SQL Server 2008新特性——更改跟踪
在大型的数据库应用中,经常会遇到部分数据的脱机和多个数据库的合并问题。比如现在有一个全省范围使用的应用程序,每个市都部署了单独的相同的应用程序服务器和数据库服务器,每个月需要将全省所有市的数据全部汇总起来用于出全省的报表,这是一种很常见的数据库合并问题。再比如我们做了一个SmartClient的应用程序,每个客户端都有应用程序和数据库,另外还有一个中心数据库用于汇总所有客户端的数据。每个智能客户端上都可以对自己的数据库进行增删改查,一旦智能客户端连接到网络上时,系统就将客户端数据库中的数据更改全部应用到中心数据库中,这种偶尔连接的应用程序也是需要数据库的同步的。
对于前面说到的这些应用,最简单的同步方法就是删除原有数据,然后重新填充新的数据,对于小数据量的表来说这并没有什么问题,但是如果每个市都有几百万几千万条数据,那么要将省数据库中的数据删除了再把每个市中的数据全部填充到省数据库中显然是不可行的。这种情况下应该使用跟踪数据更改的方法,将每个市这个月的数据更改应用到省数据库中(感觉有点像是差异备份一样,只记录更改的)。在SQL Server 2008中提供了两种跟踪数据更改的方案:
变更数据捕获(Change Data Capture)
更改跟踪(Chang Tracking)
今天我主要说的是更改跟踪,变更数据捕获在以后进行讲解。
启用更改跟踪
更改跟踪是SQL Server 2008的一个新特性,默认情况下是没启用的。更改跟踪可以应用跟踪到具体一个数据库中的具体表甚至是具体的列。更改跟踪并不会创建触发器之类的对象,只是在用户对启用了更改跟踪的表进行了增加、修改和删除操作时,系统自动将该操作生成一个版本号,记录下操作的时间戳、操作的类型、受影响的数据的主键等信息。启用更改跟踪后对数据操作的性能影响不是很大。这些信息是记录到SQL Server系统表中的,系统自动负责清理和维护。
要使用更改跟踪需要启用数据库的更改跟踪功能和表的更改跟踪功能。在SSMS中数据库的属性窗口中可以启用数据库的更改跟踪:
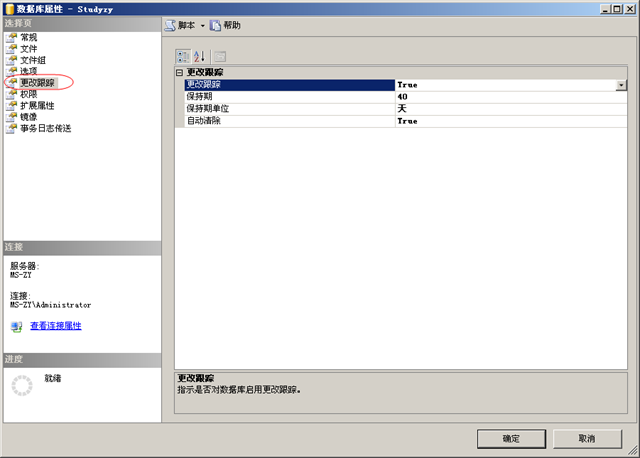
这里将更改跟踪选项设置为true既可启用更改跟踪。另外3个选项就是跟踪的数据自动清理的开关和清理的时间,这个自动清理的时间必须大于我们要同步数据的周期,比如我们的数据是一个月同步一次,那么这个保持期就应该大于31天,如果设置保持期太短,那么我们的跟踪数据还没来得及同步就被自动清理了。
这里只是启用了数据库的更改跟踪,接下来是要启用表的更改跟踪。这里我们创建一个新的表t1并初始化几条数据:
CREATETABLEt1( c1 INTIDENTITYPRIMARYKEY, c2 VARCHAR(50)NOTNULL, c3 DATETIMENOTNULL, c4 VARCHAR(max))GOINSERTINTO t1 VALUES('test1','2009-1-1','www.cnblogs.com/studyzy')INSERTINTO t1 VALUES('test2','2009-1-1','www.cnblogs.com/studyzy')INSERTINTO t1 VALUES('test3','2009-1-2','www.cnblogs.com/studyzy')复制
接下来在SSMS中查看表t1的属性窗口,可以在属性窗口中启用该表的更改跟踪功能:
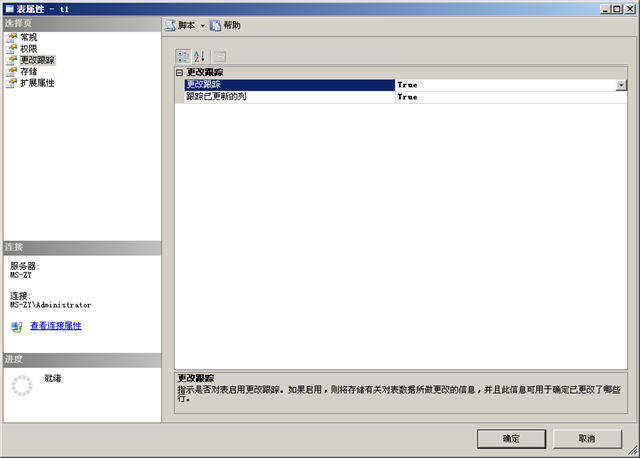
其中第二个选项“跟踪已更新的列”是表示是否将更改跟踪细化到列上。对于一般的表来说,我们只需要知道具体哪些行进行了更改,然后在合并数据时将整行数据更新到中心数据库既可,但是如果表中有大对象列(text image varchar(max) varbinary(max) xml等数据类型的列)时,将整行进行更新可能非常慢,所以我们可以启用“跟踪已更新的列”将具体更新了哪些列记录下来,这样在合并数据时就直接更新这些列既可。
更改跟踪常用函数
在更改跟踪中最重要的一点就是版本号,版本号从0开始一直递增,对表的每一次更改操作都会产生一个新的版本号。使用
SELECTCHANGE_TRACKING_MIN_VALID_VERSION(OBJECT_ID('dbo.t1'))复制
可以获得t1表最小版本号,由于是刚创建更改跟踪,所以这里返回的是0,如果我们进行了大量的操作以后,而且这些操作的时间已经超过了数据库更改跟踪中设置的保持期时间,那么过期的版本就会被系统自动清理,清理后最小版本就不是0了,而是保留的可用的最早版本。
SELECT CHANGE_TRACKING_CURRENT_VERSION()可以获得当前数据库的更改跟踪的最新版本。这里由于我们启用更改跟踪后还没有进行数据库操作,所以返回的也是0。
现在我们向表t1中插入一条数据,然后查看当前最新版本:
INSERTINTO t1 VALUES('test','2009-1-4','www.cnblogs.com/studyzy')SELECTCHANGE_TRACKING_CURRENT_VERSION()--返回1复制
现在返回的版本号就是1了。
接下来我们再修改2条数据和删除1条数据,再查看版本号:
UPDATE t1 SET c3=GETDATE()WHERE c1<3--受影响2条数据
DELETEFROM t1 WHERE c2='test3'--受影响1条数据
SELECTCHANGE_TRACKING_CURRENT_VERSION()--返回3复制
这里我们总共影响了4条数据,但是版本号为3说明版本号并不是以受影响的行实来定的,一次更新操作中不管影响了好多条数据(当然这里不能为0条)版本号只增加1。
现在版本号有了,接下来就是查询出这段时间t1的更改情况,需要使用表值函数:CHANGETABLE(CHANGES [要查询更改跟踪的表名], 从哪个版本开始的更改)。这里要查询t1表从0版本开始到现在的所有数据更改,那么对应的查询语句是:
SELECT*FROMCHANGETABLE(CHANGES dbo.t1,0)as ct复制
系统返回结果:
SYS_CHANGE_VERSION | SYS_CHANGE_CREATION_VERSION | SYS_CHANGE_OPERATION | SYS_CHANGE_COLUMNS | SYS_CHANGE_CONTEXT | c1 |
2 | NULL | U | 0x0000000003000000 | NULL | 1 |
2 | NULL | U | 0x0000000003000000 | NULL | 2 |
3 | NULL | D | NULL | NULL | 3 |
1 | 1 | I | NULL | NULL | 4 |
这里每个列的数据类型、含义等在联机丛书里面解释的很清楚,我这里只简单介绍下返回的这个表:
在版本号为1的数据更改操作中是插入了一条数据,插入数据的主键c1=4;在版本号2的操作中更新了2条数据,分别是c1=1和c1=2的行;在版本3的操作中删除了c1=3的一条数据。
根据更改跟踪同步数据
现在所有的更改已经查询出来了,接下来就可以根据查询出来的这个结果同步数据了。为了演示方便,我这里将在同一个实例中建立TestDB1数据库并初始化t1表用于表示中心数据库。那么同步数据的操作应该是:
--首先将新增的数据插入到中心数据库中:
SETIDENTITY_INSERT TestDB1.dbo.t1 ONINSERTINTO TestDB1.dbo.t1(c1,c2,c3,c4)SELECT t1.*FROMCHANGETABLE(CHANGES dbo.t1,0)AS ct
INNERJOIN t1
ON ct.c1=t1.c1
WHERE ct.SYS_CHANGE_OPERATION='I'--接下来将更改的数据应用到中心数据库中:
UPDATE TestDB1.dbo.t1
SET c2=newt1.c2,c3=newt1.c3,c4=newt1.c4
FROMCHANGETABLE(CHANGES dbo.t1,0)AS ct
INNERJOIN dbo.t1 AS newt1
ON ct.c1=newt1.c1
WHERE ct.SYS_CHANGE_OPERATION='U'AND t1.c1=newt1.c1 --将删除的数据从中心数据库删除:
DELETEFROM TestDB1.dbo.t1
WHERE c1 IN(SELECT c1 FROMCHANGETABLE(CHANGES dbo.t1,0)AS ct WHERE ct.SYS_CHANGE_OPERATION='D')复制
这样我们就使用更改跟踪实现了数据库的同步。该同步操作时的版本号是3,这个版本号必须要单独记下来,那么下次再进行同步是就从3开始查询。
通过更改跟踪更新列
前面的同步脚本中关于数据update操作是:
UPDATE TestDB1.dbo.t1
SET c2=newt1.c2,c3=newt1.c3,c4=newt1.c4复制
由于c4是大对象数据类型,如果里面存放了几十兆或者更大的数据,而实际上我们更新的并不是c4列,那么这种更新方式必然很浪费时间和资源。前面我们对t1表已经启用了“跟踪已更新的列”,那么就可以根据实际更新的列来更新数据。
使用CHANGE_TRACKING_IS_COLUMN_IN_MASK()函数可以判断一个列是否发生了更改,如果发生了更改则返回1,没有更改则返回0。比如查询c2是否发生更改:
SELECT*,CHANGE_TRACKING_IS_COLUMN_IN_MASK(COLUMNPROPERTY(OBJECT_ID('dbo.t1'),'c2','ColumnId'),SYS_CHANGE_COLUMNS)FROMCHANGETABLE(CHANGES dbo.t1,0)AS ct
WHERE ct.SYS_CHANGE_OPERATION='U'复制
这里返回0说明没有更改c2列,同样的方法可以判断出c3列发生了更改。
既然可以判断哪些列发生了更改,那么就可以根据发生更改的列来更新该列的数据,比如对于c2的更新语句就是:
UPDATE TestDB1.dbo.t1
SET c2=newt1.c2 --更新c2列
FROMCHANGETABLE(CHANGES dbo.t1,0)AS ct
INNERJOIN dbo.t1 AS newt1
ON ct.c1=newt1.c1
WHERE ct.SYS_CHANGE_OPERATION='U'AND t1.c1=newt1.c1
ANDCHANGE_TRACKING_IS_COLUMN_IN_MASK(COLUMNPROPERTY(OBJECT_ID('dbo.t1'),'c2','ColumnId'), ct.SYS_CHANGE_COLUMNS)=1--发生更改时才更新复制
同样的方法可以写出c3列、c4列的更新语句。如果觉得这样重复的写很麻烦,那么可以写一个存储过程,传入列名,检查该列是否更改,如果更改了则更新。
总结
更改跟踪是在偶尔连接的数据库应用和同步数据时非常有用的一个特性。更改跟踪里面的核心就是版本号,每次在同步数据时记录下当前的版本号,下次再同步时CHANGETABLE函数就传入上次同步的版本号,这样可以避免重复同步。
更改跟踪的跟踪记录数据是保存到系统表中的,由系统来维护,在开启数据库的更改跟踪时可以设置自动清除的时间,从而保证系统不会因为记录太多的跟踪数据而导致数据库文件大小急剧膨胀。
更改跟踪启用后对一般的DML操作(增删改)是不会有影响的,所有的DML SQL语句照常使用,而且启用更改跟踪后并不会对系统性能造成明细影响。
相关文章:
SQL Server 2008新特性——更改跟踪
在大型的数据库应用中,经常会遇到部分数据的脱机和多个数据库的合并问题。比如现在有一个全省范围使用的应用程序,每个市都部署了单独的相同的应用程序服务器和数据库服务器,每个月需要将全省所有市的数据全部汇总起来用于出全省的报表&#…...

四六级真题长难句分析与应用
一、基本结构的长难句 基本结构的长难句主要考点:断开和简化 什么是长难句? 其实就是多件事连在了一块,这时候句子就变长、变难了 分析步骤: 第一件事就是要把长难句给断开,把多件事断开成一件一件的事情࿰…...
 | 机试题算法+思路 【2023】)
华为OD机试 - 玩牌高手(Python) | 机试题算法+思路 【2023】
最近更新的博客 华为OD机试 - 寻找路径 | 备考思路,刷题要点,答疑 【新解法】 华为OD机试 - 五键键盘 | 备考思路,刷题要点,答疑 【新解法】 华为OD机试 - IPv4 地址转换成整数 | 备考思路,刷题要点,答疑 【新解法】 华为OD机试 - 对称美学 | 备考思路,刷题要点,答疑 …...
【论文阅读】 Few-shot object detection via Feature Reweighting
Few-shot object detection的开山之作之一 ~~ 特征学习器使用来自具有足够样本的基本类的训练数据来 提取 可推广以检测新对象类的meta features。The reweighting module将新类别中的一些support examples转换为全局向量,该全局向量indicates meta features对于检…...

现代卷积神经网络经典架构图
卷积神经网络(LeNet) LeNet 的简化版深层卷积神经网络(AlexNet) 从LeNet(左)到AlexNet(右)改进: dropOut层 - 不改变期望但是改变方差ReLU层 - 减缓梯度消失MaxPooling数…...
有关eclipse的使用tips
一、alt/键 会产生单词提示,可以提高编程速度。例如不需要辛辛苦苦的打出:System.out.println();整句,只需要在eclipse中输入syso,然后按住ALT/就会出来System.out.println();在alt键/不管用的情况下,可使用以下方法来…...
之CRUD)
Mybatis(4)之CRUD
首先是 增 ,我们要在数据库中增加一个数据 先来看看我们之前的插入语句 <insert id"insertRole">insert into try(id,name,age) values(3,nuonuo,20)</insert> 请注意,我们这里的 insert 是固定的,但在实际的业务场…...

OSG三维渲染引擎编程学习之五十七:“第五章:OSG场景渲染” 之 “5.15 光照”
目录 第五章 OSG场景渲染 5.15 光照 5.15.1 osg::Light光 5.15.2 osg::LightSource光源 第五章 OSG场景渲染 OSG存在场景树和渲染树,“场景数”的构建在第三章“OSG场景组织”已详细阐明,本章开始深入探讨“渲染树”。 渲染树一棵以状态集(StateSet)和渲染叶(RenderLe…...
[教你传话,表白,写信]
第一步 关注飞鸽传话助手 第二部 点击链接进入 第三步 点击发送,输入内容 第四步 就可以收到了...

物联网在智慧农业中的应用
随看现代科技的不断发展,近年来我国农业的进步是显而易见的。从八九十年代农业生产以人力为主,到之后的机械渐渐代替人力,再到如今物联网技术在农业领域的应用,多种前沿技术应用于农业物联网,对智慧农业生产的各个环节…...
【RabbitMQ】Windows 安装 RabbitMQ
文章目录工具下载Eralng 安装与配置RabbitMQ 安装工具下载 RabbitMQ 3.7.4版本 网盘链接:https://pan.baidu.com/s/1pO6Q8fUbiMrtclpq2KqVVQ?pwdgf29 提取码:gf29 Eralng 网盘链接:https://pan.baidu.com/s/1irf8fgK77k8T9QzsIRwa7g?pwd9…...

MQTT8-MQTT在智能汽车公司的实际应用
一、引言 智能汽车的发展概况 智能汽车作为一种新兴的汽车类型,它的发展历程可以追溯到20世纪90年代。近年来,随着人工智能、物联网、自动驾驶等技术的发展,智能汽车迅速崛起,已经成为汽车行业的一股重要趋势。 智能汽车通过安装传感器、通讯设备和计算设备等,实现了车…...

在elasticsearch8.3中安装elasticsearch-analysis-ik中文分词插件
title: 在elasticsearch8.3中安装elasticsearch-analysis-ik中文分词插件 date: 2022-08-28 00:00:00 tags: ElasticSearchelasticsearch-analysis-ik中文分词插件 categories:ElasticSearch 安装 手动下载 在官方发布页面下载安装包 elasticsearch-analysis-ik-[版本].zip&…...
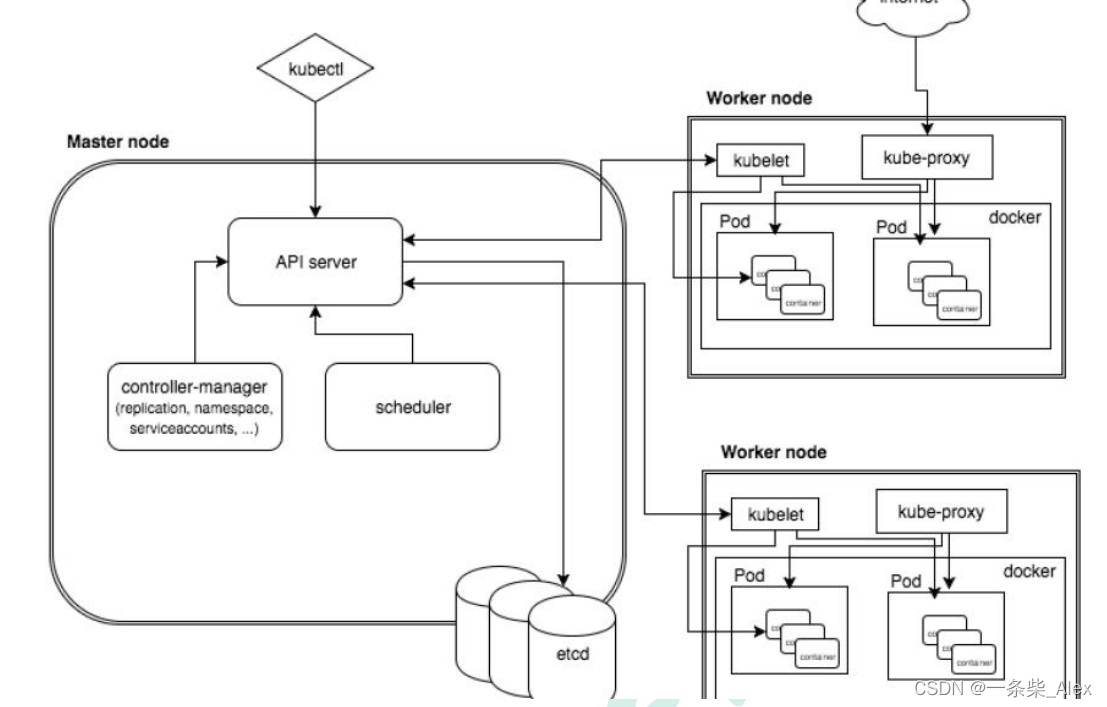
初识K8s
概览 k8s 概念和架构从零搭建K8s 集群k8s 核心概念搭建集群监控平台搭建高可用k8s集群集群环境 实际部署项目 k8s 概念和架构 1、K8S概述和特性 概述: k8s是谷歌在2014年开源的容器化集群管理系统使用k8s进行容器化应用部署使用k8s利于应用扩展k8s目标实施让部…...
搭建企业级docker仓库—Harbor
一、简介 docker 官方提供的私有仓库 registry,用起来虽然简单 ,但在管理的功能上存在不足。 Harbor是一个用于存储和分发Docker镜像的企业级Registry服务器,harbor使用的是官方的docker registry(v2命名是distribution)服务去完成。harbor在…...
)
【Linux】shell中运算符(整数、字符串)
文章目录1. 整数1.1、算数运算符1.1.1 加减乘除运算1.1.2 号关系运算1.1.2.1 (赋值)、(等于)、!(不等于)的使用1.1.2.2 >、>、<、<的使用1.2 $((运算式)) 双括号形式 、 $[运算式] 语法 进行运算1.3 -eq关系运算符1.4 、、-eq的区别2 字符串2.1 字符串运算3 逻辑运…...

【从零单排Golang】第八话:通过cache缓存模块示范interface该怎么用
和许多面向对象的编程语言一样,Golang也存在interface接口这样的概念。interface相当于是一个中间层,下游只需要关心interface实现了什么行为,利用这些行为做些业务级别事情,而上游则负责实现interface,把这些行为具象…...

解析从Linux零拷贝深入了解Linux-I/O(上)
本文将从文件传输场景以及零拷贝技术深究 Linux I/O 的发展过程、优化手段以及实际应用。前言 存储器是计算机的核心部件之一,在完全理想的状态下,存储器应该要同时具备以下三种特性: 速度足够快:存储器的存取速度应当快于 CPU …...

JavaScript系列之公有、私有和静态属性和方法
文章の目录一、公有属性、公有方法1、定义2、理解3、ES54、ES6二、私有属性、私有方法1、定义2、理解3、ES54、ES6三、静态属性、静态方法1、定义2、理解3、ES54、ES6写在最后一、公有属性、公有方法 1、定义 指的是所属这个类的所有对象都可以访问的属性,叫做公有…...

过滤器与拦截器
文章目录一、前言1、概述2、过滤器与拦截器异同2.1 简介2.2 异同2.3 总结3、Filters vs HandlerInterceptors二、过滤器1、概述2、生命周期2.1 生命周期概述2.2 基于函数回调实现原理3、自定义过滤器两种实现方式3.1 WebFilter注解注册3.2 过滤器(配置类注册过滤器&…...

fold命令行工具:高效文本数据聚合与分析的瑞士军刀
1. 项目概述:一个为“折叠”而生的高效工具 最近在折腾一些数据处理和文件整理的工作流时,我一直在寻找一个能让我“折叠”起来思考的工具。我说的“折叠”,不是物理上的,而是逻辑上的——把复杂的、多维度的信息,按照…...

Claw框架数据库迁移工具claw-migrate:原理、实践与团队协作指南
1. 项目概述:一个专为Claw设计的迁移工具最近在折腾一个叫Claw的开源项目,它本身是一个轻量级的Web框架,用起来挺顺手。但项目迭代过程中,难免会遇到数据库结构变更、数据迁移这类“脏活累活”。手动写SQL脚本?太原始&…...

物联网安防系统故障排查与ESP8266固件刷写实战指南
1. 物联网安防系统故障排查实战做物联网安防系统,最怕的就是“哑火”。你花了好几天时间,把ESP8266、Raspberry Pi、MQTT Broker、Adafruit.IO和IFTTT像搭积木一样连起来,满心期待它能在关键时刻给你发条短信。结果,门被推开了&am…...

【最新 v2.7.1 版本安装包】OpenClaw 零基础无痛部署,无需命令零代码保姆级快速上手
OpenClaw(小龙虾)Windows 一键部署保姆级教程 | 10 分钟搭建专属数字员工【点击下载最新OpenClaw安装包】 前言 2026 年开源圈热门 AI 智能体 OpenClaw(昵称小龙虾),GitHub 星标突破 28 万,凭借本地运行 …...

深度解析VS Code Live Server:高效前端开发实时预览配置秘籍
深度解析VS Code Live Server:高效前端开发实时预览配置秘籍 【免费下载链接】vscode-live-server Launch a development local Server with live reload feature for static & dynamic pages. 项目地址: https://gitcode.com/gh_mirrors/vs/vscode-live-serv…...

解密ComfyUI-WanVideoWrapper:在ComfyUI中突破AI视频生成的技术壁垒
解密ComfyUI-WanVideoWrapper:在ComfyUI中突破AI视频生成的技术壁垒 【免费下载链接】ComfyUI-WanVideoWrapper 项目地址: https://gitcode.com/GitHub_Trending/co/ComfyUI-WanVideoWrapper 你是否曾想过将脑海中的创意场景转化为生动的视频内容࿰…...

PPO 原理与应用
1. PPO 在 RLHF 里到底是干什么的? 在 RLHF 里,我们通常已经有了一个经过 SFT 的模型。这个模型已经比较会回答问题了,但还不一定最符合人类偏好。 于是我们再训练一个 奖励模型 Reward Model,让它模仿人类判断: 这个回…...

3分钟掌握FanControl:Windows风扇控制终极指南
3分钟掌握FanControl:Windows风扇控制终极指南 【免费下载链接】FanControl.Releases This is the release repository for Fan Control, a highly customizable fan controlling software for Windows. 项目地址: https://gitcode.com/GitHub_Trending/fa/FanCon…...

SMAPI模组加载器:星露谷物语模组玩家的终极完整指南
SMAPI模组加载器:星露谷物语模组玩家的终极完整指南 【免费下载链接】SMAPI The modding API for Stardew Valley. 项目地址: https://gitcode.com/gh_mirrors/smap/SMAPI 你是否厌倦了手动安装星露谷物语模组时的繁琐步骤?是否担心模组冲突导致游…...

Filecoin挖矿硬件怎么选?用Lotus-bench实测RTX 2080 Ti到GTX 1060的密封性能
Filecoin挖矿硬件实战指南:从GPU选型到Lotus-bench深度优化 在Filecoin挖矿生态中,GPU性能直接决定了密封效率和区块奖励获取能力。面对市场上从高端RTX 2080 Ti到入门级GTX 1060的各类显卡,矿工往往陷入选择困境——官方推荐列表中的参数是否…...