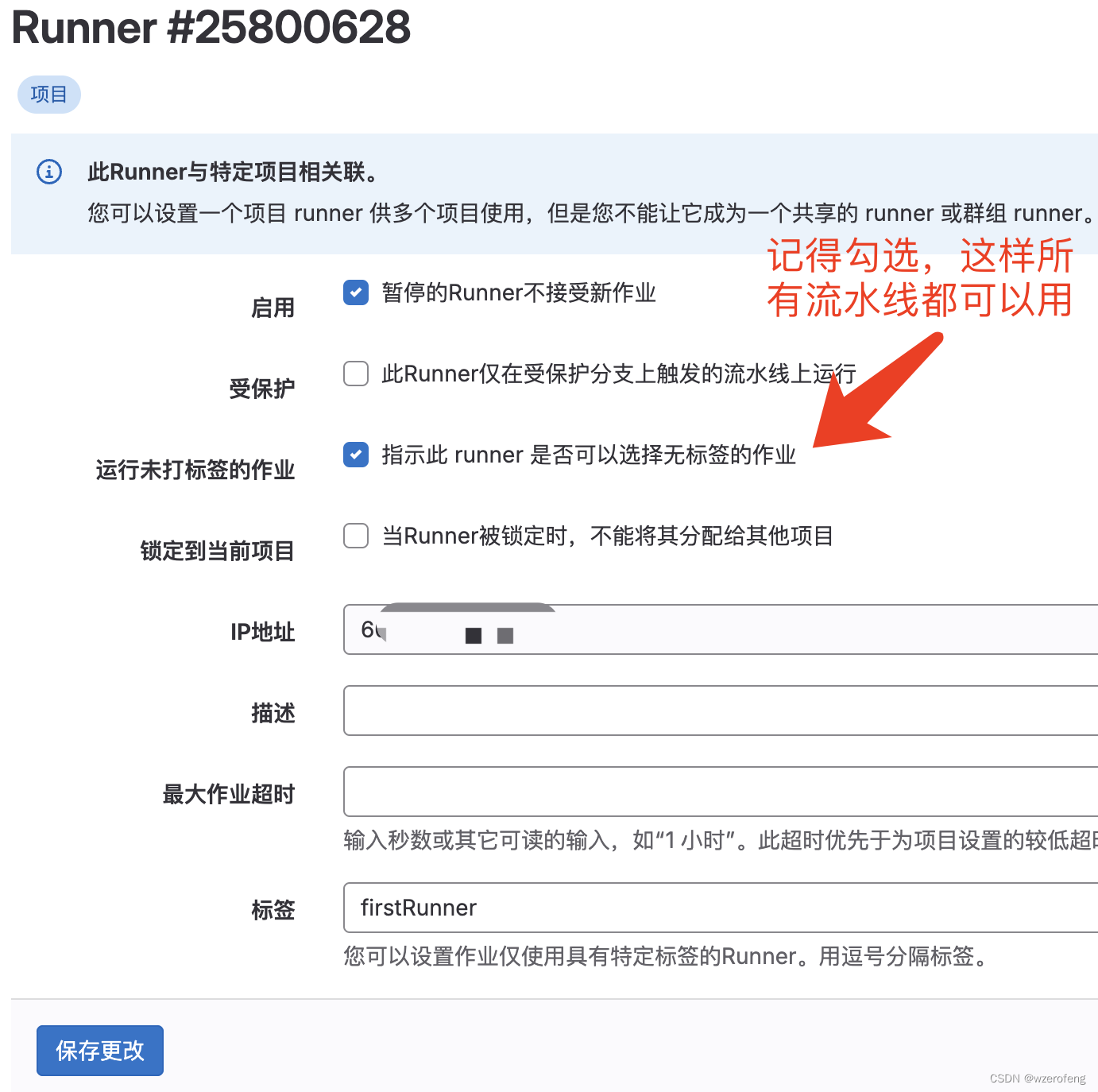
gitlab-Runner搭建
root wget https://packages.gitlab.com/runner/gitlab-runner/packages/fedora/29/gitlab-runner-12.6.0-1.x86_64.rpm/download.rpm rpm -ivh download.rpm ---- 安装 rpm -Uvh download.rpm -----更新升级 然后运行: gitlab-runner register --url https://git…...

【ChatGPT 指令大全】销售怎么借力ChatGPT提高效率
目录 销售演说 电话销售 产出潜在客户清单 销售领域计划 销售培训计划 总结 随着人工智能技术的不断进步,我们现在有机会利用ChatGPT这样的智能助手来改进我们的销售工作。在接下来的时间里,我将为大家介绍如何运用ChatGPT提高销售效率并取得更好的…...

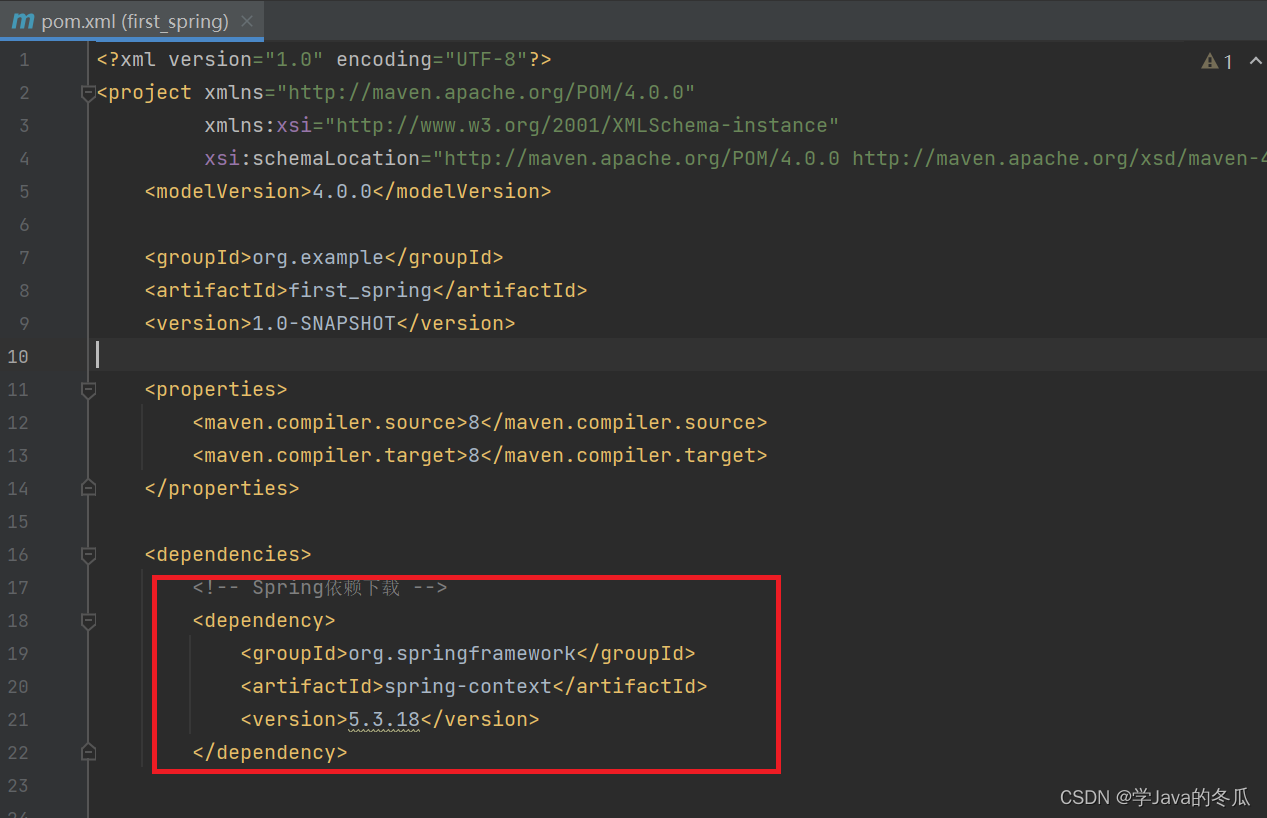
【Spring】-Spring项目的创建
作者:学Java的冬瓜 博客主页:☀冬瓜的主页🌙 专栏:【Framework】 主要内容:创建spring项目的步骤:先创建一个maven项目,再在pom.xml中添加spring框架支持,最后写一个启动类。 文章目…...

SQL | 使用通配符进行过滤
6-使用通配符进行过滤 6.1-LIKE操作符 前面介绍的所有操作符都是通过已知的值进行过滤,或者检查某个范围的值。但是如果我们想要查找产品名字中含有bag的数据,就不能使用前面那种过滤情况。 利用通配符,可以创建比较特定数据的搜索模式。 …...

make: *** [Makefile:719: ext/openssl/openssl.lo] Error 1
在ubuntu系统上编译安装PHP7.4.33时,会报错如下 make: *** [Makefile:719: ext/openssl/openssl.lo] Error 1 原因分析:这个错误提示的意思是PHP配置过程中缺少OpenSSL库文件,因此在编译过程中出现了问题;Ubuntu 22.04 中openss…...
Android Studio实现简单ListView
效果图 MainActivity package com.example.listviewtest;import androidx.appcompat.app.AppCompatActivity;import android.os.Bundle; import android.widget.ListView;import com.example.listviewtest.adapter.PartAdapter; import com.example.listviewtest.bean.PartB…...

【设计模式】模板模式
什么是模板模式? 模板方法模式(Template Method Pattern),又叫模板模式(Template Pattern),在一个抽象类公开定义了执行它的方法的模板。它的子类可以按需要重写方法实现,但调用将以抽象类中定义的方式进行…...
配置docker和复现
1.Nginx环境搭建 选择centos7来进行安装 1.1 创建Nginx的目录并进入 mkdir /soft && mkdir /soft/nginx/ cd /soft/nginx/ 1.2 下载Nginx的安装包,可以通过FTP工具上传离线环境包,或者通过wget命令在线获取安装包 wget https://nginx.org/down…...

Qt应用开发(基础篇)——工具箱 QToolBox
一、前言 QToolBox类继承于QFrame,QFrame继承于QWidget,是Qt常用的基础工具部件。 框架类QFrame介绍 QToolBox工具箱类提供了一列选项卡窗口,当前项显示在当前选项卡下面,适用于分类浏览、内容展示、操作指引这一类的使用场景。 二…...
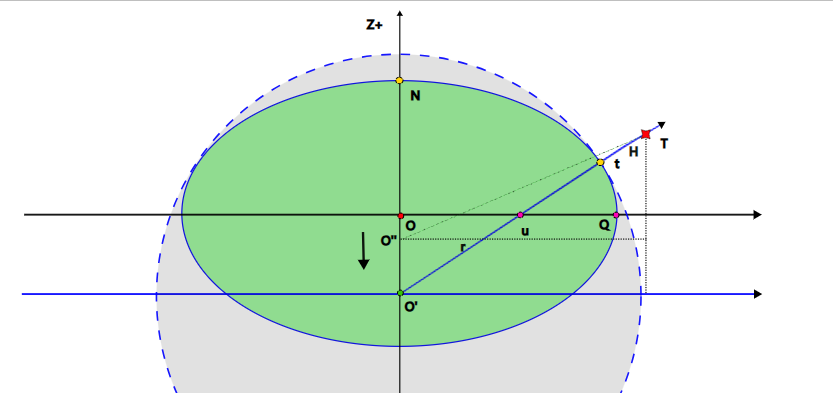
地理测绘基础知识(1) 坐标系经纬度与ECEF直角坐标的基本换算
经纬度与ECEF直角坐标的基本换算 我们目前最常用的全球坐标系是WGS-84坐标系,各种手机、地图基本用经纬度来标记位置。然而,经纬度对于空间的计算是很复杂的,需要很多三角函数操作。平面直角坐标系利用向量的运算,可以非常方便的…...
【UE4 RTS】08-Setting up Game Clock
前言 本篇实现的效果是在游戏运行后能够记录当前的游戏时间(年月日时分秒),并且可以通过修改变量从而改变游戏时间进行的快慢。 效果 步骤 1. 在Blueprints文件夹中新建如下两个文件夹,分别命名为“GameSettings”、“Player”…...
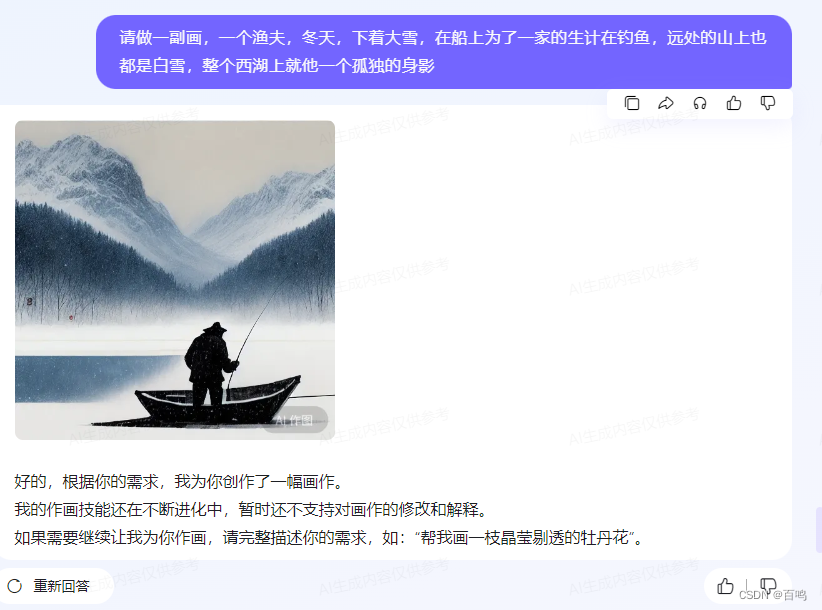
百度chatgpt内测版
搜索AI伙伴 申请到了百度的chatgpt: 完整的窗口布局: 三个哲学问题: 灵感中心: 请做一副画,一个渔夫,冬天,下着大雪,在船上为了一家的生计在钓鱼,远处的山上也都是白雪&a…...

[GAN] 使用GAN网络进行图片生成的“调参人”入门指南——生成向日葵图片
[GAN] 使用GAN网络进行图片生成的“炼丹人”日志——生成向日葵图片 文章目录 [GAN] 使用GAN网络进行图片生成的“炼丹人”日志——生成向日葵图片1. 写在前面:1.1 应用场景:1.2 数据集情况:1.3 实验原理讲解和分析(简化版&#x…...

(十)人工智能应用--深度学习原理与实战--模型的保存与加载使用
目的:将训练好的模型保存为文件,下次使用时直接加载即可,不必重复建模训练。 神经网络模型训练好之后,可以保存为文件以持久存储,这样下次使用时就不重新建模训练,直接加载就可以。TensorfLow提供了灵活的模型保存方案,既可以同时保存网络结构和权重(即保存全模型),也可…...

Java“牵手”1688商品详情页面数据获取方法,1688API实现批量商品数据抓取示例
背景:1688商城是一个网上购物平台,售卖各类商品,包括服装、鞋类、家居用品、美妆产品、电子产品等。要获取1688商品详情数据,您可以通过开放平台的接口或者直接访问1688商城的网页来获取商品详情信息。以下是两种常用方法的介绍&a…...

Docker_docker runContainerd
docker run-Containerd docker run -it 运行容器交互式方式启动守护进程方式启动其他命令 docker部署nginx服务k8s废弃docker原因安装和配置containerdcontainerd常用命令 docker run -it 运行容器 交互式方式启动 # 以交互式方式启动并进入容器 docker run --namehello -it …...

AstrBot:一体化开源AI聊天机器人平台部署与架构解析
1. 项目概述:一个开源的、全能的AI聊天机器人平台 如果你正在寻找一个能够无缝接入你日常使用的QQ、微信、飞书、钉钉、Telegram等主流即时通讯软件,并且功能强大到足以构建个人AI伴侣、智能客服、自动化助手乃至企业知识库的解决方案,那么A…...
Stream-Translator 终极指南:实时直播音频转录与翻译实战
Stream-Translator 终极指南:实时直播音频转录与翻译实战 【免费下载链接】stream-translator 项目地址: https://gitcode.com/gh_mirrors/st/stream-translator 在全球化内容消费的时代,语言障碍成为跨文化沟通的最大挑战。无论是国际电竞赛事、…...

Windows下npm run dev报错‘NODE_OPTIONS‘不是命令?手把手教你用cross-env一劳永逸
Windows下npm run dev报错NODE_OPTIONS不是命令?手把手教你用cross-env一劳永逸 最近在Windows上跑Vite项目时,不少开发者都踩过这个坑:明明在Mac/Linux上运行良好的npm run dev命令,到了Windows却报错NODE_OPTIONS 不是内部或外部…...

终极指南:如何免费使用Navicat Mac版无限重置试用期
终极指南:如何免费使用Navicat Mac版无限重置试用期 【免费下载链接】navicat_reset_mac navicat mac版无限重置试用期脚本 Navicat Mac Version Unlimited Trial Reset Script 项目地址: https://gitcode.com/gh_mirrors/na/navicat_reset_mac 想象一下&…...
)
Spring Boot项目里,如何给OpenFeign接口加上详细的请求和响应日志(附Log4j2配置)
Spring Boot项目中OpenFeign请求/响应日志全链路配置实战 微服务架构下,接口调用如同神经网络中的突触传递——每一次通信都承载着关键业务数据。当某个Feign调用出现异常时,开发者的第一反应往往是:"到底发送了什么参数?服…...

百度网盘直链解析终极指南:告别限速,实现高速下载的简单方法
百度网盘直链解析终极指南:告别限速,实现高速下载的简单方法 【免费下载链接】baidu-wangpan-parse 获取百度网盘分享文件的下载地址 项目地址: https://gitcode.com/gh_mirrors/ba/baidu-wangpan-parse 你是否曾经面对百度网盘的下载速度限制感到…...

开源AI录屏工具Bloom:本地优先架构与智能工作流实践
1. 项目概述:从本地录屏到AI就绪的工作流革命 如果你和我一样,日常工作中充斥着大量的屏幕录制需求——可能是给同事演示一个功能,记录一个线上会议,或者复盘自己解决一个复杂Bug的过程——那你肯定对Loom这类工具不陌生。它们方…...

3分钟快速上手:免费解锁网易云音乐NCM格式的完整指南
3分钟快速上手:免费解锁网易云音乐NCM格式的完整指南 【免费下载链接】ncmdump 项目地址: https://gitcode.com/gh_mirrors/ncmd/ncmdump 还在为网易云音乐下载的歌曲只能在特定客户端播放而烦恼吗?ncmdump是你需要的终极解决方案!这…...

百度网盘直链解析工具:终极高速下载解决方案
百度网盘直链解析工具:终极高速下载解决方案 【免费下载链接】baidu-wangpan-parse 获取百度网盘分享文件的下载地址 项目地址: https://gitcode.com/gh_mirrors/ba/baidu-wangpan-parse 还在为百度网盘龟速下载而烦恼吗?百度网盘直链解析工具&am…...

抖音直播保存终极指南:douyin-downloader完整解决方案
抖音直播保存终极指南:douyin-downloader完整解决方案 【免费下载链接】douyin-downloader A practical Douyin downloader for both single-item and profile batch downloads, with progress display, retries, SQLite deduplication, and browser fallback suppo…...