石子合并问题
一.试题
在一个园形操场的四周摆放N堆石子(N≤100),现要将石子有次序地合并成一堆。规定
每次只能选相邻的两堆合并成新的一堆,并将新的一堆的石子数,记为该次合并的得分。
编一程序,由文件读入堆数N及每堆的石子数(≤20),
①选择一种合并石子的方案,使得做N-1次合并,得分的总和最小;
②选择一种合并石子的方案,使得做N-1次合并,得分的总和最大。
例如,所示的4堆石子,每堆石子数(从最上面的一堆数起,顺时针数)依
次为4594。则3次合并得分总和最小的方案:8+13+22=43
得分最大的方案为:14+18+22=54
输入数据:
文件名由键盘输入,该文件内容为:
第一行为石子堆数N;
第二行为每堆的石子数,每两个数之间用一个空格符分隔。
输出数据:
输出文件名为output.txt
从第1至第N行为得分最小的合并方案。第N+1行是空行。从第N+2行到第2N+1行是得
分最大合并方案。
每种合并方案用N行表示,其中第i行(1≤i≤N)表示第i 次合并前各堆的石子数(依
顺时针次序输出,哪一堆先输出均可)。 要求将待合并的两堆石子数以相应的负数表示,以便标识。
输入输出范例:
输入文件内容:
4
4 59 4
输出文件内容:
-4 5 9 -4
-8-5 9
-13 -9
22
4 -5 -9 4
4 -14 -4
-4-18
22
二.算法分析
竞赛中多数选手都不约而同地采用了尽可能逼近目标的贪心法来逐次合并:从最上面
的一堆开始,沿顺时针方向排成一个序列。 第一次选得分最小(最大)的相邻两堆合并,
形成新的一堆;接下来,在N-1堆中选得分最小(最大)的相邻两堆合并……,依次类推,
直至所有石子经N-1次合并后形成一堆。
例如有6堆石子,每堆石子数(从最上面一堆数起,顺时针数)依次为3 46 5 4 2
要求选择一种合并石子的方案,使得做5次合并,得分的总和最小。
按照贪心法,合并的过程如下:
每次合并得分
第一次合并 3 4 6 5 4 2 ->5
第二次合并 5 4 6 5 4 ->9
第三次合并 9 6 5 4 ->9
第四次合并 9 6 9 ->15
第五次合并 15 9 ->24
24
总得分=5+9+9+15+24=62
但是当我们仔细琢磨后,可得出另一个合并石子的方案:
每次合并得分
第一次合并 3 4 6 5 4 2 ->7
第二次合并 7 6 5 4 2 ->13
第三次合并 13 5 4 2 ->6
第四次合并 13 5 6 ->11
第五次合并 13 11 ->24
24
总得分=7+6+11+13+24=61
显然,后者比贪心法得出的合并方案更优。 题目中的示例故意造成一个贪心法解题的
假像,诱使读者进入“陷阱”。为了帮助读者从这个“陷阱”里走出来, 我们先来明确一个问题:
1.最佳合并过程符合最佳原理
使用贪心法至所以可能出错,
是因为每一次选择得分最小(最大)的相邻两堆合并,不一定保证余下的合并过程能导致最优解。聪明的读者马上会想到一种理想的假设:如果N-1次合并的全局最优解包含了每一次合并的子问题的最优解,那么经这样的N-1次合并后的得分总和必然是最优的。
例如上例中第五次合并石子数分别为13和11的相邻两堆。
这两堆石头分别由最初的第1,2,3堆(石头数分别为3,4,6)和第4,5,6堆(石头数分别为5,4,2)经4次合并后形成的。于是问题又归结为如何使得这两个子序列的N-2
次合并的得分总和最优。为了实现这一目标,我们将第1个序列又一分为二:第1、2堆构成子序列1,
第3堆为子序列2。第一次合并子序列1中的两堆,得分7;
第二次再将之与子序列2的一堆合并,得分13。显然对于第1个子序列来说,这样的合并方案是最优的。同样,我们将第2个子序列也一分为二;第4堆为子序列1,第5,6堆构成子序列2。第三次合并子序列2中的2堆,得分6;第四次再将之与子序列1中的一堆合并,得分13。显然对于第二个子序列来说,这样的合并方案也是最优的。
由此得出一个结论──6堆石子经
过这样的5次合并后,得分的总和最小。我们把每一次合并划分为阶段,当前阶段中计算出的得分和作为状态,
如何在前一次合并的基础上定义一个能使目前得分总和最大的合并方案作为一次决策。很显然,某阶段的状态给定后,则以后各阶段的决策不受这阶段以前各段状态的影响。
这种无后效性的性质符最佳原理,因此可以用动态规划的算法求解。
2.动态规划的方向和初值的设定
采用动态规划求解的关键是确定所有石子堆子序列的最佳合并方案。 这些石子堆子序列包括:
{第1堆、第2堆}、{第2堆、第3堆}、……、{第N堆、第1堆};
{第1堆、第2堆、第3堆}、{第2堆、第3堆、第4堆}、……、{第N堆、第1堆、第2堆};……
{第1堆、……、第N堆}{第1堆、……、第N堆、第1堆}……{第N堆、第1堆、……、第N-1堆}
为了便于运算,我们用〔i,j〕表示一个从第i堆数起,顺时针数j堆时的子序列{第i堆、第i+1堆、……、第(i+j-1)mod n堆}
它的最佳合并方案包括两个信息:
①在该子序列的各堆石子合并成一堆的过程中,各次合并得分的总和;
②形成最佳得分和的子序列1和子序列2。由于两个子序列是相邻的, 因此只需记住子序列1的堆数;
设
f〔i,j〕──将子序列〔i,j〕中的j堆石子合并成一堆的最佳得分和;
c〔i,j〕──将〔i,j〕一分为二,其中子序列1的堆数;
(1≤i≤N,1≤j≤N)
显然,对每一堆石子来说,它的
f〔i,1〕=0
c〔i,1〕=0 (1≤i≤N)
对于子序列〔i,j〕来说,若求最小得分总和,f〔i,j〕的初始值为∞; 若求最大得分总和,f〔i,j〕的初始值为0。(1≤i≤N,2≤j≤N)。
动态规划的方向是顺推(即从上而下)。先考虑含二堆石子的N个子序列(各子序列分别从第1堆、第2堆、……、第N堆数起,顺时针数2堆)的合并方案
f〔1,2〕,f〔2,2〕,……,f〔N,2〕
c〔1,2〕,c〔2,2〕,……,c〔N,2〕
然后考虑含三堆石子的N个子序列(各子序列分别从第1堆、第2堆、……、第N堆数起,顺时针数3堆)的合并方案
f〔1,3〕,f〔2,3〕,……,f〔N,3〕
c〔1,3〕,c〔2,3〕,……,c〔N,3〕
……
依次类推,直至考虑了含N堆石子的N个子序列(各子序列分别从第1堆、第2堆、 ……、第N堆数起,顺时针数N堆)的合并方案
f〔1,N〕,f〔2,N〕,……,f〔N,N〕
c〔1,N〕,c〔2,N〕,……,c〔N,N〕
最后,在子序列〔1,N〕,〔2,N〕,……,〔N,N〕中,选择得分总和(f值)最小(或最大)的一个子序列〔i,N〕(1≤i≤N),由此出发倒推合并过程。
3.动态规划方程和倒推合并过程
对子序列〔i,j〕最后一次合并,其得分为第i堆数起,顺时针数j堆的石子总数t。被合并的两堆石子是由子序列〔i,k〕和〔(i+k-1)mod
n+1,j-k〕(1≤k≤j-1)经有限次合并形成的。为了求出最佳合并方案中的k值,我们定义一个动态规划方程:
当求最大得分总和时
f〔i,j〕=max{f〔i,k〕+f〔x,j-k〕+t}
1≤k≤j-1
c〔i,j〕=k│ f〔i,j〕=f〔i,k〕+f〔x,j-k〕+t
(2≤j≤n,1≤i≤n)
当求最小得分总和时
f〔i,j〕=min{f〔i,k〕+f〔x,j-k〕+t}
1≤k≤j-1
c〔i,j〕=k│ f〔i,j〕=f〔i,k〕+f〔x,j-k〕+t
(2≤j≤n,1≤i≤n)
其中x=(i+k-1)modn+1,即第i堆数起,顺时针数k+1堆的堆序号。
例如对上面例子中的6(3 4 6 5 4 2 )堆石子,按动态规划方程顺推最小得分和。 依次得出含二堆石子的6个子序列的合并方案
f〔1,2〕=7 f〔2,2〕=10 f〔3 ,2〕=11
c〔1,2〕=1 c〔2,2〕=1 c〔3,2〕=1
f〔4,2〕=9 f〔5,2〕=6 f〔6,2〕=5
c〔4,2〕=1 c〔5, 2〕=1 c〔6,2〕=1
含三堆石子的6(3 4 6 5 4 2 )个子序列的合并方案
f〔1,3〕=20 f〔2,3〕=25 f〔3,3〕=24
c〔1,3〕=2 c〔2,3〕=2 c〔3,3〕=1
f〔4,3〕=17 f〔5,3〕=14 f〔6,3〕=14
c〔4,3〕=1 c〔5,3〕=1 c〔6,3〕=2
含四堆石子的6(3 4 6 5 4 2 )个子序列的合并方案
f〔1,4〕=36 f〔2,4〕=38 f〔3,4〕=34
c〔1,4〕=2 c〔2,4〕=2 c〔3,4〕=1
f〔4,4〕=28 f〔5,4〕=26 f〔6,4〕=29
c〔4,4〕=1 c〔5,4〕=2 c〔6,4〕=3
含五堆石子的6(3 4 6 5 4 2 )个子序列的合并方案
f〔1,5〕=51 f〔2,5〕=48 f〔3,5〕=45
c〔1,5〕=3 c〔2,5〕=2 c〔3,5〕=2
f〔4,5〕=41 f〔5,5〕=43 f〔6,5〕=45
c〔4,5〕=2 c〔5,5〕=3 c〔6,5〕=3
含六堆石子的6(3 4 6 5 4 2 )个子序列的合并方案
f〔1,6〕=61 f〔2,6〕=62 f〔3,6〕=61
c〔1,6〕=3 c〔2,6〕=2 c〔3,6〕=2
f〔4,6〕=61 f〔5,6〕=61 f〔6,6〕=62
c〔4,6〕=3 c〔5,6〕=4 c〔6,6〕=3
f〔1,6〕是f〔1,6〕,f〔2,6〕,……f〔6,6〕中的最小值,表明最小得分和是由序列〔1,6〕经5次合并得出的。我们从这个序列出发,
按下述方法倒推合并过程:
由c〔1,6〕=3可知,第5次合并的两堆石子分别由子序列〔1,3〕和子序列〔4,3〕经4次合并后得出。其中c〔1,3〕=2可知由子序列〔1,3〕合并成的一堆石子是由子序列〔1,2〕和第三堆合并而来的。而c〔1,2〕=1,以表明了子序列〔1,2〕的合并方案是第1堆合并第2堆。
由此倒推回去,得出第1,第2次合并的方案,每次合并得分
第一次合并 3 4 6…… ->7
第二次合并 7 6…… ->13
13……
子序列〔1,3〕经2次合并后合并成1堆, 2次合并的得分和=7+13=20。
c〔4,3〕=1,可知由子序列〔4,3〕合并成的一堆石子是由第4堆和子序列〔5,
2〕合并而来的。而c〔5,2〕=1,又表明了子序列〔5,2〕的合并方案是第5堆合并第6堆。由此倒推回去,得出第3、第4次合并的方案
每次合并得分:
第三次合并 ……54 2 ->6
第四次合并 ……5 6 ->11
……11
子序列〔4,3〕经2次合并后合并成1堆,2次合并的得分和=6+11=17。
第五次合并是将最后两堆合并成1堆,该次合并的得分为24。
显然,上述5次合并的得分总和为最小
20+17+24=61
上述倒推过程,可由一个print(〔子序列〕)的递归算法描述
procedure print (〔i,j〕)
begin
if j〈〉1 then {继续倒推合并过程
begin
print(〔i,c〔i,j〕〕;{倒推子序列1的合并过程}
print(〔i+c〔i,j〕-1〕mod n+1,j-c〔i,j〕)
{倒推子序列2的合并过程}
for K:=1 to N do{输出当前被合并的两堆石子}
if (第K堆石子未从圈内去除)
then begin
if(K=i)or(K=X)then置第K堆石子待合并标志
else第K堆石子未被合并;
end;{then}
第i堆石子数←第i堆石子数+第X堆石子数;
将第X堆石子从圈内去除;
end;{then}
end;{print}
例如,调用print(〔1,6〕)后的结果如下:
print(〔1,6〕)⑤
┌──────┴──────┐
print(〔1,3〕)② print(〔4,3〕)④
┌─────┴─────┐ ┌─────┴─────┐
print(〔1,2〕)① print(〔3,1〕) print(〔4,1〕) print(〔5,2〕)③
┌──────┴──────┐ ┌──────┴──────┐
print(〔1,1〕) print(〔2,1〕) print(〔5,1〕)
print(〔6,1〕)
(图6.2-5)
其中回溯至
① 显示 3 46 5 4
② 显示 7 65 4 2
③ 显示 13 54 2
④ 显示 135 6
⑤ 显示 13 11
注:调用print过程后,应显示6堆石子的总数作为第5次合并的得分。
Program Stones;
Type
Node = Record{当前序列的合并方案}
c : Longint;{得分和}
d : Byte{子序列1的堆数}
End;
SumType = Array [1..100,1..100] of Longint;
{sumtype[i,j]-子序列[i,j]的石子总数}
Var
List : Array [1..100,1..100] of Node;
{list[i,j]-子序列[i,j]的合并方案}
Date, Dt : Array [1..100] of Integer;
{Date[i]-第i堆石子数,Dt-暂存Date}
Sum : ^SumType;{sum^[i,j]-指向子序列[i,j]的石子总数的指针}
F : Text;{文件变量}
Fn : String;{文件名串}
N, i, j : Integer;{N-石子堆数,i,j-循环变量}
Procedure Print(i, j : Byte);{递归打印子序列[i,j]的合并过程}
Var
k, x : Shortint;{k-循环变量;x-子序列2中首堆石子的序号}
Begin
If j <> 1 Then Begin{继续倒推合并过程}
Print(i, List[i,j].d);{倒推子序列1的合并过程}
x := (i + List[i, j].d - 1) Mod N + 1;{求子序列2中首堆石子的序号}
Print(x, j - List[i, j].d);{倒推子序列2的合并过程}
For k := 1 to N Do{输出当前合并第i堆,第x堆石子的方案}
If Date[k] > 0 Then Begin
If (i= k)or(x=k)Then Write(F, - Date[k], ' ')
Else Write(F, Date[k], ' ')
End; { Then }
Writeln(F);{输出换行符}
Date[i] := Date[i] + Date[x];{原第i堆和第x堆合并成第i堆}
Date[x] := - Date[x]{将原第x堆从圈内去除}
End { Then }
End; { Print }
Procedure Main(s : Shortint);
Var
i, j, k : Integer;
t, x : Longint;
Begin
For i := 1 to N Do Begin{仅含一堆石子的序列不存在合并}
List[i, 1].c := 0;
List[i, 1].d := 0
End; {For}
For j := 2 to N Do{顺推含2堆,含3堆……含N堆石子的各子序列的合并方案}
For i := 1 to N Do Begin{当前考虑从第i堆数起,顺时针数j堆的子序列}
If s = 1 Then List[i, j].c := Maxlongint{合并[i,j]子序列的得分和初始化}
Else List[i, j].c := 0;
t := Sum^[i, j];{最后一次合并的得分为[i,j]子序列的石子总数}
For k := 1 to j - 1 Do Begin{子序列1的石子堆数依次考虑1堆……j-1堆}
x := (i + k - 1) Mod N + 1;{求子序列2首堆序号}
If (s=1) And (List[i,k].c + List[x,j-k].c+t < List[i, j].c)
Or (s=2) And (List[i,k].c + List[x,j-k].c+t > List[i, j].c)
{ 若该合并方案为目前最佳,则记下}
Then Begin
List[i, j].c := List[i, k].c + List[x, j - k].c + t;
List[i, j].d := k
End { Then }
End { For }
End; { For }
{在子序列[1,N],[2,N],……,[N, N]中选择得分总和最小(或最大)的一个子序列}
k := 1; x := List[1, N].c;
For i := 2 to N Do
If (s = 1) And (List[i, N].c < x) Or (s = 2) And
(List[i, N].c > x) Then Begin
k := i; x := List[i, N].c
End; { Then }
Print(k, N);{由此出发,倒推合并过程}
Writeln(F, Sum^[1, N]);{输出最后一次将石子合并成一堆的石子总数}
Writeln(F);
Writeln(list[k, N].c)
End; { Main }
Begin
Write('File name = ');{输入文件名串}
Readln(Fn);
Assign(F, Fn);{该文件名串与文件变量连接}
Reset(F);{文件读准备}
Readln(F, N);{读入石子堆数}
For i := 1 to N Do Read(F, Date[i]);{读入每堆石子数}
New(Sum);{求每一个子序列的石子数sum}
For i := 1 to N Do Sum^[i, 1] := Date[i];
For j := 2 to N Do
For i := 1 to N Do
Sum^[i, j] := Date[i] + Sum^[i Mod N + 1, j - 1];
Dt := Date;{暂存合并前的各堆石子,结构相同的变量可相互赋值}
Close(F);{关闭输入文件}
Assign(F, 'OUTPUT.TXT');{文件变量与输出文件名串连接}
Rewrite(F);{文件写准备}
Main(1);{求得分和最小的合并方案}
Date := Dt;{恢复合并前的各堆石子}
Main(2);{求得分和最大的合并方案}
Close(F){关闭输出文件}
相关文章:

石子合并问题
一.试题 在一个园形操场的四周摆放N堆石子(N≤100),现要将石子有次序地合并成一堆。规定 每次只能选相邻的两堆合并成新的一堆,并将新的一堆的石子数,记为该次合并的得分。 编一程序,由文件读入…...

剑指Offer-搜索与回溯算法
文章目录 剑指 Offer 32 - I. 从上到下打印二叉树题意:解:代码: 剑指 Offer 32 - II. 从上到下打印二叉树 II题意:解:代码: 剑指 Offer 32 - III. 从上到下打印二叉树 III题意:解:代…...

【云原生】Docker 详解(三):Docker 镜像管理基础
Docker 详解(三):Docker 镜像管理基础 1.镜像的概念 镜像可以理解为应用程序的集装箱,而 Docker 用来装卸集装箱。 Docker 镜像含有启动容器所需要的文件系统及其内容,因此,其用于创建并启动容器。 Dock…...
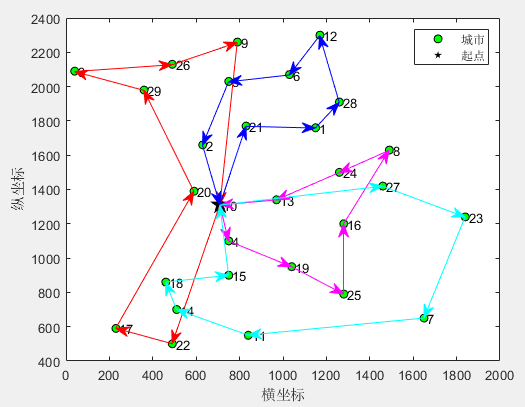
SD-MTSP:蜘蛛蜂优化算法SWO求解单仓库多旅行商问题MATLAB(可更改数据集,旅行商的数量和起点)
一、蜘蛛蜂优化算法SWO 蜘蛛蜂优化算法(Spider wasp optimizer,SWO)由Mohamed Abdel-Basset等人于2023年提出,该算法模型雌性蜘蛛蜂的狩猎、筑巢和交配行为,具有搜索速度快,求解精度高的优势。蜘蛛蜂优化算…...
) 使用】)
【ARM 嵌入式 编译系列 3.1 -- GCC __attribute__((used)) 使用】
文章目录 __attribute__((used)) 属性介绍代码演示编译与输出GCC 编译选项 上篇文章:ARM 嵌入式 编译系列 3 – GCC attribute((weak)) 弱符号使用 下篇文章:ARM 嵌入式 编译系列 3.2 – glibc 学习 __attribute__((used)) 属性介绍 在普通的 C/C 程序中…...
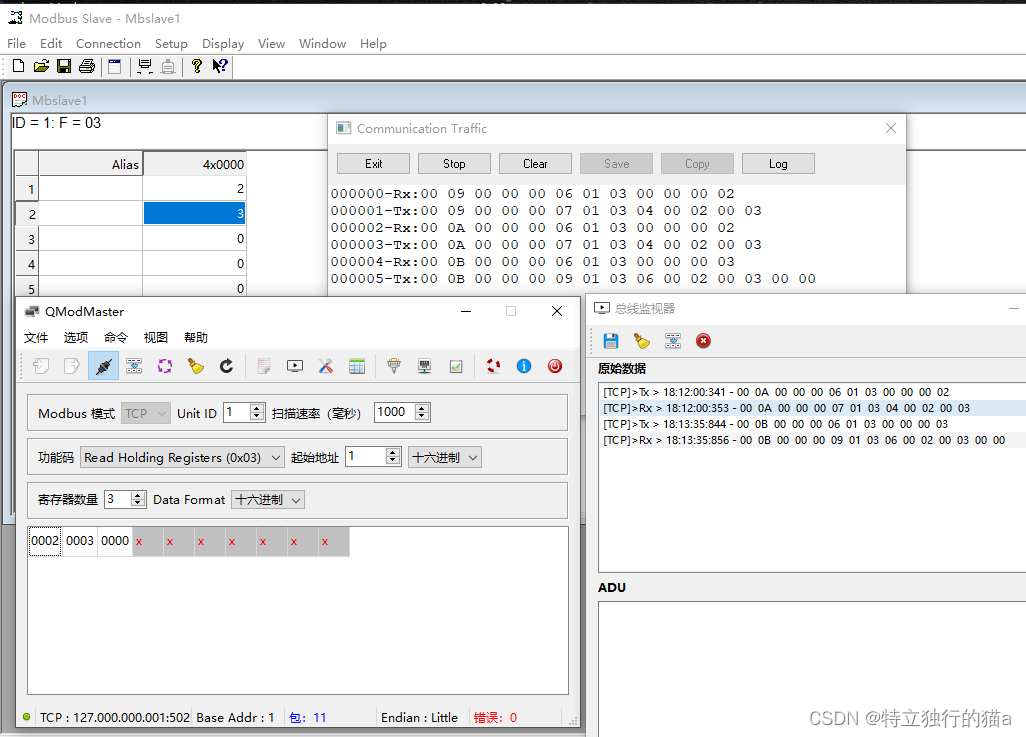
C++ ModBUS TCP客户端工具 qModMaster 介绍及使用
qModMaster工具介绍 QModMaster是一个基于Qt的Modbus主站(Master)模拟器,用于模拟和测试Modbus TCP和RTU通信。它提供了一个直观的图形界面,使用户能够轻松设置和发送Modbus请求,并查看和分析响应数据。 以下是QModM…...
笔记本电脑如何把sd卡数据恢复
在使用笔记本电脑过程中,如果不小心将SD卡里面的重要数据弄丢怎么办呢?别着急,本文将向您介绍SD卡数据丢失常见原因和恢复方法。 ▌一、SD卡数据丢失常见原因 - 意外删除:误操作或不小心将文件或文件夹删除。 - 误格式化&#…...

【2023 华数杯全国大学生数学建模竞赛】 B题 不透明制品最优配色方案设计 39页论文及python代码
【2023 华数杯全国大学生数学建模竞赛】 B题 不透明制品最优配色方案设计 39页论文及python代码 1 题目 B 题 不透明制品最优配色方案设计 日常生活中五彩缤纷的不透明有色制品是由着色剂染色而成。因此,不透明制品的配色对其外观美观度和市场竞争力起着重要作用。…...
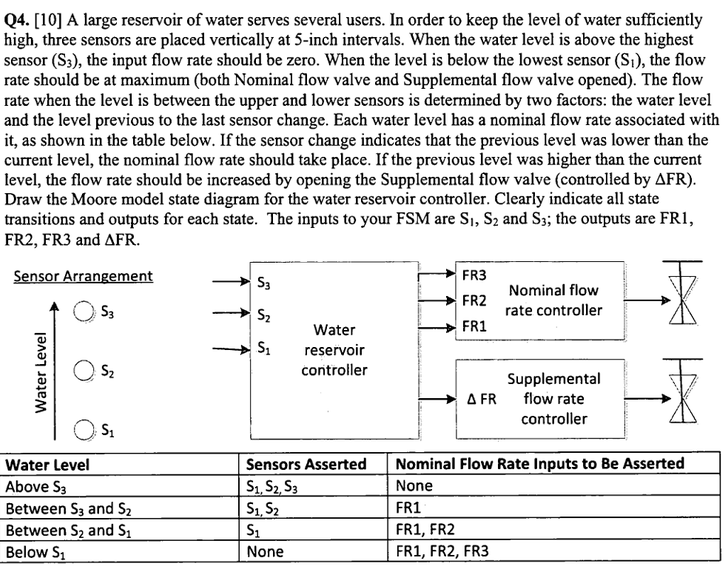
Exams/ece241 2013 q4
蓄水池问题 S3 S2 S1 例如:000 代表 无水 ,需要使FR3, FR2, FR1 都打开(111) S3 S2 S1 FR3 FR2 FR1 000 111 001 011 011 001 111 000 fr代表水变深为…...
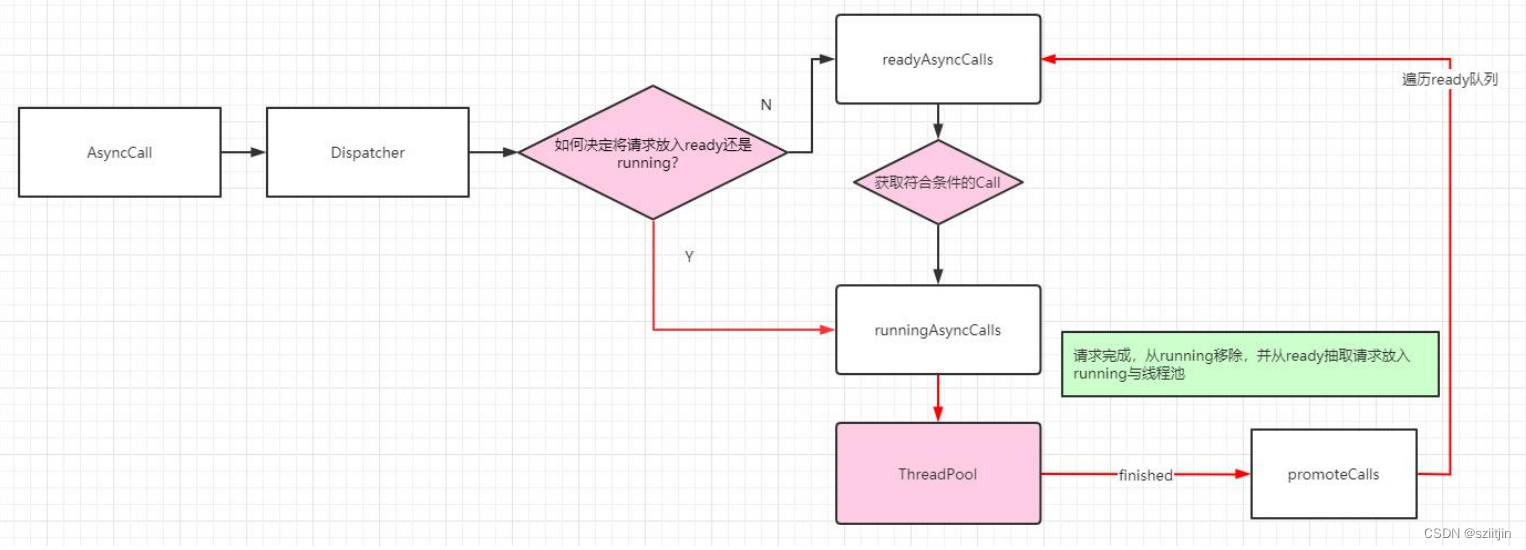
Android OkHttp源码分析--分发器
OkHttp是当下Android使用最频繁的网络请求框架,由Square公司开源。Google在Android4.4以后开始将源码中 的HttpURLConnection底层实现替换为OKHttp,同时现在流行的Retrofit框架底层同样是使用OKHttp的。 OKHttp优点: 1、支持Http1、Http2、Quic以及Web…...
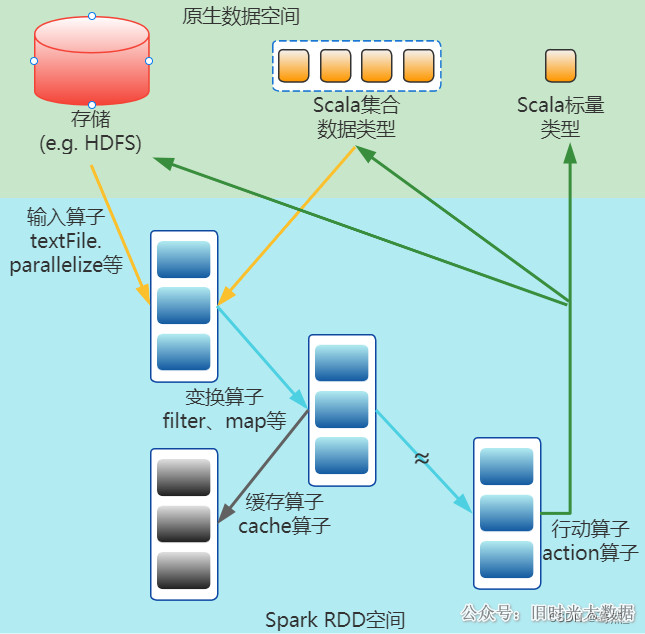
大数据面试题:说下Spark中的Transform和Action,为什么Spark要把操作分为Transform和Action?
面试题来源: 《大数据面试题 V4.0》 大数据面试题V3.0,523道题,679页,46w字 可回答:Spark常见的算子介绍一下 参考答案: 我们先来看下Spark算子的作用: 下图描述了Spark在运行转换中通过算…...
【图像去噪的扩散滤波】基于线性扩散滤波、边缘增强线性和非线性各向异性滤波的图像去噪研究(Matlab代码实现)
💥💥💞💞欢迎来到本博客❤️❤️💥💥 🏆博主优势:🌞🌞🌞博客内容尽量做到思维缜密,逻辑清晰,为了方便读者。 ⛳️座右铭&a…...
)
python函数、运算符等简单介绍2(无顺序)
list(列表) 列表是Python的一种内置数据类型,列表是可以装各种数据类 型的容器 # 第一种list创建方式 list_name [晓东,小刚,明明,小红,123,123.4,123] print(list_name) print(type(list_name)) # 输出结果: [晓东, 小刚, 明明…...

k8s 自身原理 3
前面有分享到 master 主节点上的 四个组件,etcd,ApiServer,scheduler,controller manager 接下来我们分享一波 woker 节点上的组件,xdm 还记得 worker 节点上都有什么吗? kubeletkube-proxy实际的服务对应…...
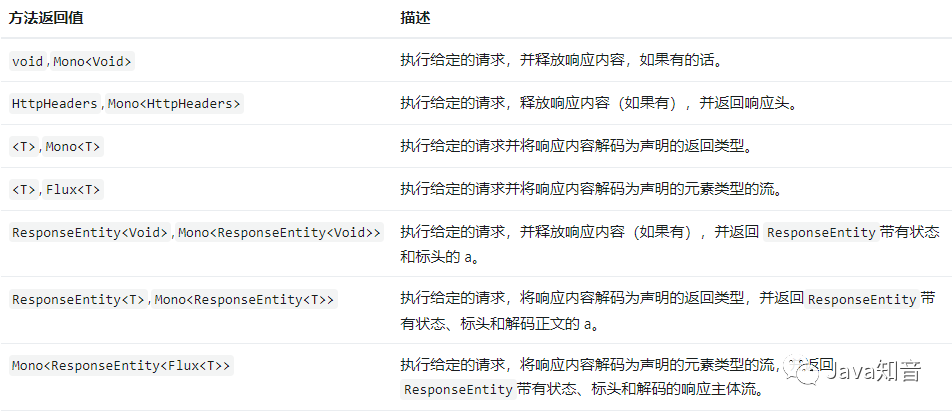
SpringBoot 3自带的 HTTP 客户端工具
原理 Spring的HTTP 服务接口是一个带有HttpExchange方法的 Java 接口,它支持的支持的注解类型有: HttpExchange:是用于指定 HTTP 端点的通用注释。在接口级别使用时,它适用于所有方法。GetExchange:为 HTTP GET请求指…...
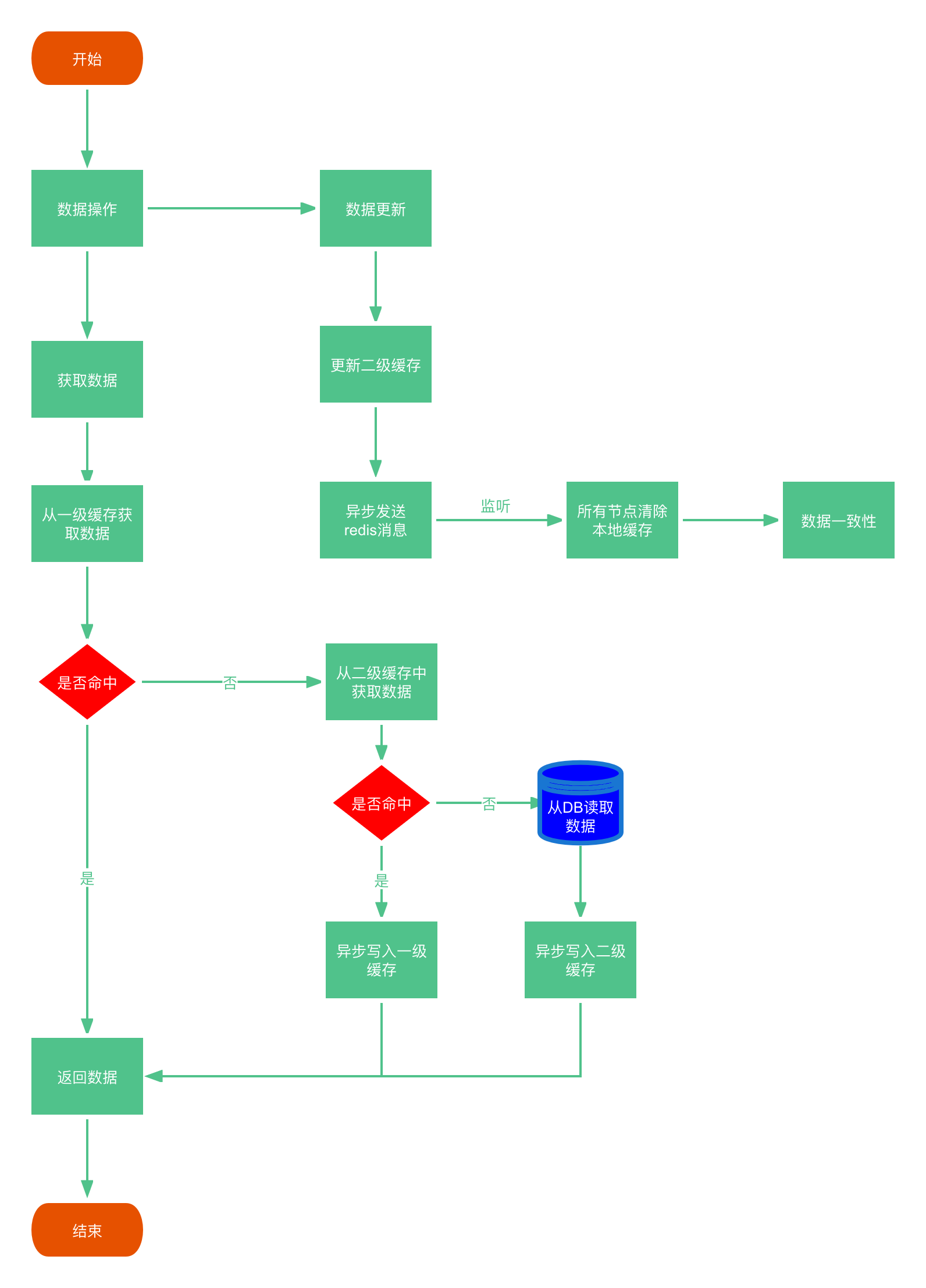
Spring Boot多级缓存实现方案
1.背景 缓存,就是让数据更接近使用者,让访问速度加快,从而提升系统性能。工作机制大概是先从缓存中加载数据,如果没有,再从慢速设备(eg:数据库)中加载数据并同步到缓存中。 所谓多级缓存,是指在整个系统架…...
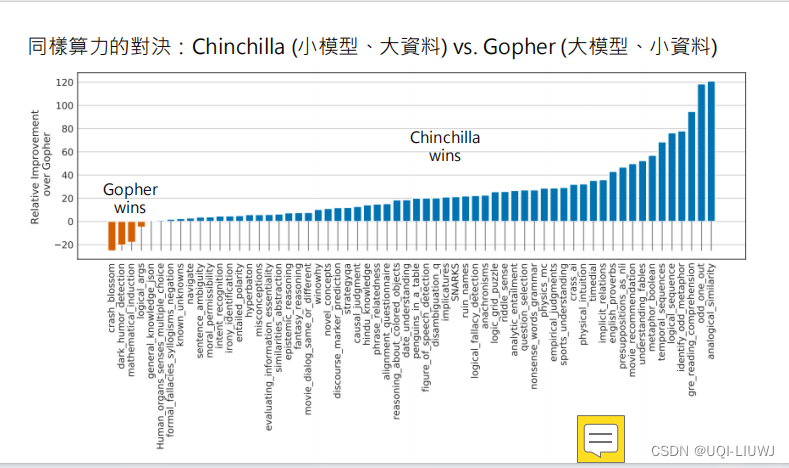
机器学习笔记:李宏毅chatgpt 大模型 大资料
1 大模型 1.1 大模型的顿悟时刻 Emergent Abilities of Large Language Models,Transactions on Machine Learning Research 2022 模型的效果不是随着模型参数量变多而慢慢变好,而是在某一个瞬间,模型“顿悟”了 这边举的一个例子是&#…...

2023年中国智慧公安行业发展现况及发展趋势分析:数据化建设的覆盖范围不断扩大[图]
智慧公安基于互联网、物联网、云计算、智能引擎、视频技术、数据挖掘、知识管理为技术支撑,公安信息化为核心,通过互联互通、物联化、智能方式促进公安系统各功能模块的高度集成、协同作战实现警务信息化“强度整合、高度共享、深度应用”警察发展的新概…...

Apache Dubbo概述
一、课程目标 1. 【了解】软件架构的演进过程 2. 【理解】什么是RPC 3. 【掌握】Dubbo架构 4. 【理解】注册中心Zookeeper 5. 【掌握】Zookeeper的安装和使用 6. 【掌握】Dubbo入门程序 7. 【掌握】Dubbo管理控制台的安装和使用 8. 【理解】Dubbo配置二、分布式RPC框架Apache …...
React UI组件库
1 流行的开源React UI组件库 1 material-ui(国外) 官网: Material UI: React components based on Material Design github: GitHub - mui/material-ui: MUI Core: Ready-to-use foundational React components, free forever. It includes Material UI, which implements Go…...

超越Arduino_GFX:在ESP-IDF中用面向对象思想重构ST7701S SPI驱动
超越Arduino_GFX:在ESP-IDF中用面向对象思想重构ST7701S SPI驱动 当你在ESP32平台上驱动一块ST7701S RGB屏幕时,是否曾为代码的混乱和难以维护而头疼?传统的驱动实现往往将SPI配置、屏幕初始化、图形库耦合在一起,导致代码难以复用…...

Claude AI编程协作:从工具到协作者的工作流进化与实践指南
1. 项目概述:当开发者遇上Claude,一个全新的协作范式最近在GitHub上闲逛,发现了一个挺有意思的项目,叫davepoon/buildwithclaude。光看名字,你可能会觉得这又是一个“如何用Claude写代码”的教程合集。但点进去仔细研究…...

抖音无水印下载器终极指南:三步搞定视频批量下载与去水印
抖音无水印下载器终极指南:三步搞定视频批量下载与去水印 【免费下载链接】douyin-downloader A practical Douyin downloader for both single-item and profile batch downloads, with progress display, retries, SQLite deduplication, and browser fallback su…...

为什么 Agent 还要分成多个?多 Agent 到底在解决什么问题
为什么 Agent 还要分成多个?多 Agent 到底在解决什么问题前面我们已经顺着一条很清晰的线往下走:先讲 Agent 为什么会跑偏,再讲怎么下任务、怎么做规划、怎么管理状态、怎么评估和调试;接着又进入框架层,讲了 LangChai…...
)
C++26 Contracts正式落地:从Clang 19/MSVC 2026 Preview到GCC 14.3,三编译器兼容性避坑清单(附自动契约注入脚本)
更多请点击: https://intelliparadigm.com 第一章:C26 Contracts正式落地:从Clang 19/MSVC 2026 Preview到GCC 14.3,三编译器兼容性避坑清单(附自动契约注入脚本) C26 Contracts 已在 ISO WG21 最新草案中…...
的永磁同步电机无位置传感器FOC控制)
从理论到实践:基于扩展卡尔曼滤波(EKF)的永磁同步电机无位置传感器FOC控制
1. 扩展卡尔曼滤波(EKF)基础与电机控制的关系 我第一次接触扩展卡尔曼滤波是在研究生阶段,当时实验室的永磁同步电机总因为编码器故障导致停机。导师扔给我一篇论文说:"试试这个无位置传感器方案"。现在回想起来&#x…...
)
别再死磕PID了!用Python+MPC给机械臂做个‘未来视’控制器(附ROS2实战代码)
用PythonMPC为机械臂打造预测未来能力的智能控制器 机械臂控制领域正在经历一场静默革命——当大多数工程师还在用PID控制器解决90%的基础问题时,前沿实验室和科技公司早已将目光转向了更具前瞻性的控制策略。想象一下,如果你的控制器不仅能对当前误差做…...

LeetCode热题100 完全平方数
题目描述 给你一个整数 n ,返回 和为 n 的完全平方数的最少数量 。 完全平方数 是一个整数,其值等于另一个整数的平方;换句话说,其值等于一个整数自乘的积。例如,1、4、9 和 16 都是完全平方数,而 3 和 11…...

AI试衣系统源码-一键换衣换装-支持姿态识别+纹理融合-批量生成-SAAS模式-电商创业利器
温馨提示:文末有资源获取方式在电商竞争日益激烈的今天,商品展示效果直接决定着转化率的高低。尤其是服装类目,传统的模特拍摄不仅成本高昂,而且周期长、效率低。针对这一市场难题,我们团队倾力打造了一款革命性的AI试…...

Optuna超参数优化:提升机器学习模型调优效率
1. 超参数优化入门:为什么选择Optuna?在机器学习项目中,模型调优往往是最耗时的环节之一。传统网格搜索(Grid Search)和随机搜索(Random Search)虽然简单直接,但当参数空间较大时,这两种方法要么计算成本过高ÿ…...