Python爬虫的requests(学习于b站尚硅谷)
目录
- 一、requests
- 1. requests的基本使用
- (1)文档
- (2)安装
- (3)响应response的属性以及类型
- (4)代码演示
- 2.requests之get请求
- 3. requests之post请求
- (1)演示示例-爬取百度翻译
- (2)get和post区别
- 4. requests之代理
- 5. requests之cookie登陆古诗文网(含验证码、隐藏域反爬、session)
- 6. requests_超级鹰打码平台的使用
说明:该文章是学习 尚硅谷在B站上分享的视频 Python爬虫教程小白零基础速通的 p51-104而记录的笔记,笔记来源于本人,关于python基础可以去CSDN上阅读本人学习黑马程序员的笔记。 若有侵权,请联系本人删除。笔记难免可能出现错误或笔误,若读者发现笔记有错误,欢迎在评论里批评指正。 请合法合理使用爬虫,不爬取任何涉密以及涉及隐私的内容,合理控制请求次数,爬取的内容未经授权请不要用于商用,保护自己,免受牢狱之灾。
本章将学习requests,首先,requests和urllib的作用几乎一模一样。但是,在处理某些页面时,requests会更加方便、更加简单、更加强大。这里用表格对比一下urllib以及requests学习的内容。
| 方法 | urllib | requests |
|---|---|---|
| 主要内容 | 一个类型以及六个方法 get请求 post请求 百度翻译 ajax的get请求 ajax的post请求 cookie登陆 微博 代理 | 一个类型以及六个属性 get请求 post请求 代理 cookie 验证码 |
一、requests
1. requests的基本使用
(1)文档
官方文档https://requests.readthedocs.io/projects/cn/zh_CN/latest/
快速上手https://requests.readthedocs.io/projects/cn/zh_CN/latest/user/quickstart.html
官方文档内容比较多,快速上手的文档里面就是一些基本使用、基本操作。
(2)安装
安装命令:pip install requests -i https://pypi.mirrors.ustc.edu.cn/simple/
安装具体步骤:如下图,先打开“命令提示符”。
然后在命令提示符里安装requests。
(3)响应response的属性以及类型
| 类型 | models.Response |
| r.text | 获取网站源码 |
| r.encoding | 访问或定制编码方式 |
| r.url | 获取请求的url |
| r.content | 响应的字节类型 |
| r.status_code | 响应的状态码 |
| r.headers | 响应的头信息 |
(4)代码演示
创建文件夹“爬虫的requests”。
创建文件“084_requests的基本使用.py”。
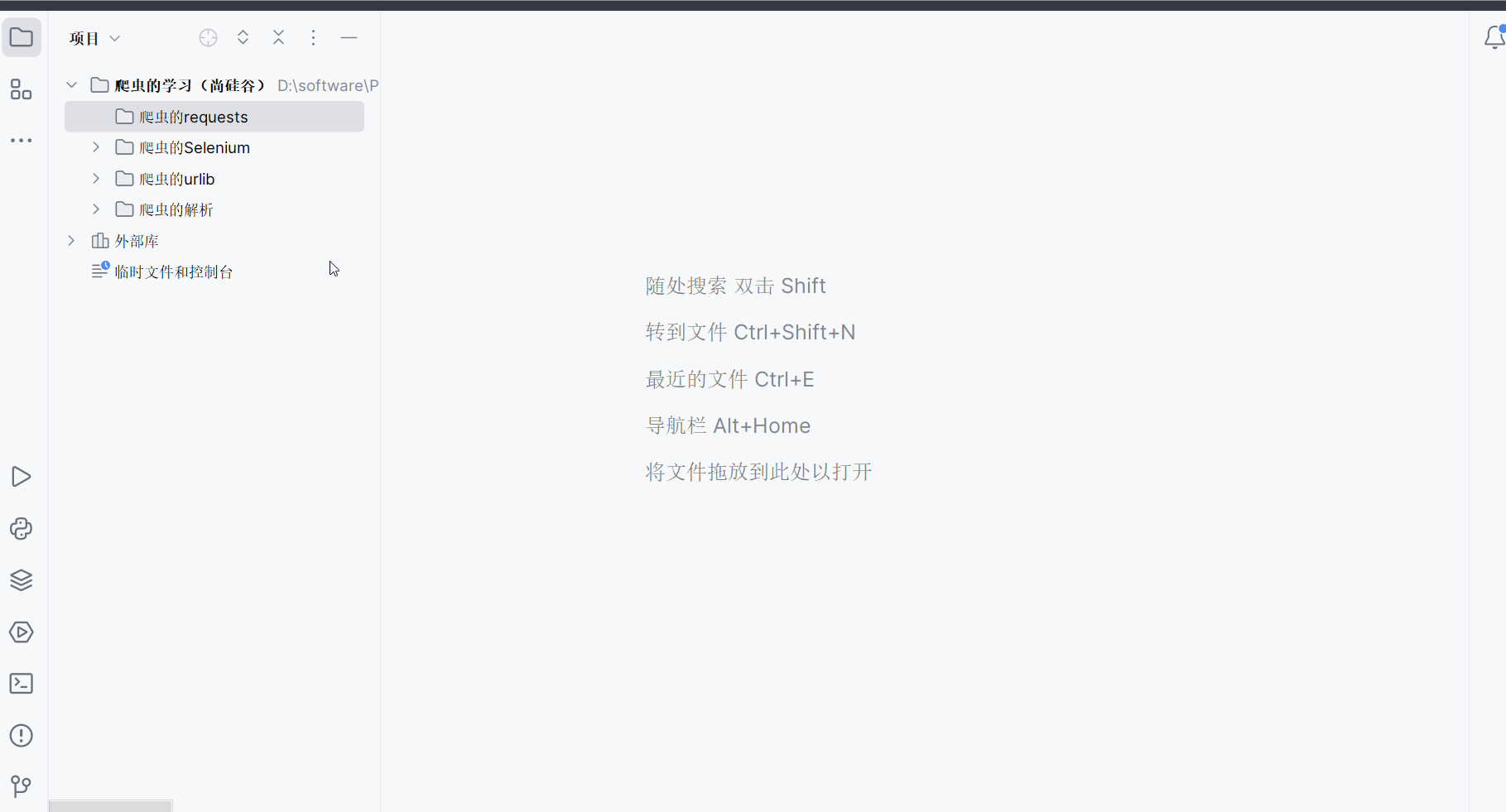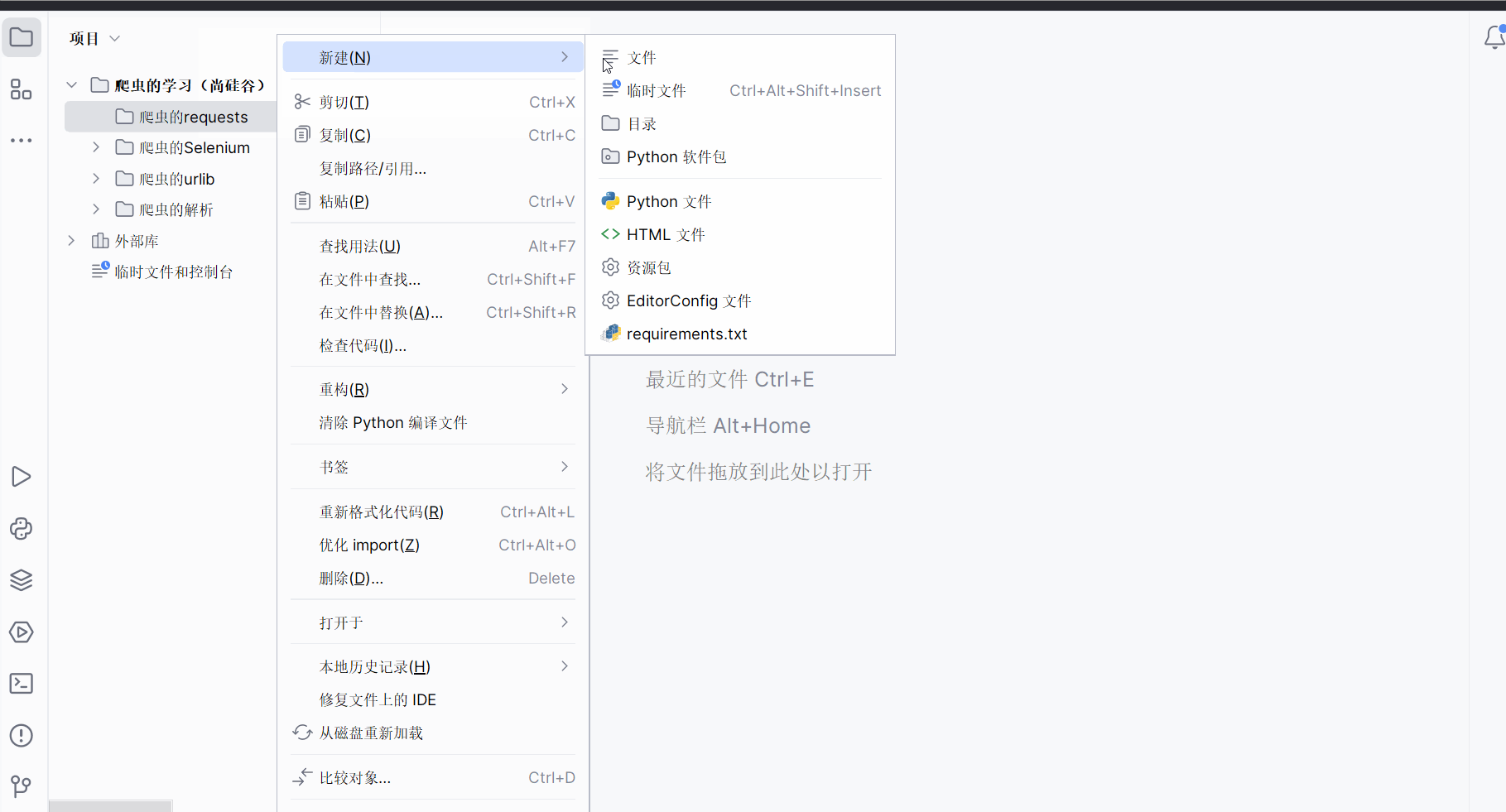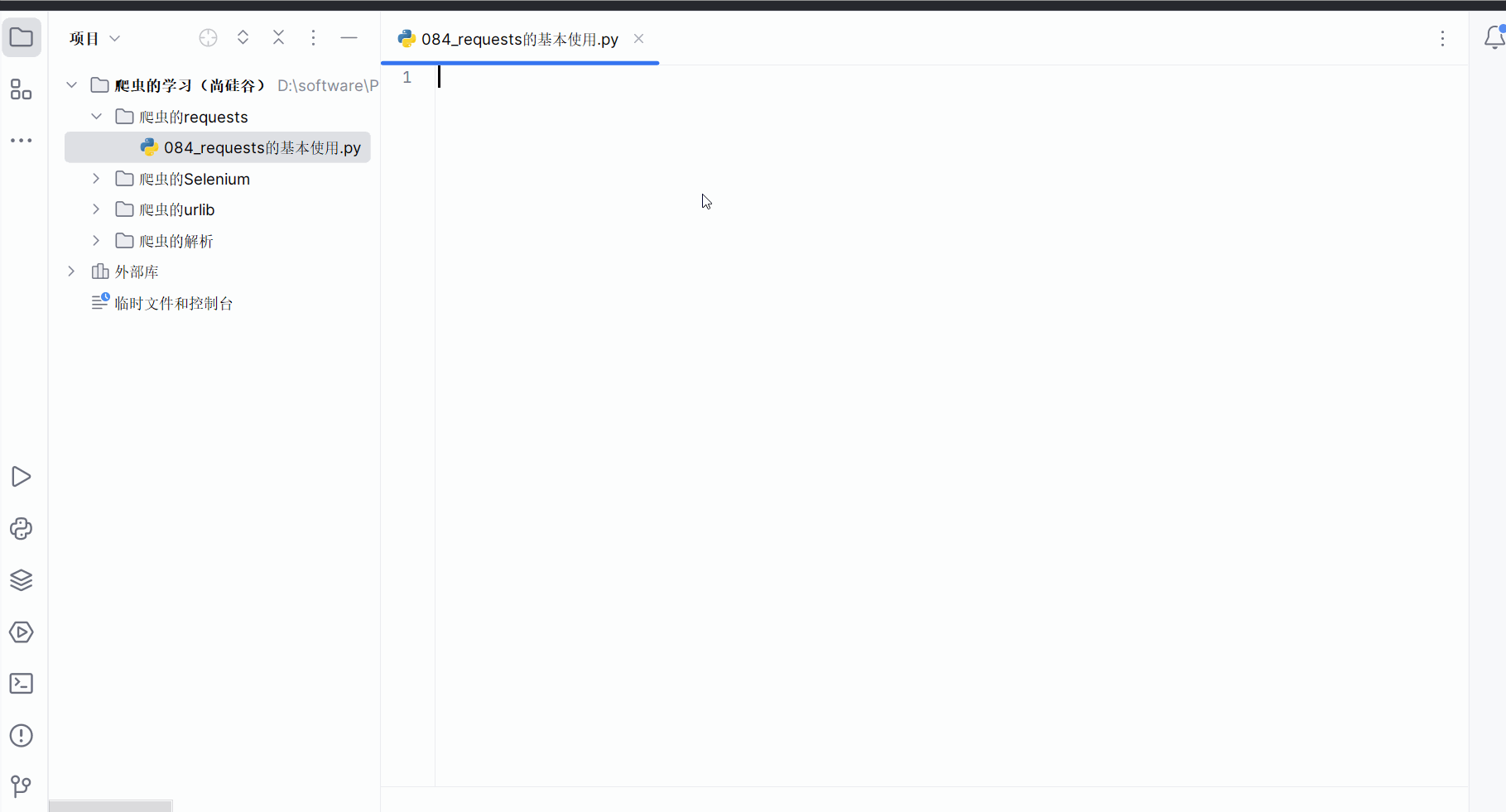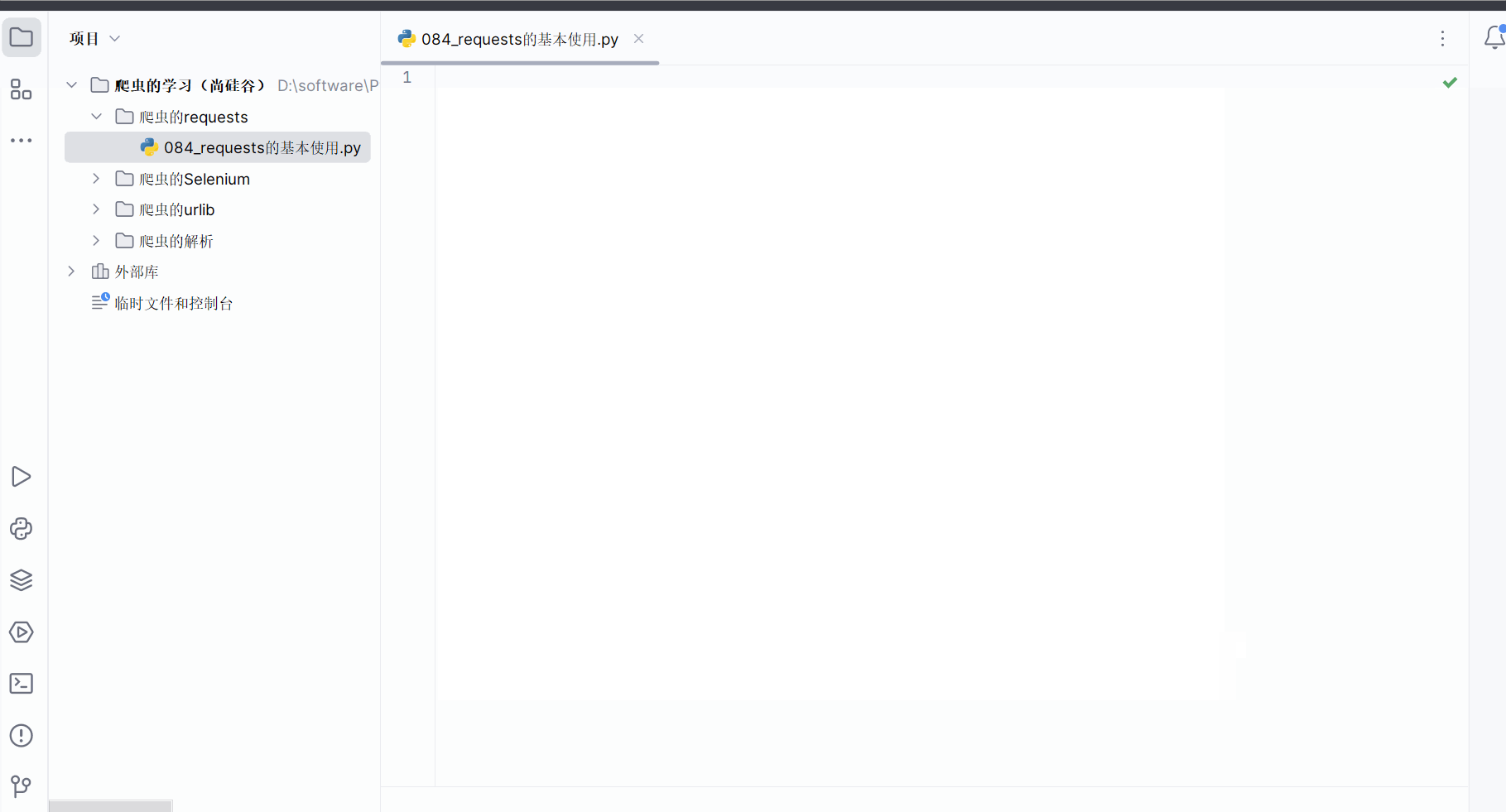
如下编程,发现requests的响应的类型为Response,这和urllib不一样,在之前的学习中我们知道urllib返回的响应的类型为HTTPResponse。
"""
requests的基本使用
"""
import requestsurl = 'http://www.baidu.com'
# 访问网址并接收产生的响应
response = requests.get(url)# 一个类型和六个属性
# Response类型
print(f"respons的类型:{type(response)}")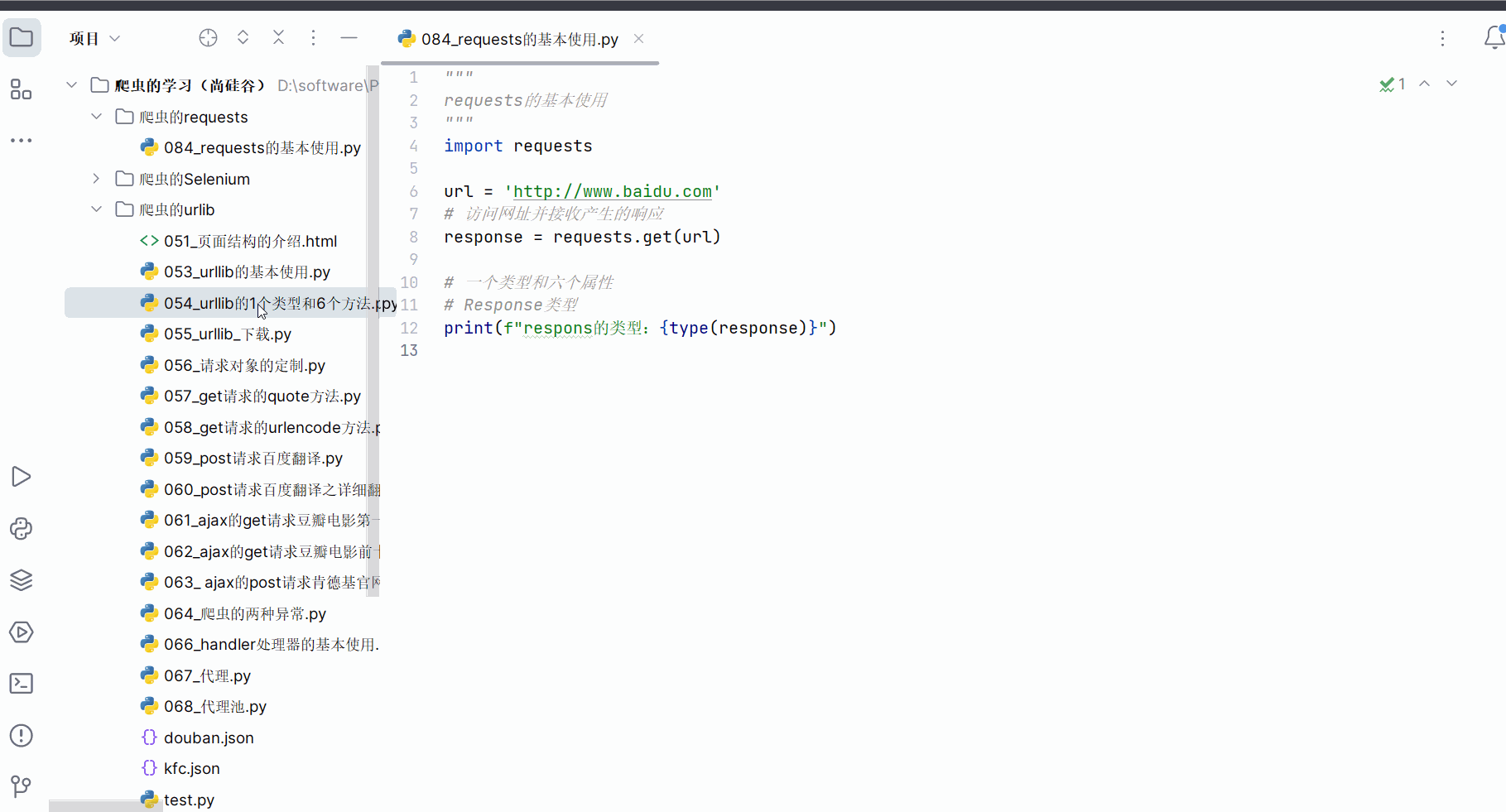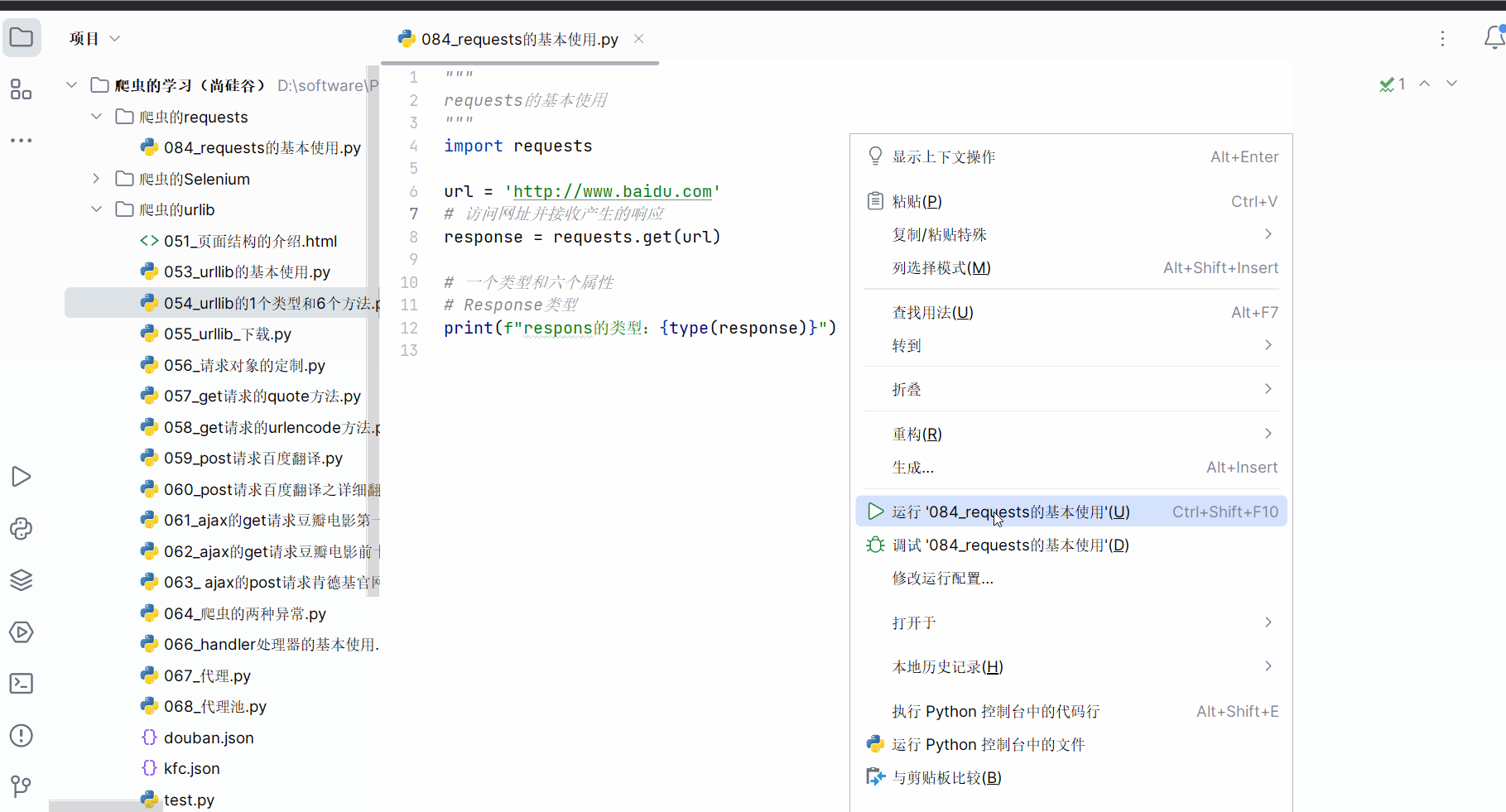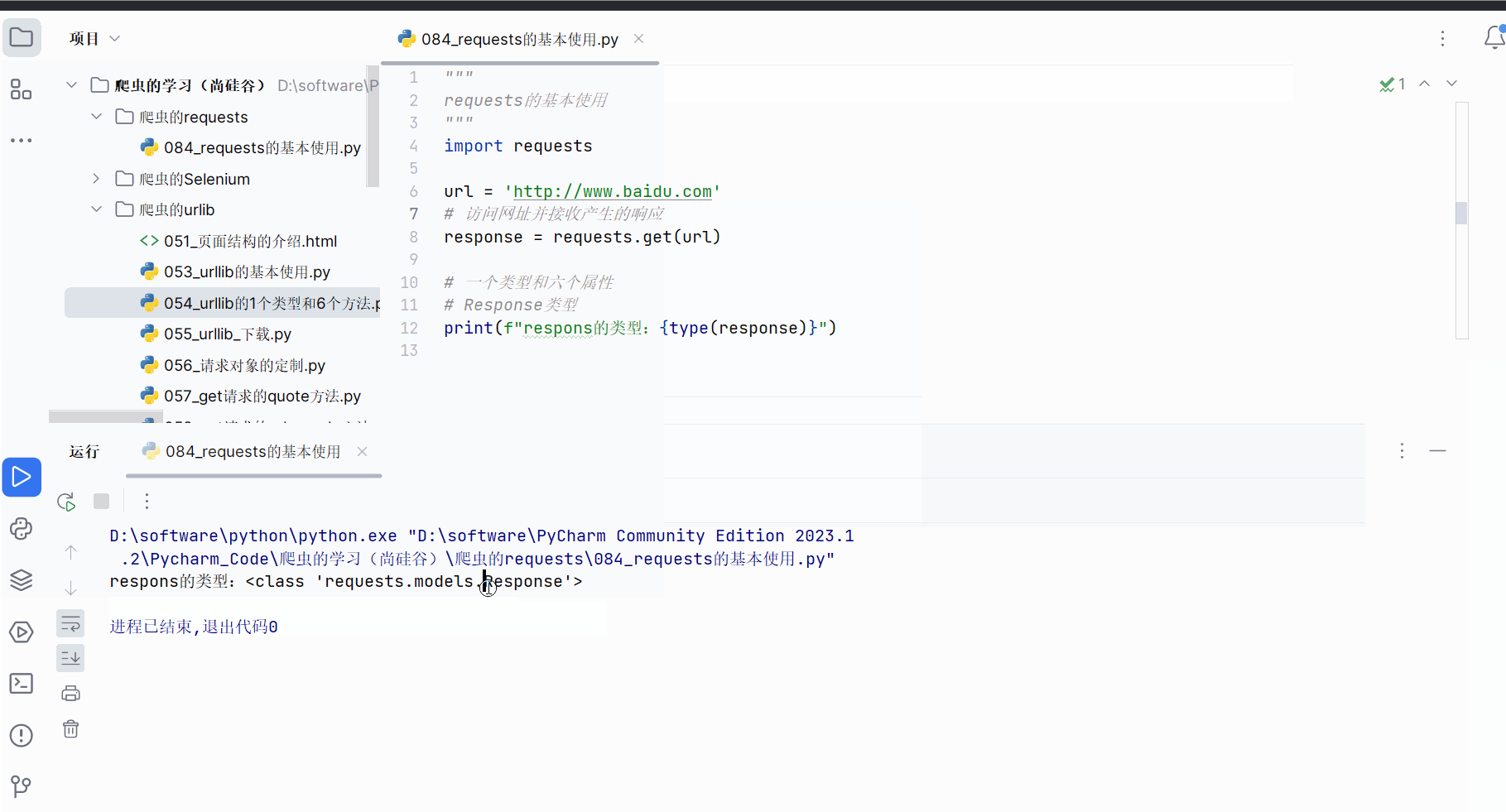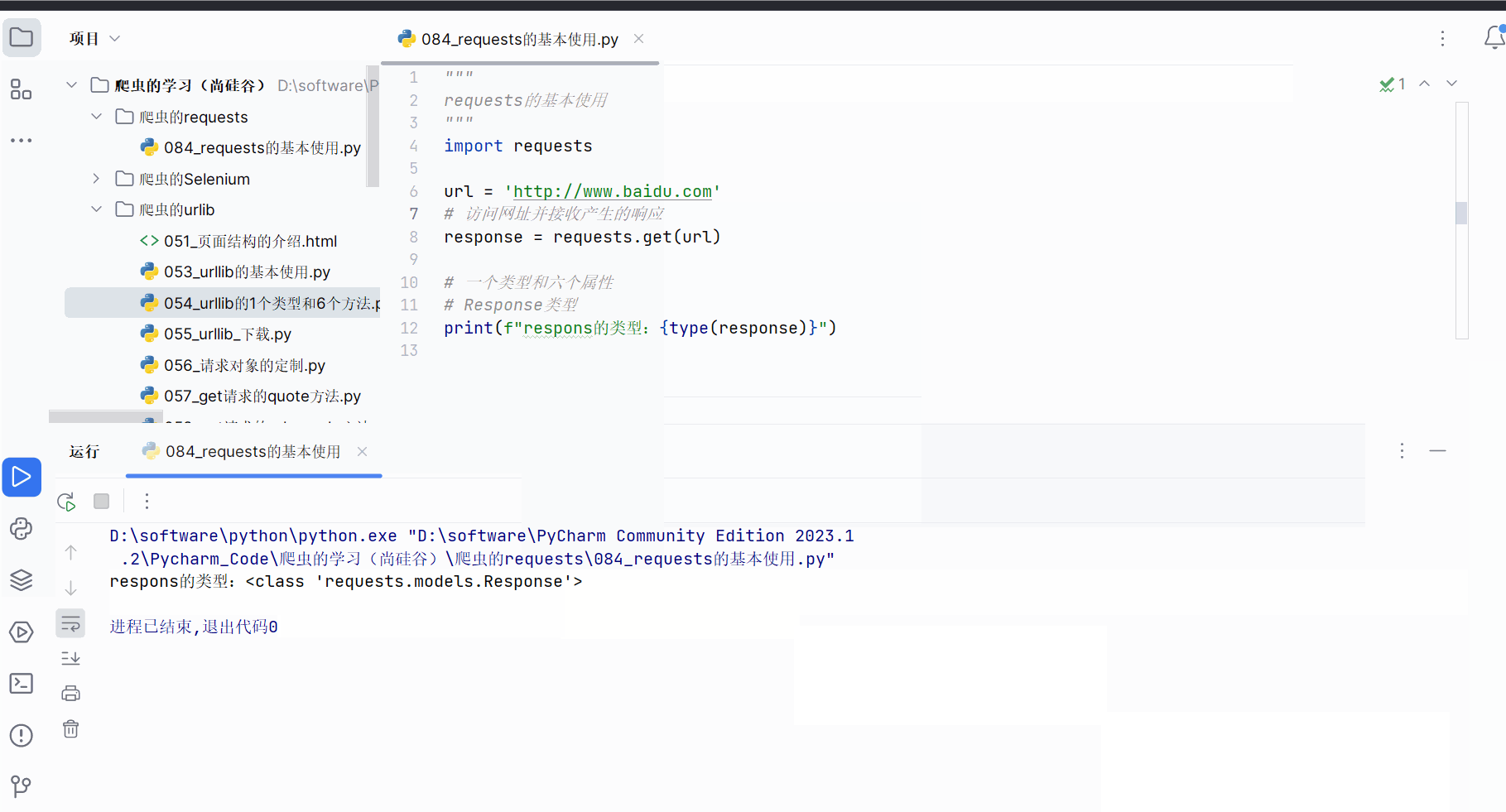
如下编程,发现如果不设置编码格式,获取的网页源码会有乱码出现。
"""
requests的基本使用
"""
import requestsurl = 'http://www.baidu.com'
# 访问网址并接收产生的响应
response = requests.get(url)# 一个类型和六个属性
# Response类型
print(f"respons的类型:{type(response)}")# (1)以字符串的形式返回网页源码
print(f"response.text的内容:{response.text}")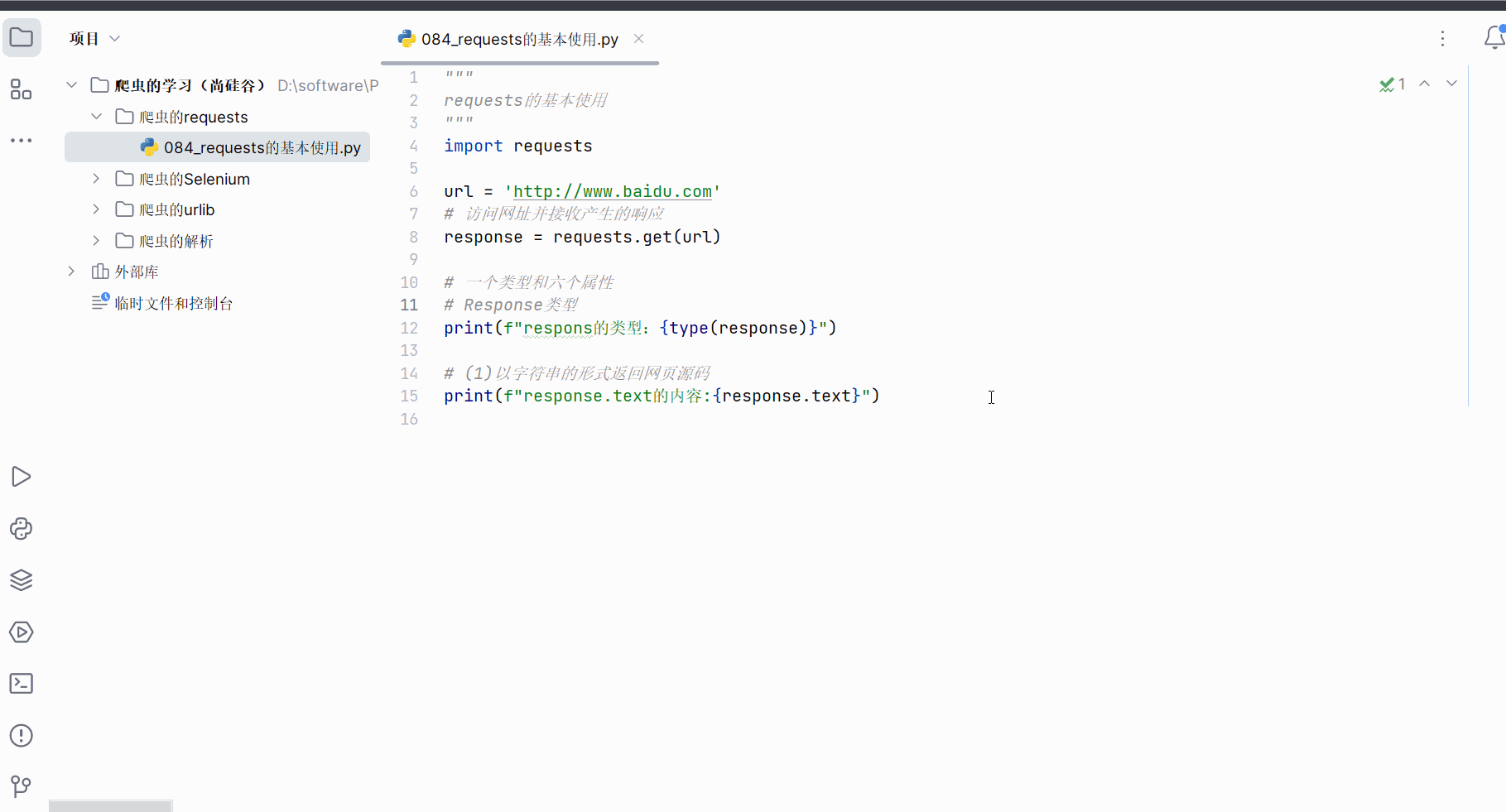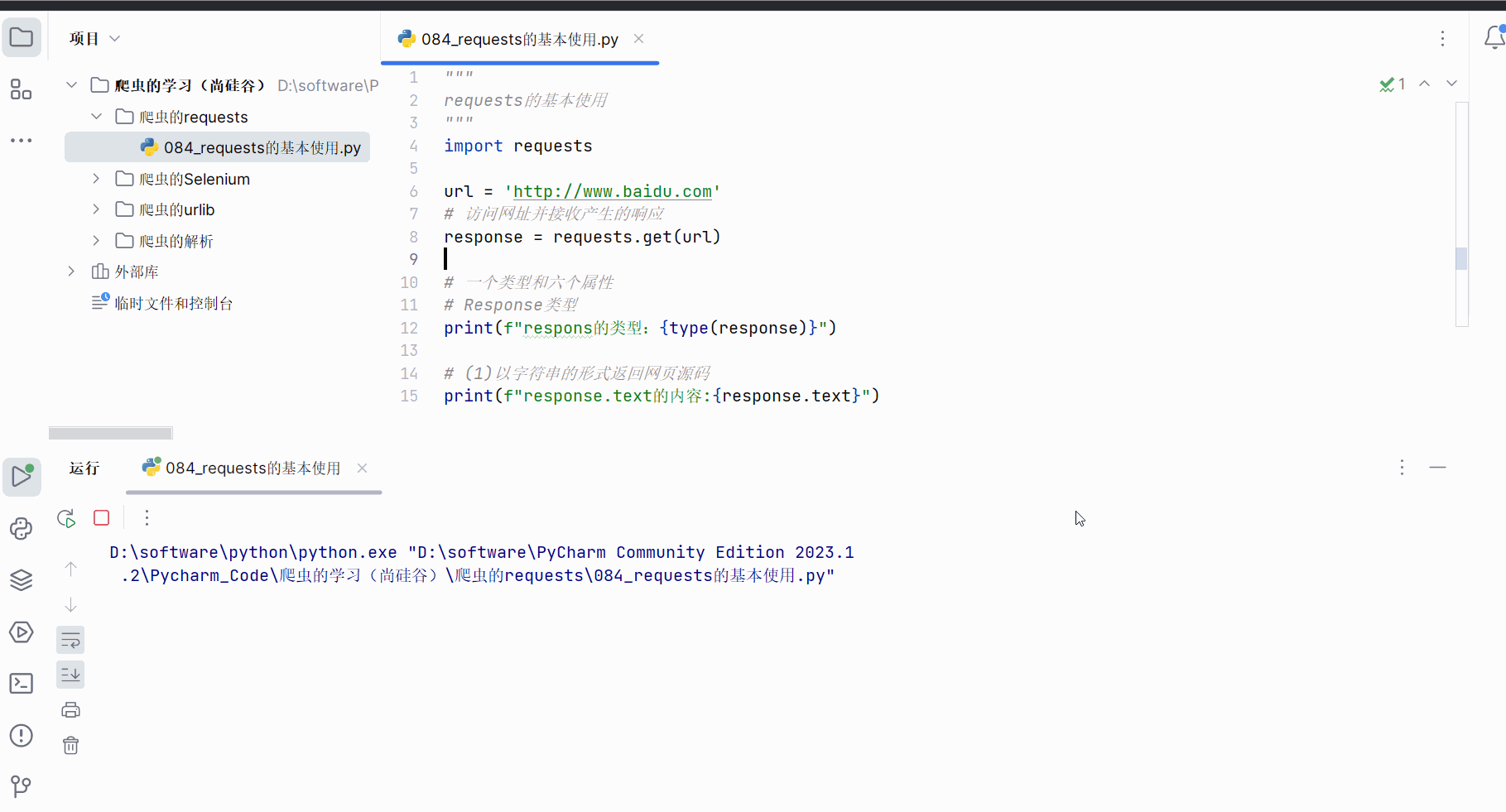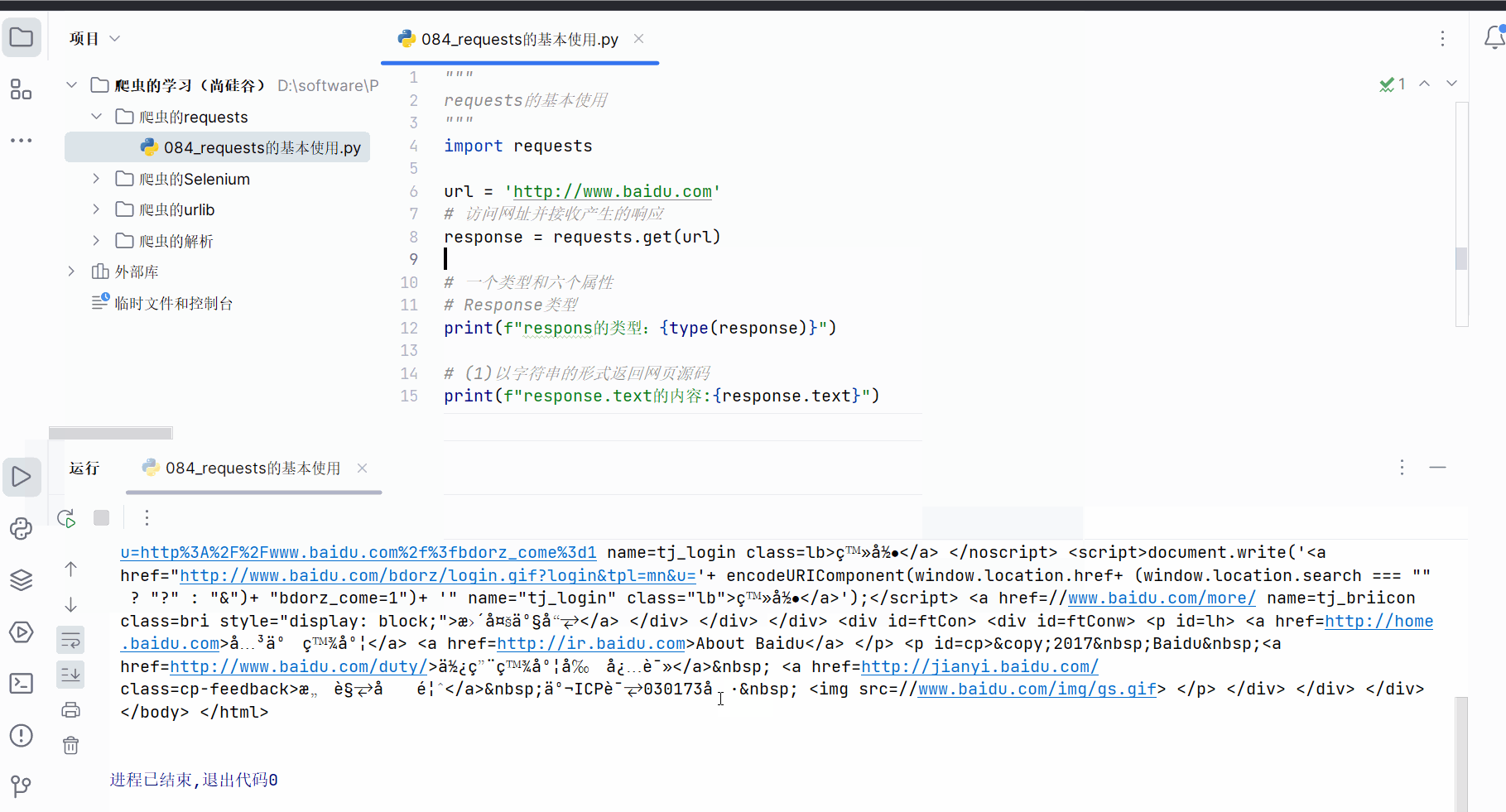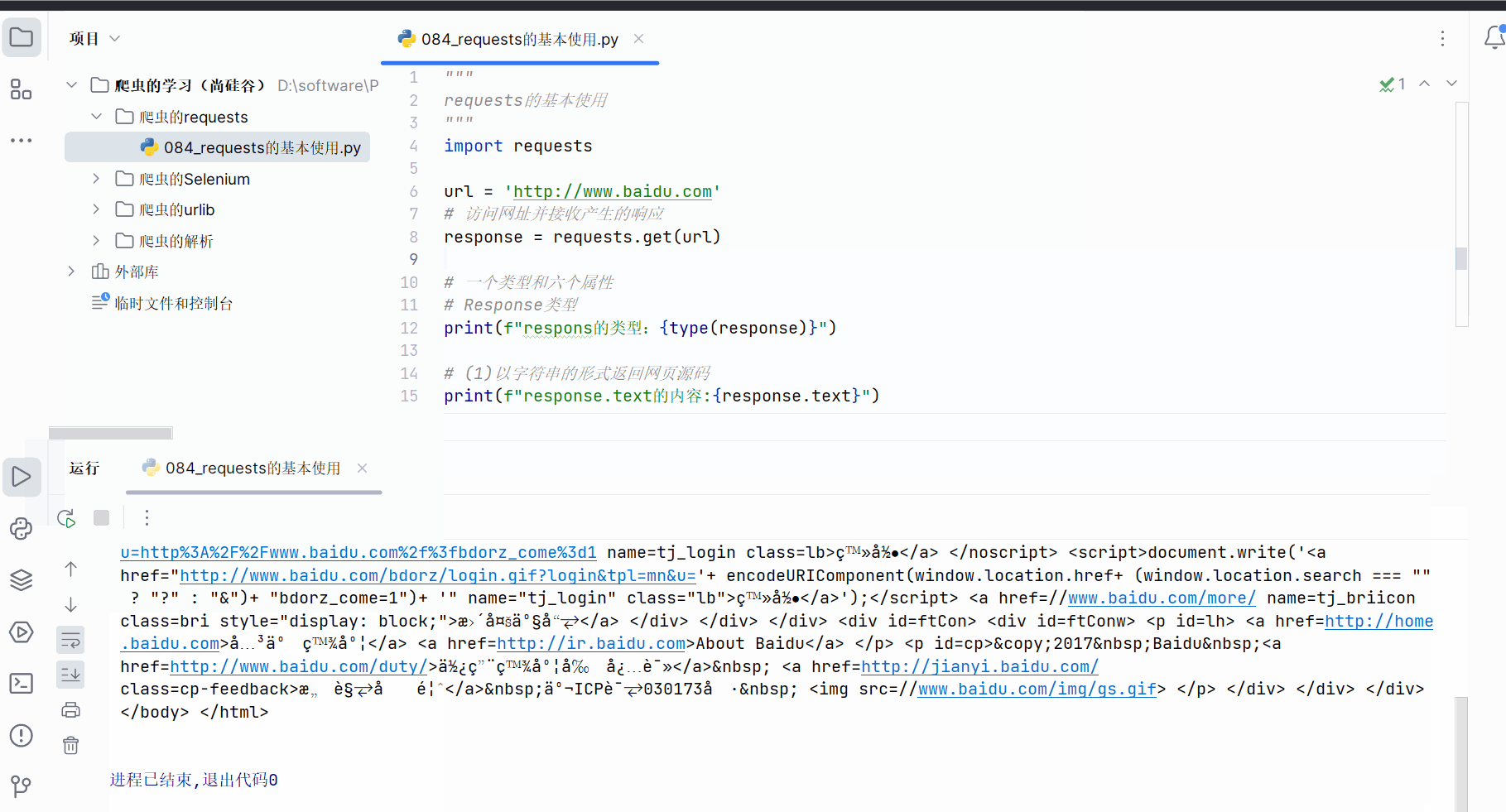
如下,设置编码格式为’UTF-8’后,就没有乱码了。
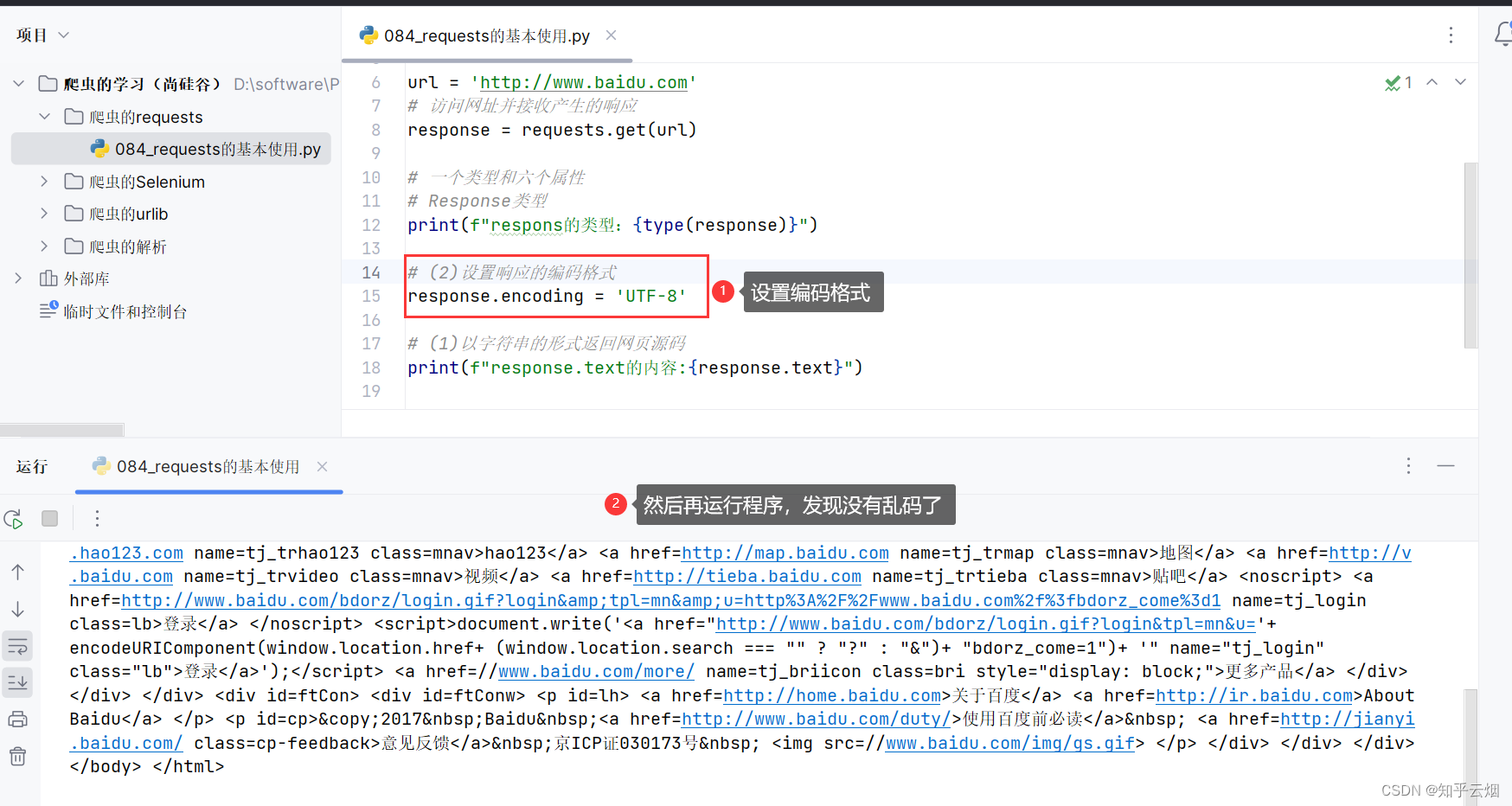
继续编程,熟悉其他4个类型。
"""
requests的基本使用
"""
import requestsurl = 'http://www.baidu.com'
# 访问网址并接收产生的响应
response = requests.get(url)# 一个类型和六个属性
# Response类型
# print(f"respons的类型:{type(response)}")# # (2)设置响应的编码格式
# response.encoding = 'UTF-8'# # (1)以字符串的形式返回网页源码
# print(f"response.text的内容:{response.text}")# (3)返回一个url地址
print(f"response.url返回的内容:{response.url}")# (4)返回二进制数据
print(f"response.content返回的内容:{response.content}")# (5)返回响应的状态码
print(f"response.status_code返回的内容:{response.status_code}")# (6)返回的是请求头
print(f"response.headers返回的内容:{response.headers}")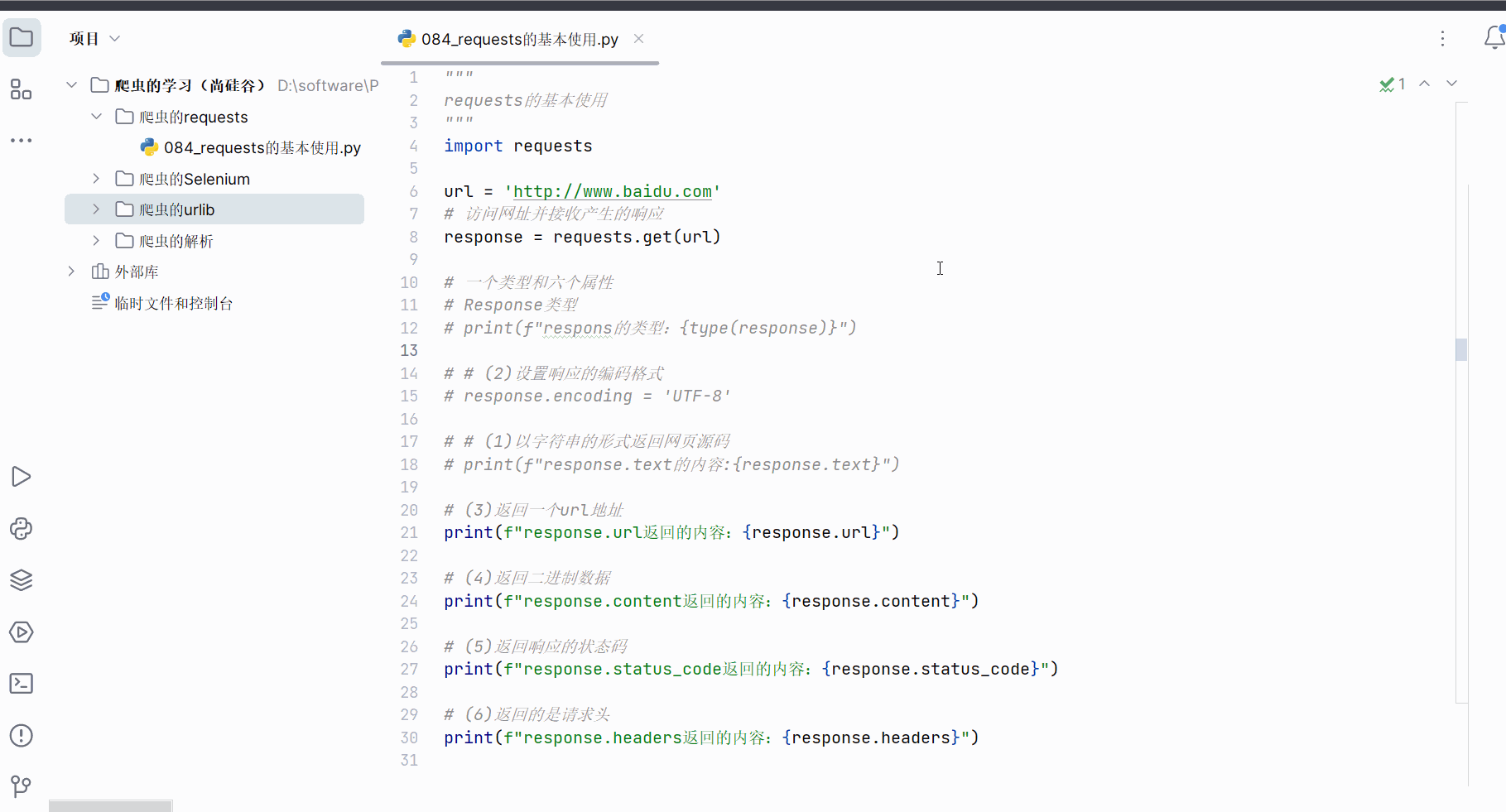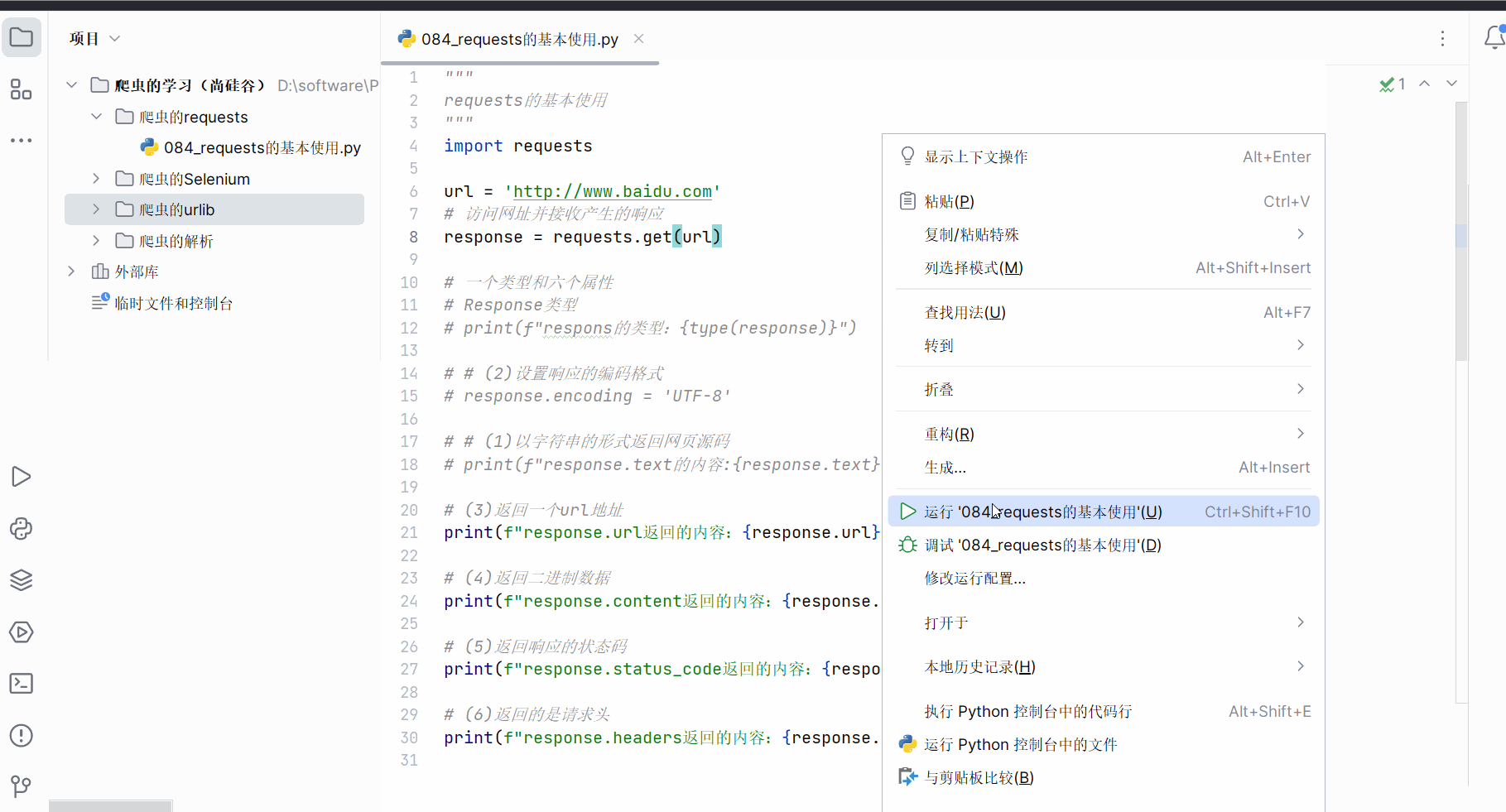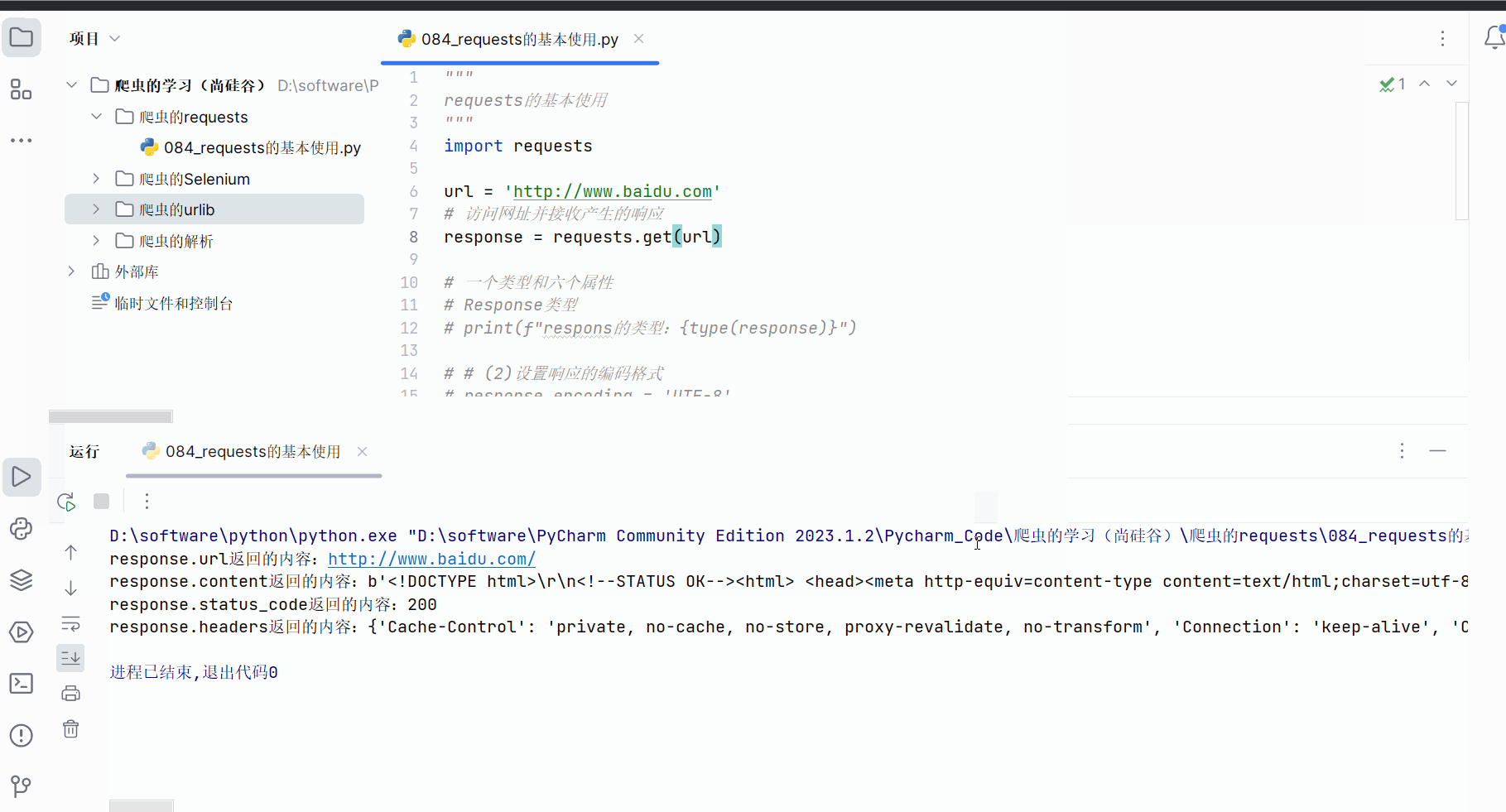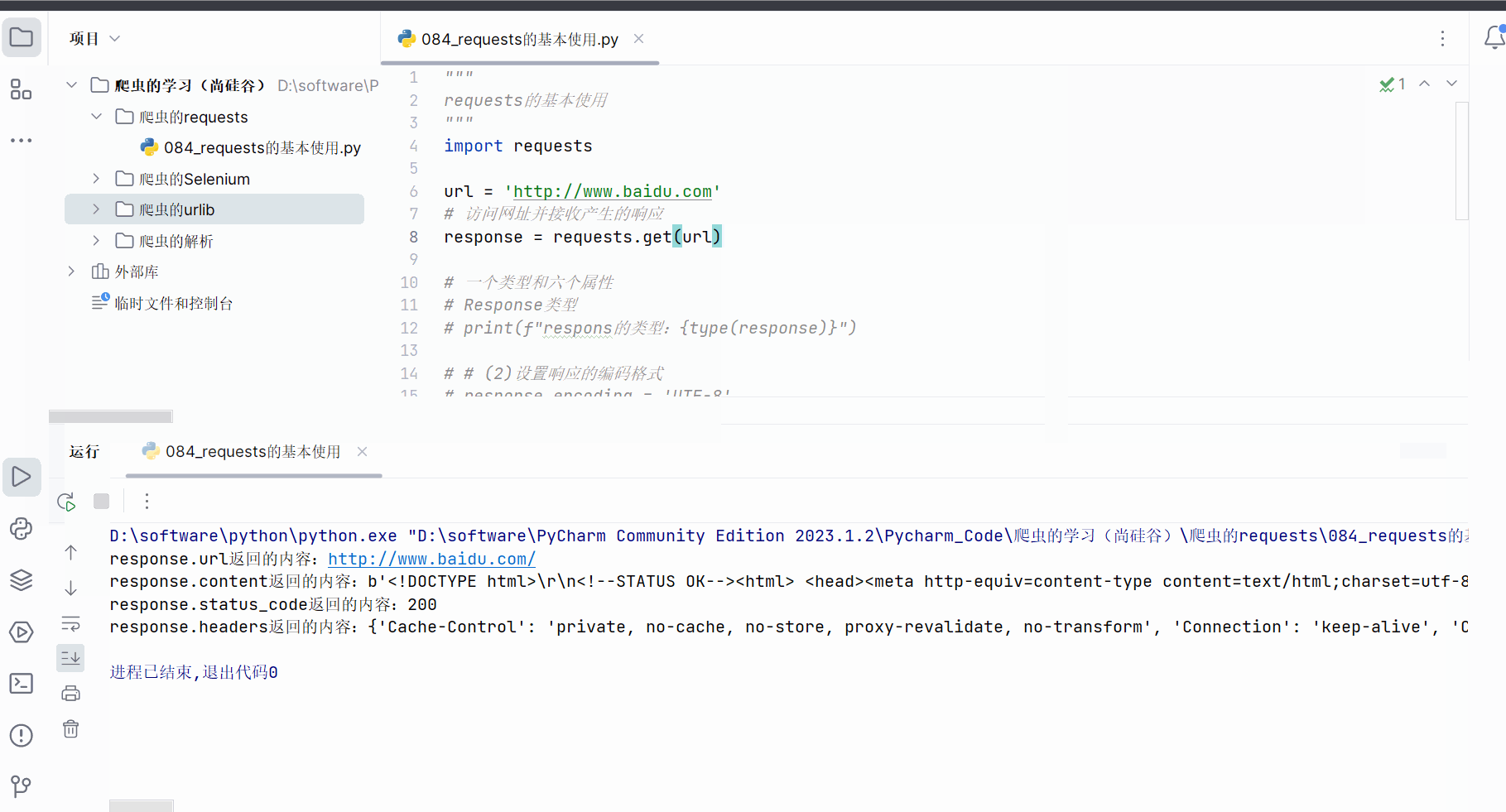
2.requests之get请求
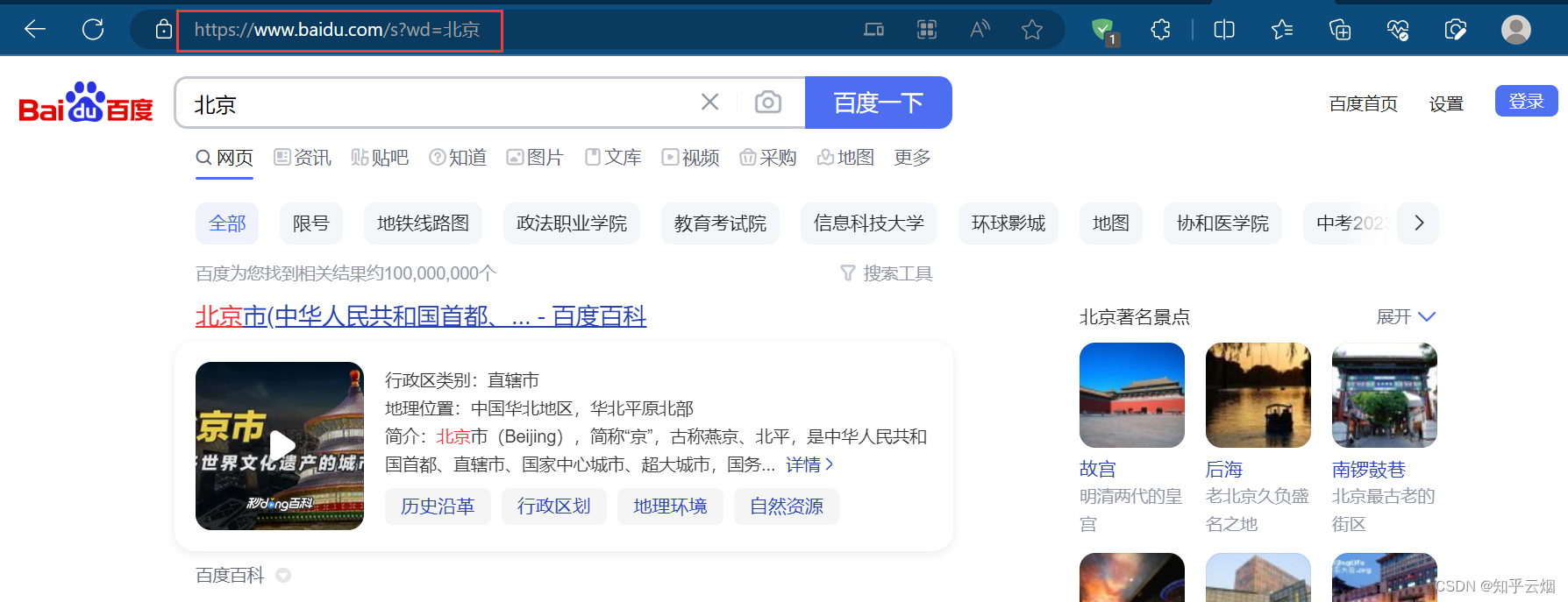
如下图,本次需要获取“https://www.baidu.com/s?wd=北京”的网页源码,但是“北京”存在编码问题,需要在代码中进行处理。
创建文件“085_requests之get请求.py”。
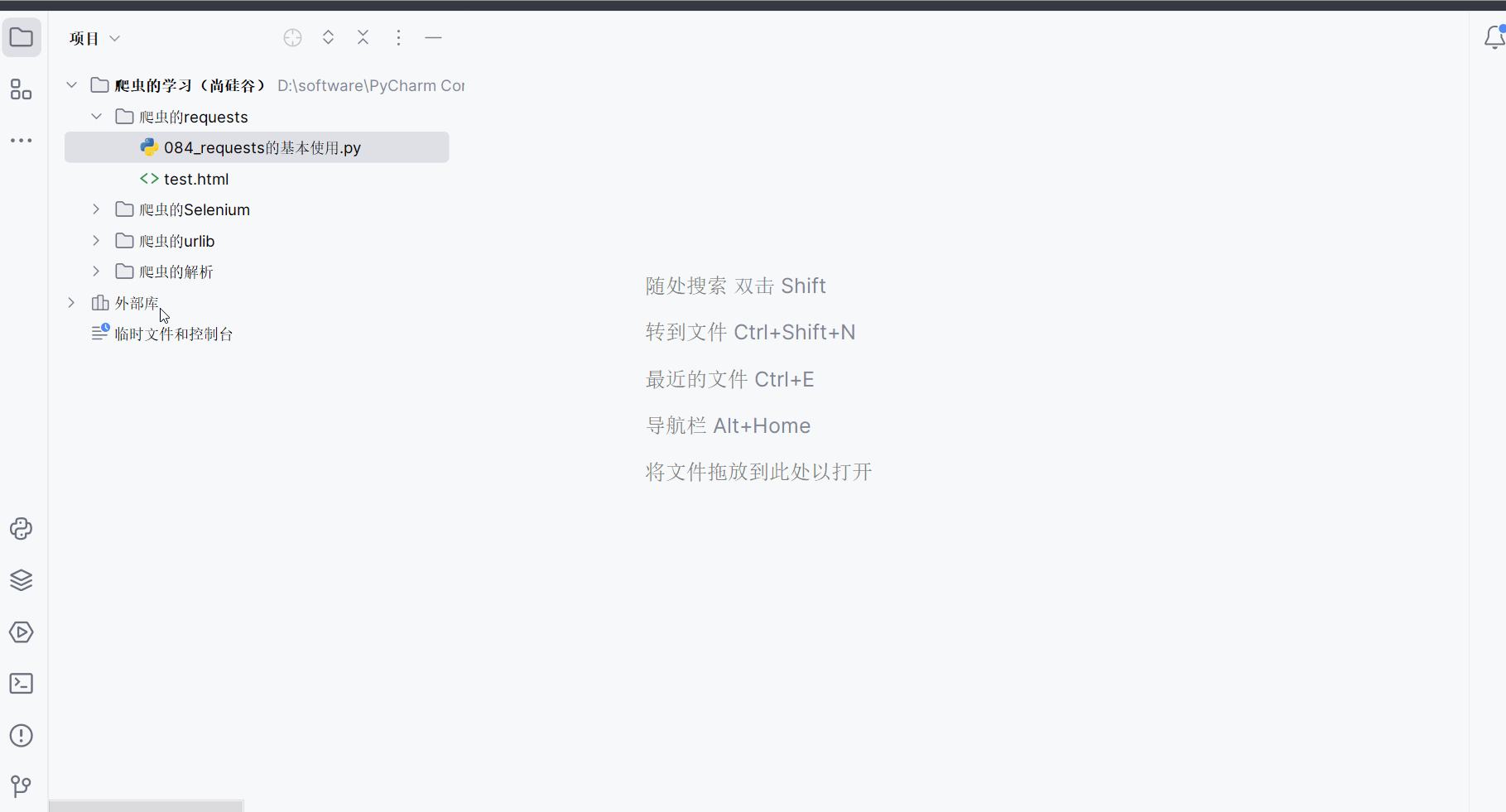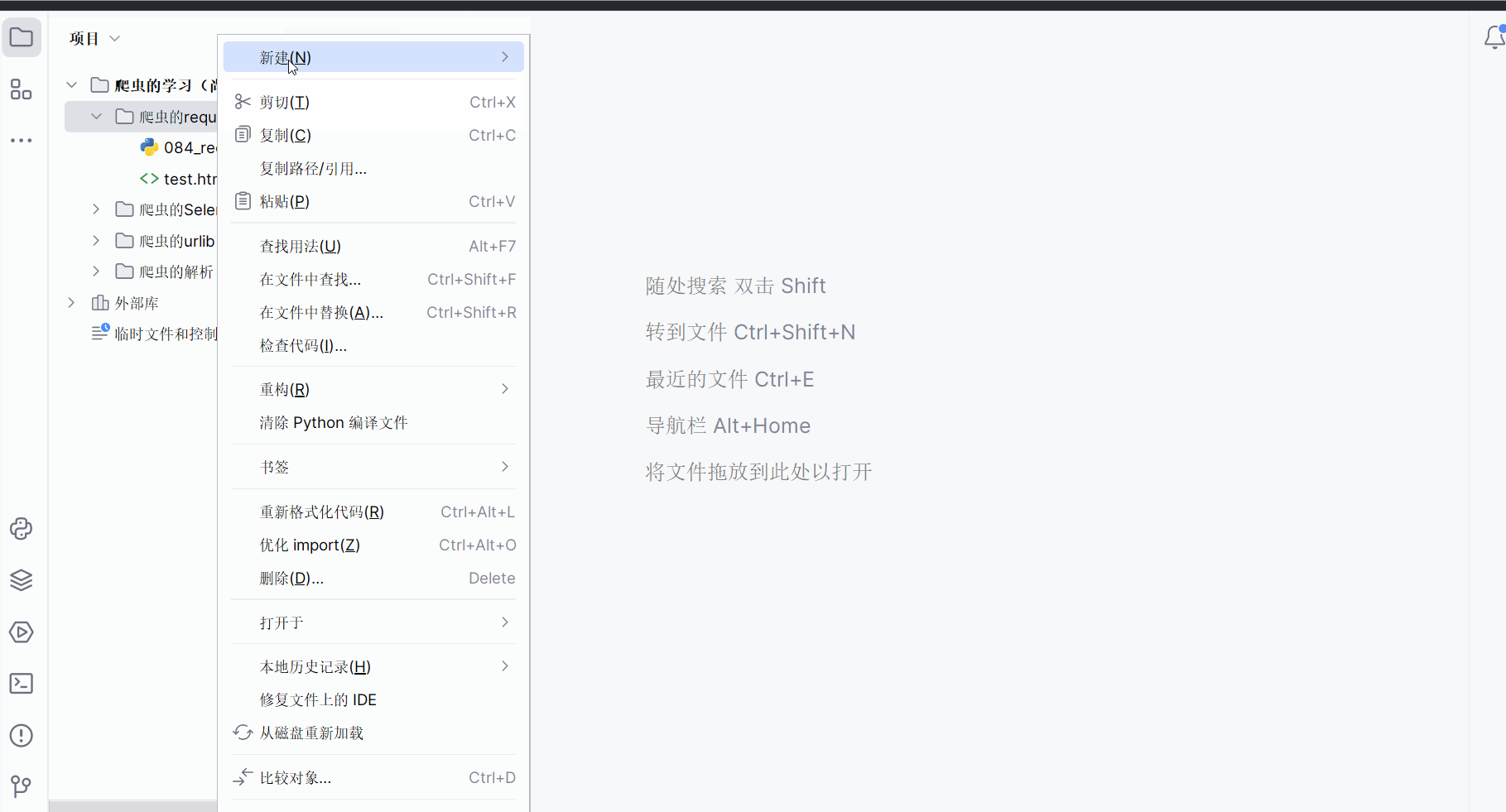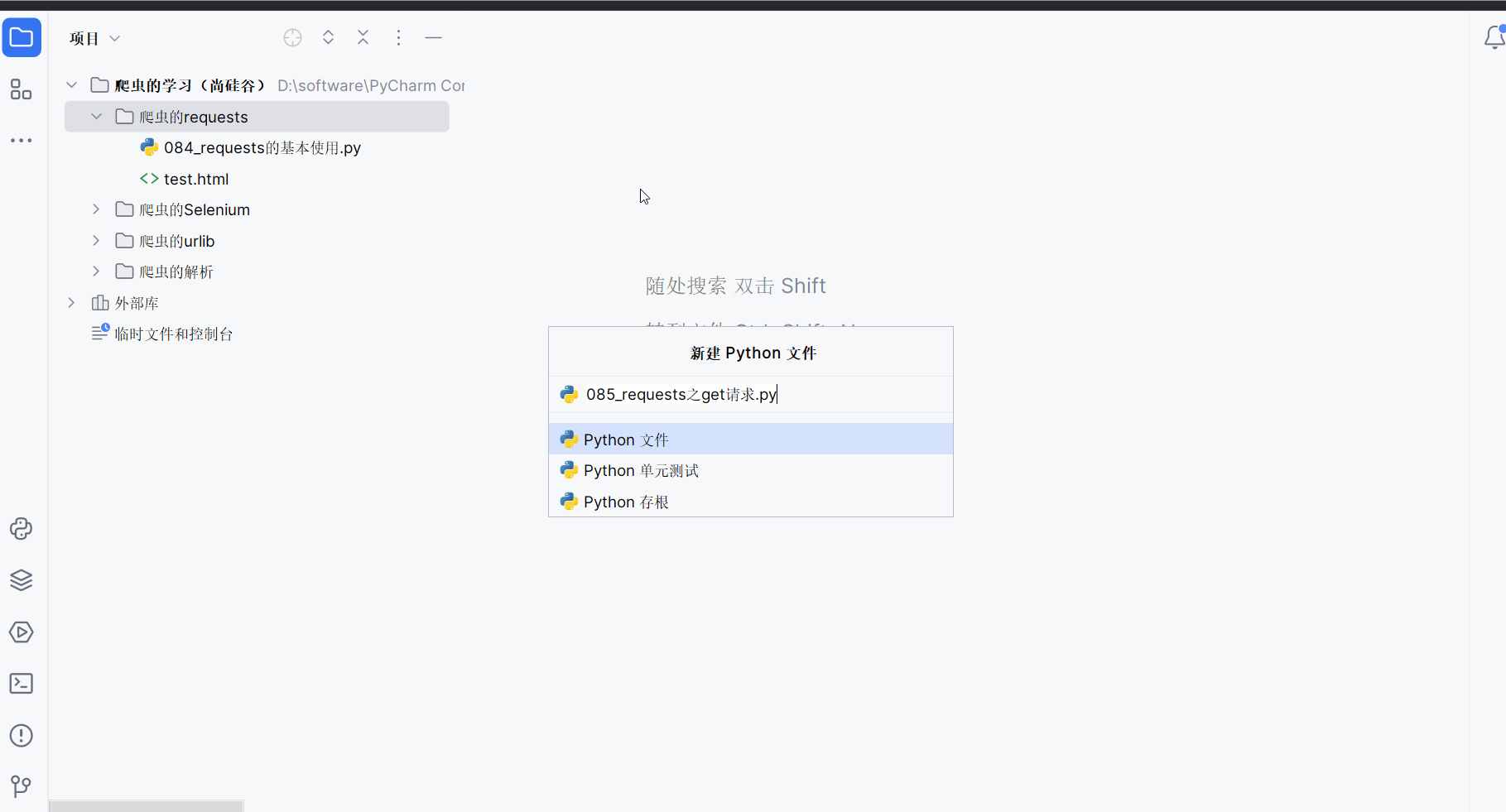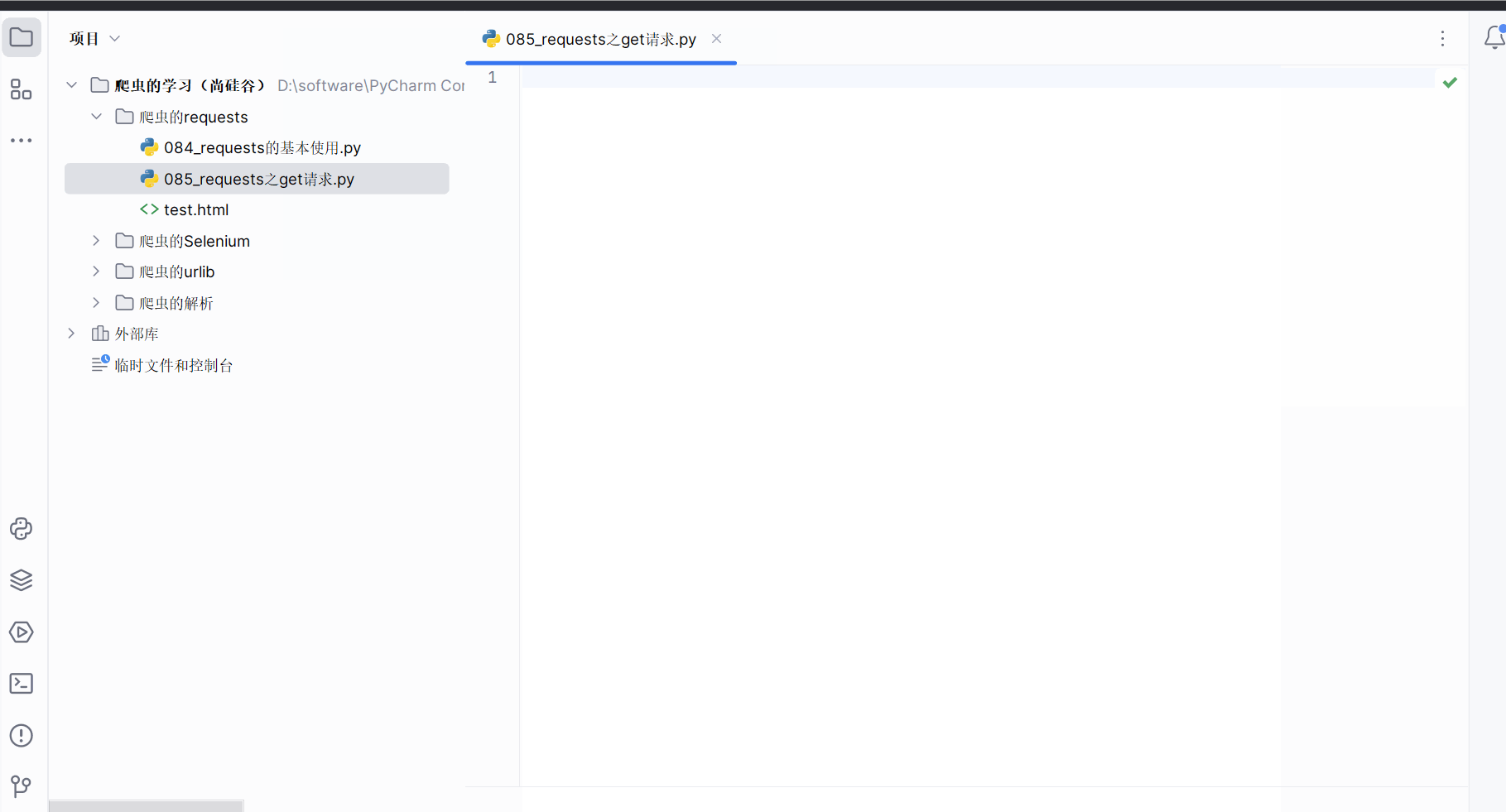
如下编程并运行(注:下面代码需要在请求头中加Cookie才能没有百度的安全验证)。
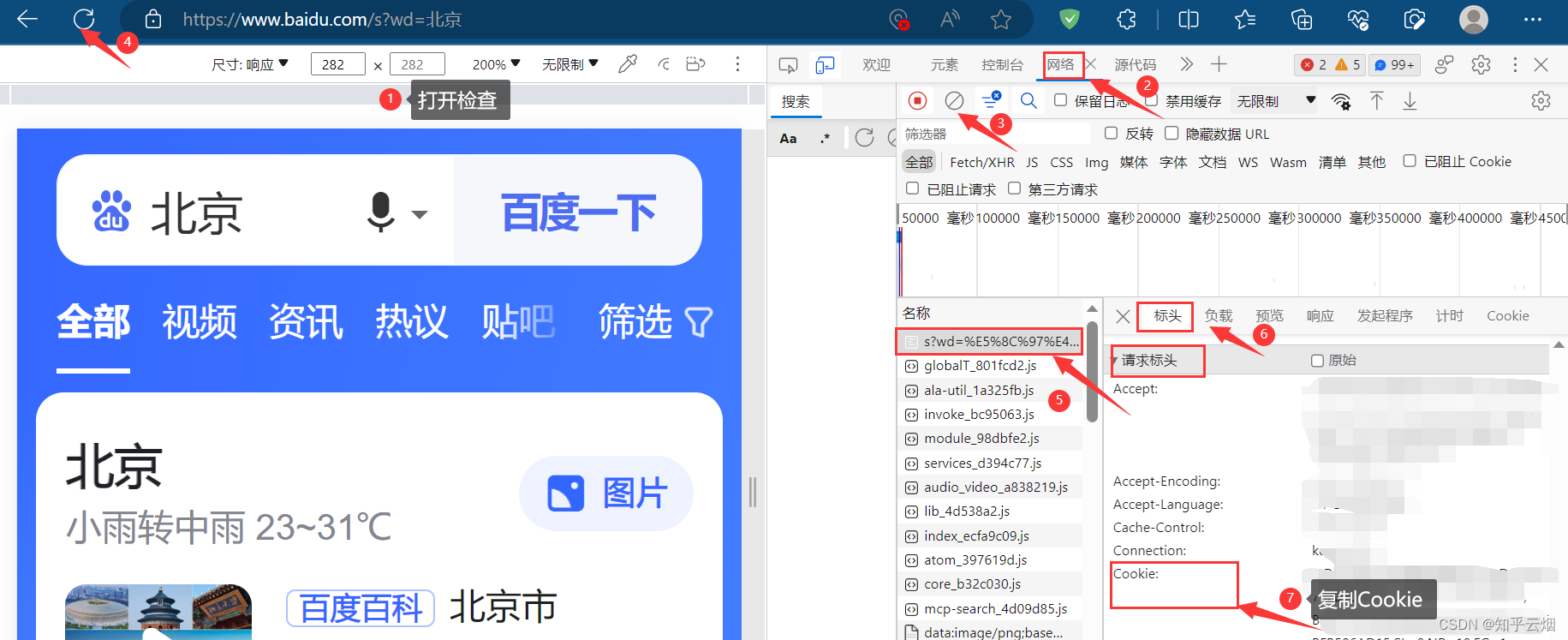
"""
requests之get请求
"""
import requestsurl = 'https://www.baidu.com/s?'
# 请求头
headers = {'User-Agent':'Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N) AppleWeb-Kit/537.36 (KHTML, like Gecko) Chrome/115.0.0.0 Mobile Safari/537.36 Edg/115.0.1901.200',
}
data = {'wd': '北京'
}# url 请求资源路径
# params 参数
# kwargs 字典
response = requests.get(url=url, params=data, headers=headers)
response.encoding = 'UTF-8'
content = response.textprint(content)# 总结:
# (1)参数使用params传递
# (2)参数无需urlencode编码
# (3)不需要请求对象的定制
# (4)请求资源路径中的?可以加,也可以不加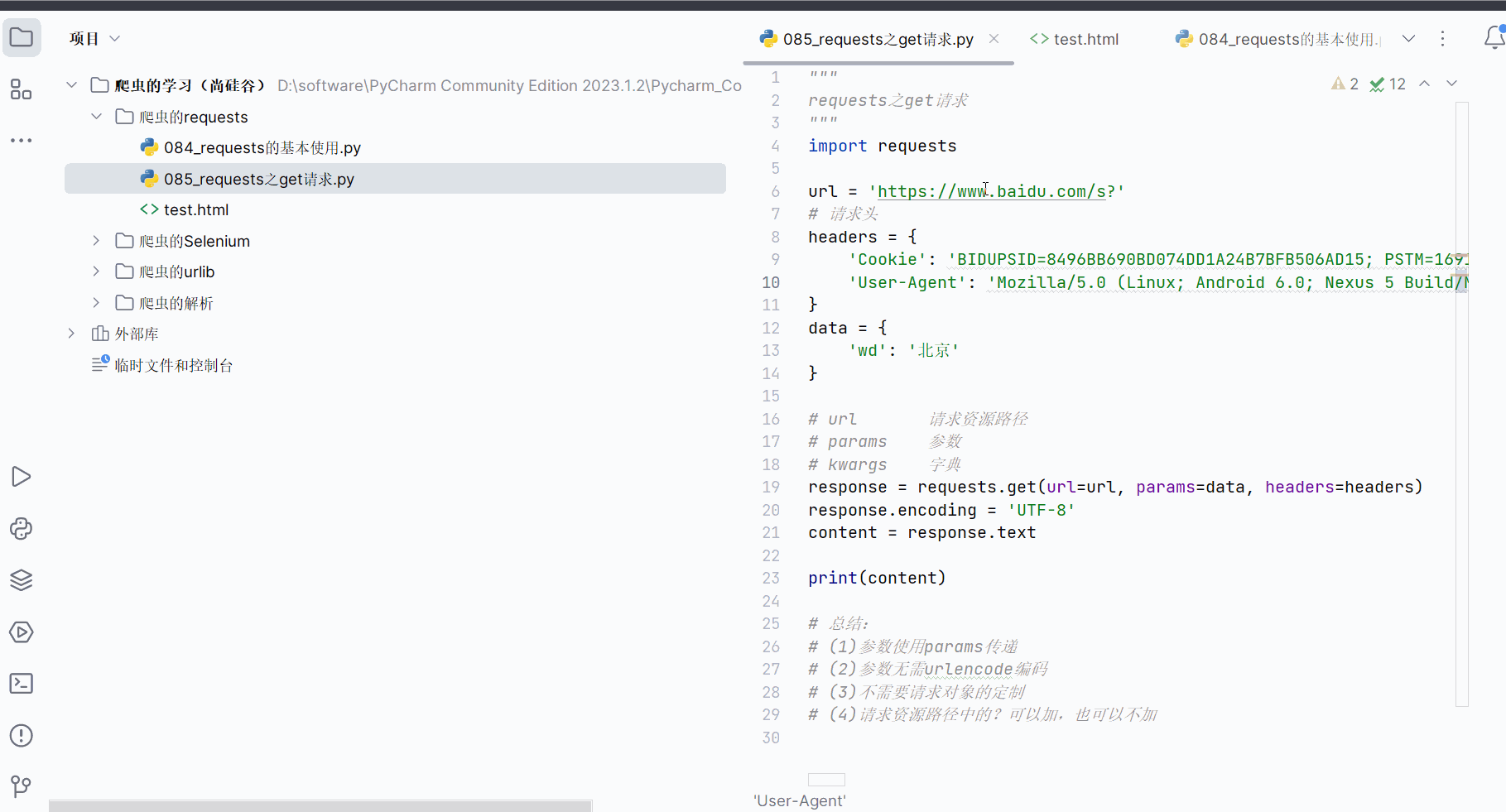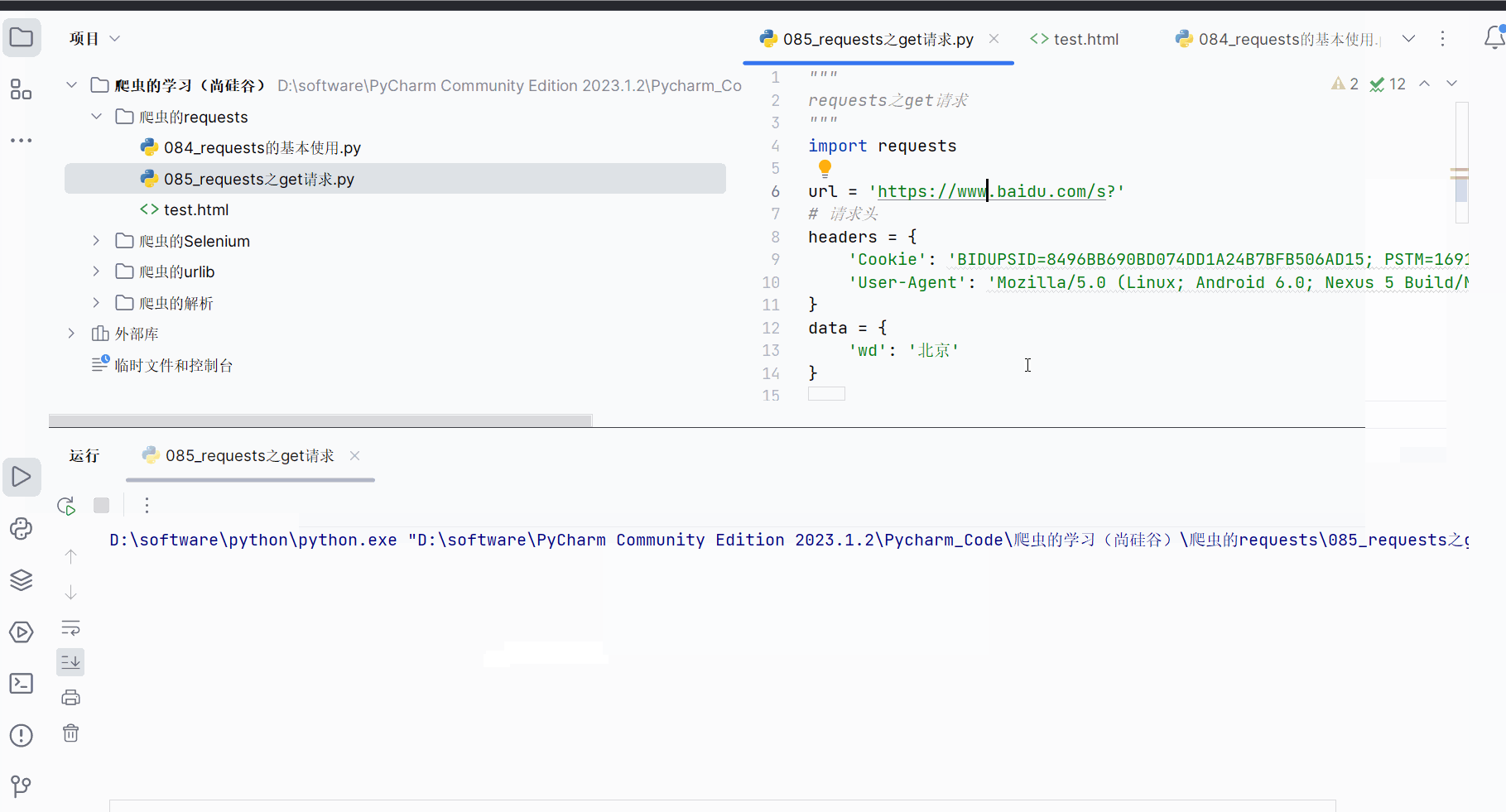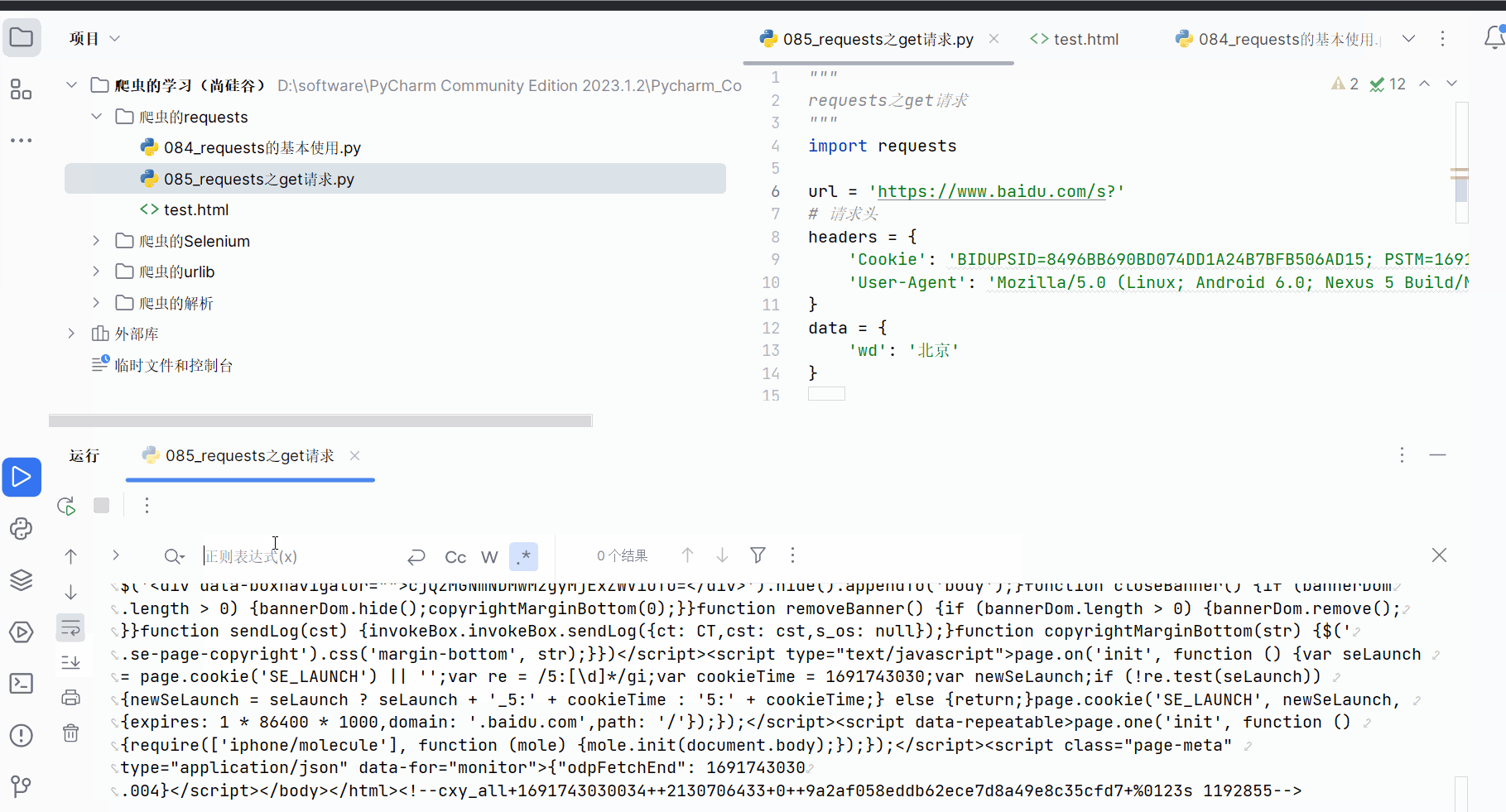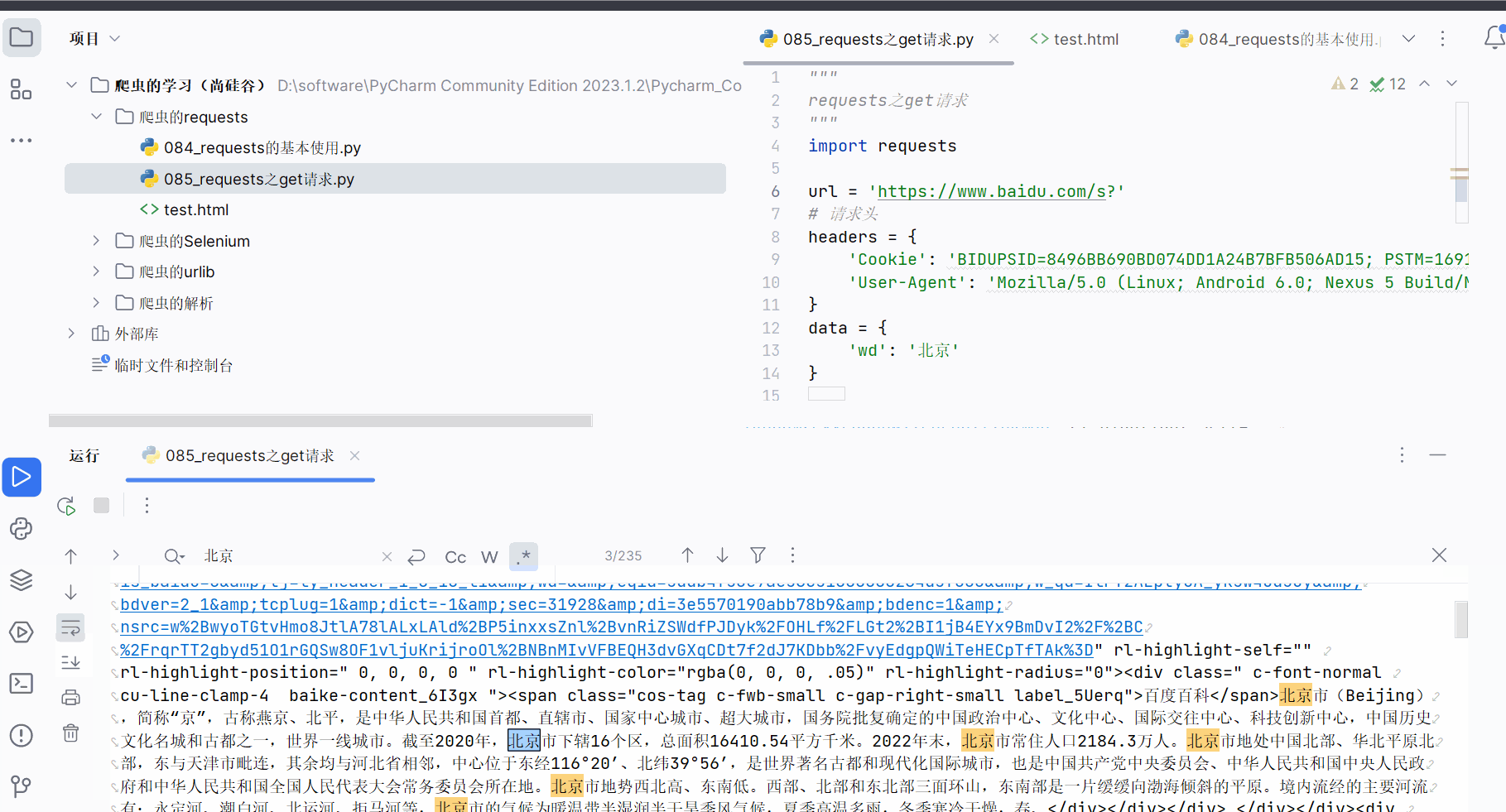
3. requests之post请求
(1)演示示例-爬取百度翻译
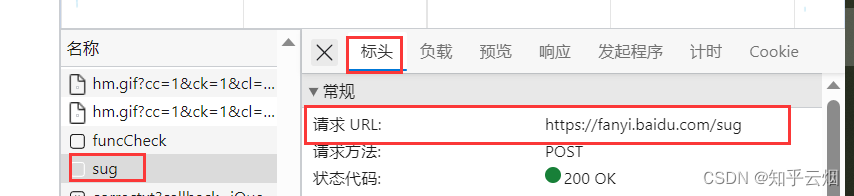
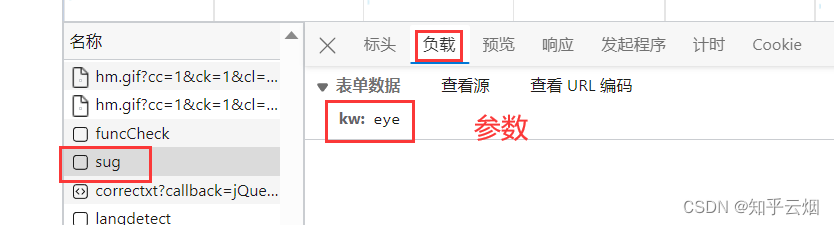
如下图,寻找百度翻译的接口。首先打开百度翻译(“https://fanyi.baidu.com/”),打开检查,点击网络。然后随便输入一个单词,之后根据接口的负载找到对应的接口,发现它是一个post请求。
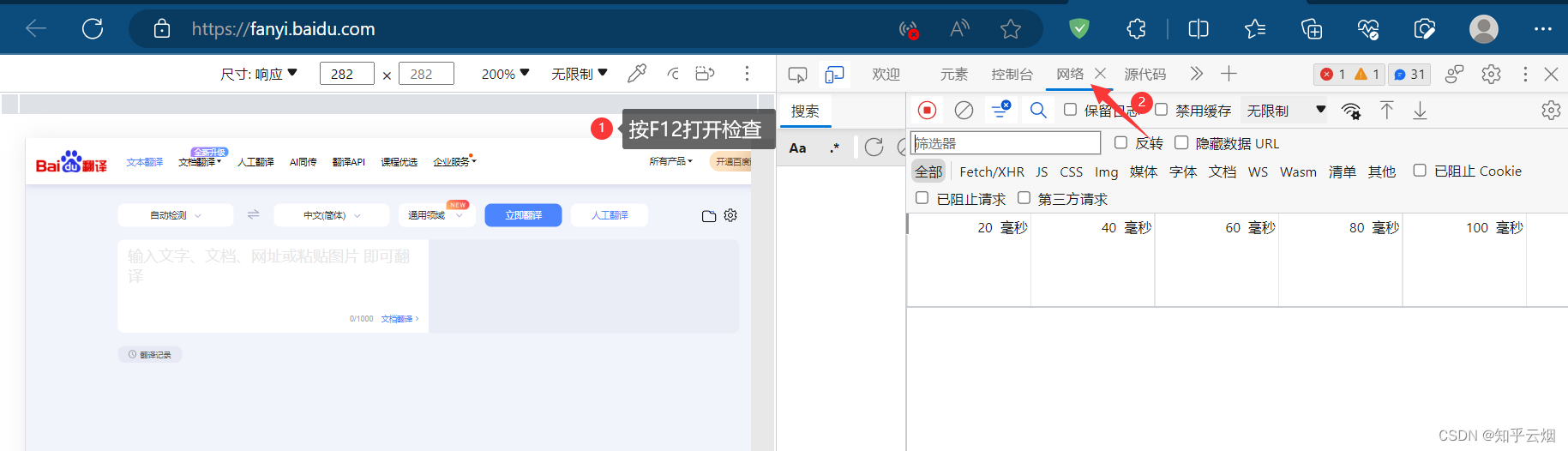
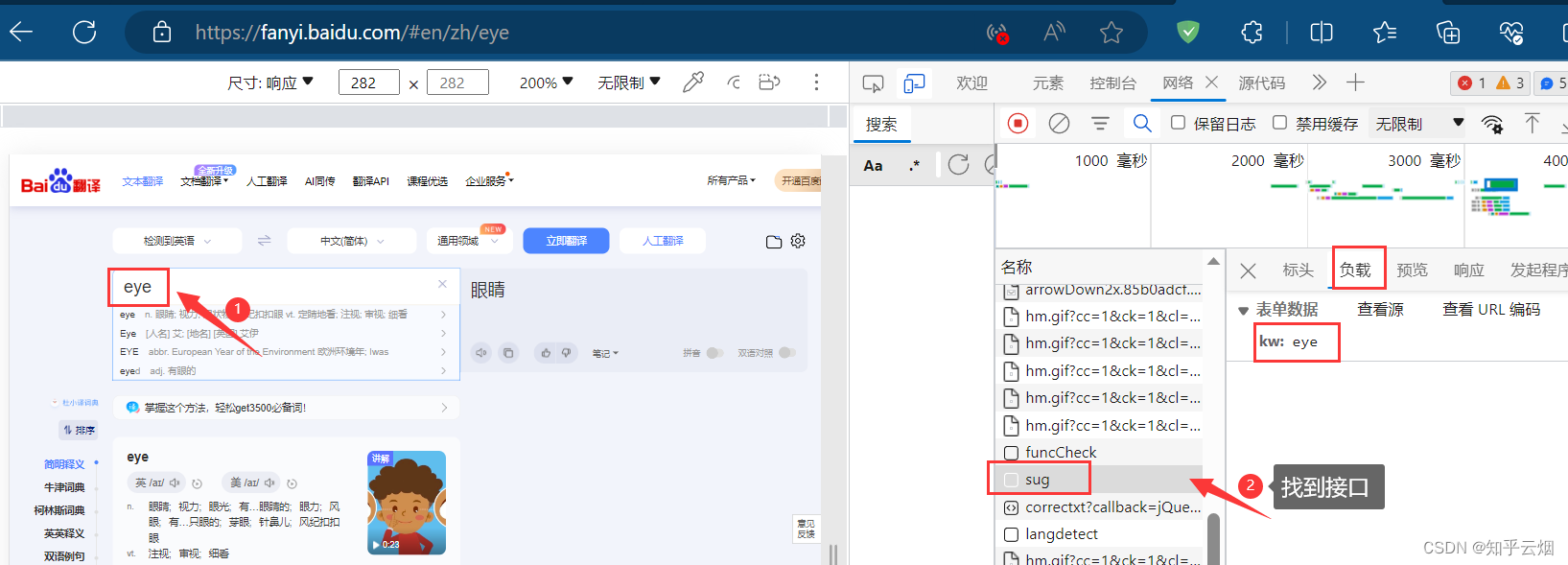
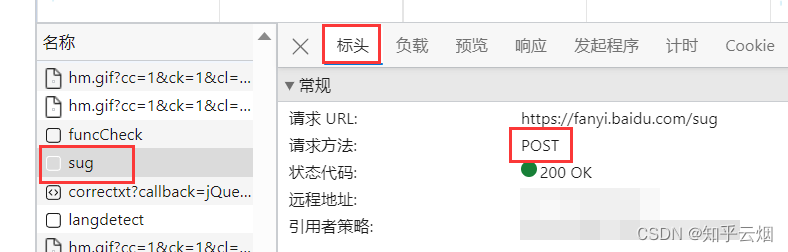
创建文件“086_requests之post请求.py”,并将接口的请求地址、参数复制过来。
如下编程并运行。
"""
requests之post请求
"""
import encodings.utf_8import requests
import jsonurl = 'https://fanyi.baidu.com/sug'
headers = {'User-Agent': 'Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N) Ap-pleWebKit/537.36 (KHTML, like Gecko) Chrome/115.0.0.0 Mobile Safari/537.36 Edg/115.0.1901.200',
}
data = {'kw': 'eye'
}response = requests.post(url=url, data=data, headers=headers)
content = response.text
# print(content) # 测试代码,验证是否获取到网页源码obj = json.loads(content)
print(obj)# 总结:
# (1)post请求 是不需要编解码
# (2)post请求的参数是data
# (3)不需要请求对象的定制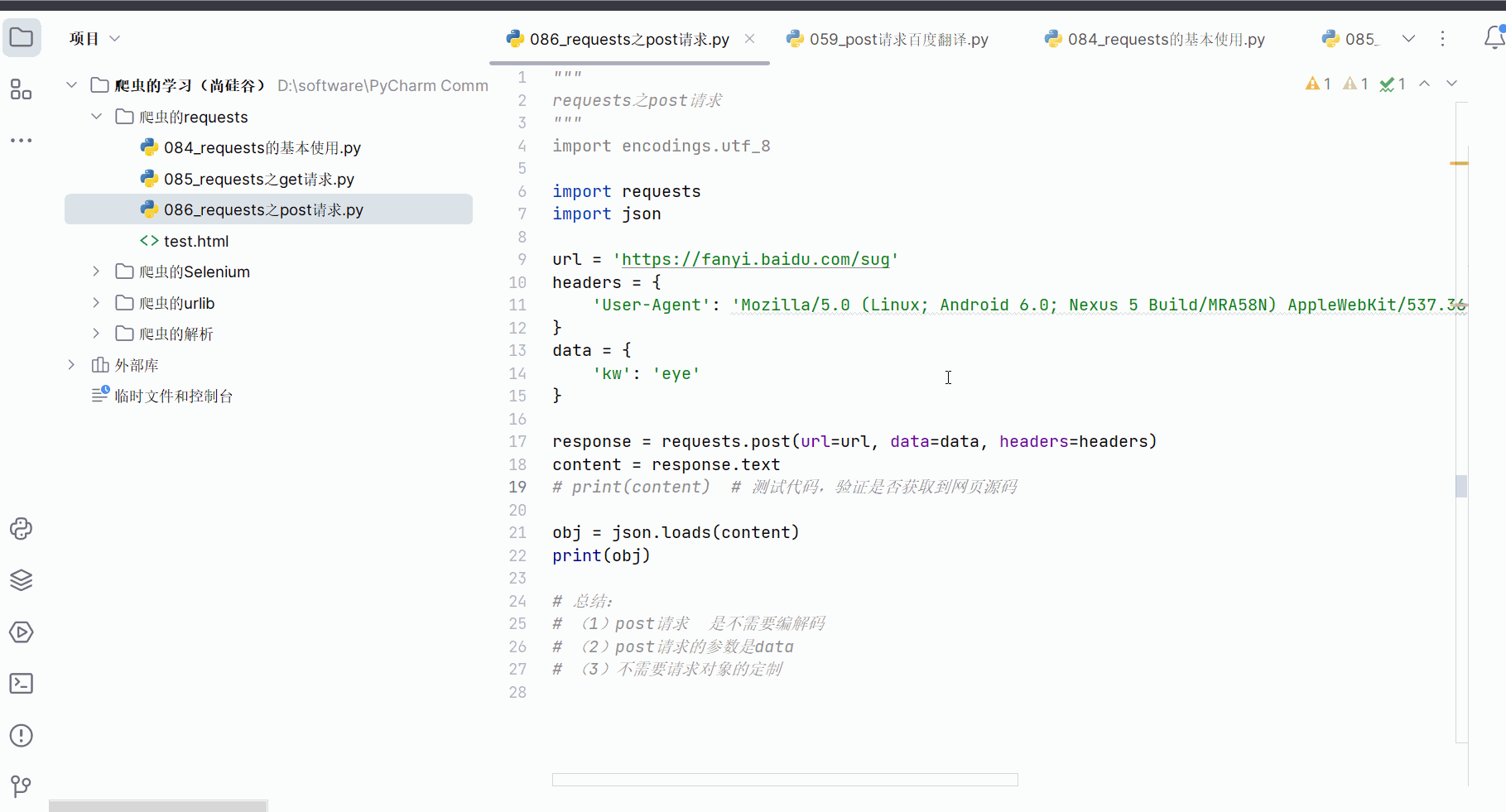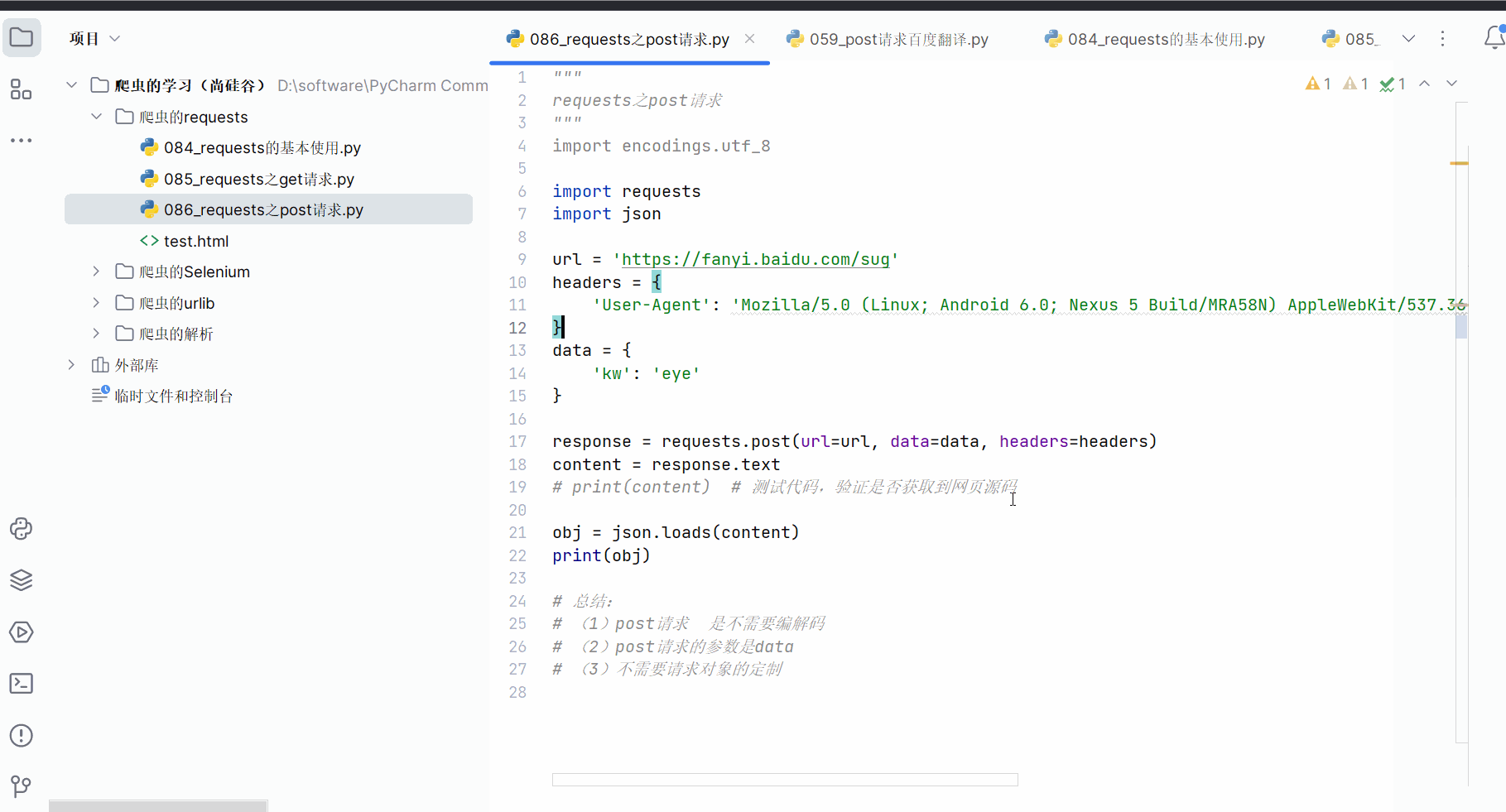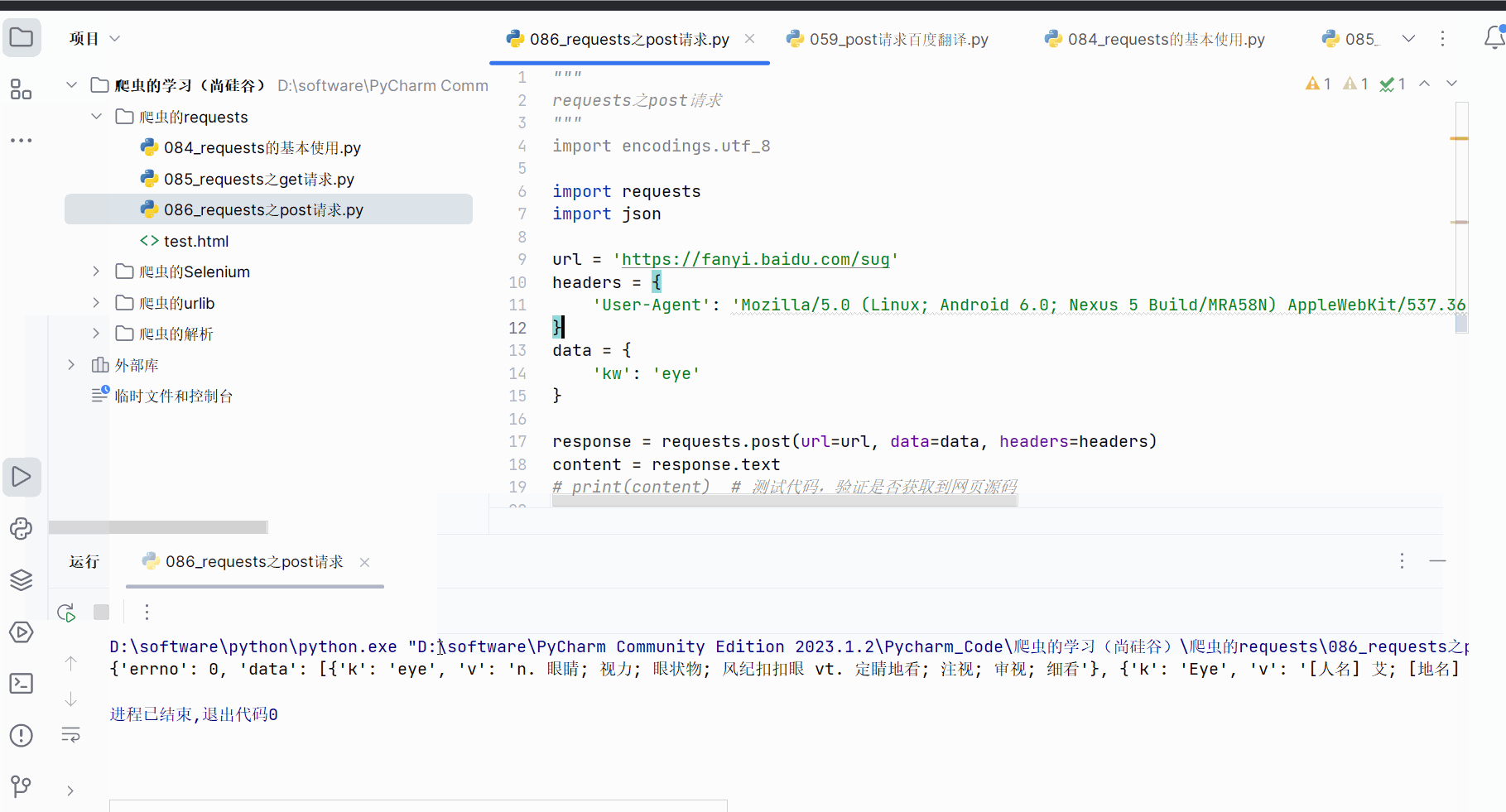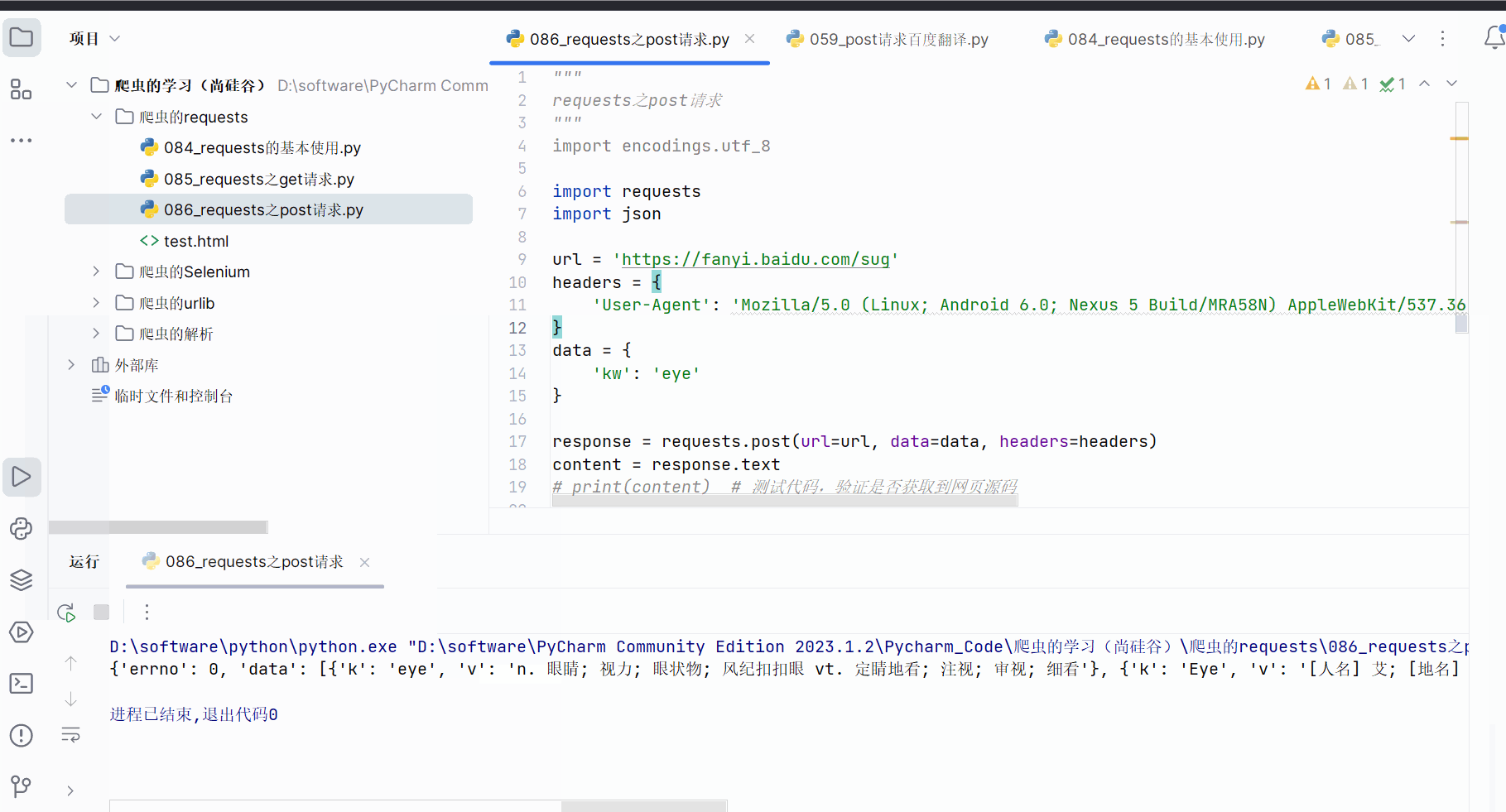
(2)get和post区别
①get请求的参数名字是params post请求的参数的名字是data
②get请求资源路径后面可以不加?
③不需要手动编解码
④不需要做请求对象的定制
4. requests之代理
requests的代理和urllib的代理都差不多,主要都是想解决当我们在模拟浏览器向服务器发送请求时,我们在短时间内快速、高频次访问某个网站面临ip被封的问题。
本次将保存搜索“ip”这一页的网页源码,再使用快代理使用国内其他省份的ip(试了,快代理上的免费ip没用,失败了。本人穷鬼一个,没钱,就不去花钱来演示了),具体步骤如下。
先直接在百度上搜索“ip”,删去网址中含广告的部分后,剩余“https://www.baidu.com/s?wd=ip”。
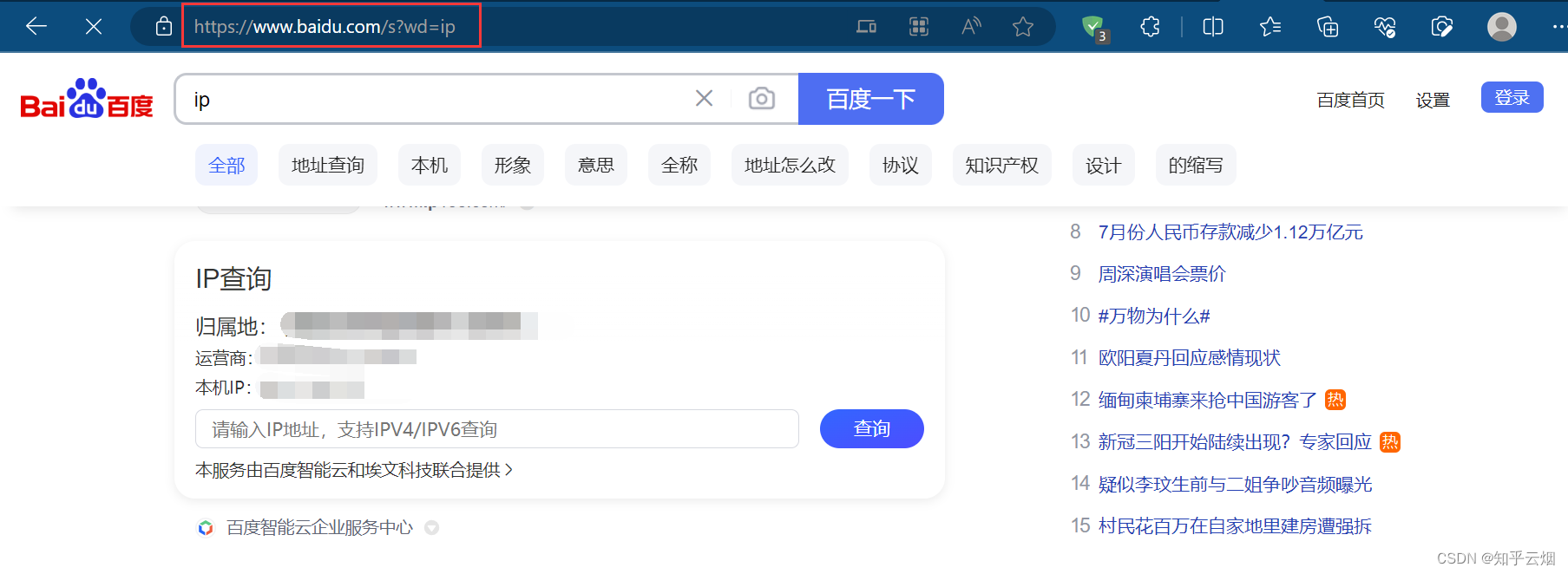
创建文件“087_requests之代理.py”。
先如下编程,保存搜索“ip”这一页的网页源码,可以查到本人当前ip地址属于中国重庆。
"""
requests之代理
"""
import requestsurl = 'https://www.baidu.com/s?'
headers = {'User-Agent': 'Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N) Ap-pleWebKit/537.36 (KHTML, like Gecko) Chrome/115.0.0.0 Mobile Safari/537.36 Edg/115.0.1901.200',
}
data = {'wd': 'ip'
}
response = requests.get(url=url, params=data, headers=headers)content = response.textwith open('代理.html', 'w', encoding='UTF-8') as fp:fp.write(content)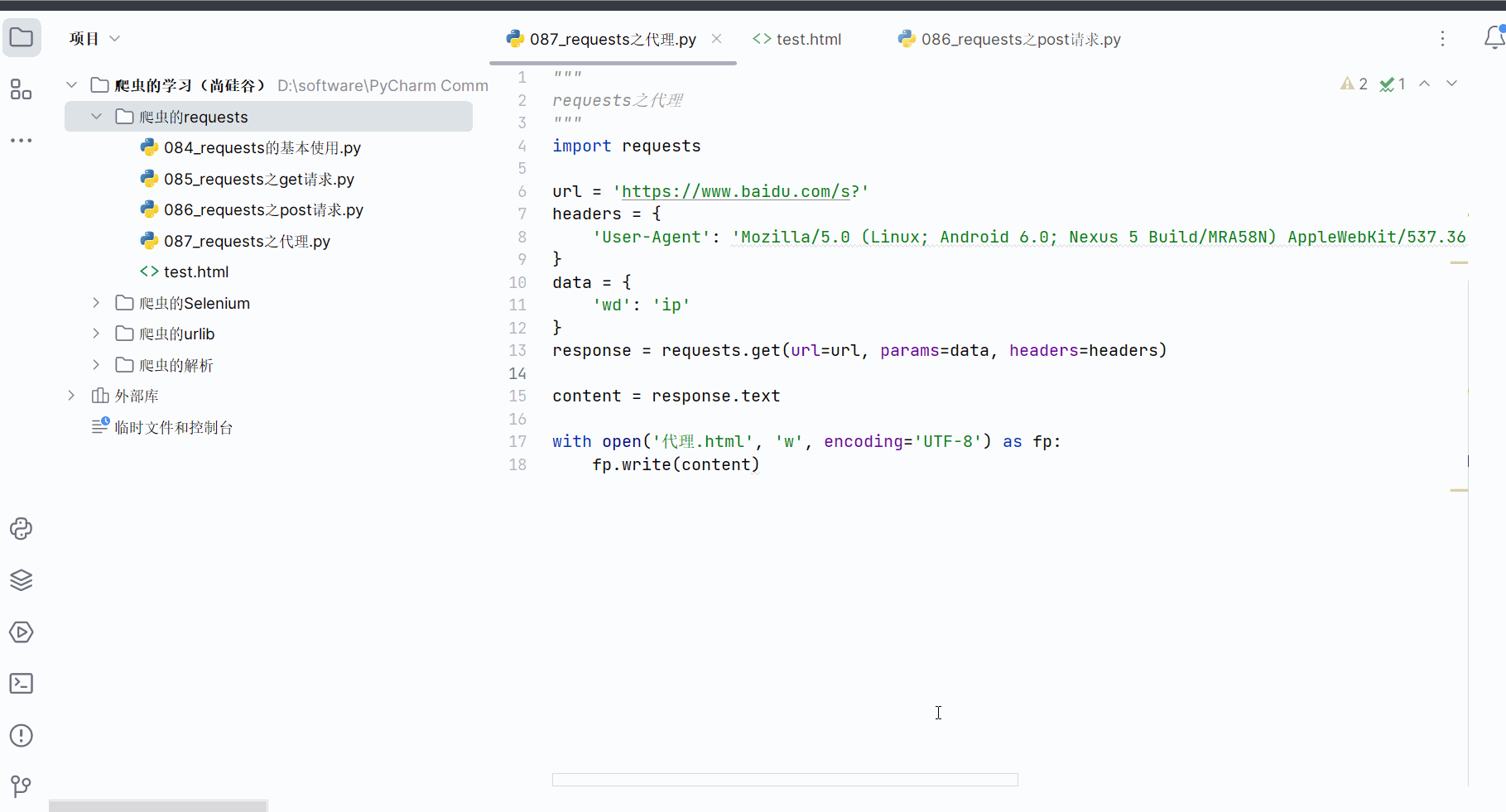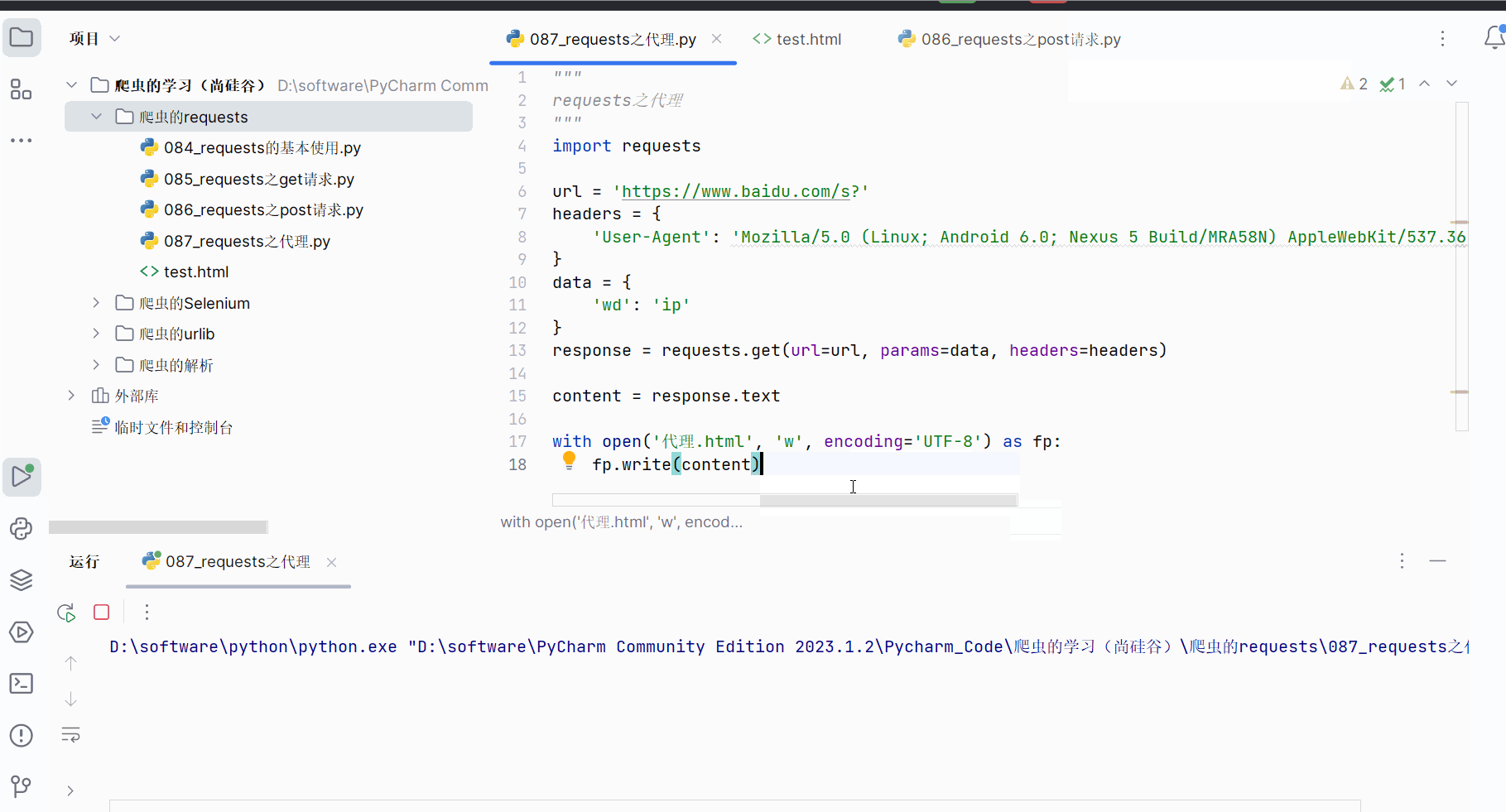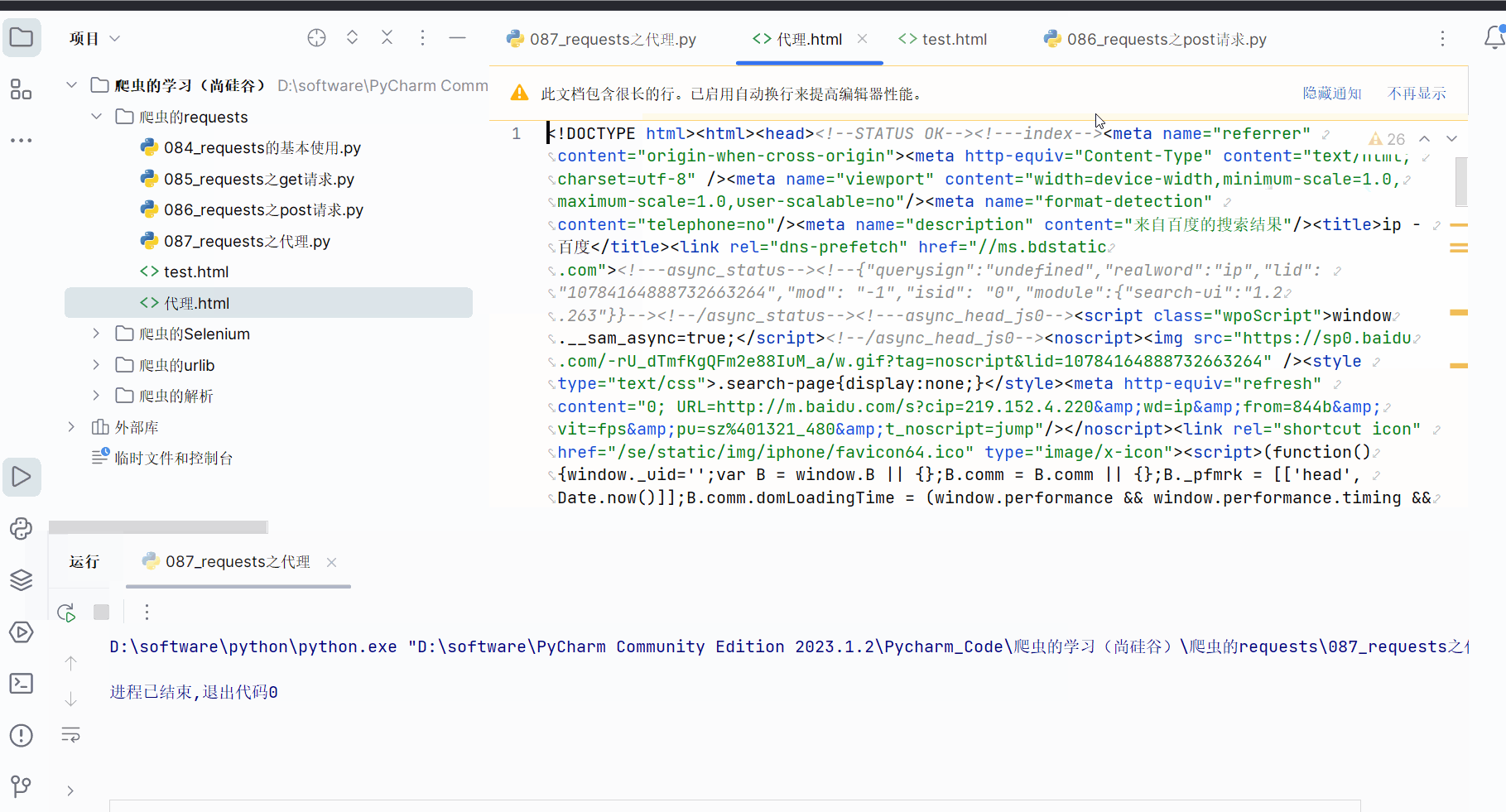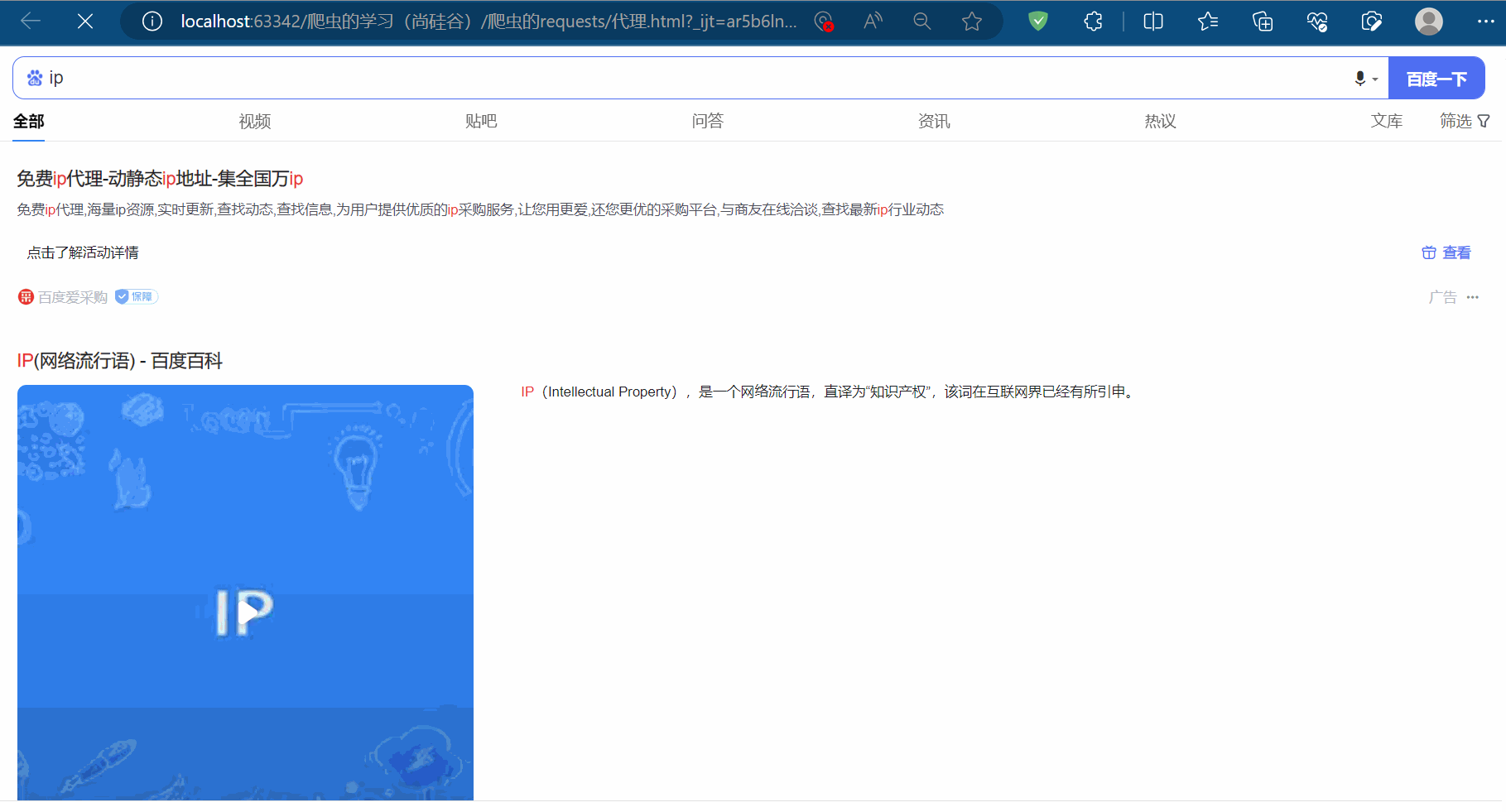
如下图,打开快代理的官网,试一试免费代理的ip。
继续编程,使用快代理的免费“ip”,发现不好用,切换失败。如果家里有条件,可以去买个ip来试。
"""
requests之代理
"""
import requestsurl = 'https://www.baidu.com/s?'
headers = {'User-Agent': 'Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N) Ap-pleWebKit/537.36 (KHTML, like Gecko) Chrome/115.0.0.0 Mobile Safari/537.36 Edg/115.0.1901.200',
}
data = {'wd': 'ip'
}# 设置其他ip
proxy={'http':'58.20.184.187:9091'
}response = requests.get(url=url, params=data, headers=headers,proxies=proxy)content = response.textwith open('代理.html', 'w', encoding='UTF-8') as fp:fp.write(content)5. requests之cookie登陆古诗文网(含验证码、隐藏域反爬、session)
如下图,进入古诗词网(“https://www.gushiwen.cn/”),点击“我的”,发现有一登陆页面。本次演示需要通过程序端输入账号和密码,然后在程序端填写验证码并登陆(精通图像识别大佬可以加个图像识别,个人本科时捣鼓的粗浅的神经网络做的数字识别率太差了,而且现在又忘得差不多了)。

如下图,先注册一账号以便程序使用(本人使用的是临时邮箱,不用打码了)。


创建文件“088_requests之cookie登陆古诗文网(含验证码).py”。
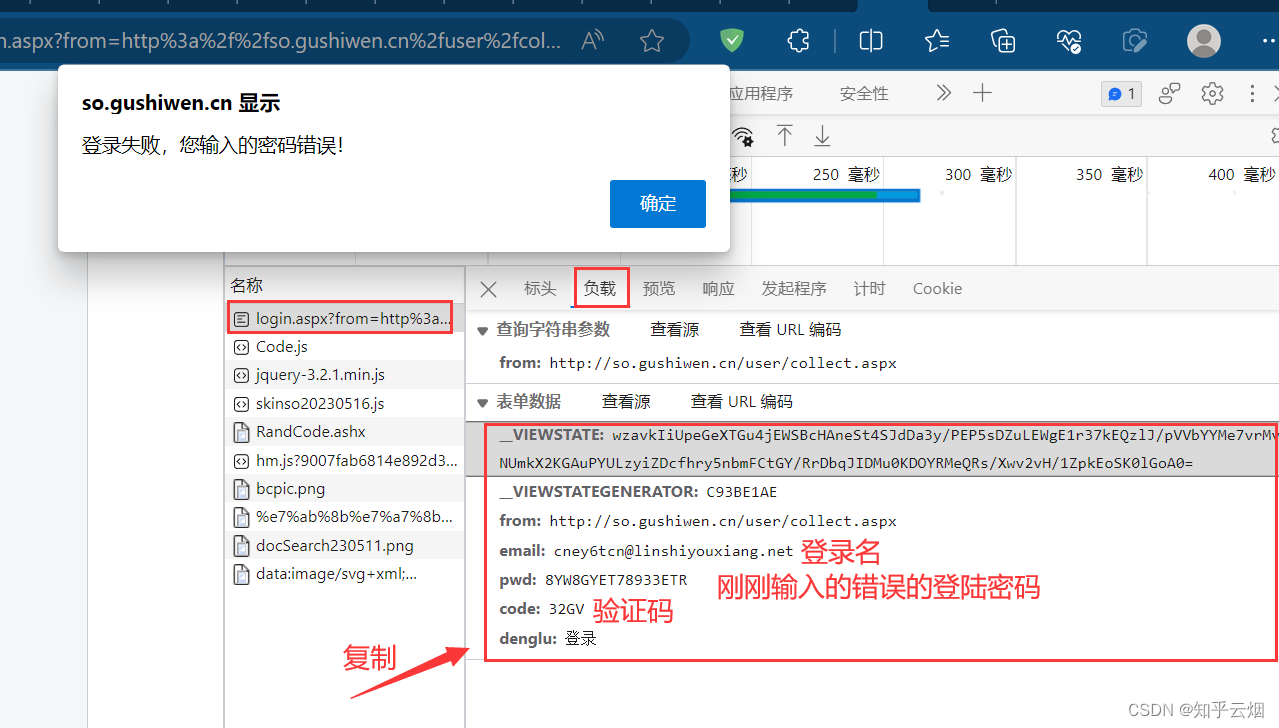
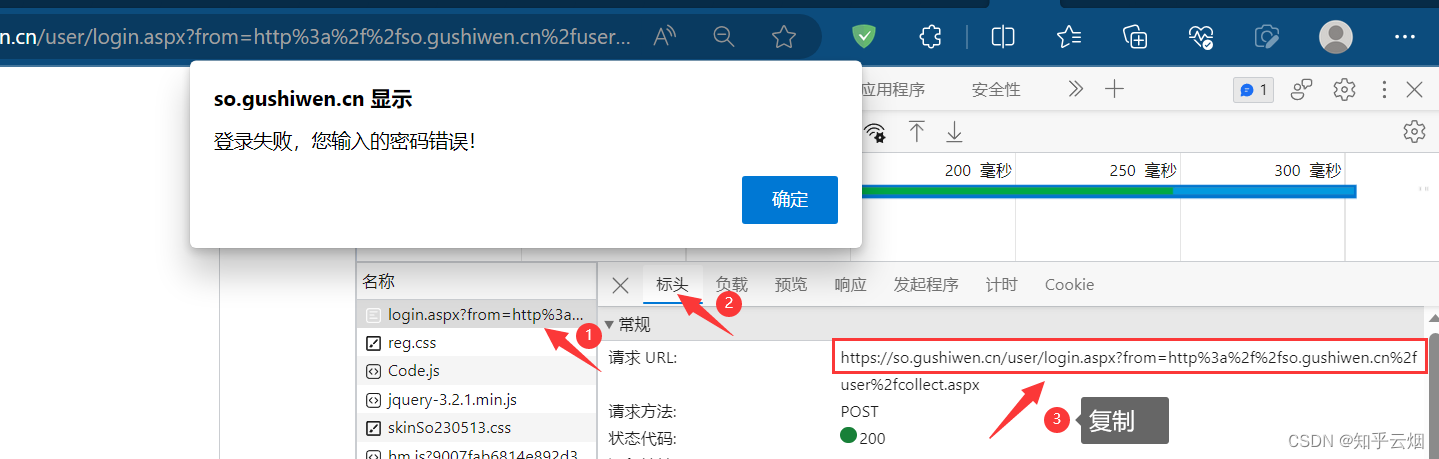
如下图,寻找登陆接口。打开检查,点击网络,清空列表,输入正确邮箱、错误密码、正确验证码,点击登陆,然后保持住浏览器的网页不要动。

在含有登陆英文login的接口里寻找登陆接口,发现某一接口里含登陆名、密码、验证码,说明它正是我们需要找的登陆接口,然后将参数复制到PyCharm中,然后进行思考实现我们的需求需要怎么做。
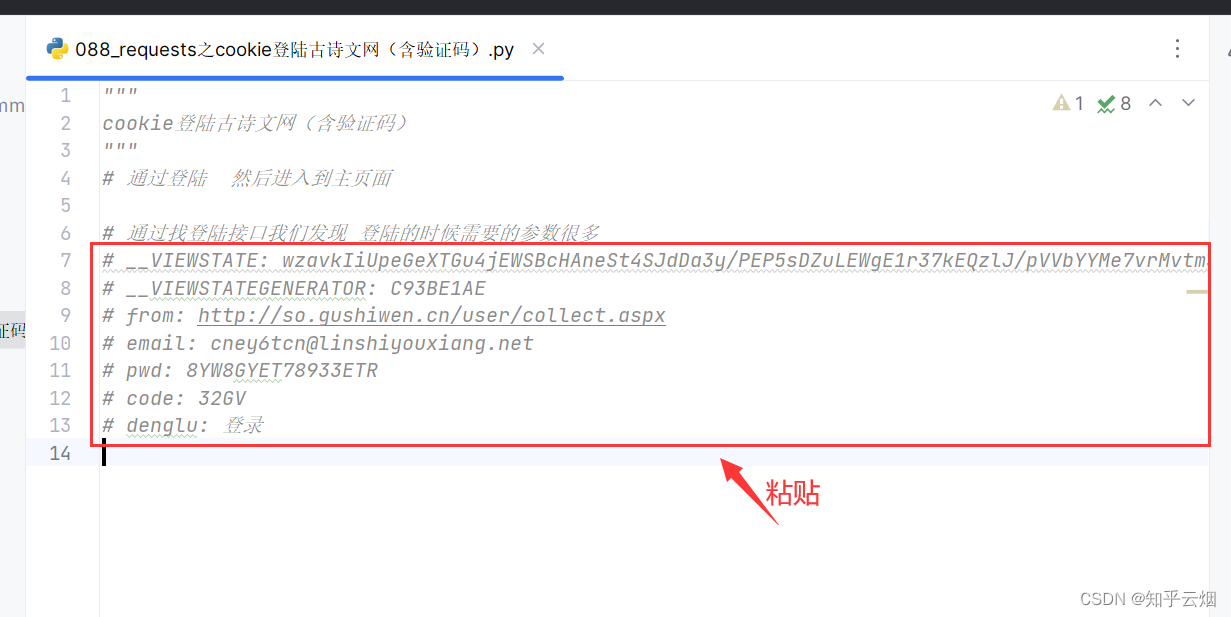
如下图所示,点击确定,回到登陆页面,在网页源码中寻找到其中两个参数。
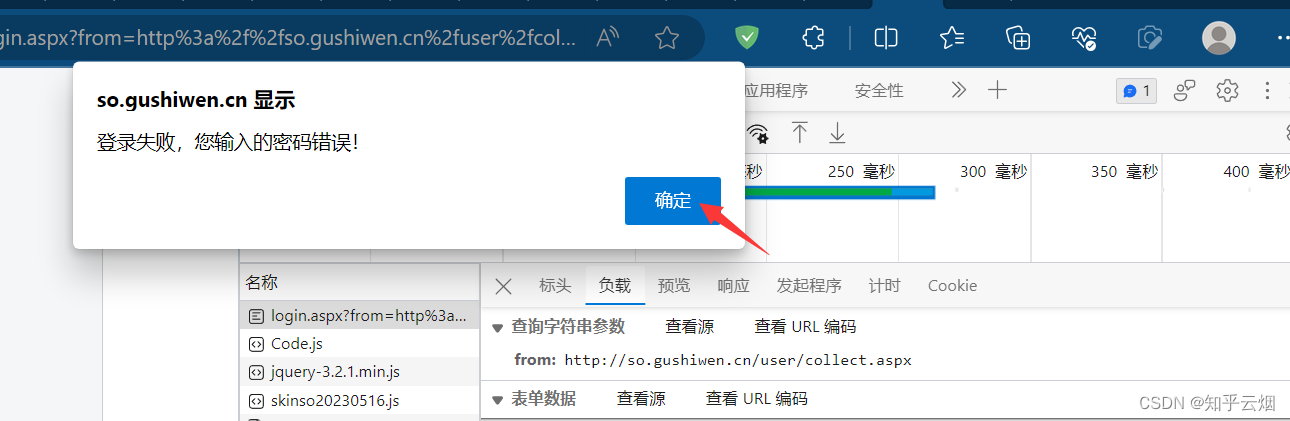
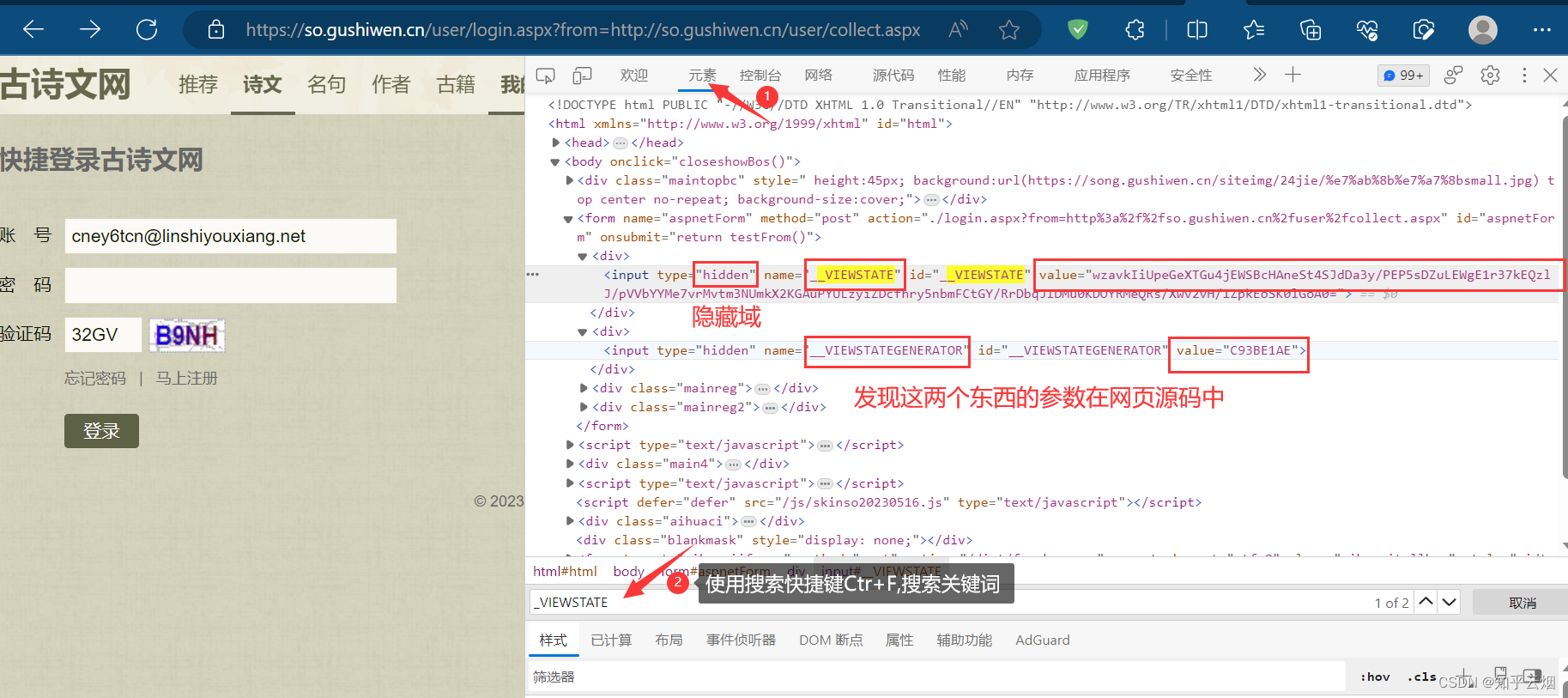

如下操作,找到需要的网页源码的请求地址,并复制到PyCharm中。
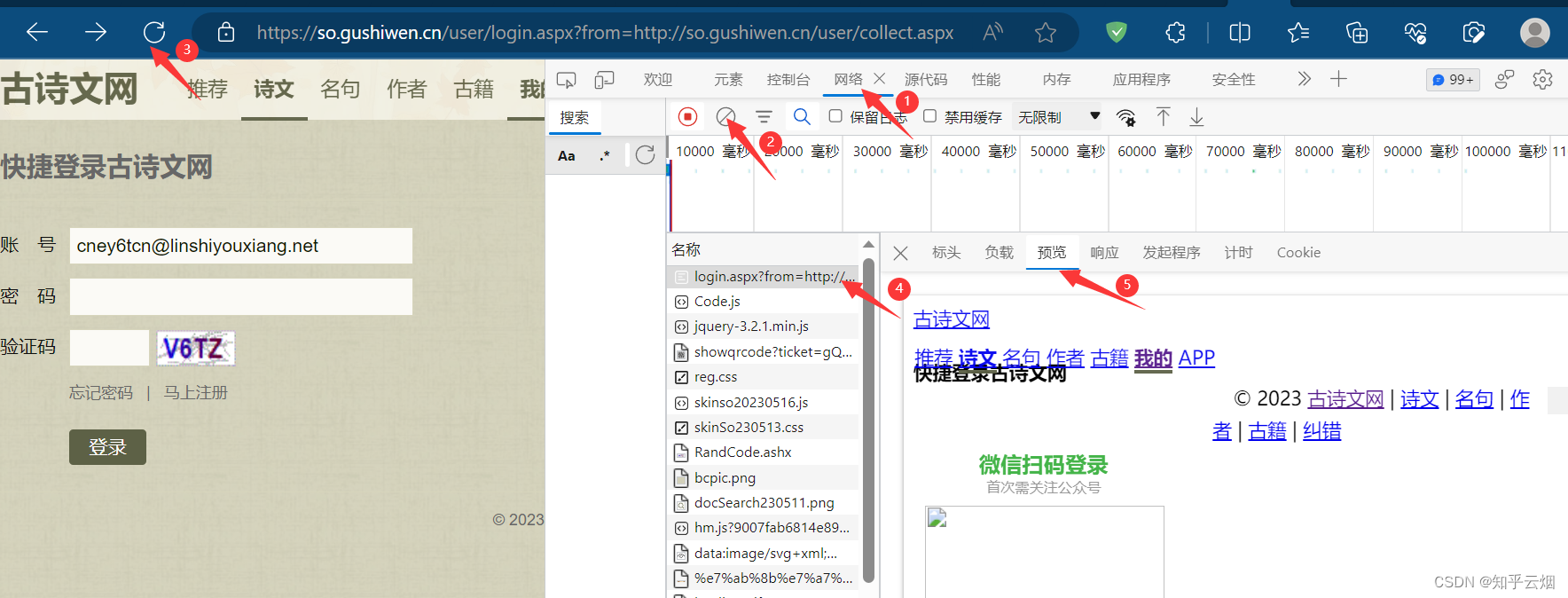
如下编程,获取网页源码,并使用快捷键Ctr+F去搜一下,确定有无需要的数据。
"""
cookie登陆古诗文网(含验证码)
"""
# 通过登陆 然后进入到主页面# 通过找登陆接口我们发现 登陆的时候需要的参数很多
# __VIEWSTATE: wzavkIiUpeGeXT-Gu4jEWSBcHAneSt4SJdDa3y/PEP5sDZuLEWgE1r37kEQzlJ/pVVbYYMe7vrMvtm3NUmkX2KGAuPYULzyiZDcfhry5nbmFCtGY/RrDbqJIDMu0KDOYRMeQRs/Xwv2vH/1ZpkEoSK0lGoA0=
# __VIEWSTATEGENERATOR: C93BE1AE
# from: http://so.gushiwen.cn/user/collect.aspx
# email: cney6tcn@linshiyouxiang.net
# pwd: 8YW8GYET78933ETR
# code: 32GV
# denglu: 登录# 我们观察到_VIEWSTATE __VIEWSTATEGENERATOR code是一个可以变化的量# 难点:(1)_VIEWSTATE __VIEWSTATEGENERATOR 一般情况看不到的数据 都是在页面的源码中
# 我们观察到这两个数据在页面的源码中 所以我们需要获取页面的源码 然后进行解析就可以获取了
# (2)验证码import requests# 这是登陆页面的url地址
url = 'https://so.gushiwen.cn/user/login.aspx?from=http://so.gushiwen.cn/user/collect.a'headers = {'User-Agent': 'Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N) Ap-pleWebKit/537.36 (KHTML, like Gecko) Chrome/115.0.0.0 Mobile Safari/537.36 Edg/115.0.1901.200',
}
response = requests.get(url=url, headers=headers)
content = response.text
print(content) # 测试代码,验证能否获取网页源码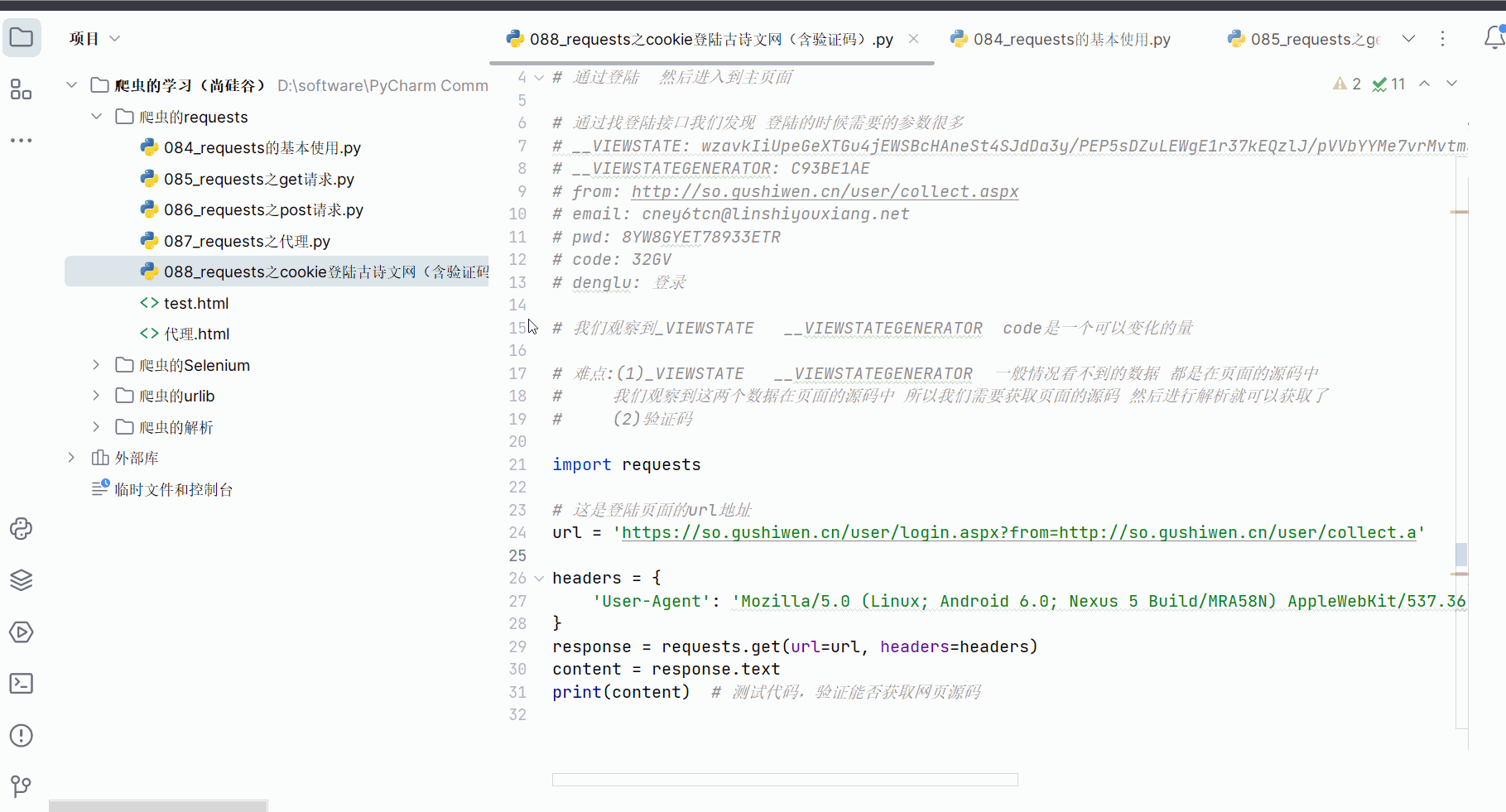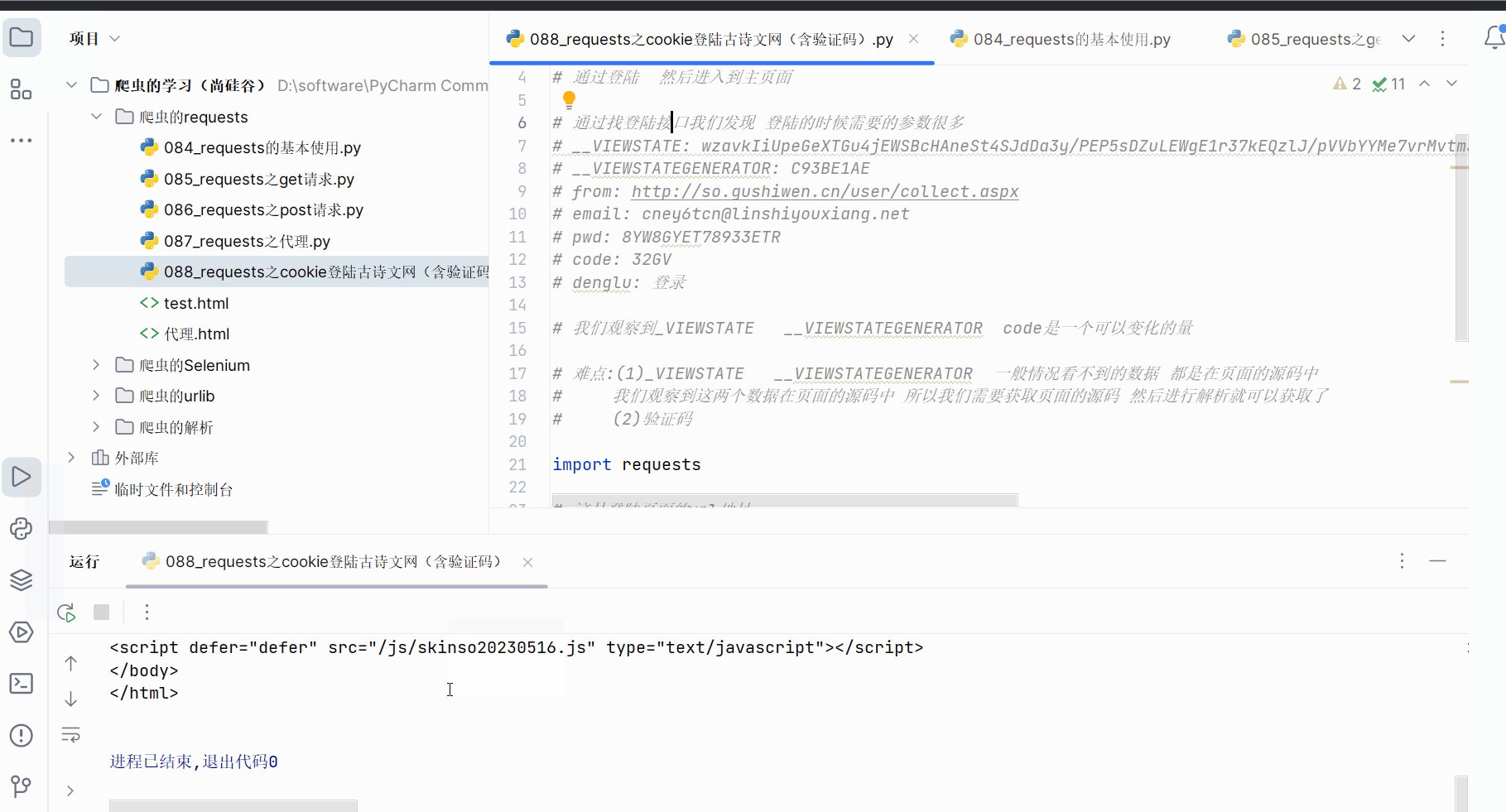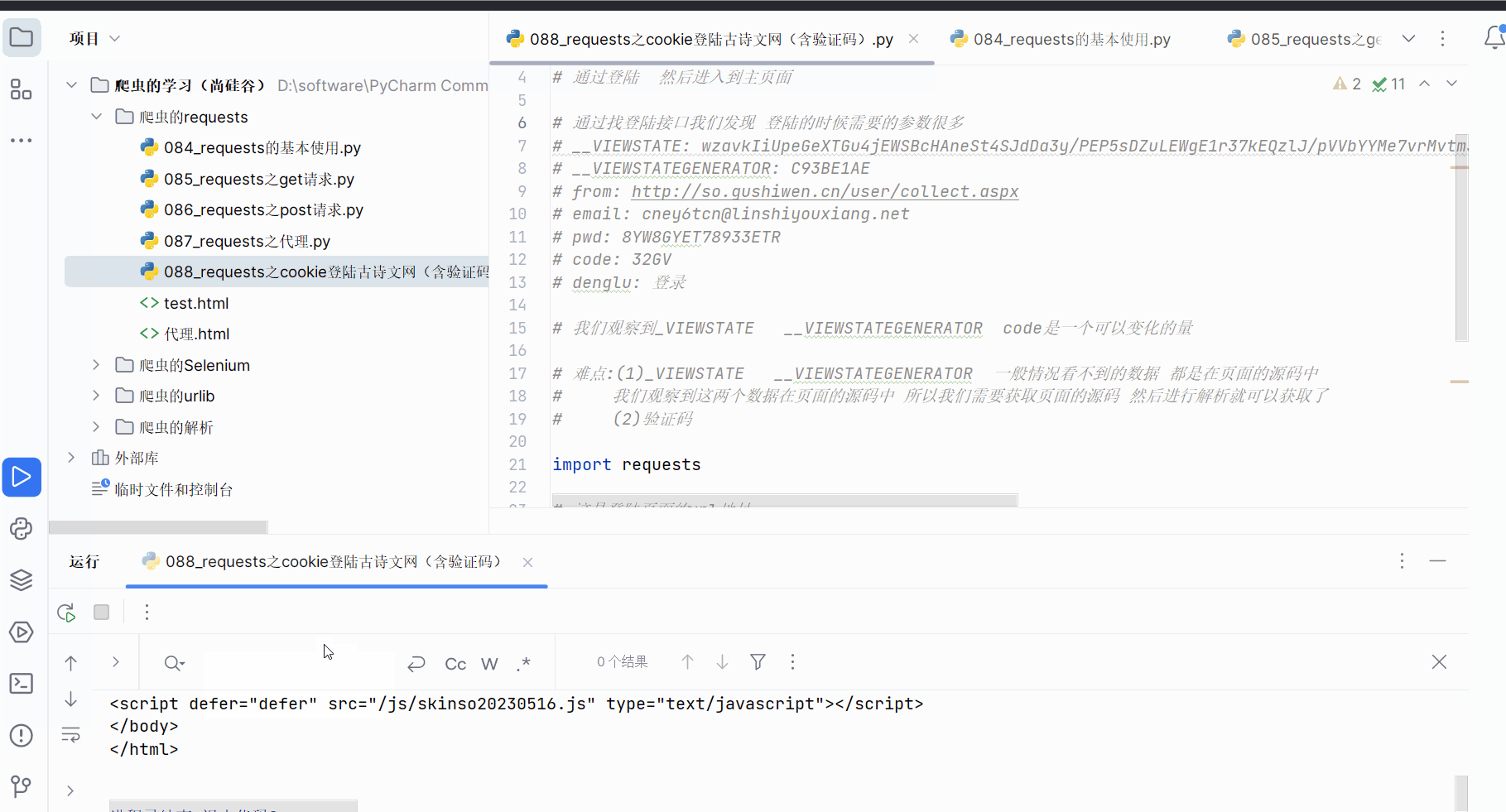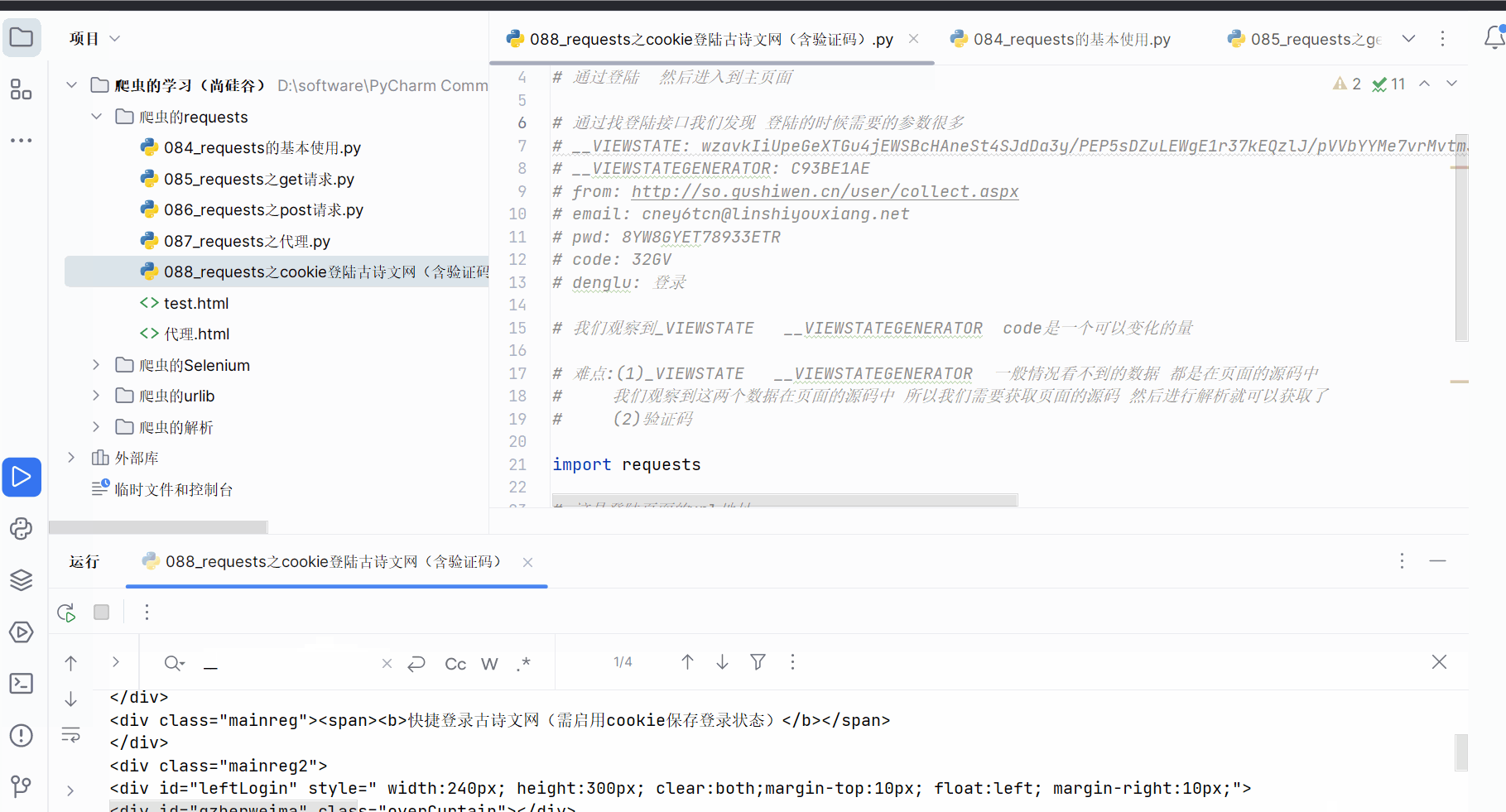
如下图,根据检查里的元素思考寻找其中两个变量的参数的方法。
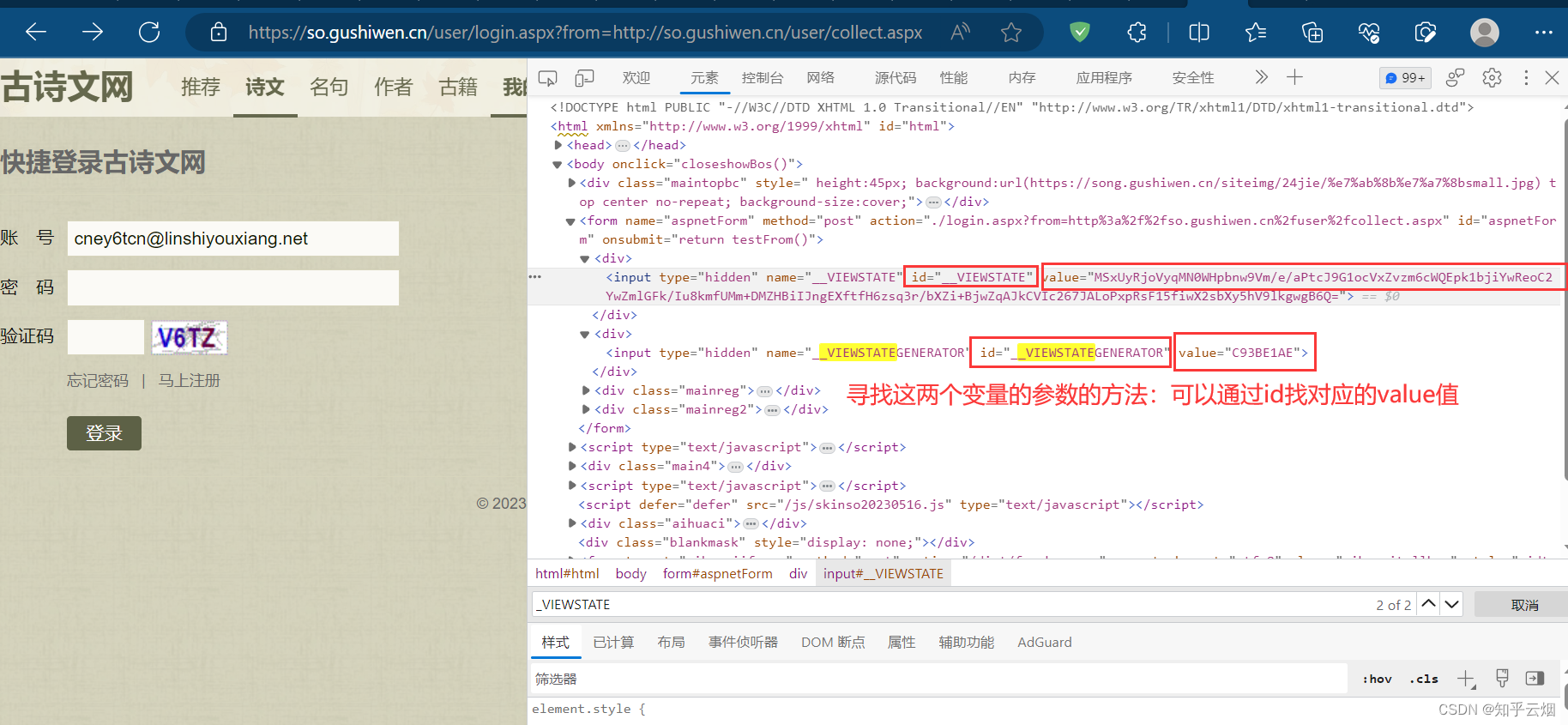
如下编程,成功获取这两个变量的参数(“_VIEWSTATE”需改为“__VIEWSTATE”,笔误)。
"""
cookie登陆古诗文网(含验证码)
"""
# 通过登陆 然后进入到主页面# 通过找登陆接口我们发现 登陆的时候需要的参数很多
# __VIEWSTATE: wzavkIiUpeGeXT-Gu4jEWSBcHAneSt4SJdDa3y/PEP5sDZuLEWgE1r37kEQzlJ/pVVbYYMe7vrMvtm3NUmkX2KGAuPYULzyiZDcfhry5nbmFCtGY/RrDbqJIDMu0KDOYRMeQRs/Xwv2vH/1ZpkEoSK0lGoA0=
# __VIEWSTATEGENERATOR: C93BE1AE
# from: http://so.gushiwen.cn/user/collect.aspx
# email: cney6tcn@linshiyouxiang.net
# pwd: 8YW8GYET78933ETR
# code: 32GV
# denglu: 登录# 我们观察到__VIEWSTATE __VIEWSTATEGENERATOR code是一个可以变化的量# 难点:(1)__VIEWSTATE __VIEWSTATEGENERATOR 一般情况看不到的数据 都是在页面的源码中
# 我们观察到这两个数据在页面的源码中 所以我们需要获取页面的源码 然后进行解析就可以获取了
# (2)验证码import requests
from bs4 import BeautifulSoup# 这是登陆页面的url地址
url = 'https://so.gushiwen.cn/user/login.aspx?from=http://so.gushiwen.cn/user/collect.a'headers = {'User-Agent': 'Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N) Ap-pleWebKit/537.36 (KHTML, like Gecko) Chrome/115.0.0.0 Mobile Safari/537.36 Edg/115.0.1901.200',
}
response = requests.get(url=url, headers=headers)
content = response.text
# print(content) # 测试代码,验证能否获取网页源码# 解析页面源码 然后获取__VIEWSTATE __VIEWSTATEGENERATOR
soup = BeautifulSoup(content, 'lxml')# 获取__VIEWSTATE
# .select返回列表,需用切片取出对应标签 .attrs.get获取属性值
viewstate = soup.select('#__VIEWSTATE')[0].attrs.get('value')# 获取__VIEWSTATEGENERATOR
viewstategenerator = soup.select('#__VIEWSTATEGENERATOR')[0].attrs.get('value')print(viewstate)
print(viewstategenerator)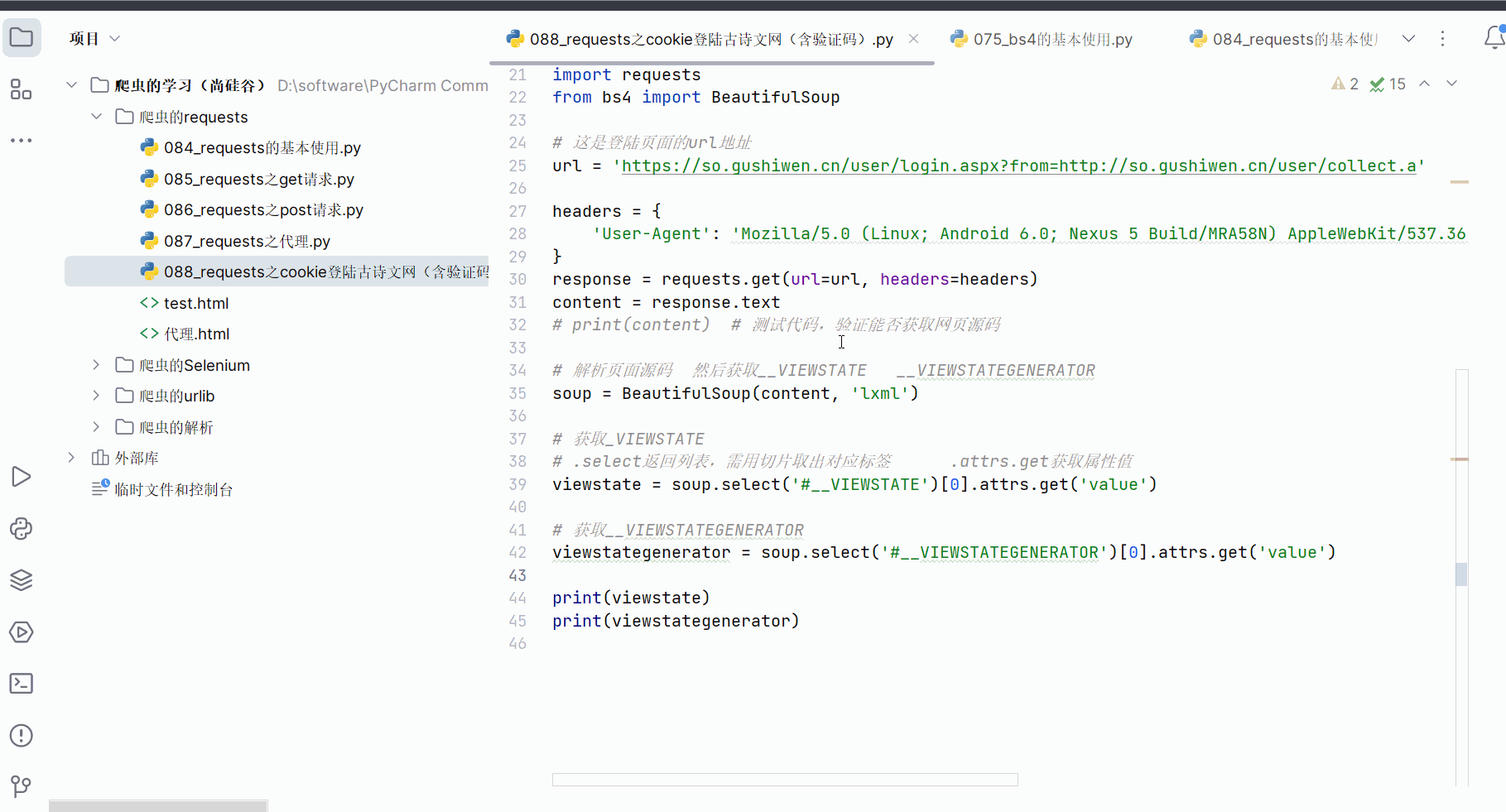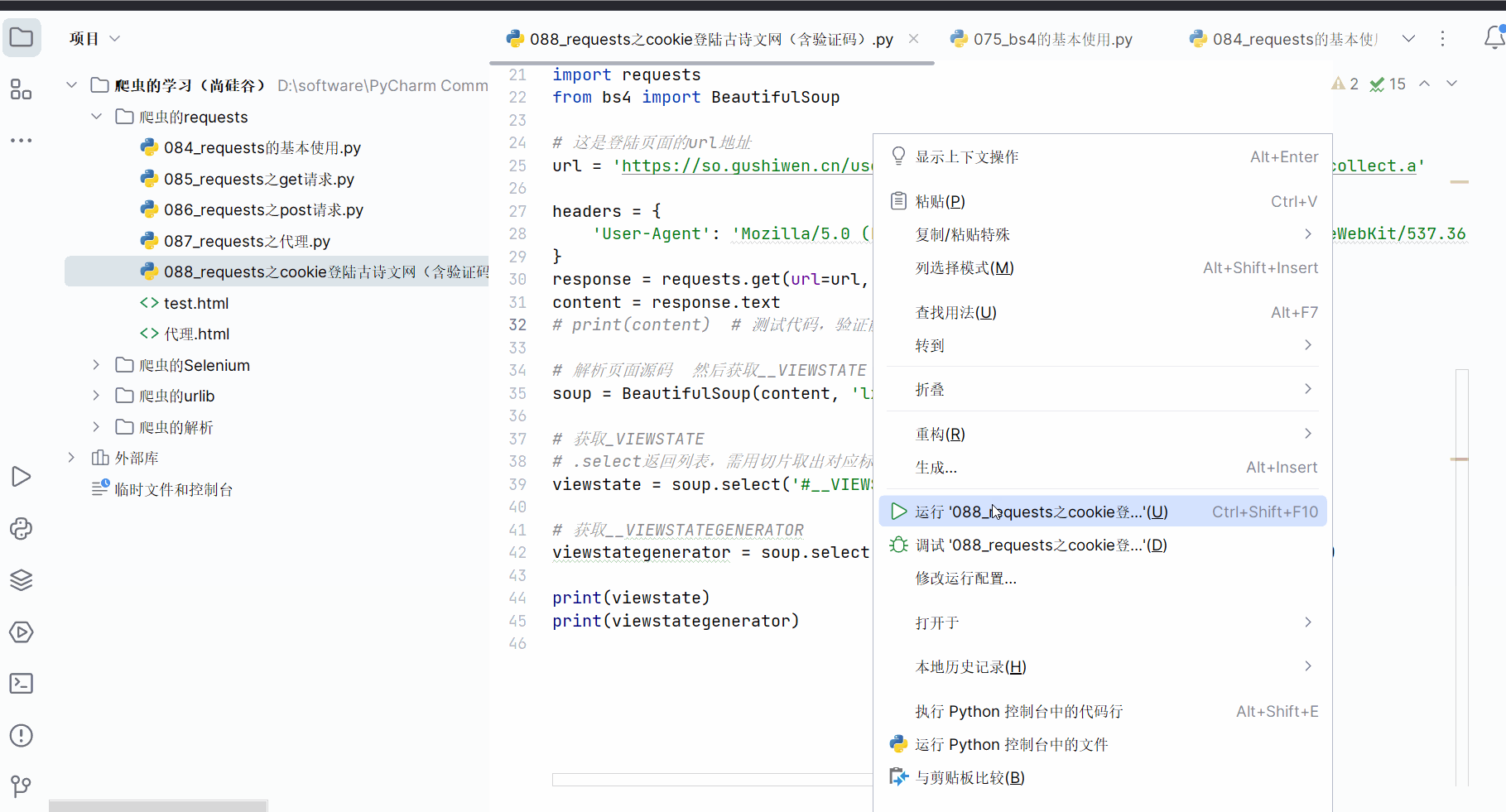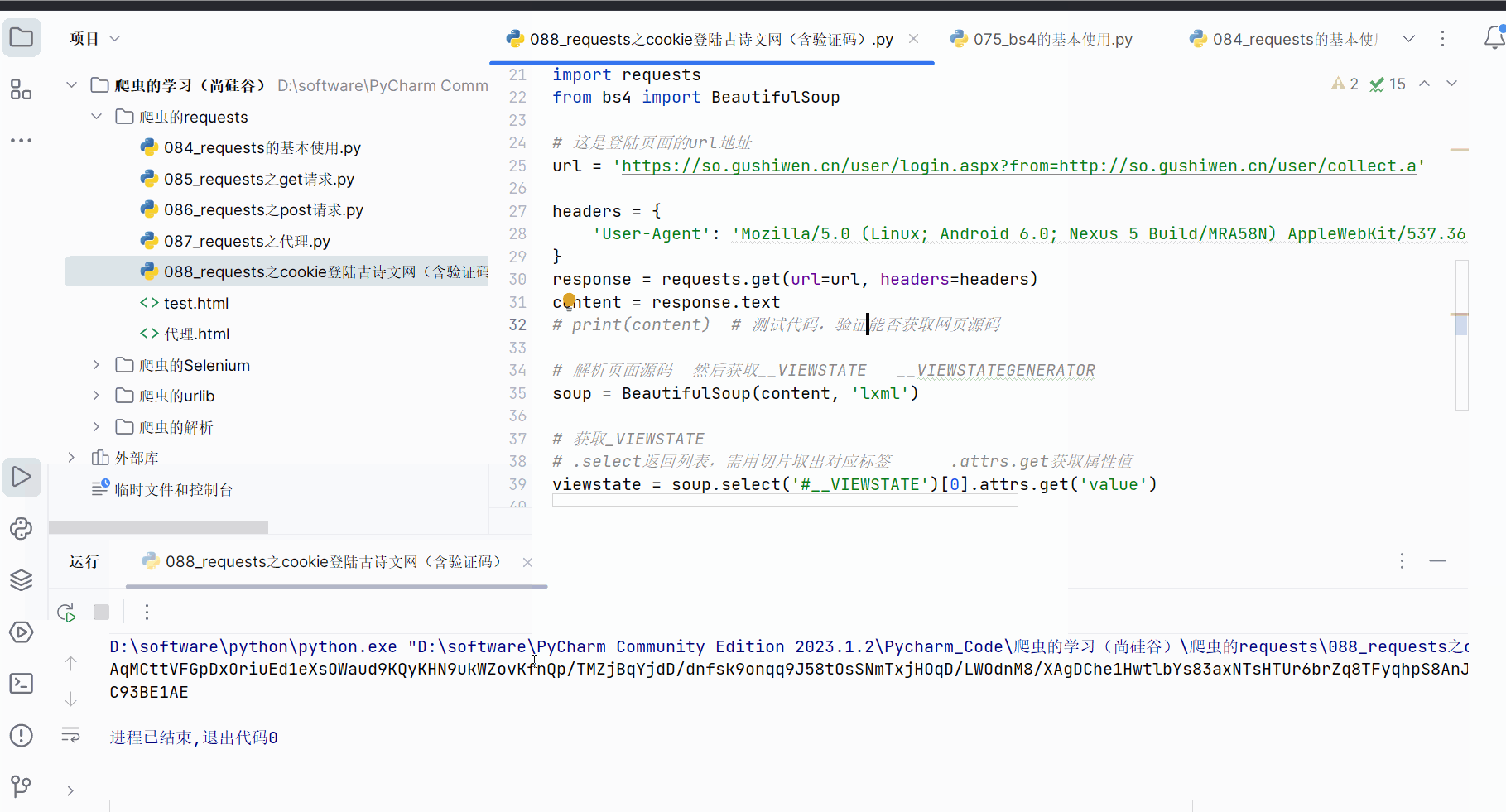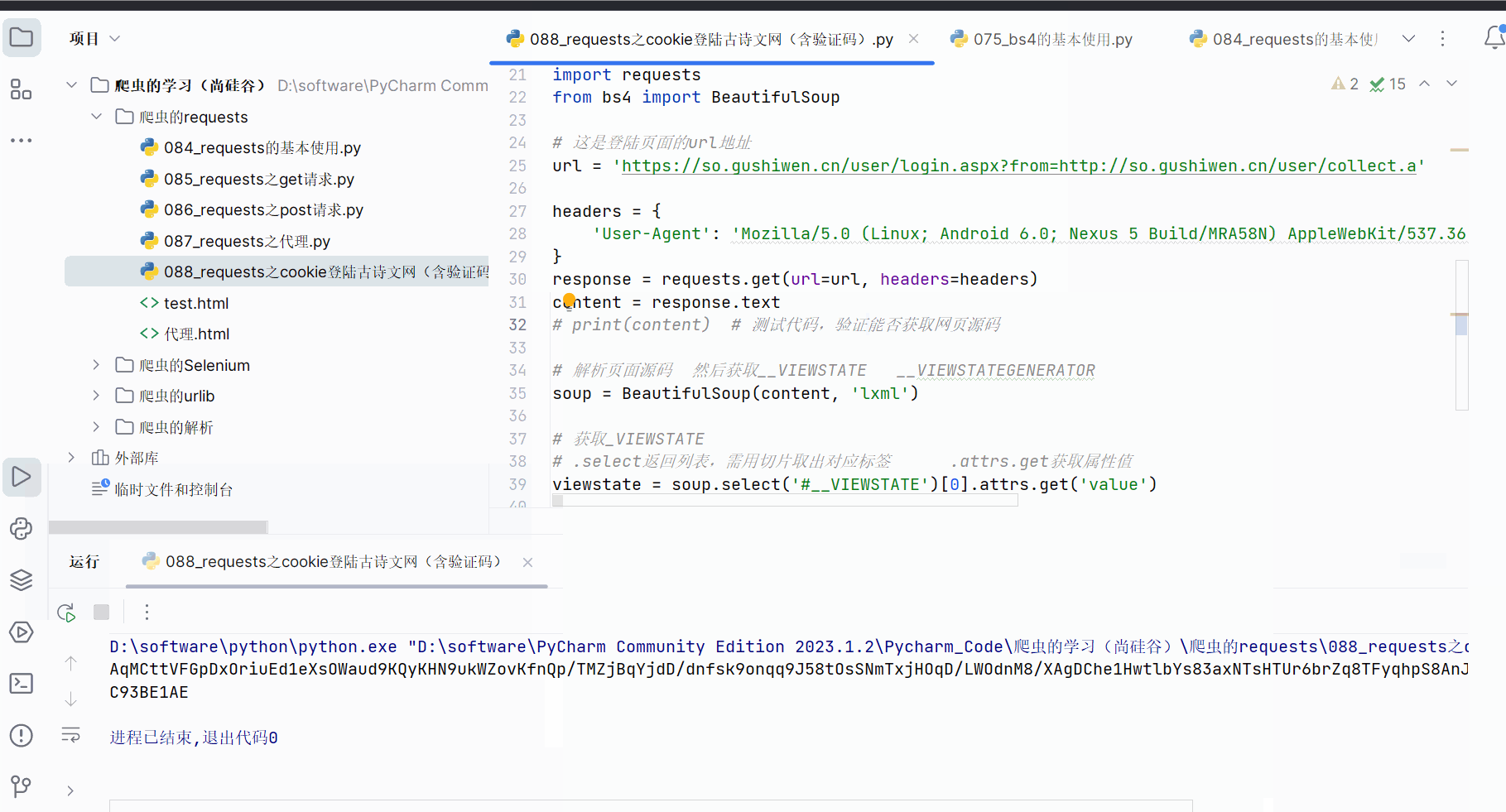
接下来还需要寻找验证码。如图,点击验证码,右击选择检查,将鼠标放在src处等待一会,观察后发现,可根据id找到验证码的图片链接的参数,说明验证码图片链接需要拼接。
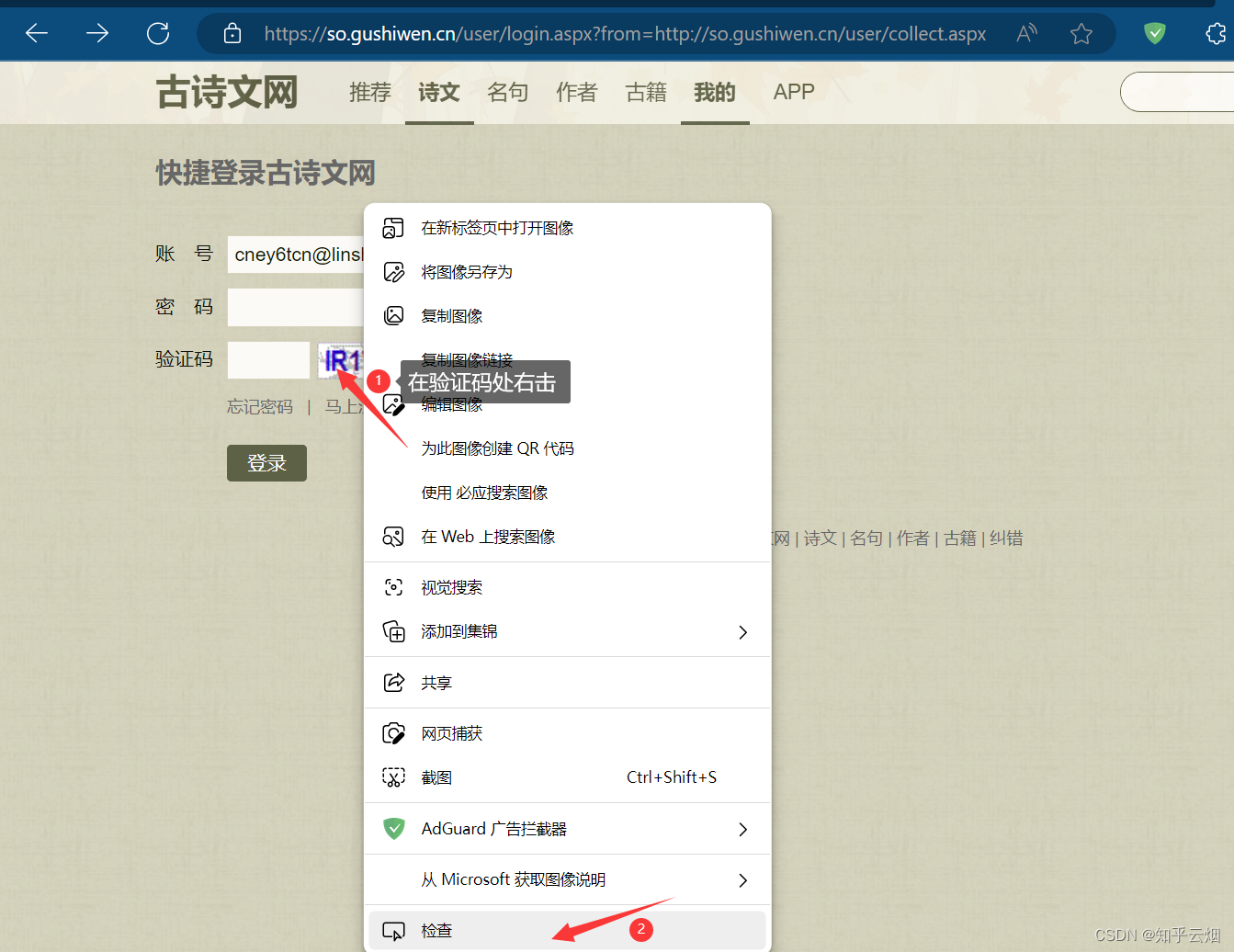
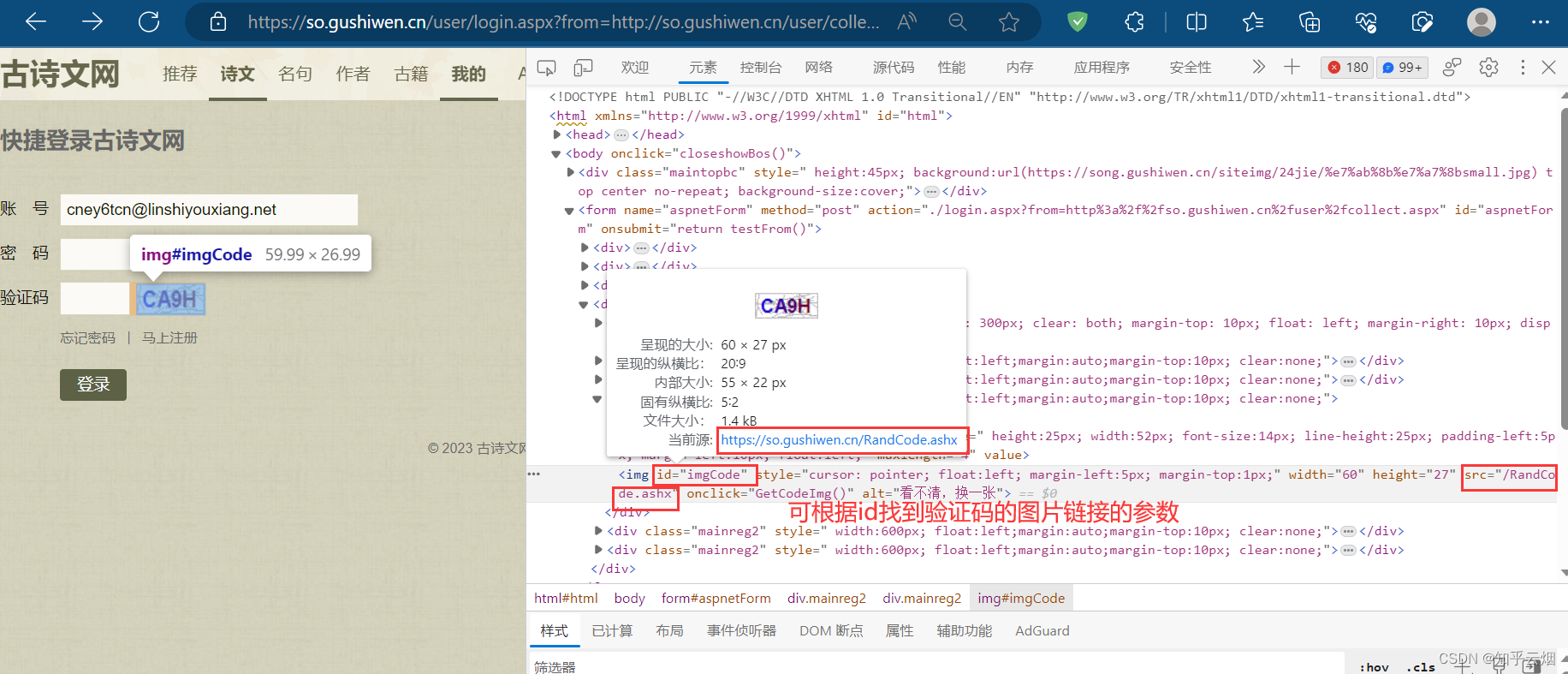
如下编程,成功获取到验证码图片的url。
"""
cookie登陆古诗文网(含验证码)
"""
# 通过登陆 然后进入到主页面# 通过找登陆接口我们发现 登陆的时候需要的参数很多
# __VIEWSTATE: wzavkIiUpeGeXT-Gu4jEWSBcHAneSt4SJdDa3y/PEP5sDZuLEWgE1r37kEQzlJ/pVVbYYMe7vrMvtm3NUmkX2KGAuPYULzyiZDcfhry5nbmFCtGY/RrDbqJIDMu0KDOYRMeQRs/Xwv2vH/1ZpkEoSK0lGoA0=
# __VIEWSTATEGENERATOR: C93BE1AE
# from: http://so.gushiwen.cn/user/collect.aspx
# email: cney6tcn@linshiyouxiang.net
# pwd: 8YW8GYET78933ETR
# code: 32GV
# denglu: 登录# 我们观察到__VIEWSTATE __VIEWSTATEGENERATOR code是一个可以变化的量# 难点:(1)__VIEWSTATE __VIEWSTATEGENERATOR 一般情况看不到的数据 都是在页面的源码中
# 我们观察到这两个数据在页面的源码中 所以我们需要获取页面的源码 然后进行解析就可以获取了
# (2)验证码import requests
from bs4 import BeautifulSoup# 这是登陆页面的url地址
url = 'https://so.gushiwen.cn/user/login.aspx?from=http://so.gushiwen.cn/user/collect.a'headers = {'User-Agent': 'Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N) Ap-pleWebKit/537.36 (KHTML, like Gecko) Chrome/115.0.0.0 Mobile Safari/537.36 Edg/115.0.1901.200',
}
response = requests.get(url=url, headers=headers)
content = response.text
# print(content) # 测试代码,验证能否获取网页源码# 解析页面源码 然后获取__VIEWSTATE __VIEWSTATEGENERATOR
soup = BeautifulSoup(content, 'lxml')# 获取__VIEWSTATE
# .select返回列表,需用切片取出对应标签 .attrs.get获取属性值
viewstate = soup.select('#__VIEWSTATE')[0].attrs.get('value')# 获取__VIEWSTATEGENERATOR
viewstategenerator = soup.select('#__VIEWSTATEGENERATOR')[0].attrs.get('value')# print(viewstate) # 测试代码,验证是否获取到__VIEWSTATE的参数
# print(viewstategenerator) # 测试代码,验证是否获取到__VIEWSTATEGENERATOR的参数# 获取验证码图片
code_url_para = soup.select('#imgCode')[0].attrs.get('src')
code_url = 'https://so.gushiwen.cn/' + code_url_para
print(code_url) # 测试代码,验证是否获取到验证码的图片的url
如之前所说的,通过输入正确邮箱、错误密码、正确验证码,点击登陆,来寻找登陆接口,然后将接口的请求地址复制到PyCharm中。
如下编程,发现直接获取验证码,然后在程序端输入验证码后登不进去。这是因为“urllib.request.urlretrieve”下载图片提交的请求和“requests.post”提交的请求不是同一个导致的,requests.post”提交的请求时验证码已经改变。
"""
cookie登陆古诗文网(含验证码)
"""
# 通过登陆 然后进入到主页面# 通过找登陆接口我们发现 登陆的时候需要的参数很多
# __VIEWSTATE: wzavkIiUpeGeXT-Gu4jEWSBcHAneSt4SJdDa3y/PEP5sDZuLEWgE1r37kEQzlJ/pVVbYYMe7vrMvtm3NUmkX2KGAuPYULzyiZDcfhry5nbmFCtGY/RrDbqJIDMu0KDOYRMeQRs/Xwv2vH/1ZpkEoSK0lGoA0=
# __VIEWSTATEGENERATOR: C93BE1AE
# from: http://so.gushiwen.cn/user/collect.aspx
# email: cney6tcn@linshiyouxiang.net
# pwd: 8YW8GYET78933ETR
# code: 32GV
# denglu: 登录# 我们观察到__VIEWSTATE __VIEWSTATEGENERATOR code是一个可以变化的量# 难点:(1)__VIEWSTATE __VIEWSTATEGENERATOR 一般情况看不到的数据 都是在页面的源码中
# 我们观察到这两个数据在页面的源码中 所以我们需要获取页面的源码 然后进行解析就可以获取了
# (2)验证码import requests
from bs4 import BeautifulSoup
import urllib.request# 这是登陆页面的url地址
url = 'https://so.gushiwen.cn/user/login.aspx?from=http://so.gushiwen.cn/user/collect.a'headers = {'User-Agent': 'Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N) Ap-pleWebKit/537.36 (KHTML, like Gecko) Chrome/115.0.0.0 Mobile Safari/537.36 Edg/115.0.1901.200',
}
response = requests.get(url=url, headers=headers)
content = response.text
# print(content) # 测试代码,验证能否获取网页源码# 解析页面源码 然后获取__VIEWSTATE __VIEWSTATEGENERATOR
soup = BeautifulSoup(content, 'lxml')# 获取__VIEWSTATE
# .select返回列表,需用切片取出对应标签 .attrs.get获取属性值
viewstate = soup.select('#__VIEWSTATE')[0].attrs.get('value')# 获取__VIEWSTATEGENERATOR
viewstategenerator = soup.select('#__VIEWSTATEGENERATOR')[0].attrs.get('value')# print(viewstate) # 测试代码,验证是否获取到__VIEWSTATE的参数
# print(viewstategenerator) # 测试代码,验证是否获取到__VIEWSTATEGENERATOR的参数# 获取验证码图片
code_url_para = soup.select('#imgCode')[0].attrs.get('src')
code_url = 'https://so.gushiwen.cn/' + code_url_para
# print(code_url) # 测试代码,验证是否获取到验证码的图片的url# 有坑
# 在浏览器的检查的网络里找登陆接口时,如果不勾选检查的网络里的保留日志
# 且输入正确的名字、正确的密码、正确的验证码并登陆后,老版浏览器或者可能别的浏览器会
# 出现登陆接口会消失的情况, 进而导致无法寻找到登陆接口
urllib.request.urlretrieve(url=code_url, filename='code.jpg')# 获取了验证码的图片之后 下载到本地 然后观察验证码 观察之后 然后在控制台输入这个验证码
# 就可以捋这个值给code的参数 就可以登陆
code_name = input('请输入你的验证码')# 点击登陆
url_post = 'https://so.gushiwen.cn/user/login.aspx?from=http%3a%2f%2fso.gushiwen.cn%2fuser%2fcollect.aspx'
data_post = {'__VIEWSTATE': viewstate,'__VIEWSTATEGENERATOR': viewstategenerator,'from': 'http://so.gushiwen.cn/user/collect.aspx','email': 'cney6tcn@linshiyouxiang.net','pwd': 'u89w7829e', # 此处请输入正确的密码'code': code_name,'denglu': '登录',
}response_post = requests.post(url=url_post, headers=headers, data=data_post)
content_post=response_post.textwith open('古诗文.html','w',encoding='UTF-8') as fp:fp.write(content_post)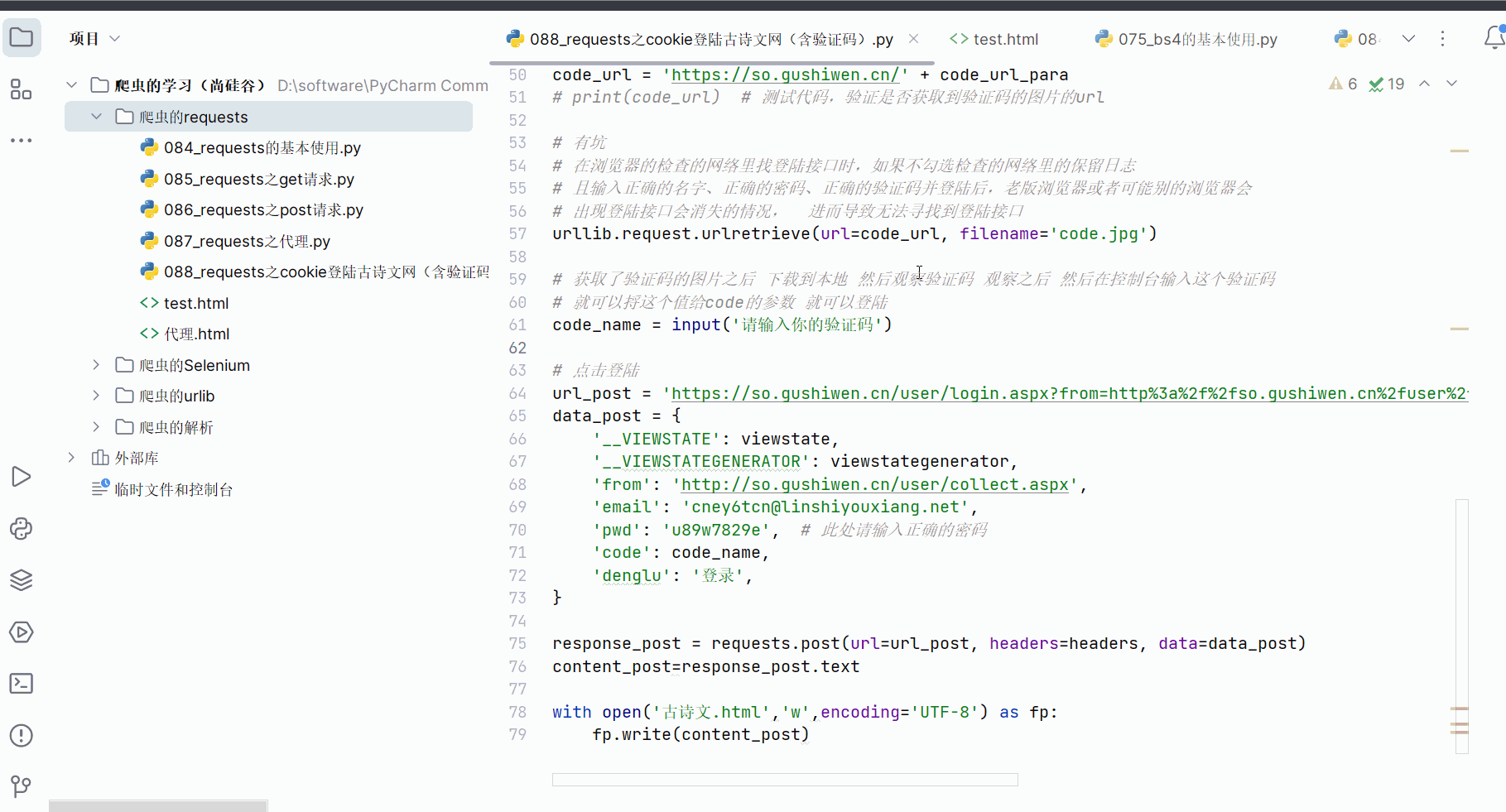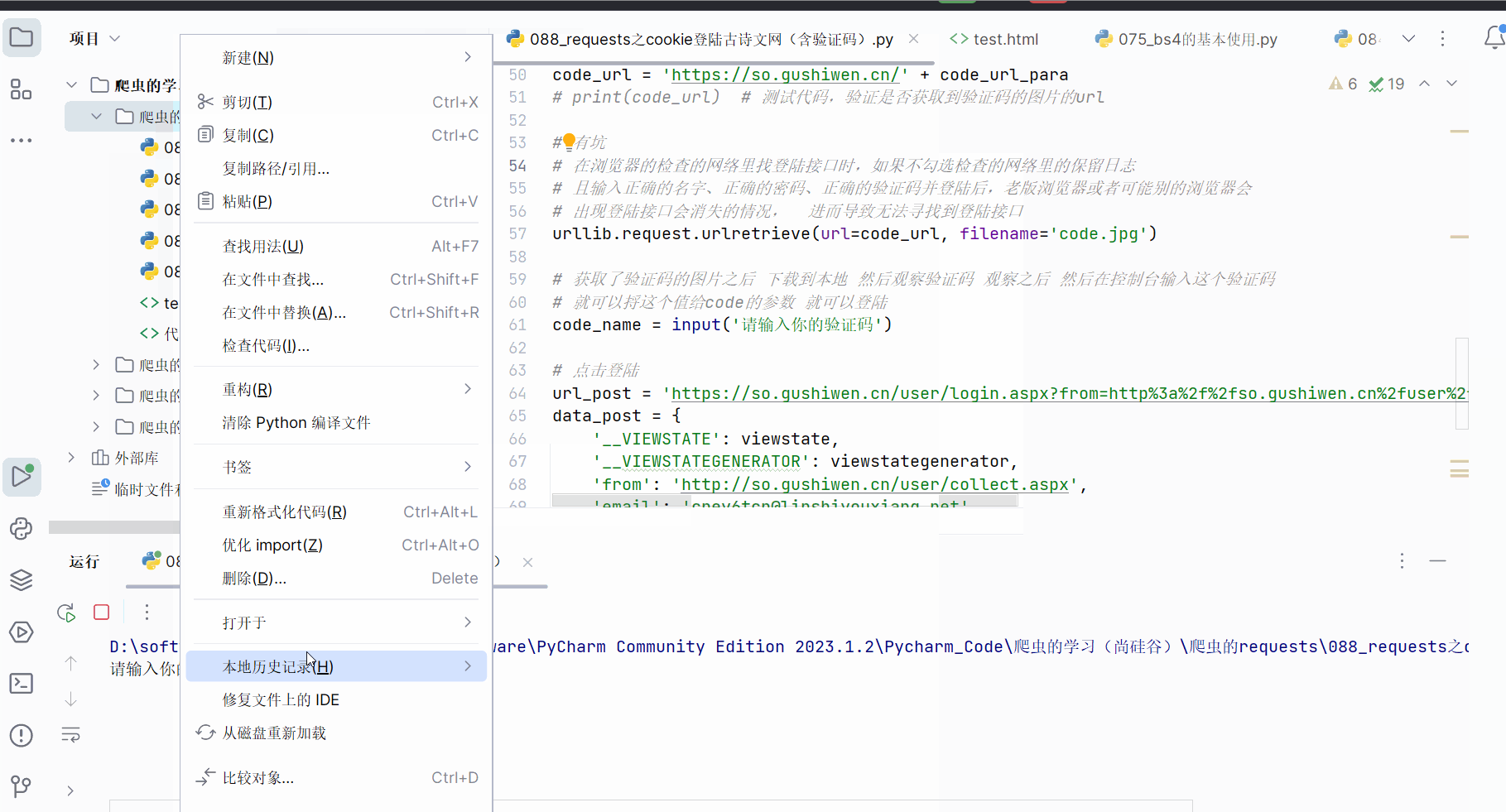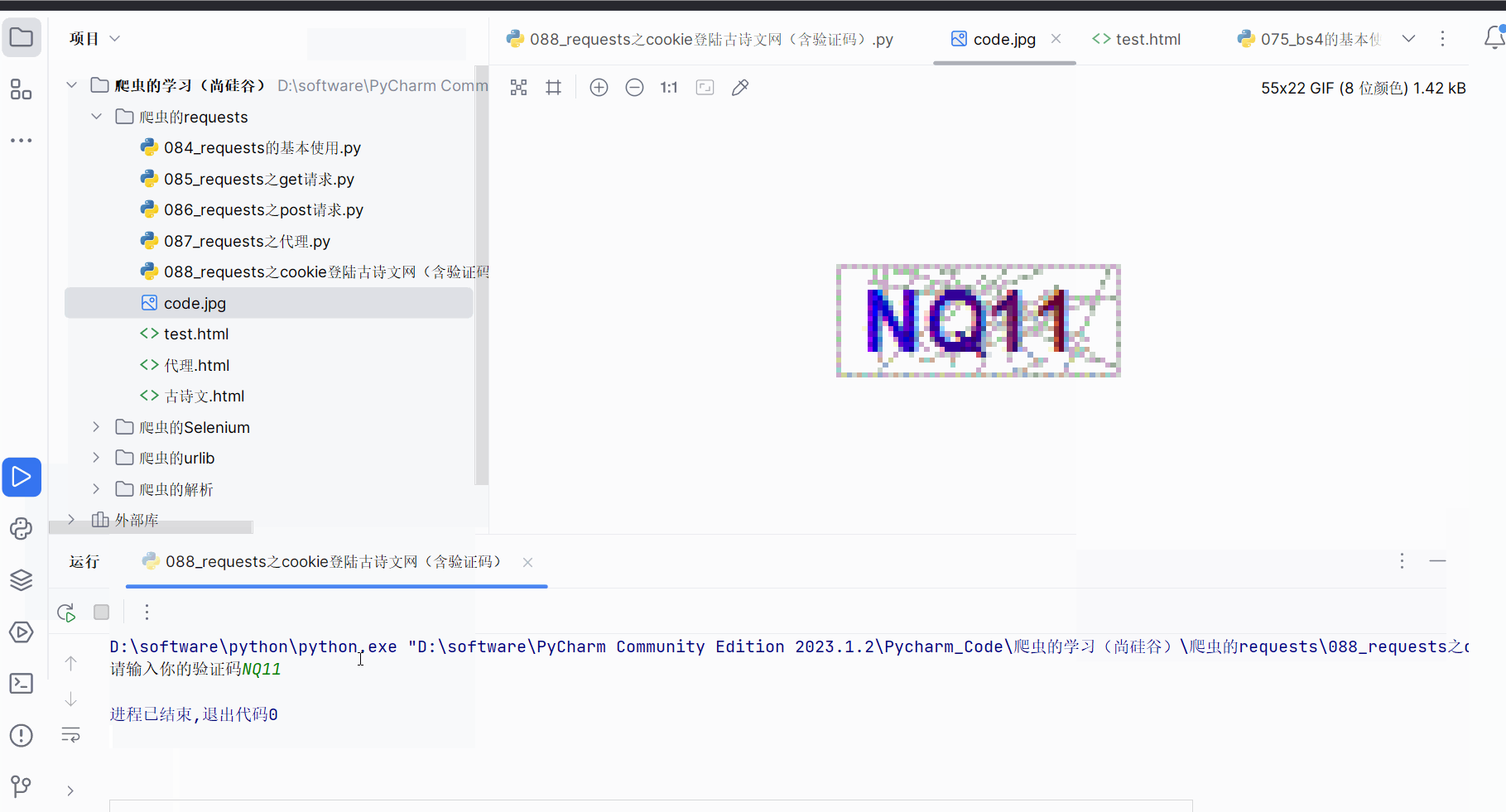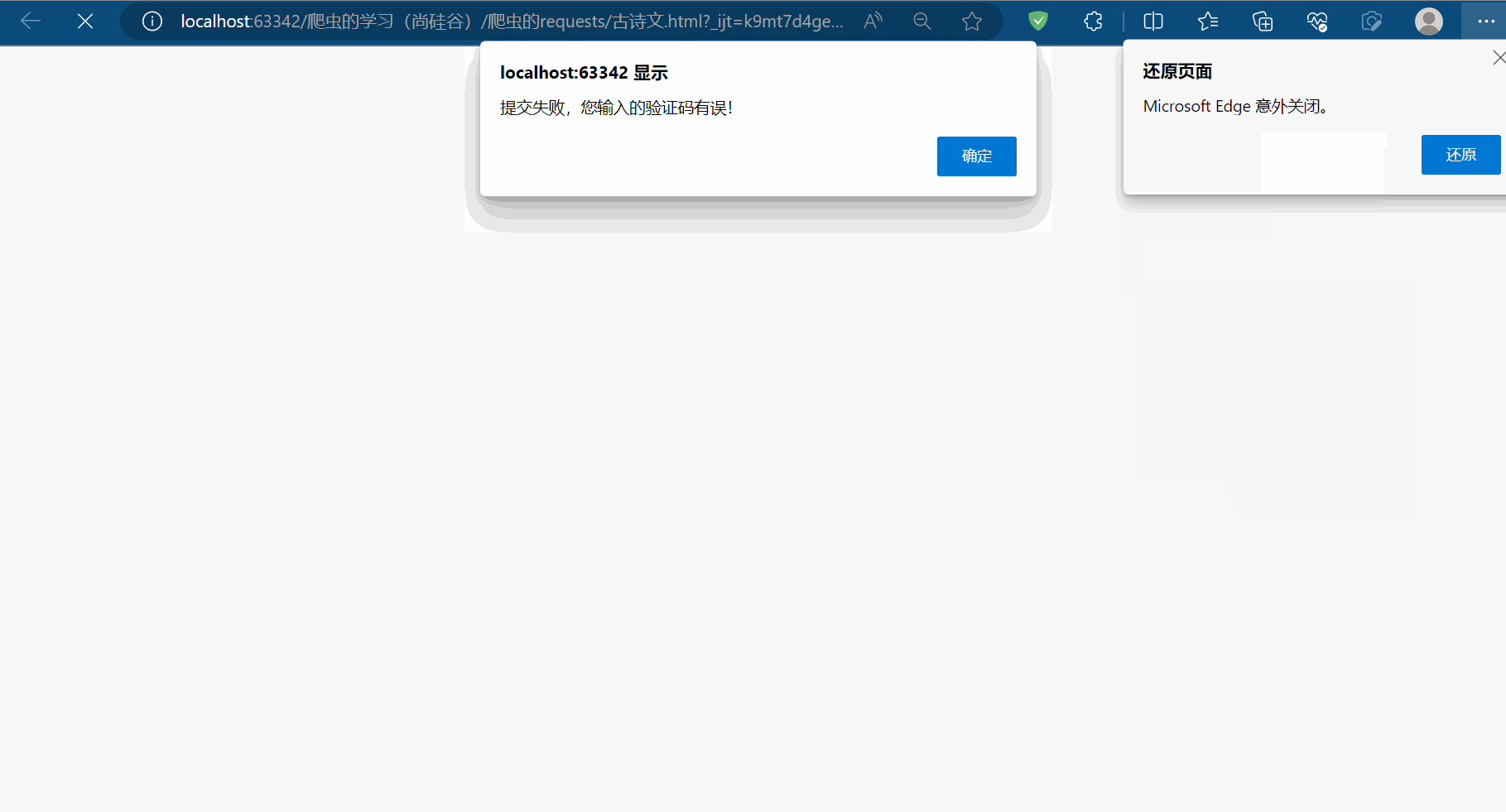
删去文件“code.jpg”和“古诗文.html”。
如下编程并运行,成功登陆网页。
"""
cookie登陆古诗文网(含验证码)
"""
# 通过登陆 然后进入到主页面# 通过找登陆接口我们发现 登陆的时候需要的参数很多
# __VIEWSTATE: wzavkIiUpeGeXT-Gu4jEWSBcHAneSt4SJdDa3y/PEP5sDZuLEWgE1r37kEQzlJ/pVVbYYMe7vrMvtm3NUmkX2KGAuPYULzyiZDcfhry5nbmFCtGY/RrDbqJIDMu0KDOYRMeQRs/Xwv2vH/1ZpkEoSK0lGoA0=
# __VIEWSTATEGENERATOR: C93BE1AE
# from: http://so.gushiwen.cn/user/collect.aspx
# email: cney6tcn@linshiyouxiang.net
# pwd: 8YW8GYET78933ETR
# code: 32GV
# denglu: 登录# 我们观察到__VIEWSTATE __VIEWSTATEGENERATOR code是一个可以变化的量# 难点:(1)__VIEWSTATE __VIEWSTATEGENERATOR 一般情况看不到的数据 都是在页面的源码中
# 我们观察到这两个数据在页面的源码中 所以我们需要获取页面的源码 然后进行解析就可以获取了
# (2)验证码import requests
from bs4 import BeautifulSoup
import urllib.request# 这是登陆页面的url地址
url = 'https://so.gushiwen.cn/user/login.aspx?from=http://so.gushiwen.cn/user/collect.a'headers = {'User-Agent': 'Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N) Ap-pleWebKit/537.36 (KHTML, like Gecko) Chrome/115.0.0.0 Mobile Safari/537.36 Edg/115.0.1901.200',
}
response = requests.get(url=url, headers=headers)
content = response.text
# print(content) # 测试代码,验证能否获取网页源码# 解析页面源码 然后获取__VIEWSTATE __VIEWSTATEGENERATOR
soup = BeautifulSoup(content, 'lxml')# 获取__VIEWSTATE
# .select返回列表,需用切片取出对应标签 .attrs.get获取属性值
viewstate = soup.select('#__VIEWSTATE')[0].attrs.get('value')# 获取__VIEWSTATEGENERATOR
viewstategenerator = soup.select('#__VIEWSTATEGENERATOR')[0].attrs.get('value')# print(viewstate) # 测试代码,验证是否获取到__VIEWSTATE的参数
# print(viewstategenerator) # 测试代码,验证是否获取到__VIEWSTATEGENERATOR的参数# 获取验证码图片
code_url_para = soup.select('#imgCode')[0].attrs.get('src')
code_url = 'https://so.gushiwen.cn/' + code_url_para
# print(code_url) # 测试代码,验证是否获取到验证码的图片的url# 有坑
# (1)在浏览器的检查的网络里找登陆接口时,如果不勾选检查的网络里的保留日志
# 且输入正确的名字、正确的密码、正确的验证码并登陆后,老版浏览器或者可能别的浏览器会
# 出现登陆接口会消失的情况, 进而导致无法寻找到登陆接口
# (2)“urllib.request.urlretrieve”下载图片提交的请求和“requests.post”提交的请求不是同一个,
# 会导致“requests.post”提交的请求时,程序端输入的验证码失效
# requests里面有一个方法 session() 通过session的返回值 就能使用请求变成一个对象
# urllib.request.urlretrieve(url=code_url, filename='code.jpg')
session = requests.session()
# 验证码的url的内容
response_code = session.get(code_url)
# 注意此时要使用二进制数据,通过二进制下载图片
content_code = response_code.content
# wb的模式就是将二进制数据写入到文件
with open('code.jpg', 'wb') as fp:fp.write(content_code)# 获取了验证码的图片之后 下载到本地 然后观察验证码 观察之后 然后在控制台输入这个验证码
# 就可以捋这个值给code的参数 就可以登陆
code_name = input('请输入你的验证码')# 点击登陆
url_post = 'https://so.gushiwen.cn/user/login.aspx?from=http%3a%2f%2fso.gushiwen.cn%2fuser%2fcollect.aspx'
data_post = {'__VIEWSTATE': viewstate,'__VIEWSTATEGENERATOR': viewstategenerator,'from': 'http://so.gushiwen.cn/user/collect.aspx','email': 'cney6tcn@linshiyouxiang.net','pwd': 'u89w7829e', # 此处请输入正确的密码'code': code_name,'denglu': '登录',
}response_post = session.post(url=url_post, headers=headers, data=data_post)
content_post = response_post.textwith open('古诗文.html', 'w', encoding='UTF-8') as fp:fp.write(content_post)# 难点
# (1) 隐藏域
# (2) 验证码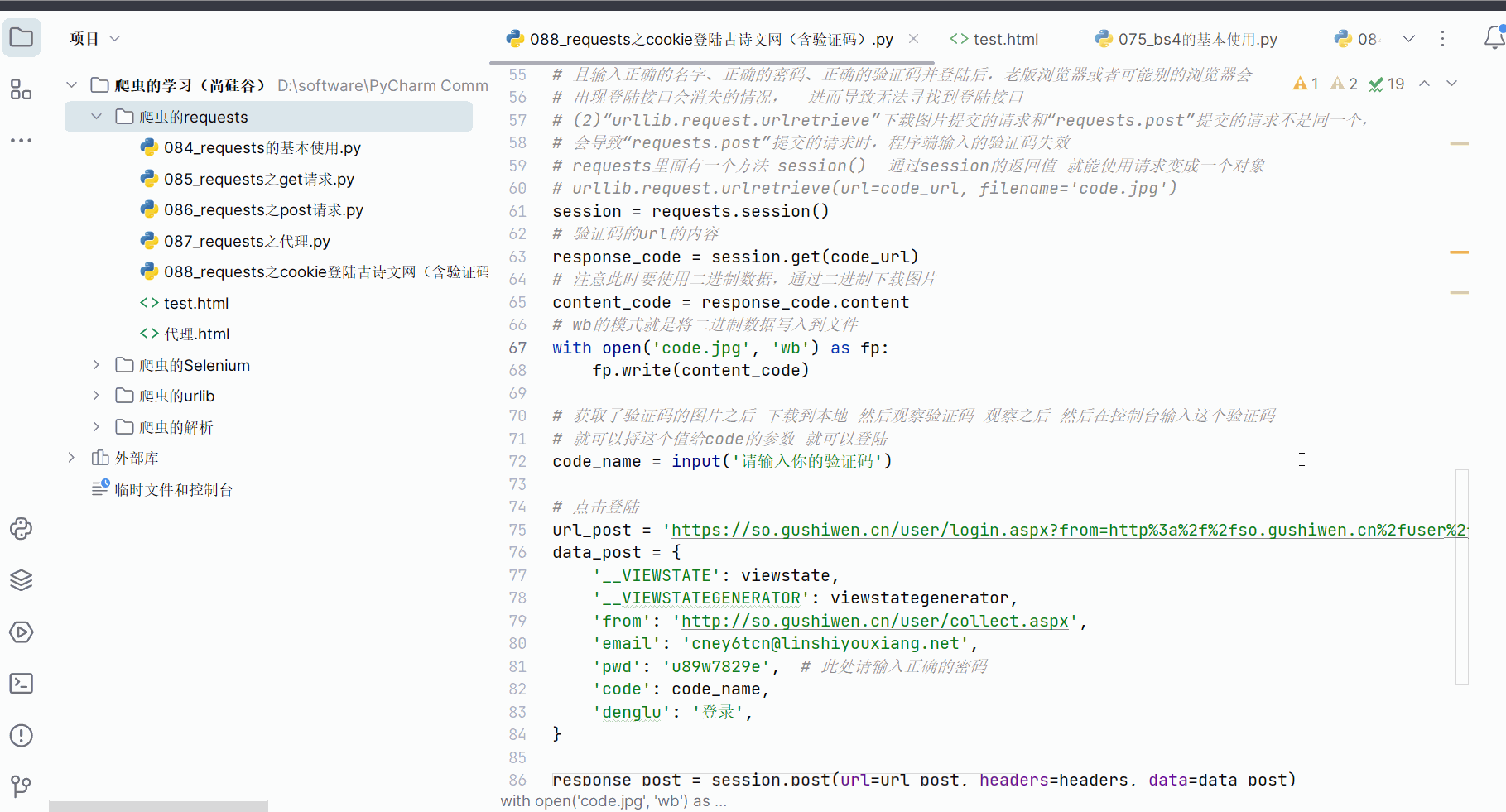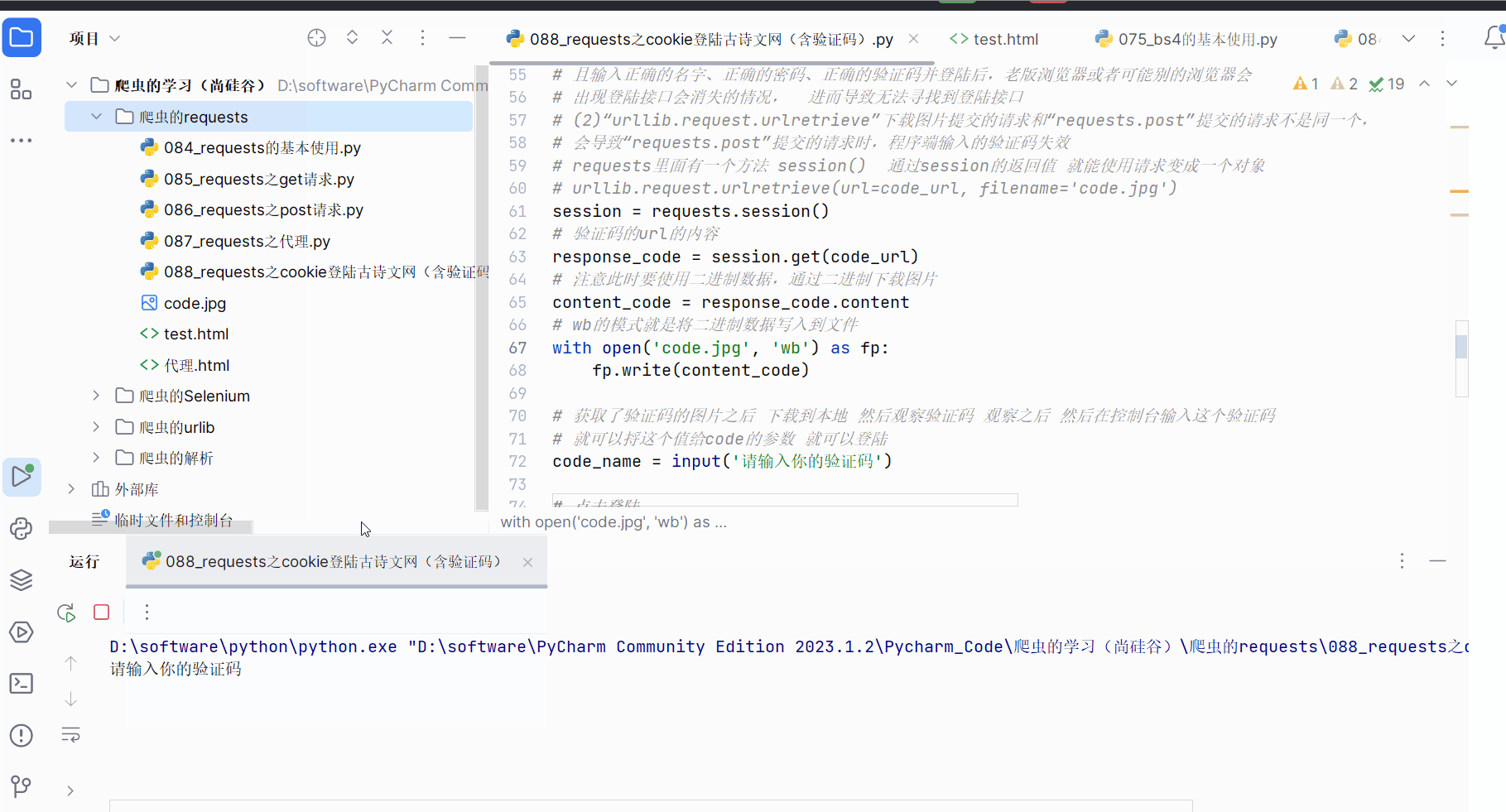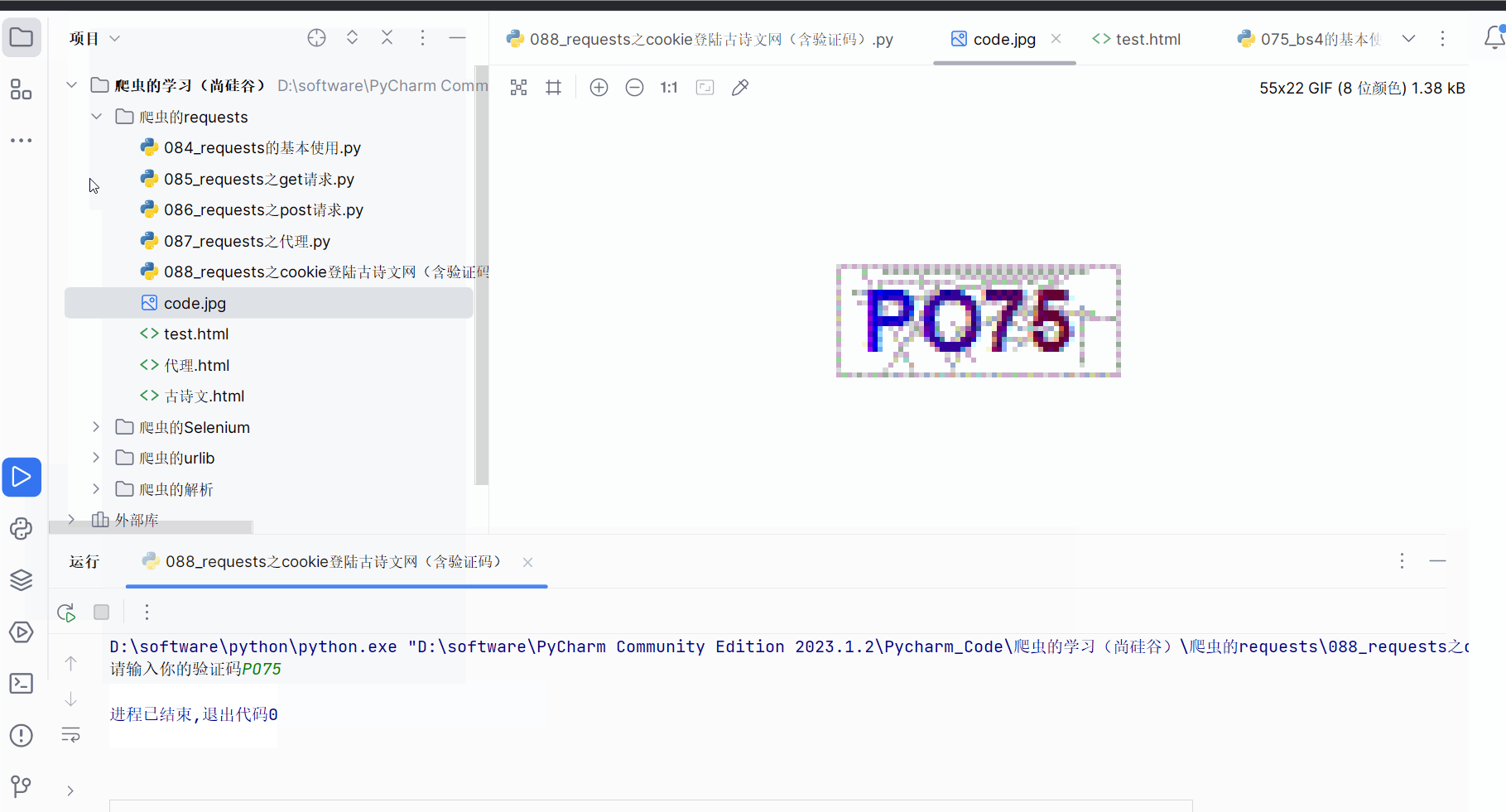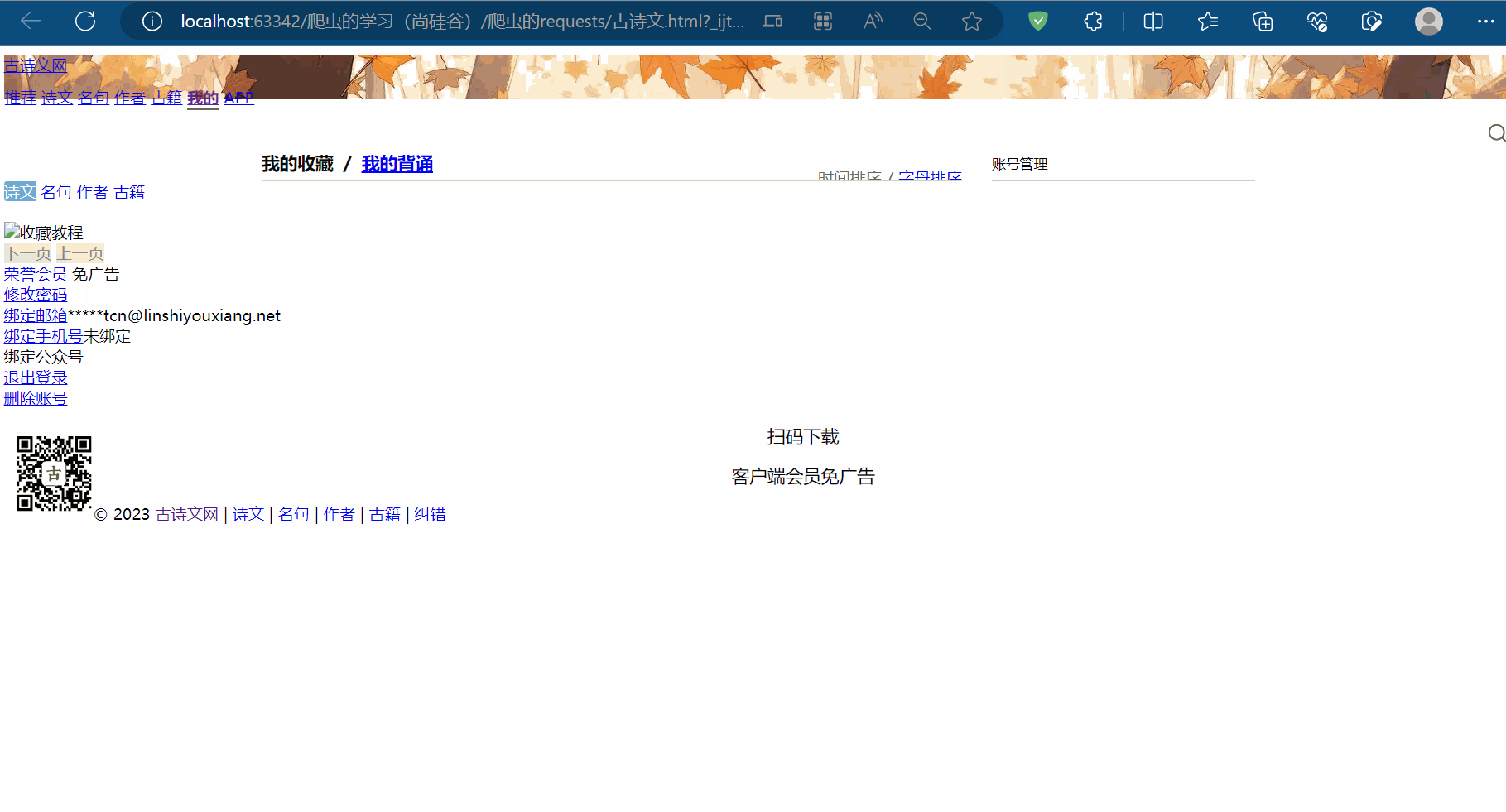
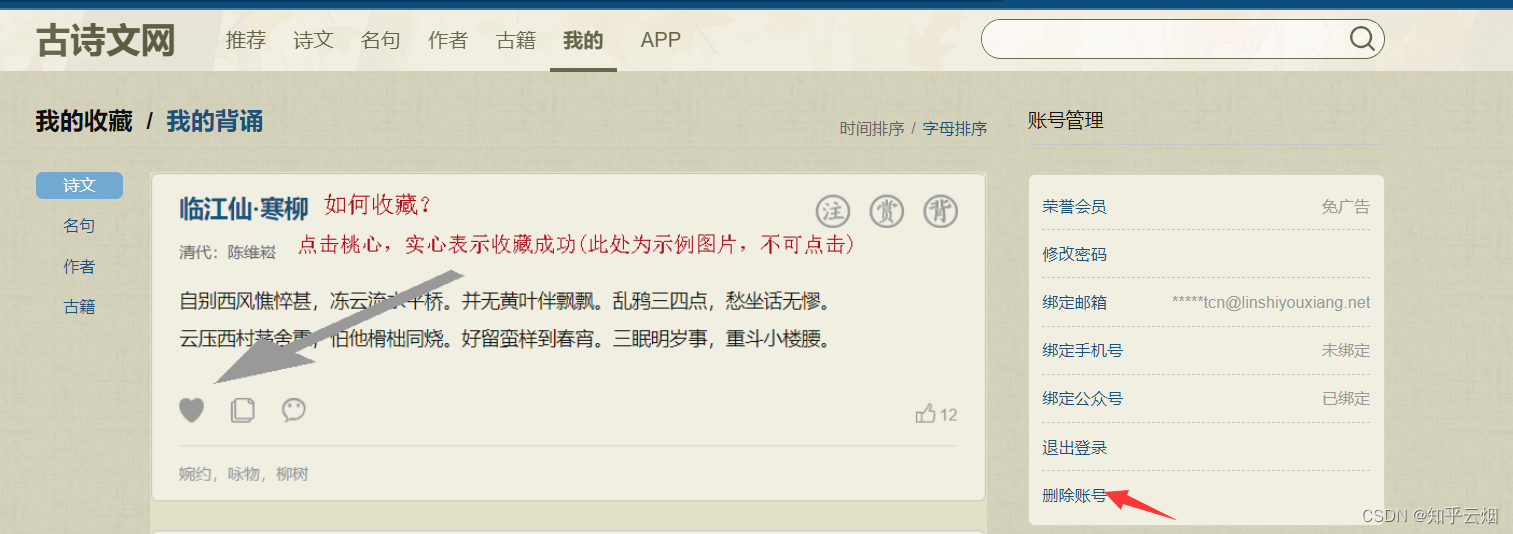
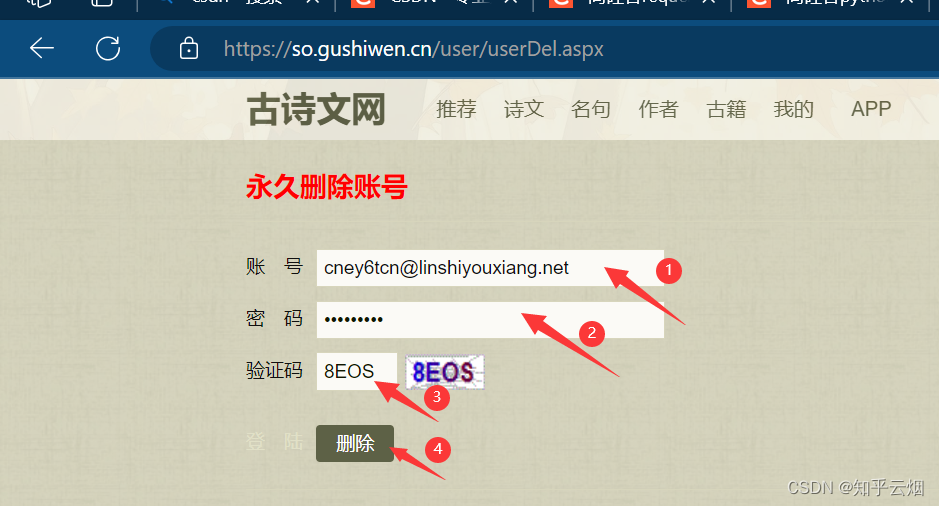
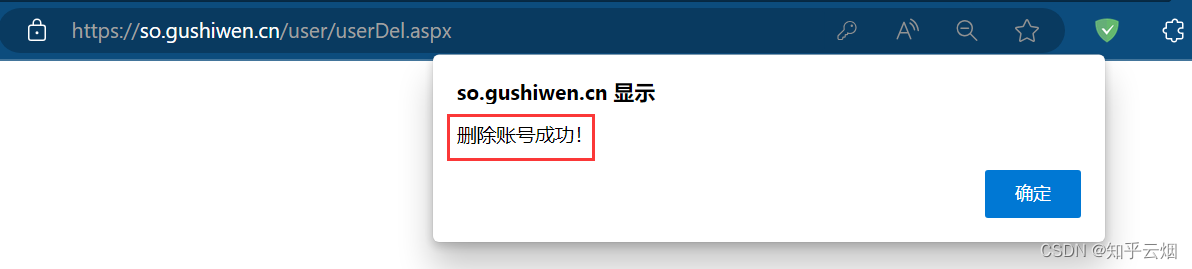
如果不再使用该网站的账号,可以删除该账号。
6. requests_超级鹰打码平台的使用
本次将演示如何使用超级鹰打码平台来识别验证码。如下图所示,打开超级鹰平台(“http://www.chaojiying.com/”),然后点击开发文档,找到并点击“超级鹰图像识别Python语言Demo下载”,然后选择“点击这里下载”。
然后解压下载的文件,将其中的两个文件(即“a.jpg”和“chaojiying.py”)复制到PyCharm的文件夹“爬虫的requests”中,然后可以打开这两个文件浏览一下有哪些内容。
然后在网站中可以使用一个临时邮箱注册,如果有需要的可以使用长久邮箱注册。
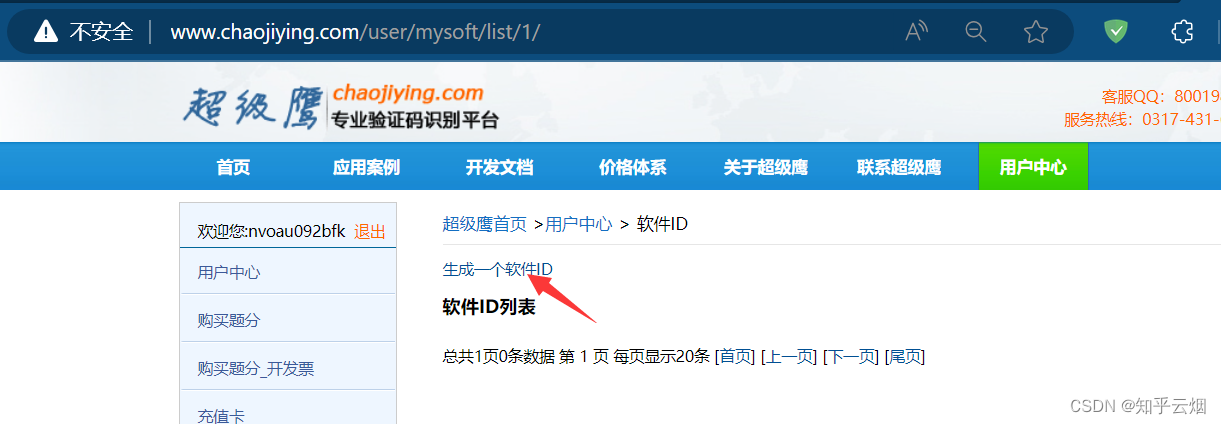
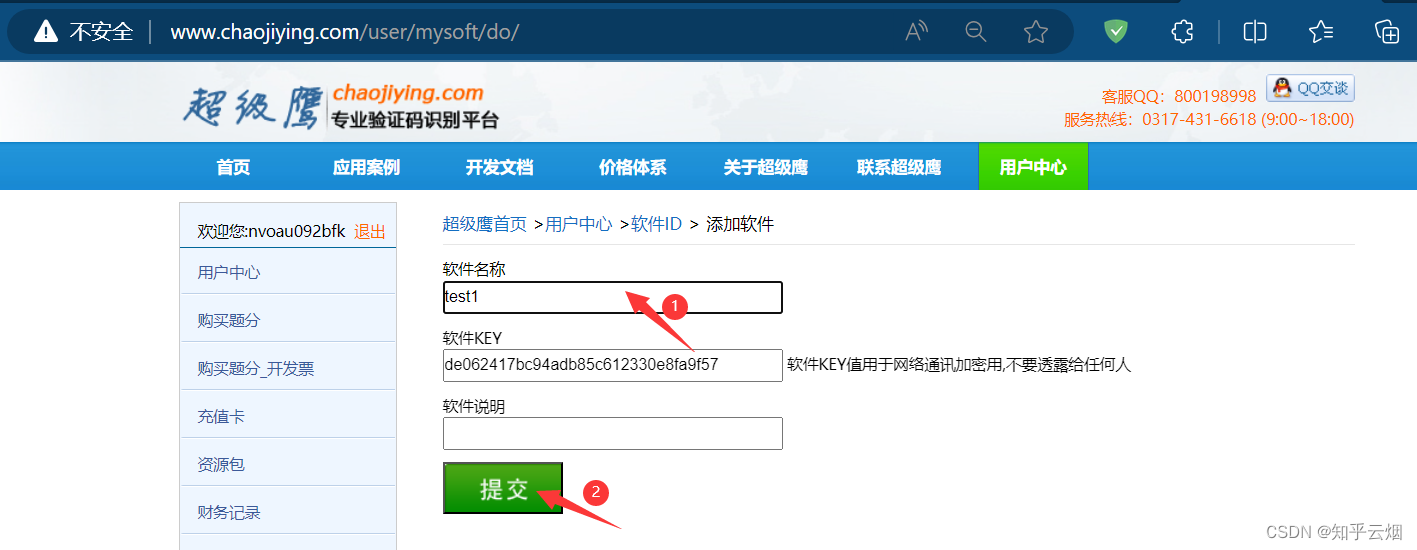
如下图,注册后会自动登陆,然后点击“软件ID”,去生成一个ID。
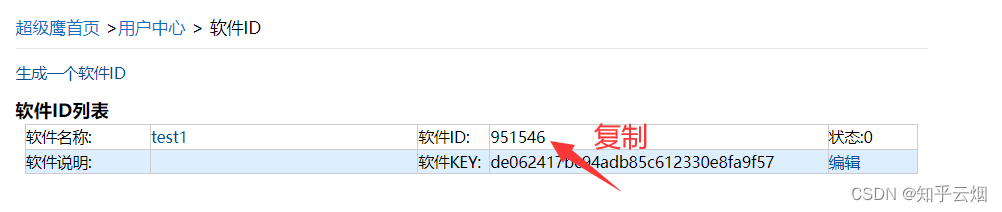
再将ID复制到PyCharm中,并在代码的对应位置输入账号和密码,print处也要加括号。
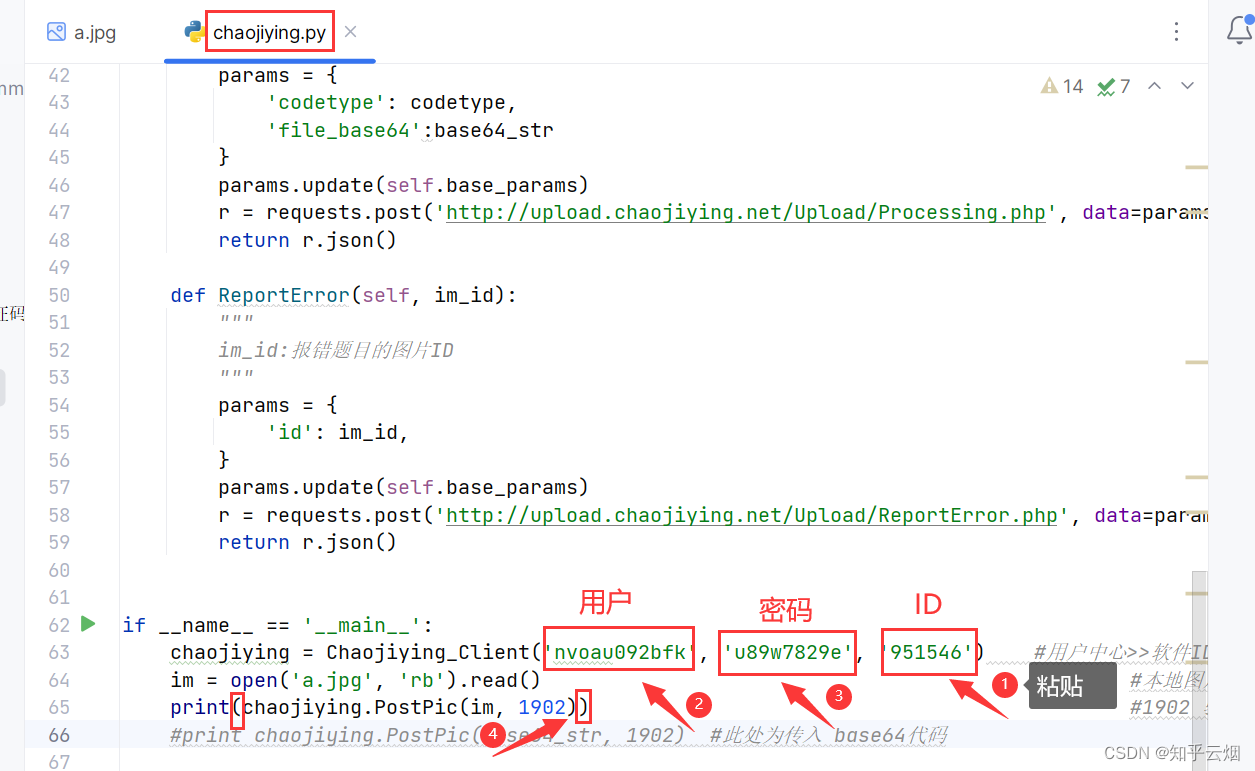
如下所示编程,按理说能够发现该代码能够获取图片的验证码,可是超级鹰需要题分,即需要关注以及充钱之类的,这个,本人没钱。
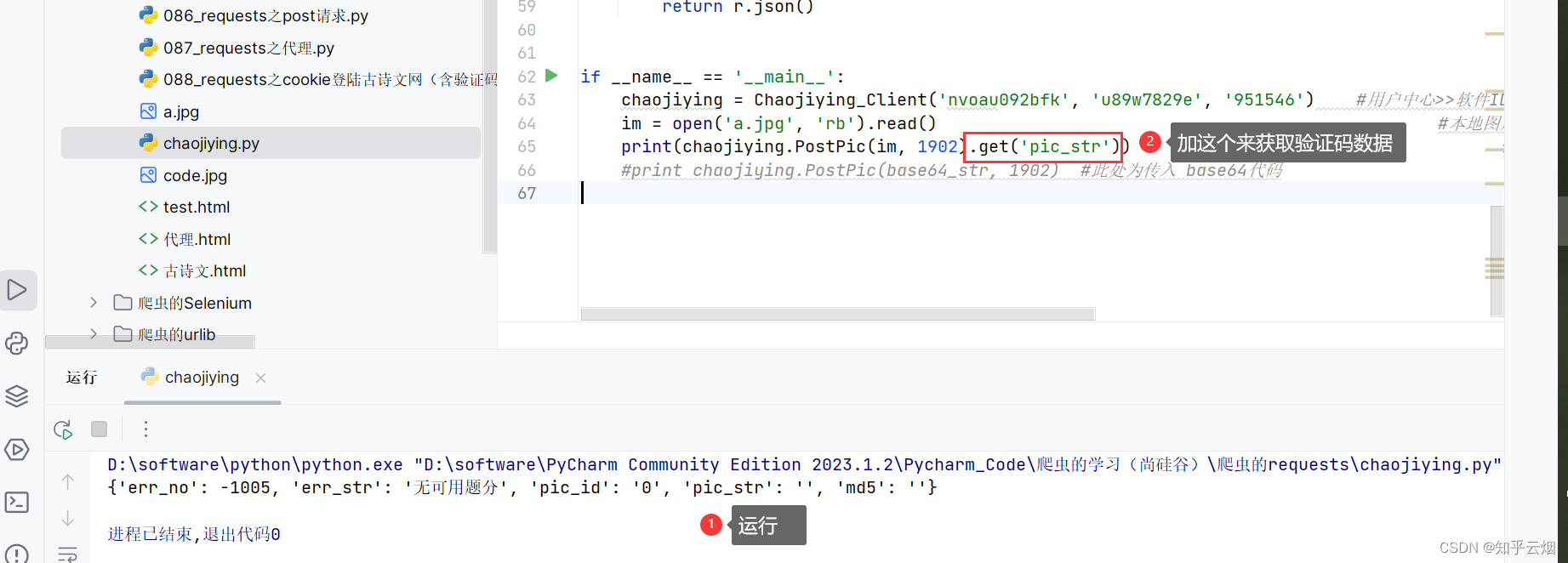
#!/usr/bin/env python
# coding:utf-8import requests
from hashlib import md5class Chaojiying_Client(object):def __init__(self, username, password, soft_id):self.username = usernamepassword = password.encode('utf8')self.password = md5(password).hexdigest()self.soft_id = soft_idself.base_params = {'user': self.username,'pass2': self.password,'softid': self.soft_id,}self.headers = {'Connection': 'Keep-Alive','User-Agent': 'Mozilla/4.0 (compatible; MSIE 8.0; Windows NT 5.1; Tri-dent/4.0)',}def PostPic(self, im, codetype):"""im: 图片字节codetype: 题目类型 参考 http://www.chaojiying.com/price.html"""params = {'codetype': codetype,}params.update(self.base_params)files = {'userfile': ('ccc.jpg', im)}r = requests.post('http://upload.chaojiying.net/Upload/Processing.php', da-ta=params, files=files, headers=self.headers)return r.json()def PostPic_base64(self, base64_str, codetype):"""im: 图片字节codetype: 题目类型 参考 http://www.chaojiying.com/price.html"""params = {'codetype': codetype,'file_base64':base64_str}params.update(self.base_params)r = requests.post('http://upload.chaojiying.net/Upload/Processing.php', da-ta=params, headers=self.headers)return r.json()def ReportError(self, im_id):"""im_id:报错题目的图片ID"""params = {'id': im_id,}params.update(self.base_params)r = requests.post('http://upload.chaojiying.net/Upload/ReportError.php', da-ta=params, headers=self.headers)return r.json()if __name__ == '__main__':chaojiying = Chaojiying_Client('nvoau092bfk', 'u89w7829e', '951546') #用户中心>>软件ID 生成一个替换 96001im = open('a.jpg', 'rb').read() #本地图片文件路径 来替换 a.jpg 有时WIN系统须要//print(chaojiying.PostPic(im, 1902).get('pic_str')) #1902 验证码类型 官方网站>>价格体系 3.4+版 print 后要加()#print chaojiying.PostPic(base64_str, 1902) #此处为传入 base64代码好了,本章的笔记到此结束,谢谢大家阅读。
相关文章:
Python爬虫的requests(学习于b站尚硅谷)
目录 一、requests 1. requests的基本使用 (1)文档 (2)安装 (3)响应response的属性以及类型 (4)代码演示 2.requests之get请求 3. requests之post请求 &#x…...

PHP最简单自定义自己的框架view使用引入smarty(8)--自定义的框架完成
1、实现效果。引入smarty, 实现assign和 display 2、下载smarty,创建缓存目录cache和扩展extend 点击下面查看具体下载使用,下载改名后放到extend PHP之Smarty使用以及框架display和assign原理_PHP隔壁老王邻居的博客-CSDN博客 3、当前控…...

字符串的常用操作
1.拼接字符串 使用运算符""可以对多个字符串进行拼接将几个字符串拼成一个字符串。 2.计算字符串的长度 使用len()函数计算字符串的长度 len(string) 其中string用于指定要进行长度统计的字符串。 3.截取字符串 由于字符串也属于序列,所以要截取字…...
开启想象翅膀:轻松实现文本生成模型的创作应用,支持LLaMA、ChatGLM、UDA、GPT2、Seq2Seq、BART、T5、SongNet等模型,开箱即用
开启想象翅膀:轻松实现文本生成模型的创作应用,支持LLaMA、ChatGLM、UDA、GPT2、Seq2Seq、BART、T5、SongNet等模型,开箱即用 TextGen: Implementation of Text Generation models 1.介绍 TextGen实现了多种文本生成模型,包括&a…...

文心一言 VS 讯飞星火 VS chatgpt (74)-- 算法导论7.2 2题
二、如果用go语言,当数组A的所有元素都具有相同值时,QUICKSORT的时间复杂度是什么? 文心一言: 在Go语言中,对一个所有元素都相等的数组进行快速排序(QuickSort)的时间复杂度是O(n log n)。 快速排序是一…...

大数据第二阶段测试
大数据第二阶段测试 一、简答题 Flume 采集使用上下游的好处是什么? 参考答案一 -上游和下游可以实现解耦,上游不需要关心下游的处理逻辑,下游不需要关心上游的数据源。 -上游和下游可以并行处理,提高整体处理效率。 -可以实现…...
06 为什么需要多线程;多线程的优缺点;程序 进程 线程之间的关系;进程和线程之间的区别
为什么需要多线程 CPU、内存、IO之间的性能差异巨大多核心CPU的发展线程的本质是增加一个可以执行代码工人 多线程的优点 多个执行流,并行执行。(多个工人,干不一样的活) 多线程的缺点 上下文切换慢,切换上下文典型值…...

datax-web报错收集
在查看datax时发现日志出现了如上错误,因为项目是部署在本地linux虚拟机上的,使用的是nat网络地址转换,不知道为什么虚拟机的端口号发生了变化,导致数据库根本连接不进去,更新linux虚拟机的ip地址就好...
YOLO相关原理(文件结构、视频检测等)
超参数进化(hyperparameter evolution) 超参数进化是一种使用了genetic algorithm(GA)遗传算法进行超参数优化的一种方法。 YOLOv5的文件结构 images文件夹内的文件和labels中的文件存在一一对应关系 激活函数:非线性处理单元 activation f…...

深入解析Spring Boot的核心特性与示例代码
系列文章目录 文章目录 系列文章目录前言一、自动配置(Auto-Configuration)二、起步依赖(Starter Dependencies)三、命令行界面(CLI)四、微服务支持五、内嵌Web服务器六、配置文件管理七、简化的日志配置八、健康检查与监控九、注解驱动开发十、外部化配置总结前言 Spri…...

什么是Java中的观察者模式?
Java中的观察者模式是一种设计模式,它允许一个对象在状态发生改变时通知它的所有观察者。这种模式在许多情况下都非常有用,例如在用户界面中,当用户与界面交互时,可能需要通知其他对象。 下面是一个简单的Java代码示例࿰…...

无涯教程-Perl - endhostent函数
描述 此函数告诉系统您不再希望使用gethostent从hosts文件读取条目。 语法 以下是此函数的简单语法- endhostent返回值 此函数不返回任何值。 例 以下是显示其基本用法的示例代码- #!/usr/bin/perlwhile( ($name, $aliases, $addrtype, $length, addrs)gethostent() ) …...

Vue2使用easyplayer
说一下easyplayer在vue2中的使用,vue3中没测试,估计应该差不多,大家可自行验证。 安装: pnpm i easydarwin/easyplayer 组件封装 习惯性将其封装为单独的组件 <template><div class"EasyPlayer"><e…...
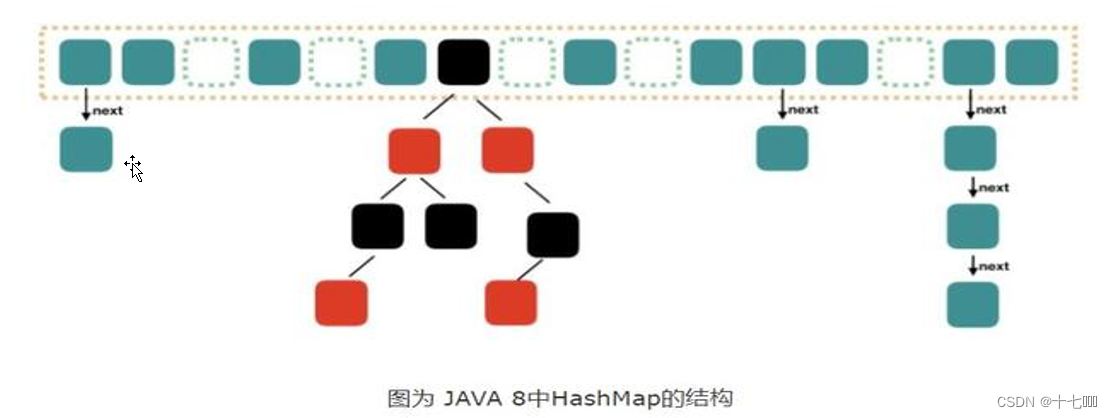
Map映射学习
一、Map的遍历 创建Map集合 Map<String, Integer> map new HashMap<>();添加元素 map.put("java", 99);map.put("c", 88);map.put("c", 93);map.put("python", 96);map.put("Go", 88); 遍历方法: …...

【每日一题Day292】LC1572矩阵对角线元素的和 模拟
矩阵对角线元素的和【LC1572】](https://leetcode.cn/problems/matrix-diagonal-sum/) 思路 简单模拟,主对角线的元素横纵坐标相等,副对角线的元素横纵坐标相加为n-1,注意避免重复计算 实现 class Solution {public int diagonalSum(int[][]…...
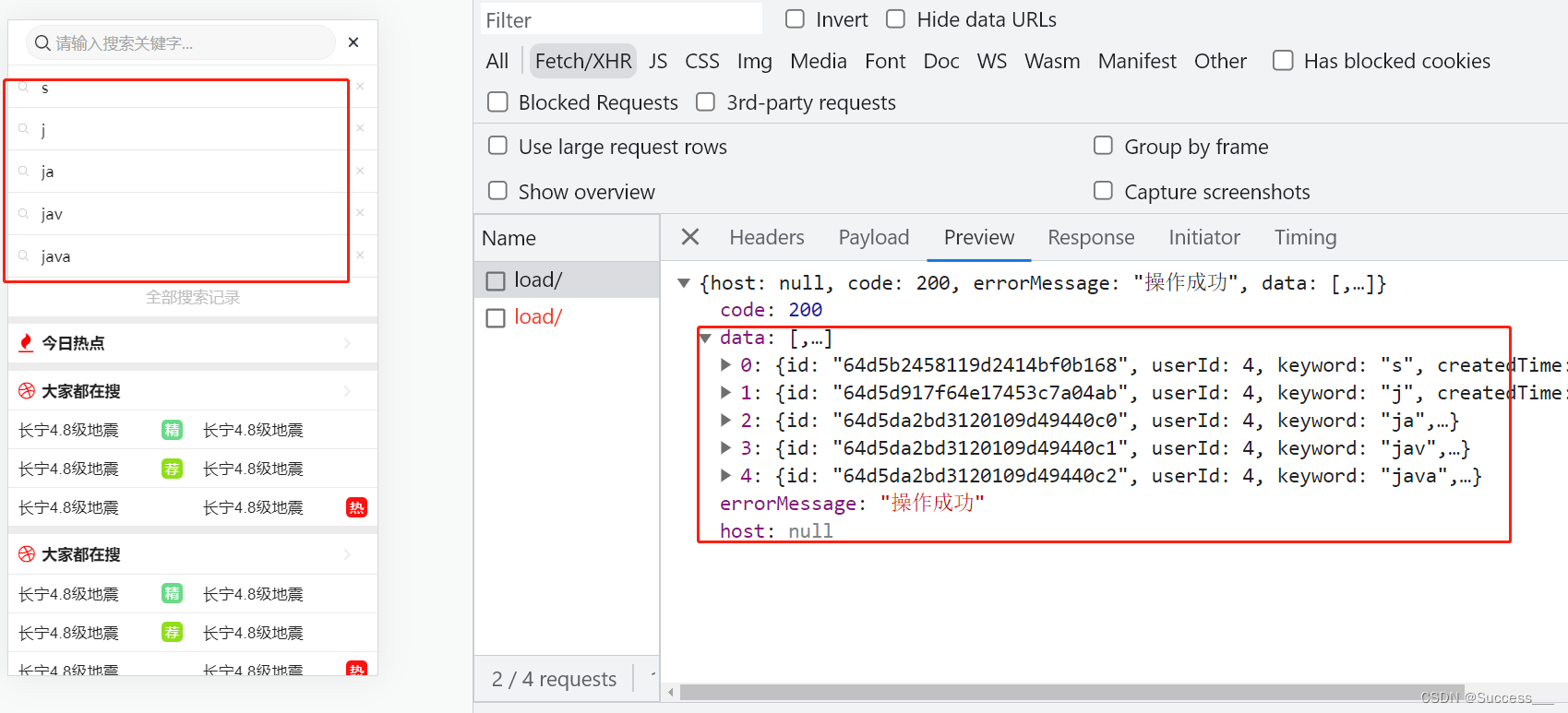
Mongodb:业务应用(2)
需求: 1、获取保存到mongodb库中的搜索记录列表 2、实现删除搜索记录接口 保存搜索记录数据参考上篇Mongodb:业务应用(1)_Success___的博客-CSDN博客 获取记录列表 1、创建controller package com.heima.search.controller.v1;…...

DSO学习笔记
最近在学习DSO系列的代码,整理记录一下 DOS代码流程 TODO DSO跑kitti数据集 参考高翔大佬的LDSO中LDSO/examples/run_dso_kitti.cc,由于kitti数据集木有光度参数标定文件,其实最重要的就是相机内参文件camera.txt按照格式来就行了ÿ…...
中实现右上角及右下角数字显示】)
【Windows 常用工具系列 5 -- 如何在网页(CSDN)中实现右上角及右下角数字显示】
文章目录 网页右上角/右下角标号写法 网页右上角/右下角标号写法 在网页撰写文章时经常遇到需要平方的写法,比如书写 X 的 2次方, 可以通过下面方法完成: <sup>x</sup> : x 上移到右上角;<sub>x</sub> : x 下移到右下角。 实…...

sql注入--报错注入
常用的简单测试语句和注释符号说明 sql语句的注释符号,是sq注入语句的关键点:常用 # 和 -- 1、# 和 --(有个空格)表示注释,可以使它们后面的语句不被执行。在url中,如果是get请求也就是我们在浏览器地址栏…...

Nginx常用功能
Nginx 介绍 Nginx 是开源、高性能、高可靠的 Web 和反向代理服务器,而且支持热部署,几乎可以做到 7 * 24 小时不间断运行,即使运行几个月也不需要重新启动,还能在不间断服务的情况下对软件版本进行热更新。性能是 Nginx 最重要的…...

React Hooks原理:为什么不能写在if里?揭开Hook的“魔法”面纱
前言 Hooks刚出的时候,大家都觉得是“黑魔法”:一个函数组件,居然能记住自己的状态?还能模拟生命周期?很多人用了很久,却不知道原理。导致遇到奇怪的问题(比如无限循环、状态不更新)…...

LIO-SAM只用6轴IMU行不行?从原理到代码的深度避坑解析
LIO-SAM与6轴IMU兼容性实战指南:从传感器原理到代码级优化 在机器人定位与建图领域,LIO-SAM作为基于紧耦合激光-惯性里程计的系统,其性能高度依赖IMU数据的质量。许多开发者存在一个根深蒂固的认知误区:认为缺少磁力计的6轴IMU无法…...

Python空间分析利器:GeoPandas的四大部署策略与避坑指南
1. 裸机Python环境部署:硬核玩家的选择 裸机安装GeoPandas就像自己组装一台高性能电脑——过程充满挑战但成就感十足。我曾在三个不同版本的Windows系统上反复测试,发现Python 3.8确实是最稳定的选择。最新版本虽然诱人,但GDAL等依赖包的兼容…...

从理论到实践:AM信号包络检波器的设计与仿真分析
1. AM信号与包络检波基础 收音机里传来的音乐、对讲机中的对话,这些我们熟悉的无线通信场景背后,都离不开一个关键技术——AM调幅信号。AM全称Amplitude Modulation,也就是幅度调制。它的核心思想很简单:用低频的声音信号…...
)
当ArcSWAT遇上Windows 11/10:那些因系统环境导致的诡异报错与根治方案(.NET/权限/数据库)
ArcSWAT在Windows 11/10环境下的系统级故障排查指南 当水文建模专家在新一代操作系统上运行ArcSWAT时,常常会遇到一系列令人困惑的系统级报错。这些错误往往与软件本身无关,而是现代Windows系统环境与传统建模工具之间的兼容性问题。本文将深入剖析这些&…...
)]指定对齐方式与硬件SIMD指令的内存要求)
Rust的#[repr(align(N))]指定对齐方式与硬件SIMD指令的内存要求
在现代高性能计算领域,SIMD(单指令多数据)指令集是提升程序性能的关键技术之一。要充分发挥SIMD的潜力,数据的内存对齐必须满足特定要求。Rust作为一门注重安全与性能的系统级语言,提供了#[repr(align(N))]属性&#x…...
安装)
LFM2-2.6B-GGUF快速部署:Ubuntu系统依赖(libglib2.0-0等)安装
LFM2-2.6B-GGUF快速部署:Ubuntu系统依赖(libglib2.0-0等)安装 1. 项目介绍 LFM2-2.6B-GGUF是由Liquid AI公司开发的大语言模型,经过GGUF量化处理后特别适合在资源有限的设备上运行。这个2.6B参数的模型经过量化后体积大幅缩小&a…...

Keras深度学习框架入门与实践指南
1. Keras深度学习库概述 Keras是一个基于Python的高级神经网络API,它能够以TensorFlow、Theano或CNTK作为后端运行。作为一个接口设计精良的深度学习框架,Keras让研究人员和开发者能够快速实现和验证各种深度学习模型。我在实际项目中使用Keras已有五年…...

0基础开始VLA复现
1.首先先写直觉的东西(随学习进度更新) Github:外国代码创意工坊百度网盘 大部分代码、学习路线东西上面都有 免费下载 Hugging Face:Github大模型版 里面有你可以调用的大模型和数据集 但是有些数据集你得登录才能有权限下载 这…...

机器学习分类算法超参数调优实战指南
1. 机器学习分类算法超参数调优实战指南在机器学习项目中,算法超参数的选择往往决定了模型的最终表现。与模型训练过程中自动学习的参数不同,超参数需要我们在训练前手动设置。这就引出了一个关键问题:面对众多超参数选项,我们该如…...